
Вы знаете, что «нобелевку» по научной фантастике получил китайский автор Лю Цысинь (Liu Cixin, 劉慈欣) с произведением The Three-Body Problem ( 三體). На эту книгу обратили внимание Барак Обама (пруф) и Марк Цукерберг (пруф).

Ольга Браатхен по своей инициативе перевела книгу на русский (вот тут можно качнуть fb2), за что ей большое спасибо.
Еще один кандидат на «нобелевку» в 2016 — это Нил Стивенсон (написавший «Лавину» и «Криптономикон») с произведением Seveneves (качнуть на английском можно тут, жаль, что на русский никто не взялся переводить).
Разработчики компании EDISON создали программу Управления доступом к электронным документам, о чем я писал пару лет назад, а сегодня речь пойдет об SDK для внедрения поддержки электронных книг в формате FB2.
Введение
Применение информационных технологий в библиотечной сфере привело к появлению интернет-сервисов, предоставляющих читателям удаленный доступ к богатому набору художественной, научной и технической литературы. Такие сервисы выводят библиотечное дело на новый уровень. Библиотеки могут объединяться в единую сеть, формируя огромную географически распределенную базу оцифрованного контента, а предоставление библиотечных услуг в интернет расширяет целевую аудиторию и дает дополнительный доход. Ключевые пользователи также получают преимущества: не нужно тратить время на поездку в библиотеку, брать книги в личное пользование и заботиться о своевременной сдаче; возможен доступ к редкой литературе, отсутствующей в конкретном населенном пункте. Правообладатели могут получать роялти, предоставляя контент на взаимовыгодных условиях.
Особое внимание в библиотечных сервисах отводится соблюдению авторских прав и защите от копирования. На транспортном уровне используются проприетарные форматы, а программное обеспечение на стороне клиента не должно сохранять полученный контент на диске.
Основная часть контента формируется путем ручной оцифровки физических носителей с применением сканеров и последующим распознаванием текста для обеспечения возможности поиска, но это не единственный источник. Существует множество цифровых форматов, предназначенных для хранения электронных книг, и уже оцифрованных книг в данных форматах тоже не мало. Соответственно, нужна поддержка различных электронных форматов в библиотечных сервисах. Расскажу о разработке SDK (инструментария разработчика) для внедрения поддержки электронных книг в формате Fiction Book в один из сервисов.
Задача
Сервис доставки контента предоставляет пользователям постраничный доступ к литературе в удаленном хранилище. Доступ к каждой странице фиксируется и тарифицируется. В сервисе реализован полнотекстовый поиск, результаты которого подсвечиваются полупрозрачными прямоугольниками. Трафик между сервером и клиентом защищен и представляет собой проприетарный бинарный формат.
Перед программистами EDISON стояла задача создать SDK, предоставляющую конечному разработчику набор готовых к использованию функций, способствующих упрощению процедуры внедрения поддержки электронных книг в формате FB2, а также использованию общей кодовой базы при построении серверной и клиентской части решения.
Исходя из функциональных возможностей сервиса, требования к набору функций SDK были определены заранее:
- получение библиографической информации;
- получение количества страниц электронной книги;
- получение результатов полнотекстового поиска со ссылками на соответствующие страницы;
- получение координат прямоугольников для подсветки результатов полнотекстового поиска;
- получение контента произвольной страницы в бинарном формате и рендеринг страницы.
Реализация и технологии: С++ / Qt
Решение
Электронная книга в FB2 — одностраничный документ. В формате не предусмотрено информации как должен выглядеть документ. В первую очередь, предстояло решить проблему с разбиением FB2-документа на страницы, не дублируя при этом содержимое документа. В результате был спроектирован формат индексного файла, который хранит мета-данные об исходном FB2-документе, полученные в результате парсинга оригинального документа, рендеринга и разбиения документа на страницы.
Индексный файл содержит местонахождение фрагментов XML документа в виде смещения от начала документа и длины фрагмента в количестве знаков, а также XML-префикс.
Структура индексного файла включает три раздела:
- description — фрагмент с описанием документа;
- binary — фрагменты с картинками в оригинальном документе;
- page — фрагменты документа, где начинаются и заканчиваются страницы, полученные в результате рендеринга с заданными параметрами размера страницы, отступов и шрифта.
