Приветствую Вас, уважаемые читатели и писатели Хабра!
Так сложилось, что я меломан и программист – и мне однажды захотелось совместить это.
Попробую рассказать, что из этого вышло.
В данной статье будет описано, как я пытался создать алгоритм, который бы мог определять на каком инструменте сыграна мелодия.
Наши исходные данные:
В итоге хочется получить какие-то значения признаков, которые бы помогли проклассифицировать музыкальные сигналы и легли в основу алгоритма классификации.
Стратегия будет следующей:
Собственно вот о б этом и пойдет дальше речь.
На этом этапе мы различными методами (анализ Фурье и прочие) мы получим значения для наших 9 характеристик.
Воспользуемся методом Иерархический классификации. Результат кластеризации данным методом представлен на рисунке ниже(кластеры выделены красными кружками).
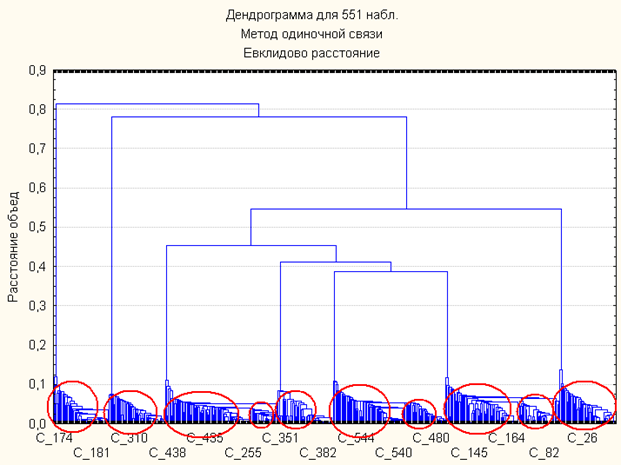
В данном случае мы можем наблюдать 10 кластеров, о которых нам априорно известно, таким образом, мы все же имеем возможность классификации по имеющемуся набору входных данных.
Имеющийся в нашем распоряжении набор входных данных имеет довольно большую размерность, а следовательно с ним не совсем удобно работать. Осуществим попытку снизить размерность входных данных, то есть решить задачу редукции данных.
Для этого мы воспользуемся сначала Факторным анализом, как более грубым инструментом, а потом к результатам Факторного анализа применим метод Многомерного шкалирования.
Проведем факторный анализ. Так как мы не знаем заведомо, сколько факторов будет выделено, то проведем для 9 факторов. Собственные значения представлены в таблице ниже:
Собственные значения Выделение: Главные компоненты
Соб. зн. % общей дисперсии Кумулятивн. собств знач Кумулятивн. %
1 3,640494 40,44993 3,640494 40,4499
2 1,875795 20,84217 5,516289 61,2921
3 1,028626 11,42918 6,544915 72,7213
4 0,869353 9,65948 7,414268 82,3808
5 0,636831 7,07590 8,051100 89,4567
6 0,410692 4,56325 8,461792 94,0199
7 0,261768 2,90854 8,723560 96,9284
8 0,204545 2,27272 8,928105 99,2012
9 0,071895 0,79883 9,000000 100,0000
Как мы видим из этой таблицы, суммарная доля объясненной дисперсии не превышает 80%, отсюда мы можем сделать вывод о нелинейной зависимости данных, то есть данные аппроксимируются нелинейной моделью. О числе факторов можно судить по графику каменистой осыпи:
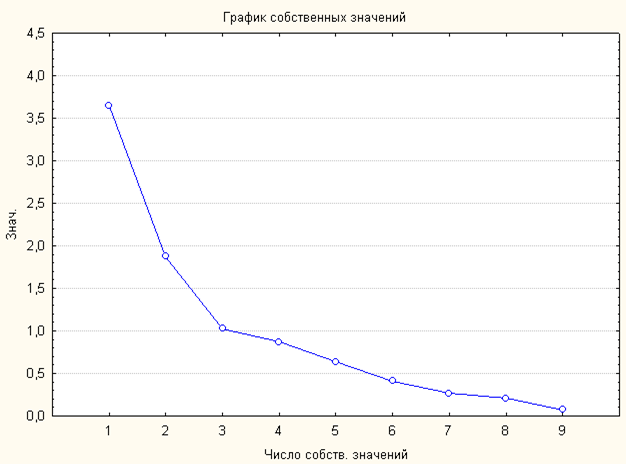
По графику каменистой осыпи, мы видим, что можно выделить 3 фактора.
Проведение анализа по методу многомерного шкалирования не дало улучшение ситуации с редукцией данных. О том, что проведение многомерного шкалирования не дало результатов, свидетельствует диаграмма Шепарда, которая для удачного анализа должна представлять из себя прямую.
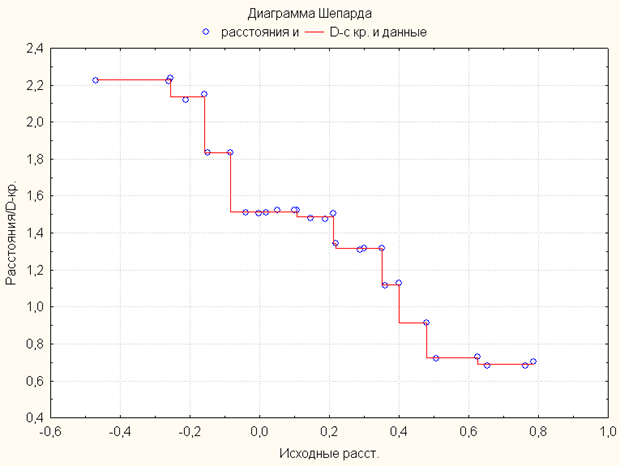
Ввиду того, что мы априорно знаем, о существовании 10 кластеров в исходных данных, а также что мы имеем некоторое доказательство их существования (то есть имеется возможность классификации по имеющемуся набору характеристик): результат кластеризации по методу Иерархической классификации, а также полученные выводы при предварительном исследовании входных данных,– решено применить весьма «тонкий» инструмент – Деревья Классификации. Решено так же применить одномерное ветвление по методу CART, как наиболее точному методу для задач классификации.
Алгоритм построил следующее дерево классификации:
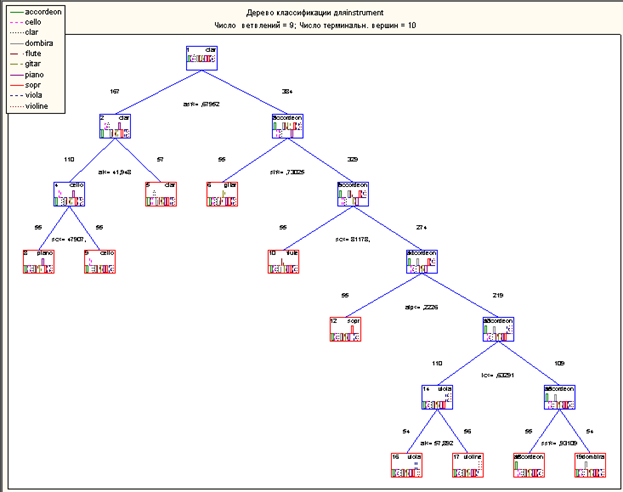
Произведем описание полученных результатов. Как мы можем видеть, дерево классификации построено корректно: мы не имеем повторений в терминальных вершинах, таким образом, произошло четкое разбиение на классы на основе значений характеристик аудио- сигнала, представленного во входных данных.
Все эксперименты проводились при помощи друзей-музыкантов и математического пакета Statistica.
В итоге были получены значения признаков аудио сигнала, благодаря которым, я могу распознать на каком музыкальном инструменте была сыграна мелодия.
Алгоритм пока работает для мелодий, которые сыграны на одном музыкальном инструменте, но в планах и много-инструментальные мелодии.
Так сложилось, что я меломан и программист – и мне однажды захотелось совместить это.
Попробую рассказать, что из этого вышло.
В данной статье будет описано, как я пытался создать алгоритм, который бы мог определять на каком инструменте сыграна мелодия.
Итак, поехали
Наши исходные данные:
- 550 записей по 5 минут для 10 инструментов – по 55 записей на инструмент.
