Каждый активный абонент в среднем получает более четырех нежелательных звонков в неделю — это реклама, предложения банков, иногда просто мошенничество. Большинство клиентов негативно реагируют на такого рода звонки. Для решения этой проблемы мы разработали услугу “Блокировка спам-звонков”, подключив которую, пользователь перестает получать нежелательные звонки, а в конце каждого дня система оповещает абонента о вызовах, которые были заблокированы. В этой статье data scientist’ы МТС Анна Рожкова (@RogotulkA) и Ольга Герасимова(@ynonaolga) расскажут как разработали алгоритм, отличающий номера спамеров от остальной абонентской базы.

Итак, перед нами стояла задача бинарной классификации.
Действительно, как отличить абонента (даже очень общительного, с большим кругом новых контактов) от спамера, который неустанно навязывает услуги очередного медицинского центра? Сначала мы считали за спам те номера, которые обзванивают много разных абонентов, но их оказалось трудно отличить от интернет-магазинов. Потом мы решили взять номера, чьи звонки часто сбрасывают, но люди иногда скидывают звонки, когда им просто неудобно говорить. Еще мы проверили гипотезу, что абоненты не будут перезванивать на номера спамеров (в течение короткого промежутка времени после пропущенного звонка), но таких номеров оказалось слишком много, возможно, для некоторых абонентов это стандартное поведение, они не перезванивают и знакомым. В итоге мы пришли к решению, что спам-номера отличаются уровнем недовольства пользователей по отношению к ним. Поэтому в качестве целевой переменной были взяты номера, на которые поступает много жалоб, а отрицательными примерами разметили тех, которые имеют мало негативных отзывов или таковые вовсе отсутствуют.
В качестве признаков использовались агрегированные данные звонковой активности абонентов: средняя длительность звонков, периоды суток с наибольшей активностью, средняя длительность перерыва между звонками, скорость обновления круга контактов и многие другие. Также мы заметили, что многие спамеры подбирают “красивые номера” или похожие на известные существующие (к примеру номер горячей линии банка) и добавили такие бинарные фичи.
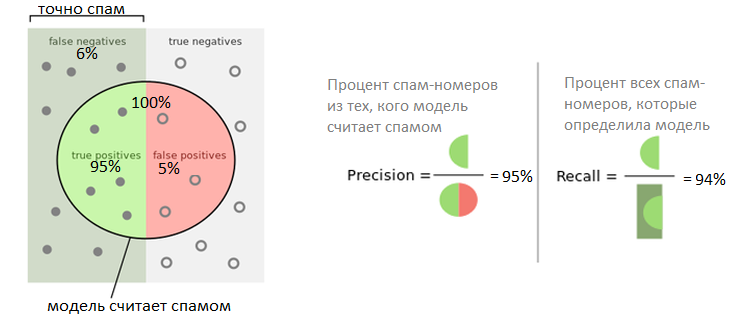
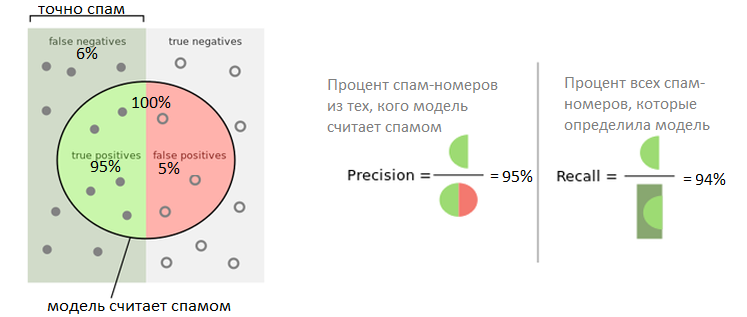
Следующим шагом был выбор метрики оптимизации. В нашем решении было важно не блокировать звонки от обычных номеров, поэтому мы определили, что точность модели должна быть не менее 95%. Точность (precision) — это процент номеров, распознанных как объекты спам-класса, которые модель предсказала верно. Но важно заблокировать как можно больше нежелательных номеров, поэтому выбираем максимальный охват (recall) для допустимого уровня точности. Итоговая версия модели имеет следующие показатели: 95% precision, recall 94%. Сейчас модель стоит на регламенте и регулярно переобучается, чтобы отмечать изменения в звонковой активности различных групп абонентов, и на эти метрики стоит проверка, чтобы они не падали ниже 90% каждая.
