
Мы много раз рассказывали о том, как мы пишем автотесты, какие технологии используем, как помогаем разработчикам с производительностью юнит-тестов и так далее. А вот про стратегию всего процесса тестирования, включая ручное, ещё ни разу не писали. Пришло время восполнить этот пробел.
Стратегии тестирования бывают разные. Они зависят от множества факторов: выбранных технологий, направленности бизнеса, логики приложений, культуры компании и много чего ещё. То, что хорошо подходит для встраиваемых систем, может не подойти для мобильных приложений, а то, что хорошо работает в бухгалтерии, не всегда замечательно приживётся в производстве ПО для самолётов.
Кто-то очень тщательно подходит к вопросам документирования всего и вся, кто-то считает, что код должен быть хорошо читаем и этого более чем достаточно. Берусь утверждать, что многие правы: если у них в компании принятые методологии и практики работают, значит, это именно то, что им нужно.
Так же и у нас в Badoo: многие подходы, которые мы используем, хорошо работают именно у нас, в нашей культуре и в нашем постстартап-мире, где из-за взрывного роста компании мы наступили на кучу разных граблей и набили много шишек. Мне несказанно приятно, что многое из того, что мы взяли за основу, за базовые ценности в самом начале, всё ещё хорошо работает и прекрасно масштабируется.
Рассказывать про процесс я буду на примере одной из команд – команды мобильного веба (Mobile Web Team). Это платформа на стыке веба и мобайла, когда в мобильном браузере мы загружаем полноценное HTML5-приложение, которое по специальному протоколу общается с сервером. К слову, похожим образом взаимодействуют с сервером и все остальные клиентские приложения Badoo, включая Desktop Web.
Во-первых, этот процесс более-менее общий для всех команд, которые делают продукт (за небольшими исключениями), а во-вторых, на конкретном примере вам будет проще понять то, что я описываю.
Процесс
Как и во многих других командах Badoo, задача в Mobile Web начинается с PRD (Product Requirements Document). Это документ, который составляет продакт-менеджер и в котором он описывает, как должно выглядеть запрашиваемое в разработке изменение. Новый функционал, изменение поведения существующего – для обозначения всего этого мы используем термин «фича». PRD содержит в себе дизайн интерфейса от дизайнеров, бизнес-логику, требования к аналитике после запуска фичи и много чего ещё. Это – основа взаимодействия продактов и разработки.
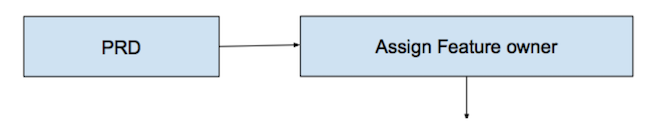
Далее технический лид команды разбирает поступившие требования и отдаёт документ полностью либо по частям (если фича очень большая) разработчикам. С этого момента у фичи появляется владелец – микропроджектменеджер, который не только отвечает за реализацию функционала, но и за сроки его реализации и при этом в процессе реализации взаимодействует с другими командами, если это требуется (уточняет PRD, дизайн и т. д.).
Если над проектом работает несколько человек, то таким микропроджектменеджером от разработки является один из них, обычно – самый опытный. Чтобы, как говорится, у семи нянек дитя без глаза не осталось. В общем, так мы пытаемся избежать ситуации коллективной ответственности. Ведь если за что-то отвечают все, значит, де-факто не отвечает никто.
Прежде чем приступать к разработке, мы составляем план, это общий сценарий того, как фича будет разрабатываться, тестироваться, релизиться, какие бизнес-метрики могут потребоваться для анализа после запуска, какие эксперименты могут понадобиться перед окончательным запуском и прочее. Этот план утверждается продактом на специальной встрече, которая называется KickOff: он оценивает общую канву, уточняет и корректирует нюансы, если необходимо, и даёт добро на реализацию в соответствии с планом.
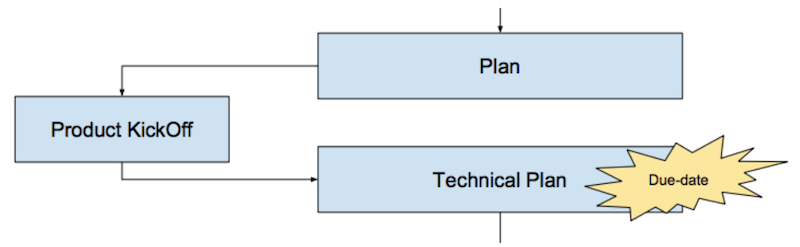
Далее девелопер готовит технический план (либо самостоятельно, либо с помощью коллег и менеджера). Это, по сути, тот же план, что утверждён ранее, но с уточнениями по технической реализации на каждом этапе: как то, что требуется, оптимально совместить с имеющимся функционалом, какие технологии и механизмы использовать, в каком порядке это всё будет релизиться и так далее. Именно на этом этапе появляется более-менее предсказуемый срок реализации. Его разработчик определяет сам, согласует с руководителем и впоследствии старается четко его выдерживать.
