
В предыдущей статье было рассказано про найм в нашу компанию, но это ещё полбеды — ведь не менее важно и грамотно ввести нового сотрудника в курс происходящего! Нашим опытом в этой области я и поделюсь в новом материале.

Если всё срослось — сотрудник выходит на работу. Мы выдаём ему корпоративную технику — DevOps-инженерам, например, рабочий ноутбук и проверенную на качество и совместимость с нужным железом гарнитуру. Всё это отправляем домой с помощью службы доставки.
На ноутбуке устанавливается необходимое ПО (в том числе, интеграция с внутренними сервисами) и обеспечиваются обязательные меры безопасности (например, шифрование данных). У всех инженеров — Ubuntu. Исходники интеграции с нашими сервисами открыты для сотрудников.
Мы вообще любим открытое ПО: исходники всех внутренних проектов доступны любому инженеру. И на любом из них вы можете увидеть, например, такое:
Нажав на номер коммита, вы переходите к нему во внутреннем GitLab. Не нравится что-то? Хотите подправить? Читайте код, правьте, присылайте merge request — мы же инженеры в конце концов!
Примечание: Наша любовь к Open Source, впрочем, простирается и дальше. Целый ряд своих разработок мы открыли сообществу на GitHub, а до его использования, примерно с 2009 года, делали это с помощью иных ресурсов. И продолжаем по возможности открывать (hint: на подходе у нас ещё один проект, исходники которого уже публично доступны… следите за анонсами в нашем блоге!). Кроме того, контрибьютим в близкие нам проекты (вроде Helm и GitLab) и иногда балуемся.
«Флант» работает по гибким методологиям, но вместо холиваров о правильности формулировок в Agile-манифесте мы реализуем методологии в коде. Внутренние сервисы для трекинга задач, времени, проектов и прочего хорошо интегрированы друг с другом и лишают нас огромного количества головной боли. Как?
Например, у нас своя система учёта «карточек» и времени на день, сделанная с помощью двух веб-сервисов: Nixon и Ford (по именам американских президентов).
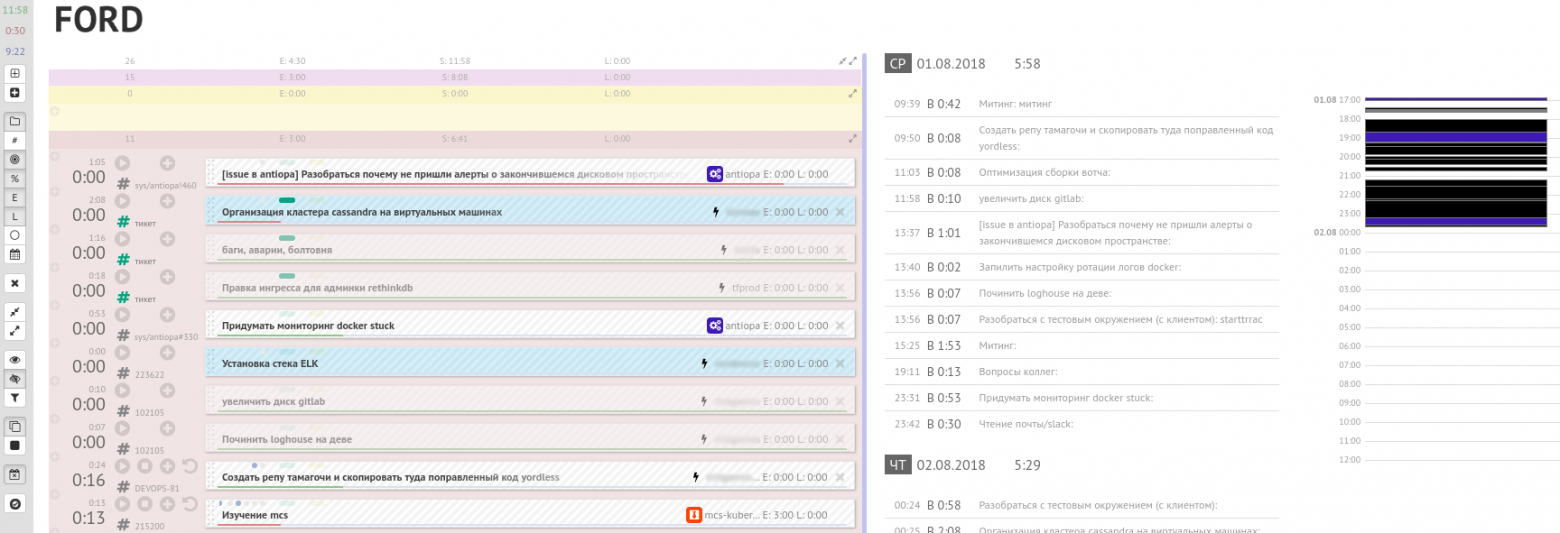

Почему не Trello? Потому что наши Nixon и Ford, помимо прочего, умеют:
Проще говоря — эти сервисы максимально оптимизированы под наши специфичные запросы, которые со временем меняются, а также дополняются обширной обратной связью от непосредственных пользователей (инженеров).