Из-за того что спам-номеров намного меньше, чем обычных, то есть выборка несбалансированная, количество отрицательных примеров было уменьшено относительно положительных (undersampling). На валидационной выборке соотношение классов было выбрано реальным, чтобы иметь представление о качестве работы модели “в бою”. Также в выборку попали только те спам-номера, которые были активны на определенную дату из-за непостоянности спамеров: есть периоды активного прозвона, а есть период пассивности, когда они совершают несколько звонков, скорее для поддержания номера. Иногда номера после проведенной кампании блокируются и переходят другому владельцу.
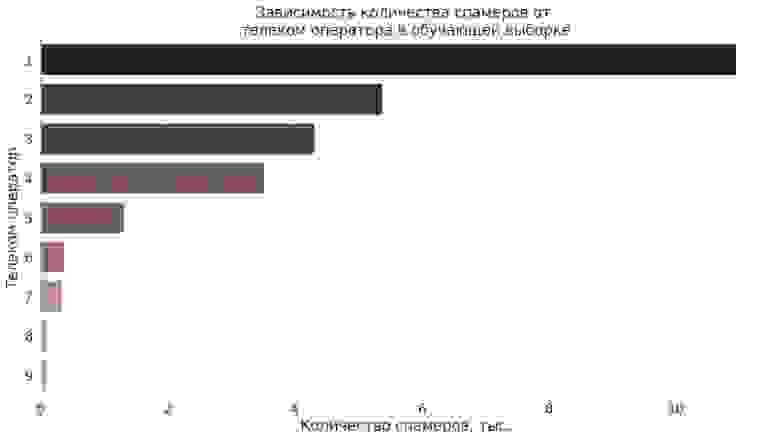
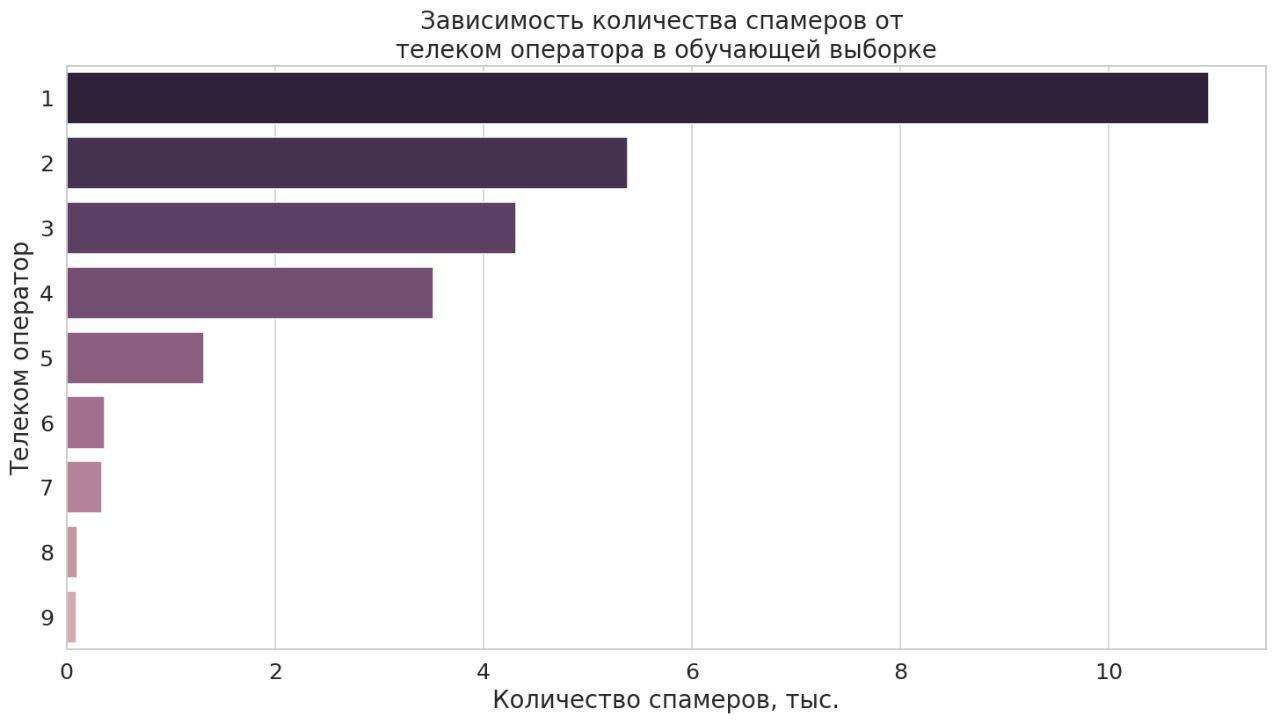
В качестве алгоритма была использована реализация бустинга xgboost, так как она дала лучшие результаты на валидационной выборке. Важными признаками для модели оказались: данные активности абонентов в разное время суток, количество коротких звонков, широта круга общения. Интересным фактом стало то, что в топ фичей вошел признак оператора связи. Ниже на графике мы анонимизировали мобильных операторов и представили статистику по использованию их номеров спамерами:
В этой задаче не было возможности провести A/B тестирование: услуга на уровне сети не предполагает наличие различных списков спам-номеров, поэтому пилот первой версии модели мы запустили внутри компании, тестировщиками стали коллеги и топ-менеджмент. Одна из положительных особенностей внутреннего тестирования – быстрая обратная связь. Нам тут же начали сыпаться вопросы:
Наш личный опыт также стал дополнительным поводом для поиска новых фичей для модели, когда после длительного ожидания доставки из интернет-магазина телефон курьера обнаруживался в списке заблокированных.
Еще одной серьезной проблемой классификации номеров была разница представлений о том, что такое спам: для кого-то звонки с предложением кредита – ненужная информация, а кто-то ждет персональных предложений и выбирает лучшее из них, поэтому абоненту была предоставлена возможность просматривать список звонивших ему номеров с опцией отключения тех, которые для него потенциально полезны.

Одним из самых популярных запросов от пользователей на доработку услуги было расширение информативности смс-отчета о заблокированных за день номерах данными о категориях звонков, например, банки, медуслуги или недвижимость.
Первые версии модели были построены на фичах, собранных за длительный период времени, но мы обратили внимание, что модель часто не считает спамом номера, которые появились недавно, т.е. новые номера или те, которые начали активный обзвон абонентов после периода “тишины”. Для решения этой проблемы мы построили дополнительную модель на фичах, собранных за меньший период. Недостаточно было добавить “короткие” фичи в витрину для обучения, так как сами обучающие выборки различны: абоненты, активные в течение длительного и короткого периодов времени, не совпадают.
В наши дальнейшие планы по развитию продукта входят создание индивидуальных спам-листов, с учетом профиля клиента и его потребностей, перевод работы модели в онлайн-режим, чтобы она улавливала начинающийся здесь и сейчас пик активности спамеров.
Построение модели
Итак, перед нами стояла задача бинарной классификации.
Действительно, как отличить абонента (даже очень общительного, с большим кругом новых контактов) от спамера, который неустанно навязывает услуги очередного медицинского центра? Сначала мы считали за спам те номера, которые обзванивают много разных абонентов, но их оказалось трудно отличить от интернет-магазинов. Потом мы решили взять номера, чьи звонки часто сбрасывают, но люди иногда скидывают звонки, когда им просто неудобно говорить. Еще мы проверили гипотезу, что абоненты не будут перезванивать на номера спамеров (в течение короткого промежутка времени после пропущенного звонка), но таких номеров оказалось слишком много, возможно, для некоторых абонентов это стандартное поведение, они не перезванивают и знакомым. В итоге мы пришли к решению, что спам-номера отличаются уровнем недовольства пользователей по отношению к ним. Поэтому в качестве целевой переменной были взяты номера, на которые поступает много жалоб, а отрицательными примерами разметили тех, которые имеют мало негативных отзывов или таковые вовсе отсутствуют.
