В этой статье расскажем о том, как и для чего мы разработали Систему Взаимодействия – механизм, передающий информацию между клиентскими приложениями и серверами 1С:Предприятия – от постановки задачи до продумывания архитектуры и деталей реализации.
Система Взаимодействия (далее – СВ) – это распределенная отказоустойчивая система обмена сообщениями с гарантированной доставкой. СВ спроектирован как высоконагруженный сервис с высокой масштабируемостью, доступен и как онлайновый сервис(предоставляется фирмой 1С), и как тиражный продукт, который можно развернуть на своих серверных мощностях.
СВ использует распределенное хранилище Hazelcast и поисковую систему Elasticsearch. Еще речь пойдет о Java и о том, как мы горизонтально масштабируем PostgreSQL.
Чтобы было понятно, зачем мы делали Систему Взаимодействия, расскажу немного о том, как устроена разработка бизнес-приложений в 1С.
Для начала – немного о нас для тех, кто еще не знает, чем мы занимаемся:) Мы делаем технологическую платформу «1С:Предприятие». Платформа включает в себя средство разработки бизнес-приложений, а также runtime, позволяющий бизнес-приложениям работать в кросс-платформенном окружении.
Бизнес-приложения, созданные на «1С:Предприятии», работают в трёхуровневой клиент-серверной архитектуре «СУБД – сервер приложений – клиент». Прикладной код, написанный на встроенном языке 1С, может выполняться на сервере приложений или на клиенте. Вся работа с прикладными объектами (справочниками, документами и т.д.), а также чтение и запись базы данных выполняется только на сервере. Функциональность форм и командного интерфейса также реализована на сервере. На клиенте выполняется получение, открытие и отображение форм, «общение» с пользователем (предупреждения, вопросы…), небольшие расчеты в формах, требующие быстрой реакции (например, умножение цены на количество), работа с локальными файлами, работа с оборудованием.
В прикладном коде заголовках процедур и функций надо явно указывать, где будет выполняться код — с помощью директив &НаКлиенте / &НаСервере (&AtClient / &AtServer в англоязычном варианте языка). Разработчики на 1С сейчас поправят меня, сказав, что директив на самом деле больше, но для нас это сейчас не существенно.
Из клиентского кода можно вызвать серверный код, а вот из серверного кода вызвать клиентский нельзя. Это фундаментальное ограничение, сделанное нами по ряду причин. В частности потому, что серверный код должен быть написан так, чтобы одинаково выполняться, откуда бы его ни вызвали – с клиента или с сервера. А в случае вызова серверного кода из другого серверного кода клиент отсутствует как таковой. И потому, что в ходе выполнения серверного кода клиент, вызвавший его, мог закрыться, выйти из приложения, и серверу будет уже некого вызывать.
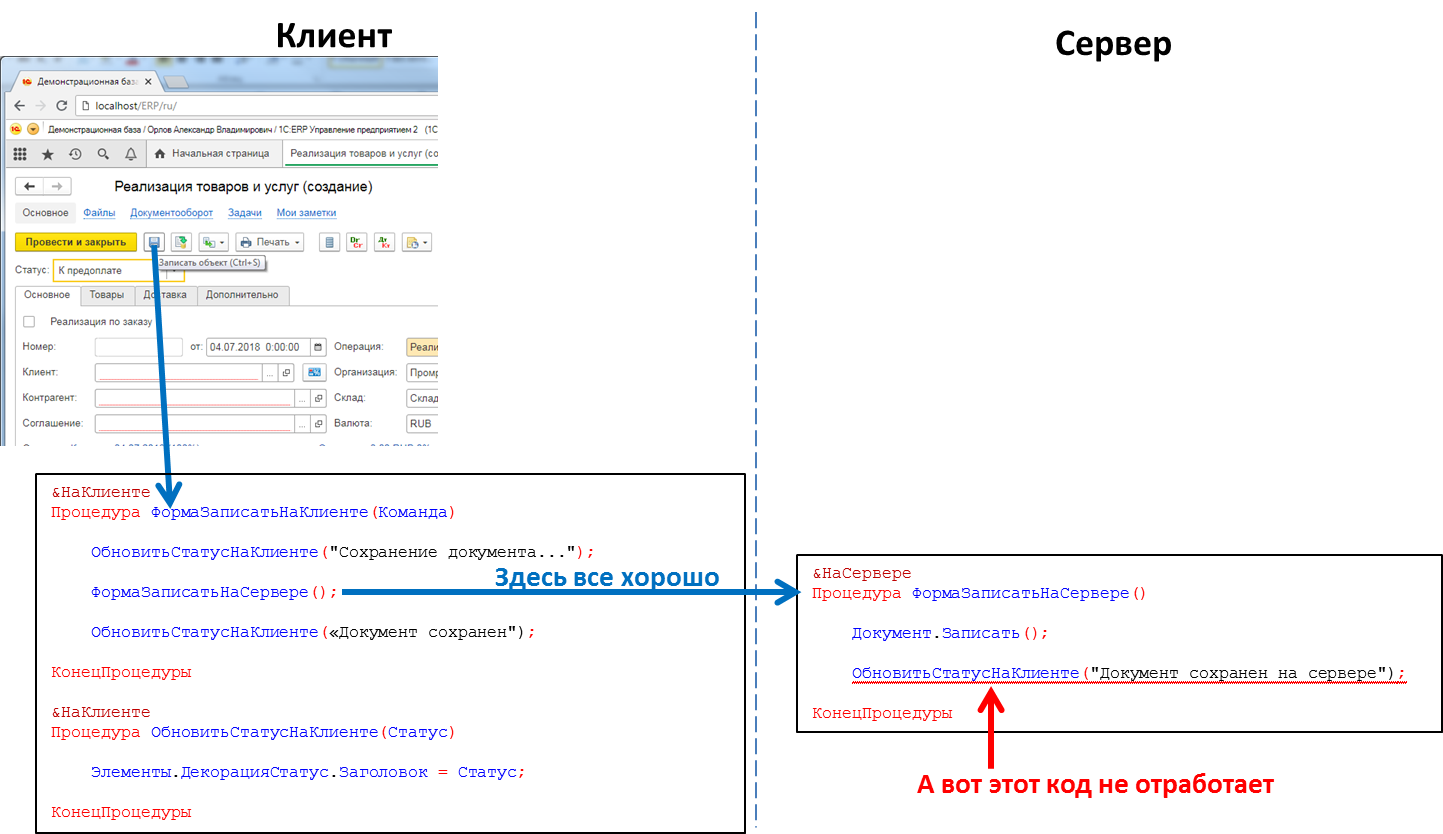
Код, обрабатывающий нажатие кнопки: вызов серверной процедуры с клиента сработает, вызов клиентской процедуры с сервера — нет
Это значит, что если мы с сервера захотим передать какое-то сообщение в клиентское приложение, например, что закончилось формирование «долгоиграющего» отчета и отчет можно посмотреть – такого способа у нас нет. Приходится идти на ухищрения, например, из клиентского кода периодически опрашивать сервер. Но такой подход загружает систему лишними вызовами, да и вообще выглядит не очень изящно.
А еще есть необходимость, например, при поступившем телефонном SIP-звонке оповестить об этом клиентское приложение, чтобы оно по номеру звонящего нашло его в базе контрагентов и показало пользователю информацию о звонящем контрагенте. Или, например, при поступлении на склад заказа уведомить об этом клиентское приложение заказчика. В общем, кейсов, где такой механизм бы пригодился, немало.
Создать механизм обмена сообщениями. Быстрый, надежный, с гарантированной доставкой, с возможностью гибкого поиска сообщений. На базе механизма реализовать мессенджер (сообщения, видеозвонки), работающий внутри приложений 1С.
Спроектировать систему горизонтально масштабируемой. Возрастающая нагрузка должна закрываться увеличением количества нод.
Серверную часть СВ мы решили не встраивать непосредственно в платформу 1С:Предприятие, а реализовывать как отдельный продукт, API которого можно вызывать из кода прикладных решений 1С. Сделано это было по ряду причин, главная из которых – хотелось сделать возможным обмен сообщениями между разными приложениями 1С (например, между Управлением Торговлей и Бухгалтерией). Разные приложения 1С могут работать на разных версиях платформы 1С:Предприятие, находиться на разных серверах и т.п. В таких условиях реализация СВ как отдельного продукта, находящегося «сбоку» от инсталляций 1С – оптимальное решение.
Итак, мы решили делать СВ как отдельный продукт. Небольшим компаниям мы рекомендуем пользоваться сервером СВ, который мы установили в своем облаке (wss://1cdialog.com), чтобы избежать накладных расходов, связанных с локальной установкой и настройкой сервера. Крупные же клиенты, возможно, сочтут целесообразной установку собственного сервера СВ на своих мощностях. Аналогичный подход мы использовали в нашем облачном SaaS продукте 1cFresh – он выпускается как тиражный продукт для инсталляции у клиентов, и также развернут в нашем облаке https://1cfresh.com/.
