В первой части своей статьи я рассказал о том, как мы в Badoo создали первую версию системы патчей. Если коротко, то нам нужно было найти способ исправления серьёзных ошибок прямо на production, доступный всем разработчикам. Однако первая версия была не без недостатков: мы использовали своеобразный способ раскладки, который не позволял гарантировать атомарность выкладок патчей и консистентность кода.
В этой части статьи я расскажу о новом способе раскладки кода, который мы придумали, пытаясь решить наши проблемы, и о том, как с ним преобразилась наша система патчей.

Изображение: источник
После очередного пересмотра нашей системы Юра youROCK Насретдинов заявил, что у него есть идея, как решить все наши проблемы. Всё, что он просил, — кучу времени, чтобы переделать систему раскладки. Так появилась концепция Multiversional Deployment Kit, или, в простонародье, MDK (Юра сравнивал ее с другими способами раскладки кода в своем докладе на HighLoad++).
Новая система была призвана изменить нашу процедуру раскладки. Тем, кто не читал мою первую часть статьи, вкратце расскажу, как у нас выглядит процесс деплоя: сначала мы собираем все нужные файлы в одной директории, потом сохраняем и доставляем состояние директории до серверов.
До эпохи MDK для сохранения и доставки мы использовали блочные устройства (то есть образы файловой системы), которые называли лупами. Директория копировалась в пустой луп, он архивировался и отправлялся на серверы.
В новой системе мы версионируем не директорию целиком, а каждый файл по отдельности так, чтобы версия файла однозначно коррелировала с его содержимым. Для директорий существуют карты (maps) — специальные файлы, в которых записаны версии всех файлов в директории. Эти карты тоже версионируются, и выглядит всё это приблизительно так:
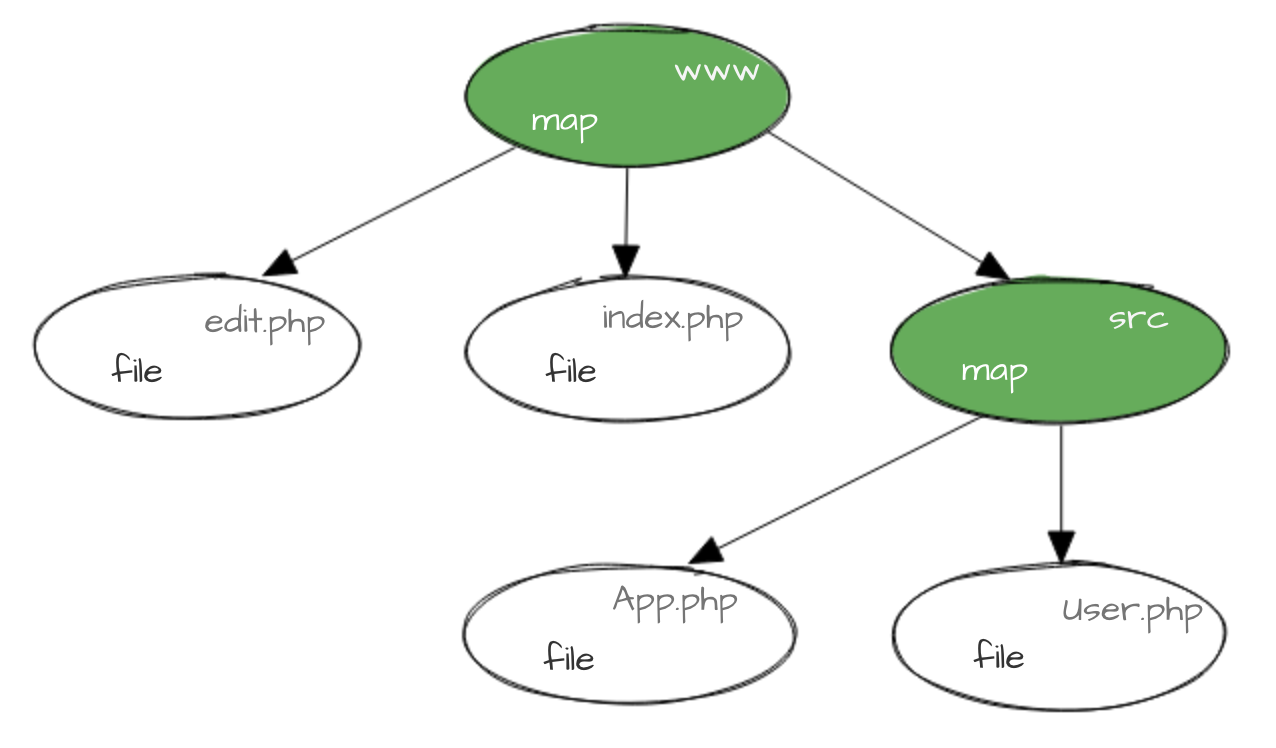
Выглядит знакомо? Именно так устроены объекты в Git (можете почитать об этом здесь, но для понимания статьи это не обязательно).
