Привет, Хабр!
Меня зовут Виталий Котов, я работаю в отделе тестирования Badoo. Большую часть времени я работаю с Selenium. Этот замечательный инструмент мы используем для решения разнообразных задач: от тестирования функционала до упрощения работы с логами ошибок и проверки взаимодействия с API.
О том, какие задачи нам помогает решать Selenium, и пойдёт речь в этой статье. Поехали! :)

Первое, что расскажет нам Google по запросу “Selenium”:
Selenium позволяет делать почти то же самое, что мы могли бы делать руками: открывать страницы и взаимодействовать с ними. Однако он делает это быстрее и надёжнее, так как у него не может “замылиться” глаз и он не может по ошибке кликнуть не туда.
В автоматизации тестирования первое, для чего используется Selenium, — проверка функционала сайта.
Что обычно пользователи делают на сайте? Они его открывают, кликают туда-сюда, видят какие-то результаты своих кликов: редиректы, попапы, подсветку элементов и так далее. Этот процесс хочется (и нужно) тестировать. Необходимо удостовериться, что пользователь увидит именно тот отклик на своё действие, который заложен в нашей бизнес-логике.
Для этого создаются сценарии, которые описывают действия пользователей. Например:
Если на сайте сломана авторизация (например, программист что-то напутал — и метод getUser теперь всегда возвращает false), у Selenium не получится пройти шаг 6. Тест упадёт и сообщит нам об этом. На деле же где-то в коде будет брошен Exception, и процесс завершится соответствующим кодом ошибки.
Такая последовательность действий называется функциональным тестированием. Это, пожалуй, самый распространённый способ использования Selenium. Но бывают и более интересные.
Обычный пользователь JS-ошибки не видит. Это и правильно — ему незачем. А вот разработчикам важно понимать, не “стреляет” ли их код в каких-то случаях. JS-ошибки я бы разделил в данном контексте на два вида: заметные пользователю и те, которые пользователю не мешают.
С первым видом ошибок всё понятно. Если на сайте из-за JS-ошибки не произойдёт отклика на действие пользователя, Selenium-тест это заметит.
Со вторым видом ошибок всё сложнее. Если они не мешают пользоваться приложением, стоит ли их фиксить? В Badoo мы стараемся такие ошибки исправлять наравне с ошибками первого вида. Во-первых, любая ошибка так или иначе сигнализирует о какой-то проблеме. Во-вторых, если она не мешает пользователю в одном случае, это не значит, что она не помешает ему в другом.
Для сбора JS-ошибок разработчики Badoo используют самописное решение. Когда на клиенте возникает ошибка, код собирает все возможные данные и отправляет их в специальное хранилище. В нём хранятся информация о времени возникновения ошибки, данные о пользователе и трейс. Но даже этой информации иногда недостаточно для воспроизведения ошибки. Здесь нам и помогает Selenium.
Наши Selenium-тесты проверяют все самые популярные действия, которые совершают пользователи на сайте. Если ошибка есть, она наверняка произойдёт во время прохождения этих тестов. Достаточно просто научить Selenium обращать на такие ошибки внимание.
Решал я эту задачу следующим образом: добавил темплейт, который подключался только для тестовых серверов. В этом темплейте был кусочек JS-кода, который собирал JS-ошибки в определённый объект. Как-то так:
То же самое можно было бы делать в самом Selenium-тесте при помощи команды execute. Она позволяет исполнять JS-код на странице так, будто пользователь открыл консоль браузера и исполнил код в ней. Но тогда мы могли бы упустить часть ошибок.
Дело в том, что исполнить этот код в Selenium-тесте можно только после полной загрузки страницы. Следовательно, все ошибки, которые появятся в ходе самой загрузки, останутся незамеченными. С темплейтом такой проблемы нет, поскольку код в нём исполняется до основного JS-кода.
После добавления темплейта все ошибки начали собираться в объект errorObj, доступный глобально. И вот теперь можно было использовать команду execute. Я добавил в наш Selenium-фреймворк метод, который исполнял errorObj.getErrors(), то есть получал все ошибки, которые попали в errorObj, и сохранял их на стороне самого Selenium-теста.
Напомню, что Selenium-тесты мы пишем на PHP. Код сбора ошибок получился примерно такой:
Мы получаем ошибки из JS-объекта errorObj и каждую обрабатываем.
Некоторые ошибки нам уже известны. Мы знаем, что они есть на проекте и либо уже находятся в процессе исправления, либо воспроизводятся только в “лабораторных” условиях. Например, ошибки, которые появляются только для тестовых пользователей и которые связаны с тем способом, которым мы их подготовили к тесту. Такие ошибки в тесте мы игнорируем.
Если одна и та же ошибка за время прохождения теста происходит второй раз, мы её тоже игнорируем — нас интересуют только уникальные.
Для каждой новой ошибки мы добавляем URL и сохраняем всю информацию в массив.
Метод collectJsErrors() мы вызываем после каждого действия на сайте: открытие страницы, ожидание и клик по элементу, ввод каких-то данных и так далее. Как бы мы ни взаимодействовали с интерфейсом, мы обязательно убеждаемся, что это действие не стало причиной возникновения ошибки.
Массив с собранными ошибками мы проверяем только в конце теста в tearDown(). Ведь если ошибка как-то затронет пользователя, тест и так упадёт. А если не затронет, то ронять тест сразу плохо, сначала нужно проверить сценарий до конца. Вдруг за этой ошибкой есть более серьёзные проблемы.
Таким образом нам удалось научить Selenium-тесты отлавливать клиентские ошибки. А сами ошибки стало проще воспроизводить, зная, какой тест их ловит.
