
В рамках кредитных конвейеров юридических лиц банки запрашивают у компаний оригиналы различных документов. Зачастую сканы этих документов поступают в виде единого многостраничного файла – «потока». Для удобства использования потоки нужно сегментировать на отдельные документы (одностраничные или многостраничные) и классифицировать их. Под катом мы расскажем о применении алгоритмов машинного обучения в классификации уже сегментированных документов.

Тип документа определяется как текстом, так и визуальной информацией. Например, паспорт или трудовую книжку легко различить визуально без анализа текста внутри. Более того, качество распознавания текста в таких документах достаточно низкое, если используются неспециализированные решения. Поэтому визуальная составляющая несет намного больше релевантной информации для классификации. Договор аренды и устав общества могут быть визуально похожи, однако текстовая информация, которую они содержат, значимо отличается. В результате задача классификации документов сводится к data fusion модели, которая должна объединить два источника неструктурированных данных: визуальное представление документа и результаты распознавания текстовой информации.
Отметим, что в банковской деятельности классификация документов также используется в конвейерах физических лиц на сканах или фотографиях документов, для сортировки накопленных фондов документов, для фильтрации отзывов клиентов с целью улучшения качества обслуживания, для сортировки платежных документов, для дополнительной фильтрации новостных потоков и т. п.
Для решения нашей задачи мы использовали модель BERT (Bidirectional Encoder Representations from Transformer) — это языковая модель, в основе которой лежит мультислойный двунаправленный кодирующий Трансформер. Трансформер получает на вход последовательность токенов (кодов слов или частей слов) и после внутренних преобразований выдает закодированное представление этой последовательности — набор эмбеддингов. Далее эти эмбеддинги можно применять для решения различных задач.

Архитектура модели Трансформера
Если более детально, то на вход подается последовательность из токенов, суммированная с кодами позиций этих токенов и кодами сегментов (предложений), в которых располагаются токены. Для каждой входной последовательности Трансформер генерирует контекстно-зависимое представление (набор эмбеддингов для всей последовательности), основанное на адаптивном механизме «внимания». В каждом выходном эмбеддинге закодировано «внимание» одних токенов относительно других.
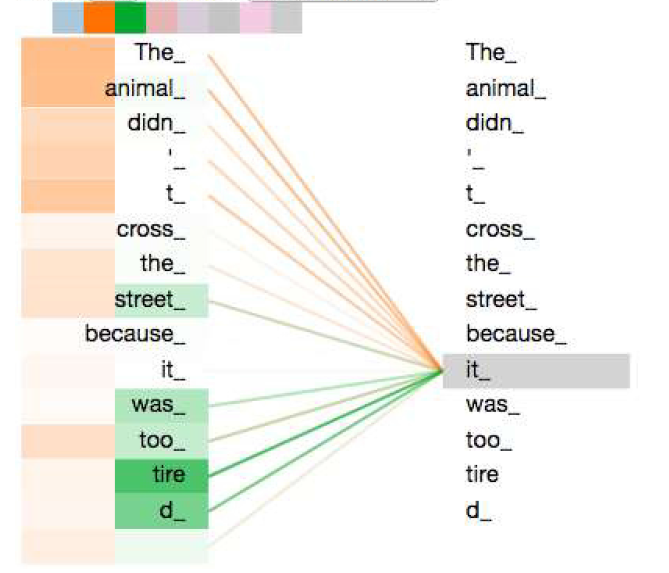
Кодируем слово it, часть механизма «внимания» сфокусировалась на The Animal и зафиксировала часть его представления в кодировку it (из блога The Illustrated Transfomer)
Модель BERT строится в два шага: предобучение и файнтюнинг. Во время предобучения модель решает две задачи: MLM (Masked Language Model) и NSP (Next Sentence Prediction). В задаче MLM случайно метится (маскируется) определенная доля токенов во входной последовательности, и задача состоит в том, чтобы восстановить значения токенов, которые были замаскированы. Задача NSP — это бинарная классификация на парах предложений, когда нужно предсказать, является ли второе предложение логичным продолжением первого. Во время файнтюнинга предобученные Трансформеры дообучаются на данных конкретных задач. Файнтюнинг на основе Трансформеров зарекомендовал себя во многих задачах NLP (Natural Language Processing): автоматические чат-боты, переводчики, анализаторы текста и др.