Очевидно, что срок в этом случае понимается как дата, когда новый функционал станет доступен пользователю: не «мне на программирование надо три часа», а «задачу я выложу третьего августа в утреннем релизе». Естественно, чтобы определить такой срок, необходимо учесть массу нюансов и пообщаться со всеми, кто будет принимать участие в процессе, продумать зависимости (особенно внешние), согласовать с другими отделами сроки и ресурсы, и, конечно, уточнить у тестировщиков время на тестирование.
На этом этапе важно знать, что технический лид в QA, который оценивает время на тестирование, даёт оценку времени, необходимого для тестирования одной итерации (без учёта переоткрытий), то есть буквально: сколько человеко-часов необходимо на то, чтобы оценить качество текущей задачи. Почему мы говорим об одной итерации? Всё просто: потому что мы не можем предсказать, сколько багов будет и сколько раз нам придётся их чинить.
Понятно, что срок в отдалённой перспективе контролировать сложно. Поэтому для фиксирования текущей ситуации мы используем поле Situation в задачах и с разной периодичностью для разных команд корректируем сроки. Важно помнить, что при изменении или уточнении срока необходимо зафиксировать, что нас заставило это сделать, чтобы иметь возможность в дальнейшем (на ретроспективе, например) выполнить анализ проекта и в следующий раз дать более точный прогноз.
Только после этого этапа разработчик может приступать к программированию.
После того, как разработчик закончил реализацию фичи или её части и считает, что она готова, он организует Visual QA. Это специальная встреча с продакт-менеджером, на которой разработчик демонстрирует, что у него получилось. Продакт может принять фичу либо уточнить какие-нибудь требования, если это необходимо (в этом случае фича дорабатывается, и все этапы повторяются ещё раз). На этом шаге мы также гарантируем, что разработчик сам проверил как минимум позитивные сценарии использования приложения и пофиксил баги, если они были. Иначе что он покажет продакту?
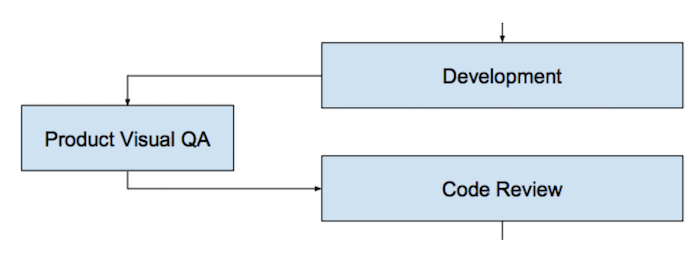
Только после успешного Visual QA с продактом задача отправляется на Code Review. Почему не раньше? Потому что в случае если у продакта появятся дополнительные требования, мы зря потратим время других участников процесса: ревьювера, тестировщиков и т. д.
Code Review – очень важный этап процесса обеспечения качества. На этом этапе желательно, чтобы разработчик не только проанализировал код на предмет оформления и общих соглашений, но и буквально «протестировал» его глазами и головой, прошёл по сценарию, запрограммированному другим разработчиком. Дополнительный «незамыленный» взгляд помогает избежать очень многих базовых ошибок.
Следующий этап в процессе – QA. Тестирование у нас состоит из нескольких этапов в разных окружениях и включает в себя ручное и автоматизированное тестирование разных уровней и элементов системы (подробнее о том, как именно мы проводим тестирование, я расскажу ниже).
И, наконец, релиз фичи. Для многих задач это – не последний этап, далее могут быть ещё различные доработки, A/B-тесты, анализ пользовательского поведения и оптимизация фичи. Ретроспектива и анализ полезности фичи для бизнеса и всего приложения в целом. Есть фичи, которые «не взлетают»; мы их дорабатываем или удаляем из приложений, это нормальная практика. А те фичи, которые успешно прошли все предыдущие стадии, становятся основным функционалом наших приложений.
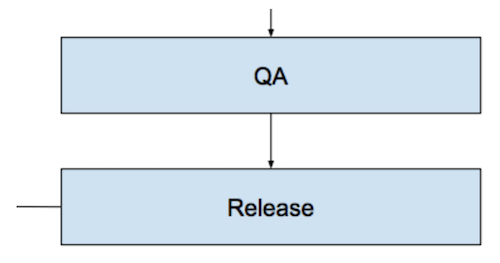
Вот так выглядит полная схема описанного процесса.