Для версионирования мы используем первые восемь символов от MD5-хеша (от его шестнадцатиричного представления, если быть точным), взятого от содержимого файла. Эта версия записывается в конец имени файла или в начало имени карты (чтобы можно было отличить файл map от сгенерированной карты версий):
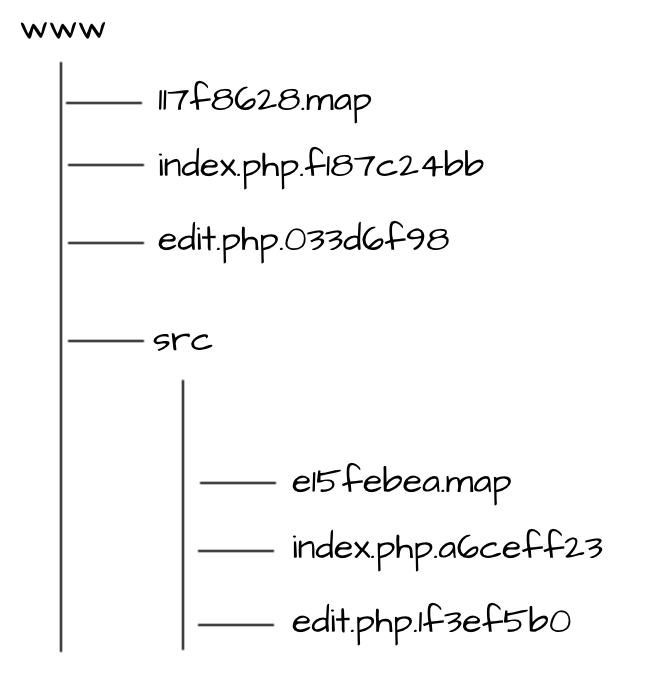
Версия кода — это версия карты корневой директории www. Для того чтобы найти текущую карту, у нас есть символическая ссылка (symlink) current.map.
MDK нужен, чтобы сохранить состояние директории в конце сборки. Для этого у нас есть специальное место, которое мы назвали репозиторием, — хранилище всех версий файлов, которые представляют для нас ценность (то есть которые мы можем захотеть разложить). Когда новое содержимое директории готово, мы вычисляем версии всех файлов в ней и докладываем в репозиторий недостающие.
Во время раскладки на каждом из принимающих серверов мы запускаем скрипт, который проверяет, все ли необходимые файлы есть на сервере, и запрашивает из репозитория те, которых не хватает. Нам остаётся только переключить версию на новую, поменяв симлинк current.map.
Предполагалось, что, если в новой версии изменилось всего несколько файлов, её сборка и раскладка с помощью новой системы должна быть как минимум сравнима по времени с раскладкой патча отдельными файлами. Если это так, то для каждого патча мы просто будем генерировать новую версию.
У MDK был один недостаток: на конечных машинах в названии каждого файла должна быть его версия. Именно это позволяет хранить в директории сразу очень много версий одного файла, но это же не позволяет сделать include user.php из кода — обязательно нужно указать конкретную версию. Добавьте к этому различные баги, которые вполне могли остаться в коде системы раскладки, новый алгоритм раскладки, который был сложнее старого, — и станет ясно, почему мы решили внедрять новую систему небольшими шагами. Мы начали буквально с одного-двух серверов и постепенно расширяли их список, попутно исправляя возникающие проблемы.
