
Компания Cerebras Systems выпустила самую большую микросхему в истории компьютерной техники. С площадью 46 225 мм² и 1,2 трлн транзисторов она примерно в 56,7 раз больше, чем самый большой GPU (21,1 млрд транзисторов, 815 мм²). Фото: Jessica Chou / The New York Times
Самые большие компьютерные чипы обычно помещаются в ладони. Некоторые могут уместиться на кончике пальца. Известно, что увеличение физических размеров вызывает массу проблем. Однако стартап из Кремниевой долины бросает вызов этой идее. Сегодня на конференции Hot Chips в Пало-Альто компания Cerebras Systems и её производственный партнер TSMC представили «крупнейшую микросхему в истории компьютерной техники» размером примерно с обеденную тарелку, пишет NY Times.
Процессор предназначен для дата-центров по обработке вычислений в области машинного обучения и искусственного интеллекта (AI).
Инженеры Cerebras Systems считают, что микросхему под названием WSE можно использовать для облачных вычислений в разных приложениях машинного обучения: от беспилотных автомобилей до цифровых ассистентов с распознаванием речи, таких как Alexa от Amazon.
Разработкой чипов для AI занимаются многие компании, в том числе традиционные представители индустрии, такие как Intel, Qualcomm, а также различные стартапы в США, Великобритании и Китае. Некоторые эксперты считают, что эти чипы будут играть ключевую роль в гонке за создание искусственного интеллекта, потенциально влияя на баланс сил между технологическими компаниями и даже странами. Теоретически, они могут дать преимущество в работе коммерческих продуктов и государственных технологий, включая системы наблюдения и автономное оружие.
Google уже разработала собственный AI-ускоритель, используя его в широком спектре проектов AI, включая Google Assistant, который распознаёт голосовые команды на телефонах Android, и Google Translate для перевода текстов: «В этой области наблюдается чудовищный рост, — говорит основатель и исполнительный директор Cerebras Эндрю Фельдман (Andrew Feldman), ветеран полупроводниковой индустрии, который продал свой предыдущий стартап AMD.
Новые системы AI полагаются на нейронные сети и требует специфических вычислителей. Сегодня большинство компаний обрабатывает данные на GPU. Хотя графические процессоры изначально предназначены для других задач, но хорошо подходят для обсчёта математики нейросетей.
Около шести лет назад, когда технологические гиганты Google, Facebook и Microsoft сосредоточились на технологиях AI, они начали покупать огромное количество GPU у Nvidia. За год компания продала графических процессоров на $143 млн, удвоив продажи по сравнению с предыдущим годом.
Но компаниям требовалось ещё больше вычислительной мощности, поэтому Google разработала чип специально для нейронных сетей — тензорный процессор, или TPU. Несколько других производителей последовали её примеру.
Системы AI работают в многопоточном режиме, а узким местом становится перемещение данных между чипами: «Соединение этих чипов на самом деле замедляет их — и требует много энергии, — объясняет Субраманьян Айер (Subramanian Iyer), профессор Калифорнийского университета в Лос-Анджелесе, который специализируется на разработке чипов для искусственного интеллекта.
Производители оборудования изучают множество различных вариантов. Некоторые пытаются расширить межпроцессорные соединения. Трёхлетний стартап Cerebras, который получил более $200 млн венчурного финансирования, предлагает новый подход. Идея в том, чтобы сохранить все данные на гигантском чипе — и тем самым ускорить вычисления.
Работать с одним большим чипом очень сложно. Обычно микросхемы создаются на круглых кремниевых пластинах диаметром около 12 дюймов (30,5 см). Каждая из них обычно содержит около 100 чипов.

Пример кремниевой пластины. Фото: ARM
Многие из этих микросхем после снятия с пластины выбрасываются и никогда не используются. Травление цепей в кремнии — такой сложный процесс, что производители не могут полностью устранить дефекты. Некоторые цепи просто не работают. Это одна из причин, почему производители предпочитают сохранять маленький размер микросхем — так остаётся меньше места для ошибок. А вот Cerebras Systems уверяет, что создала одну микросхему размером с целую пластину. Технологический партнёр TSMC производит эти чипы по техпроцессу 16 нм.
Некоторые стартапы раньше пробовали такой подход, но безуспешно. Пожалуй, самым известным является стартап под названием Trilogy, который основал в 1980 году известный инженер из компании IBM Джин Амдал (Gene Amdahl). Несмотря на более $230 млн финансирования, Trilogy в конечном итоге сочла задачу слишком трудной и спустя пять лет свернула деятельность.
Почти через 35 лет Cerebras собирается исправить ошибки предшественника. Стартап планирует начать поставки микросхем WSE небольшому числу клиентов уже в сентябре 2019 года. Основатель компании говорит, что WSE способен обучать системы AI в 100−1000 раз быстрее, чем существующее оборудование.
