
В любой системе возникает задача понять, как взаимодействуют компоненты между собой. Особенно важно это в распределённых системах. Как понять, какие компоненты обработали запрос, сколько времени это заняло, какой был порядок обработки. Всё это можно узнать, но нужно добавить немного инфраструктуры.
Егор Гришечко — работал разработчиком в компании Insolar. Команда Егора делает полностью распределенную систему, и поэтому они сталкиваются с большинством проблем, которые присущи распределенным системам. Сейчас Егор трудится в Uber и занимается разработкой инфраструктуры.
Под катом — текстовая расшифровка и видео доклада Егора с конференции DotNext 2019 Moscow. Доклад будет полезен разработчикам микросервисных систем, которые смогут для себя открыть эти технологии. А также будет интересен бэкенд-разработчикам, интересующимся метриками и мониторингом.
В докладе
- Что такое observability/наблюдаемость;
- Зачем это нужно;
- Распределенные trace-метки;
- Jaeger;
- OpenTracing и OpenCensus;
- Немного про будущее.
Далее — повествование от лица спикера.
Поговорим немного про observability, зачем это нужно, про распределенные trace-метки, поговорим про Jaeger — это такая система сбора trace-меток, потом я расскажу о перипетиях и Санта-Барбаре вокруг OpenTracing и OpenCensus и чем это всё закончится.
Мы живем в мире, который становится сложнее с каждым днем. Есть миллионы картинок про прекрасный frontend, ужасный backend, но чаще всего юзер видит какую-то верхушку айсберга.
Я нашел прекрасную картинку про .NET.

Картинка отображает ход нашего времени. Картинка, датируемая 2016 годом, но ничего по сути не поменялось. В 2005 у нас было классическое распределенное приложение, которое я застал, начиная работу. У нас есть какой-то веб-сервер, какая-то база, какая-то логика, мы вот ходим, отдаем, все счастливы.
Сейчас это не работает. Из-за возросших нагрузок, из-за микросервисов и из-за того, что все хотят быть модными и многого другого.

Раньше у нас было классическое приложение, которое было одним бинарем, распространялось максимум по двум машинам, и мы счастливо с этим жили.
На смену этому пришли микросервисы, и нам стало тяжелее. Представим, что у нас система, состоящая из множества компонентов. Чем больше у нас компонентов, тем больше у нас точек отказа.
Потом у нас появились вот эти ребята.
Они появились относительно недавно, но это еще один слой абстракции. Мы что-то грузим в docker, куда-то отправляем, он где-то крутится, что-то происходит. Что с этим делать — непонятно.
У нас постоянно растет комплексность наших систем, добавляется количество компонентов. Мы строим комплексные системы, а комплексным системам свойственен достаточно обширный класс проблем, которые можно классифицировать.
В любой комплексной системе есть проблемы. Чем больше вы делаете, тем больше у вас может сломаться. Поведение распределенной системы патологически непредсказуемо. Здесь вступает в дело обычная комбинаторика, то есть комбинации сбоев могут дублироваться.
Посчитайте формулу комбинации сбоев. Каждый микросервис у вас может отказывать тремя или пятью способами и просто посчитайте количество ваших микросервисов, и вы примерно увидите, сколько у вас комбинаций сбоев может быть.
Из этого следует, что мы не всегда можем предсказать комбинации этих сбоев. Это самое ужасное. В моей практике этот пункт — это главная боль, которую я испытываю на протяжении уже долгого времени. Когда ты такой: «Да, я написал, работает — круто».
Пускаешь тестировать, и потом три дня чекаешь логи и метрики, чтобы понять, что одно сообщение пришло раньше другого на 2 милисекунды, из-за этого всё сломалось.
Мы отрасль, которая работает для бизнеса, мы делаем услуги, мы делаем так, чтобы бизнесу было хорошо. Бизнес платит за это деньги. Нам критически важно, чтобы в наших системах мы могли понять, что сломалось. Мы хотим знать, почему это не работает или работает не так, как мы предполагаем.
Что такое observability?