Учитывая, что переключение на новую систему должно было занять много времени, нам пришлось подумать о том, как будут работать наши патчи во время переходного периода. В то время для раскладки патчей мы использовали самописную утилиту mscp, которой раскладывали файлы по одному. Мы заранее научили её подменять текущие файлы на серверах с MDK, но вот добавить новый файл на такие серверы не получалось (потому что нужно было менять карту файлов). Внедрять какое-то очень сложное промежуточное решение не хотелось — ведь мы шли в светлое будущее, где mscp не нужен. В итоге пришлось мириться с этой проблемой. Вообще за время переходного периода разработчики успели настрадаться, но сейчас нам кажется, что оно того стоило.

Изображение: источник
Наверное, закономерным будет вопрос, а не случится ли коллизия версий в MDK (т.е. ситуация, когда двум файлам с разным содержимым присвоится одна версия)?
На самом деле, мы достаточно хорошо защищены от такого рода ошибок. Мы именуем файлы так:
Но однажды что-то всё же пошло не так. После очередной выкладки мы обратили внимание на рост числа ошибок с HTTP-кодом 404 (файл не найден). Небольшое расследование показало, что не хватает части файлов статики. Выяснилось, что мы разложили очень старую карту статики и даём ссылки на файлы, которых уже и не должно быть на серверах. Но откуда эта карта взялась? В первой части статьи я отмечал, что статика раскладывается отдельным процессом, и с PHP-кодом уезжает только карта версий. Когда мы генерируем новую версию MDK, мы докладываем недостающие версии файлов в репозиторий, из которого ничего не удаляется (места много, нам не жалко). А ещё мы достаточно часто выкладываемся на стейджинг, и поэтому карта версий статики — один из тех файлов, которые изменяются чаще других. Всё это привело к тому, что мы столкнулись с коллизией. Проверив версию, MDK решил, что всё хорошо, потому что файл такой версии уже есть, и разложил его на серверы. Хорошо, что ошибку мы обнаружили быстро.
Теперь, помимо версии, мы проверяем размер файла: если в репозитории он такой же, то, скорее всего, это один и тот же файл. В худшем случае у нас будет история для новой статьи.

Изображение: источник
И ещё об одной ошибке мне хочется рассказать, потому что она как минимум забавная. Нетрудно догадаться, что у нас был процесс очистки старых версий файлов на конечных серверах. В попытке быстро решить одну из проблем мы приняли судьбоносное решение: выставили период очистки в одни сутки (вместо семи, как было раньше). Это сработало — и проблема ушла. Мы даже прожили так какое-то время.
Где-то в пять часов утра в воскресенье у меня в спальне зазвонил телефон, звонил дежурный мониторщик: «У нас не работают скрипты. Говорят, что ты знаешь, в чём дело». Для меня это прозвучало примерно как «В офисе соковыжималка сгорела. Говорят, ты знаешь, в чём дело». Про принципы работы нашего скриптового фреймворка я знал только по статьям и рассказам, никаких «личных отношений» у меня с ним не было, и уж тем более я его никогда не чинил. Но я полез на серверы, чтобы выяснить, что происходит, и обнаружил, что проблема действительно «на нашей стороне»: на серверах просто не было кода.
Я выложил код заново — и всё заработало. Ошибка, кстати, оказалась примитивной: в субботу не было разложено ни одной новой версии MDK, а скрипт очистки, как оказалось, не делал никаких проверок, чтобы не удалить текущую версию. В итоге в пять утра он (по расписанию) удалил со всех серверов код. Уже после этой истории мы поняли, что со старыми настройками это всплыло бы на праздниках длиной в 7 дней, например в новогодние каникулы, как раз в канун Рождества. «Христос родился — код удалился» — ещё долго у нас можно было услышать эту шутку.
В конечном итоге мы внедрили новую систему раскладки — и пришло время переделывать систему патчей. Больше не было нужды в mscp и не нужно было избегать генерации новых версий. Для начала мы изменили цикл жизни патча. Теперь после подтверждения изменений он попадает обратно к разработчику, который принимает решение, когда патч готов к выкладке. Он нажимает на кнопку Deploy, после чего мы добавляем патч в master, генерируем и раскладываем новую версию MDK. Участие разработчика на этом этапе больше не требуется.
Мы добились очень хорошей скорости раскладки: изменения попадают на серверы буквально в течение минуты. Для этого, правда, нам пришлось прибегнуть к паре хитростей: например, мы всё ещё не генерируем статику или переводы — вместо этого мы берём версию из последнего разложенного билда. Из-за этого мы сохраняем ограничение на патчи для JS- и CSS-файлов.
