
Задача резервирования основного шлюза — одна из самых популярных в сетевом администрировании. У нее есть целый ряд решений, которые реализуют механизмы приоритезации или балансировки исходящих каналов для абсолютного большинства современных маршрутизаторов, в том числе и маршрутизаторов на базе Linux.

В статье об отказоустойчивом роутере мы вскользь упоминали свой корпоративный стандарт для решения этой задачи — Open Source-продукт NetGWM — и обещали рассказать об этой утилите подробнее. Из этой статьи вы узнаете, как устроена утилита, какие «фишки» можно использовать в работе с ней и почему мы решили отказаться от использования альтернативных решений.
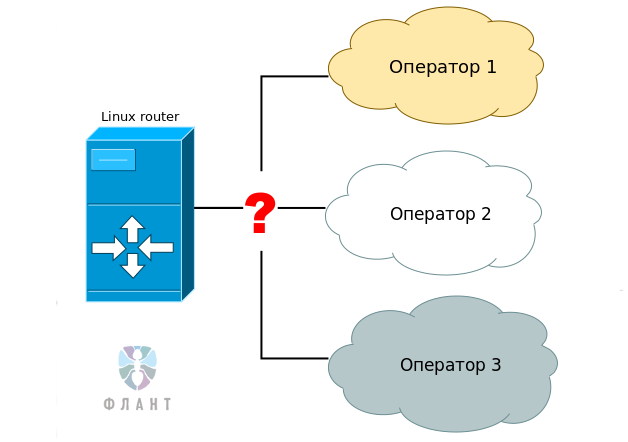
Классическая схема резервирования основного шлюза в Linux, реализуемая средствами iproute2, выглядит практически во всех источниках примерно одинаково:
Подробности этой схемы легко гуглятся по запросу «linux policy routing». На наш взгляд, схема имеет ряд очевидных недостатков, которые и стали основным мотиватором создания утилиты NetGWM:
Мы посмотрели, что поможет нам решить все 4 проблемы: простое и управляемое средство с поддержкой 2 и более шлюзов по умолчанию, умеющее диагностировать доступность канала и тестировать его на стабильность. И не нашли такого варианта. Именно так и появился NetGWM.
NetGWM (Network GateWay Manager) — это небольшая утилита приоритезации основного шлюза, написанная на Python и распространяемая под свободной лицензией GNU GPL v3. Автор первоначальной версии — driusha (Андрей Половов).
Исходный код и документация на английском языке доступны на GitHub, а краткая документация и описание на русском языке — здесь.
Установка из GitHub:
Кроме того, готовый DEB-пакет с NetGWM можно установить из репозитория для Ubuntu компании «Флант». Установка для Ubuntu 14.04 LTS выглядит так:
Добавлять служебную таблицу маршрутизации и настраивать cron в Ubuntu не потребуется. Таблица автоматически добавится при установке пакета. Кроме того, при установке будет зарегистрирована служба
В основе работы NetGWM также лежит policy-роутинг, и нам придется предварительно настроить таблицы маршрутизации для каждого оператора.
Допустим, есть 3 оператора, и необходимо сделать так, чтобы основным оператором был оператор 1, в случае отказа — использовался оператор 2, а в случае отказа из обоих — оператор 3.
Пусть первый оператор у нас подключен к интерфейсу eth1, второй — к eth2, третий — к eth3. Первый оператор имеет шлюз 88.88.88.88, второй оператор — шлюз 99.99.99.99, третий — 100.100.100.100.
Мы почти всегда при настройке сети с несколькими основными шлюзами используем маркировку пакетов и модуль conntrack из NetFilter. Это хорошая практика, помогающая распределять пакеты по таблицам маршрутизации с учетом состояния, но не являющаяся обязательной.
Настроим маркинг пакетов и conntrack:
2. Добавим правила маршрутизации для промаркированных пакетов. Мы это делаем с помощью скрипта, который вызывается из
3. Объявим таблицы маршрутизации в
4. Настроим NetGWM. По умолчанию,
5. Настроим действия при переключении
Если произойдет переключение, то после смены основного шлюза будут выполнены все исполняемые файлы из каталога
В скрипте можно на основании этих переменных описать логику действий в зависимости от подключаемого оператора (добавить или удалить маршруты, отправить уведомления, настроить шейпинг и т.п.). Для примера приведу скрипт на shell, отправляющий уведомления:
6. Стартуем сервис
Если вы получили NetGWM из GitHub, то установленное ранее задание в cron уже и так проверяет доступность вашего основного шлюза, дополнительных действий не требуется.
События по переключению NetGWM регистрирует в журнале
Сохраненная история переключений помогает произвести анализ инцидента и определить причины перерыва в связи.
Уже около 4 лет NetGWM используется в нашей компании на 30+ маршрутизаторах Linux разных масштабов. Надежность утилиты многократно проверена в работе. Для примера, на одной из инсталляций, с мая 2014 года NetGWM обработал 137 переключений операторов без каких-либо проблем.
Стабильность, покрытие всех наших потребностей и отсутствие проблем в эксплуатации в течение длительного времени привели к тому, что мы практически не занимаемся развитием проекта. Код NetGWM написан на Python, поэтому отсутствует и необходимость в адаптации утилиты к новым версиям операционных систем. Тем не менее, мы будем очень рады, если вы решите принять участие в развитии NetGWM, отправив свои патчи в GitHub или просто написав feature request в комментариях.
С NetGWM мы имеем стабильную, гибкую и расширяемую (с помощью скриптов) утилиту, которая полностью закрывает наши потребности в управлении приоритетом основного шлюза.
Любые вопросы по использованию NetGWM также приветствуются — можно прямо здесь в комментариях.
P.S. Читайте также в нашем блоге: «Наш рецепт отказоустойчивого Linux-роутера» — и подписывайтесь на него, чтобы не пропускать новые материалы!
В статье об отказоустойчивом роутере мы вскользь упоминали свой корпоративный стандарт для решения этой задачи — Open Source-продукт NetGWM — и обещали рассказать об этой утилите подробнее. Из этой статьи вы узнаете, как устроена утилита, какие «фишки» можно использовать в работе с ней и почему мы решили отказаться от использования альтернативных решений.
Почему NetGWM?
Классическая схема резервирования основного шлюза в Linux, реализуемая средствами iproute2, выглядит практически во всех источниках примерно одинаково:
- Дано: 2 провайдера.
- Создаем для каждого оператора свою таблицу маршрутизации.
- Создаем правила (
ip rule), по которым трафик попадает в ту или иную таблицу маршрутизации (например, по источнику и/или по метке из iptables). - Метриками или ifupdown-скриптами определяем приоритет основного шлюза.
Подробности этой схемы легко гуглятся по запросу «linux policy routing». На наш взгляд, схема имеет ряд очевидных недостатков, которые и стали основным мотиватором создания утилиты NetGWM:
- Сложность внесения изменений в схему, плохая управляемость.
- Если количество шлюзов 3 и более, логика скриптов усложняется, как и реализация выбора шлюза на основе метрик.
- Проблема обнаружения пропадания канала. Зачастую, физический линк и даже шлюз оператора могут быть доступны, при этом из-за проблем внутри инфраструктуры оператора или у его вышестоящего поставщика услуг реально сеть оказывается недоступной. Решение этой проблемы требует добавление дополнительной логики в ifupdown-скрипты, а в маршрутизации на основе метрик она нерешаема в принципе.
- Проблема «шалтай-болтай». Такая проблема проявляется, если на высокоприоритетном канале наблюдаются кратковременные частые перерывы в связи. При этом шлюз успешно переключается на резервный. Откуда здесь, казалось бы, может взяться проблема? Дело в том, что ряд сервисов, таких как телефония, видеосвязь, VPN-туннели и другие, требуют некоторого таймаута для определения факта обрыва и установления нового сеанса. В зависимости от частоты обрывов это приводит к резкому снижению качества сервиса или его полной недоступности. Решение этой проблемы также требует усложнения логики скриптов и тоже совершенно нерешаема метриками.
Мы посмотрели, что поможет нам решить все 4 проблемы: простое и управляемое средство с поддержкой 2 и более шлюзов по умолчанию, умеющее диагностировать доступность канала и тестировать его на стабильность. И не нашли такого варианта. Именно так и появился NetGWM.
Установка из GitHub и репозитория «Флант»
NetGWM (Network GateWay Manager) — это небольшая утилита приоритезации основного шлюза, написанная на Python и распространяемая под свободной лицензией GNU GPL v3. Автор первоначальной версии — driusha (Андрей Половов).
Исходный код и документация на английском языке доступны на GitHub, а краткая документация и описание на русском языке — здесь.