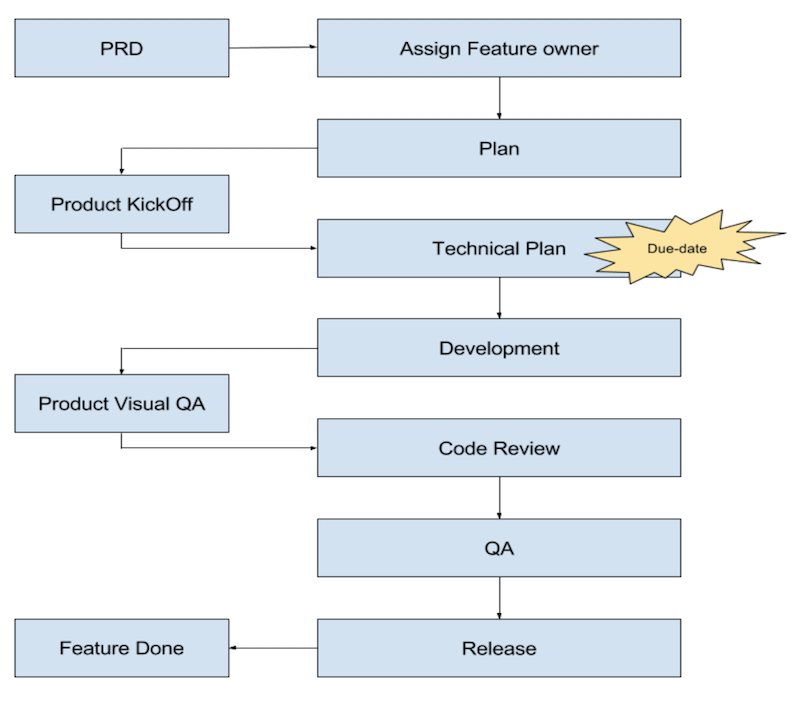
Тестирование
Из описания процесса понятно, как выглядит жизненный цикл фичи, из каких стадий он складывается. И, по моему опыту, большинство этих стадий понимаются (плюс-минус) правильно всеми участниками процесса. Как выглядит PRD, как раздаются задачи, как делается код-ревью и прочее – это всё понятно, и многие используют это в своих командах.
Но когда дело касается QA, начинается полный раздрай. У разных людей на разных уровнях порой совершенно фантастические представления о работе «этих странноватых ребят из QA». Хорошо, когда ситуацию понимают как «они там что-то делают, тыкают-кликают, а потом приносят нам баги». Бывает и так, что разработчик сам вдумчиво проверяет результаты своей работы и заявляет: «Мне тестировщики не нужны – я уверен в качестве своего продукта». Но таких случаев мало.
Были на моей практике и ситуации, когда разработчики считали, что тестировщики «находят слишком много багов и не дают нам релизиться». Может быть и такое, что разработчик говорит: «Найдите мне все-все баги, мы их пофиксим, и всё» или «Вы проверьте, вы же лучше меня знаете, как работает наш продукт». Сразу возникает вопрос: а как же ты тогда код-то писал, если не знаешь, как он работает?
В общем, мало кто действительно понимает, как происходит процесс тестирования. Давайте попробуем разобраться.
Что такое качество?
Для начала нужно условиться, что все баги найти нельзя. Это аксиома, с которой согласны даже самые упёртые индивидуумы, – здравый смысл не обманешь.
Если представить себе «диаграмму багов» на временном промежутке, то получится что-то вроде такой схемы:
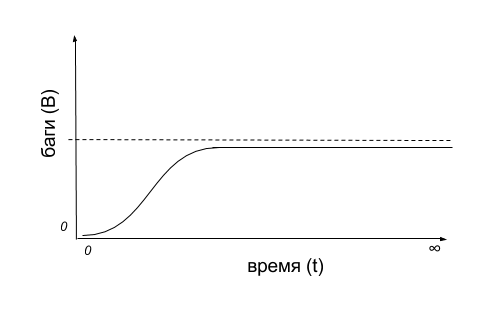
Количество найденных багов (B) сначала небольшое – пока мы знакомимся с системой или подготавливаем среду. Потом оно может даже расти в единицу времени (t), когда мы нашли «больной» участок приложения. Но потом в какой-то момент времени, какие бы механизмы и способы мы ни использовали, багов мы находим всё меньше и меньше. В результате время уходит в бесконечность, а все баги системы всё равно не будут найдены.
Можно представить ситуацию, когда мы не ограничены по времени и обладаем безграничными ресурсами, но по формулировке уже понятно, что такая ситуация очень уж синтетическая: слишком много допущений и отсутствие какой-либо связи с суровой реальностью. В реальном мире стартапов и высокой конкуренции большинство стремится получить выгоду за максимально короткий срок, и задача скорее ставится так: найти как можно больше багов за как можно меньший промежуток времени.
Есть такое важное понятие, как скорость нахождения багов: S = B/t. Оно условное, но многие стремятся его сразу же оптимизировать. Видимо, потому что оно интуитивно понятно. Именно поэтому возникают такие вещи, как смоук-тестирование, автоматизированное тестирование (да, не только для проверки регрессии), развиваются инструменты и методологии, позволяющие точнее определять потенциально «рисковые» места продуктов (классы эквивалентности, например). И самое главное, давать как можно быстрее как можно более полную оценку качества вашего продукта.