Для распределения нагрузки и отказоустойчивости развернем не одно Java-приложение, а несколько, перед ними поставим балансировщик нагрузки. Если нужно передать сообщение с ноды на ноду – используем publish/subscribe в Hazelcast.
Общение клиента с сервером – по websocket. Он хорошо подходит для систем реального времени.
Выбирали между Redis, Hazelcast и Ehcache. На дворе 2015 год. Redis только-только зарелизили новый кластер (слишком новый, страшно), есть Sentinel с кучей ограничений. Ehcache не умеет собираться в кластер (этот функционал появился позже). Решили попробовать с Hazelcast 3.4.
Hazelcast собирается в кластер «из коробки». В режиме одной ноды он не очень полезен и может сгодиться только как кэш – не умеет скидывать данные на диск, потеряли единственную ноду – потеряли данные. Мы разворачиваем несколько Hazelcast-ов, между которыми бэкапим критические данные. Кэш не бэкапим – его не жалко.
Для нас Hazelcast – это:
Проверили, что канала нет. Взяли блокировку, снова проверили, создали. Если после взятия блокировки не проверять, то есть шанс, что другой поток в этот момент тоже проверил и сейчас попробует создать такое же обсуждение – а оно уже существует. Делать блокировку через synchronized или обычный java Lock нельзя. Через базу – медленно, да и базу жалко, через Hazelcast – то, что надо.
У нас большой и успешный опыт работы с PostgreSQL и сотрудничества с разработчиками этой СУБД.
С кластером у PostgreSQL непросто – есть XL, XC, Citus, но, в общем-то, это не noSQL, которые масштабируются из коробки. NoSQL как основное хранилище рассматривать не стали, хватило и того, что берем Hazelcast, с которым прежде не работали.
Раз нужно масштабировать реляционную БД – значит, шардинг. Как вы знаете, при шардинге мы разделяем базу данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер.
Первый вариант нашего шардинга предполагал возможность разнести каждую из таблиц нашего приложения по разным серверам в разных пропорциях. Много сообщений на сервере А – пожалуйста, давайте перенесем часть этой таблицы на сервер Б. Такое решение просто-таки вопило о преждевременной оптимизации, так что мы решили ограничиться multi-tenant подходом.
Почитать про multi-tenant можно, например, на сайте Citus Data.
В СВ есть понятия приложения и абонента. Приложение – это конкретная инсталляция бизнес-приложения, например, ERP или Бухгалтерии, со своими пользователями и бизнес-данными. Абонент – это организация или физическое лицо, от имени которого выполняется регистрация приложения в сервере СВ. У абонента может быть зарегистрировано несколько приложений, и эти приложения могут обмениваться сообщениями между собой. Абонент и стал жильцом (tenant) в нашей системе. Сообщения нескольких абонентов могут находиться в одной физической базе; если мы видим, что какой-то абонент стал генерировать много трафика – мы выносим его в отдельную физическую базу (или даже отдельный сервер БД).
У нас есть главная БД, где хранится таблица роутинга с информацией о локации всех абонентских базах данных.
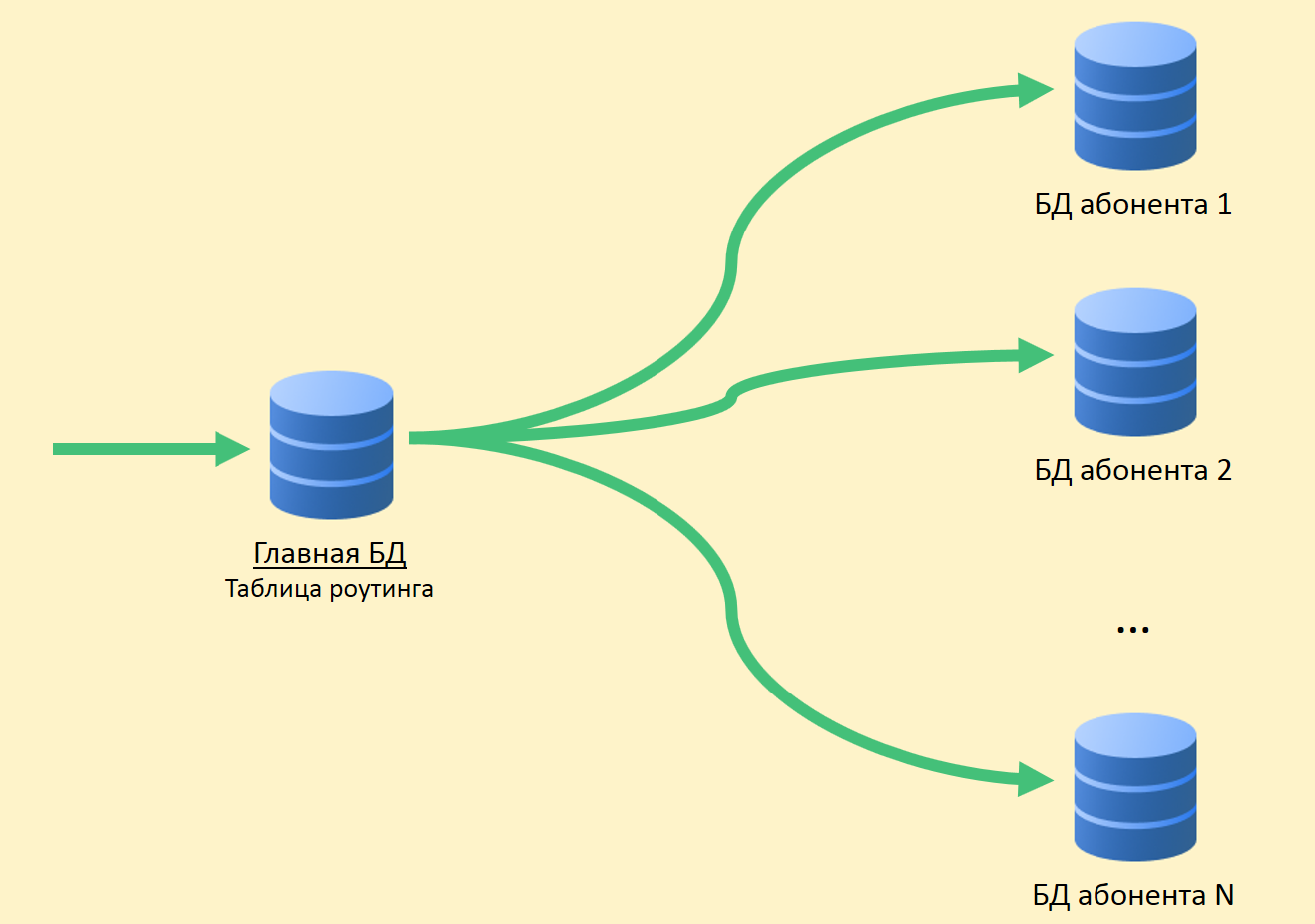
Чтобы главная БД не была узким местом, таблицу роутинга (и другие часто востребованные данные) мы держим в кэше.
Если начнет тормозить БД абонента, будем внутри резать на партиции. На других проектах для партиционирования больших таблиц используем pg_pathman.
Поскольку терять сообщения пользователей плохо, мы поддерживаем наши БД репликами. Комбинация синхронной и асинхронной реплик позволяет подстраховаться на случай потери основной БД. Потеря сообщения произойдет только в случае одновременного отказа основной БД и ее синхронной реплики.
Если теряется синхронная реплика – асинхронная реплика становится синхронной.
Если теряется основная БД – синхронная реплика становится основной БД, асинхронная реплика – синхронной репликой.
Поскольку, помимо прочего, СВ – это еще и мессенджер, здесь нужен быстрый, удобный и гибкий поиск, с учетом морфологии, по неточным соответствиям. Мы решили не изобретать велосипед и использовать свободную поисковую систему Elasticsearch, созданную на основе библиотеки Lucene. Elasticsearch мы также разворачиваем в кластере (master – data – data), чтобы исключить проблемы в случае выхода из строя узлов приложения.
На github мы нашли плагин русской морфологии для Elasticsearch и используем его. В индексе Elasticsearch мы храним корни слов (которые определяет плагин) и N-граммы. По мере того, как пользователь вводит текст для поиска, мы ищем набираемый текст среди N-грамм. При сохранении в индекс слово «тексты» разобьется на следующие N-граммы:
[те, тек, текс, текст, тексты, ек, екс, екст, ексты, кс, кст, ксты, ст, сты, ты],
А также будет сохранен корень слова «текст». Такой подход позволяет искать и по началу, и по середине, и по окончанию слова.
Повтор картинки из начала статьи, но уже с разъяснениями:
В процессе разработки и тестирования СВ мы столкнулись с рядом интересных особенностей продуктов, используемых нами.
