Вы разработчик и хотите увидеть, что ваша страница стала быстрее открываться после всех оптимизаций. Или вам нужно доказать начальству, что вы не верблюд и всё действительно ускорили. А, может быть, вы хотите убедиться, что ваши пользователи не будут страдать от медленно открывающихся страниц. Или, как в нашем случае, вы тестировщик, который теперь отвечает за клятую клиентскую производительность, и пропущенные тормоза на продакшен не дают спать по ночам.
Измерять клиентскую производительность – нетривиальная задача. Особенно если у вас в проекте сотни страниц на множестве стендов. Каждая наполнена js кодом, и сотни разработчиков каждый день оптимизируют, меняют, пересоздают их. Нужно спроектировать систему сбора, обработки и хранения данных. Какое хранилище выбрать? Как спроектировать базу, и в какой СУБД? Немало интересных задач, которые меркнут перед лаконичным «сколько времени открывалась страница?». Для нас поиск ответа на этот вопрос вылился в квест с детективными расследованиями, жаркими спорами и поиском истины. Его самые интересные моменты – в этой статье.

В давние времена, до web 2.0, определить окончание загрузки страницы было сравнительно просто: прилетел документ от сервера ± несколько мс, и считаем, что страница загрузилась. Затем выросло число запросов, подгружающих изображения, стили и прочие ресурсы. Определить окончание загрузки страницы стало чуть сложнее: теперь нужно было дожидаться загрузки всех ресурсов, все стали завязываться на различные js события, e.g. window.onload. Интернет развивался, страницы тяжелели и прежние подходы перестали работать. Теперь загрузка страницы после получения всех ресурсов не останавливалась. Появились запросы, которые выполняются из js напрямую, появился прелоадинг и прочие механизмы, которые сильно размыли ту самую точку, которую можно считать окончанием загрузки страницы. И теперь можно встретить разные варианты для определения окончания загрузки страницы. Пройдёмся вкратце по каждому из них.
Сетевая активность. Из самого определения (окончание загрузки страницы) мы видим, что нам нужно дождаться момента, когда страница перестала выполнять запросы, т.е. у нас нет запросов в состоянии «pending», и какое-то время не выполнялись новые запросы. Определить это, вроде, не сложно, и формулировка понятная. Но вот только не работоспособная для большинства сайтов. После загрузки документа очень много времени может уходить на инициализацию js, что увеличит время построения страницы. И то пресловутое «страница загрузилась» состоится для пользователя значительно позже окончания загрузки. Также неприятным сюрпризом может стать прелоадинг, который срабатывает после загрузки страницы и может длиться несколько секунд. К тому же не редко бывают различные механизмы на странице, которые без перерыва обмениваются информацией с сервером. Поэтому сетевая активность может вообще никогда не закончиться.
События. Теперь правильно говорить не «страница загрузилась», а «страница построилась». С момента уже упомянутого window.onload были добавлены новые события, к которым можно привязать не только срабатывание js-кода, но и полное открытие нашей страницы. Как логическое продолжение, в 2012-ом году начинается работа над стандартом. Тут выводится уже целая серия событий, связанных с процессом загрузки страницы. Но на практике оказывается, что эти события срабатывают раньше, чем происходит полное построение страницы. Это видно как на синтетических тестах, так и при тесте на коленке. Да, в теории можно создать некое искусственное событие, которое показывало бы, что страница окончательно загрузилась. Но тогда нам потребовалось бы делать это для всех страниц отдельно. Плюс при любых изменениях перепроверять правильность нового подхода. Это все опять приводит к исходной задаче — как понять, что страница загрузилась.
Визуальные изменения. Клиентская производительность, так или иначе, крутится вокруг пользователя. Т.е. для нас важно то, что человек чувствует, когда работает с нашим продуктом. И тут можно не подумав, рвануть вперёд, посадить живого человека и поручить ему определять «на глазок» время загрузки страницы. Идея обречена на провал, т.к. определить тормозит или не тормозит страница, человек может, а вот сказать, насколько тормозит по 10-бальной шкале, уже вряд ли. Однако тут мы понимаем, что визуальные изменения – пожалуй, один из лучших показателей того, что страница загрузилась. Мы можем постоянно следить за отображением страницы и, как только у нас прекратились визуальные изменения, считать, что страница загрузилась. Но все ли изменения страницы одинаково важны?
Вот у нас первый раз отрисовалась страница, вот появилось обрамление, появился текст, загрузились картинки, стали подгружаться счётчики, социальные кнопки, комментарии, etc. В разных ситуациях важны разные этапы загрузки страницы. Где-то важна первая отрисовка, а кому-то важно знать, когда пользователь увидел комментарии. Но, как правило, в большинстве случаев для нас важна загрузка основного контента. Именно визуальное появление основного контента и считается тем самым «страница загрузилась». Поэтому при прочих равных мы можем отталкиваться от этого события, оценивая скорость загрузки страницы. Для того, чтобы работать со страницей комплексно, есть замечательный подход под названием «speed index», который описан тут.
Идея в следующем: мы пытаемся понять, насколько равномерно загружалась страница. Две версии одной страницы могли открыться за 2 секунды, но в первой 90% визуальных изменений произошли спустя секунду после открытия, а у второй спустя 1.7 секунды. Пользователю при равном времени открытия первая страница будет казаться значительно более быстрой, чем вторая.
Работоспособность. Итак, мы теперь точно понимаем, что такое «страница открылась». Можем на этом остановиться? А вот и нет. Страница загрузилась, мы нажимаем на кнопку добавления нового комментария и… штаны ни во что не превращаются – страница игнорирует наши клики. Что делать? Добавлять очередную метрику. Нам нужно выбрать целевой элемент. А дальше выяснить, когда он станет доступен для взаимодействия. Как будет рассказано далее, это самая сложная задача.
Вроде разобрались, что считать окончанием загрузки страницы. А что у нас с началом открытия? Тут, вроде, всё понятно – считаем с момента, когда мы дали браузеру команду открыть страницу, но опять чёртовы детали. Есть такие события как beforeunload. Код, который срабатывает при их наступлении, может значительно повлиять на время открытия страницы. Можем, конечно, всегда предварительно переходить на about:blank, но в этом случае мы можем пропустить подобную проблему. И при отличных показателях наших тестов пользователи будут жаловаться на тормоза. Опять же, выбираем, исходя из своей специфики. Мы для сравнительных замеров начинаем всегда с пустой страницы. А проблемы с переходами со страницы на страницу отлавливаем в рамках измерения времени работы критичных бизнес-сценариев.
