
Существует мнение, что разработка занимает около 10% времени, а отладка — 90%. Возможно, это утверждение утрировано, но любой разработчик согласится с тем, что отладка — крайне затратный по ресурсам процесс, особенно в больших многопоточных системах.
Таким образом, оптимизация и систематизация процесса debugging'а может приносить весомые плоды в виде сэкономленных человеко-часов, повышения скорости решения проблем и, в конце концов, увеличения лояльности ваших пользователей.

Сергей Щегрикович (dotmailer) на конференции DotNext 2018 Piter предложил взглянуть на отладку как на процесс, который может быть описан и оптимизирован. Если вы до сих пор не имеете четкого плана поиска багов — под катом видео и текстовая расшифровка доклада Сергея.
(А еще в конце поста мы добавили обращение Джона Скита ко всем дотнетчикам, обязательно посмотрите)
Моя цель — ответить на вопрос: как фиксить баги эффективно и на чем должен быть фокус. Я думаю, что ответ на этот вопрос — процесс. Процесс debugging'а, который состоит из очень простых правил, и вы хорошо их знаете, но, наверно, используете неосознанно. Поэтому моя задача — это систематизировать их и на примере показать как стать более эффективными.
Мы выработаем общий язык общения во время отладки, а также увидим прямой путь к поиску основных проблем. На своих примерах я покажу что получалось из-за нарушения этих правил.
Конечно, любой debugging невозможен без утилит для отладки. Моими любимыми являются:
Начнем с примера из моей жизни, в котором я покажу, как бессистемность процесса debugging'а ведет к неэффективности.
Наверно, у каждого такое бывало, когда ты приходишь в новую компанию в новую команду на новый проект, то с самого первого дня хочется нанести непоправимую пользу. Так было и у меня. В то время у нас был сервис, который на вход принимал html, а на выход выдавал картинки.
Сервис был написан под .Net 3.0 и было это очень давно. У этого сервиса была маленькая особенность — он падал. Падал часто, примерно раз в два-три часа. Пофиксили мы это элегантно — выставили в свойствах сервиса рестарт после падения.

Сервис был для нас не критичен и мы могли это пережить. Но к проекту подключился я и первое, что решил сделать — исправить это.
Куда .NET-разработчики идут в случае, если что-то не работает? Они идут в EventViewer. Но там я не нашел ничего, кроме записи о том, что сервис упал. Ни сообщений о нативной ошибке, ни call-stack'а не было.
Есть проверенный инструмент что делать дальше — оборачиваем весь
Идея простая:
Повторяем процесс: сервис падает, ошибок в логах нет. Последнее, что может помочь — это
Компилируем, деплоим, сервис падает, ошибок нет. За этим процессом проходит три дня, теперь уже приходят мысли о том, что надо наконец-то начать думать и делать что-нибудь другое. Делать можно много чего: попробовать воспроизвести ошибку на локальной машине, смотреть дампы памяти и тд. Казалось, еще дня два и я пофикшу этот баг…
Прошло две недели.

Я смотрел в PerformanceMonitor, где видел сервис, который падает, потом поднимается, потом снова падает. Это состояние называется отчаяние и выглядит вот так:

В этом разнообразии меток ты пытаешься понять, где же на самом деле проблема? После нескольких часов медитации проблема вдруг обнаруживается:

Красная линия — это количество нативных handle'ов, которыми владеет процесс. Нативный handle — это ссылка на ресурс операционной системы: файл, реестр, ключ реестра, мьютекс и тд. По какому-то непонятному стечению обстоятельств падение роста количества handle'ов совпадает с моментами падения сервиса. Это наталкивает на мысль о том, что где-то есть утечка handle'ов.
Берем дамп памяти, открываем его в WinDbg. Начинаем выполнять команды. Попробуем посмотреть очередь финализации тех объектов, которые должны быть освобождены приложением.
В самом конце списка я нашел web-браузер.
Решение простое — взять WebBrowser и вызывать для него
Выводы из этой истории можно сделать такие: две недели — это долго и слишком много, чтобы найти невызванный
После этого у меня возник вопрос: а как дебажить эффективно и что для этого делать?
Для этого надо знать всего три вещи:
Это довольно понятные правила, которые сами себя описывают.
Повтори ошибку. Очень простое правило, поскольку, если ты не можешь повторить ошибку, то, возможно, и фиксить нечего. Но бывают разные случаи, особенно это касается багов в многопоточной среде. У нас как-то была ошибка, которая появлялась только на процессорах Itanium и только на продакшн-серверах. Поэтому первая задача в процессе отладки — найти такую конфигурации тестового стенда, на которой бы ошибка воспроизводилась.
Если ты не исправил ошибку, то она не исправлена. Иногда бывает такое: в баг-трекере лежит баг, который появлялся пол года назад, уже его давно никто не видел, и есть желание его просто закрыть. Но в этот момент мы упускаем шанс на знание, шанс на то, чтобы понять как работает наша система и что с ней действительно происходит. Поэтому любой баг — это новая возможность что-то выучить, узнать больше о своей системе.
Пойми систему. Брайан Керниган сказал как-то, что если мы были такие умные, чтобы написать эту систему, то нам нужно быть вдвойне умными, чтобы её дебажить.
Небольшой пример к правилу. Наш мониторинг рисует графики:

Это график количества запросов, обработанных нашим сервисом. Однажды посмотрев на него мы пришли к идеи о том, что можно было бы увеличить скорость работы сервиса. В этом случае график поднимется, возможно, удастся уменьшить количество серверов.
Оптимизация web-performance делается просто: берем PerfView, запускаем его на продакшн-машине, он снимает trace в течении 3-4 минут, мы этот trace забираем на локальную машину и начинаем его изучать.
Одна из статистик, которую показывает PerfView — garbage collector.

Посмотрев на эту статистику мы увидели, что 85% времени сервис тратит на сборку мусора. Можно в PerfView увидеть где конкретно тратится это время.
В нашем случае — это создание строк. Исправление напрашивается само самой: заменяем все string'и на StringBuilder'ы. Локально получаем прирост производительности на 20-30%. Деплоим на продакшн, смотрим результаты в сравнении со старым графиком:
Правило «Пойми систему» — это не только о том, чтобы понять как в вашей системе происходят взаимодействия, как ходят сообщения, а о том, чтобы попробовать смоделировать свою систему.
В примере график показывает пропускную способность. Но если посмотреть на всю систему с точки зрения теории очередей, то окажется, что пропускная способность нашей системы зависит только от одного параметра — от скорости прихода новых сообщений. По факту в системе просто не было больше 80 сообщений единовременно, поэтому оптимизировать этот график не получится никак.
Проверь штепсель. Если открыть документацию любого домашнего прибора, то там обязательно будет написано: если прибор не работает, проверь, что вилка вставлена в розетку. После нескольких часов в отладчике часто ловлю себя на мысли, что надо было просто перекомпилировать, либо просто забрать последнюю версию.
Правило «проверь штепсель» — это про факты и данные. Отладка не начинается с запуска WinDbg или PerfView на продакшн-машинах, она начинается с проверок фактов и данных. Если сервис не отвечает, возможно он просто не запущен.
Разделяй и властвуй. Это первое и, наверно, единственное правило, которое включает в себя отладку как процесс. Оно про гипотезы, их выдвижение и проверку.
Один из наших сервисов не хотел останавливаться.
Делаем гипотезу: возможно, в проекте есть цикл, который бесконечно что-то обрабатывает.
Проверить гипотезу можно по-разному, один из вариантов — это взять дамп памяти. Из дампа вытаскиваем call-stack'и всех потоков с помощью команды

Первый поток находится в Main'е, второй — в обработчике
Наш сервис работает следующим образом. Есть две задачи — инициализационная и рабочая. Инициализационная открывает connection к базе данных, рабочая начинает обработку данных. Связь между ними происходит через общий флаг, который реализован с помощью
Делаем вторую гипотезу: возможно, у нас deadlock одной задачи на вторую. Чтобы это проверить, можно через WinDbg посмотреть каждую задачу по-отдельности.