Observability или «Наблюдаемость распределённых систем» — Ссылка
Наблюдаемость — это обеспечение прозрачности процесса работы наших систем. Оbservability — это то, что помогает понять, как работает ваша система. Если ваша система работает непонятно как, у вас есть метрики, трейсы, логи, но вы не можете понять, что сломалось, у вас нет observability.
Observability — это про то, как вы подходите к разработке систем, как вы настраиваете процесс тестирования, как вы настраиваете процесс раскатки, метрики и так далее. Можно подумать, что это мониторинг, но это не так. Опять же картинка с той чудесной книжки:
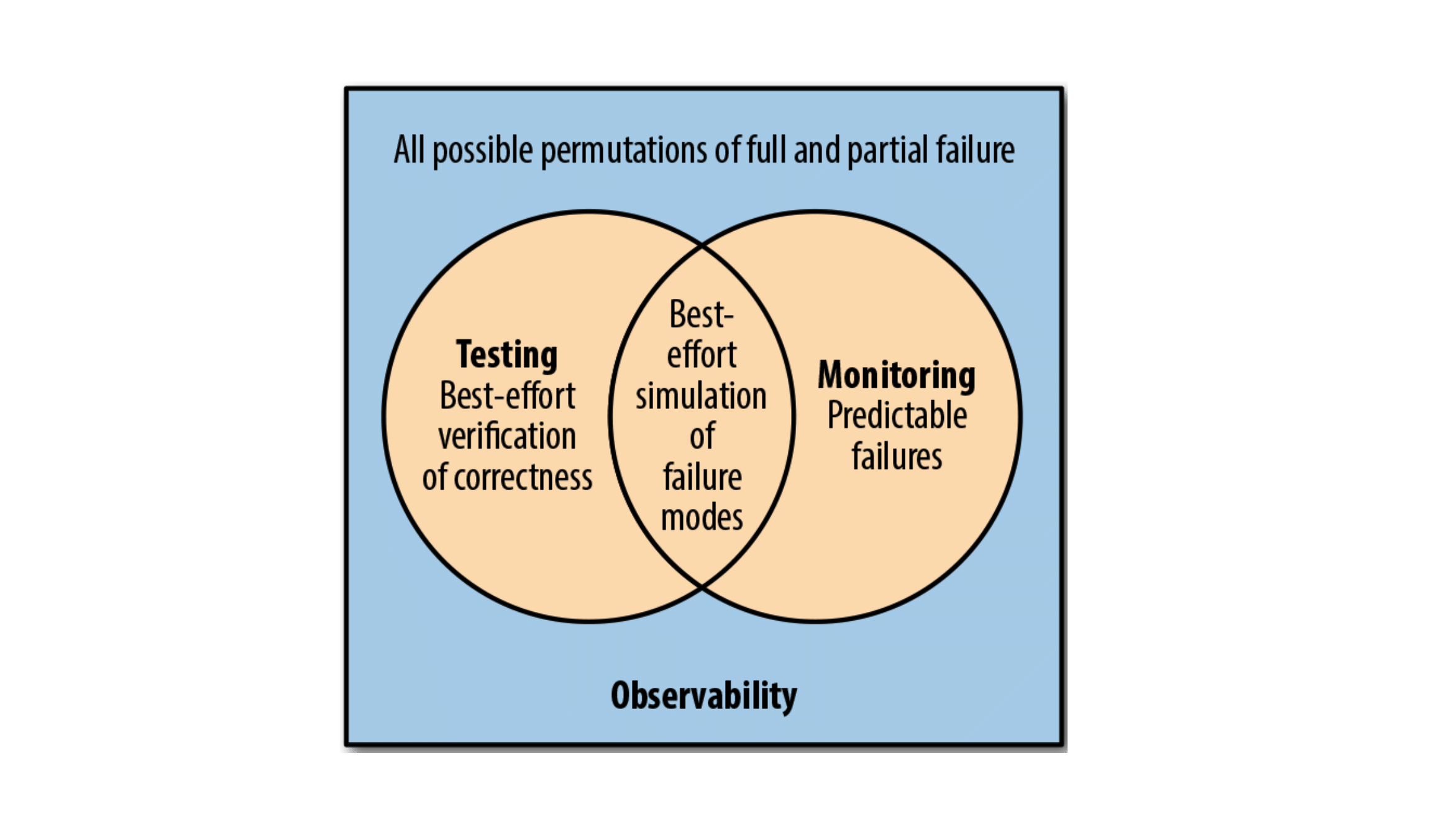
С помощью мониторинга мы можем покрыть предсказуемые падения. Допустим, налепим метрик на то, что у нас падают контроллеры, налепим метрик на репозитории. У нас там что-то упало, повысился rate падающих запросов, — мы увидели, всё хорошо. Тестирование — это тоже чудесно, оно помогает нам предсказать, проверить сбой, который мы можем предсказать.
У нас есть ещё гигантское множество проблем, которое мы не можем покрыть. Разрывы сети, асинхронное движение сообщений, дедлоки. В практике я очень часто сталкиваюсь с тремя проблемами: сообщение пришло не туда, куда нужно, сообщение пришло не так, как нужно, и мы задедлочились в себя. Это описание моих главных проблем за последние полгода.
На данной картинке все эти комбинации сбоев представлены в синем квадрате, и observability по сути закрывает собой этот синий квадрат. Оbservability, с точки зрения девелопера — это такой супер-сет мониторинга, более модный и более накрученный, но в базе его лежит мониторинг.
Зачем нужен Observability
Пример немножко абстрактный, реальный код пойдёт чуть позже.
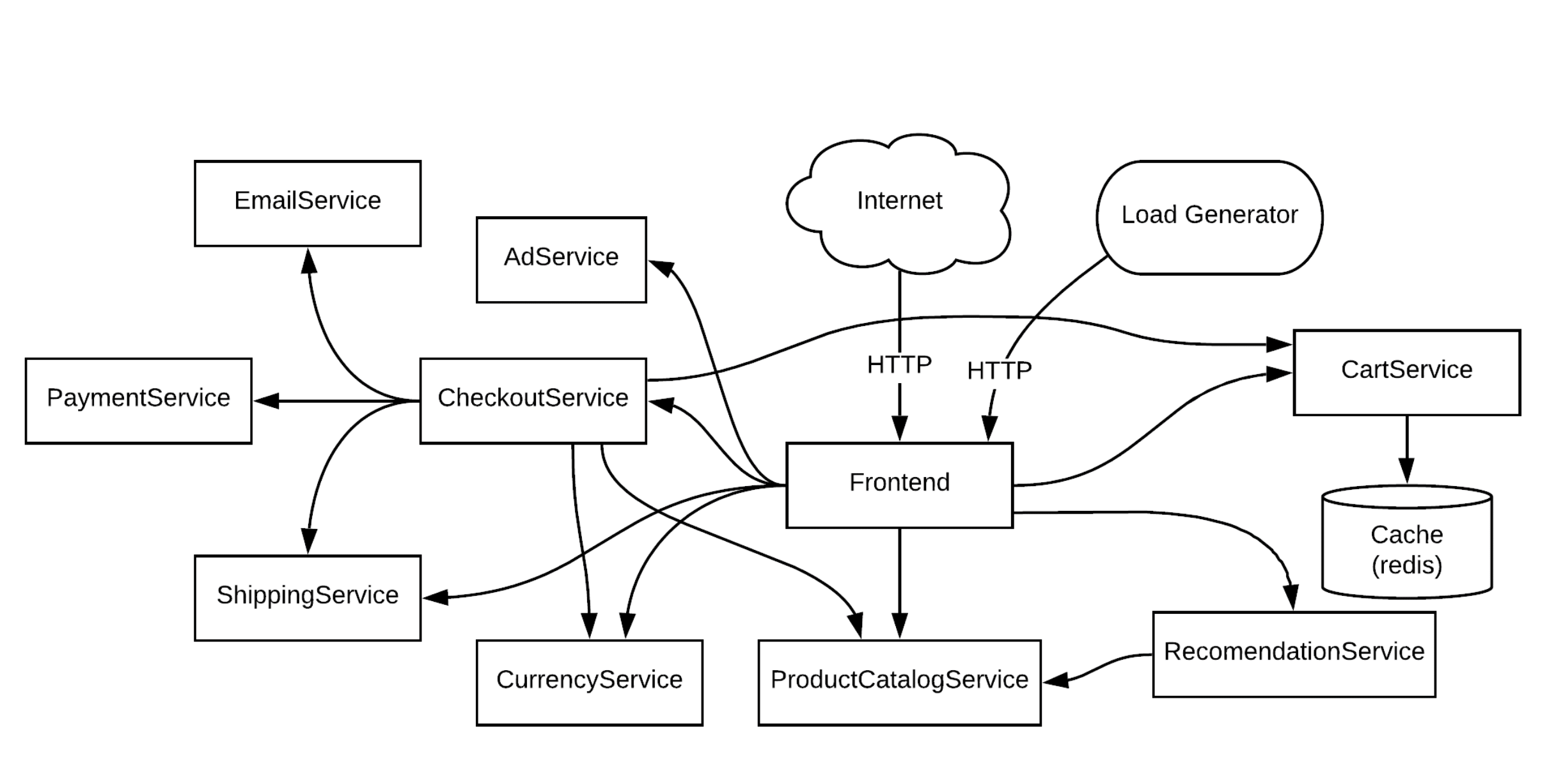
Microservices-Demo — Ссылка
Картинка с репозитория Google Cloud Platform, которая показывает микросервис-демо, там примерно 8 языков, в том числе .NET.
Представим, что у нас где-то сообщение пошло не туда, куда нужно. Как нам по-быстрому понять, что у нас, допустим, сломался CurrencyService, или ЕmailService, или ещё что-то. В данной ситуации нам нужно понять, что сломалось.
Еще есть вариант — это грепать логи (grep — это утилита для Linux, которая помогает искать по тексту). Я на своей текущей работе прошёл через этот этап, когда у нас распределённая система, мы такие: «Да, логи нам помогут». Ты два дня пытаешься грепать логи, сидишь-сидишь-сидишь, а потом понимаешь что больше или равно с меньше попутал или еще что-то.
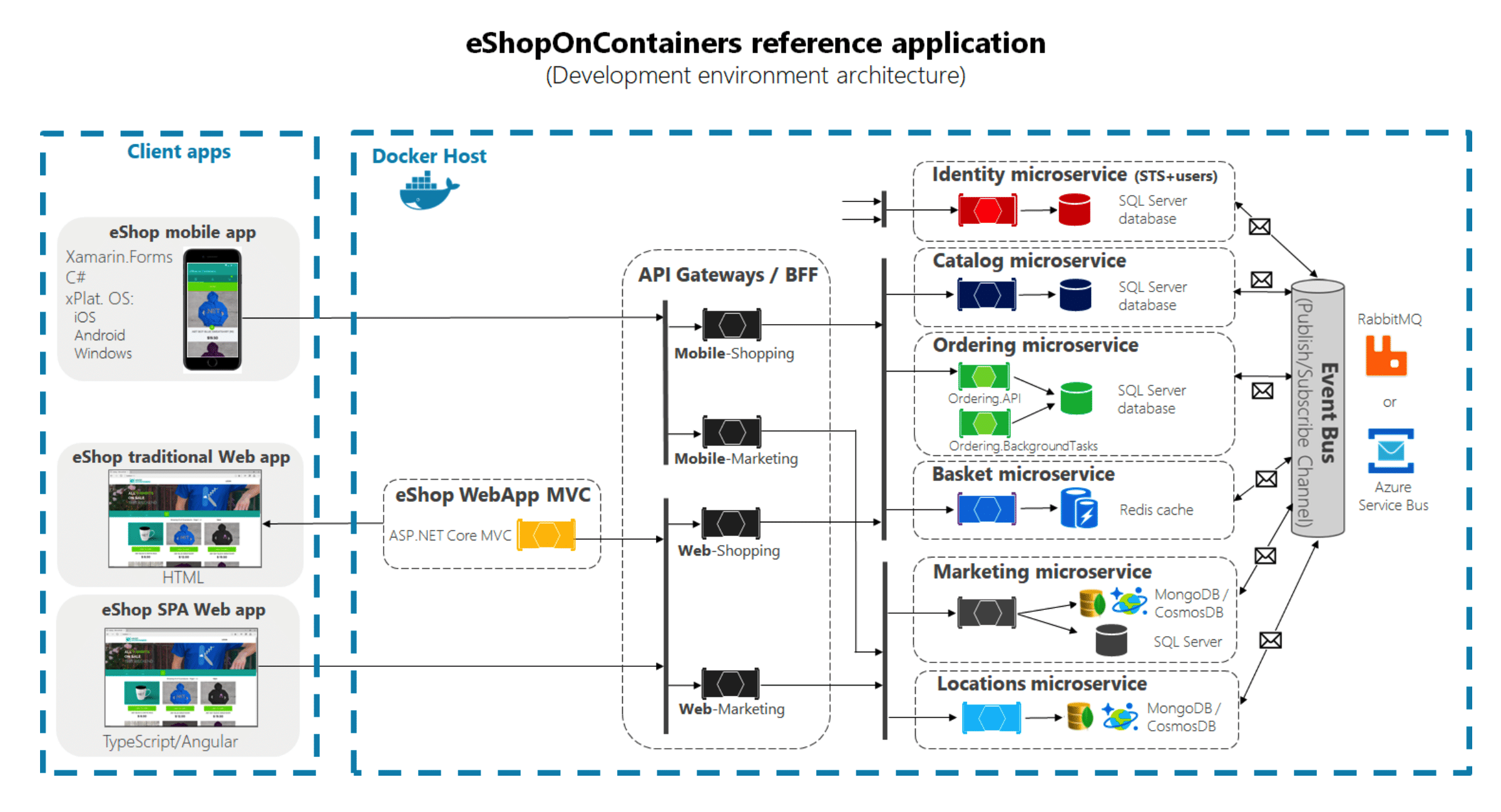
eShopOnContainers — Ссылка
Кто не любит Google — картинка из репозитория Microsoft, на которой изображено примерно то же самое. У нас какие-то есть микросервисы, что-то мы туда ходим, у нас мобильное приложение, web-shop. А если что-то сломалось, как нам понять?
Чтобы это всё можно было предсказать и повысить наблюдаемость системы с точки зрения девелопера, существуют три столпа observability, и они основаны на трех общеизвестных понятиях — логи, метрики и трейсы.
Что такое Trace
Я позволил себе своровать картинки из репозитория Jaeger — продукта, о котором я буду рассказывать. Давайте представим: у нас есть 5 микросервисов, которые пронумерованы латинскими буквами от A до E. Для того, чтобы вам понять, как сообщение течет по вашей системе, вы присваиваете какой-то уникальный Trace ID.
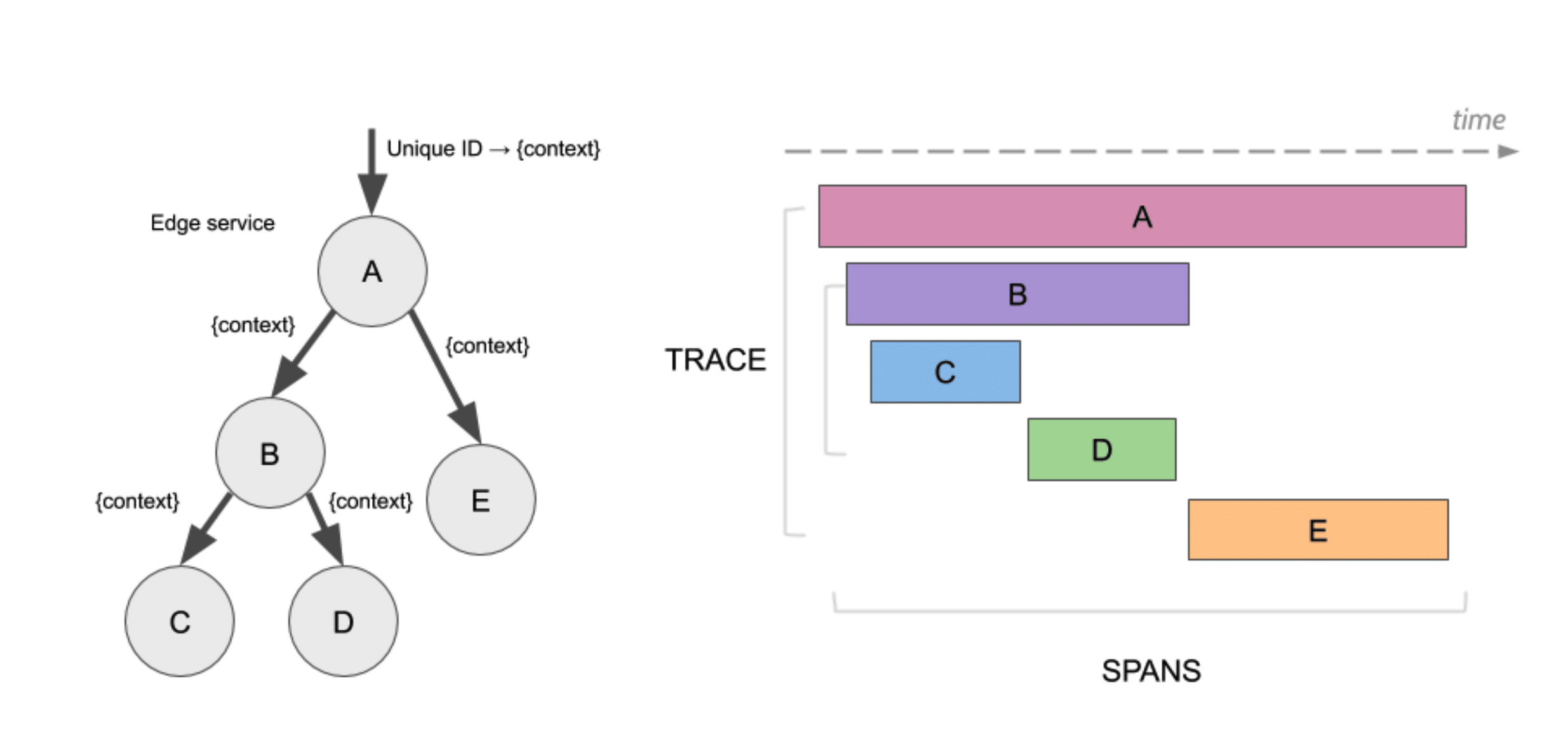
Сообщение пришло в вашу систему, допустим, на Nginx или майкрософтовский веб-сервис, вы присвоили GUID, и этот GUID ходит по системе, и потом вы можете собрать его путь. По сути трейсы — про это.
Трейсы — про то, как ваше сообщение пройдет через систему, и вы сможете это визуализировать. В картинке выше запрос пришел в A, потом пошел в B, потом пошел в C, после C он пошел в D, и потом он завершил свое выполнение в E. Мы видим, что у нас время течет слева направо, и мы имеем какое-то вложенное дерево вызовов, видим его вложенность.
Давайте посмотрим на более реальном примере.
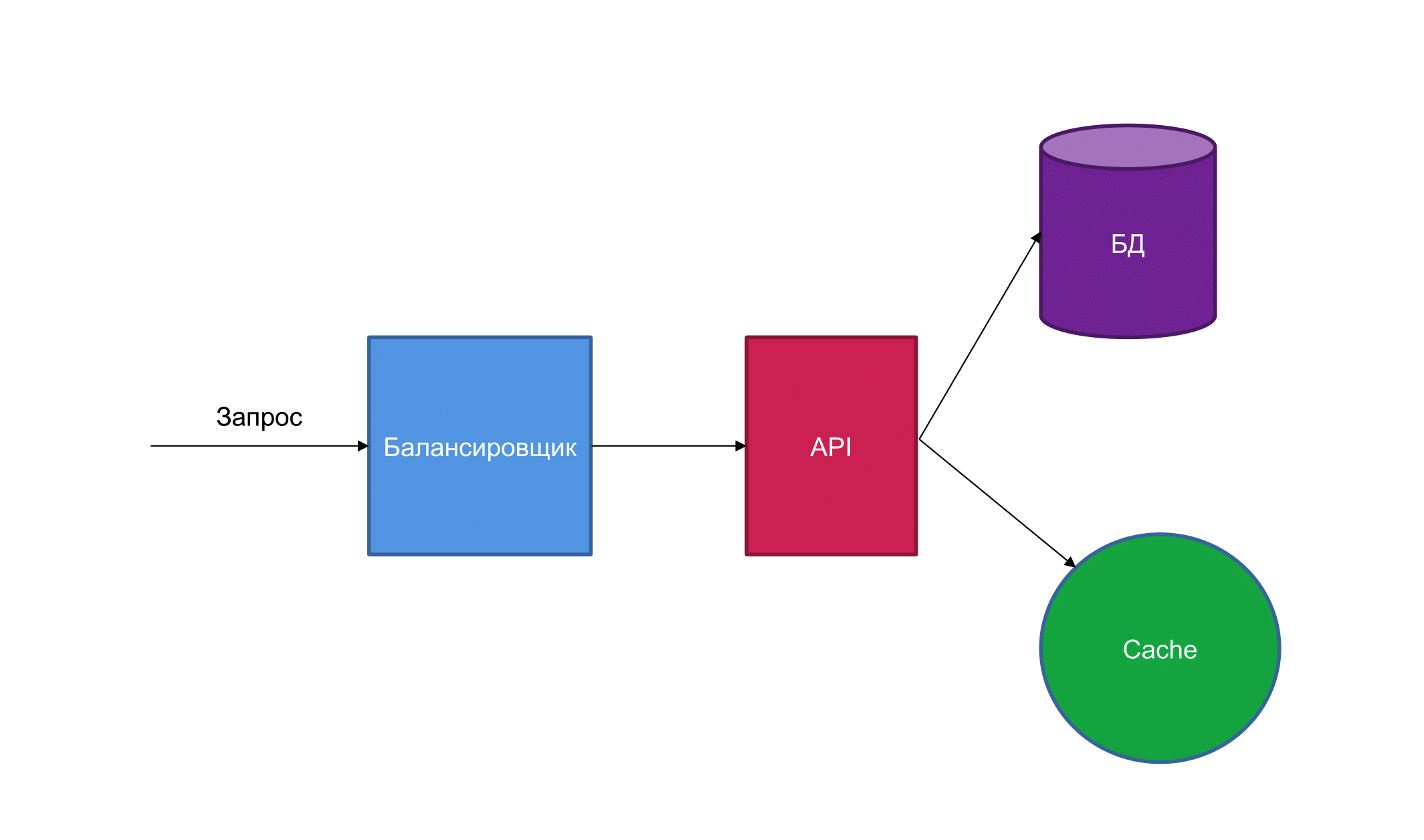
У нас есть запрос, он куда-то приходит в балансировщик, потом приходит в API, из API он может пойти в Cache, — если не найдет в Cache, он пойдет в БД. Если мы нарисуем trace этого запроса, он будет выглядеть примерно так.
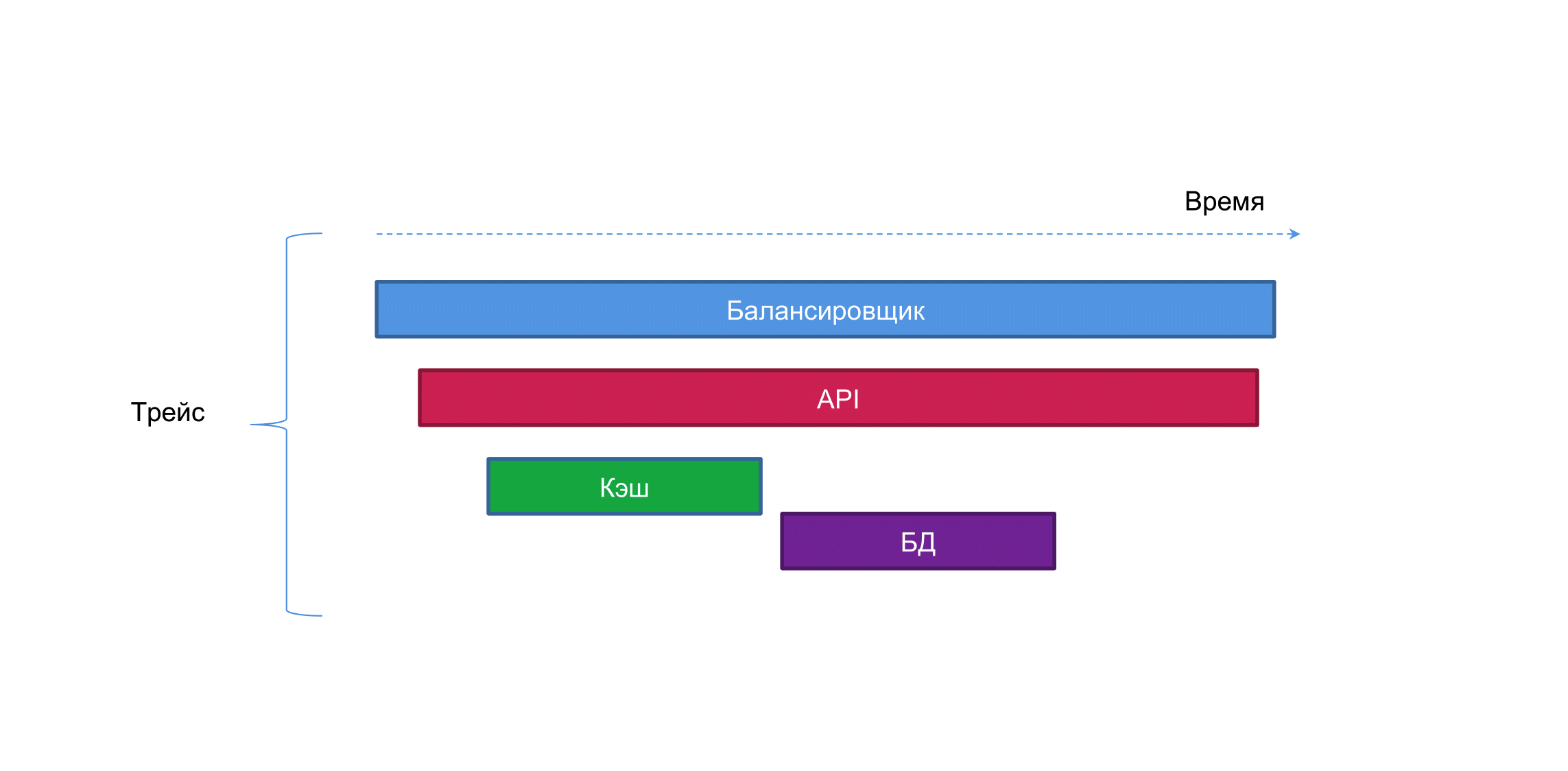
При этом хочу обратить внимание, что каждый из этих прямоугольников называется span-ом. Span — это идентификатор какой-то операции, который говорит «Вот ты меня вызвал в этом месте, всё, что после меня исполнялось там дальше, а я занял какое-то время». Он позволяет нам понять, сколько у нас выполнялся запрос.
Запрос пришел на балансировщик, балансировщик открыл span и передал запрос API. API в свою очередь открыл span, передал запрос Cache. Cache такой: «У меня нет, сорян». И API такая: «Ну ладно, пойду к БД». Сходила к БД, вернула и говорит: «Я закрываю свой span» и отдает запрос назад балансировщику. Балансировщик: «О, я получил наконец-таки ответ» и возвращается назад.
В визуальном виде мы можем получить картинку, которая отображает наш запрос. Причем отображает наш запрос понятно, так как мы можем посмотреть, сколько какой этап занимал времени, можем посмотреть, куда он пошел, как он пошел и зачем он пошел.
Добавлю, что span существуют не только на уровне компонентов, они существуют на уровне репозиториев, контроллеров, не только на уровне сервиса. У вас может быть два сервиса, и вы в каждом методе можете вызывать span и примерно смотреть, как запрос путешествует даже по вашей системе.
Как всё развивалось
В 2010 году Google опубликовал такой paper, который называется Dapper — высоко эскалируемая система распределенных трейс-меток. Это не тот Dapper, о котором вы думаете, это не ORM, это метрики.