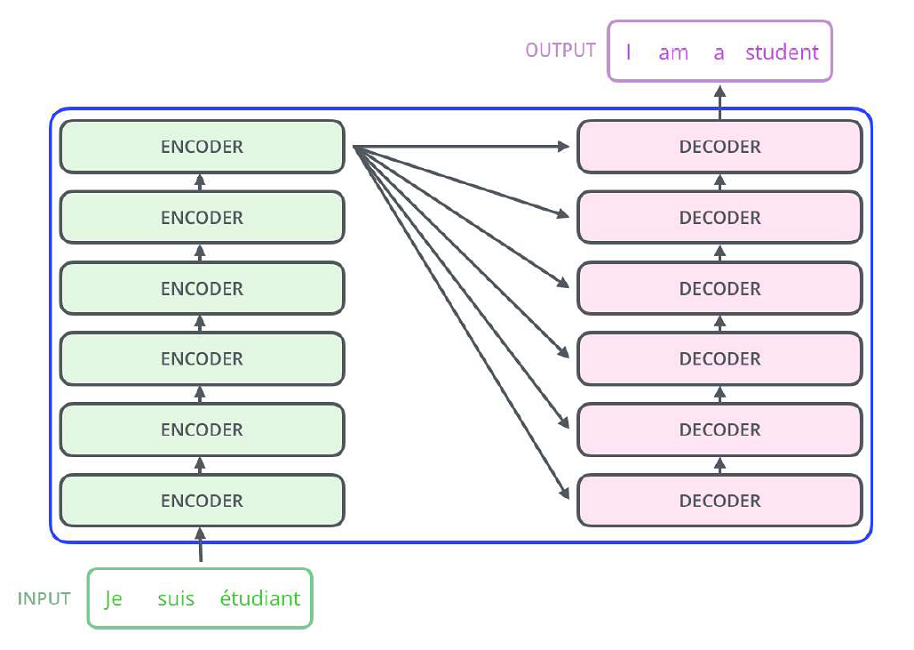
Схема Трансформера для автоматического переводчика с французского языка на английский (из блога The Illustrated Transfomer)
До появления модели BERT методы постраничной классификации сканов использовали: сверточные признаки из картинок (полученные с помощью сверточных нейросетей CNN — Convolutional Neural Network), частотные текстовые признаки (TF-IDF), тематические текстовые признаки (LDA топики), сверточные текстовые признаки (1-D свертка), эмбеддинги слов (WordToVec, GloVe) и их комбинации.
Ранее разработанные методы дают неплохое качество. Но чем ближе качество подбирается к максимальному, тем сложнее его улучшать. Как мы покажем далее, когда мы уже имели качество, близкое к максимальному, использование модели BERT помогло сделать его еще выше.
Поскольку мы работаем в основном с русскими текстами, то использовали модель BERT, предобученную на некоторых корпусах русских текстов (RuBERT, Russian, cased от компании DeepPavlov).
Выборка документов, на которой мы решали задачу классификации, состоит из сканов корпоративных документов компаний, накопленных в Банке ВТБ за многие годы. Корпоративные многостраничные документы сегментировались в полуавтоматическом режиме из отсканированного потока, и их страницы классифицировались платными решениями.
Большинство сканов черно-белые, и небольшая доля — цветные (в основном за счет цветных печатей).
Заказчики бизнес-подразделений выделили 10 основных категорий документов (около 30 000 уже сегментированных многостраничных документов, ~ 122 000 страниц). Документы пришлось очистить вручную из-за допущенных ошибок при сегментации. Также была введена одна категория «Иное», в которую объединились все остальные категории менее значимых документов (около 300 категорий, ~33 000 уже сегментированных многостраничных документов, ~110 000 страниц), также в категорию «Иное» мы добавили порядка 10 000 картинок из датасета ImageNet (для «защиты от дурака»)… В результате мы будем строить классификатор с 11 классами.
Основные 10 категорий — это:
В категорию «Иное» попали различные удостоверения личности (заграничные паспорта, миграционные карты и т. п.), иные свидетельства, вопросники ИП, заявления, акты, доверенности, опросники, решения арбитражного суда, картинки из ImageNet и др.
