
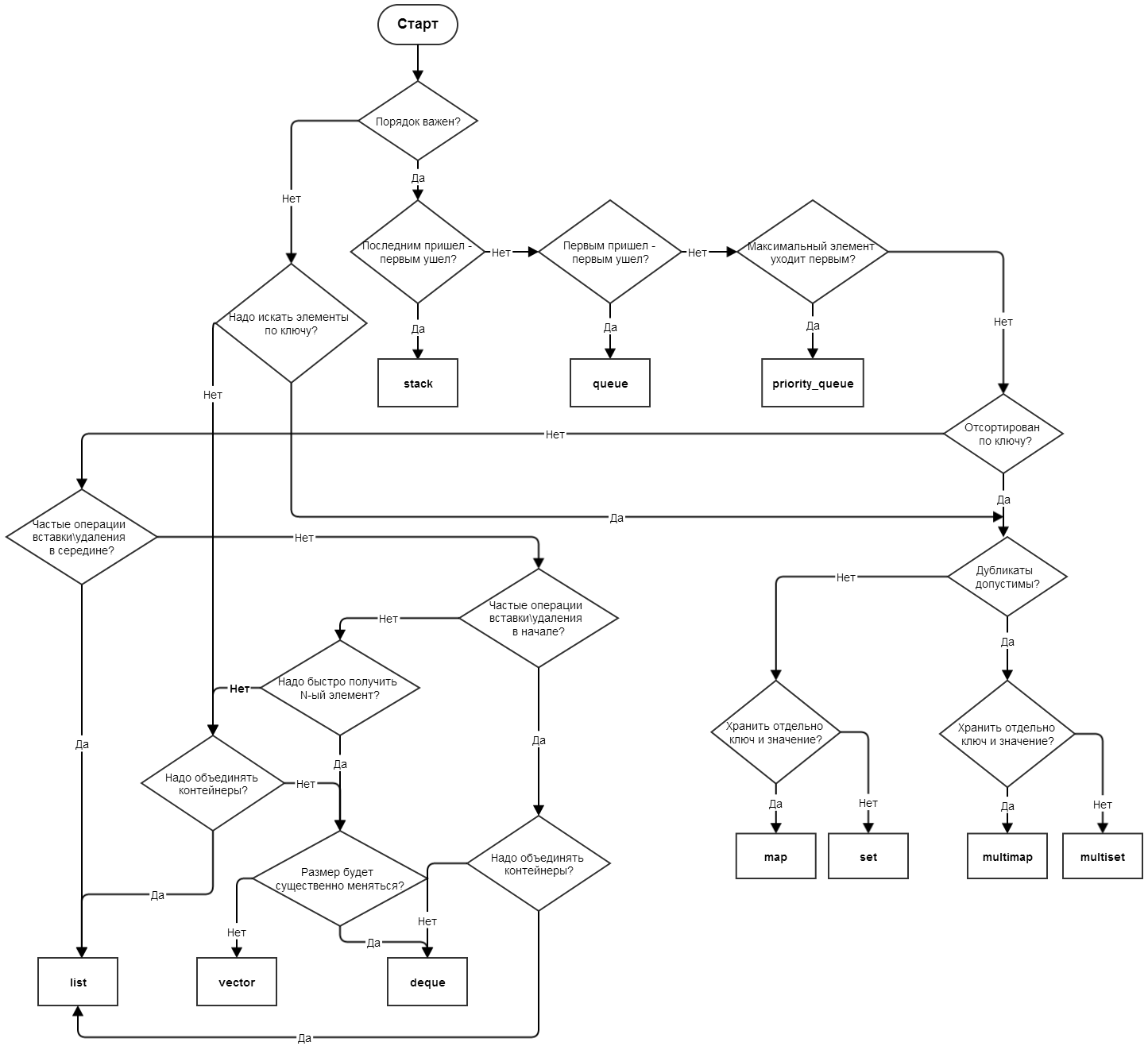
UPD: схема заменена на вариант с контейнерами из С++11, соавторы — в комментариях ниже
Первый вариант схемы - без контейнеров из С++11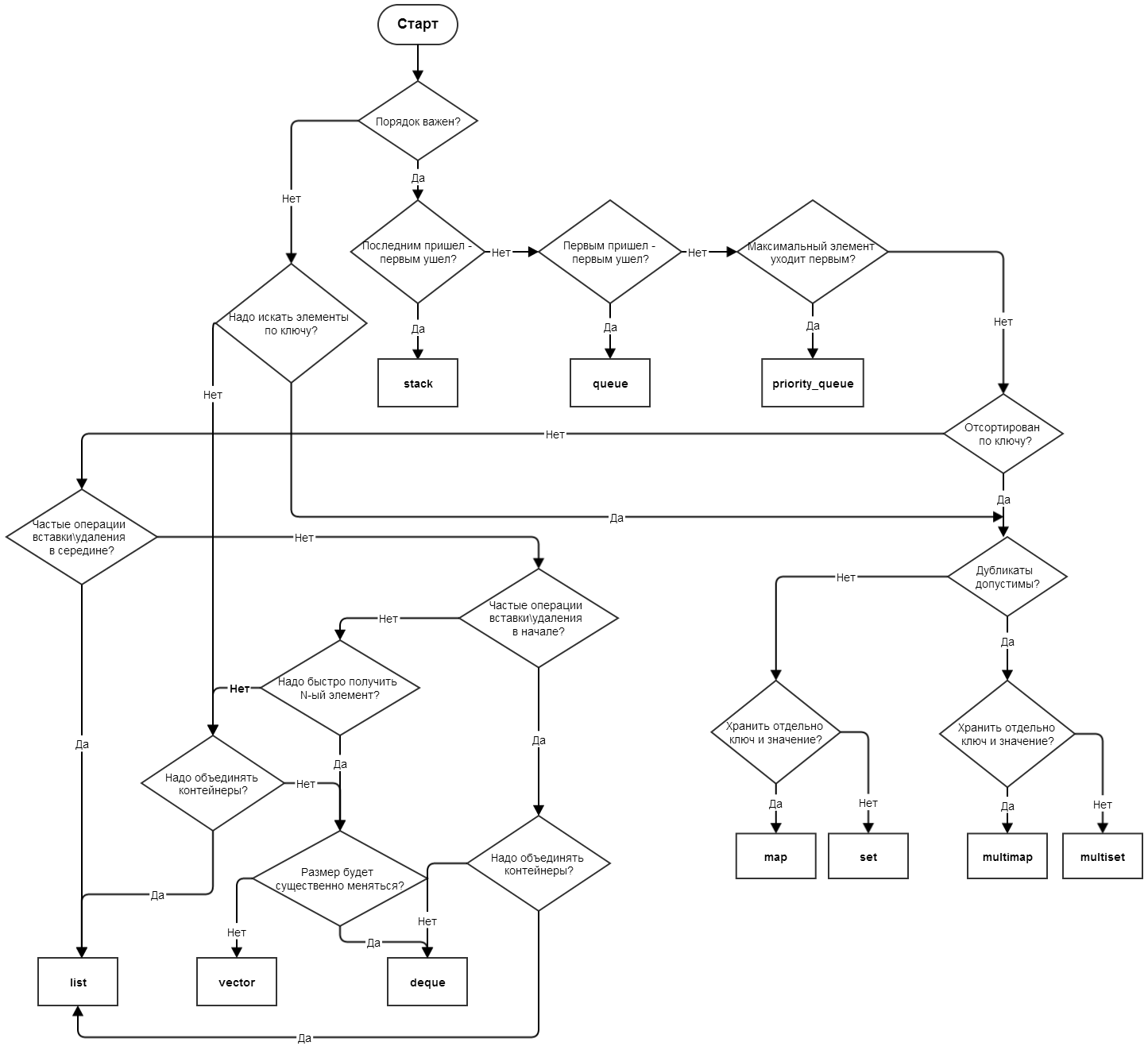
Only registered users can participate in poll. Log in, please.
Стоит по результатам обсуждения в комментариях расширить схему для контейнеров С++11?
6.55% Нет, ты что, это же перевод, должно быть точно как в оригинале!73
12.2% Надо бы, конечно, но вряд ли мы тут всё правильно придумаем136
81.26% А почему бы и нет? Давай, конечно!906
1115 users voted. 393 users abstained.
