
В первой части мы ознакомились с методами доменной адаптации с помощью глубоко обучения. Поговорили об основных датасетах, а также о подходах discrepancy-based и adversarial-based non-generative. Эти методы хорошо себя показывают для некоторых задач. А в этот раз мы разберём наиболее сложные и перспективные adversarial-based методы: generative models, а также алгоритмы, показывающие наилучшие результаты на датасете VisDA (адаптации с синтетических данных под реальные фотографии).

Generative Models
В основе этого подхода лежит способность GAN'а генерировать данные из необходимого распределения. Благодаря этому свойству можно получить нужное количество синтетических данных и использовать их для обучения. Главная идея методов из семейства generative models заключается в генерировании с помощью домена-источника данных, максимально похожих на представителей целевого домена. Таким образом, новые синтетические данные будут иметь те же лэйблы, что и представители исходного домена, на основе которых они были получены. Затем модель для целевого домена просто обучается на этих сгенерированных данных.
Представленный на ICML-2018 метод CyCADA: Cycle-Consistent Adversarial Domain Adaptation (код) является характерным представителем семейства generative models. Он комбинирует в себе несколько успешных подходов из GAN'ов и domain adaptation. Важной его частью является использование cycle-consistency loss, впервые представленной в статье о CycleGAN. Идея cycle-consistency loss заключается в том, что изображение, полученное генерированием из исходного в целевой домен с последующим обратным преобразованием, должно быть близко к начальному изображению. Кроме того, CyCADA включает в себя адаптацию на уровне пикселей и на уровне векторных представлений, а также semantic loss для сохранения структуры в сгенерированном изображении.
Пусть  и
и  — сети для целевого и исходного доменов соответственно,
— сети для целевого и исходного доменов соответственно,  и
и  — целевой и исходный домены,
— целевой и исходный домены,  — разметка на исходном домене,
— разметка на исходном домене,  и
и  — генераторы из исходного в целевой домен и наоборот,
— генераторы из исходного в целевой домен и наоборот,  и
и  — дискриминаторы принадлежности к целевому и исходному доменам соответственно. Тогда функция потерь, которая минимизируется в CyCADA, является суммой шести loss-функций (ниже представлена схема обучения с номерами loss'ов):
— дискриминаторы принадлежности к целевому и исходному доменам соответственно. Тогда функция потерь, которая минимизируется в CyCADA, является суммой шести loss-функций (ниже представлена схема обучения с номерами loss'ов):
 — классификация модели на сгенерированных данных и псевдо-лэйблах из исходного домена.
— классификация модели на сгенерированных данных и псевдо-лэйблах из исходного домена. — adversarial-loss для обучения генератора .
— adversarial-loss для обучения генератора . — adversarial-loss для обучения генератора .
— adversarial-loss для обучения генератора . (cycle-consistency loss) —
(cycle-consistency loss) —  -loss, гарантирующий, что изображения, полученные из и будут близки.
-loss, гарантирующий, что изображения, полученные из и будут близки.  — adversarial-loss для векторных представлений и на сгенерированных данных (по аналогии с тем, что используется в ADDA).
— adversarial-loss для векторных представлений и на сгенерированных данных (по аналогии с тем, что используется в ADDA). (semantic consistency loss) — loss, отвечающий за то, что будет схожим образом работать как на изображениях, полученныех из , так и из .
(semantic consistency loss) — loss, отвечающий за то, что будет схожим образом работать как на изображениях, полученныех из , так и из .