И поскольку мы сразу условились, что все баги найти невозможно, да и во времени мы ограничены, очевидно, что где-то на графике должна быть точка пересечения B и t, которая бы показывала текущее состояние качества продукта, чтобы ответить на вопрос: хватит уже тестировать или надо продолжать?
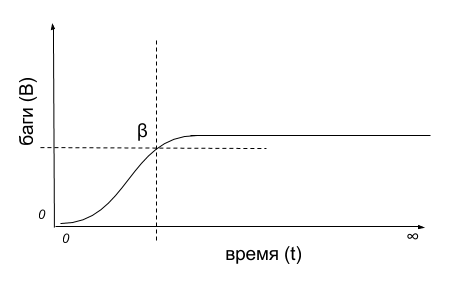
Так каково же оно, это идеальное значение β = ƒ(B,t)?
А его нет, идеального – оно разное для всех проектов. Более того, оно варьируется от задачи к задаче даже в пределах одной, слаженной команды. Оно зависит от массы внешних условий, начиная с технологий реализации, культуры внутри каждой конкретной команды и заканчивая маркетинговыми мероприятиями, сроками и решением заказчика «Да ладно, и так сойдёт».
Всё было бы ещё печальнее, если бы минимальное «универсальное» значение β тоже было неизвестно. А оно есть и формулируется легко и понятно каждому: «У продукта достаточно хорошее качество, если пользователь готов его купить». Причём я имею в виду не только покупку за деньги: если пользователь готов пользоваться вашим продуктом, если он готов после падения приложения открыть его заново и продолжить им пользоваться, значит, хорошее β достигнуто.
А вот дальше уже вступают в силу множество дополнительных условий. Есть ли у вашего продукта конкуренты на рынке? Какая категория пользователей будет пользоваться вашим продуктом? Готовы ли вы вкладывать дополнительные средства в перфекционизм? Ждёт ли вас пресс-конференция с демонстрацией вашей новой суперидеи? Когда планируется рост нагрузки? И так далее.
Кто “делает” качество?
Если вы обратили внимание, то с начала предыдущего раздела я ни разу не упомянул тестировщиков. Я сделал это намеренно, потому что любой необходимый уровень β вполне достижим даже в том случае, когда такой структуры, как QA, в компании нет. А уж про минимальный уровень качества и говорить нечего – его должен обеспечить разработчик.
В команде Mobile Web у нас достигнутое минимальное β дополнительно контролируется хитростью с Visual QA. Прежде чем передать задачу следующим участникам процесса, разработчик должен сам прийти к продакт-менеджеру и показать ему результат своей работы. И первый скрупулезный пользователь его продукта – это сам заказчик, тот, кто писал PRD.
Дополнительный бонус от общения с продактом на этом этапе заключается в том, что он может отсечь что-то несущественное. Например, для первого запуска новой идеи он вполне может быть готов опробовать концепт – не выверенный до идеала, до каждого пикселя красивейший интерфейс, а вполне себе приемлемо работающий и демонстрирующий работоспособность идеи «полуфабрикат». И в процессе Visual QA критерии готовности могут быть уточнены. Главное – не забыть это отразить в PRD, чтобы остальные участники процесса не удивлялись несоответствию.
Когда я пришёл в Badoo, мы сразу условились: в нашей компании за качество отвечают разработчики. Этот прекрасный принцип и по сей день регулярно напоминается старым сотрудникам и рассказывается новым. И во многих дискуссиях этот аргумент помогает мне убеждать людей на разных уровнях в том, что надо делать именно так, а не иначе.
Почему разработчики? Зачем тогда вообще нужны тестировщики? Давайте разбираться.
Прежде всего, тестировщики не делают баги: либо баги в продукте есть, либо их нет. Их количество можно попытаться уменьшить, влияя на процесс, можно совершенствовать инженерную культуру, использовать общие правила и рекомендации (форматирование кода – яркий пример, как бы это иногда ни казалось избыточным (табы или пробелы, kekeke). Но изначально грамотное планирование и архитектура будущего проекта колоссальным образом влияют на качество конечного продукта.
Но как бы то ни было, непосредственно руки к коду прикладывают разработчики, и именно от них зависит, будут там баги или нет. Тестировщики на следующих этапах могут просто их найти. А могут и не найти, даже если применят все модные подходы и самые распоследние версии инструментов.
Тестировщик – он как страховка в цирке у акробата. Всю тяжёлую работу выполняет акробат, вертясь на трапециях, а страховщик стоит внизу и «ничего не делает» (прямо как тестировщик). Акробат вполне может выполнить свой трюк без страховки, но со страховкой ему намного спокойнее, он знает, что в случае ошибки ему не дадут упасть. Именно это имеют в виду, когда говорят: «Мы – одна команда, мы сообща работаем над одним и тем же» и т. д. Команда одна, это верно, но вся ответственность и главное – решение о том, нужна страховка или нет – лежит на плечах акробата. А в нашем случае – на плечах разработчика.
