
Прим. перев.: Этот материал, озаглавленный в оригинале как «What happens when… Kubernetes edition!» и написанный Jamie Hannaford из компании Rackspace, является отличной иллюстрацией работы многих механизмов Kubernetes, которые зачастую скрыты от нашего глаза, но весьма полезны для лучшего понимания устройства этой Open Source-системы, алгоритма работы и взаимосвязей её компонентов. Поскольку вся статья весьма объёмна, её перевод разбит на две части. В первой речь идёт про работу kubectl, kube-apiserver, etcd и initializers.
P.S. Некоторые оригинальные ссылки на код в master-ветках были заменены на последние к моменту перевода коммиты, чтобы актуальность номеров строк, к которым отсылает автор, сохранялась долгое время.
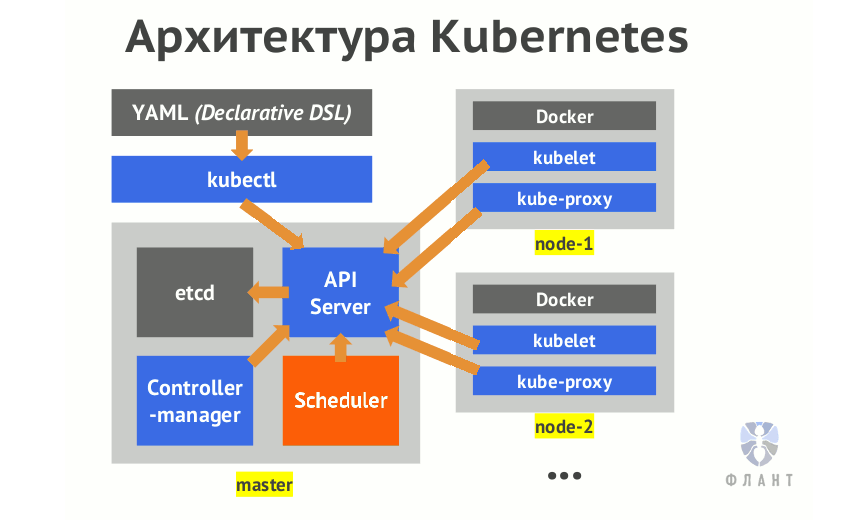
Представим, что я хочу задеплоить nginx в кластере Kubernetes. Я введу в терминале нечто такое:
… и нажму на Enter. Через несколько секунд увижу 3 пода с nginx, распределённые по всем рабочим узлам. Работает — словно по волшебству, и это здорово! Но что на самом деле происходит под капотом?
Одно из замечательных свойств Kubernetes — как эта система обслуживает развёртывание рабочих нагрузок в инфраструктуре через дружелюбные к пользователям API. Вся сложность скрыта простой абстракцией. Однако для того, чтобы полностью осознать ценность, которую приносит K8s, полезно понимать внутреннюю кухню. Эта статья проведёт вас через весь жизненный цикл запроса от клиента до kubelet, при необходимости ссылаясь на исходный код для иллюстрации происходящего.
Это живой документ. Если вы найдёте, что улучшить или переписать, изменения приветствуются! (Речь, конечно, об оригинальной англоязычной статье в GitHub — прим. перев.)
Итак, начнём. Мы только что нажали на Enter в терминале. И что теперь?
В первую очередь kubectl выполнит валидацию на стороне клиента. Он убедится, что нерабочие запросы (например, создание ресурса, который не поддерживается, или использование образа с неправильно указанным названием) быстро прервутся и не будут отправлены в kube-apiserver. Так улучшается производительность системы — благодаря снижению ненужной нагрузки.
После валидации kubectl начинает составлять HTTP-запрос, который будет отправлен kube-apiserver. Все попытки получить доступ к состоянию или изменить его в системе Kubernetes проходят через сервер API, который в свою очередь общается с etcd. И kubectl здесь не исключение. Чтобы составить HTTP-запрос, kubectl использует так называемые генераторы (generators) — абстракцию, реализующую сериализацию.
