
Привет, Хабр! В апреле мы официально выложили в открытый доступ лучшие видеозаписи с DotNext 2017 Moscow. В результате получился плейлист из 25 докладов. Просто напомню здесь об этом магическом плейлисте.
Я сейчас отсматриваю самые интересные видео и приглашаю присоединиться! Чтобы было легче влиться в просмотр записей конференции, под катом вас ждут короткие заметки о десяти докладах, которые получили наивысшие оценки от посетителей прошлого DotNext. Если из 25 штук вы чувствуете себя в силах посмотреть всего несколько докладов, смело выбирайте из этого списка.
Формально, чем ниже по списку, тем выше рейтинг. Но тут есть важное уточнение: все доклады из первой десятки имеют очень-очень высокий рейтинг, и их точное положение сильно зависит от нюансов подсчета. Например, если использовать soft quorum, то кейноут Андрея Акиньшина про перформанс-тестирование обгонит доклад Саши Гольдштейна про отладку и профилирование на Linux. Иначе говоря, смотрите всё :-)
Под катом будет оглавление для удобной навигации по содержимому поста.

Оглавление
- Завершающий кейноут: Unchain my heart
- ASP.NET Core: Механизмы предотвращения атак 2.0
- Patterns for high-performance C#: from algorithm optimization to low-level techniques
- NUKE: Build automation for C# developers
- Искусственный интеллект и нейросети для .NET-разработчиков
- Akka Streams для простых смертных
- The Metrix has you…
- Life, liberty and the pursuit of APIness: the secret to happy code
- Кейноут: Поговорим про performance-тестирование
- Debugging and Profiling .NET Core Apps on Linux
Завершающий кейноут: Unchain my heart
Dino Esposito, JetBrains
Давая человеку задачу, обязательно нужно проверить, что он не просто запомнил твои слова, но и понимает, что делать дальше. Что ты вынес из нашего разговора? Какие будут первые шаги? Простые, действенные вопросы.
Этот рассказ Дино — не стандартный доклад, а завершающий кейноут. Так же как цель открывающего кейноута — задать направление конференции, завершающий кейноут задает дальнейшую жизнь участника. Что ты вынес с конференции? Как это повлияет на твою жизнь?
В этом докладе Дино перемещает с помощью машины времени нас на 30 лет вперед и добавляет к этим стандартным вопросам еще один уровень глубины. Вернувшись из будущего, как мы будем относиться к настоящему?

Дино рассказывает большой — на сорок минут — и весьма обоснованный прогноз на ближайшие годы. В него попадает и блокчейн, и бигдата, и даже цифровая душа. Завоюют ли нас роботы? Спойлер: в конце все умрут! (Да, там творится реальная дичь).
Но тут хотелось бы поспорить. Очень нравится недавнее обсуждение на Реддите: «Как вы захватите мир, если окажетесь в 1990 году со всеми текущими воспоминаниями, но в теле того ребенка, которым были когда-то?» Короткий перевод одного из ответов недавно сделал Владимир Гуриев (это тот человек, который ранее подарил нам учебник современного маркетинга), но лучше читать оригинал. Мы как инженеры и люди, посвятившие себя улучшению мира путем создания неких технических чудес, легко верим в человека будущего, который из палок и верёвок (таких же, как сегодня, но немного лучше) может слепить ядерный звездолёт. Но если вернуться в реальность, то обычные глупые люди (такие, как я, например), делают куда более скучные и мерзкие штуки.
Советую посмотреть кейноут Дино и самостоятельно определиться на этот счет. Возможно, написать свою историю в комментариях на Хабре? Чем мы хуже Реддита?
ASP.NET Core: Механизмы предотвращения атак 2.0
Михаил Щербаков
Новая часть доклада Михаила про следующие виды обороны:
- Защита от Open Redirect;
- Data Protection;
- Защита от XSS;
- Настройка CSP;
- Anti-Request Forgery;
- Настройка CORS;
- Использование cookies.
Доклад получился по результатам участия Михаила в бессрочной Microsoft Bug Bounty Program. Первый найденный им баг как раз был в защите от Open Redirect, которая демонстрируется в начале доклада буквально за минуту.
Для понимания темы в других частях доклада рассказывается про изменения Data Protection API, после чего мы на сорок минут погружаемся в работу с безопасностью и дырами в ней. Разбирается, как работают встроенные механизмы защиты от XSS и CSRF, какие возможности криптографии доступны из коробки, как устроено управление сессиями и так далее.
Сам я интересуюсь этой темой и часто смотрю доклады по безопасности на YouTube. Самое ужасное, что тебя ожидает как зрителя: два часа нудятины, на 90% состоящей из банальностей вида «если ты тупой, то всё очень плохо», под конец которых ты обнаруживаешь себя спящим носом в клавиатуру. Доклад Миши выгодно отличается тем, что на нём спать некогда: четко обрисованные мысли, реальные примеры кода для их иллюстрации, если вводятся какие-то понятия — слайды с формулировками и ссылками на расширенные материалы.
Такие доклады стоит смотреть сразу же, как научился писать свой первый контроллер, просто чтобы потом не переписывать много кода за зря.
Кстати, в феврале мы опубликовали расшифровку доклада Михаила на Хабре. Если нет времени смотреть, всегда можно почитать.
Patterns for high-performance C#: from algorithm optimization to low-level techniques
Federico Lois, Corvalius
Зверская история о том, как настолько жестоко обращаться с C#, что он становится сам на себя не похож — но начинает очень быстро и хорошо работать.
Справедливости ради, на это претендует примерно каждый второй тред о перформансе на Хабре или каждая первая дискуссия за баночкой пива.
Мы ведь довольно часто пишем обзоры чего-то на Хабр и давно уже поняли сущность понятия «хардкор» для российского разработчика. Хардкор и перформанс — близнецы-братья. Говорим о перформансе — подразумеваем хардкор, говорим о хардкоре — подразумеваем перформанс.
Федерико же разработал свою собственную шкалу:

Это доклад о перфомансе, всё, как вы любите. Причем очень циничный и доходчивый. С докладчиком не очень просто спорить, учитывая, что он — один из разработчиков RavenDB, а она как раз целиком про скорость. Будут неприятные штуки про то, что нельзя использовать try-catch и LINQ, будет про инлайнг, про закон Парето (превратившийся в чеклист) — что угодно, лишь бы обмануть систему и добиться значительного ускорения.
Все это напоминает мне вот такой ролик:
Оператор: Подожди секунду, дай сниму высоту. Ну нафиг! Вот на эту крышу ты прыгаешь.
Трейсер: Готов?
Оператор: Да.
Трейсер: молча разбегается, прыгает, молча же пробивает собой крышу здания и топором уходит в глубину
Необходимость использовать такое читерство для ускорения кода сейчас представляется мне таким вот «прыжком веры». Но если однажды придется прыгать, то лучше посмотреть этот доклад, чем не посмотреть (а если лень смотреть, то читайте наш перевод).
NUKE: Build automation for C# developers
Matthias Koch, JetBrains
NUKE — один из проектов, над которыми работает Матиас. Это такая система автоматизации сборки, где описывать всё можно на C# DSL.
C# тут при том, что это позволяет описывать сборку в привычной инфраструктуре, в IDE, с приличным автодополнением, а не мучиться с прокликиванием кнопочек в Jenkins или, к примеру, впихивать условия в виде строк в MSBuild. Чуть ли не одна пятая доклада посвящена обсуждению применимости дженкинсов и мсбилдов.
Очень круто, что это видео появилось в открытом доступе. Дело в том, что у меня есть долгая личная история нелюбви к Jenkins, и каждому новому человеку нужно заново объяснять одну и ту же балалайку про причины и выводы. Теперь достаточно давать ссылку на это видео.
Что касается основной части доклада — это куча практического материала о том, что такое Nuke и как с ним жить. Сейчас у них на гитхабе больше семисот коммитов и больше десятка контрибьюторов, так что, наверное, это уже можно использовать. Доклад от создателя технологии как нельзя лучше может помочь в освоении.
Искусственный интеллект и нейросети для .NET-разработчиков
Дмитрий Сошников, Microsoft
Очень крутой доклад, который закладывает основы программирования нейросетей на С# для тех, кто этого еще не умел, но очень хочется.
Были у меня ситуации, когда надо быстро наколбасить распознавание картинок. Взялся за популярные курсы по нейросетям и обнаружил, что на мой запрос они никак не отвечают, а скорей занимаются общим образованием. В результате распознавалку написали друзья :-) И вот этот доклад Дмитрия — прямо бальзам на душу, потому что отвечает на все актуальные запросы обычного человека, после которых понятно — что читать и в чем разбираться.
Вначале есть небольшое введение о том, чем занимается Microsoft и какие нейросетевые технологии у них есть. Дмитрий явно сказал, что сократил количество маркетинговых слайдов Microsoft до минимума, хотя вот именно здесь я этого хейта «маркетинга» не понимаю — всё равно именно этими технологиями мы будем пользоваться, именно их будем искать. Как будто есть какой-то выбор.
Дальше коротко обозначается, как живут дата-сатанисты в своём Jupyter Notebook и что его можно не устанавливать, а получить в облаке. Что характерно, Jupyter Notebook у Дмитрия заглючил прямо в момент лайвкодинга — по-моему, лучшей демонстрации, зачем нужен C#, и придумать нельзя.
Значительная часть доклада — это рассказ о том, сложно ли написать все это самому. Примеры показываются на основе распознавания цифр на картинках.

Вначале ручками на циклах пишется k-nearest neighbors, который выходит точным (94%), но дико медленным — ни одна демка k-NN так и не отработала на докладе до конца. Потом тот же k-NN кодится на Accord.NET, и это работает чуть быстрей, но не особо, потому что алгоритм тот же самый. Но фича Accord.NET в том, что это уже прилично выглядящий код, и можно быстро подменить классификатор на какой-нибудь другой. Дмитрий подставил туда support vector machine, и все резко ускорилось (сет на 5 тысяч картинок стал пробегаться за считанные секунды, точность почти не упала — 92%).
Но можно делать все еще круче и притащить нейросетки. В демке Accord.NET SVM был заменен на нейросетку, почти без изменения кода. Но так делать не надо, потому что есть другие, более крутые и быстрые фреймворки. Дмитрий сказал пару слов про TensorFlow и оставшуюся часть доклада проговорил о Microsoft Cognitive Toolkit (ранее известный, как CNTK). Просмотрев множество демок, мы увидели, что в результате получаются сверхточные сети (98%) со сложным, но, тем не менее, вполне понимаемым кодом.
Посмотрев этот доклад, теперь уже не смогу уснуть просто так. Все эти штуки записаны понятным кодом, и вроде бы у них есть ясные математические основания, доступные для понимания студенту, но в результате они творят чудеса. Отличить фотку кошки от фотки собаки — это ведь чудо, вы ни за что не придумаете алгоритм для этого, а нейросетка это как-то делает прямо у тебя на глазах.
А вдруг мой мозг — это просто аппарат, аппроксимирующий функцию? И вся жизнь — это просто одно больше перемножение матриц с небольшой нелинейной частью, которое можно записать сравнительно небольшим куском кода… Как с этим теперь жить?
(по ссылке доступна расшифровка доклада)
Akka Streams для простых смертных
Вагиф Абилов, Miles
Это концептуальный доклад, рассказывающий о жизни в мире стримов. Там есть примеры вот такого вида:

К ним показывается постепенно усложняющийся вполне конкретный код, обсуждаются детали. Но все-таки главное — это общее представление о вопросе.
Для людей, не погруженных в тему, может казаться, что для понимания Akka Streams нужно отлично разбираться в Akka и отлично разбираться в реактивщине. Вагиф утверждает, что это не совсем так, чем снимает груз с души и понижает порог вхождения в тему.
Лично для меня вся тема стримов казалась (да и кажется до сих пор, нельзя же докладам верить, не попробовав) довольно жуткой, как раз потому, что она напрямую связана с темой функциональных преобразований и управления данными вне привычной модели тредов-локов. Да, управление тредами и построение конструкций из олдскульных фреймворков для них — занятие мерзкое, но зато понятное и заезженное годами.
Вагиф поясняет за переход на акторы, раскрывает тему того, что акторы не компонуются (точнее, компонуются в том смысле, в котором компонуется человеческое общество), и от этого переходит к Reactive Streams как к средству еще сильней поднять уровень абстракции и экспрессии.
По стеке Reactive Streams есть какой-то набор интерфейсов (Publisher, Subscriber, Subscription, Processor), но никто не ожидает, что мы будем вручную резолвить эти интерфейсы. Есть разработчики библиотек, которые для нас это сделают — например, это сделано в Akka Streams.
Для меня стало открытием, что динамический push/pull в Reactive Streams есть из коробки, и это совсем не больно — точнее, не так больно, когда ты пытаешься самостоятельно закодить backpressure.
Причем автор не ударяется в какой-то стримовый фанатизм и не забывает об альтернативах (RX, TPL DataFlow, Orleans Streams), рассказывает о плюсах и минусах. Отсутствие фанатизма — это прям огромный бонус по сравнению с типичным рассказом любителя реактивщины, душой прикипевшего к одной конкретной библиотеке.
В целом я понял идею так: когда используем микросервисы и прочие многокомпонентные архитектуры — за деревьями не видно леса, и стримы — это такой способ подняться на уровень выше и получить представление об общем процессе. Чтобы перейти на такие рельсы, нужно взять Akka Streams, и всё будет в шоколаде.
Хотите замотивировать себя перейти на стримы? Надо смотреть.
The Metrix has you…
Анатолий Кулаков, Paladyne Systems
Многие разработчики не любят думать о тех жутких вещах, которые пользователи делают с их приложениями. Зачастую на вопрос «как посмотреть метрики» коллеги начинали говорить лютую дичь о «погрепай логи», «посмотри в MySQL» и так далее, и убедить их задуматься о вопросе было непросто.
Этот доклад Анатолия — как раз такая минутка просветления. Она начинается с объяснения отличий между мониторингом и логированием, с подробным изложением мотивации. Дальше нашего предполагаемого любителя погрепать погружают в конкретные примеры того, что придется делать.
Делать придется Time Series (про которые рассказывается теоретический минимум — зачем нужны, какие преимущества, в чем суть оптимизаций) на примере известной базы данных InfluxDB (про которую разобрана специфика, возможности и недостатки). И так далее и тому подобное. Куча хорошего контента, включая живые демки с экспериментами над локальной Grafana и приложением-архиватором, данные о производительности которого собираются через BenchmarkDotNet.
Если для вас неважно время чтения-записи, если вы не упираетесь в throughput, если не знаете, что такое downsampling, если не нужны специализированные функции статистики и агрегации, если вы мечтаете удалять все данные по одной строчке руками, если не упираетесь в размер ваших данных и точно знаете, что у вас никогда не будет высоких нагрузок — можете продолжать сохранять данные о метриках в RDBMS, грепать логи и жить счастливо. Всем остальным нужно использовать современные средства и смотреть этот доклад (или читать расшифровку).
Life, liberty and the pursuit of APIness: the secret to happy code
Dylan Beattie, Spotlight
Dylan Beattie — человек с таким количеством рабочих достижений и интересных проектов, что полный список проще прочитать на нашем сайте. В контексте доклада интересно, что Дилан — системный архитектор, который прямо сейчас занимается вопросами построения сложных современных распределенных приложений, и, соответственно, — вопросами разработки правильных API для них. Ну и, конечно, его знают совершенно все, кто бывал на вечеринках DotNext.
Осознаем мы или нет, каждый раз при создании новых программ мы создаем и user experience. Люди будут взаимодействовать с нашим кодом — как конечные пользователи или, может быть, как члены команды разработки. А может быть, они — разработчики мобильного приложения, использующие твое API, или это кто-то кому нужно ехать в ночь, чтобы исправлять возникшие проблемы. Со стороны это может казаться совершенно разными кейсами, но на самом деле у них есть кое-что общее. Дилан называет это словом «discoverability».
Отсюда и появился этот весьма философский и вместе с тем — сугубо практический доклад. Вначале Дилан дает подробную вводную о психологии обучения и различных моделях обучения. Как думаете, какая из кривых обучения лучше?
Дальше идет рассказ о том, как discoverability проявляется для конечных пользователей системы, и потом — самое главное — как всё это относится к коду, данным, API и другим вещам, составляющим жизнь программиста. Шаг за шагом, на всех уровнях приложения.
Не верите, что автодополнение, hypermedia или fluent API делают жизнь лучше? А как насчет красивых дашбордов, понятных метрик или например, уровней логирования, названных не по уровню угрозы, а по смыслу? Может быть, вы всё это понимаете, но не знаете, как правильно рассказать об этом коллегам, чтобы они наконец начали использовать всё это? Тогда вам срочно нужно смотреть этот доклад (кстати, весной мы уже публиковали на Хабре перевод).
Кейноут: Поговорим про performance-тестирование
Андрей Акиньшин, JetBrains
У Андрея была очень непростая задача: рассказать о перформансе, но при этом — в формате открывающего кейноута. Как вы, наверное, знаете, у кейноута есть несколько целей, из них главная — передать дух и суть того, что будет твориться на конференции. Из этого следует, что такой доклад должны понимать более-менее все подряд. С другой стороны, перформанс — это второе имя хардкора, то есть тема сложная и специфичная.
Не зря Андрей постоянно получает свои самые высокие рейтинги, он выкрутился. Понятно, что большинство компаний сейчас не занимаются тестированием перформанса никак либо тестируют уже на живых людях в проде. Нет никакой стройной теории решения такого рода проблем, поэтому и рассказывать зубодробильную матчасть не нужно. Нужно некое базовое понимание темы.
Доклад посвящен 13 заметкам о перформансе. Рассказывать все тринадцать я не буду, ибо зачем плодить спойлеры. Например, первая заметка посвящена источникам перформанс-данных. Или, например, если у вас есть список перформанс-аномалий, то убирание мелких проблем, о которых рассказывает Андрей, упростит анализ проблем производительности (проблем, которых вы еще не написали, но скоро напишете). Один из таких вариантов, которому посвящена «заметка 6» — кластеризация на примере операционных систем.
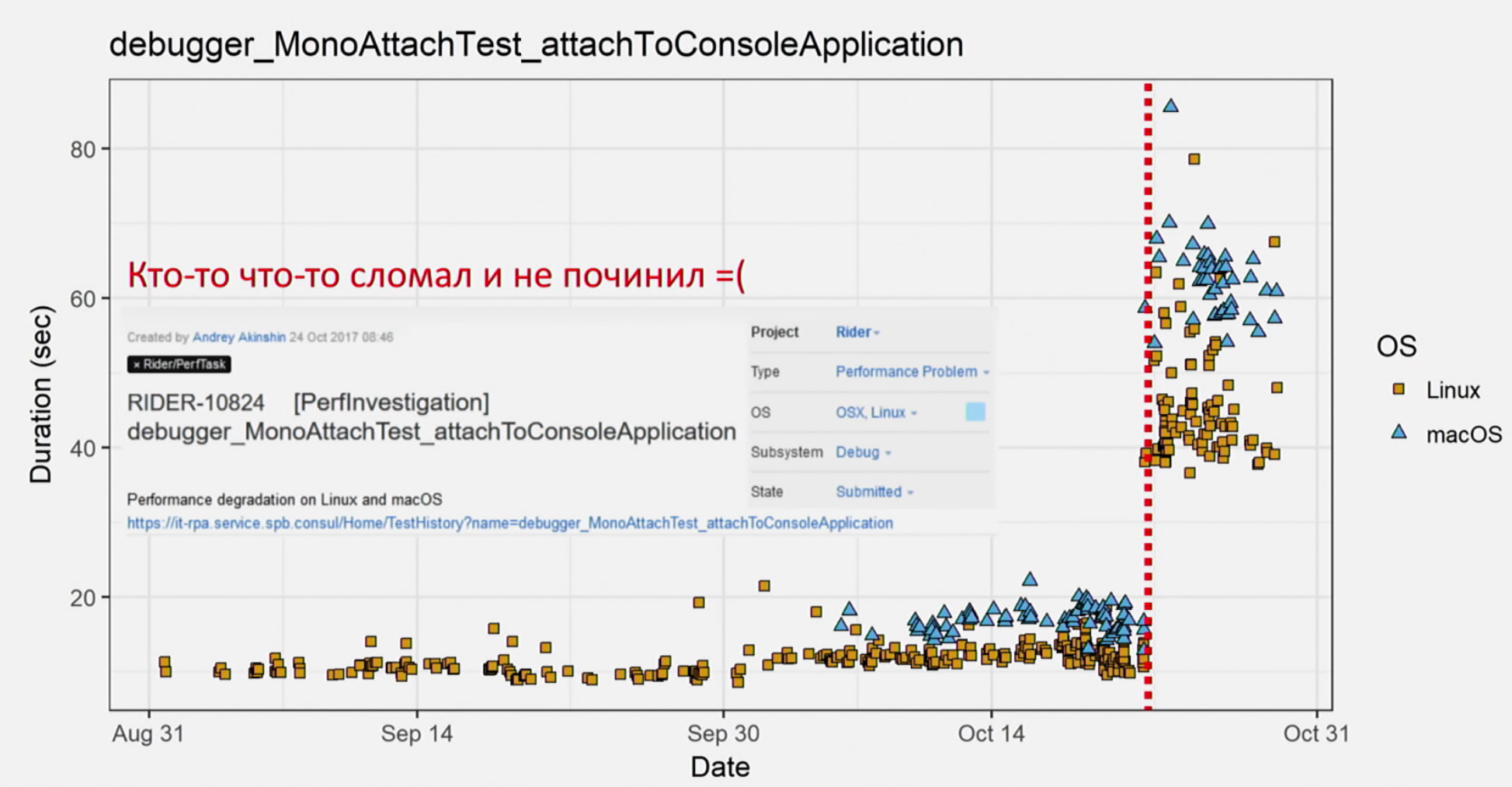
Перформанс-тестирование — это интересно, но сложно. Более того, тестировать производительность можно и нужно. Имхо, доклад уникален тем, что здесь раскрывается куча вещей, которые люди хотели бы делать, но либо не делают, либо врут, что делают. Поэтому смотрите доклад Андрея, набирайтесь перформанс-чистоты и перформанс-культуры, и тогда ваши продукты будут супербыстрыми, отзывчивыми, гладкими и шелковистыми.
Debugging and Profiling .NET Core Apps on Linux
Sasha Goldshtein, Sela Group
Саша — выдающийся перформанс-инженер, и нет ничего удивительного, что он попал на самый верх рейтинга. Другая причина победы: сейчас стало очень модно добавлять «.NET Core» в название доклада просто ради хайпа. Рассказов про нечто, где .NET Core играет осмысленную роль не так много, и этот доклад — один из них. Или вот еще идея: это сугубо практический доклад об использовании бесплатных инструментов, сразу идущих вместе с операционной системой и рантаймом, и всё это довольно удобно и работает с низким оверхедом — стыдно было бы в этом не разобраться.
Представьте, что-таки удалось запустить на Linux ваше любимое ASP.NET-приложение или даже что-то с консольным интерфейсом. Что дальше? Счастливый конец? О, нет. По факту, придется встретиться с утечками памяти, странными падениями, проблемами с производительностью и многими другими неприятностями — и что делать, когда всё это происходит на продакшне? На Windows у нас есть куча интересных инструментов, но в Linux они работать не будут, и простых альтернатив пока не существует. В этом докладе Саша рассказывает, как сейчас выглядит отладка и профилирование приложений .NET Core на Linux. Как проводить расследования с помощью perf, как LTTNG используется в качестве замены для событий ETW, как собирать и понимать трейсы LTTNG и многое другое. Саша расскажет о сборе core dumps и как достать из них интересную для .NET-разработчика информацию с помощью lldb и SOS.
Короче, все, кто решатся посмотреть видео, отправятся в непростое детективное путешествие сквозь дебри недоделанных утилит и особой магии командной строки. Со счастливым концом (но это не точно).
Если доклады из списка вас заинтересовали, обращаем ваше внимание: мы уже анонсировали следующий DotNext, и там вам может быть не менее интересно. При этом билеты со временем дорожают, так что не стоит откладывать с покупкой билета на новый DotNext до того, как пересмотрите все доклады с предыдущего!