Сами по себе Selenium-тесты не предназначены для проверки вёрстки. Конечно, если элемент, с которым придётся взаимодействовать, невидим или скрыт другим элементом, тест нам об этом “скажет”. Такое Selenium умеет делать “из коробки”. А вот если кнопка уехала куда-то вниз и выглядит плохо, тут уже Selenium-тесту в целом всё равно — его задача по ней кликнуть…
Тем не менее проверять вёрстку вручную перед каждым релизом (а для Desktop Web, например, у нас их два в день) на каждой странице, на каждом браузере — это долго. Да и снова может вмешаться человеческий фактор: глаз “замыливается”, о чём-то можно забыть… Нужно этот процесс как-то автоматизировать.
Сначала мы создали простенькое хранилище для картинок. По POST-запросу в него можно было отправить скриншот, указав дополнительно версию релиза, а по GET-запросу с указанием версии релиза — получить все скриншоты, имеющие отношение к этому релизу.
Далее мы написали Selenium-тесты, которые поднимали все интересующие нас браузеры, на которых открывали все интересующие нас страницы, попапы, оверлеи и так далее. В каждом месте они делали скриншот страницы и отправляли его в это хранилище.
Интерфейс хранилища позволял быстро пролистать все скриншоты вручную и убедиться, что на всех браузерах все страницы выглядит прилично. Мелкий баг таким образом, разумеется, поймать сложно. Но если вёрстка ломалась существенно, это сразу бросалось в глаза. И в любом случаем листать скриншоты быстрее и проще, чем прокликивать сайт во всех браузерах руками.
Первое время скриншотов у нас было не так много и с этим можно было жить. Однако через какое-то время мы захотели тестировать письма, вариантов которых у нас значительно больше, чем страниц на сайте.
Для получения скриншотов писем пришлось прибегнуть к некоторой хитрости. Дело в том, что получить HTML сгенеренного письма в тесте значительно проще, чем зайти на реальный почтовый сервис (а мы говорим всё ещё про Selenium-тесты), найти там нужное письмо, открыть его и сделать скриншот. Просто потому, что получить HTML письма можно на нашей стороне, используя “бекдор” (у нас есть инструмент QaAPI, который позволяет в тестовом окружении для тестовых пользователей с помощью простого cURL-запроса получать данные о конкретном пользователе и манипулировать ими). А вот для стороннего сервиса пришлось бы писать, стабилизировать и поддерживать Page Object’ы: локаторы, методы и так далее.
Понятно, что почти все почтовые клиенты отображают письмо несколько иначе, чем мы это увидим на “голом” HTML. Но какие-то серьёзные ошибки в вёрстке, ломающие внешний вид письма даже вне контекста, таким образом успешно ловятся.
Но что делать с полученным HTML? Как убедиться, что он отображается корректно во всех браузерах? Оказалось, довольно просто. На нашем коллекторе есть пустая страничка, куда может зайти Selenium-тест и выполнить простой execute:
Если выполнить это на нужном браузере, можно увидеть, как HTML будет в нём выглядеть. Осталось только сделать скриншот и отправить его в тот же коллектор.
После того как это было сделано, скриншотов оказалось много. И проверять их вручную дважды в день стало по-настоящему непросто.
Для решения этой задачи можно прибегнуть к простому сравнению картинок по пикселям. В этом случае придётся учесть все переменные, которые есть на вашем проекте. В примере с письмом, например, это могут быть имя пользователя и его фотография. В таком случае прежде чем делать скриншот, придётся чуток подправить HTML, заменив картинки и имена на дефолтные. Или же генерить письма для пользователей с одинаковыми именем и фото. :)
Для менее постоянного контента таких манипуляций может быть гораздо больше.
Далее можно получать количество несовпадающих пикселей и делать вывод о том, насколько критичны изменения. Можно строить дифф, помечая на проверяемой картинке те зоны, которые не совпадают с эталонными.
В PHP для этих целей отлично подходит библиотека ImageMagick. Также подобные тесты у нас пишут JavaScript-разработчики, они используют Resemble.js.
