
Прим. перев.: Эта статья написана Julia Evans — инженером международной компании Stripe, специализирующейся на интернет-платежах. Разбираться во внутренностях работы планировщика Kubernetes её побудил периодически возникающий баг с «зависанием» пода, о котором около месяца назад также сообщили специалисты из Rancher Labs (issue 49314). Проблема была решена и позволила поделиться деталями о техническом устройстве одного из базовых механизмов Kubernetes, которые и представлены в этом статье с необходимыми выдержками из соответствующего кода проекта.
На этой неделе мне стали известны подробности о том, как работает планировщик Kubernetes, и я хочу поделиться ими с теми, кто готов погрузиться в дебри организации того, как это в действительности работает.
Дополнительно отмечу, что этот случай стал наглядной иллюстрацией того, как без необходимости в чьей-либо помощи перейти от состояния «Не имею понятия, как эта система даже спроектирована» к «Окей, думаю, что мне понятны базовые архитектурные решения и чем они обусловлены».
Надеюсь, этот небольшой поток сознания окажется для кого-то полезным. Во время изучения данной темы мне больше всего пригодился документ Writing Controllers из замечательной-замечательной-замечательной документации Kubernetes для разработчиков.
Планировщик Kubernetes отвечает за назначение узлов подам (pods). Суть его работы сводится к следующему:
Он не отвечает за реальный запуск пода — это уже работа kubelet. Всё, что от него в принципе требуется, — гарантировать, что каждому поду назначен узел. Просто, не так ли?
В Kubernetes применяется идея контроллера. Работа контроллера заключается в следующем:
Планировщик — один из видов контроллера. Вообще же существует множество разных контроллеров, у всех разные задачи и выполняются они независимо.
В общем виде работу планировщика можно представить как такой цикл:
Если вас не интересуют детали о том, как же работает планировщик в Kubernetes, возможно, на этом читать статью достаточно, т.к. этот цикл заключает в себе вполне корректную модель.
Вот и мне казалось, что планировщик на самом деле работает подобным образом, потому что так работает и контроллер
Но на этой неделе мы увеличивали нагрузку на кластер Kubernetes и столкнулись с проблемой.
Иногда под навсегда «застревал» в состоянии
Такое поведение не сходилось с моей внутренней моделью того, как работает планировщик Kubernetes: если под ожидает назначения узла, то планировщик обязан обнаружить это и назначить узел. Планировщик не должен перезапускаться для этого!
Пришло время обратиться к коду. И вот что мне удалось выяснить — как всегда, возможно, что здесь есть ошибки, т.к. всё довольно сложно, а на изучение ушла только неделя.
Начнём с scheduler.go. (Объединение всех нужных файлов доступно здесь — для удобства навигации по содержимому.)
Основной цикл планировщика (на момент коммита e4551d50e5) выглядит так:
… что означает: «Вечно запускай
Окей, а что делает
Окей, всё достаточно просто! Есть очередь из подов (
Но как поды попадают в эту очередь? Вот соответствующий код:
То есть существует обработчик события, который при добавлении нового пода добавляет его в очередь.
Теперь, когда мы прошлись по коду, можно подвести итог:
Здесь есть интересная деталь: если по какой-либо причине под не попадает к планировщику, планировщик не станет предпринимать повторную попытку для него. Под будет убран из очереди, его планирование не выполнится, и всё на этом. Единственный шанс будет упущен! (Пока вы не перезапустите планировщик, в случае чего все поды снова будут добавлены в очередь.)
Конечно, в действительности планировщик умнее: если под не попал к планировщику, в общем случае вызывается обработчик ошибки вроде этого:
Вызов функции
Всё очень просто: оказалось, что эта функция
Думаю, что более надёжная архитектура выглядит следующим образом:
Так почему же вместо такого подхода мы видим все эти сложности с кэшами, запросами, обратными вызовами? Глядя на историю, приходишь к мнению, что основная причина — в производительности. Примеры — это обновление о масштабируемости в Kubernetes 1.6 и эта публикация CoreOS об улучшении производительности планировщика Kubernetes. В последней говорится о сокращении времени планирования для 30 тысяч подов (на 1 тысяче узлов — прим. перев.) с 2+ часов до менее 10 минут. 2 часа — это довольно долго, а производительность важна!
