
Со стороны может показаться, что Kotlin упростил Android-разработку, вообще не принеся при этом новых сложностей: язык ведь Java-совместимый, так что даже большой Java-проект можно постепенно переводить на него, не забивая ничем голову, так? Но если заглядывать глубже, в каждой шкатулке найдётся двойное дно, а в трюмо — потайная дверца. Языки программирования — слишком сложные проекты, чтобы их совмещение обходилось без хитрых нюансов.
Разумеется, это не означает «всё плохо и использовать Kotlin вместе с Java не надо», а означает, что стоит знать о нюансах и учитывать их. На нашей конференции Mobius Сергей Рябов рассказал, как писать на Kotlin такой код, к которому будет комфортно обращаться из Java. И доклад так понравился зрителям, что мы не только решили разместить видеозапись, но и сделали для Хабра текстовую версию:
Я пишу на Kotlin уже более трёх лет, сейчас только на нём, но поначалу притаскивал Kotlin в существующие Java-проекты. Поэтому вопрос «как связать вместе Java и Kotlin» на моём пути возникал довольно часто.
Зачастую при добавлении в проект Kotlin можно увидеть, как вот это…
… превращается в это:
Специфика последней пары лет: самые популярные библиотеки обзаводятся «обёртками» для того, чтобы можно было использовать их из Kotlin более идиоматично.
Если вы писали на Kotlin, то знаете, что есть классные extension-функции, inline-функции, лямбда-выражения, которые доступны из Java 6. И это круто, это притягивает нас к Kotlin, но возникает вопрос. Одна из самых больших, самых разрекламированных фич языка — interoperability с Java. Если принять во внимание все перечисленные фичи, то почему бы тогда просто не писать библиотеки на Kotlin? Они все будут отлично работать из коробки с Java, и не нужно будет поддерживать все эти обёртки, все будут счастливы и довольны.
Но, конечно, на практике не всё так радужно, как в рекламных проспектах, всегда есть «приписочка мелким шрифтом», есть острые грани на стыке Kotlin и Java, и сегодня мы об этом немного поговорим.
Начнём с различий. Например, в курсе ли вы, что в Kotlin нет ключевых слов volatile, synchronized, strictfp, transient? Они заменены одноимёнными аннотациями, находящимися в пакете kotlin.jvm. Так вот, о содержимом этого пакета и пойдёт большая часть разговора.
Есть Timber — такая библиотечка-абстракция над логгерами от небезызвестного Жеки Вартанова. Она позволяет вам в вашем приложении везде использовать её, а всё, куда вы хотите отправить логи (в logcat, или на ваш сервер для анализа, или в crash reporting, и так далее), оборачивается в плагинчики.
Давайте для примера представим, что мы хотим написать аналогичную библиотеку, только для аналитики. Тоже абстрагироваться.
Берём тот же самый паттерн построения, у нас одна точка входа — это Analytics. Мы можем посылать туда ивенты, добавлять плагины и смотреть, что у нас там уже добавлено.
Plugin — интерфейс плагина, который абстрагирует какое-то конкретное аналитическое API.
И, собственно, класс Event, содержащий ключ и наши атрибуты, которые мы отправляем. Здесь доклад не про то, стоит ли использовать синглтоны, поэтому давайте не будем разводить холивар, а будем смотреть, как это все дело причесать.
Теперь немножко погрузимся. Вот пример использования нашей библиотеки в Kotlin:
В принципе, выглядит так, как и ожидается. Одна точка входа, методы вызываются а-ля статики. Event без параметров, event с атрибутами. Проверяем, есть ли у нас плагины, запихиваем туда пустой плагин для того, чтобы просто какой-то «dry run»-прогон сделать. Либо добавляем несколько других плагинов, выводим их, ну и так далее. В общем, стандартные юзкейсы, надеюсь, всё пока понятно.
А теперь посмотрим, что происходит в Java, когда мы делаем то же самое:
В глаза сразу бросается сыр-бор с INSTANCE, который протянут наверх, наличие явных значений для дефолтного параметра с атрибутами, какие-то геттеры со стрёмными названиями. Так как мы, в общем-то, и собрались здесь, чтобы превратить это во что-то похожее на предыдущий файл с Kotlin, то давайте пройдёмся по каждому моменту, который нам не нравится, и попробуем его как-то адаптировать.
Начнём с Event. Удаляем из второй строчки параметр Colletions.emptyMap(), и вылезает ошибка компилятора. С чем же это связано?
Наш конструктор имеет дефолтный параметр, в который мы передаём значение. Мы приходим из Java в Kotlin, логично предположить, что наличие дефолтного параметра генерирует два конструктора: один полный с двумя параметрами, и один частичный, у которого можно задать только name. Очевидно, компилятор так не считает. Давайте посмотрим, почему он считает, что мы не правы.
Наш основной инструмент для анализа всех перипетий того, как Kotlin превращается в JVM-байткод — Kotlin Bytecode Viewer. В Android Studio и IntelliJ IDEA он находится в меню Tools — Kotlin — Show Kotlin Bytecode. Можно просто нажать Cmd+Shift+A и вписать в строку поиска Kotlin Bytecode.
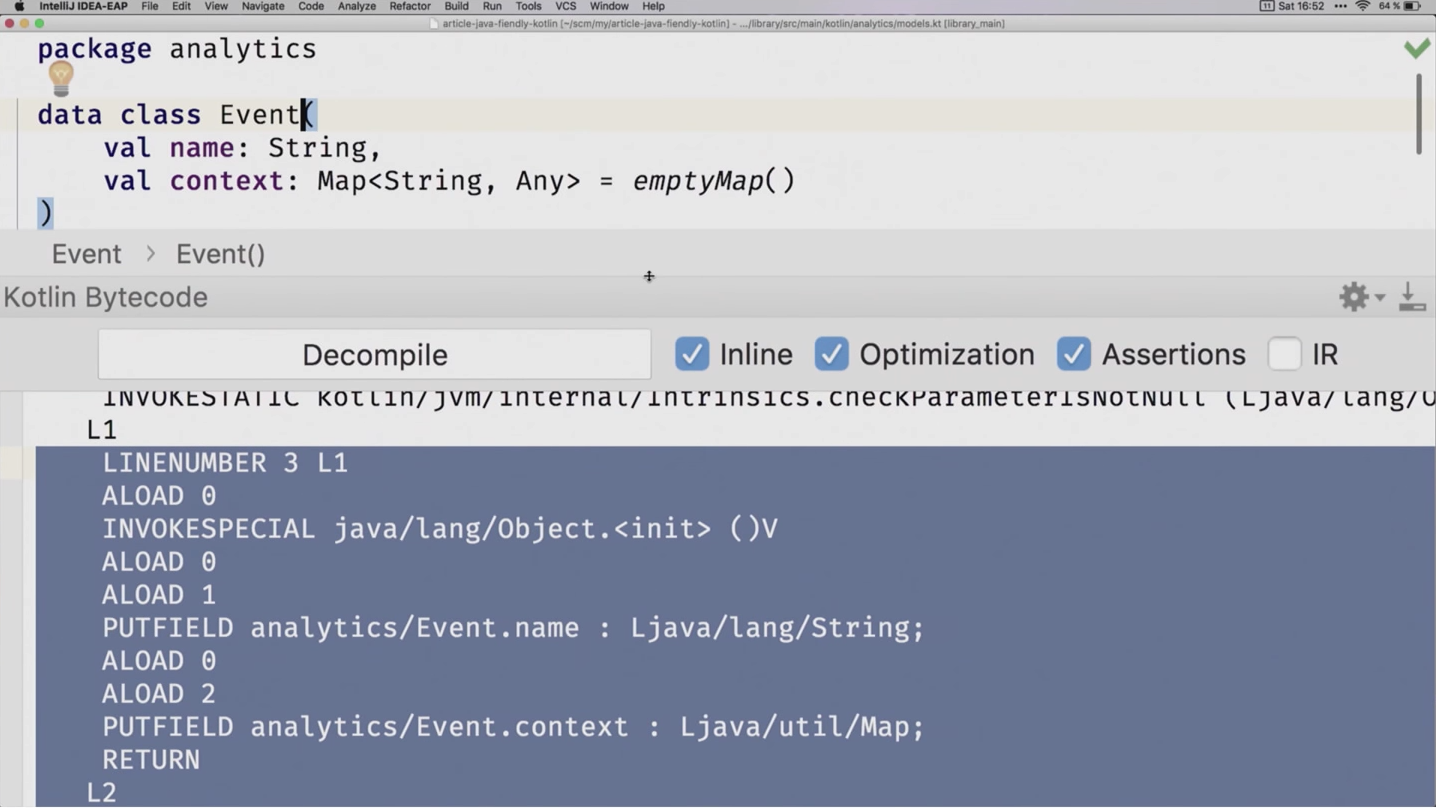
Здесь, как ни удивительно, мы видим байткод того, во что превращается наш Kotlin-класс. Я не ожидаю от вас отличного знания байткода, и, самое главное, разработчики IDE тоже не ожидают. Поэтому они сделали кнопочку Decompile.
После её нажатия мы видим такой примерно неплохой Java-код:
Видим наши поля, геттеры, ожидаемый конструктор с двумя параметрами name и context, всё происходит нормально. А ниже мы видим второй конструктор, и вот он с неожиданной сигнатурой: не с одним параметром, а почему-то с четырьмя.
Тут можно смутиться, а можно залезть немного глубже и покопаться. Начав разбираться, мы поймём, что DefaultConstructorMarker — это приватный класс из стандартной библиотеки Kotlin, добавленный сюда, чтобы не было коллизий с нами написанными конструкторами, т. к. мы не можем задать руками параметр типа DefaultConstructorMarker. А интересное всего int var3 — битовая маска того, какие дефолтные значения мы должны использовать. В данном случае, если битовая маска совпадает с двойкой, мы знаем, что var2 не задан, наши атрибуты не заданы, и мы используем дефолтное значение.
Как мы можем исправить ситуацию? Для этого есть чудо-аннотация @JvmOverloads из того пакета, о котором я уже говорил. Мы должны навесить её на конструктор.
И что она сделает? Обратимся к тому же инструменту. Теперь там видим и наш полный конструктор, и конструктор с DefaultConstructorMarker, и, о чудо, конструктор с одним параметром, который доступен теперь из Java:
И, как видите, он делегирует всю работу с дефолтными параметрами в тот наш конструктор с битовыми масками. Таким образом, мы не плодим информации о том, что за дефолтное значение нам нужно засунуть туда, мы просто делегируем всё в один конструктор. Славно. Проверяем, что у нас получилось со стороны Java: компилятор рад и не возмущается.
Давайте посмотрим, что нам не нравится дальше. Нам не нравится этот INSTANCE, который в IDEA мозолит фиолетовым цветом. Не люблю фиолетовый цвет :)
Давайте проверим, за счёт чего так получается. Снова глянем в байткод.
Выделим, например, функцию init и убедимся, что init действительно сгенерирован не статическим.
То есть, как ни крути, нам нужно работать с инстансом этого класса и вызывать у него эти методы. Но мы можем зафорсить генерацию всех этих методов как статическую. Для этого есть своя чудесная анннотация @JvmStatic. Давайте добавим её к функциям init и send и проверим, что теперь думает компилятор на этот счёт.
Мы видим, что к public final init() добавилось ключевое слово static, и мы избавили себя от работы с INSTANCE. Убедимся в этом в Java-коде.
Компилятор теперь подсказывает нам, что мы вызываем статический метод из контекста INSTANCE. Это можно поправить: нажать Alt+Enter, выбрать «Cleanup Code», и вуаля, INSTANCE исчезает, всё выглядит примерно так же, как было в Kotlin:
Теперь у нас есть схема работы со статическими методами. Добавим эту аннотацию везде, где нам это важно:
И комментарий: если методы у нас — очевидно методы instance, то, например, с пропертями не всё так очевидно. Сами поля (например, plugins) генерируются как статические. А вот геттеры и сеттеры работают как методы инстанса. Поэтому для пропертей вам тоже нужно добавлять эту аннотацию, чтобы зафорсить сеттеры и геттеры, как статические. Например, видим переменную isInited, добавляем ей аннотацию @JvmStatic, и теперь мы видим в Kotlin Bytecode Viewer, что метод isInited() стал статическим, всё отлично.
Теперь пойдем в Java-код, «за-clean-up-им» его, и всё выглядит примерно как в Kotlin, за исключением точек с запятой и слова new — ну, от них вы не избавитесь.
Следующий шаг: мы видим этот стрёмно названный геттер getHasPlugins с двумя префиксами сразу. Я, конечно, не большой знаток английского языка, но мне кажется, здесь что-то другое подразумевалось. Почему так происходит?
Как знают плотно общавшиеся с Kotlin, для пропертей названия геттеров и сеттеров генерируются по правилам JavaBeans. Это значит, что геттеры в общем случае будут с префиксами get, сеттеры с префиксами set. Но есть одно исключение: если у вас булево поле и в его названии есть префикс is, то и геттер будет с префиксом is. Это можно увидеть на примере вышеупомянутного поля isInited.
К сожалению, далеко не всегда булевы поля должны называться через is. isPlugins не совсем удовлетворяло бы тому, что мы хотим семантически показать именем. Как же нам быть?
А быть нам несложно, для этого есть своя аннотация (как вы уже поняли, я сегодня буду часто это повторять). Аннотация @JvmName позволяет задать любое имя, которое мы хотим (естественно, поддерживаемое Java). Добавим её:
Проверим, что у нас получилось в Java: метода getHasPlugins больше нет, а вот hasPlugins вполне себе есть. Это решило нашу проблему, опять-таки, одной аннотацией. Сейчас всё аннотациями порешаем!
Как видите, здесь мы навесили аннотацию прямо на геттер. С чем это связано? С тем, что под пропертёй лежит много всего, и непонятно, к чему применяется @JvmName. Если перенести аннотацию на сам val hasPlugins, то компилятор не поймёт, к чему её применять.
Однако в Kotlin есть и возможность специфицировать место применения аннотации прямо в ней. Можно указать целью геттер, файл целиком, параметр, делегат, поле, проперти, receiver extension-функции, сеттер и параметр сеттера. В нашем случае интересен геттер. И если сделать вот так, будет тот же самый эффект, как когда мы навешивали аннотацию на get:
Соответственно, если у вас нет кастомного геттера, то вы можете навесить прямо на вашу проперти, и все будет ОK.
Следующий момент, который немного нас смущает — это «Analytics.INSTANCE.getEMPTY_PLUGIN()». Тут дело уже даже не в английском, а просто: ПОЧЕМУ? Ответ примерно такой же, но сперва небольшое введение.
Для того, чтобы сделать из поля константу, у вас есть два пути. Если константу вы определяете как примитивный тип либо как String, и ещё она внутри объекта, то вы можете использовать ключевое слово const, и тогда не будет сгенерировано геттеров-сеттеров и прочего. Это будет обычная константа — private final static — и она будет заинлайнена, то есть абсолютно обычная Java-штука.
Но если вы хотите сделать константу из объекта, который отличен от строки, то у вас не выйдет использовать для этого слово const. Вот у нас есть val EMPTY_PLUGIN = EmptyPlugin(), по нему, очевидно сгенерировался тот страшный геттер. Мы можем аннотацией @JvmName переименовать, убрать этот префикс get, но всё равно это останется методом — со скобками. Значит, старые решения не подойдут, ищем новые.
И тут для этого аннотация @JvmField, которая говорит: «Не хочу здесь геттеров, не хочу сеттеров, сделай мне поле». Поставим её перед val EMPTY_PLUGIN и проверим, что всё действительно так.
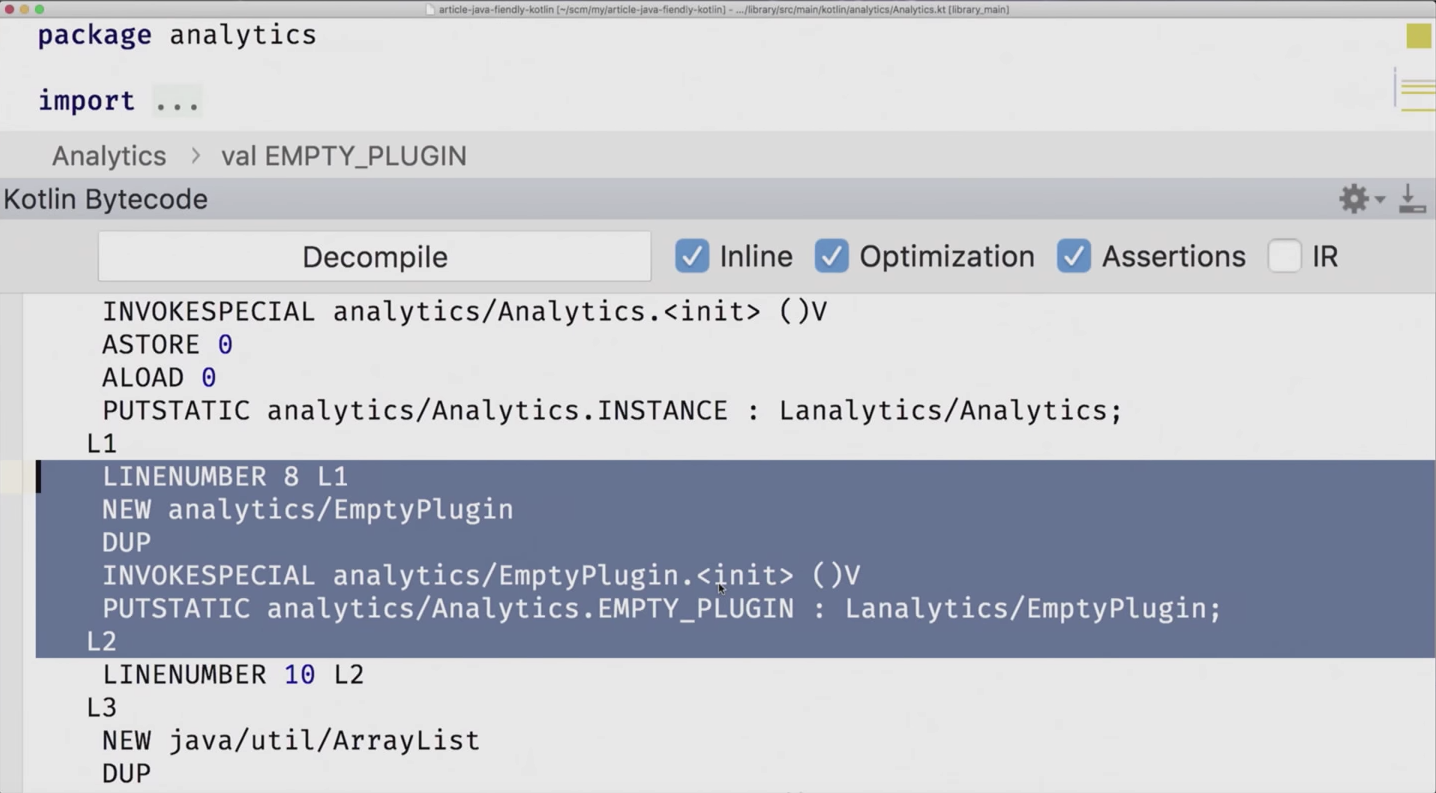
Kotlin Bytecode Viewer показывает выделенным тот кусок, на котором вы сейчас стоите в файле. Мы сейчас стоим на EMPTY_PLUGIN, и вы видите, что здесь какая-то инициализация написана в конструкторе. Дело в том, что геттера-то больше нет и доступ к нему только на запись идёт. А если нажать decompile, видим, что появилось «public static final EmptyPlugin EMPTY_PLUGIN», это именно то, чего мы и добивались. Славно. Проверяем, что всех всё радует, в частности, компилятор. Самый главный, кого нужно ублажить — это компилятор.
Давайте немного оторвёмся от кода и посмотрим на дженерики. Это довольно острая тема. Или скользкая, кому что больше не нравится. В Java есть свои сложности, но Kotlin отличается. В первую очередь нас волнует вариантность. Что это такое?
Вариантность — это способ переноса информации о иерархии типов с базовых типов на производные, например, на контейнеры или на дженерики. Вот у нас есть классы Animal и Dog с вполне очевидной связью: Dog — это подтип, Animal — надтип, стрелка идёт от подтипа.