Основываясь на этом paper-е в 2012 году компания Twitter сделала такую систему, которая называлась Zipkin. Zipkin был написан на Java, он и сейчас написан на Java, несколько раз переписывался.
Distributed-systems-tracing-with-Zipkin — Ссылка
В 2012 не существовало такой штуки, которая сейчас называется Cloud Native Computing Foundation. Это такая Foundation, в которую заносят деньги большие компании, и суть его заключается в том, что она поддерживает проекты, которые позволяют строить Cloud Native приложения.
Если совсем просто, на приложения, которые можно обернуть в Docker, запустить в Kubernetes и безболезненно проэскалировать.
Zipkin был написан в 2012 году, у него была не совсем удачная архитектура, его было болезненно разворачивать, и была одна большая проблема. Она заключалась в том, что когда у вас есть система сбора чего-то, вам нужны клиентские библиотеки под разные языки.
Twitter не поддерживал официальные библиотеки под все языки, у него была библиотека под Java, а всё остальное было в open source.
Немного ранее 2012 года на свет появилась компания Uber. В 2015 году компания Uber столкнулась с проблемой, что у них больше 500 микросервисов, и эти микросервисы написаны на разных языках: на Go, на Python, на Java.
Они начали имплементировать Zipkin и столкнулись с проблемами в конфигурации, с проблемами в том, что клиентские библиотеки работали не так, как им нужно. Когда есть большая компания, у неё есть проблема и у нее есть деньги, она пишет свой велосипед. Этот велосипед называется Jaeger. По картинке можно понять, что он написан на Go.

