
Возможно, время от времени вам попадались новости с заголовком, похожим на этот. (Если нет, то вот несколько примеров: первый, второй.)
«Первое место в мире» — звучит круто! Но одновременно с этим возникает много вопросов. Кто участвует? Как участники соревнуются? А кто распределяет места?
Мы хотим познакомить вас с самым авторитетным на сегодняшний день «чемпионатом мира» по распознаванию лиц, NIST Face Recognition Vendor Test (FRVT) — что он из себя представляет, для чего создан, как проходит соревнование и главное, насколько он действительно важен для разработчиков и бизнеса.
Что такое NIST?
Национальный институт стандартов и технологий (National Institute of Standards and Technology, NIST) был основан Конгрессом в 1901 году для обеспечения промышленной конкурентоспособности страны по сравнению с ведущими в те годы экономиками — в первую очередь, Германией и Великобританией; и с тех самых пор он является главным государственным органом США по метрологии и стандартизации. Такой, проще говоря, американский аналог нашего Росстандарта, который издаёт американские «госты».
Здесь иной читатель скажет: при чём тут распознавание лиц? где, простите, «госты» и где инновации, какая вообще связь? А связь самая прямая. Когда в нашу жизнь врывается какая-то новая технология, первое, что должны понять её разработчики и пользователи — как эту технологий «померить». Какие исчисляемые показатели можно предложить, чтобы, анализируя их и сопоставляя с какими-то целевыми значениями, делать вывод о состоятельности технологии и целесообразности её применения? И органу по стандартизации здесь самое место — и в части выбора таких показателей, и в части разработки и утверждения безусловно приемлемой для всех заинтересованных сторон методики их измерения.
Измерениями и стандартизацией в области биометрии — технологий распознавания человека по его физическим или поведенческих характеристикам — NIST занимается очень давно. Сфера его интересов охватывает все практически применимые модальности: отпечатки пальцев и радужную оболочку глаза, анализ речи и идентификацию человека по голосу. Первые серьёзные исследования в области распознавания лица человека начались в 2003 году (стимулом к их проведению послужили трагические события 11 сентября), а с 17 февраля 2017 года институт запустил FRVT в качестве регулярно возобновляемого соревнования среди разработчиков технологии. С тех пор в общей сложности протестировали 662 алгоритма, представленные 248 компаниями.
Как организовано тестирование
Соревнование состоит из нескольких треков (позже мы обсудим их подробнее), каждый из которых представляет свой сценарий тестирования. Чтобы принять участие, любой желающий разработчик может отправить свой алгоритм организаторам, и через какое-то время его результаты появятся на сайте. Тест — по крайней мере, на сегодняшний день — проводится регулярно и бессрочно, но обновить алгоритм можно не чаще чем раз в четыре месяца. Участие бесплатное.
Алгоритм должен реализовывать программный интерфейс (API) испытательного стенда, его спецификация описана в документации для каждого конкретного трека. Для удобства организаторы уже реализовали соответствующий шаблон в своем репозитории — участникам нужно только заменить модели на свои собственные, собрать посылку (бинарный файл динамической библиотеки) зашифровать её и отправить. Исходный код алгоритма, вопреки расхожему заблуждению, передавать не нужно. Тестирование проводится на CPU — графические ускорители NIST не поддерживает.
В ходе испытаний замеряют операционные характеристики, иллюстрирующие точность и скорость работы алгоритмов, а также некоторые дополнительные метрики (например, размер вектора признаков в байтах). Все эти сведения для всех протестированных алгоритмов включаются в очередной отчёт, который публикуется на сайте NIST примерно раз в месяц.
Кто участвует в тесте
Количество участников FRVT растет год от года. Если подсчитать всех, кто хоть раз отправлял свой алгоритм в трек FRVT 1:1 Verification с 2020 года, получится такое распределение (в скобках — число участников):
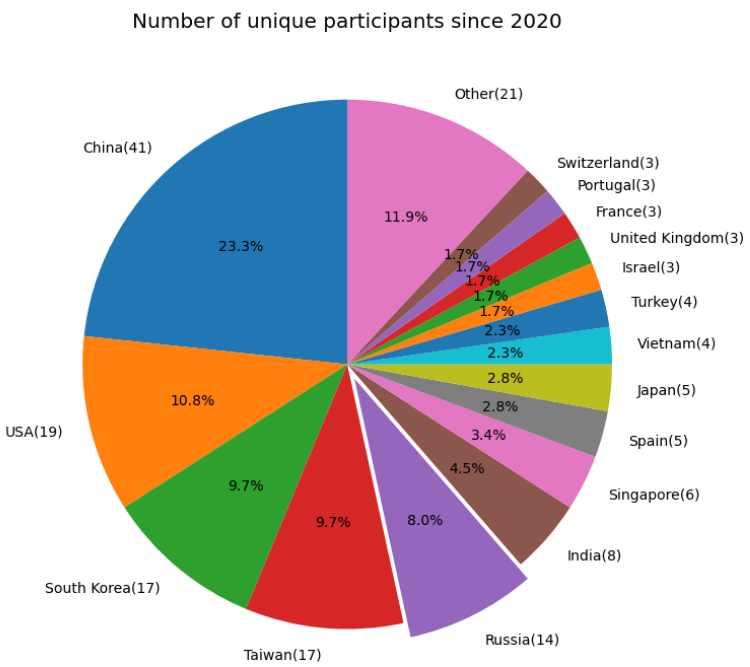
Более половины участников представляют пять стран: Китай, США, Южную Корею, Тайвань и Россию. Если же обратиться к таблице с результатами, то верхние позиции преимущественно занимают организации из России, Китая, США, Южной Кореи и Японии.
Среди участников есть как крупные корпорации, такие как Intel, Samsung или Tencent, так и учебные заведения: МГУ и ИТМО. Здесь есть как компании, специализирующиеся на видеоаналитике, так и те, для которых это направление не является основным — например, банки.
Датасеты и домены
Важным фактором, влияющим на качество работы алгоритма распознавания — это условия, в которых он применяется. Для тестирования алгоритмов NIST использует собственные массивы данных, доступа к которым у участников нет. О датасетах известно немного: описание доменов и пара примеров на каждый из них.
Одна большая часть изображений связана с иммиграционным контролем — как правило, это достаточно качественные фронтальные портретные изображения, которые делятся на следующие домены в зависимости от способа получения изображений:
Visa (Application) — фронтальные портретные снимки, собранные в иммиграционных офисах, на белом фоне, с использованием специального оборудования для захвата и освещения. Размер фотографий примерно 300×300 пикселей. Всего таких изображений 1,6 миллиона, по одному на человека.
Border (Immigration Lane) — фотографии, сделанные сотрудниками миграционной службы в кооперативном режиме (при взаимодействии с объектом съёмки). Возможны небольшие повороты головы, иногда встречается фоновая засветка и искажение перспективы из-за съемки с близкого расстояния. Количество таких изображений — порядка миллиона.
Kiosk — фотографии, собранные при взаимодействии мигранта с автоматическим киоском. Камера расположена над дисплеем киоска, поэтому для этих изображений характерен наклон головы вперёд, иногда значительный (45° и более).

Вторая — самая значительная по объёму — часть изображений связана с деятельностью правоохранительных органов. В ней представлены три подмножества:
Mugshot — самый большой домен, содержит около 86% от всех изображений. Фотографии достаточно качественные, с небольшими отклонениями от фронтального положения.

Profile — изображения в профиль, которые собраны одновременно с фронтальными фотографиями. Размер выборки невелик, около 200 тысяч снимков.

Webcam — изображения, собранные с помощью недорогой веб-камеры, имеют размер 240×240 пикселей. Как видно на иллюстрации, встречаются отклонения от фронтального ракурса, низкая контрастность и плохое пространственное разрешение.

Последний, самый сложный домен, представленный в FRVT — Wild. Он включает множество изображений, полученных при репортажной съёмке (в некооперативном режиме). Разрешение варьируется в очень широких пределах, изображения очень непринужденные, с широкими вариациями положения головы, лица могут быть частично перекрыты, например волосами или руками.

Треки
Мы уже упоминали, что NIST FRVT состоит из нескольких треков. Нас интересуют два из них, FRVT 1:1 Verification и FRVT 1:N Identification, непосредственно связанные с распознаванием лиц.
Здесь мы хотим отослать читателя к одной из наших предыдущих статей, где мы рассказывали об основах распознавания лиц:
верификация (она же сопоставление 1:1) представляет собой сравнение двух образцов для исследования их принадлежности одному и тому же человеку. Верификация, в частности, выполняется, когда вы пытаетесь разблокировать смартфон при помощи изображения лица — здесь биометрическая система отвечает на вопрос, достаточна ли высока её уверенность в том, что предъявленное изображение принадлежит владельцу устройства;
идентификация (она же поиск, она же сопоставление 1:N) подразумевает отбор из некоторого множества образцов-кандидатов тех, что предположительно принадлежат тому же человеку, что и представленный системе искомый образец. В качестве примера можно предложить систему контроля доступа, которая отпирает магнитный замок, когда «видит» на камере знакомое лицо.
Оба трека исчисляют для каждого алгоритма одну и ту же метрику качества, FNMR@FMR= (она же FNIR@FPIR=, она же 1 - TMR@FMR=).
Верификация
Сценарий тестирования верификации выглядит следующим образом: из тестового датасета составляется большое количество пар картинок. Какие-то пары будут «позитивными» (включают два изображения одного и того же человека), какие-то — «негативными» (изображения принадлежат разным людям), причем программа испытательного стенда точно знает, где какая пара. Все эти пары сопоставляются тестируемым алгоритмом, который возвращает соответствующие степени схожести.
Полученные результат можно проиллюстрировать примерно следующим образом (зелёные галочки отмечают позитивные пары, а красные крестики — негативные, сами алгоритмы при этом ничего не знают о позитивности или негативности):

Одна и та же картинка может участвовать в нескольких парах. Если тестовый датасет невелик, можно сформировать вообще все возможные пары, а на больших датасетах стандарты предписывают, чтобы на каждую позитивную пару предлагалось не менее 30 негативных пар.
На полученном примере посчитаем FNMR@FMR=0,1. Сначала выберем значение степени схожести, при котором FMR=0,1, то есть такое значение, при котором 10% всех негативных пар алгоритм ошибочно принимает за позитивные. Отсортируем по возрастанию степени схожести, исчисленные для негативных пар:
0,24 0,32 0,33 0,42 0,48 0,49 0,51 0,57 0,61 0,69
Так как в этом примере мы сопоставляли всего 10 негативных пар, порог должен быть таким, чтобы алгоритм счёл позитивной только одну из них — он должен быть меньше 0,69, но больше 0,61.
Оценим, каково будет отношение FNMR — то есть, какую долю позитивных пар алгоритм ошибочно признает негативными — при значении порога 0,61. Отсортируем по возрастанию значения степени схожести, исчисленные для позитивных пар:
0,59 0,72 0,84 0,86
Видно, что установив порог в 0,61, из четырёх сопоставленных позитивных пар алгоритм пропустит одну — ту, для которой получена степени схожести 0,59. Значит, FNMR@FMR=0,1 = 0,25.
(Более подробно об оценке алгоритмов распознавания мы рассказывали в этой статье.)
При тестировании верификации NIST составляет пары из изображений одного датасета или смешивает картинки разных датасетов — например, в тесте VISABORDER изображения датасета Visa сопоставляются датасетом Border. Есть и дополнительный трек, FRVT Face Mask Effects, в котором изучается, насколько хорошо алгоритмы справляются с медицинскими масками. Чтобы избежать дорогостоящего сбора дополнительных данных, однотонную маску искусственно подрисовывают:

Идентификация
Сценарий тестирования второго трека, FRVT 1:N, подразумевает, что накоплена база с изображениями лиц (может быть, достаточно большая) и есть некоторый набор фотографий. Про каждую из них нужно выяснить, есть ли в базе изображение этого человека или нет. Как и в случае с верификацией, какие-то поиски будут позитивными, когда априори известно, что фото этого человека есть в базе, какие-то — негативными.
Проиллюстрируем поиск такой схемой и попробуем по ней вычислить метрику FNIR@FPIR=0,5 (false negative identification rate, при условии что false positive identification rate равен 0,5):

Как и ранее, сначала необходимо найти порог схожести, при котором FPIR = 0,5. Негативных поисков здесь всего два, чтобы один из них мы ошибочно сочли позитивным, порог схожести должен быть равен 0,45. Организаторы FRVT предлагают два варианта подсчета метрики: Identification (T>0) и Investigation (R=1, T=0).
При Identification (T>0) важно, чтобы у положительных поисков схожесть с правильной картинкой была выше порога, и не важно, если в базе найдется какая-то другая картинка с ещё большей схожестью. В этом случае, оба положительных поиска будут успешными, так как 0,65 > 0,45 и 0,8 > 0,45. Следовательно, FNIR@FPIR=0,5 = 0.
При Investigation (R=1, T=0) порог для положительных поисков не важен, но правильная картинка из базы должна давать самую высокую схожесть. Здесь самый нижний поиск на картинке будет неудачным, так как 0,65 < 0,75. Следовательно, FNIR@FPIR=0,5 = 0,5.
Ещё один интересный трек — FRVT Paperless Travel. Его идея заключается в том, чтобы протестировать возможность пересадки при транзитном авиарейсе без использования бумажных документов, только по биометрическим данным.
В этом сценарии составляется 567 групп, по 420 человек в каждой (примерное число пассажиров рейса). Чтобы симулировать реальный перелет, группы формируются с учетом географии, то есть в одну группу попадают люди из одного региона. При прилете в страну транзита делается входное фото пассажира, которое сразу же попадает в базу пассажиров, вылетающих транзитным рейсом из страны. При посадке на вылетающий рейс делается еще одно, выходное фото пассажира, которое сверяется с базой входных лиц, и если путешественник найден в базе, он допускается на борт.
Дополнительные показатели
Метрики производительности
Помимо метрик качества NIST также предоставляет некоторую информацию о параметрах модели. Для этого нужно перейти во вкладку “Resources” на странице трека:

Например, в треке FRVT 1:1 могут быть интересны следующие показатели:
А. Размер вектора признаков модели в байтах — позволяет грубо оценить вычислительные ресурсы, требуемые для обработки поискового массива.
В. Время построения вектора признаков из картинки в миллисекундах. В это время входит весь пайплайн, от детектора лиц до отработки модели. Замеры, напомним, выполняются на CPU. Следует отметить, что в данном треке есть ограничение на этот показатель — он не должен превышать 1500 миллисекунд.
С. Время подсчета схожести между двумя векторами признаков в наносекундах.
Похожие показатели можно найти и для трека FRVT 1:N:
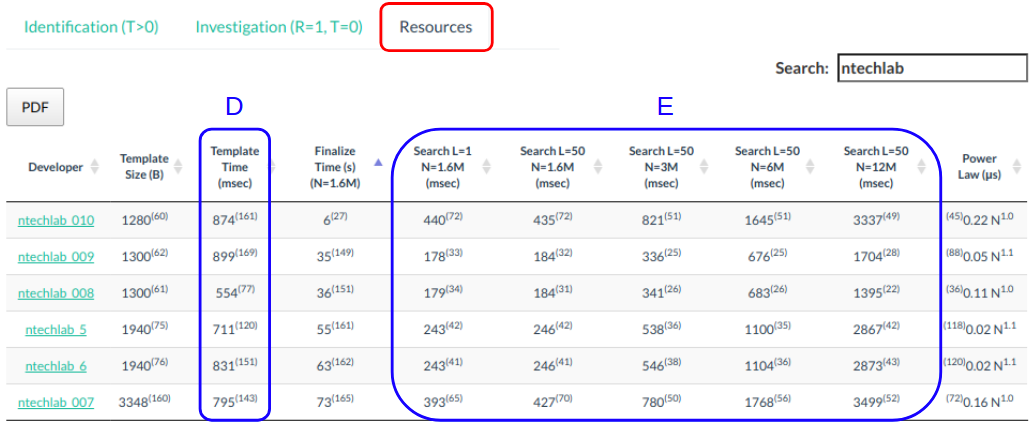
D. Время построения вектора признаков из картинки в миллисекундах. В этом треке более жёсткие ограничения: не выше 1000 миллисекунд.
Е. Время поиска по базе в миллисекундах. Здесь N означает размер базы, а L — ранг идентификации (какое количество кандидатов следует вернуть).
Сами по себе приведенные в этих таблицах цифры, возможно, представляют не самый большой интерес для конечного пользователя, так как условия реального применения алгоритма могут довольно сильно отличаться от тестовых.
Графики и диаграммы
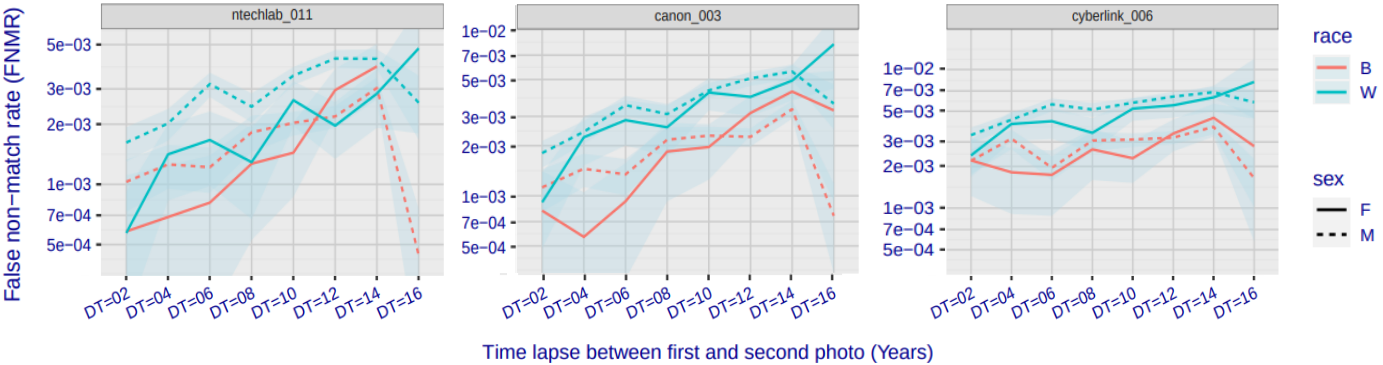
По итогам каждой очередной итерации тестирования NIST публикует объёмный отчёт — несколько сотен страниц с графиками, иллюстрациями и подробными разъяснениями. Среди прочего, он позволяет выяснить, как разные алгоритмы ведут себя при сопоставлении лиц разного пола, возраста, этнической принадлежности. Мы изучим соответствующие графики на примере трёх алгоритмов: ntechlab_011 (один из лидеров NIST), canon_003 (алгоритм из top25) и cyberlink_006 (алгоритм из top50) — при этом мы не ставим себе задачу сравнивать эти алгоритмы между собой.

