Всем привет!
Сегодня расскажем об опыте одного из наших DevOps проектов. Мы решили реализовать новое приложение под Linux с использованием .Net Core на микросервисной архитектуре.
Мы рассчитываем, что проект будет активно развиваться, а пользователей будет всё больше и больше. Поэтому он должен легко масштабироваться как по функционалу, так и по производительности.
Нам нужна отказоустойчивая система — если один из блоков функциональности не работает, то остальные должны работать. Также хотим обеспечить непрерывную интеграцию, включая развертывание решения на серверах заказчика.
Поэтому использовали такие технологии:
В этой статье поделимся подробностями нашего решения.

Это расшифровка нашего выступления на .NET-митапе, вот ссылка на видео выступления.
Наш заказчик — это федеральная компания, где есть мерчендайзеры — это люди, которые отвечают за то, как представлены товары в магазинах. А ещё есть супервайзеры – это руководители мерчендайзеров.
В компании есть процесс обучения и оценки работы мерчендайзеров супервайзерами, который необходимо было автоматизировать.

Вот как работает наше решение:
1. Супервайзер составляет анкету – это чеклист того, что нужно проверить в работе мерчендайзера.
2. Далее супервайзер выбирает сотрудника, чью работу будет проверять. Назначается дата анкетирования.
3. Далее активность отправляется на мобильное устройство супервайзера.
4. Затем анкета заполняется и отправляется на портал.
5. На портале формируются результаты и различные отчеты.
1. Мы в перспективе хотим легко расширять функционал, так как подобных бизнес-процессов в компании много.
2. Мы хотим, чтобы решение было отказоустойчивым. Если какая-то часть перестанет функционировать, решение сможет самостоятельно восстановить свою работу, а отказ одной части не сильно повлияет на работу решения в целом.
3. Компания, для которого мы реализуем решение, имеет много филиалов. Соответственно, количество пользователей решения постоянно растёт. Поэтому хотелось, чтобы это не повлияло на производительность.
В итоге мы решили использовать микросервисы на этом проекте, что потребовало принять ряд нетривиальных решений.
• Docker упрощает распространение дистрибутива решения. Дистрибутив в нашем случае — это набор образов микросервисов
• Поскольку микросервисов в нашем решении много, нам необходимо ими управлять. Для этого мы используем Kubernetes.
• Сами микросервисы мы реализуем с помощью .Net Core.
• Чтобы быстро обновлять решение у заказчика, мы должны реализовать удобную непрерывную интеграцию и доставку.
Вот наш набор технологий в целом:
• .Net Core мы используем для создания микросервисов,
• Микросервис упаковывается в Docker-образ,
• Непрерывная интеграция и непрерывная доставка реализуется с помощью TFS,
• Фронтэндная часть реализована на Angular,
• Для мониторинга и логирования мы используем Elasticsearch и Kibana,
• RabbitMQ и MassTransit используются как шина интеграции.
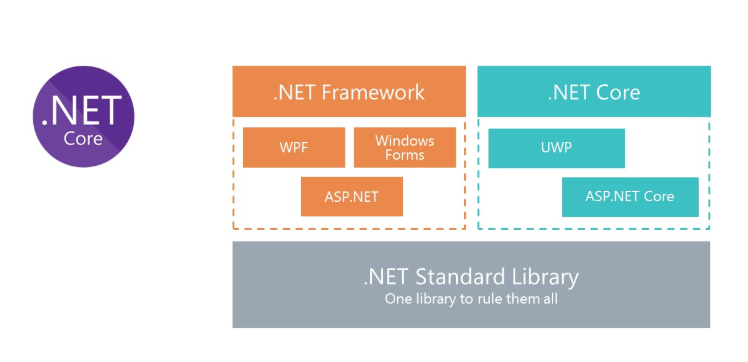
Все мы знаем, что такое классический .Net Framework. Основным минусом платформы является то, что она не кроссплатформенная. Соответственно, мы не можем запустить в Docker решения на платформе .Net Framework под Linux.
Чтобы предоставить возможность использования C# в Docker, Microsoft переосмыслил .Net Framework и создал .Net Core. А чтобы использовать одни и те же библиотеки, Microsoft создал спецификацию .Net Standard Library. Сборки .Net Standart Library могут использоваться и в .Net Framework, и в .Net Core.
Kubernetes используется для управления и кластеризации Docker-контейнеров. Вот главные преимущества Kubernetes, которыми мы воспользовались:
— предоставляет возможность легкой настройки окружения микросервисов,
— упрощает управление окружением (Dev, QA, Stage),
— из коробки предоставляет возможность репликации микросервисов и балансировки нагрузки на реплики.

В начале работы мы задались вопросом, каким образом разделять функционал на микросервисы. Разбиение было сделано по принципу единой ответственности, только на уровне больше. Его главная задача — чтобы изменения в одном сервисе как можно меньше влияли на другие микросервисы. В итоге в нашем случае микросервисы начали выполнять обособленную область функционала.
В результате у нас появились сервисы, которые занимаются планированием анкетирования, микросервис отображения результатов, микросервис работы с мобильным приложением и другие микросервисы.
Microsoft в своей книге о микросервисах «Микросервисы .NET. Архитектура контейнерных приложений .NET» предлагает три возможные реализации взаимодействия с микросервисами. Мы рассмотрели все три и выбрали наиболее подходящий.
• API Gateway service
API Gateway service — это реализация фасада для запросов пользователей к другим сервисам. Проблема решения в том, что если фасад не будет работать, то всё решение перестанет функционировать. От этого подхода решили отказаться ради отказоустойчивости.
• API Gateway with Azure API Management
Microsoft предоставляет возможность использования облачного фасада в Azure. Но это решение не подошло, поскольку мы собирались развернуть решение не в облаке, а на серверах заказчика.
• Direct Client-To-Microservice communication
В итоге у нас остался последний вариант — непосредственное взаимодействие пользователей с микросервисами. Его мы и выбрали.

Его плюс в отказоустойчивости. Минусы в том, что часть функциональности придется воспроизводить на каждом сервисе отдельно. Например, настроить авторизацию пришлось отдельно на каждом микросервисе, к которому имеют доступ пользователи.
Конечно, возникает вопрос, каким образом будем балансироваться нагрузка и каким образом осуществляется отказоустойчивость. Тут все просто — этим занимается Ingress Controller Kubernetes.
Node 1, node 2 и node 3 – это реплики одного микросервиса. Если одна из реплик перестанет работать, то load balancer автоматически перенаправит нагрузку на другие микросервисы.
Вот как мы организовали инфраструктуру нашего решения:
• Каждый микросервис имеет свою БД (если она ему, конечно, нужна), другие сервисы к БД другого микросервиса не обращаются.
• Микросервисы общаются между собой только по шине RabbitMQ + Mass Transit, а также с помощью HTTP запросов.
• Каждый сервис имеет свою четко обозначенную ответственность.
• Для логирования мы используем Elasticsearch и Kibana и библиотеку для работы с ним Serilog.

Сервис баз данных был развернут на отдельной виртуальной машине, а не в Kubernetes, потому что СУБД Microsoft не рекомендует использовать Docker на продуктовых средах.
Сервис логирования тоже был развернут на отдельной виртуалке из соображений отказоустойчивости — если у нас будут неполадки с Kubernetes, то мы сможем разобраться, в чем проблема.
На нашей инфраструктуре создано 3 неймспейса в Kubernetes. Все три окружения обращаются к одному сервису баз данных и одному сервису логирования. И, конечно, каждая среда смотрит на свой БД.

На инфраструктуре заказчика у нас также есть две среды — это предпрод и продакшн. На продакшене у нас есть отдельные серверы баз данных для предпрода и продуктовой среды. Для логирования у нас выделено по одному серверу ELK на нашей инфраструктуре и на инфраструктуре заказчика.
В среднем у нас 10 сервисов на проект и три среды: QA, DEV, Stage, на которых развернуто в сумме около 30 микросервисов. Причем это только на инфраструктуре разработки! Добавим ещё 2 среды на инфраструктуре заказчика, и у нас получается 50 микросервисов.
Понятно, что такое таким количеством сервисов необходимо как-то управлять. В этом нам помогает Kubernetes.
Для того, чтобы развернуть микросервис, необходимо
• Развернуть secret,
• Развернуть deployement,
• Развернуть service.
Про secret напишем ниже.
Деплоймент — это инструкция для Kubernetes, на основе которой он запустит Docker контейнер нашего микросервиса. Вот команда, которой развёртывается deployment:
Этот файл описывает, как называется деплоймент (imtob-etr-it-dictionary-api), какой образ ему необходимо использовать для исполнения, плюс другие настройки. В секции secret мы будем настраивать наше окружение.
После развертывания deployment нам необходимо развернуть service, если это необходимо.
Сервисы нужны тогда, когда необходим доступ к микросервису извне. Например, когда нужно, чтобы пользователь или другой микросервис смог сделать Get запрос другому микросервису.
Обычно описание service небольшое. В нем мы видим название сервиса, каким образом к нему можно обратиться и номер порта.
В итоге для развертывания среды нам нужны
• набор файлов с secret-ами для всех микросервисов,
• набор файлов с deployment-ами всех микросервисов,
• набор файлов с service-ами всех микросервисов.
Все эти скрипты мы храним в git репозитории.
Для развертывания решения у нас получился набор из трех видов скриптов:
• папка с сикретами — это конфигурации для каждой среды,
• папка с deployment-ами для всех микросервисов,
• папка с service-ами для некоторых микросервисов,
в каждой – примерно по десять команд, по одной на каждый микросервис. Для удобства мы завели страницу со скриптами в Confluence, которая помогает нам быстро развернуть новое окружение.
Тут представлен скрипт развертывания deployment (подобные наборы есть для secret и для service):
Каждый сервис находится в своей папке, плюс у нас есть одна папка с общими компонентами.

Также для каждого микросервиса есть Build Definition и Release Definition. Мы настроили запуск Build Definion при коммите в соответствующий сервис или при коммите в соответствующую папку. Если обновляется содержимое папки с общими компонентами, то разворачиваются все микросервисы.
Какие плюсы от такой организации Build-а мы видим:
1. Решение находится в одном git-репозитории,
2. При изменении в нескольких микросервисах сборка запускается параллельно при наличии свободных агентов сборки,
3. Каждый Build Definition представляет простой сценарий из сборки образа и его push-а в Nexus Registry.
Как развернуть VSTS-агент, мы ранее описали в этой статье.
Сначала идёт Build Definition. По команде TFS VSTS агент запускает билд Dockerfile. В результате у нас получается образ микросервиса. Этот образ сохраняется локально на той среде, где запущен VSTS агент.
После билда запускается Push, который отправляет образ, который мы получили в предыдущем шаге, в Nexus Registry. Теперь его можно использовать извне. Nexus Registry — это своего рода Nuget, только не для библиотек, а для образов Docker и не только.
После того, как образ готов и доступен извне, его нужно развернуть. Для этого у нас есть Release Definition. Здесь все просто — мы выполняем команду set image:
После этого он обновит образ для нужного микросервиса и запустит новый контейнер. В итоге, наш сервис обновлен.
Давайте теперь сравним сборку с Dockerfile и без него.

Без Dockerfile у нас получается много шагов, в которой много специфики .Net-а. Справа мы видим билд образа Docker. Все стало намного проще.
Весь процесс сборки образа описан в Dockerfile. Эту сборку можно отлаживать у себя локально.

1. Разделение разработки и развертывания. Сборка описывается в Dockerfile и лежит на плечах разработчика.
2. При настройке CI/CD не нужно знать о деталях и особенностях сборки — работа ведется только с Dockerfile-ом.
3. Обновляем только измененные микросервисы.
Далее требуется настрить RabbitMQ в K8S: об этом мы написали отдельную статью.
Так или иначе, нам необходимо конфигурировать микросервисы. Основная часть окружения настраивается в корневом файле конфигурации Appsettings.json. В этом файле хранятся настройки, которые не зависят от среды.
Те настройки, которые зависят от среды, мы храним в папке secrets в файле appsettings.secret.json. Мы взяли подход, описанный в статье Managing ASP.NET Core App Settings on Kubernetes.
В файле appsettings.secrets.json хранятся настройки индексов Elastic Search и строка подключения к БД.
Для того, чтобы добавить этот файл, его нужно развернуть в Docker-контейнере. Это делается в файле deployment-а кубернетиса. В deployment-е описывается в какой папке нужно создать файл c secret и с каким secret-ом нужно ассоциировать файл.
Создать secret в Kubernetes можно с помощью утилиты kubectl. Мы видим тут название secret-а и путь до файла. Также мы тут указываем название окружения, для которого создаем secret.
1. Высокий порог входа. Если делаете подобный проект впервые, будет много новой информации.
2. Микросервисы → более сложное проектирование. Необходимо применять много неочевидных решений из-за того, что у нас не монолитное решение, а микросервисное.
3. Не все реализовано для Docker. Не все можно запустить в микросервисной архитектуре. Например, пока SSRS нет в докере.
1. Инфраструктура как код
Описание инфраструктуры хранится в source control. В момент развертывания не нужно адаптировать окружение.
2. Масштабирование как на уровне функционала, так и на уровне производительности из коробки.
3. Микросервисы хорошо изолированы
Практически нет критичных частей, отказ которых приводит к неработоспособности системы в целом.
4. Быстрая доставка изменений
Обновляются только те микросервисы, в которых были изменения. Если не учитывать время на согласования и другие вещи, связанные с человеческим фактором, то обновление одного микросервиса у нас происходит за 2 минуты и меньше.
1. На .NET Core можно и нужно реализовывать промышленные решения.
2. K8S действительно облегчил жизнь, упростил обновление сред, облегчает конфигурирование сервисов.
3. TFS можно использовать для реализации CI/CD для Linux.
Сегодня расскажем об опыте одного из наших DevOps проектов. Мы решили реализовать новое приложение под Linux с использованием .Net Core на микросервисной архитектуре.
Мы рассчитываем, что проект будет активно развиваться, а пользователей будет всё больше и больше. Поэтому он должен легко масштабироваться как по функционалу, так и по производительности.
Нам нужна отказоустойчивая система — если один из блоков функциональности не работает, то остальные должны работать. Также хотим обеспечить непрерывную интеграцию, включая развертывание решения на серверах заказчика.
Поэтому использовали такие технологии:
- .Net Core для реализации микросервисов. В нашем проекте использовалась версия 2.0,
- Kubernetes для оркестрации микросервисов,
- Docker для создания образов микросервисов,
- шина интеграции Rabbit MQ и Mass Transit,
- Elasticsearch и Kibana для логирования,
- TFS для реализации конвейера CI/CD.
В этой статье поделимся подробностями нашего решения.

Это расшифровка нашего выступления на .NET-митапе, вот ссылка на видео выступления.
Наша бизнес-задача
Наш заказчик — это федеральная компания, где есть мерчендайзеры — это люди, которые отвечают за то, как представлены товары в магазинах. А ещё есть супервайзеры – это руководители мерчендайзеров.
В компании есть процесс обучения и оценки работы мерчендайзеров супервайзерами, который необходимо было автоматизировать.
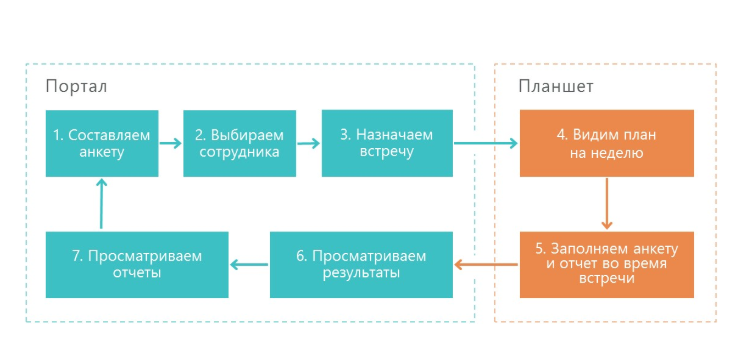
Вот как работает наше решение:
1. Супервайзер составляет анкету – это чеклист того, что нужно проверить в работе мерчендайзера.
2. Далее супервайзер выбирает сотрудника, чью работу будет проверять. Назначается дата анкетирования.
3. Далее активность отправляется на мобильное устройство супервайзера.
4. Затем анкета заполняется и отправляется на портал.
5. На портале формируются результаты и различные отчеты.
Микросервисы помогут нам решить три задачи:
1. Мы в перспективе хотим легко расширять функционал, так как подобных бизнес-процессов в компании много.
2. Мы хотим, чтобы решение было отказоустойчивым. Если какая-то часть перестанет функционировать, решение сможет самостоятельно восстановить свою работу, а отказ одной части не сильно повлияет на работу решения в целом.
3. Компания, для которого мы реализуем решение, имеет много филиалов. Соответственно, количество пользователей решения постоянно растёт. Поэтому хотелось, чтобы это не повлияло на производительность.
В итоге мы решили использовать микросервисы на этом проекте, что потребовало принять ряд нетривиальных решений.
Какие технологии помогли реализовать это решение:
• Docker упрощает распространение дистрибутива решения. Дистрибутив в нашем случае — это набор образов микросервисов
• Поскольку микросервисов в нашем решении много, нам необходимо ими управлять. Для этого мы используем Kubernetes.
• Сами микросервисы мы реализуем с помощью .Net Core.
• Чтобы быстро обновлять решение у заказчика, мы должны реализовать удобную непрерывную интеграцию и доставку.
Вот наш набор технологий в целом:
• .Net Core мы используем для создания микросервисов,
• Микросервис упаковывается в Docker-образ,
• Непрерывная интеграция и непрерывная доставка реализуется с помощью TFS,
• Фронтэндная часть реализована на Angular,
• Для мониторинга и логирования мы используем Elasticsearch и Kibana,
• RabbitMQ и MassTransit используются как шина интеграции.
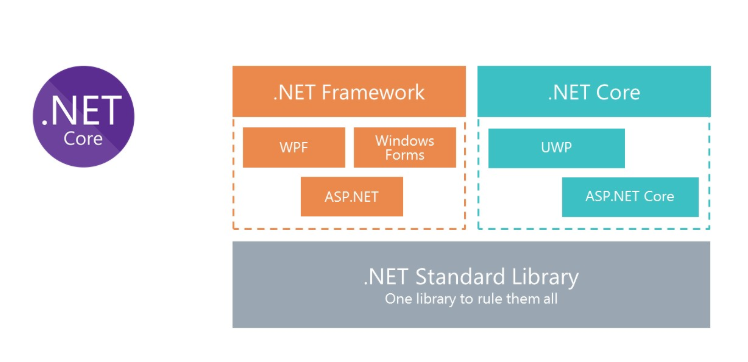
.NET Core для решений под Linux
Все мы знаем, что такое классический .Net Framework. Основным минусом платформы является то, что она не кроссплатформенная. Соответственно, мы не можем запустить в Docker решения на платформе .Net Framework под Linux.
Чтобы предоставить возможность использования C# в Docker, Microsoft переосмыслил .Net Framework и создал .Net Core. А чтобы использовать одни и те же библиотеки, Microsoft создал спецификацию .Net Standard Library. Сборки .Net Standart Library могут использоваться и в .Net Framework, и в .Net Core.
Kubernetes – для оркестрации микросервисов
Kubernetes используется для управления и кластеризации Docker-контейнеров. Вот главные преимущества Kubernetes, которыми мы воспользовались:
— предоставляет возможность легкой настройки окружения микросервисов,
— упрощает управление окружением (Dev, QA, Stage),
— из коробки предоставляет возможность репликации микросервисов и балансировки нагрузки на реплики.
Архитектура решения
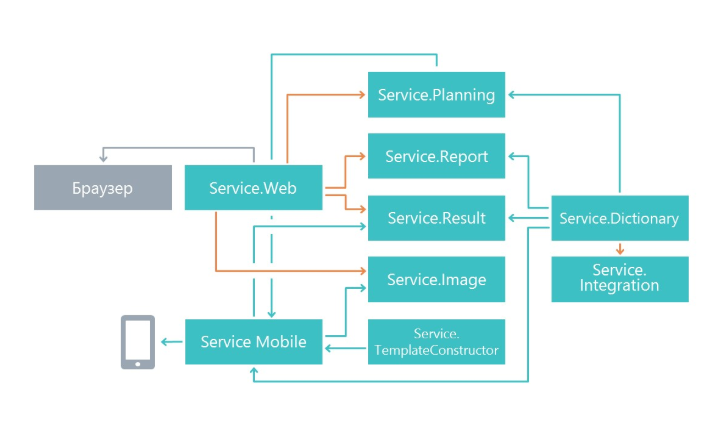
В начале работы мы задались вопросом, каким образом разделять функционал на микросервисы. Разбиение было сделано по принципу единой ответственности, только на уровне больше. Его главная задача — чтобы изменения в одном сервисе как можно меньше влияли на другие микросервисы. В итоге в нашем случае микросервисы начали выполнять обособленную область функционала.
В результате у нас появились сервисы, которые занимаются планированием анкетирования, микросервис отображения результатов, микросервис работы с мобильным приложением и другие микросервисы.
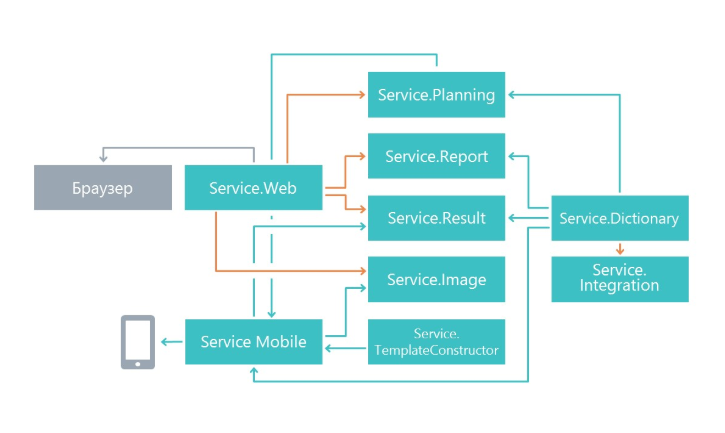
Варианты взаимодействия с внешними потребителями
Microsoft в своей книге о микросервисах «Микросервисы .NET. Архитектура контейнерных приложений .NET» предлагает три возможные реализации взаимодействия с микросервисами. Мы рассмотрели все три и выбрали наиболее подходящий.
• API Gateway service
API Gateway service — это реализация фасада для запросов пользователей к другим сервисам. Проблема решения в том, что если фасад не будет работать, то всё решение перестанет функционировать. От этого подхода решили отказаться ради отказоустойчивости.
• API Gateway with Azure API Management
Microsoft предоставляет возможность использования облачного фасада в Azure. Но это решение не подошло, поскольку мы собирались развернуть решение не в облаке, а на серверах заказчика.
• Direct Client-To-Microservice communication
В итоге у нас остался последний вариант — непосредственное взаимодействие пользователей с микросервисами. Его мы и выбрали.
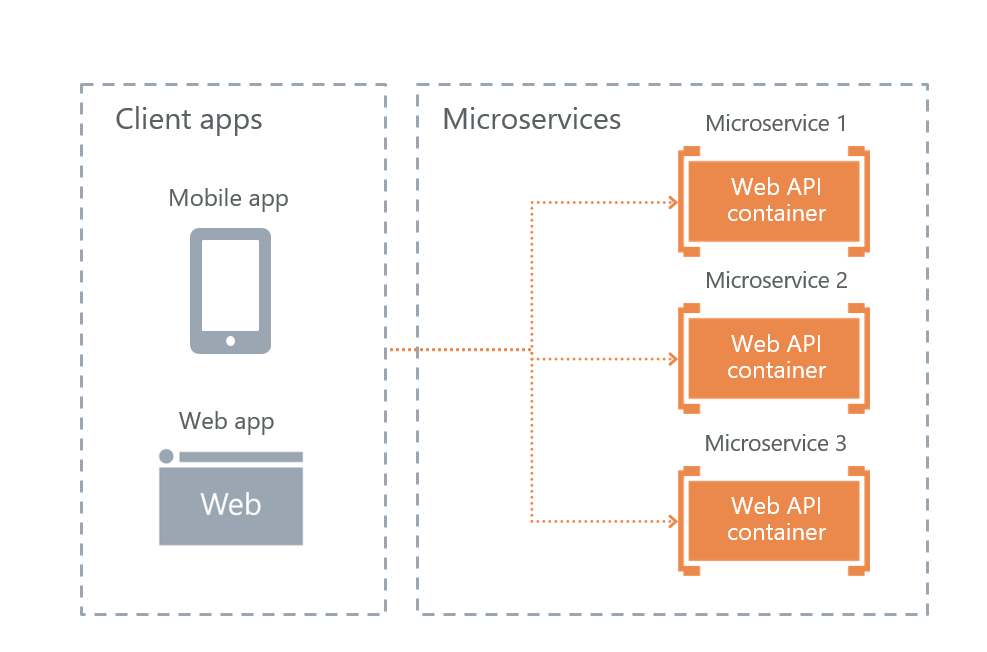
Его плюс в отказоустойчивости. Минусы в том, что часть функциональности придется воспроизводить на каждом сервисе отдельно. Например, настроить авторизацию пришлось отдельно на каждом микросервисе, к которому имеют доступ пользователи.
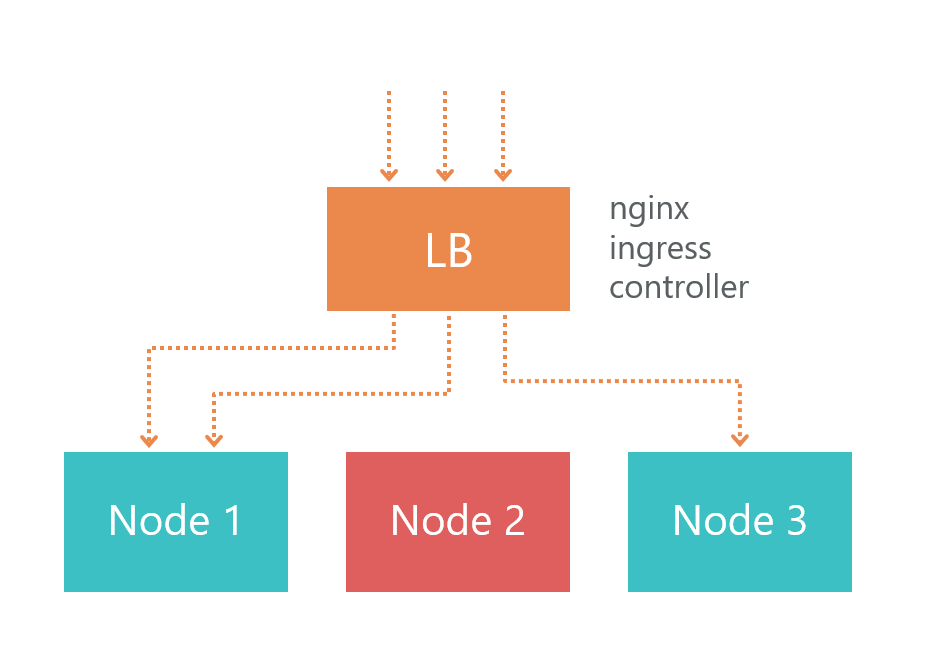
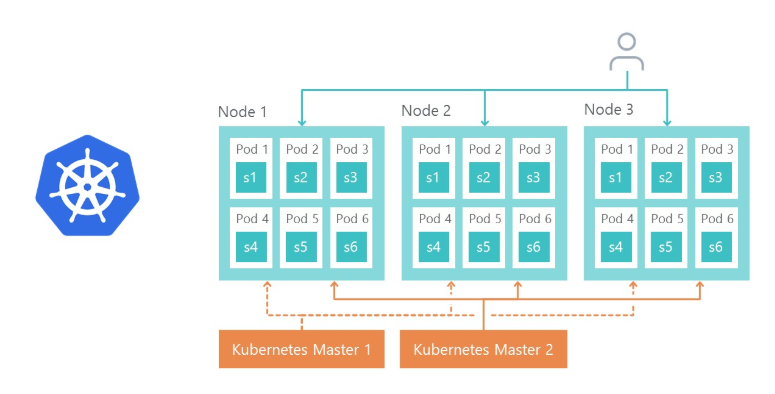
Конечно, возникает вопрос, каким образом будем балансироваться нагрузка и каким образом осуществляется отказоустойчивость. Тут все просто — этим занимается Ingress Controller Kubernetes.

Node 1, node 2 и node 3 – это реплики одного микросервиса. Если одна из реплик перестанет работать, то load balancer автоматически перенаправит нагрузку на другие микросервисы.
Физическая архитектура
Вот как мы организовали инфраструктуру нашего решения:
• Каждый микросервис имеет свою БД (если она ему, конечно, нужна), другие сервисы к БД другого микросервиса не обращаются.
• Микросервисы общаются между собой только по шине RabbitMQ + Mass Transit, а также с помощью HTTP запросов.
• Каждый сервис имеет свою четко обозначенную ответственность.
• Для логирования мы используем Elasticsearch и Kibana и библиотеку для работы с ним Serilog.
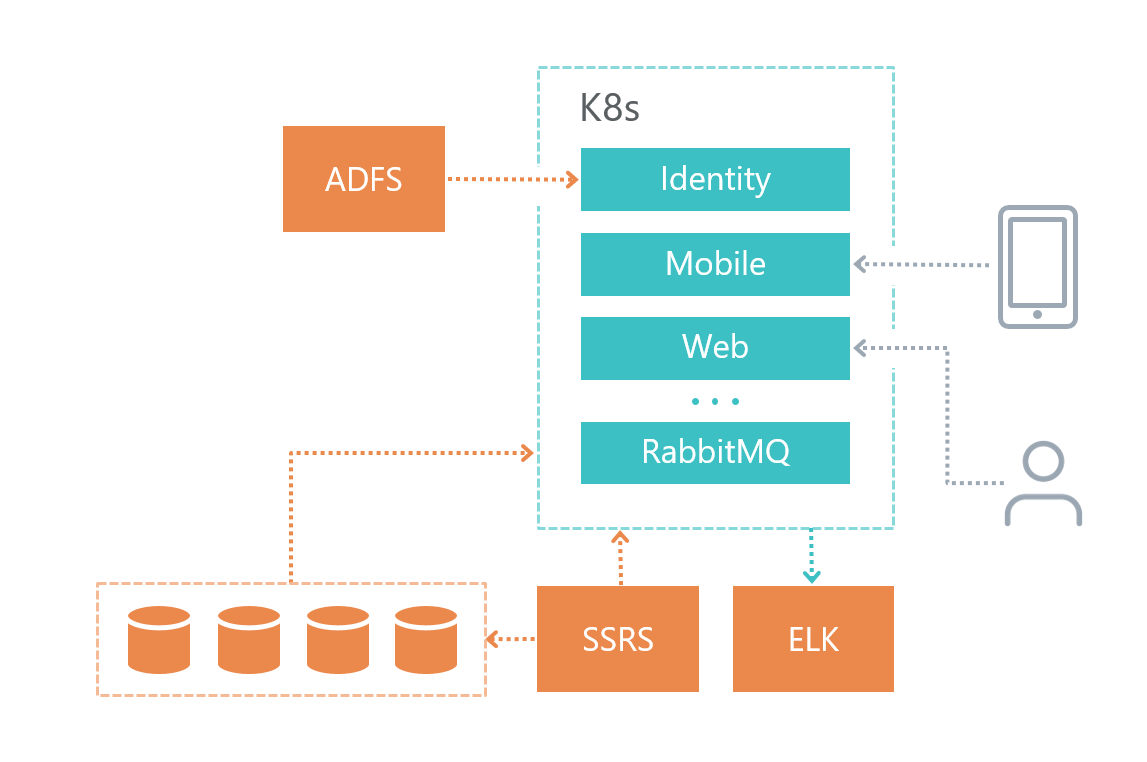
Сервис баз данных был развернут на отдельной виртуальной машине, а не в Kubernetes, потому что СУБД Microsoft не рекомендует использовать Docker на продуктовых средах.
Сервис логирования тоже был развернут на отдельной виртуалке из соображений отказоустойчивости — если у нас будут неполадки с Kubernetes, то мы сможем разобраться, в чем проблема.
Развертывание: как мы организовали разработческие и продуктовые окружения
На нашей инфраструктуре создано 3 неймспейса в Kubernetes. Все три окружения обращаются к одному сервису баз данных и одному сервису логирования. И, конечно, каждая среда смотрит на свой БД.
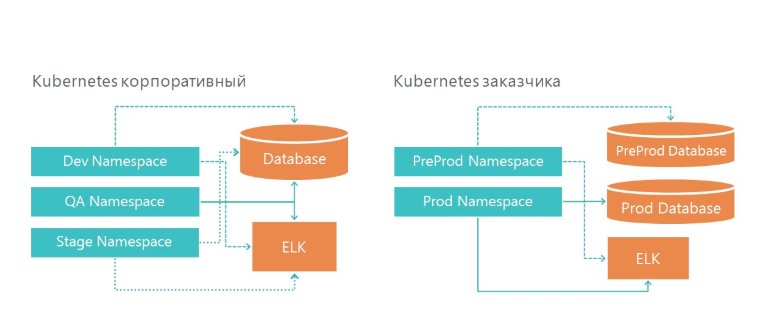
На инфраструктуре заказчика у нас также есть две среды — это предпрод и продакшн. На продакшене у нас есть отдельные серверы баз данных для предпрода и продуктовой среды. Для логирования у нас выделено по одному серверу ELK на нашей инфраструктуре и на инфраструктуре заказчика.
Как развернуть 5 сред с 10 микросервисами в каждом?
В среднем у нас 10 сервисов на проект и три среды: QA, DEV, Stage, на которых развернуто в сумме около 30 микросервисов. Причем это только на инфраструктуре разработки! Добавим ещё 2 среды на инфраструктуре заказчика, и у нас получается 50 микросервисов.
Понятно, что такое таким количеством сервисов необходимо как-то управлять. В этом нам помогает Kubernetes.
Для того, чтобы развернуть микросервис, необходимо
• Развернуть secret,
• Развернуть deployement,
• Развернуть service.
Про secret напишем ниже.
Деплоймент — это инструкция для Kubernetes, на основе которой он запустит Docker контейнер нашего микросервиса. Вот команда, которой развёртывается deployment:
kubectl apply -f .\(yaml конфигурация deployment-а) --namespace=DEVapiVersion: apps/v1beta1
kind: Deployment
metadata:
name: imtob-etr-it-dictionary-api
spec:
replicas: 1
template:
metadata:
labels:
name: imtob-etr-it-dictionary-api
spec:
containers:
- name: imtob-etr-it-dictionary-api
image: nexus3.company.ru:18085/etr-it-dictionary-api:18289
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
volumeMounts:
- name: secrets
mountPath: /app/secrets
readOnly: true
volumes:
- name: secrets
secret:
secretName: secret-appsettings-dictionary
Этот файл описывает, как называется деплоймент (imtob-etr-it-dictionary-api), какой образ ему необходимо использовать для исполнения, плюс другие настройки. В секции secret мы будем настраивать наше окружение.
После развертывания deployment нам необходимо развернуть service, если это необходимо.
Сервисы нужны тогда, когда необходим доступ к микросервису извне. Например, когда нужно, чтобы пользователь или другой микросервис смог сделать Get запрос другому микросервису.
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEVapiVersion: v1
kind: Service
metadata:
name: imtob-etr-it-dictionary-api-services
spec:
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
selector:
name: imtob-etr-it-dictionary-apiОбычно описание service небольшое. В нем мы видим название сервиса, каким образом к нему можно обратиться и номер порта.
В итоге для развертывания среды нам нужны
• набор файлов с secret-ами для всех микросервисов,
• набор файлов с deployment-ами всех микросервисов,
• набор файлов с service-ами всех микросервисов.
Все эти скрипты мы храним в git репозитории.
Для развертывания решения у нас получился набор из трех видов скриптов:
• папка с сикретами — это конфигурации для каждой среды,
• папка с deployment-ами для всех микросервисов,
• папка с service-ами для некоторых микросервисов,
в каждой – примерно по десять команд, по одной на каждый микросервис. Для удобства мы завели страницу со скриптами в Confluence, которая помогает нам быстро развернуть новое окружение.
Тут представлен скрипт развертывания deployment (подобные наборы есть для secret и для service):
Скрипт развертывания deployment
kubectl apply -f .\imtob-etr-it-image-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-mobile-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-planning-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-result-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-web.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-report-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-template-constructor-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-integration-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-identity-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-mobile-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-planning-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-result-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-web.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-report-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-template-constructor-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-integration-api.yml --namespace=DEV
kubectl apply -f .\imtob-etr-it-identity-api.yml --namespace=DEV
Реализация CI/CD
Каждый сервис находится в своей папке, плюс у нас есть одна папка с общими компонентами.
Также для каждого микросервиса есть Build Definition и Release Definition. Мы настроили запуск Build Definion при коммите в соответствующий сервис или при коммите в соответствующую папку. Если обновляется содержимое папки с общими компонентами, то разворачиваются все микросервисы.
Какие плюсы от такой организации Build-а мы видим:
1. Решение находится в одном git-репозитории,
2. При изменении в нескольких микросервисах сборка запускается параллельно при наличии свободных агентов сборки,
3. Каждый Build Definition представляет простой сценарий из сборки образа и его push-а в Nexus Registry.
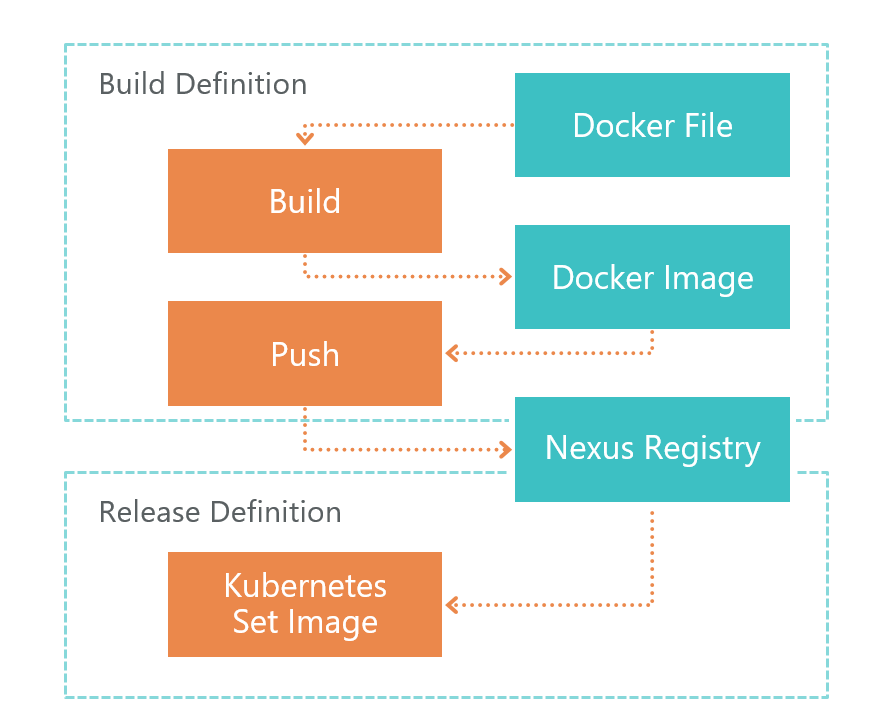
Build definition и Release Definition
Как развернуть VSTS-агент, мы ранее описали в этой статье.
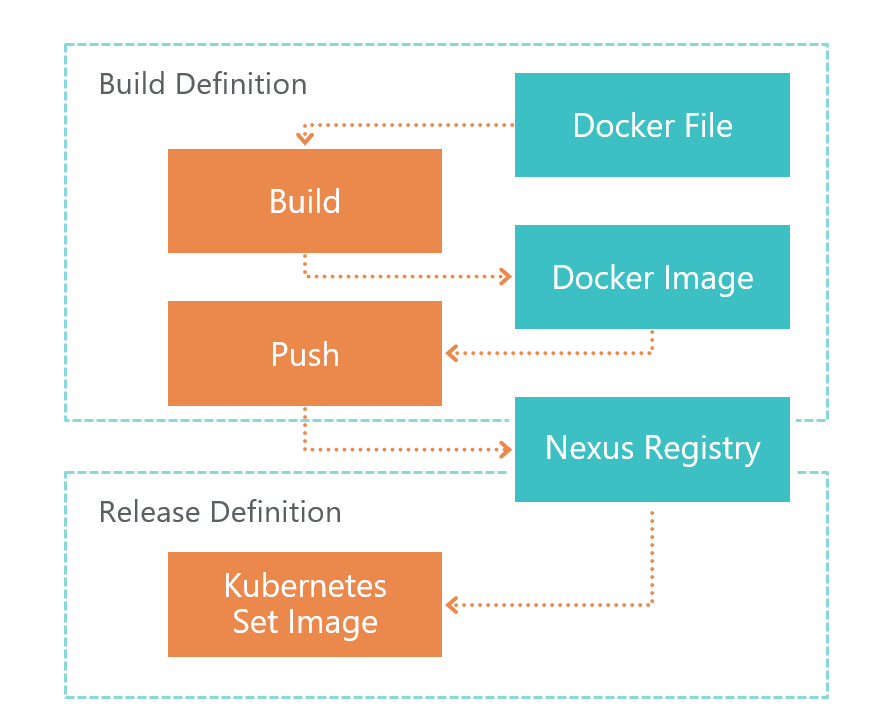
Сначала идёт Build Definition. По команде TFS VSTS агент запускает билд Dockerfile. В результате у нас получается образ микросервиса. Этот образ сохраняется локально на той среде, где запущен VSTS агент.
После билда запускается Push, который отправляет образ, который мы получили в предыдущем шаге, в Nexus Registry. Теперь его можно использовать извне. Nexus Registry — это своего рода Nuget, только не для библиотек, а для образов Docker и не только.
После того, как образ готов и доступен извне, его нужно развернуть. Для этого у нас есть Release Definition. Здесь все просто — мы выполняем команду set image:
kubectl set image deployment/imtob-etr-it-dictionary-api imtob-etr-it-dictionary-api=nexus3.company.ru:18085/etr-it-dictionary-api:$(Build.BuildId)После этого он обновит образ для нужного микросервиса и запустит новый контейнер. В итоге, наш сервис обновлен.
Давайте теперь сравним сборку с Dockerfile и без него.
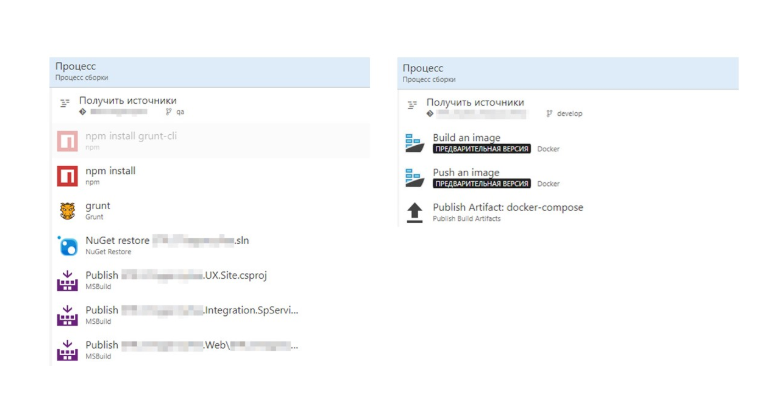
Без Dockerfile у нас получается много шагов, в которой много специфики .Net-а. Справа мы видим билд образа Docker. Все стало намного проще.
Весь процесс сборки образа описан в Dockerfile. Эту сборку можно отлаживать у себя локально.

Итого: мы получили простой и прозрачный CI/CD
1. Разделение разработки и развертывания. Сборка описывается в Dockerfile и лежит на плечах разработчика.
2. При настройке CI/CD не нужно знать о деталях и особенностях сборки — работа ведется только с Dockerfile-ом.
3. Обновляем только измененные микросервисы.
Далее требуется настрить RabbitMQ в K8S: об этом мы написали отдельную статью.
Настройка окружения
Так или иначе, нам необходимо конфигурировать микросервисы. Основная часть окружения настраивается в корневом файле конфигурации Appsettings.json. В этом файле хранятся настройки, которые не зависят от среды.
Те настройки, которые зависят от среды, мы храним в папке secrets в файле appsettings.secret.json. Мы взяли подход, описанный в статье Managing ASP.NET Core App Settings on Kubernetes.
var configuration = new ConfigurationBuilder()
.AddJsonFile($"appsettings.json", true)
.AddJsonFile("secrets/appsettings.secrets.json", optional: true)
.Build();В файле appsettings.secrets.json хранятся настройки индексов Elastic Search и строка подключения к БД.
{
"Serilog": {
"WriteTo": [
{
"Name": "Elasticsearch",
"Args": {
"nodeUris": "http://192.168.150.114:9200",
"indexFormat": "dev.etr.it.ifield.api.dictionary-{0:yyyy.MM.dd}",
"templateName": "dev.etr.it.ifield.api.dictionary",
"typeName": "dev.etr.it.ifield.api.dictionary.event"
}
}
]
},
"ConnectionStrings": {
"DictionaryDbContext": "Server=192.168.154.162;Database=DEV.ETR.IT.iField.Dictionary;User Id=it_user;Password=PASSWORD;"
}
}
Добавляем файл конфигурации в Kubernetes
Для того, чтобы добавить этот файл, его нужно развернуть в Docker-контейнере. Это делается в файле deployment-а кубернетиса. В deployment-е описывается в какой папке нужно создать файл c secret и с каким secret-ом нужно ассоциировать файл.
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: imtob-etr-it-dictionary-api
spec:
replicas: 1
template:
metadata:
labels:
name: imtob-etr-it-dictionary-api
spec:
containers:
- name: imtob-etr-it-dictionary-api
image: nexus3.company.ru:18085/etr-it-dictionary-api:18289
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"
volumeMounts:
- name: secrets
mountPath: /app/secrets
readOnly: true
volumes:
- name: secrets
secret:
secretName: secret-appsettings-dictionary
Создать secret в Kubernetes можно с помощью утилиты kubectl. Мы видим тут название secret-а и путь до файла. Также мы тут указываем название окружения, для которого создаем secret.
kubectl create secret generic secret-appsettings-dictionary
--from-file=./Dictionary/appsettings.secrets.json --namespace=DEMOВыводы
Минусы выбранного подхода
1. Высокий порог входа. Если делаете подобный проект впервые, будет много новой информации.
2. Микросервисы → более сложное проектирование. Необходимо применять много неочевидных решений из-за того, что у нас не монолитное решение, а микросервисное.
3. Не все реализовано для Docker. Не все можно запустить в микросервисной архитектуре. Например, пока SSRS нет в докере.
Плюсы подхода, проверенные на себе
1. Инфраструктура как код
Описание инфраструктуры хранится в source control. В момент развертывания не нужно адаптировать окружение.
2. Масштабирование как на уровне функционала, так и на уровне производительности из коробки.
3. Микросервисы хорошо изолированы
Практически нет критичных частей, отказ которых приводит к неработоспособности системы в целом.
4. Быстрая доставка изменений
Обновляются только те микросервисы, в которых были изменения. Если не учитывать время на согласования и другие вещи, связанные с человеческим фактором, то обновление одного микросервиса у нас происходит за 2 минуты и меньше.
Выводы для нас
1. На .NET Core можно и нужно реализовывать промышленные решения.
2. K8S действительно облегчил жизнь, упростил обновление сред, облегчает конфигурирование сервисов.
3. TFS можно использовать для реализации CI/CD для Linux.
