В этой статье мы хотим рассказать о том, какая модель работы с данными выбрана в платформе 1С:Предприятия и почему.
Для бизнес-приложений работа с данными — это очень важный архитектурный вопрос. Так или иначе, но вся работа приложения строится вокруг данных. Причем, если в некоторых классах программных систем данные носят вспомогательный характер, то в бизнес-приложениях данные являются основным содержанием решаемых задач.
Здесь (в этой статье) мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения. Почему же данные так важны для бизнес-приложений?
Потому, что они описывают саму предметную область. Какие сущности имеются в бизнесе, как они связаны между собой. Данные очень хорошо описывают и саму решаемую задачу. Ведь при проектировании приложений нас не интересуют абсолютно все данные, а интересуют те данные (и их взаимосвязи), которые тем или иным способом влияют на решаемую задачу (включая некоторый запас развития системы в потенциально интересных направлениях). Например, если мы автоматизируем процесс развития персонала, то нас будет интересовать по сотрудникам образование, история работы. Но мы не будем отражать информацию по размерам одежды и обуви. Но, если, например, мы хотим автоматизировать учет спецодежды, то это становится уже интересным. Хотя, пытливый проектировщик может и тут поставить вопрос. Где развитие персонала, там и мотивация. А где мотивация, там и, возможно, изготовление одежды с фирменной символикой. Здесь видно, что количество данных в природе бесконечно, и искусство моделирования данных во многом определяет искусство проектирования приложений.
Конечно, очень важное место в бизнес-приложениях занимают и процессы. Хотя очень хочется (и нам, и разработчикам других платформ для разработки бизнес приложений) больший вес в проектировании приложений возложить на процессы, но данные все равно остаются наиболее значимым аспектом предметной области. И именно на отражении данных строится основная модель приложений.
Сделаем только небольшую оговорку. Под данными здесь понимаются и данные, сопровождающие процессы. То есть, получается, что процессы тоже косвенно выражаются через модель данных.
В платформе 1С:Предприятие есть и механизмы для отражения именно процессов, но это тема отдельной статьи.
Существует несколько традиционных парадигм работы с данными.
Прежде всего – есть классическая реляционная модель. В ней данные описываются в виде реляционных таблиц (обычно хранимых в реляционных DBMS). Эта парадигма хотя и совсем не новая, но вполне актуальная.
Есть объектная парадигма. В ней данные описываются в виде объектов языка программирования и каким-то образом сохраняются в базе данных. Это может быть реляционная или объектная база данных. В первом случае возможности моделирования определяются DBMS, во втором случае — используемым ORM.
Есть еще методики и подходы, которые применяются реже (при создании бизнес-приложений). Например, подход, основанный на слабоструктурированных данных.
Теперь, собственно, о том подходе, который мы выбрали для платформы 1С:Предприятия. Для него нет официально принятого названия. Назовем его «модель типов прикладных объектов». Суть подхода в том, что платформа предлагает разработчику некоторый набор типов прикладных объектов. Каждый тип предназначен для отражения в модели приложения некоторой категории сущностей предметной области. Разработчик приложения при отражении предметной области решаемой задачи в модели приложения должен выбрать подходящие типы объектов и с помощью них описать модель данных. На самом деле при этом он описывает не только модель данных, но и, во многом, модель самого приложения. Но об этом чуть позже.
Что представляет собой тип прикладных объектов?
Это некоторый заложенный в платформу шаблон (можно еще считать его абстрактным классом), определяющий множество различных аспектов работы с сущностью предметной области.
Типы прикладных объектов проявляются и при разработке (в design-time) и при работе системы (в run-time). В design-time это мета-модель описания объектов в метаданных и классы для манипулирования данными в программной модели. В run-time это различные аспекты поведения системы при работе с объектами этого типа. Например, поведение механизма блокировок.
В 1С:Предприятии существует несколько типов прикладных объектов.
Для примера возьмем три типа:
Справочники предназначены для отражения в системе некоторой условно постоянной информации (списков сотрудников, товаров, клиентов…).
Документы отражают некоторые события предметной области (продажу, прием сотрудника на работу, перечисление денег в банк). Иногда они называются по названиям печатных форм («платежное поручение», «приказ о приеме на работу», …). Но это только для удобства понимания. По сути, это именно тип события, а не печатной формы.
Регистры накопления предназначены для отражения в приложении некоторой системы учета. Например, учета хранения денежных средств или товаров на складах.
Посмотрим, что все-таки входит в «комплект» возможностей, предоставляемый типами прикладных объектов
Прежде всего, конечно, тип прикладного объекта описывает модель данных и обеспечивает отображение данных на реляционную модель хранения. Но это только небольшая часть того, что он определяет.
Например, для справочника:
Для документа — похоже, но есть стандартный реквизит Дата, отражающий положение события относительно других событий на оси времени, а также признак «Проведен», определяющий, отражается документ в системе учета или является черновиком.
Для регистра накопления поля делятся на измерения, ресурсы и реквизиты. Измерения описывают систему координат модели учета (например, товар, склад), ресурсы – показатели (например, количество, сумма), реквизиты – просто дополнительные поля (не влияющие на модель учета, но комментирующие записи движений).
Почему мы оперируем типами прикладных объектов, а не оперируем, например, просто таблицами (или просто сущностями – entity)?
Это очень важный момент. Таблицы имеют много преимуществ. Они ближе к простейшему моделированию в реляционной модели, они не ограничивают разработчика рамками заложенных типов. Но таблицы и не дают тех возможностей, которые дает выбранный нами подход.
Суть выбранного нами подхода в том (если говорить простыми словами), что в нашем подходе сама система (платформа) «много чего знает» про описанные объекты и «много чего умеет с ними делать». На основании этих знаний и умений система автоматически обеспечивает работу более десятка разных механизмов, работающих прямо или косвенно с этими объектами. То есть, получается, что разработчик приложения выбирает тип объекта и описывает конкретный объект, а платформа, зная тип и описание конкретного объекта, сама обеспечивает множество различных полезных функций и механизмов. Это достигается за счет того, что на уровне типа объекта определена семантика объектов данного типа (назначение объекта «по крупному»), а модель метаданных позволяет уточнить семантику конкретного объекта за счет различных свойств и специализированных моделей, описывающих различные аспекты жизнедеятельности.
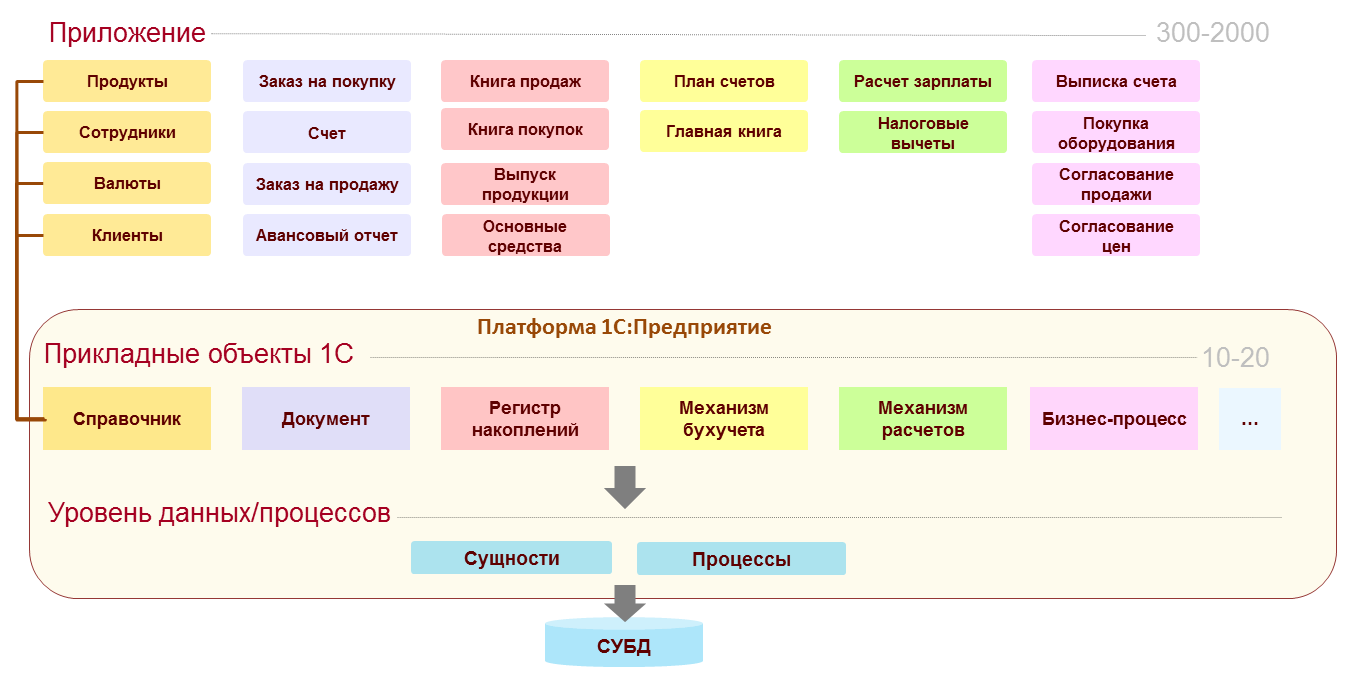
Перечислим только некоторые из них:
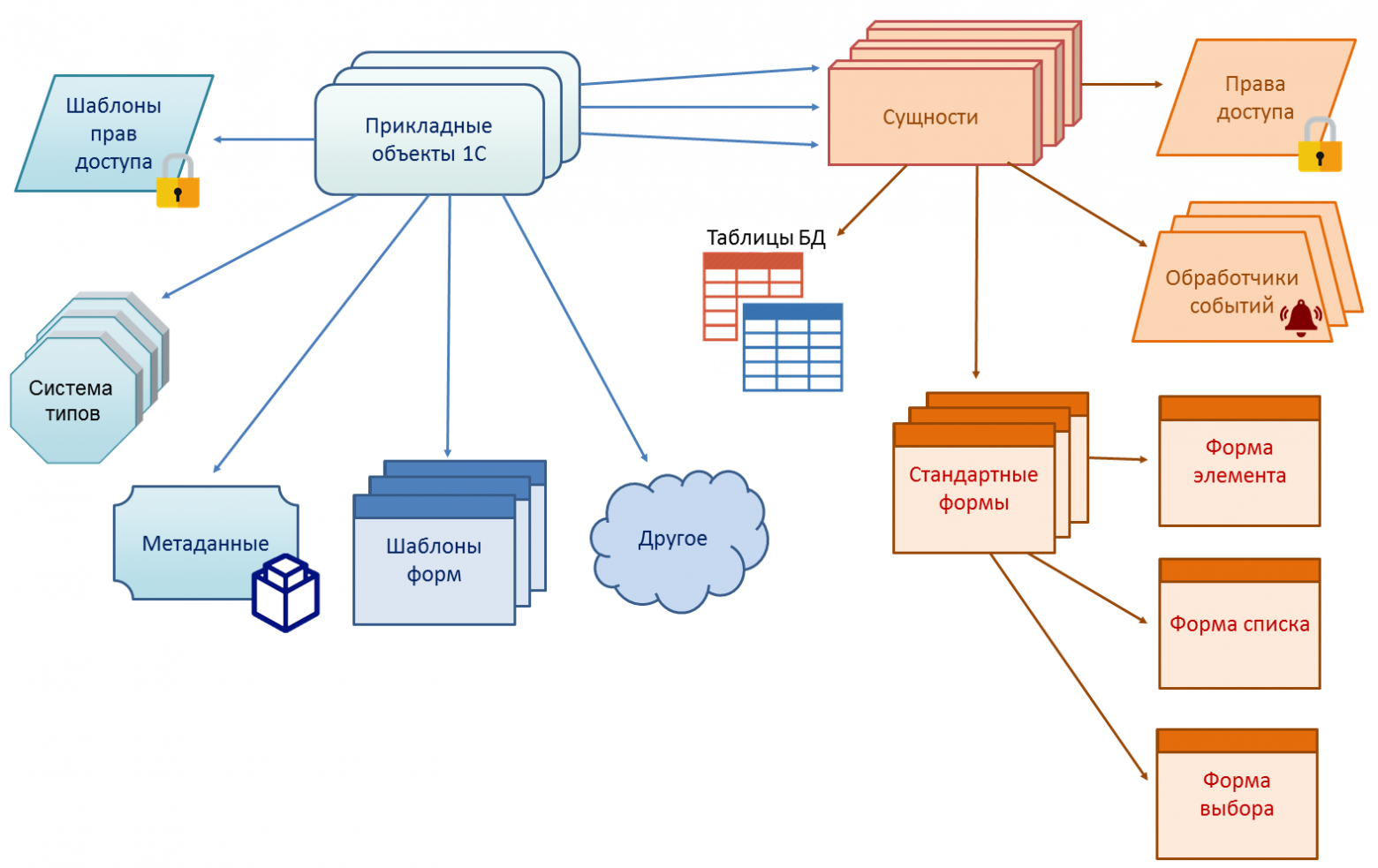
На схеме изображены далеко не все механизмы платформы, которые работают на основе прикладных объектов, а только некоторые.
В каком-то смысле типы прикладных объектов пересекаются с аспектно-ориентированным подходом. Так как все перечисленные возможности — это некоторые предопределенные аспекты, в которых отражаются типы прикладных объектов. Можно сказать, что типы