Информация о местонахождении фрагмента XML-документа позволяет вычитать нужный кусок информации из оригинального документа без необходимости его парсинга, XML-префикс позволяет построить миниатюрный XML-документ, содержащий разметку только нужной страницы, распарсить ее и тут же отрендерить нужную страницу по запросу пользователя.
Пример индексного файла с разбиением документа на страницы.
<document>
<description>
<fragment>
<offset>418</offset>
<length>5230</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink">]]></prefix>
</fragment>
</description>
<binary id="cover.jpg" >
<fragment>
<offset>43034</offset>
<length>48151</length>
</fragment>
</binary>
<page number="1" >
<fragment>
<offset>5657</offset>
<length>1779</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body>]]></prefix>
</fragment>
</page>
<page number="2" >
<fragment>
<offset>7436</offset>
<length>2366</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body><section><section><p>]]></prefix>
</fragment>
</page>
</document>Когда появилось представление об алгоритме разбиения документа на страницы, мы приступили к его реализации. Для формирования индекса был выбран метод потокового парсинга оригинального документа с использованием стандартных классов библиотеки Qt, благодаря возможности последовательного чтения XML-файла и сохранения информации о смещении в файле в количестве знаков, посредством метода QXmlStreamReader::characterOffset.
В процессе парсинга FB2-документа по мере продвижения от тега к тегу, параграфы документа разбираются на наборы слов, которые затем снова собираются в строки. В соответствии с файлом настроек каждой строке задается максимальная ширина с учетом заданной ширины полей страницы и отступа для параграфов. Для строк также задается межстрочный интервал, указанный в файле настроек. В зависимости от тегов XML-документа задаются параметры шрифта, размер, начертание и выравнивание. Для заголовков и подзаголовков задается выравнивание по центру, для эпиграфов — выравнивание по правому краю, по умолчанию — выравнивание по левому краю. По мере добавления слов в строку длина строки пересчитывается путем сложения длины всех добавленных слов. Если длина строки превышает заданную ширину страницы, то строка добавляется к объекту страницы; слово, которое не влезло в строку, добавляется в очередную строку. По мере добавления строк к странице, пересчитывается высота всех строк с учетом межстрочного интервала. При внедрении картинок за высоту строки пришлось считать максимальную высоту объекта, добавленного к строке. Если высота всех добавленных строк превышает заданную высоту страницы с учетом отступов, в индексный файл добавляется очередной фрагмент. Описанный алгоритм применяется как при разбиении FB2-документа на страницы, так и при произвольном доступе к странице по средством использования индексного файла.
Так как метод QXmlStreamReader::characterOffset возвращает смещение в количестве знаков, а не в байтах, то при произвольном доступе к страницам документа пришлось вычитывать начало оригинального файла, и только затем вычитывать интересующую часть документа, так как документ может содержать кириллицу и латиницу, и использование одного лишь смещения по файлу в байтах, используя метод seek, неизбежно привело бы к ошибкам.
QString Document::documentFragment(uint offset, uint length)
{
QString fragment;
QFile file(m_fileName);
if (!file.open(QIODevice::ReadOnly))
{
m_error = IOError;
return fragment;
}
QTextStream fileStream(&file);
fileStream.setCodec("UTF-8");
fileStream.setAutoDetectUnicode(true);
fileStream.seek(0);
fileStream.read(offset);
fragment = fileStream.read(length);
file.close();
if ((uint) fragment.size() < length)
{
m_error = IOError;
fragment = QString();
return fragment;
}
return fragment;
}Несмотря на это, потери в производительности нет, доступ к последней странице документа осуществляется так же быстро, как и к первой странице, и занимает менее секунды. Дело в том, что средний объем книги без картинок в формате FB2 редко превышает 10 Мб.
Разбиение 7 Мб файла на 998 страниц и подготовка индекса занимают около 10 секунд. Разбиение 9 Мб файла на 1576 страниц занимает около 15 секунд. В среднем за одну секунду рендерится порядка 100 страниц. При наличии индекса документ открывается за 50 миллисекунд.