Выпуск каждого релиза СВ – это нагрузочное тестирование. Оно пройдено успешно, когда:
Тестовую базу заполняем данными – для этого получаем с продакшн-сервера информацию о самом активном абоненте, умножаем его цифры на 5 (количество сообщений, обсуждений, пользователей) и так тестируем.
Нагрузочное тестирование системы взаимодействия мы проводим в трех конфигурациях:
При стресс-тесте мы запускаем несколько сотен потоков, и те без остановки нагружают систему: пишут сообщения, создают обсуждения, получают список сообщений. Имитируем действия обычных пользователей (получить список моих непрочитанных сообщений, написать кому-нибудь) и программных решений (передать пакет другой конфигурации, обработать оповещение).
Например, вот так выглядит часть стресс-теста:
Сценарий «Только подключения» появился не просто так. Бывает ситуация: пользователи подключили систему, но пока не втянулись. Каждый пользователь утром в 09:00 включает компьютер, устанавливает соединение с сервером и молчит. Эти ребята опасны, их много – из пакетов у них только PING/PONG, но соединение до сервера они держат (не держать не могут – а вдруг новое сообщение). Тест воспроизводит ситуацию, когда за полчаса в системе пытаются авторизоваться большое число таких пользователей. Он похож на стресс-тест, но фокус у него именно на этом первом входе – чтобы не было отказов (человек не пользуется системой, а она уже отваливается – сложно придумать что-то хуже).
Сценарий регистрации абонентов берет свое начало с первого запуска. Мы провели стресс-тест и были уверены, что в переписке система не тормозит. Но пошли пользователи и начала по таймауту отваливаться регистрация. При регистрации мы использовали /dev/random, который завязан на энтропию системы. Сервер не успевал скопить достаточно энтропии и при запросе нового SecureRandom застывал на десятки секунд. Выходов из такой ситуации много, например: перейти на менее безопасный /dev/urandom, поставить специальную плату, которая формирует энтропию, генерировать случайные числа заранее и хранить в пуле. Мы временно закрыли проблему пулом, но с тех пор прогоняем отдельный тест на регистрацию новых абонентов.
В качестве генератора нагрузки мы используем JMeter. Работать с вебсокетом он не умеет, нужен плагин. Первыми в поисковой выдаче по запросу «jmeter websocket» идут статьи с BlazeMeter, в которых рекомендуют плагин от Maciej Zaleski.
С него мы и решили начать.
Почти сразу после начала серьезного тестирования мы обнаружили, что в JMeter начались утечки памяти.
Плагин – это отдельная большая история, при 176 звездах у него 132 форка на github-е. Сам автор в него не коммитит с 2015 года (мы брали его в 2015 году, тогда это не вызвало подозрений), несколько github issues по поводу утечек памяти, 7 незакрытых pull request-ов.
Если решите проводить нагрузочное тестирование с помощью этого плагина, обратите внимание на следующие обсуждения:
Это из тех, что на github-е. Что мы сделали:
И все-таки он течет!
Память стала заканчиваться не за день, а за два. Времени совсем не оставалось, решили запускать меньше потоков, но на четырех агентах. Этого должно было хватить, как минимум, на неделю.
Прошло два дня…
Теперь память стала заканчиваться у Hazelcast-а. В логах было видно, что спустя пару дней тестирования Hazelcast начинает жаловаться на нехватку памяти, а еще через некоторое время кластер разваливается, и ноды продолжают погибать поодиночке. Мы подключили JVisualVM к hazelcast-у и увидели «восходящую пилу» – он регулярно вызывал GC, но никак не мог очистить память.
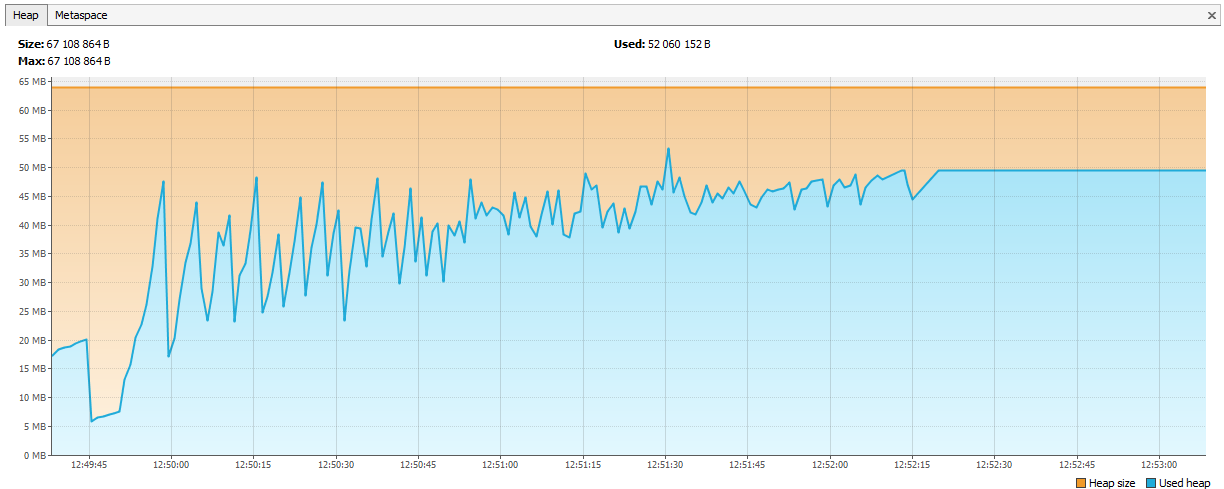
Оказалась, что в hazelcast 3.4 при удалении map / multiMap (map.destroy()) память освобождается не полностью:
github.com/hazelcast/hazelcast/issues/6317
github.com/hazelcast/hazelcast/issues/4888
Сейчас ошибка исправлена в 3.5, но тогда это была проблема. Мы создавали новые multiMap с динамическими именами и удаляли по нашей логике. Код выглядел примерно так:
Вызов:
multiMap создавался для каждой подписки и удалялся, когда он был не нужен. Решили, что заведем Map<String,Set>, в качестве ключа будет название подписки, а в качестве значений идентификаторы сессий (по которым потом можно получить идентификаторы пользователей, если нужно).
Графики выправились.
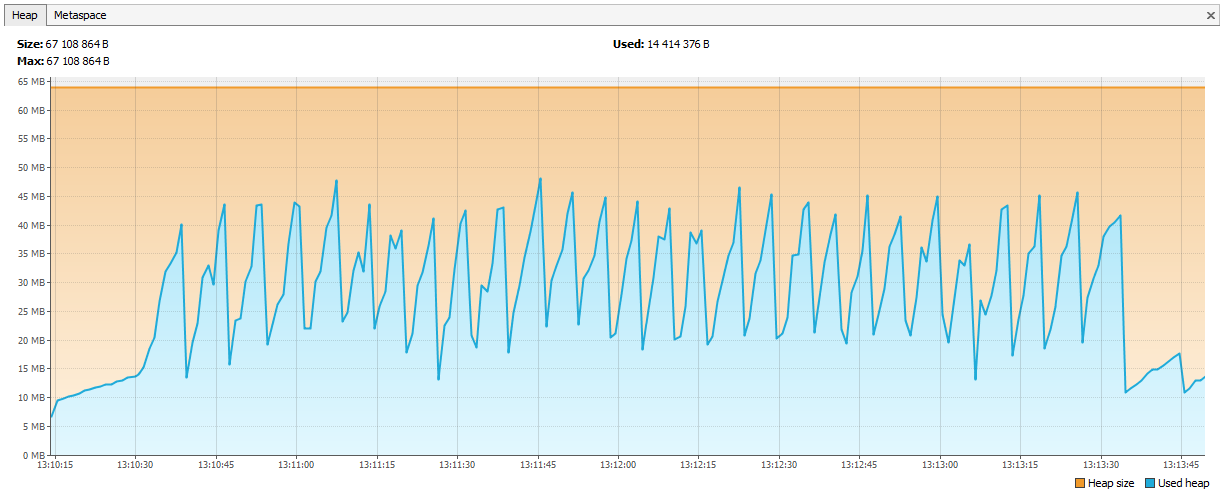
Hazelcast для нас был новым продуктом, мы начали работать с ним с версии 3.4.1, сейчас на нашем production сервере стоит версия 3.9.2 (на момент написания статьи последняя версия Hazelcast – 3.10).
Мы начинали с целочисленных идентификаторов. Давайте представим, что нам нужен очередной Long для новой сущности. Sequence в БД не подходит, таблицы участвуют в шардинге – получится, что есть сообщение ID=1 в БД1 и сообщение ID=1 в БД2, в Elasticsearch по такому ID не положишь, в Hazelcast тоже, но самое страшное, если вы захотите свести данные с двух БД в одну (например, решив, что одной базы достаточно для этих абонентов). Можно завести в Hazelcast несколько AtomicLong и держать счетчик там, тогда производительность получения нового ID – incrementAndGet плюс время на запрос в Hazelcast. Но в Hazelcast есть кое-что более оптимальное – FlakeIdGenerator. Каждому клиенту при обращении выдается диапазон ID, например, первому – от 1 до 10 000, второму – от 10 001 до 20 000 и так далее. Теперь клиент может выдавать новые идентификаторы самостоятельно, пока не закончится выданный ему диапазон. Работает быстро, но при перезапуске приложения (и клиента Hazelcast) начинается новая последовательность – отсюда пропуски и т.д. К тому же разработчикам не очень понятно, почему ID целочисленные, но идут так сильно вразнобой. Мы все взвесили и перешли на UUID-ы.
Кстати, для тех, кто хочет быть как Твиттер, есть такая библиотека Snowcast – это реализация Snowflake поверх Hazelcast. Посмотреть можно здесь:
github.com/noctarius/snowcast
github.com/twitter/snowflake
Но у нас до нее уже руки не дошли.
Еще один сюрприз: TransactionalMap.replace не работает. Вот такой тест:
Пришлось написать свой replace, использовав getForUpdate:
Тестируйте не только обычные структуры данных, но и их транзакционные версии. Бывает, что IMap работает, а TransactionalMap уже нет.
Сначала мы решили записывать в Hazelcast объекты своих классов. Например, у нас есть класс Application, мы хотим его сохранить и прочитать. Сохраняем:
Читаем:
Все работает. Потом мы решили построить индекс в Hazelcast, чтобы искать по нему:
И при записи новой сущности начали получать ClassNotFoundException. Hazelcast пытался дополнить индекс, но ничего не знал про наш класс и хотел, чтобы ему подложили JAR с этим классом. Мы так и сделали, все заработало, но появилась новая проблема: как обновить JAR без полной остановки кластера? Hazelcast не подхватывает новый JAR при понодовом обновлении. В этот момент мы решили, что вполне можем жить без поиска по индексу. Ведь если использовать Hazelcast как хранилище типа ключ-значение, то все будет работать? Не совсем. Здесь снова разное поведение IMap и TransactionalMap. Там где IMap-у все равно, TransactionalMap кидает ошибку.
IMap. Записываем 5000 объектов, считываем. Все ожидаемо.
А в транзакции не работает, получаем ClassNotFoundException:
В 3.8 появился механизм User Class Deployment. Вы можете назначить одну главную ноду и обновлять JAR-файл на ней.
Сейчас мы полностью сменили подход: сами сериализуем в JSON и сохраняем в Hazelcast. Hazelcast-у не нужно знать структуру наших классов, а мы можем обновляться без даунтайма. Версионированием доменных объектов управляет приложение. Одновременно могут быть запущены разные версии приложения, и возможна ситуация, когда новое приложение пишет объекты с новыми полями, а старое еще про эти поля не знает. И в то же время новое приложение вычитывает объекты, записанные старым приложением, в которых нет новых полей. Такие ситуации обрабатываем внутри приложения, но для простоты не меняем и не удаляем поля, только расширяем классы путем добавления новых полей.
Ходить за данными в кэш всегда лучше, чем в БД, но и хранить невостребованные записи не хочется. Решение о том, что кэшировать, мы откладываем на последний этап разработки. Когда новая функциональность закодирована, мы включаем в PostgreSQL логгирование всех запросов (log_min_duration_statement в 0) и запускаем нагрузочное тестирование минут на 20. По собранным логам утилиты типа pgFouine и pgBadger умеют строить аналитические отчеты. В отчетах мы в первую очередь ищем медленные и частые запросы. Для медленных запросов строим план выполнения (EXPLAIN) и оцениваем, можно ли такой запрос ускорить. Частые запросы по одним и тем же входным данным хорошо ложатся в кэш. Запросы стараемся держать «плоскими», по одной таблице в запросе.
СВ как онлайн-сервис была запущена в эксплуатацию весной 2017 года, как отдельный продукт СВ вышел в ноябре 2017 (на тот момент в статусе бета-версии).
Более чем за год эксплуатации серьезных проблем в работе онлайн-сервиса СВ не случалось. Онлайн-сервис мониторим через Zabbix, собираем и деплоим из Bamboo.
Дистрибутив сервера СВ поставляется в виде нативных пакетов: RPM, DEB, MSI. Плюс для Windows мы предоставляем единый инсталлятор в виде одного EXE, который устанавливает сервер, Hazelcast и Elasticsearch на одну машину. Сначала мы называли эту версию установки «демонстрационной», но сейчас стало понятно, что это самый популярный вариант развертывания.
Система Взаимодействия (далее – СВ) – это распределенная отказоустойчивая система обмена сообщениями с гарантированной доставкой. СВ спроектирован как высоконагруженный сервис с высокой масштабируемостью, доступен и как онлайновый сервис(предоставляется фирмой 1С), и как тиражный продукт, который можно развернуть на своих серверных мощностях.
СВ использует распределенное хранилище Hazelcast и поисковую систему Elasticsearch. Еще речь пойдет о Java и о том, как мы горизонтально масштабируем PostgreSQL.
Постановка задачи
Чтобы было понятно, зачем мы делали Систему Взаимодействия, расскажу немного о том, как устроена разработка бизнес-приложений в 1С.
Для начала – немного о нас для тех, кто еще не знает, чем мы занимаемся:) Мы делаем технологическую платформу «1С:Предприятие». Платформа включает в себя средство разработки бизнес-приложений, а также runtime, позволяющий бизнес-приложениям работать в кросс-платформенном окружении.
Клиент-серверная парадигма разработки
Бизнес-приложения, созданные на «1С:Предприятии», работают в трёхуровневой клиент-серверной архитектуре «СУБД – сервер приложений – клиент». Прикладной код, написанный на встроенном языке 1С, может выполняться на сервере приложений или на клиенте. Вся работа с прикладными объектами (справочниками, документами и т.д.), а также чтение и запись базы данных выполняется только на сервере. Функциональность форм и командного интерфейса также реализована на сервере. На клиенте выполняется получение, открытие и отображение форм, «общение» с пользователем (предупреждения, вопросы…), небольшие расчеты в формах, требующие быстрой реакции (например, умножение цены на количество), работа с локальными файлами, работа с оборудованием.
В прикладном коде заголовках процедур и функций надо явно указывать, где будет выполняться код — с помощью директив &НаКлиенте / &НаСервере (&AtClient / &AtServer в англоязычном варианте языка). Разработчики на 1С сейчас поправят меня, сказав, что директив на самом деле больше, но для нас это сейчас не существенно.
Из клиентского кода можно вызвать серверный код, а вот из серверного кода вызвать клиентский нельзя. Это фундаментальное ограничение, сделанное нами по ряду причин. В частности потому, что серверный код должен быть написан так, чтобы одинаково выполняться, откуда бы его ни вызвали – с клиента или с сервера. А в случае вызова серверного кода из другого серверного кода клиент отсутствует как таковой. И потому, что в ходе выполнения серверного кода клиент, вызвавший его, мог закрыться, выйти из приложения, и серверу будет уже некого вызывать.