Для обработки инцидентов у дежурных инженеров есть Polk (да, был и такой президент) — он тоже проинтегирован со всем чем можно. Быстрое создание задач (если инцидент не срочный и требует больших трудозатрат), сбор прилетающих алертов из нескольких видов мониторинга, прямая связь с клиентами через Slack-бота и множество других нужных функций… Эффективную работу иначе мы себе уже просто не представляем.
Или, например, управление проектами. Есть сервис Bush, который помнит всё о клиентах, их проектах, сотрудниках и командах. Создаёшь проект во внутреннем GitLab? Просто вбей нужную информацию в Bush’е — он сам создаст все настройки, предоставит все доступы и заведёт репозиторий.
Первым делом новичок проходит курс молодого бойца в специализированной команде, занимающейся распространением знаний. Мы обучаем его необходимому минимуму, с которым он может сразу выйти в свою команду, имея понимание происходящего и разбираться уже в специфике клиентских проектов. На это уходят первые 3-4 дня, после чего инженер под чутким вниманием тимлида и инженеров команды распространения знаний начинает погружаться в реальные боевые задачи.
Чтобы новичок благополучно сориентировался в потоке новых знаний, мы формулируем для него список достижений — «ачивок». Первое время очень страшно и круто одновременно, и мы прикладываем много усилий, чтобы «круто» превалировало.

Позже, когда инженер пройдёт испытательный срок (по умолчанию это 3 месяца, но бывает и меньше в зависимости от различных критериев — см. примечание ниже), список достижений на квартал будет формироваться индивидуально, но на первых порах мы перехватываем инициативу и даём ему ключевые точки наподобие:
Примечание: К слову, одним из дополнительных стимулов для завершения испытательного срока (на его протяжении сотрудники получают фикс) являются те самые бонусы, которые приходят в нашей системе оплаты сразу после него.
Ключевые задачи мы постепенно заворачиваем во внутренние курсы и руководства в базе знаний.
Подобные достижения помогают тимлиду правильно выбирать исполнителя для задач. Всегда есть соблазн скинуть задачи на тех, кто разберётся с ними быстро, проигнорировав тех, кому нужно подтянуть навыки. Мы успешно боремся с этим.
Ключевая точка, к которой новичок стремится прийти, — выход на дежурства в своей команде. Каждый инженер команды по очереди тратит один из своих рабочих дней на то, чтобы дежурить на проектах команды: оперативно отвечать на вопросы клиентов и реагировать на аварии. Конечно, он не остаётся в одиночестве: простейшие вопросы закрывают первая и вторая линия поддержки, более сложные — уходят на более опытные команды. Да и сама команда — всегда на подхвате, дежурный при необходимости может позвать нужных инженеров на помощь.
Это помогает всем участникам команды быть в курсе всех проектов, а также даёт им реальную картину проблем, которые можно ликвидировать в зародыше, и благодаря этому начать получать больше денег.
Мы стремимся достигать результатов с помощью наших мозгов, а не чудовищных вложений сил и времени. Поэтому чем больше проектов берёт команда без потери эффективности, тем больше денег получают сотрудники. У нас сложилась достаточно хитрая и редкая система оплаты, которая у некоторых вызывает удивление. Попробую объяснить.