Далее предстояло решить задачу полнотекстового поиска с привязкой к страницам документа. И тут для обеспечения быстродействия всё-таки пришлось дублировать содержимое документа, но уже без XML-разметки, а в виде обычного текстового файла. В текстовый индекс вставляются маркеры начала и окончания страницы в виде нулевого байта. Для привязки результатов поиска к страницам и хранения координат прямоугольников, понадобилось организовать два вспомогательных индекса в бинарном формате. Вспомогательный индекс для привязки результатов поиска к страницам хранит номер страницы, порядковый номер начального и конечного байта маркера страницы в текстовом индексе.
Полнотекстовый поиск осуществлялся с помощью библиотеки, предоставленной заказчиком, которая возвращает все словоформы по заданному слову. Поисковый запрос разбивается на набор слов, затем по каждому слову находятся все словоформы, затем по сформированному массиву найденных словоформ осуществляется поиск в текстовом индексе. С помощью вспомогательного индекса и маркеров начала/окончания страницы в текстовом индексе определяются номера страниц, к которым принадлежат результаты поиска. Вспомогательный индекс с координатами прямоугольников формируется лишь при запросе страницы. На каждую страницу формируется отдельный индексный файл. В процессе получения координат прямоугольников задействован все тот же алгоритм разбиения оригинального документа на страницы благодаря разбиению строк на слова и вычислению границ каждого слова, а индекс служит для того, чтобы не вызывать этот алгоритм повторно при переходе на ту же страницу.
Создание индексов для полнотекстового поиска занимает уже около минуты на документах объемом около 10 Мб. Поиск же, при наличии индексов, работает около одной секунды на документе с 1576 страницами.
Очередным сюрпризом было отображение полупрозрачных прямоугольников над найденными фрагментами текста. Так как изначально математика по расчету границ слов была в пикселях, это вызвало неточности в несколько пикселей при масштабировании страниц документа. Решение было найдено: пришлось всего лишь перевести все вычисления в дюймы с учетом DPI-устройства вывода, используя при этом значения с плавающей точкой вместо целочисленных, исправив при этом существенную часть кода.
m_dpiX = (qreal) QApplication::desktop()->physicalDpiX();
m_dpiY = (qreal) QApplication::desktop()->physicalDpiY();
QFontMetricsF fm(m_font);
m_rect = fm.boundingRect(m_text);
m_textDescent = fm.descent() / m_dpiY;
qreal width = m_rect.width() / m_dpiX;
qreal height = m_rect.height() / m_dpiY;
m_rect.setSize(QSizeF(width, height)); На финишной прямой оставалось решить вопрос с сериализацией представления страницы, включая набор прямоугольников, в бинарный формат и обратного чтения из него для передачи содержимого страницы на клиента и последующего рендеринга посредством все той же SDK. Тут оказалось все достаточно просто: на помощь пришел стандартный класс библиотеки QT, QDataStream.
В процессе декомпозиции при решении задачи были выделены следующие классы.
- Fb2Document — документ FB2, основной класс, инкапсулирует логику парсинга документа, разбиения на страницы, формирования индекса, предоставления доступа к произвольной странице с использованием сформированного индекса, а также полнотекстовый поиск.
- Fb2Page — страница FB2-документа, инкапсулирует логику заполнения страницы набором строк документа и рендеринга страницы, определение признака окончания страницы. Предоставляет интерфейс для задания размера страницы в дюймах по ширине и высоте, а также отступы от краев страницы.
- Fb2Word — слово, инкапсулирует логику вычисления границ слова в дюймах на канве документа, в соответствии с заданными параметрами шрифта, сериализацию слов страницы документа в бинарный формат, чтение слов из бинарного формата.
- Fb2String — строка из набора слов (Fb2Word), инкапсулирует логику заполнения строк списком слов, определение признака окончания строки, выравнивание строки по левому, правому краю и по центру, учет межстрочного интервала заданного в файле настроек, сериалиазацию строк страницы документа в бинарный формат, чтение из строк из бинарного формата.
- Fb2Image — изображение, инкапсулирует логику рендеринга картинок документа, сериализацию картинок в бинарный формат, чтение картинок из бинарного формата.
- Fb2Index — индекс, инкапсулирует логику формирования индексного файла и чтение из него.