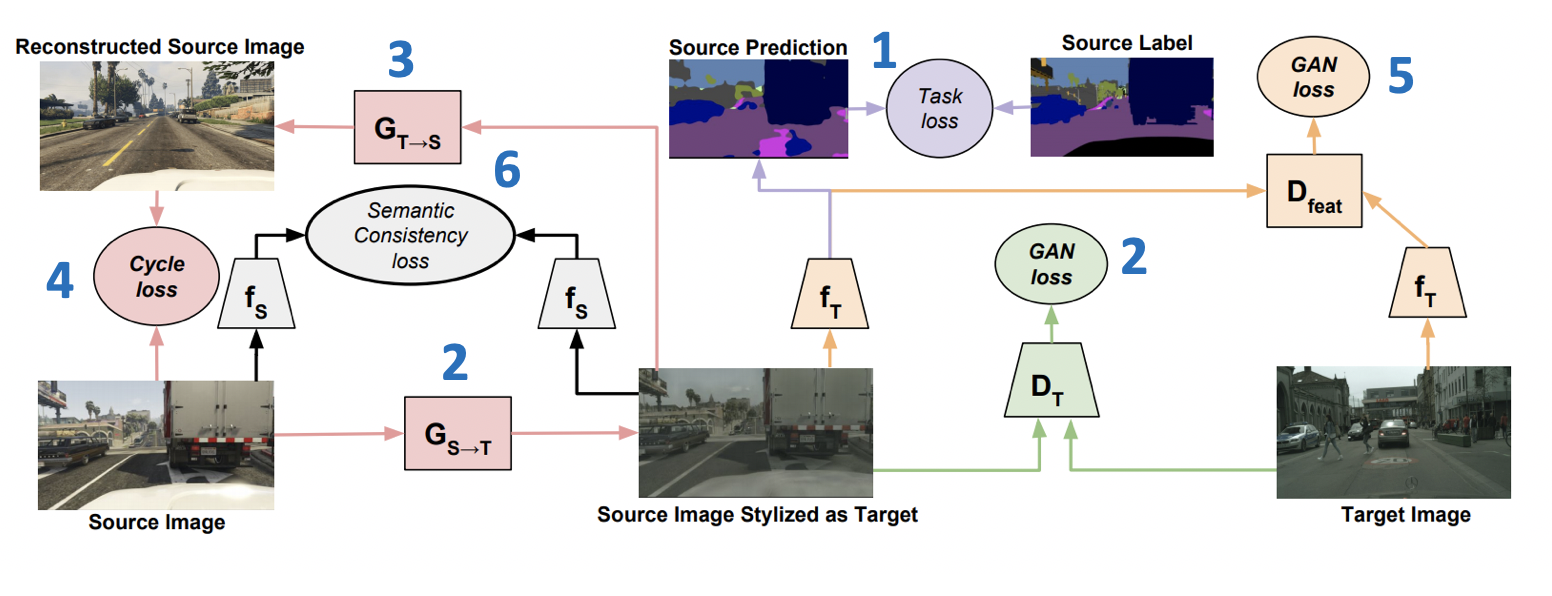
Результаты CyCADA:
- На паре цифровых доменов USPS -> MNIST: 95,7 %.
- На задаче сегментации GTA 5 -> Cityscapes: Mean IoU = 39,5 %.
В рамках подхода Generate To Adapt: Aligning Domains using Generative Adversarial Networks (код) обучают такой генератор  , чтобы на выходе он выдавал изображения, близкие к исходному домену. Такой позволяет преобразовывать данные из целевого домена и применять к ним обученный на размеченных данных домена-источника классификатор.
, чтобы на выходе он выдавал изображения, близкие к исходному домену. Такой позволяет преобразовывать данные из целевого домена и применять к ним обученный на размеченных данных домена-источника классификатор.
Чтобы обучить такой генератор, авторы используют модифицированный дискриминатор  из статьи AC-GAN. Особенность этого заключается в том, что он не только отвечает 1, если на вход ему пришли данные из домена-источника, и 0 в противном случае, но и в случае позитивного ответа классифицирует входные данные по классам исходного домена.
из статьи AC-GAN. Особенность этого заключается в том, что он не только отвечает 1, если на вход ему пришли данные из домена-источника, и 0 в противном случае, но и в случае позитивного ответа классифицирует входные данные по классам исходного домена.