Мы всю жизнь жили на почасовке, но упёрлись в то, что народ постепенно выгорает и не решает задачи системно. Со временем мы перешли на новый подход, который подразумевает сумму из: фиксированной ставки + некоторой части, зависящей от затраченных часов, + бонусов за эффективность команды. Переход потребовал от инженеров мужества, но в результате все остались довольны, стали получать большую зарплату и лучше высыпаться.
Деньги, которые команда получила сверх минимума, необходимого на покрытие зарплат, тимлид распределяет, исходя из договорённостей со своей командой. Чаще всего туша добытого медведя делится исходя из затраченных часов и уровня зарплат.
Для понимания общего уровня: зарплата нашего инженера в регионах — примерно от 90 до 150 тысяч рублей в месяц (на руки). Конечно, это «средняя температура по больнице», потому что это всегда область личной договорённости и совокупность из множества различных факторов.
Все сотрудники нашей компании с первого дня работают «в белую», официциально, по бессрочному трудовому договору и в соответствии с ТК РФ. Полностью белая зарплата (выплачивается двумя частями в фиксированные даты месяца) подразумевает, что с неё платятся налоги и делаются отчисления во все необходимые фонды. Как следствие, весь доход наших сотрудников отображается в справках 2НДФЛ и не возникает проблем при оформлении кредитов.
Кроме того, «Флант», конечно же, оплачивает в полном размере больничные листы и отпуска. Кстати, отпусков у нас два вида: ежегодный (продолжительностью 28 календарных дней) и дополнительный, ещё три оплачиваемых дня в году. Отгулы или дни отпуска без содержания тоже возможны, но важно предупредить команду, согласовать вопрос с тимлидом и сделать так, чтобы отсутствие сотрудника не привело к критическим последствиям. Понимая, что бывают случаи срочной необходимости, мы стараемся найти способы отпустить сотрудника и в таких ситуациях, невзирая на законодательные ограничения (ТК РФ требует предупреждать об их отпусках и отгулах заранее).

Пусть это уже не совсем тема статьи, не могу обойти вниманием тот факт, что рост в компании — это не пустой маркетинговый оборот для нас. Мы действительно стремимся предоставить все возможности для долгосрочных отношений с сотрудниками и участвуем в их развитии (в соответствии с предрасположенностями и предпочтениями). Тем более, благодаря уже имеющемуся масштабу компании и разнообразию клиентов и связанной с ними деятельности (включая наши внутренние процессы), нам действительно есть что предложить.
Конечно, есть «путь по умолчанию» L1 → L2 → DevOps-инженер (в том числе и выполняющий функции L3) → ведущий инженер, тимлид, PM… Но случаются и более сложные ходы, которые зависят не только от способностей человека, но и актуальных потребностей компании. Так, например, однажды у нас появилась должность «директора по сервису», до которой вырос один из дежурных (L1/L2) инженеров, а ещё достаточно вспомнить, что у нас есть особые команды, такие как R&D.
Если у читателей будет интерес (пишите в комментариях!) — мы расскажем о том, какие истории роста и развития в компании реально случались у наших сотрудников и появляются сейчас.
Процессы адаптации стали актуальными как никогда по мере роста компании. В нашем случае переломный момент — этап, на котором мы почувствовали, что для бизнеса критичен качественный сдвиг в работе с новыми инженерами, — произошёл в районе отметки 50 сотрудников. Однако во многом это только начало пути — наш подход к адаптации активно развивается прямо сейчас. Мы выстраиваем процессы внутреннего найма и обмена опытом, дорабатываем инструменты для повседневной работы и развиваем базу знаний. Впрочем, это уже совсем иная история…
Выражаю благодарность коллегам: HR-директору Анне и shurup — за помощь в подготовке обеих частей этой статьи. С радостью поделимся своим опытом и в других вопросах, связанных с этой «внутренней кухней» нашей компании, по вашим запросам.
Читайте также в нашем блоге:

Выход на работу и первые ~три месяца
Если всё срослось — сотрудник выходит на работу. Мы выдаём ему корпоративную технику — DevOps-инженерам, например, рабочий ноутбук и проверенную на качество и совместимость с нужным железом гарнитуру. Всё это отправляем домой с помощью службы доставки.
