Часть 1. Мониторинг инженерной инфраструктуры в дата-центре. Основные моменты.
Часть 2. Как устроен мониторинг энергоснабжения в дата-центре.
Часть 3. Мониторинг холодоснабжения на примере дата-центра NORD-4.
Часть 4. Сетевая инфраструктура: физическое оборудование.
Статью про устройство мониторинга в дата-центре мы обещали еще в сентябре. Тема обширная, одной статьей тут не отделаться, поэтому решили сделать серию постов. Начнем с базовых моментов, о которых важно помнить при проектировании и настройке мониторинга. Затем подробно остановимся на основных инженерных системах (энергоснабжение и холодоснабжение) и расскажем про инструменты для их мониторинга.
В статьях будем делиться своим опытом, тем, что пробовали и используем сами в собственных дата-центрах. На полноту не претендуем, зато все будет из жизни, а не из учебника.
В комментариях можно попробовать повлиять на редакторскую политику и предложить для рассмотрения интересные именно для вас аспекты мониторинга.

С организационными моментами вроде разобрались, приступим к азбуке мониторинга в редакции DataLine :). Итак, сегодня речь пойдет о концептуальных вещах, которые нужно учитывать на этапе проектирования, внедрения и настройки системы мониторинга. Сабж рассмотрим на примере нашего мониторинга, построенного на базе Nagios и Cacti.
В этой серии статей мы будем говорить о “классическом” мониторинге, т.е. без автоматизированного управления.
Мониторинг можно трактовать по-разному: как систему и как процесс. В нашем случае это две стороны одной медали – одно без другого существовать не может.
Мониторинг как система помогает непрерывно собирать, хранить и анализировать параметры оборудования и систем. Он снабжает данными, на основе которых инженер делает выводы о текущем состоянии и о возможном будущем поведении наблюдаемого объекта.
Система мониторинга дает лишь вводную информацию, дальше дело за людьми и процессами. Четкие регламенты в штатных и аварийных ситуациях, выстроенная система уведомления ответственных лиц – все это превращает мониторинг из простого сбора данных в полезный инструмент для управления инфраструктурой.
Тогда же, когда и начинаете проектировать инженерную инфраструктуру. Если заниматься мониторингом уже после запуска дата-центра, то какое-то время служба эксплуатации будет работать вслепую. Дежурные инженеры не смогут отслеживать ошибки в работе оборудования, пропустят предаварийные ситуации. Единственный доступный способ мониторинга в такой ситуации – это физический обход всех инженерных систем и ИТ-оборудования.
Пример 1: дата-центр запустили в эксплуатацию. Первые месяцы зал был почти пустой и из трех кондиционеров работал только один. С заполнением зала температура в зале выросла. Так как мониторинга нет, то службе эксплуатации будет сложно определить момент, когда включить второй, а в случае аварии – резервный.
Наверстать пробел с мониторингом на этапе эксплуатации будет сложно, а иногда и невозможно без остановок в работе серверной или дата-центра. Например, чтобы установить анализаторы тока в распределительные щиты, придется отключать как минимум один луч. В худшем случае под них может не оказаться места, тогда совершенно новый шкаф нужно будет модернизировать или менять вовсе.
Есть хорошее выражение: невозможно управлять тем, что нельзя измерить. Это как раз про эксплуатацию инженерной инфраструктуры без мониторинга. Продумывайте мониторинг заранее.
Мониторинг инженерной инфраструктуры нужно вести по возможности на трех уровнях: автономные датчики, оборудование и системы в целом.
Под автономными датчиками мы в первую очередь подразумеваем датчики протечек, температурные датчики, датчики объема и движения.
Оборудование нужно мониторить по возможности все: ИБП, ДГУ, кондиционеры, PDU, АВР, камеры и пр. По каждому важно получать следующую информацию:
Следить за каждой единицей оборудования в изоляции недостаточно. Чтобы понимать общую картину, отслеживайте системы целиком. Так вы сможете видеть взаимосвязь оборудования в единой цепочке, и вам будет легче понять, на каком этапе возникла неисправность. Взаимосвязи оборудования в системе можно визуализировать с помощью принципиальных схем.
Пример 2: отключился распределительный щит в машинном зале. Если мы мониторим оборудование по отдельности, то понадобится время, чтобы понять источник поломки – щит или ИБП, от которого он питается. Если же у нас перед глазами будет схема всей системы, то мы быстро увидим слабое звено.
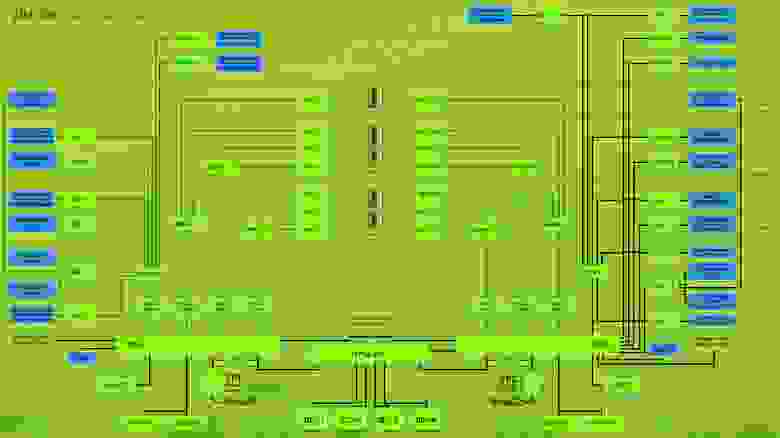
Схема системы энергоснабжения, показывающая все оборудование в одной цепочке.
По мере того, как определяемся с объектами и параметрами мониторинга, составляем документацию по системе. В ней фиксируем:
Это тоже лучше делать на этапе проектирования, чтобы у службы эксплуатации была полная документация с самого начала и они понимали:
Без такой шпаргалки службе эксплуатации придется исследовать систему мониторинга заново.
Под мониторинг лучше использовать отдельное серверное и сетевое оборудование с выделенным сетевым сегментом.
Серверы должны быть зарезервированы так, чтобы при выходе из строя одного из серверов мониторинг продолжил работать на втором. Совсем хорошо, если серверы кластера разнесены по разным машинным залам. В одном из следующих постов подробно рассмотрим устройство и принцип работы подобного кластера.
Мониторы, на которые выводятся схемы, уведомления, также должны быть подключены к бесперебойному питанию с резервом. По сети также — сетевые розетки подключены к разным коммутаторам. Так дежурные инженеры не останутся наедине потухшими экранами, когда в дата-центре происходит что-то интересное.
Всю информацию с датчиков, оборудования и систем нужно сводить в единый интерфейс и выборочно отображать на экранах в центре мониторинга.
За всем этим хозяйством должен следить круглосуточно хотя бы один дежурный инженер. Здесь же все уведомления регистрируются в виде инцидентов на ответственных лиц или отделы.
Это своего рода ЦУП и первый рубеж обороны в случае аварии в дата-центре.

Центр мониторинга на площадке OST.
В каждом профильном отделе можно дополнительно повесить экраны со схемами и оповещениями, которые входят в зону ответственности данного отдела: для инженеров эксплуатации – одни экраны, для сетевиков – другие.
Следить за работой дата-центра только с помощью уведомлений можно, но для наглядности основные инженерные системы и их параметры стоит визуализировать в виде схем и карт.

Сводная схема дата-центра OST-2.
Со схемой дежурному инженеру будет легче понять, в каком машинном зале находится сломанный кондиционер, что происходит с температурой в ближайшем холодном коридоре. Кроме того, визуализация дает возможность увидеть взаимосвязь между отдельными элементами инженерной системы и быстрее определить первоисточник проблемы.
Учитывайте специфику инженерных систем при настройке времени опроса. Для системы энергоснабжения чем чаще будут сниматься показания, тем лучше. Например, в нашем мониторинге значения напряжения снимаются каждую секунду. А для кондиционеров, это слишком часто, достаточно и минутного интервала.
Устанавливайте разное время опроса для разных систем. Так вы не пропустите важных событий и не перегрузите систему слишком частыми запросами.
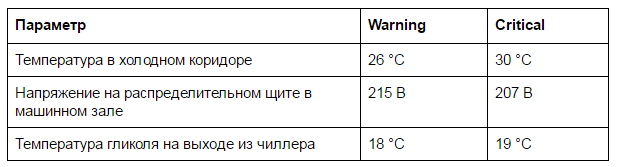
Прописывайте критические значения, по достижении которых будут срабатывать оповещения. Лучше предусмотреть как минимум два уровня оповещения – предупреждения и критические ошибки. В Nаgios, например, такому разделению соответствуют warning и critical:
Правильное разделение уведомлений позволит сократить количество ложных тревог. Провести четкую черту между warning и critical сложно, но понимание приходит с опытом. Если монитор перманентно красный от аварий, значит что-то настроено неправильно. Для инженера такой мониторинг быстро станет неинформативным, будут возникать ложные тревоги, а настоящие аварии могут остаться незамеченными среди рутинных оповещений.
При необходимости корректируйте пороговые значения для разных типов уведомлений.
Примеры warning и alarm
Все сообщения об авариях должны быть актуальными. Если на экране висит сообщение об аварии, то значит, что она произошла только что. Как только это уведомление зарегистрировано в виде инцидента на ответственное лицо, оно должно пропасть с экрана.
Не пропустить аварию важно, но еще важнее правильно на нее среагировать и запустить процесс реакции на инцидент.
У дежурного инженера должна быть четкая инструкция, по которой он действует, и контакты людей, которых нужно оповестить в случае аварийной ситуации.
Вся информация должна быть перед глазами и ясно сформулирована, чтобы инженеру не приходилось тратить время на поиски или расшифровывание пунктов инструкции.
Для удобства дежурных инженеров каждое уведомление можно сопроводить всплывающей подсказкой с контактами ответственного лица и инструкцией. Регламенты же прописываются заранее и проверяются на жизнеспособность во время плановых тестирований.
Не заставляйте дежурного инженера придумывать план действий с нуля, когда в дата-центре авария.
Вещь полезная при правильном использовании. Для небольших серверных такие оповещения могу заменить круглосуточного дежурного инженера. В большом дата-центре это своего рода резервирование дежурного инженера. Но и здесь важно не перестараться и не рассылать уведомления ответственным лицам по любому чиху.
Если будет много оповещений по некритичным ошибкам (выше мы называли их warning), то со временем их просто начнут игнорировать, и серьезная авария останется незамеченной.
Помимо онлайн-мониторинга, полезно собирать и долгосрочную статистику. Это позволит оценить параметры в динамике, выявить значения, приводящие к аварийным ситуациям. С этой статистикой можно делать выводы по работе оборудования при различной нагрузке, разных погодных условиях. Эта же информация потом используется для разбора полетов после аварий.
Это все моменты, которые мы хотели бы отметить отдельно, прежде чем пускаться в рассказы про мониторинг конкретных инженерных систем. В следующей статье разберем, что и как нужно мониторить в системе энергоснабжения дата-центра и серверной.
Часть 2. Как устроен мониторинг энергоснабжения в дата-центре.
Часть 3. Мониторинг холодоснабжения на примере дата-центра NORD-4.
Часть 4. Сетевая инфраструктура: физическое оборудование.
Статью про устройство мониторинга в дата-центре мы обещали еще в сентябре. Тема обширная, одной статьей тут не отделаться, поэтому решили сделать серию постов. Начнем с базовых моментов, о которых важно помнить при проектировании и настройке мониторинга. Затем подробно остановимся на основных инженерных системах (энергоснабжение и холодоснабжение) и расскажем про инструменты для их мониторинга.
В статьях будем делиться своим опытом, тем, что пробовали и используем сами в собственных дата-центрах. На полноту не претендуем, зато все будет из жизни, а не из учебника.
В комментариях можно попробовать повлиять на редакторскую политику и предложить для рассмотрения интересные именно для вас аспекты мониторинга.

С организационными моментами вроде разобрались, приступим к азбуке мониторинга в редакции DataLine :). Итак, сегодня речь пойдет о концептуальных вещах, которые нужно учитывать на этапе проектирования, внедрения и настройки системы мониторинга. Сабж рассмотрим на примере нашего мониторинга, построенного на базе Nagios и Cacti.
Что такое мониторинг
В этой серии статей мы будем говорить о “классическом” мониторинге, т.е. без автоматизированного управления.
Мониторинг можно трактовать по-разному: как систему и как процесс. В нашем случае это две стороны одной медали – одно без другого существовать не может.
Мониторинг как система помогает непрерывно собирать, хранить и анализировать параметры оборудования и систем. Он снабжает данными, на основе которых инженер делает выводы о текущем состоянии и о возможном будущем поведении наблюдаемого объекта.
Система мониторинга дает лишь вводную информацию, дальше дело за людьми и процессами. Четкие регламенты в штатных и аварийных ситуациях, выстроенная система уведомления ответственных лиц – все это превращает мониторинг из простого сбора данных в полезный инструмент для управления инфраструктурой.
Когда нужно озадачиться системой мониторинга
Тогда же, когда и начинаете проектировать инженерную инфраструктуру. Если заниматься мониторингом уже после запуска дата-центра, то какое-то время служба эксплуатации будет работать вслепую. Дежурные инженеры не смогут отслеживать ошибки в работе оборудования, пропустят предаварийные ситуации. Единственный доступный способ мониторинга в такой ситуации – это физический обход всех инженерных систем и ИТ-оборудования.
Пример 1: дата-центр запустили в эксплуатацию. Первые месяцы зал был почти пустой и из трех кондиционеров работал только один. С заполнением зала температура в зале выросла. Так как мониторинга нет, то службе эксплуатации будет сложно определить момент, когда включить второй, а в случае аварии – резервный.
Наверстать пробел с мониторингом на этапе эксплуатации будет сложно, а иногда и невозможно без остановок в работе серверной или дата-центра. Например, чтобы установить анализаторы тока в распределительные щиты, придется отключать как минимум один луч. В худшем случае под них может не оказаться места, тогда совершенно новый шкаф нужно будет модернизировать или менять вовсе.
Есть хорошее выражение: невозможно управлять тем, что нельзя измерить. Это как раз про эксплуатацию инженерной инфраструктуры без мониторинга. Продумывайте мониторинг заранее.
За чем нужно следить
Мониторинг инженерной инфраструктуры нужно вести по возможности на трех уровнях: автономные датчики, оборудование и системы в целом.
Под автономными датчиками мы в первую очередь подразумеваем датчики протечек, температурные датчики, датчики объема и движения.
- датчики протечек нужны всегда, особенно если в дата-центре используется система охлаждения с жидким теплоносителем или фреоновая с увлажнением. Размещаем их под каждым кондиционером, узлом и краном трубопровода, т. е. в тех местах, где может закапать.
- температурные датчики устанавливаем в холодных и горячих коридорах машинных залов, в помещениях с инженерной инфраструктурой (насосные, помещения АКБ, ГРЩ и пр.).
- датчики объема/движения, открытия и закрытия дверей стоек. В отличие от предыдущих, они опциональны. Их можно использовать в залах или для группы стоек, огороженной забором (cage).
Оборудование нужно мониторить по возможности все: ИБП, ДГУ, кондиционеры, PDU, АВР, камеры и пр. По каждому важно получать следующую информацию:
- работает ли;
- какие ошибки возникают в работе;
- значения отдельных параметров (напряжение в ИБП, сила тока, уровень топлива в баке ДГУ, температура на входе и выходе кондиционера, скорость вращения вентилятора и пр.).
Следить за каждой единицей оборудования в изоляции недостаточно. Чтобы понимать общую картину, отслеживайте системы целиком. Так вы сможете видеть взаимосвязь оборудования в единой цепочке, и вам будет легче понять, на каком этапе возникла неисправность. Взаимосвязи оборудования в системе можно визуализировать с помощью принципиальных схем.
Пример 2: отключился распределительный щит в машинном зале. Если мы мониторим оборудование по отдельности, то понадобится время, чтобы понять источник поломки – щит или ИБП, от которого он питается. Если же у нас перед глазами будет схема всей системы, то мы быстро увидим слабое звено.

Схема системы энергоснабжения, показывающая все оборудование в одной цепочке.
Документация по мониторингу
По мере того, как определяемся с объектами и параметрами мониторинга, составляем документацию по системе. В ней фиксируем:
- список датчиков и оборудования на мониторинге;
- место их установки;
- отслеживаемые параметры и конкретные значения;
- схемы подключения;
- пороговые значения для уведомлений об аварийных ситуациях
Это тоже лучше делать на этапе проектирования, чтобы у службы эксплуатации была полная документация с самого начала и они понимали:
- все ли интересующие объекты поставлены на мониторинг;
- где искать проблему в случае неисправности самой системы мониторинга;
- какие пороговые значения используются.
Без такой шпаргалки службе эксплуатации придется исследовать систему мониторинга заново.
Независимость и резервирование системы мониторинга
Под мониторинг лучше использовать отдельное серверное и сетевое оборудование с выделенным сетевым сегментом.
Серверы должны быть зарезервированы так, чтобы при выходе из строя одного из серверов мониторинг продолжил работать на втором. Совсем хорошо, если серверы кластера разнесены по разным машинным залам. В одном из следующих постов подробно рассмотрим устройство и принцип работы подобного кластера.
Мониторы, на которые выводятся схемы, уведомления, также должны быть подключены к бесперебойному питанию с резервом. По сети также — сетевые розетки подключены к разным коммутаторам. Так дежурные инженеры не останутся наедине потухшими экранами, когда в дата-центре происходит что-то интересное.
Единый центр мониторинга
Всю информацию с датчиков, оборудования и систем нужно сводить в единый интерфейс и выборочно отображать на экранах в центре мониторинга.
За всем этим хозяйством должен следить круглосуточно хотя бы один дежурный инженер. Здесь же все уведомления регистрируются в виде инцидентов на ответственных лиц или отделы.
Это своего рода ЦУП и первый рубеж обороны в случае аварии в дата-центре.

Центр мониторинга на площадке OST.
В каждом профильном отделе можно дополнительно повесить экраны со схемами и оповещениями, которые входят в зону ответственности данного отдела: для инженеров эксплуатации – одни экраны, для сетевиков – другие.
Визуализация
Следить за работой дата-центра только с помощью уведомлений можно, но для наглядности основные инженерные системы и их параметры стоит визуализировать в виде схем и карт.
Сводная схема дата-центра OST-2.
Со схемой дежурному инженеру будет легче понять, в каком машинном зале находится сломанный кондиционер, что происходит с температурой в ближайшем холодном коридоре. Кроме того, визуализация дает возможность увидеть взаимосвязь между отдельными элементами инженерной системы и быстрее определить первоисточник проблемы.
Разное время опроса для разных систем
Учитывайте специфику инженерных систем при настройке времени опроса. Для системы энергоснабжения чем чаще будут сниматься показания, тем лучше. Например, в нашем мониторинге значения напряжения снимаются каждую секунду. А для кондиционеров, это слишком часто, достаточно и минутного интервала.
Устанавливайте разное время опроса для разных систем. Так вы не пропустите важных событий и не перегрузите систему слишком частыми запросами.
Правильно выбранные пороговые значения для уведомлений
Прописывайте критические значения, по достижении которых будут срабатывать оповещения. Лучше предусмотреть как минимум два уровня оповещения – предупреждения и критические ошибки. В Nаgios, например, такому разделению соответствуют warning и critical:
- warning предупреждает о том, что какие-то параметры оборудования или системы подходят к критическому значению;
- critical означает аварийную ситуацию, когда что-то сломалось, ошибка в оборудовании.
Правильное разделение уведомлений позволит сократить количество ложных тревог. Провести четкую черту между warning и critical сложно, но понимание приходит с опытом. Если монитор перманентно красный от аварий, значит что-то настроено неправильно. Для инженера такой мониторинг быстро станет неинформативным, будут возникать ложные тревоги, а настоящие аварии могут остаться незамеченными среди рутинных оповещений.
При необходимости корректируйте пороговые значения для разных типов уведомлений.
Примеры warning и alarm
Все сообщения об авариях должны быть актуальными. Если на экране висит сообщение об аварии, то значит, что она произошла только что. Как только это уведомление зарегистрировано в виде инцидента на ответственное лицо, оно должно пропасть с экрана.
Четкий регламент действий при аварийных ситуациях
Не пропустить аварию важно, но еще важнее правильно на нее среагировать и запустить процесс реакции на инцидент.
У дежурного инженера должна быть четкая инструкция, по которой он действует, и контакты людей, которых нужно оповестить в случае аварийной ситуации.
Вся информация должна быть перед глазами и ясно сформулирована, чтобы инженеру не приходилось тратить время на поиски или расшифровывание пунктов инструкции.
Для удобства дежурных инженеров каждое уведомление можно сопроводить всплывающей подсказкой с контактами ответственного лица и инструкцией. Регламенты же прописываются заранее и проверяются на жизнеспособность во время плановых тестирований.
Не заставляйте дежурного инженера придумывать план действий с нуля, когда в дата-центре авария.
Оповещение по email и смс
Вещь полезная при правильном использовании. Для небольших серверных такие оповещения могу заменить круглосуточного дежурного инженера. В большом дата-центре это своего рода резервирование дежурного инженера. Но и здесь важно не перестараться и не рассылать уведомления ответственным лицам по любому чиху.
Если будет много оповещений по некритичным ошибкам (выше мы называли их warning), то со временем их просто начнут игнорировать, и серьезная авария останется незамеченной.
Сбор статистики
Помимо онлайн-мониторинга, полезно собирать и долгосрочную статистику. Это позволит оценить параметры в динамике, выявить значения, приводящие к аварийным ситуациям. С этой статистикой можно делать выводы по работе оборудования при различной нагрузке, разных погодных условиях. Эта же информация потом используется для разбора полетов после аварий.
Это все моменты, которые мы хотели бы отметить отдельно, прежде чем пускаться в рассказы про мониторинг конкретных инженерных систем. В следующей статье разберем, что и как нужно мониторить в системе энергоснабжения дата-центра и серверной.