Обозначим  как свёрточную сеть, которая выдаёт векторное представление изображения,
как свёрточную сеть, которая выдаёт векторное представление изображения,  — классификатор, который работает на векторе, полученном из . Схемы обучения и инференса алгоритма:
— классификатор, который работает на векторе, полученном из . Схемы обучения и инференса алгоритма:
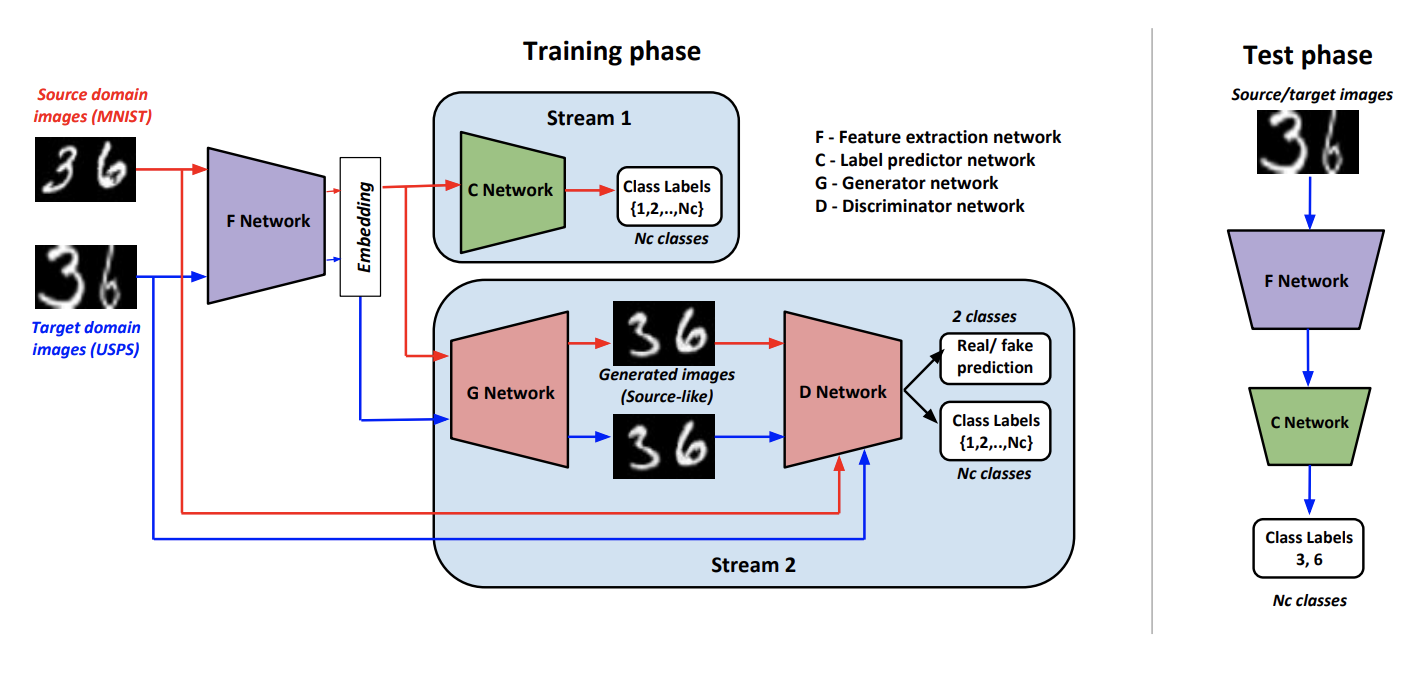
Процедура обучения состоит из нескольких компонентов:
- Дискриминатор учится определять домен для всех полученных из данных, а для исходного домена ещё добавляется классификационный loss, как было описано выше.
- На данных из домена-источника с помощью комбинации adversarial-loss и классификационного loss'а обучается генерировать результат, похожий на домен источник, и правильно классифицируемый .
- и учатся классифицировать данные из домена-источника. Также с помощью другого классификационного loss'а изменяется так, чтобы увеличить качество классификации .
- При помощи adversarial-loss обучается «обманывать» на данных из целевого домена.
- Авторы эмпирически вывели, что перед подачей в имеет смысл конкатинировать вектор из с нормальный шум и one-hot вектором класса (
 для target data).
для target data).
Результаты метода на бенчмарках:
- На цифровых доменах USPS -> MNIST: 90,8 %.
- На датасете Office среднее качество адаптации для пар доменов Amazon и Webcam: 86,5 %.
- На датасете VisDA среднее значение качества по 12 категориям без unknown класса: 76,7 %.