Он представляет из себя решение, которое позволяет вам собирать распределенные метрики ваших решений.
При этом он построен так, что его можно модульно конфигурировать, у него есть официальная поддержка под кучу разных языков. Uber специально для создания Jaeger создал отдельный департамент в Нью-Йорке, создал много библиотек и посадил команду, которая отдельно занимается всей этой историей.
Посмотрим небольшое демо:
Ссылка на демонстрацию (16:22-33:18)
Live-кодинг
У меня есть простой проект.
Ссылка на демонстрацию (16:22-17:18)
Он состоит из трех микросервисов. В них есть по простому контроллеру.
Что делают эти контроллеры? Они считают — 1, 2, 3. Микросервис 1 возвращает 1, делает запрос ко второму, а потом коннектит запрос второго к слову «первый» и возвращает. Есть микросервис 2, который делает то же самое, но возвращает слово «второй». И есть третий микросервис, который делает всё то же самое и возвращает слово «третий».
Я хотел показать, как легко запустить Jaeger.
Ссылка на демонстрацию (17:18-18:34)
Дело в том, что мы очень часто сталкиваемся с тем, что нам сложно что-то начать использовать, особенно если речь заходит про инфраструктуру или разворачивание чего-то.
Дело, конечно, становится всё лучше, но мы постоянно сталкиваемся с проблемой, что чтобы начать что-то использовать, нам надо потратить два дня. В случае с Jaeger вы можете стартануть, просто выполнив команду docker run. Я специально вынес эту команду в readme, она есть в официальной документации и она доступна в репозитории, который я создал для DotNext.
Эта команда запускает образ, который собирает в себя все компоненты Jaeger. Так как он полностью модульный, там несколько docker-образов. Запуском этой команды мы запускаем docker docker-образов, который полностью поставляет нам готовое к использованию решение.
На моем текущем месте работы мы так и делаем: у нас есть такой специальный ssh-файл, который называется «монитор SSH». Мы его запускаем, он нам запускает метрики и запускает вот так Jaeger, который хранит все данные у нас в мемори, и когда он он умирает, мы его заново запускаем и всё. Для локальных целей разработки более чем достаточно.
Ссылка на демонстрацию (18:34-19:14)
Все эти порты нужны для того, чтобы поддерживать разные варианты отправки трейсов. В Jaeger есть такая фича, после того, как они столкнулись с проблемой c Zipkin, они поддержали на определенном моменте обратную совместимость с Zipkin. Они заявляют, что если в вашей инфраструктуре есть Zipkin, вы ничего не меняете, просто переключаете трафик на Jaeger, и у вас всё заработает.
Давайте запустим этот файл. У меня уже скачан образ. Он запустился, качается он примерно секунд 30, то есть он не очень большой.
Ссылка на демонстрацию (19:14-19:32)
Так как для просмотров трейсов, нам нужен UI, я специально в readme вынес адрес, по которому мы можем посмотреть, давайте по нему перейдем.
Ссылка на демонстрацию (19:32-20:00)
У нас откроется чудесный UI, в котором на данный момент нет ничего по понятным причинам, потому что мы ещё ничего не отправили, но по сути это дефолтное средство для просмотра трейсов. Мы можем выбирать какие-то сервисы, мы можем выбирать специфичные операции, можем фильтровать по всяким штукам, искать и так далее.
Для запуска решения я написал отдельный файл, в котором нет никакой магии. Оно убивает предыдущий запуск, потому что, что-то было запущено и просто стартует наше первое, второе и третье решение.
Ссылка на демонстрацию (20:00-20:49)
Мы видим чудесный выпуск скрипта, видим, что я где-то написал async и забыл await, всё нормально. А теперь .NET стартует. Мы видим, что всё стартануло.
Попробуем отправить запрос.
Ссылка на демонстрацию (20:49-21:10)
Для этого я использую curl, потому что у нас максимально простая API.
Первый, второй, третий запросы пошли по системе, давайте посмотрим, что произошло с Jaeger.
В это время в Jaeger у нас появилось 3 микросервиса, и мы можем посмотреть, что с ними происходило.
Ссылка на демонстрацию (21:10-23:11)
Мы сразу видим, что наш запрос занял примерно 500 миллисекунд. Повторим его.
Обновим Jaeger и видим, что один запрос у нас занял где-то 500 миллисекунд, а второй занял уже 16 миллисекунд. Повторим третий раз.
Видим, что запросы проходят всё быстрее и быстрее. Первый запрос самый долгий, дальше всё идет побыстрее. Провалимся в запрос и посмотрим, что в нем происходило. Эти штуки по сути отображают полную жизнь одного запроса. Я запустил get-запрос, он провалился в систему, прошел по микросервисам, вернулся — теперь каждый из этих запросов отображается в UI.
Провалимся в него и увидим картину со span.
Мы видим, что у нас запрос типа get, он пришел в первый микросервис, выполнил какие-то действия, потом он прошел во второй микросервис, выполнил какие-то действия, прошел в третий микросервис начал, вернул какие-то действия, написал какие-то логи, причем логи достаточно подробные, это одна из фичей библиотек, которые подключаются. Потом у нас вернулся результат.
Мы видим, что запросы были вложенные, нигде не было параллельных запросов, мы сначала прошлись по первому, потом прошлись по второму, потом прошлись по третьему.
Посмотрим другую фичу Jaeger, которая называется построение графа зависимости ваших микросервисов. Там маленький граф из трех нод.
Ссылка на демонстрацию (23:11-23:59)
Мы можем его развернуть в нашу нормальную проекцию и увидеть, что сначала запросы пришли в первый микросервис в количестве трех штук, потом провалились во второй микросервис в количестве трех штук и дошли до третьего. Мы можем построить карту наших микросервисов и посмотреть, как запросы ходят по системе — это достаточно круто.
Перейдем к коду и посмотрим, как я это всё подключил. Для этого перейдем в Startup.c.s первого проекта.
Ссылка на демонстрацию (23:59-26:00)
Чтобы Jaeger заработал, нам нужны 2 набора библиотек или 2 библиотеки. Первая из них Jaeger, вторая из них OpenTracing.
Подключаем OpenTracing в проект и регистрируем такой интерфейс, который называется Tracer, который помогает нам строить эти трейсы. Мы берем имя приложения, создаем трейсер из библиотеки Jaeger, регистрируем его глобально.
Так как это регистрация для Dependency Injection ASP.NET Core, у нас может быть какой-то код, где мы тоже хотим использовать trace, где у нас нет инъектора, для этого у нас есть статические классы. Возвращаем имплементацию и пользуемся.
AddOpenTracing добавляет стандартные обработчики для логирования, для ASP.NET Core. Мы добавляем логи для ASP.NET Core, для CoreFX, для EntifyFrameworkCore и так далее. Чтобы заработали все те трейсы, что я показал, достаточно выполнить этот код и запустить Docker run.
Даже с поиском документации в первый раз у меня это заняло где-то минут 30 — всё заработало и было классно.
Я хочу вам показать, что я ничего в первый Controller не прописывал. Вот первый репозиторий, какой-то код, HTTP-запрос, и при этом всё работает — просто магия, всё чудесно.
Ссылка на демонстрацию (26:00-26:53)
Немного накрутим наше решение и продемонстрируем, что Jaeger у нас на самом деле кроссплатформенный. Я написал вражеский сервис или Alien, чужой сервис, который работает на Go и который тоже в себе содержит Jaeger.
Запустим решение и посмотрим, что произойдет. Запускаем и видим, что Go у нас немножечко стартанул, потому что там ничего нет. .NET тоже стартанул. Давайте опять отправим запрос.
Мы стартовали сервис, но он же не принимает у нас ответы.
Ссылка на демонстрацию (26:53-27:27)
Настало время того кода, который я вам показал до этого. У нас есть третий микросервис, и теперь он будет посылать запрос на Alien микросервис.
Ещё раз перезапустим наше решение, ещё раз введем пароль. Всё заработало без пароля, чудесно. Дождемся, пока всё запустится. Выполним запрос.
Мы видим, что запрос поменялся, он ушел в Go.
Посмотрим, как это всё отобразилось Jaeger.
Ссылка на демонстрацию (27:27-28:04)