В train было взято около 81% уже сегментированных многостраничных документов (от числа всех таких документов), dev — 9%, test — 10%. Для чистоты эксперимента выборка разбивалась так, чтобы страницы любого сегментированного многостраничного документа попадали целиком в одну часть: либо train, либо dev, либо test.
Зачастую корпоративные клиенты предоставляют не оригиналы, а копии документов, многие из которых заверяются у нотариуса или руководителями компании. Кроме того, многостраничные документы часто сшивают, прописывают дату прошивки и опять же заверяют на последней странице.
Поэтому в нашем датасете много таких многостраничных документов, где на последнем скане (странице) имеются печати, даты и другая информация, касающаяся прошивки или реквизитов заверителей, но никак не касающаяся класса документа. Ниже приведены последние страницы двух разных сегментированных из потока многостраничных документов, которые практически невозможно правильно классифицировать, если не смотреть на остальные страницы.

Одинаковые последние страницы документов различных классов
Хотя сканирование документов обычно проходит в офисах банка (на хорошей копировальной технике), клиенты часто приносят уже пересканированные неоднократно копии документов. И качество таких копий сильно страдает: на сканах много шума и артефактов, которые могут появиться от плохого качества тонеров, от голограмм и текстуры на многих документах и по другим причинам.
В датасете много документов с неправильной ориентацией скана, особенно это характерно для удостоверений личности и текстовых документов, созданных в альбомном режиме. Но в основном текст повернут на угол, кратный 90 градусов (± 5 градусов). При извлечении текста нами дополнительно определялась «правильная» ориентация картинки, чтобы большинство текста было ориентировано вертикально.
Поскольку большинство документов начинают сканировать с первой страницы, на ней обычно достаточно информации для определения класса, и многие многостраничные документы хорошо различаются по одной первой странице.
Поэтому мы будем строить наш baseline классификатор многостраничных документов только по их первым страницам.
Отметим, что хотя мы и не рассматриваем в этой статье задачу сегментации многостраничных потоков (PSS — Page Stream Segmentation), но если добавить в обучение нашего классификатора остальные страницы документов, а не только первые, то можно легко получить решение задачи сегментации PSS бинарной классификацией: для страниц из потока предсказывать по очереди два класса: «новый документ» или «тот же документ».
Поскольку многие картинки сканов имеют большой размер, и это влияет на скорость обработки, мы изначально сжимаем все сканы так, чтобы оба размера картинки (ширина и высота) были не более 2000 пикселей.
Для извлечения текстов из картинок мы использовали свободно распространяемый пакет Tesseract 4.0 от компании Google. Версия 4.0 (и выше) этого пакета довольно хорошо работает при шумах (в отличие от предыдущих версий), поэтому мы не убирали шум из текстов, но определяли «правильную» ориентацию перед извлечением текста из картинки скана, для чего также использовали специальные функции в Tesseract 4.0.
Из каждого документа мы получали сверточные признаки с помощью предобученной сверточной нейронной сети (ResNet34). Для этого брали выходы последнего сверточного слоя — вектор из 512 сверточных признаков. Перед прогоном через нейронную сеть картинки сканов из train проходили некоторую аугментацию, чтобы противостоять переобучению.
В качестве модели классификатора на сверточных признаках пробовались логистическая регрессия и бустинги с подбором параметров на dev.
Качество лучшей модели сверточного классификатора на test составило около 76.1% (accuracy) на логистической регрессии.
Такой метод позволил классифицировать сканы, которые внешне хорошо отличаются друг от друга. Но для прогона картинок через нейросеть их сжимали до размеров входа нейронной сети (ResNet34 имеет размер 224х224 пикселя на входе), поэтому и получается низкое качество классификации: мелкий шрифт документов становится нечитаемым, и классификатор может «зацепиться» только за какие-то сверточные признаки, получающиеся из крупного шрифта, каких-то объектов на странице с особенным расположением и т. п., но суть текста такой классификатор не учитывает.

Скан первой страницы договора аренды помещения и первой страницы устава компании визуально хорошо отличаются
Но мы решаем задачу классификации корпоративных документов, где многие виды документов содержат в основном текстовую информацию, и их сложно отличить визуально – сложно визуально «зацепиться» только за «вытянутые пятна» строчек при одинаковых шапках документов:

Уменьшенные копии сканов свидетельств из двух разных категорий визуально почти неразличимы
Мы предполагаем, что текстовые признаки улучшат качество, и поэтому добавим текстовые признаки, вернее, создадим для baseline модели текстовый классификатор.
