
Распределение IP-адресов в 185/8, последнем свободном блоке RIPE, в 2012 году (слева) и 2018 году (справа), источник
17 апреля 2018 года Сетевой координационный центр RIPE — одна из пяти Региональных регистратур — распределил последние 1024 адресов IPv4 из последнего блока /8, полученного от IANA в 2011 году. Хотя последний блок 185/8 полностью распределён между европейскими компаниями, но в пуле RIPE NCC осталось 9 млн «восстановленных» адресов (то есть адресов, изъятых у бывших владельцев). По расчётам Координационного центра, этого хватит ещё примерно на два года, если выдавать по заявкам локальных регистраторов по /22 каждому.
На данный момент каждый адрес IPv4 — исключительно дефицитный товар, а последние выделенные IP-адреса используются очень интенсивно. Поэтому особенно неприятны ситуации вроде нынешней массовой блокировки IP-адресов в России. На пике блокировки 18 млн заблокированных Роскомнадзором IP-адресов соответствовали 5,5 млн заблокированных доменов — это около 2,45% из 223 млн известных доменов в интернете.
К счастью, сейчас российский регулятор постепенно снимает блокаду. Сейчас в блокировке осталось лишь 14,6 млн адресов по статистике бота RKNSHOWTIME или 14,7 млн по статистике другого сервиса RKN block digest. Разница связана с тем, в первом случае считаются только явно указанные IP-адреса, а во втором — и IP-адреса, и домены (некоторые записи в выгрузке Роскомнадзора содержат только название домена).
Как распределялся последний блок /8
Когда RIPE NCC получил последний /8 (блок 185/8, 16 777 216 адресов), в пуле RIPE оставалось около 75 млн адресов, так что они продолжали свободно распределяться по заявкам локальных регистраторов (LIR). Но в сентябре 2012 года единственным свободным блоком остался 185/8 — и тогда вступил в действие раздел 5.6 Политики распределения адресов IPv4 в европейском регионе. Эти правила специально приняли, когда стало понятно, что дефицита адресов не избежать.
Правила распределяют дефицитный ресурс в ограниченных количествах (по одному блоку каждому локальному регистратору). По итогу можно сказать, что правила очень помогли. Последний блок /8 растянули на 5,5 лет, в то время как предыдущий блок /8 по старым правилам раздали за пять месяцев.
Ниже приводим раздел 5.6 из новых правил в некотором сокращении. В частности, мы сократили часть по выделению адресов точкам обмена трафиком, для которых зарезервировали один диапазон /16 (65 536 адресов). Он распределяется блоками от /24 до /22, то есть от 256 до 1024 адресов.
5.6 Использование последнего блока /8 (Use of last /8 for PA Allocations)
Когда RIPE NCC начнёт выделять блоки адресов IPv4 из последнего блока /8, полученного от IANA, будет применяться политика, изложенная ниже.
- Выделение блоков для LIR из последнего /8.
Порядок удовлетворения заявок LIR на адреса IPv4 следующий:
- LIR может получить только один блок из последнего блока /8. Размер блока — /22.
- LIR получит только один блок /22, даже если потребность в адресах намного выше.
- LIR может запросить этот блок и получить его в соответствии с политикой распределения адресного пространства, которая действовала на момент запроса.
- Блоки IPv4 будет выданы только тем LIR'ам, которые получили адреса IPv6 от вышестоящего локального регистратора (upstream LIR) или от RIPE NCC.
- Выделение точкам обмена трафиком (Internet Exchange Point).
- Непредвиденные обстоятельства (Unforeseen circumstances).
- Блок /16 будет зарезервирован для будущих непредвиденных целей. Если таковых не окажется, то к моменту, когда последний /8 будет израсходован, этот блок будет распределен в соответствии с п. 1.
- Повторное использование адресов (Post-depletion Address Recycling)
Данные положения касаются только адресного пространства, возвращённого в RIPE NCC и не подлежащего возврату в IANA.
- Любое адресное пространство, возвращённое в RIPE NCC, будет распределяться по правилам, описанным в части 1.
- Минимальный размер блока, выделяемого из последнего /8, может быть при необходимости изменён.
- Если адресов для выделения блока /22 будет недостаточно, адреса будут выделены несколькими блоками (multiple allocations), но в количестве, эквивалентном /22.
Итак, в течение пяти с половиной лет RIPE NCC выделял блоки /22 из последнего /8 по этим правилам, за исключением двух блоков /16, зарезервированных для непредвиденных обстоятельств и для точек обмена трафиком.
Суть новых правил в том, что независимо от потребностей локальных регистраторов им выдавали только по 1024 адреса, то есть только по одному блоку /22 — и только когда они уже получили блок IPv6. Тем не менее, по статистике за 2012−2018 годы, скорость выделения адресов IPv4 в Европе росла в соответствии с квадратичной функцией. RIPE NCC объясняет это тем, что регистрировалось всё больше и больше локальных регистраторов.

Этот рост регистраций RIPE NCC использует для прогноза по распределению остатков адресов IPv4
Сетевой координационный центр отметил увеличение количества регистраций в качестве членов RIPE NCC организаций, которые сами не распределяют адреса, а обслуживают конечных пользователей. По мнению специалистов, для организаций членство в RIPE NCC оказалось наиболее дешёвым способом раздобыть дополнительные адреса IPv4 для собственной инфраструктуры.
Оказалось также, что стимулы к переходу на IPv6 тоже не работают. Большинство организаций, которые зарегистрировали диапазоны IPv6-адресов перед получением блока IPv4, никак их не использовали. Более того, чтобы избежать бесполезной траты адресного пространства IPv6, в марте 2015 года RIPE вообще убрал требование об обязательной регистрации блока IPv6.
В ноябре 2015 года RIPE запретил регистрацию дополнительных локальных регистраторов членами RIPE NCC, но это тоже не помогло, так что в мае 2016 года ограничение сняли. К этому моменту организации начали регистрировать новые юридические лица, чтобы получить дефицитные блоки /22. Как сообщается, некий член RIPE NCC сумел получить 66 блоков /22, хотя выдавали только по одному на каждого локального регистритора. Ограничение сняли, потому что решили, что лучше пусть организации воспользуются легальной лазейкой в действующие процедуре, а не будут искать обходные пути.
Вот как распределились дефицитные ресурсы по странам (файл статистики). Для упрощения цифры на карте округлены до /22, хотя многие блоки разбивались на /23 и /24.
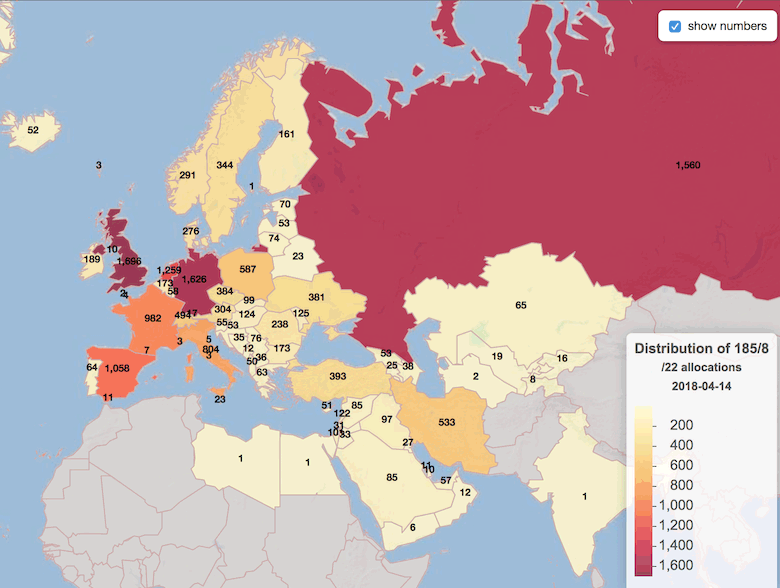
На карте можно заметить некоторые аномалии: например, необычно мало блоков выделено организациям из Бельгии, Португалии и Беларуси, по сравнению с их более «предприимчивыми» соседями.
Только к 2015 году специалисты RIPE NCC осознали, что большое количество блоков /22 сразу после выделения меняют своего владельца и в течение нескольких дней или недель переходят к другому регистратору (transfer). Тогда регулятор запретил трансферы для адресов IPv4 до истечения 24 месяцев после выделения. Но судя по графику ежемесячных трансферов, это тоже не помогло, просто на два года заморозило трансферы свежих диапазонов.
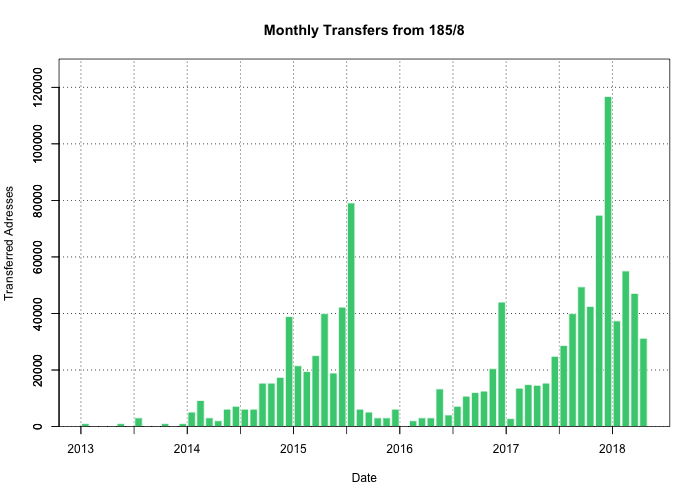
Когда закончатся последние адреса IPv4?
Как уже упоминалось, в пуле RIPE NCC осталось около 9,03 млн адресов IPv4, которых хватит ещё примерно на два года. Из них четыре миллиона — это 1/5 от 20 млн адресов, которые восстановила IANA (Администрация адресного пространства Интернет) и раздала пяти региональным регистратурам в течение последних четырёх лет. Ещё 5 млн адресов RIPE забрал самостоятельно, проведя «перекличку» организаций. По условиям процедуры, если отклика от владельца не было получено, то IP-адреса у него изымались.
В то же время провайдеры научились справляться с дефицитом адресного пространства. Многие освоили технику трансляции адресов (NAT), когда пользователям выделяются частные адреса IPv4 или IPv6, при этом используется меньшее количество глобальных адресов IPv4.
Если экстраполировать график, то нынешнего пула хватит примерно до мая 2020 года.
Предложения по купле-продаже или аренде IPv4 обсуждаются на форумах провайдеров и на Хабре. Судя по всему, сдача в аренду адресов IPv4 превратилась в неплохой бизнес.
Утилизация IPv4 и IPv6
Очень многие организации зарегистрировали на себя огромные по нынешним временам диапазоны IPv4, которые практически не используют и не собираются отдавать (например, 16,8 млн адресов в блоке 44.0.0.0/8, зарегистрированных якобы для любительского радио, или 218 млн IP-адресов у Министерства обороны США: 11.0.0.0/8, 22.0.0.0/8, 26.0.0.0/8, 28.0.0.0/8, 29.0.0.0/8, 30.0.0.0/8 и 33.0.0.0/8 ).
Другие блоки используются очень интенсивно. Например, визуализация кривыми Гильберта хорошо показывает, как распределено адресное пространство из примерно 4,2 млрд (2³²) адресов.
Распределение адресного пространства IPv4, апрель 2018 года (кликабельна)
Для сравнения, вот как выглядит на сегодняшний день распределение адресного пространства IPv6.

Распределение адресного пространства IPv6, апрель 2018 года
Объявляем акцию «Больше киберзащиты спорту»!

GlobalSign присоединяется к празднованию самого грандиозного события всех спортсменов и футбольных болельщиков – ЧЕМПИОНАТУ МИРА ПО ФУТБОЛУ 2018 и ДАРИТ 1 ГОД SSL ЗАЩИТЫ!*
Условия акции:
* При покупке любого однолетнего SSL-сертификата DV, OV или EV уровня, второй год вы получаете в подарок.
• Акция распространяется на все сайты спортивной тематики.
• Акция действует только на новые заказы и не распространяется на партнеров.
• Чтобы воспользоваться предложением, отправьте запрос на сайте с указанием промо-кода: SL003HBFR.
Акция продлится до 15 июля 2018 г.
Получить дополнительную информацию по акции вы можете у менеджеров GlobalSign Russia по телефону: +7 (499) 678 2210.
БОЛЬШЕ ЗАЩИТЫ c GlobalSign!

{kind=link}
{kind=link}
{kind=link}