В статье From source to target and back: symmetric bi-directional adaptive GAN (код) была представлена модель SBADA-GAN, которая довольно похожа на CyCADA и целевая функция которой так же, как и в CyCADA состоит из 6 слагаемых. В обозначениях авторов  и
и  — генераторы из исходного домена в целевой и наоборот,
— генераторы из исходного домена в целевой и наоборот,  и
и  — дискриминаторы, которые отличают реальные данные от сгенерированных в исходный и целевой домены соответственно,
— дискриминаторы, которые отличают реальные данные от сгенерированных в исходный и целевой домены соответственно,  и
и  — классификаторы, которые обучены на данных из исходного домена и на их трансформированных в целевой домен версиях.
— классификаторы, которые обучены на данных из исходного домена и на их трансформированных в целевой домен версиях.
SBADA-GAN как и CyCADA использует идею из CycleGAN, consistency loss и псевдо-лэйблы для сгенерированных в целевой домен данных, составляя целевую функцию из соответствующих слагаемых. К особенностям SBADA-GAN можно отнести:
- На вход генераторам подаётся изображение + шум.
- В тесте используется линейная комбинация из предсказаний target-модели и source-модели на результате трансформации .
Схема обучения SBADA-GAN:
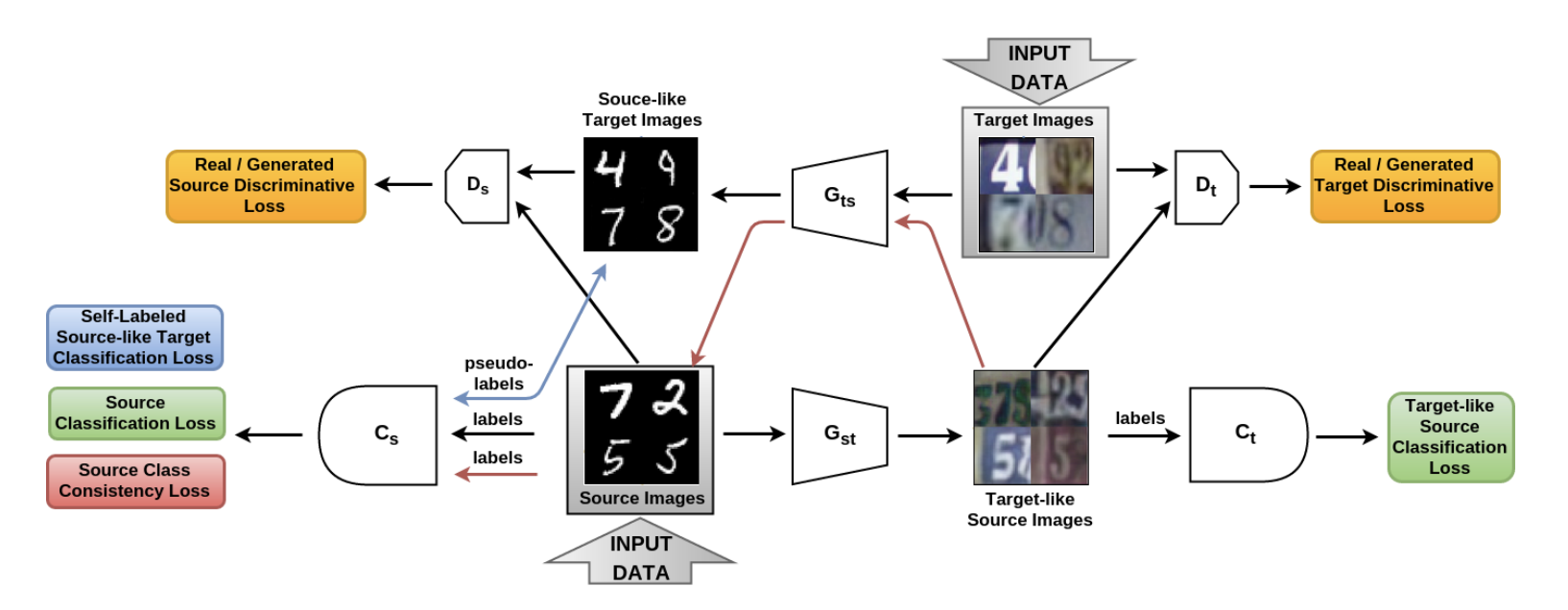
Авторы SBADA-GAN провели больше экспериментов, чем авторы CyCADA, и получили следующие результаты:
- На доменах USPS -> MNIST: 95,0 %.
- На доменах MNIST -> SVHN: 61,1 %.
- На дорожных знаках Synth Signs -> GTSRB: 97,7 %.
Из семейства generative models имеет смысл рассмотреть ещё такие значимые статьи:
Visual Domain Adaptation Challenge
В рамках воркшопа на конференциях ECCV и ICCV проводится конкурс по доменной адаптации Visual Domain Adaptation Challenge. В нём участникам предлагается обучить на синтетических данных классификатор и адаптировать его на неразмеченные данные из ImageNet.
Алгоритм, представленный в Self-ensembling for visual domain adaptation (код), победил в VisDA-2017. Этот метод построен на идее self-ensembling: есть сеть-учитель (teacher model) и сеть-ученик (student model). На каждой итерации входное изображение прогоняется через обе эти сети. Ученик обучается с помощью суммы classification loss и сonsistency loss, где classification loss — это обычная cross-entropy с известной меткой класса, а сonsistency loss — это средний квадрат разностей между предсказаниями учителя и ученика (squared difference). Веса сети-учителя вычисляются как экспоненциальное скользящее среднее от весов сети-ученика. Ниже проиллюстрирована эта процедура обучения.
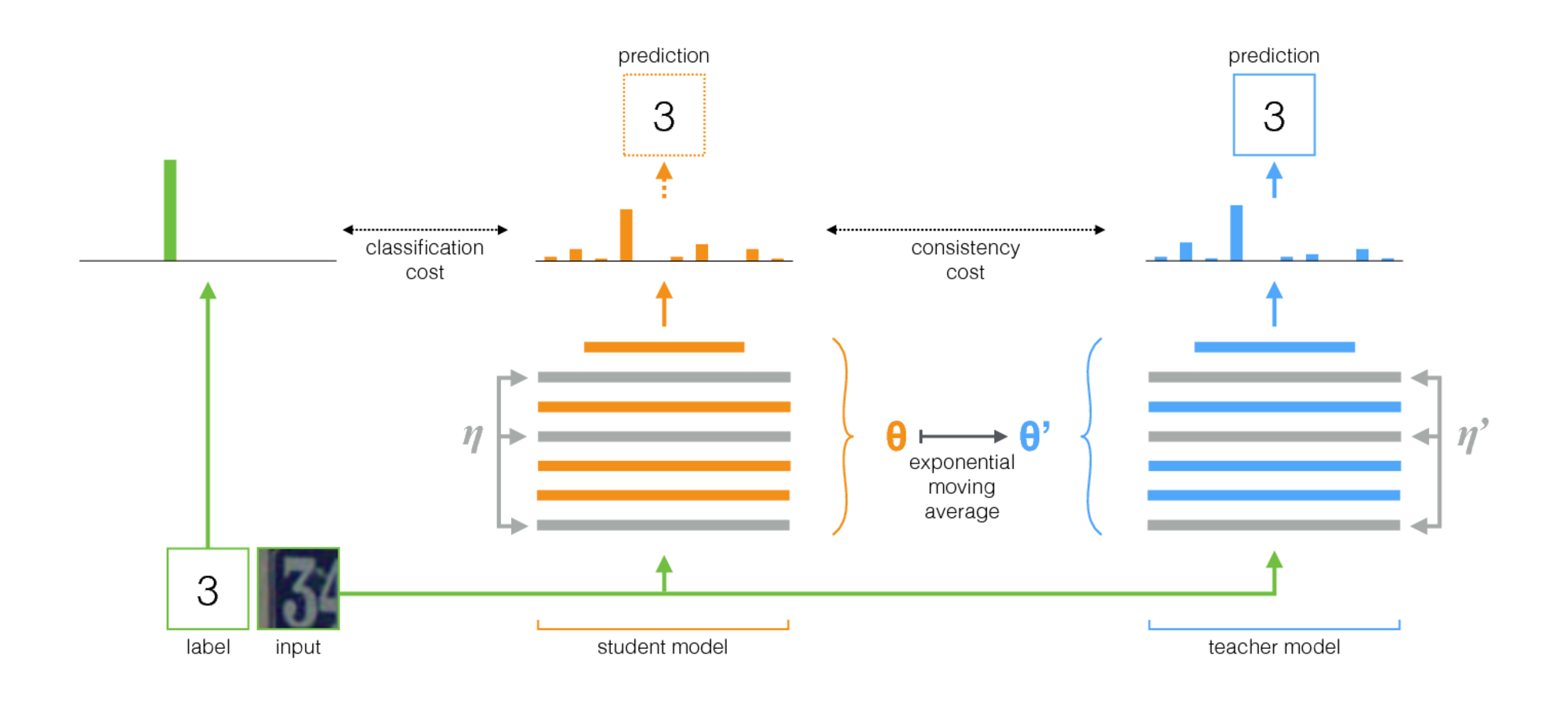
Важными особенностями применения этого метода для доменной адаптации являются:
- В батче при обучении смешаны данные из исходного домена
 с метками классов
с метками классов  и данные из целевого домена
и данные из целевого домена  без меток.
без меток. - Ко входным изображениям перед подачей в нейронные сети применяются разнообразные сильные аугментации: Гауссовские шумы, аффинные преобразования и т.д.
- В обеих сетях применялись сильные методы регуляризации (например, dropout).
 — выход сети-ученика,
— выход сети-ученика,  — сети-учителя. Если входные данные были из целевого домена, то вычисляется только сonsistency loss между и , cross-entropy loss = 0.
— сети-учителя. Если входные данные были из целевого домена, то вычисляется только сonsistency loss между и , cross-entropy loss = 0.- Для устойчивости обучения применяется confidence thresholding: если предсказание учителя меньше порога (0,9), то сonsistency loss loss = 0.
Схема описанной процедуры:

На основных датасетах алгоритм достиг высоких показателей. Правда, под каждую задачу авторы отдельно подбирали набор аугментаций.
- USPS -> MNIST: 99,54 %.
- MNIST -> SVHN: 97,0 %.
- Synth Numbers -> SVHN: 97,11 %.
- На дорожных знаках Synth Signs -> GTSRB: 99,37 %.
- На датасете VisDA среднее значение качества по 12 категориям без класса Unknown: 92,8 %. Важно отметить, что этот результат получен с помощью ансамбля из 5 моделей и с использованием test time augmentation.
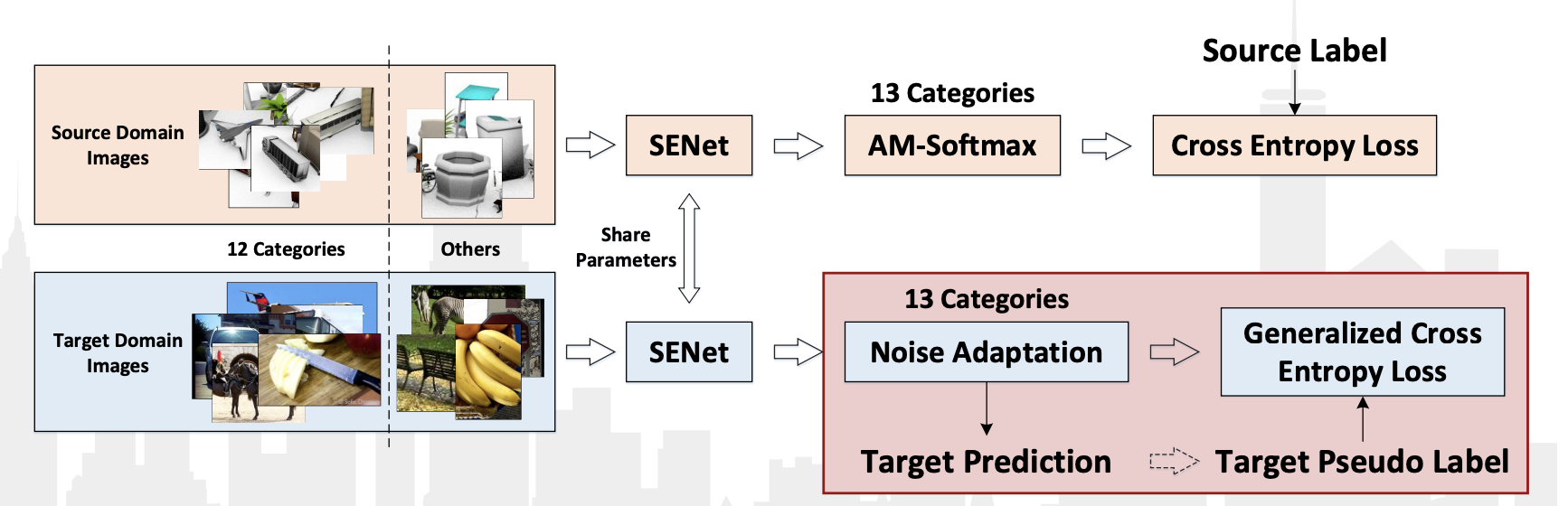
Соревнование VisDA-2018 проводилось в этом году в рамках конференции ECCV-2018. В этот раз добавили 13-й класс: Unknown, куда попало всё, что не попало в 12 классов. Кроме того, проводился отдельный конкурс по детектированию объектов, относящихся к этим 12 классам. В обеих номинациях победила китайская команда JD AI Research. На классификационном конкурсе они добились результата 92,3 % (среднее значение качества по 13 категориям). Публикации с подробным описанием их метода пока нет, есть только презентация с воркшопа.
Из особенностей их алгоритма можно отметить:
- Использование псевдо-лэйблов для данных из целевого домена и дообучение классификатора на них вместе с данными из исходного домена.
- Использование свёрточной сети SE-ResNeXt-101, слоёв AM-Softmax и Noise adaption layer, Generalized cross entropy loss для данных из целевого домена.
Схема алгоритма из презентации:
Заключение
По большей части мы обсуждали методы адаптации, построенные на adversarial-based подходе. Однако, в двух последних конкурсах VisDA победили алгоритмы, не связанные с ним и использующие обучение на псевдо-лэйблах и модификации более классических методов глубокого обучения. На мой взгляд, это связано с тем, что методы, основанные на GAN'ах, ещё только в начале своего развития и крайне нестабильны. Но с каждым годом мы получаем всё больше и больше новых результатов, улучшающих работу GAN'ов. К тому же, фокус интереса научного сообщества в сфере доменной адаптации в основном сосредоточен именно на adversarial-based методах, и новых статьях в основном исследуется этот подход. Поэтому велика вероятность, что алгоритмы, связанные с GAN'ами, постепенно выйдут на первые роли в вопросах адаптации.
Но исследования в не adversarial-based подходах также продолжаются. Вот несколько интересных статей из этой области:
Discrepancy-based методы можно отнести к разряду «исторических», однако многие идеи из них применяются в новейших методах: MMD, псевдо-лэйблы, metric-learning и т.д. К тому же, иногда в несложных задачах адаптации имеет смысл применять эти методы в силу их относительной простоты обучения и лучшей интерпретируемости результатов.
В заключение хочу отметить, что методы доменной адаптации пока ищут своё применение в прикладных областях, но перспективных задач, требующих использования адаптации, постепенно становится всё больше и больше. Например, domain adaptation активно используется в обучении модулей автономных автомобилей: поскольку набирать реальные данные на улицах городов для обучения автопилотов дорого и долго, в автономных машинах используются синтетические данные (базы SYNTHIA и GTA 5 служат их примерами), в частности. для решения задачи сегментации того, что «видит» камера из автомобиля.
Получение качественных моделей на основе глубокого обучения в Computer Vision во многом упирается в наличие больших размеченных датасетов для обучения. Разметка практически всегда требует большого количества времени и денег, что существенно увеличивает цикл разработки моделей и, как следствие, продуктов на их основе.
Методы доменной адаптации направлены на решение этой проблемы и потенциально могут способствовать прорыву во многих прикладных задачах и в искусственном интеллекте в целом. Перенос знаний с одного домена на другой — действительно трудная и интересная задача, которая в настоящее время активно исследуется. Если вы страдаете от нехватки данных в своих задачах, и можете эмулировать данные или найти похожие домены, то рекомендую попробовать методы доменной адаптаций!
