
В прошлых двух статьях мы рассказывали об IIoT — индустриальном интернете вещей — строили архитектуру, чтобы принимать данные от сенсоров, паяли сами сенсоры. Краеугольным камнем архитектур IIoT да и вообще любых архитектур работающих с BigData является потоковая обработка данных. В ее основе лежит концепция передачи сообщений и очередей. Стандартом работы с рассылкой сообщений сейчас стала Apache Kafka. Однако, для того, чтобы разобраться в ее преимуществах (и понять ее недостатки) было бы хорошо разобраться в основах работы систем очередей в целом, механизмах их работы, шаблонах использования и основной функциональности.

Мы нашли отличную серию статей, которая сравнивает функциональность Apache Kafka и другого (незаслуженно игнорируемого) гиганта среди систем очередей — RabbitMQ. Эту серию статей мы перевели, снабдили своими комментариями и дополнили. Хотя серия и написана в декабре 2017 года, мир систем обмена сообщениями (и особенно Apache Kafka) меняется так быстро, что уже к лету 2018-го года некоторые вещи изменились.
Источник
RabbitMQ vs Kafka
Рассылка сообщений (messaging) — центральная часть множества архитектур, и двумя столпами в этой сфере являются RabbitMQ и Apache Kafka. К настоящему моменту Apache Kafka стала практически индустриальным стандартом в обработке данных и аналитике, поэтому в этой серии мы детально рассмотрим RabbitMQ и Kafka в контексте их использования в инфраструктурах реального времени.
Apache Kafka сейчас на подъеме, а о RabbitMQ как будто бы стали забывать. Весь хайп сконцентрировался на Kafka, и это происходит по понятным причинам, но RabbitMQ по-прежнему является отличным выбором для обмена сообщениями. Одна из причин, по которой Kafka переключила внимание на себя — общая одержимость масштабируемостью, и, очевидно, Kafka более масштабируема, нежели RabbitMQ, но большинство из нас не имеет дел с масштабами, при которых у RabbitMQ появляются проблемы. Большинство из нас не Google и не Facebook. Большинство из нас имеет дело с ежедневными объемами сообщений от сотен тысяч до сотен миллионов, а не с объемами от миллиардов до триллионов (но кстати, существуют кейсы, когда люди масштабировали RabbitMQ до миллиардов ежедневных сообщений).
Таким образом, в нашей серии статей мы не будем говорить о случаях когда требуется экстремальная масштабируемость (и это прерогатива Kafka), а сосредоточимся на уникальных преимуществах, которые предлагает каждая из рассматриваемых систем. Что интересно, у каждой системы свои преимущества, но при этом они довольно сильно отличаются друг от друга. Я, конечно, довольно много писал про RabbitMQ, но уверяю, что никакого особого предпочтения ей не отдаю. Мне нравится хорошо сделанные вещи, а RabbitMQ и Kafka обе вполне зрелые, надежные и, да, масштабируемые messaging-системы.
Начнем мы с верхнего уровня, а затем начнем изучать различные аспекты этих двух технологий. Эта серия статей предназначена для специалистов, занимающихся организацией messaging-систем или архитекторов/инженеров, которые хотят понять детали нижнего уровня и их применение. Мы не будем писать код, а вместо этого сосредоточимся на функциональности, предлагаемой обеими системами, шаблонами процесса обмена сообщениями, которые предлагает каждая из них, и решениях, которые должны принимать разработчики решений и архитекторы.
RabbitMQ против Kafka: два разных подхода к обмену сообщениями
В этой части мы рассмотрим, что такое RabbitMQ и Apache Kafka, и их подход к обмену сообщениями. Обе системы подходят к архитектуре обмена сообщениями с разных сторон, у каждой из которых имеются сильные и слабые стороны. В этой главе мы не придем к каким-либо важным выводам, вместо этого, предлагаем воспринимать эту статью как пособие по технологиям для начинающих, для того, чтобы мы могли погрузиться глубже в следующих статьях серии.
RabbitMQ
RabbitMQ — это распределенная система управления очередью сообщений. Распределенная, поскольку обычно работает как кластер узлов, где очереди распределяются по узлам и, опционально, реплицируются в целях устойчивости к ошибкам и высокой доступности. Штатно, она реализует AMQP 0.9.1 и предлагает другие протоколы, такие как STOMP, MQTT и HTTP через дополнительные модули.
RabbitMQ использует как классический, так и новаторский подходы к обмену сообщениями. Классический в том смысле, что она ориентирована на очередь сообщений, а новаторский — в возможности гибкой маршрутизации. Именно эта возможность маршрутизации является ее уникальным преимуществом. Создание быстрой, масштабируемой и надежной распределенной системы сообщений само по себе является достижением, но функциональность маршрутизации сообщений делает ее действительно выдающейся среди множества технологий обмена сообщениями.
Exchange'и и очереди
Супер-упрощенный обзор:
- Паблишеры (publishers) отправляют сообщения на exchange’и
- Exchange’и отправляют сообщения в очереди и в другие exchange’и
- RabbitMQ отправляет подтверждения паблишерам при получении сообщения
- Получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь(-и) они получают
- RabbitMQ проталкивает (push) сообщения получателям
- Получатели отправляют подтверждения успеха/ошибки
- После успешного получения, сообщения удаляются из очередей
В этом списке скрыто огромное количество решений, которые должны принять разработчики и администраторы, чтобы получить нужные им гарантии доставки, характеристики производительности и т. д., каждую из которых мы рассмотрим позже.
Давайте посмотрим пример работы с одним паблишером, exchange’м, очередью и получателем:

Рис. 1. Один паблишер и один получатель
Что делать, если у вас несколько паблишеров одного и того же
сообщения? Что делать, если у нас есть несколько получателей, каждый из которых хочет получать все сообщения?

Рис. 2. Несколько паблишеров, несколько независимых получателей
Как вы можете видеть, паблишеры отправляют свои сообщения на тот же обменник, который отправляет каждое сообщение в три очереди, в каждой из которых есть один получатель. В случае RabbitMQ, очереди позволяют различным получателям получать все сообщения. Сравните с диаграммой ниже:
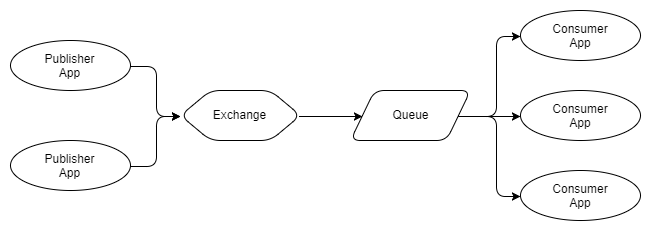
Рис. 3. Несколько паблишеров, одна очередь с несколькими конкурирующими получателями
На рисунке 3 мы видим трех получателей, которые используют одну очередь. Это конкурирующие получатели, то есть они конкурируют за получение сообщений из очереди. Таким образом, можно ожидать, что в среднем каждый получатель будет получать одну треть сообщений из очереди. Мы используем конкурирующих получателей для масштабирования нашей системы обработки сообщений, а с помощью RabbitMQ сделать это очень просто: добавьте или удалите получателей по запросу. Независимо от того, сколько у вас конкурирующих получателей, RabbitMQ обеспечит доставку сообщений только одному получателю.
Мы можем скомбинировать рис. 2 и 3, чтобы получить несколько наборов, конкурирующих получателей, где каждый набор получает каждое сообщение.

Рис. 4. Несколько паблишеров, несколько очередей с конкурирующими получателями
Стрелки между обменниками и очередями называются привязками (bindings), и мы еще поговорим о них подробнее.
Гарантии
RabbitMQ дает гарантии «одноразовой доставки» и «хотя бы одной доставки», но не «ровно одной доставки».
Примечание переводчика: до версии Kafka 0.11 доставка сообщений exactly-once delivery была недоступна, в настоящее время подобная функциональность присутствует и в Kafka.
Сообщения доставляются в порядке их прибытия в очередь (в конце концов, это и есть определение очереди). Это не гарантирует, что завершение обработки сообщений совпадает с тем же самым порядком, когда у вас есть конкурирующие получатели. Это не ошибка RabbitMQ, а фундаментальная реальность параллельной обработки упорядоченного набора сообщений. Эту проблему можно решить, используя Consistent Hashing Exchange, как вы увидите в следующей главе по шаблонам и топологиям.
Проталкивание (push) и предварительная выборка получателей
RabbitMQ проталкивает (push) сообщения получателям (существует также API для выгрузки (pull) сообщений из RabbitMQ, но в настоящий момент эта функциональность устарела). Это может переполнить получателей, если сообщения прибудут в очередь быстрее, чем получатели могут их обработать. Чтобы этого избежать, каждый получатель может настроить предел предварительной выборки (также известный как предел QoS). По сути, предел QoS это ограничение на количество скопившихся неподтвержденных получателем сообщений. Это действует как предохранитель, когда получатель начинает отставать.
Зачем принято решение о том, что сообщения в очереди проталкиваются (push), а не выгружаются (pull)? Во-первых, потому, что так меньше время задержки. Во-вторых, в идеале, когда у нас есть конкурирующие получатели из одной очереди, мы хотим равномерно распределить нагрузку между ними. Если каждый получатель запрашивает/выгружает сообщения, то в зависимости от того, сколько они запрашивают, распределение работы может стать довольно неравномерным. Чем более неравномерно распределение сообщений, тем больше задержка и дальнейшая потеря порядка сообщений во время обработки. Эти факторы ориентируют архитектуру RabbitMQ на механизм проталкивания “одно-сообщение-за-раз”. Это одно из ограничений масштабирования RabbitMQ. Ограничение смягчается тем, что подтверждения можно группировать.
Маршрутизация
Exchange’и — это, в основном, маршрутизаторы сообщений для очередей и/или других exchange’ей. Чтобы сообщение перемещалось из exchange’а в очередь или на другой exchange, необходима привязка. Разные exchange’и требуют разных привязок. Существует четыре типа exchange’ей и связанные с ними привязки:
- Fanout (разветвляющий). Направляет во все очереди и обменники, имеющие привязку к exchange’у Стандартная подмодель Pub.
- Direct (прямой). Маршрутизирует сообщения на основе ключа маршрутизации, который несет с собой сообщение, задается паблишером. Ключ маршрутизации — короткая строка. Прямые обменники отправляют сообщения в очереди/exchange’и, у которых есть ключ сопряжения, который точно соответствует ключу маршрутизации.
- Topic (тематический). Маршрутизирует сообщения на основе ключа маршрутизации, но позволяет использовать неполное соответствие (wildcard).
- Header (заголовочный). RabbitMQ позволяет добавлять к сообщениям заголовки получателей. Заголовочные exchange’и передают сообщения в соответствии с этими значениями заголовка. Каждая привязка включает в себя точное соответствие значений заголовка. К привязке можно добавить несколько значений с ЛЮБЫМИ или ВСЕМИ значениями, необходимыми для соответствия.
- Consistent Hashing (консистентное хэширование). Это обменник, который хэширует либо ключ маршрутизации, либо заголовок сообщения, и отправляет только в одну очередь. Это полезно, когда вам нужно соблюсти гарантии порядка обработки и при этом иметь возможность масштабировать получателей.

Рис. 5. Пример topic exchange’а
Мы еще рассмотрим маршрутизацию более подробно, но выше приведен пример topic exchange’а. В этом примере паблишеры публикуют журналы ошибок с использованием формата ключа маршрутизации LEVEL(Уровень ошибки).AppName.
Очередь 1 будет получать все сообщения, так как использует № подстановочного знака с несколькими словами.
Очередь 2 получит любой уровень ведения журнала приложения ECommerce.WebUI. Она использует wildcard *, таким образом захватывая уровень одного именования топика (ERROR.Ecommerce.WebUI, NOTICE.ECommerce.WebUI итп).
В очереди 3 будут отображаться все сообщения уровня ERROR из любого приложения. Она использует wildcard # для охвата всех приложений (ERROR.ECommerce.WebUi, ERROR.SomeApp.SomeSublevel итп).
Благодаря четырем способам маршрутизации сообщений и с возможностью exchange-ам передавать сообщения на другие exchange’и RabbitMQ позволяет использовать мощный и гибкий набор шаблонов обменов сообщениями. Дальше мы поговорим об exchange’ах с недоставленными сообщениями (dead letter exchange), об exchange’ах и очередях без данных (ephemeral exchanges and queues), и RabbitMQ развернется в полную мощь.
Exchange’и с недоставленными сообщениями
Примечание переводчика: Когда сообщения из очереди не могут быть получены по тем или иным причинам (мощности потребителей не хватает, сетевые проблемы и так далее), их можно откладывать и обрабатывать отдельно.
Мы можем настроить очереди так, чтобы сообщения отсылались на exchange при следующих условиях:
- Очередь превышает заданное количество сообщений.
- Очередь превышает заданное количество байт.
- Время передачи сообщения (TTL) истекло. Паблишер может установить время жизни сообщения, и сама очередь тоже может иметь заданное TTL для сообщения. В таком случае будет использоваться более короткий TTL из двух.
Мы создаем очередь, которая имеет привязку к exchange’ам с недоставленными сообщениями, и эти сообщения сохраняются там до тех пор, пока не будут предпринято какое-либо действие.
Как и многие функции RabbitMQ, exchange’и с недоставленными сообщениями дают возможность использовать шаблоны, которые непредусмотренны изначально. Мы можем использовать TTL сообщений и exchange’и с недоставленными сообщениями для реализации отложенных очередей и повторных очередей.
Обменники и очереди без данных
Exchange’и и очереди могут быть созданы динамически, при этом можно задать критерии для их автоматического удаления. Это позволяет использовать такие шаблоны, как очереди ответов для RPC на основе сообщений.
Дополнительные модули
Первый подключаемый модуль, который вы наверняка захотите установить — это плагин управления, который предоставляет HTTP-сервер с веб-интерфейсом и REST API. Он очень прост в установке и у него простой в использовании интерфейс. Развертывание сценариев через REST API тоже очень простое.
Кроме того:
- Consistent Hashing Exchange, Sharding Exchange и многое другое
- протоколы, такие как STOMP и MQTT
- веб-хуки
- дополнительные типы обменников
- интеграция SMTP
Существует еще множество вещей, которые можно рассказать про RabbitMQ, но это хороший пример, который позволяет описать что RabbitMQ может делать. Теперь мы рассмотрим Kafka, который использует совершенно иной подход к обмену сообщениями и, при этом, также имеет свой набор отличительных, интересных возможностей.
Apache Kafka
Kafka — это распределенный реплицированный журнал фиксации изменений (commit log). У Kafka’и нет концепции очередей, что сначала может показаться странным, учитывая, что его используют в качестве системы обмена сообщениями. Очереди долгое время были синонимом систем обмена сообщениями. Давайте для начала разберемся, что значит «распределенный, реплицированный журнал фиксации изменений»:
- Распределенный, поскольку Kafka развертывается как кластер узлов, как для устойчивости к ошибкам, так и для масштабирования
- Реплицированный, поскольку сообщения обычно реплицируются на нескольких узлах (серверах).
- Журнал фиксации изменений, потому что сообщения хранятся в сегментированных, append-only журналах, которые называются топиками. Эта концепция журналирования является основным уникальным преимуществом Kafka’и.
Понимание журнала (и топика) и партиций являются ключом к пониманию Kafka’и. Итак, чем партиционированный журнал отличается от набора очередей? Давайте представим, как это выглядит.
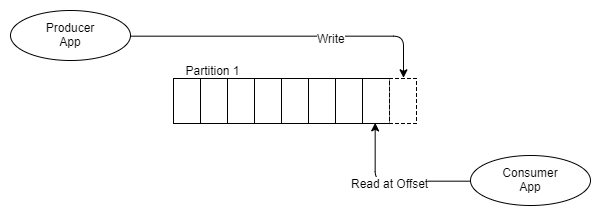
Рис. 6 Один продюсер, один сегмент, один получатель
Вместо того, чтобы помещать сообщения в очередь FIFO и отслеживать статус этого сообщения в очереди, как это делает RabbitMQ, Kafka просто добавляет его в журнал, и на этом все.
Сообщение остается, вне зависимости от того, будет ли оно получено один или несколько раз. Удаляется оно в соответствии с политикой удерживания данных (retention policy, также называемый window time period). Каким же образом информация забирается из топика?
Каждый получатель отслеживает, где она находится в журнале: имеется указатель на последнее полученное сообщение и этот указатель называется адресом смещения. Получатели поддерживают этот адрес через клиентские библиотеки, и в зависимости от версии Kafka адрес сохраняется либо в ZooKeeper, либо в самой Kafka’е.
Отличительная особенность модели журналирования в том, что она мгновенно устраняет множество сложностей, касающихся состояния доставки сообщений и, что более важно для получателей, позволяет им перематывать назад, возвращаться и получать сообщения по предыдущему относительному адресу. Например, представьте, что вы разворачиваете сервис, который выставляет счета, учитывающие заказы, размещаемые клиентами. У службы случилась ошибка, и она неправильно рассчитывает все счета за 24 часа. С RabbitMQ в лучшем случае вам нужно будет как-то переопубликовать эти заказы только на сервисе счетов. Но с Kafka вы просто перемещаете относительный адрес для этого получателя на 24 часа назад.
Итак, давайте посмотрим, как это выглядит, когда есть топик, в котором есть одна партиция и два получателя, каждый из которых должен получить каждое сообщение.

Рис. 7. Один продюсер, одна партиция, два независимых получателя
Как видно из диаграммы, два независимых получателя получают одну и туже партицию, но читают по разным адресам смещения. Возможно, сервис выставления счетов дольше обрабатывает сообщения, чем служба пуш-нотификаций. или, может быть, сервис выставления счетов был недоступен какое-то время и пытался догнать уже позже. Или, может, была ошибка, и адрес смещения пришлось отложить на несколько часов.
Теперь предположим, что сервис выставления счетов необходимо разделить на три части, потому что она не может поспеть за скоростью сообщения. С RabbitMQ мы просто разворачиваем еще два приложения-сервиса выставления счетов, которые получают из очереди обслуживания счетов. Но Kafka не поддерживает конкурирующих получателей в одной партиции, блок параллельности Kafka — это сама партиция. Поэтому, если нам нужны три получателя счетов, нам нужно как минимум три партиции. Итак, теперь у нас есть:
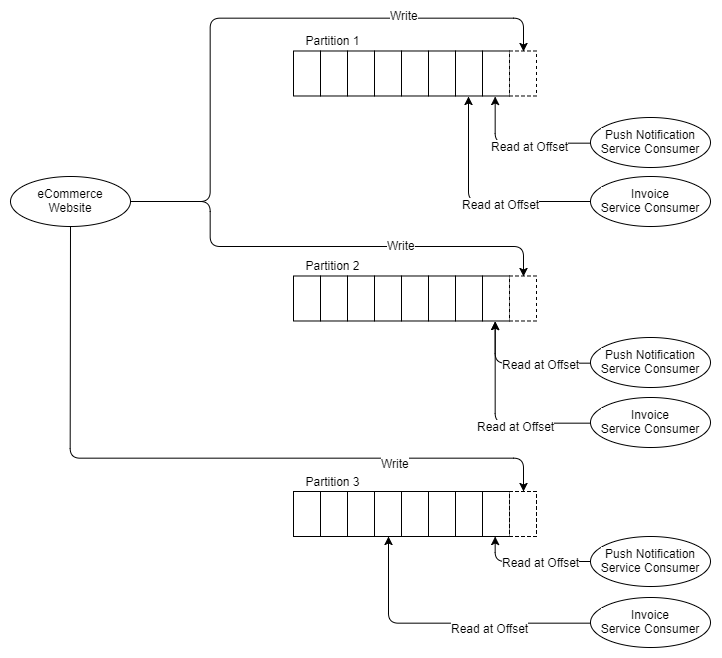
Рис. 8. Три партиции и две группы по три получателей
Таким образом, подразумевается, что вам нужно как минимум столько же партиций, сколько у наиболее отмасштабированного горизонтально получателя. Давайте немного поговорим о партициях.
Партиции и группы получателей
Каждая партиция представляет собой отдельный файл, в котором гарантируется очередность сообщений. Это важно помнить: порядок сообщений гарантируется только в одной партиции. В дальнейшем это может привести к некоторому противоречию между потребностями в очередности сообщений и потребностями в производительности, поскольку производительность в Kafka также масштабируется партициями. Партиция не может поддерживать конкурирующих получателей, поэтому наше приложение для выставления счетов может использовать только одну часть для каждого раздела.
Сообщения могут быть перенаправлены на сегменты по циклическому алгоритму или через функцию хэширования: hash (message key) % количество партиций. Использование функции хэширования имеет некоторые преимущества, поскольку мы можем создавать ключи сообщений, чтобы сообщения от одного объекта, например, информация о бронированиях, которая должна быть обработана последовательно, всегда переходили в один сегмент. Это позволяет использовать многие шаблоны работы с очередями и гарантии очередности сообщений.
Группы получателей похожи на конкурирующих получателей RabbitMQ. Каждый получатель в группе является частью одного приложения и будет обрабатывать подмножество всех сообщений в теме. В то время, как все конкурирующие получатели RabbitMQ получают из одной очереди, каждый получатель в группе получателей получает из разных партиций одной и той же темы. Таким образом, в приведенных выше примерах все три части службы счетов принадлежат одной и той же группе получателей.
Пока что RabbitMQ выглядит немного более гибкой системой с его гарантией очередности сообщений и хорошо интегрированной способностью справляться с изменением количества конкурирующих получателей. С Kafka важно, как вы распределяете журналы по партициям.
Существует неявное, но важное преимущество, которое было у Kafka с самого начала, а в RabbitMQ добавилось позже — очередность сообщений и параллелизм. RabbitMQ поддерживает глобальный порядок всей очереди, но не предлагает способа поддерживать это расположение во время ее параллельной обработки. Kafka не может предложить глобальное расположение топика, но предлагает очередность на уровне партиции. Поэтому, если вам нужно только выстраивать очередность связанных сообщений, то Kafka предлагает как упорядоченную доставку сообщений, так и упорядоченную обработку сообщений.
Представьте, что у вас есть сообщения, которые показывают последнее состояние бронирования клиента, поэтому вы хотите всегда последовательно обрабатывать сообщения об этом бронировании (последовательно по времени). Если вы партиционируете сообщения по идентификатору бронирования, то все сообщения о данном бронировании прибудут в одну партицию, где у нас сообщения упорядочены. Таким образом, вы можете создать большое количество партиций, что делает вашу обработку чрезвычайно распараллеленной, а также получите необходимые гарантии для упорядочения сообщений.
Эта возможность существует и в RabbitMQ — с помощью Consistent Hashing exchange, который одинаково распределяет сообщения по очередям. Однако особенность Kafka’и заключается в том, что Kafka организует эту упорядоченную обработку таким образом, что только один получатель в каждой группе может получить сообщения из одной партиции, и упрощает работу, поскольку, чтобы обеспечить соблюдение этого правила, для вас всю работу выполняет узел-координатор. В RabbitMQ все равно могут быть конкурирующие получатели, получающие одну очередь от партиции, и вам придется убедиться, что этого не происходит.
Здесь также есть подводные камни: в тот момент, когда вы меняете количество партиций, сообщения с номером Id 1000 теперь переходят в другую партицию, поэтому сообщения с номером Id 1000 существуют в двух партициях. В зависимости от того, как вы обрабатываете сообщения, это может вызвать проблему. Теперь существуют сценарии, когда сообщения обрабатываются не по порядку.
Проталкивание (push) против выгрузки (pull)
RabbitMQ использует модель проталкивания (push) и, таким образом, перегрузку сообщений получателями с помощью настроенного получателем предела предварительной выборки. Это отлично подходит для обмена сообщениями с низким значением задержки и хорошо работает для архитектуры RabbitMQ на основе очереди. С другой стороны, Kafka использует модель вытягивания (pull), где получатели запрашивают партии сообщений с заданного относительного смещения. Чтобы избежать бесконечных пустых циклов, когда никаких сообщений не существует за пределами текущего относительного адреса, Kafka допускает long-polling.
Модель вытягивания (pull) имеет смысл для Kafka из-за его сегментов. Поскольку Kafka гарантирует порядок сообщений в партиции без конкурирующих получателей, мы можем выгодно применить пакетирование сообщений для более эффективной доставки сообщений, что дает нам более высокую пропускную способность.
Это не имеет особого значения для RabbitMQ, так как в идеале мы хотим как можно быстрее распространять сообщения по очереди, чтобы обеспечить равномерную параллельность работы, а сообщения обрабатываются близко к тому порядку, в котором они попали в очередь. Но с Kafka партиция является единицей параллелизма и упорядочения сообщений, поэтому ни один из этих двух факторов не является для нас проблемой.
Публикация и подписка
Kafka поддерживает базовый шаблон продюсер/подписчик» с некоторыми дополнительными шаблонами, связанными с тем, что это журнал и он имеет партиции. Продюсеры добавляют сообщения в конец разделов журнала, и получателей с их относительными адресами можно разместить в любом месте партиции.
Рис. 9. Получатели с различными относительными адресами
Этот стиль диаграммы не так легко интерпретировать, когда есть несколько париций и групп получателей, поэтому для остальной части диаграмм для Kafka я буду использовать следующий стиль:
Рис. 10. Один продюсер, три партиции и одна группа из трех получателей

Нет необходимости иметь такое же количество получателей в нашей группе получателей, поскольку есть партиции:

Рис. 11. Некоторые получатели считывают из нескольких партиций
Получатели в одной группе получателей будут координировать получение партиций, гарантируя, что одна партиция не будет получена более чем одним получателем из той же группы получателей.
Аналогично, если у нас больше получателей, чем партиций, дополнительный получатель будет оставаться бездействующим, в резерве.

Рис. 12. Один бездействующий получатель
После добавления и удаления получателей группа получателей может стать несбалансированной. Перебалансировка перераспределяет получателей по партициям как можно более равномерно.

Перебалансировка автоматически запускается после того как:
- получатель присоединяется к группе получателей
- получатель уходит из группы получателей (в случае, когда он отключается или начинает считается неработающим)
- добавлены новые партиции
Перебалансировка станет причиной короткого периода дополнительной задержки в доступе к данным, в то время как получатели перестанут читать партии сообщений и будут размещены в разные партиции. Любое состояние данных в памяти, которое поддерживалось получателем, теперь может стать недействительным.
Одна из моделей получения Kafka – это способность направить все сообщения данного объекта, например, бронирования, в ту же партицию и, следовательно, одному и тому же получателю. Это называется локальностью данных. При перебалансировке данных любые данные в памяти об этих данных будут бесполезны, если получатель не будет размещен в той же партиции. Поэтому получатели, которые поддерживают состояние, должны будут сохранятся внешним образом.
Сжатие журнала
Стандартная политика хранения данных — это политика на основе времени и пространства. Например, хранение до последней недели сообщений или до 50 ГБ. Но существует другой тип политики хранения данных – сжатие журнала. Когда журнал сжимается, результатом является то, что сохраняется только последнее сообщение для каждого ключа сообщения, остальные удаляются.
Представим себе, что мы получаем сообщение, содержащее текущее состояние бронирования пользователя. Каждый раз, когда происходит изменение бронирования, генерируется новое событие с текущим состоянием бронирования. У этого топика может быть несколько сообщений для этого одного бронирования, которые представляют состояния этого бронирования с момента его создания. После того, как топик будет сжат, будет сохранено только самое последнее сообщение, связанное с этим бронированием.
В зависимости от количества бронирований и размера каждого бронирования вы могли бы теоретически навсегда сохранить все бронирования в этом топике. Периодически сжимая тему, мы гарантируем, что мы сохраняем только одно сообщение на бронирование.
Подробнее об упорядочении сообщений
Мы рассмотрели, что масштабирование и поддержание порядка сообщений одновременно возможно как с RabbitMQ, так и с Kafka, но с Kafka это намного проще. С RabbitMQ мы должны использовать консистентное хэширование и вручную внедрять логику группы получателей, используя распределенный обобщенный сервис, такой как ZooKeeper или Consul.
Но у RabbitMQ есть одна интересная возможность, которой нет у Kafka. Это не является особенностью самой RabbitMQ, а любой системы обмена сообщениями, основанной на очереди на основе подписки. Возможность такова: системы обмена сообщениями на основе очереди позволяют подписчикам упорядочивать произвольные группы событий.
Давайте разберемся немного поподробнее. Различные приложения не могут разделять очередь между собой, потому что тогда они будут конкурировать за получение сообщений. Им нужна их собственная очередь. Это дает приложениям свободу конфигурировать свою очередь любым образом, каким они посчитают нужным. Они могут направить несколько типов событий из нескольких топиков в свою очередь. Это позволяет приложениям поддерживать упорядочение связанных событий. Те события, которые потребуется объединить, могут быть настроены по-разному для каждого приложения.
Это просто невозможно с помощью системы обмена сообщениями на основе журнала, такой как Kafka, поскольку журналы являются общими ресурсами. Несколько приложений читают один журнал. Таким образом, любая группировка связанных событий в одной теме является решением, принятым на более широком уровне архитектуры системы.
Таким образом, здесь победитель не очевиден. RabbitMQ позволяет поддерживать относительный порядок в произвольных наборах событий, а Kafka обеспечивает простой способ поддержания упорядочения с поддержкой масштабирования.
Выводы
RabbitMQ предлагает широкий спектр шаблонов обмена сообщениями благодаря множеству функциональных возможностей, которые у него есть. Благодаря своей полнофункциональной маршрутизации он может избавить получателей от необходимости извлекать, десериализовывать и проверять каждое сообщение, когда ему требуется только подмножество. С ним легко работать, масштабирование вверх и вниз осуществляется путем простого добавления и удаления получателей. Его архитектура дополнительных модулей позволяет ему поддерживать другие протоколы и добавлять новые функции, такие как консистентное хэширование обменов, что является важным дополнением.
Распределенный журнал Kafka с относительными адресами получателей делает возможным путешествие во времени. Его возможность маршрутизировать сообщения с одним и тем же ключом одному и тому же получателю, в свою очередь делает возможной чрезвычайно параллелизованную упорядоченную обработку. Сжатие журнала Kafka и сохранение данных позволяют создавать новые шаблоны, которые RabbitMQ просто не может выполнить. Наконец, хотя Kafka и может масштабироваться больше, чем RabbitMQ, большинство из нас имеет дело с таким объемом сообщений, который оба подхода могут обработать без проблем.
В следующей части мы более подробно рассмотрим шаблоны обмена сообщениями и топологии с RabbitMQ.
Завели, кстати, тематический чат в телеграме про IoT и все, что с этим связано. Присоединяйтесь: t.me/justiothings