Мы видим, что у нас появился четвертый запрос, в нём появился Alien, видим, что он опять у нас занял примерно 600 миллисекунд, видим, что он появился в span-е, видим, что он выполнен другой версией Jaeger для языка Go.
Там тоже достаточно просто подключается библиотека, это почти всё работает из коробки.
Немного поиграем со span-ами. Я вам показал только базовые возможности, но мы можем сделать много всего интересного. Для этого в конструктор я заинжектил интерфейс, который называется ITracer, который я вам уже показывал, который мы регистрировали.
Ссылка на демонстрацию (28:04-29:20)
Скажем, что мы хотим какой-то свой чудесный span, в которой напишем лог.
Пишем tracer, build span: «я новый span». Потом на Span пишем Log. Это такое средство, которое позволяет нам добавить информацию Span, которую мы увидим. Давайте напишем: «Я новый чудесный Log». Запускаем приложение.
Ничего с этим не поделать, мы же пишем на javascript, нам перекомпиляцию надо, перезапуститься, подождать. Оно всё конечно быстрое, но…
Снова делаем запрос. Он прошёл, давайте посмотрим, что получилось.
Ссылка на демонстрацию (29:20-30:30)
Мы добавляли в код. Ничего не произошло. На самом деле это очень важная штука, на которую я натыкался много раз и захотел отдельно вынести — Span надо закрывать.
Надо всегда, вне зависимости от языка и конструкций, писать span.Finish. Если это не сделать, span повиснет и не отобразится. Перекомпиливаем.
Ссылка на демонстрацию (30:30-30:40)
Выполняем запрос, идем в Jaeger, ищем новый span, и видим — «Я новый лог». Мы чудесно сообщили себе, что происходит внутри кода.
Ссылка на демонстрацию (30:40-31:38)
Для Jaeger покажу последнюю прикольную фишку, которая меня тоже пару раз спасала — называется SetTag и в ней мы пишем:
span.SetTag(“error”, true);Она поможет красиво отображать ошибки, например, чтобы анализировать span, когда случается что-то нехорошее. Вы пишете вот так, перекомпилируете решение, отправляете curl-запрос, идете в Jaeger, обновляете trace и видите, что случилось.
Например, «Я новый спан» сломался, с ним что-то не так и нужно что-то делать. Очень красноречиво и помогает фильтровать snap, работать с ними.
Самая прикольная фича Jaeger, которая мне нравится — это сравнение запросов.
Ссылка на демонстрацию (31:38-33:18)
У нас есть два запроса: один с alien, второй без. Мы знаем, что ни разные, но, допустим, у нас trace на 500 span-ов, и мы хотим их сравнить.
Переходим на страницу Compare, берем id, пишем слева, потом берем второй span, id, и видим, что они различаются. У меня перестал работать скролл — это проблема.
При приближении вы сможете увидеть разницу ваших запросов. Можно увидеть, что у нас все запросы шли одинаково, а потом после третьего один сразу возвращает результат, а второй еще куда-то уходит, что-то делает и это достаточно странная штука.
Очень помогает при дебаггинге, пару кейсов я решил с помощью этого тулы.
Это базовое демо, его достаточно для включения Jaeger в ваши проекты. Когда вы в первый раз построите карту микросервисов, если ещё не построили — скажете «Вау!» и увидите, какие-то сообщения уходят не туда.
Как это все работает
На самом деле все работает примитивно.
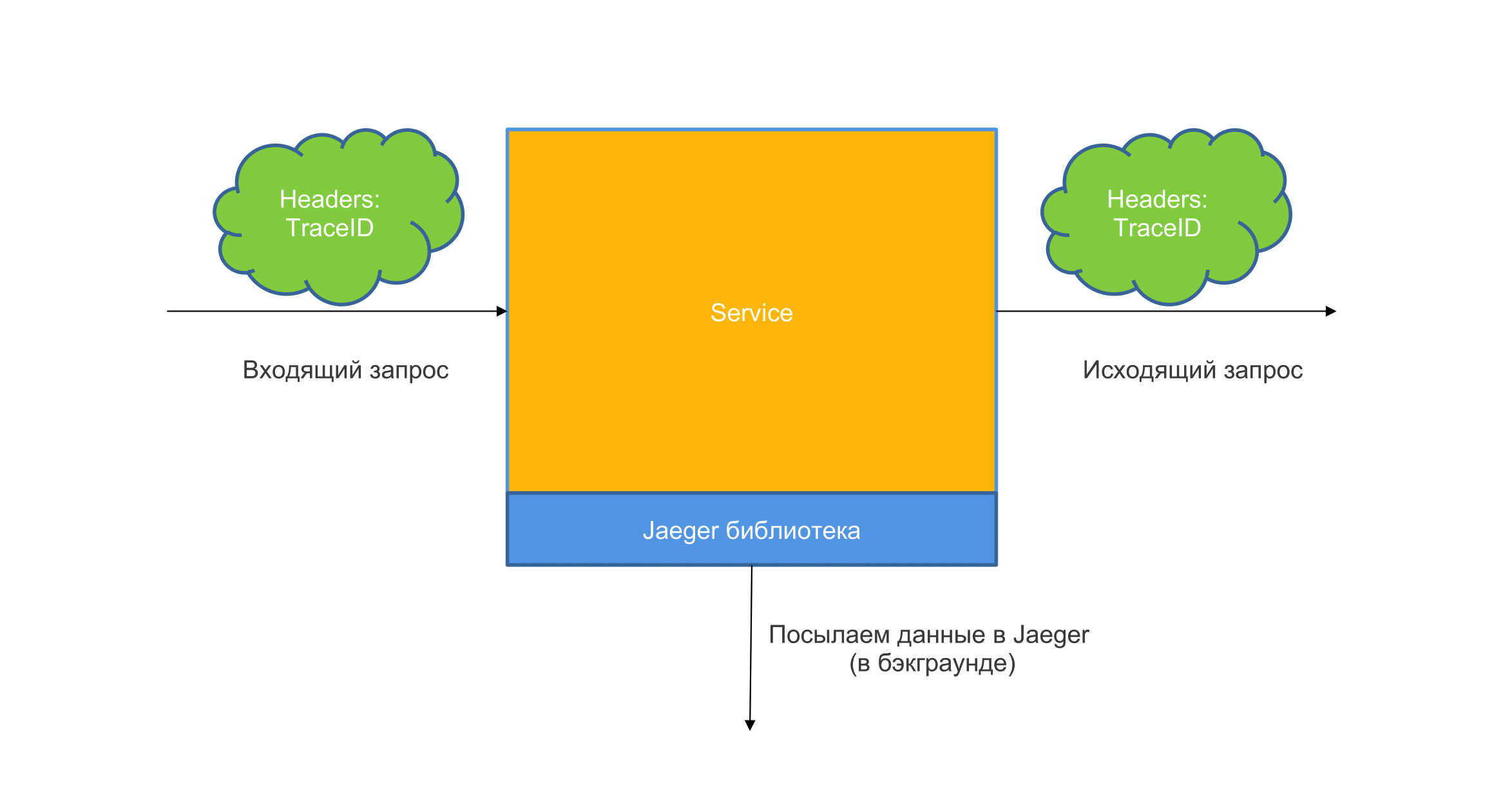
У нас есть какие-то запросы, мы таскаем с ними информацию, которая характеризует этот запрос, и отправляем это куда-то в бэкенде. Когда запрос приходит в систему, первый микросервис, в который включен Jaeger, и в вашем коде включен Jaeger, он просматривает header. Есть trace id у header, если он есть — Jaeger парсит его для себя, если нет — создает новый.
Все наши запросы просто таскаются с header id, это где-то 16 символов, захешированная строка. Она путешествует на вход, на выход, и потом в бэкграунде отдельной библиотекой отправляются в коллектор, который помогает в отображении этого всего.
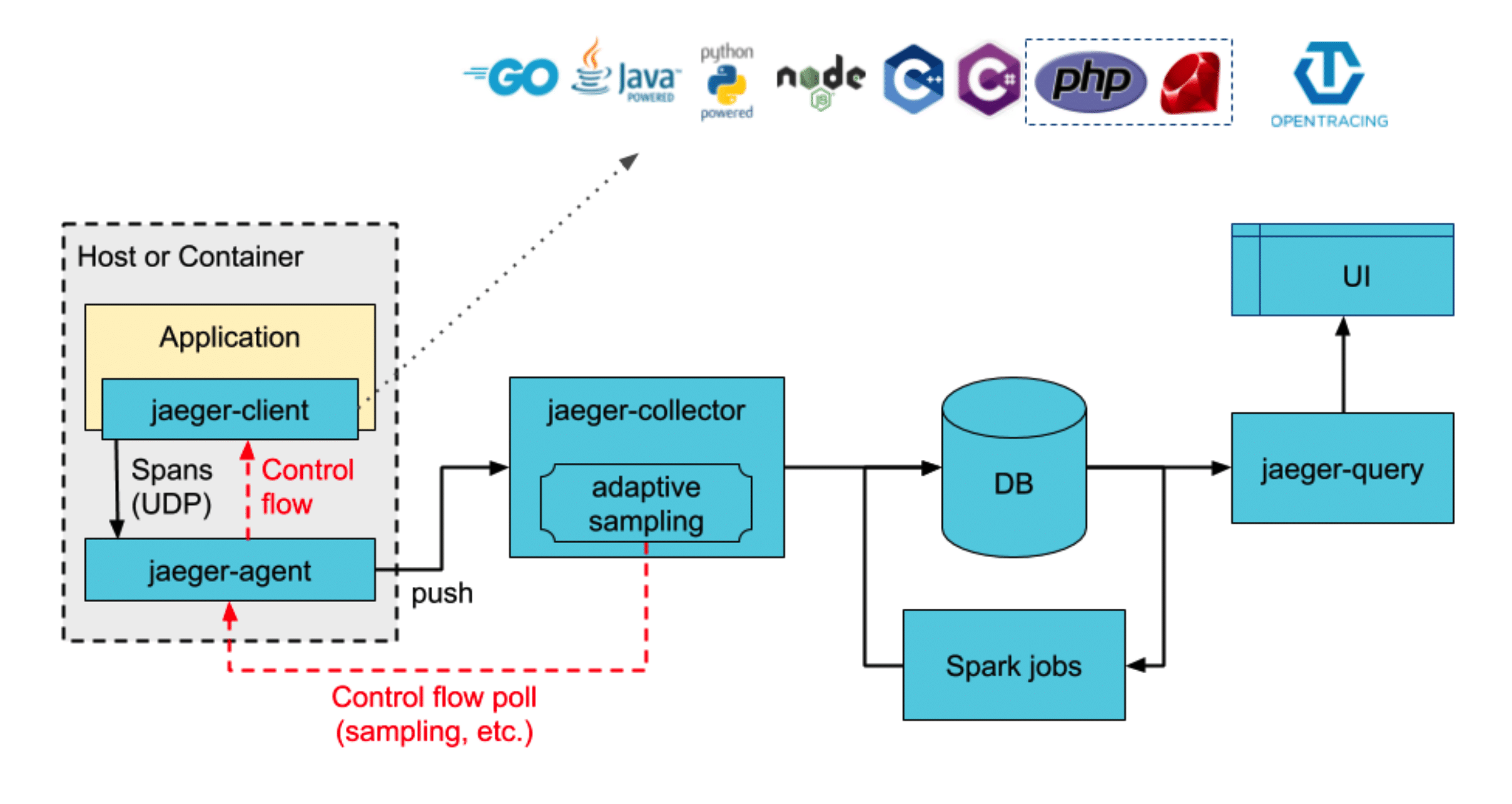
В чем заключается модульность структуры Jaeger: в Jaeger есть 4 важных части. Это клиентская часть, это коллектор, DB-часть и UI.
Клиентская часть — это ваше приложение, в котором вы включаете какой-то код (подключаете библиотеку), которая информацию о span-ах включает в Agent.
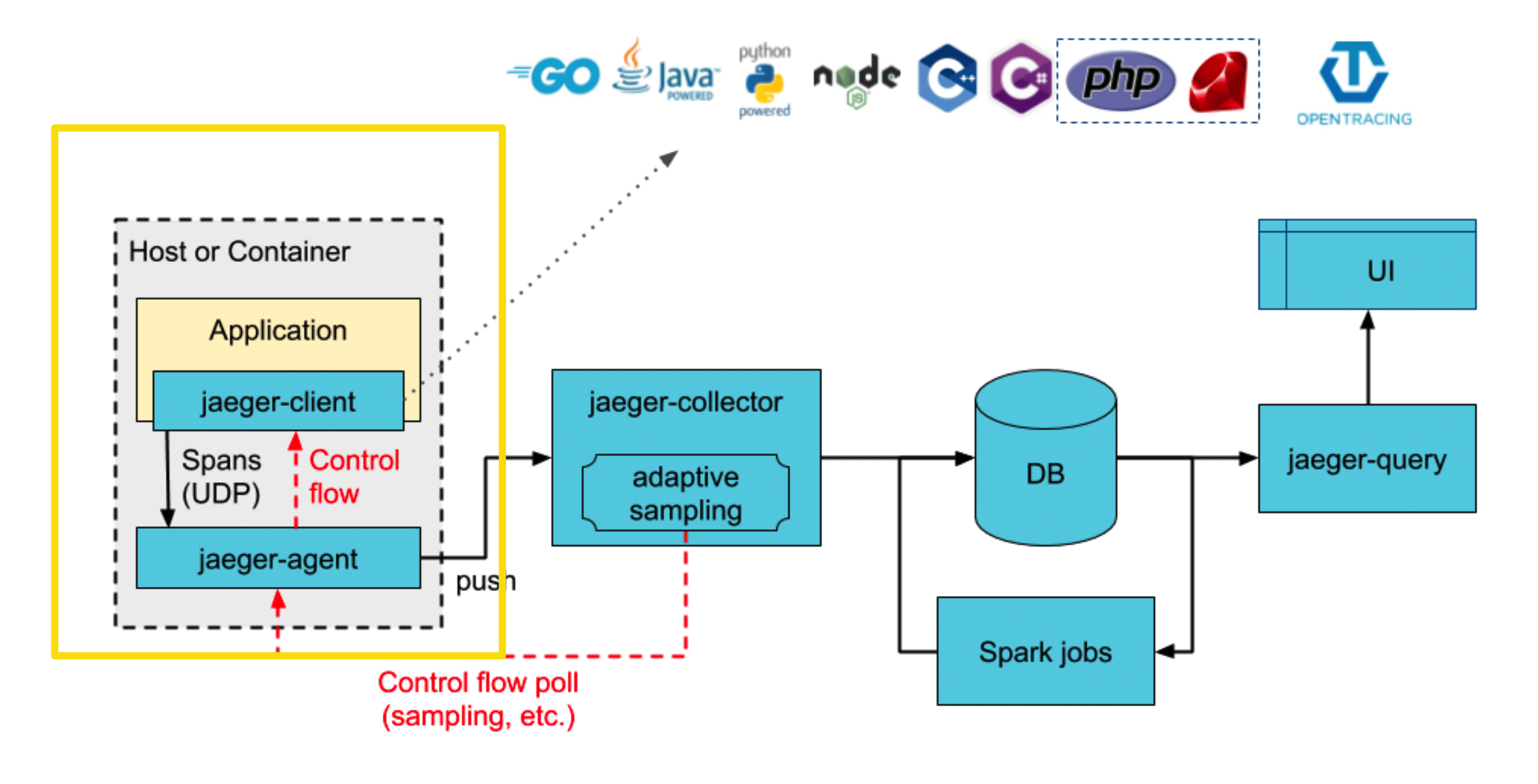
В agent она шлет по UDP и предполагается, что этот agent будет развернут у вас в sidecar, рядом в docker, или на той же машине. Оно посылается по UDP, по быстрому loopback и клиентское приложение почти не грузится — мы не получаем никаких проблем с производительностью из-за отправки куда-то span-ов.
Далее Jaeger-agent по gRPC отправляет это в collector.
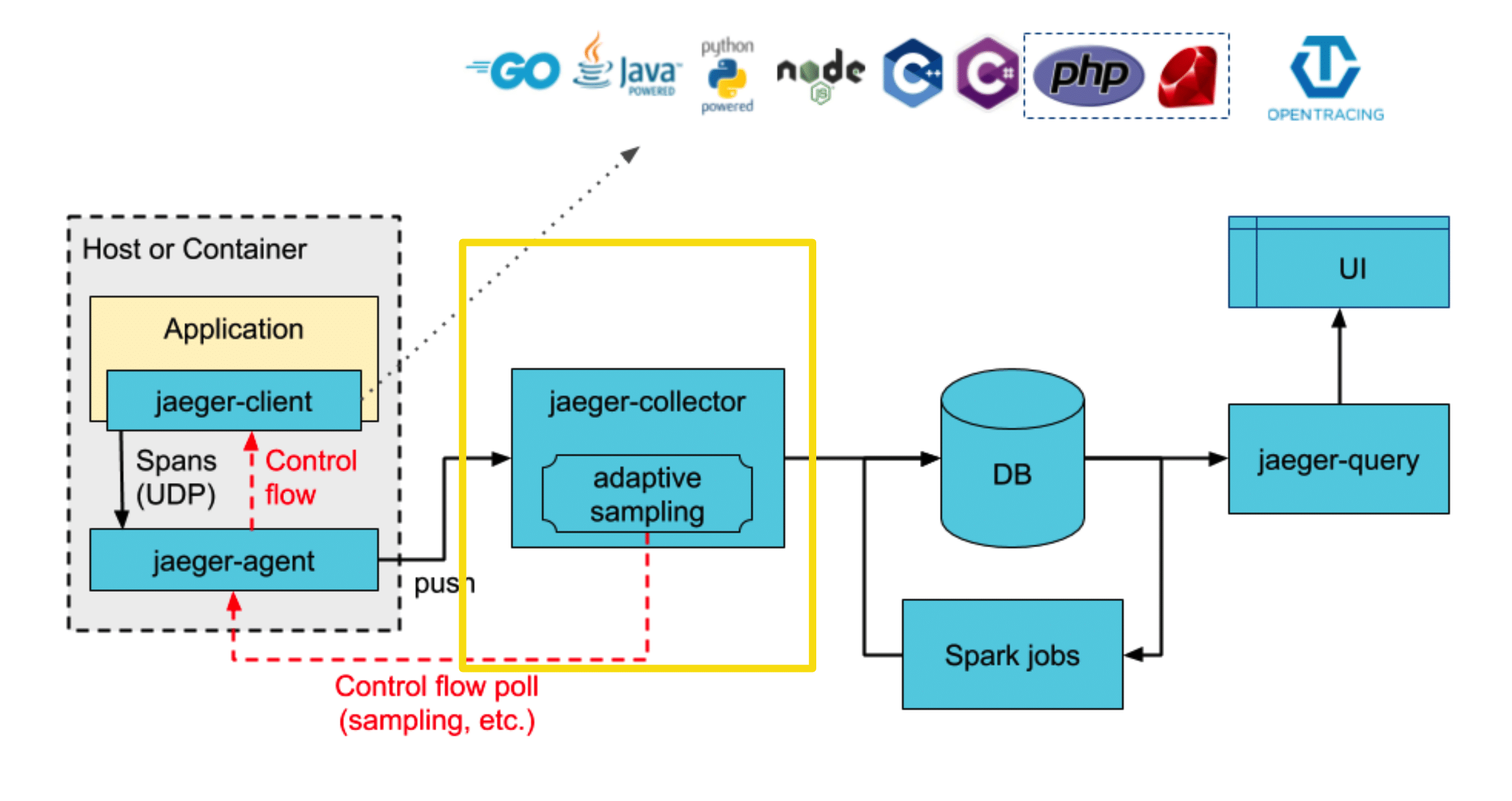
Это такая «умная» штука, которая сортирует span, складывает их, работает с ними — то есть в него льются потоки данных, а он их льет в базу. В то же время коллекторы — это такая штука, которая может хранить удаленные настройки.
Вы написали настройки, поставили кучу сервисов и когда сервисы подключаются к коллектору — они читают настройки и просто работают по ним. Сейчас они очень много работают над адаптивными настройками, чтобы в зависимости от течения трафика у вас изменялось количество span, которые вы принимаете.
На самом деле существует проблема и в Uber, я знаю некоторые российские компании, которые столкнулись с той же проблемой: когда у вас очень много span-ов, нужно очень много железа.
Для этого существует sampling. Вы можете отправлять не каждый span и не каждый trace в бэкенд Jaeger. Вы их шлете и шлете, а сохраняется, допустим, каждый сотый или тысячный. Сейчас они очень сильно работают, чтобы сэмплинг был адаптивный и подстраивался под условия.
Следующая часть — DB.
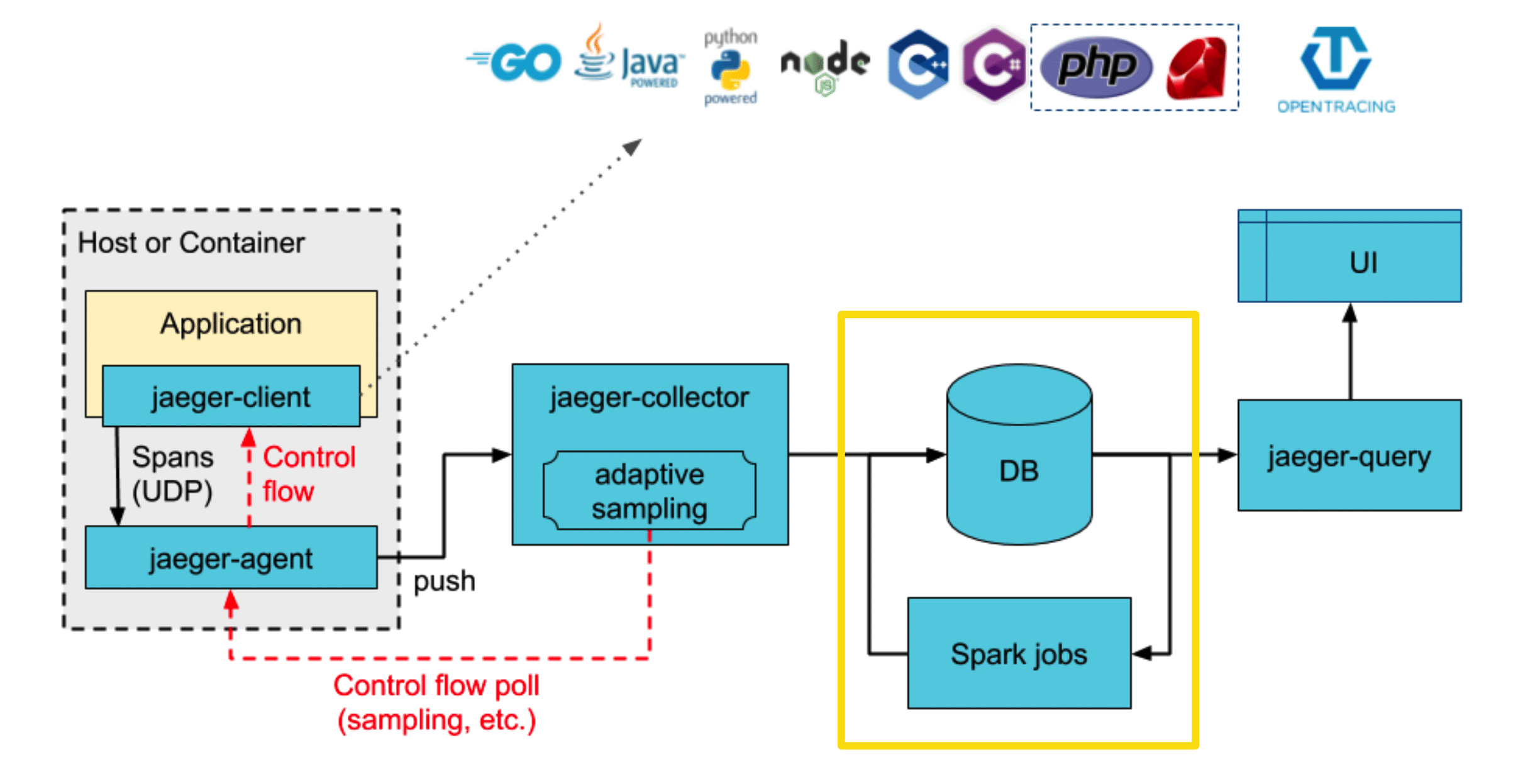
Они не стали придумывать и просто дали возможность подключать несколько внешних хранилищ. Одно из них — Cassandra. Это штука, написанная Twitter, очень быстрая на чтение и немного медленная на запись. Elasticsearch — это elasticsearch. Можно всё это запиливать в Kafka и потом как-то читать. Когда вы запускаете docker, у вас стартует memory storage, который просто складывает данные как key value в памяти.
Что происходит с данными, которые вы храните в памяти — выключаете программу, приходит уборщица из-за чего данные пропадают.
UI, который вам показал, и за ним query-движок, который строит запросы, агрегирует их, помогает отображать на UI, чтобы все было красиво.
Немного поговорим о теории.
OpenTracing
Когда я продемонстрировал вам, как Jaeger подключается к проектам, я подключил две библиотеки: Jaeger и OpenTracing.
Представим абстрактный контроллер в вакууме, ASP.NET Core. Инджектим в него какой-то репозиторий и можем поменять реализацию базы данных. Пишем репозиторий, потом мы устали от SQL-схемы или нам нужно увести нашу базу в облака, как-то меняем нашу реализацию и у нас все работает.
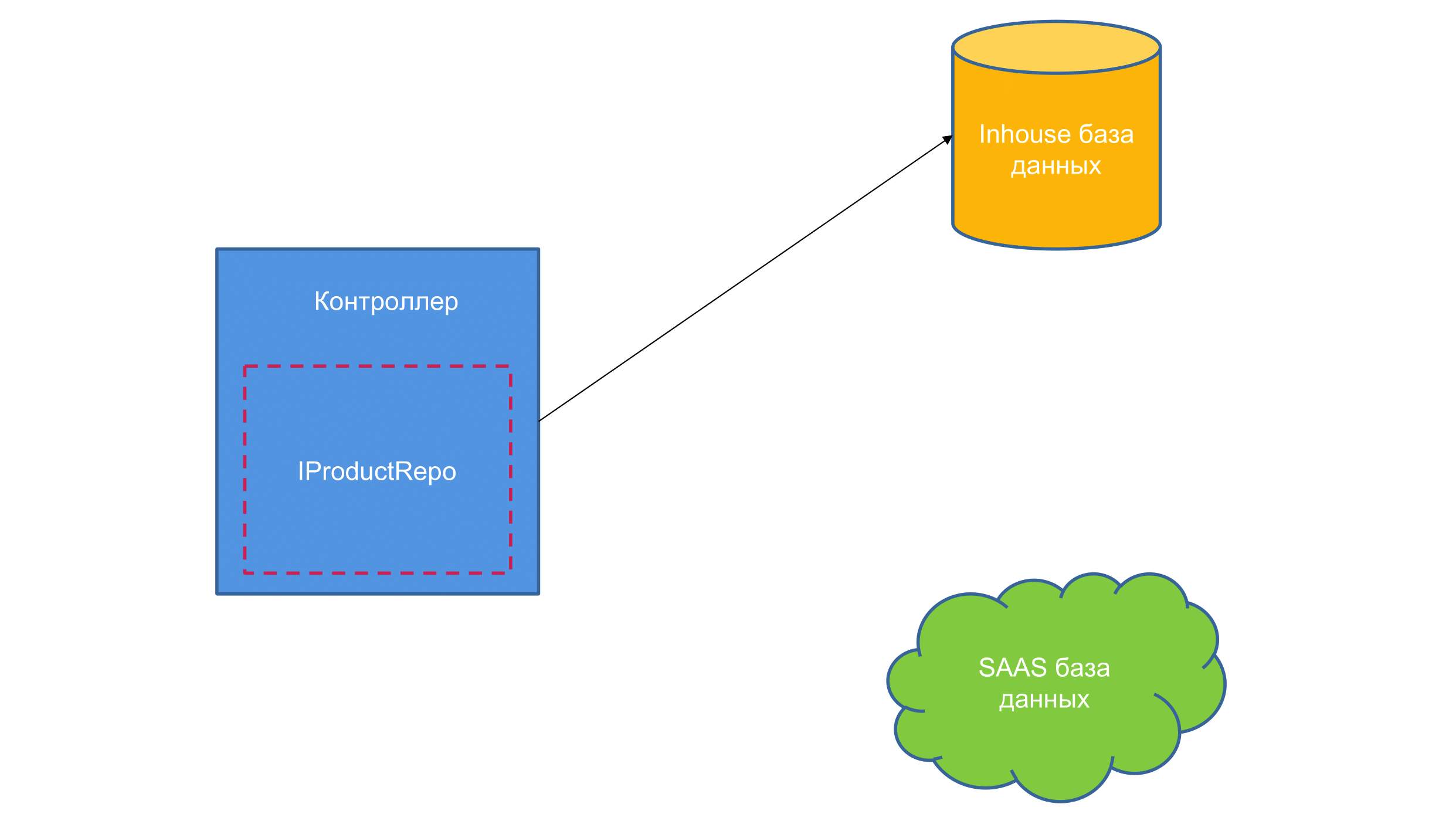
OpenTracing — это примерно то же самое. Это набор интерфейсов, абстракция, которая помогает нам работать с распределенными трассировками.
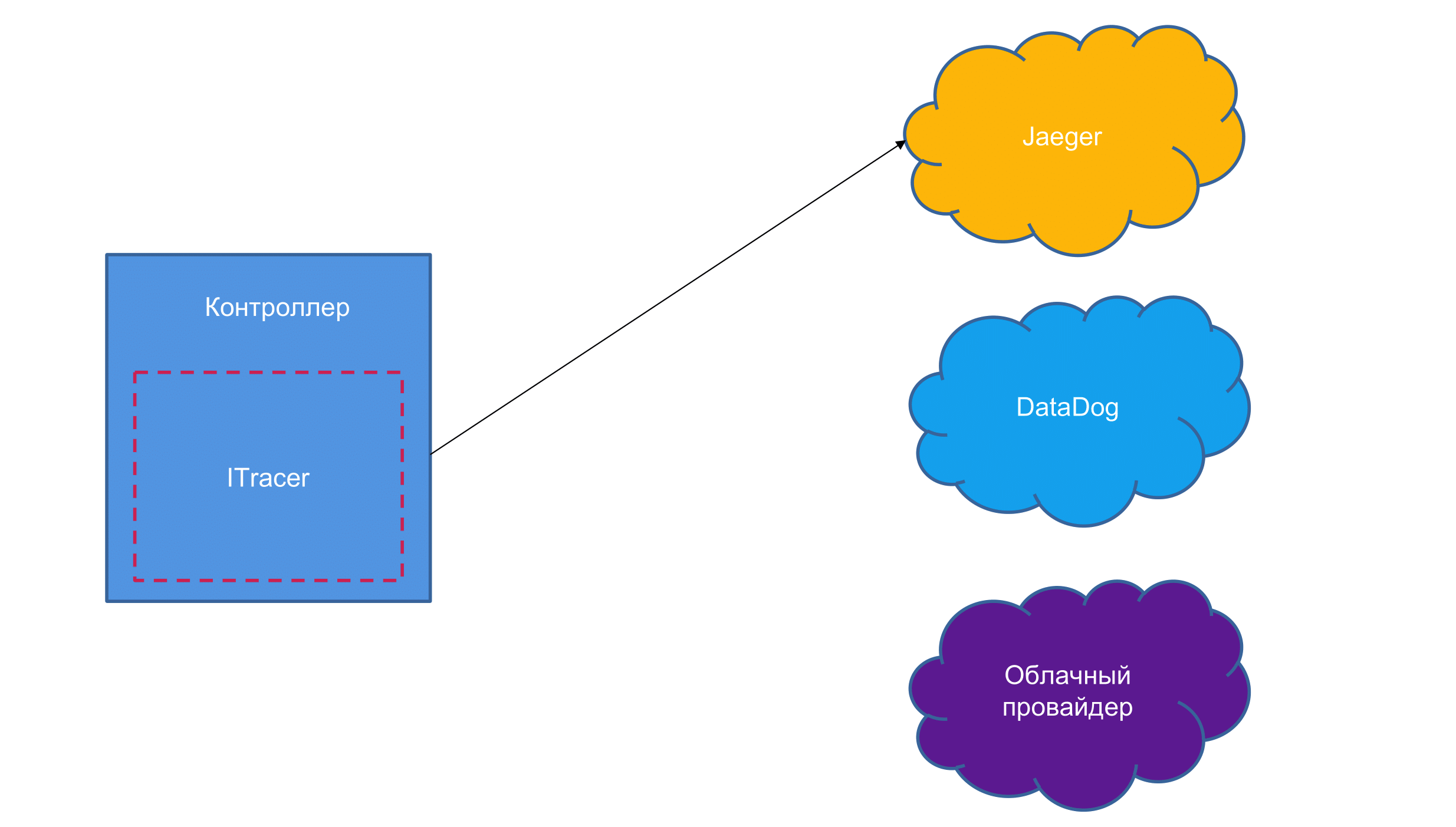
Она говорит: «Я даю тебе интерфейс, ты используешь интерфейс и не паришься, так как ты конечный потребитель, а потом, где-то там подключишь библиотеку и сможешь относительно безболезненно поменять реализацию span-ов на другого провайдера».
Мы подключили эту библиотеку и интерфейсы. Сейчас мы используем Jaeger, потом нам дали денег, и мы счастливые решили подключить DataDog. Это относительно без проблем стартует, вы вообще не будете переписывать код, только немножечко помучаетесь с конфигурациями, чтобы это все подключить.
OpenTracing — это спецификации и набор интерфейсов, которые реализуют эту спецификацию. Он существует под несколько языков, в том числе под .NET, лежит все это на GitHub, и проект, на самом деле, достаточно простой.
Он содержит набор интерфейсов и несколько вспомогательных утилит: iTracer, iSpan, который инкапсулирует работу со span-ами, интерфейсы для SpanBuilder, чтобы строить span-ы и несколько интерфейсов, связанных со scope-ами.