Кроме того, возлагая ответственность за качество на разработчика, мы ещё и избегаем ситуации, которая порой очень комфортна – найти виноватого. «Кто виноват?» – «Вася. Потому что не нашел мой баг». На самом же деле, виноватого искать смысла нет. От этого никому не станет легче – тут нужен конструктив. А конструктив может быть только такой: что сделать в следующий раз, чтобы подобное не повторилось? Причём ответ на этот вопрос должен дать сам разработчик как первоисточник проблемы: что ему помешало в этот раз, и как сделать так, чтобы в следующий раз это «что-то» ему не помешало? При этом упор нужно делать на то, что решение должно быть надёжным. Решение «Попросить Васю в следующий раз быть внимательнее» – плохое. Оно ничего не гарантирует: мы все – люди, и в следующий раз Вася может ошибиться так же, как сейчас. А вот решение «Покрыть этот участок автотестом» или «Переписать метод так, чтобы он принимал параметры только определённого типа» может оказаться очень эффективным.
Таким образом, тестирование следует воспринимать как индикатор, как дополнительный инструмент в богатом наборе разработчика, который может помочь ему ответить на вопрос: готов код к выкладке на продакшн или ещё не готов? А обвинять транспортир в том, что вы неверно отмерили угол, — как минимум неконструктивно.
Как происходит процесс тестирования?
Итак, задача успешно прошла все предыдущие стадии процесса и добралась до тестирования. Что дальше? Такой вопрос часто возникает не только у людей, непосредственно не участвующих в тестировании, но и у самих специалистов. Особенно после каких-нибудь курсов, на которых так красочно рассказывали про виды тестирования, методологии, чёрные-серые-белые ящики, юнит-интеграционное-системное тестирование и т. д. Как организовать проверки? С чего начать?
Немаловажным вопросом также является момент, когда следует возвращать задачу на доработку. После первого бага? Или после десятого? А, может, после полной проверки всех сценариев? Понятно, что с точки зрения бизнеса хочется ещё и значение β держать на оптимальном уровне (помните: за минимальное время найти максимальное количество багов?).
В некоторых компаниях используют фиксированный набор тестовых сценариев. У некоторых есть даже тестовые аналитики, которые эти самые сценарии пишут и либо сами, либо с помощью других (часто менее квалифицированных) тестировщиков проверяют.
Выглядят такие сценарии как последовательность шагов и список результатов, к которым они приводят. Часто сценарии могут быть в виде Given-When-Then, но это необязательно. Зайди в такую-то секцию меню под пользователем с правами администратора, ткни на зелёную кнопку, получи в результате такой-то экран, проверь что на нем отображено “Hello, world”.
Такой подход может быть оправдан, если вы готовы экономить на качестве сотрудников. Можно набрать людей с совсем небогатым опытом работы на компьютере, а в мобайл – так и вовсе «с улицы», телефоны-то есть почти у всех.
Но в то же время этот подход имеет ряд недостатков. Очевидно, что для обеспечения оптимального β такой подход даже вреден. Время прохождения сценариев константно для сеанса тестирования, и с появлением новых сценариев в списке оно только увеличивается. К тому же, подход имеет изъяны, связанные с психологией обывателя: с одной стороны, он сужает угол зрения до заранее описанного, и даже элементарные вещи начинают упускаться просто потому, что они не зафиксированы в виде сценариев; с другой стороны, у людей есть свойство, проверив один сценарий, помечать похожие как проверенные («Я ведь только что проверил авторизацию по e-mail, она работает. Зачем мне проверять ещё и авторизацию по номеру телефона? Там за сто последних запусков проблем не было ни разу»).
В одной из моих предыдущих компаний подход к переоткрытию задач был таким: нашёл баг – отправляй задачу на доработку. У нас был даже формальный документ-регламент, составленный моим руководителем, в котором был список вещей, после которых следовало переоткрывать задачу:
- Код в задаче не оформлен по стандартам кодирования? На доработку!
- Юнит-тестов нет? На доработку!
- Юнит-тесты не проходят? На доработку!
- Текст на экране сформулирован иначе, чем в задании? На доработку!
- Интерфейс в продукте не соответствует макету? На доработку!
- ?????
- PROFIT!
Такой подход тоже неоптимален с точки зрения параметра β. Мы увеличиваем общий срок тестирования задачи за счёт того, что каждый раз, после каждого изъяна, добавляем дополнительное время работы разработчика. На переключение контекста от той задачи, которой он занимается сейчас. На время ожидания задачи в очереди других задач. На еще один этап Code Review. На много другого, не всегда оправданного, взаимодействия. Ну, и после того, как задача снова вернётся в тестирование, её ведь придётся тестировать заново, а значит, повторить все те проверки, которые уже были сделаны, а это уже время работы тестировщика. Следовательно, время t, требуемое на весь процесс тестирования, удваивается, утраивается и так далее с каждым переоткрытием задачи. А если при этом используются ещё и предопределённые тестовые сценарии, то совсем беда.
Поэтому в Badoo мы следим за счётчиком переоткрытия задач и стараемся, чтобы его значение всё время уменьшалось. Переоткрывать задачу – дорого с точки зрения временных затрат всех участников процесса (хотя если смотреть на ситуацию только с точки зрения комфорта тестировщиков, такой подход выглядит весьма заманчиво).
Но горе руководителю, который требует от своих подчинённых минимального количества переоткрытий, не объяснив причину. В этом случае может сработать подмена целей, и вместо устранения причины болезни мы будем лечить симптомы. Вместо того чтобы совершенствовать инженерную культуру и выяснять, как сделать так, чтобы в следующий раз бы не наступить на эти грабли, мы можем прийти к ситуации, когда цифры становятся самоцелью. Как это отражается на работе – очевидно: разработчик пытается обмануть систему. Он не переводит задачу на тестировщика, а приходит к нему с просьбой а-ля «Потыкай, а то ты переоткроешь, а меня накажут», и показатель β опять страдает – тестирование не только происходит непрозрачно, так его ещё и контролировать в этом случае становится сложно. Время t становится не определено. В общем, будьте с этим предельно аккуратны.
В другой крупной и известной компании время t вообще хитрым образом свели к минимуму. Там есть бюджет «на ошибки», а вот тестирования нет вообще. Любой разработчик с первого дня работы имеет доступ к выкладке кода в продакшн и, проверив всё сам, перекрестясь и помолясь своим богам, в определённый момент просто отправляет свой продукт сразу пользователям. После этого он, конечно, следит за тем, что происходит, и если что-то сломалось, откатывает свои изменения, разбирается с проблемами и повторяет процесс снова. Я даже слышал, что в случае если бюджет не тратится полностью за какой-то период, руководство напоминает своим сотрудникам о том, что тем надо «больше рисковать».
Не берусь комментировать хорошо это или плохо, поскольку процесс изнутри я не видел. Но я уверен, что для некоторых видов бизнеса при определённой толерантности и толстокожести менеджмента такой подход вполне применим. Более того, то, что эта компания вполне себе здравствует на рынке и вообще является лидером в своей отрасли, наводит на мысли, что их всё вполне устраивает.
В нашей компании мы очень широко используем Exploratory testing (исследовательское тестирование) и Ad hoc testing (интуитивное тестирование). Это когда тестировщик в процессе тестирования изучает продукт или фичу и, используя накопленный ранее опыт и базовые знания, определяет, в какие уголки тестируемого продукта ему следует заглянуть и как на них подействовать. Благодаря этому в нашем коллективе очень хорошо приживаются профессионалы с «чутьем» и талантом тестировщика, но с другой стороны, это исключает возможность найма людей «с улицы». Наши тестировщики – это профессионалы с большой буквы, которые дорого стоят на рынке. Вероятно, это может являться минусом для некоторых компаний, пытающихся сэкономить на качестве.
Предопределённого списка тестовых сценариев у нас нет. Вместо этого мы используем два подхода. Во-первых, автоматизируем всё что можно; и во-вторых, используем чек-листы. Автотесты помогают минимизировать время t, необходимое для проверки функционала, особенно регресии, а чек-листы позволяют не забыть про важные части продукта во время исследовательского тестирования. Важно, чтобы чек-листы не писались в формате «Зайди туда, нажми на такую-то кнопку и проверь, что появилась жёлтая плашка», а были просто напоминанием. «Проверить пользователя из Зимбабве 80 лет при поиске машин красного цвета», «Девочка видит скрытые для мальчиков комментарии» и «Изменилась форма авторизации – проверь её же, почистив куки» – вот хорошие напоминалки, которые недекларативно указывают нам уязвимые части приложения, позволяя в полной мере применить свою фантазию.
Для того чтобы определить правильное время для переоткрытия задачи, я рекомендую использовать следующую пирамиду:

Сначала проверяем все позитивные сценарии. Делает ли приложение то, что заявлено? Делает ли оно это именно так, как заявлено? Ведь если разработчик написал новую корзину на сайте интернет-магазина, а в эту корзину ничего нельзя положить, это означает, что функционал не работает, а цена его труду – 0 рублей 0 копеек, даже если он проработал все выходные до глубокой ночи и сильно устал. Такой «товар» пользователя не интересует, и в нашей высококонкурентной среде он уйдёт и больше не вернётся.
Более того, как вы помните, у нас в компании за качество отвечает разработчик. Плюс мы стремимся к минимальному количеству переоткрытий задач. Поэтому мы требуем от разработчиков самостоятельной проверки позитивных сценариев. И в этом нам снова помогает Visual QA. Прежде чем отдавать задачу следующим участникам процесса (на ревью кода, на тестирование и далее), разработчик должен прийти к продакт-менеджеру и продемонстрировать ему результат своего труда. Очевидно, что он заинтересован в том, чтобы всё работало так, как указал продакт-менеджер в PRD.
