

К нашему огромному удивлению на хабре не оказалось ни одного материала про замечательный Open Source-инструмент для резервного копирования данных — Borg (не путать с одноимённым прародителем Kubernetes!). Поскольку уже более года мы с удовольствием используем его в production, в этой статье я поделюсь накопленными у нас «впечатлениями» о Borg.
Предыстория: опыт с Bacula и Bareos
В 2017 году мы устали от Bacula и Bareos, которые использовали с самого начала своей деятельности (т.е. около 9 лет в production на тот момент). Почему? За время эксплуатации у нас накопилось немало недовольства:
- Зависает SD (Storage Daemon). Если у вас настроена параллельность, то обслуживание SD усложняется, а его зависание блокирует дальнейшие бэкапы по расписанию и возможность восстановления.
- Нужно генерировать конфиги и клиенту, и директору. Даже если автоматизировать это (в нашем случае в разное время применялись и Chef, и Ansible, и своя разработка), нужно мониторить, что директор после своего reload’а на самом деле подхватил конфиг. Это отслеживается только в выводе команды reload и вызове messages после (чтобы получить сам текст ошибки).
- Расписание бэкапов. Разработчики Bacula решили пойти собственным путём и написали свой формат расписаний, который не получится просто распарсить или конвертировать в другой. Вот примеры стандартных расписаний бэкапов в наших старых инсталяциях:
- Ежедневный полный бэкап по средам и инкрементальные в остальные дни:
Run = Level=Full Pool="Foobar-low7" wed at 18:00
Run = Level=Incremental Pool="Foobar-low7" at 18:00 - Полный бэкап wal-файлов 2 раза в месяц и инкремент каждый час:
Run = Level=Full FullPool=CustomerWALPool 1st fri at 01:45
Run = Level=Full FullPool=CustomerWALPool 3rd fri at 01:45
Run = Level=Incremental FullPool=CustomerWALPool IncrementalPool=CustomerWALPool on hourly - Сгенерированных
scheduleна все случаи жизни (в разные дни недели каждые 2 часа) у нас получилось примерно 1665… из-за чего Bacula/Bareos периодически сходили с ума.
- Ежедневный полный бэкап по средам и инкрементальные в остальные дни:
- У bacula-fd (и bareos-fd) на каталогах с большим количеством данных (скажем, 40 ТБ, из которых на 35 ТБ приходятся крупные файлы [100+ Мб], а на оставшиеся 5 Тб — мелкие [от 1 Кб до 100 Мб]) начинается медленная утечка памяти, что на production ну совсем неприятная ситуация.
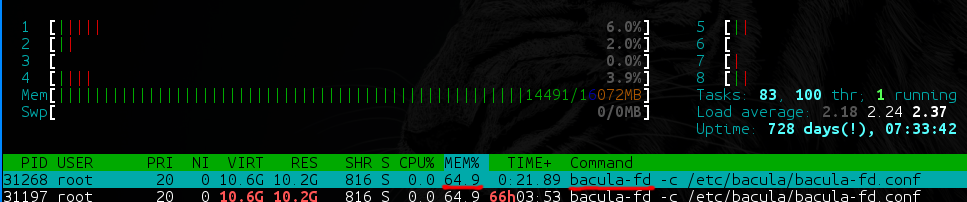
- На бэкапах с большим количеством файлов Bacula и Bareos очень сильно зависят от производительности используемой СУБД. На каких она дисках? Насколько мастерски вы умеете её тюнить под эти специфичные нужды? А в базе, между прочим, создаётся одна(!) непартицируемая таблица со списком всех файлов во всех бэкапах и вторая — со списком всех путей во всех бэкапах. Если вы не готовы выделить хотя бы 8 Гб RAM под базу + 40 Гб SSD для вашего бэкап-сервера — сразу готовьтесь к тормозам.