Установка из GitHub:
## Предварительно в системе требуется установить:
## iproute2, conntrack, модуль python-yaml
## После этого клонируем репозиторий:
$ git clone git://github.com/flant/netgwm.git netgwm
## И устанавливаем (понадобятся права суперпользователя):
$ cd netgwm && sudo make install
## Добавим служебную таблицу маршрутизации, которая будет использоваться NetGWM
$ sudo sh -c "echo '100 netgwm_check' >> /etc/iproute2/rt_tables"
## Добавляем в cron пользователя root вызов netgwm с той частотой,
## с которой вам бы хотелось проверять доступность основного шлюза
## (например, раз в минуту):
$ sudo crontab -e
*/1 * * * * /usr/lib/netgwm/newtgwm.pyКроме того, готовый DEB-пакет с NetGWM можно установить из репозитория для Ubuntu компании «Флант». Установка для Ubuntu 14.04 LTS выглядит так:
## Установим репозиторий:
$ sudo wget https://apt.flant.ru/apt/flant.trusty.common.list \
-O /etc/apt/sources.list.d/flant.common.list
## Импортируем ключ:
$ wget https://apt.flant.ru/apt/archive.key -O- | sudo apt-key add -
## Понадобится HTTPS-транспорт — установите его, если не сделали это раньше:
$ sudo apt-get install apt-transport-https
## Обновим пакетную базу и установим netgwm:
$ sudo apt-get update && sudo apt-get install netgwmДобавлять служебную таблицу маршрутизации и настраивать cron в Ubuntu не потребуется. Таблица автоматически добавится при установке пакета. Кроме того, при установке будет зарегистрирована служба
netgwm, init-скрипт которой стартует в качестве демона небольшой shell-скрипт /usr/bin/netgwm, который, в свою очередь, читает из файла /etc/default/netgwm значение параметра INTERVAL (в секундах) и с указанной периодичностью сам вызывает netgwm.py. Настройка
В основе работы NetGWM также лежит policy-роутинг, и нам придется предварительно настроить таблицы маршрутизации для каждого оператора.
Допустим, есть 3 оператора, и необходимо сделать так, чтобы основным оператором был оператор 1, в случае отказа — использовался оператор 2, а в случае отказа из обоих — оператор 3.
Пусть первый оператор у нас подключен к интерфейсу eth1, второй — к eth2, третий — к eth3. Первый оператор имеет шлюз 88.88.88.88, второй оператор — шлюз 99.99.99.99, третий — 100.100.100.100.
Мы почти всегда при настройке сети с несколькими основными шлюзами используем маркировку пакетов и модуль conntrack из NetFilter. Это хорошая практика, помогающая распределять пакеты по таблицам маршрутизации с учетом состояния, но не являющаяся обязательной.
Настроим маркинг пакетов и conntrack:
iptables -t mangle -A PREROUTING -i eth1 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A PREROUTING -i eth2 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A PREROUTING -i eth3 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x3/0x3
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A OUTPUT -o eth1 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A OUTPUT -o eth2 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A OUTPUT -o eth3 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x3/0x3
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A POSTROUTING -o eth1 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A POSTROUTING -o eth2 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A POSTROUTING -o eth3 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x3/0x3
iptables -t mangle -A POSTROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff2. Добавим правила маршрутизации для промаркированных пакетов. Мы это делаем с помощью скрипта, который вызывается из
/etc/network/interfaces при событии post-up на интерфейсе lo:#!/bin/bash
/sbin/ip rule flush
# operator 1
/sbin/ip rule add priority 8001 iif eth1 lookup main
/sbin/ip rule add priority 10001 fwmark 0x1/0x3 lookup operator1
/sbin/ip rule add from 88.88.88.88 lookup operator1
# operator 2
/sbin/ip rule add priority 8002 iif eth2 lookup main
/sbin/ip rule add priority 10002 fwmark 0x2/0x3 lookup operator2
/sbin/ip rule add from 99.99.99.99 lookup operator2
# operator 3
/sbin/ip rule add priority 8002 iif eth3 lookup main
/sbin/ip rule add priority 10002 fwmark 0x3/0x3 lookup operator3
/sbin/ip rule add from 100.100.100.100 lookup operator33. Объявим таблицы маршрутизации в
/etc/iproute2/rt_tables:# Зарезервированные значения:
255 local
254 main
253 default
0 unspec
# Служебная таблица, которую мы (или dpkg) добавили ранее:
100 netgwm_check
# Таблицы для операторов, которые мы должны добавить сейчас:
101 operator1
102 operator2
103 operator34. Настроим NetGWM. По умолчанию,
netgwm.py будет искать конфигурационный файл по адресу /etc/netgwm/netgwm.yml, однако вы можете переопределить это с помощью ключа -c. Настроим работу утилиты:# Описываем маршруты по умолчанию для каждого оператора и приоритеты
# Меньшее значение (число) имеет больший приоритет. 1 - самый высокий приоритет
# Обратите внимание, что для смены шлюза по умолчанию на другой достаточно просто
# изменить значения приоритетов в этом файле. И уже при следующем запуске (через
# минуту в нашем случае) шлюз изменится на более приоритетный (если он доступен).
# Наименование оператора должно совпадать с именем таблицы маршрутизации из
# /etc/iproute2/rt_tables
gateways:
operator1: {ip: 88.88.88.88, priority: 1}
operator2: {ip: 99.99.99.99, priority: 2}
operator3: {ip: 100.100.100.100, priority: 3}
# Этот параметр решает проблему «шалтай-болтай», когда приоритетного
# оператора (из доступных) «штормит».
# Параметр определяет время постоянной доступности (в секундах),
# после которого netgwm будет считать, что связь стабильна
min_uptime: 900
# Массив удаленных хостов, которые будут использоваться netgwm для
# проверки работоспособности каждого оператора. Здесь стоит указать либо важные
# для вас хосты в интернете, либо общедоступные и стабильно работающие ресурсы,
# как сделано в примере. Шлюз считается недоступным, если netgwm НЕ СМОГ
# установить через него связь до ВСЕХ (условие AND) указанных хостов
check_sites:
- 8.8.8.8 # Google public DNS
- 4.2.2.2 # Verizon public DNS
# По умолчанию netgwm проверяет доступность только для самого
# приоритетного шлюза. Если тот недоступен — до второго по приоритетности и т.д.
# Данная опция, будучи установленной в true, заставит netgwm проверять
# доступность всех шлюзов при каждом запуске
check_all_gateways: false5. Настроим действия при переключении
Если произойдет переключение, то после смены основного шлюза будут выполнены все исполняемые файлы из каталога
/etc/netgwm/post-replace.d/*. При этом каждому файлу будут переданы 6 параметров командной строки:-
$1— наименование нового оператора; -
$2— IP вновь установленного шлюзе или NaN, если новый шлюз установить не удалось; -
$3— имя устройства нового шлюза или NaN, если шлюз установить не удалось; -
$4— наименование старого оператора или NaN, если шлюз устанавливается впервые; -
$5— IP старого оператора или NaN, если шлюз устанавливается впервые; -
$6— имя устройства старого оператора или NaN, если шлюз устанавливается впервые.
В скрипте можно на основании этих переменных описать логику действий в зависимости от подключаемого оператора (добавить или удалить маршруты, отправить уведомления, настроить шейпинг и т.п.). Для примера приведу скрипт на shell, отправляющий уведомления:
#!/bin/bash
# Определяем, что произошло: переключение или старт netgwm
if [ "$4" = 'NaN' ] && [ "$5" = 'NaN' ]
then
STATE='start'
else
STATE='switch'
fi
# Отправляем уведомление дежурным инженерам о произошедшем
case $STATE in
'start')
/usr/bin/flant-integration --sms-send="NetGWM on ${HOSTNAME} has been started and now use gw: $1 - $2"
;;
'switch')
/usr/bin/flant-integration --sms-send="NetGWM on ${HOSTNAME} has switched to new gw: $1 - $2 from gw: $4 - $5"
;;
*)
/usr/bin/logger -t netgwm "Unknown NetGWM state. Try restarting service fo fix it."
;;
esac
exit6. Стартуем сервис
netgwm в Ubuntu, если вы установили DEB-пакет:$ sudo service netgwm startЕсли вы получили NetGWM из GitHub, то установленное ранее задание в cron уже и так проверяет доступность вашего основного шлюза, дополнительных действий не требуется.
Журналирование
События по переключению NetGWM регистрирует в журнале
/var/log/netgwm:$ tail -n 3 /var/log/netgwm.log
2017-07-14 06:25:41,554 route replaced to: via 88.88.88.88
2017-07-14 06:27:09,551 route replaced to: via 99.99.99.99
2017-07-14 07:28:48,573 route replaced to: via 88.88.88.88Сохраненная история переключений помогает произвести анализ инцидента и определить причины перерыва в связи.
Проверено в production
Уже около 4 лет NetGWM используется в нашей компании на 30+ маршрутизаторах Linux разных масштабов. Надежность утилиты многократно проверена в работе. Для примера, на одной из инсталляций, с мая 2014 года NetGWM обработал 137 переключений операторов без каких-либо проблем.
Стабильность, покрытие всех наших потребностей и отсутствие проблем в эксплуатации в течение длительного времени привели к тому, что мы практически не занимаемся развитием проекта. Код NetGWM написан на Python, поэтому отсутствует и необходимость в адаптации утилиты к новым версиям операционных систем. Тем не менее, мы будем очень рады, если вы решите принять участие в развитии NetGWM, отправив свои патчи в GitHub или просто написав feature request в комментариях.
Заключение
С NetGWM мы имеем стабильную, гибкую и расширяемую (с помощью скриптов) утилиту, которая полностью закрывает наши потребности в управлении приоритетом основного шлюза.
Любые вопросы по использованию NetGWM также приветствуются — можно прямо здесь в комментариях.
P.S. Читайте также в нашем блоге: «Наш рецепт отказоустойчивого Linux-роутера» — и подписывайтесь на него, чтобы не пропускать новые материалы!