На ноутбуке устанавливается необходимое ПО (в том числе, интеграция с внутренними сервисами) и обеспечиваются обязательные меры безопасности (например, шифрование данных). У всех инженеров — Ubuntu. Исходники интеграции с нашими сервисами открыты для сотрудников.
Мы вообще любим открытое ПО: исходники всех внутренних проектов доступны любому инженеру. И на любом из них вы можете увидеть, например, такое:

Нажав на номер коммита, вы переходите к нему во внутреннем GitLab. Не нравится что-то? Хотите подправить? Читайте код, правьте, присылайте merge request — мы же инженеры в конце концов!
Примечание: Наша любовь к Open Source, впрочем, простирается и дальше. Целый ряд своих разработок мы открыли сообществу на GitHub, а до его использования, примерно с 2009 года, делали это с помощью иных ресурсов. И продолжаем по возможности открывать (hint: на подходе у нас ещё один проект, исходники которого уже публично доступны… следите за анонсами в нашем блоге!). Кроме того, контрибьютим в близкие нам проекты (вроде Helm и GitLab) и иногда балуемся.
Гибкие методологии как код
«Флант» работает по гибким методологиям, но вместо холиваров о правильности формулировок в Agile-манифесте мы реализуем методологии в коде. Внутренние сервисы для трекинга задач, времени, проектов и прочего хорошо интегрированы друг с другом и лишают нас огромного количества головной боли. Как?
Например, у нас своя система учёта «карточек» и времени на день, сделанная с помощью двух веб-сервисов: Nixon и Ford (по именам американских президентов).
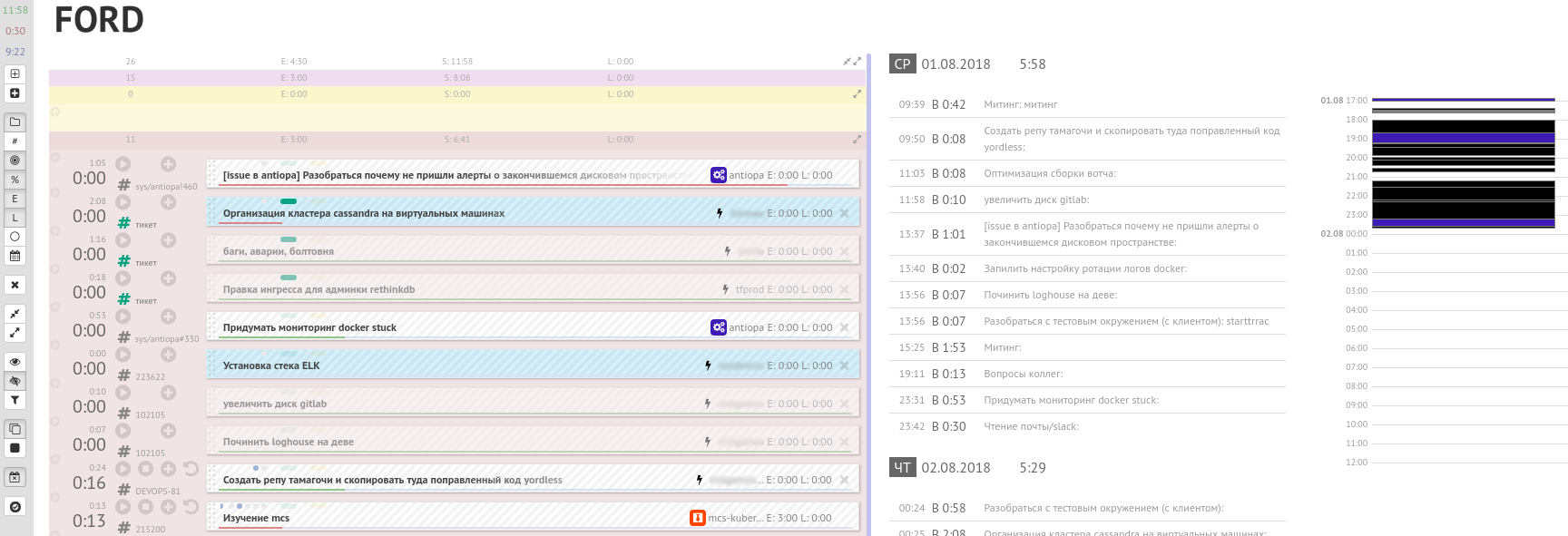

Почему не Trello? Потому что наши Nixon и Ford, помимо прочего, умеют:
- понимать, что человек может решать задачи в разных командах в течение дня (и ему нужно делать это удобно!);
- одним кликом создавать из карточек задачи в Redmine, а также интегрироваться с GitLab и GitHub;
- делить карточки по приоритетам, откладывать их на дату или в бэклог;
- организовывать нехитрый workflow с подтверждением;
- фильтровать, искать и предоставлять множество актуальных hotkey’ев.