В качестве примера можно рассмотреть страницу авторизации Badoo:
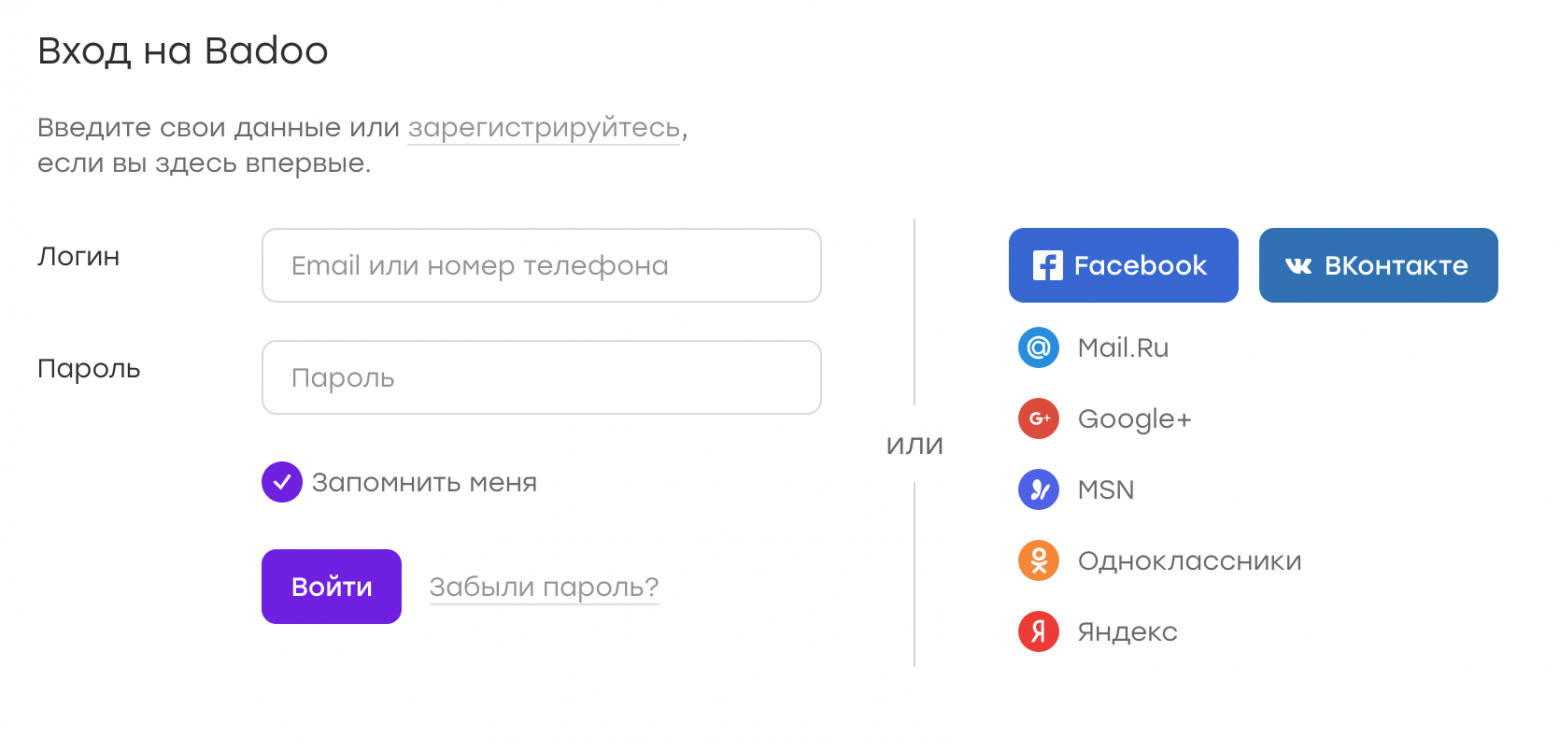
Допустим, по какой-то причине потерялся чекбокс «запомнить меня». Из-за этого кнопка сабмита оказалась чуть выше. Тогда дифф будет выглядеть следующим образом:
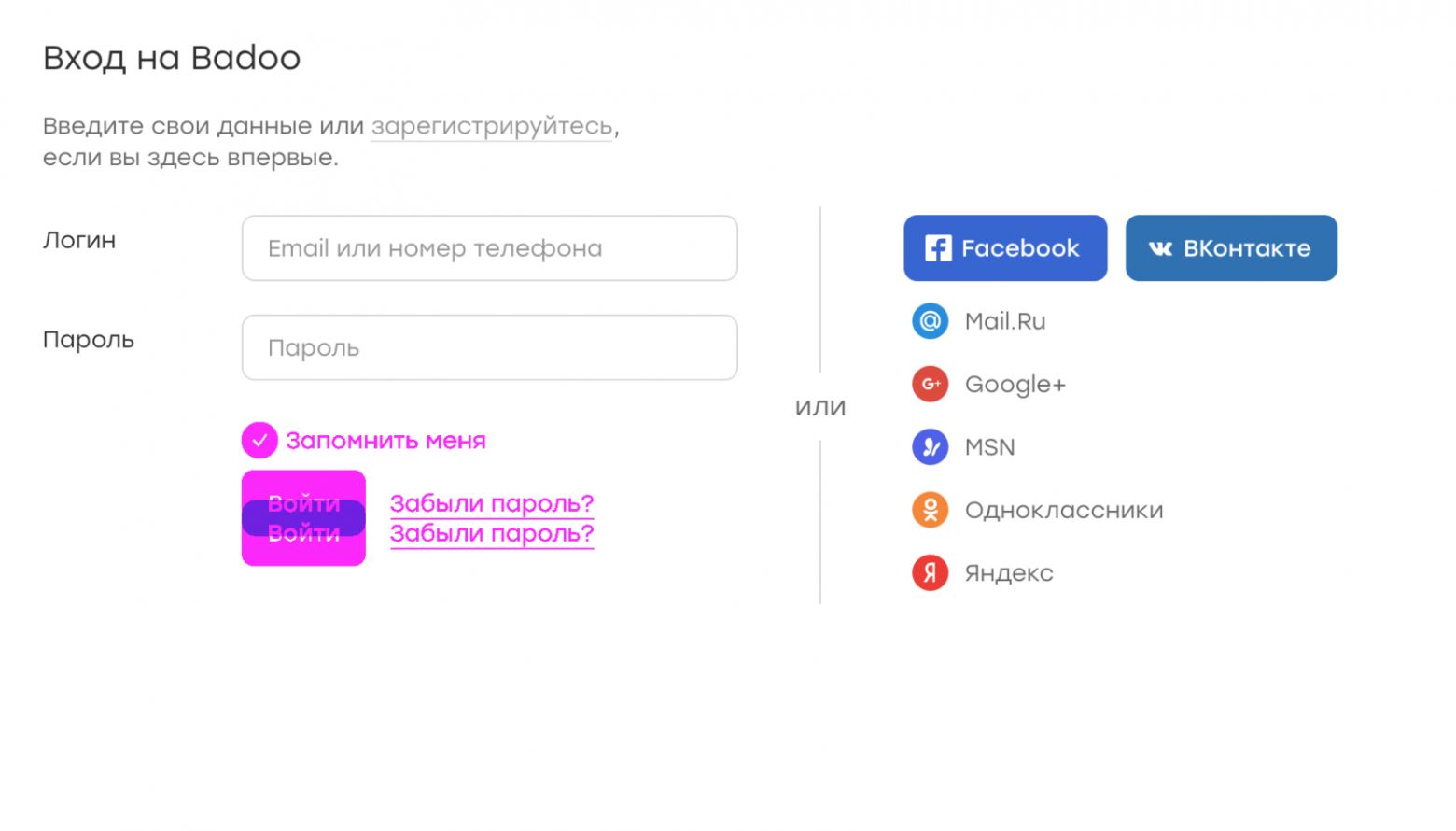
На картинке фиолетовым отмечены расхождения между эталонным скриншотом и тем, на котором не хватает элемента. Сразу видно, что именно не так.