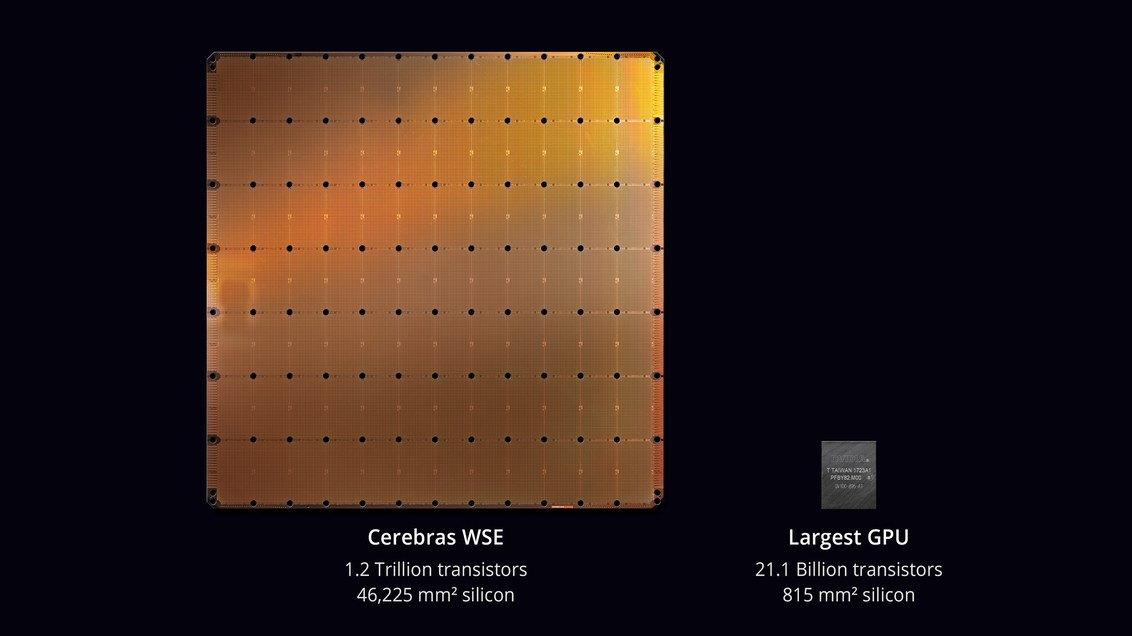
Фото: Cerebras Systems
18 гигабайт быстрой локальной SRAM — единственный уровень иерархии оперативной памяти. Скорость обмена данных с памятью — 9 петабайт в секунду, пишет VentureBeat.
Гигантская микросхема разделена на более мелкие секции (ядра), с учётом того, что некоторые из них не будут работать. Общее количество ядер — 400 000. Чип разработан с возможностью маршрутизации вокруг дефектных областей. Программируемые ядра SLAC (Sparse Linear Algebra Cores) оптимизированы для линейной алгебры, то есть для вычислений в векторном пространстве. Компания также разработала технологию «утилизации разреженности» (sparsity harvesting) для повышения производительности вычислений при разреженных рабочих нагрузках (содержащих нули), таких как глубокое обучение. Векторы и матрицы в векторном пространстве обычно содержат множество нулевых элементов (от 50% до 98%), поэтому на традиционных GPU большая часть вычислений уходит впустую. В отличие от них, ядра SLAC предварительно отфильтровывают нулевые данные.
Коммуникации между ядрами обеспечивает система Swarm с пропускной способностью 100 петабит в секунду. Маршрутизация аппаратная, задержки измеряются в наносекундах.
NY Times отмечает, что заявления Cerebras Systems не подтверждены независимыми экспертами. Достоверно не известно, какова производительность микросхемы и сколько ядер работоспособны в реальных образцах.
Цена микросхемы будет зависеть и от процента брака. Разработка и производство таких изделий является «намного более трудоёмким процессом», признаёт Брэд Полсен (Brad Paulsen), старший вице-президент TSMC. Чип такого размера также потребляет большое количество энергии: значит, и охлаждать его будет сложно и дорого. Другими словами, создание чипа — только часть задачи.
Cerebras планирует продавать чип в составе гораздо более крупной машины, которая включает сложное оборудование для жидкостного охлаждения. Это не совсем то, с чем привыкли работать крупные технологические компании и государственные учреждения: «Дело не в том, что люди не могли создать такой чип, — говорит Ракеш Кумар (Rakesh Kumar), профессор университета Иллинойса, который также изучает большие чипы для AI. — Проблема в том, что никто не мог сделать это коммерчески осуществимым».
Таким образом, основной вопрос — сколько будет стоить эта система с жидкостным охлаждением и микросхемой Cerebras внутри.










