
Прим. перев.: эта небольшая (но ёмкая!) статья, написанная Michael Hausenblas из команды OpenShift в Red Hat, настолько пришлась нам «по душе», что практически сразу же после её обнаружения была добавлена в нашу внутреннюю базу знаний по Kubernetes. А поскольку представленная в ней информация явно будет полезной и для более широкого русскоязычного ИТ-сообщества, с удовольствием выкладываем её перевод.

Как вы могли догадаться, заголовок этой публикации — отсылка к мультфильму Pixar 1998-го года «A Bug’s Life» (в российском прокате он назывался «Приключения Флика» или «Жизнь насекомого» — прим. перев.), и действительно: между муравьём-рабочим и подом в Kubernetes есть много схожего. Мы внимательно посмотрим на полный жизненный цикл пода с практической точки зрения — в частности, на способы, которыми вы можете повлиять на поведение при старте и завершении работы, а также на правильные подходы к проверке состояния приложения.
Вне зависимости от того, создали вы под сами или же, что лучше, через контролер вроде Deployment, DaemonSet или StatefulSet, под может находиться в одной из следующих фаз:
Выполняя
Теперь взглянем на конкретный пример жизненного цикла пода от начала до конца, продемонстрированный на следующей схеме:

Что здесь произошло? Этапы следующие:
Как я пришёл к указанной выше последовательности и её таймингу? Для этого использовался следующий Deployment, созданный специально для отслеживания порядка происходящих событий (сам по себе он не очень полезен):
Заметьте, что для насильного завершения работы пода в момент, когда основной контейнер работал, я выполнил следующую команду:
Мы посмотрели на конкретную последовательность событий в действии и готовы теперь двигаться дальше — к практикам в области управления жизненным циклом пода. Они таковы:
В этой публикации не рассматриваются initializers (некоторые подробности о них можно найти в конце этого материала — прим. перев.). Это полностью новая концепция, представленная в Kubernetes 1.7. Инициализаторы работают внутри control plane (API Server) вместо того, чтобы находиться в контексте kubelet, и могут использоваться для «обогащения» подов, например, sidecar-контейнерами или приведением в исполнение политик безопасности. Кроме того, не были рассмотрены PodPresets, которые в дальнейшем могут быть замещены более гибкой концепцией инициализаторов.
Читайте также в нашем блоге:

Как вы могли догадаться, заголовок этой публикации — отсылка к мультфильму Pixar 1998-го года «A Bug’s Life» (в российском прокате он назывался «Приключения Флика» или «Жизнь насекомого» — прим. перев.), и действительно: между муравьём-рабочим и подом в Kubernetes есть много схожего. Мы внимательно посмотрим на полный жизненный цикл пода с практической точки зрения — в частности, на способы, которыми вы можете повлиять на поведение при старте и завершении работы, а также на правильные подходы к проверке состояния приложения.
Вне зависимости от того, создали вы под сами или же, что лучше, через контролер вроде Deployment, DaemonSet или StatefulSet, под может находиться в одной из следующих фаз:
- Pending (ожидание): API Server создал ресурс пода и сохранил его в etcd, но под ещё не был запланирован, а образы его контейнеров — не получены из реестра;
- Running (функционирует): под был назначен узлу и все контейнеры созданы kubelet'ом;
- Succeeded (успешно завершён): функционирование всех контейнеров пода успешно завершено и они не будут перезапускаться;
- Failed (завершено с ошибкой): функционирование всех контейнеров пода прекращено и как минимум один из контейнеров завершился со сбоем;
- Unknown (неизвестно): API Server не смог опросить статус пода, обычно из-за ошибки во взаимодействии с kubelet.
Выполняя
kubectl get pod, обратите внимание, что столбец STATUS может показывать и другие (кроме этих пяти) сообщения — например, Init:0/1 или CrashLoopBackOff. Так происходит по той причине, что фаза — это лишь часть общего состояния пода. Хороший способ узнать, что же конкретно произошло, — запустить kubectl describe pod/$PODNAME и посмотреть на запись Events: внизу. Она выводит список актуальных действий: что образ контейнера был получен, под был запланирован, контейнер находится в «проблемном» (unhealthy) состоянии.Теперь взглянем на конкретный пример жизненного цикла пода от начала до конца, продемонстрированный на следующей схеме:
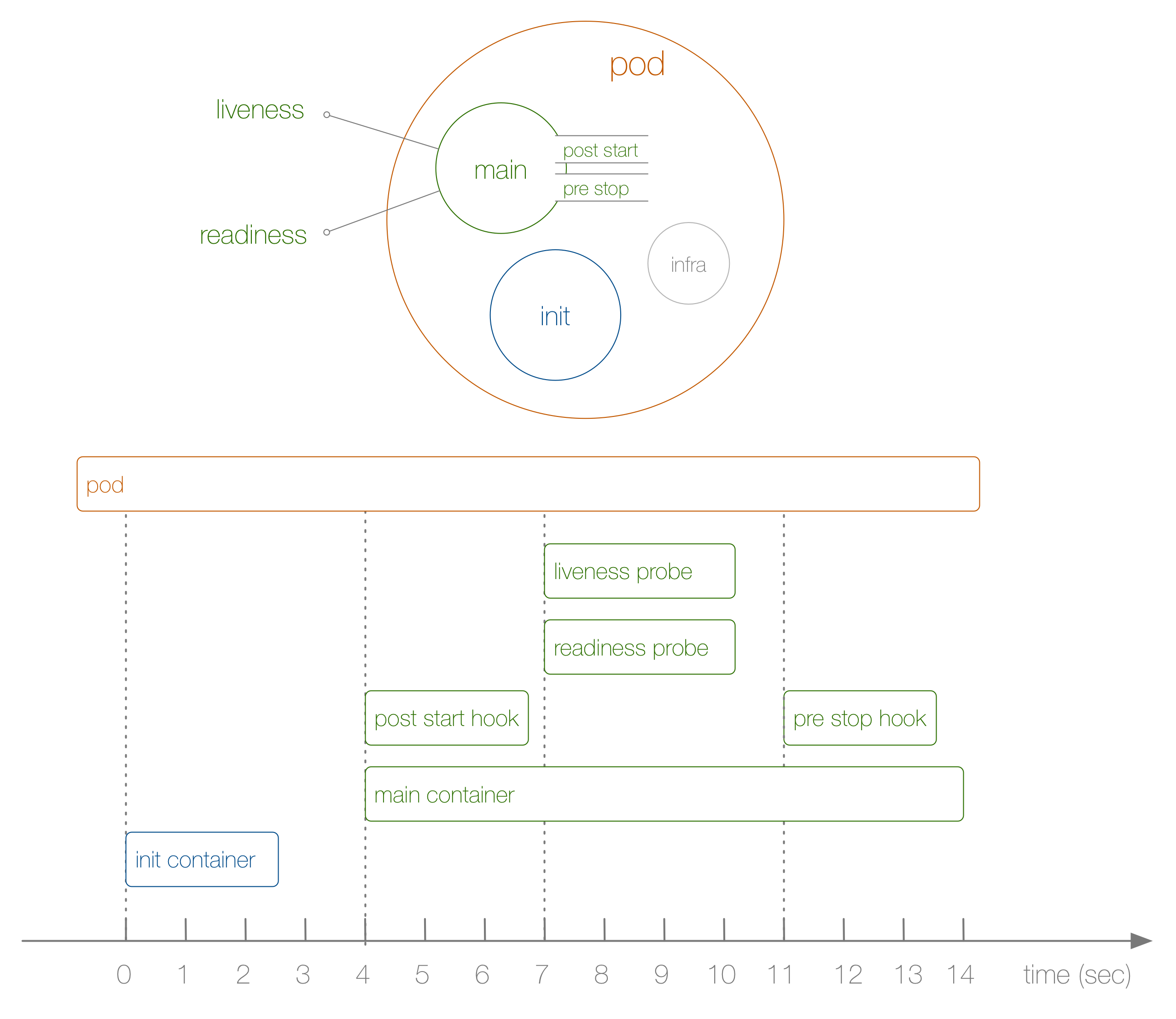
Что здесь произошло? Этапы следующие:
- На схеме это не показано, но в самом начале запускается специальный infra-контейнер и настраивает пространства имён, к которым присоединяются остальные контейнеры.
- Первый определённый пользователем контейнер, который запускается, — это init-контейнер; его можно использовать для задач инициализации.
- Далее одновременно запускаются главный контейнер и хук post-start; в нашем случае это происходит через 4 секунды. Хуки определяются для каждого контейнера.
- Затем, на 7-й секунде, вступают в дело liveness- и readiness-пробы, опять же для каждого контейнера.
- На 11-й секунде, когда под убит, срабатывает хук pre-stop и главный контейнер убивается после непринудительного (grace) периода. Обратите внимание, что в реальности процесс завершения работы пода несколько сложнее.