Проще говоря — эти сервисы максимально оптимизированы под наши специфичные запросы, которые со временем меняются, а также дополняются обширной обратной связью от непосредственных пользователей (инженеров).
Для обработки инцидентов у дежурных инженеров есть Polk (да, был и такой президент) — он тоже проинтегирован со всем чем можно. Быстрое создание задач (если инцидент не срочный и требует больших трудозатрат), сбор прилетающих алертов из нескольких видов мониторинга, прямая связь с клиентами через Slack-бота и множество других нужных функций… Эффективную работу иначе мы себе уже просто не представляем.
Или, например, управление проектами. Есть сервис Bush, который помнит всё о клиентах, их проектах, сотрудниках и командах. Создаёшь проект во внутреннем GitLab? Просто вбей нужную информацию в Bush’е — он сам создаст все настройки, предоставит все доступы и заведёт репозиторий.
Адаптация
Первым делом новичок проходит курс молодого бойца в специализированной команде, занимающейся распространением знаний. Мы обучаем его необходимому минимуму, с которым он может сразу выйти в свою команду, имея понимание происходящего и разбираться уже в специфике клиентских проектов. На это уходят первые 3-4 дня, после чего инженер под чутким вниманием тимлида и инженеров команды распространения знаний начинает погружаться в реальные боевые задачи.
Чтобы новичок благополучно сориентировался в потоке новых знаний, мы формулируем для него список достижений — «ачивок». Первое время очень страшно и круто одновременно, и мы прикладываем много усилий, чтобы «круто» превалировало.

Позже, когда инженер пройдёт испытательный срок (по умолчанию это 3 месяца, но бывает и меньше в зависимости от различных критериев — см. примечание ниже), список достижений на квартал будет формироваться индивидуально, но на первых порах мы перехватываем инициативу и даём ему ключевые точки наподобие:
- Установленный своими руками Kubernetes-кластер. Возможна эпизодическая помощь коллег. Максимум — за 2 рабочих дня.
- Полностью самостоятельно развёрнутый Ceph в Kubernetes.
- Принятый MR или созданный Issue в любом проекте документации.
- Закрытый день, наполненный корректно оформленными карточками с корректными таймерами.
- …
Примечание: К слову, одним из дополнительных стимулов для завершения испытательного срока (на его протяжении сотрудники получают фикс) являются те самые бонусы, которые приходят в нашей системе оплаты сразу после него.
Ключевые задачи мы постепенно заворачиваем во внутренние курсы и руководства в базе знаний.
Подобные достижения помогают тимлиду правильно выбирать исполнителя для задач. Всегда есть соблазн скинуть задачи на тех, кто разберётся с ними быстро, проигнорировав тех, кому нужно подтянуть навыки. Мы успешно боремся с этим.
Ключевая точка, к которой новичок стремится прийти, — выход на дежурства в своей команде. Каждый инженер команды по очереди тратит один из своих рабочих дней на то, чтобы дежурить на проектах команды: оперативно отвечать на вопросы клиентов и реагировать на аварии. Конечно, он не остаётся в одиночестве: простейшие вопросы закрывают первая и вторая линия поддержки, более сложные — уходят на более опытные команды. Да и сама команда — всегда на подхвате, дежурный при необходимости может позвать нужных инженеров на помощь.
Это помогает всем участникам команды быть в курсе всех проектов, а также даёт им реальную картину проблем, которые можно ликвидировать в зародыше, и благодаря этому начать получать больше денег.
