Общие слова
Профилирование приложений — это процесс анализа программы для определения её характеристик: времени выполнения различных частей кода и использования ресурсов.
Основные этапы профилирования всегда более-менее одинаковы:
Измерение времени выполнения. Cколько времени требуется для выполнения различных частей кода?
Анализ использования памяти. Сколько памяти потребляется различными частями программы?
Выявление узких мест. Какие части кода замедляют работу программы и/или используют слишком много ресурсов?
Оптимизация производительности. Принятие мер для улучшения скорости выполнения и эффективности использования ресурсов на основе полученных данных.
А как вообще работает профилировщик?
Детальному обзору будет посвящена отдельная статья, пока можно ограничится базовой классификацией:
Детерминированные (deterministic) профилировщики. Главный представитель - встроенный
cProfile. Такой профилировщик считает количество вызовов каждой функции и потраченное функцией время. Проблема в том, что время ожидания асинхронных вызовов не учитывается.Статистические (statistical) профилировщики. Распространённые представители -
scalene,py-spy,yappi,pyinstrument,austin. Такие профилировщики с некоторой частотой снимают "слепок" с процесса и применяют методы статистического анализа для поиска узких мест.
Основные типы узких мест в асинхронном Python-коде
Для асинхронного кода существует небольшое количество специфических "узких мест", которые лучше перечислить заранее.
Каждому типу сопоставим пример кода.
Список допущений
Используется один и только один event-loop
Python 3.12
Блокирующие операции
import asyncio
import time
async def main():
print('Start')
# Blocking call
time.sleep(3) # This blocks the entire event loop
print('End')
asyncio.run(main())Последовательный вызов асинхронных задач
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = ["http://habr.com"] * 10
async with aiohttp.ClientSession() as session:
# Inefficient: Sequential requests
for url in urls:
await fetch(session, url)
asyncio.run(main())Слишком частое переключение контекста
import asyncio
async def tiny_task():
await asyncio.sleep(0.0001)
async def main():
# Excessive context switching due to many small tasks
await asyncio.gather(*(tiny_task() for _ in range(100000)))
asyncio.run(main())Неравномерное распределение ресурсов
В англоязычной литературе такой сценарий называется "Resource Starvation".
import asyncio
async def long_running_task():
await asyncio.sleep(10)
print("Long task executed")
async def quick_task():
await asyncio.sleep(1)
print("Quick task executed")
async def main():
await asyncio.gather(
long_running_task(),
quick_task() # May be delayed excessively
)
asyncio.run(main())Чрезмерный расход памяти
import asyncio
async def large_data_task():
data = "h" * 10**8 # Large memory usage
await asyncio.sleep(1)
async def main():
tasks = [large_data_task() for _ in range(100)] # High memory consumption
await asyncio.gather(*tasks)
asyncio.run(main())Использование "scalene" для профилирования
Почему scalene? Потому что этот инструмент позволяет профилировать и CPU, и GPU, и память; 10k+ звёзд на гитхабе, проект активно развивается.
Посмотрим что скажет scalene для каждого "проблемного" кода из списка выше.
Запускать будем в режиме scalene --cpu --memory --cli script_name.py
Блокирующие операции
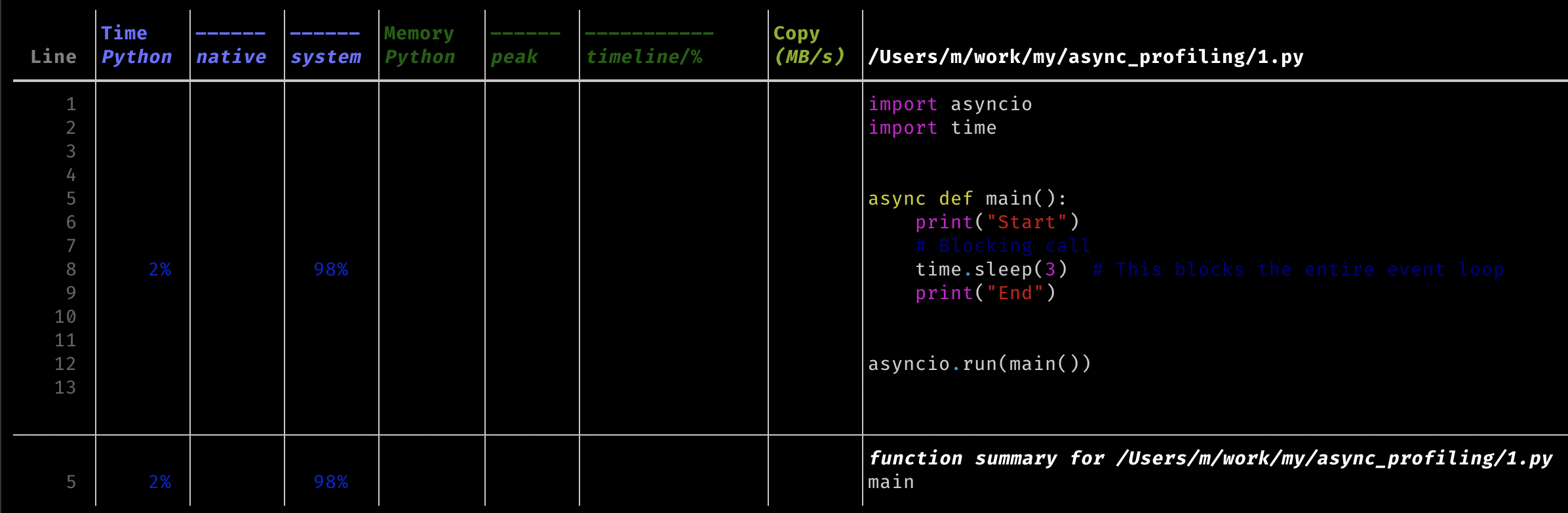
Проблемную строку с блокирующим вызовов видно сразу - 2% времени на Python, 98% - на системные вызовы.
Последовательный вызов асинхронных задач

Здесь чуть сложнее. Видно, что 90% времени уходит на системные вызовы, но поменялась строка - теперь это сам asyncio.run(). Такой паттерн вывода профилировщика лучше всего просто запомнить.
Слишком частое переключение контекста

Видим, как растёт потребление памяти в asyncio.gather() - делаем вывод о слишком сильном "дроблении" задач.
Неравномерное распределение ресурсов

И снова соотношение времени system vs python не в пользу python-операций.
Чрезмерный расход памяти

Здесь профилировщик сделал всё за нас и сразу показал проблемный код.
Заключение
Надо обратить внимание, что для трёх случаев - "блокирующие операции", "последовательный вызов асинхронных задач" и "неравномерное распределение ресурсов" профилировщик показал нам одну и ту же картину - system % >> python %. Для уточнения причины требуется, собственно, разработчик.
Профилировать Python - несложная и достаточно приятная задача, если знать основные типы узких мест и быть готовым внимательно читать вывод профилировщика.