Вот, например, как разные алгоритмы ведут себя при работе с лицами, отнесёнными к разным когортам: белые мужчины, белые женщины, темнокожие мужчины и темнокожие женщины. Для каждой когорты показана зависимость ошибки второго рода (когда алгоритм ошибочно принимает двух разных людей за одного человека) от порога схожести, на основе которого принято решение (если исчисленная при сопоставлении схожесть выше порога, это один и тот же человек, если ниже — разные):

Поведение моделей может также значительно варьироваться в зависимости от других критериев. На следующих диаграммах зеленая и красная точки показывают пороги для FMR=0,001 и FMR=0,0001 соответственно при работе с лицами разной этнической принадлежности:

...разного возраста (обратите внимание, то самую большую сложность представляют маленькие дети):

Наконец, интересно также изучить, насколько хорошо алгоритмы справляются с возрастными изменениями — когда сопоставляются снимки, сделанные с определённой разницей во времени (дополнительно можно посмотреть результаты в разрезе пола и цвета кожи). На следующей диаграмме порог для каждого алгоритма зафиксирован для FMR=0,0001 на общей совокупности негативных пар:
В чём практическая польза
Давайте поразмышляем, какую практическую пользу можно извлечь из наблюдения за соревнованием NIST FRVT.
Если вы просто интересуетесь распознаванием лиц
Даже у простого обывателя, который никак не связан с разработкой алгоритмов и не собирается внедрять решения на основе лицевой биометрии, так или иначе могут возникать вопросы: насколько хорошо сегодня работает распознавание лиц? насколько ему можно доверять? — ведь технология уже прочно вошла в нашу повседневную жизнь. Возможно, уже завтра мы будем проходить контроль в аэропорту, не предъявляя никаких документов, а покупки будем оплачивать не карточкой и не смартфоном, а просто посмотрев в камеру кассового терминала.
Или всё-таки не завтра? Достаточно ли точны алгоритмы? Не окажусь ли я в ситуации, когда из-за ошибки системы деньги за покупку, которую я не совершал, будут списаны с моего счёта? Экстраполируя результаты теста NIST FRVT, можно даже попытаться оценить размер потенциальных потерь от таких ошибок.
Если вы разработчик
Для разработчиков ответ очевиден: NIST FRVT — пожалуй, самый авторитетный на сегодняшний день бенчмарк, и, если вам интересно, где находится разработанная вами технология по сравнению со всем остальным миром (а как это может не быть интересно?!), вам просто необходимо в нём участвовать.
Но не только это — участие в соревновании поможет вам оценить состоятельность принятых вами решений: улучшилась ли точность системы после реализации новой функции потерь? как повлияло на качество работы изменение параметров обучения? NIST FRVT покрывает огромное количество различных сценариев и аспектов тестирования — и дело не только в том, что реализовать их все при собственном «ин-хаус» тестировании было бы очень трудоёмко и затратно, о некоторых из них многие (особенно, начинающие) разработчики даже и не задумываются.
А если ваш алгоритм будет действительно хорош, то… в общем, см. фразу, вынесенную в заголовок этой статьи!
Если вы планируете внедрение технологии
На что стоит смотреть в NIST FRVT и как выбрать вендора под свою задачу, если ваша компания планирует внедрить технологию распознавания лиц?
Во-первых, нужно понять, какой из сценариев тестирования, представленных в NIST FRVT, больше всего похож на ваш. Если планируете сравнивать между собой пары лиц, стоит обратить внимание на FRVT 1:1 Verification (примером может быть подтверждение подлинности документов, когда фото на документе сравнивается с лицом предъявителя, или авторизация по лицу при входе в информационную систему).
Если вам нужен поиск по лицу в базе, стоит рассмотреть результаты FRVT 1:N Identification и FRVT Paperless Travel. Вообще, системы типа «один ко многим» можно условно разделить на две группы в зависимости от их толерантности к ложноотрицательным и ложноположительным срабатываниям.