Важно ли замерять один в один как у клиентов? Возможно. Но будет ли от этого непосредственная польза для разработки и ускорения? Далеко не факт. Вот отличная статья, которая говорит о том, что важно просто выбрать хотя бы одну метрику и отталкиваться от неё для оценки времени открытия страниц. С одним выбранным показателем будет гораздо проще работать, отслеживать оптимизации, строить тренды. А уже потом, при наличии на то ресурсов, дополнять вспомогательными метриками.

Отлично, теперь все в компании разговаривают на одном языке. Разработчики, тестировщики, менеджеры под временем открытия страницы понимают время отображения основного контента на странице. Мы даже создали инструмент, который с высокой точностью выполняет эти замеры. У нас довольно стабильные результаты, мера разброса минимальна. Мы публикуем наш первый отчёт и… получаем множество недовольных комментариев. Самый популярный из них – «а я тут померял, и у меня всё по-другому!». Даже если считать, что была соблюдена методология замеров и использован такой же инструмент – оказывается, что у всех совершенно разные результаты. Начинаем копаться и выясняем, что кто-то делал замеры через Wi-Fi, у кого-то комп с 32-мя ядрами, а кто-то открывал сайт с телефона. Получается, проблема замеров уже не многогранна, а многомерна. При различных условиях мы получаем разные результаты.
Тут встал вопрос: а какие факторы влияют на время открытия страницы? На скорую руку была составлена такая ассоциативная карта.
Получилось что-то около 60-70 различных факторов. И началась серия экспериментов, которая преподносила нам порой весьма любопытные результаты.
Кэш или не кэш – вот в чём вопрос. Первая аномалия, с которой мы столкнулись, была обнаружена ещё в самых первых отчётах. Мы выполняли замеры с пустым кэшем и с заполненным. Часть страниц с заполненным кэшем отдавалась не быстрее, чем с незаполненным. А некоторые страницы – ещё и дольше. При этом объём трафика при первом открытии измерялся в мегабайтах, а при повторном был менее 100 KB. Открываем DevTools (к слову сам DevTools может оказывать сильное влияние на замеры, но для сравнительного исследования — это то, что нужно), запускаем сбор данных и открываем страницу. И получаем вот такую картинку:
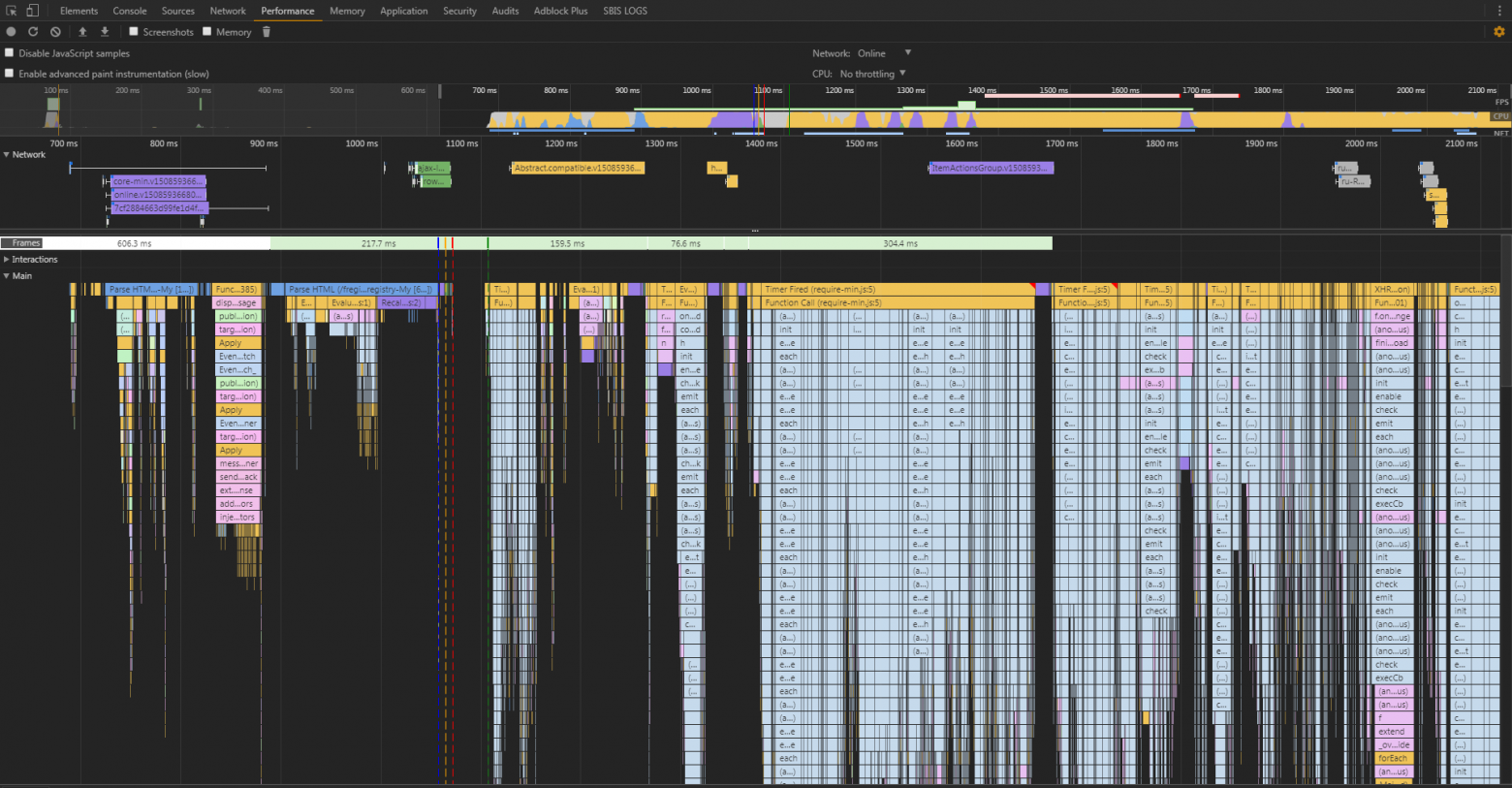
Здесь хорошо видно, что большую часть времени браузер занимался разбором/инициализацией js-файлов. Т.е. у нас так много js-кода, а браузер так оптимально использует время на получение файлов по сети, что по большей части мы зависим от скорости инициализации js-модулей, чем от скорости их получения. Сетевой трафик очень важен, но ввиду идеального соединения (меряем же изнутри сети) получаем именно такую картину. Эту проблему уже ни раз освещали, например, Эдди Османи.
Так, ОК, со страницами, которые в нашем отчёте практически не ускорились с заполнением кэша, всё понятно. А почему часть страниц стала открываться еще дольше? Тут пришлось очень внимательно вглядываться на вкладку Network, на которой и обнаружилась проблема. Пытаясь уменьшить число запросов, мы объединяли почти все js модули с лишними зависимостями в один большой файл. И вот на одной странице этот файл стал весить аж целых 3 МБ. Диск был не SSD, а канал с нулевым пингом. Ко всему прочему Chrome очень кучеряво работает с дисковым кэшем, создавая тормоза порой на ровном месте. Поэтому из кэша файл доставался дольше, чем летел по сети. Что, в конечном счёте, и привело к росту общего времени.
Да, объём страницы критически важен, и его нужно уменьшать. Но сейчас не менее важным становится оптимизация структуры данных. Какая польза от уменьшения размера небольшого файла на 10% через новый алгоритм сжатия, если пользователь потратит на распаковку лишние 50 мс? А если взглянуть на статистику с сайта httparchive.org, то увидим, что дальше подобная ситуация может только усугубиться:
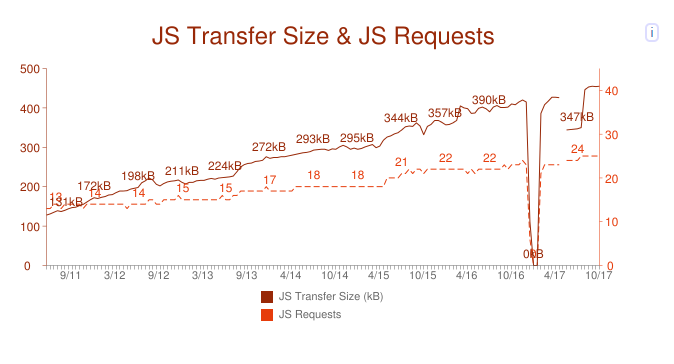
Нижняя шкала — это месяцы и годы, левая шкала — объёмы js кода на страницу в среднем, а правая шкала — число запросов на страницу в среднем.
Про сетевые условия. Хоть выше и говорилось о том, что мы измеряем в основном на идеальном канале, иногда возникает необходимость в исследовании того, что же происходит у пользователя при открытии наших страниц через Wi-Fi или 3G. А, может, где-то остался dial-up, и вы хотите понять, будет ли в принципе открываться ваша страница у бабы Фроси из деревни Кукуево. И тут мы, конечно, можем поставить одну из нод для замеров в ту самую деревню или же выполнить эмуляцию плохого канала. Последнее тянет на отдельную статью или даже целую книгу, поэтому ограничимся лишь стеком инструментов, которые успешной используются у нас.
Во-первых, это различные http-прокси: BrowserMobProxy (в light-режиме), Fiddler, mitm, etc. Они, конечно, никак не эмулируют плохой канал, а просто создают задержки каждые n KB. Но как показывает практика, для приложений, работающих по http в целом, этого достаточно. Когда же мы хотим действительно эмулировать, на помощь приходят netem и clumsy.
При таком тестировании желательно понимать, как сеть влияет на производительность веб-приложений. Если для получения результатов это не так важно, то для их интерпретации стоит в этом действительно разобраться, дабы не выдавать в баг-репорте «тут тормозит». Одна из лучших книг на эту тему — «High Performance Browser Networking» от Ильи Григорика.
Браузеры. Несомненно, очень важную роль во времени открытия страницы играют сами браузеры. Причём речь сейчас идёт даже не о тех бенчмарк-тестах, которые каждый создатель браузера проектирует под себя, дабы показать, что уж их-то конь самый шустрый на планете. Сейчас речь про различные особенности движков или самих браузеров, влияющие, в конечном счёте, на время открытия страницы. Так, например, Chrome большие js файлы инициализирует по мере получения в отдельном потоке. А вот что авторы подразумевают под «большими файлами», нигде не уточняется. Но если заглянуть в исходники Chromium, то оказывается, что речь про 30 КБ.
И вот так получается, что иногда, немного увеличив js модуль, мы можем ускорить время загрузки страницы. Правда, не настолько конечно, чтобы теперь просто так увеличивать все js модули подряд.
Это маленькая деталь. А если посмотреть шире, то у нас есть различные настройки браузеров, открытые вкладки, различные плагины, различное состояние хранилищ и кэша. И всё это, так или иначе, участвует в работе браузера и может повлиять на то, как быстро откроется та или иная страница для конкретного пользователя.
Мы выяснили, что существует множество факторов, оказывающих значительное или небольшое влияние на наши замеры. Что же с этим делать? Перебирать все комбинации? Тогда мы получим комбинаторный взрыв и не успеем толком замерить даже одну страницу за релиз. Правильное решение — выбрать одну конфигурацию для основных постоянных замеров, т.к. воспроизводимость результатов при тестировании имеет первостепенное значение.
Что же касается остальных ситуаций, то тут мы решили проводить отдельные единичные эксперименты. К тому же все наши предположения о пользователях могут оказаться неправдой, и желательно научиться собирать показатели напрямую (RUM).
Инструментов, посвященных замерам и производительности веба в целом, много (gmetrix, pingdom, webpagetest, etc.). Если вооружимся гуглом и попробуем десяток из них, то сможем сделать следующие выводы:
Далее про самые практичные.
WebPageTest. Из всего разнообразия инструментов положительно выделяется WebPageTest. Это здоровенный мультикомбайн, постоянно развивающийся и выдающий отличный результат.
Одни из самых главных плюсов этого инструмента:
Про последний плюс стоит отдельно сказать. Тут, пожалуй, действительно собраны почти все способы. Самые интересные — Speed Index и First Interactive. Про первую упоминали раньше. А вторая говорит нам, спустя какое время после появления страница начнёт откликаться на наши действия. А вдруг коварный разработчик начал генерировать на сервере картинки и присылать их нам (надеюсь, нет ).
Если развернуть такое решение локально, то вы покроете почти все свои потребности в тестировании производительности. Но, увы, не все. Если вы всё же хотите получать точное время появления основного контента, добавить возможность выполнять целые сценарии, используя удобные фреймворки, вам придётся сделать свой инструмент. Чем мы в своё время и занялись.
Selenium. Скорее по привычке, чем осознанно, для первого блина был выбран Selenium. Не учитывая мелких деталей, вся суть решения выглядела так:
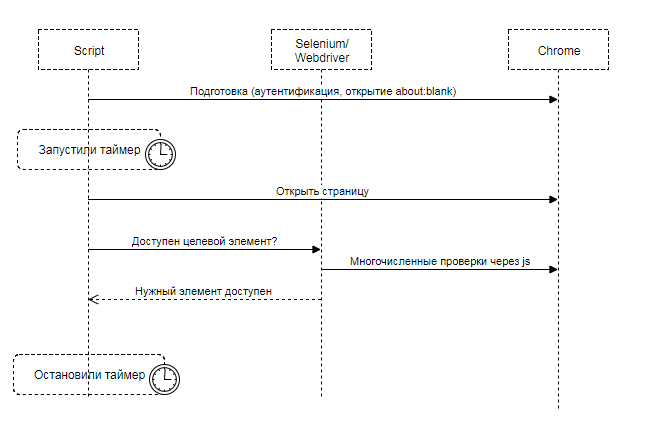
Переводим браузер в нужное состояние, открываем страницу, и начинаем ждать, когда Selenium посчитает целевой элемент доступным и видимым для пользователя. Целевой элемент – то, что пользователь ожидает увидеть: текст сообщения, текст статьи, картинка, etc.
Все эти замеры выполнялись по 10 раз, и высчитывались усреднённые результаты (e.g. медиана, среднее арифметическое,… ). В целом, от раза к разу получался более-менее стабильный результат. Вроде бы, вот оно счастье, но наш многострадальный лоб опять сталкивается с вселенскими граблями. Оказалось, что время хоть и было стабильным при одной неизменной странице, начинало необоснованно прыгать при изменении этой страницы. Разобраться в этом нам помогла видеозапись. Мы сравнивали две версии одной и той же страницы. По видеозаписи страницы открывались почти одновременно (±100 мс). А замеры через Selenium упорно говорили нам, что страница стала открываться на полторы секунды дольше. Причём стабильно дольше.
Расследование привело к реализации is_displayed в Selenium. Вычисление этого свойства состояло из проверки нескольких js свойств элемента, e.g. что он есть в DOM дереве, что он видим, имеет не нулевой размер, и так далее. При этом все эти проверки проводятся также и по всем родительским элементам рекурсивно. Мало того, что у нас бывает очень большое DOM дерево, но и сами проверки, будучи реализованными на js, могут выполняться очень долго в момент открытия страницы из-за процессов инициализации js модулей и выполнение прочего js кода.
В итоге мы приняли решение о замене Selenium'а на что-то другое. Сначала это был WebPageTest, но после ряда экспериментов мы реализовали своё простое и рабочее решение.

Поскольку мы главным образом хотели замерять время визуального появления основного контента на странице, то и для инструмента выбрали замеры через снятие скриншотов с частотой в 60 fps. Механизм самого замера выглядит следующим образом:

Через debug-режим подключаемся к браузеру Chrome, добавляем нужные куки, проверяем окружение и запускаем в параллели на той же машине снятие скриншотов через PIL. Открываем нужную нам страницу в тестируемом приложении (UAT). Затем дожидаемся прекращения значимой сетевой и визуальной активности длительностью в 10 секунд. После этого сохраняем полученные результаты и артефакты: скриншоты, HAR-файлы, Navigation Timing API и прочее.
По итогу получаем несколько сотен скриншотов и обрабатываем их.

Обычно после удаления всех дубликатов из сотен скриншотов остаётся не более 8 штук. Теперь нам нужно вычислить некоторый diff между соседними скриншотами. Diff’ом в простейшем случае является, к примеру, число изменённых пикселей. Для большей надёжности мы считаем разницу не всех скриншотов, а только некоторых. После чего, просуммировав все diff’ы, мы получим общее число изменений (100%). Теперь нам остаётся лишь найти скриншот, после которого произошло >90% изменений страницы. Время получения этого скриншота и будет временем открытия страницы.
Вместо подключения к Chrome через debug-протокол можно с тем же успехом использовать и Selenium. Т.к. с 63-ей версии Chrome поддерживает множественную удалённую отладку, у нас остаётся доступ ко всему множеству данных, а не только к тем, что даёт нам Selenium.
Как только у нас появилась первая версия такого решения, мы стартовали серию нудных, кропотливых, но очень нужных тестов. Да-да, инструменты для тестирования ваших продуктов тоже нужно тестировать.
Для тестирования мы использовали два основных подхода:
Тесты проводим регулярно, т.к. меняется сам инструмент, меняются тестируемые приложения. При написании этой статьи взял одну из стабильных страниц (серверная часть выполняется почти мгновенно) и провёл серию из 100 испытаний через 3 разных подхода. Через видео замерял 10 раз и подсчитал медиану.
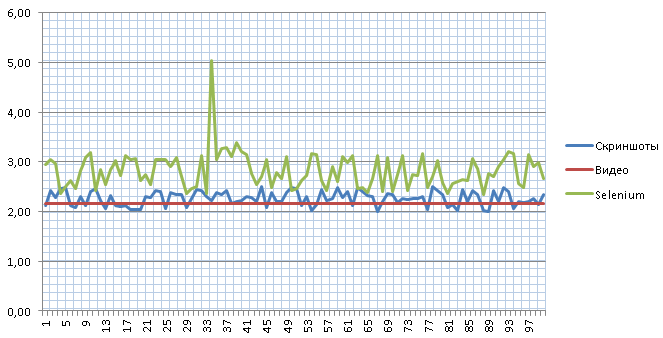
Как видим, через скриншоты мы получаем близкий к реальности результат в пределах 10 мс погрешности. А вот через Selenium у нас присутствует довольно сильный разброс с непонятным выбросом до 5 секунд.
Да, опять же про сферического коня в вакууме, это не универсальный способ. Такой алгоритм работает у нас, с нашими продуктами, но может запросто не работать для других сайтов. К тому же, как и со многими предыдущими подходами, он не лишён парадокса наблюдателя, как в квантовой физике. Мы не можем увидеть результат, гарантированно на него не влияя. Можно только снизить степень погрешности.
Как минимум PIL также утилизирует часть ресурсов. Но, тем не менее, такое решение успешно используется в компании последний год. Оно регулярно дорабатывается, но основная идея остаётся неизменной.
Автор Сергей Докучаев
Измерять клиентскую производительность – нетривиальная задача. Особенно если у вас в проекте сотни страниц на множестве стендов. Каждая наполнена js кодом, и сотни разработчиков каждый день оптимизируют, меняют, пересоздают их. Нужно спроектировать систему сбора, обработки и хранения данных. Какое хранилище выбрать? Как спроектировать базу, и в какой СУБД? Немало интересных задач, которые меркнут перед лаконичным «сколько времени открывалась страница?». Для нас поиск ответа на этот вопрос вылился в квест с детективными расследованиями, жаркими спорами и поиском истины. Его самые интересные моменты – в этой статье.

Что такое «страница открылась»?
В давние времена, до web 2.0, определить окончание загрузки страницы было сравнительно просто: прилетел документ от сервера ± несколько мс, и считаем, что страница загрузилась. Затем выросло число запросов, подгружающих изображения, стили и прочие ресурсы. Определить окончание загрузки страницы стало чуть сложнее: теперь нужно было дожидаться загрузки всех ресурсов, все стали завязываться на различные js события, e.g. window.onload. Интернет развивался, страницы тяжелели и прежние подходы перестали работать. Теперь загрузка страницы после получения всех ресурсов не останавливалась. Появились запросы, которые выполняются из js напрямую, появился прелоадинг и прочие механизмы, которые сильно размыли ту самую точку, которую можно считать окончанием загрузки страницы. И теперь можно встретить разные варианты для определения окончания загрузки страницы. Пройдёмся вкратце по каждому из них.
Сетевая активность. Из самого определения (окончание загрузки страницы) мы видим, что нам нужно дождаться момента, когда страница перестала выполнять запросы, т.е. у нас нет запросов в состоянии «pending», и какое-то время не выполнялись новые запросы. Определить это, вроде, не сложно, и формулировка понятная. Но вот только не работоспособная для большинства сайтов. После загрузки документа очень много времени может уходить на инициализацию js, что увеличит время построения страницы. И то пресловутое «страница загрузилась» состоится для пользователя значительно позже окончания загрузки. Также неприятным сюрпризом может стать прелоадинг, который срабатывает после загрузки страницы и может длиться несколько секунд. К тому же не редко бывают различные механизмы на странице, которые без перерыва обмениваются информацией с сервером. Поэтому сетевая активность может вообще никогда не закончиться.
События. Теперь правильно говорить не «страница загрузилась», а «страница построилась». С момента уже упомянутого window.onload были добавлены новые события, к которым можно привязать не только срабатывание js-кода, но и полное открытие нашей страницы. Как логическое продолжение, в 2012-ом году начинается работа над стандартом. Тут выводится уже целая серия событий, связанных с процессом загрузки страницы. Но на практике оказывается, что эти события срабатывают раньше, чем происходит полное построение страницы. Это видно как на синтетических тестах, так и при тесте на коленке. Да, в теории можно создать некое искусственное событие, которое показывало бы, что страница окончательно загрузилась. Но тогда нам потребовалось бы делать это для всех страниц отдельно. Плюс при любых изменениях перепроверять правильность нового подхода. Это все опять приводит к исходной задаче — как понять, что страница загрузилась.
Визуальные изменения. Клиентская производительность, так или иначе, крутится вокруг пользователя. Т.е. для нас важно то, что человек чувствует, когда работает с нашим продуктом. И тут можно не подумав, рвануть вперёд, посадить живого человека и поручить ему определять «на глазок» время загрузки страницы. Идея обречена на провал, т.к. определить тормозит или не тормозит страница, человек может, а вот сказать, насколько тормозит по 10-бальной шкале, уже вряд ли. Однако тут мы понимаем, что визуальные изменения – пожалуй, один из лучших показателей того, что страница загрузилась. Мы можем постоянно следить за отображением страницы и, как только у нас прекратились визуальные изменения, считать, что страница загрузилась. Но все ли изменения страницы одинаково важны?
Вот у нас первый раз отрисовалась страница, вот появилось обрамление, появился текст, загрузились картинки, стали подгружаться счётчики, социальные кнопки, комментарии, etc. В разных ситуациях важны разные этапы загрузки страницы. Где-то важна первая отрисовка, а кому-то важно знать, когда пользователь увидел комментарии. Но, как правило, в большинстве случаев для нас важна загрузка основного контента. Именно визуальное появление основного контента и считается тем самым «страница загрузилась». Поэтому при прочих равных мы можем отталкиваться от этого события, оценивая скорость загрузки страницы. Для того, чтобы работать со страницей комплексно, есть замечательный подход под названием «speed index», который описан тут.
Идея в следующем: мы пытаемся понять, насколько равномерно загружалась страница. Две версии одной страницы могли открыться за 2 секунды, но в первой 90% визуальных изменений произошли спустя секунду после открытия, а у второй спустя 1.7 секунды. Пользователю при равном времени открытия первая страница будет казаться значительно более быстрой, чем вторая.
Работоспособность. Итак, мы теперь точно понимаем, что такое «страница открылась». Можем на этом остановиться? А вот и нет. Страница загрузилась, мы нажимаем на кнопку добавления нового комментария и… штаны ни во что не превращаются – страница игнорирует наши клики. Что делать? Добавлять очередную метрику. Нам нужно выбрать целевой элемент. А дальше выяснить, когда он станет доступен для взаимодействия. Как будет рассказано далее, это самая сложная задача.
Вроде разобрались, что считать окончанием загрузки страницы. А что у нас с началом открытия? Тут, вроде, всё понятно – считаем с момента, когда мы дали браузеру команду открыть страницу, но опять чёртовы детали. Есть такие события как beforeunload. Код, который срабатывает при их наступлении, может значительно повлиять на время открытия страницы. Можем, конечно, всегда предварительно переходить на about:blank, но в этом случае мы можем пропустить подобную проблему. И при отличных показателях наших тестов пользователи будут жаловаться на тормоза. Опять же, выбираем, исходя из своей специфики. Мы для сравнительных замеров начинаем всегда с пустой страницы. А проблемы с переходами со страницы на страницу отлавливаем в рамках измерения времени работы критичных бизнес-сценариев.
Важно ли замерять один в один как у клиентов? Возможно. Но будет ли от этого непосредственная польза для разработки и ускорения? Далеко не факт. Вот отличная статья, которая говорит о том, что важно просто выбрать хотя бы одну метрику и отталкиваться от неё для оценки времени открытия страниц. С одним выбранным показателем будет гораздо проще работать, отслеживать оптимизации, строить тренды. А уже потом, при наличии на то ресурсов, дополнять вспомогательными метриками.

А почему у меня другой результат?
Отлично, теперь все в компании разговаривают на одном языке. Разработчики, тестировщики, менеджеры под временем открытия страницы понимают время отображения основного контента на странице. Мы даже создали инструмент, который с высокой точностью выполняет эти замеры. У нас довольно стабильные результаты, мера разброса минимальна. Мы публикуем наш первый отчёт и… получаем множество недовольных комментариев. Самый популярный из них – «а я тут померял, и у меня всё по-другому!». Даже если считать, что была соблюдена методология замеров и использован такой же инструмент – оказывается, что у всех совершенно разные результаты. Начинаем копаться и выясняем, что кто-то делал замеры через Wi-Fi, у кого-то комп с 32-мя ядрами, а кто-то открывал сайт с телефона. Получается, проблема замеров уже не многогранна, а многомерна. При различных условиях мы получаем разные результаты.
Тут встал вопрос: а какие факторы влияют на время открытия страницы? На скорую руку была составлена такая ассоциативная карта.
Получилось что-то около 60-70 различных факторов. И началась серия экспериментов, которая преподносила нам порой весьма любопытные результаты.
Кэш или не кэш – вот в чём вопрос. Первая аномалия, с которой мы столкнулись, была обнаружена ещё в самых первых отчётах. Мы выполняли замеры с пустым кэшем и с заполненным. Часть страниц с заполненным кэшем отдавалась не быстрее, чем с незаполненным. А некоторые страницы – ещё и дольше. При этом объём трафика при первом открытии измерялся в мегабайтах, а при повторном был менее 100 KB. Открываем DevTools (к слову сам DevTools может оказывать сильное влияние на замеры, но для сравнительного исследования — это то, что нужно), запускаем сбор данных и открываем страницу. И получаем вот такую картинку:
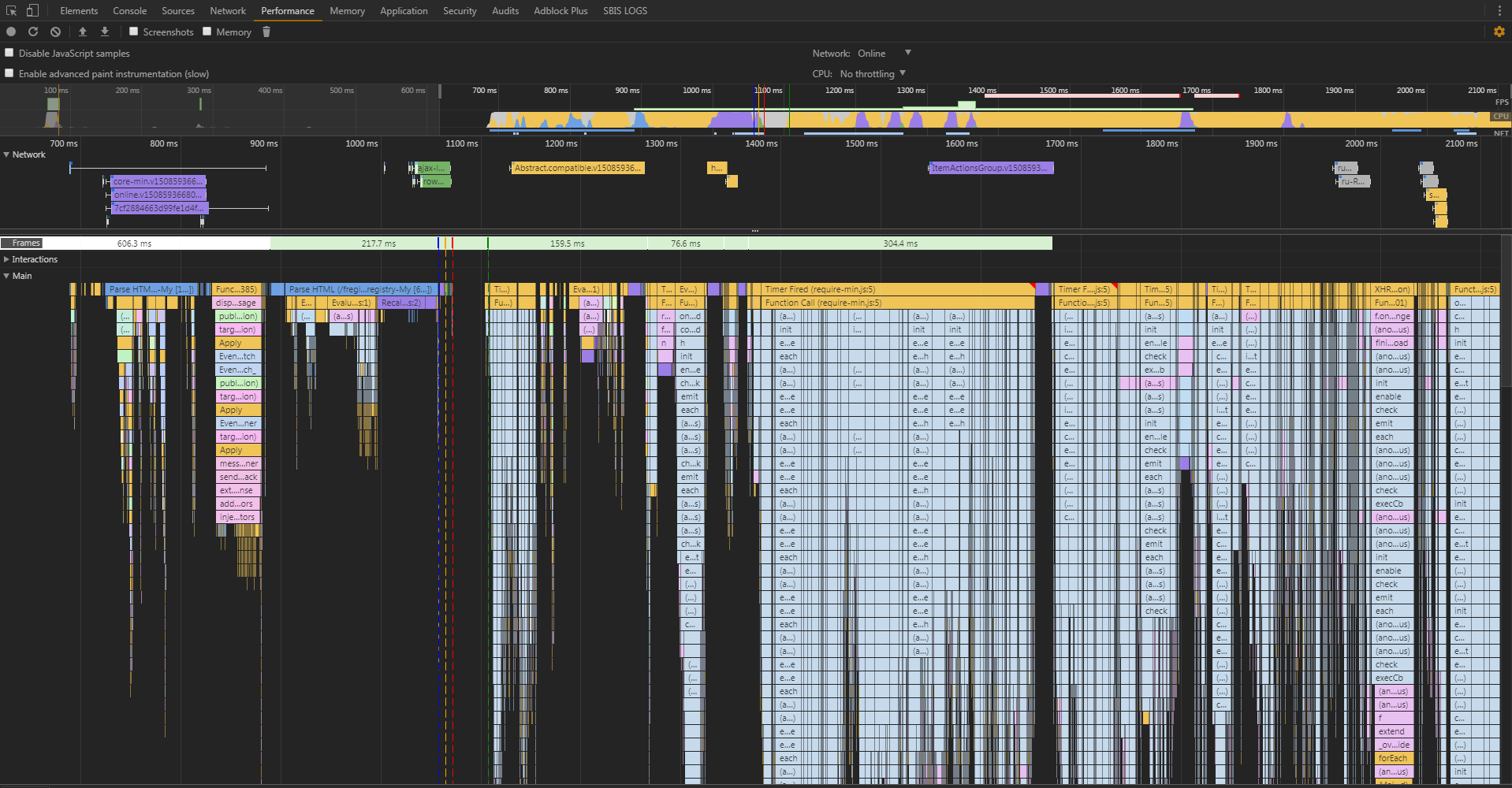
Здесь хорошо видно, что большую часть времени браузер занимался разбором/инициализацией js-файлов. Т.е. у нас так много js-кода, а браузер так оптимально использует время на получение файлов по сети, что по большей части мы зависим от скорости инициализации js-модулей, чем от скорости их получения. Сетевой трафик очень важен, но ввиду идеального соединения (меряем же изнутри сети) получаем именно такую картину. Эту проблему уже ни раз освещали, например, Эдди Османи.
Так, ОК, со страницами, которые в нашем отчёте практически не ускорились с заполнением кэша, всё понятно. А почему часть страниц стала открываться еще дольше? Тут пришлось очень внимательно вглядываться на вкладку Network, на которой и обнаружилась проблема. Пытаясь уменьшить число запросов, мы объединяли почти все js модули с лишними зависимостями в один большой файл. И вот на одной странице этот файл стал весить аж целых 3 МБ. Диск был не SSD, а канал с нулевым пингом. Ко всему прочему Chrome очень кучеряво работает с дисковым кэшем, создавая тормоза порой на ровном месте. Поэтому из кэша файл доставался дольше, чем летел по сети. Что, в конечном счёте, и привело к росту общего времени.
Да, объём страницы критически важен, и его нужно уменьшать. Но сейчас не менее важным становится оптимизация структуры данных. Какая польза от уменьшения размера небольшого файла на 10% через новый алгоритм сжатия, если пользователь потратит на распаковку лишние 50 мс? А если взглянуть на статистику с сайта httparchive.org, то увидим, что дальше подобная ситуация может только усугубиться:
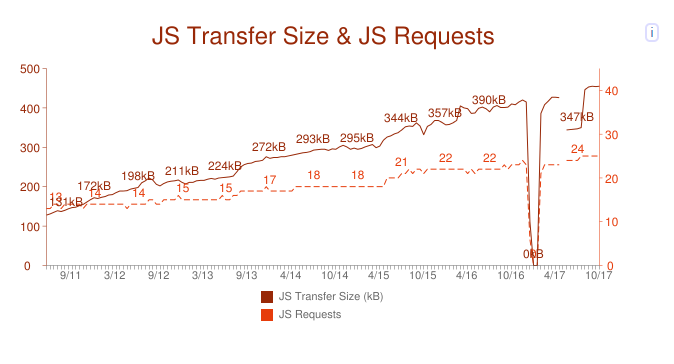
Нижняя шкала — это месяцы и годы, левая шкала — объёмы js кода на страницу в среднем, а правая шкала — число запросов на страницу в среднем.
Про сетевые условия. Хоть выше и говорилось о том, что мы измеряем в основном на идеальном канале, иногда возникает необходимость в исследовании того, что же происходит у пользователя при открытии наших страниц через Wi-Fi или 3G. А, может, где-то остался dial-up, и вы хотите понять, будет ли в принципе открываться ваша страница у бабы Фроси из деревни Кукуево. И тут мы, конечно, можем поставить одну из нод для замеров в ту самую деревню или же выполнить эмуляцию плохого канала. Последнее тянет на отдельную статью или даже целую книгу, поэтому ограничимся лишь стеком инструментов, которые успешной используются у нас.
Во-первых, это различные http-прокси: BrowserMobProxy (в light-режиме), Fiddler, mitm, etc. Они, конечно, никак не эмулируют плохой канал, а просто создают задержки каждые n KB. Но как показывает практика, для приложений, работающих по http в целом, этого достаточно. Когда же мы хотим действительно эмулировать, на помощь приходят netem и clumsy.
При таком тестировании желательно понимать, как сеть влияет на производительность веб-приложений. Если для получения результатов это не так важно, то для их интерпретации стоит в этом действительно разобраться, дабы не выдавать в баг-репорте «тут тормозит». Одна из лучших книг на эту тему — «High Performance Browser Networking» от Ильи Григорика.
Браузеры. Несомненно, очень важную роль во времени открытия страницы играют сами браузеры. Причём речь сейчас идёт даже не о тех бенчмарк-тестах, которые каждый создатель браузера проектирует под себя, дабы показать, что уж их-то конь самый шустрый на планете. Сейчас речь про различные особенности движков или самих браузеров, влияющие, в конечном счёте, на время открытия страницы. Так, например, Chrome большие js файлы инициализирует по мере получения в отдельном потоке. А вот что авторы подразумевают под «большими файлами», нигде не уточняется. Но если заглянуть в исходники Chromium, то оказывается, что речь про 30 КБ.
И вот так получается, что иногда, немного увеличив js модуль, мы можем ускорить время загрузки страницы. Правда, не настолько конечно, чтобы теперь просто так увеличивать все js модули подряд.
Это маленькая деталь. А если посмотреть шире, то у нас есть различные настройки браузеров, открытые вкладки, различные плагины, различное состояние хранилищ и кэша. И всё это, так или иначе, участвует в работе браузера и может повлиять на то, как быстро откроется та или иная страница для конкретного пользователя.
Мы выяснили, что существует множество факторов, оказывающих значительное или небольшое влияние на наши замеры. Что же с этим делать? Перебирать все комбинации? Тогда мы получим комбинаторный взрыв и не успеем толком замерить даже одну страницу за релиз. Правильное решение — выбрать одну конфигурацию для основных постоянных замеров, т.к. воспроизводимость результатов при тестировании имеет первостепенное значение.
Что же касается остальных ситуаций, то тут мы решили проводить отдельные единичные эксперименты. К тому же все наши предположения о пользователях могут оказаться неправдой, и желательно научиться собирать показатели напрямую (RUM).
Инструменты
Инструментов, посвященных замерам и производительности веба в целом, много (gmetrix, pingdom, webpagetest, etc.). Если вооружимся гуглом и попробуем десяток из них, то сможем сделать следующие выводы:
- все инструменты по-разному понимают, что такое «время открытия страницы»
- хостов, с которых выполняется открытие страницы, не так-то и много. А для России – еще меньше.
- сайты с аутентификацией замерять очень сложно. Мало где имеется способ преодоления такой проблемы.
- отчёты по большей части без подробностей, всё ограничивается лесенкой из запросов и простейшей статистикой
- результаты не всегда стабильны, и порой совершенно неясно почему
Далее про самые практичные.
WebPageTest. Из всего разнообразия инструментов положительно выделяется WebPageTest. Это здоровенный мультикомбайн, постоянно развивающийся и выдающий отличный результат.
Одни из самых главных плюсов этого инструмента:
- возможность развернуть локальную ноду и тестировать свои сайты из корпоративной сети
- потрясающие подробнейшие отчёты (включая скриншоты и видео)
- хорошее API
- множество способов для определения времени открытия страницы
Про последний плюс стоит отдельно сказать. Тут, пожалуй, действительно собраны почти все способы. Самые интересные — Speed Index и First Interactive. Про первую упоминали раньше. А вторая говорит нам, спустя какое время после появления страница начнёт откликаться на наши действия. А вдруг коварный разработчик начал генерировать на сервере картинки и присылать их нам (надеюсь, нет ).
Если развернуть такое решение локально, то вы покроете почти все свои потребности в тестировании производительности. Но, увы, не все. Если вы всё же хотите получать точное время появления основного контента, добавить возможность выполнять целые сценарии, используя удобные фреймворки, вам придётся сделать свой инструмент. Чем мы в своё время и занялись.
Selenium. Скорее по привычке, чем осознанно, для первого блина был выбран Selenium. Не учитывая мелких деталей, вся суть решения выглядела так:
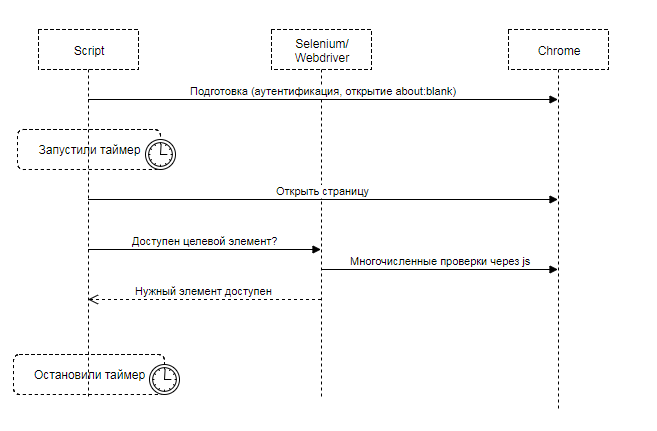
Переводим браузер в нужное состояние, открываем страницу, и начинаем ждать, когда Selenium посчитает целевой элемент доступным и видимым для пользователя. Целевой элемент – то, что пользователь ожидает увидеть: текст сообщения, текст статьи, картинка, etc.
Все эти замеры выполнялись по 10 раз, и высчитывались усреднённые результаты (e.g. медиана, среднее арифметическое,… ). В целом, от раза к разу получался более-менее стабильный результат. Вроде бы, вот оно счастье, но наш многострадальный лоб опять сталкивается с вселенскими граблями. Оказалось, что время хоть и было стабильным при одной неизменной странице, начинало необоснованно прыгать при изменении этой страницы. Разобраться в этом нам помогла видеозапись. Мы сравнивали две версии одной и той же страницы. По видеозаписи страницы открывались почти одновременно (±100 мс). А замеры через Selenium упорно говорили нам, что страница стала открываться на полторы секунды дольше. Причём стабильно дольше.
Расследование привело к реализации is_displayed в Selenium. Вычисление этого свойства состояло из проверки нескольких js свойств элемента, e.g. что он есть в DOM дереве, что он видим, имеет не нулевой размер, и так далее. При этом все эти проверки проводятся также и по всем родительским элементам рекурсивно. Мало того, что у нас бывает очень большое DOM дерево, но и сами проверки, будучи реализованными на js, могут выполняться очень долго в момент открытия страницы из-за процессов инициализации js модулей и выполнение прочего js кода.
В итоге мы приняли решение о замене Selenium'а на что-то другое. Сначала это был WebPageTest, но после ряда экспериментов мы реализовали своё простое и рабочее решение.
Свой велосипед

Поскольку мы главным образом хотели замерять время визуального появления основного контента на странице, то и для инструмента выбрали замеры через снятие скриншотов с частотой в 60 fps. Механизм самого замера выглядит следующим образом:

Через debug-режим подключаемся к браузеру Chrome, добавляем нужные куки, проверяем окружение и запускаем в параллели на той же машине снятие скриншотов через PIL. Открываем нужную нам страницу в тестируемом приложении (UAT). Затем дожидаемся прекращения значимой сетевой и визуальной активности длительностью в 10 секунд. После этого сохраняем полученные результаты и артефакты: скриншоты, HAR-файлы, Navigation Timing API и прочее.
По итогу получаем несколько сотен скриншотов и обрабатываем их.

Обычно после удаления всех дубликатов из сотен скриншотов остаётся не более 8 штук. Теперь нам нужно вычислить некоторый diff между соседними скриншотами. Diff’ом в простейшем случае является, к примеру, число изменённых пикселей. Для большей надёжности мы считаем разницу не всех скриншотов, а только некоторых. После чего, просуммировав все diff’ы, мы получим общее число изменений (100%). Теперь нам остаётся лишь найти скриншот, после которого произошло >90% изменений страницы. Время получения этого скриншота и будет временем открытия страницы.
Вместо подключения к Chrome через debug-протокол можно с тем же успехом использовать и Selenium. Т.к. с 63-ей версии Chrome поддерживает множественную удалённую отладку, у нас остаётся доступ ко всему множеству данных, а не только к тем, что даёт нам Selenium.
Как только у нас появилась первая версия такого решения, мы стартовали серию нудных, кропотливых, но очень нужных тестов. Да-да, инструменты для тестирования ваших продуктов тоже нужно тестировать.
Для тестирования мы использовали два основных подхода:
- Создание эталонной страницы, время загрузки которой известно заранее.
- Использование альтернативных вариантов для определения времени открытия страниц и выполнение большого числа (>100 для каждой страницы) замеров. Больше всего тут подошла видеозапись экрана.
Тесты проводим регулярно, т.к. меняется сам инструмент, меняются тестируемые приложения. При написании этой статьи взял одну из стабильных страниц (серверная часть выполняется почти мгновенно) и провёл серию из 100 испытаний через 3 разных подхода. Через видео замерял 10 раз и подсчитал медиану.
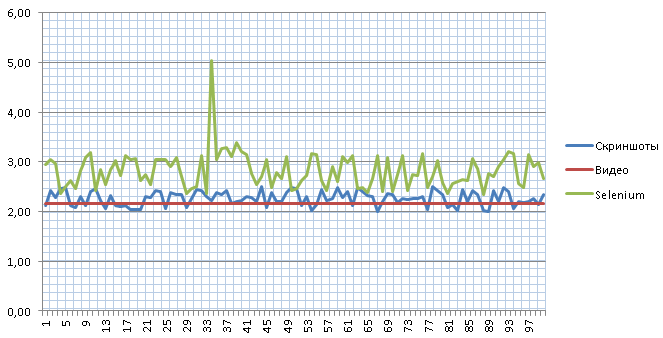
Как видим, через скриншоты мы получаем близкий к реальности результат в пределах 10 мс погрешности. А вот через Selenium у нас присутствует довольно сильный разброс с непонятным выбросом до 5 секунд.
Да, опять же про сферического коня в вакууме, это не универсальный способ. Такой алгоритм работает у нас, с нашими продуктами, но может запросто не работать для других сайтов. К тому же, как и со многими предыдущими подходами, он не лишён парадокса наблюдателя, как в квантовой физике. Мы не можем увидеть результат, гарантированно на него не влияя. Можно только снизить степень погрешности.
Как минимум PIL также утилизирует часть ресурсов. Но, тем не менее, такое решение успешно используется в компании последний год. Оно регулярно дорабатывается, но основная идея остаётся неизменной.
Автор Сергей Докучаев