Системе сравнения можно задать критическое количество пискелей, и если ни один скриншот не превышает это количество, можно слать уведомление, что все хорошо. Если же какие-то скриншоты стали отличаться существенно — бить в набат…
Таким образом можно навсегда забыть о проверке скриншотов в ручную, просматривая только то, что действительно заслуживает внимание.
В Badoo все клиенты (Desktop Web, Mobile Web, Android- и iOS-приложения) общаются с сервером по определённому API, основанному на HTTP. У такого подхода есть ряд преимуществ. Например, намного проще разрабатывать клиенты и сервер параллельно.
Однако и здесь есть место ошибкам. Может получиться так, что клиент обращается к серверу чаще, чем должен, из-за бага или из-за в целом неправильно продуманной архитектуры. В таком случае будет создаваться лишняя нагрузка, не говоря уже о том, что, возможно, что-то будет работать некорректно.
Чтобы мониторить такие вещи ещё на этапе разработки и тестирования, мы тоже используем Selenium-тесты. В начале этих тестов мы генерим cookie, которую называем “device id”. Её значение мы передаём на сервер, который для данного “device id” начинает записывать все API-запросы, которые к нему приходят.
После этого запускаются сами тесты, которые выполняют определённые сценарии: открывают страницы, пишут друг другу, лайкают и так далее. Всё это время сервер считает запросы.
По окончании тестов мы отправляем серверу сигнал о прекращении записи. Сервер генерит специальный лог, по которому можно понять, сколько запросов каких типов было сделано. Если это количество отклоняется от эталонного более чем на N процентов, автотестировщикам приходит специальное уведомление, и мы начинаем разбираться в ситуации. Иногда это поведение ожидаемое (например, при появлении нового запроса, связанного с новым функционалом на сайте) — тогда мы корректируем эталонные значения. А иногда оказывается, что клиент по ошибке создаёт лишние запросы, и это нужно исправить.
Такие тесты мы запускаем на стейджинге до того, как новая версия клиента окажется у пользователя. Визуально сравнение количества запросов от релиза к релизу выглядит примерно так:
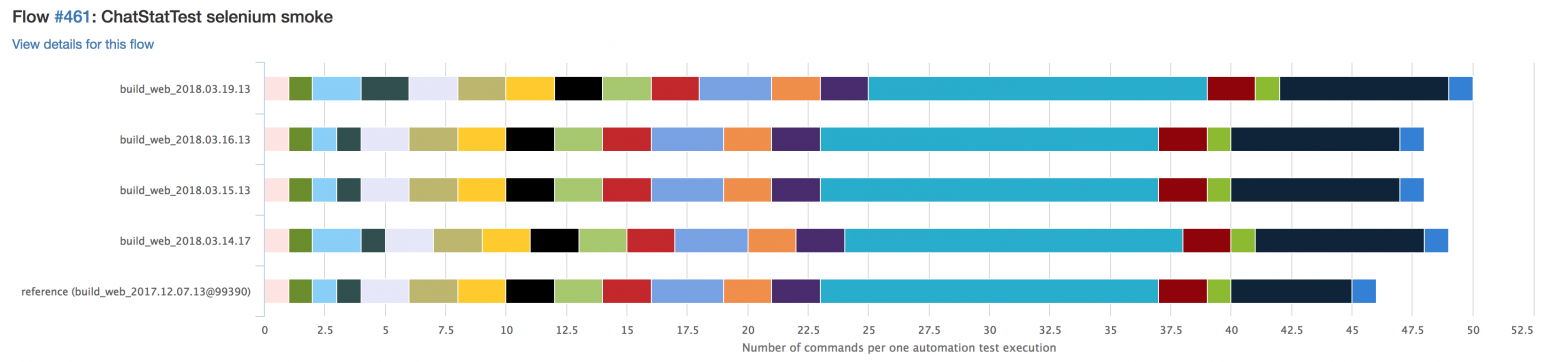
Каждый цвет обозначает определённый тип запроса. Если какой-то запрос станет повторяться чаще, визуально это будет заметно. На этот случай у нас тоже есть специальное уведомление, так что не нужно заходить и смотреть статистику перед каждым релизом.
К похожей хитрости мы прибегаем для того, чтобы быстрее разбираться с ошибками в серверных логах. Когда на стейджинге появляется новая ошибка, не всегда понятно, как её воспроизвести и из-за какого тикета она появилась.
В самом начале любого Selenium-теста создаётся специальная cookie “testname”, в которую мы передаём название текущего теста. Соответственно, если ошибка на сервере сгенерилась во время прохождения автотеста, воспроизвести её в большинстве случаев проще, так как мы знаем сценарий воспроизведения. Чтобы найти задачу, из которой ошибка пришла в релиз, можно запустить Selenium-тест на всех релизящихся задачах и посмотреть их логи.
У нас этот процесс автоматизирован, об этом я писал в предыдущей статье.
В целом такой подход позволяет намного быстрее разбираться с серверными ошибками в релизе и локализовывать их.
А почему, собственно, нет? :)

Selenium — это инструмент, позволяющий манипулировать браузером. А как именно и зачем, это уже решать тем, кто этот инструмент использует. Проявив смекалку, можно существенно облегчить себе жизнь.
Само собой, для некоторых видов проверок существуют свои, более подходящие, инструменты. Например, Selenium не сможет полноценно заменить сканеры уязвимостей или быстрые парсеры, написанные, скажем, на cURL-библиотеках. Также его довольно странно использовать для нагрузочного тестирования — в этом случае скорее удастся проверить отказоустойчивость Selenium-фермы, нежели боевого приложения. :)
Однако есть некий набор задач, для которых Selenium отлично подходит. Я рассказал о том, как он помогает нам. Буду рад услышать об интересных способах использования Selenium в ваших компаниях.
Спасибо за внимание.
Меня зовут Виталий Котов, я работаю в отделе тестирования Badoo. Большую часть времени я работаю с Selenium. Этот замечательный инструмент мы используем для решения разнообразных задач: от тестирования функционала до упрощения работы с логами ошибок и проверки взаимодействия с API.
О том, какие задачи нам помогает решать Selenium, и пойдёт речь в этой статье. Поехали! :)

Немного о Selenium
Первое, что расскажет нам Google по запросу “Selenium”:
Selenium — это инструмент для автоматизации действий веб-браузера. В большинстве случаев используется для тестирования Web-приложений, но этим не ограничивается.
Selenium позволяет делать почти то же самое, что мы могли бы делать руками: открывать страницы и взаимодействовать с ними. Однако он делает это быстрее и надёжнее, так как у него не может “замылиться” глаз и он не может по ошибке кликнуть не туда.
В автоматизации тестирования первое, для чего используется Selenium, — проверка функционала сайта.
Проверка функционала
Что обычно пользователи делают на сайте? Они его открывают, кликают туда-сюда, видят какие-то результаты своих кликов: редиректы, попапы, подсветку элементов и так далее. Этот процесс хочется (и нужно) тестировать. Необходимо удостовериться, что пользователь увидит именно тот отклик на своё действие, который заложен в нашей бизнес-логике.
Для этого создаются сценарии, которые описывают действия пользователей. Например:
- Открыть сайт.
- Кликнуть на кнопку авторизации.
- Дождаться загрузки формы авторизации.
- Ввести логин и пароль.
- Кликнуть на кнопку сабмита.
- Дождаться редиректа на авторизованную страницу.
Если на сайте сломана авторизация (например, программист что-то напутал — и метод getUser теперь всегда возвращает false), у Selenium не получится пройти шаг 6. Тест упадёт и сообщит нам об этом. На деле же где-то в коде будет брошен Exception, и процесс завершится соответствующим кодом ошибки.
Такая последовательность действий называется функциональным тестированием. Это, пожалуй, самый распространённый способ использования Selenium. Но бывают и более интересные.
Сбор JS-ошибок
Обычный пользователь JS-ошибки не видит. Это и правильно — ему незачем. А вот разработчикам важно понимать, не “стреляет” ли их код в каких-то случаях. JS-ошибки я бы разделил в данном контексте на два вида: заметные пользователю и те, которые пользователю не мешают.
С первым видом ошибок всё понятно. Если на сайте из-за JS-ошибки не произойдёт отклика на действие пользователя, Selenium-тест это заметит.
Со вторым видом ошибок всё сложнее. Если они не мешают пользоваться приложением, стоит ли их фиксить? В Badoo мы стараемся такие ошибки исправлять наравне с ошибками первого вида. Во-первых, любая ошибка так или иначе сигнализирует о какой-то проблеме. Во-вторых, если она не мешает пользователю в одном случае, это не значит, что она не помешает ему в другом.
Для сбора JS-ошибок разработчики Badoo используют самописное решение. Когда на клиенте возникает ошибка, код собирает все возможные данные и отправляет их в специальное хранилище. В нём хранятся информация о времени возникновения ошибки, данные о пользователе и трейс. Но даже этой информации иногда недостаточно для воспроизведения ошибки. Здесь нам и помогает Selenium.
Наши Selenium-тесты проверяют все самые популярные действия, которые совершают пользователи на сайте. Если ошибка есть, она наверняка произойдёт во время прохождения этих тестов. Достаточно просто научить Selenium обращать на такие ошибки внимание.
Решал я эту задачу следующим образом: добавил темплейт, который подключался только для тестовых серверов. В этом темплейте был кусочек JS-кода, который собирал JS-ошибки в определённый объект. Как-то так:
var errorObj = {
_errors : [],
addError : function(message, source, lineno) {
this._errors.push(
"Message: " + message + "\n" +
"Source: " + source + "\n" +
"Line: " + lineno
);
},
getErrors : function() {
return this._errors;
}
}
window.onerror = function(message, source, line_no) {
errorObj.addError(message, source, line_no);
}
То же самое можно было бы делать в самом Selenium-тесте при помощи команды execute. Она позволяет исполнять JS-код на странице так, будто пользователь открыл консоль браузера и исполнил код в ней. Но тогда мы могли бы упустить часть ошибок.
Дело в том, что исполнить этот код в Selenium-тесте можно только после полной загрузки страницы. Следовательно, все ошибки, которые появятся в ходе самой загрузки, останутся незамеченными. С темплейтом такой проблемы нет, поскольку код в нём исполняется до основного JS-кода.