- Музыкальные инструменты: пианино, виолончель, домбра, флейта, дудка, гитара, аккордеон, кларнет, альт, скрипка.
- 9 признаков музыкального звукового сигнала.
Что хотим в итоге?
В итоге хочется получить какие-то значения признаков, которые бы помогли проклассифицировать музыкальные сигналы и легли в основу алгоритма классификации.
Как будем делать
Стратегия будет следующей:
- Подготовка входных данных
- Кластерный анализ
- Снижение размерности входных данных
- Анализ методом Деревьев Классификации
Собственно вот о б этом и пойдет дальше речь.
Подготовка входных данных
На этом этапе мы различными методами (анализ Фурье и прочие) мы получим значения для наших 9 характеристик.
Кластерный анализ
Воспользуемся методом Иерархический классификации. Результат кластеризации данным методом представлен на рисунке ниже(кластеры выделены красными кружками).
В данном случае мы можем наблюдать 10 кластеров, о которых нам априорно известно, таким образом, мы все же имеем возможность классификации по имеющемуся набору входных данных.
Снижение размерности входных данных
Имеющийся в нашем распоряжении набор входных данных имеет довольно большую размерность, а следовательно с ним не совсем удобно работать. Осуществим попытку снизить размерность входных данных, то есть решить задачу редукции данных.
Для этого мы воспользуемся сначала Факторным анализом, как более грубым инструментом, а потом к результатам Факторного анализа применим метод Многомерного шкалирования.
Проведем факторный анализ. Так как мы не знаем заведомо, сколько факторов будет выделено, то проведем для 9 факторов. Собственные значения представлены в таблице ниже:
Собственные значения Выделение: Главные компоненты
Соб. зн. % общей дисперсии Кумулятивн. собств знач Кумулятивн. %
1 3,640494 40,44993 3,640494 40,4499
2 1,875795 20,84217 5,516289 61,2921
3 1,028626 11,42918 6,544915 72,7213
4 0,869353 9,65948 7,414268 82,3808
5 0,636831 7,07590 8,051100 89,4567
6 0,410692 4,56325 8,461792 94,0199
7 0,261768 2,90854 8,723560 96,9284
8 0,204545 2,27272 8,928105 99,2012
9 0,071895 0,79883 9,000000 100,0000
Как мы видим из этой таблицы, суммарная доля объясненной дисперсии не превышает 80%, отсюда мы можем сделать вывод о нелинейной зависимости данных, то есть данные аппроксимируются нелинейной моделью. О числе факторов можно судить по графику каменистой осыпи:
По графику каменистой осыпи, мы видим, что можно выделить 3 фактора.
Проведение анализа по методу многомерного шкалирования не дало улучшение ситуации с редукцией данных. О том, что проведение многомерного шкалирования не дало результатов, свидетельствует диаграмма Шепарда, которая для удачного анализа должна представлять из себя прямую.
Анализ методом Деревьев Классификации
Ввиду того, что мы априорно знаем, о существовании 10 кластеров в исходных данных, а также что мы имеем некоторое доказательство их существования (то есть имеется возможность классификации по имеющемуся набору характеристик): результат кластеризации по методу Иерархической классификации, а также полученные выводы при предварительном исследовании входных данных,– решено применить весьма «тонкий» инструмент – Деревья Классификации. Решено так же применить одномерное ветвление по методу CART, как наиболее точному методу для задач классификации.
Алгоритм построил следующее дерево классификации:
Произведем описание полученных результатов. Как мы можем видеть, дерево классификации построено корректно: мы не имеем повторений в терминальных вершинах, таким образом, произошло четкое разбиение на классы на основе значений характеристик аудио- сигнала, представленного во входных данных.
Заключение
Все эксперименты проводились при помощи друзей-музыкантов и математического пакета Statistica.
В итоге были получены значения признаков аудио сигнала, благодаря которым, я могу распознать на каком музыкальном инструменте была сыграна мелодия.
Алгоритм пока работает для мелодий, которые сыграны на одном музыкальном инструменте, но в планах и много-инструментальные мелодии.
