В первой части статьи мы начали разговор о новом классе высокоуровневых моделей предметной области, названных понятийными. В отличие от других аналогичных моделей в понятийных моделях связи между понятиями сами являются понятиями, а модель строится на основе выявления и описания абстракций, послуживших образованию (определению) понятий предметной области. Это позволяет конечным пользователям строить и актуализировать модели предметной области путем простых и естественных операций создания, изменения и удаления понятий и их сущностей.
Здесь, во второй части, поговорим о том, как может быть реализована полнофункциональная информационная система, основанная на понятийном моделировании предметных областей. Теперь уже в деталях рассмотрим информационную систему LANCAD, которую в нашей компании “ИНСИСТЕМС” используют для организации проектной деятельности по разработке проектно-сметной документации для строительства.
Следует заметить, что появление информационной системы LANCAD явилось результатом реализации нескольких крупных проектов компании.
Всякая информационная система в слое представления должна использовать некоторый формальный язык (формальную теорию) для описания сущностей моделируемой ею предметной области.
Языков для текстового представления сущностей информационной системы разработано великое множество: XML (англ. Extensible Markup Language), JSON (англ. JavaScript Object Notation), XBRL (англ. Extensible Business Reporting Language) и др.
Однако все эти языки обладают одним существенным недостатком, препятствующим их эффективному использованию в информационных системах: у них нет выразительных средств для обеспечения рекурсивной целостности. Иными словами, если у некоторого объекта или его потомков имеется в качестве поля ссылка на этот объект, то преобразование такого объекта в текст может привести к бесконечному циклу или игнорированию ссылки на этот объект.
Этим недостатком не обладает разве что язык сериалиации YAML (англ. Yet Another Markup Language), который допускает описание рекурсивных структур данных путем задания якорей, отмечающих ссылочный объект, и алиасов, указывающих места вставки ссылок на объект, помеченный якорем.
Для решения проблемы эффективного описания рекурсивных структур данных, присутствующих в понятийных моделях по определению, разработан (еще один) язык NN (англ. Notion Notation) для текстового представления объектов информационных систем.
Текст на языке NN представляет собой последовательность комментариев и пар вида «Имя-Значение» с разделенным знаком «Равно» и оканчивающихся знаком «Шарп», которые записываются с точностью до пробельных знаков: «//x = y #» (комментарий, начинающийся с двух знаков «Слэш»), «x = y #» (имя x со значением y).
Если в тексте несколько раз встречаются пары «Имя-Значение» с одним и тем же именем, то создается одноименный массив значений. В свою очередь, описание объекта (абстрактного понятия), рассматриваемого как множество неупорядоченных множеств пар «Имя-Значение», всегда начинается с имени объекта без указания значения, после чего перечисляются входящие в него пары «Имя-Значение», а по завершению перечисления добавляется знак «Шарп»:
Для указания ссылки на ранее описанные объекты используются неименованные значения, задающие путь к ссылочному объекту, начиная от корня (от начала описания):
Если в объекте-ссылке задать дополнительные пары «Имя-Значение», то они будут пополнять ссылочный объект. Это удобно использовать тогда, когда ссылочный объект «должен знать» о своих ссылках или для объектов, которые в момент описания частично определены.
Последняя ситуация возникла при описании планов проекта, где задача как объект возникает раньше, а назначенные ей ресурсы определяются позже. В этом случае в описание ресурса добавляется ссылка на задачу, к которой ресурс привязан, а сама задача дополняется описанием назначенного ей ресурса.
Следует заметить, что имена в NN – это произвольные последовательности знаков, кроме знаков «Равно» и «Шарп», которые, если встретятся в имени, обрамляются фигурными скобками: «x{=}5 = y #», «{#}x = y #». В значениях обрамлению подлежит только знак «Шарп»: «x = y{#} #». Допускается использовать пустое имя « = y» и пустое значение «x = {} #».
Если имя (значение) имеет граничные пробельные знаки, или имя заключено в фигурные скобки, или имя начинается с двух знаков «Слэш», или требуется подавление интерпретации значения как простого типа данных, то такое имя (значение) также обрамляется фигурными скобками: «{ x} = {{y}} #», «{//x} = y #», «x = {-132}#».
Этот раздел логико-философский. Кому такой аспект не интересен, могут раздел пропустить. Однако по вопросам, которые я получил к первой части статьи, сужу о «продвинутости» читателей Хабра и не уверен, что этот раздел надо из статьи исключить.
И так, продолжим… Всякий формальный язык характеризуемый такими свойствами как полнота и непротиворечивость.
Полнота формального языка рассматривается как свойство, характеризующее достаточность для каких-либо целей его выразительных качеств. Для установления семантической полноты используется отображение, которое устанавливает соответствие между множеством описаний на формальном языке и сущностями некоторой предметной области, которую называют областью интерпретации. Если отображение найдено, то такой формальный язык называется семантически полным относительно этой интерпретации.
Наряду со свойством семантической полноты определяется и другое свойство, которое рассматривается как внутреннее свойство самого языка, не зависящее ни от одной из его интерпретаций. Формальный язык называют синтаксически полным, если порождаемое им множество описаний достаточно для любой области интерпретации.
Известно, что исчисление предикатов первого порядка (логика предикатов) является единственным формальным языком, который непротиворечив и обладает полнотой. В то время как арифметика натуральных чисел хотя и непротиворечива, но уже не полна. А про теорию множеств даже нельзя сказать, что она непротиворечива.
Отсюда делаем вывод, что все информационные системы, которые не используют исчисление предикатов для моделирования предметных областей, возможно непротиворечивы, но существенно неполны.
Однако при использовании исчисления предикатов возникает непреодолимая проблема разрешимости (определения принадлежности произвольной строки множеству строк языка) и трудно преодолимая проблема вычислимости (неполиномиальная сложность обработки описаний на формальном языке).
По этой причине найдено сужение исчисления предикатов, названное дискрипционной логикой, где запрещено использование предикатов с числом аргументов более одного (предикат – логическая функция от предметных переменных). В результате этого проблема разрешимости исчезла. Однако проблема эффективной вычислимости осталась.
Возникает закономерный вопрос о непротиворечивости, полноте, разрешимости и вычислимости используемого в информационной системе LANCAD исчисления понятий и соответствующего этому исчислению языка.
Для начала выясним, в чем состоит причина непротиворечивости и полноты исчисления предикатов. Понятие логической истины достаточно определенно сформулировал Г. Лейбниц. Он назвал формулу логически истинной, если она истинна во всех «мирах», т.е. во всех интерпретациях. Это означает, что логика не содержит никаких фактических истин, относящихся к какому-либо конкретному «миру».