Нам действительно удалось решить все проблемы, которые у нас были раньше. Больше не нужно думать о том, как правильно сформировать изменения, которые не вызовут сложностей при пофайловой раскладке, — достаточно просто не трогать статику, и всё будет работать.
Зато появилась новая трудность. Раньше мы разрешали разработчикам раскладывать свои изменения на один или несколько серверов, чтобы просто убедиться в том, что с ними всё будет работать. С новой системой эта возможность пропала, ведь master теперь стала актуальной версией для всех серверов без исключения.

Изображение: источник
Из-за этого появилось новое требование к системе патчей: нужна возможность проверить свои изменения на небольшом количестве серверов без добавления изменений в master. Новую функциональность мы назвали экспериментами.
Для разработчика процесс выглядит приблизительно так: после получения апрува в интерфейсе системы патчей становится доступна новая страница, где можно выбрать серверы, на которых хочется поэкспериментировать. Это может быть группа серверов, один сервер или любая комбинация, которую поймёт наша система. Система раскладывает патч и уведомляет об этом разработчика. В этот же момент на странице появляется лог последних ошибок с затронутых серверов.
Мы никак не ограничиваем разработчиков, они могут создавать эксперименты на одних и тех же серверах. Один может экспериментировать на 10% кластера, другой — на всём кластере.
Это стало возможным благодаря тому, что у нас появилась та самая «версия патчей», которой нам так не хватало. Это версия, которая в теории может быть уникальна для каждого сервера. Она выглядит как строка из идентификаторов, разделённых запятыми, например, «32,45,79». Это значит, что на сервере должны быть все изменения из мастера и патчи под номерами 32, 45 и 79. Для каждой такой версии мы генерируем собственную версию MDK. Мы берём свежие изменения из основной ветки, а затем последовательно накладываем каждый из патчей. Если во время генерации какой-то из версий возникает конфликт, мы просто отменяем эксперимент для самого свежего патча и уведомляем об этом разработчика.
С первого дня существования системы патчей мы пошли на хитрость: отказались от генерации статики, чтобы изменения попадали на серверы как можно быстрее. Конечно, нам очень хотелось заполучить возможность менять JS-код так же, как мы меняем PHP-код, но все попытки построить этот процесс не увенчивались успехом.
Около полугода назад мы снова вернулись к этому вопросу. Цель: нужно менять статику, но нельзя жертвовать скоростью раскладки PHP-кода. Основная проблема: полная сборка занимает восемь минут. Что делать?
Нужно идти на компромиссы. Начали с того, что JS-код нельзя будет раскладывать в рамках экспериментов. Это должно заметно сэкономить время: достаточно поддерживать одну версию статики в актуальном состоянии вместо генерации десятков разных версий для разных групп машин. Но это всё ещё долго. На чём ещё можно сэкономить? Мы не придумали, как сократить время, но решили, что проблемы не будет, если сборка не будет блокировать раскладку PHP-кода.
Мы начали генерировать статику асинхронно. С изменениями JS- или CSS-файлов мы запускаем отдельный процесс, который создаёт новую карту версий статики. Процесс сборки PHP-кода в начале работы проверяет, нет ли новой карты статики, и, если она есть, забирает и раскладывает её на все серверы. Решили проблему? Практически. С таким подходом мы пошли на новое ограничение: нельзя поменять JS- и PHP-код в одном патче, потому что мы раскладываем эти изменения асинхронно и не можем гарантировать, что они окажутся на машинах одновременно.
Мы очень довольны обновлением. Оно далось нам нелегко, но сделало нашу систему намного надёжнее. Экспериментам разработчики нашли альтернативное применение: с ними можно легко собрать специфические логи с пары серверов, не добавляя свои изменения в master.
У нас все еще есть идеи по улучшению системы, на реализацию которых пока не хватило времени. Например, мы хотим переделать процесс создания патча и добавить возможность изменения JS-файлов одновременно с основным кодом, чтобы избавиться от последних ограничений.
Ежедневно мы выкладываем примерно 60 патчей, иногда их бывает в несколько раз больше, например, во время разработки какого-то функционала, доступного пока только тестировщикам. Около трети патчей проходит через эксперименты до того, как будут выложены. Всего за время существования системы у нас было порядка 46 000 патчей для мастера.
В этой части статьи я расскажу о новом способе раскладки кода, который мы придумали, пытаясь решить наши проблемы, и о том, как с ним преобразилась наша система патчей.

Изображение: источник
Универсальное решение — Multiversional Deployment Kit
После очередного пересмотра нашей системы Юра youROCK Насретдинов заявил, что у него есть идея, как решить все наши проблемы. Всё, что он просил, — кучу времени, чтобы переделать систему раскладки. Так появилась концепция Multiversional Deployment Kit, или, в простонародье, MDK (Юра сравнивал ее с другими способами раскладки кода в своем докладе на HighLoad++).
Новая система была призвана изменить нашу процедуру раскладки. Тем, кто не читал мою первую часть статьи, вкратце расскажу, как у нас выглядит процесс деплоя: сначала мы собираем все нужные файлы в одной директории, потом сохраняем и доставляем состояние директории до серверов.
До эпохи MDK для сохранения и доставки мы использовали блочные устройства (то есть образы файловой системы), которые называли лупами. Директория копировалась в пустой луп, он архивировался и отправлялся на серверы.
В новой системе мы версионируем не директорию целиком, а каждый файл по отдельности так, чтобы версия файла однозначно коррелировала с его содержимым. Для директорий существуют карты (maps) — специальные файлы, в которых записаны версии всех файлов в директории. Эти карты тоже версионируются, и выглядит всё это приблизительно так:
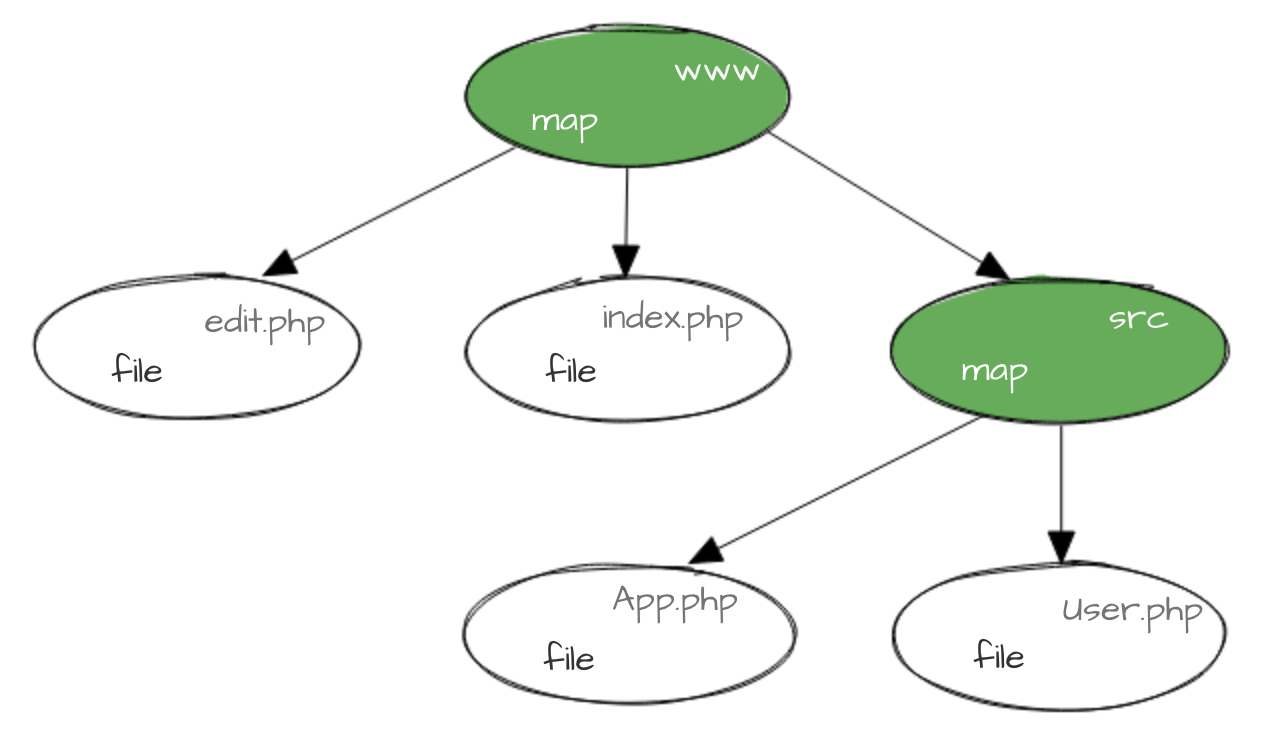
Выглядит знакомо? Именно так устроены объекты в Git (можете почитать об этом здесь, но для понимания статьи это не обязательно).
Для версионирования мы используем первые восемь символов от MD5-хеша (от его шестнадцатиричного представления, если быть точным), взятого от содержимого файла. Эта версия записывается в конец имени файла или в начало имени карты (чтобы можно было отличить файл map от сгенерированной карты версий):

Версия кода — это версия карты корневой директории www. Для того чтобы найти текущую карту, у нас есть символическая ссылка (symlink) current.map.
Почему не использовать Git?
Несмотря на то, что MDK частично заимствует идеи у Git, у них есть и несколько отличий. Самое главное — то, как хранятся файлы в рабочей директории (т.е. на машинах). Если Git хранит там только одну, текущую, версию, то MDK держит там все доступные версии файлов. При этом на текущую версию кода указывает только один симлинк current.map, который использует в своей работе autoload и который можно атомарно поменять. Для сравнения, Git для изменения версии использует git-checkout, который меняет файлы по очереди и не атомарен.
Сборка с MDK
MDK нужен, чтобы сохранить состояние директории в конце сборки. Для этого у нас есть специальное место, которое мы назвали репозиторием, — хранилище всех версий файлов, которые представляют для нас ценность (то есть которые мы можем захотеть разложить). Когда новое содержимое директории готово, мы вычисляем версии всех файлов в ней и докладываем в репозиторий недостающие.
Раскладка с MDK
Во время раскладки на каждом из принимающих серверов мы запускаем скрипт, который проверяет, все ли необходимые файлы есть на сервере, и запрашивает из репозитория те, которых не хватает. Нам остаётся только переключить версию на новую, поменяв симлинк current.map.
Как это должно решить наши проблемы
Предполагалось, что, если в новой версии изменилось всего несколько файлов, её сборка и раскладка с помощью новой системы должна быть как минимум сравнима по времени с раскладкой патча отдельными файлами. Если это так, то для каждого патча мы просто будем генерировать новую версию.
Внедрение MDK
У MDK был один недостаток: на конечных машинах в названии каждого файла должна быть его версия. Именно это позволяет хранить в директории сразу очень много версий одного файла, но это же не позволяет сделать include user.php из кода — обязательно нужно указать конкретную версию. Добавьте к этому различные баги, которые вполне могли остаться в коде системы раскладки, новый алгоритм раскладки, который был сложнее старого, — и станет ясно, почему мы решили внедрять новую систему небольшими шагами. Мы начали буквально с одного-двух серверов и постепенно расширяли их список, попутно исправляя возникающие проблемы.
Учитывая, что переключение на новую систему должно было занять много времени, нам пришлось подумать о том, как будут работать наши патчи во время переходного периода. В то время для раскладки патчей мы использовали самописную утилиту mscp, которой раскладывали файлы по одному. Мы заранее научили её подменять текущие файлы на серверах с MDK, но вот добавить новый файл на такие серверы не получалось (потому что нужно было менять карту файлов). Внедрять какое-то очень сложное промежуточное решение не хотелось — ведь мы шли в светлое будущее, где mscp не нужен. В итоге пришлось мириться с этой проблемой. Вообще за время переходного периода разработчики успели настрадаться, но сейчас нам кажется, что оно того стоило.
Не верь никому

Изображение: источник
Наверное, закономерным будет вопрос, а не случится ли коллизия версий в MDK (т.е. ситуация, когда двум файлам с разным содержимым присвоится одна версия)?