Стало ясно, что опрашивать все 30 тысяч подов вашей системы каждый раз при планировании для нового пода — это слишком долго, поэтому действительно приходится придумать более сложный механизм.
Хочу сказать ещё об одном моменте, который кажется очень важным для архитектуры всех контроллеров Kubernetes. Это идея «информаторов» (informers). К счастью, есть документация, которая находится гуглением «kubernetes informer».
Этот крайне полезный документ называется Writing Controllers и рассказывает о дизайне для тех, кто пишет свой контроллер (вроде планировщика или упомянутого контроллера
Если бы этот документ нашёлся в первую очередь, думаю, что понимание происходящего пришло бы чуть быстрее.
Итак, информаторы! Вот что говорит документация:
Когда контроллер запускается, он создаёт
Контроллер
В той же документации (Writing Controllers) есть и инструкции по тому, как обрабатывать повторное помещение элементов в очередь:
Выглядит как хороший совет: корректно обработать все ошибки может быть нелегко, поэтому важно наличие простого способа, гарантирующего, что рецензенты кода увидят, корректно ли обрабатываются ошибки. Клёво!
И последняя интересная деталь за время моего расследования.
У informers используется концепция «синхронизации» (sync). Она немного похожа на рестарт программы: вы получаете список всех ресурсов, за которыми наблюдаете, поэтому можете проверить, что всё действительно в порядке. Вот что то же руководство говорит о синхронизации:
Проще говоря, «необходимо делать синхронизацию; если вы не синхронизируете, можете столкнуться с ситуацией, когда элемент потерян, а новая попытка помещения в очередь не будет предпринята». Именно это и произошло в нашем случае!
Итак, после знакомства с концепцией синхронизации… приходишь к выводу, что, похоже, планировщик Kubernetes никогда её не выполняет? В этом коде всё выглядит именно так:
Эти числа «0» означают «период повторной синхронизации» (resync period), что логично интерпретировать как «ресинхронизация не происходит». Интересно! Почему так сделано? Не имея уверенности на сей счёт и прогуглив «kubernetes scheduler resync», удалось найти pull request #16840 (добавляющий resync для планировщика) с двумя следующими комментариями:
Выходит, что мейнтейнеры проекта решили не выполнять повторную синхронизацию, потому что лучше, чтобы баги, заложенные в коде, всплывали и исправлялись, а не прятались с помощью выполнения resync.
Насколько мне известно, нигде не описана реальная работа планировщика Kubernetes изнутри (как и многие другие вещи!).
Вот пара приёмов, которые помогли мне при чтении нужного кода:
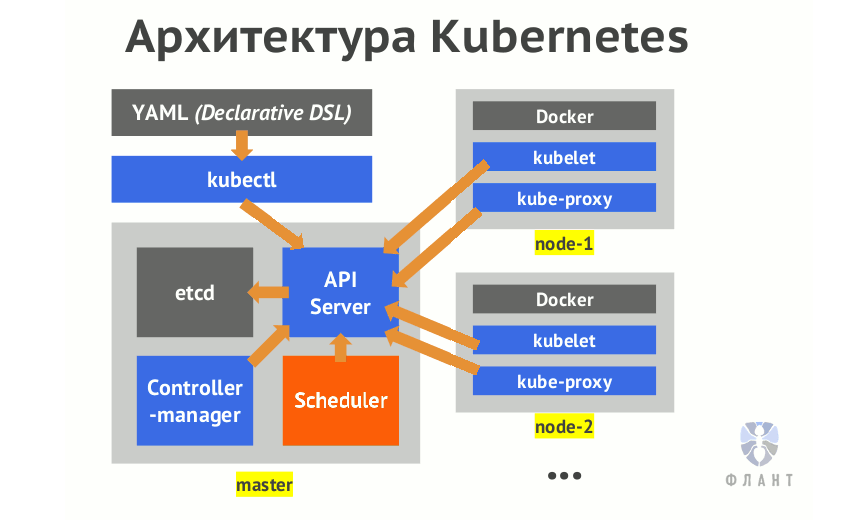
Kubernetes — по-настоящему сложное программное обеспечение. Даже для того, чтобы получить работающий кластер, потребуется настроить как минимум 6 различных компонентов: api server, scheduler, controller manager, container networking вроде flannel, kube-proxy, kubelet. Поэтому (если вы хотите понимать программное обеспечение, которое запускаете, как и я) необходимо понимать, что все эти компоненты делают, как они взаимодействуют друг с другом и как настроить каждую из их 50 триллионов возможностей для получения того, что требуется.
Тем не менее, документация достаточно хороша, а когда что-либо недостаточно документировано, код весьма прост для чтения, и pull requests, похоже, действительно рецензируются.
Мне пришлось по-настоящему и более обычного практиковать принцип «читай документацию и, если её нет, то читай код». Но в любом случае это отличный навык, чтобы стать лучше!
P.S. от переводчика. Читайте также в нашем блоге:
На этой неделе мне стали известны подробности о том, как работает планировщик Kubernetes, и я хочу поделиться ими с теми, кто готов погрузиться в дебри организации того, как это в действительности работает.
Дополнительно отмечу, что этот случай стал наглядной иллюстрацией того, как без необходимости в чьей-либо помощи перейти от состояния «Не имею понятия, как эта система даже спроектирована» к «Окей, думаю, что мне понятны базовые архитектурные решения и чем они обусловлены».
Надеюсь, этот небольшой поток сознания окажется для кого-то полезным. Во время изучения данной темы мне больше всего пригодился документ Writing Controllers из замечательной-замечательной-замечательной документации Kubernetes для разработчиков.
Для чего планировщик?
Планировщик Kubernetes отвечает за назначение узлов подам (pods). Суть его работы сводится к следующему:
- Вы создаёте под.
- Планировщик замечает, что у нового пода нет назначенного ему узла.
- Планировщик назначает поду узел.
Он не отвечает за реальный запуск пода — это уже работа kubelet. Всё, что от него в принципе требуется, — гарантировать, что каждому поду назначен узел. Просто, не так ли?
В Kubernetes применяется идея контроллера. Работа контроллера заключается в следующем:
- посмотреть на состояние системы;
- заметить, где актуальное состояние не соответствует желаемому (например, «этому поду должен быть назначен узел»);
- повторить.
Планировщик — один из видов контроллера. Вообще же существует множество разных контроллеров, у всех разные задачи и выполняются они независимо.
В общем виде работу планировщика можно представить как такой цикл:
while True:
pods = get_all_pods()
for pod in pods:
if pod.node == nil:
assignNode(pod)Если вас не интересуют детали о том, как же работает планировщик в Kubernetes, возможно, на этом читать статью достаточно, т.к. этот цикл заключает в себе вполне корректную модель.
Вот и мне казалось, что планировщик на самом деле работает подобным образом, потому что так работает и контроллер
cronjob — единственный компонент Kubernetes, код которого был мною прочитан. Контроллер cronjob перебирает все cron-задания, проверяет, что ни для одного из них не надо ничего делать, ожидает 10 секунд и бесконечно повторяет этот цикл. Очень просто!Однако работает всё не совсем так
Но на этой неделе мы увеличивали нагрузку на кластер Kubernetes и столкнулись с проблемой.
Иногда под навсегда «застревал» в состоянии
Pending (когда узел не назначен на под). При перезагрузке планировщика под выходил из этого состояния (вот тикет).Такое поведение не сходилось с моей внутренней моделью того, как работает планировщик Kubernetes: если под ожидает назначения узла, то планировщик обязан обнаружить это и назначить узел. Планировщик не должен перезапускаться для этого!
Пришло время обратиться к коду. И вот что мне удалось выяснить — как всегда, возможно, что здесь есть ошибки, т.к. всё довольно сложно, а на изучение ушла только неделя.
Как работает планировщик: беглый осмотр кода
Начнём с scheduler.go. (Объединение всех нужных файлов доступно здесь — для удобства навигации по содержимому.)
Основной цикл планировщика (на момент коммита e4551d50e5) выглядит так:
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)… что означает: «Вечно запускай
sched.scheduleOne». А что происходит там?func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
// do all the scheduler stuff for `pod`
}Окей, а что делает
NextPod()? Откуда растут ноги?func (f *ConfigFactory) getNextPod() *v1.Pod {
for {
pod := cache.Pop(f.podQueue).(*v1.Pod)
if f.ResponsibleForPod(pod) {
glog.V(4).Infof("About to try and schedule pod %v", pod.Name)
return pod
}
}
}Окей, всё достаточно просто! Есть очередь из подов (
podQueue), и следующие поды приходят из неё.Но как поды попадают в эту очередь? Вот соответствующий код:
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
if err := c.podQueue.Add(obj); err != nil {
runtime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
},То есть существует обработчик события, который при добавлении нового пода добавляет его в очередь.
Как работает планировщик: простым языком
Теперь, когда мы прошлись по коду, можно подвести итог:
- В самом начале каждый под, которому потребуется планировщик, помещается в очередь.
- Когда создаются новые поды, они тоже добавляются в очередь.
- Планировщик постоянно берёт поды из очереди и осуществляет для них планирование.
- Вот и всё!
Здесь есть интересная деталь: если по какой-либо причине под не попадает к планировщику, планировщик не станет предпринимать повторную попытку для него. Под будет убран из очереди, его планирование не выполнится, и всё на этом. Единственный шанс будет упущен! (Пока вы не перезапустите планировщик, в случае чего все поды снова будут добавлены в очередь.)
Конечно, в действительности планировщик умнее: если под не попал к планировщику, в общем случае вызывается обработчик ошибки вроде этого:
host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister)
if err != nil {
glog.V(1).Infof("Failed to schedule pod: %v/%v", pod.Namespace, pod.Name)
sched.config.Error(pod, err)Вызов функции
sched.config.Error снова добавляет под в очередь, поэтому для него всё-таки будет предпринята повторная попытка обработки.Подождите. Почему же тогда «застрял» наш под?
Всё очень просто: оказалось, что эта функция
Error не всегда вызывалась, когда реально происходила ошибка. Мы сделали патч (патч был опубликован в том же issue — прим. перев.), чтобы вызывать её корректно, после чего восстановление стало происходить правильно. Класс!Почему планировщик спроектирован так?
Думаю, что более надёжная архитектура выглядит следующим образом:
while True:
pods = get_all_pods()
for pod in pods:
if pod.node == nil:
assignNode(pod)Так почему же вместо такого подхода мы видим все эти сложности с кэшами, запросами, обратными вызовами? Глядя на историю, приходишь к мнению, что основная причина — в производительности. Примеры — это обновление о масштабируемости в Kubernetes 1.6 и эта публикация CoreOS об улучшении производительности планировщика Kubernetes. В последней говорится о сокращении времени планирования для 30 тысяч подов (на 1 тысяче узлов — прим. перев.) с 2+ часов до менее 10 минут. 2 часа — это довольно долго, а производительность важна!
Стало ясно, что опрашивать все 30 тысяч подов вашей системы каждый раз при планировании для нового пода — это слишком долго, поэтому действительно приходится придумать более сложный механизм.