Построим для baseline модели текстовый классификатор только на признаках TF-IDF (Term Frequency – Inverse Document Frequency) на текстах, извлеченных из сканов. Перед составлением терм-матрицы TF-IDF тексты приводились к нижнему регистру; из текстов удалялась пунктуация, стоп-слова; слова проверялись на правильность написания и приводились к начальной форме лемматизацией (пакет Pymystem3).
В качестве модели классификатора мы пробовали снова логистическую регрессию и бустинги, параметры подбирались на dev. Поскольку терм-матрицы получаются большой размерности и являются очень разреженными, неплохое качество показала логистическая регрессия, и качество составило 85.4% (accuracy) на test.
Для получения ансамбля мы взяли блендинг сверточного и текстового классификаторов с весами, подобранными на выборке dev. То есть для каждого скана S берем с весом α набор вероятностей YCNN (11-значный по числу категорий), выдаваемый сверточным классификатором, также берем 11-значный набор вероятностей YTF-IDF, выдаваемый текстовым классификатором, с весом 1–α, и суммируем эти взвешенные наборы, получая выход смешанного baseline-классификатора:
YCNN+TF-IDF(S) = α YCNN + (1 – α) YTF-IDF
В результате получили качество смешанного классификатора 90.2% (accuracy) на test.
Результаты классификаторов: сверточного (YCNN), текстового на признаках tf-idf (YTF-IDF) и их ансамбля (YCNN+TF-IDF):
При анализе результатов ансамбля классификаторов оказалось, что он часто ошибается на сканах из категории «Паспорт (РФ)», классифицируя паспорта как «Иное», поскольку в этой категории содержится много удостоверений личности. Причем их сканы, как и сканы паспортов, также имеют зачастую плохое качество, что мешает качественной классификации.
Поэтому мы решили проводить классификацию в два шага.
Мы перекинули в категорию «Паспорт РФ» все удостоверения личности из категории «Иное» в соответствии с изначальным разбиением на train, dev и test.
Основные 10 категорий:
Категория «Иное»:
Обучили на такой измененной выборке ансамбль классификаторов.
Вторым шагом мы провели бинарную классификацию внутри категории 6, полученной на первом шаге: «Паспорт РФ» (класс 1) против «Различные удостоверения личности» (класс 0). Для этого по аналогии обучили сверточный и текстовый классификаторы (в обеих моделях была логистическая регрессия) и взвесили их выходы, получив ансамбль.
Общее качество классификации на двух шагах получилось 95.7 % (accuracy) на test. В этом случае качество удовлетворяет требованиям наших бизнес-заказчиков (порог – 95%).
Мы построили двухшаговую классификацию, аналогично тому, как делали выше, но на каждом шаге вместо признаков TF-IDF использовали текстовые эмбеддинги страниц, полученные из модели RuBERT. Для каждой страницы текст токенизировался, и на вход модели RuBERT подавалась последовательность из первых 256 токенов (с дополнением pad-символами до длины 512, т.е. до размера входа модели).
Для большей эффективности перед получением текстовых эмбеддингов мы предобучили модель MLM (Masked Language Model) на текстах из нашего датасета по аналогии с тем, как это делали авторы модели BERT: подавая на вход модели RuBERT последовательность токенов, мы заменяли токеном [MASK] определенную долю случайно взятых токенов. Для чистоты эксперимента предобучение проводилось только на текстах из train. Последовательности токенов брались на всех страницах сегментированных документов, а не только на первых. Начало последовательностей выбиралось случайным образом из токенизированного текста.
На этапе получения эмбеддингов в качестве текстового эмбеддинга страницы брался усредненный вектор полученных выходов модели RuBERT.
Предобучение дало улучшение в двухшаговой классификации: при использовании текстовых эмбеддингов, полученных из модели RuBERT, качество увеличилось до 96.3% (accuracy) на test. Отметим тот факт, что чем ближе точность (accuracy) к 100%, тем сложнее ее улучшать. Поэтому полученный прирост 0.6% можно считать существенным.
Увеличение длины входных последовательностей токенов до 512 (до размера входа модели BERT) заметного прироста не дало.
Итоговая схема работы модели:

Качество всех протестированных моделей:
где YCNN — сверточный классификатор, YTF-IDF — текстовый классификатор на признаках TF-IDF.
YCNN +TF-IDF — ансамбль классификаторов (YCNN +TF-IDF (S) = α YCNN + (1 – α) YTF-IDF, α = 0.45).
YCNN +TF-IDF+2steps — двухшаговая классификация: 1) удостоверения личности перекидываются в категорию «Паспорта РФ + Удостоверения личности», и строится ансамбль классификаторов на полученной выборке с 11 классами; 2) в категории «Паспорта РФ + Удостоверения личности» строится ансамбль классификаторов с двумя классами: класс 1 — Паспорт РФ, класс 0 — Удостоверения личности.
YCNN +RuBERT+2steps — двухшаговая классификация; вместо TF-IDF признаков берутся текстовые эмбеддинги модели RuBERT, предобученной на нашем датасете.

Тип документа определяется как текстом, так и визуальной информацией. Например, паспорт или трудовую книжку легко различить визуально без анализа текста внутри. Более того, качество распознавания текста в таких документах достаточно низкое, если используются неспециализированные решения. Поэтому визуальная составляющая несет намного больше релевантной информации для классификации. Договор аренды и устав общества могут быть визуально похожи, однако текстовая информация, которую они содержат, значимо отличается. В результате задача классификации документов сводится к data fusion модели, которая должна объединить два источника неструктурированных данных: визуальное представление документа и результаты распознавания текстовой информации.
Отметим, что в банковской деятельности классификация документов также используется в конвейерах физических лиц на сканах или фотографиях документов, для сортировки накопленных фондов документов, для фильтрации отзывов клиентов с целью улучшения качества обслуживания, для сортировки платежных документов, для дополнительной фильтрации новостных потоков и т. п.
Модель BERT
Для решения нашей задачи мы использовали модель BERT (Bidirectional Encoder Representations from Transformer) — это языковая модель, в основе которой лежит мультислойный двунаправленный кодирующий Трансформер. Трансформер получает на вход последовательность токенов (кодов слов или частей слов) и после внутренних преобразований выдает закодированное представление этой последовательности — набор эмбеддингов. Далее эти эмбеддинги можно применять для решения различных задач.
Архитектура модели Трансформера
Если более детально, то на вход подается последовательность из токенов, суммированная с кодами позиций этих токенов и кодами сегментов (предложений), в которых располагаются токены. Для каждой входной последовательности Трансформер генерирует контекстно-зависимое представление (набор эмбеддингов для всей последовательности), основанное на адаптивном механизме «внимания». В каждом выходном эмбеддинге закодировано «внимание» одних токенов относительно других.

Кодируем слово it, часть механизма «внимания» сфокусировалась на The Animal и зафиксировала часть его представления в кодировку it (из блога The Illustrated Transfomer)
Модель BERT строится в два шага: предобучение и файнтюнинг. Во время предобучения модель решает две задачи: MLM (Masked Language Model) и NSP (Next Sentence Prediction). В задаче MLM случайно метится (маскируется) определенная доля токенов во входной последовательности, и задача состоит в том, чтобы восстановить значения токенов, которые были замаскированы. Задача NSP — это бинарная классификация на парах предложений, когда нужно предсказать, является ли второе предложение логичным продолжением первого. Во время файнтюнинга предобученные Трансформеры дообучаются на данных конкретных задач. Файнтюнинг на основе Трансформеров зарекомендовал себя во многих задачах NLP (Natural Language Processing): автоматические чат-боты, переводчики, анализаторы текста и др.

Схема Трансформера для автоматического переводчика с французского языка на английский (из блога The Illustrated Transfomer)
До появления модели BERT методы постраничной классификации сканов использовали: сверточные признаки из картинок (полученные с помощью сверточных нейросетей CNN — Convolutional Neural Network), частотные текстовые признаки (TF-IDF), тематические текстовые признаки (LDA топики), сверточные текстовые признаки (1-D свертка), эмбеддинги слов (WordToVec, GloVe) и их комбинации.