На самом деле, мы достаточно хорошо защищены от такого рода ошибок. Мы именуем файлы так:
{оригинальное имя}.{версия}, а значит, должно совпасть гораздо больше, чем восемь символов, чтобы произошла ошибка.Но однажды что-то всё же пошло не так. После очередной выкладки мы обратили внимание на рост числа ошибок с HTTP-кодом 404 (файл не найден). Небольшое расследование показало, что не хватает части файлов статики. Выяснилось, что мы разложили очень старую карту статики и даём ссылки на файлы, которых уже и не должно быть на серверах. Но откуда эта карта взялась? В первой части статьи я отмечал, что статика раскладывается отдельным процессом, и с PHP-кодом уезжает только карта версий. Когда мы генерируем новую версию MDK, мы докладываем недостающие версии файлов в репозиторий, из которого ничего не удаляется (места много, нам не жалко). А ещё мы достаточно часто выкладываемся на стейджинг, и поэтому карта версий статики — один из тех файлов, которые изменяются чаще других. Всё это привело к тому, что мы столкнулись с коллизией. Проверив версию, MDK решил, что всё хорошо, потому что файл такой версии уже есть, и разложил его на серверы. Хорошо, что ошибку мы обнаружили быстро.
Теперь, помимо версии, мы проверяем размер файла: если в репозитории он такой же, то, скорее всего, это один и тот же файл. В худшем случае у нас будет история для новой статьи.
MDK — похититель Рождества

Изображение: источник
И ещё об одной ошибке мне хочется рассказать, потому что она как минимум забавная. Нетрудно догадаться, что у нас был процесс очистки старых версий файлов на конечных серверах. В попытке быстро решить одну из проблем мы приняли судьбоносное решение: выставили период очистки в одни сутки (вместо семи, как было раньше). Это сработало — и проблема ушла. Мы даже прожили так какое-то время.
Где-то в пять часов утра в воскресенье у меня в спальне зазвонил телефон, звонил дежурный мониторщик: «У нас не работают скрипты. Говорят, что ты знаешь, в чём дело». Для меня это прозвучало примерно как «В офисе соковыжималка сгорела. Говорят, ты знаешь, в чём дело». Про принципы работы нашего скриптового фреймворка я знал только по статьям и рассказам, никаких «личных отношений» у меня с ним не было, и уж тем более я его никогда не чинил. Но я полез на серверы, чтобы выяснить, что происходит, и обнаружил, что проблема действительно «на нашей стороне»: на серверах просто не было кода.
Я выложил код заново — и всё заработало. Ошибка, кстати, оказалась примитивной: в субботу не было разложено ни одной новой версии MDK, а скрипт очистки, как оказалось, не делал никаких проверок, чтобы не удалить текущую версию. В итоге в пять утра он (по расписанию) удалил со всех серверов код. Уже после этой истории мы поняли, что со старыми настройками это всплыло бы на праздниках длиной в 7 дней, например в новогодние каникулы, как раз в канун Рождества. «Христос родился — код удалился» — ещё долго у нас можно было услышать эту шутку.
Новая система патчей
В конечном итоге мы внедрили новую систему раскладки — и пришло время переделывать систему патчей. Больше не было нужды в mscp и не нужно было избегать генерации новых версий. Для начала мы изменили цикл жизни патча. Теперь после подтверждения изменений он попадает обратно к разработчику, который принимает решение, когда патч готов к выкладке. Он нажимает на кнопку Deploy, после чего мы добавляем патч в master, генерируем и раскладываем новую версию MDK. Участие разработчика на этом этапе больше не требуется.
Мы добились очень хорошей скорости раскладки: изменения попадают на серверы буквально в течение минуты. Для этого, правда, нам пришлось прибегнуть к паре хитростей: например, мы всё ещё не генерируем статику или переводы — вместо этого мы берём версию из последнего разложенного билда. Из-за этого мы сохраняем ограничение на патчи для JS- и CSS-файлов.
Эксперименты
Нам действительно удалось решить все проблемы, которые у нас были раньше. Больше не нужно думать о том, как правильно сформировать изменения, которые не вызовут сложностей при пофайловой раскладке, — достаточно просто не трогать статику, и всё будет работать.
Зато появилась новая трудность. Раньше мы разрешали разработчикам раскладывать свои изменения на один или несколько серверов, чтобы просто убедиться в том, что с ними всё будет работать. С новой системой эта возможность пропала, ведь master теперь стала актуальной версией для всех серверов без исключения.

Изображение: источник
Из-за этого появилось новое требование к системе патчей: нужна возможность проверить свои изменения на небольшом количестве серверов без добавления изменений в master. Новую функциональность мы назвали экспериментами.
