Введение
Пришла пора покупать СХД. Какую взять, кого слушать? Вендор А рассказывает про вендора B, а еще есть интегратор C, который рассказывает обратное и советует вендора D. В такой ситуации и у опытного архитектора по системам хранения голова пойдет кругом, особенно со всеми новыми вендорами и модными сегодня SDS и гиперконвергенцией.
Итак, как же во всем этом разобраться и не оказаться в дураках? Мы (AntonVirtual Антон Жбанков и korp Евгений Елизаров) попробуем об этом рассказать русским языком по белому.
Статья во многом перекликается, и фактически является расширением “Дизайна виртуализованного ЦОД” в плане выбора систем хранения данных и обзора технологий систем хранения. Мы кратко рассмотрим общую теорию, но рекомендуем ознакомиться и с указанной статьей.
Зачем
Часто можно наблюдать ситуацию как приходит новый человек на форум или в специализированный чатик, как например Storage Discussions и задает вопрос: “вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете”?
И начинается мерянье у кого какие особенности реализации страшных и непонятных фишек, которые для неподготовленного человека и вовсе китайская грамота.
Так вот, ключевой и самый первый вопрос, который нужно себе задать задолго до сравнивания спецификаций в коммерческих предложениях — ЗАЧЕМ? Зачем нужна эта СХД?

Ответ будет неожиданным, и очень в стиле Тони Роббинса — чтобы хранить данные. Спасибо, капитан! И тем не менее, иногда мы так далеко углубляемся в сравнение деталей, что забываем зачем все это вообще делаем.
Так вот, задача системы хранения данных — это хранение и предоставление доступа к ДАННЫМ с заданной производительностью. С данных же мы и начнем.
Данные
Тип данных
Что за данные мы планируем хранить? Очень важный вопрос, который может вычеркнуть очень многие СХД даже из рассмотрения. Например, планируется хранение видеозаписей и фотографий. Сразу можно вычеркивать системы, рассчитанные под случайный доступ малым блоком, или системы с фирменными фишками в компрессии / дедупликации. Это могут быть просто превосходные системы, ничего плохого не хотим сказать. Но в данном случае их сильные стороны или станут напротив слабыми (видео и фото не компрессируются) или просто значительно увеличат стоимость системы.
И наоборот, если целевое использование нагруженная транзакционная СУБД, то превосходные потоковые системы под мультимедиа, способные выдавать гигабайты в секунду, будут плохим выбором.
Объем данных
Сколько данных мы планируем хранить? Количество всегда перерастает в качество, это не нужно забывать никогда, особенно в наше время экспоненциального роста объема данных. Системы петабайтного класса уже не редкость, но чем больше петабайт объема, тем более специфической становится система, тем менее будет доступно привычной функциональности систем со случайным доступом малого и среднего объема. Банально потому что одни только таблицы статистики доступа по блокам становятся больше доступного объема оперативной памяти на контроллерах. Не говоря уже о компрессии / тиринге. Предположим, мы хотим переключить алгоритм компрессии на более мощный и пережать 20 петабайт данных. Сколько это займет: полгода, год?
С другой стороны, зачем городить огород, если хранить и обрабатывать надо 500 ГБ данных? Всего 500. Бытовые SSD (с низким DWPD) подобного объема стоят всего ничего. Зачем для этого строить фабрику Fiber Channel и покупать внешнюю СХД высокого класса стоимостью в чугунный мост?
Какой процент от общего объема горячие данные? Насколько неравномерна нагрузка по объему данных? Именно тут может очень помочь технология многоуровневого хранения или Flash Cache, если объем горячих данных мизерный по сравнению с общим. Либо наоборот, при равномерной нагрузке по всему объему, часто встречающейся в потоковых системах (видеонаблюдение, некоторые системы аналитики) подобные технологии не дадут ничего, и лишь увеличат стоимость / сложность системы.
ИС
Обратная сторона данных — это информационная система, использующая эти данные. ИС обладает набором требований, которые наследуют данные. Подробнее об ИС см в “Дизайне виртуализованного ЦОД”.
Требования по отказоустойчивости / доступности
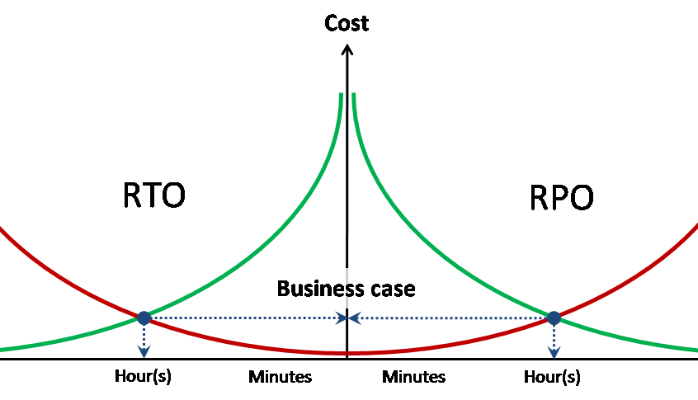
Требования по отказоустойчивости / доступности данных наследуются от использующей их ИС и выражаются в трех числах — RPO, RTO, доступность.
Доступность — доля за заданный промежуток времени, в течение которого данные доступны для работы с ними. Выражается обычно в количестве 9. Например, две девятки в год означает, что доступность равна 99%, или иначе допускается 95 часов недоступности в год. Три девятки — 9,5 часов в год.
RPO / RTO — это показатели не суммарные, а на каждый инцидент (аварию), в отличие от доступности.
RPO — объем потерянных при аварии данных (в часах). Например, если происходит резервное копирование раз сутки, то RPO = 24 часа. Т.е. При аварии и полной потере СХД могут быть потеряны данные объемом до 24 часов (с момента резервной копии). Исходя из заданного для ИС RPO, например, пишется регламент резервного копирования. Также, исходя из RPO, можно понять насколько нужна синхронная / асинхронная репликация данных.
RTO — время восстановления сервиса (доступа к данным) после аварии. Исходя из заданного значения RTO мы можем понять нужен ли метрокластер, или достаточно однонаправленной репликации. Нужна ли многоконтроллерная СХД hi end класса — тоже.
Требования по производительности
Несмотря на то, что это вполне очевидный вопрос, с ним то как раз и возникает большинство трудностей. В зависимости от того, есть у вас уже какая то инфраструктура или нет и будут строиться пути сбора необходимой статистики.
У вас уже есть СХД и вы ищите ей замену или хотите приобрести ещё одну для расширения. Здесь всё просто. Вы понимаете, какие сервисы у вас уже есть и какие вы планируете внедрять в ближайшей перспективе. Основываясь на текущих сервисах вы имеете возможность собрать статистику по производительности. Определиться с текущим количеством IOPS и нынешних задержках — каковы эти показатели и хватает ли их для ваших задач? Сделать это можно как на самой системе хранения данных, так и со стороны хостов, которые к ней подключены.
Причём смотреть нужно не просто текущую нагрузку, а за какой то период (лучше месяц). Посмотреть каковы максимальные пики в дневное время, какую нагрузку создаёт резервное копирование и т.д. Если ваша СХД или ПО к ней не даёт вам полный набор этих данных, можно воспользоваться бесплатным RRDtool, который умеет работать с большинством наиболее популярных СХД и коммутаторов и сможет предоставить вам подробную статистику по производительности. Также стоит смотреть нагрузку и на хостах, которые работают с данной СХД, по конкретным виртуальным машинам или что конкретно у вас работает на данном хосте.
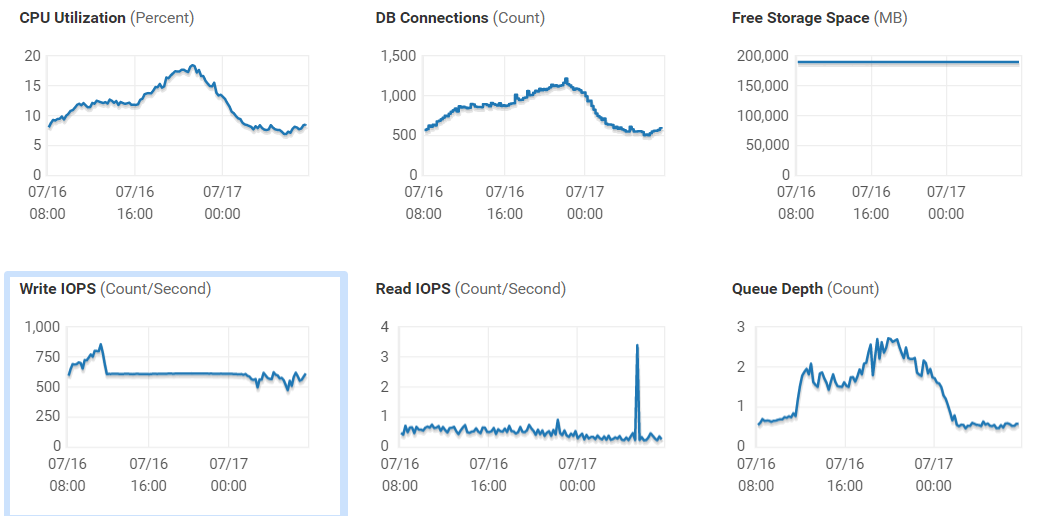
Стоит отдельно отметить, что если задержки на томе и датасторе, который находится на данном томе отличаются довольно сильно — стоит обратить внимание на вашу SAN-сеть, высока вероятность, что с ней есть проблемы и прежде чем приобретать новую систему, стоит разобраться с этим вопросом, ведь очень высока вероятность увеличения производительности текущей системы.
Вы строите инфраструктуру с нуля, либо приобретаете систему под какой то новый сервис, о нагрузках которого вы не в курсе. Тут есть несколько вариантов: пообщаться с коллегами на профильных ресурсах, чтобы попытаться узнать и спрогнозировать нагрузку, обратиться к интегратору, у которого есть опыт внедрения подобных сервис и который сможет рассчитать нагрузку за вас. И третий вариант (обычно самый сложный, особенно если это касается самописных или редких приложений) попытаться выяснить требования к производительности у разработчиков системы.
И, внимание, самый правильный вариант с точки зрения практического применения — это пилот на текущем оборудовании, либо оборудовании предоставленном для теста вендором / интегратором.
Спецтребования
Спецтребования — все то, что не подпадает под требования о производительности, отказоустойчивости и функциональности по непосредственной обработке и предоставлению данных.
Одним из самых простых спецтребований к системе хранения данных можно назвать “отчуждаемые носители информации”. И сразу становится понятно, что данная система хранения данных должна включать в себя ленточную библиотеку или просто стример, на который сбрасывается резервная копия. После чего специально обученный человек подписывает ленту и гордо несет ее в специальный сейф.
Другой пример спецтребования — защищенное противоударное исполнение.
Где
Второй главной составляющей в выборе той или иной СХД является информация о том, ГДЕ будет стоять эта СХД. Начиная от географии или климатических условий, и заканчивая персоналом.
Заказчик
Для кого планируется данная СХД? Вопрос имеет под собой следующие основания:
Госзаказчик / коммерческий.
Коммерческий заказчик не имеет никаких ограничений, и не обязан даже тендеры проводить, кроме как по собственным внутренним регламентам.
Госзаказчик — дело иное. 44 ФЗ и прочие прелести с тендерами и ТЗ, которые могут быть оспорены.
Заказчик под санкциями
Ну тут вопрос очень простой — выбор ограничивается только доступными для данного заказчика предложениями.
Внутренние регламенты / разрешенные к закупке вендоры / модели
Вопрос тоже крайне прост, но о нем надо помнить.
Где физически
В данной части мы рассматриваем все вопросы с географией, каналами связи, и микроклиматом в помещении размещения.
Персонал
Кто будет работать с данной СХД? Это не менее важно, чем то, что СХД непосредственно умеет.
Насколько бы не была перспективна, крута и замечательна СХД от вендора А, смысла ставить ее наверное немного, если персонал умеет работать только с вендором B, и дальнейших закупок и постоянного сотрудничества с А не планируется.
И разумеется, обратная сторона вопроса — насколько доступен в данной географической локации подготовленный персонал непосредственно в компании и потенциально на рынке труда. Для регионов может иметь значительный смысл выбор СХД с простыми интерфейсами или возможностью удаленного централизованного управления. Иначе в какой то момент может стать мучительно больно. Интернет полон историй как пришедший новый сотрудник, вчерашний студент, наконфигурячил такого, что вся контора полегла.

Окружение
Ну и разумеется немаловажный вопрос — в каком окружении будет работать данная СХД.
- Что с электропитанием / охлаждением?
- Какое подключение
- Куда она будет смонтирована
- И тд.
Зачастую данные вопросы считаются сами собой разумеющимися и особо не рассматриваются, но иногда именно они могут перевернуть все с точностью до наоборот.
Что
Вендор
На сегодня (середина 2019) российский рынок СХД можно поделить на условные 5 категорий:
- Высший дивизион — заслуженные компании с широкой линейкой от самых простых дисковых полок до hi-end (HPE, DellEMC, Hitachi, NetApp, IBM / Lenovo)
- Второй дивизион — компании с ограниченной линейкой, нишевые игроки, серьезные вендоры SDS или поднимающиеся новички (Fujitsu, Datacore, Infinidat, Huawei, Pure и тд)
- Третий дивизион — нишевые решения в ранге low end, дешевый SDS, наколенные поделия на ceph и других открытых проектах (Infortrend, Starwind и тд)
- SOHO сегмент — малые и сверхмалые СХД уровня дом/малый офис (Synology, QNAP и тд)
- Импортозамещенные СХД — сюда входят как железо первого дивизиона с переклеенными лейблами, так и редкие представители второго (RAIDIX, дадим им авансом второй), но в основном это третий дивизион (Aerodisk, Baum, Depo и тд)
Деление достаточно условное, и совсем не означает, что третий или SOHO сегмент плохи и их нельзя использовать. В специфических проектах с четко определенным набором данных и профилем нагрузки они могут отработать очень хорошо, далеко превосходя первый дивизион по соотношению цена/качество. Важно сначала определиться с задачами, перспективами роста, требуемой функциональностью — и тогда Synology будет служить вам верой и правдой, а волосы станут мягкими и шелковистыми.
Один из немаловажных факторов при выборе вендора — текущая среда. Сколько и каких СХД у вас уже есть, с какими СХД умеют работать инженеры. Нужен ли вам еще один вендор, еще одна точка контакта, будете ли вы мигрировать постепенно всю нагрузку с вендора А на вендора B?
Не следует плодить сущности сверх необходимого.
iSCSI / FC / File
По вопросу протоколов доступа нет единого мнения среди инженеров, а споры напоминают более теологические дискуссии, чем инженерные. Но в целом можно отметить следующие пункты:
FCoE скорее мертв, чем жив.
FC vs iSCSI. Одно из ключевых преимуществ FC в 2019 перед IP СХД, выделенная фабрика под доступ к данным, нивелируется выделенной IP сетью. Глобальных преимуществ у FC перед IP сетями нет и на IP можно строить СХД любого уровня нагрузки, вплоть до систем для тяжелых СУБД для АБС крупного банка. С другой стороны, смерть FC пророчат уже не первый год, но этому постоянно что то мешает. На сегодня, например, некоторые игроки на рынке СХД активно развивают стандарт NVMEoF. Разделит ли он участь FCoE — покажет время.
Файловый доступ также не является чем то недостойным внимания. NFS / CIFS прекрасно показывают себя в продуктивных средах и при правильном проектировании имеют не больше нареканий, чем блочные протоколы.
Гибридные / All Flash Array
Классические СХД бывают 2 видов:
- AFA (All Flash Array) — системы, оптимизированные для использования SSD.
- Гибридные — позволяющие использовать как HDD, так и SSD или их сочетание.
Главное их отличие — поддерживаемых технологии эффективности хранения и максимальный уровень производительности (высокие показатели IOPS и низкие задержки). И те и другие системы (в большинстве своих моделей, не считая low-end сегмент) могут работать как блочные устройства, так и файловые. От уровня системы зависит и поддерживаемый функционал, и у младших моделей, он чаще всего урезан до минимального уровня. На это стоит обращать внимание, когда вы изучаете характеристики конкретной модели, а не просто возможности всей линейки в целом. Так же, конечно, от уровня систему зависят и её технические характеристики, такие как процессор, объём памяти, кэша, количество и типы портов и т.д. С точки зрения же По управления, AFA от гибридных (дисковых) систем отличаются лишь в вопросах реализации механизмов работы с SSD накопителями, и даже если вы используете SSD в гибридной системе, это совсем не значит, что вы сможете получить уровень производительности на уровне AFA системы. Так же в большинстве случаев inline механизмы эффективного хранения на гибридных системах отключены, а их включение ведёт к потере в производительности.
Специальные СХД
Помимо СХД общего назначения, ориентированных прежде всего на оперативную обработку данных, существуют специальные СХД с ключевыми принципами, в корне отличающимися от привычных (низкая задержка, много IOPS):
Медиа.
Данные системы предназначены под хранение и обработку медиа-файлов, отличающихся большим размером. Соотв. задержка становится практически неважной, а на первый план выходит способность отдавать и принимать данные широкой полосой в много параллельных потоков.
Дедуплицирующие СХД для резервных копий.
Поскольку резервные копии отличаются редкой в обычных условиях похожестью друга на друга (средняя резервная копия отличается от вчерашней на 1-2%), данный класс систем крайне эффективно упаковывает записанные на них данные в рамках достаточно небольшого количества физических носителей. Например, в отдельных случаях коэффициенты компрессии данных могут достигать 200 к 1.
Объектные СХД.
В этих СХД нет привычных томов с блочным доступом и файловых шар, а более всего они напоминают огромную базу данных. Доступ к объекту, хранящемуся в подобной системе, осуществляется по уникальному идентификатору, либо по метаданным (например все объекты формата JPEG, с датой создания между XX-XX-XXXX и YY-YY-YYYY).
Compliance системы.
Не так часто встречаются в России на сегодня, но упомянуть о них стоит. Назначение таких СХД — гарантированное хранение данных для соответствия политикам безопасности или требованиям регуляторов. В некоторых системах (например EMC Centera) была реализована функция запрета на удаление данных — как только ключ повернут и система перешла в данный режим, ни администратор, ни кто либо другой физически не могут удалить уже записанные данные.
Фирменные технологии
Flash cache
Flash Cache – общее название для всех фирменных технологий использования флэш-памяти в качестве кэша второго уровня. При использовании флэш кэша СХД как правило рассчитывается для обеспечения с магнитных дисков установившейся нагрузки, в то время как пиковую обслуживает кэш.
При этом необходимо понимать профиль нагрузки и степень локализации обращений к блокам томов хранения. Флэш кэш – технология для нагрузок с высокой локализацией запросов, и практически неприменима для равномерно нагруженных томов (как например для систем аналитики).
На рынке доступны две реализации флэш кэша:
- Read Only. В этом случае кэшируются только данные на чтение, а запись проходит сразу на диски. Некоторые производители, как например, NetApp, считают что запись на их СХД проходит и так оптимальным образом, и кэш никак не поможет.
- Read/Write. Кэшируется не только чтение, но и запись, что позволяет буферизовать поток и снизить влияние RAID Penalty, а как следствие повысить общую производительность для СХД с не таким оптимальным механизмом записи.
Tiering
Многоуровневое хранение (тиринг) — технология объединения в единый дисковый пул уровней с разной производительностью, как например SSD и HDD. В случае ярко выраженной неравномерности обращений к блокам данных система сможет автоматически отбалансировать блоки данных, переместив нагруженные на высокопроизводительный уровень, а холодные, наоборот, на более медленный.
Гибридные системы нижнего и среднего классов используют многоуровневое хранение с перемещением данных между уровнями по расписанию. При этом размер блока многоуровневого хранения у лучших моделей составляет 256 МБ. Данные особенности не позволяют считать технологию многоуровневого хранения технологией повышения производительности, как ошибочно считается многими. Многоуровневое хранение в системах нижнего и среднего классов – это технология оптимизации стоимости хранения для систем с выраженной неравномерностью нагрузки.
Snapshot
Сколько мы бы не говорили о надёжности СХД, существует множество возможностей потерять данные, не зависящие от аппаратных проблем. Это могут быть как вирусы, хакеры или любое другое, непреднамеренное удаление/порча данных. По этой причине, резервное копирование продуктивных данных является неотъемлемой частью работы инженера.
Снапшот — это снимок тома на какой то момент времени. При работе большинства систем, таких как виртуализация, БД и тд. нам необходимо снять такой снимок, из которого мы будем копировать данные в резервную копию, при этом наши ИС смогут спокойно продолжать работать с этим томом. Но стоит помнить — не все снапшоты одинаково полезны. У разных вендоров, разные подходы к созданию снапшотов, связанные с их архитектурой.
CoW (Copy-On-Write). При попытке записи блока данных его оригинальное содержимое копируется в специальную область, после чего запись проходит нормально. Таким образом предотвращается повреждение данных внутри снапшота. Естественно все эти «паразитные» манипуляции с данными вызывают дополнительную нагрузку на СХД и по этой причине вендоры с подобной реализацией не рекомендуют использовать более десятка снапшотов, а на высоконагруженных томах не использовать их вообще.
RoW (Redirect-on-Write). В данном случае, оригинальноый том натурально замораживается, а при попытке записи блока данных СХД пишет данные в специальную область в свободном пространстве, изменяя местоположение данного блока в таблице метаданных. Это позволяет уменьшить количество операций перезаписи, что в итоге нивелирует падение производительности и снимает ограничения на снапшоты и их количество.
Снапшоты бывают также двух типов по отношению к приложениям:
Application consitent. В момент создания снапшота СХД дергает агента в операционной системе потребителя, который принудительно сбрасывает дисковые кэши из памяти на диск и заставляет сделать это приложение. В этом случае при восстановлении из снапшота данные будут консистентны.
Crash consistent. В данном случае ничего подобного не происходит и снапшот создается как есть. В случае восстановления из такого снапшота картина идентична как если бы внезапно отключилось питание и возможна некоторая потеря данных, зависших в кэшах и так и не дошедших до диска. Такие снапшоты проще в реализации и не вызывают просадки производительности в приложениях, но менее надежны.
Зачем нужны снапшоты на системах хранения данных?
- Безагентное резервное копирование напрямую с СХД
- Создание тестовых сред на основе реальных данных
- В случае с файловыми СХД может использоваться для создания сред VDI через использование снапшотов СХД вместо гипервизора
- Обеспечение низких RPO путем создания снапшотов по расписанию с частотой значительно выше частоты резервного копирования
Cloning
Клонирование тома — работает по аналогичному принципу, что и снапшоты, но служит не просто для чтения данных, а для полноценной работы с ними. Мы имеем возможность получить точную копию нашего тома, со всем данными на нём, не делая физической копии, что позволит сэкономить место. Обычно клонирование томов используется или в Test&Dev или если вы хотите проверить работоспособность каких то обновлений на вашей ИС. Клонирование позволит сделать это максимально быстро и экономично с точки зрения дисковых ресурсов, т.к. записаны будут только изменённые блоки данных.
Репликация / журналирование
Репликация — механизм создания копии данных на другой физической СХД. Обычно существует фирменная технология у каждого вендора, работающая только внутри собственной линейки. Но также есть и сторонние решения, в том числе работающие на уровне гипервизора, как например VMware vSphere Replication.
Функциональность фирменных технологий и удобство их использования обычно сильно превосходят универсальные, но оказываются неприменимы, когда например необходимо делать реплику с NetApp на HP MSA.
Репликация делится на два подвида:
Синхронная. В случае синхронной репликации операция записи пересылается на вторую СХД немедленно и не подтверждается исполнение до тех пор, пока удаленная СХД не подтвердит. За счет этого растет задержка доступа, но зато мы имеем точную зеркальную копию данных. Т.е. RPO = 0 для случая потери основной СХД.
Асинхронная. Операции записи исполняются только на главной СХД и подтверждаются немедленно, параллельно накапливаясь в буфере для пакетной передачи на удаленную СХД. Подобный вид репликации актуален для менее ценных данных, либо для каналов низкой пропускной способности либо имеющих высокую задержку (характерно для расстояний свыше 100 км). Соответственно RPO = частоте пакетной отправки.
Зачастую вместе с репликацией существует механизм журналирования дисковых операций. В этом случае выделяется специальная область для журналирования и хранятся операции записи определенной глубины по времени, либо ограниченные объемом журнала. Для отдельных фирменных технологий, как например EMC RecoverPoint, существует интеграция с системным ПО, позволяющим привязать определенные закладки на конкретную запись в журнале. Благодаря этому возможно откатить состояние тома (либо создать клон) не просто на 23 апреля 11 часов 59 секунд 13 миллисекунд, а на момент, предшествовавший “DROP ALL TABLES; COMMIT”.
Metro cluster
Метро кластер — технология, позволяющая создать двунаправленную синхронную репликацию между двумя СХД таким образом, что со стороны эта пара выглядит как одна СХД. Применяется для создания кластеров с географически разнесенными плечами на метро- расстояниях (менее 100 км).
На примере использования в среде виртуализации метрокластер позволяет создать датастор с виртуальными машинами, доступный на запись сразу из двух датацентров. В этом случае создается кластер на уровне гипервизоров, состоящий из хостов в разных физических датацентрах, подключенный к данному датастору. Что позволяет сделать следующее:
- Полная автоматизация процесса восстановления после смерти одного из датацентров. Без каких либо дополнительных средств все ВМ, работавшие в умершем датацентре, будут автоматически перезапущены в оставшемся. RTO = таймаут кластера высокой доступности (15 секунд для VMware) + время загрузки операционной системы и старта сервисов.
- Disaster avoidance или, по-русски, избежание катастроф. Если запланированы работы по электропитанию в датацентре 1, то мы заранее, до начала работ, имеем возможность мигрировать всю важную нагрузку в датацентр 2 нон стоп.
Виртуализация
Виртуализация СХД — это технически использование томов с другой СХД в качестве дисков. СХД-виртуализатор может просто прокинуть чужой том до потребителя как свой, попутно зеркалировав его на еще одну СХД, или даже создать RAID из внешних томов.
Классические представители в классе виртуализации СХД — это EMC VPLEX и IBM SVC. Ну и разумеется СХД с функцией виртуализации — NetApp, Hitachi, IBM / Lenovo Storwize.
Зачем может понадобиться?
- Резервирование на уровне СХД. Создается зеркало между томами, причем одна половина может быть на HP 3Par, а другая на NetApp. А виртуализатор от EMC.
- Переезд данных с минимальным простоем между СХД разных производителей. Предположим, что данные надо мигрировать со старого 3Par, который пойдет под списание, на новый Dell. В этом случае потребители отключаются от 3Par, тома прокидываются под VPLEX и уже презентуются потребителям заново. Поскольку ни бита на томе не изменилось, работа продолжается. Фоном запускается процесс зеркалирования тома на новый Dell, а по завершению зеркало разбивается и 3Par отключается.
- Организация метрокластеров.
Компрессия / дедупликация
Компресиия и дедупликаия — это те технологии, которые позволяют вам экономить дисковое пространство на вашей СХД. Стоит сразу упомянуть, что далеко не все данные подлежат компрессии и/или дедупликации в принципе, при этом некоторые типы данных жмутся и дедуплицируются лучше, а какие то — наоборот.
Компрессия и дедупликация бывают 2 видов:
Inline — сжатие и дедупликация блоков данных происходит до записи этих данных на диск. Таким образом система только вычисляет хэш блока и сравнивает его по таблице с уже имеющимися. Во-первых это выполняется быстрее, чем просто запись на диск, во-вторых мы не расходуем лишнее дисковое пространство.
Post — когда эти операция проводят уже на записанных данных, которые находятся на дисках. Соответственно данные сначала записываются на диск, а только потом, вычисляется хэш и происходит удаление лишних блоков и высвобождение дисковых ресурсов.