Соответственно, если в процессе тестирования мы находим недостатки в позитивных сценариях использования, задача переоткрывается. Это первый повод для переоткрытия задачи.
Автоматизированные тесты – если их нет для задачи, либо они не проходят – это тоже тот этап проверки, который может привести к переоткрытию задачи. Понятно, что в общем списке тестов сценарии разные, и негативные среди них тоже имеются. Но автоматизированные тесты проходят быстро (и мы постоянно работаем над их оптимизацией) и могут выполняться параллельно с ручными проверками, а значит, на общую цель – оптимизировать β – они работают очень хорошо уже на этом этапе. Следовательно, следить за тем, что тесты проходят в ветке его задачи, должен тоже разработчик.
После проверки позитивных сценариев мы приступаем к негативным. Площадь этого участка в пирамиде больше – соответственно, времени на тестирование этих сценариев может потребоваться тоже больше. На данном этапе мы проверяем нестандартное поведение пользователя. Где-то он мог ошибиться в запланированном сценарии покупки, а система дала ему это сделать. Где-то просто случайно ткнул не туда, и его разлогинило. Ввёл в поле для номера телефона фамилию – и приложение упало. В общем, мы всячески пытаемся «сломать систему» и прощупать «защиту от дурака». Проверки информационной безопасности, кстати, тоже относятся к этой категории.
Подход к переоткрытию задачи, соответственно, следующий: проверили негативные сценарии, собрали всё, что нашли, в тикет, переоткрыли задачу.
При проверке негативных сценариев мы стараемся руководствоваться здравым смыслом и проверять большинство вероятных сценариев. В случае со следующей частью пирамиды – Corner cases, как мы их называем – грань между ними и негативными сценариями не такая очевидная. Сюда следует отнести совсем уж специфические с точки зрения пользователя моменты, иногда даже спорные. Например, проверить, выставлена ли опция Exclusive touch для iOS. Или покрутить экран несколько раз и вернуть назад из ориентации экрана, отличной от той, в которой экран изначально открывался, для Android. Такой тип тестирования очень затратен по времени и для некоторых компаний является непомерно дорогим.
Тем не менее в ряде команд мы регулярно делаем проверку Corner cases. Более того, в некоторых случаях те ошибки, которые повторяются от задачи к задаче, каждый раз вынуждая нас (разработчиков, тестировщиков, наших пользователей) страдать и откладывать релиз, мы вынесли на более ранние этапы проверок. Например, проверить, что мобильное приложение нормально возвращается из фонового режима или после блокировки экрана, должен разработчик перед тем, как отдать задачу на Code Review. У нас для этого имеется специальный чек-лист разработчика, не пройдя по которому, задачу просто нельзя перевести в следующий статус в багтрекере. Поворот мобильного устройства в ландшафтный/ портретный режим, кстати, в этом чек-листе тоже есть. Таким образом, мы, потратив пять–десять минут времени разработчика на проверки собственного творения, экономим часы и сутки, которые могли бы быть затрачены на дальнейших этапах процесса.
Автоматизация
В большинстве наших продуктовых команд мы проверяем качество в несколько этапов. В отдельных случаях этапов может быть пять.
Если бы мы не стремились постоянно оптимизировать процессы так, чтобы β было удовлетворительным, чтобы постоянно увеличивалась скорость нахождения багов S, мы бы проводили за проверками наших приложений очень много времени. Однако команда Mobile Web, к примеру, релизится ежедневно (а иногда и чаще, если того требует бизнес).
Достигаем мы такой скорости за счёт распараллеливания многих этапов проверки и за счёт выноса момента нахождения проблем на как можно более ранние стадии.
Например, если какие-то вещи можно проверить автоматически, и это занимает не много времени, то почему бы такие проверки не вынести в хуки системы контроля версий кода и не блокировать попадание «плохого» кода в общее хранилище на самом раннем этапе? В таких хуках мы проверяем код линтером, общие соглашения по форматированию, хранению кода, организации своих тикетов в багтрекере и так далее.
К слову, во многих случаях автоматизация процесса – ключ к распараллеливанию и ускорению. Мы запускаем автотесты по ветке задачи, как только разработчик передаёт её на следующий этап. AIDA прогоняет тесты и пишет отчёт о прохождении тестов в задачу. Таким образом, тестировщик, приступающий к проверке задачи, получает первое впечатление о проделанной работе прямо в тикете багтрекера. Некоторые команды пошли дальше и попросили сделать так, чтобы AIDA переоткрывала задачу, если в ней не проходят тесты либо упал процент покрытия кода тестами.