Оказывается, одна из задач упала, а вторая — нет. В проекте мы увидели такой код:
Он означает, что инициализационная задача открывает connection и после этого выставляет
В этом примере мы выдвигали две гипотезы: о бесконечном цикле и о deadlock'e. Правило «разделяй и властвуй» помогает локализовать ошибку. Последовательными приближениями и решаются такие проблемы.
Самое важное в этом правиле — это гипотезы, поскольку со временем они превращаются в паттерны. И в зависимости от гипотезы мы применяем разные действия.
Освежись. Это правило о том, что надо просто встать из-за стола и пройтись, выпить воды, сока или кофе, сделать что угодно, но самое главное — отвлечься от своей проблемы.
Есть очень хороший метод под названием «уточка». Согласно методу мы должны рассказать о своей проблеме уточке. В качестве уточки можно использовать коллегу. Причем, ему не обязательно отвечать, достаточно слушать и соглашаться. И зачастую, после первых проговоров проблемы, ты сам находишь решение.
Это твой баг. Об этом правиле расскажу на примере.
Была проблема в одном

По этому багу было понятно, что где-то нарушается целостность памяти. К счастью, в то время мы уже использовали change management system. В итоге через пару часов стало понятно что произошло: мы поставили .Net 4.5.2 на наши продакшн-машины.

Соответственно, мы отправляем баг в Microsoft, они его рассматривают, мы с ними общаемся, они исправляют баг в .Net 4.6.1.

Для меня это вылилось в 11 месяцев работы с поддержкой Microsoft, конечно, не ежедневно, но от начала до fix'а прошло именно 11 месяцев. Кроме этого, мы отправили им десятки гигабайт дампов памяти, мы ставили сотни private-сборок, чтобы поймать эту ошибку. И все это время мы не могли сказать нашим клиентам, что виновата Microsoft, а не мы. Поэтому баг всегда ваш.
Пять почему. Мы у себя в компании используем Elastic. Elastic хорош для агрегации логов.
Ты приходишь с утра на работу, а Elastic лежит.
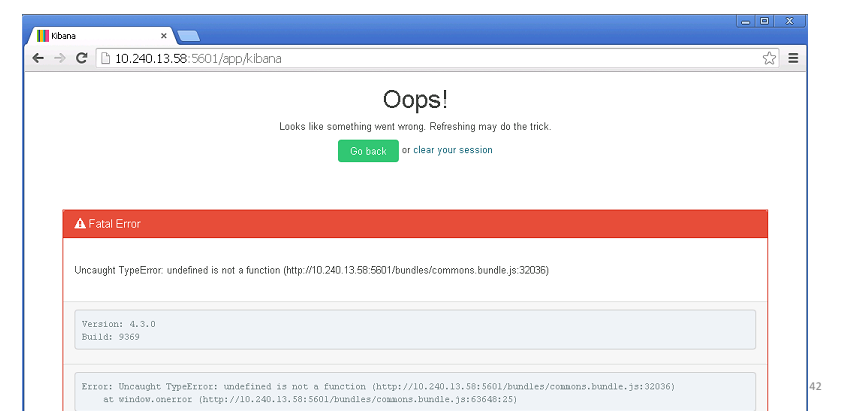
Первый вопрос — почему лежит Elastic? Практически сразу стало понятно — упали Master Nodes. Они координируют работу всего кластера и, когда они падают, то весь кластер перестает отвечать. Почему они не поднялись? Наверно, должен стоять автостарт? Поискав ответ, нашли — не соответствует версия плагина. Почему же Master Nodes вообще упали? Их убил OOM Killer. Это такая штука на linux-машинах, которая в случае нехватки памяти закрывает ненужные процессы. Почему же стало мало памяти? Потому что запустился процесс обновления, что следует из системных логов. Почему же раньше это работало, а сейчас нет? А потому что мы неделей раньше добавили новые узлы, соответственно Master Nodes понадобилось больше памяти для хранения индексов, конфигурации кластера.
Вопросы «почему?» помогают найти корень проблемы. В примере мы много раз могли свернуть с правильного пути, но полный fix выглядит так: обновляем плагин, запускаем сервисы, наращиваем память и делаем пометку на будущее, что в следующий раз, при добавлении новых узлов в кластер, нужно убедиться в достаточности памяти на Master Nodes.
Применение этих правил позволяет вскрыть реальные проблемы, сдвигает ваш фокус на решение этих проблем и помогает общаться. Но было бы еще лучше, если бы эти правила образовывали систему. И такая система есть, она называется — алгоритм отладки.
Впервые про алгоритм отладки я прочитал в книге Джона Роббинса «Debugging applications». Он описывает процесс отладки так:

Этот алгоритм полезен своим внутренним циклом — работой с гипотезой.
С каждым витком цикла мы можем себя проверить: знаем ли мы больше о системе или нет? Если мы выдвигаем гипотезы, проверяем, они не срабатывают, мы не узнаем ничего нового о работе системы, то, наверно, пора освежиться. Два актуальных вопроса на этот момент: какие гипотезы ты уже проверил и какую гипотезу проверяешь сейчас.
Этот алгоритм очень хорошо согласуется с правилами отладки, о которых мы говорили выше: повтори ошибку — это твой баг, опиши проблему — пойми систему, сформулируй гипотезу — разделяй и властвуй, проверь гипотезу — проверь штепсель, убедись что исправлено — пять почему.
На этот алгоритм у меня есть хороший пример. На одном из наших web-сервисов падал exception.

Первая наша мысль — это не наша проблема. Но по правилам, это все-таки проблема наша.
Во-первых, повторяем ошибку. На каждую тысячу запросов примерно один
Во-вторых, пытаемся описать проблему: если пользователь делает http-запрос на наш сервис в момент, когда StructureMap пытается сделать новую зависимость, то в этом случае происходит исключение.
В-третьих, выдвигаем гипотезу о том, что StructureMap — это wrapper и внутри что-то есть, что кидает внутреннее исключение. Проверяем гипотезу с помощью procdump.exe.
Оказывается, что внутри лежит
Исследуя call-stack этого исключения понимаем, что оно происходит внутри object-builder'а в самом StructureMap.