Понятие логической истины уточнил А. Тарский. Он показал, что термин «истинно» выражает только свойство нашего знания, в частности, свойство высказываний, а не самой реальности. Следовательно, инвариантность истины в различных областях интерпретации проистекает не из свойств этих областей, а из свойств нашего сознания.
Тогда существуют ли кроме исчисления предикатов другие семантические инварианты? Если мы хотим использовать исчисление понятий для моделирования произвольных предметных областей, то это исчисление должно быть семантически инвариантным.
Напомним, что понятия образуются при абстрагировании. Абстрагирование – одна из форм умственной деятельности человека, позволяющая мысленно выделить и превратить в самостоятельные представления отдельные свойства, стороны, элементы или состояния объектов, процессов и явлений окружающего мира.
Очевидно, что процесс абстрагирования не зависит ни от какой области интерпретации, а определяется только качествами самого познающего субъекта. Тогда на основе формализации способов образования и выражения понятий может быть построено исчисление, претендующее, как и исчисление предикатов, на семантическую инвариантность во всех «мыслимых мирах».
В отличие от исчисления предикатов, имеющего в качестве семантического инварианта область логической интерпретации, исчисление понятий определено с учетом другого семантического инварианта – области понятийной интерпретации.
Непротиворечивость исчисления понятий обеспечивается отсутствием в понятийной структуре логических циклов или определений понятий прямо или косвенно через самих себя. Последнее признается недопустимым в любой формальной или содержательной теории, претендующей на адекватность.
Определение логических циклов осуществляется при создании понятия путем верификации понятийной структуры. Так как число понятий конечно, то верификации является разрешимой задачей. Очевидно, разрешимыми задачами являются и все задачи, описанные ранее.
Таким образом, информационная система LANCAD в слое представления использует язык моделирования, который непротиворечив, полон, разрешим и эффективно вычислим.
В основе любой информационной системы, предназначенной для обработки знаний, лежит механизм представления знаний и манипулирования ими с целью имитации рассуждений человека для решения поставленных прикладных задач. В свою очередь, под базой знаний понимается база данных, содержащая факты о некоторой предметной области, а также правила вывода, позволяющие автоматически на основе имеющихся фактов выполнять умозаключения и получать новые утверждения об имеющихся или вновь вводимых фактах.
Информационная система с понятийной моделью предметной области может рассматриваться как база знаний. В этом случае понятийная структура задает правила вывода на знаниях, а содержание понятий (строки соответствующих таблиц) – факты (суждения) о предметной области.
Факты. Фактами являются высказываниями о принадлежности сущностей предметной области некоторому понятию. В нашем случае сущность принадлежит понятию, если и только если набор значений признаков (атрибутов) этой сущности встречается в виде строки в таблице соответствующего понятия.
Суждения. Суждения представляют собой высказывания с логическим связками «И», «ИЛИ», «НЕ», в которых используются два вида предикатов:
Умозаключения. Любое умозаключение может быть определено как переход от одного или нескольких суждений, составляющих посылку умозаключения, к утверждению – следствию умозаключения.
Правила построения умозаключений задаются правилами вывода, принимаемыми в предметной области в качестве общезначимых, т.е. порождающих истинные утверждения при всех возможных посылках. В логике таким правилом является всем известное правило Modus ponens: если имеет место А и из А следует В, то верно и В.
В нашем случае правила построения умозаключений задаются правилами вывода, хранящимися в понятийной структуре, а сама понятийная структура рассматривается как содержательная теория предметной области, которая сохраняет истинность всех выводимых в ней следствий.
Следует заметить, что информационная система LANCAD реализует модель открытого мира, так как в процессе ее функционирования нарушается монотонность вывода. Вывод называется монотонным, если для любого полученного ранее утверждения при поступлении новых фактов выводимость этого утверждения не исчезает.
Запросы. Для превращения информационной системы в полноценную базу знаний необходимо реализовать запросы для извлечения фактов (суждений) и вывода утверждений о моделируемой предметной области. Следует обратить внимание на то, что все требуемые для запросов высказывания могут быть выражены на языке базы данных.
На рис. 14 приведена форма простого запроса, предназначенная для поиска сущностей понятия, удовлетворяющих условиям, задаваемым с помощью шаблона. Шаблон состоит из списка атрибутов понятия и отображается в левой панели формы при установленном указателе на узле поиска (узел с пиктограммой «Бинокль).
После задания ограничений на значения одного или нескольких атрибутов информационная система выполняет поиск сущностей, удовлетворяющих заданным условиям, и выводит последние в виде дочерних узлов (помечены синим цветом).
 Рис. 14. Поиск
Рис. 14. Поиск
Упрощенный поиск сущностей понятия осуществляется после ввода строки поиска – произвольной искомой подстроки – в название узла поиска (<Строка поиска> на рис. 14).
Для более сложного поиска используются запросы к базе знаний в целом, а не только к одному ее понятию. Для этого предусмотрен соответствующий интерфейс и поддерживающая его машина вывода. Однако для многих прикладных запросов оказывается достаточным использования адресной строки клиентского приложения для нахождения в понятийной структуре понятий по их именам, с последующим поиском требуемых сущностей в таблицах найденных понятий.
Помимо задач представления, извлечения и актуализации знаний имеется другая важная задача – их репрезентация. Репрезентация знаний заключается в изменении формы их представления и осуществляется на основе построения понятийных подмоделей с последующей их обработкой (визуализацией) специальными программами.
Обработке (визуализации) подлежит далеко не вся понятийная модель. Поэтому для репрезентации знаний требуется построение некоторого ее фрагмента. Для этого применяется следующая процедура.
Вначале задается сущность или сущности, подлежащие репрезентации.
Далее строится начальное приближение понятийной структуры, куда включаются те понятия, которые необходимы для определения начальных сущностей.
Затем понятийная структура пополняется понятиями, которые необходимы для определения понятий в текущем их множестве. Итерации завершаются, когда строящаяся понятийная структура перестает пополняться новыми понятиями.
В завершении процедуры создается описание сущностей, необходимых для репрезентации понятий, входящих в построенную понятийную структуру.
Выраженная на языке NN подмодель передается соответствующему приложению, которое осуществляет ее обработку, например, визуализацию.
Управление проектами. В качестве примера репрезентации знаний рассмотрим процесс визуализации планов проекта. Для управления проектами строится понятийная модель (рис. 15), в которой используются такие понятия как «Задача» (вкладка «Задачи»), «Ресурс» (вкладка «Ресурсы»), а также связи между задачами и назначение задачам ресурсов (вкладка «План»).
 Рис. 15. Понятийная модель плана проекта
Рис. 15. Понятийная модель плана проекта
Для отображения такой модели могут использоваться формы, реализуемые соответствующими прикладными программами: диаграммы Ганта (рис. 16), ресурсные списки, графики использования ресурсов и т.п. Для этого в состав информационной системы включается модуль, выполняющий визуализацию плана проекта на основе его понятийной модели с помощью других приложений.
 Рис. 16. Визуализация плана-графика
Рис. 16. Визуализация плана-графика
Для визуализированных планов реализована и обратная связь, при которой изменения, внесенные в план, могут актуализировать понятийную модель, использованную для создания такого плана.
Генерация документов. Другим примером использования понятийных моделей является автоматическое создание различного рода документов. В этом случае репрезентируемая модель используется вместе с правилами выражения понятий в теле документа. Выразительные средства, необходимые для такой репрезентации, будут зависеть от требуемой формы отображения (текст, графика, звук, анимация и др.).
Для отображения понятийной модели в текстовом виде правила выражения понятий могут быть оформлены в виде шаблона документа. При создании шаблона используется специальный язык разметки, позволяющий задать формы выражения понятий в тексте.
На рис. 17 приведена формальная грамматика языка текстовой репрезентации понятийных моделей, где слева до знака «Стрелка» заданы нетерминальные понятия языка, а справа – их выражение в виде последовательности терминальных и нетерминальных понятий.
 Рис. 17. Грамматика языка текстовой репрезентации
Рис. 17. Грамматика языка текстовой репрезентации
Грамматика задана с точностью до пробельных знаков, необязательные вхождения понятий заключены в квадратные скобки, а альтернатива показана знаком «Вертикальная черта». Терминальные понятия представлены строками, заключенными в одинарные кавычки.
Текст шаблона состоит из произвольных строк и операторов (правило 1). Для репрезентации понятийной модели используются операторы извлечения, вычисления, установки, выбора и итерации (правило 2).
Оператор извлечения позволяет получить и вставить на место своего нахождения отформатированное значение, извлекаемое по заданному пути в понятийной модели (правило 3). Оператор вычисления используется для репрезентации в виде текста отформатированного значения некоторого вычисляемого выражения (правило 4). Синтаксис и семантика выражений – как у языков высокого уровня.
Оператор установки служит для изменения значений в понятийной модели и может использоваться, в том числе, для создания временных простых понятий или переменных (правило 5). Оператор выбора необходим для реализации текстового ветвления в процессе репрезентации модели (правило 6), а оператор итерации – для репрезентации составных понятий (правило 7). Операторы могут быть вложены друг в друга, так как все части операторов представляют собой обычный текст.
В качестве примера на рис. 18 показан шаблон документа, а на рис. 19 – сам документ, полученный в результате репрезентации некоторой понятийной модели.
 Рис. 18. Шаблон документа
Рис. 18. Шаблон документа
 Рис. 19. Текстовый документ
Рис. 19. Текстовый документ
Другие формы репрезентации. Аналогичным образом создаются понятийные модели других устойчивых фрагментов предметных областей для их репрезентации в соответствующей форме, например:
«Кодируем помаленьку» – аллюзия на высказывание изобретателя эвристической машины для «отвечания на любые вопросы» Машкина Эдельвейса Захаровича из повести А. и Б. Стругацких «Сказка о тройке».
Давайте обсудим методы и средства решения задач на понятийных моделях для получения ответов, непосредственно в них не содержащихся. Форма таких ответов уже не может быть утверждением. Для получения утверждений используется вывод на базе знаний. Ничего другого не остается, кроме того, что результатом решения прикладных задача будет порождение нового знания, выраженного в виде актуализированной или вновь созданной понятийной модели.
Абстрагируясь от конкретного содержания действий, составляющих алгоритмы решения той или иной прикладной задачи, можно сделать вывод о том, что все такие алгоритмы формулируются через ранее рассмотренные операции над понятиями. В противном случае необходимо предъявить описание алгоритма, который не выражался бы на понятийном уровне. Очевидно, наличие такого описания и даже сам его поиск выглядят абсурдно.
Таким образом, семантически инвариантной (не зависящей от предметной области) формой описания решений любых прикладных задач в слое представления является алгоритм, состоящий из трех элементарных операций над сущностями понятий.
Необходимо отдельно выделить понятия-значения, над которыми могут выполняться операции, предусмотренные для соответствующего им типа данных. Например, для чисел должны быть предусмотрены стандартные арифметические операции, для строк – операции конкатенация строк, поиска подстроки и замены ее на другую подстроку, и т.д.
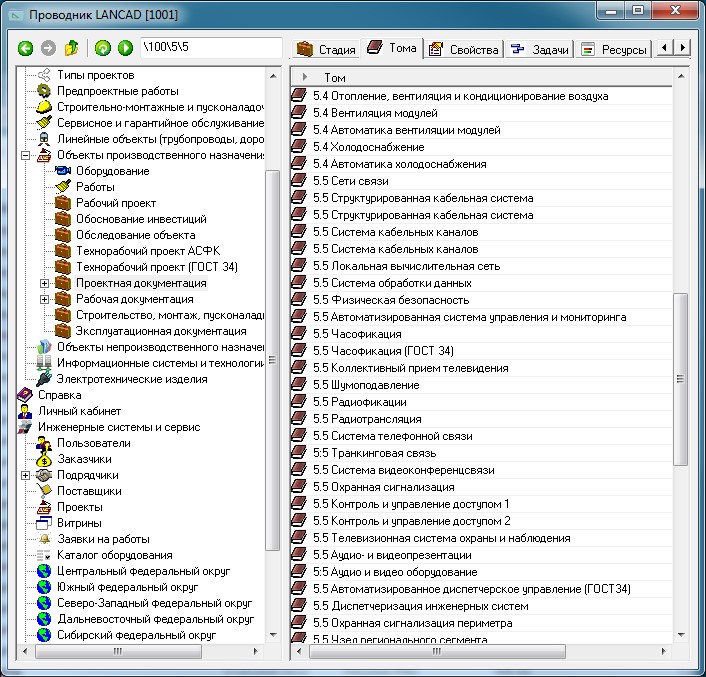
В качестве примера решения задач на понятийных моделях рассмотрим следующую задачу. Известно, что одним из основных документов рабочей документации для строительства является спецификация изделий, оборудования и материалов (рис. 20).
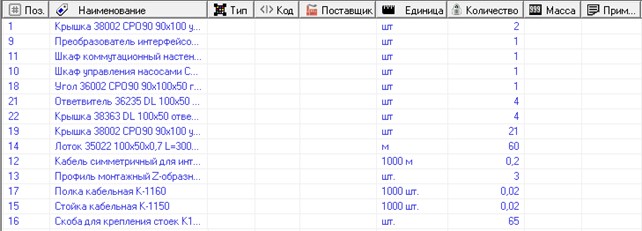 Рис. 20. Спецификация
Рис. 20. Спецификация
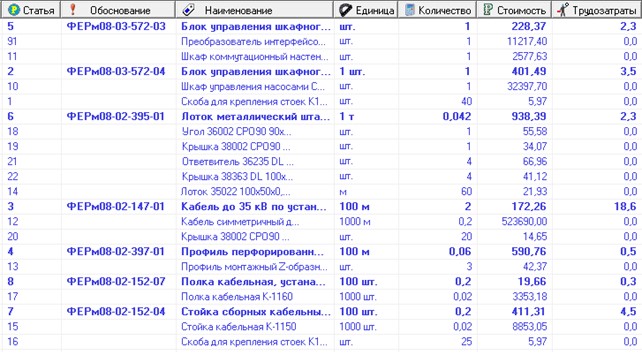
Часто возникает задача, используя базу сметных нормативов, получить из нее локальную смету на производство работ (рис. 21).
 Рис. 21. Смета
Рис. 21. Смета
Для решения этой задачи разработан и используется специальный модуль, который загружается из слоя базы данных и исполняется в слое представления (рис. 22).
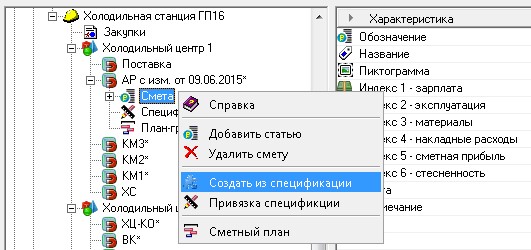 Рис. 22. Вызов модуля создания сметы
Рис. 22. Вызов модуля создания сметы
Следует обратить внимание на то, что сама информационная система тоже имеет некоторую понятийную модель, работа с которой происходит через клиентское приложение (рис. 23). В эту модель могут входить такие понятия как:
 Рис. 23 – Клиентское приложение
Рис. 23 – Клиентское приложение
В настоящей статье описано построение информационной системы с понятийной моделью предметной области. Модели предметной области названы понятийными, чтобы отличать их от известных концептуальных моделей. В концептуальных моделях задаются понятия (концепты) и разного рода связи (отношения) между ними, несущие часть семантической нагрузки модели. Другая часть семантики концептуальной модели содержится в дополнительных данных, доопределяющих связи между понятиями в виде логических выражений, формул, функций и т.п.
В понятийных моделях связи между понятиями сами являются понятиями, а модель строится на основе выявления и описания абстракций, послуживших образованию (определению) понятий. Отказ от описания ассоциаций в виде связей с различной семантической разметкой делает понятийную структуру предметной области представимой в виде дерева и более наглядной.
Предметная семантика полностью задается понятийной структурой, а атрибуты понятий определяют не более чем структурированность описаний понятий в слое базы данных. В этом случае не требуется задавать логические высказывания (формулы, функции), характеризующие понятия и являющиеся правилами вывода. Все, что необходимо для вывода на знаниях, содержится в понятийной структуре предметной области и таблицах понятий.
Таким образом, коренное отличие рассмотренного подхода заключается в использовании помимо логики, еще одного семантического инварианта – правил образования и выражения понятий. Это потребовало определения ассоциаций (связей) между понятиями в виде самостоятельных понятий.
Другими немаловажными достоинствами информационных систем с понятийным моделированием предметной области являются:
В итоге, информационная система с понятийным моделированием предметной области является представителем нового поколения информационных систем в методологическом, технологическом и эксплуатационном плане. Использование понятийной модели создает предпосылки для улучшения прозрачности бизнес-процессов предприятия, способствует оптимизации затрат и повышению инвестиционной привлекательности, уменьшает риски владения информационной системой, а именно:
Здесь, во второй части, поговорим о том, как может быть реализована полнофункциональная информационная система, основанная на понятийном моделировании предметных областей. Теперь уже в деталях рассмотрим информационную систему LANCAD, которую в нашей компании “ИНСИСТЕМС” используют для организации проектной деятельности по разработке проектно-сметной документации для строительства.
Следует заметить, что появление информационной системы LANCAD явилось результатом реализации нескольких крупных проектов компании.

Язык мой – друг мой
Всякая информационная система в слое представления должна использовать некоторый формальный язык (формальную теорию) для описания сущностей моделируемой ею предметной области.
Языков для текстового представления сущностей информационной системы разработано великое множество: XML (англ. Extensible Markup Language), JSON (англ. JavaScript Object Notation), XBRL (англ. Extensible Business Reporting Language) и др.
Однако все эти языки обладают одним существенным недостатком, препятствующим их эффективному использованию в информационных системах: у них нет выразительных средств для обеспечения рекурсивной целостности. Иными словами, если у некоторого объекта или его потомков имеется в качестве поля ссылка на этот объект, то преобразование такого объекта в текст может привести к бесконечному циклу или игнорированию ссылки на этот объект.
Этим недостатком не обладает разве что язык сериалиации YAML (англ. Yet Another Markup Language), который допускает описание рекурсивных структур данных путем задания якорей, отмечающих ссылочный объект, и алиасов, указывающих места вставки ссылок на объект, помеченный якорем.
Для решения проблемы эффективного описания рекурсивных структур данных, присутствующих в понятийных моделях по определению, разработан (еще один) язык NN (англ. Notion Notation) для текстового представления объектов информационных систем.
Текст на языке NN представляет собой последовательность комментариев и пар вида «Имя-Значение» с разделенным знаком «Равно» и оканчивающихся знаком «Шарп», которые записываются с точностью до пробельных знаков: «//x = y #» (комментарий, начинающийся с двух знаков «Слэш»), «x = y #» (имя x со значением y).
В качестве значений язык допускает значения простых типов данных:
- целых чисел (13, -2),
- дробных чисел (-3.557),
- чисел с плавающей запятой (1.2e-12),
- времени (12:34, 2:3:4.1),
- дней (12.04.2018, 2018-12-04, 04/12/2018),
- дат (12.04.2018 12:34, 2018-12-04 2:3:4, 04/12/2018 2:3:4.1),
- символов (a, я, \),
- строк (aбвгде),
- двоичных данных (0x34DF48FA87D139B3EE2378),
- функций ((x): x + 1, (x, y): x * y).
Если в тексте несколько раз встречаются пары «Имя-Значение» с одним и тем же именем, то создается одноименный массив значений. В свою очередь, описание объекта (абстрактного понятия), рассматриваемого как множество неупорядоченных множеств пар «Имя-Значение», всегда начинается с имени объекта без указания значения, после чего перечисляются входящие в него пары «Имя-Значение», а по завершению перечисления добавляется знак «Шарп»:
// Объект x #
x = #
a = 12.4 #
b = 12.4e-1 #
c = 3:4:5 #
d = 12.4.2018 #
e = 12.4.2018 3:4:5 #
f = с #
g = строка #
h = 0x34DF48FA87D139B3EE2378 #
// Метод i, умножающий аргумент на элемент a объекта x #
i = (a): a * $.a #
// Массив j #
j = 1 #
j = 3:4:5 #
j = #
u = -2.5 #
v = abcd #
#
#
Для указания ссылки на ранее описанные объекты используются неименованные значения, задающие путь к ссылочному объекту, начиная от корня (от начала описания):
// Объект x #
x = #
// Объект x.y #
y = #
// Объект x.y.z = x.y #
z = #
// Ссылка на объект x.y #
x # y #
// Дополнение объекта x.y #
c = 12 #
#
// Место ссылочного дополнения c = 12 #
#
#
Если в объекте-ссылке задать дополнительные пары «Имя-Значение», то они будут пополнять ссылочный объект. Это удобно использовать тогда, когда ссылочный объект «должен знать» о своих ссылках или для объектов, которые в момент описания частично определены.
Последняя ситуация возникла при описании планов проекта, где задача как объект возникает раньше, а назначенные ей ресурсы определяются позже. В этом случае в описание ресурса добавляется ссылка на задачу, к которой ресурс привязан, а сама задача дополняется описанием назначенного ей ресурса.
Следует заметить, что имена в NN – это произвольные последовательности знаков, кроме знаков «Равно» и «Шарп», которые, если встретятся в имени, обрамляются фигурными скобками: «x{=}5 = y #», «{#}x = y #». В значениях обрамлению подлежит только знак «Шарп»: «x = y{#} #». Допускается использовать пустое имя « = y» и пустое значение «x = {} #».
Если имя (значение) имеет граничные пробельные знаки, или имя заключено в фигурные скобки, или имя начинается с двух знаков «Слэш», или требуется подавление интерпретации значения как простого типа данных, то такое имя (значение) также обрамляется фигурными скобками: «{ x} = {{y}} #», «{//x} = y #», «x = {-132}#».
Что истинно во всех мирах
Этот раздел логико-философский. Кому такой аспект не интересен, могут раздел пропустить. Однако по вопросам, которые я получил к первой части статьи, сужу о «продвинутости» читателей Хабра и не уверен, что этот раздел надо из статьи исключить.
И так, продолжим… Всякий формальный язык характеризуемый такими свойствами как полнота и непротиворечивость.
Полнота формального языка рассматривается как свойство, характеризующее достаточность для каких-либо целей его выразительных качеств. Для установления семантической полноты используется отображение, которое устанавливает соответствие между множеством описаний на формальном языке и сущностями некоторой предметной области, которую называют областью интерпретации. Если отображение найдено, то такой формальный язык называется семантически полным относительно этой интерпретации.
Наряду со свойством семантической полноты определяется и другое свойство, которое рассматривается как внутреннее свойство самого языка, не зависящее ни от одной из его интерпретаций. Формальный язык называют синтаксически полным, если порождаемое им множество описаний достаточно для любой области интерпретации.
Известно, что исчисление предикатов первого порядка (логика предикатов) является единственным формальным языком, который непротиворечив и обладает полнотой. В то время как арифметика натуральных чисел хотя и непротиворечива, но уже не полна. А про теорию множеств даже нельзя сказать, что она непротиворечива.
Отсюда делаем вывод, что все информационные системы, которые не используют исчисление предикатов для моделирования предметных областей, возможно непротиворечивы, но существенно неполны.
Однако при использовании исчисления предикатов возникает непреодолимая проблема разрешимости (определения принадлежности произвольной строки множеству строк языка) и трудно преодолимая проблема вычислимости (неполиномиальная сложность обработки описаний на формальном языке).
По этой причине найдено сужение исчисления предикатов, названное дискрипционной логикой, где запрещено использование предикатов с числом аргументов более одного (предикат – логическая функция от предметных переменных). В результате этого проблема разрешимости исчезла. Однако проблема эффективной вычислимости осталась.
Возникает закономерный вопрос о непротиворечивости, полноте, разрешимости и вычислимости используемого в информационной системе LANCAD исчисления понятий и соответствующего этому исчислению языка.
Для начала выясним, в чем состоит причина непротиворечивости и полноты исчисления предикатов. Понятие логической истины достаточно определенно сформулировал Г. Лейбниц. Он назвал формулу логически истинной, если она истинна во всех «мирах», т.е. во всех интерпретациях. Это означает, что логика не содержит никаких фактических истин, относящихся к какому-либо конкретному «миру».
Понятие логической истины уточнил А. Тарский. Он показал, что термин «истинно» выражает только свойство нашего знания, в частности, свойство высказываний, а не самой реальности. Следовательно, инвариантность истины в различных областях интерпретации проистекает не из свойств этих областей, а из свойств нашего сознания.
Тогда существуют ли кроме исчисления предикатов другие семантические инварианты? Если мы хотим использовать исчисление понятий для моделирования произвольных предметных областей, то это исчисление должно быть семантически инвариантным.
Напомним, что понятия образуются при абстрагировании. Абстрагирование – одна из форм умственной деятельности человека, позволяющая мысленно выделить и превратить в самостоятельные представления отдельные свойства, стороны, элементы или состояния объектов, процессов и явлений окружающего мира.
Очевидно, что процесс абстрагирования не зависит ни от какой области интерпретации, а определяется только качествами самого познающего субъекта. Тогда на основе формализации способов образования и выражения понятий может быть построено исчисление, претендующее, как и исчисление предикатов, на семантическую инвариантность во всех «мыслимых мирах».
В отличие от исчисления предикатов, имеющего в качестве семантического инварианта область логической интерпретации, исчисление понятий определено с учетом другого семантического инварианта – области понятийной интерпретации.
Непротиворечивость исчисления понятий обеспечивается отсутствием в понятийной структуре логических циклов или определений понятий прямо или косвенно через самих себя. Последнее признается недопустимым в любой формальной или содержательной теории, претендующей на адекватность.
Определение логических циклов осуществляется при создании понятия путем верификации понятийной структуры. Так как число понятий конечно, то верификации является разрешимой задачей. Очевидно, разрешимыми задачами являются и все задачи, описанные ранее.
Таким образом, информационная система LANCAD в слое представления использует язык моделирования, который непротиворечив, полон, разрешим и эффективно вычислим.
Когда данные – знания
В основе любой информационной системы, предназначенной для обработки знаний, лежит механизм представления знаний и манипулирования ими с целью имитации рассуждений человека для решения поставленных прикладных задач. В свою очередь, под базой знаний понимается база данных, содержащая факты о некоторой предметной области, а также правила вывода, позволяющие автоматически на основе имеющихся фактов выполнять умозаключения и получать новые утверждения об имеющихся или вновь вводимых фактах.
Информационная система с понятийной моделью предметной области может рассматриваться как база знаний. В этом случае понятийная структура задает правила вывода на знаниях, а содержание понятий (строки соответствующих таблиц) – факты (суждения) о предметной области.
Факты. Фактами являются высказываниями о принадлежности сущностей предметной области некоторому понятию. В нашем случае сущность принадлежит понятию, если и только если набор значений признаков (атрибутов) этой сущности встречается в виде строки в таблице соответствующего понятия.
Например, если в базе данных имеется таблица, описывающая пользователей, и имеется конкретный пользователь, то зная его атрибуты (имя и пароль) легко установить, является ли он пользователем информационной системы. Для этого таблица должна содержаться запись с именем и паролем этого пользователя.
Суждения. Суждения представляют собой высказывания с логическим связками «И», «ИЛИ», «НЕ», в которых используются два вида предикатов:
- одноместные предикаты N(E) определения принадлежности сущности E понятию N;
- отношения вида P[E]*V, где P[E] – функтор, возвращающий значение атрибута P сущности E, * – знак отношения (=, !=, >, >=, <, <= и т.п.), V – сущность некоторого понятия.
Например, «Иванов — Сотрудник», а в предикатной форме Сотрудник(Иванов). Или «Атрибут Пароль Пользователя Петров равен *****».
Умозаключения. Любое умозаключение может быть определено как переход от одного или нескольких суждений, составляющих посылку умозаключения, к утверждению – следствию умозаключения.
Правила построения умозаключений задаются правилами вывода, принимаемыми в предметной области в качестве общезначимых, т.е. порождающих истинные утверждения при всех возможных посылках. В логике таким правилом является всем известное правило Modus ponens: если имеет место А и из А следует В, то верно и В.
В нашем случае правила построения умозаключений задаются правилами вывода, хранящимися в понятийной структуре, а сама понятийная структура рассматривается как содержательная теория предметной области, которая сохраняет истинность всех выводимых в ней следствий.
Рассмотрим простой пример. Пусть имеется понятийная модель, которая описывает штатно-должностную структура компании. В этой модели могут быть такие понятия как Стажер, Сотрудник, Должность, Подразделение, Работник (понятие-обобщение понятий Стажер и Сотрудник) и Штат (понятие-ассоциация понятий Подразделение, Должность, Работник). Тогда в штатно-должностном мире возможны суждения вида «X (некоторая сущность) является Стажером (Сотрудником, Должностью, Подразделением, Работником, Штатом)», и умозаключения вида «если (А, В, С) — сущность понятия Штат, то А — Подразделение, В — Должность, С — Работник» и любые производные от него, где одно или несколько суждений в заключении опущены, а также «если X — Стажер (Сотрудник), то X — Работник» и «если X — Работник, то X — Сотрудник или X — Стажер».
Следует заметить, что информационная система LANCAD реализует модель открытого мира, так как в процессе ее функционирования нарушается монотонность вывода. Вывод называется монотонным, если для любого полученного ранее утверждения при поступлении новых фактов выводимость этого утверждения не исчезает.
Запросы. Для превращения информационной системы в полноценную базу знаний необходимо реализовать запросы для извлечения фактов (суждений) и вывода утверждений о моделируемой предметной области. Следует обратить внимание на то, что все требуемые для запросов высказывания могут быть выражены на языке базы данных.
На рис. 14 приведена форма простого запроса, предназначенная для поиска сущностей понятия, удовлетворяющих условиям, задаваемым с помощью шаблона. Шаблон состоит из списка атрибутов понятия и отображается в левой панели формы при установленном указателе на узле поиска (узел с пиктограммой «Бинокль).
После задания ограничений на значения одного или нескольких атрибутов информационная система выполняет поиск сущностей, удовлетворяющих заданным условиям, и выводит последние в виде дочерних узлов (помечены синим цветом).
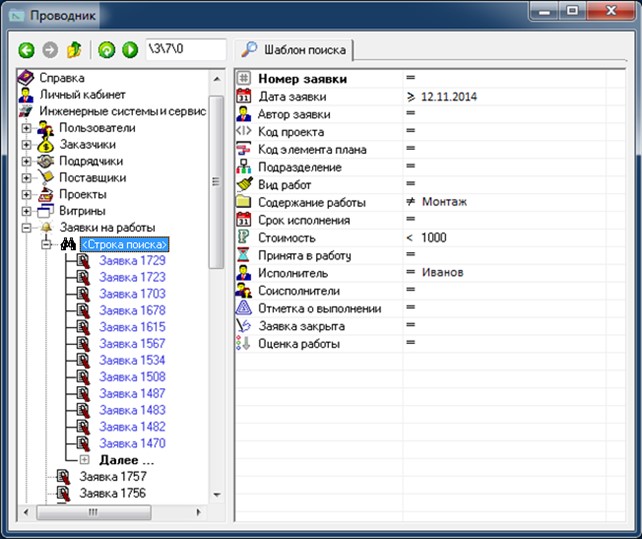
Упрощенный поиск сущностей понятия осуществляется после ввода строки поиска – произвольной искомой подстроки – в название узла поиска (<Строка поиска> на рис. 14).
Для более сложного поиска используются запросы к базе знаний в целом, а не только к одному ее понятию. Для этого предусмотрен соответствующий интерфейс и поддерживающая его машина вывода. Однако для многих прикладных запросов оказывается достаточным использования адресной строки клиентского приложения для нахождения в понятийной структуре понятий по их именам, с последующим поиском требуемых сущностей в таблицах найденных понятий.
Не логикой единой…
Помимо задач представления, извлечения и актуализации знаний имеется другая важная задача – их репрезентация. Репрезентация знаний заключается в изменении формы их представления и осуществляется на основе построения понятийных подмоделей с последующей их обработкой (визуализацией) специальными программами.
Обработке (визуализации) подлежит далеко не вся понятийная модель. Поэтому для репрезентации знаний требуется построение некоторого ее фрагмента. Для этого применяется следующая процедура.
Вначале задается сущность или сущности, подлежащие репрезентации.
Далее строится начальное приближение понятийной структуры, куда включаются те понятия, которые необходимы для определения начальных сущностей.
Затем понятийная структура пополняется понятиями, которые необходимы для определения понятий в текущем их множестве. Итерации завершаются, когда строящаяся понятийная структура перестает пополняться новыми понятиями.
В завершении процедуры создается описание сущностей, необходимых для репрезентации понятий, входящих в построенную понятийную структуру.
Выраженная на языке NN подмодель передается соответствующему приложению, которое осуществляет ее обработку, например, визуализацию.
Управление проектами. В качестве примера репрезентации знаний рассмотрим процесс визуализации планов проекта. Для управления проектами строится понятийная модель (рис. 15), в которой используются такие понятия как «Задача» (вкладка «Задачи»), «Ресурс» (вкладка «Ресурсы»), а также связи между задачами и назначение задачам ресурсов (вкладка «План»).
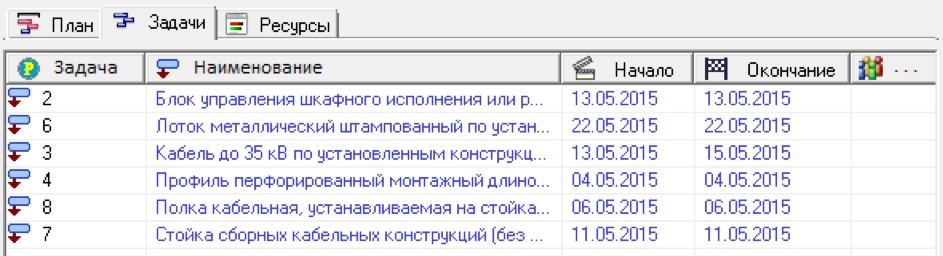
Для отображения такой модели могут использоваться формы, реализуемые соответствующими прикладными программами: диаграммы Ганта (рис. 16), ресурсные списки, графики использования ресурсов и т.п. Для этого в состав информационной системы включается модуль, выполняющий визуализацию плана проекта на основе его понятийной модели с помощью других приложений.
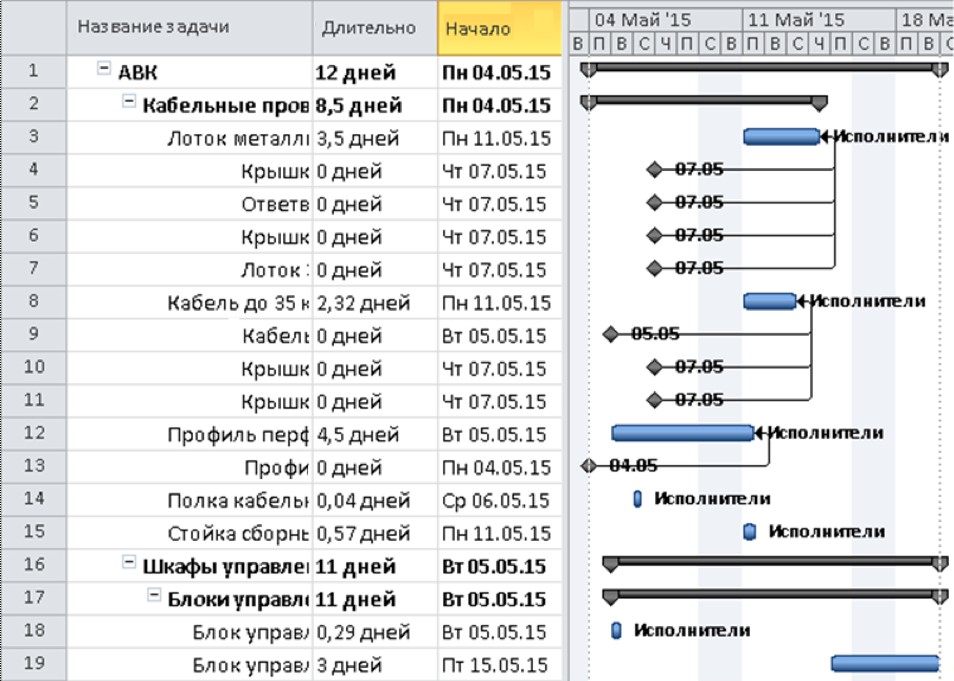
Для визуализированных планов реализована и обратная связь, при которой изменения, внесенные в план, могут актуализировать понятийную модель, использованную для создания такого плана.
Генерация документов. Другим примером использования понятийных моделей является автоматическое создание различного рода документов. В этом случае репрезентируемая модель используется вместе с правилами выражения понятий в теле документа. Выразительные средства, необходимые для такой репрезентации, будут зависеть от требуемой формы отображения (текст, графика, звук, анимация и др.).
Для отображения понятийной модели в текстовом виде правила выражения понятий могут быть оформлены в виде шаблона документа. При создании шаблона используется специальный язык разметки, позволяющий задать формы выражения понятий в тексте.
На рис. 17 приведена формальная грамматика языка текстовой репрезентации понятийных моделей, где слева до знака «Стрелка» заданы нетерминальные понятия языка, а справа – их выражение в виде последовательности терминальных и нетерминальных понятий.

Грамматика задана с точностью до пробельных знаков, необязательные вхождения понятий заключены в квадратные скобки, а альтернатива показана знаком «Вертикальная черта». Терминальные понятия представлены строками, заключенными в одинарные кавычки.
Текст шаблона состоит из произвольных строк и операторов (правило 1). Для репрезентации понятийной модели используются операторы извлечения, вычисления, установки, выбора и итерации (правило 2).
Оператор извлечения позволяет получить и вставить на место своего нахождения отформатированное значение, извлекаемое по заданному пути в понятийной модели (правило 3). Оператор вычисления используется для репрезентации в виде текста отформатированного значения некоторого вычисляемого выражения (правило 4). Синтаксис и семантика выражений – как у языков высокого уровня.
Оператор установки служит для изменения значений в понятийной модели и может использоваться, в том числе, для создания временных простых понятий или переменных (правило 5). Оператор выбора необходим для реализации текстового ветвления в процессе репрезентации модели (правило 6), а оператор итерации – для репрезентации составных понятий (правило 7). Операторы могут быть вложены друг в друга, так как все части операторов представляют собой обычный текст.
В качестве примера на рис. 18 показан шаблон документа, а на рис. 19 – сам документ, полученный в результате репрезентации некоторой понятийной модели.

Другие формы репрезентации. Аналогичным образом создаются понятийные модели других устойчивых фрагментов предметных областей для их репрезентации в соответствующей форме, например:
- графики и диаграммы (графическое представление данных линейными отрезками или геометрическими фигурами);
- инфографика (графическое представление графов, карт, рисунков, формул и т.п.);
- техническая графика (графическое представление схем, чертежей, аксонометрий);
- динамические модели бизнес-процессов в различных нотациях (графическое представление процессов и их текущих состояний).
Кодируем помаленьку
«Кодируем помаленьку» – аллюзия на высказывание изобретателя эвристической машины для «отвечания на любые вопросы» Машкина Эдельвейса Захаровича из повести А. и Б. Стругацких «Сказка о тройке».
Давайте обсудим методы и средства решения задач на понятийных моделях для получения ответов, непосредственно в них не содержащихся. Форма таких ответов уже не может быть утверждением. Для получения утверждений используется вывод на базе знаний. Ничего другого не остается, кроме того, что результатом решения прикладных задача будет порождение нового знания, выраженного в виде актуализированной или вновь созданной понятийной модели.
Абстрагируясь от конкретного содержания действий, составляющих алгоритмы решения той или иной прикладной задачи, можно сделать вывод о том, что все такие алгоритмы формулируются через ранее рассмотренные операции над понятиями. В противном случае необходимо предъявить описание алгоритма, который не выражался бы на понятийном уровне. Очевидно, наличие такого описания и даже сам его поиск выглядят абсурдно.
Таким образом, семантически инвариантной (не зависящей от предметной области) формой описания решений любых прикладных задач в слое представления является алгоритм, состоящий из трех элементарных операций над сущностями понятий.
Необходимо отдельно выделить понятия-значения, над которыми могут выполняться операции, предусмотренные для соответствующего им типа данных. Например, для чисел должны быть предусмотрены стандартные арифметические операции, для строк – операции конкатенация строк, поиска подстроки и замены ее на другую подстроку, и т.д.
В качестве примера решения задач на понятийных моделях рассмотрим следующую задачу. Известно, что одним из основных документов рабочей документации для строительства является спецификация изделий, оборудования и материалов (рис. 20).
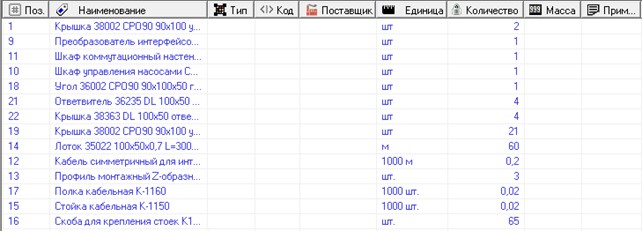
Часто возникает задача, используя базу сметных нормативов, получить из нее локальную смету на производство работ (рис. 21).
Для решения этой задачи разработан и используется специальный модуль, который загружается из слоя базы данных и исполняется в слое представления (рис. 22).
Следует обратить внимание на то, что сама информационная система тоже имеет некоторую понятийную модель, работа с которой происходит через клиентское приложение (рис. 23). В эту модель могут входить такие понятия как:
- модуль, подключаемый в процессе работы клиентского приложения и служащий для реализации специфической функции отображения понятийной модели или решения специфической задачи предметной области;
- событие, регистрируемое в информационной системе и позволяющее задать обработчик для операций создания, удаления или изменения понятий;
- форма, создаваемая для реализации различных специфических сценариев ввода данных пользователем;
- другие понятия, необходимые для реализации требований к модели конкретной предметной области.
В заключение: сложности и преимущества
В настоящей статье описано построение информационной системы с понятийной моделью предметной области. Модели предметной области названы понятийными, чтобы отличать их от известных концептуальных моделей. В концептуальных моделях задаются понятия (концепты) и разного рода связи (отношения) между ними, несущие часть семантической нагрузки модели. Другая часть семантики концептуальной модели содержится в дополнительных данных, доопределяющих связи между понятиями в виде логических выражений, формул, функций и т.п.
В понятийных моделях связи между понятиями сами являются понятиями, а модель строится на основе выявления и описания абстракций, послуживших образованию (определению) понятий. Отказ от описания ассоциаций в виде связей с различной семантической разметкой делает понятийную структуру предметной области представимой в виде дерева и более наглядной.
Предметная семантика полностью задается понятийной структурой, а атрибуты понятий определяют не более чем структурированность описаний понятий в слое базы данных. В этом случае не требуется задавать логические высказывания (формулы, функции), характеризующие понятия и являющиеся правилами вывода. Все, что необходимо для вывода на знаниях, содержится в понятийной структуре предметной области и таблицах понятий.
Таким образом, коренное отличие рассмотренного подхода заключается в использовании помимо логики, еще одного семантического инварианта – правил образования и выражения понятий. Это потребовало определения ассоциаций (связей) между понятиями в виде самостоятельных понятий.
Другими немаловажными достоинствами информационных систем с понятийным моделированием предметной области являются:
- прозрачность – использование предельно общих и естественных методов анализа предметной области, унификация обследования предприятия перед внедрением информационной системы;
- настраиваемость – возможность учета отраслевой специфики предприятий, применимость на предприятиях любого размера и сферы деятельности, быстрота и поэтапность внедрения;
- адаптируемость – возможность формирования понятийных подмоделей для конкретных пользователей и их групп, использование единого унифицированного интерфейса пользователя, широкие возможности по настройке прав доступа к понятийной модели или ее части;
- гибкость – быстрое реагирование на изменения в предметной области, простая актуализация понятийной модели в соответствии с изменяющимися внешними условиями, легкая модифицируемость информационной системы;
- открытость – небольшое число унифицированных и устойчивых межслойных интерфейсов, способность взаимодействовать с другими информационными системами;
- масштабируемость – возможность создания и использования сложных и многоаспектных понятийных моделей, расширяемость информационной системы путем увеличения числа серверов в каждом слое и динамического распределения нагрузки на серверы нижележащих слоев;
- интегрированность – легкий перенос данных из других информационных систем на основе языка понятийной модели, репрезентация знаний с помощью сторонних программных средств.
Основные трудности при использовании информационных систем с понятийными моделями – это необходимость освоения новой методологии и технологии моделирования предметной области и репрезентации накопленных знаний, а также отказ от устоявшихся узкоспециализированных форм пользовательского интерфейса.
В итоге, информационная система с понятийным моделированием предметной области является представителем нового поколения информационных систем в методологическом, технологическом и эксплуатационном плане. Использование понятийной модели создает предпосылки для улучшения прозрачности бизнес-процессов предприятия, способствует оптимизации затрат и повышению инвестиционной привлекательности, уменьшает риски владения информационной системой, а именно:
- проектные риски, связанные с созданием информационной системы;
- технологические риски, связанные с потерей или искажением данных в процессе актуализации модели;
- эксплуатационные риски, связанные с поддержанием информационной системы в работоспособном состоянии и обеспечением независимости от поставщика;
- риски сопровождения, связанные с изменчивостью предметной области.
Напоминаю про наши вакансии.