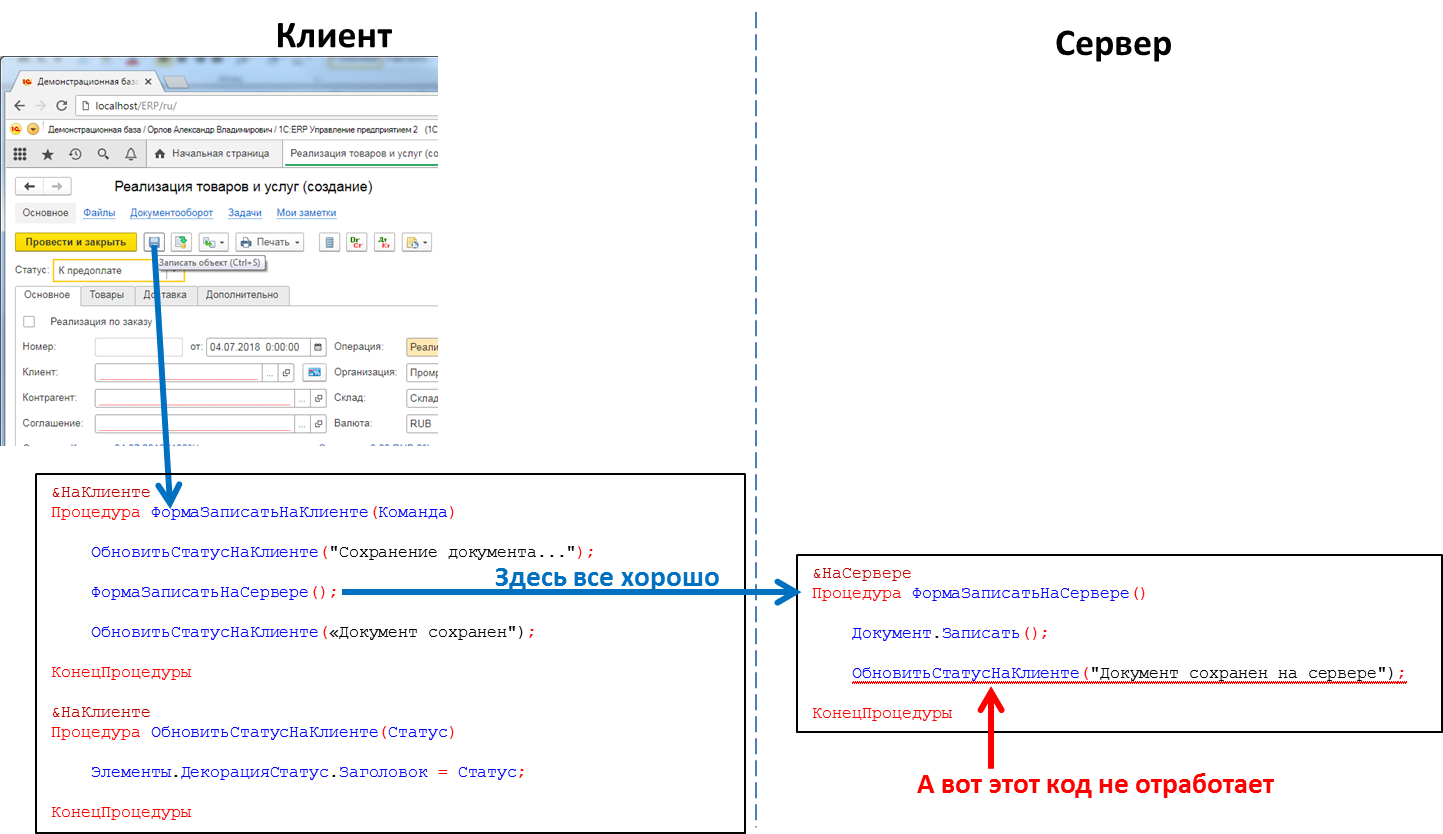
Код, обрабатывающий нажатие кнопки: вызов серверной процедуры с клиента сработает, вызов клиентской процедуры с сервера — нет
Это значит, что если мы с сервера захотим передать какое-то сообщение в клиентское приложение, например, что закончилось формирование «долгоиграющего» отчета и отчет можно посмотреть – такого способа у нас нет. Приходится идти на ухищрения, например, из клиентского кода периодически опрашивать сервер. Но такой подход загружает систему лишними вызовами, да и вообще выглядит не очень изящно.
А еще есть необходимость, например, при поступившем телефонном SIP-звонке оповестить об этом клиентское приложение, чтобы оно по номеру звонящего нашло его в базе контрагентов и показало пользователю информацию о звонящем контрагенте. Или, например, при поступлении на склад заказа уведомить об этом клиентское приложение заказчика. В общем, кейсов, где такой механизм бы пригодился, немало.
Собственно постановка
Создать механизм обмена сообщениями. Быстрый, надежный, с гарантированной доставкой, с возможностью гибкого поиска сообщений. На базе механизма реализовать мессенджер (сообщения, видеозвонки), работающий внутри приложений 1С.
Спроектировать систему горизонтально масштабируемой. Возрастающая нагрузка должна закрываться увеличением количества нод.
Реализация
Серверную часть СВ мы решили не встраивать непосредственно в платформу 1С:Предприятие, а реализовывать как отдельный продукт, API которого можно вызывать из кода прикладных решений 1С. Сделано это было по ряду причин, главная из которых – хотелось сделать возможным обмен сообщениями между разными приложениями 1С (например, между Управлением Торговлей и Бухгалтерией). Разные приложения 1С могут работать на разных версиях платформы 1С:Предприятие, находиться на разных серверах и т.п. В таких условиях реализация СВ как отдельного продукта, находящегося «сбоку» от инсталляций 1С – оптимальное решение.
Итак, мы решили делать СВ как отдельный продукт. Небольшим компаниям мы рекомендуем пользоваться сервером СВ, который мы установили в своем облаке (wss://1cdialog.com), чтобы избежать накладных расходов, связанных с локальной установкой и настройкой сервера. Крупные же клиенты, возможно, сочтут целесообразной установку собственного сервера СВ на своих мощностях. Аналогичный подход мы использовали в нашем облачном SaaS продукте 1cFresh – он выпускается как тиражный продукт для инсталляции у клиентов, и также развернут в нашем облаке https://1cfresh.com/.
Приложение
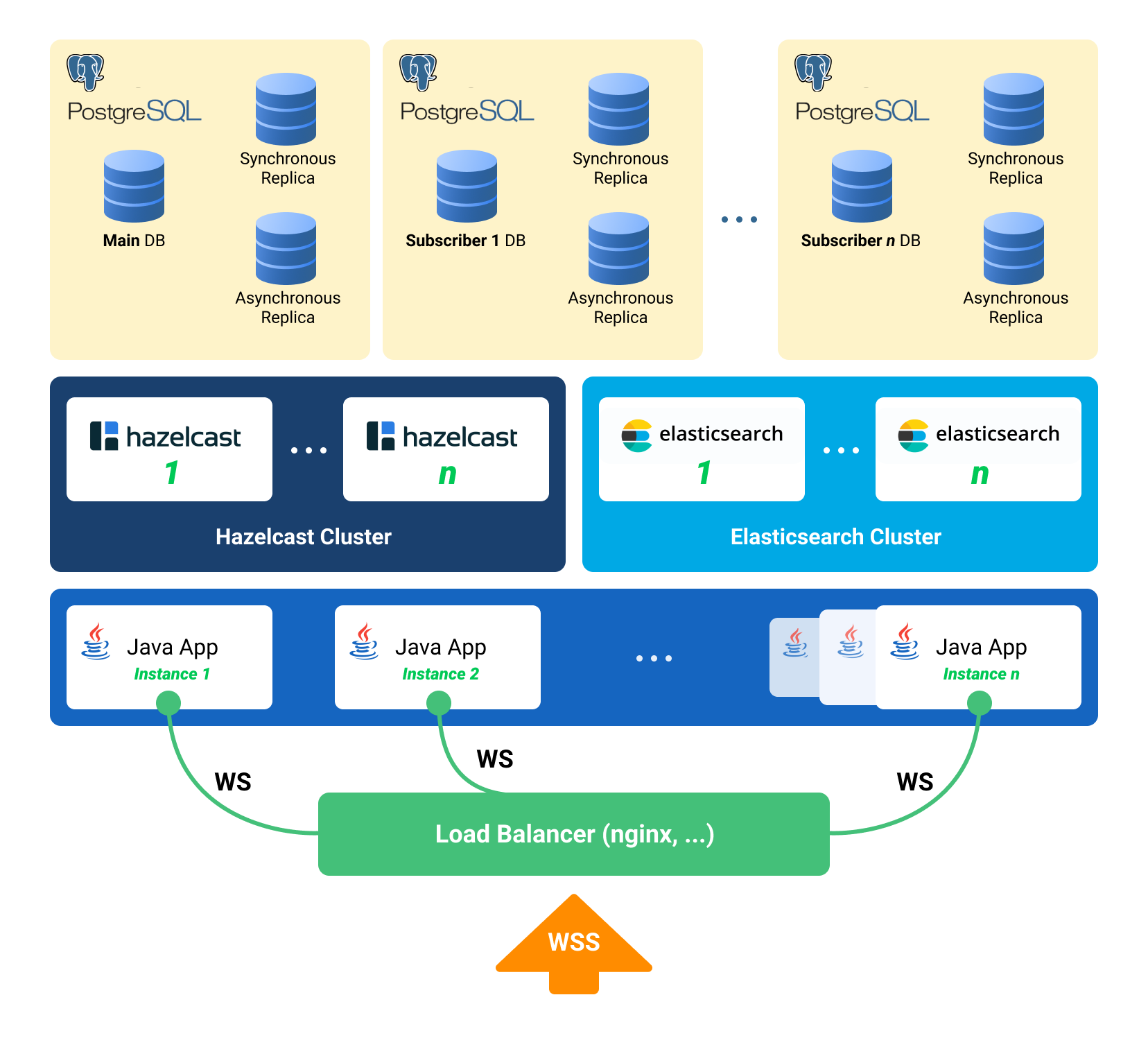
Для распределения нагрузки и отказоустойчивости развернем не одно Java-приложение, а несколько, перед ними поставим балансировщик нагрузки. Если нужно передать сообщение с ноды на ноду – используем publish/subscribe в Hazelcast.
Общение клиента с сервером – по websocket. Он хорошо подходит для систем реального времени.