А какая связь будет у их производных? Давайте рассмотрим несколько кейсов.
Первый — это Iterator. Определять, что есть надтип, а что есть подтип, мы будем, руководствуясь правилом подстановки Барбары Лисков. Сформулировать его можно так:«подтип должен требовать не больше, а предоставлять не меньше».
В нашей ситуации единственное, что делает Iterator — отдаёт нам типизированные объекты, например, Animal. Если мы где-то принимаем Iterator, мы вполне можем засунуть туда Iterator, и из метода next() получим Animal, потому что собака — это тоже Animal. Мы предоставляем не меньше, а больше, потому что собака — это подтип.

Повторюсь: из этого типа мы только читаем, поэтому здесь сохраняется зависимость между типом и подтипом. И такие типы называются ковариантными.
Другой кейс: Action. Action — это функция, которая не возвращает ничего, принимает один параметр, и мы только пишем в Action, то есть он принимает у нас собаку или животное.
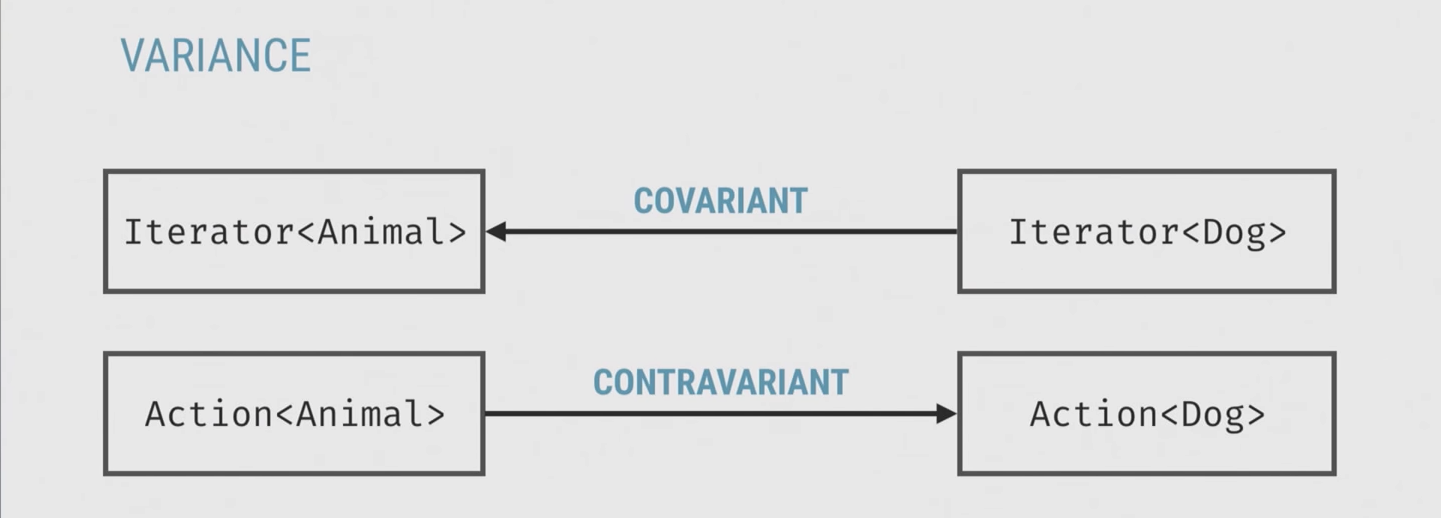
Таким образом, здесь мы уже не предоставляем, а требуем, и требовать мы должны не больше. Это значит, что зависимость у нас меняется. «Не больше» у нас Animal (Animal меньше, чем собака). И такие типы называются контравариантными.
Есть еще третий кейс — например, ArrayList, из которого мы и читаем, и пишем. Поэтому в данном случае мы нарушаем одно из правил, на запись требуем больше (собаку, а не животное). Такие типы никак не связаны отношением, и они называются инвариантными.
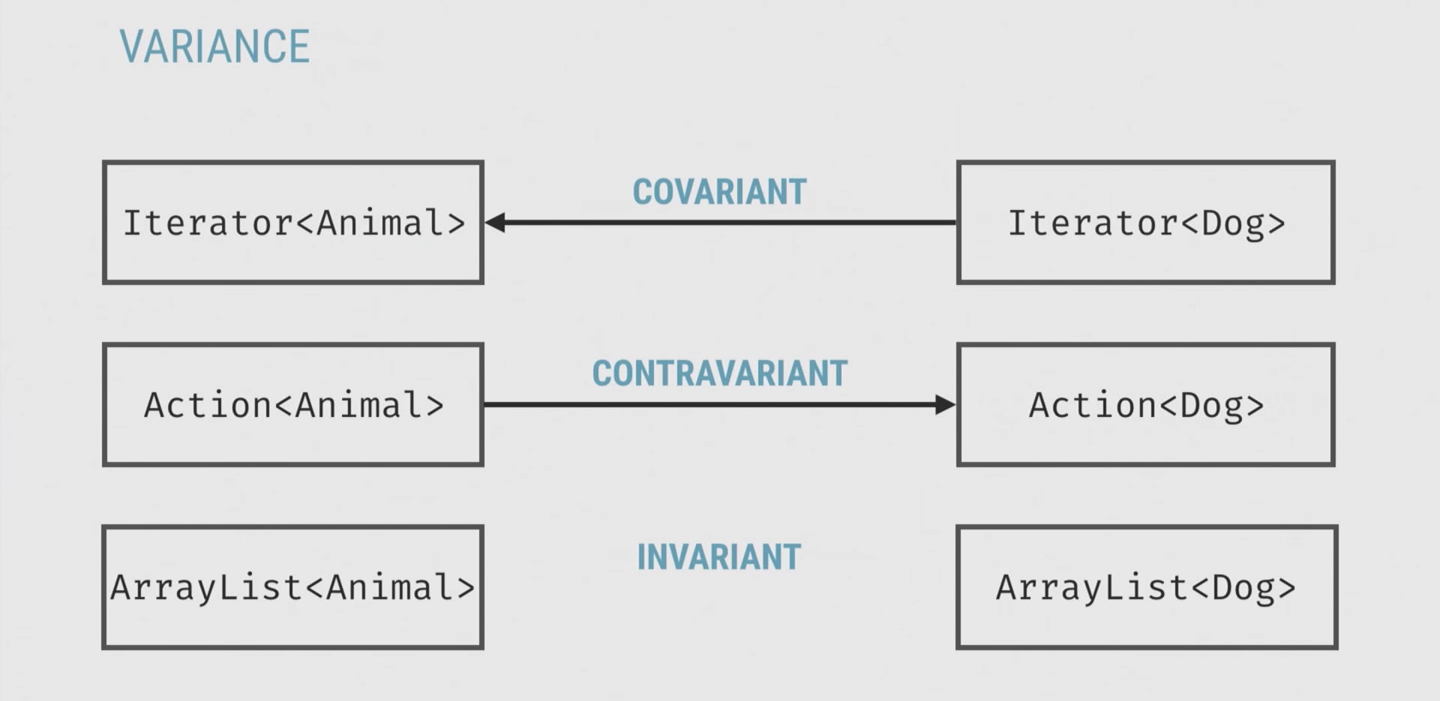
Так вот, в Java, когда её проектировали ещё до версии 1.5 (где появились дженерики), по умолчанию сделали массивы ковариантными. Это значит, что вы можете присвоить массиву объектов массив строк, потом передать его куда-то в метод, где нужен массив объектов, и попробовать туда запихнуть объект, хотя это массив строк. Всё свалится у вас.
Научившись на горьком опыте, что так делать нельзя, при проектировании дженериков они решили «коллекции мы сделаем инвариантными, ничего не будем с ними делать».
И в итоге получается, что в такой, казалось бы, очевидной штуке всё должно быть ок, а на самом деле не ок:
Но нам же нужно как-то определять, что всё-таки мы можем: если мы только читаем из этого листа, почему бы не сделать возможной передачу сюда листа собак? Поэтому есть возможность с помощью wildcard охарактеризовать то, какая же вариантность будет у этого типа:
Как вы видите, вариантность эта указывается на месте использования, там, где мы присваиваем собак. Поэтому это называется use-site variance.
Какие негативные стороны у этого есть? Негативная сторона в том, что вы должны везде, где используете ваш API, указывать эти страшные wildcard, и это всё очень плодится в коде. А вот в Kotlin почему-то такая штука работает из коробки, и не нужно ничего указывать:
С чем это связано? С тем, что листы на самом деле разные. List в Java подразумевает запись, а в Kotlin он read-only, не подразумевает. Поэтому, в принципе, мы можем сразу сказать, что отсюда только читаем, поэтому мы можем быть ковариантными. И это задаётся именно в объявлении типа ключевым словом out, заменяющим wildcard:
Это называется declaration-site variance. Таким образом, мы в одном месте всё указали, и там, где используем, мы больше не затрагиваем эту тему. И это ништяк.
Поехали обратно в наши пучины. Вот у нас есть метод addPlugins, он принимает List:
Благодаря тому, что List в Kotlin ковариантный, мы можем без проблем передать сюда лист наследников плагина. Всё сработает, компилятор не возражает. Но из-за того, что у нас есть declaration-site variance, где мы всё указали, мы не можем тогда на этапе использования контролировать связь с Java. А что же будет, если мы реально хотим туда лист Plugin, не хотим туда никаких наследников? Никаких модификаторов для этого нет, но есть что? Правильно, есть аннотация. А аннотация называется @JvmSuppressWildcards, то есть по умолчанию мы считаем, что здесь тип с wildcard, тип ковариантный.
Говоря SuppressWildcards, мы suppress'им все эти вопросики, и наша сигнатура фактически меняется. Даже более того, я покажу, как всё выглядит в байткоде:
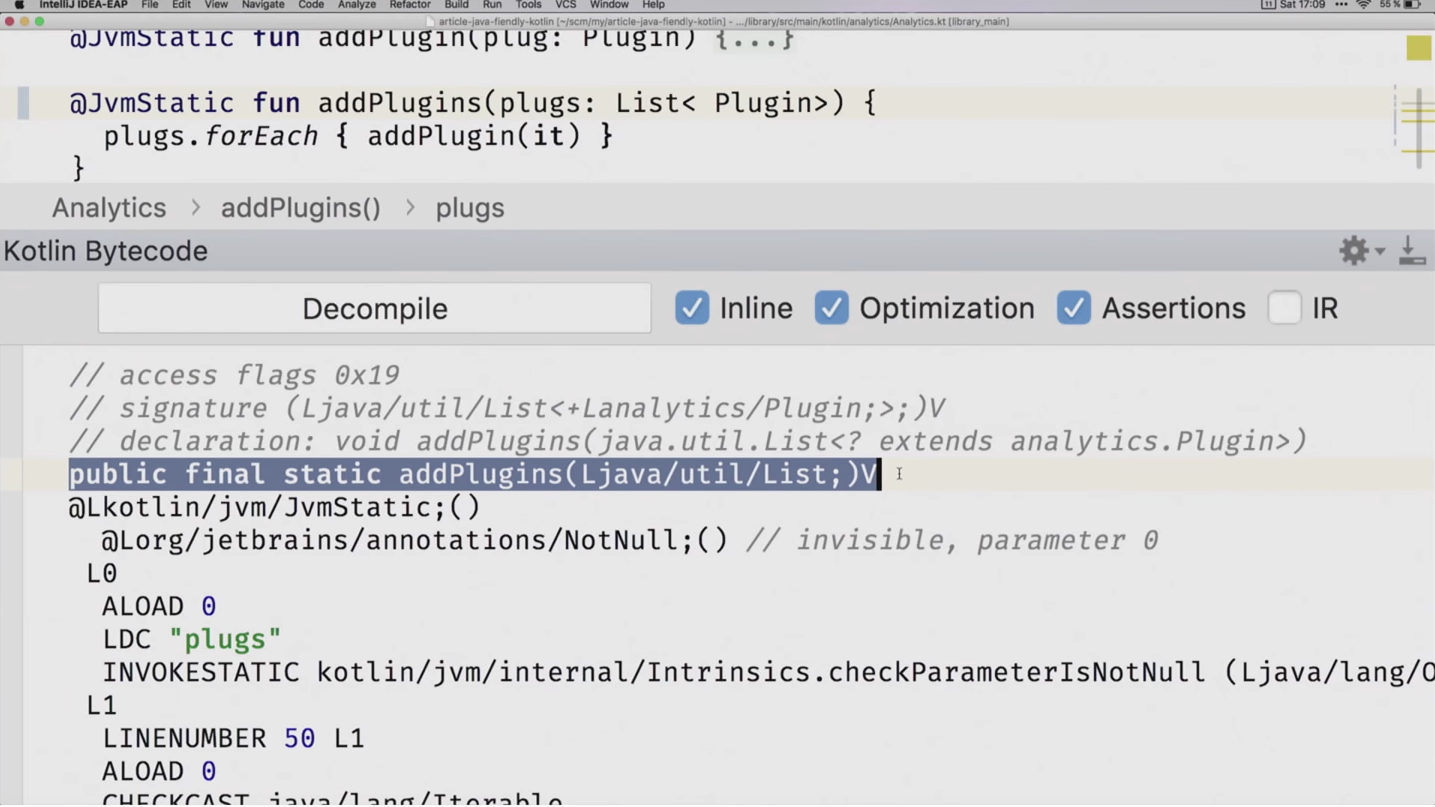
Удалю пока из кода аннотацию. Вот наш метод. Вы наверняка знаете, что существует type erasure. И у вас в байткоде нет никакой информации о том, что же там за вопросики-то были, ну и вообще дженерики. Но компилятор за этим следит и подписывает в комментариях к байткоду: а это у нас с вопросиком тип.

