

Больше примеров — в конце поста
В последние годы большие языковые модели на архитектуре трансформеров стали вершиной развития нейросетей в задачах NLP. С каждым месяцем они становятся всё больше и сложнее. Чтобы обучить подобные модели, уже сейчас требуются миллионы долларов, лучшие специалисты и годы разработки. В результате доступ к современным технологиям остался лишь у крупнейших IT-компаний. При этом у исследователей и разработчиков со всего мира есть потребность в доступе к таким решениям. Без новых исследований развитие технологий неизбежно снизит темпы. Единственный способ избежать этого — делиться с сообществом своими наработками.
Год назад мы впервые рассказали Хабру о семействе языковых моделей YaLM и их применении в Алисе и Поиске. Сегодня мы выложили в свободный доступ нашу самую большую модель YaLM на 100 млрд параметров. Она обучалась 65 дней на 1,7 ТБ текстов из интернета, книг и множества других источников с помощью 800 видеокарт A100. Модель и дополнительные материалы опубликованы на Гитхабе под лицензией Apache 2.0, которая допускает применение как в исследовательских, так и в коммерческих проектах. Сейчас это самая большая в мире GPT-подобная нейросеть в свободном доступе как для английского, так и для русского языков.
В этой статье мы поделимся не только моделью, но и нашим опытом её обучения. Может показаться, что если у вас уже есть суперкомпьютер, то с обучением больших моделей никаких проблем не возникнет. К сожалению, это заблуждение. Под катом мы расскажем о том, как смогли обучить языковую модель такого размера. Вы узнаете, как удалось добиться стабильности обучения и при этом ускорить его в два раза. Кстати, многое из того, что будет описано ниже, может быть полезно при обучении нейросетей любого размера.
Как ускорить обучение модели?
В масштабах обучения больших нейронных сетей ускорение на 10% может сэкономить неделю работы дорогостоящего кластера. Здесь мы поговорим об итоговом ускорении более чем в два раза.
Обычно одна итерация обучения состоит из следующих шагов:

На этапе forward мы вычисляем активации и loss, на этапе backward — вычисляем градиенты, затем — обновляем веса модели. Давайте обсудим, как эти шаги можно ускорить.
Ищем узкие места
Чтобы понять, куда уходит время вашего обучения, стоит профилировать. В PyTorch это можно сделать при помощи модуля torch.autograd.profiler (статья). Вот пример трейса, который мы получили, используя профайлер:

Это трейс небольшой 12-слойной нейронной сети. Сверху вы можете увидеть шаги forward, снизу — backward. Какую проблему можно увидеть в этом трейсе? Одна из операций занимает слишком много времени, около 50% работы всего обучения. Оказалось, что мы забыли изменить размер эмбеддинга токенов, когда копировали конфигурацию обучения большой модели. Это привело к слишком большому матричному умножению в конце сети. Уменьшение размера эмбеддинга помогло сильно ускорить обучение.
При помощи профайлера мы находили и более серьёзные проблемы, так что рекомендуем почаще им пользоваться.
Используем быстрые типы данных
В первую очередь на скорость вашего обучения и инференса влияет тип данных, в котором вы храните модель и производите вычисления. Мы используем четыре типа данных:
- single-precision или fp32 — обычный float, очень точный, но занимает четыре байта и вычисления на нём очень долгие. Именно этот тип будет у вашей модели в PyTorch по умолчанию.
- half-precision или fp16 — 16-битный тип данных, работает гораздо быстрее fp32 и занимает вдвое меньше памяти.
- bfloat16 — ещё один 16-битный тип. По сравнению с fp16 мантисса на 3 бита меньше, а экспонента на 3 бита больше. Как итог — число может принимать больший диапазон значений, но страдает от потери точности при числовых операциях.
- TensorFloat или tf32 — 19-битный тип данных, обладающий экспонентой от bf16 и мантиссой от fp16. Занимает те же четыре байта, что и fp32, но работает гораздо быстрее.
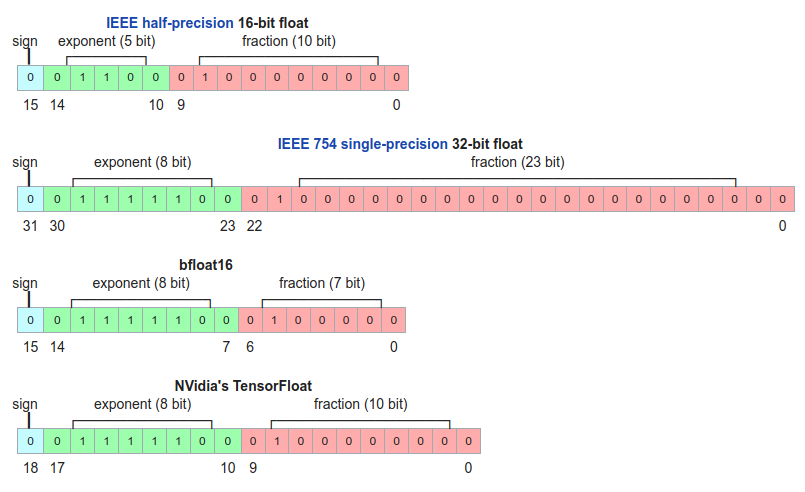
На видеокартах a100 и новее 16-битные типы в пять раз быстрее fp32, а tf32 — в 2,5 раза. Если вы используете a100, то tf32 всегда будет применяться вместо fp32, если вы явно не укажете другое поведение.
На более старых видеокартах bf16 и tf32 не поддерживаются, а fp16 всего вдвое быстрее fp32. Но это большой прирост в скорости. Имеет смысл всегда производить вычисления в half или bf16, хотя и у такого подхода есть свои недостатки. Мы их ещё обсудим.
Ускоряем операции на GPU
Что собой представляют операции на GPU, и как их ускорить, хорошо написано в этой статье. Мы здесь приведем пару основных идей оттуда.
Загружаем GPU полностью
Для начала давайте поймём, как выглядит вычисление одного CUDA-kernel на GPU. Можно привести удобную аналогию с заводиком:

У GPU есть память — склад, и вычислитель — заводик. При выполнении одного ядра вычислитель заказывает из памяти нужные данные, вычисляет результат и записывает его обратно в память.
Что происходит, если заводик не загружен наполовину?

Тогда, как и в случае с реальным заводом, половина мощностей GPU будет простаивать. Как это поправить в обучении? Самая простая идея: увеличить батч.
Для небольших моделей увеличение батча в n раз может приводить к кратному ускорению обучения, хотя время итерации замедлится. Для больших моделей с миллиардами параметров увеличение размера батча также даст прирост, хотя и небольшой.
Уменьшаем взаимодействие с памятью
Вторая идея из статьи заключается в следующем. Пусть у нас есть три ядра, которые последовательно обрабатывают одни и те же данные:

В этом случае всё время будет тратиться не только на вычисления, но и на работу с памятью: такие операции не бесплатны. Чтобы уменьшить количество таких операций, ядра можно объединить — «зафьюзить»:

Как это сделать? Есть несколько способов:
- Использовать torch.jit.script. Такой простой атрибут приведёт к компиляции кода функции в одно ядро. В коде ниже как раз происходит фьюзинг трёх операций: сложения тензоров, dropout и ещё одного сложения тензоров.
def bias_dropout_add(x, bias, residual, prob, training): # type: (Tensor, Tensor, Tensor, float, bool) -> Tensor out = torch.nn. functional.dropout (x + bias, p=prob, training=training) out = residual + out return out def get_bias_dropout_add (training): def _bias_dropout_add(x, bias, residual, prob): return bias_dropout_add(x, bias, residual, prob, training) return _bias_dropout_add @torch.jit.script def bias_dropout_add_fused_train(x, bias, residual, prob): # type: (Tensor, Tensor, Tensor, float) -> Tensor return bias dropout add(x, bias, residual, prob, True)
Такой подход обеспечил нам 5-процентный прирост скорости обучения. - Можно писать CUDA-ядра. Это позволит не просто зафьюзить операции, но и оптимизировать использование памяти, избежать лишних операций. Но написание такого кода требует очень специфичных знаний, и разработка такого ядра может оказаться слишком дорогой.
- Можно использовать уже готовые CUDA-ядра. Коротко расскажу о ядрах в библиотеках Megatron-LM и DeepSpeed, с ними мы много работаем:
- Attention softmax с треугольной маской даёт ускорение 20-100%. Ускорение особенно велико на маленьких сетях и в случае вычисления в fp32.
- Attention softmax с произвольной маской даёт ускорение до 90%.
- Fused LayerNorm — зафьюженный вариант LayerNorm в fp32. Мы такое ядро не использовали, но оно тоже должен дать прирост в скорости.
- DeepSpeed Transformers — целиком зафьюженный блок трансформера. Даёт прирост в скорости, но его крайне сложно расширять и поддерживать, поэтому мы его не используем.
Использование зафьюженных тем или иным образом ядер позволило нам ускорить обучение больше чем в полтора раза.
Дропауты
Если у вас много данных и нет переобучения с dropout == 0, отключайте их! Наши вычисления это ускорило на 15%.
Случай с несколькими картами
Что меняется в случае с несколькими картами? Теперь схема выглядит так:

На этапе Reduce grads мы усредняем градиенты по видеокартам, чтобы объединить работу всех видеокарт, затем обновляем веса модели.
Усреднение всех градиентов — не быстрый шаг. Каждая видеокарта должна отправить и получить минимум столько же градиентов, сколько параметров есть в сети. Давайте посмотрим, как существенно ускорить этот шаг и шаг step.
Коммуникации
Как вообще устроены оптимальные коммуникации? Библиотека NVIDIA NCCL, которую мы используем, просчитывает их во время инициализации и позволяет GPU общаться друг с другом по сети без посредников в виде CPU. Тем самым обеспечивается максимальную скорость коммуникаций. Вот статья NVIDIA про эту библиотеку, а вот наша хабрастатья про борьбу с ложной загрузкой GPU, в том числе про NCCL.
С точки зрения кода это выглядит примерно так:
from torch.distributed import all_reduce, all_gather
tensor_to_sum = torch.randn(100, 100, device='cuda')
all_reduce(tensor_to_sum) # Когда этот метод будет вызван на всех процессах, значение tensor_to_sum обновится на сумму входных тензоров
tensor_to_gather = torch.randn(100, 100, device='cuda')
gathered_tensors = [torch.zeros(100, 100, device='cuda') for i in range(proc_count)]
all_gather(gathered_tensors, tensor_to_gather) # Тензоры из различных tensor_to_gather будут собраны в gathered_tensorsNCCL-коммуникации очень быстрые, но даже с ними скорость шага all_reduce будет отнимать много времени. В ускорении нам помогает ZeRO.
ZeRO
ZeRO (Zero Redundancy Optimizer) — это оптимизатор с нулевой избыточностью.
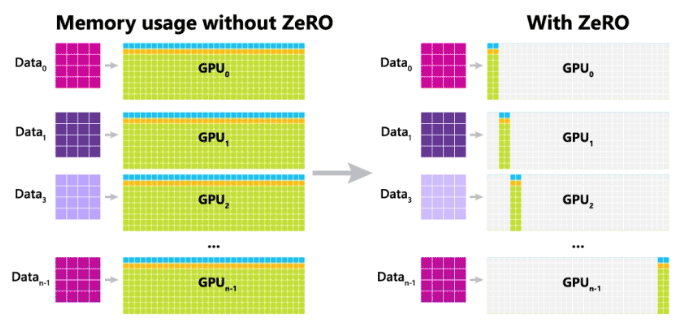
Слева на картинке — обычное обучение на нескольких GPU. В стандартной схеме мы распределяем между процессами все параметры и состояния оптимизатора, а также градиенты после усреднения. Как следствие, довольно много памяти тратится зря.
Справа изображён примерный принцип работы ZeRO. Мы назначаем каждый процесс ответственным за некоторую группу параметров. Процесс всегда хранит эти параметры, их состояния оптимизатора, и только он может их обновлять. За счёт этого достигается коллосальная экономия памяти, которую мы можем использовать под большие батчи. Но взамен добавляется новый шаг: all_gather весов — нам надо собрать все параметры сети на каждом процессе, чтобы сделать forward и backward. Теперь сложности операций после подсчёта градиентов будут такими:
all_reduce gradients: O(N), где N — количество параметров.
step: O(N/P), где P — количество процессов. Это уже хорошее ускорение.
all_gather parameters: O(N).
Видно, что один шаг ускорился, но ценой добавления новых, тяжёлых операций. Как можно ускорить их? Оказалось, здесь нет ничего сложного: их можно делать асинхронно!