- Зависимость от БД достойна ещё одного пункта. Bacula/Bareos на каждый файл спрашивают директора, был ли уже такой файл. Директор, конечно, лезет в БД, в те самые огромные таблицы… Получается, что резервное копирование можно заблокировать просто тем фактом, что одновременно запустились несколько тяжёлых бэкапов — даже если diff’а там на несколько мегабайт.
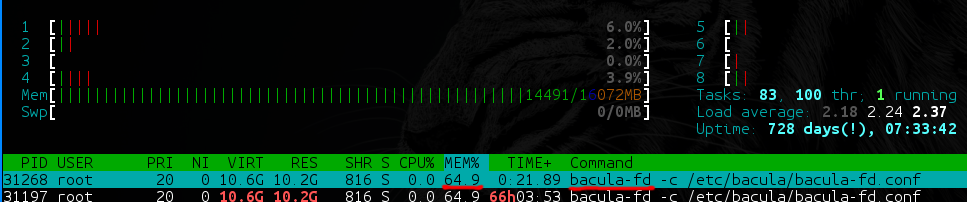
Несправедливо будет сказать, что никакие проблемы не решались совсем, но мы дошли до того состояния, когда действительно устали от различных workaround’ов, и хотели надёжного решения «здесь и сейчас».
Bacula/Bareos прекрасно работают с небольшим количеством (10-30) однородных job’ов. Сломалось какая-то мелочь раз в неделю? Ничего страшного: отдали задачу дежурному (или другому инженеру) — починили. Однако у нас есть проекты, где количество job’ов исчисляется сотнями, а количество файлов в них — сотнями тысяч. В итоге, 5 минут в неделю на починку бэкапа (не считая нескольких часов настройки до этого) начали приумножаться. Всё это привело к тому, что 2 часа в день нужно было заниматься починкой бэкапов во всех проектах, потому что буквально везде что-то по мелочи или серьёзно ломалось.
Тут кто-то может подумать, что бэкапами должен заниматься выделенный для этого специальный инженер. Непременно, он будет максимально бородат и суров, а от его взгляда бэкапы чинятся моментально, пока он спокойно попивает кофе. И эта мысль в чем-то может быть верна… Но всегда есть но. Не все могут позволить себе круглосуточно чинить и следить за бэкапами, а уж тем более — выделенного под эти цели инженера. Мы же просто уверены, что эти 2 часа в день лучше тратить на что-то более продуктивное и полезное. Поэтому перешли к поискам альтернативных решений, которые «просто работают».
Borg как новый путь
Поиски других Open Source-вариантов были размазаны во времени, поэтому сложно оценить общие затраты, но в один прекрасный момент (в прошлом году) наше внимание устремилось к «виновнику торжества» — BorgBackup (или просто Borg). Отчасти тому способствовал реальный опыт его использования одним из наших инженеров (на предыдущем месте работы).
Borg написан на Python (необходима версия >= 3.4.0), а требовательный к производительности код (сжатие, шифрование и т.п.) реализован на C/Cython. Распространяется на условиях свободной лицензии BSD (3-clause). Поддерживает множество платформ включая Linux, *BSD, macOS, а также на экспериментальном уровне Cygwin и Linux Subsystem of Windows 10. Для инсталляции BorgBackup доступны пакеты для популярных Linux-дистрибутивов и других ОС, а также исходники, устанавливаемые в том числе и через pip, — более подробную информацию об этом можно найти в документации проекта.
Чем же Borg нас так сильно подкупил? Вот его основные достоинства:
- Дедупликация: настоящая и очень эффективная (примеры будут ниже). Файлы в рамках одного Borg repository (т.е. специальном каталоге в специфичном для Borg формате) делятся на блоки по n мегабайт, а повторяющиеся блоки Borg дедуплицирует. Дедупликация происходит именно до сжатия.
- Сжатие: после дедупликации данные ещё и сжимаются. Доступны разные алгоритмы сжатия: lz4, lzma, zlib, zstd. Стандартная фича любого бэкапа, но от этого не менее полезная.