Распределенный кэш
Выбирали между Redis, Hazelcast и Ehcache. На дворе 2015 год. Redis только-только зарелизили новый кластер (слишком новый, страшно), есть Sentinel с кучей ограничений. Ehcache не умеет собираться в кластер (этот функционал появился позже). Решили попробовать с Hazelcast 3.4.
Hazelcast собирается в кластер «из коробки». В режиме одной ноды он не очень полезен и может сгодиться только как кэш – не умеет скидывать данные на диск, потеряли единственную ноду – потеряли данные. Мы разворачиваем несколько Hazelcast-ов, между которыми бэкапим критические данные. Кэш не бэкапим – его не жалко.
Для нас Hazelcast – это:
- Хранилище пользовательских сессий. Каждый раз ходить за сессией в базу – долго, поэтому все сессии кладем в Hazelcast.
- Кэш. Ищешь профиль пользователя – проверь в кэше. Написал новое сообщение – положи в кэш.
- Топики для общения инстансов приложения. Нода генерирует событие и помещает его в топик Hazelcast. Другие ноды приложения, подписанные на этот топик, получают и обрабатывают событие.
- Кластерные блокировки. Например, создаем обсуждение по уникальному ключу (обсуждение-синглтон в рамках базы 1С):
conversationKeyChecker.check("БЕНЗОКОЛОНКА");
doInClusterLock("БЕНЗОКОЛОНКА", () -> {
conversationKeyChecker.check("БЕНЗОКОЛОНКА");
createChannel("БЕНЗОКОЛОНКА");
});Проверили, что канала нет. Взяли блокировку, снова проверили, создали. Если после взятия блокировки не проверять, то есть шанс, что другой поток в этот момент тоже проверил и сейчас попробует создать такое же обсуждение – а оно уже существует. Делать блокировку через synchronized или обычный java Lock нельзя. Через базу – медленно, да и базу жалко, через Hazelcast – то, что надо.
Выбираем СУБД
У нас большой и успешный опыт работы с PostgreSQL и сотрудничества с разработчиками этой СУБД.
С кластером у PostgreSQL непросто – есть XL, XC, Citus, но, в общем-то, это не noSQL, которые масштабируются из коробки. NoSQL как основное хранилище рассматривать не стали, хватило и того, что берем Hazelcast, с которым прежде не работали.
Раз нужно масштабировать реляционную БД – значит, шардинг. Как вы знаете, при шардинге мы разделяем базу данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер.
Первый вариант нашего шардинга предполагал возможность разнести каждую из таблиц нашего приложения по разным серверам в разных пропорциях. Много сообщений на сервере А – пожалуйста, давайте перенесем часть этой таблицы на сервер Б. Такое решение просто-таки вопило о преждевременной оптимизации, так что мы решили ограничиться multi-tenant подходом.
Почитать про multi-tenant можно, например, на сайте Citus Data.
В СВ есть понятия приложения и абонента. Приложение – это конкретная инсталляция бизнес-приложения, например, ERP или Бухгалтерии, со своими пользователями и бизнес-данными. Абонент – это организация или физическое лицо, от имени которого выполняется регистрация приложения в сервере СВ. У абонента может быть зарегистрировано несколько приложений, и эти приложения могут обмениваться сообщениями между собой. Абонент и стал жильцом (tenant) в нашей системе. Сообщения нескольких абонентов могут находиться в одной физической базе; если мы видим, что какой-то абонент стал генерировать много трафика – мы выносим его в отдельную физическую базу (или даже отдельный сервер БД).
У нас есть главная БД, где хранится таблица роутинга с информацией о локации всех абонентских базах данных.

Чтобы главная БД не была узким местом, таблицу роутинга (и другие часто востребованные данные) мы держим в кэше.
Если начнет тормозить БД абонента, будем внутри резать на партиции. На других проектах для партиционирования больших таблиц используем pg_pathman.
Поскольку терять сообщения пользователей плохо, мы поддерживаем наши БД репликами. Комбинация синхронной и асинхронной реплик позволяет подстраховаться на случай потери основной БД. Потеря сообщения произойдет только в случае одновременного отказа основной БД и ее синхронной реплики.
Если теряется синхронная реплика – асинхронная реплика становится синхронной.
Если теряется основная БД – синхронная реплика становится основной БД, асинхронная реплика – синхронной репликой.
Elasticsearch для поиска
Поскольку, помимо прочего, СВ – это еще и мессенджер, здесь нужен быстрый, удобный и гибкий поиск, с учетом морфологии, по неточным соответствиям. Мы решили не изобретать велосипед и использовать свободную поисковую систему Elasticsearch, созданную на основе библиотеки Lucene. Elasticsearch мы также разворачиваем в кластере (master – data – data), чтобы исключить проблемы в случае выхода из строя узлов приложения.
На github мы нашли плагин русской морфологии для Elasticsearch и используем его. В индексе Elasticsearch мы храним корни слов (которые определяет плагин) и N-граммы. По мере того, как пользователь вводит текст для поиска, мы ищем набираемый текст среди N-грамм. При сохранении в индекс слово «тексты» разобьется на следующие N-граммы:
[те, тек, текс, текст, тексты, ек, екс, екст, ексты, кс, кст, ксты, ст, сты, ты],
А также будет сохранен корень слова «текст». Такой подход позволяет искать и по началу, и по середине, и по окончанию слова.
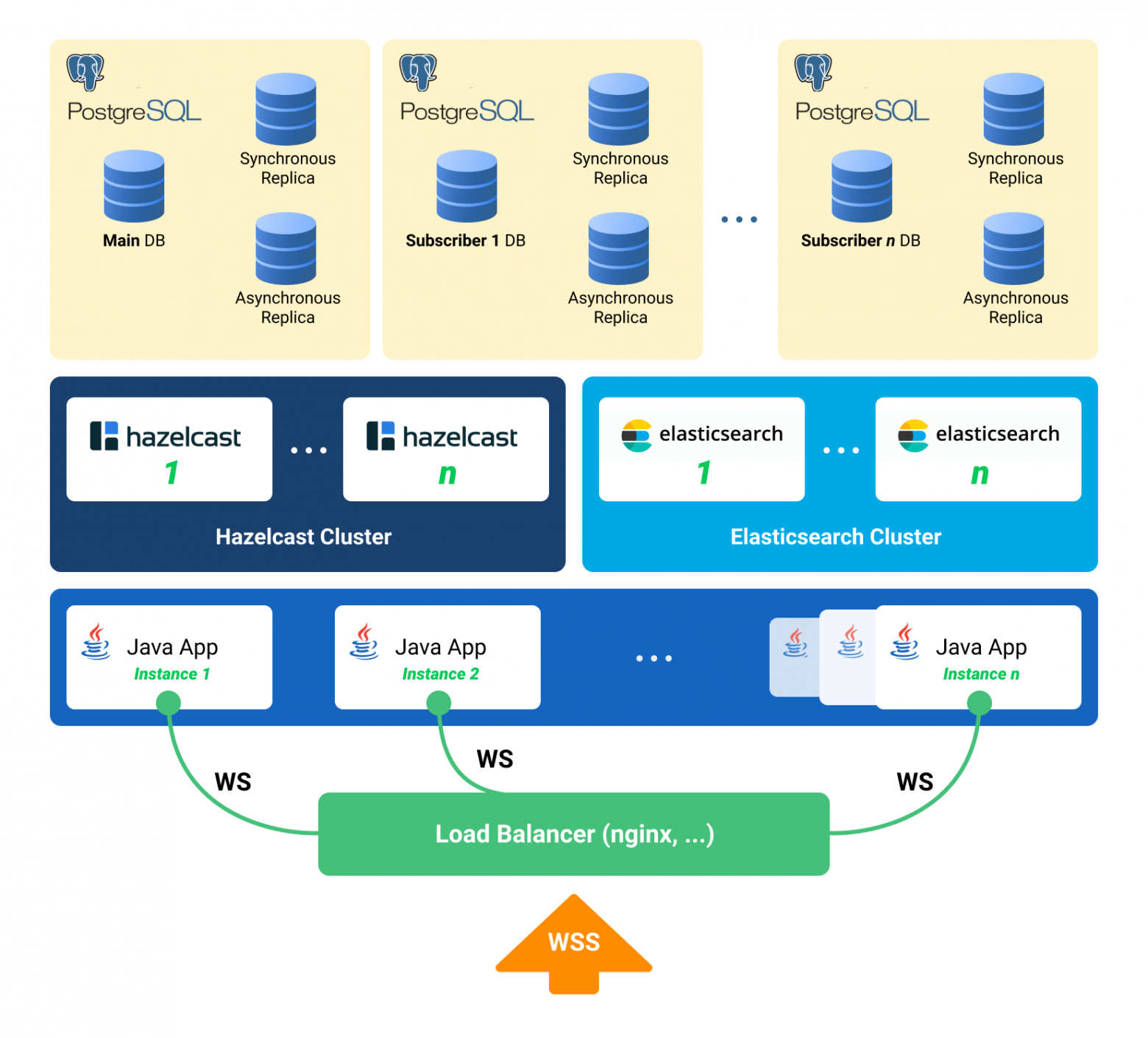
Общая картина
Повтор картинки из начала статьи, но уже с разъяснениями:
- Балансировщик, выставленный в интернет; у нас – nginx, может быть любой.
- Инстансы Java-приложения общаются между собой через Hazelcast.
- Для работы с веб-сокетом используем Netty.
- Java-приложение написано на Java 8, состоит из бандлов OSGi. В планах – миграция на Java 10 и переход на модули.
Разработка и тестирование
В процессе разработки и тестирования СВ мы столкнулись с рядом интересных особенностей продуктов, используемых нами.
Нагрузочное тестирование и утечки памяти
Выпуск каждого релиза СВ – это нагрузочное тестирование. Оно пройдено успешно, когда:
- Тест работал несколько суток и не было отказов в обслуживании
- Время отклика по ключевым операциям не превысило комфортного порога
- Ухудшение производительности по сравнению с предыдущей версией не больше 10%
Тестовую базу заполняем данными – для этого получаем с продакшн-сервера информацию о самом активном абоненте, умножаем его цифры на 5 (количество сообщений, обсуждений, пользователей) и так тестируем.
Нагрузочное тестирование системы взаимодействия мы проводим в трех конфигурациях:
- Стресс-тест
- Только подключения
- Регистрация абонентов
При стресс-тесте мы запускаем несколько сотен потоков, и те без остановки нагружают систему: пишут сообщения, создают обсуждения, получают список сообщений. Имитируем действия обычных пользователей (получить список моих непрочитанных сообщений, написать кому-нибудь) и программных решений (передать пакет другой конфигурации, обработать оповещение).
Например, вот так выглядит часть стресс-теста:
- В систему заходит пользователь
- Запрашивает свои непрочитанные обсуждения
- С 50% вероятностью читает сообщения
- С 50% вероятностью пишет сообщения
- Далее пользователь:
- С 20% вероятностью создает новое обсуждение
- Случайно выбирает любое из своих обсуждений
- Заходит внутрь
- Запрашивает сообщения, профили пользователей
- Создает пять сообщений, адресованных случайным пользователям из этого обсуждения
- Выходит из обсуждения
- Повторяет 20 раз
- Выходит из системы, возвращается обратно к началу сценария
- В систему заходит чат-бот (эмулирует обмен сообщениями из кода прикладных решений)
- С 50% вероятностью создает новый канал для обмена данными (специальное обсуждение)
- С 50% вероятностью пишет сообщение в любой из существующих каналов
Сценарий «Только подключения» появился не просто так. Бывает ситуация: пользователи подключили систему, но пока не втянулись. Каждый пользователь утром в 09:00 включает компьютер, устанавливает соединение с сервером и молчит. Эти ребята опасны, их много – из пакетов у них только PING/PONG, но соединение до сервера они держат (не держать не могут – а вдруг новое сообщение). Тест воспроизводит ситуацию, когда за полчаса в системе пытаются авторизоваться большое число таких пользователей. Он похож на стресс-тест, но фокус у него именно на этом первом входе – чтобы не было отказов (человек не пользуется системой, а она уже отваливается – сложно придумать что-то хуже).
Сценарий регистрации абонентов берет свое начало с первого запуска. Мы провели стресс-тест и были уверены, что в переписке система не тормозит. Но пошли пользователи и начала по таймауту отваливаться регистрация. При регистрации мы использовали /dev/random, который завязан на энтропию системы. Сервер не успевал скопить достаточно энтропии и при запросе нового SecureRandom застывал на десятки секунд. Выходов из такой ситуации много, например: перейти на менее безопасный /dev/urandom, поставить специальную плату, которая формирует энтропию, генерировать случайные числа заранее и хранить в пуле. Мы временно закрыли проблему пулом, но с тех пор прогоняем отдельный тест на регистрацию новых абонентов.
В качестве генератора нагрузки мы используем JMeter. Работать с вебсокетом он не умеет, нужен плагин. Первыми в поисковой выдаче по запросу «jmeter websocket» идут статьи с BlazeMeter, в которых рекомендуют плагин от Maciej Zaleski.
С него мы и решили начать.
Почти сразу после начала серьезного тестирования мы обнаружили, что в JMeter начались утечки памяти.
Плагин – это отдельная большая история, при 176 звездах у него 132 форка на github-е. Сам автор в него не коммитит с 2015 года (мы брали его в 2015 году, тогда это не вызвало подозрений), несколько github issues по поводу утечек памяти, 7 незакрытых pull request-ов.
Если решите проводить нагрузочное тестирование с помощью этого плагина, обратите внимание на следующие обсуждения:
- В многопоточной среде использовался обычный LinkedList, в итоге получали NPE в рантайме. Решается либо переходом на ConcurrentLinkedDeque, либо synchronized-блоками. Для себя выбрали первый вариант (https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43).
- Утечка памяти, при дисконнекте не удаляется информация о соединении (https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44).
- В режиме streaming (когда вебсокет не закрывается в конце сэмпла, а используется дальше в плане) не работают Response pattern-ы (https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19).
Это из тех, что на github-е. Что мы сделали:
- Взяли форк Elyran Kogan (@elyrank) – в нем исправлены проблемы 1 и 3
- Решили проблему 2
- Обновили jetty с 9.2.14 на 9.3.12
- Обернули SimpleDateFormat в ThreadLocal; SimpleDateFormat не потокообезопасный, что приводило к NPE в рантайме
- Устранили еще одну утечку памяти (неправильно закрывалось соединение при дисконнекте)
И все-таки он течет!
Память стала заканчиваться не за день, а за два. Времени совсем не оставалось, решили запускать меньше потоков, но на четырех агентах. Этого должно было хватить, как минимум, на неделю.
Прошло два дня…
Теперь память стала заканчиваться у Hazelcast-а. В логах было видно, что спустя пару дней тестирования Hazelcast начинает жаловаться на нехватку памяти, а еще через некоторое время кластер разваливается, и ноды продолжают погибать поодиночке. Мы подключили JVisualVM к hazelcast-у и увидели «восходящую пилу» – он регулярно вызывал GC, но никак не мог очистить память.
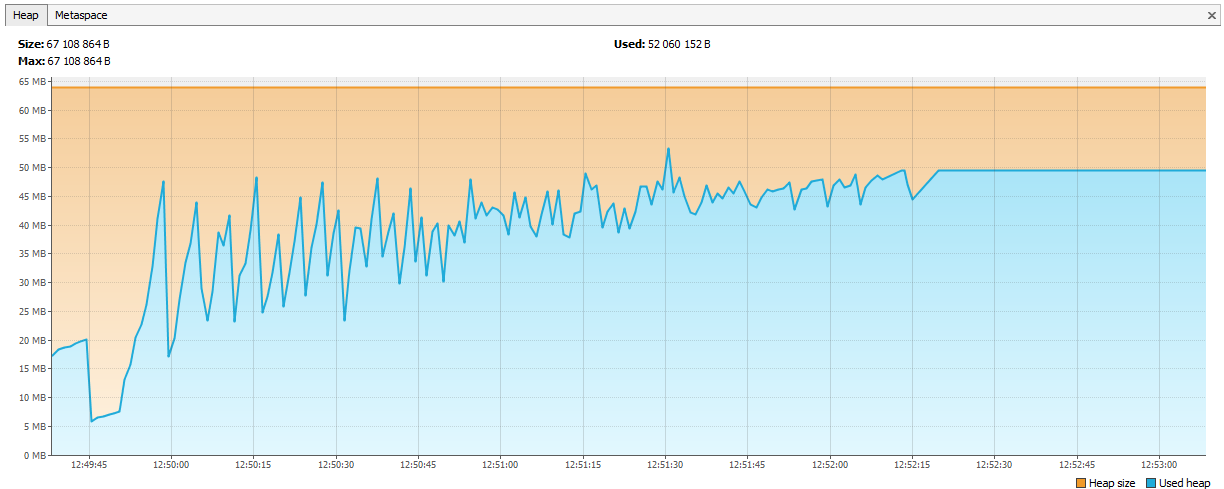
Оказалась, что в hazelcast 3.4 при удалении map / multiMap (map.destroy()) память освобождается не полностью:
github.com/hazelcast/hazelcast/issues/6317
github.com/hazelcast/hazelcast/issues/4888
Сейчас ошибка исправлена в 3.5, но тогда это была проблема. Мы создавали новые multiMap с динамическими именами и удаляли по нашей логике. Код выглядел примерно так:
public void join(Authentication auth, String sub) {
MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub);
sessions.put(auth.getUserId(), auth);
}
public void leave(Authentication auth, String sub) {
MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub);
sessions.remove(auth.getUserId(), auth);
if (sessions.size() == 0) {
sessions.destroy();
}
}Вызов:
service.join(auth1, "НОВЫЕ_СООБЩЕНИЯ_В_ОБСУЖДЕНИИ_UUID1");
service.join(auth2, "НОВЫЕ_СООБЩЕНИЯ_В_ОБСУЖДЕНИИ_UUID1");multiMap создавался для каждой подписки и удалялся, когда он был не нужен. Решили, что заведем Map<String,Set>, в качестве ключа будет название подписки, а в качестве значений идентификаторы сессий (по которым потом можно получить идентификаторы пользователей, если нужно).
public void join(Authentication auth, String sub) {
addValueToMap(sub, auth.getSessionId());
}
public void leave(Authentication auth, String sub) {
removeValueFromMap(sub, auth.getSessionId());
}Графики выправились.