Но
Выдвигаем следующую гипотезу: наш код почему-то возвращает зависимость null. Учитывая, что в .Net все объекты в памяти располагаются один за одним, если мы посмотрим на объекты в куче, которые лежат до
В WinDbg есть команда — List Near Objects:
В этом коде мы сначала проверяем существует ли значение в
По идее этот код никогда не сможет вернуть null. Но проблема здесь в
Корень проблемы найден, мы обновились до последней версии StructureMap'а, задеплоили, убедились, что все исправлено. Последний шаг нашего алгоритма — это «научись и расскажи». В нашем случае это был поиск в коде всех
Итак, алгоритм отладки — это интуитивный алгоритм, который существенно экономит время. Он делает упор на гипотезу — а это самое главное в отладке.
По своей сути проактивная отладка отвечает на вопрос «что произойдет, когда появится баг».
Важность техники проактивной отладки можно увидеть на диаграмме цикла жизни бага.

Проблема в том, что чем дольше баг живет, тем больше мы ресурсов (времени) на него тратим.
Правила отладки и алгоритм отладки фокусируют нас на моменте, когда баг найден и мы можем придумать что дальше с ним делать. На самом же деле мы хотим сместить свой фокус на момент создания бага. Я считаю, что мы должны делать Minimum Debuggable Product (MDP), то есть такой продукт, который имеет минимально необходимый набор инфраструктуры для эффективной отладки в продакшене.
MDP состоит из двух вещей: фитнес-функции и USE метода.
Фитнес-функции. Были популяризированы Нил Фордом и соавторами в книге «Building Evolutionary Architectures ». По своей сути фитнес-функции, по мнению авторов книги, выглядят так: есть архитектура приложения, которую мы можем разрезать под разными углами, получая такие свойства архитектуры, как maintainability, performance и прочее, и на каждый такой разрез мы должны писать тест — фитнес-функцию. Таким образом, фитнес-функция — это тест на архитектуру.
В случае MDP, фитнес-функция — это проверка debuggability. Для написания таких тестов можно использовать все что угодно: NUnit, MSTest и тд. Но, поскольку, отладка — это, зачастую, работа с внешними tool'ами, я покажу на примере использование Pester'а (powershell unit testing framework). Его плюс здесь в том, что он хорошо работает с командной строкой.
Например, внутри компании мы договариваемся, что будем использовать конкретные библиотеки для логирования; при логировании мы будем использовать конкретные паттерны; pdb-символы должны быть отданы всегда на symbol server. Это и будет являться теми условностями, которые мы будем проверять в наших тестах.
Этот тест проверяет, что все pdb-символы были отданы на symbol server и были отданы правильно, то есть те, которые содержат номера строк внутри. Для этого берем скомпилированную версию продакшена, находим все exe- и dll-файлы, пропускаем все эти бинарники через утилиту syschk.exe, которая входит в пакет «Debugging tools for windows». Утилита syschk.exe сверяет бинарник с symbol server'ом и, если находит там pdb-файл, печатает отчет об этом. В отчете мы ищем строку «Line numbers: TRUE». И в финале проверяем, чтобы результат был не «null or empty».
Такие тесты необходимо встраивать в continuous deployment pipeline. После того, как прошли интеграционные тесты и unit-тесты, запускаются фитнес-функции.
Покажу ещё один пример с проверкой нужных библиотек в коде.
В тесте мы берем все файлы packages.config и пытаемся найти в них библиотеки nlog. Аналогично мы можем проверить, что внутри поля nlog используется поле correlation id.
USE методы. Последнее, из чего состоит MDP — это метрики, которые нужно собирать.
Продемонстрирую на примере метода USE, который был популяризирован Бренданом Греггом. Идея простая: если в коде есть какая-то проблема, достаточно взять три метрики: utilization (использование), saturation (насыщение), errors (ошибки), которые помогут осознать где проблема.
Некоторые компании, например Circonus (они делают monitoring soft), свои дашборды выстраивают в виде обозначенных метрик.

Если посмотреть детально, например, на память, то использование — это количество свободной памяти, насыщение — это количество обращений к диску, ошибки — это любые ошибки, которые появлялись. Поэтому чтобы делать удобные для отладки продукты, нужно собирать USE-метрики для всех фич и всех частей подсистемы.
Если взять какую-нибудь бизнес-фичу, то, скорее всего, в ней можно выделить три метрики:
В качестве примера посмотрим на график количества обработанных запросов, которые делает одна из наших систем. Как можно заметить, последние три часа сервис не обрабатывал запросы.

Первая гипотеза, которую мы сделали, — сервис упал и надо его запустить заново. При проверке оказывается, что сервис работает, использует 4-5% CPU.
Вторая гипотеза — внутри сервиса падает ошибка, которую мы не видим. Воспользуемся утилитой etrace.
Утилита позволяет в realtime подписываться к ETW-events и выводить их на экран.

Видим, что падает
Следующая гипотеза — кто-то съедает всю память. Согласно дампу памяти, больше всего объектов находится в кэше.
Из кода видно, что каждый час кэш должен очищаться. Но памяти уже не хватало, до очистки даже не доходили. Посмотрим на пример метрики USE для кеша.
По графику сразу видно — возросла память, сразу начались ошибки.
Итак, выводы о том, что же такое проактивная отладка.
В этот раз спонсор нашей рекламы — Jon Skeet. Даже если вы не собираетесь в Москву на новый DotNext, видео стоит посмотреть (Джон очень старался).
Таким образом, оптимизация и систематизация процесса debugging'а может приносить весомые плоды в виде сэкономленных человеко-часов, повышения скорости решения проблем и, в конце концов, увеличения лояльности ваших пользователей.

Сергей Щегрикович (dotmailer) на конференции DotNext 2018 Piter предложил взглянуть на отладку как на процесс, который может быть описан и оптимизирован. Если вы до сих пор не имеете четкого плана поиска багов — под катом видео и текстовая расшифровка доклада Сергея.
(А еще в конце поста мы добавили обращение Джона Скита ко всем дотнетчикам, обязательно посмотрите)
Моя цель — ответить на вопрос: как фиксить баги эффективно и на чем должен быть фокус. Я думаю, что ответ на этот вопрос — процесс. Процесс debugging'а, который состоит из очень простых правил, и вы хорошо их знаете, но, наверно, используете неосознанно. Поэтому моя задача — это систематизировать их и на примере показать как стать более эффективными.
Мы выработаем общий язык общения во время отладки, а также увидим прямой путь к поиску основных проблем. На своих примерах я покажу что получалось из-за нарушения этих правил.
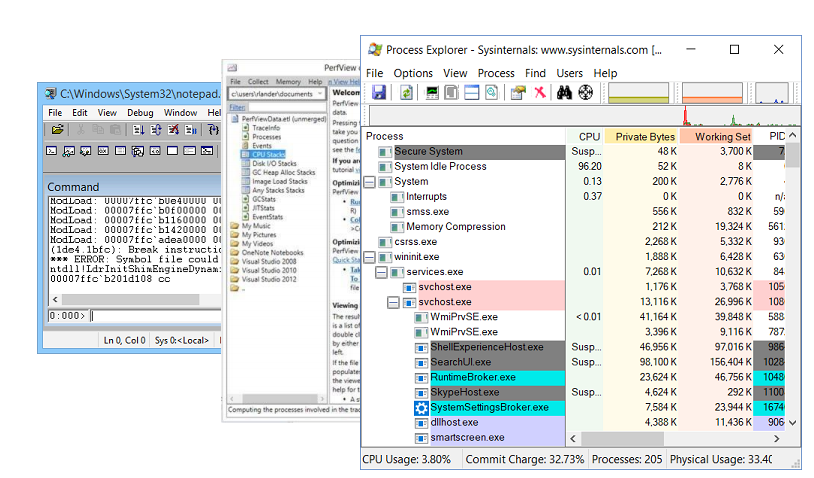
Утилиты отладки
Конечно, любой debugging невозможен без утилит для отладки. Моими любимыми являются:
- Windbg, который помимо самого debugger'а, имеет богатый функционал по изучению дампов памяти. Дамп памяти — это срез состояния процесса. В нем можно найти значение полей объектов, call-stack'и, но, к сожалению, дамп памяти статичен.
- PerfView — это профилировщик, написанный поверх ETW-технологии.
- Sysinternals — утилита, написанная Марком Руссиновичем, которая позволяет чуть дальше копнуть внутрь устройства операционной системы.
Падающий сервис
Начнем с примера из моей жизни, в котором я покажу, как бессистемность процесса debugging'а ведет к неэффективности.
Наверно, у каждого такое бывало, когда ты приходишь в новую компанию в новую команду на новый проект, то с самого первого дня хочется нанести непоправимую пользу. Так было и у меня. В то время у нас был сервис, который на вход принимал html, а на выход выдавал картинки.
Сервис был написан под .Net 3.0 и было это очень давно. У этого сервиса была маленькая особенность — он падал. Падал часто, примерно раз в два-три часа. Пофиксили мы это элегантно — выставили в свойствах сервиса рестарт после падения.
Сервис был для нас не критичен и мы могли это пережить. Но к проекту подключился я и первое, что решил сделать — исправить это.
Куда .NET-разработчики идут в случае, если что-то не работает? Они идут в EventViewer. Но там я не нашел ничего, кроме записи о том, что сервис упал. Ни сообщений о нативной ошибке, ни call-stack'а не было.
Есть проверенный инструмент что делать дальше — оборачиваем весь
main в try-catch.try {
ProcessRequest();
} catch (Exception ex) {
LogError(ex);
}
Идея простая:
try-catch сработает, залогирует нам ошибку, мы её прочитаем и пофиксим сервис. Компилируем, деплоим в продакшн, сервис падает, ошибки нет. Добавляем ещё один catch. try {
ProcessRequest();
} catch (Exception ex) {
LogError(ex);
} catch {
LogError();
}
Повторяем процесс: сервис падает, ошибок в логах нет. Последнее, что может помочь — это
finally, который вызывается всегда.try {
ProcessRequest();
} catch (Exception ex) {
LogError(ex);
} catch {
LogError();
} finally {
LogEndOfExecution();
}
Компилируем, деплоим, сервис падает, ошибок нет. За этим процессом проходит три дня, теперь уже приходят мысли о том, что надо наконец-то начать думать и делать что-нибудь другое. Делать можно много чего: попробовать воспроизвести ошибку на локальной машине, смотреть дампы памяти и тд. Казалось, еще дня два и я пофикшу этот баг…
Прошло две недели.
Я смотрел в PerformanceMonitor, где видел сервис, который падает, потом поднимается, потом снова падает. Это состояние называется отчаяние и выглядит вот так:
В этом разнообразии меток ты пытаешься понять, где же на самом деле проблема? После нескольких часов медитации проблема вдруг обнаруживается:
Красная линия — это количество нативных handle'ов, которыми владеет процесс. Нативный handle — это ссылка на ресурс операционной системы: файл, реестр, ключ реестра, мьютекс и тд. По какому-то непонятному стечению обстоятельств падение роста количества handle'ов совпадает с моментами падения сервиса. Это наталкивает на мысль о том, что где-то есть утечка handle'ов.
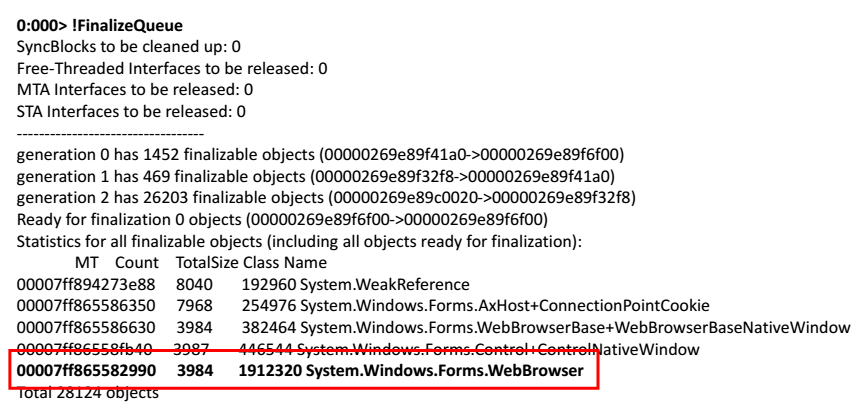
Берем дамп памяти, открываем его в WinDbg. Начинаем выполнять команды. Попробуем посмотреть очередь финализации тех объектов, которые должны быть освобождены приложением.
0:000> !FinalizeQueue
В самом конце списка я нашел web-браузер.
Решение простое — взять WebBrowser и вызывать для него
dispose:private void Process() {
using (var webBrowser = new WebBrowser()) {
// Processing
...
}
}
Выводы из этой истории можно сделать такие: две недели — это долго и слишком много, чтобы найти невызванный
dispose; то, что мы нашли решение проблемы — везение, так как не было какого-то определенного подхода, не было системности. После этого у меня возник вопрос: а как дебажить эффективно и что для этого делать?
Для этого надо знать всего три вещи:
- Правила отладки.
- Алгоритм нахождения ошибок.
- Проактивные техники отладки.
Правила отладки
- Повтори ошибку.
- Если ты не исправил ошибку, то она не исправлена.
- Пойми систему.
- Проверь штепсель.
- Разделяй и властвуй.
- Освежись.
- Это твой баг.
- Пять почему.
Это довольно понятные правила, которые сами себя описывают.
Повтори ошибку. Очень простое правило, поскольку, если ты не можешь повторить ошибку, то, возможно, и фиксить нечего. Но бывают разные случаи, особенно это касается багов в многопоточной среде. У нас как-то была ошибка, которая появлялась только на процессорах Itanium и только на продакшн-серверах. Поэтому первая задача в процессе отладки — найти такую конфигурации тестового стенда, на которой бы ошибка воспроизводилась.
Если ты не исправил ошибку, то она не исправлена. Иногда бывает такое: в баг-трекере лежит баг, который появлялся пол года назад, уже его давно никто не видел, и есть желание его просто закрыть. Но в этот момент мы упускаем шанс на знание, шанс на то, чтобы понять как работает наша система и что с ней действительно происходит. Поэтому любой баг — это новая возможность что-то выучить, узнать больше о своей системе.
Пойми систему. Брайан Керниган сказал как-то, что если мы были такие умные, чтобы написать эту систему, то нам нужно быть вдвойне умными, чтобы её дебажить.
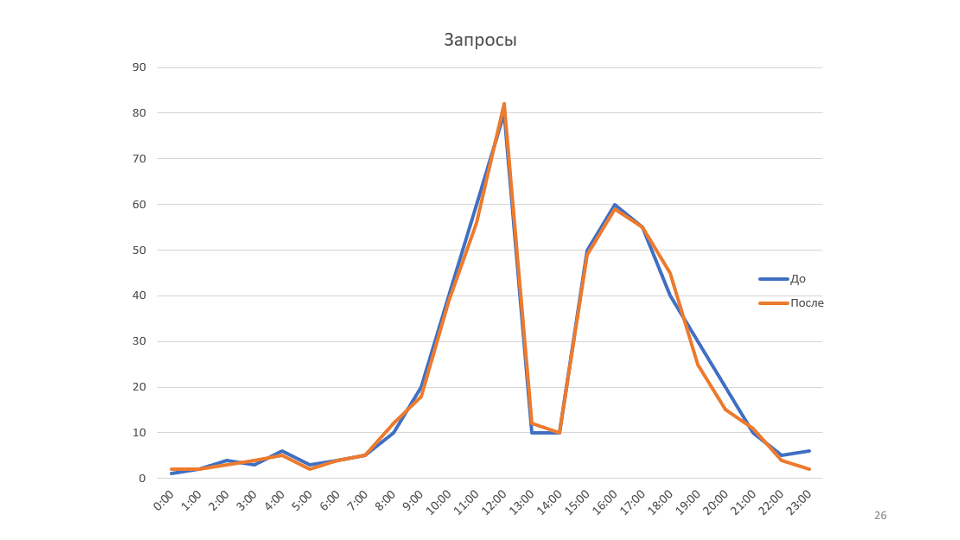
Небольшой пример к правилу. Наш мониторинг рисует графики:
Это график количества запросов, обработанных нашим сервисом. Однажды посмотрев на него мы пришли к идеи о том, что можно было бы увеличить скорость работы сервиса. В этом случае график поднимется, возможно, удастся уменьшить количество серверов.
Оптимизация web-performance делается просто: берем PerfView, запускаем его на продакшн-машине, он снимает trace в течении 3-4 минут, мы этот trace забираем на локальную машину и начинаем его изучать.
Одна из статистик, которую показывает PerfView — garbage collector.
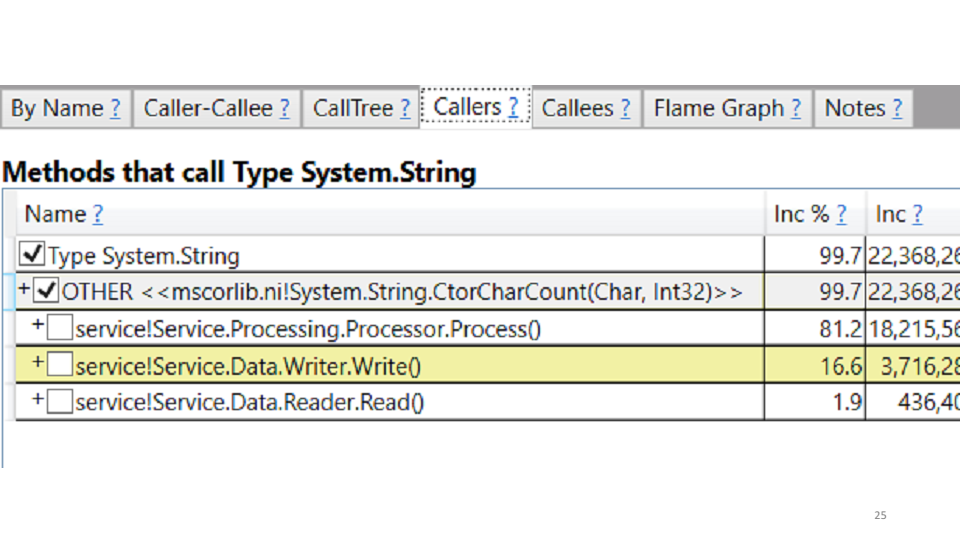
Посмотрев на эту статистику мы увидели, что 85% времени сервис тратит на сборку мусора. Можно в PerfView увидеть где конкретно тратится это время.
В нашем случае — это создание строк. Исправление напрашивается само самой: заменяем все string'и на StringBuilder'ы. Локально получаем прирост производительности на 20-30%. Деплоим на продакшн, смотрим результаты в сравнении со старым графиком:
Правило «Пойми систему» — это не только о том, чтобы понять как в вашей системе происходят взаимодействия, как ходят сообщения, а о том, чтобы попробовать смоделировать свою систему.
В примере график показывает пропускную способность. Но если посмотреть на всю систему с точки зрения теории очередей, то окажется, что пропускная способность нашей системы зависит только от одного параметра — от скорости прихода новых сообщений. По факту в системе просто не было больше 80 сообщений единовременно, поэтому оптимизировать этот график не получится никак.
Проверь штепсель. Если открыть документацию любого домашнего прибора, то там обязательно будет написано: если прибор не работает, проверь, что вилка вставлена в розетку. После нескольких часов в отладчике часто ловлю себя на мысли, что надо было просто перекомпилировать, либо просто забрать последнюю версию.
Правило «проверь штепсель» — это про факты и данные. Отладка не начинается с запуска WinDbg или PerfView на продакшн-машинах, она начинается с проверок фактов и данных. Если сервис не отвечает, возможно он просто не запущен.
Разделяй и властвуй. Это первое и, наверно, единственное правило, которое включает в себя отладку как процесс. Оно про гипотезы, их выдвижение и проверку.
Один из наших сервисов не хотел останавливаться.
Делаем гипотезу: возможно, в проекте есть цикл, который бесконечно что-то обрабатывает.
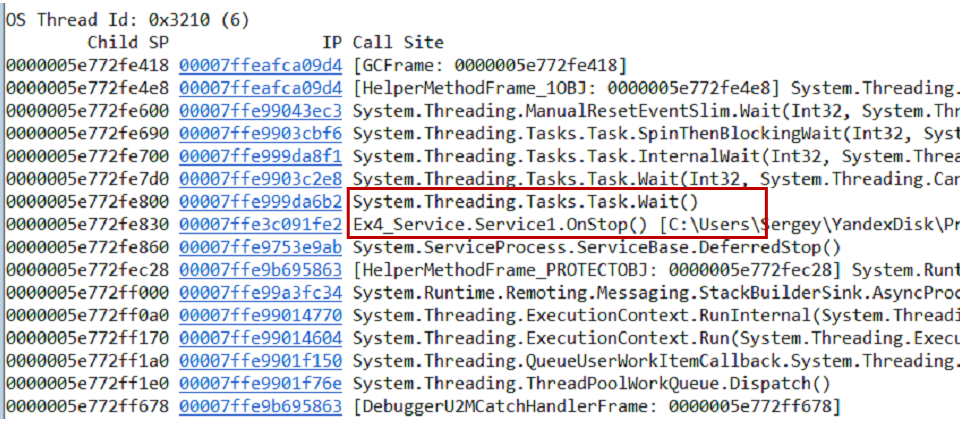
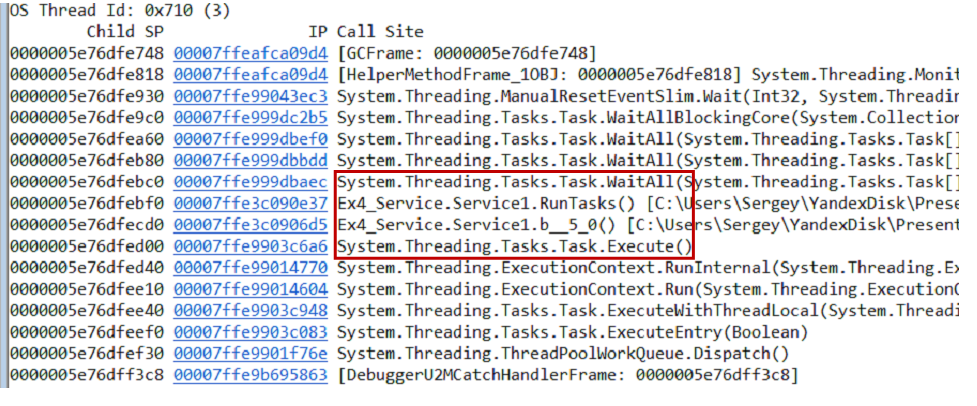
Проверить гипотезу можно по-разному, один из вариантов — это взять дамп памяти. Из дампа вытаскиваем call-stack'и всех потоков с помощью команды
~*e!ClrStack. Начинаем смотреть и видим три потока.Первый поток находится в Main'е, второй — в обработчике
OnStop(), а третий поток ждал какие-то внутренние задачи. Таким образом, наша гипотеза не оправдывается. Здесь нет зацикливания, все потоки чего-то ждут. Скорее всего, deadlock. Наш сервис работает следующим образом. Есть две задачи — инициализационная и рабочая. Инициализационная открывает connection к базе данных, рабочая начинает обработку данных. Связь между ними происходит через общий флаг, который реализован с помощью
TaskCompletionSource. Делаем вторую гипотезу: возможно, у нас deadlock одной задачи на вторую. Чтобы это проверить, можно через WinDbg посмотреть каждую задачу по-отдельности.
Оказывается, одна из задач упала, а вторая — нет. В проекте мы увидели такой код:
await openAsync();
_initLock.SetResult(true);
Он означает, что инициализационная задача открывает connection и после этого выставляет
TaskCompletionSource в true. А что, если здесь упадет Exception? Тогда мы не успеваем выставить SetResult в true, поэтому fix к этому багу был такой:try {
await openAsync();
_initLock.SetResult(true);
} catch(Exception ex) {
_initLock.SetException(ex);
}
В этом примере мы выдвигали две гипотезы: о бесконечном цикле и о deadlock'e. Правило «разделяй и властвуй» помогает локализовать ошибку. Последовательными приближениями и решаются такие проблемы.
Самое важное в этом правиле — это гипотезы, поскольку со временем они превращаются в паттерны. И в зависимости от гипотезы мы применяем разные действия.
Освежись. Это правило о том, что надо просто встать из-за стола и пройтись, выпить воды, сока или кофе, сделать что угодно, но самое главное — отвлечься от своей проблемы.
Есть очень хороший метод под названием «уточка». Согласно методу мы должны рассказать о своей проблеме уточке. В качестве уточки можно использовать коллегу. Причем, ему не обязательно отвечать, достаточно слушать и соглашаться. И зачастую, после первых проговоров проблемы, ты сам находишь решение.
Это твой баг. Об этом правиле расскажу на примере.
Была проблема в одном
AccessViolationException. Посмотрев в call-stack я увидел, что он возникал, когда мы генерировали LinqToSql-запрос внутри sql-клиента.По этому багу было понятно, что где-то нарушается целостность памяти. К счастью, в то время мы уже использовали change management system. В итоге через пару часов стало понятно что произошло: мы поставили .Net 4.5.2 на наши продакшн-машины.
Соответственно, мы отправляем баг в Microsoft, они его рассматривают, мы с ними общаемся, они исправляют баг в .Net 4.6.1.
Для меня это вылилось в 11 месяцев работы с поддержкой Microsoft, конечно, не ежедневно, но от начала до fix'а прошло именно 11 месяцев. Кроме этого, мы отправили им десятки гигабайт дампов памяти, мы ставили сотни private-сборок, чтобы поймать эту ошибку. И все это время мы не могли сказать нашим клиентам, что виновата Microsoft, а не мы. Поэтому баг всегда ваш.
Пять почему. Мы у себя в компании используем Elastic. Elastic хорош для агрегации логов.
Ты приходишь с утра на работу, а Elastic лежит.
Первый вопрос — почему лежит Elastic? Практически сразу стало понятно — упали Master Nodes. Они координируют работу всего кластера и, когда они падают, то весь кластер перестает отвечать. Почему они не поднялись? Наверно, должен стоять автостарт? Поискав ответ, нашли — не соответствует версия плагина. Почему же Master Nodes вообще упали? Их убил OOM Killer. Это такая штука на linux-машинах, которая в случае нехватки памяти закрывает ненужные процессы. Почему же стало мало памяти? Потому что запустился процесс обновления, что следует из системных логов. Почему же раньше это работало, а сейчас нет? А потому что мы неделей раньше добавили новые узлы, соответственно Master Nodes понадобилось больше памяти для хранения индексов, конфигурации кластера.
Вопросы «почему?» помогают найти корень проблемы. В примере мы много раз могли свернуть с правильного пути, но полный fix выглядит так: обновляем плагин, запускаем сервисы, наращиваем память и делаем пометку на будущее, что в следующий раз, при добавлении новых узлов в кластер, нужно убедиться в достаточности памяти на Master Nodes.
Применение этих правил позволяет вскрыть реальные проблемы, сдвигает ваш фокус на решение этих проблем и помогает общаться. Но было бы еще лучше, если бы эти правила образовывали систему. И такая система есть, она называется — алгоритм отладки.
Алгоритм отладки
Впервые про алгоритм отладки я прочитал в книге Джона Роббинса «Debugging applications». Он описывает процесс отладки так:
Этот алгоритм полезен своим внутренним циклом — работой с гипотезой.
С каждым витком цикла мы можем себя проверить: знаем ли мы больше о системе или нет? Если мы выдвигаем гипотезы, проверяем, они не срабатывают, мы не узнаем ничего нового о работе системы, то, наверно, пора освежиться. Два актуальных вопроса на этот момент: какие гипотезы ты уже проверил и какую гипотезу проверяешь сейчас.
Этот алгоритм очень хорошо согласуется с правилами отладки, о которых мы говорили выше: повтори ошибку — это твой баг, опиши проблему — пойми систему, сформулируй гипотезу — разделяй и властвуй, проверь гипотезу — проверь штепсель, убедись что исправлено — пять почему.
На этот алгоритм у меня есть хороший пример. На одном из наших web-сервисов падал exception.
Первая наша мысль — это не наша проблема. Но по правилам, это все-таки проблема наша.
Во-первых, повторяем ошибку. На каждую тысячу запросов примерно один
StructureMapException, поэтому воспроизвести проблему можем.Во-вторых, пытаемся описать проблему: если пользователь делает http-запрос на наш сервис в момент, когда StructureMap пытается сделать новую зависимость, то в этом случае происходит исключение.
В-третьих, выдвигаем гипотезу о том, что StructureMap — это wrapper и внутри что-то есть, что кидает внутреннее исключение. Проверяем гипотезу с помощью procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
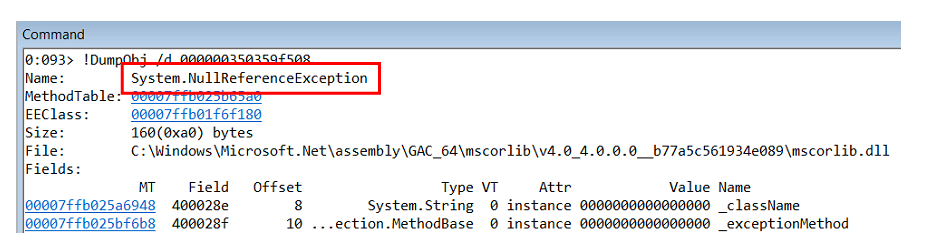
Оказывается, что внутри лежит
NullReferenceException.Исследуя call-stack этого исключения понимаем, что оно происходит внутри object-builder'а в самом StructureMap.
Но
NullReferenceException — это не сама проблема, а следствие. Нужно понять где оно возникает и кто его генерирует. Выдвигаем следующую гипотезу: наш код почему-то возвращает зависимость null. Учитывая, что в .Net все объекты в памяти располагаются один за одним, если мы посмотрим на объекты в куче, которые лежат до
NullReferenceException, то они нам, возможно, укажут на код, который сгенерировал исключение.В WinDbg есть команда — List Near Objects:
!lno. Она показывает, что интересный нам объект — это лямбда-функция, которая используется в следующем коде.public CompoundInterceptor FindInterceptor(Type type) {
CompoundInterceptop interceptor;
if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) {
lock (_locker) {
if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) {
var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type));
interceptor = new CompoundInterceptor(interceptorArray);
_analyzedInterceptors.Add(type, interceptor);
}
}
}
return interceptor;
}
В этом коде мы сначала проверяем существует ли значение в
Dictionary в _analyzedInterceptors, если не находим, то внутри lock добавляем новое значение. По идее этот код никогда не сможет вернуть null. Но проблема здесь в
_analyzedInterceptors, который использует обычный Dictionary в многопоточной среде, а не ConcurrentDictionary. Корень проблемы найден, мы обновились до последней версии StructureMap'а, задеплоили, убедились, что все исправлено. Последний шаг нашего алгоритма — это «научись и расскажи». В нашем случае это был поиск в коде всех
Dictionary, которые используются в lock'е и проверка, что все они используются правильно.Итак, алгоритм отладки — это интуитивный алгоритм, который существенно экономит время. Он делает упор на гипотезу — а это самое главное в отладке.
Проактивная отладка
По своей сути проактивная отладка отвечает на вопрос «что произойдет, когда появится баг».
Важность техники проактивной отладки можно увидеть на диаграмме цикла жизни бага.
Проблема в том, что чем дольше баг живет, тем больше мы ресурсов (времени) на него тратим.
Правила отладки и алгоритм отладки фокусируют нас на моменте, когда баг найден и мы можем придумать что дальше с ним делать. На самом же деле мы хотим сместить свой фокус на момент создания бага. Я считаю, что мы должны делать Minimum Debuggable Product (MDP), то есть такой продукт, который имеет минимально необходимый набор инфраструктуры для эффективной отладки в продакшене.
MDP состоит из двух вещей: фитнес-функции и USE метода.
Фитнес-функции. Были популяризированы Нил Фордом и соавторами в книге «Building Evolutionary Architectures ». По своей сути фитнес-функции, по мнению авторов книги, выглядят так: есть архитектура приложения, которую мы можем разрезать под разными углами, получая такие свойства архитектуры, как maintainability, performance и прочее, и на каждый такой разрез мы должны писать тест — фитнес-функцию. Таким образом, фитнес-функция — это тест на архитектуру.
В случае MDP, фитнес-функция — это проверка debuggability. Для написания таких тестов можно использовать все что угодно: NUnit, MSTest и тд. Но, поскольку, отладка — это, зачастую, работа с внешними tool'ами, я покажу на примере использование Pester'а (powershell unit testing framework). Его плюс здесь в том, что он хорошо работает с командной строкой.
Например, внутри компании мы договариваемся, что будем использовать конкретные библиотеки для логирования; при логировании мы будем использовать конкретные паттерны; pdb-символы должны быть отданы всегда на symbol server. Это и будет являться теми условностями, которые мы будем проверять в наших тестах.
Describe 'Debuggability’ {
It 'Contains line numbers in PDBs’ {
Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") `
| ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } `
| Where-Object { $_ -like "*Line nubmers: TRUE*" } `
| Should -Not –BeNullOrEmpty
}
}
Этот тест проверяет, что все pdb-символы были отданы на symbol server и были отданы правильно, то есть те, которые содержат номера строк внутри. Для этого берем скомпилированную версию продакшена, находим все exe- и dll-файлы, пропускаем все эти бинарники через утилиту syschk.exe, которая входит в пакет «Debugging tools for windows». Утилита syschk.exe сверяет бинарник с symbol server'ом и, если находит там pdb-файл, печатает отчет об этом. В отчете мы ищем строку «Line numbers: TRUE». И в финале проверяем, чтобы результат был не «null or empty».
Такие тесты необходимо встраивать в continuous deployment pipeline. После того, как прошли интеграционные тесты и unit-тесты, запускаются фитнес-функции.
Покажу ещё один пример с проверкой нужных библиотек в коде.
Describe 'Debuggability’ {
It 'Contains package for logging’ {
Get-ChildItem -Path . -Recurse -Name "packages.config" `
| ForEach-Object { Get-Content "$_" } `
| Where-Object { $_ -like "*nlog*" } `
| Should -Not –BeNullOrEmpty
}
}
В тесте мы берем все файлы packages.config и пытаемся найти в них библиотеки nlog. Аналогично мы можем проверить, что внутри поля nlog используется поле correlation id.
USE методы. Последнее, из чего состоит MDP — это метрики, которые нужно собирать.
Продемонстрирую на примере метода USE, который был популяризирован Бренданом Греггом. Идея простая: если в коде есть какая-то проблема, достаточно взять три метрики: utilization (использование), saturation (насыщение), errors (ошибки), которые помогут осознать где проблема.
Некоторые компании, например Circonus (они делают monitoring soft), свои дашборды выстраивают в виде обозначенных метрик.
Если посмотреть детально, например, на память, то использование — это количество свободной памяти, насыщение — это количество обращений к диску, ошибки — это любые ошибки, которые появлялись. Поэтому чтобы делать удобные для отладки продукты, нужно собирать USE-метрики для всех фич и всех частей подсистемы.
Если взять какую-нибудь бизнес-фичу, то, скорее всего, в ней можно выделить три метрики:
- Использование — время обработки запроса.
- Насыщение — длина очереди.
- Ошибки — любые исключительные ситуации.
В качестве примера посмотрим на график количества обработанных запросов, которые делает одна из наших систем. Как можно заметить, последние три часа сервис не обрабатывал запросы.
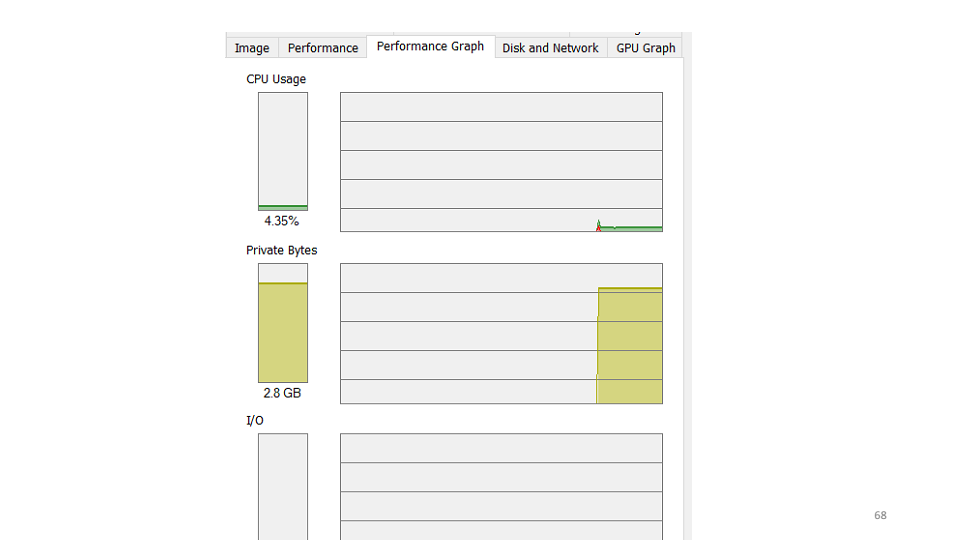
Первая гипотеза, которую мы сделали, — сервис упал и надо его запустить заново. При проверке оказывается, что сервис работает, использует 4-5% CPU.
Вторая гипотеза — внутри сервиса падает ошибка, которую мы не видим. Воспользуемся утилитой etrace.
etrace --kernel Process ^
--where ProcessName=Ex5-Service ^
--clr Exception
Утилита позволяет в realtime подписываться к ETW-events и выводить их на экран.
Видим, что падает
OutOfMemoryException. Но, второй вопрос, почему его нет в логах? Ответ находится быстро — мы его перехватываем, пытаемся подчистить память, немного подождать и начать работать заново.while (ShouldContinue()) {
try {
Do();
} catch (OutOfMemoryException) {
Thread.Sleep(100);
GC.CollectionCount(2);
GC.WaitForPendingFinalizers();
}
}
Следующая гипотеза — кто-то съедает всю память. Согласно дампу памяти, больше всего объектов находится в кэше.
public class Cache {
private static ConcurrentDictionary<int, String> _items = new ...
private static DateTime _nextClearTime = DateTime.UtcNow;
public String GetFromCache(int key) {
if (_nextClearTime < DateTime.UtcNow) {
_nextClearTime = DateTime.UtcNow.AddHours(1);
_items.Clear();
}
return _items[key];
}
}
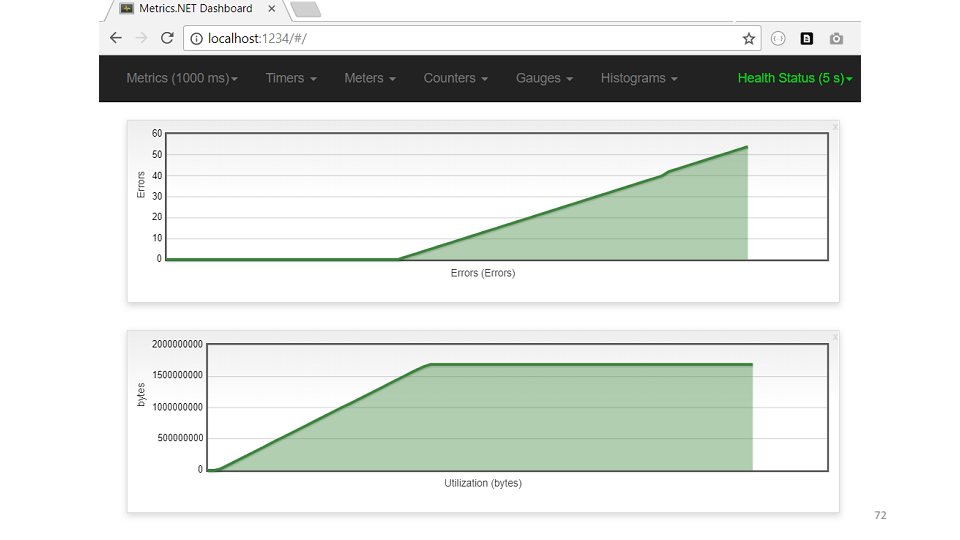
Из кода видно, что каждый час кэш должен очищаться. Но памяти уже не хватало, до очистки даже не доходили. Посмотрим на пример метрики USE для кеша.
По графику сразу видно — возросла память, сразу начались ошибки.
Итак, выводы о том, что же такое проактивная отладка.
- Отладка — это требование к архитектуре. По сути, то, что мы разрабатываем — это модель работы системы. Сама же система — это байты и биты, которые лежат в памяти на продакшн-серверах. Проактивная отладка говорит о том, что необходимо думать о своем операционном окружении.
- Уменьшайте путь бага в системе. К техникам проактивной отладки относятся и проверка всех публичных методов и их аргументов; кидать Exception сразу, как он появился, а не отлаживать до какого-то момента и тд.
- Minimum Debuggable Product — хороший инструмент, чтобы коммуницировать между собой и вырабатывать требования к отлаживаемости продукта.
Итак, как фиксить баги эффективно?
- Применяйте проактивную отладку.
- Следуйте алгоритму.
- Проверяйте гипотезы.
В этот раз спонсор нашей рекламы — Jon Skeet. Даже если вы не собираетесь в Москву на новый DotNext, видео стоит посмотреть (Джон очень старался).