Ранее разработанные методы дают неплохое качество. Но чем ближе качество подбирается к максимальному, тем сложнее его улучшать. Как мы покажем далее, когда мы уже имели качество, близкое к максимальному, использование модели BERT помогло сделать его еще выше.
Поскольку мы работаем в основном с русскими текстами, то использовали модель BERT, предобученную на некоторых корпусах русских текстов (RuBERT, Russian, cased от компании DeepPavlov).
Наш датасет
Описание
Выборка документов, на которой мы решали задачу классификации, состоит из сканов корпоративных документов компаний, накопленных в Банке ВТБ за многие годы. Корпоративные многостраничные документы сегментировались в полуавтоматическом режиме из отсканированного потока, и их страницы классифицировались платными решениями.
Большинство сканов черно-белые, и небольшая доля — цветные (в основном за счет цветных печатей).
Заказчики бизнес-подразделений выделили 10 основных категорий документов (около 30 000 уже сегментированных многостраничных документов, ~ 122 000 страниц). Документы пришлось очистить вручную из-за допущенных ошибок при сегментации. Также была введена одна категория «Иное», в которую объединились все остальные категории менее значимых документов (около 300 категорий, ~33 000 уже сегментированных многостраничных документов, ~110 000 страниц), также в категорию «Иное» мы добавили порядка 10 000 картинок из датасета ImageNet (для «защиты от дурака»)… В результате мы будем строить классификатор с 11 классами.
Основные 10 категорий — это:
- Договор аренды
- Выписка из реестра участников
- Устав компании
- Свидетельство о постановке на учет в налоговом органе
- Вопросник для юридических лиц
- Паспорт РФ
- Лист записи ЕГРЮЛ
- Свидетельство о государственной регистрации юридического лица
- Приказы/Распоряжения
- Решения/Протоколы
В категорию «Иное» попали различные удостоверения личности (заграничные паспорта, миграционные карты и т. п.), иные свидетельства, вопросники ИП, заявления, акты, доверенности, опросники, решения арбитражного суда, картинки из ImageNet и др.
В train было взято около 81% уже сегментированных многостраничных документов (от числа всех таких документов), dev — 9%, test — 10%. Для чистоты эксперимента выборка разбивалась так, чтобы страницы любого сегментированного многостраничного документа попадали целиком в одну часть: либо train, либо dev, либо test.
Страницы «заверено-прошито»
Зачастую корпоративные клиенты предоставляют не оригиналы, а копии документов, многие из которых заверяются у нотариуса или руководителями компании. Кроме того, многостраничные документы часто сшивают, прописывают дату прошивки и опять же заверяют на последней странице.
Поэтому в нашем датасете много таких многостраничных документов, где на последнем скане (странице) имеются печати, даты и другая информация, касающаяся прошивки или реквизитов заверителей, но никак не касающаяся класса документа. Ниже приведены последние страницы двух разных сегментированных из потока многостраничных документов, которые практически невозможно правильно классифицировать, если не смотреть на остальные страницы.

Одинаковые последние страницы документов различных классов
Качество сканов
Хотя сканирование документов обычно проходит в офисах банка (на хорошей копировальной технике), клиенты часто приносят уже пересканированные неоднократно копии документов. И качество таких копий сильно страдает: на сканах много шума и артефактов, которые могут появиться от плохого качества тонеров, от голограмм и текстуры на многих документах и по другим причинам.
Ориентация
В датасете много документов с неправильной ориентацией скана, особенно это характерно для удостоверений личности и текстовых документов, созданных в альбомном режиме. Но в основном текст повернут на угол, кратный 90 градусов (± 5 градусов). При извлечении текста нами дополнительно определялась «правильная» ориентация картинки, чтобы большинство текста было ориентировано вертикально.
Baseline
Поскольку большинство документов начинают сканировать с первой страницы, на ней обычно достаточно информации для определения класса, и многие многостраничные документы хорошо различаются по одной первой странице.
Поэтому мы будем строить наш baseline классификатор многостраничных документов только по их первым страницам.
Отметим, что хотя мы и не рассматриваем в этой статье задачу сегментации многостраничных потоков (PSS — Page Stream Segmentation), но если добавить в обучение нашего классификатора остальные страницы документов, а не только первые, то можно легко получить решение задачи сегментации PSS бинарной классификацией: для страниц из потока предсказывать по очереди два класса: «новый документ» или «тот же документ».