Что еще мы узнали о нагрузочном тестировании
- JSR223 нужно писать на groovy и включать compilation cache – это сильно быстрее. Ссылка.
- Графики Jmeter-Plugins проще понимать, чем стандартные. Ссылка.
Про наш опыт с Hazelcast
Hazelcast для нас был новым продуктом, мы начали работать с ним с версии 3.4.1, сейчас на нашем production сервере стоит версия 3.9.2 (на момент написания статьи последняя версия Hazelcast – 3.10).
Генерация ID
Мы начинали с целочисленных идентификаторов. Давайте представим, что нам нужен очередной Long для новой сущности. Sequence в БД не подходит, таблицы участвуют в шардинге – получится, что есть сообщение ID=1 в БД1 и сообщение ID=1 в БД2, в Elasticsearch по такому ID не положишь, в Hazelcast тоже, но самое страшное, если вы захотите свести данные с двух БД в одну (например, решив, что одной базы достаточно для этих абонентов). Можно завести в Hazelcast несколько AtomicLong и держать счетчик там, тогда производительность получения нового ID – incrementAndGet плюс время на запрос в Hazelcast. Но в Hazelcast есть кое-что более оптимальное – FlakeIdGenerator. Каждому клиенту при обращении выдается диапазон ID, например, первому – от 1 до 10 000, второму – от 10 001 до 20 000 и так далее. Теперь клиент может выдавать новые идентификаторы самостоятельно, пока не закончится выданный ему диапазон. Работает быстро, но при перезапуске приложения (и клиента Hazelcast) начинается новая последовательность – отсюда пропуски и т.д. К тому же разработчикам не очень понятно, почему ID целочисленные, но идут так сильно вразнобой. Мы все взвесили и перешли на UUID-ы.
Кстати, для тех, кто хочет быть как Твиттер, есть такая библиотека Snowcast – это реализация Snowflake поверх Hazelcast. Посмотреть можно здесь:
github.com/noctarius/snowcast
github.com/twitter/snowflake
Но у нас до нее уже руки не дошли.
TransactionalMap.replace
Еще один сюрприз: TransactionalMap.replace не работает. Вот такой тест:
@Test
public void replaceInMap_putsAndGetsInsideTransaction() {
hazelcastInstance.executeTransaction(context -> {
HazelcastTransactionContextHolder.setContext(context);
try {
context.getMap("map").put("key", "oldValue");
context.getMap("map").replace("key", "oldValue", "newValue");
String value = (String) context.getMap("map").get("key");
assertEquals("newValue", value);
return null;
} finally {
HazelcastTransactionContextHolder.clearContext();
}
});
}
Expected : newValue
Actual : oldValueПришлось написать свой replace, использовав getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) {
TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext();
if (context != null) {
log.trace("[CACHE] Replacing value in a transactional map");
TransactionalMap<K, V> map = context.getMap(mapName);
V value = map.getForUpdate(key);
if (oldValue.equals(value)) {
map.put(key, newValue);
return true;
}
return false;
}
log.trace("[CACHE] Replacing value in a not transactional map");
IMap<K, V> map = hazelcastInstance.getMap(mapName);
return map.replace(key, oldValue, newValue);
}Тестируйте не только обычные структуры данных, но и их транзакционные версии. Бывает, что IMap работает, а TransactionalMap уже нет.
Подложить новый JAR без даунтайма
Сначала мы решили записывать в Hazelcast объекты своих классов. Например, у нас есть класс Application, мы хотим его сохранить и прочитать. Сохраняем:
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
map.set(id, application);Читаем:
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
return map.get(id);Все работает. Потом мы решили построить индекс в Hazelcast, чтобы искать по нему:
map.addIndex("subscriberId", false);И при записи новой сущности начали получать ClassNotFoundException. Hazelcast пытался дополнить индекс, но ничего не знал про наш класс и хотел, чтобы ему подложили JAR с этим классом. Мы так и сделали, все заработало, но появилась новая проблема: как обновить JAR без полной остановки кластера? Hazelcast не подхватывает новый JAR при понодовом обновлении. В этот момент мы решили, что вполне можем жить без поиска по индексу. Ведь если использовать Hazelcast как хранилище типа ключ-значение, то все будет работать? Не совсем. Здесь снова разное поведение IMap и TransactionalMap. Там где IMap-у все равно, TransactionalMap кидает ошибку.
IMap. Записываем 5000 объектов, считываем. Все ожидаемо.
@Test
void get5000() {
IMap<UUID, Application> map = hazelcastInstance.getMap("application");
UUID subscriberId = UUID.randomUUID();
for (int i = 0; i < 5000; i++) {
UUID id = UUID.randomUUID();
String title = RandomStringUtils.random(5);
Application application = new Application(id, title, subscriberId);
map.set(id, application);
Application retrieved = map.get(id);
assertEquals(id, retrieved.getId());
}
}А в транзакции не работает, получаем ClassNotFoundException:
@Test
void get_transaction() {
IMap<UUID, Application> map = hazelcastInstance.getMap("application_t");
UUID subscriberId = UUID.randomUUID();
UUID id = UUID.randomUUID();
Application application = new Application(id, "qwer", subscriberId);
map.set(id, application);
Application retrievedOutside = map.get(id);
assertEquals(id, retrievedOutside.getId());
hazelcastInstance.executeTransaction(context -> {
HazelcastTransactionContextHolder.setContext(context);
try {
TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t");
Application retrievedInside = transactionalMap.get(id);
assertEquals(id, retrievedInside.getId());
return null;
} finally {
HazelcastTransactionContextHolder.clearContext();
}
});
}В 3.8 появился механизм User Class Deployment. Вы можете назначить одну главную ноду и обновлять JAR-файл на ней.
Сейчас мы полностью сменили подход: сами сериализуем в JSON и сохраняем в Hazelcast. Hazelcast-у не нужно знать структуру наших классов, а мы можем обновляться без даунтайма. Версионированием доменных объектов управляет приложение. Одновременно могут быть запущены разные версии приложения, и возможна ситуация, когда новое приложение пишет объекты с новыми полями, а старое еще про эти поля не знает. И в то же время новое приложение вычитывает объекты, записанные старым приложением, в которых нет новых полей. Такие ситуации обрабатываем внутри приложения, но для простоты не меняем и не удаляем поля, только расширяем классы путем добавления новых полей.
Как мы обеспечиваем высокую производительность
Четыре похода в Hazelcast – хорошо, два в БД – плохо
Ходить за данными в кэш всегда лучше, чем в БД, но и хранить невостребованные записи не хочется. Решение о том, что кэшировать, мы откладываем на последний этап разработки. Когда новая функциональность закодирована, мы включаем в PostgreSQL логгирование всех запросов (log_min_duration_statement в 0) и запускаем нагрузочное тестирование минут на 20. По собранным логам утилиты типа pgFouine и pgBadger умеют строить аналитические отчеты. В отчетах мы в первую очередь ищем медленные и частые запросы. Для медленных запросов строим план выполнения (EXPLAIN) и оцениваем, можно ли такой запрос ускорить. Частые запросы по одним и тем же входным данным хорошо ложатся в кэш. Запросы стараемся держать «плоскими», по одной таблице в запросе.
Эксплуатация
СВ как онлайн-сервис была запущена в эксплуатацию весной 2017 года, как отдельный продукт СВ вышел в ноябре 2017 (на тот момент в статусе бета-версии).
Более чем за год эксплуатации серьезных проблем в работе онлайн-сервиса СВ не случалось. Онлайн-сервис мониторим через Zabbix, собираем и деплоим из Bamboo.
Дистрибутив сервера СВ поставляется в виде нативных пакетов: RPM, DEB, MSI. Плюс для Windows мы предоставляем единый инсталлятор в виде одного EXE, который устанавливает сервер, Hazelcast и Elasticsearch на одну машину. Сначала мы называли эту версию установки «демонстрационной», но сейчас стало понятно, что это самый популярный вариант развертывания.