Зарплата и премии
Мы стремимся достигать результатов с помощью наших мозгов, а не чудовищных вложений сил и времени. Поэтому чем больше проектов берёт команда без потери эффективности, тем больше денег получают сотрудники. У нас сложилась достаточно хитрая и редкая система оплаты, которая у некоторых вызывает удивление. Попробую объяснить.
Мы всю жизнь жили на почасовке, но упёрлись в то, что народ постепенно выгорает и не решает задачи системно. Со временем мы перешли на новый подход, который подразумевает сумму из: фиксированной ставки + некоторой части, зависящей от затраченных часов, + бонусов за эффективность команды. Переход потребовал от инженеров мужества, но в результате все остались довольны, стали получать большую зарплату и лучше высыпаться.
Деньги, которые команда получила сверх минимума, необходимого на покрытие зарплат, тимлид распределяет, исходя из договорённостей со своей командой. Чаще всего туша добытого медведя делится исходя из затраченных часов и уровня зарплат.
Для понимания общего уровня: зарплата нашего инженера в регионах — примерно от 90 до 150 тысяч рублей в месяц (на руки). Конечно, это «средняя температура по больнице», потому что это всегда область личной договорённости и совокупность из множества различных факторов.
Все сотрудники нашей компании с первого дня работают «в белую», официциально, по бессрочному трудовому договору и в соответствии с ТК РФ. Полностью белая зарплата (выплачивается двумя частями в фиксированные даты месяца) подразумевает, что с неё платятся налоги и делаются отчисления во все необходимые фонды. Как следствие, весь доход наших сотрудников отображается в справках 2НДФЛ и не возникает проблем при оформлении кредитов.
Кроме того, «Флант», конечно же, оплачивает в полном размере больничные листы и отпуска. Кстати, отпусков у нас два вида: ежегодный (продолжительностью 28 календарных дней) и дополнительный, ещё три оплачиваемых дня в году. Отгулы или дни отпуска без содержания тоже возможны, но важно предупредить команду, согласовать вопрос с тимлидом и сделать так, чтобы отсутствие сотрудника не привело к критическим последствиям. Понимая, что бывают случаи срочной необходимости, мы стараемся найти способы отпустить сотрудника и в таких ситуациях, невзирая на законодательные ограничения (ТК РФ требует предупреждать об их отпусках и отгулах заранее).
Рост в компании

Пусть это уже не совсем тема статьи, не могу обойти вниманием тот факт, что рост в компании — это не пустой маркетинговый оборот для нас. Мы действительно стремимся предоставить все возможности для долгосрочных отношений с сотрудниками и участвуем в их развитии (в соответствии с предрасположенностями и предпочтениями). Тем более, благодаря уже имеющемуся масштабу компании и разнообразию клиентов и связанной с ними деятельности (включая наши внутренние процессы), нам действительно есть что предложить.
Конечно, есть «путь по умолчанию» L1 → L2 → DevOps-инженер (в том числе и выполняющий функции L3) → ведущий инженер, тимлид, PM… Но случаются и более сложные ходы, которые зависят не только от способностей человека, но и актуальных потребностей компании. Так, например, однажды у нас появилась должность «директора по сервису», до которой вырос один из дежурных (L1/L2) инженеров, а ещё достаточно вспомнить, что у нас есть особые команды, такие как R&D.
Если у читателей будет интерес (пишите в комментариях!) — мы расскажем о том, какие истории роста и развития в компании реально случались у наших сотрудников и появляются сейчас.
Вместо заключения
Процессы адаптации стали актуальными как никогда по мере роста компании. В нашем случае переломный момент — этап, на котором мы почувствовали, что для бизнеса критичен качественный сдвиг в работе с новыми инженерами, — произошёл в районе отметки 50 сотрудников. Однако во многом это только начало пути — наш подход к адаптации активно развивается прямо сейчас. Мы выстраиваем процессы внутреннего найма и обмена опытом, дорабатываем инструменты для повседневной работы и развиваем базу знаний. Впрочем, это уже совсем иная история…
P.S.
Выражаю благодарность коллегам: HR-директору Анне и shurup — за помощь в подготовке обеих частей этой статьи. С радостью поделимся своим опытом и в других вопросах, связанных с этой «внутренней кухней» нашей компании, по вашим запросам.
P.P.S.
Читайте также в нашем блоге:
