
На прошедших выходных (20-22 апреля) в офисе Mail.ru Group прошел студенческий хакатон по машинному обучению. Хакатон объединил студентов разных ВУЗов, разных курсов и, что самое любопытное, разных направлений: от программистов до безопасников.

От Почты Mail.ru было предоставлено три задачи:
Разрешалось выбрать одну задачу из первых двух, а в решении третьей можно было поучаствовать по желанию. Мы выбрали вторую задачу, так как понимали, что в первой однозначно выиграют нейронки, с которыми у нас было мало опыта работы. Зато со второй задачей была надежда, что выстрелит классический ML. Вообще, идея разделения задач нам очень понравилась, так как во время хакатона можно было обсудить решения и идеи с неконкурирующими командами.
Хакатон примечателен тем, что не было публичного лидерборда, а модель тестировалась в конце хакатона на закрытом датасете.
Нам предоставили почтовые письма от магазинов с подтверждением сделанных заказов или рассылкой рекламных акций. Помимо исходных емейлов был предоставлен скрипт для их парсинга и размеченные результаты его работы, которые и представляли собой датасет для обучения моделей.
Письмо парсится построчно, каждая строка разбивается на токены и каждому токену задаётся метка (label).
В размеченном файле сначала идет распарсенная строка, начинающаяся с символа "#", затем результата парсинга в виде трех колонок: (номер строки, токен, метка класса).
Метки бывают следующих типов:
Обязательный префикс «B-» обозначает начало токена в предложении. Для оценки модели использовалась f1-метрика по всем меткам, кроме OUT.
Распределение меток в обучающем датасете выглядит следующим образом:
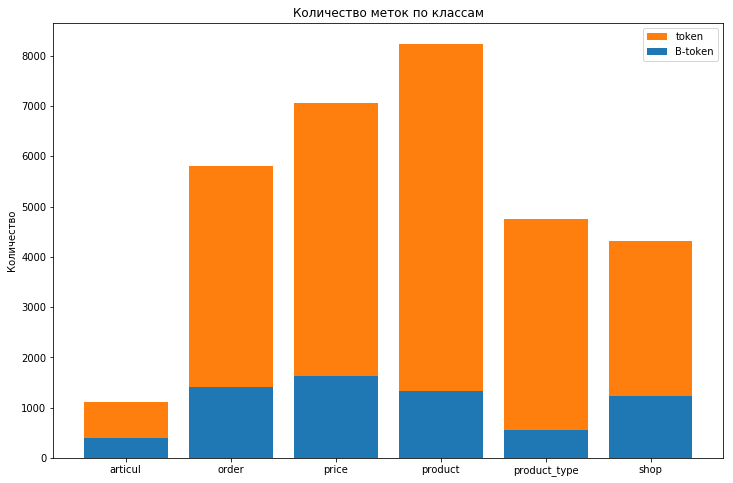
Меток класса OUT почти 580k
Виден сильный дисбаланс классов, а метку OUT вообще не имеет смысла учитывать для оценки качества модели. Чтобы учесть дисбаланс классов, добавили в лес параметр class_weight='balanced'. Это хоть и уменьшило балл на трейне и на тесте ( с 0,27 и 0,15 до 0,09 и 0,08), однако позволило избавиться от переобучения (уменьшилась разница между этими показателями).
Для представления слов в виде вектора использовался fastText'овский word embedding для русского языка, что позволило представить токен в виде вектора из 300 значений. Пока часть команды пыталась написать нейронку, были опробованы стандартные алгоритмы классификации, такие как логрег, случайный лес, knn и xgboost. По итогам проб в качестве запасного варианта был выбран случайный лес, на случай, если нейронка не взлетит. Выбор был во многом обоснован хорошей скоростью обучения и предсказания модели (что сильно спасло под конец соревнования) при удовлетворительном качестве на фоне других моделей.
Имея опыт прохождения курса mlcourse_open от ODS, мы понимали, что значительно повысить балл могут только качественные фичи, на генерацию которых и потратили оставшееся время. Первое, что пришло на ум — добавить простые признаки, такие как индекс токена в предложении; длина токена; является ли токен буквенно-числовым; состоит только из прописных или строчных букв, и т.п. Это дало прирост метрики f1 до 0,21 на тестовой выборке. При дальнейшем изучении датасета сделали вывод, что важен контекст, и в зависимости от него два одинаковых токена могли иметь различные метки класса. Чтобы учесть контекст, взяли окно — к вектору признаков добавлял предыдущий и последующий токены. Это увеличило балл уже до 0,55 на трейне и 0,43 на тесте. В последнюю ночь хакатона мы пытались увеличить окно и впихнуть больше признаков в 12 гигабайтов оперативки ноута. Как оказалось, оно не впихивается. Бросив эти попытки, начали думать, какие еще признаки можно добавить в модель. Обратились к библиотеке pymorphy2, но прикрутить ее должным образом не успели.
До выдачи тестового датасета и первого сабмита оставалось пару часов. После выдачи датасета давался час на то, чтобы сделать предсказания и отправить организаторам — это был первый сабмит. После этого давался еще час на вторую попытку. Итак, пришло время начать делать препроцессинг и обучить лес на всей выборке. Также нас все еще не покидала вера в нейронку. Препроцессинг и обучение леса из 50-ти деревьев прошли на удивление быстро: минут 10 на препроцессинг (вместе с пятиминутной загрузкой словаря для эмбеддинга) и еще 10 минут на обучение леса на матрице размером (609101, 906). Такая скорость нас порадовала, ведь это говорило о том, что мы сможем быстро поправить модель ко второму сабмиту и заново ее обучить. Обученный лес показал балл 0,59 на всей выборке. Учитывая предыдущие тестирования модели на отложенной выборке, мы надеялись показать результат не меньше 0,4 на лидерборде, ну, или хотя бы не меньше 0,3.
Получив тестовый датасет из ~300 000 токенов и имея уже обученную модель, мы буквально за 2 минуты сделали предсказание. Стали первыми и получили балл 0,2997. Ожидая результаты других команд и обдумывая планы по улучшению собственной модели, к нам пришла идея добавить к обучающей выборке только что размеченную тестовую. Во-первых, это не противоречило правилам, так как запрещалась ручная разметка, во-вторых нам самим стало интересно, что из этого получится. В это время узнали результаты других команд — они все оказались позади нас, чему мы приятно удивились. Однако у ближайшей к нам результат был равен 0,28, что давало соперникам шанс нас обойти. Также мы не были уверены, что у них не припасено козырей в рукаве. Второй час прошел напряженно, команды держали сабмиты до последнего, а наша идея с увеличением обучающей выборки провалилась: ноуту не понравилась идея впихнуть в его память в 1,5 раза больше данных, и в знак своего протеста отвечал зависаниями и MemoryError.
Когда время истекло, появился окончательный лидерборд, некоторые команды улучшили результат, а у некоторых результат ухудшился, но мы по-прежнему были на первом месте. Однако предстояла валидация ответа: необходимо было показать рабочую модель и сделать предсказание перед организаторами, а у нас только что перезагрузившийся ноут, на котором обучались деревья, а модель не была сохранена. Что делать? Тут организаторы пошли нам на встречу и согласились подождать, пока модель обучится и сделает предсказания. Однако была загвоздка: лес-то случайный, SEED мы не зафиксировали, а точность предсказания нужно было подтвердить до последней цифры. Мы надеялись на лучшее, а также запустили обучение на втором ноуте, где уже был загружен словарь. В это время организаторы тщательно исследовали данные и код, расспрашивали о модели, фичах. Ноут не переставал действовать на нервы и иногда подвисал на несколько минут, так, что даже время не менялось. Когда обучение завершилось, сделали повторное предсказание и отправили организаторам. В это время второй ноут завершил обучение, а предсказания на обучающей выборке на обоих ноутах совпали идеально, что повысило нашу веру в успешную валидацию результата. И вот, спустя несколько секунд, организаторы поздравляют с победой и жмут руки :)
Мы отлично провели выходные в офисе Mail.Ru Group, послушали интересные доклады на тему ML и DL от команды Почты. Наслаждались бесконечными запасами печенек, молочного шоколада (молоко, однако, оказалось ресурсом конечным, но восполняемым) и пиццей, а также незабываемой атмосферой и общением с интересными людьми.
Если рассмотреть саму задачу и наш опыт, то можно сделать следующие выводы:

Команда «EpicTeam» — победители в задаче NER. Слева направо:

От Почты Mail.ru было предоставлено три задачи:
- Распознавание и классификация логотипов компаний. Эта задача полезна в антиспаме для определения фишинговых писем.
- Определение по тексту письма, какие из его частей относятся к определенным категориям. Задача распознавания именованных сущностей (Named Entity Recognition, NER)
- Реализация последней задачи не регламентировалась. Необходимо было придумать и сделать прототип новой полезной функции для Почты. Критериями оценки являлись полезность, качество реализации, применение ML и хайповость фичи.
Разрешалось выбрать одну задачу из первых двух, а в решении третьей можно было поучаствовать по желанию. Мы выбрали вторую задачу, так как понимали, что в первой однозначно выиграют нейронки, с которыми у нас было мало опыта работы. Зато со второй задачей была надежда, что выстрелит классический ML. Вообще, идея разделения задач нам очень понравилась, так как во время хакатона можно было обсудить решения и идеи с неконкурирующими командами.
Хакатон примечателен тем, что не было публичного лидерборда, а модель тестировалась в конце хакатона на закрытом датасете.
Описание задачи
Нам предоставили почтовые письма от магазинов с подтверждением сделанных заказов или рассылкой рекламных акций. Помимо исходных емейлов был предоставлен скрипт для их парсинга и размеченные результаты его работы, которые и представляли собой датасет для обучения моделей.
Письмо парсится построчно, каждая строка разбивается на токены и каждому токену задаётся метка (label).
Пример размеченных данных
# [](http://t.adidas-news.adidas.com/res/adidas-t/spacer.gif) Итого к оплате
39 []( OUT
39 http OUT
39 :// OUT
39 t OUT
39 . OUT
39 adidas OUT
39 - OUT
39 news OUT
39 . OUT
39 adidas OUT
39 . OUT
39 com OUT
39 / OUT
39 res OUT
39 / OUT
39 adidas OUT
39 - OUT
39 t OUT
39 / OUT
39 spacer OUT
39 . OUT
39 gif OUT
39 ) OUT
39 Итого B-PRICE
39 к PRICE
39 оплате PRICE
В размеченном файле сначала идет распарсенная строка, начинающаяся с символа "#", затем результата парсинга в виде трех колонок: (номер строки, токен, метка класса).
Метки бывают следующих типов:
- Артикул товара: B-ARTICUL, ARTICUL
- Заказ и его номер: B-ORDER, ORDER
- Итоговая сумма заказа: B-PRICE, PRICE
- Заказанные товары: B-PRODUCT, PRODUCT
- Тип товара: B-PRODUCT_TYPE, PRODUCT_TYPE
- Продавец: B-SHOP, SHOP
- Все остальные токены: OUT
Обязательный префикс «B-» обозначает начало токена в предложении. Для оценки модели использовалась f1-метрика по всем меткам, кроме OUT.
Балл для логрега как бейзлайна
Training time 157.34269189834595 s
================================================TRAIN======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.7981220657276995 Tokenwise recall: 0.188470066518847 Tokenwise f-measure: 0.30493273542600896
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.9154929577464789 Tokenwise recall: 0.04992319508448541 Tokenwise f-measure: 0.09468317552804079
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.6538461538461539 Tokenwise recall: 0.0160075329566855 Tokenwise f-measure: 0.03125000000000001
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.5172413793103449 Tokenwise recall: 0.02167630057803468 Tokenwise f-measure: 0.04160887656033287
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7852941176470588 Tokenwise recall: 0.05550935550935551 Tokenwise f-measure: 0.1036893203883495
================================================TEST=======================================
+++++++++++++++++++++++ ARTICUL +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ ORDER +++++++++++++++++++++++
Tokenwise precision: 0.8064516129032258 Tokenwise recall: 0.205761316872428 Tokenwise f-measure: 0.3278688524590164
+++++++++++++++++++++++ PRICE +++++++++++++++++++++++
Tokenwise precision: 0.8666666666666667 Tokenwise recall: 0.05263157894736842 Tokenwise f-measure: 0.09923664122137404
+++++++++++++++++++++++ PRODUCT +++++++++++++++++++++++
Tokenwise precision: 0.4 Tokenwise recall: 0.0071174377224199285 Tokenwise f-measure: 0.013986013986013988
+++++++++++++++++++++++ PRODUCT_TYPE +++++++++++++++++++++++
Tokenwise precision: 0.3333333333333333 Tokenwise recall: 0.011627906976744186 Tokenwise f-measure: 0.02247191011235955
+++++++++++++++++++++++ SHOP +++++++++++++++++++++++
Tokenwise precision: 0.0 Tokenwise recall: 0.0 Tokenwise f-measure: 0.0
+++++++++++++++++++++++ CORPUS MEAN METRIC +++++++++++++++++++++++
Tokenwise precision: 0.7528089887640449 Tokenwise recall: 0.05697278911564626 Tokenwise f-measure: 0.10592885375494071
Распределение меток в обучающем датасете выглядит следующим образом:
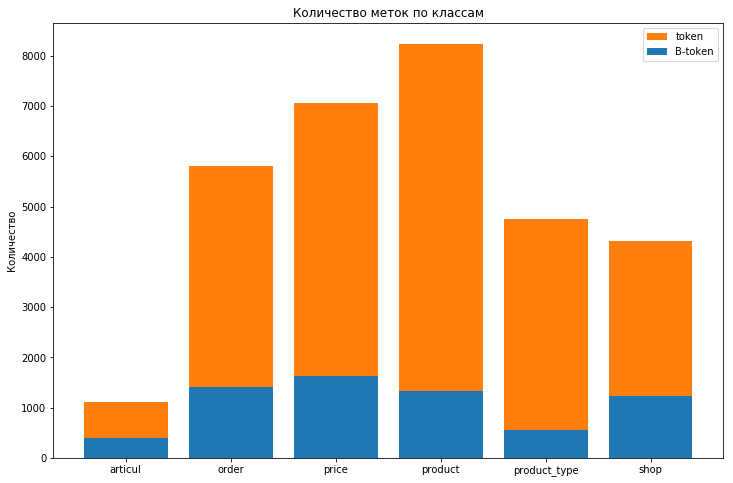
Меток класса OUT почти 580k
Виден сильный дисбаланс классов, а метку OUT вообще не имеет смысла учитывать для оценки качества модели. Чтобы учесть дисбаланс классов, добавили в лес параметр class_weight='balanced'. Это хоть и уменьшило балл на трейне и на тесте ( с 0,27 и 0,15 до 0,09 и 0,08), однако позволило избавиться от переобучения (уменьшилась разница между этими показателями).
Модели
Для представления слов в виде вектора использовался fastText'овский word embedding для русского языка, что позволило представить токен в виде вектора из 300 значений. Пока часть команды пыталась написать нейронку, были опробованы стандартные алгоритмы классификации, такие как логрег, случайный лес, knn и xgboost. По итогам проб в качестве запасного варианта был выбран случайный лес, на случай, если нейронка не взлетит. Выбор был во многом обоснован хорошей скоростью обучения и предсказания модели (что сильно спасло под конец соревнования) при удовлетворительном качестве на фоне других моделей.
Имея опыт прохождения курса mlcourse_open от ODS, мы понимали, что значительно повысить балл могут только качественные фичи, на генерацию которых и потратили оставшееся время. Первое, что пришло на ум — добавить простые признаки, такие как индекс токена в предложении; длина токена; является ли токен буквенно-числовым; состоит только из прописных или строчных букв, и т.п. Это дало прирост метрики f1 до 0,21 на тестовой выборке. При дальнейшем изучении датасета сделали вывод, что важен контекст, и в зависимости от него два одинаковых токена могли иметь различные метки класса. Чтобы учесть контекст, взяли окно — к вектору признаков добавлял предыдущий и последующий токены. Это увеличило балл уже до 0,55 на трейне и 0,43 на тесте. В последнюю ночь хакатона мы пытались увеличить окно и впихнуть больше признаков в 12 гигабайтов оперативки ноута. Как оказалось, оно не впихивается. Бросив эти попытки, начали думать, какие еще признаки можно добавить в модель. Обратились к библиотеке pymorphy2, но прикрутить ее должным образом не успели.
Сабмит
До выдачи тестового датасета и первого сабмита оставалось пару часов. После выдачи датасета давался час на то, чтобы сделать предсказания и отправить организаторам — это был первый сабмит. После этого давался еще час на вторую попытку. Итак, пришло время начать делать препроцессинг и обучить лес на всей выборке. Также нас все еще не покидала вера в нейронку. Препроцессинг и обучение леса из 50-ти деревьев прошли на удивление быстро: минут 10 на препроцессинг (вместе с пятиминутной загрузкой словаря для эмбеддинга) и еще 10 минут на обучение леса на матрице размером (609101, 906). Такая скорость нас порадовала, ведь это говорило о том, что мы сможем быстро поправить модель ко второму сабмиту и заново ее обучить. Обученный лес показал балл 0,59 на всей выборке. Учитывая предыдущие тестирования модели на отложенной выборке, мы надеялись показать результат не меньше 0,4 на лидерборде, ну, или хотя бы не меньше 0,3.
Получив тестовый датасет из ~300 000 токенов и имея уже обученную модель, мы буквально за 2 минуты сделали предсказание. Стали первыми и получили балл 0,2997. Ожидая результаты других команд и обдумывая планы по улучшению собственной модели, к нам пришла идея добавить к обучающей выборке только что размеченную тестовую. Во-первых, это не противоречило правилам, так как запрещалась ручная разметка, во-вторых нам самим стало интересно, что из этого получится. В это время узнали результаты других команд — они все оказались позади нас, чему мы приятно удивились. Однако у ближайшей к нам результат был равен 0,28, что давало соперникам шанс нас обойти. Также мы не были уверены, что у них не припасено козырей в рукаве. Второй час прошел напряженно, команды держали сабмиты до последнего, а наша идея с увеличением обучающей выборки провалилась: ноуту не понравилась идея впихнуть в его память в 1,5 раза больше данных, и в знак своего протеста отвечал зависаниями и MemoryError.
Когда время истекло, появился окончательный лидерборд, некоторые команды улучшили результат, а у некоторых результат ухудшился, но мы по-прежнему были на первом месте. Однако предстояла валидация ответа: необходимо было показать рабочую модель и сделать предсказание перед организаторами, а у нас только что перезагрузившийся ноут, на котором обучались деревья, а модель не была сохранена. Что делать? Тут организаторы пошли нам на встречу и согласились подождать, пока модель обучится и сделает предсказания. Однако была загвоздка: лес-то случайный, SEED мы не зафиксировали, а точность предсказания нужно было подтвердить до последней цифры. Мы надеялись на лучшее, а также запустили обучение на втором ноуте, где уже был загружен словарь. В это время организаторы тщательно исследовали данные и код, расспрашивали о модели, фичах. Ноут не переставал действовать на нервы и иногда подвисал на несколько минут, так, что даже время не менялось. Когда обучение завершилось, сделали повторное предсказание и отправили организаторам. В это время второй ноут завершил обучение, а предсказания на обучающей выборке на обоих ноутах совпали идеально, что повысило нашу веру в успешную валидацию результата. И вот, спустя несколько секунд, организаторы поздравляют с победой и жмут руки :)
Итог
Мы отлично провели выходные в офисе Mail.Ru Group, послушали интересные доклады на тему ML и DL от команды Почты. Наслаждались бесконечными запасами печенек, молочного шоколада (молоко, однако, оказалось ресурсом конечным, но восполняемым) и пиццей, а также незабываемой атмосферой и общением с интересными людьми.
Если рассмотреть саму задачу и наш опыт, то можно сделать следующие выводы:
- Не стоит гнаться за модой и сразу применять DL, возможно, классические модели могут неплохо взлететь.
- Генерируйте больше полезных фич, а уже потом оптимизируйте модель и подбирайте гиперпараметры.
- Фиксируйте SEED и сохраняйте свои модели, а также делайте бекапы :)

Команда «EpicTeam» — победители в задаче NER. Слева направо:
- Леонид Жариков, МГТУ им. Баумана, студент ТехноПарка.
- Андрей Атаманюк, МГТУ им. Баумана, студент ТехноПарка.
- Милия Фатхутдинова, РЭУ им. Плеханова.
- Андрей Пашков, НИЯУ «МИФИ», студент ТехноАтома.
