Автор — Zeesha Currimbhoy, Senior Data Products Engineer в Evernote

После прихода в Evernote я первым делом начала работать над продумыванием и реализацией автоматических подсказок в поисковой строке в Evernote для Mac.
Вот как это выглядит сейчас:
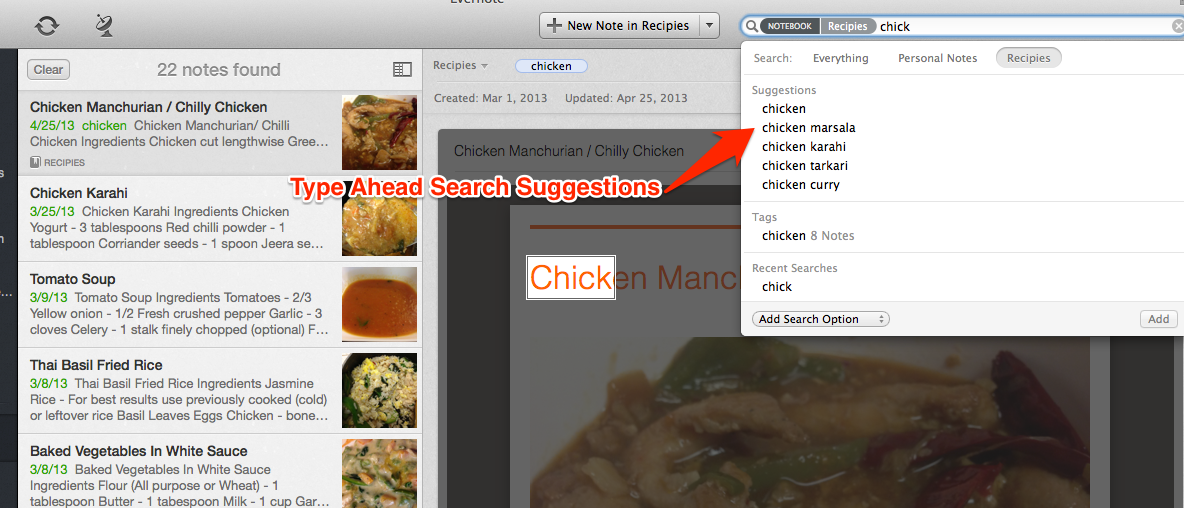
Большинство из нас периодически сталкивается с тем, что не может точно сформулировать запрос, оказавшись один на один с поисковой строкой и мигающим курсором. Для решения этой проблемы мы добавили динамические поисковые подсказки, предлагаемые по мере ввода текста, которые формируются на основе заметок самого пользователя.
В этой статье я хочу коснуться некоторых особенностей реализации поисковых подсказок в Evernote.
Для многих из нас поисковые подсказки стали неотъемлемой частью повседневной жизни. Уже не так просто вспомнить, каким был поиск в Google до подсказок. Несмотря на то, что широкое распространение они получили не так давно, мы уже инстинктивно ожидаем выпадающий список подходящих вариантов запроса от любой поисковой строки, которая нам встречается.
Так похожие внешне, подсказки у различных сервисов на самом деле работают по-разному. Google формирует варианты из своей непрерывно растущей базы поисковых запросов. Так что пользователю подсказывают варианты, которые часто искали другие люди до него, но эти варианты, возможно, совсем ему не знакомы. Вместе с тем эта модель хорошо работает для веб-поиска, который должен находить самую разнообразную информацию по всему миру.
В случае же с поиском в Evernote речь идет о собственной информации. В результатах поиска Evernote вы видите те данные, которые сами когда-то добавили, и именно их мы используем для формирования подсказок. Мы имеем дело с изолированным набором заметок и не можем дополнить их данными посторонних пользователей. Таким образом, пока многие другие сервисы говорят о проблеме «Больших данных» (Big Data), Evernote сталкивается с миллионами и миллионами проблем «малых данных». Каждый набор данных, как и каждый пользователь, уникален.
Еще одно отличие — тип контента, который мы используем для формирования подсказок. Многие сервисы, поддерживающие поисковые подсказки, предлагают дискретные варианты запросов из конечного (хотя и большого) набора – это могут быть ранее введенные поисковые запросы, люди, компании и т. д. В Evernote же подсказки могут извлекаться из любого контента, как структурированного, так и нет, который присутствует в любой из ваших заметок и на любом языке. Система определяет релевантность подсказок для пользователя, анализируя контент самих заметок.
Мы работаем над кроссплатформенным сервисом и стараемся, чтобы пользователям Evernote было одинаково удобно работать на всех устройствах, которые они любят. Поэтому нам пришлось принять нелегкое решение при выборе платформы для реализации подсказок в самом начале, выбирая, создать ли систему на стороне сервера, чтобы иметь потенциальную возможность сразу использовать ее на всех клиентах, или же начать с нативной реализации в отдельно взятом клиенте. Мы выбрали второй вариант и начали с Mac по нескольким причинам.
Три главных компонента, лежащих в основе данной функциональности, это индекс терминов, создание подсказок и их извлечение.
Индекс терминов
Поисковые подсказки хранятся в инвертированном индексе, отдельно от основного поискового индекса. Мы рассматривали возможность использования самого поискового индекса, но обнаружили, что хотя теоретически его и можно взять за основу, он слишком заточен под поиск отдельных ключевых слов, и на выходе получаются подсказки очень низкого качества.
Так что в нашем индексе мы связали каждый термин со списком заметок, которые его содержат.
Создание подсказок
Механизм поисковых подсказок начинает работать еще до того, как пользователь начнет печатать в поисковой строке. Каждый раз при создании, изменении или удалении заметок мы генерируем список потенциальных подсказок из заголовка, меток и содержимого заметки, которые затем упорядочиваются и попадают в инвертированный индекс.
Работает это следующим образом.
Мы начинаем с обнаружения отдельных слов в тексте заметки. Слова проходят через серию фильтров, нормализующих текст (например, перевод в нижний регистр, ликвидация диакритических знаков) и удаляющих стоп-слова (чересчур общие). Отфильтрованные слова затем могут дополнительно группироваться во фразы, которые могут быть релевантными тому или иному тексту. Наконец, слова и фразы, прошедшие фильтры, сериализуются в виде записей индекса.
На данном шаге также необходимо учитывать особенности некоторых языков. Например, китайский и японский языки не используют пробелы для отделения слов друг от друга. Поэтому приходится применять более сложные алгоритмы поиска границ слов. Эта проблема становится еще интереснее (и сложнее), если учесть, что в заметке могут быть записи сразу на нескольких языках.
И конечно, весь процесс должен проходить в фоновом режиме, используя незанятые в данный момент ресурсы системы, и не мешать пользователю.
Извлечение подсказок
Мы готовы к поиску — что же происходит теперь? Когда пользователь начинает вводить текст в поисковой строке, система извлечения подсказок в первую очередь определяет набор заметок, которые попадают в вводимый запрос по контексту и удовлетворяют комбинации блокнотов и меток, по которым ищет пользователь. Затем введенная часть поискового запроса ищется в индексе подсказок, чтобы получить набор возможных завершений фразы. И наконец, мы отфильтровываем все завершения, которые не попадают в подходящие по контексту заметки.
Затем мы оцениваем каждую подсказку и ранжируем по релевантности по специальной формуле на базе TF-IDF. Наиболее высоко оцененные подсказки выходят в финал, где очень похожие подсказки (например, «ice skate» и «ice skating») объединяются.
Во многом, этот компонент — самый сложный, но он же должен быть и самым быстрым, поскольку требуется выдать пользователю результат менее чем за секунду. Поэтому в плане производительности мы уделили этой части системы подсказок особое внимание.
Если вы работаете с Evernote для Mac и еще не пробовали эту возможность, я бы очень хотела, чтобы вы поработали с ней и рассказали о впечатлениях.
В будущем мы добавим эту функциональность в некоторые другие клиенты Evernote.

После прихода в Evernote я первым делом начала работать над продумыванием и реализацией автоматических подсказок в поисковой строке в Evernote для Mac.
Вот как это выглядит сейчас:
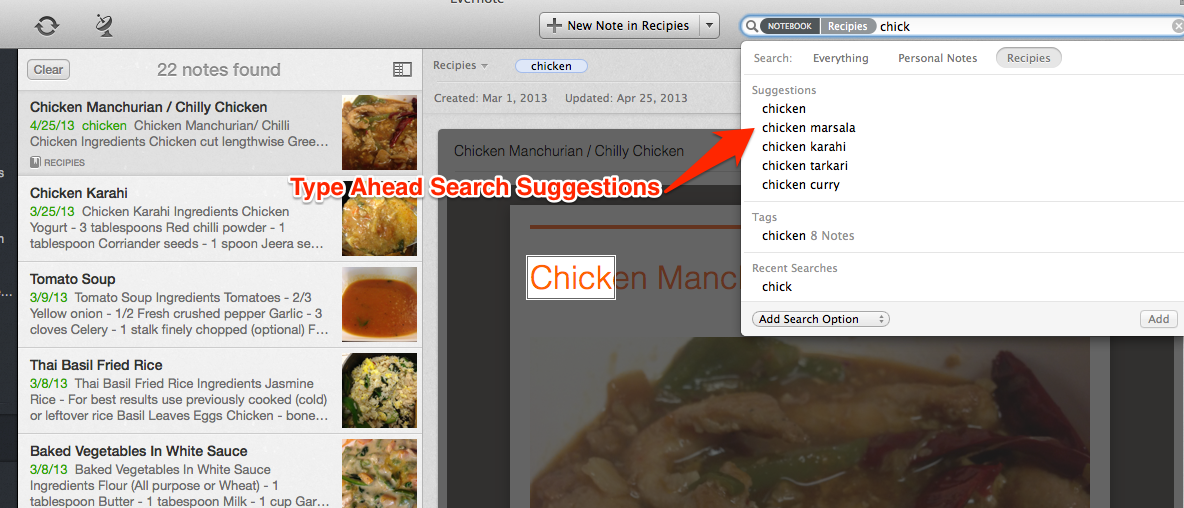
Большинство из нас периодически сталкивается с тем, что не может точно сформулировать запрос, оказавшись один на один с поисковой строкой и мигающим курсором. Для решения этой проблемы мы добавили динамические поисковые подсказки, предлагаемые по мере ввода текста, которые формируются на основе заметок самого пользователя.
В этой статье я хочу коснуться некоторых особенностей реализации поисковых подсказок в Evernote.
Чем отличаются поисковые подсказки Evernote от любых других?
Для многих из нас поисковые подсказки стали неотъемлемой частью повседневной жизни. Уже не так просто вспомнить, каким был поиск в Google до подсказок. Несмотря на то, что широкое распространение они получили не так давно, мы уже инстинктивно ожидаем выпадающий список подходящих вариантов запроса от любой поисковой строки, которая нам встречается.
Так похожие внешне, подсказки у различных сервисов на самом деле работают по-разному. Google формирует варианты из своей непрерывно растущей базы поисковых запросов. Так что пользователю подсказывают варианты, которые часто искали другие люди до него, но эти варианты, возможно, совсем ему не знакомы. Вместе с тем эта модель хорошо работает для веб-поиска, который должен находить самую разнообразную информацию по всему миру.
В случае же с поиском в Evernote речь идет о собственной информации. В результатах поиска Evernote вы видите те данные, которые сами когда-то добавили, и именно их мы используем для формирования подсказок. Мы имеем дело с изолированным набором заметок и не можем дополнить их данными посторонних пользователей. Таким образом, пока многие другие сервисы говорят о проблеме «Больших данных» (Big Data), Evernote сталкивается с миллионами и миллионами проблем «малых данных». Каждый набор данных, как и каждый пользователь, уникален.
Еще одно отличие — тип контента, который мы используем для формирования подсказок. Многие сервисы, поддерживающие поисковые подсказки, предлагают дискретные варианты запросов из конечного (хотя и большого) набора – это могут быть ранее введенные поисковые запросы, люди, компании и т. д. В Evernote же подсказки могут извлекаться из любого контента, как структурированного, так и нет, который присутствует в любой из ваших заметок и на любом языке. Система определяет релевантность подсказок для пользователя, анализируя контент самих заметок.