Препроцессинг
Поскольку многие картинки сканов имеют большой размер, и это влияет на скорость обработки, мы изначально сжимаем все сканы так, чтобы оба размера картинки (ширина и высота) были не более 2000 пикселей.
Для извлечения текстов из картинок мы использовали свободно распространяемый пакет Tesseract 4.0 от компании Google. Версия 4.0 (и выше) этого пакета довольно хорошо работает при шумах (в отличие от предыдущих версий), поэтому мы не убирали шум из текстов, но определяли «правильную» ориентацию перед извлечением текста из картинки скана, для чего также использовали специальные функции в Tesseract 4.0.
Сверточный классификатор на картинках
Из каждого документа мы получали сверточные признаки с помощью предобученной сверточной нейронной сети (ResNet34). Для этого брали выходы последнего сверточного слоя — вектор из 512 сверточных признаков. Перед прогоном через нейронную сеть картинки сканов из train проходили некоторую аугментацию, чтобы противостоять переобучению.
В качестве модели классификатора на сверточных признаках пробовались логистическая регрессия и бустинги с подбором параметров на dev.
Качество лучшей модели сверточного классификатора на test составило около 76.1% (accuracy) на логистической регрессии.
Такой метод позволил классифицировать сканы, которые внешне хорошо отличаются друг от друга. Но для прогона картинок через нейросеть их сжимали до размеров входа нейронной сети (ResNet34 имеет размер 224х224 пикселя на входе), поэтому и получается низкое качество классификации: мелкий шрифт документов становится нечитаемым, и классификатор может «зацепиться» только за какие-то сверточные признаки, получающиеся из крупного шрифта, каких-то объектов на странице с особенным расположением и т. п., но суть текста такой классификатор не учитывает.

Скан первой страницы договора аренды помещения и первой страницы устава компании визуально хорошо отличаются
Но мы решаем задачу классификации корпоративных документов, где многие виды документов содержат в основном текстовую информацию, и их сложно отличить визуально – сложно визуально «зацепиться» только за «вытянутые пятна» строчек при одинаковых шапках документов:

Уменьшенные копии сканов свидетельств из двух разных категорий визуально почти неразличимы
Мы предполагаем, что текстовые признаки улучшат качество, и поэтому добавим текстовые признаки, вернее, создадим для baseline модели текстовый классификатор.
Текстовый классификатор
Построим для baseline модели текстовый классификатор только на признаках TF-IDF (Term Frequency – Inverse Document Frequency) на текстах, извлеченных из сканов. Перед составлением терм-матрицы TF-IDF тексты приводились к нижнему регистру; из текстов удалялась пунктуация, стоп-слова; слова проверялись на правильность написания и приводились к начальной форме лемматизацией (пакет Pymystem3).
В качестве модели классификатора мы пробовали снова логистическую регрессию и бустинги, параметры подбирались на dev. Поскольку терм-матрицы получаются большой размерности и являются очень разреженными, неплохое качество показала логистическая регрессия, и качество составило 85.4% (accuracy) на test.
Ансамбль классификаторов
Для получения ансамбля мы взяли блендинг сверточного и текстового классификаторов с весами, подобранными на выборке dev. То есть для каждого скана S берем с весом α набор вероятностей YCNN (11-значный по числу категорий), выдаваемый сверточным классификатором, также берем 11-значный набор вероятностей YTF-IDF, выдаваемый текстовым классификатором, с весом 1–α, и суммируем эти взвешенные наборы, получая выход смешанного baseline-классификатора:
YCNN+TF-IDF(S) = α YCNN + (1 – α) YTF-IDF
В результате получили качество смешанного классификатора 90.2% (accuracy) на test.
Результаты классификаторов: сверточного (YCNN), текстового на признаках tf-idf (YTF-IDF) и их ансамбля (YCNN+TF-IDF):
- YCNN – 76.1%
- Ytf-idf – 85.4%
- YCNN+TF-IDF – 90.2%
Двухшаговая классификация
При анализе результатов ансамбля классификаторов оказалось, что он часто ошибается на сканах из категории «Паспорт (РФ)», классифицируя паспорта как «Иное», поскольку в этой категории содержится много удостоверений личности. Причем их сканы, как и сканы паспортов, также имеют зачастую плохое качество, что мешает качественной классификации.