После добавления темплейта все ошибки начали собираться в объект errorObj, доступный глобально. И вот теперь можно было использовать команду execute. Я добавил в наш Selenium-фреймворк метод, который исполнял errorObj.getErrors(), то есть получал все ошибки, которые попали в errorObj, и сохранял их на стороне самого Selenium-теста.
Напомню, что Selenium-тесты мы пишем на PHP. Код сбора ошибок получился примерно такой:
public function collectJsErrors()
{
$return_errorObj = /** @lang JavaScript */
'if (typeof errorObj !== "undefined") {return errorObj.getErrors();} else {return null;}';
$js_result = $this->execute($return_errorObj)->sync();
foreach ($js_result as $result) {
$current_stacktrace = $result;
//check if an error is known
foreach (self::$known_js_errors as $known_error) {
if (strpos($current_stacktrace, $known_error) !== false) {
continue 2;
}
}
//check if the error already caught
foreach ($this->getJsErrors() as $error) {
$existed_stacktrace = $error['error'];
if ($current_stacktrace == $existed_stacktrace) {
continue 2;
}
}
//collect an error
$this->addJsError([
'error' => $result,
'location' => $this->getLocation(),
]);
}
}
Мы получаем ошибки из JS-объекта errorObj и каждую обрабатываем.
Некоторые ошибки нам уже известны. Мы знаем, что они есть на проекте и либо уже находятся в процессе исправления, либо воспроизводятся только в “лабораторных” условиях. Например, ошибки, которые появляются только для тестовых пользователей и которые связаны с тем способом, которым мы их подготовили к тесту. Такие ошибки в тесте мы игнорируем.
Если одна и та же ошибка за время прохождения теста происходит второй раз, мы её тоже игнорируем — нас интересуют только уникальные.
Для каждой новой ошибки мы добавляем URL и сохраняем всю информацию в массив.
Метод collectJsErrors() мы вызываем после каждого действия на сайте: открытие страницы, ожидание и клик по элементу, ввод каких-то данных и так далее. Как бы мы ни взаимодействовали с интерфейсом, мы обязательно убеждаемся, что это действие не стало причиной возникновения ошибки.
Массив с собранными ошибками мы проверяем только в конце теста в tearDown(). Ведь если ошибка как-то затронет пользователя, тест и так упадёт. А если не затронет, то ронять тест сразу плохо, сначала нужно проверить сценарий до конца. Вдруг за этой ошибкой есть более серьёзные проблемы.
Таким образом нам удалось научить Selenium-тесты отлавливать клиентские ошибки. А сами ошибки стало проще воспроизводить, зная, какой тест их ловит.
Проверка вёрстки
Сами по себе Selenium-тесты не предназначены для проверки вёрстки. Конечно, если элемент, с которым придётся взаимодействовать, невидим или скрыт другим элементом, тест нам об этом “скажет”. Такое Selenium умеет делать “из коробки”. А вот если кнопка уехала куда-то вниз и выглядит плохо, тут уже Selenium-тесту в целом всё равно — его задача по ней кликнуть…
Тем не менее проверять вёрстку вручную перед каждым релизом (а для Desktop Web, например, у нас их два в день) на каждой странице, на каждом браузере — это долго. Да и снова может вмешаться человеческий фактор: глаз “замыливается”, о чём-то можно забыть… Нужно этот процесс как-то автоматизировать.
Сначала мы создали простенькое хранилище для картинок. По POST-запросу в него можно было отправить скриншот, указав дополнительно версию релиза, а по GET-запросу с указанием версии релиза — получить все скриншоты, имеющие отношение к этому релизу.
Далее мы написали Selenium-тесты, которые поднимали все интересующие нас браузеры, на которых открывали все интересующие нас страницы, попапы, оверлеи и так далее. В каждом месте они делали скриншот страницы и отправляли его в это хранилище.
Интерфейс хранилища позволял быстро пролистать все скриншоты вручную и убедиться, что на всех браузерах все страницы выглядит прилично. Мелкий баг таким образом, разумеется, поймать сложно. Но если вёрстка ломалась существенно, это сразу бросалось в глаза. И в любом случаем листать скриншоты быстрее и проще, чем прокликивать сайт во всех браузерах руками.
Первое время скриншотов у нас было не так много и с этим можно было жить. Однако через какое-то время мы захотели тестировать письма, вариантов которых у нас значительно больше, чем страниц на сайте.
Для получения скриншотов писем пришлось прибегнуть к некоторой хитрости. Дело в том, что получить HTML сгенеренного письма в тесте значительно проще, чем зайти на реальный почтовый сервис (а мы говорим всё ещё про Selenium-тесты), найти там нужное письмо, открыть его и сделать скриншот. Просто потому, что получить HTML письма можно на нашей стороне, используя “бекдор” (у нас есть инструмент QaAPI, который позволяет в тестовом окружении для тестовых пользователей с помощью простого cURL-запроса получать данные о конкретном пользователе и манипулировать ими). А вот для стороннего сервиса пришлось бы писать, стабилизировать и поддерживать Page Object’ы: локаторы, методы и так далее.
Понятно, что почти все почтовые клиенты отображают письмо несколько иначе, чем мы это увидим на “голом” HTML. Но какие-то серьёзные ошибки в вёрстке, ломающие внешний вид письма даже вне контекста, таким образом успешно ловятся.
Но что делать с полученным HTML? Как убедиться, что он отображается корректно во всех браузерах? Оказалось, довольно просто. На нашем коллекторе есть пустая страничка, куда может зайти Selenium-тест и выполнить простой execute:
public function drawMailHTML(string $html)
{
$js = /** @lang JavaScript */
'document.write("{HTML}")';
$js = str_replace('{HTML}', $html, $js);
$this->execute($js)->sync();
}
Если выполнить это на нужном браузере, можно увидеть, как HTML будет в нём выглядеть. Осталось только сделать скриншот и отправить его в тот же коллектор.