прикладных объектов это не просто шаблоны, а параметризованные шаблоны. Параметризация осуществляется за счет набора свойств метаданных. Выбрав значение свойства, разработчик параметризует шаблон выбранного типа прикладного объекта и уточняет тем поведение объекта в конкретном аспекте. Например, он может выбрать тип нумерации документа (в пределах года, квартала, месяца…) и система будет автоматически обеспечивать присвоение и контроль номеров с заданной периодичностью.
Типы прикладных объектов обеспечивают знание о семантике не только самих сущностей, но и о семантике их взаимосвязей. Например, существует стандартная связь между документами и регистрами, отражающая то, как в предметной области события отражаются в модели учета. Определив такую связь, разработчик сразу получает готовую функциональность по совместному времени жизни документа и связанных с ним записей регистра.
Отдельно стоит сказать о важных предметно ориентированных аспектах.
Например, для справочников есть возможность одним флажком включить поддержку иерархии. При этом система обеспечит поддержку иерархических справочников во всем: в пользовательском интерфейсе, в отчетах, в объектной модели.
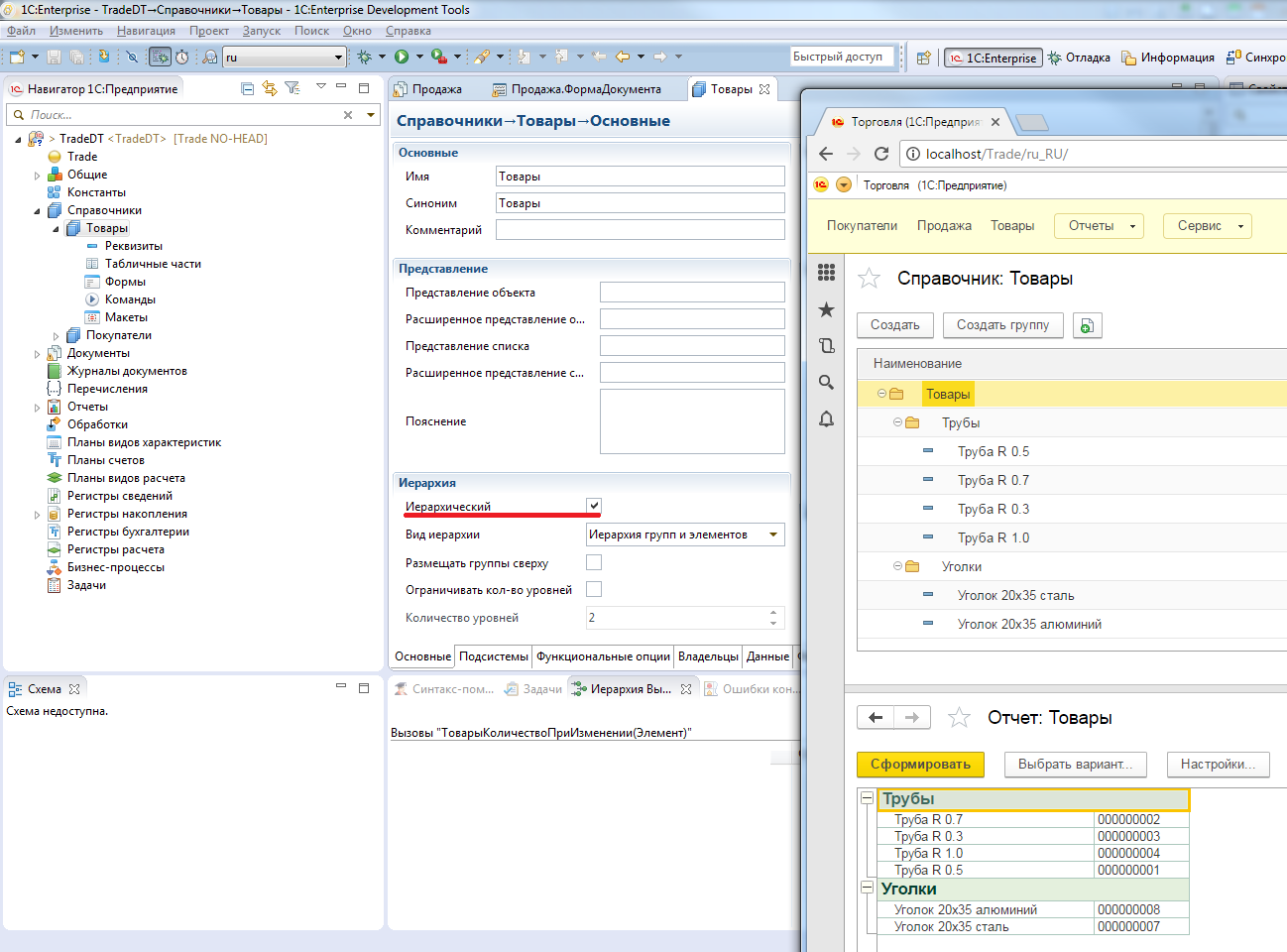
Установка одного свойства справочника «Иерархический справочник» сразу поддерживает иерархию в пользовательском интерфейсе, в отчетах, в объектной модели.