Что на самом деле использует планировщик: informers в Kubernetes
Хочу сказать ещё об одном моменте, который кажется очень важным для архитектуры всех контроллеров Kubernetes. Это идея «информаторов» (informers). К счастью, есть документация, которая находится гуглением «kubernetes informer».
Этот крайне полезный документ называется Writing Controllers и рассказывает о дизайне для тех, кто пишет свой контроллер (вроде планировщика или упомянутого контроллера
cronjob). Очень здорово!Если бы этот документ нашёлся в первую очередь, думаю, что понимание происходящего пришло бы чуть быстрее.
Итак, информаторы! Вот что говорит документация:
ИспользуйтеSharedInformers.SharedInformersпредлагают хуки для получения уведомлений о добавлении, изменении или удалении конкретного ресурса. Также они предлагают удобные функции для доступа к разделяемым кэшам и для определения, где кэш применим.
Когда контроллер запускается, он создаёт
informer (например, pod informer), который отвечает за:- вывод всех подов (в первую очередь);
- уведомления об изменениях.
Контроллер
cronjob не использует информаторов (работа с ними всё усложняет, а в данном случае, думаю, ещё не стоит вопрос производительности), однако многие другие (большинство?) — используют. В частности, планировщик так делает. Настройку его информаторов можно найти в этом коде.Повторное помещение в очередь
В той же документации (Writing Controllers) есть и инструкции по тому, как обрабатывать повторное помещение элементов в очередь:
Для надёжного повторного помещения в очередь выносите ошибки на верхний уровень. Для простой реализации с разумным откатом естьworkqueue.RateLimitingInterface.
Главная функция контроллера должна возвращать ошибку, когда необходимо повторное помещение в очередь. Когда его нет, используйтеutilruntime.HandleErrorи возвращайтеnil. Это значительно упрощает изучение случаев обработки ошибок и гарантирует, что контроллер ничего не потеряет, когда это необходимо.
Выглядит как хороший совет: корректно обработать все ошибки может быть нелегко, поэтому важно наличие простого способа, гарантирующего, что рецензенты кода увидят, корректно ли обрабатываются ошибки. Клёво!
Необходимо «синхронизировать» своих информаторов (не так ли?)
И последняя интересная деталь за время моего расследования.
У informers используется концепция «синхронизации» (sync). Она немного похожа на рестарт программы: вы получаете список всех ресурсов, за которыми наблюдаете, поэтому можете проверить, что всё действительно в порядке. Вот что то же руководство говорит о синхронизации:
Watches и Informers будут «синхронизироваться». Периодически они доставляют вашему методуUpdateкаждый подходящий объект в кластере. Хорошо для случаев, когда может потребоваться выполнить дополнительное действие с объектом, хотя это может быть нужно и не всегда.
В случаях, когда вы уверены, что повторное помещение в очередь элементов не требуется и новых изменений нет, можно сравнить версию ресурса у нового и старого объектов. Если они идентичны, можете пропустить повторное помещение в очередь. Будьте осторожны. Если повторное помещение элемента будет пропущено при каких-либо ошибках, он может потеряться (никогда не попасть в очередь повторно).
Проще говоря, «необходимо делать синхронизацию; если вы не синхронизируете, можете столкнуться с ситуацией, когда элемент потерян, а новая попытка помещения в очередь не будет предпринята». Именно это и произошло в нашем случае!
Планировщик Kubernetes не синхронизируется повторно
Итак, после знакомства с концепцией синхронизации… приходишь к выводу, что, похоже, планировщик Kubernetes никогда её не выполняет? В этом коде всё выглядит именно так:
informerFactory := informers.NewSharedInformerFactory(kubecli, 0)
// cache only non-terminal pods
podInformer := factory.NewPodInformer(kubecli, 0)Эти числа «0» означают «период повторной синхронизации» (resync period), что логично интерпретировать как «ресинхронизация не происходит». Интересно! Почему так сделано? Не имея уверенности на сей счёт и прогуглив «kubernetes scheduler resync», удалось найти pull request #16840 (добавляющий resync для планировщика) с двумя следующими комментариями:
@brendandburns — что здесь планируется исправить? Я действительно против таких маленьких периодов повторной синхронизации, потому что они значительно скажутся на производительности.
Согласен с @wojtek-t. Если resync вообще когда-либо и может решить проблему, это означает, что где-то в коде есть баг, который мы пытаемся спрятать. Не думаю, что resync — правильное решение.
Выходит, что мейнтейнеры проекта решили не выполнять повторную синхронизацию, потому что лучше, чтобы баги, заложенные в коде, всплывали и исправлялись, а не прятались с помощью выполнения resync.
Советы по чтению кода
Насколько мне известно, нигде не описана реальная работа планировщика Kubernetes изнутри (как и многие другие вещи!).
Вот пара приёмов, которые помогли мне при чтении нужного кода:
- Объедините всё нужное в большой файл. Выше уже написано об этом, но вот действительно: переходить между вызовами функций стало намного проще по сравнению с переключением между файлами, особенно когда ещё не знаешь, как всё полностью организовано.
- Имейте несколько конкретных вопросов. В моём случае — «Как обработка ошибок должна работать? Что произойдет, если под не попадёт к планировщику?». Потому что есть много кода о близком… как выбирается конкретный узел, который будет назначен поду, но меня это мало волновало (и я до сих пор не знаю, как это работает).
Работать с Kubernetes довольно-таки здорово!
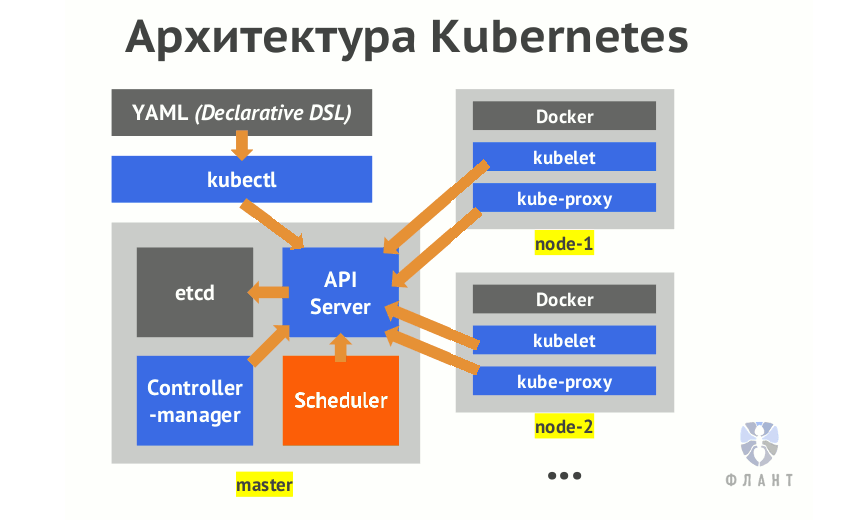
Kubernetes — по-настоящему сложное программное обеспечение. Даже для того, чтобы получить работающий кластер, потребуется настроить как минимум 6 различных компонентов: api server, scheduler, controller manager, container networking вроде flannel, kube-proxy, kubelet. Поэтому (если вы хотите понимать программное обеспечение, которое запускаете, как и я) необходимо понимать, что все эти компоненты делают, как они взаимодействуют друг с другом и как настроить каждую из их 50 триллионов возможностей для получения того, что требуется.
Тем не менее, документация достаточно хороша, а когда что-либо недостаточно документировано, код весьма прост для чтения, и pull requests, похоже, действительно рецензируются.
Мне пришлось по-настоящему и более обычного практиковать принцип «читай документацию и, если её нет, то читай код». Но в любом случае это отличный навык, чтобы стать лучше!
P.S. от переводчика. Читайте также в нашем блоге:
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Зачем нужен Kubernetes и почему он больше, чем PaaS?»;
- «Начало работы в Kubernetes с помощью Minikube» (перевод).