В качестве признаков использовались агрегированные данные звонковой активности абонентов: средняя длительность звонков, периоды суток с наибольшей активностью, средняя длительность перерыва между звонками, скорость обновления круга контактов и многие другие. Также мы заметили, что многие спамеры подбирают “красивые номера” или похожие на известные существующие (к примеру номер горячей линии банка) и добавили такие бинарные фичи.
Выбор метрики
Следующим шагом был выбор метрики оптимизации. В нашем решении было важно не блокировать звонки от обычных номеров, поэтому мы определили, что точность модели должна быть не менее 95%. Точность (precision) — это процент номеров, распознанных как объекты спам-класса, которые модель предсказала верно. Но важно заблокировать как можно больше нежелательных номеров, поэтому выбираем максимальный охват (recall) для допустимого уровня точности. Итоговая версия модели имеет следующие показатели: 95% precision, recall 94%. Сейчас модель стоит на регламенте и регулярно переобучается, чтобы отмечать изменения в звонковой активности различных групп абонентов, и на эти метрики стоит проверка, чтобы они не падали ниже 90% каждая.
Из-за того что спам-номеров намного меньше, чем обычных, то есть выборка несбалансированная, количество отрицательных примеров было уменьшено относительно положительных (undersampling). На валидационной выборке соотношение классов было выбрано реальным, чтобы иметь представление о качестве работы модели “в бою”. Также в выборку попали только те спам-номера, которые были активны на определенную дату из-за непостоянности спамеров: есть периоды активного прозвона, а есть период пассивности, когда они совершают несколько звонков, скорее для поддержания номера. Иногда номера после проведенной кампании блокируются и переходят другому владельцу.
В качестве алгоритма была использована реализация бустинга xgboost, так как она дала лучшие результаты на валидационной выборке. Важными признаками для модели оказались: данные активности абонентов в разное время суток, количество коротких звонков, широта круга общения. Интересным фактом стало то, что в топ фичей вошел признак оператора связи. Ниже на графике мы анонимизировали мобильных операторов и представили статистику по использованию их номеров спамерами:
Тестирование
В этой задаче не было возможности провести A/B тестирование: услуга на уровне сети не предполагает наличие различных списков спам-номеров, поэтому пилот первой версии модели мы запустили внутри компании, тестировщиками стали коллеги и топ-менеджмент. Одна из положительных особенностей внутреннего тестирования – быстрая обратная связь. Нам тут же начали сыпаться вопросы:
- а почему этот номер дозвонился?
- а этот номер вы за что заблокировали?
- мне не нужна еще одна страховка на машину (сколько можно?!)
Наш личный опыт также стал дополнительным поводом для поиска новых фичей для модели, когда после длительного ожидания доставки из интернет-магазина телефон курьера обнаруживался в списке заблокированных.
Запуск в прод
Еще одной серьезной проблемой классификации номеров была разница представлений о том, что такое спам: для кого-то звонки с предложением кредита – ненужная информация, а кто-то ждет персональных предложений и выбирает лучшее из них, поэтому абоненту была предоставлена возможность просматривать список звонивших ему номеров с опцией отключения тех, которые для него потенциально полезны.
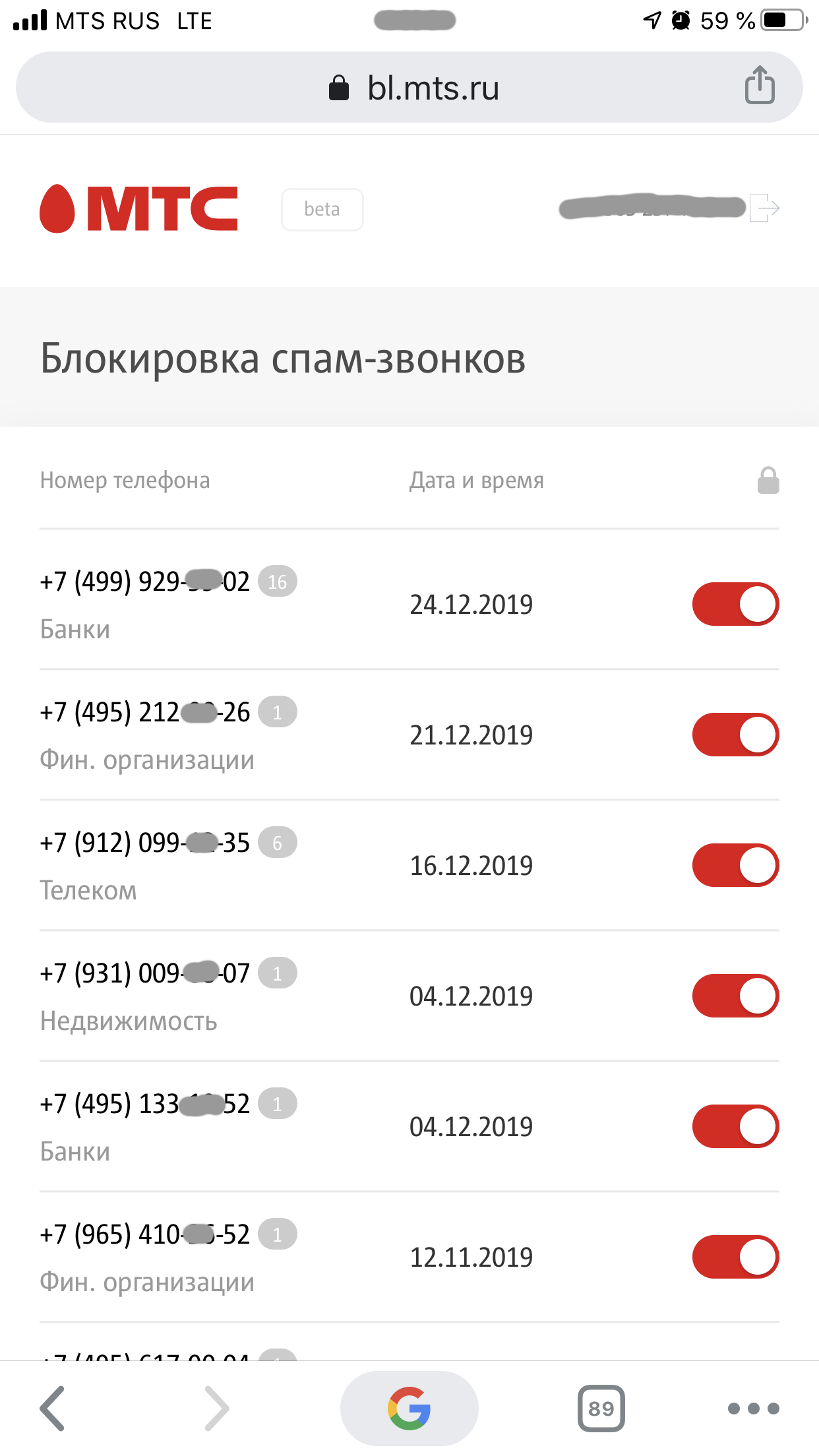
Одним из самых популярных запросов от пользователей на доработку услуги было расширение информативности смс-отчета о заблокированных за день номерах данными о категориях звонков, например, банки, медуслуги или недвижимость.
Первые версии модели были построены на фичах, собранных за длительный период времени, но мы обратили внимание, что модель часто не считает спамом номера, которые появились недавно, т.е. новые номера или те, которые начали активный обзвон абонентов после периода “тишины”. Для решения этой проблемы мы построили дополнительную модель на фичах, собранных за меньший период. Недостаточно было добавить “короткие” фичи в витрину для обучения, так как сами обучающие выборки различны: абоненты, активные в течение длительного и короткого периодов времени, не совпадают.
В наши дальнейшие планы по развитию продукта входят создание индивидуальных спам-листов, с учетом профиля клиента и его потребностей, перевод работы модели в онлайн-режим, чтобы она улавливала начинающийся здесь и сейчас пик активности спамеров.