Как я пришёл к указанной выше последовательности и её таймингу? Для этого использовался следующий Deployment, созданный специально для отслеживания порядка происходящих событий (сам по себе он не очень полезен):
kind: Deployment
apiVersion: apps/v1beta1
metadata:
name: loap
spec:
replicas: 1
template:
metadata:
labels:
app: loap
spec:
initContainers:
- name: init
image: busybox
command: ['sh', '-c', 'echo $(date +%s): INIT >> /loap/timing']
volumeMounts:
- mountPath: /loap
name: timing
containers:
- name: main
image: busybox
command: ['sh', '-c', 'echo $(date +%s): START >> /loap/timing;
sleep 10; echo $(date +%s): END >> /loap/timing;']
volumeMounts:
- mountPath: /loap
name: timing
livenessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): LIVENESS >> /loap/timing']
readinessProbe:
exec:
command: ['sh', '-c', 'echo $(date +%s): READINESS >> /loap/timing']
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'echo $(date +%s): POST-START >> /loap/timing']
preStop:
exec:
command: ['sh', '-c', 'echo $(date +%s): PRE-HOOK >> /loap/timing']
volumes:
- name: timing
hostPath:
path: /tmp/loapЗаметьте, что для насильного завершения работы пода в момент, когда основной контейнер работал, я выполнил следующую команду:
$ kubectl scale deployment loap --replicas=0Мы посмотрели на конкретную последовательность событий в действии и готовы теперь двигаться дальше — к практикам в области управления жизненным циклом пода. Они таковы:
- Используйте init-контейнеры для подготовки пода к нормальному функционированию. Например, для получения внешних данных, создания таблиц в базе данных или ожидания доступности сервиса, от которого под зависит. При необходимости можно создавать множество init-контейнеров, и все они должны успешно завершиться до того, как будут запущены обычные контейнеры.
- Всегда добавляйте
livenessProbeиreadinessProbe. Первая используется kubelet'ом, чтобы понять, нужно ли и когда нужно перезапускать контейнер, и deployment'ом, чтобы решить, был ли успешным rolling update. Вторая — используется service'ом для принятия решения о направлении трафика на под. Если эти пробы не определены, kubelet для обоих предполагает, что они успешно выполнились. Это приводит к двум последствиям: а) политика рестарта не может быть применена, б) контейнеры в поде мгновенно получают трафик от стоящего перед ними service'а, даже если они всё ещё заняты процессом запуска. - Используйте хуки для правильной инициализации контейнера и полного его уничтожения. Например, это полезно в случае функционирования приложения, к исходному коду которого у вас нет доступа или нет возможности его модификации, но которое требует некой инициализации или подготовки к завершению работы — например, очистки подключений к базе данных. Заметьте, что при использовании service'а завершение работы API Server, контроллера endpoint'ов и kube-proxy может занять некоторое время (например, удаление соответствующих записей из iptables). Таким образом, завершающий свою работу под может повлиять на запросы к приложению. Зачастую для решения этой проблемы достаточно простейшего хука с вызовом sleep.
- Для нужд отладки и для понимания в целом, почему под прекратил работу, приложение может писать в
/dev/termination-log, а вы — просматривать сообщения с помощьюkubectl describe pod …. Эти настройки по умолчанию меняются черезterminationMessagePathи/или с помощьюterminationMessagePolicyв спецификации пода — подробнее см. в API reference.
В этой публикации не рассматриваются initializers (некоторые подробности о них можно найти в конце этого материала — прим. перев.). Это полностью новая концепция, представленная в Kubernetes 1.7. Инициализаторы работают внутри control plane (API Server) вместо того, чтобы находиться в контексте kubelet, и могут использоваться для «обогащения» подов, например, sidecar-контейнерами или приведением в исполнение политик безопасности. Кроме того, не были рассмотрены PodPresets, которые в дальнейшем могут быть замещены более гибкой концепцией инициализаторов.
P.S. от переводчика
Читайте также в нашем блоге:
- «Что происходит в Kubernetes при запуске kubectl run?»: часть 1 и часть 2;
- «Как на самом деле работает планировщик Kubernetes?»;
- «Иллюстрированное руководство по устройству сети в Kubernetes»;
- «Наш опыт с Kubernetes в небольших проектах» (видео доклада, включающего в себя знакомство с техническим устройством Kubernetes);
- «Play with Kubernetes — сервис для практического знакомства с K8s»;
- «Инфраструктура с Kubernetes как доступная услуга».