Рассмотрим пример:

Я заинджектил iTracer, я его как-то использую.
public interface ITracer
{
…
ISpanBuilder BuildSpan(string operationName);
…
}Интерфейс iTracer — это интерфейс, на котором определенный метод BuildSpan принимает string и возвращает другой интерфейс, который называется IBuildSpan.
Вызываем Start.

Интерфейс ISpanBuilder представляет из себя:
public interface ISpanBuilder
{
…
ISpan Start();
…
}Это интерфейс, в котором есть метод, который возвращает интерфейс.

Мы вызываем какие-то методы на следующие интерфейсы. Это интерфейс ISpan, который тоже определяет на себе какие-то методы, вот тут же этот обязательный финиш, про который стоит помнить.
public interface ISpan
{
ISpan SetTag(string key, bool value);
ISpan Log(string @event);
void Finish();
}Работаем через интерфейс: инкапсуляция, полиморфизм — вот это всё, что мы любим или не любим.
Интерфейс возвращает интерфейс, интерфейс, интерфейс… Мы работаем максимально высокоуровнево и вообще не знаем, что там происходит в бэкенде, счастливы, довольны.
Когда мы хотим подключить реализацию, просто подключаем реализацию от провайдера, который создал вам совместимость с OpenTracing.

OpenTracing — это набор интерфейсов, который лежит на GitHub и для которого разные провайдеры и создатели Trace-систем обеспечивают совместимость.
Компания Jaeger знала про OpenTracing, она такая: «окей, мои библиотеки будут совместимы с OpenTracing». DataDog — аналогично.
Я нашел 4 провайдера, которые совместимы с OpenTracing для .NET. Уже не раз упоминаемый DataDog, Jaeger, LightStep и Instana.

Чтобы поменять реализацию, нам достаточно будет подключить LightStep.Options и всё. Мы поменяли имплементацию, просто работаем с нашими интерфейсами и где-то в бэкенде поменяли реализацию.

OpenCensus
В это время в этой же галактике существовала такая компания, как Google. В своих внутренних продуктах компания использовала библиотеку OpenCensus, которую в определенный момент тоже заопенсорсила.

OpenCensus — Ccылка
OpenCensus — это open source решение, основная цель которого упростить работу с метриками, с трейсами для разработчиков. Авторы понимают: у нас столько провайдеров, у нас столько всего, мы хотим просто.

Вот это просто — это библиотека OpenCensus. Мы тоже представляем какой-то унифицированный интерфейс, который помогает нам подключаться к различным провайдерам.

Вот пример работы этой библиотеки. Он напоминает то, что я вам показывал с OpenTracing. У нас есть какой-то SpanBuilder, что-то мы там стартуем, что-то делаем и так далее.
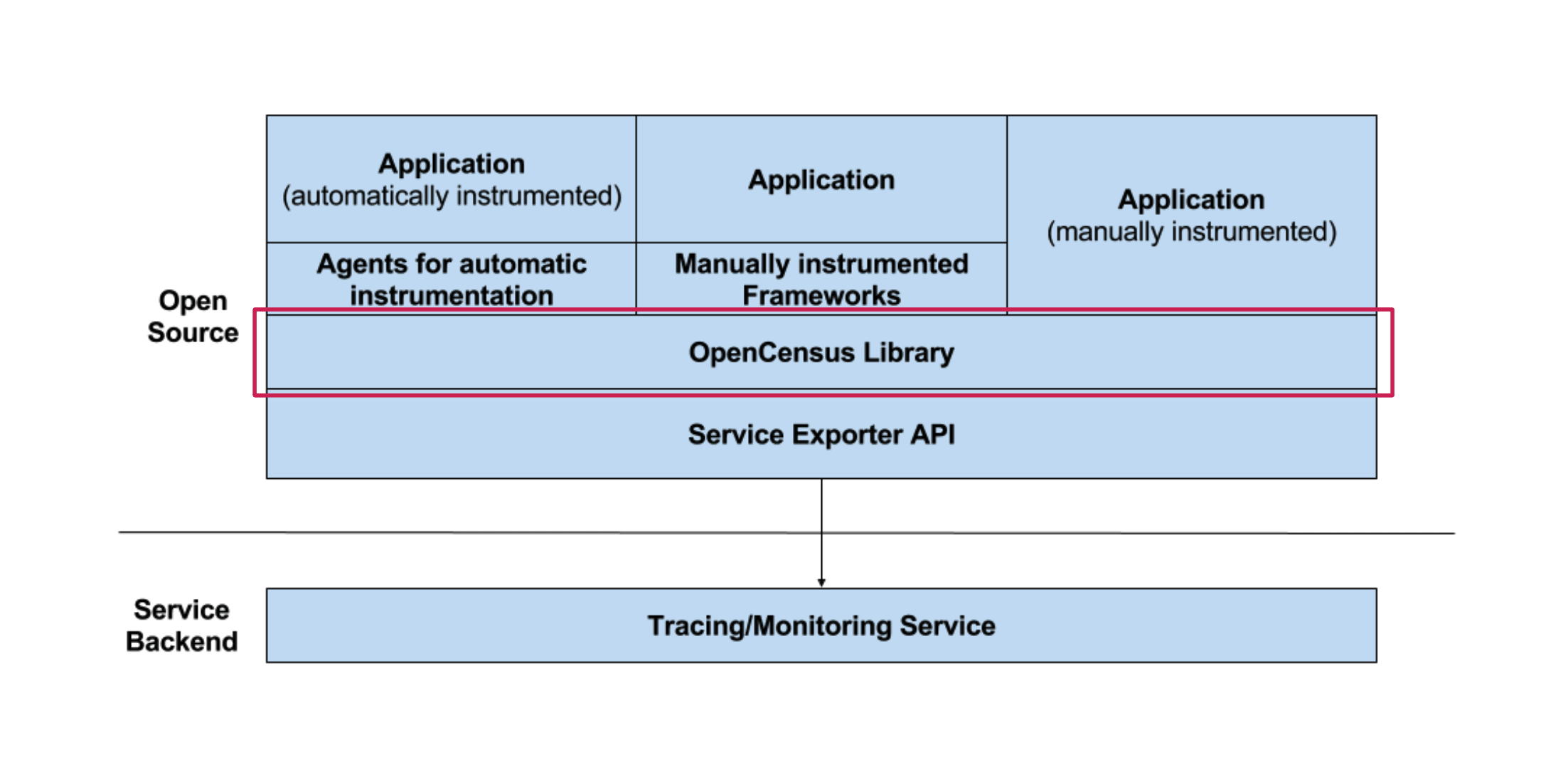
Спецификация OpenCensus — Ссылка
Реализация работает примерно похоже: у нас есть какое-то наше приложение, под ним лежат интерфейсы, мы работаем через эти интерфейсы, куда-то шлются данные, и мы вообще не паримся об этом.
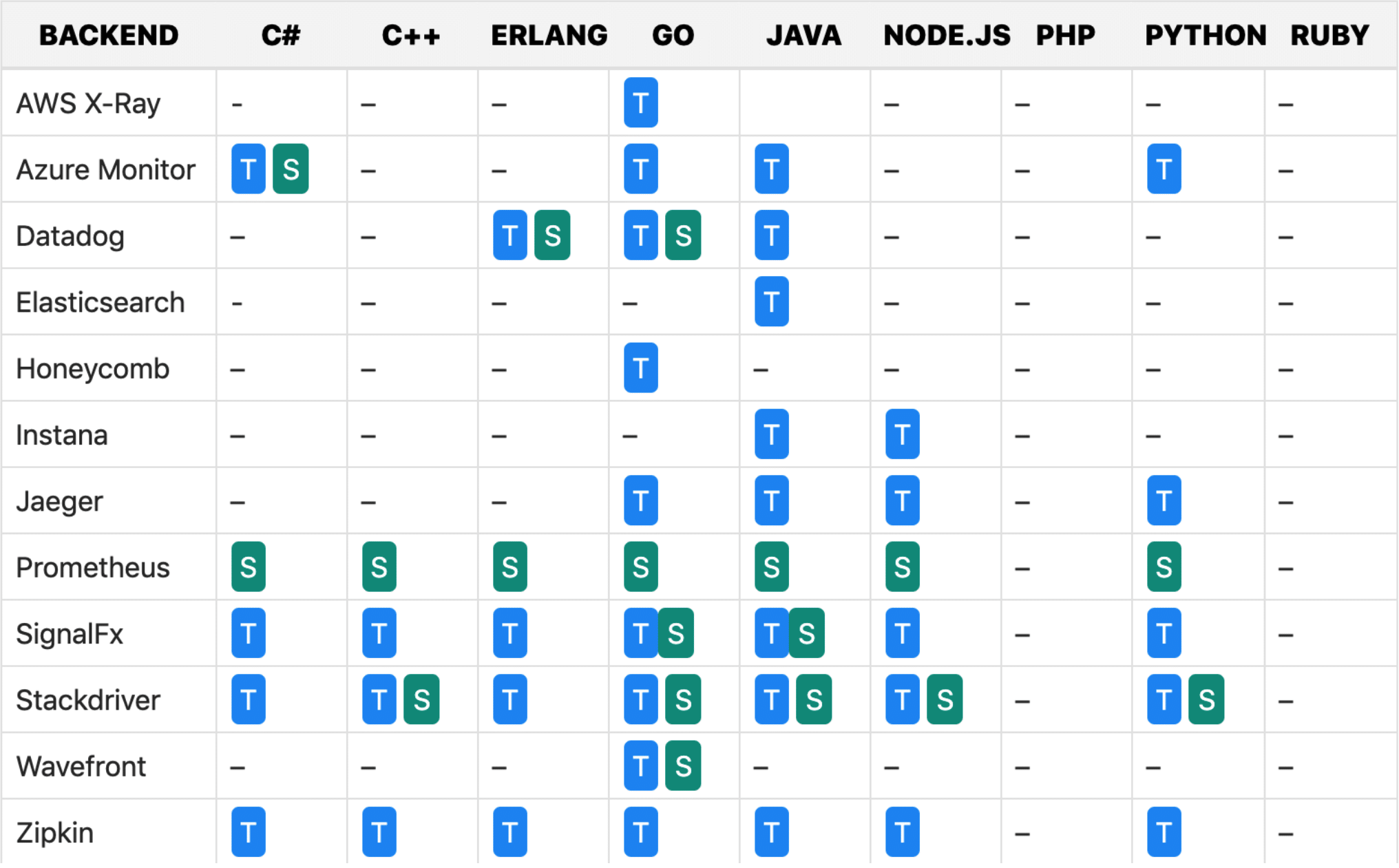
OpenCensus дополнительно поставляет реализацию. Если OpenTracing — это просто интерфейсы, то OpenCensus — это интерфейсы + реализация. Кроме трейсов он позволяет работать с метриками. Для C# мы можем видеть, что реализованы экспортеры для Azure, для Prometheus, для Jaeger. Для разных языков реализованы разные экспортеры. Если OpenTracing — это просто интерфейсы, то OpenCensus — это такой: у нас есть интерфейсы, но мы не верим компаниям, которые создают решения, и мы напишем свои экспортеры.
Получается: у нас есть OpenCensus, который делает интерфейсы плюс реализации, в левом углу ринга, и в правом углу ринга у нас OpenTracing, который делает примерно то же самое, только про интерфейсы.
Я просто ради интереса привел сравнение.

В OpenCensus и OpenTracing есть interface ITracer. Они делают одно и то же, они возвращают даже интерфейс один и тот же по названию. Они немного отличаются по функции, но делают всё то же самое.
То же самое для SpanBuilder, то же самое для ISpan.


У нас существует два решения, которые делают примерно одно и то же с некоторыми различиями. Ребята, которые поддерживают эти проекты, работают в больших компаниях, и они смогли договориться. Они собрались на нейтральной территории между кампусами Microsoft и Google где-нибудь в Сиэтле и решили сделать проект, который называется OpenTelemetry.
OpenTelemetry