- Работа по SSH: Borg бэкапит на удалённый сервер по SSH. На стороне сервера нужен просто установленный Borg и всё! Отсюда сразу вытекают такие плюсы, как безопасность и шифрование. Вы можете настроить доступ только по ключам и, более того, выполнение Borg’ом только одной своей команды при заходе на сервер. Например, так:
$ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc… - Поставляется как в PPA (мы преимущественно используем Ubuntu), так и статичным бинарником. Borg в виде статичного бинарника даёт возможность запускать его практически везде, где есть хоть минимально современный glibc. (Но не везде — например, не удалось запустить на CentOS 5.)
- Гибкая очистка от старых бэкапов. Можно задать как хранение n последних бэкапов, так и 2 бэкапа в час/день/неделю. В последнем случае будет оставлен последний на конец недели бэкап. Условия можно комбинировать, сделав хранение 7 ежедневных бэкапов за последние 7 дней и 4 недельных.
Переход на Borg начал осуществляться медленно, на небольших проектах. По началу это были простые скрипты в cron, которые каждый день делали своё дело. Всё так продолжалось около полугода. За это время нам приходилось много раз доставать бэкапы… и оказалось, что Borg не пришлось чинить буквально совсем! Почему? Потому что тут работает простой принцип: «Чем проще механизм, тем меньше мест, где он сломается».
Практика: как сделать бэкап с Borg?
Рассмотрим простой пример создания бэкапа:
- Скачиваем последний релизный бинарник на сервер бэкапа и машину, которую будем бэкапить, с официального репозитория:
sudo wget https://github.com/borgbackup/borg/releases/download/1.1.6/borg-linux64 -O /usr/local/bin/borg sudo chmod +x /usr/local/bin/borg
Примечание: Если для теста вы используете локальную машину и как источник и как приёмник, то вся разница будет только в URI, который мы передадим, но мы же помним, что бэкап нужно хранить отдельно, а не на той же машине. - На сервере бэкапов создаём пользователя
borg:
sudo useradd -m borg
Просто: без групп и со стандартным shell’ом, но обязательно с домашним каталогом. - На клиенте генерируется SSH-ключ:
ssh-keygen - На сервере пользователю
borgдобавляем сгенерированный ключ:
mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh - Инициализируем borg repo на сервере с клиента:
ssh borg@172.17.0.3 hostname # просто для проверки соединения borg init -e none borg@172.17.0.3:MyBorgRepo
Ключ-eслужит для выбора метода шифрования репозитория (да, вы можете дополнительно зашифровать каждый репозиторий своим паролем!). В данном случае, т.к. это пример, шифрованием мы не пользуемся.MyBorgRepo— это имя каталога, в котором будет borg repo (создавать его заранее не нужно — Borg всё сделает сам). - Запускаем первый бэкап с помощью Borg:
borg create --stats --list borg@172.17.0.3:MyBorgRepo::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" /etc /root
Про ключи:
-
--statsи--listдают нам статистику по бэкапу и попавшим в него файлам; -
borg@172.17.0.3:MyBorgRepo— тут всё понятно, это наш сервер и каталог. А что дальше за магия?.. -
::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}"— это имя архива внутри репозитория. Оно произвольно, но мы придерживаемся форматаИмя_бэкапа-timestamp(timestamp в формате Python).
-
Что дальше? Конечно, посмотреть, что же попало в наш бэкап! Список архивов внутри репозитория:
borg@b3e51b9ed2c2:~$ borg list MyBorgRepo/
Warning: Attempting to access a previously unknown unencrypted repository!
Do you want to continue? [yN] y
MyFirstBackup-2018-08-04_16:55:53 Sat, 2018-08-04 16:55:54 [89f7b5bccfb1ed2d72c8b84b1baf477a8220955c72e7fcf0ecc6cd5a9943d78d]Видим бэкап с timestamp’ом и как Borg спрашивает нас, действительно ли мы хотим обратиться к нешифрованному репозиторию, в котором ещё ни разу не были.
Смотрим список файлов:
borg list MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53Достаём файл из бэкапа (можно и весь каталог):
borg@b3e51b9ed2c2:~$ borg extract MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 etc/hostname
borg@b3e51b9ed2c2:~$ ll etc/hostname
-rw-r--r-- 1 borg borg 13 Aug 4 16:27 etc/hostnameПоздравляю, ваш первый бэкап с Borg готов!
Практика: автоматизируй это [с GitLab]!
Завернув всё это в скрипты, мы настроили бэкапы вручную подобным образом примерно на 40 хостах. Поняв, что Borg действительно работает, начали переводить на него больше и более крупные проекты…
И тут мы столкнулись с тем, что есть в Bareos, но нет у Borg! А именно: WebUI или какого-то централизованного места для настройки бэкапов. И мы очень надеемся, что это временное явление, но пока нам надо было что-то решить. Погуглив готовые инструменты и собравшись в видеоконференции, мы взялись за дело. Была замечательная идея интеграции Borg с нашими внутренними сервисами, как мы делали раньше с Bacula (сама Bacula забирала список job’ов из нашего централизованного API, к которому мы имели свой интерфейс, интегрированный с другими настройками проектов). Подумали, как можно сделать, обрисовали план, как и куда это можно встроить, но… Нормальные бэкапы нужны сейчас, а на грандиозные планы времени взять неоткуда. Что делать?
Вопросы и требования стояли примерно следующим образом:
- Что использовать как централизованное управление бэкапами?
- Что умеет любой Linux-администратор?
- Что сможет понять и настроить даже менеджер, показывающий график бэкапов клиентам?
- Что каждый день выполняет по расписанию задания на вашей системе?
- Что не будет трудным в настройке и не будет ломаться?..
Ответ был очевиден: это старый добрый crond, который героически выполняет свой долг каждый день. Простой. Не зависает. Сможет поправить даже менеджер, который с Unix на «вы».
Итак, crontab, но где же всё это держать? Неужели каждый раз ходить на машину проекта и править файл руками? Конечно, нет. Мы можем положить наше расписание в Git-репозиторий и настроить GitLab Runner, который по коммиту будет обновлять его на хосте.
Примечание: Именно GitLab был выбран в качестве средства автоматизации, потому что он удобен для поставленной задачи и в нашем случае есть практически везде. Но должен заметить, что он ни в коем случае не является необходимостью.
Раскладывать crontab для бэкапов вы можете привычным для себя средством автоматизации или вообще вручную (на маленьких проектах или домашних инсталляциях).
Итак, вот что понадобится для простой автоматизации:
1. GitLab и репозиторий, в котором для начала будет два файла:
-
schedule— расписание бэкапов, -
borg_backup_files.sh— простой скрипт бэкапа файлов (как в примере выше).
Пример
schedule:# WARNING! CRONTAB MANAGED FROM GITLAB CI RUNNER IN ${CI_PROJECT_URL}
# CI_COMMIT_SHA: ${CI_COMMIT_SHA}
# Branch/tag: ${CI_COMMIT_REF_NAME}
# Timestamp: ${TIMESTAMP}
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
# MyRemoteHost
0 0 * * * ${CI_PROJECT_DIR}/borg_backup_files.sh 'SYSTEM /etc,/opt'Переменные CI используются для того, чтобы проверить успешность обновления crontab’а, а
CI_PROJECT_DIR — каталог, в котором окажется репозиторий после клонирования runner’ом. Последняя строка указывает на то, что бэкап выполняется каждый день в полночь.Пример
borg_backup_files.sh:#!/bin/bash
BORG_SERVER="borg@10.100.1.1"
NAMEOFBACKUP=${1}
DIRS=${2}
REPOSITORY="${BORG_SERVER}:$(hostname)-${NAMEOFBACKUP}"
borg create --list -v --stats \
$REPOSITORY::"files-{now:%Y-%m-%d_%H:%M:%S}" \
$(echo $DIRS | tr ',' ' ') || \
echo "borg create failed"Первым аргументом здесь передаётся имя бэкапа, а вторым — список директорий для бэкапа, через запятую. Строго говоря, списком может являться и набор отдельных файлов.
2. GitLab Runner, запущенный на машине, которую необходимо бэкапить, и заблокированный только на выполнение job’ов этого репозитория.
3. Сам CI-сценарий, реализуемый файлом
.gitlab-ci.yml:stages:
- deploy
Deploy:
stage: deploy
script:
- export TIMESTAMP=$(date '+%Y.%m.%d %H:%M:%S')
- cat schedule | envsubst | crontab -
tags:
- borg-backup4. SSH-ключ у пользователя
gitlab-runner c доступом к серверу бэкапов (в примере это 10.100.1.1). По умолчанию он должен лежать в .ssh/id_rsa домашнего каталога пользователя (gitlab-runner).5. Пользователь
borg на том же 10.100.1.1 с доступом только к команде borg serve:$ cat .ssh/authorized_keys
command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAA...Теперь при коммите в репозиторий Runner заполнит содержимое crontab’а. А при наступлении времени срабатывания cron’а выполнится бэкап каталогов
/etc и /opt, который окажется на сервере бэкапов в каталоге MyHostname-SYSTEM сервера 10.100.1.1.
Вместо заключения: что можно ещё?
Применение Borg на этом, конечно, не заканчивается. Вот несколько идей для дальнейшей реализации, часть которых мы у себя уже реализовали:
- Добавить универсальные скрипты для разных бэкапов, которые по окончанию выполнения запускают
borg_backup_files.sh, направленный на каталог с результатом своей работы. Например, так можно бэкапить PostgreSQL (pg_basebackup), MySQL (innobackupex), GitLab (встроенный rake job, создающий архив). - Центральный хост со schedule для бэкапа. Не настраивать же на каждом хосте GitLab Runner? Пусть он будет один на сервере бэкапов, а crontab при запуске передаёт скрипт бэкапа на машину и запускает его там. Для этого, конечно, понадобится пользователь
borgна машине клиенте иssh-agent, чтобы не раскладывать ключ к серверу бэкапов на каждой машине. - Мониторинг. Куда же без него! Алерты о некорректно завершённом бэкапе обязательно должны быть.
- Очистка borg repository от старых архивов. Несмотря на хорошую дедупликацию, старые бэкапы всё равно приходится чистить. Для этого можно сделать вызов
borg pruneпо окончанию работы скрипта бэкапа. - Веб-интерфейс к расписанию. Пригодится, если правка crontab руками или в web-интерфейсе для вас выглядит не солидно/неудобно.
- Pie charts. Немного графиков для наглядного представления процента успешно выполненных бэкапов, времени их выполнения, ширины «съеденного» канала. Не зря я уже писал, что не хватает WebUI, как в Bareos…
- Простые действия, которые хотелось бы получать по кнопке: запуск бэкапа по требованию, восстановление на машину и т.п.
И в самом конце хотелось бы добавить пример эффективности дедупликации на реальном рабочем бэкапе WAL-файлов PostgreSQL в production-среде:
borg@backup ~ $ borg info PROJECT-PG-WAL
Repository ID: 177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6
Location: /mnt/borg/PROJECT-PG-WAL
Encrypted: No
Cache: /mnt/borg/.cache/borg/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6
Security dir: /mnt/borg/.config/borg/security/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
All archives: 6.68 TB 6.70 TB 19.74 GB
Unique chunks Total chunks
Chunk index: 11708 3230099Это 65 дней бэкапа WAL-файлов, которые делались каждый час. При использовании Bacula/Bareos, т.е. без дедупликации, мы получили бы 6,7 Тб данных. Только подумайте: можем позволить себе хранить почти 7 терабайт данных, прошедших через PostgreSQL, всего в 20 Гб фактически занимаемого места.
P.S.
Читайте также в нашем блоге:
