
До конца кампании на Kickstarter осталось чуть меньше недели, но графический редактор Krita уже собрал средства на две главные задачи этого года: анимацию и рисование огромных изображений. И если с анимацией все более менее понятно, то вот с большими изображениями возникают вопросы. Как просчитать и отобразить на экране изображение в 100 млн. пикселов? Как обеспечить, чтобы кисть размером в 1 млн. пикселов отрисовывалась без задержек 500 раз в секунду? На эти вопросы я постараюсь ответить в этой статье.
Откуда берутся задержки при рисовании?
Для начала нужно разобраться, как происходит рисование в современном графическом редакторе. Любая кисть представляет собой изображение («мазок» или «dab»), которое либо загружается пользователем напрямую, либо генерируется параметрически. Когда пользователь делает штрих кистью, это изображение последовательно накладывается на холст с определенным шагом (spacing) (обычно 10-20% от размера кисти). Полученное изображение попадает в конвейер рендеринга, где оно сливается со всеми слоями и передается в пользовательский интерфейс, где уже отрисовывается на экране монитора. Со стороны это выглядит просто, но на самом деле даже для простой кисти на протяжении конвейера сделанный пользователем штрих будет обработан около 7(!) раз.
Подробная структура конвейера
При рисовании кистью, каждый мазок проходит через следующие стадии:
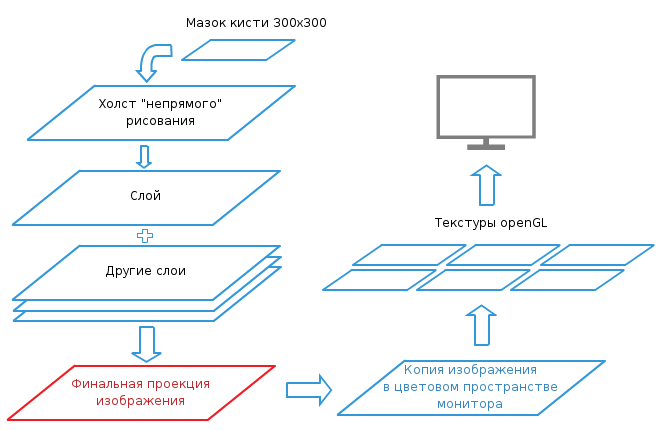
- Маска кисти заполняется цветом и формируется сам мазок
- Мазок рисуется поверх временного холста, который позволяет штрихам не накладываться друг на друга (режим непрямого рисования или «Wash Mode»)
- Временный холст рисуется поверх содержимого слоя
- Все слои сливаются в одно изображение
- Изображение копируется в пользовательский интерфейс
- В интерфейсе происходит преобразование цветового пространства изображения, чтобы соответствовать цветовому пространству монитора
- Финальная картинка загружается в текстуру openGL и отрисовывается на экране
Пример
Итак, каждый «мазок» претерпевает минимум 7 преобразований. Много это или мало? Давайте рассмотрим простой пример. Представим, что мы рисуем кистью 300х300 пикселов (300 * 300 * 4 = 312 КБ) на холсте формата A4 300dpi (3508x2480 пикселов).
Скорость, с которой художник может комфортно двигать стилус планшета (с учетом зума) составляет около 18 пикселов в миллисекунду. Тогда (при шаге кисти 10%) средняя скорость, с которой мы должны успевать отрисовывать кисть на холсте составит 600 «мазков» в секунду.
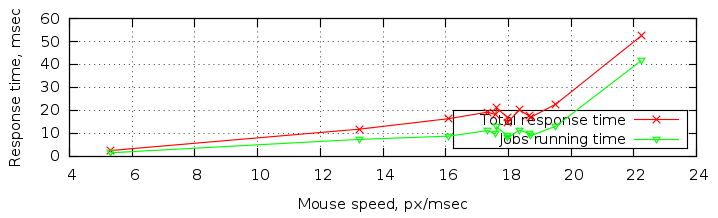
Распределение скоростей рисования
График скорости просчета «мазков» в зависимости от скорости мыши.
Кисть: 300 пикс.
Изображение: A4 300dpi (3508x2480 пикс.), зум 25%
CPU: Core i7 4700MQ
Кисть: 300 пикс.
Изображение: A4 300dpi (3508x2480 пикс.), зум 25%
CPU: Core i7 4700MQ
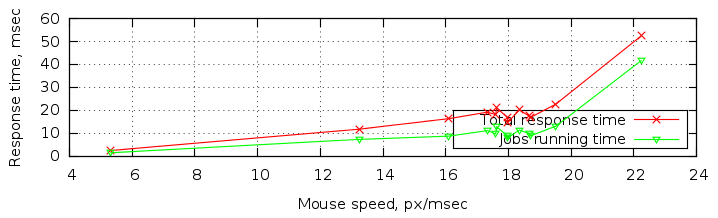
С учетом размера кисти получается, что на каждой стадии конвейера редактору нужно обрабатывать порядка 187 МБ в секунду, что составляет более 1,2 ГБ/с (!) на весь конвейер. И это даже не учитывая того факта, что почти на всех стадиях конвейер не просто преобразовывает одну область размером 300х300, а берет два изображения, просчитывает их композицию (минимум одна операция деления на пиксел) и записывает результат обратно в память. Получается, что даже на таких относительно небольших размерах кисти и изображения мы достаточно близко приближаемся к теоретическим пределам скорости работы оперативной памяти (10-20ГБ/с).
«WTF?!» — спросит внимательный читатель. «Как ж это тогда вообще работает?!» Конечно, на каждом этапе конвейера применяется множество оптимизаций. Вся область разбивается на несколько потоков, которые, мало того выполняются параллельно, так еще используют векторные инструкции SSE/AVX, позволяющие обрабатывать до 8 пикселов одновременно. Кроме того, в некоторых частных случаях (например, один из пикселов целиком прозрачен или непрозрачен), композиция вырождается в простое копирование байтов.
Однако все эти меры помогут очень слабо, если мы начнем говорить о кистях размером в 1000 пикселов и более. Ведь при увеличении размера кисти в 3 раза объем обрабатываемых данных увеличится уже не в 3, а в 9 раз! Обрабатывать по 12 ГБ в секунду? Ну уж нет! Так как же быть?
MIP-текстурирование и уровни детализации

В трехмерной графике есть известный прием, который позволяет повышать скорость и качество текстурирования объектов, находящихся далеко от камеры. Дело в том, что когда объект удаляется от наблюдателя, он становится меньше в размерах и, соответственно, его текстура должна так же масштабироваться. Чтобы ускорить этот процесс была придумана технология MIP-текстурирования. Её смысл заключается в том, что вместе с самой текстурой хранится множество ее уменьшенных копий: в 2, 4, 8, 16 и т.д. раз. И когда графическому процессору требуется нарисовать уменьшенную версию текстуры, он уже не занимается масштабированием оригинала, а просто берет заранее подготовленную копию и работает с ней. Это увеличивает не только скорость прорисовки объектов, но и сильно повышает их качество, так как при предварительной генерации можно использовать более точные «медленные» алгоритмы.
Уровни детализации в Крите
Здесь стоит учесть одно наблюдение, что если пользователь решит рисовать на изображении шириной в 10k пикселов, то большую часть времени он будет использовать масштаб в 20-15%. Иначе это изображение чисто технически не уместится на экране его Full HD монитора, шириной едва дотягивающего до 2k. Этим фактом мы и воспользуемся!
В начале этого года мы сделали прототип системы отложенного просчета изображения для Krita. Когда пользователь рисует кистью по холсту, Крита не спешит просчитывать все его действия. Вместо этого она берет уменьшенную копию изображения и отрисовывает все штрихи на ней. Так как уменьшенная копия имеет размер в 2-4 раза меньше оригинала, то и рисование на ней происходит в 4-16 раз быстрее, и поэтому отсутствуют какие-либо задержки, отвлекающие художника от его творческого процесса. А так как художник не может рисовать все 100% времени, то у Криты будет еще множество времени, когда можно в фоновом режиме, не торопясь, просчитать штрихи на оригинальном изображении.
Видео, демонстрирующее рисование 1k кистью на 8k изображении. Обратите внимание, как через несколько секунд после завершения штриха приходит вторая волна обновлений.
В итоге мы решили главную задачу. Теперь мы не пытаемся обработать гигабайты данных в реальном времени. В реальном времени нам нужно просчитать лишь превью, который позволит пользователю комфортно работать. А оригиналом можно заняться и потом.
Предварительные выводы
На данный момент у нас есть готовый прототип системы работы с уровнями детализации. В нем работает лишь один движок кистей, и то не со всеми параметрами. Однако он уже позволяет сделать нам некоторые выводы:
- Мы решили главную задачу: пользователь видит, что он рисует
- Качество превью достойное. Проблемы возникают лишь на границах областей обновления, где меняется алгоритм интерполяции, используемый в openGl-шейдерах. Нужно решать.
- В качестве бонуса openGL 3.0 и выше позволяет загружать/читать информацию напрямую с определенного уровня детализации (GLSL 1.3: textureLod(). Т.е. нам не нужно держать копии всех текстур, просто обновляем определенный уровень, говорим шейдеру про него, а тот читает напрямую
- Главный недостаток подхода заключается в том, что эта система привела к серьезному усложнению планировщика задач Криты. Требуется решить очень много проблем. Например, две копии изображения (оригинал и уменьшенная копия) нужно регулярно синхронизировать. И это усугубляется тем фактом, что не все действия в Крите можно выполнить над уменьшенной копией. Многие действия (т.н. legacy-действия) требуют полного контроля над изображением. Они работают подобно барьерам: перед их запуском все «раздвоенные» действия должны быть завершены, а после их завершения копии изображения должны быть синхронизированы.
- Соответственно, если пользователь запустит legacy-действие, то ему придется ожидать, пока завершится вся фоновая обработка. Что может, конечно, не совсем удобно. Единственным решением этой проблемы может быть лишь уменьшение количества legacy действий...
Наш проект на Kickstarter уже достиг минимальной цели, поэтому следующие несколько месяцев мы потратим на реализацию полноценной системы работы с уровнями детализации. И уже совсем скоро любой желающий сможет протестировать рисование огромными кистями в Крите!
Ссылки
Страница проекта на Kickstarter: ссылка
Группа русскоязычных пользователей в ВК: http://vk.com/ilovefreeart
Официальный сайт: krita.org