Можем асинхронно собирать слои друг за другом во время выполнения forward:
- Собираем первый слой по всем процессам.
- Пока собираем второй слой — делаем forward по первому.
- Пока собираем третий слой — делаем forward по второму.
И так далее, до полного завершения forward. Почти таким же способом можно ускорить и backward.
На наших запусках это дало прирост скорости 80%! Даже на маленьких моделях (размера 100M на 16 GPU) мы видели ускорение в 40-50%. Такой подход требует достаточно быстрой сети, но если она у вас есть, вы можете существенно ускорить обучение на нескольких GPU.
Ускорение. Итоги
Мы в своём обучении применили четыре подхода:
- Зафьюзили часть операций: +5% скорости
- Использовали softmax attention kernel с треугольной маской: +20-80%
- Отключили dropout: +15%
- Применили ZeRO: +80%
Получилось неплохо. Двигаемся дальше.
Борьба с расхождениями
Казалось бы, если есть достаточно вычислительных мощностей, можно просто запустить обучение, уйти на два месяца в отпуск, и в итоге вас будет ждать готовая модель. Но долгая итерация — не единственное, что может помешать обучению действительно больших моделей. При таких масштабах они довольно хрупкие и склонны к расхождениям. Что такое расхождения и как с ними бороться?
Расхождения
Допустим, вы поставили обучение. Смотрите на графики — видите, что loss падает, и так три дня подряд. А утром четвёртого дня график loss'а оказывается таким:

Loss поднялся выше, чем был через несколько часов после начала обучения. Более того: модель буквально забыла всё, что знала. Её уже не восстановить, несколько дней обучения ушло впустую. Это и есть расхождение. В чём же причина?
Первые наблюдения
Мы заметили три вещи:
- Оптимизатор LAMB куда менее склонен к расхождению, чем Adam.
- Уменьшая значения learning rate, можно побороть проблему расхождения. Но не всё так просто:
- Подбор lr требует множества перезапусков обучений.
- Уменьшение lr часто приводит к замедлению обучения. Например, здесь уменьшение lr в два раза привело к замедлению на 30%:

- Проблемы расхождения в fp16 проявлялись чаще, чем в fp32. В основном это было связано с переполнением значений fp16 в активациях и градиентах. Максимум fp16 по модулю — 65535. Итогом переполнения становился NaN в loss'е.
Градусники
Одно из решений, которые помогли нам поддерживать обучение достаточно долго, — это градусники. Мы замеряли максимумы/минимумы активаций на разных участках сети, замеряли глобальную норму градиентов. Вот пример градусников обучения с расхождением:
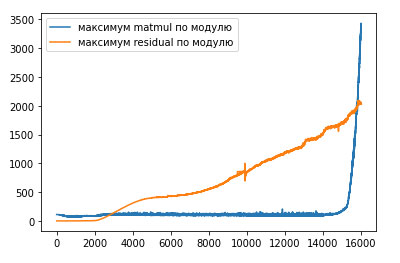
Хорошо видно: начиная примерно с 14 тысяч итераций максимумы matmul в attention резко стали расти. Этот рост — и есть причина расхождения. Если откатить обучение до 13 тысяч итераций и пропустить злополучные батчи, на которых расхождение началось, либо уменьшить learning rate, то можно существенно снизить вероятность повторного расхождения.
Проблемы такого подхода:
- Он не решает проблему расхождений на 100%.
- Мы теряем драгоценное время на откатывание обучения. Это, конечно лучше, чем проводить его впустую, но тем не менее.
Позднее мы внедрили несколько трюков, которые позволили снизить вероятность расхождения настолько, что мы спокойно и без проблем обучили множество моделей самых разных размеров, включая 100B.
Стабилизации. BFloat 16
BFloat 16 не переполняется даже при достаточно больших значениях градиентов и активаций. Поэтому оказалось хорошей идеей хранить веса и производить вычисления именно в нём. Но этот тип недостаточно точный, поэтому при произвольных арифметических операциях могла накапливаться ошибка, приводящая к замедлению обучения или расхождениям другой природы.
Чтобы компенсировать расхождения, мы стали вычислять следующие слои и операции в tf32 (или fp32 на старых карточках):
- Softmax в attention (вот и пригодились наши ядра), softmax по токенам перед лоссом.
- Все слои LayerNorm.
- Все операции с Residual — это позволило не накапливать ошибку и градиенты по глубине сети.
- all_reduce градиентов, о котором было написано раньше.
Все эти стабилизации замедлили обучение всего на 2%.
Стабилизации. LayerNorm
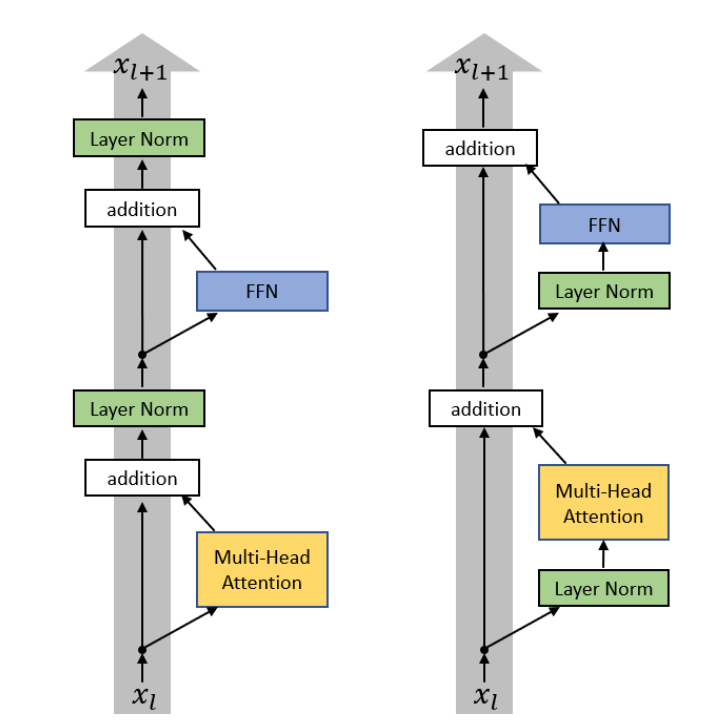
Если в статьях про BERT и GPT использовался подход, который сейчас называется post-layernorm (слева на картинке), то с точки зрения стабильности и скорости сходимости больших моделей хорошо себя показал pre-layernorm (справа). В реальных моделях мы используем именно его.
Неожиданный метод стабилизации открыли участники воркшопа BigScience: layernorm в самом начале сети, после эмбеддингов, также заметно снижает вероятность расхождения.
Стабилизации. Curriculum learning
Также мы внедрили к себе подход из статьи Curriculum learning. Мы хотим обучаться с большим батчем и большой длиной строк, но начинаем с маленького батча и коротких строк, а в ходе обучения постепенно их увеличиваем.
У этого подхода два плюса:
- Loss в самом начале падает достаточно быстро, вне зависимости от числа токенов, которые модель видит на каждой итерации. Поскольку мы уменьшаем количество вычислений в начале обучения, то быстрее проходим этот этап выхода лосса на плато.
- Авторы статьи пишут, что такой подход приводит к стабильному обучению.
Стабилизации. Итоги
Мы внедрили пять подходов:
bf16 как основной тип для весов.
Вычисления, требующие точности, делаем в tf32.
Pre-layernorm.
LayerNorm сразу после эмбеддингов.
Curriculum learning.
Как итог, мы уже больше полугода обучаем модели без расхождений. Они бывают разных размеров. В том числе эти стабилизации помогли обучить модель со 100 млрд параметров, которой мы сейчас и делимся со всем сообществом.
И напоследок:
Ещё немного примеров общения с YaLM 100B