Теперь мы снова вставим аннотацию и видим, что это у нас тип без вопросиков.
Теперь наш предыдущий код перестанет компилироваться именно по причине того, что мы отрубили Wildcards. Вы можете в этом убедиться сами.
Мы разобрали ковариантные типы. Теперь обратная ситуация.
Мы считаем, что List у нас с вопросом. Очевидно предположить, что когда этот лист возвращается из getPlugins, он тоже будет с вопросом. А что это значит? Это значит, что мы не сможем в него записать, потому что тип ковариантный, а не контравариантный. Давайте взглянем, что происходит в Java.
Никто не возмущается, что в последней строчке мы что-то записываем, а это значит, что кто-то здесь не прав. Если заглянем в байткод, то убедимся в верности своих подозрений. Мы никаких аннотаций не навешивали, а тип почему-то без вопроса.
Сюрприз основан вот на чём. Kotlin постулирует себя, как язык прагматичный, поэтому, когда всё это проектировали, собирали статистику, как вообще используются wildcards в Java. Оказалось, что на вход чаще всего вариантность разрешают, то есть делают типы ковариантными. Ну полезно везде, где мы хотим List, иметь возможность засунуть туда лист любого наследника от Plugin. А вот там, где мы возвращаем, наоборот, мы хотим иметь чистые типы: как есть лист Plugin, так он и будет возвращён.
И здесь мы воочию видим пример этого. Это кажется немного контринтуитивно, зато порождает в вашем коде меньше чудных аннотаций, потому что это наиболее частый usecase, и если вы не пользуетесь какими-то приколами, всё будет работать из коробки.
Но в этом случае мы видим, что такая ситуация не для нас, потому что мы не хотим, чтобы туда можно было что-то записать. И также мы не хотим, чтобы это можно было сделать из Java. В Kotlin здесь List — это read only-тип, и мы туда ничего не можем записать, а пришёл клиент нашей библиотеки из Java и напихал туда всё подряд — кому это понравится? Поэтому мы собираемся зафорсить, чтобы этот метод возвращал List с wildcard. И мы можем это сделать понятно, как. Добавив аннотацию @JvmWildcard мы говорим: сгенерируй нам тип с вопросом, всё достаточно просто. Теперь посмотрим, что происходит в Java в этом месте. Java говорит «что ты делаешь?»:
Мы можем здесь даже привести к правильному типу List<? extends Plugin>, но она всё равно говорит «что ты делаешь?» И, в принципе, эта ситуация нас пока что устраивает. Но найдётся script kiddie, который скажет «я же видел исходники, это же опенсорс, я знаю, что там ArrayList, и я вас похачу». И всё сработает, потому что там действительно ArrayList и он знает, что туда можно записывать.
Поэтому, конечно, клёво аннотации навешивать, но всё равно нужно использовать defensive-копирование, которое давным-давно известно. Сорян, без него никуда, если вы хотите, чтобы script kiddies вас не похачили.
Добавлю только, что аннотацию @JvmSuppressWildcard можно навешивать как на параметр, тогда только он будет об этом знать, так и на функцию, так и на весь класс, тогда расширяется его зона действия.
Вроде бы всё хорошо, с нашей аналитикой мы разобрались. А теперь другая сторона, с которой мы можем подойти: плагин.
Мы хотим реализовать плагин на стороне Java. Как хорошие пацаны, мы репортим его исключение:
Здесь же всё видно:
В Kotlin же нет checked exception. И мы говорим в документации: сюда можно кидать. Ну мы и кидаем, кидаем, кидаем. А Java не нравится почему-то. Говорит: «а нет Throws почему-то в вашей сигнатуре, месье»:
А как тут добавить-то, тут же Kotlin? Ну, вы знаете ответ…
Есть аннотация @Throws, которая именно это и делает. Она меняет throws-часть в сигнатуре метода. Мы говорим, что можем кинуть сюда IOExсeption:
И ещё добавим это дело заодно в интерфейс:
И теперь что? Теперь наш плагин, написанный на Java, где у нас есть информация об exception, всем доволен. Всё работает, компилируется. В принципе, с аннотациями на этом более-менее всё, но есть ещё два нюанса того, как использовать @JvmName. Один интересный.
Мы все эти аннотации добавляли для того, чтобы в Java было красиво. А вот здесь…
Предположим, на Java нам здесь всё равно, уберём аннотацию. Опачки, теперь IDE показывает ошибку в обеих функциях. Как вы считаете, с чем это связано? Да, без аннотации они генерируются с одинаковыми именами, но здесь же написано, что один на List, другой на List. Верно, type erasure. Мы даже можем проверить это дело:
Вы уже в курсе, как я понял, что все top-level функции генерируются в статическом контекcте. И вот без этой аннотации мы постараемся сгенерировать printReversedSum от List, а ниже ещё один тоже от List. Потому что Kotlin-компилятор знает о дженериках, а Java-байткод не знает. Поэтому это единственный случай, когда аннотации из пакета kotlin.jvm нужны не для того, чтобы в Java было хорошо и удобно, а для того, чтобы ваш Kotlin собрался. Задаём новое имя — раз работаем со строками, то используем concatenation — и всё работает хорошо, теперь всё компилируется.
И второй юзкейс. Он связан вот с чем. У нас есть extension-функция reverse.
Этот reverse компилируется в статический метод класса, который называется ReverserKt.
Это, я думаю, не новость для вас. Нюанс в том, что чуваки, использующие нашу библиотеку в Java, могут заподозрить что-то неладное. Мы просочили детали имплементации нашей библиотеки на сторону юзера и хотим замести свои следы. Как мы можем это делать? Как уже понятно, аннотацией @JvmName, о которой я сейчас рассказываю, но есть один нюанс.
Для начала зададим ей такое имя, которое хотим, не палимся, и важно сказать, что мы применяем эту аннотацию на файле, переименовать нам надо именно файл.
Теперь компилятору в Java не нравится ReverserKt, но это ожидаемо, заменяем на ReverserUtils и все довольны. И такой «юзкейс 2.1» — частый случай, когда вы хотите методы нескольких ваших top-level файлов собрать под одним классом, под одним фасадом. Например, про вы не хотите, чтобы методы вышеприведённого sums.kt вызывались из SumsKt, а хотите, чтобы это всё тоже было про reversing и дёргалось из ReverserUtils. Тогда добавляем и туда эту чудную аннотацию @JvmName, пишем «ReverserUtils», в принципе, всё ок, можно даже попробовать это дело скомпилировать, но нет.
Хотя заранее среда не предупреждает, но при попытке компиляции нам скажут, что «вы хотите сгенерировать два класса в одном пакете с один именем, ата-та». Что нужно сделать? Добавить последнюю в этом пакете аннотацию @JvmMultifileClass, говорящую, что содержимое нескольких файлов будет превращаться в один класс, то есть для этого всего будет один фасад.
Добавляем в обоих случаях "@file:JvmMultifileClass", и можно заменять SumsKt на ReverserUtils, все довольны — поверьте мне. С аннотациями закончили!
Мы поговорили с вами об этом пакете, обо всех аннотациях. В принципе, уже из их названий понятно, для чего используется каждая. Есть хитрые кейсы, когда нужно, например, @JvmName использовать даже просто в Kotlin.
Но, скорее всего это не всё, что вы хотели бы узнать. Ещё важно отметить, как работать с Kotlin-специфичными вещами.
Например, inline-функции. Они в Kotlin инлайнятся и, казалось бы, а будут ли они вообще доступны из Java в байткоде? Оказывается, будут, всё будет хорошо, и методы реально доступны для Java. Хотя если вы пишете, например, Kotlin-only проект, это не совсем хорошо сказывается на вашем dex count limit. Потому что в Kotlin они не нужны, а реально в байткоде будут.
Дальше надо отметить Reified type parameters. Такие параметры специфичны для Kotlin, они доступны только для инлайн-функций и позволяют воротить такие хаки, которые в Java с рефлексией недоступны. Так как это Kotlin-only штука, она доступна только для Kotlin, и в Java вы не сможете использовать функции с reified, к сожалению.
java.lang.Class. Если мы хотим немного порефлексировать, а библиотека наша и для Java, то и её надо поддержать. Давайте посмотрим пример. Есть у нас такой «свой Retrofit», быстро написанный на коленке (я вообще не понимаю, чего парни так долго писали):
Есть метод, который работает с классом Java, есть метод, который работает с котлиновским KClass, вам не нужно делать две разные реализации, вы можете использовать extension-проперти, которые из KClass достают Class, из Class достают KClass (он называется Kotlin, в принципе очевидно).
Это всё будет работать, но это немного неидиоматично. В Kotlin-коде вы не передаёте KClass, вы пишете с использованием Reified-типов, поэтому лучше метод переделать на вот такой:
Всё шикардос. Теперь пойдём в Kotlin и посмотрим, как эта штука используется. Там val api = retrofit.create(Api::class) превратилось в val api = retrofit.create<Api>(), никаких явных ::class не вылезает. Это типичное использование Reified-функции, и всё будет супер-пупер.
Unit. Если ваша функция возвращает Unit, то она прекрасно компилируется в функцию, которая возвращает void в Java, и обратно. Вы можете работать с этим взаимозаменяемо. Но всё это заканчивается в том месте, где у вас лямбды начинают возвращать юниты. Если кто-то работал со Scala, то в Scala есть вагон и маленькая тележка интерфейсов, которые возвращают какие-то значения, и такой же вагон с тележкой интерфейсов, которые не возвращают ничего, то есть с void.
А в Kotlin этого нет. В Kotlin есть только 22 интерфейса, которые принимают разный набор параметров и что-то возвращают. Таким образом, лямбда, которая возвращает Unit, будет возвращать не void, а Unit. И это накладывает свои ограничения. Как выглядит лямбда, которая возвращает Unit? Вот, посмотрим на неё в этом фрагменте кода. Познакомимся.
Использование её из Kotlin: все хорошо, мы используем даже method reference, если можем, и читается отлично, глаза не мозолит.
Что происходит в Java? В Java происходит вот такая байда:
Из-за того, что мы должны возвращать что-то здесь. Это как Void с большой буквы, мы не можем просто взять и забить на него. Мы не можем использовать здесь метод референсы, которые возвращают void, к сожалению. И это, наверное, пока первая штука, которая реально мозолит глаза после всех наших манипуляций с аннотациями. К сожалению, вам придется возвращать инстанс Unit отсюда. Можно null, всё равно он никому не нужен. В смысле, возвращаемое значение никому не нужно.
Поехали дальше: Typealiases — это тоже довольно специфичная штука, это просто алиасы или синонимы, они доступны только из Kotlin, и в Java, к сожалению, вы будете использовать то, что под этими алиасами. Либо это портянка трижды вложенных дженериков, либо какие-то вложенные классы. Java-программисты привыкли с этим жить.
А теперь интересное: visibility. А точнее, internal visibility. Вы наверняка знаете, что в Kotlin нет package private, если вы пишете без каких-либо модификаторов, это будет public. Зато есть internal. Internal — это такая хитрая штука, что мы сейчас на неё даже посмотрим. В Retrofit у нас есть internal-метод validate.
Он не может быть вызван из Kotlin, и это понятно. Что происходит с Java? Можем ли мы вызвать validate? Возможно, для вас не секрет, что internal превращается в public. Если вы не верите мне, поверьте Kotlin bytecode viewer.
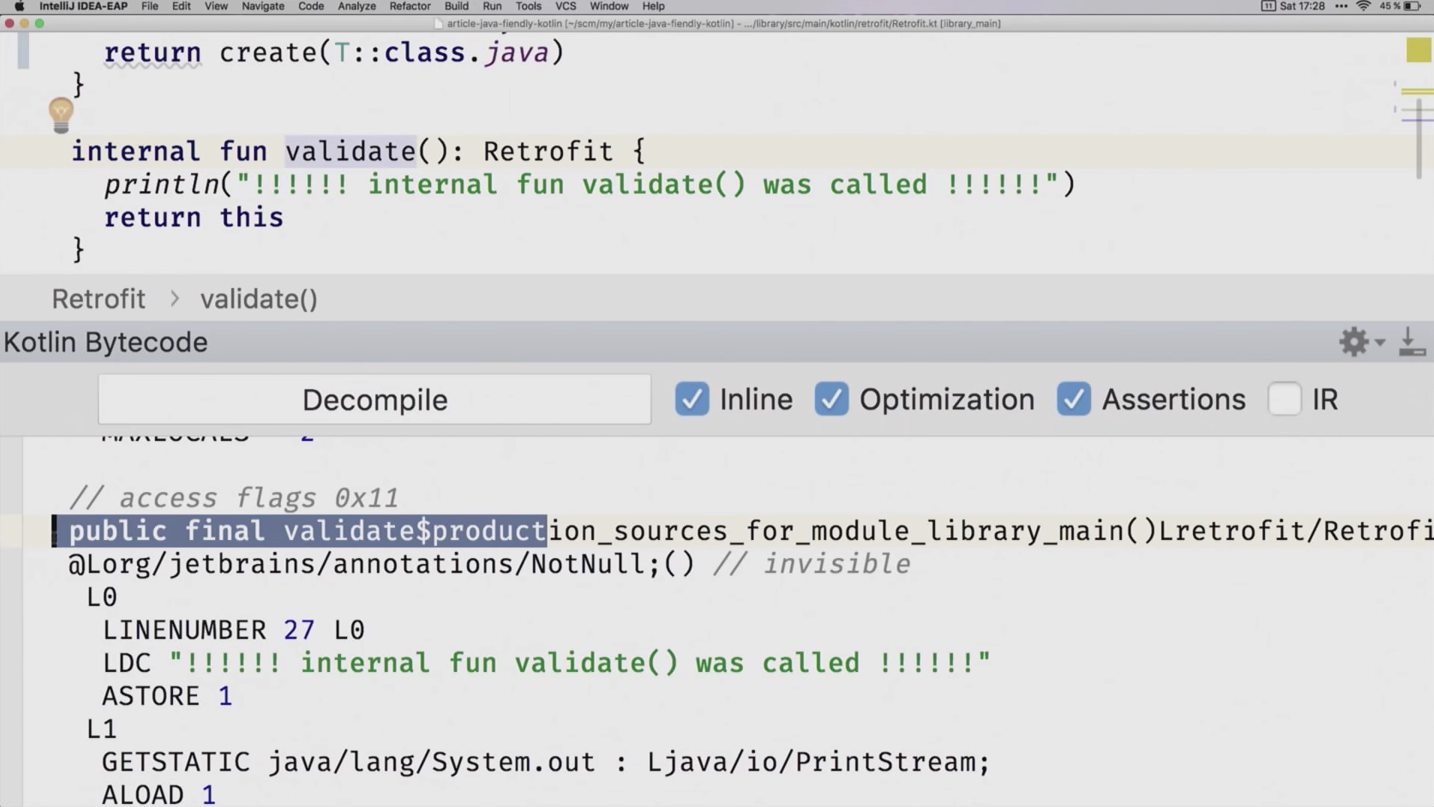
Это действительно public, но с такой страшной сигнатурой, которая намекает человеку, что это, наверное, не совсем так было задумано, что в публичное API пролезает вот такая портянка. Если у кого-то форматирование на 80 символов сделано, то такой метод может даже не влезть в одну строчку.
В Java у нас сейчас так:
Давайте попробуем скомпилировать это дело. Так, по крайней мере, это не скомпилируется, уже неплохо. На этом можно было бы остановиться, но let me explain this to you. Что, если я сделаю вот так?
Тогда компилируется. И возникает вопрос «Почему так?» Что я могу сказать… MAGIC!
Поэтому очень важно, если вы засовываете что-то критическое в internal, это плохо, потому что это просочится в ваше публичное API. И если script kiddie будет вооружён Kotlin Bytecode Viewer, то будет плохо. Не используйте ничего очень важного в методах с internal visibility.
Если вам хочется еще немного радости, то рекомендую две вещи. Чтобы было комфортней работать с байткодом и читать его, рекомендую доклад от Жени Вартанова, есть бесплатное видео, несмотря на то, что это с мероприятия SkillsMatter. Очень круто.
И довольно старая серия из трёх статей от Кристофа Бейлса про то, во что превращаются разные Kotlin-фичи. Там всё классно написано, что-то неактуально сейчас, но в целом весьма доходчиво. Всё тоже с Kotlin bytecode viewer и всё такое.
Спасибо!
Разумеется, это не означает «всё плохо и использовать Kotlin вместе с Java не надо», а означает, что стоит знать о нюансах и учитывать их. На нашей конференции Mobius Сергей Рябов рассказал, как писать на Kotlin такой код, к которому будет комфортно обращаться из Java. И доклад так понравился зрителям, что мы не только решили разместить видеозапись, но и сделали для Хабра текстовую версию:
Я пишу на Kotlin уже более трёх лет, сейчас только на нём, но поначалу притаскивал Kotlin в существующие Java-проекты. Поэтому вопрос «как связать вместе Java и Kotlin» на моём пути возникал довольно часто.
Зачастую при добавлении в проект Kotlin можно увидеть, как вот это…
compile 'rxbinding:x.y.x'
compile 'rxbinding-appcompat-v7:x.y.x'
compile 'rxbinding-design:x.y.x'
compile 'autodispose:x.y.z'
compile 'autodispose-android:x.y.z'
compile 'autodispose-android-archcomponents:x.y.z'
… превращается в это:
compile 'rxbinding:x.y.x'
compile 'rxbinding-kotlin:x.y.x'
compile 'rxbinding-appcompat-v7:x.y.x'
compile 'rxbinding-appcompat-v7-kotlin:x.y.x'
compile 'rxbinding-design:x.y.x'
compile 'rxbinding-design-kotlin:x.y.x'
compile 'autodispose:x.y.z'
compile 'autodispose-kotlin:x.y.z'
compile 'autodispose-android:x.y.z'
compile 'autodispose-android-kotlin:x.y.z'
compile 'autodispose-android-archcomponents:x.y.z'
compile 'autodispose-android-archcomponents-kotlin:x.y.z'
Специфика последней пары лет: самые популярные библиотеки обзаводятся «обёртками» для того, чтобы можно было использовать их из Kotlin более идиоматично.
Если вы писали на Kotlin, то знаете, что есть классные extension-функции, inline-функции, лямбда-выражения, которые доступны из Java 6. И это круто, это притягивает нас к Kotlin, но возникает вопрос. Одна из самых больших, самых разрекламированных фич языка — interoperability с Java. Если принять во внимание все перечисленные фичи, то почему бы тогда просто не писать библиотеки на Kotlin? Они все будут отлично работать из коробки с Java, и не нужно будет поддерживать все эти обёртки, все будут счастливы и довольны.
Но, конечно, на практике не всё так радужно, как в рекламных проспектах, всегда есть «приписочка мелким шрифтом», есть острые грани на стыке Kotlin и Java, и сегодня мы об этом немного поговорим.
Острые грани
Начнём с различий. Например, в курсе ли вы, что в Kotlin нет ключевых слов volatile, synchronized, strictfp, transient? Они заменены одноимёнными аннотациями, находящимися в пакете kotlin.jvm. Так вот, о содержимом этого пакета и пойдёт большая часть разговора.
Есть Timber — такая библиотечка-абстракция над логгерами от небезызвестного Жеки Вартанова. Она позволяет вам в вашем приложении везде использовать её, а всё, куда вы хотите отправить логи (в logcat, или на ваш сервер для анализа, или в crash reporting, и так далее), оборачивается в плагинчики.
Давайте для примера представим, что мы хотим написать аналогичную библиотеку, только для аналитики. Тоже абстрагироваться.
object Analytics {
fun send(event: Event) {}
fun addPlugins(plugs: List<Plugin>) {}
fun getPlugins(): List<Plugin> {}
}
interface Plugin {
fun init()
fun send(event: Event)
fun close()
}
data class Event(
val name: String,
val context: Map<String, Any> = emptyMap()
)
Берём тот же самый паттерн построения, у нас одна точка входа — это Analytics. Мы можем посылать туда ивенты, добавлять плагины и смотреть, что у нас там уже добавлено.
Plugin — интерфейс плагина, который абстрагирует какое-то конкретное аналитическое API.
И, собственно, класс Event, содержащий ключ и наши атрибуты, которые мы отправляем. Здесь доклад не про то, стоит ли использовать синглтоны, поэтому давайте не будем разводить холивар, а будем смотреть, как это все дело причесать.
Теперь немножко погрузимся. Вот пример использования нашей библиотеки в Kotlin:
private fun useAnalytics() {
Analytics.send(Event("only_name_event"))
val props = mapOf(
USER_ID to 1235,
"my_custom_attr" to true
)
Analytics.send(Event("custom_event", props))
val hasPlugins = Analytics.hasPlugins
Analytics.addPlugin(EMPTY_PLUGIN) // dry-run
Analytics.addPlugins(listOf(LoggerPlugin("ALog"), SegmentPlugin)))
val plugins = Analytics.getPlugins()
// ...
}
В принципе, выглядит так, как и ожидается. Одна точка входа, методы вызываются а-ля статики. Event без параметров, event с атрибутами. Проверяем, есть ли у нас плагины, запихиваем туда пустой плагин для того, чтобы просто какой-то «dry run»-прогон сделать. Либо добавляем несколько других плагинов, выводим их, ну и так далее. В общем, стандартные юзкейсы, надеюсь, всё пока понятно.
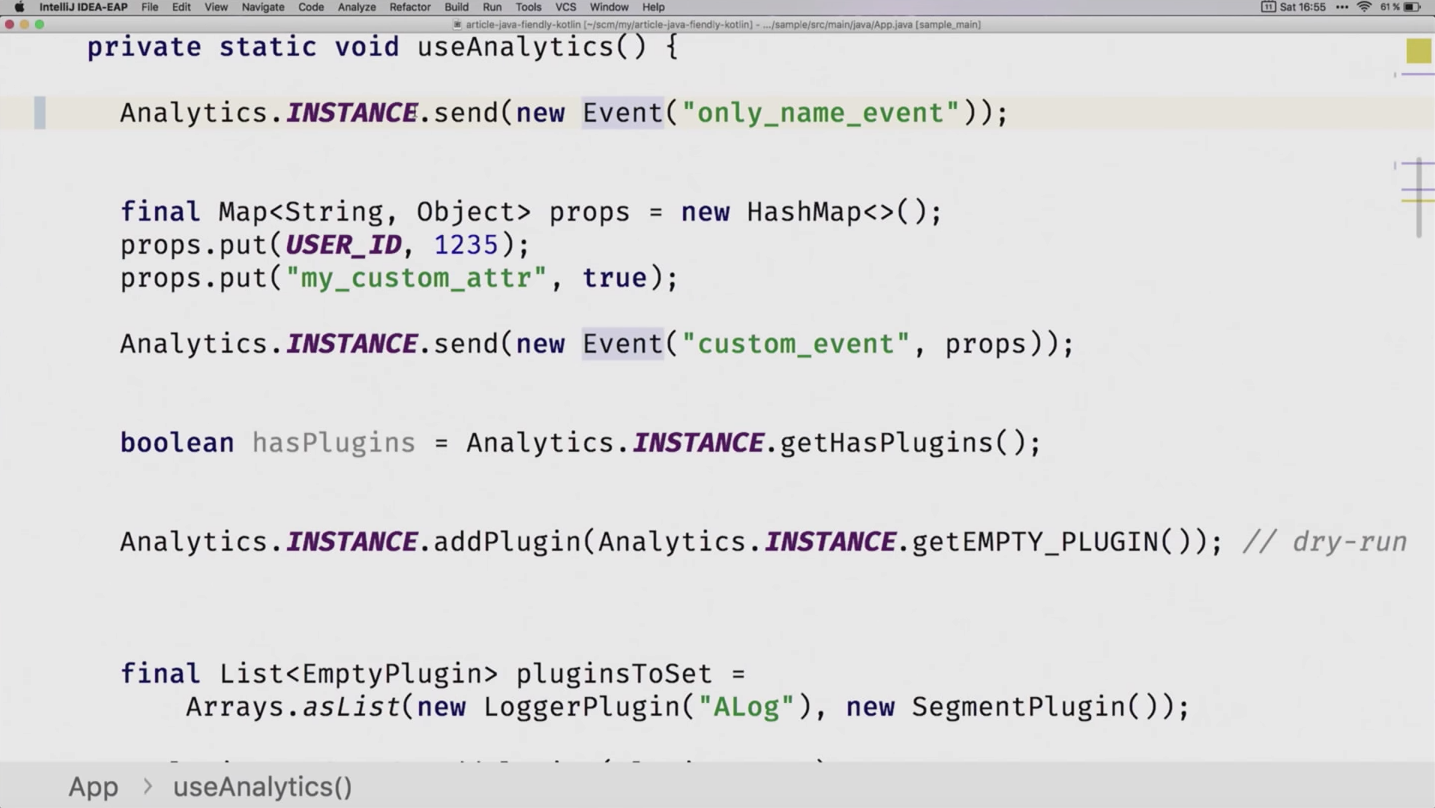
А теперь посмотрим, что происходит в Java, когда мы делаем то же самое:
private static void useAnalytics() {
Analytics.INSTANCE.send(new Event("only_name_event", Collections.emptyMap()));
final Map<String, Object> props = new HashMap<>();
props.put(USER_ID, 1235);
props.put("my_custom_attr", true);
Analytics.INSTANCE.send(new Event("custom_event", props));
boolean hasPlugins = Analytics.INSTANCE.getHasPlugins();
Analytics.INSTANCE.addPlugin(Analytics.INSTANCE.getEMPTY_PLUGIN()); // dry-run
final List<EmptyPlugin> pluginsToSet = Arrays.asList(new LoggerPlugin("ALog"), new SegmentPlugin());
// ...
}
В глаза сразу бросается сыр-бор с INSTANCE, который протянут наверх, наличие явных значений для дефолтного параметра с атрибутами, какие-то геттеры со стрёмными названиями. Так как мы, в общем-то, и собрались здесь, чтобы превратить это во что-то похожее на предыдущий файл с Kotlin, то давайте пройдёмся по каждому моменту, который нам не нравится, и попробуем его как-то адаптировать.
Начнём с Event. Удаляем из второй строчки параметр Colletions.emptyMap(), и вылезает ошибка компилятора. С чем же это связано?
data class Event(
val name: String,
val context: Map<String, Any> = emptyMap()
)
Наш конструктор имеет дефолтный параметр, в который мы передаём значение. Мы приходим из Java в Kotlin, логично предположить, что наличие дефолтного параметра генерирует два конструктора: один полный с двумя параметрами, и один частичный, у которого можно задать только name. Очевидно, компилятор так не считает. Давайте посмотрим, почему он считает, что мы не правы.
Наш основной инструмент для анализа всех перипетий того, как Kotlin превращается в JVM-байткод — Kotlin Bytecode Viewer. В Android Studio и IntelliJ IDEA он находится в меню Tools — Kotlin — Show Kotlin Bytecode. Можно просто нажать Cmd+Shift+A и вписать в строку поиска Kotlin Bytecode.

Здесь, как ни удивительно, мы видим байткод того, во что превращается наш Kotlin-класс. Я не ожидаю от вас отличного знания байткода, и, самое главное, разработчики IDE тоже не ожидают. Поэтому они сделали кнопочку Decompile.
После её нажатия мы видим такой примерно неплохой Java-код:
public final class Event {
@NotNull
private final String name;
@NotNull
private final Map context;
@NotNull
public final String getName() { return this.name; }
@NotNull
public final Map getContext() { return this.context; }
public Event(@NotNull String name, @NotNull Map context) {
Intrinsics.checkParameterIsNotNull(name, "name");
Intrinsics.checkParameterIsNotNull(context, "context");
super();
this.name = name;
this.context = context;
}
// $FF: Synthetic method
public Event(String var1, Map var2, int var3, DefaultConstructorMarker var4) {
if ((var3 & 2) != 0) {
var2 = MapsKt.emptyMap();
}
// ...
}
Видим наши поля, геттеры, ожидаемый конструктор с двумя параметрами name и context, всё происходит нормально. А ниже мы видим второй конструктор, и вот он с неожиданной сигнатурой: не с одним параметром, а почему-то с четырьмя.
Тут можно смутиться, а можно залезть немного глубже и покопаться. Начав разбираться, мы поймём, что DefaultConstructorMarker — это приватный класс из стандартной библиотеки Kotlin, добавленный сюда, чтобы не было коллизий с нами написанными конструкторами, т. к. мы не можем задать руками параметр типа DefaultConstructorMarker. А интересное всего int var3 — битовая маска того, какие дефолтные значения мы должны использовать. В данном случае, если битовая маска совпадает с двойкой, мы знаем, что var2 не задан, наши атрибуты не заданы, и мы используем дефолтное значение.
Как мы можем исправить ситуацию? Для этого есть чудо-аннотация @JvmOverloads из того пакета, о котором я уже говорил. Мы должны навесить её на конструктор.
data class Event @JvmOverloads constructor(
val name: String,
val context: Map<String, Any> = emptyMap()
)
И что она сделает? Обратимся к тому же инструменту. Теперь там видим и наш полный конструктор, и конструктор с DefaultConstructorMarker, и, о чудо, конструктор с одним параметром, который доступен теперь из Java:
@JvmOverloads
public Event(@NotNull String name) {
this.name, (Map)null, 2, (DefaultConstructorMarker)null);
}
И, как видите, он делегирует всю работу с дефолтными параметрами в тот наш конструктор с битовыми масками. Таким образом, мы не плодим информации о том, что за дефолтное значение нам нужно засунуть туда, мы просто делегируем всё в один конструктор. Славно. Проверяем, что у нас получилось со стороны Java: компилятор рад и не возмущается.
Давайте посмотрим, что нам не нравится дальше. Нам не нравится этот INSTANCE, который в IDEA мозолит фиолетовым цветом. Не люблю фиолетовый цвет :)

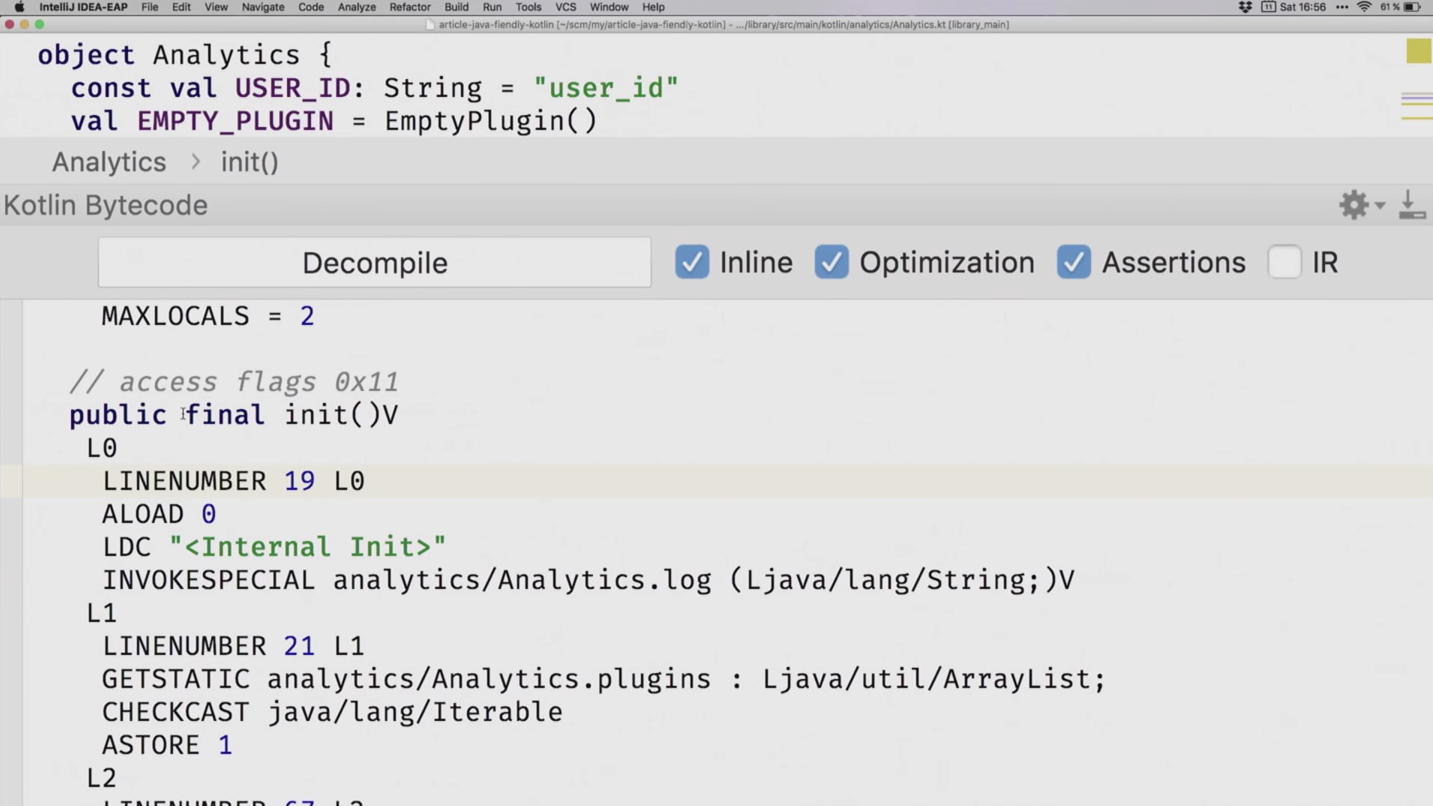
Давайте проверим, за счёт чего так получается. Снова глянем в байткод.
Выделим, например, функцию init и убедимся, что init действительно сгенерирован не статическим.

То есть, как ни крути, нам нужно работать с инстансом этого класса и вызывать у него эти методы. Но мы можем зафорсить генерацию всех этих методов как статическую. Для этого есть своя чудесная анннотация @JvmStatic. Давайте добавим её к функциям init и send и проверим, что теперь думает компилятор на этот счёт.
Мы видим, что к public final init() добавилось ключевое слово static, и мы избавили себя от работы с INSTANCE. Убедимся в этом в Java-коде.
Компилятор теперь подсказывает нам, что мы вызываем статический метод из контекста INSTANCE. Это можно поправить: нажать Alt+Enter, выбрать «Cleanup Code», и вуаля, INSTANCE исчезает, всё выглядит примерно так же, как было в Kotlin:
Analytics.send(new Event("only_name_event"));
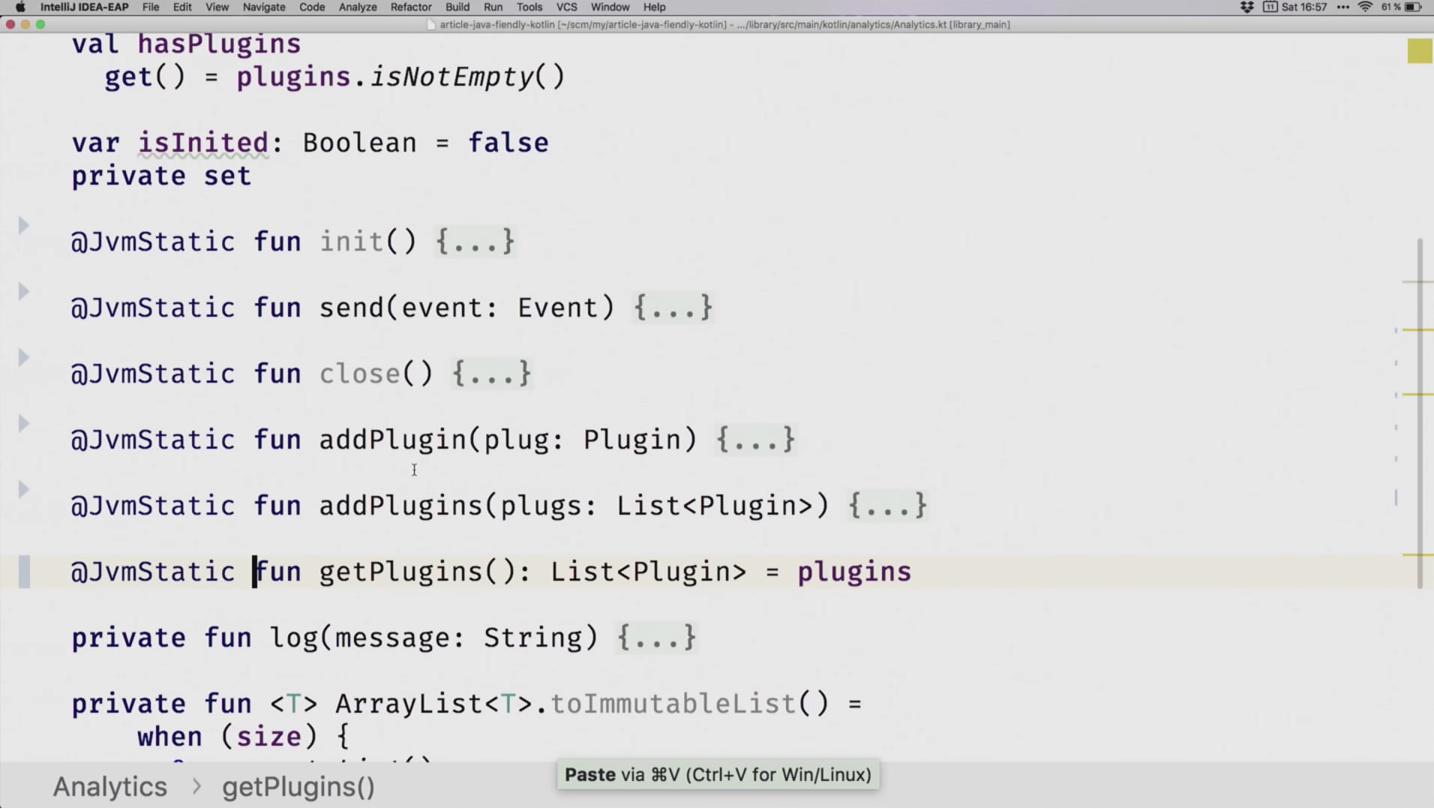
Теперь у нас есть схема работы со статическими методами. Добавим эту аннотацию везде, где нам это важно:

И комментарий: если методы у нас — очевидно методы instance, то, например, с пропертями не всё так очевидно. Сами поля (например, plugins) генерируются как статические. А вот геттеры и сеттеры работают как методы инстанса. Поэтому для пропертей вам тоже нужно добавлять эту аннотацию, чтобы зафорсить сеттеры и геттеры, как статические. Например, видим переменную isInited, добавляем ей аннотацию @JvmStatic, и теперь мы видим в Kotlin Bytecode Viewer, что метод isInited() стал статическим, всё отлично.
Теперь пойдем в Java-код, «за-clean-up-им» его, и всё выглядит примерно как в Kotlin, за исключением точек с запятой и слова new — ну, от них вы не избавитесь.
public static void useAnalytics() {
Analytics.send(new Event("only_name_event"));
final Map<String, Object> props = new HashMap<>();
props.put(USER_ID, 1235);
props.put("my_custom_attr", true);
Analytics.send(new Event("custom_event", props));
boolean hasPlugins = Analytics.getHasPlugins();
Analytics.addPlugin(Analytics.INSTANCE.getEMPTY_PLUGIN()); // dry-run
// ...
}
Следующий шаг: мы видим этот стрёмно названный геттер getHasPlugins с двумя префиксами сразу. Я, конечно, не большой знаток английского языка, но мне кажется, здесь что-то другое подразумевалось. Почему так происходит?
Как знают плотно общавшиеся с Kotlin, для пропертей названия геттеров и сеттеров генерируются по правилам JavaBeans. Это значит, что геттеры в общем случае будут с префиксами get, сеттеры с префиксами set. Но есть одно исключение: если у вас булево поле и в его названии есть префикс is, то и геттер будет с префиксом is. Это можно увидеть на примере вышеупомянутного поля isInited.
К сожалению, далеко не всегда булевы поля должны называться через is. isPlugins не совсем удовлетворяло бы тому, что мы хотим семантически показать именем. Как же нам быть?
А быть нам несложно, для этого есть своя аннотация (как вы уже поняли, я сегодня буду часто это повторять). Аннотация @JvmName позволяет задать любое имя, которое мы хотим (естественно, поддерживаемое Java). Добавим её:
@JvmStatic val hasPlugins
@JvmName("hasPlugin") get() = plugins.isNotEmpty()
Проверим, что у нас получилось в Java: метода getHasPlugins больше нет, а вот hasPlugins вполне себе есть. Это решило нашу проблему, опять-таки, одной аннотацией. Сейчас всё аннотациями порешаем!
Как видите, здесь мы навесили аннотацию прямо на геттер. С чем это связано? С тем, что под пропертёй лежит много всего, и непонятно, к чему применяется @JvmName. Если перенести аннотацию на сам val hasPlugins, то компилятор не поймёт, к чему её применять.
Однако в Kotlin есть и возможность специфицировать место применения аннотации прямо в ней. Можно указать целью геттер, файл целиком, параметр, делегат, поле, проперти, receiver extension-функции, сеттер и параметр сеттера. В нашем случае интересен геттер. И если сделать вот так, будет тот же самый эффект, как когда мы навешивали аннотацию на get:
@get:JvmName("hasPlugins") @JvmStatic val hasPlugins
get() = plugins.isNotEmpty()
Соответственно, если у вас нет кастомного геттера, то вы можете навесить прямо на вашу проперти, и все будет ОK.
Следующий момент, который немного нас смущает — это «Analytics.INSTANCE.getEMPTY_PLUGIN()». Тут дело уже даже не в английском, а просто: ПОЧЕМУ? Ответ примерно такой же, но сперва небольшое введение.
Для того, чтобы сделать из поля константу, у вас есть два пути. Если константу вы определяете как примитивный тип либо как String, и ещё она внутри объекта, то вы можете использовать ключевое слово const, и тогда не будет сгенерировано геттеров-сеттеров и прочего. Это будет обычная константа — private final static — и она будет заинлайнена, то есть абсолютно обычная Java-штука.
Но если вы хотите сделать константу из объекта, который отличен от строки, то у вас не выйдет использовать для этого слово const. Вот у нас есть val EMPTY_PLUGIN = EmptyPlugin(), по нему, очевидно сгенерировался тот страшный геттер. Мы можем аннотацией @JvmName переименовать, убрать этот префикс get, но всё равно это останется методом — со скобками. Значит, старые решения не подойдут, ищем новые.
И тут для этого аннотация @JvmField, которая говорит: «Не хочу здесь геттеров, не хочу сеттеров, сделай мне поле». Поставим её перед val EMPTY_PLUGIN и проверим, что всё действительно так.
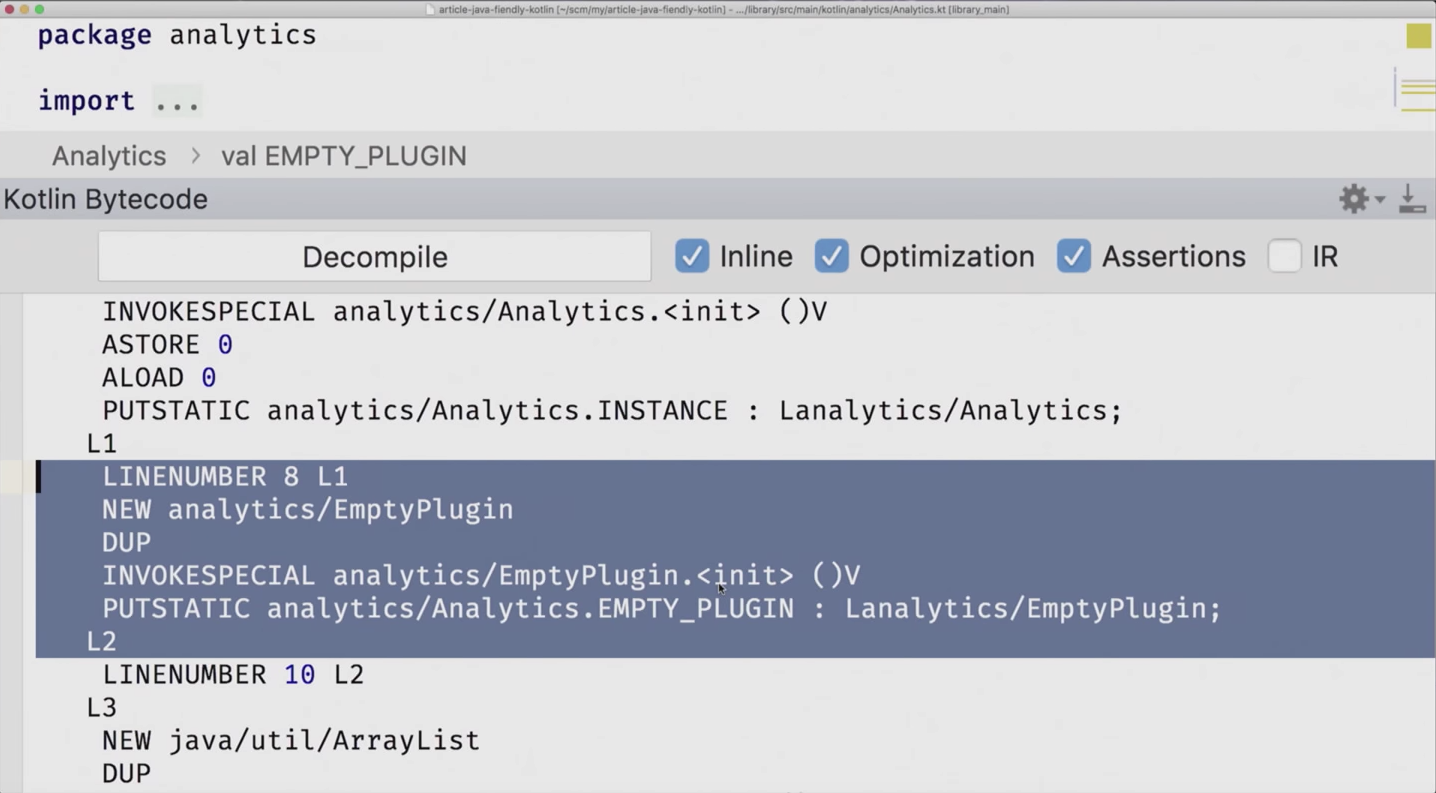
Kotlin Bytecode Viewer показывает выделенным тот кусок, на котором вы сейчас стоите в файле. Мы сейчас стоим на EMPTY_PLUGIN, и вы видите, что здесь какая-то инициализация написана в конструкторе. Дело в том, что геттера-то больше нет и доступ к нему только на запись идёт. А если нажать decompile, видим, что появилось «public static final EmptyPlugin EMPTY_PLUGIN», это именно то, чего мы и добивались. Славно. Проверяем, что всех всё радует, в частности, компилятор. Самый главный, кого нужно ублажить — это компилятор.
Generics
Давайте немного оторвёмся от кода и посмотрим на дженерики. Это довольно острая тема. Или скользкая, кому что больше не нравится. В Java есть свои сложности, но Kotlin отличается. В первую очередь нас волнует вариантность. Что это такое?
Вариантность — это способ переноса информации о иерархии типов с базовых типов на производные, например, на контейнеры или на дженерики. Вот у нас есть классы Animal и Dog с вполне очевидной связью: Dog — это подтип, Animal — надтип, стрелка идёт от подтипа.

А какая связь будет у их производных? Давайте рассмотрим несколько кейсов.
Первый — это Iterator. Определять, что есть надтип, а что есть подтип, мы будем, руководствуясь правилом подстановки Барбары Лисков. Сформулировать его можно так:«подтип должен требовать не больше, а предоставлять не меньше».
В нашей ситуации единственное, что делает Iterator — отдаёт нам типизированные объекты, например, Animal. Если мы где-то принимаем Iterator, мы вполне можем засунуть туда Iterator, и из метода next() получим Animal, потому что собака — это тоже Animal. Мы предоставляем не меньше, а больше, потому что собака — это подтип.

Повторюсь: из этого типа мы только читаем, поэтому здесь сохраняется зависимость между типом и подтипом. И такие типы называются ковариантными.
Другой кейс: Action. Action — это функция, которая не возвращает ничего, принимает один параметр, и мы только пишем в Action, то есть он принимает у нас собаку или животное.

Таким образом, здесь мы уже не предоставляем, а требуем, и требовать мы должны не больше. Это значит, что зависимость у нас меняется. «Не больше» у нас Animal (Animal меньше, чем собака). И такие типы называются контравариантными.
Есть еще третий кейс — например, ArrayList, из которого мы и читаем, и пишем. Поэтому в данном случае мы нарушаем одно из правил, на запись требуем больше (собаку, а не животное). Такие типы никак не связаны отношением, и они называются инвариантными.

Так вот, в Java, когда её проектировали ещё до версии 1.5 (где появились дженерики), по умолчанию сделали массивы ковариантными. Это значит, что вы можете присвоить массиву объектов массив строк, потом передать его куда-то в метод, где нужен массив объектов, и попробовать туда запихнуть объект, хотя это массив строк. Всё свалится у вас.
Научившись на горьком опыте, что так делать нельзя, при проектировании дженериков они решили «коллекции мы сделаем инвариантными, ничего не будем с ними делать».
И в итоге получается, что в такой, казалось бы, очевидной штуке всё должно быть ок, а на самом деле не ок:
// Java
List<Dog> dogs = new ArrayList<>();
List<Animal> animals = dogs;
Но нам же нужно как-то определять, что всё-таки мы можем: если мы только читаем из этого листа, почему бы не сделать возможной передачу сюда листа собак? Поэтому есть возможность с помощью wildcard охарактеризовать то, какая же вариантность будет у этого типа:
List<Dog> dogs = new ArrayList<>();
List<? extends Animal> animals = dogs;
Как вы видите, вариантность эта указывается на месте использования, там, где мы присваиваем собак. Поэтому это называется use-site variance.
Какие негативные стороны у этого есть? Негативная сторона в том, что вы должны везде, где используете ваш API, указывать эти страшные wildcard, и это всё очень плодится в коде. А вот в Kotlin почему-то такая штука работает из коробки, и не нужно ничего указывать:
val dogs: List<Dog> = ArrayList()
val animals: List<Animal> = dogs
С чем это связано? С тем, что листы на самом деле разные. List в Java подразумевает запись, а в Kotlin он read-only, не подразумевает. Поэтому, в принципе, мы можем сразу сказать, что отсюда только читаем, поэтому мы можем быть ковариантными. И это задаётся именно в объявлении типа ключевым словом out, заменяющим wildcard:
interface List<out E> : Collection<E>
Это называется declaration-site variance. Таким образом, мы в одном месте всё указали, и там, где используем, мы больше не затрагиваем эту тему. И это ништяк.
Снова к коду
Поехали обратно в наши пучины. Вот у нас есть метод addPlugins, он принимает List:
@JvmStatic fun addPlugins (plugs: List<Plugin>) {
plugs.forEach { addPlugin(it) }
}
А мы передаём ему, как видно, List<EmptyPlugin>, ну, просто закастили всё это дело:
<source lang="java">
final List<EmptyPlugin> pluginsToSet =
Arrays.asList(new LoggerPlugin("Alog"), new SegmentPlugin());
Благодаря тому, что List в Kotlin ковариантный, мы можем без проблем передать сюда лист наследников плагина. Всё сработает, компилятор не возражает. Но из-за того, что у нас есть declaration-site variance, где мы всё указали, мы не можем тогда на этапе использования контролировать связь с Java. А что же будет, если мы реально хотим туда лист Plugin, не хотим туда никаких наследников? Никаких модификаторов для этого нет, но есть что? Правильно, есть аннотация. А аннотация называется @JvmSuppressWildcards, то есть по умолчанию мы считаем, что здесь тип с wildcard, тип ковариантный.
@JvmStatic fun addPlugins(plugs: List<@JvmSuppressWildcards Plugin>) {
plugs.forEach { addPlugin(it) }
}
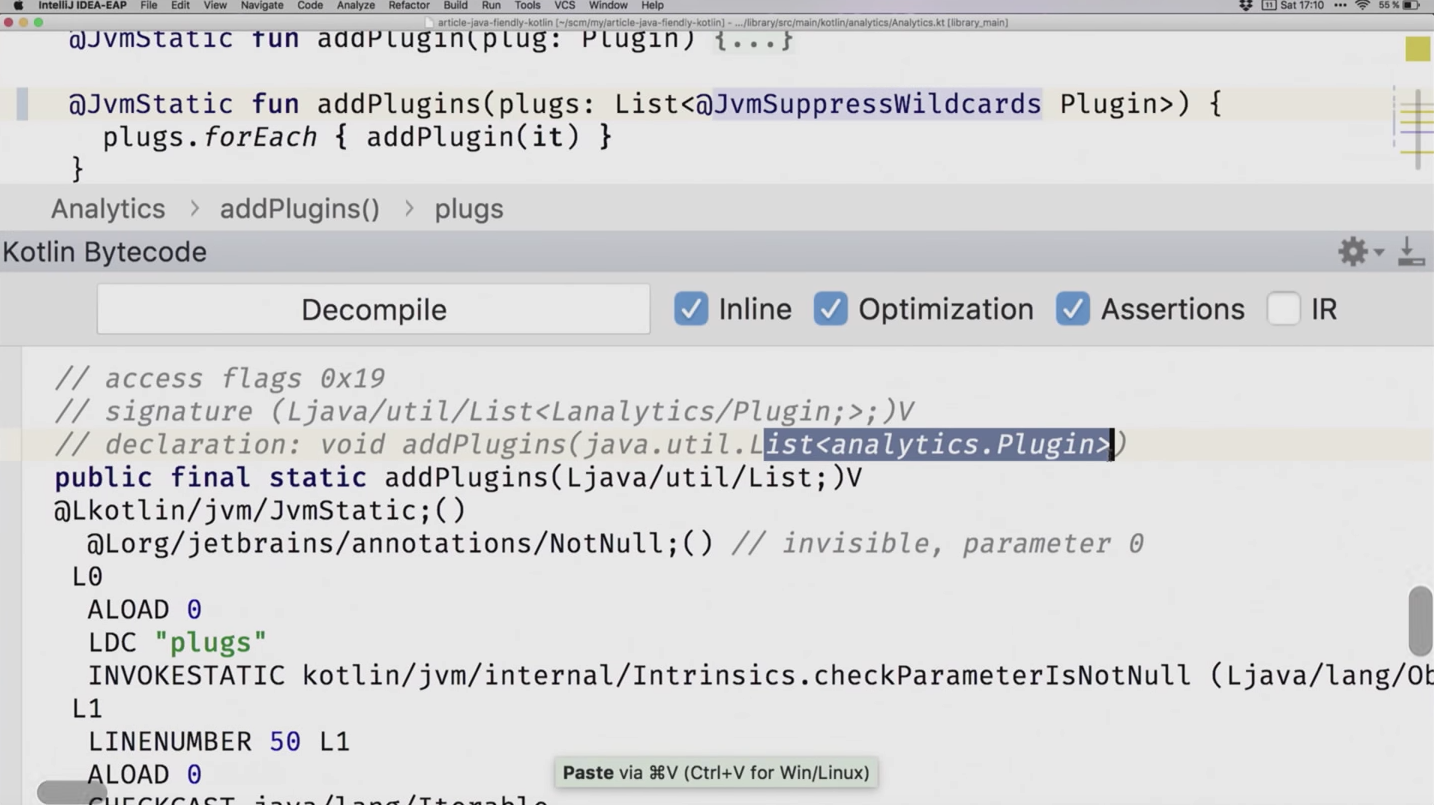
Говоря SuppressWildcards, мы suppress'им все эти вопросики, и наша сигнатура фактически меняется. Даже более того, я покажу, как всё выглядит в байткоде:

Удалю пока из кода аннотацию. Вот наш метод. Вы наверняка знаете, что существует type erasure. И у вас в байткоде нет никакой информации о том, что же там за вопросики-то были, ну и вообще дженерики. Но компилятор за этим следит и подписывает в комментариях к байткоду: а это у нас с вопросиком тип.
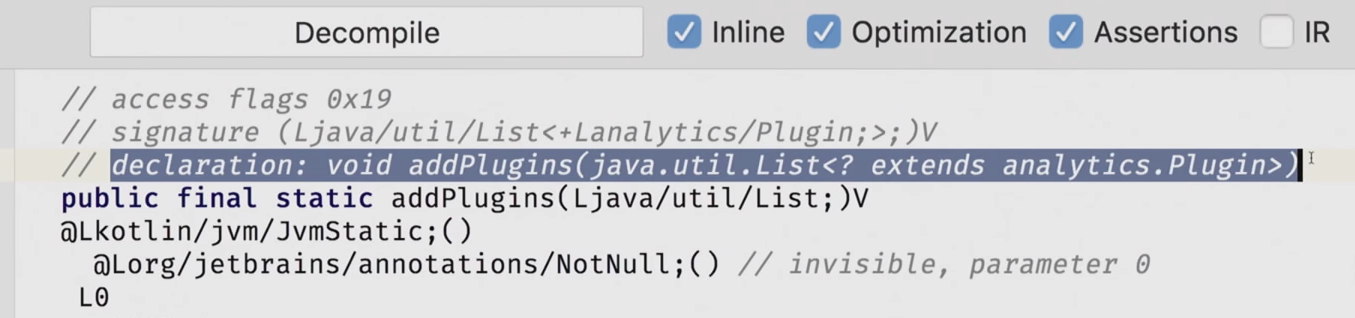
Теперь мы снова вставим аннотацию и видим, что это у нас тип без вопросиков.

Теперь наш предыдущий код перестанет компилироваться именно по причине того, что мы отрубили Wildcards. Вы можете в этом убедиться сами.
Мы разобрали ковариантные типы. Теперь обратная ситуация.
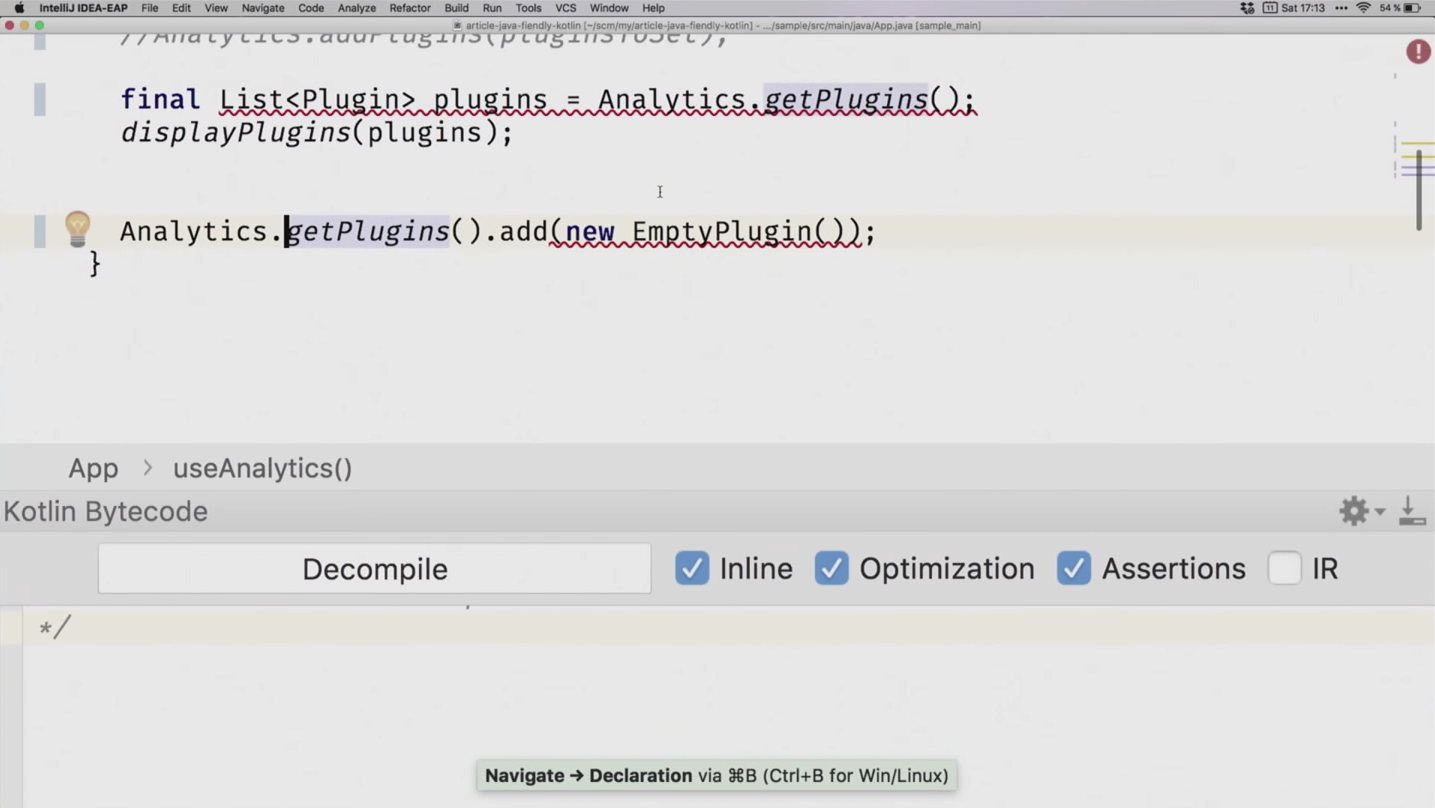
Мы считаем, что List у нас с вопросом. Очевидно предположить, что когда этот лист возвращается из getPlugins, он тоже будет с вопросом. А что это значит? Это значит, что мы не сможем в него записать, потому что тип ковариантный, а не контравариантный. Давайте взглянем, что происходит в Java.
final List<Plugin> plugins = Analytics.getPlugins();
displayPlugins(plugins);
Analytics.getPlugins().add(new EmptyPlugin());
Никто не возмущается, что в последней строчке мы что-то записываем, а это значит, что кто-то здесь не прав. Если заглянем в байткод, то убедимся в верности своих подозрений. Мы никаких аннотаций не навешивали, а тип почему-то без вопроса.
Сюрприз основан вот на чём. Kotlin постулирует себя, как язык прагматичный, поэтому, когда всё это проектировали, собирали статистику, как вообще используются wildcards в Java. Оказалось, что на вход чаще всего вариантность разрешают, то есть делают типы ковариантными. Ну полезно везде, где мы хотим List, иметь возможность засунуть туда лист любого наследника от Plugin. А вот там, где мы возвращаем, наоборот, мы хотим иметь чистые типы: как есть лист Plugin, так он и будет возвращён.
И здесь мы воочию видим пример этого. Это кажется немного контринтуитивно, зато порождает в вашем коде меньше чудных аннотаций, потому что это наиболее частый usecase, и если вы не пользуетесь какими-то приколами, всё будет работать из коробки.
Но в этом случае мы видим, что такая ситуация не для нас, потому что мы не хотим, чтобы туда можно было что-то записать. И также мы не хотим, чтобы это можно было сделать из Java. В Kotlin здесь List — это read only-тип, и мы туда ничего не можем записать, а пришёл клиент нашей библиотеки из Java и напихал туда всё подряд — кому это понравится? Поэтому мы собираемся зафорсить, чтобы этот метод возвращал List с wildcard. И мы можем это сделать понятно, как. Добавив аннотацию @JvmWildcard мы говорим: сгенерируй нам тип с вопросом, всё достаточно просто. Теперь посмотрим, что происходит в Java в этом месте. Java говорит «что ты делаешь?»:

Мы можем здесь даже привести к правильному типу List<? extends Plugin>, но она всё равно говорит «что ты делаешь?» И, в принципе, эта ситуация нас пока что устраивает. Но найдётся script kiddie, который скажет «я же видел исходники, это же опенсорс, я знаю, что там ArrayList, и я вас похачу». И всё сработает, потому что там действительно ArrayList и он знает, что туда можно записывать.
((ArrayList<Plugin>) Analytics.getPlugins()).add(new EmptyPlugin());
Поэтому, конечно, клёво аннотации навешивать, но всё равно нужно использовать defensive-копирование, которое давным-давно известно. Сорян, без него никуда, если вы хотите, чтобы script kiddies вас не похачили.
@JvmStatic fun getPlugins(): List<@JvmWildcard Plugin> =
plugin.toImmutableList()
Добавлю только, что аннотацию @JvmSuppressWildcard можно навешивать как на параметр, тогда только он будет об этом знать, так и на функцию, так и на весь класс, тогда расширяется его зона действия.
Вроде бы всё хорошо, с нашей аналитикой мы разобрались. А теперь другая сторона, с которой мы можем подойти: плагин.
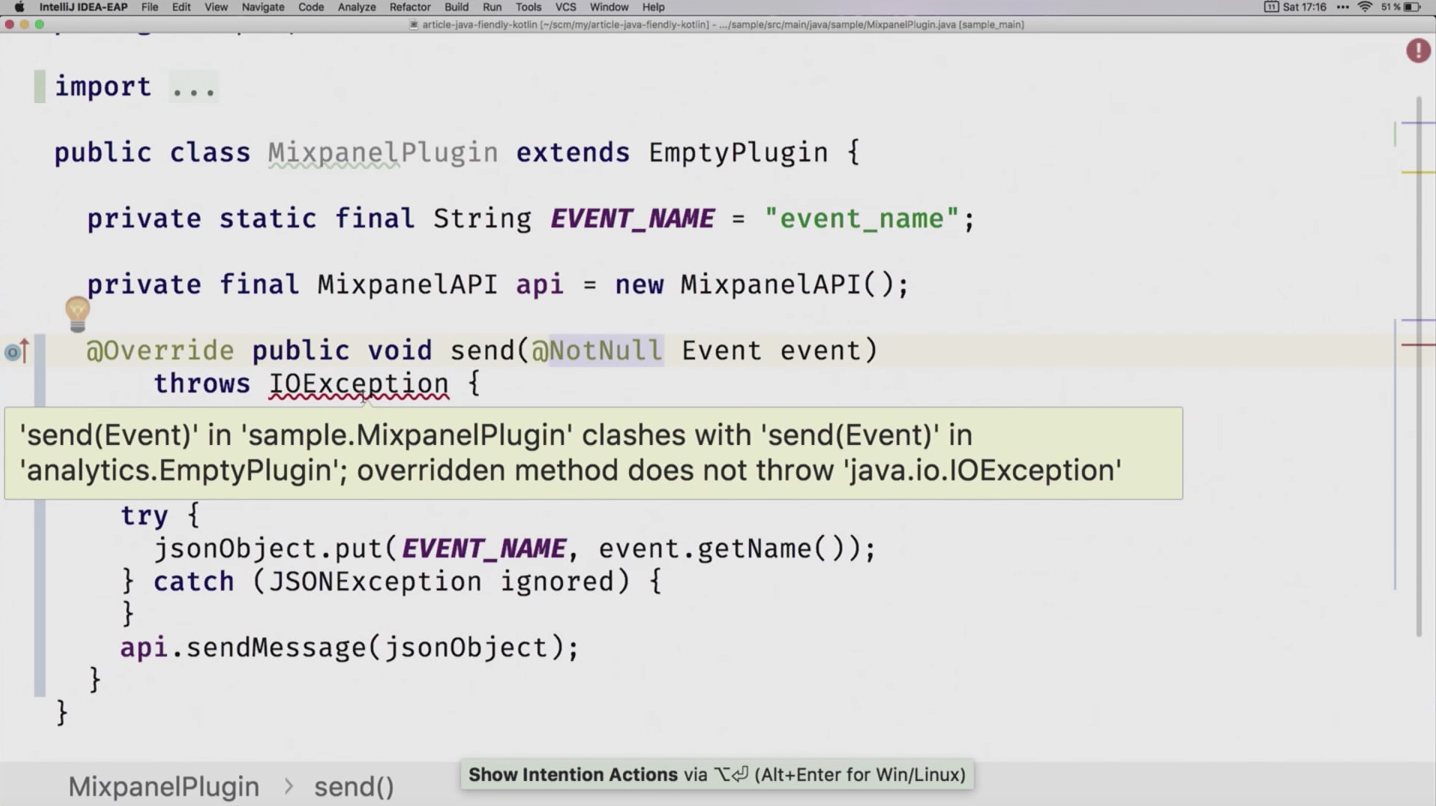
Мы хотим реализовать плагин на стороне Java. Как хорошие пацаны, мы репортим его исключение:
@Override public void send(@NotNull Event event)
throws IOException
Здесь же всё видно:
interface Plugin {
fun init()
/** @throws IOException if sending failed */
fun send(event: Event)
// ...
}
В Kotlin же нет checked exception. И мы говорим в документации: сюда можно кидать. Ну мы и кидаем, кидаем, кидаем. А Java не нравится почему-то. Говорит: «а нет Throws почему-то в вашей сигнатуре, месье»:

А как тут добавить-то, тут же Kotlin? Ну, вы знаете ответ…
Есть аннотация @Throws, которая именно это и делает. Она меняет throws-часть в сигнатуре метода. Мы говорим, что можем кинуть сюда IOExсeption:
open class EmptyPlugin : Plugin {
@Throws(IOException::class)
override fun send(event: Event) {}
// ...
}
И ещё добавим это дело заодно в интерфейс:
interface Plugin {
fun init()
/** @throws IOException if sending failed */
@Throws(IOException::class)
fun send(event: Event)
// ...
}
И теперь что? Теперь наш плагин, написанный на Java, где у нас есть информация об exception, всем доволен. Всё работает, компилируется. В принципе, с аннотациями на этом более-менее всё, но есть ещё два нюанса того, как использовать @JvmName. Один интересный.
Мы все эти аннотации добавляли для того, чтобы в Java было красиво. А вот здесь…
package util
fun List<Int>.printReversedSum() {
println(this.foldRight(0) { it, acc -> it + acc })
}
@JvmName("printReversedConcatenation")
fun List<String>.printReversedSum() {
println(this.foldRight(StringBuilder()) { it, acc -> acc.append(it) })
}
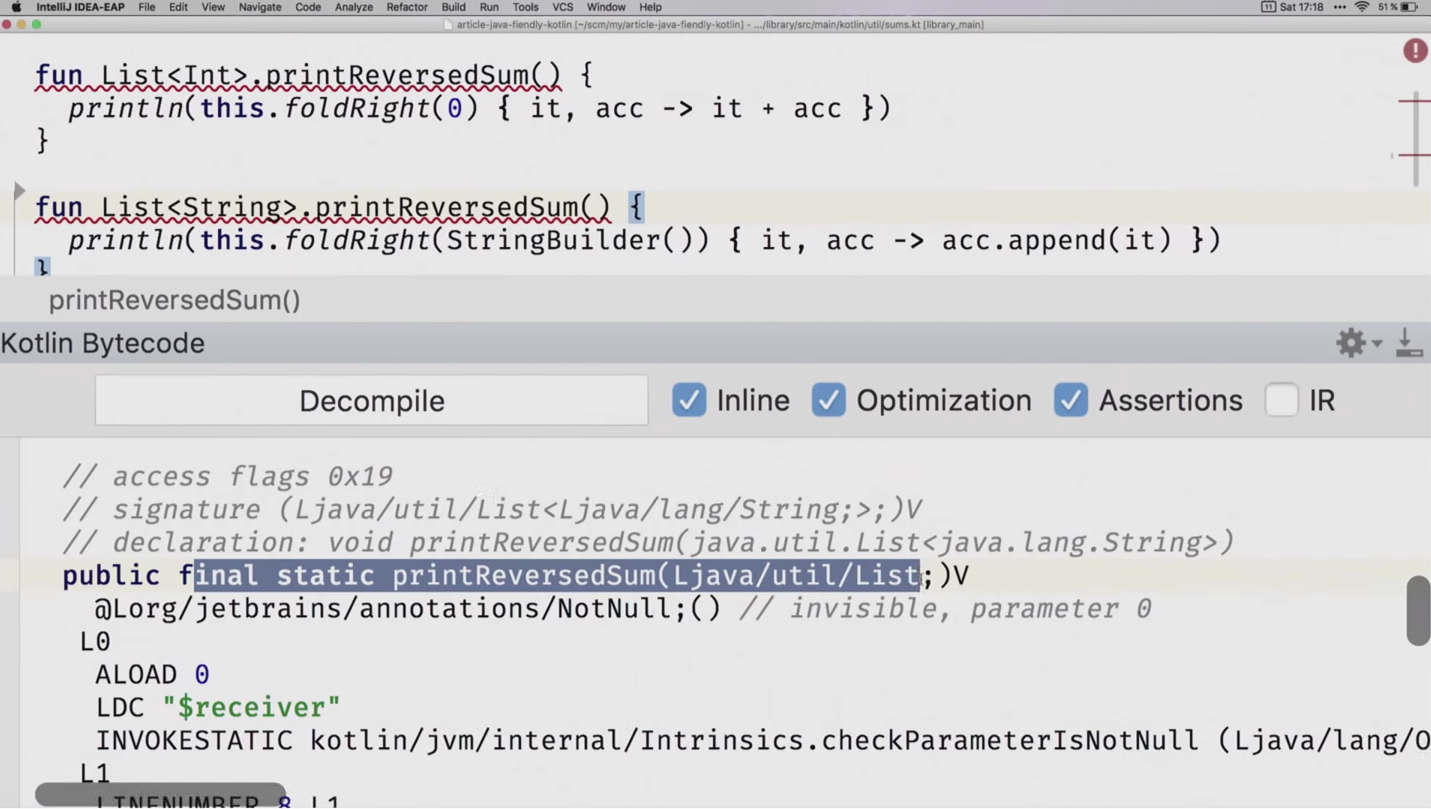
Предположим, на Java нам здесь всё равно, уберём аннотацию. Опачки, теперь IDE показывает ошибку в обеих функциях. Как вы считаете, с чем это связано? Да, без аннотации они генерируются с одинаковыми именами, но здесь же написано, что один на List, другой на List. Верно, type erasure. Мы даже можем проверить это дело:

Вы уже в курсе, как я понял, что все top-level функции генерируются в статическом контекcте. И вот без этой аннотации мы постараемся сгенерировать printReversedSum от List, а ниже ещё один тоже от List. Потому что Kotlin-компилятор знает о дженериках, а Java-байткод не знает. Поэтому это единственный случай, когда аннотации из пакета kotlin.jvm нужны не для того, чтобы в Java было хорошо и удобно, а для того, чтобы ваш Kotlin собрался. Задаём новое имя — раз работаем со строками, то используем concatenation — и всё работает хорошо, теперь всё компилируется.
И второй юзкейс. Он связан вот с чем. У нас есть extension-функция reverse.
inline fun String.reverse() =
StringBuilder(this).reverse().toString()
inline fun <reified T> reversedClassName() = T::class.java.simpleName.reverse()
inline fun <T> Iterable<T>.forEachReversed(action: (T) -> Unit) {
for (element in this.reversed()) action(element)
}
Этот reverse компилируется в статический метод класса, который называется ReverserKt.
private static void useUtils() {
System.out.println(ReverserKt.reverse("Test"));
SumsKt.printReversedSum(asList(1, 2, 3, 4, 5));
SumsKt.printReversedConcatenation(asList("1", "2", "3", "4", "5"));
}
Это, я думаю, не новость для вас. Нюанс в том, что чуваки, использующие нашу библиотеку в Java, могут заподозрить что-то неладное. Мы просочили детали имплементации нашей библиотеки на сторону юзера и хотим замести свои следы. Как мы можем это делать? Как уже понятно, аннотацией @JvmName, о которой я сейчас рассказываю, но есть один нюанс.
Для начала зададим ей такое имя, которое хотим, не палимся, и важно сказать, что мы применяем эту аннотацию на файле, переименовать нам надо именно файл.
@file:Suppress("NOTHING_TO_INLINE")
@file:JvmName("ReverserUtils")
Теперь компилятору в Java не нравится ReverserKt, но это ожидаемо, заменяем на ReverserUtils и все довольны. И такой «юзкейс 2.1» — частый случай, когда вы хотите методы нескольких ваших top-level файлов собрать под одним классом, под одним фасадом. Например, про вы не хотите, чтобы методы вышеприведённого sums.kt вызывались из SumsKt, а хотите, чтобы это всё тоже было про reversing и дёргалось из ReverserUtils. Тогда добавляем и туда эту чудную аннотацию @JvmName, пишем «ReverserUtils», в принципе, всё ок, можно даже попробовать это дело скомпилировать, но нет.
Хотя заранее среда не предупреждает, но при попытке компиляции нам скажут, что «вы хотите сгенерировать два класса в одном пакете с один именем, ата-та». Что нужно сделать? Добавить последнюю в этом пакете аннотацию @JvmMultifileClass, говорящую, что содержимое нескольких файлов будет превращаться в один класс, то есть для этого всего будет один фасад.
Добавляем в обоих случаях "@file:JvmMultifileClass", и можно заменять SumsKt на ReverserUtils, все довольны — поверьте мне. С аннотациями закончили!
Мы поговорили с вами об этом пакете, обо всех аннотациях. В принципе, уже из их названий понятно, для чего используется каждая. Есть хитрые кейсы, когда нужно, например, @JvmName использовать даже просто в Kotlin.
Kotlin-специфичное
Но, скорее всего это не всё, что вы хотели бы узнать. Ещё важно отметить, как работать с Kotlin-специфичными вещами.
Например, inline-функции. Они в Kotlin инлайнятся и, казалось бы, а будут ли они вообще доступны из Java в байткоде? Оказывается, будут, всё будет хорошо, и методы реально доступны для Java. Хотя если вы пишете, например, Kotlin-only проект, это не совсем хорошо сказывается на вашем dex count limit. Потому что в Kotlin они не нужны, а реально в байткоде будут.
Дальше надо отметить Reified type parameters. Такие параметры специфичны для Kotlin, они доступны только для инлайн-функций и позволяют воротить такие хаки, которые в Java с рефлексией недоступны. Так как это Kotlin-only штука, она доступна только для Kotlin, и в Java вы не сможете использовать функции с reified, к сожалению.
java.lang.Class. Если мы хотим немного порефлексировать, а библиотека наша и для Java, то и её надо поддержать. Давайте посмотрим пример. Есть у нас такой «свой Retrofit», быстро написанный на коленке (я вообще не понимаю, чего парни так долго писали):
class Retrofit private constructor(
val baseUrl: String,
val client: Client
) {
fun <T : Any> create(service: Class<T>): T {...}
fun <T : Any> create(service: KClass<T>): T {
return create(service.java)
}
}
Есть метод, который работает с классом Java, есть метод, который работает с котлиновским KClass, вам не нужно делать две разные реализации, вы можете использовать extension-проперти, которые из KClass достают Class, из Class достают KClass (он называется Kotlin, в принципе очевидно).
Это всё будет работать, но это немного неидиоматично. В Kotlin-коде вы не передаёте KClass, вы пишете с использованием Reified-типов, поэтому лучше метод переделать на вот такой:
inline fun <reified T : Any> create(): T {
return create(T::class.java.java)
Всё шикардос. Теперь пойдём в Kotlin и посмотрим, как эта штука используется. Там val api = retrofit.create(Api::class) превратилось в val api = retrofit.create<Api>(), никаких явных ::class не вылезает. Это типичное использование Reified-функции, и всё будет супер-пупер.
Unit. Если ваша функция возвращает Unit, то она прекрасно компилируется в функцию, которая возвращает void в Java, и обратно. Вы можете работать с этим взаимозаменяемо. Но всё это заканчивается в том месте, где у вас лямбды начинают возвращать юниты. Если кто-то работал со Scala, то в Scala есть вагон и маленькая тележка интерфейсов, которые возвращают какие-то значения, и такой же вагон с тележкой интерфейсов, которые не возвращают ничего, то есть с void.
А в Kotlin этого нет. В Kotlin есть только 22 интерфейса, которые принимают разный набор параметров и что-то возвращают. Таким образом, лямбда, которая возвращает Unit, будет возвращать не void, а Unit. И это накладывает свои ограничения. Как выглядит лямбда, которая возвращает Unit? Вот, посмотрим на неё в этом фрагменте кода. Познакомимся.
inline fun <T> Iterable<T>.forEachReversed(action: (T) -> Unit) {
for (element in this.reversed()) action(element)
}
Использование её из Kotlin: все хорошо, мы используем даже method reference, если можем, и читается отлично, глаза не мозолит.
private fun useMisc() {
listOf(1, 2, 3, 4).forEachReversed(::println)
println(reversedClassName<String>())
}
Что происходит в Java? В Java происходит вот такая байда:
private static void useMisc() {
final List<Integer> list = asList(1, 2, 3, 4);
ReverserUtils.forEachReversed(list, integer -> {
System.out.println(integer);
return Unit.INSTANCE;
});
Из-за того, что мы должны возвращать что-то здесь. Это как Void с большой буквы, мы не можем просто взять и забить на него. Мы не можем использовать здесь метод референсы, которые возвращают void, к сожалению. И это, наверное, пока первая штука, которая реально мозолит глаза после всех наших манипуляций с аннотациями. К сожалению, вам придется возвращать инстанс Unit отсюда. Можно null, всё равно он никому не нужен. В смысле, возвращаемое значение никому не нужно.
Поехали дальше: Typealiases — это тоже довольно специфичная штука, это просто алиасы или синонимы, они доступны только из Kotlin, и в Java, к сожалению, вы будете использовать то, что под этими алиасами. Либо это портянка трижды вложенных дженериков, либо какие-то вложенные классы. Java-программисты привыкли с этим жить.
А теперь интересное: visibility. А точнее, internal visibility. Вы наверняка знаете, что в Kotlin нет package private, если вы пишете без каких-либо модификаторов, это будет public. Зато есть internal. Internal — это такая хитрая штука, что мы сейчас на неё даже посмотрим. В Retrofit у нас есть internal-метод validate.
internal fun validate(): Retrofit {
println("!!!!!! internal fun validate() was called !!!!!!")
return this
}
Он не может быть вызван из Kotlin, и это понятно. Что происходит с Java? Можем ли мы вызвать validate? Возможно, для вас не секрет, что internal превращается в public. Если вы не верите мне, поверьте Kotlin bytecode viewer.

Это действительно public, но с такой страшной сигнатурой, которая намекает человеку, что это, наверное, не совсем так было задумано, что в публичное API пролезает вот такая портянка. Если у кого-то форматирование на 80 символов сделано, то такой метод может даже не влезть в одну строчку.
В Java у нас сейчас так:
final Api api = retrofit
.validate$production_sources_for_module_library_main()
.create(Api.class);
api.sendMessage("Hello from Java");
}
Давайте попробуем скомпилировать это дело. Так, по крайней мере, это не скомпилируется, уже неплохо. На этом можно было бы остановиться, но let me explain this to you. Что, если я сделаю вот так?
final Api api = retrofit
.validate$library()
.create(Api.class);
api.sendMessage("Hello from Java");
}
Тогда компилируется. И возникает вопрос «Почему так?» Что я могу сказать… MAGIC!
Поэтому очень важно, если вы засовываете что-то критическое в internal, это плохо, потому что это просочится в ваше публичное API. И если script kiddie будет вооружён Kotlin Bytecode Viewer, то будет плохо. Не используйте ничего очень важного в методах с internal visibility.
Если вам хочется еще немного радости, то рекомендую две вещи. Чтобы было комфортней работать с байткодом и читать его, рекомендую доклад от Жени Вартанова, есть бесплатное видео, несмотря на то, что это с мероприятия SkillsMatter. Очень круто.
И довольно старая серия из трёх статей от Кристофа Бейлса про то, во что превращаются разные Kotlin-фичи. Там всё классно написано, что-то неактуально сейчас, но в целом весьма доходчиво. Всё тоже с Kotlin bytecode viewer и всё такое.
Спасибо!
Если доклад понравился, обратите внимание: 8-9 декабря в Москве состоится новый Mobius, и там тоже будет много интересного. Уже известная информация о программе — на сайте, и билеты можно приобрести там же.