Но нельзя воспринимать автоматизацию как единственно возможное развитие в эволюции процессов компании. Автоматизация – это крайне важная штука, ошеломительно влияющая на скорость S, однако исключать ручное тестирование из процесса – плохая идея. Помните, мы разбирали ситуацию тестирования по предопределённым сценариям? Автоматизация позволяет исключить человеческий фактор при проверках, не пропустит ничего, однако фактор «суженности взгляда» никуда не денется.
Но этот же плюс легко превращается в минус, если не отдавать наивысший приоритет багам, найденным автотестами. Причём баги могут быть вполне легальными – например, мы можем с ними жить некоторое время и решить пофиксить их в одном из следующих релизов. Но тесты бескомпромиссны – они будут валиться при каждом прогоне. Таким образом, нужно либо исправлять баги, либо заглушать проверки, тем самым повышая вероятность забыть про баги в дальнейшем. Ещё один вариант – смириться с непроходящими тестами, количество которых с течением времени будет только расти, пока не возникнет ситуация, когда тестам уже никто не доверяет – они всё равно падают.
Кроме того, интеграционные и системные автоматизированные тесты очень дороги в написании и поддержке. Это тесты высокого уровня, «под капотом» проверяющие всю цепочку взаимодействия приложения, бекенда для него, сервисов, обслуживающих быструю обработку и хранение данных для бекенда, и т. д. В такой системе взаимодействия очень вероятны нестабильные падения тестов по разным причинам, а главное – в ней очень трудно найти источник проблем. Чтобы разобраться, что именно не работает, нужно потратить немало времени на изучение всей цепочки взаимодействий.
Ситуацию также усугубляет то, что сама природа тестов высокого уровня делает их медленными и ресурсоёмкими. Это приводит к тому, что рано или поздно архитектура таких тестов приходит к ситуации «за один сеанс проверяем как можно больше». Например, чтобы проверить что-то от лица пользователя системы, нужно каждый раз логиниться под аккаунтом с соответствующими правами. В результате многие делают так: логинятся один раз (проверили механизм авторизации), а затем сразу переходят к проверкам, будучи авторизованным пользователем. Стоит ли уточнять что в случае, когда со страницей авторизации что-то не так, все дальнейшие проверки идут насмарку? Если ручному тестировщику Васе достаточно сказать: «Пока не обращай внимания, что на кнопке «Вход» написано «Выход», – то автотест надо править. Либо максимально быстро исправлять код продукта. Пример, конечно, «притянут за уши» — многие делают именно для авторизации механизмы с быстрым логином, но я его привёл, потому что он максимально понятен.
Существует масса приёмов и подходов для правильного написания и организации автоматизированного (и не только) тестирования (Automation Pyramid, Page Object, Data-driven-testing, Model-based-testing и т. д.). Перечисляя проблемы, я лишь хочу обратить ваше внимание на то, что автоматизированное тестирование – это не такой уж очевидный и простой процесс, который часто ошибочно воспринимается как альтернатива ручному тестированию. Более быстрая, удобная, дешёвая альтернатива, что в действительности не совсем так. Ручное и автоматизированное тестирование должны всегда проходить вместе – только тогда мы можем говорить о правильном и вдумчивом изучении качества продукта.
Заключение
Надеюсь, что после прочтения поста у вас сформировалось более чёткое понимание о том, что же такое тестирование ПО и как именно тестировщики тестируют задачи. В сети информации о тестировании немало, но зачастую она представлена разрозненно, без стратегического взгляда на то, зачем это вообще нужно и почему от разработчика требуют соблюдения тех или иных правил. Было бы хорошо, если бы мой взгляд помог вам оценить процесс тестирования «с высоты птичьего полёта» и позволил воспринимать советы и рекомендации из сети более осознанно.
Помните о том, что любые изменения, нововведения, улучшения должны прежде всего вести к уточнению параметра β – минимального промежутка времени, за который вы можете найти максимальное количество багов, чтобы дать результирующую оценку качества. И хорошо, когда скорость тестирования S работает на эту же цель. Однако тут тоже можно наломать дров. Очевидный пример – неправильное использование автоматизации.
Более того, если продолжить мысль и выйти за пределы процесса тестирования, то становится понятно, что такой же универсальный параметр, как для оценки качества β, существует и для других этапов разработки, равно как и для всего проекта в целом. Он определяет готовность проекта и должен отвечать на вопрос «Как за минимальное время сделать максимальное количество фич?». Не важно, как его называть, но совершенно очевидно, что для любого бизнеса такой параметр есть (если только вы не преследуете какие-то странные цели, помимо зарабатывания денег, конечно).
И именно для этого роль микропроджектменеджера возложена на разработчика как на основного участника всего процесса. Он лучше других знает, что именно, на каком этапе и как именно влияет на скорость доставки его фичи пользователю. И только он может определить, как и почему использовать те или иные механизмы, чтобы улучшить основной показатель скорости доставки. Он должен выдержать обещанный срок и постоянно стремиться к его уменьшению, пусть даже делая ошибки. Это долгий, но необходимый процесс.
Спасибо за внимание!