- Fb2Fragment — фрагмент FB2-документа, представляет собой основную структуру индексного файла.
- Fb2Settings — файл настроек, инкапсулирует логику работы с файлом настроек чтение/запись.
- Fb2Func — класс обертка, предоставляет набор функций SDK в соответствии с интерфейсом, заданным при постановке задачи.
- Dictionary — класс обертка над морфологическим словарем.
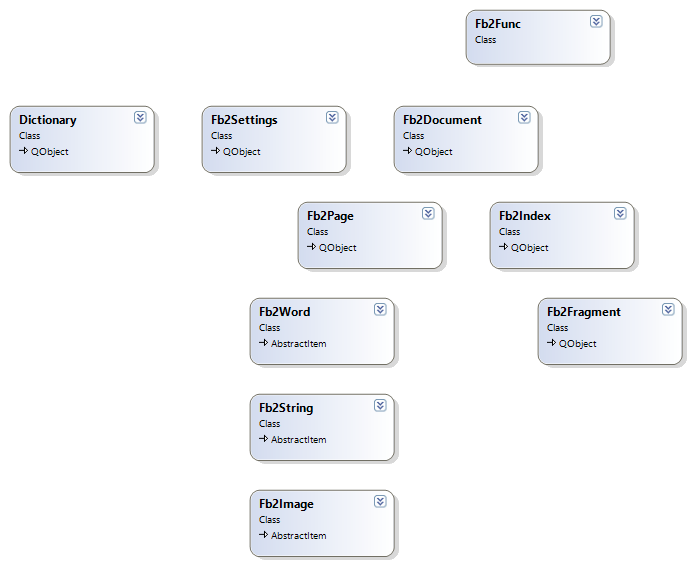
Методы всех классов SDK были покрыты модульными тестами, чтобы гарантировать корректность разбиения FB2-документа на страницы, а также что пользователь в клиентской программе увидит ровно ту же картинку при запросе страницы, что будет изначально отрендерена на стороне сервера при подготовке индексного файла.
В результате конечная цель была достигнута. Преимущество разработки SDK по сравнению с коробочным решением заключается в гибкости. Все самое сложное скрыто за вызовом простых функций, а разработчик, использующий SDK может самостоятельно принимать решения, как ее использовать: например, строить ли индексы заранее для обеспечения быстродействия функций системы и более комфортной работы пользователей или строить индексы по первому обращению к документу и первому поисковому запросу и удалять их при редком использовании для экономии дискового пространства.
Для демонстрации работоспособности SDK заказчику, на ее основе было реализовано два Desktop-приложения. FictionBookReader предоставляет функционал примитивного ридера FB2-документов с возможностью постраничного просмотра и полнотекстового поиска с подсветкой результатов поиска.
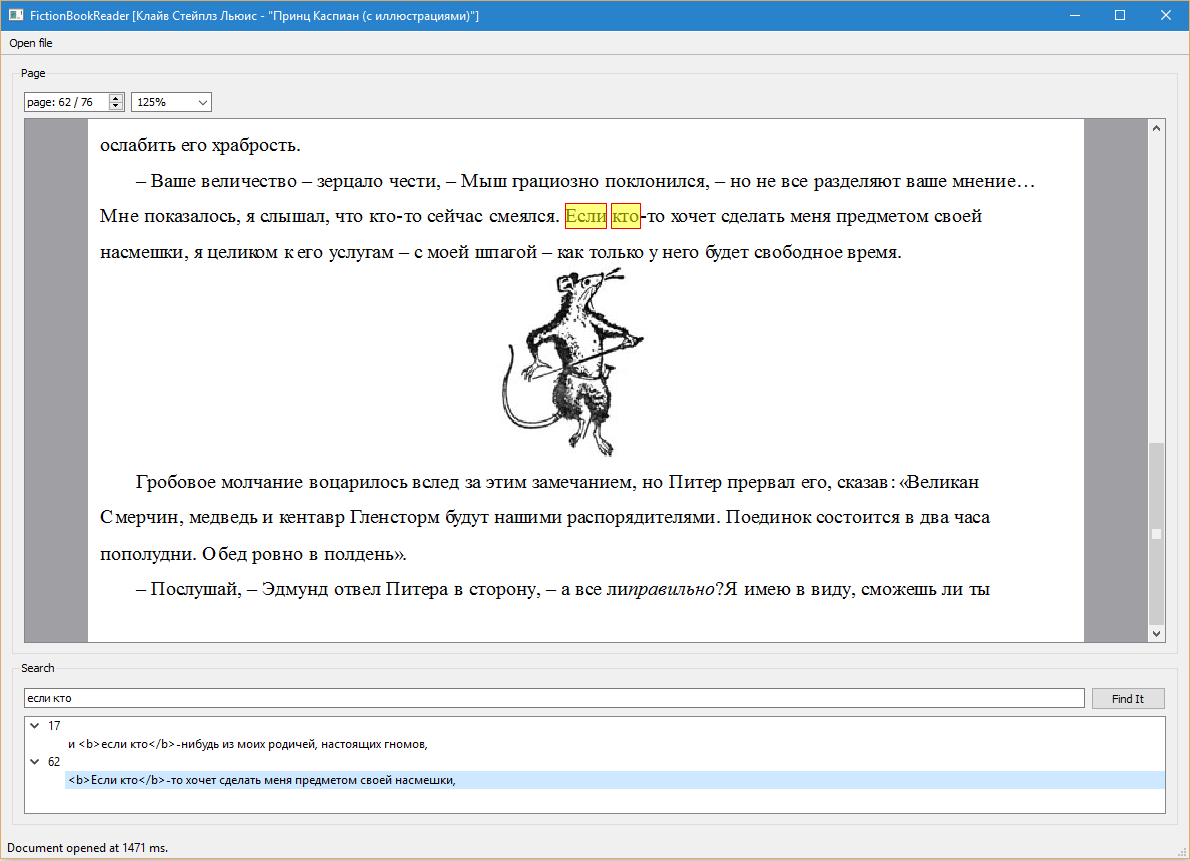
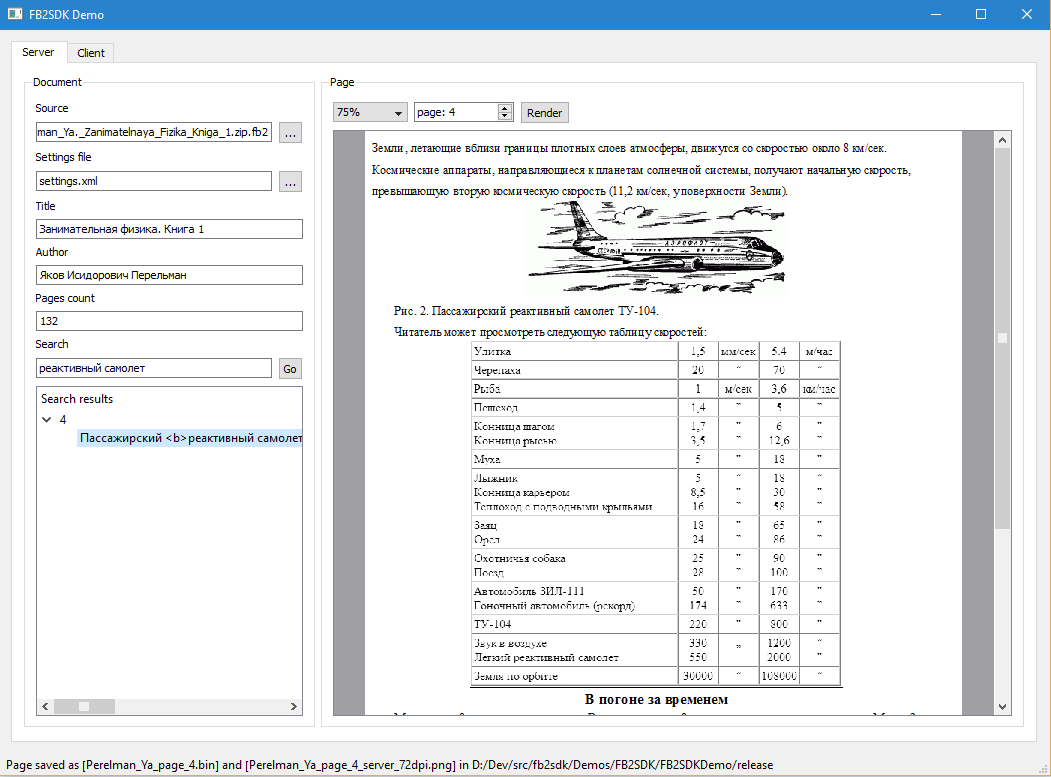
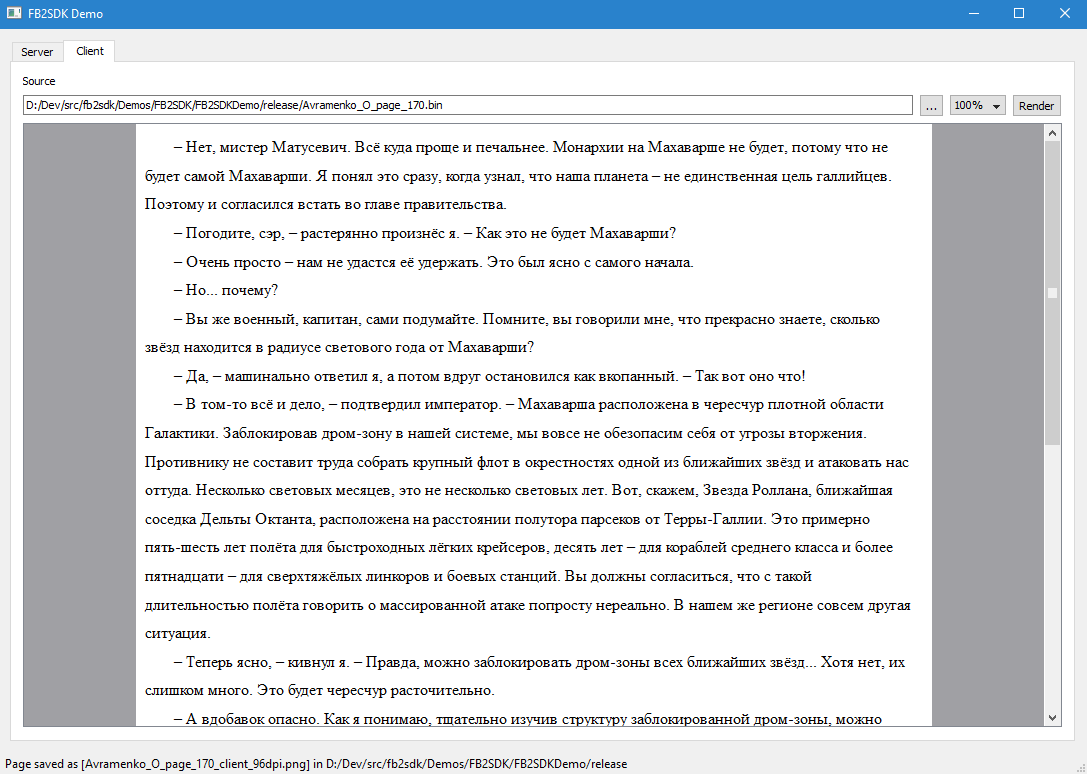
FB2SDK Demo наглядно показывает функционал серверной и клиентской части SDK. Функционал серверной части выделен во вкладку Server, которая демонстрирует парсинг документа и формирование многостраничного индекса, а также формирование файлов с прямоугольниками и полнотекстового индекса. Функционал клиентской части выделен во вкладку Client, которая демонстрирует рендеринг страницы документа по сформированному бинарному файлу.

Больше проектов:
Как за 5233 человеко-часа создать софт для микротомографа
SDK для внедрения поддержки электронных книг в формате FB2
Управление доступом к электронным документам. От DefView до Vivaldi
Интегрируем две системы видеонаблюдения: Axxon Next и SureView
Подробнее о разработке софта рентгеновского томографа
«Сфера»: как мониторить миллиарды киловатт-часов
Разработка простого плагина для JIRA для работы с базой данных
В помощь DevOps: сборщик прошивок для сетевых устройств на Debian за 1008 часов
Автообновление службы Windows через AWS для бедных