Выбор платформы реализации
Мы работаем над кроссплатформенным сервисом и стараемся, чтобы пользователям Evernote было одинаково удобно работать на всех устройствах, которые они любят. Поэтому нам пришлось принять нелегкое решение при выборе платформы для реализации подсказок в самом начале, выбирая, создать ли систему на стороне сервера, чтобы иметь потенциальную возможность сразу использовать ее на всех клиентах, или же начать с нативной реализации в отдельно взятом клиенте. Мы выбрали второй вариант и начали с Mac по нескольким причинам.
- Мы хотели, чтобы поисковые подсказки, как и другая функциональность поиска, были доступны в офлайне.
- Мы хотели использовать преимущества платформы. Mac OS предлагает внушительный набор лингвистических API, которые мы могли использовать для реализации задачи.
- Мы хотели обеспечить производительность и удобство работы пользователя, даже если это означало, что придется взять больше работы на себя.
Детали
Три главных компонента, лежащих в основе данной функциональности, это индекс терминов, создание подсказок и их извлечение.
Индекс терминов
Поисковые подсказки хранятся в инвертированном индексе, отдельно от основного поискового индекса. Мы рассматривали возможность использования самого поискового индекса, но обнаружили, что хотя теоретически его и можно взять за основу, он слишком заточен под поиск отдельных ключевых слов, и на выходе получаются подсказки очень низкого качества.
Так что в нашем индексе мы связали каждый термин со списком заметок, которые его содержат.
Создание подсказок
Механизм поисковых подсказок начинает работать еще до того, как пользователь начнет печатать в поисковой строке. Каждый раз при создании, изменении или удалении заметок мы генерируем список потенциальных подсказок из заголовка, меток и содержимого заметки, которые затем упорядочиваются и попадают в инвертированный индекс.
Работает это следующим образом.
Мы начинаем с обнаружения отдельных слов в тексте заметки. Слова проходят через серию фильтров, нормализующих текст (например, перевод в нижний регистр, ликвидация диакритических знаков) и удаляющих стоп-слова (чересчур общие). Отфильтрованные слова затем могут дополнительно группироваться во фразы, которые могут быть релевантными тому или иному тексту. Наконец, слова и фразы, прошедшие фильтры, сериализуются в виде записей индекса.
На данном шаге также необходимо учитывать особенности некоторых языков. Например, китайский и японский языки не используют пробелы для отделения слов друг от друга. Поэтому приходится применять более сложные алгоритмы поиска границ слов. Эта проблема становится еще интереснее (и сложнее), если учесть, что в заметке могут быть записи сразу на нескольких языках.
И конечно, весь процесс должен проходить в фоновом режиме, используя незанятые в данный момент ресурсы системы, и не мешать пользователю.
Извлечение подсказок
Мы готовы к поиску — что же происходит теперь? Когда пользователь начинает вводить текст в поисковой строке, система извлечения подсказок в первую очередь определяет набор заметок, которые попадают в вводимый запрос по контексту и удовлетворяют комбинации блокнотов и меток, по которым ищет пользователь. Затем введенная часть поискового запроса ищется в индексе подсказок, чтобы получить набор возможных завершений фразы. И наконец, мы отфильтровываем все завершения, которые не попадают в подходящие по контексту заметки.
Затем мы оцениваем каждую подсказку и ранжируем по релевантности по специальной формуле на базе TF-IDF. Наиболее высоко оцененные подсказки выходят в финал, где очень похожие подсказки (например, «ice skate» и «ice skating») объединяются.
Во многом, этот компонент — самый сложный, но он же должен быть и самым быстрым, поскольку требуется выдать пользователю результат менее чем за секунду. Поэтому в плане производительности мы уделили этой части системы подсказок особое внимание.
Что дальше
Если вы работаете с Evernote для Mac и еще не пробовали эту возможность, я бы очень хотела, чтобы вы поработали с ней и рассказали о впечатлениях.
В будущем мы добавим эту функциональность в некоторые другие клиенты Evernote.