После того как это было сделано, скриншотов оказалось много. И проверять их вручную дважды в день стало по-настоящему непросто.
Для решения этой задачи можно прибегнуть к простому сравнению картинок по пикселям. В этом случае придётся учесть все переменные, которые есть на вашем проекте. В примере с письмом, например, это могут быть имя пользователя и его фотография. В таком случае прежде чем делать скриншот, придётся чуток подправить HTML, заменив картинки и имена на дефолтные. Или же генерить письма для пользователей с одинаковыми именем и фото. :)
Для менее постоянного контента таких манипуляций может быть гораздо больше.
Далее можно получать количество несовпадающих пикселей и делать вывод о том, насколько критичны изменения. Можно строить дифф, помечая на проверяемой картинке те зоны, которые не совпадают с эталонными.
В PHP для этих целей отлично подходит библиотека ImageMagick. Также подобные тесты у нас пишут JavaScript-разработчики, они используют Resemble.js.
В качестве примера можно рассмотреть страницу авторизации Badoo:
Допустим, по какой-то причине потерялся чекбокс «запомнить меня». Из-за этого кнопка сабмита оказалась чуть выше. Тогда дифф будет выглядеть следующим образом:
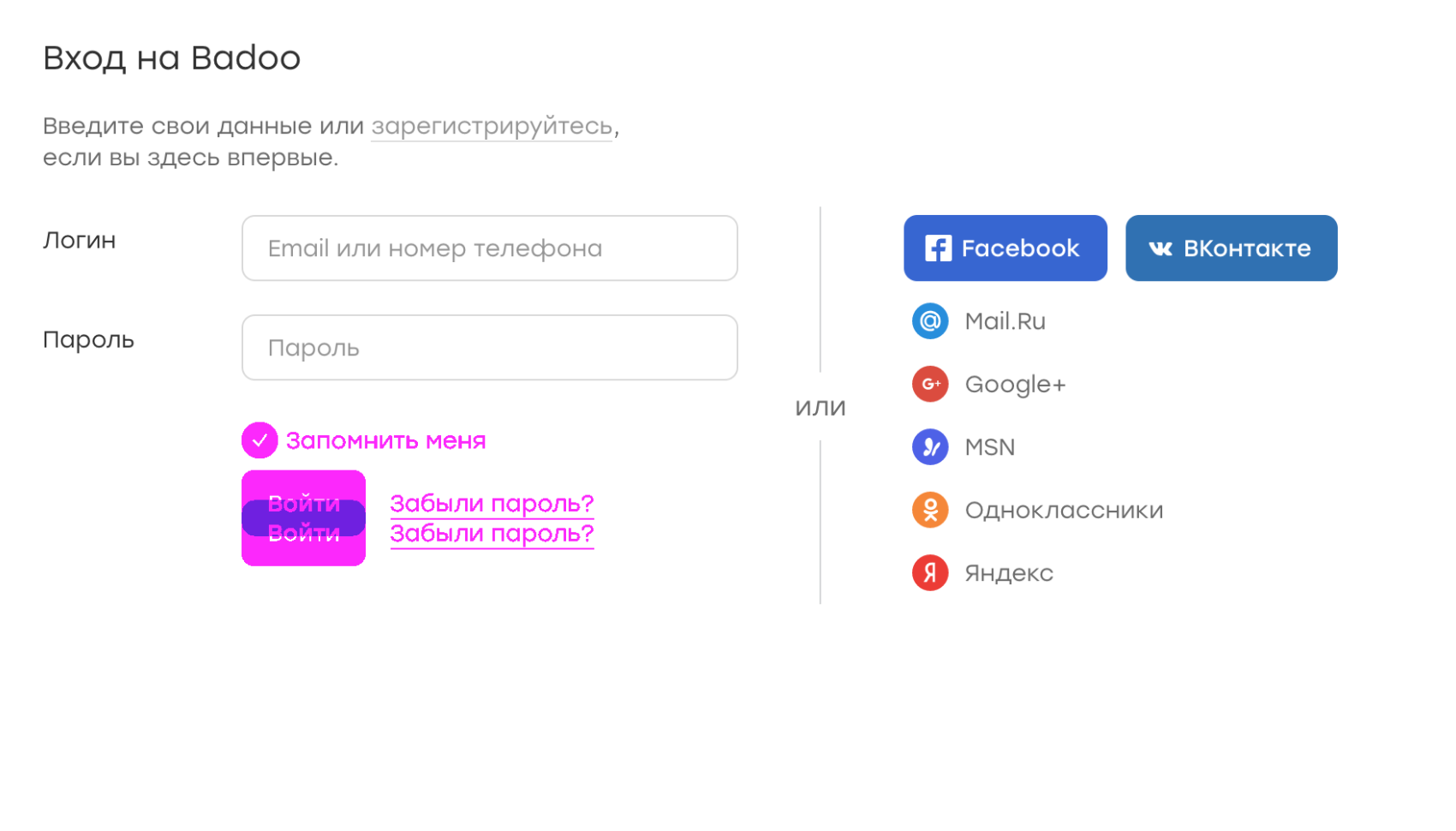
На картинке фиолетовым отмечены расхождения между эталонным скриншотом и тем, на котором не хватает элемента. Сразу видно, что именно не так.
Системе сравнения можно задать критическое количество пискелей, и если ни один скриншот не превышает это количество, можно слать уведомление, что все хорошо. Если же какие-то скриншоты стали отличаться существенно — бить в набат…
Таким образом можно навсегда забыть о проверке скриншотов в ручную, просматривая только то, что действительно заслуживает внимание.