Для документов существуют такие возможности, как журналы, объединяющие несколько типов документов, сквозная нумерация в разрезе периодов и т.д.
Для регистров накопления наиболее важной возможностью является автоматическое хранение рассчитанных итогов и готовые виртуальные таблицы для доступа к итогам в различных разрезах и с учетом периодичности.
То есть, по сути, в типы прикладных объектов заложена существенная часть универсальных (типовых) механизмов бизнес-логики приложения, характерных для соответствующей категории данных предметной области.
Получается, что разработчик собирает приложение из объектов выбранных типов, как из деталей конструктора. Причем, если бывают конструкторы с «абстрактными» деталями, то в нашем конструкторе детали уже с «назначением» — колеса, окна, двери…
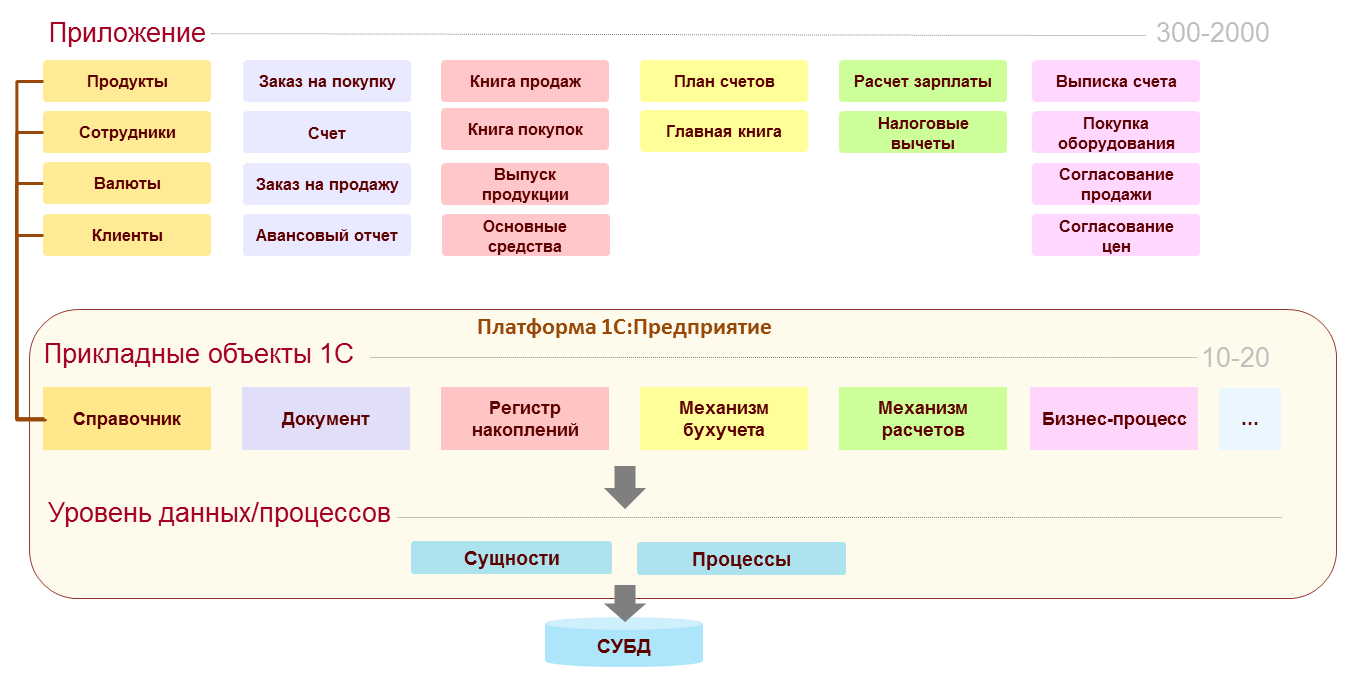 На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
Еще стоит сказать про методологическую ценность такого подхода. Все разработчики оперируют некоторым набором понятий, который помогает им лучше понимать суть приложений, упрощает общение. Открыв незнакомый проект 1С:Предприятия разработчик сразу видит знакомые понятия и может быстро разобраться в том какую роль в системе играет тот или иной объект. Например, чтобы понять суть приложения, стоит посмотреть на состав регистров – обычно она отражает основное назначение приложения. Если открыть структуру таблиц или, тем более, структуру классов незнакомого приложения написанного на инструментах, оперирующих таблицами и классами, то понимания будет существенно меньше.
Но, что еще важно, такой подход сближает язык разработчиков и представителей бизнеса (или аналитиков). Про необходимость наличия такого языка хорошо сказано в книге «Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем» Эрика Эванса. Типы прикладных объектов достаточно быстро становятся понятными не-программистам, и это позволяет обсуждать аналитикам, заказчикам и разработчикам основную функциональность проекта на одном языке. Часто можно встретить представителей бизнеса или аналитиков, которые не владеют программированием, но могут поставить задачу в терминах типов прикладных объектов 1С:Предприятия.
Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов. Когда ранее мы разработали механизм стандартного REST интерфейса (на основе стандарта OData), то во всех приложения сразу появился готовый REST интерфейс. Разработчикам ничего не пришлось для этого дорабатывать.
Почему мы не делаем еще и «просто таблицы» (в дополнение к готовым типам прикладных объектов)? Это непростой вопрос. Мы сами себе его периодически задаем.
С одной стороны это кажется заманчивым. Так мы бы закрыли все спорные случаи, когда предметная область не идеально ложится в заготовленный нами набор типов прикладных объектов. Можно было сказать разработчикам – «ну вот тебе просто таблица – и делай в ней все, как сам хочешь». Но с другой стороны это приведет к тому, что все наши стандартные механизмы будут пребывать «в растерянности» — как им обходиться с этими таблицами? Ведь они не будут знать семантику этих данных и не смогут понять, как с ними правильно работать. Ну, то есть с ними можно работать «как-то». Строго говоря, у нас есть такой опыт в части внешних источников. Для внешних источников мы описываем у себя именно таблицы (не указывая предметную направленность). И система с ними работает некоторым универсальным образом – при этом не поддерживается часть функциональности.
Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный, и мы будем продолжать про него думать.
Таким образом, возможности, которые предоставляет в готовом виде платформа 1С:Предприятия, и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С:Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.
Для бизнес-приложений работа с данными — это очень важный архитектурный вопрос. Так или иначе, но вся работа приложения строится вокруг данных. Причем, если в некоторых классах программных систем данные носят вспомогательный характер, то в бизнес-приложениях данные являются основным содержанием решаемых задач.
Здесь (в этой статье) мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения. Почему же данные так важны для бизнес-приложений?
Потому, что они описывают саму предметную область. Какие сущности имеются в бизнесе, как они связаны между собой. Данные очень хорошо описывают и саму решаемую задачу. Ведь при проектировании приложений нас не интересуют абсолютно все данные, а интересуют те данные (и их взаимосвязи), которые тем или иным способом влияют на решаемую задачу (включая некоторый запас развития системы в потенциально интересных направлениях). Например, если мы автоматизируем процесс развития персонала, то нас будет интересовать по сотрудникам образование, история работы. Но мы не будем отражать информацию по размерам одежды и обуви. Но, если, например, мы хотим автоматизировать учет спецодежды, то это становится уже интересным. Хотя, пытливый проектировщик может и тут поставить вопрос. Где развитие персонала, там и мотивация. А где мотивация, там и, возможно, изготовление одежды с фирменной символикой. Здесь видно, что количество данных в природе бесконечно, и искусство моделирования данных во многом определяет искусство проектирования приложений.
Конечно, очень важное место в бизнес-приложениях занимают и процессы. Хотя очень хочется (и нам, и разработчикам других платформ для разработки бизнес приложений) больший вес в проектировании приложений возложить на процессы, но данные все равно остаются наиболее значимым аспектом предметной области. И именно на отражении данных строится основная модель приложений.
Сделаем только небольшую оговорку. Под данными здесь понимаются и данные, сопровождающие процессы. То есть, получается, что процессы тоже косвенно выражаются через модель данных.
В платформе 1С:Предприятие есть и механизмы для отражения именно процессов, но это тема отдельной статьи.
Существует несколько традиционных парадигм работы с данными.
Прежде всего – есть классическая реляционная модель. В ней данные описываются в виде реляционных таблиц (обычно хранимых в реляционных DBMS). Эта парадигма хотя и совсем не новая, но вполне актуальная.
Есть объектная парадигма. В ней данные описываются в виде объектов языка программирования и каким-то образом сохраняются в базе данных. Это может быть реляционная или объектная база данных. В первом случае возможности моделирования определяются DBMS, во втором случае — используемым ORM.
Есть еще методики и подходы, которые применяются реже (при создании бизнес-приложений). Например, подход, основанный на слабоструктурированных данных.
Теперь, собственно, о том подходе, который мы выбрали для платформы 1С:Предприятия. Для него нет официально принятого названия. Назовем его «модель типов прикладных объектов». Суть подхода в том, что платформа предлагает разработчику некоторый набор типов прикладных объектов. Каждый тип предназначен для отражения в модели приложения некоторой категории сущностей предметной области. Разработчик приложения при отражении предметной области решаемой задачи в модели приложения должен выбрать подходящие типы объектов и с помощью них описать модель данных. На самом деле при этом он описывает не только модель данных, но и, во многом, модель самого приложения. Но об этом чуть позже.
Что представляет собой тип прикладных объектов?
Это некоторый заложенный в платформу шаблон (можно еще считать его абстрактным классом), определяющий множество различных аспектов работы с сущностью предметной области.
Типы прикладных объектов проявляются и при разработке (в design-time) и при работе системы (в run-time). В design-time это мета-модель описания объектов в метаданных и классы для манипулирования данными в программной модели. В run-time это различные аспекты поведения системы при работе с объектами этого типа. Например, поведение механизма блокировок.
В 1С:Предприятии существует несколько типов прикладных объектов.
Для примера возьмем три типа:
- Справочники
- Документы
- Регистры накопления
Справочники предназначены для отражения в системе некоторой условно постоянной информации (списков сотрудников, товаров, клиентов…).
Документы отражают некоторые события предметной области (продажу, прием сотрудника на работу, перечисление денег в банк). Иногда они называются по названиям печатных форм («платежное поручение», «приказ о приеме на работу», …). Но это только для удобства понимания. По сути, это именно тип события, а не печатной формы.
Регистры накопления предназначены для отражения в приложении некоторой системы учета. Например, учета хранения денежных средств или товаров на складах.
Посмотрим, что все-таки входит в «комплект» возможностей, предоставляемый типами прикладных объектов
Прежде всего, конечно, тип прикладного объекта описывает модель данных и обеспечивает отображение данных на реляционную модель хранения. Но это только небольшая часть того, что он определяет.
Например, для справочника:
- существует несколько стандартных реквизитов (полей), заложенных сразу в платформу (ссылка-идентификатор, код, наименование, ссылка на родителя для иерархического справочника, …)
- можно описать свои (произвольные) реквизиты (поля)
- можно описать табличные части, которые представляют собой тесно связанные сущности (containment) или еще их можно считать вложенными таблицами
Для документа — похоже, но есть стандартный реквизит Дата, отражающий положение события относительно других событий на оси времени, а также признак «Проведен», определяющий, отражается документ в системе учета или является черновиком.
Для регистра накопления поля делятся на измерения, ресурсы и реквизиты. Измерения описывают систему координат модели учета (например, товар, склад), ресурсы – показатели (например, количество, сумма), реквизиты – просто дополнительные поля (не влияющие на модель учета, но комментирующие записи движений).
Почему мы оперируем типами прикладных объектов, а не оперируем, например, просто таблицами (или просто сущностями – entity)?
Это очень важный момент. Таблицы имеют много преимуществ. Они ближе к простейшему моделированию в реляционной модели, они не ограничивают разработчика рамками заложенных типов. Но таблицы и не дают тех возможностей, которые дает выбранный нами подход.
Суть выбранного нами подхода в том (если говорить простыми словами), что в нашем подходе сама система (платформа) «много чего знает» про описанные объекты и «много чего умеет с ними делать». На основании этих знаний и умений система автоматически обеспечивает работу более десятка разных механизмов, работающих прямо или косвенно с этими объектами. То есть, получается, что разработчик приложения выбирает тип объекта и описывает конкретный объект, а платформа, зная тип и описание конкретного объекта, сама обеспечивает множество различных полезных функций и механизмов. Это достигается за счет того, что на уровне типа объекта определена семантика объектов данного типа (назначение объекта «по крупному»), а модель метаданных позволяет уточнить семантику конкретного объекта за счет различных свойств и специализированных моделей, описывающих различные аспекты жизнедеятельности.
Перечислим только некоторые из них:
- Прежде всего, конечно, это создание структур данных для хранения и автоматическое преобразование структуры при изменении модели
- Набор классов в объектной модели для манипулирования данными (чтения, записи, поиска)
- Механизм объектно-реляционного преобразования
- Набор типичных процедур обработки данных. Например, для документов это автоматическая нумерация, для регистра это расчет итогов, получение среза остатков на конкретный момент времени, и т.д.
- Отражение в системе прав. Так как система знает о назначении объекта, то знает и какие права для него будут актуальны
- Визуализация (отражение в интерфейсе). Опять же, зная о назначении и роли объектов, система сама конструирует и команды в интерфейсе приложения для доступа к объектам этого типа, и формы для просмотра и редактирования, и команды для различных действий с объектом.
- Обмен данными. На основании знания семантики данных платформа предоставляет стандартный механизм для асинхронного обмена измененными данными как среди родственных приложений (узлов распределенной базы), так и между разнородными приложениями (написанными как на 1С:Предприятии, так и на других технологиях)
- Объектные и транзакционные блокировки. Для правильного построения системы блокировки нужно знание о назначении данных и о взаимосвязях.
- Механизм характеристик (дополнительных полей, определяемых пользователем)
- Автоматически предоставляемый REST интерфейс (по стандарту OData)
- Выгрузку-загрузку данных в XML, JSON
- Кроме того, автоматически работают такие механизмы как: полнотекстовый поиск, журналирование доступа к данным, и т.д.
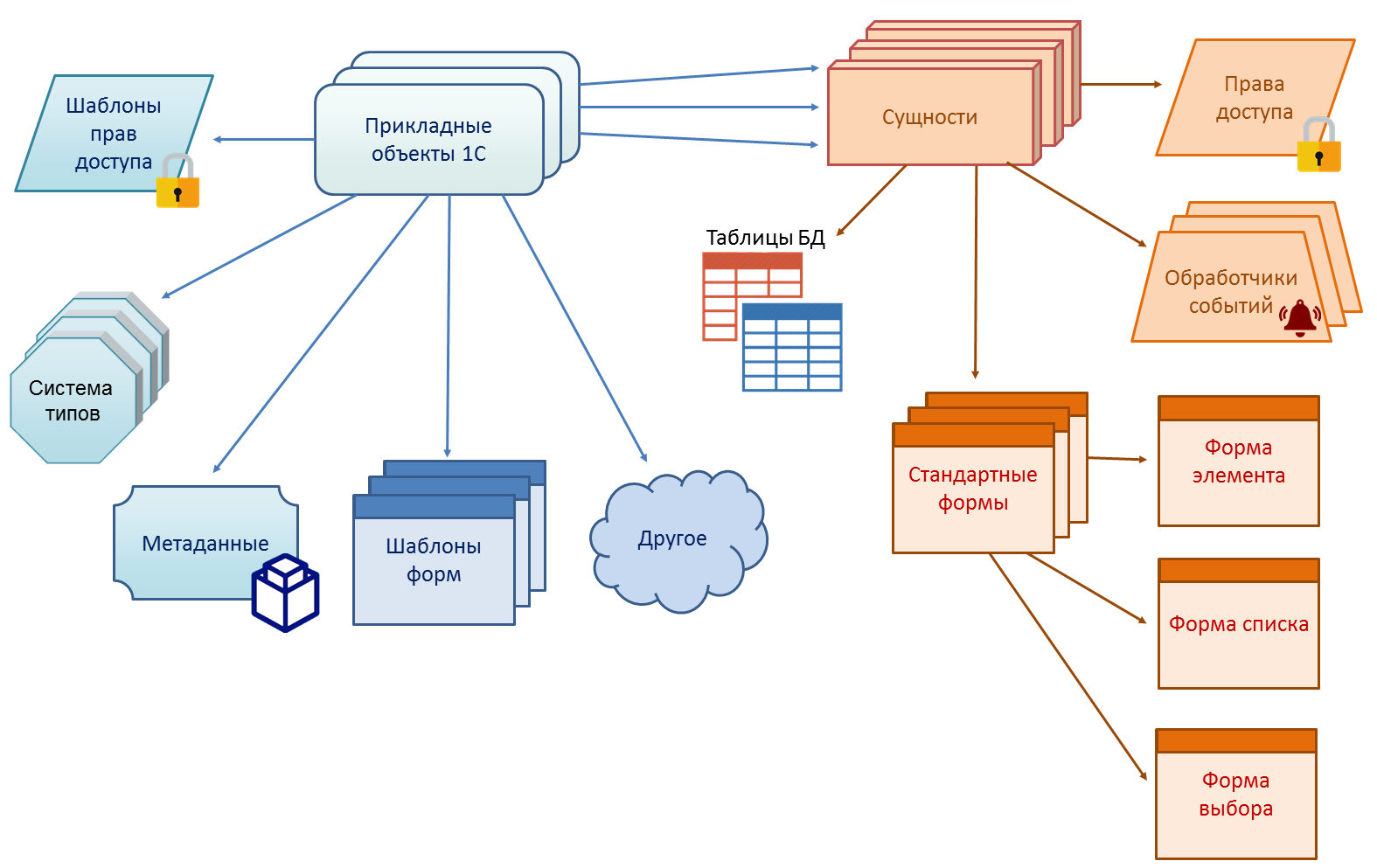
На схеме изображены далеко не все механизмы платформы, которые работают на основе прикладных объектов, а только некоторые.
В каком-то смысле типы прикладных объектов пересекаются с аспектно-ориентированным подходом. Так как все перечисленные возможности — это некоторые предопределенные аспекты, в которых отражаются типы прикладных объектов. Можно сказать, что типы прикладных объектов это не просто шаблоны, а параметризованные шаблоны. Параметризация осуществляется за счет набора свойств метаданных. Выбрав значение свойства, разработчик параметризует шаблон выбранного типа прикладного объекта и уточняет тем поведение объекта в конкретном аспекте. Например, он может выбрать тип нумерации документа (в пределах года, квартала, месяца…) и система будет автоматически обеспечивать присвоение и контроль номеров с заданной периодичностью.
Типы прикладных объектов обеспечивают знание о семантике не только самих сущностей, но и о семантике их взаимосвязей. Например, существует стандартная связь между документами и регистрами, отражающая то, как в предметной области события отражаются в модели учета. Определив такую связь, разработчик сразу получает готовую функциональность по совместному времени жизни документа и связанных с ним записей регистра.
Отдельно стоит сказать о важных предметно ориентированных аспектах.
Например, для справочников есть возможность одним флажком включить поддержку иерархии. При этом система обеспечит поддержку иерархических справочников во всем: в пользовательском интерфейсе, в отчетах, в объектной модели.
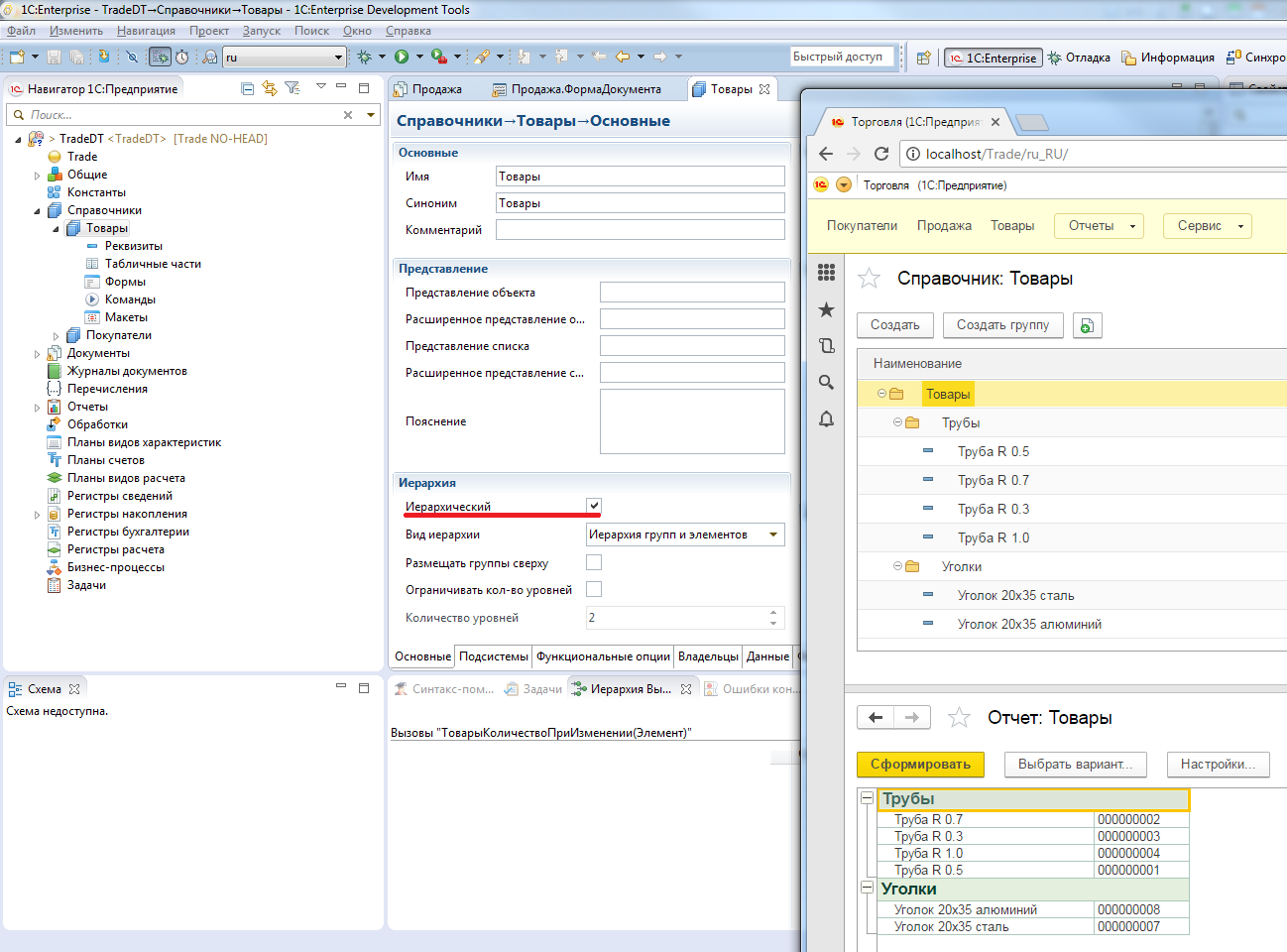
Установка одного свойства справочника «Иерархический справочник» сразу поддерживает иерархию в пользовательском интерфейсе, в отчетах, в объектной модели.
Для документов существуют такие возможности, как журналы, объединяющие несколько типов документов, сквозная нумерация в разрезе периодов и т.д.
Для регистров накопления наиболее важной возможностью является автоматическое хранение рассчитанных итогов и готовые виртуальные таблицы для доступа к итогам в различных разрезах и с учетом периодичности.
То есть, по сути, в типы прикладных объектов заложена существенная часть универсальных (типовых) механизмов бизнес-логики приложения, характерных для соответствующей категории данных предметной области.
Получается, что разработчик собирает приложение из объектов выбранных типов, как из деталей конструктора. Причем, если бывают конструкторы с «абстрактными» деталями, то в нашем конструкторе детали уже с «назначением» — колеса, окна, двери…
 На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.Еще стоит сказать про методологическую ценность такого подхода. Все разработчики оперируют некоторым набором понятий, который помогает им лучше понимать суть приложений, упрощает общение. Открыв незнакомый проект 1С:Предприятия разработчик сразу видит знакомые понятия и может быстро разобраться в том какую роль в системе играет тот или иной объект. Например, чтобы понять суть приложения, стоит посмотреть на состав регистров – обычно она отражает основное назначение приложения. Если открыть структуру таблиц или, тем более, структуру классов незнакомого приложения написанного на инструментах, оперирующих таблицами и классами, то понимания будет существенно меньше.
Но, что еще важно, такой подход сближает язык разработчиков и представителей бизнеса (или аналитиков). Про необходимость наличия такого языка хорошо сказано в книге «Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем» Эрика Эванса. Типы прикладных объектов достаточно быстро становятся понятными не-программистам, и это позволяет обсуждать аналитикам, заказчикам и разработчикам основную функциональность проекта на одном языке. Часто можно встретить представителей бизнеса или аналитиков, которые не владеют программированием, но могут поставить задачу в терминах типов прикладных объектов 1С:Предприятия.
Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов. Когда ранее мы разработали механизм стандартного REST интерфейса (на основе стандарта OData), то во всех приложения сразу появился готовый REST интерфейс. Разработчикам ничего не пришлось для этого дорабатывать.
Почему мы не делаем еще и «просто таблицы» (в дополнение к готовым типам прикладных объектов)? Это непростой вопрос. Мы сами себе его периодически задаем.
С одной стороны это кажется заманчивым. Так мы бы закрыли все спорные случаи, когда предметная область не идеально ложится в заготовленный нами набор типов прикладных объектов. Можно было сказать разработчикам – «ну вот тебе просто таблица – и делай в ней все, как сам хочешь». Но с другой стороны это приведет к тому, что все наши стандартные механизмы будут пребывать «в растерянности» — как им обходиться с этими таблицами? Ведь они не будут знать семантику этих данных и не смогут понять, как с ними правильно работать. Ну, то есть с ними можно работать «как-то». Строго говоря, у нас есть такой опыт в части внешних источников. Для внешних источников мы описываем у себя именно таблицы (не указывая предметную направленность). И система с ними работает некоторым универсальным образом – при этом не поддерживается часть функциональности.
Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный, и мы будем продолжать про него думать.
Таким образом, возможности, которые предоставляет в готовом виде платформа 1С:Предприятия, и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С:Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.