Поэтому мы решили проводить классификацию в два шага.
Шаг 1
Мы перекинули в категорию «Паспорт РФ» все удостоверения личности из категории «Иное» в соответствии с изначальным разбиением на train, dev и test.
Основные 10 категорий:
- Договор аренды
- Выписка из реестра участников
- Устав компании
- Свидетельство о постановке на учет в налоговом органе
- Вопросник для юридических лиц
- Паспорт РФ + различные удостоверения личности (заграничные паспорта, миграционные карты и т. п.)
- Лист записи ЕГРЮЛ
- Свидетельство о государственной регистрации юридического лица
- Приказы/Распоряжения
- Решения/Протоколы
Категория «Иное»:
- Иные свидетельства
- Вопросники ИП
- Заявления
- Акты
- Доверенности
- Опросники
- Решения арбитражного суда и др.
Обучили на такой измененной выборке ансамбль классификаторов.
Шаг 2
Вторым шагом мы провели бинарную классификацию внутри категории 6, полученной на первом шаге: «Паспорт РФ» (класс 1) против «Различные удостоверения личности» (класс 0). Для этого по аналогии обучили сверточный и текстовый классификаторы (в обеих моделях была логистическая регрессия) и взвесили их выходы, получив ансамбль.
Общее качество классификации на двух шагах получилось 95.7 % (accuracy) на test. В этом случае качество удовлетворяет требованиям наших бизнес-заказчиков (порог – 95%).
BERT-признаки
Мы построили двухшаговую классификацию, аналогично тому, как делали выше, но на каждом шаге вместо признаков TF-IDF использовали текстовые эмбеддинги страниц, полученные из модели RuBERT. Для каждой страницы текст токенизировался, и на вход модели RuBERT подавалась последовательность из первых 256 токенов (с дополнением pad-символами до длины 512, т.е. до размера входа модели).
Для большей эффективности перед получением текстовых эмбеддингов мы предобучили модель MLM (Masked Language Model) на текстах из нашего датасета по аналогии с тем, как это делали авторы модели BERT: подавая на вход модели RuBERT последовательность токенов, мы заменяли токеном [MASK] определенную долю случайно взятых токенов. Для чистоты эксперимента предобучение проводилось только на текстах из train. Последовательности токенов брались на всех страницах сегментированных документов, а не только на первых. Начало последовательностей выбиралось случайным образом из токенизированного текста.
На этапе получения эмбеддингов в качестве текстового эмбеддинга страницы брался усредненный вектор полученных выходов модели RuBERT.
Предобучение дало улучшение в двухшаговой классификации: при использовании текстовых эмбеддингов, полученных из модели RuBERT, качество увеличилось до 96.3% (accuracy) на test. Отметим тот факт, что чем ближе точность (accuracy) к 100%, тем сложнее ее улучшать. Поэтому полученный прирост 0.6% можно считать существенным.
Увеличение длины входных последовательностей токенов до 512 (до размера входа модели BERT) заметного прироста не дало.
Что мы получили
Итоговая схема работы модели:
Качество всех протестированных моделей:
- YCNN — 76.1%,
- YTF-IDF — 85.4%,
- YCNN +TF-IDF — 90.2%,
- YCNN +TF-IDF+2steps — 95.7%,
- YCNN+RuBERT+2steps — 96.3%,
где YCNN — сверточный классификатор, YTF-IDF — текстовый классификатор на признаках TF-IDF.
YCNN +TF-IDF — ансамбль классификаторов (YCNN +TF-IDF (S) = α YCNN + (1 – α) YTF-IDF, α = 0.45).
YCNN +TF-IDF+2steps — двухшаговая классификация: 1) удостоверения личности перекидываются в категорию «Паспорта РФ + Удостоверения личности», и строится ансамбль классификаторов на полученной выборке с 11 классами; 2) в категории «Паспорта РФ + Удостоверения личности» строится ансамбль классификаторов с двумя классами: класс 1 — Паспорт РФ, класс 0 — Удостоверения личности.
YCNN +RuBERT+2steps — двухшаговая классификация; вместо TF-IDF признаков берутся текстовые эмбеддинги модели RuBERT, предобученной на нашем датасете.