Не совсем очевидным здесь может показаться то, что в
Например, ресурсы, у которых есть
Разобравшись, что мы хотим создать Deployment, kubectl воспользуется генератором
Перед тем, как продолжим, важно отметить, что Kubernetes использует версионный API, который классифицируется по группам API (API groups). Группа API предназначена для отнесения в одну категорию схожих ресурсов, чтобы с ними было проще взаимодействовать. Кроме того, она является хорошей альтернативой единому монолитному API. Группа API для Deployment называется
(Прим. перев.: Как мы рассказывали в анонсе Kubernetes 1.8, сейчас в проекте идёт работа над созданием новой группы Workload API, в которую войдут Deployments и другие API, относящиеся к «рабочим нагрузкам».)
В общем, после того, как kubectl сгенерировал runtime-объект, он начинает искать соответствующую ему группу API и версию, после чего собирает клиента нужной версии — в нём учитывается различная REST-семантика для ресурса. Этот этап обнаружения и называется «переговором о версии» (version negotiation), включает в себя сканирование содержимого
Для улучшения производительности kubectl также кэширует OpenAPI-схему в директории
Финальный шаг — отправка HTTP-запроса. Когда она сделана и получен успешный ответ, kubectl выведет успешное сообщение с учётом предпочтительного формата вывода.
На прошлом шаге мы не упомянули аутентификацию клиента (она происходит до отправки HTTP-запроса) — рассмотрим и её.
Для успешной отправки запроса kubectl необходимо аутентифицироваться. Учётные данные пользователя почти всегда хранятся в файле
После парсинга файла определяются текущий контекст, текущий кластер и аутентификационные сведения для текущего пользователя. Если пользователь задал специальные значения через флаги (такие, как
Итак, запрос был отправлен, ура! Что дальше? В дело вступает kube-apiserver. Как упоминалось выше, kube-apiserver — основной интерфейс, используемый клиентами и системными компонентами для сохранения и получения состояния кластера. Для выполнения этой функции необходимо верифицировать запрашивающую сторону, убедившись, что она соответствует тому, за кого себя выдаёт. Этот процесс называется аутентификацией.
Как apiserver аутентифицирует запросы? Когда сервер впервые запускается, он проверяет все предоставленные пользователем консольные флаги и собирает список подходящих аутентификаторов (authenticators). Рассмотрим пример: если был передан
Если ни один из аутентификаторов не завершится с успехом, запрос не сработает и вернёт агрегированную ошибку. Если аутентификация прошла успешно, заголовок
Окей, запрос отправлен, kube-apiserver успешно верифицировал, что мы являемся теми, кем представляемся. Какое облегчение! Однако это ещё не всё. Мы можем и быть теми, кем представляемся, однако есть ли у нас права на выполнение этой операции? Идентичность и право доступа — это всё-таки не одно и то же. Чтобы продолжить, kube-apiserver должен авторизовать нас.
Способ, которым kube-apiserver выполняет авторизацию, очень схож с аутентификацией: из значений флагов он собирает цепочку авторизаторов (authorizers), которые будут использоваться для каждого входящего запроса. Если все авторизаторы запрещают запрос, он завершится с ответом
Примеры авторизаторов, входящих в состав релиза Kubernetes v1.8:
Посмотрите на метод
Окей, мы аутентифицированы и авторизованы kube-apiserver. Что осталось? Сам kube-apiserver доверяет нам и разрешает продолжить, но у других частей системы в Kubernetes могут быть собственные глубокие убеждения по поводу того, что разрешено, а что — нет. Здесь вступают в дело admission controllers.
Если авторизация отвечает на вопрос, имеет ли пользователь право, admission controllers проверяют запрос на соответствие более широкому спектру ожиданий и правил в кластере. Они являются последним оплотом контроля перед тем, как объект передаётся в etcd, и отвечают за оставшиеся в системе проверки, задающиеся целью убедиться, что действие не приведёт к неожиданным или негативным последствиям.
Принцип, по которому работают эти контроллеры, схож с аутентификаторами и авторизаторами, но имеет одно отличие: для admission controllers достаточно единственного отказа в цепочке контроллеров, чтобы прервать эту цепочку и признать запрос неудачным.
В архитектуре admission controllers прекрасна ориентация на способствование расширяемости. Каждый контроллер хранится как плагин в директории
Обычно admission controllers разбиты по категориям управления ресурсами, безопасности, установок по умолчанию и эталонной консистентности. Вот некоторые примеры контроллеров, занимающихся управлением ресурсов:
К этому моменту Kubernetes полностью одобрил входящий запрос и разрешил двигаться дальше. Следующим шагом kube-apiserver десериализует HTTP-запрос, создаёт runtime-объекты из него (нечто вроде обратного процесса тому, что делают генераторы kubectl) и сохраняет их хранилище данных. Посмотрим на это в деталях.
Откуда kube-apiserver знает, что делать, принимая наш запрос? Для этого следует довольно сложная последовательность шагов, предваряющих обработку любых запросов. Посмотрим с самого начала — когда бинарный файл впервые запускается:
К этому моменту kube-apiserver знает, какие существуют маршруты и имеет внутренний mapping, указывающий на то, какие обработчики и поставщики хранилища должны быть вызваны при соответствии запроса. Предположим, в него попал наш HTTP-запрос:
Много шагов! Удивительно вот так следовать за apiserver, потому что понимаешь, как много работы он в действительности делает. Итак, резюмируя: ресурс Deployment теперь существует в etcd. Но мало так вот просто его туда поместить — вы всё ещё не увидите его на данном этапе…
Когда объект сохранён в хранилище данных, он не является полностью видимым apiserver и не попадает в планировщик, пока не отработает набор инициализаторов (intializers). Инициализатор — это контроллер, ассоциированный с типом ресурса и исполняющий логику на ресурсе до того, как он становится доступным для внешнего мира. Если у типа ресурса нет зарегистрированных инициализаторов, этот шаг пропускается и ресурсы видны мгновенно.
Как написано во многих блогах, это мощная возможность, позволяющая выполнять общие операции «начальной загрузки» (bootstrap). Примеры могут быть такие:
Объекты
После создания этого конфига в поле ожидания (
Самые наблюдательные читатели могли заметить потенциальную проблему. Как может контроллер из пользовательского пространства обрабатывать ресурсы, если kube-apiserver ещё не сделал их видимыми? Для этого у kube-apiserver есть специальный параметр запроса
Вторую часть статьиопубликуем в ближайшее время ОБНОВЛЕНО: … опубликовали по этой ссылке. В ней рассмотрена работа контроллеров Deployments и ReplicaSets, информаторов, планировщика, kubelet.
Читайте также в нашем блоге:
P.S. Некоторые оригинальные ссылки на код в master-ветках были заменены на последние к моменту перевода коммиты, чтобы актуальность номеров строк, к которым отсылает автор, сохранялась долгое время.
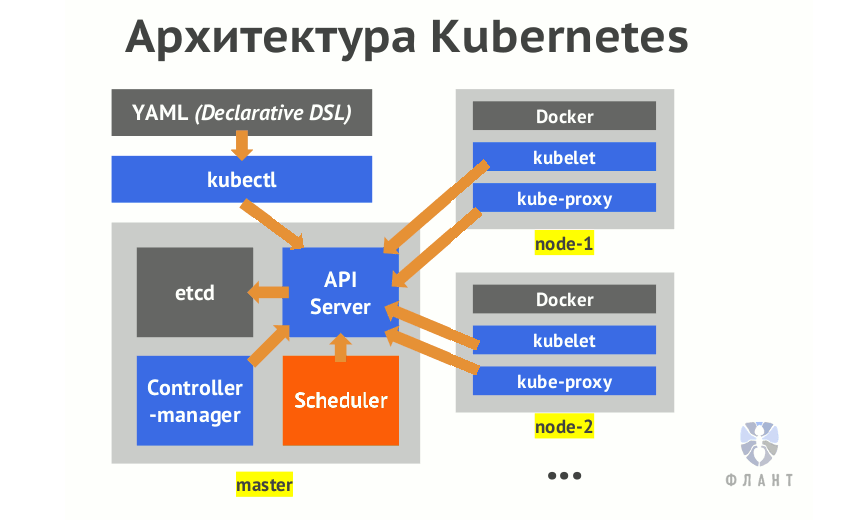
Представим, что я хочу задеплоить nginx в кластере Kubernetes. Я введу в терминале нечто такое:
kubectl run --image=nginx --replicas=3… и нажму на Enter. Через несколько секунд увижу 3 пода с nginx, распределённые по всем рабочим узлам. Работает — словно по волшебству, и это здорово! Но что на самом деле происходит под капотом?
Одно из замечательных свойств Kubernetes — как эта система обслуживает развёртывание рабочих нагрузок в инфраструктуре через дружелюбные к пользователям API. Вся сложность скрыта простой абстракцией. Однако для того, чтобы полностью осознать ценность, которую приносит K8s, полезно понимать внутреннюю кухню. Эта статья проведёт вас через весь жизненный цикл запроса от клиента до kubelet, при необходимости ссылаясь на исходный код для иллюстрации происходящего.
Это живой документ. Если вы найдёте, что улучшить или переписать, изменения приветствуются! (Речь, конечно, об оригинальной англоязычной статье в GitHub — прим. перев.)
kubectl
Валидация и генераторы
Итак, начнём. Мы только что нажали на Enter в терминале. И что теперь?
В первую очередь kubectl выполнит валидацию на стороне клиента. Он убедится, что нерабочие запросы (например, создание ресурса, который не поддерживается, или использование образа с неправильно указанным названием) быстро прервутся и не будут отправлены в kube-apiserver. Так улучшается производительность системы — благодаря снижению ненужной нагрузки.
После валидации kubectl начинает составлять HTTP-запрос, который будет отправлен kube-apiserver. Все попытки получить доступ к состоянию или изменить его в системе Kubernetes проходят через сервер API, который в свою очередь общается с etcd. И kubectl здесь не исключение. Чтобы составить HTTP-запрос, kubectl использует так называемые генераторы (generators) — абстракцию, реализующую сериализацию.
Не совсем очевидным здесь может показаться то, что в
kubectl run допускается указание множества типов ресурсов, не только Deployments. Чтобы это работало, kubectl вычисляет тип ресурса, если имя генератора не было специально указано через флаг --generator.Например, ресурсы, у которых есть
--restart-policy=Always, рассматриваются как Deployments, а ресурсы с --restart-policy=Never — как поды. Также kubectl выяснит, какие другие действия необходимо предпринять — например, запись команды (для выкатов или аудита) — и является ли эта команда пробным прогоном (по наличию флага --dry-run).Разобравшись, что мы хотим создать Deployment, kubectl воспользуется генератором
DeploymentV1Beta1 для создания runtime-объекта из предоставленных параметров. Runtime object — это обобщающий термин для ресурса.Группы API и «переговоры о версиях»
Перед тем, как продолжим, важно отметить, что Kubernetes использует версионный API, который классифицируется по группам API (API groups). Группа API предназначена для отнесения в одну категорию схожих ресурсов, чтобы с ними было проще взаимодействовать. Кроме того, она является хорошей альтернативой единому монолитному API. Группа API для Deployment называется
apps и её последняя версия — v1beta2. Именно это вы указываете вверху определений Deployment: apiVersion: apps/v1beta2.(Прим. перев.: Как мы рассказывали в анонсе Kubernetes 1.8, сейчас в проекте идёт работа над созданием новой группы Workload API, в которую войдут Deployments и другие API, относящиеся к «рабочим нагрузкам».)
В общем, после того, как kubectl сгенерировал runtime-объект, он начинает искать соответствующую ему группу API и версию, после чего собирает клиента нужной версии — в нём учитывается различная REST-семантика для ресурса. Этот этап обнаружения и называется «переговором о версии» (version negotiation), включает в себя сканирование содержимого
/apis на удалённом API для получения всех возможных групп API. Поскольку kube-apiserver выдаёт структурный документ (в формате OpenAPI) по этому пути (/apis), клиентам легко выполнять обнаружение.Для улучшения производительности kubectl также кэширует OpenAPI-схему в директории
~/.kube/schema. Если хотите посмотреть на обнаружение API в действии, попробуйте удалить этот каталог и запустить команду с максимальным значением флага -v. Вы увидите все HTTP-запросы, пытающиеся найти версии API. И их много!Финальный шаг — отправка HTTP-запроса. Когда она сделана и получен успешный ответ, kubectl выведет успешное сообщение с учётом предпочтительного формата вывода.
Аутентификация клиента
На прошлом шаге мы не упомянули аутентификацию клиента (она происходит до отправки HTTP-запроса) — рассмотрим и её.
Для успешной отправки запроса kubectl необходимо аутентифицироваться. Учётные данные пользователя почти всегда хранятся в файле
kubeconfig, хранимом на диске, однако он может находиться в разных местах. Для его поиска kubectl делает следующее:- если указан флаг
--kubeconfig— использует его; - если определена переменная окружения
$KUBECONFIG— использует её; - в ином случае проверяет предполагаемый домашний каталог вроде
~/.kubeи использует первый найденный файл.
После парсинга файла определяются текущий контекст, текущий кластер и аутентификационные сведения для текущего пользователя. Если пользователь задал специальные значения через флаги (такие, как
--username), приоритет отдаётся им и они переписывают значения, указанные в kubeconfig. Когда информация получена, kubectl устанавливает конфигурацию клиента, делая её соответствующей потребностям HTTP-запроса:- сертификаты x509 отправляются через
tls.TLSConfig(root CA тоже входит сюда); - токены клиента отправляются в HTTP-заголовке
Authorization; - пользователь и пароль отправляются через базовую аутентификацию HTTP;
- процесс аутентификации через OpenID предварительно осуществляется пользователем вручную, в результате чего появляется токен, который отправляется аналогично соответствующему пункту выше.
kube-apiserver
Аутентификация
Итак, запрос был отправлен, ура! Что дальше? В дело вступает kube-apiserver. Как упоминалось выше, kube-apiserver — основной интерфейс, используемый клиентами и системными компонентами для сохранения и получения состояния кластера. Для выполнения этой функции необходимо верифицировать запрашивающую сторону, убедившись, что она соответствует тому, за кого себя выдаёт. Этот процесс называется аутентификацией.
Как apiserver аутентифицирует запросы? Когда сервер впервые запускается, он проверяет все предоставленные пользователем консольные флаги и собирает список подходящих аутентификаторов (authenticators). Рассмотрим пример: если был передан
--client-ca-file, будет добавлен аутентификатор x509; если указан --token-auth-file — к списку добавится аутентификатор токенов. Каждый раз при получении запроса он прогоняется через цепочку аутентификаторов, пока один из них не сработает успешно:- обработчик x509 верифицирует, что HTTP-запрос зашифрован с TLS-ключом, подписанным корневым сертификатом удостоверяющего центра;
- обработчик токенов верифицирует, что предоставленный токен (определён в HTTP-заголовке
Authorization) существует в файле на диске, указанном директивой--token-auth-file; - обработчик basicauth похожим образом убедится, что учётные данные для базовой аутентификации в HTTP-запросе соответствуют локальным данным.
Если ни один из аутентификаторов не завершится с успехом, запрос не сработает и вернёт агрегированную ошибку. Если аутентификация прошла успешно, заголовок
Authorization убирается из запроса и сведения о пользователе добавляются в его контекст. Это даёт доступ к установленной ранее идентичности пользователя на последующих этапах (таких, как авторизация и admission controllers).Авторизация
Окей, запрос отправлен, kube-apiserver успешно верифицировал, что мы являемся теми, кем представляемся. Какое облегчение! Однако это ещё не всё. Мы можем и быть теми, кем представляемся, однако есть ли у нас права на выполнение этой операции? Идентичность и право доступа — это всё-таки не одно и то же. Чтобы продолжить, kube-apiserver должен авторизовать нас.
Способ, которым kube-apiserver выполняет авторизацию, очень схож с аутентификацией: из значений флагов он собирает цепочку авторизаторов (authorizers), которые будут использоваться для каждого входящего запроса. Если все авторизаторы запрещают запрос, он завершится с ответом
Forbidden и остановится на этом. Если хоть один авторизатор одобрит запрос, он пройдёт дальше.Примеры авторизаторов, входящих в состав релиза Kubernetes v1.8:
- webhook, взаимодействующий с HTTP(S)-сервисом вне кластера K8s;
- ABAC, реализующий политики из статического файла;
- RBAC, реализующий роли RBAC (Role-based access control — прим. перев.), добавленные администратором как ресурсы Kubernetes;
- Node, проверяющий, что клиенты узлов кластера — например, kubelet — могут получать доступ только к ресурсам, находящимся на них самих.
Посмотрите на метод
Authorize у каждого из них, чтобы увидеть, как они работают.Контроль допуска
Окей, мы аутентифицированы и авторизованы kube-apiserver. Что осталось? Сам kube-apiserver доверяет нам и разрешает продолжить, но у других частей системы в Kubernetes могут быть собственные глубокие убеждения по поводу того, что разрешено, а что — нет. Здесь вступают в дело admission controllers.
Если авторизация отвечает на вопрос, имеет ли пользователь право, admission controllers проверяют запрос на соответствие более широкому спектру ожиданий и правил в кластере. Они являются последним оплотом контроля перед тем, как объект передаётся в etcd, и отвечают за оставшиеся в системе проверки, задающиеся целью убедиться, что действие не приведёт к неожиданным или негативным последствиям.
Принцип, по которому работают эти контроллеры, схож с аутентификаторами и авторизаторами, но имеет одно отличие: для admission controllers достаточно единственного отказа в цепочке контроллеров, чтобы прервать эту цепочку и признать запрос неудачным.
В архитектуре admission controllers прекрасна ориентация на способствование расширяемости. Каждый контроллер хранится как плагин в директории
plugin/pkg/admission и создаётся для реализации потребностей маленького интерфейса. Каждый из них компилируется в главный бинарный файл Kubernetes.Обычно admission controllers разбиты по категориям управления ресурсами, безопасности, установок по умолчанию и эталонной консистентности. Вот некоторые примеры контроллеров, занимающихся управлением ресурсов:
-
InitialResourcesустанавливает лимиты по умолчанию для ресурсов контейнера, основываясь на предыдущем использовании; -
LimitRangerустанавливает значения по умолчанию для запросов и лимитов контейнера, гарантирует верхние границы для определённых ресурсов (512 Мб памяти по умолчанию, но не более 2 Гб); -
ResourceQuotaсчитает количество объектов (подов, rc, балансировщиков нагрузки сервисов) и общие потребляемые ресурсы (процессор, память, диск) в пространстве имён и предотвращает их превышение.
etcd
К этому моменту Kubernetes полностью одобрил входящий запрос и разрешил двигаться дальше. Следующим шагом kube-apiserver десериализует HTTP-запрос, создаёт runtime-объекты из него (нечто вроде обратного процесса тому, что делают генераторы kubectl) и сохраняет их хранилище данных. Посмотрим на это в деталях.
Откуда kube-apiserver знает, что делать, принимая наш запрос? Для этого следует довольно сложная последовательность шагов, предваряющих обработку любых запросов. Посмотрим с самого начала — когда бинарный файл впервые запускается:
- Когда бинарник kube-apiserver запущен, он создаёт цепочку server chain, делающую возможной агрегацию Kubernetes apiserver. Это и есть основа для поддержки множества apiservers (о чём нам можно не беспокоиться).
- Когда это происходит, создаётся общий (generic) apiserver, выступающий в роли реализации по умолчанию.
- Сгенерированная OpenAPI-схема наполняет конфигурацию apiserver.
- Затем kube-apiserver последовательно проходит по всем группам API, определённым в схеме, и настраивает для каждого из них поставщика хранилища (storage provider), выступающего в роли общей (generic) абстракции хранилища. С ним kube-apiserver взаимодействует, когда обращается к состоянию ресурса или изменяет его.
- Для каждой группы API последовательно перебираются все версии группы и устанавливаются REST-соответствия каждому HTTP-маршруту. Это позволяет kube-apiserver находить соответствия запросам и делегировать логику найденному результату.
- В нашем конкретном случае регистрируется POST-обработчик, который затем делегируется обработчику создания ресурса.