Проверка взаимодействия клиента с API
В Badoo все клиенты (Desktop Web, Mobile Web, Android- и iOS-приложения) общаются с сервером по определённому API, основанному на HTTP. У такого подхода есть ряд преимуществ. Например, намного проще разрабатывать клиенты и сервер параллельно.
Однако и здесь есть место ошибкам. Может получиться так, что клиент обращается к серверу чаще, чем должен, из-за бага или из-за в целом неправильно продуманной архитектуры. В таком случае будет создаваться лишняя нагрузка, не говоря уже о том, что, возможно, что-то будет работать некорректно.
Чтобы мониторить такие вещи ещё на этапе разработки и тестирования, мы тоже используем Selenium-тесты. В начале этих тестов мы генерим cookie, которую называем “device id”. Её значение мы передаём на сервер, который для данного “device id” начинает записывать все API-запросы, которые к нему приходят.
После этого запускаются сами тесты, которые выполняют определённые сценарии: открывают страницы, пишут друг другу, лайкают и так далее. Всё это время сервер считает запросы.
По окончании тестов мы отправляем серверу сигнал о прекращении записи. Сервер генерит специальный лог, по которому можно понять, сколько запросов каких типов было сделано. Если это количество отклоняется от эталонного более чем на N процентов, автотестировщикам приходит специальное уведомление, и мы начинаем разбираться в ситуации. Иногда это поведение ожидаемое (например, при появлении нового запроса, связанного с новым функционалом на сайте) — тогда мы корректируем эталонные значения. А иногда оказывается, что клиент по ошибке создаёт лишние запросы, и это нужно исправить.
Такие тесты мы запускаем на стейджинге до того, как новая версия клиента окажется у пользователя. Визуально сравнение количества запросов от релиза к релизу выглядит примерно так:
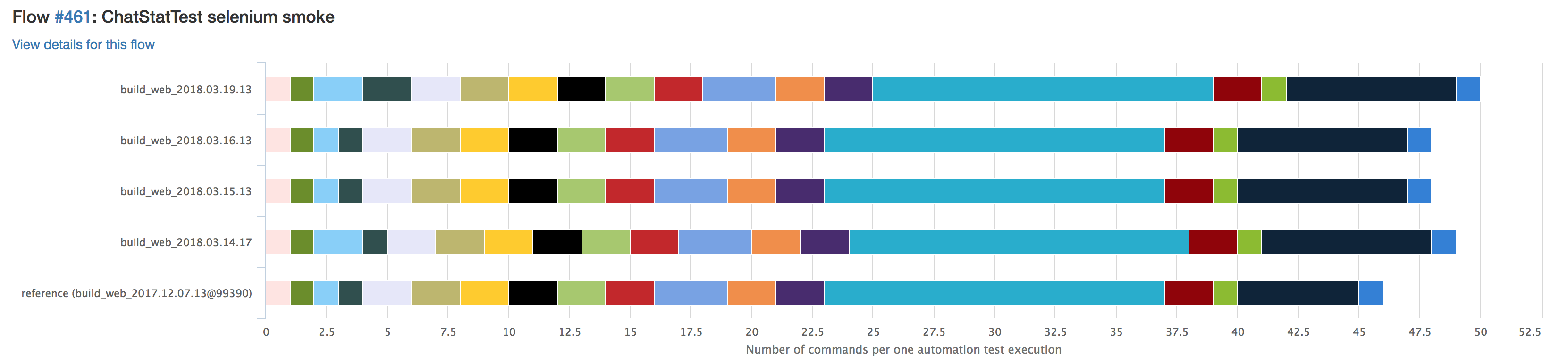
Каждый цвет обозначает определённый тип запроса. Если какой-то запрос станет повторяться чаще, визуально это будет заметно. На этот случай у нас тоже есть специальное уведомление, так что не нужно заходить и смотреть статистику перед каждым релизом.
Серверные логи
К похожей хитрости мы прибегаем для того, чтобы быстрее разбираться с ошибками в серверных логах. Когда на стейджинге появляется новая ошибка, не всегда понятно, как её воспроизвести и из-за какого тикета она появилась.
В самом начале любого Selenium-теста создаётся специальная cookie “testname”, в которую мы передаём название текущего теста. Соответственно, если ошибка на сервере сгенерилась во время прохождения автотеста, воспроизвести её в большинстве случаев проще, так как мы знаем сценарий воспроизведения. Чтобы найти задачу, из которой ошибка пришла в релиз, можно запустить Selenium-тест на всех релизящихся задачах и посмотреть их логи.
У нас этот процесс автоматизирован, об этом я писал в предыдущей статье.
В целом такой подход позволяет намного быстрее разбираться с серверными ошибками в релизе и локализовывать их.
Автоматический заказ пиццы в пятницу вечером
А почему, собственно, нет? :)

Итоги
Selenium — это инструмент, позволяющий манипулировать браузером. А как именно и зачем, это уже решать тем, кто этот инструмент использует. Проявив смекалку, можно существенно облегчить себе жизнь.
Само собой, для некоторых видов проверок существуют свои, более подходящие, инструменты. Например, Selenium не сможет полноценно заменить сканеры уязвимостей или быстрые парсеры, написанные, скажем, на cURL-библиотеках. Также его довольно странно использовать для нагрузочного тестирования — в этом случае скорее удастся проверить отказоустойчивость Selenium-фермы, нежели боевого приложения. :)
Однако есть некий набор задач, для которых Selenium отлично подходит. Я рассказал о том, как он помогает нам. Буду рад услышать об интересных способах использования Selenium в ваших компаниях.
Спасибо за внимание.