Это эксклюзивный скриншот старого сайта. Сейчас у них сайт более красивый. OpenTelemetry — это конец истории, связанной с двумя разными реализациями, и он собирается вобрать в себя лучшие стороны OpenTracing и OpenCensus, объединить их вместе и назвать OpenTelemetry.
Основная цель OpenTelemetry — создать библиотеку, решение, которое вам поможет максимально просто работать с трейсами, метриками в ваших приложениях. То есть вы подключили одну библиотеку, и у вас всё хорошо.
OpenTelemetry — это репозиторий на GitHub, у него есть какие-то реализации.
На данный момент имплементация OpenTelemetry для C# впереди планеты всей.
Она развивается быстрее, чем все остальные языки. Её поддерживают ребята из Microsoft, и она достаточно активно развивается.
Notes: OpenTelemetry .NET SIG — Ссылка
Её разработка открытая, каждую неделю проводятся daily-митинги. Microsoft слышит комьюнити, комьюнити слышит Microsoft. Эта библиотека рано или поздно выйдет в релиз.
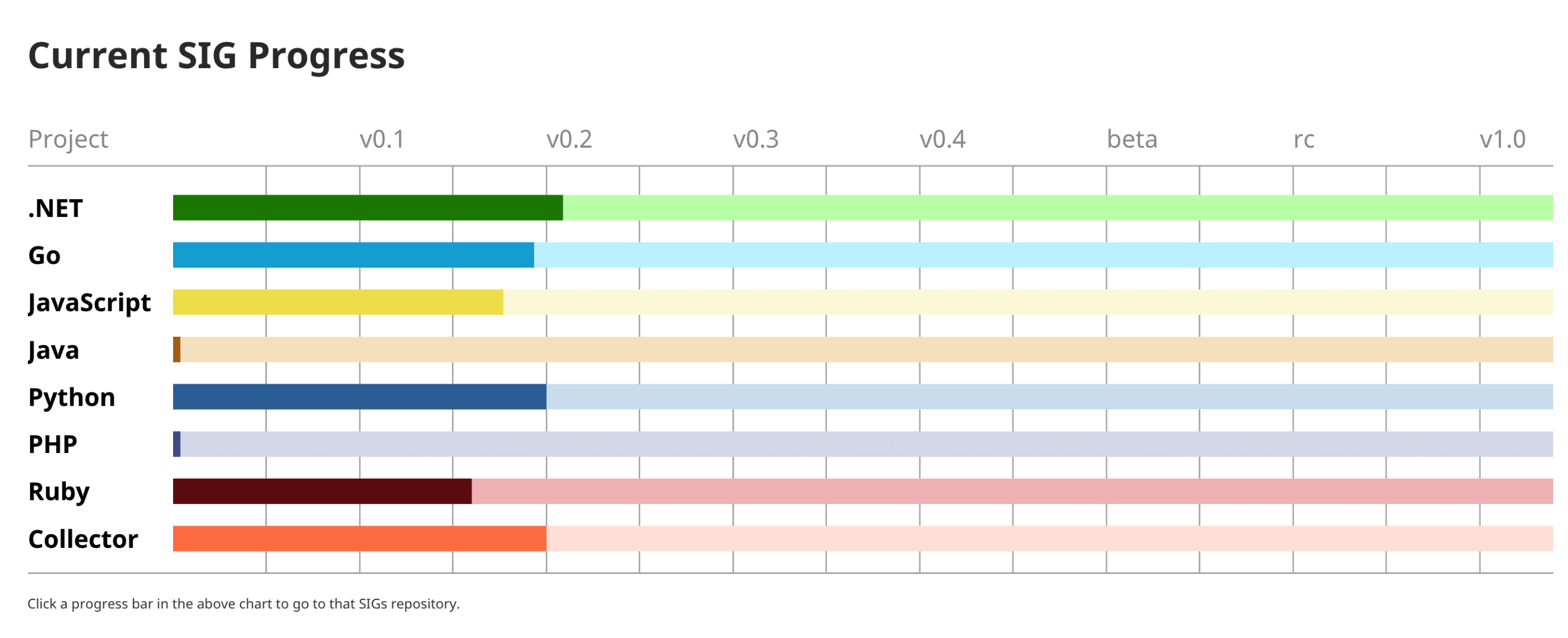
Current SIG Progress — Ссылка
С этой библиотекой связано две интересные истории: одна моя личная, вторая нет.
Первая — релиз OpenTelemetry должен был состояться в ноябре, а потом они написали во всех анонсах: «Упс, мы не рассчитали, мы что-то попробовали-попробовали, не полетело, ждите в следующем году». Релиз, судя по всему, ожидается на третий квартал 2020 года, они так пишут в чатах и в issue.
Вторая — моя личная история, как я пытался запустить OpenTelemetry на проекте.
У OpenTelemetry уже есть альфа-релиз. Я такой: «Ура, поставлю себе альфа-релиз и попробую запуститься». Я открыл доки из мастера, поставил себе nuget package и понял, что релиз был в июне, а после этого было полгода разработки, и доки не соответствуют библиотеке.
Надо подключаться к альфа-каналу, собирать альфовский new get package из Nightly-билдов, либо собирать локально сборку. Я мучился вечер, забил и решил, что вот как они опубликуют следующий релиз, это всё можно будет пробовать.
Главная история в том, что все мы там будем. Кто пользуется OpenTracing или OpenCensus или собирается пользоваться, рано или поздно это будет OpenTelemetry.
Если вы хотите делать трейсы в своем проекте, сейчас более логично будет использовать OpenTracing. По крайней мере для .NET, они взяли OpenTracing интерфейсы, немного их переименовали, совсем чуть-чуть взяли от интерфейсов из OpenCensus и взяли все экспортеры из OpenCensus. Если вы хотите сейчас делать через интерфейсы, возьмите OpenTracing, сделайте через интерфейсы, а потом немножко придётся поменять их название, но всё будет работать.
Спецификации
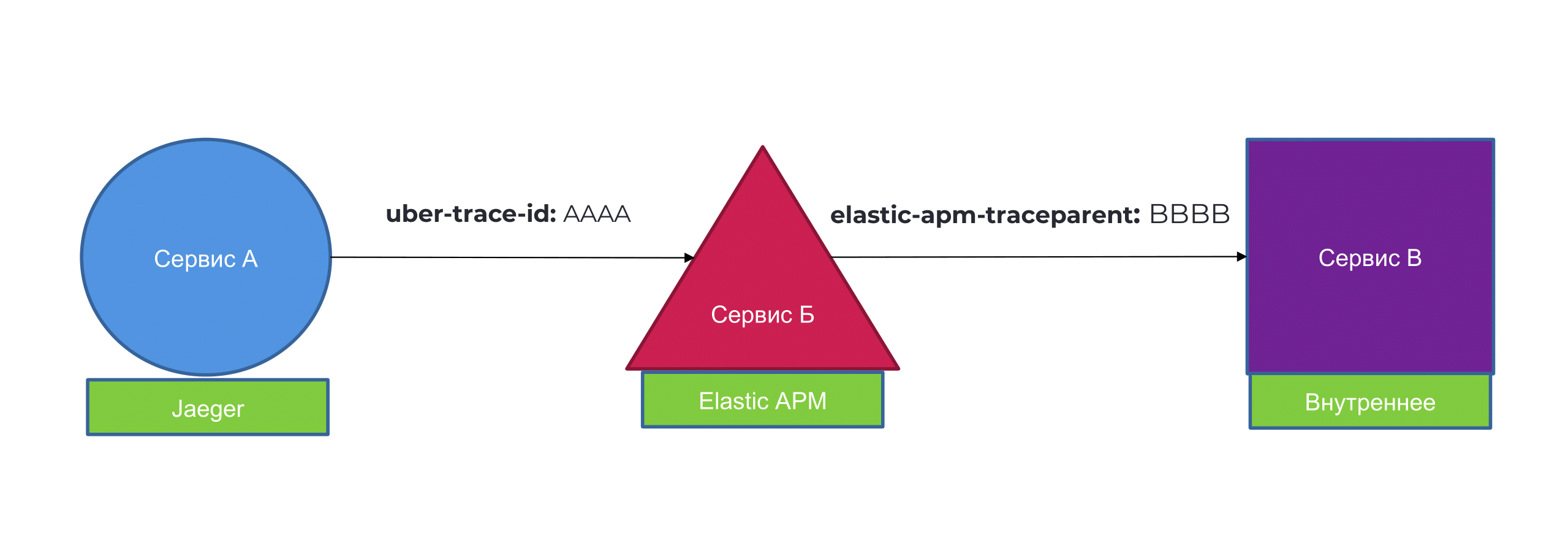
Представим, что у нас есть два сервиса: сервис А, который работает с Jaeger, сервис Б, который работает с APM и сервис В, на котором мы свои трейсы написали, в своем формате хэдеров. Uber-trace-id — это формат Jaeger, elastic-apm-traceparent — это формат хэдера для Elastic APM.
У нас разные решения или запрос ходит между системами разных провайдеров, мы хотим парсить или как-то ещё работать, но при этом не терять эту информацию. Формат trace-ов в данный момент несовместим. Тут всё не так плохо.
Комитет людей, которые работают над Open Telemetry и создатели Jaeger, который Юрий, уже работают над стандартом для Trace Context. Это как с HTML: они напишут стандарт, а вам только надо будет его заимплементить.
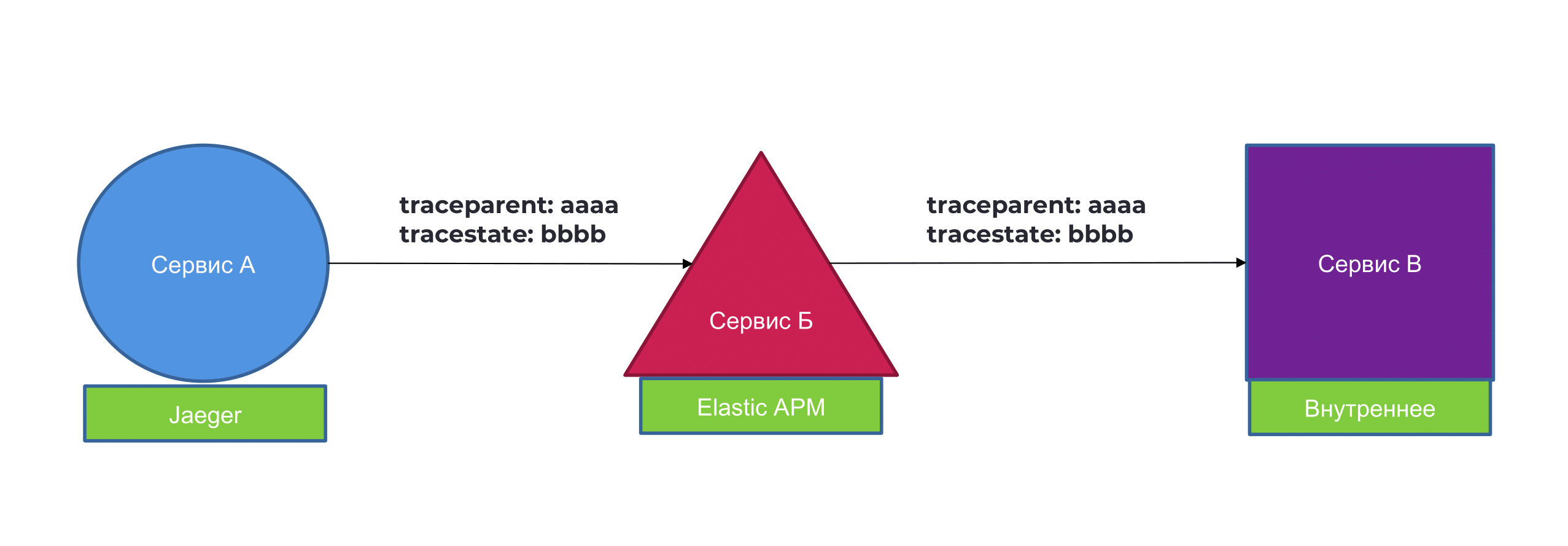
И trace-ы между всеми системами будут выглядеть примерно в таком формате.
У нас и у них будут одинаковые заголовки, и когда к вам будет приходить trace, вы без проблем сможете его спарсить. Вам не нужно будет ожидать много разных trace-ов, много разных форматов и так далее. Спецификации, интерфейсы, единообразие — это всё классно и замечательно.
Причем .NET впереди всей планеты — они уже заимплементили это в OpenTelemetry и всё хорошо.
Давид Фаулер в июне 2019 годаобъявил, что ASP.NET Core 3.0 автоматом поддерживает парсинг W3C-контекстов.
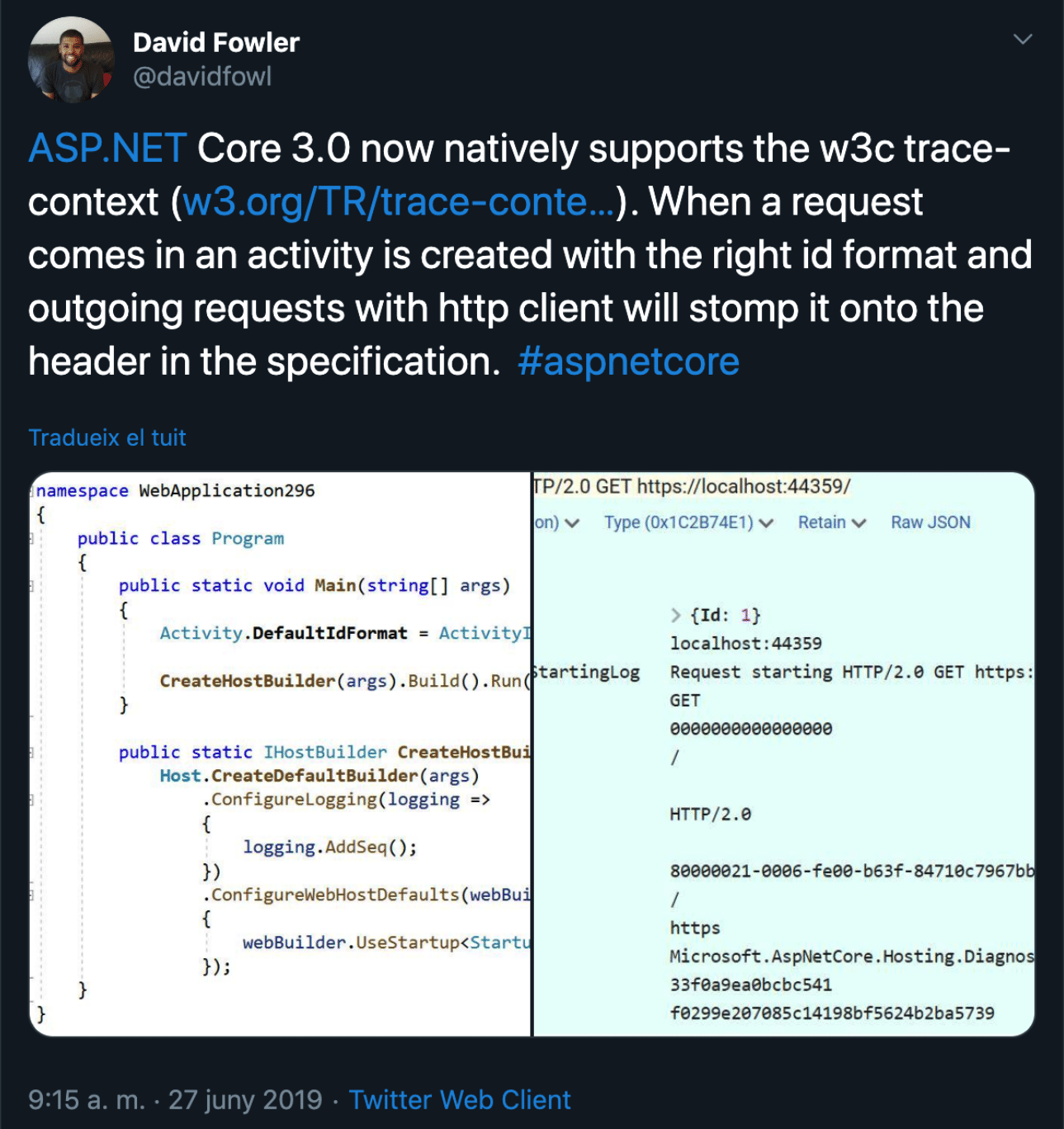
Когда приходит запрос, и в нём есть header в формате W3C, ASP.NET за вас всё спарсит и также добавит в тот же формат header, когда вы будете отправлять запросы вне.
Создатели ASP.NET уже подумали за нас.
Полезные ссылки
Ниже представлен список литературы, который Егор настоятельно рекомендует к ознакомлению:
- Все про observability.
- Jaeger.
- OpenCensus.
- OpenTelemetry.
- Блог про разницу между OpenTelemetry.
- Status проекта OpenTelemetry.
- GitHub.
- Доки для самой последней версии Jaeger.
До следующего DotNext 2020 Piter осталось меньше недели! В этот раз на конференции выступят такие известные спикеры, как Скотт Хансельман, Джон Скит и многие другие. А еще мы сделали для вас билет-абонемент, который дает доступ ко всем 8 конференциям этого сезона.