В одном случае ожидается, что человек есть в базе, и наша основная проблема — ложноположительные срабатывания. Такую ситуацию описывает FRVT Paperless Travel, где ожидается, что человек, прилетевший транзитным рейсом, успешно пройдет регистрацию на свой вылетающий рейс. Ложноотрицательное срабатывание системы в данном случае не станет большой трагедией — сотрудник авиакомпании проверит документы пассажира, а вот ложноположительное срабатывание действительно может дорого стоить.
Во втором случае ожидается, что человека в базе нет, и главной проблемой будут ложноотрицательные срабатывания. В таком случае стоит обратиться к FRVT 1:N Identification. Примером может служить проверка посетителя казино по базе шулеров, мошенников и других нежелательных личностей. Здесь ложноположительное срабатывание не страшно — «ручная» проверка позволит устранить возможные недоразумения, а ложноотрицательное срабатывание может повлечь серьезные проблемы. Другим примером может быть поиск пропавшего человека.
Сегодня неотъемлемым атрибутом человеческого лица стала медицинская маска, так что достойны изучения результаты FRVT Face Mask Effects.
Важно также понимать, какой домен наилучшим образом отражает нужные вам результаты. Если условия эксплуатацию проектируемой вами системы предполагают работу в основном с качественными фронтальными изображениями, смотрите на домены Visa и Mugshot. Если возможны произвольные поворотов головы и недостатки освещения, ваш выбор — Border и Kiosk.
Время построения шаблона (читай: скорость работы алгоритма) — важно ли оно? И да, и нет. С одной стороны, можно предположить, если один алгоритм показывает ту же точность, что и другой, но при этом работает быстрее, очевидно, что первый алгоритм окажется эффективнее. С другой стороны, реальная скорость работы будет сильно зависеть от аппаратной платформы. Во-вторых, если вам нужна действительно большая скорость, то, скорей всего, большинство разработчиков сможет предложить вам более быструю (но, вероятно, чуть менее точную) модель, о которой из отчёта NIST FRVT вы бы никогда не узнали.
Здесь также стоит отметить, что набор решений, который предлагает видеоаналитика, не ограничивается одним лишь распознаванием лиц. Разработчики могут дополнительно предлагать решения по определению пола, возраста, атрибутов лица, правильности ношения маски. Можно еще добавить подсчет людей, определения их взаимодействий, кластеризацию и многое другое — обо всем этом не узнать из отчёта NIST FRVT, не говоря уже об удобстве работы с пользовательским интерфейсом системы, качестве технической поддержки и цене.
Иными словами, для выбора решения нельзя целиком и полностью полагаться исключительно на отчёт NIST FRVT. Однако он будет самым правильным местом, чтобы начать — помимо возможности исследовать операционные характеристики алгоритма той или иной компании, сама динамика участия её алгоритма в соревновании может говорить о том, что компания, как говорится, «здесь всерьёз и надолго».
Другие соревнования
NIST FRVT является самым большим и разнообразным бенчмарком для распознавания лиц на данный момент. Можно даже сказать, что на сегодняшний день у него просто нет конкурентов, сопоставимых по масштабу и авторитету.
Стоит отметить, что за последний год сразу два вендора из Китая, Insightface и XForwardAI, попробовали создать собственные бенчмарки, их платформы использовались для проведения соревнования по распознаванию лиц в рамках ICCV 2021 Workshop. Пока оба проекта находятся в зачаточном состоянии и даже рядом не стоят с NIST FRVT.
Есть и другие способы сравнить вендоров, которыми нередко пользуются на практике. Вы можете сами построить бенчмарк на основе своих собственных данных, выбрать небольшой пул интересующих вас разработчиков и попросить их прогнать свои решения на вашем тесте. Очевидный плюс — тестирование будет проходить ровно в том сценарии, который вам нужен, и ровно на том домене данных, с которым в дальнейшем будет работать выбранный алгоритм. Если ваш домен очень специфичен, такой подход может оказаться более чем оправданным. Очевидный минус — высокая стоимость с точки зрения времени, усилий и, как следствие, денег.