К этому моменту kube-apiserver знает, какие существуют маршруты и имеет внутренний mapping, указывающий на то, какие обработчики и поставщики хранилища должны быть вызваны при соответствии запроса. Предположим, в него попал наш HTTP-запрос:
- Если цепочка обработчиков может найти соответствие запроса шаблону (т.е. зарегистрированным маршрутам), то будет вызван нужный обработчик, зарегистрированный для этого маршрута. В ином случае вызывается обработчик, основанный на путях (то же самое происходит при обращении к
/apis). Если зарегистрированных обработчиков для этого пути нет, вызывается обработчик not found, возвращающий 404. - К счастью для нас, есть зарегистрированный маршрут под названием
createHandler. Что он делает? В первую очередь, он декодирует HTTP-запрос и выполняет базовую валидацию, такую как проверка соответствия предоставленных JSON-данных с ожиданиями для ресурса из API нужной версии. - Происходит аудит и финальный допуск.
- Ресурс сохраняется в etcd путём делегирования поставщику хранилища. Обычно ключ для etcd представляется в виде
<namespace>/<name>, но это настраивается. - Любые ошибки при создании перехватываются и, наконец, поставщик хранилища выполняет вызов
get, проверяя, что объект был действительно создан. Затем он вызывает все обработчики, назначенные на момент после создания (post-create), и декораторы, если требуется дополнительная финализация. - Создаётся HTTP-запрос и отправляется обратно.
Много шагов! Удивительно вот так следовать за apiserver, потому что понимаешь, как много работы он в действительности делает. Итак, резюмируя: ресурс Deployment теперь существует в etcd. Но мало так вот просто его туда поместить — вы всё ещё не увидите его на данном этапе…
Инициализаторы
Когда объект сохранён в хранилище данных, он не является полностью видимым apiserver и не попадает в планировщик, пока не отработает набор инициализаторов (intializers). Инициализатор — это контроллер, ассоциированный с типом ресурса и исполняющий логику на ресурсе до того, как он становится доступным для внешнего мира. Если у типа ресурса нет зарегистрированных инициализаторов, этот шаг пропускается и ресурсы видны мгновенно.
Как написано во многих блогах, это мощная возможность, позволяющая выполнять общие операции «начальной загрузки» (bootstrap). Примеры могут быть такие:
- Вставка проксирующего sidecar-контейнера в под с открытым портом 80 или с конкретной аннотацией (annotation).
- Вставка тома с тестовыми сертификатами во все поды определённого пространства имён.
- Предотвращение создания секрета с длиной менее 20 символов (например, для пароля).
Объекты
initializerConfiguration позволяют определять, какие инициализаторы должны запускаться для определённых типов ресурсов. Представьте, что мы хотим запускать свой инициализатор при каждом случае создания пода. Тогда мы сделаем нечто такое:apiVersion: admissionregistration.k8s.io/v1alpha1
kind: InitializerConfiguration
metadata:
name: custom-pod-initializer
initializers:
- name: podimage.example.com
rules:
- apiGroups:
- ""
apiVersions:
- v1
resources:
- podsПосле создания этого конфига в поле ожидания (
metadata.initializers.pending) каждого пода будет добавлен custom-pod-initializer. Контроллер инициализатора будет уже развёрнут и начнёт регулярно сканировать кластер на новые поды. Когда инициализатор обнаружит под со своим (т.е. инициализатора) названием в поле ожидания, он исполнит свои действия. После завершения работы он удалит своё название из списка ожидания. Только инициализаторы, названия которых являются первыми в списке, могут управлять ресурсами. Когда все инициализаторы отработали и список ожидания пуст, объект будет считать инициализированным.Самые наблюдательные читатели могли заметить потенциальную проблему. Как может контроллер из пользовательского пространства обрабатывать ресурсы, если kube-apiserver ещё не сделал их видимыми? Для этого у kube-apiserver есть специальный параметр запроса
?includeUninitialized, позволяющий возвращать все объекты, в том числе и неинициализированные.P.S. от переводчика
Вторую часть статьи
Читайте также в нашем блоге:
- «Что происходит в Kubernetes при запуске kubectl run? Часть 2»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Как на самом деле работает планировщик Kubernetes?»;
- «Инфраструктура с Kubernetes как доступная услуга»;
- «Kubernetes 1.8: обзор основных новшеств».