Стоит сказать, что большинство вендоров используют оба вида, что позволяет оптимизировать эти процессы и тем самым повысить их эффективность. У большинства вендоров СХД, есть в наличии утилиты, которые позволяют проанализировать ваши наборы данных. Данные утилиты, работают по той же логике, что реализована и в СХД, по этому оценочный уровень эффективности будет совпадать. Также не стоит забывать, что у многих вендоров есть программы гарантии эффективности, которые обещают уровень не ниже заявленного для определённого (или всех) типов данных. И не стоит пренебрегать данной программой, ведь рассчитывая систему под свои задачи, с учётом коэффициента эффективности конкретной системы, вы можете сэкономить на объёме. Так же стоит учитывать, что эти программы рассчитаны на AFA системы, но благодаря закупке меньшего объёма SSD, нежели HDD в классических системах, это позволит снизить их стоимость, и если не сравняться со стоимостью дисковой системы, то довольно сильно к ней приблизиться.
Модель
И вот здесь мы приходим к правильно заданному вопросу.
“Вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете”
Превращается в “Вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете?
Целевая нагрузка смешанные виртуальные машины VMware с контуров продуктив / тест / разработка. Тест = продуктиву. 150 ТБ на каждый с пиковой производительностью 80 000 IOPS 8kb блоком 50% случайного доступа 80/20 чтение-запись. 300 ТБ на разработку, там 50 000 IOPS хватит, 80 случайный, 80 запись.
Продуктив предположительно в метрокластер RPO = 15 минут RTO = 1 час, разработку в асинхронную репликацию RPO = 3 часа, тест на одной площадке.
Будет 50ТБ СУБД, было бы неплохо для них журналирование.
У нас везде серверы Dell, СХД старые Hitachi, еле справляются, планируем рост 50% нагрузки по объему и производительности”
Как говорится, в правильно сформулированном вопросе содержится 80% ответа.
Дополнительная информация
С чем стоит ознакомиться дополнительно по мнению авторов
Книги
- Олифер и Олифер “Компьютерные сети”. Книга поможет систематизировать и возможно лучше понимать как работает среда передачи данных для IP / Ethernet систем хранения
- “EMC Information Storage and Management”. Прекрасная книга по основам СХД, почему, как и зачем.
Форумы и чаты
- Storage Discussions
- Nutanix / IT Russian Discussion Club
- VMware User Group Russia
- Russian Backup User Group
Общие рекомендации
Цены
Теперь что же касается цен — вообще на СХД цены если и попадаются, то обычно это List price, от которой каждый заказчик получает индивидуальную скидку. Размер скидки складывается из большого числа параметров, так что предсказать, какую конечную цену получит именно ваша компания, без запроса к дистрибьютору просто невозможно. Но при этом, в последнее время low-end модели стали появляться в обычных компьютерных магазинах, таких как, например nix.ru или xcom-shop.ru. В них можно сразу приобрести интересующую вас систему по фиксированный цене, как любые компьютерные комплектующие.
Но хочется отметить сразу, что прямое сравнение по TB/$ не является верным. Если подходить с этой точки зрения, то наиболее дешёвым решением будет простой JBOD + сервер, что не даст ни той гибкости, ни той надёжности, которые обеспечивает полноценная, двухконтроллерная СХД. Это совершенно не значит, что JBOD гадость гадостная и пакость пакостная, просто нужно опять-таки очень чётко понимать — как и для каких целей вы будете использовать это решение. Часто можно услышать, что в JBOD нечему ломаться, там же один бэкплейн. Однако и бэкплейны бывает выходят из строя. Все ломается рано или поздно.
Итого
Сравнивать системы между собой нужно не только по цене, или не только по производительности, а по совокупности всех показателей.
Покупайте HDD только если вы уверены, что вам нужны HDD. Для низких нагрузок и несжимаемых типов данных, в ином случае, стоит обратить на программы гарантии эффективности хранения на SSD, которые сейчас есть у большинства вендоров (и они действительно работают, даже в России), но тут всё зависит от приложений и данных, которые будут располагаться на данной СХД.
Не гонитесь за дешевизной. Порой под эти скрывается множество неприятных моментов, один из которых Евгений Елизаров описывал в своих статьях про Infortrend. И что, в конечном итоге, эта дешевизна может выйти вам же боком. Не стоит забыть — «скупой платит дважды».