Для разработчика процесс выглядит приблизительно так: после получения апрува в интерфейсе системы патчей становится доступна новая страница, где можно выбрать серверы, на которых хочется поэкспериментировать. Это может быть группа серверов, один сервер или любая комбинация, которую поймёт наша система. Система раскладывает патч и уведомляет об этом разработчика. В этот же момент на странице появляется лог последних ошибок с затронутых серверов.
Мы никак не ограничиваем разработчиков, они могут создавать эксперименты на одних и тех же серверах. Один может экспериментировать на 10% кластера, другой — на всём кластере.
Это стало возможным благодаря тому, что у нас появилась та самая «версия патчей», которой нам так не хватало. Это версия, которая в теории может быть уникальна для каждого сервера. Она выглядит как строка из идентификаторов, разделённых запятыми, например, «32,45,79». Это значит, что на сервере должны быть все изменения из мастера и патчи под номерами 32, 45 и 79. Для каждой такой версии мы генерируем собственную версию MDK. Мы берём свежие изменения из основной ветки, а затем последовательно накладываем каждый из патчей. Если во время генерации какой-то из версий возникает конфликт, мы просто отменяем эксперимент для самого свежего патча и уведомляем об этом разработчика.
Генерируемые файлы
С первого дня существования системы патчей мы пошли на хитрость: отказались от генерации статики, чтобы изменения попадали на серверы как можно быстрее. Конечно, нам очень хотелось заполучить возможность менять JS-код так же, как мы меняем PHP-код, но все попытки построить этот процесс не увенчивались успехом.
Около полугода назад мы снова вернулись к этому вопросу. Цель: нужно менять статику, но нельзя жертвовать скоростью раскладки PHP-кода. Основная проблема: полная сборка занимает восемь минут. Что делать?
Нужно идти на компромиссы. Начали с того, что JS-код нельзя будет раскладывать в рамках экспериментов. Это должно заметно сэкономить время: достаточно поддерживать одну версию статики в актуальном состоянии вместо генерации десятков разных версий для разных групп машин. Но это всё ещё долго. На чём ещё можно сэкономить? Мы не придумали, как сократить время, но решили, что проблемы не будет, если сборка не будет блокировать раскладку PHP-кода.
Мы начали генерировать статику асинхронно. С изменениями JS- или CSS-файлов мы запускаем отдельный процесс, который создаёт новую карту версий статики. Процесс сборки PHP-кода в начале работы проверяет, нет ли новой карты статики, и, если она есть, забирает и раскладывает её на все серверы. Решили проблему? Практически. С таким подходом мы пошли на новое ограничение: нельзя поменять JS- и PHP-код в одном патче, потому что мы раскладываем эти изменения асинхронно и не можем гарантировать, что они окажутся на машинах одновременно.
Итог
Мы очень довольны обновлением. Оно далось нам нелегко, но сделало нашу систему намного надёжнее. Экспериментам разработчики нашли альтернативное применение: с ними можно легко собрать специфические логи с пары серверов, не добавляя свои изменения в master.
У нас все еще есть идеи по улучшению системы, на реализацию которых пока не хватило времени. Например, мы хотим переделать процесс создания патча и добавить возможность изменения JS-файлов одновременно с основным кодом, чтобы избавиться от последних ограничений.
Ежедневно мы выкладываем примерно 60 патчей, иногда их бывает в несколько раз больше, например, во время разработки какого-то функционала, доступного пока только тестировщикам. Около трети патчей проходит через эксперименты до того, как будут выложены. Всего за время существования системы у нас было порядка 46 000 патчей для мастера.
Only registered users can participate in poll. Log in, please.
А вы чините проблемы на production?
14.46% У нас нет проблем на production12
1.2% Ждём плановую выкладку1
26.51% Делаем багфикс релиз с полным циклом тестирования22
57.83% Используем быстрофиксы48
83 users voted. 23 users abstained.
Only registered users can participate in poll. Log in, please.
Кто обычно чинит проблемы на production?
5.33% У нас есть команда поддержки, всё сваливаем на них4
12% Есть ротируемый дежурный, который чинит все ошибки9
73.33% Кто сломал, тот и чинит55
9.33% У нас все еще нет ошибок на production7
75 users voted. 24 users abstained.
