Привет, Хабр! Сегодня мы хотим поделиться с вами инструкцией по созданию бота, который будет анализировать вопросы и отвечать на них. Казалось бы, мы могли бы просто рассказать про QnA Maker, который выполняет эту функцию. Но, есть одна загвоздка – он поддерживает ограниченное количество языков. Поэтому, под катом мы поделимся пошаговой инструкцией создания Q&A-бота, универсального для любого языка.

Недавно наши коллеги сотрудничали с корейской компанией, которая хотела использовать на своем интернет-портале робота, способного отвечать пользователям на часто задаваемые вопросы (FAQ, QnA). Платформа Bot Framework предоставляет сервис такого типа (QnA Maker), в который для работы нужно загрузить список часто встречающихся вопросов и ответов по определенной тематике. Этот список также называют QnA-корпус. Проиндексировав такой корпус, QnA Maker предоставляет работающую через REST API службу поиска, способную находить наиболее подходящий ответ на вопрос в свободной текстовой форме.
В настоящее время QnA Maker не поддерживает корейский язык, поэтому нам пришлось создать похожую службу для ответа на частые вопросы без использования QnA Maker.
В данной статье описан способ создания внутренней службы, которая с помощью поиска Azure обеспечивает работу программы для обработки частых вопросов на языках, в настоящее время не поддерживаемых QnA Maker. В целях ознакомления с продуктом мы создадим службу для обработки вопросов на английском языке. Однако все описанные здесь шаги применимы к любому из языков, в настоящее время поддерживаемых поиском Azure (их список можно найти здесь).
Поиск Azure — это поисковая система, предлагаемая в Azure как услуга. Поиск Azure можно использовать для индексации пользовательских данных и выполнения поисковых запросов по индексированному корпусу. Мы можем настроить поиск Azure так, чтобы он проиндексировал имеющийся список вопросов и ответов и нашел наиболее близкие к вопросу пользователя ответы и метки. Поиск Azure отлично подходит для создания собственной службы вопросов и ответов не только из-за поддержки большинства распространенных языков, но и благодаря двум функциям:
В нашем решении мы обработаем в поиске Azure QnA-корпус, имеющий форму таблицы со следующими параметрами:
[
Здесь можно найти пример такой таблицы.
Использование функции профилей оценки позволяет нам создать несколько таких профилей и опробовать каждый из них на поисковом запросе для сравнения. В данном случае не существует магических чисел, определяющих идеальный профиль, и нам придется экспериментировать с различными весами полей, чтобы добиться наиболее точного результата.
Наше решение основано на использовании ключевых слов. Поле keywords помогает нам продвигать суть вопроса. Сообщив этому полю наибольший вес, мы «сдвигаем» результаты поиска в этом направлении: элементы, ключевые слова которых совпадают с ключевыми словами запроса, получат более высокую оценку.
В нашем примере мы создадим профиль оценки, в котором вышеописанным полям задан такой числовой вес:
В данном случае подразумевается, что в поле keywords содержатся ключевые слова, которые пользователь с наибольшей вероятностью использует в своем вопросе, поэтому этому полю дан наибольший вес. Следует также использовать поле question, но с меньшим весом, чем у поля keywords. В профиль оценки также следует включить поле answer: можно предположить, что некоторые слова будут употребляться и в вопросе, и в ответе на него. Однако этому полю мы зададим наименьший вес.
Чтобы облегчить создание нашей пробной модели, мы будем использовать QnA-корпус небольшого размера. Именно из-за малого объема корпуса может показаться, что мы получаем хорошую выдачу результатов и без использования профилей оценки. Однако чем больше элементов содержит корпус, тем лучше будет проявлять себя функция профиля оценки, помогая получать более точные результаты.
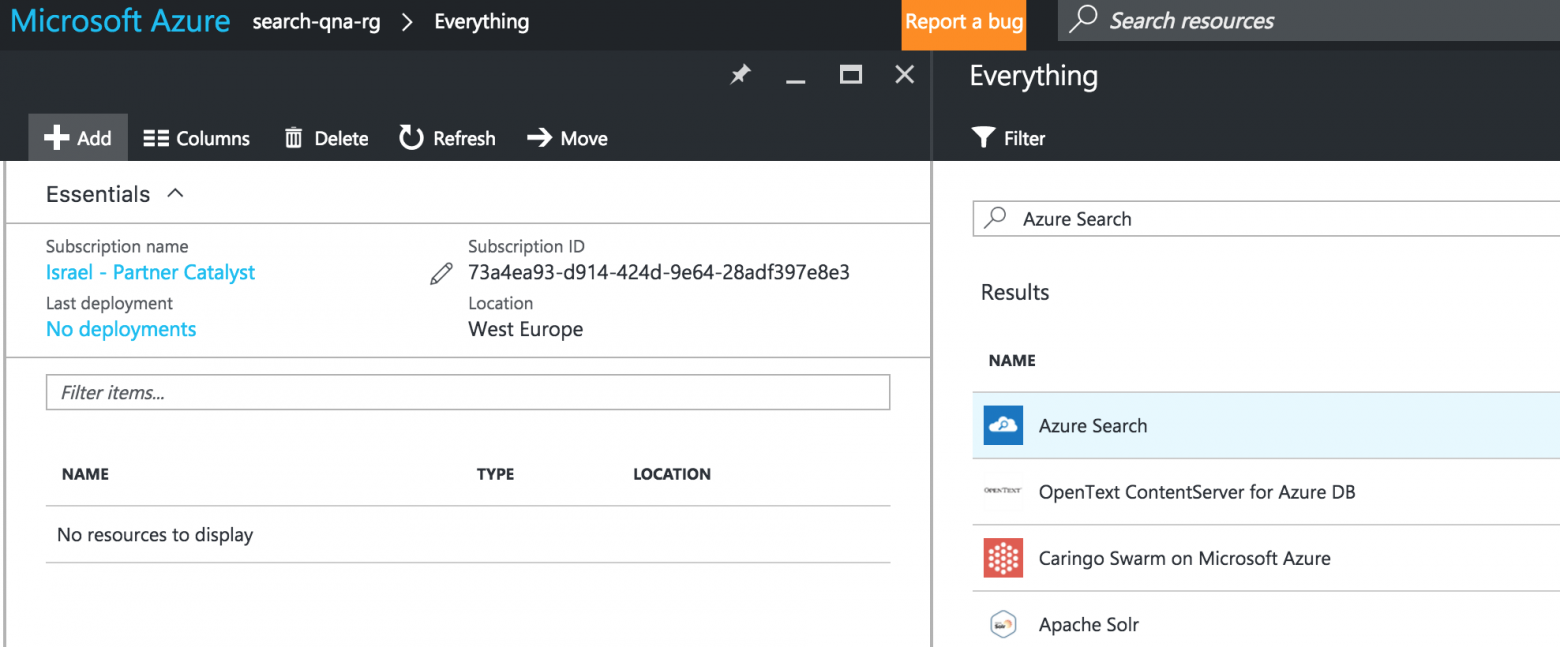
Откройте портал Azure и создайте новую группу ресурсов. Создайте в этой ресурсной группе новую службу поиска Azure так, как показано ниже:
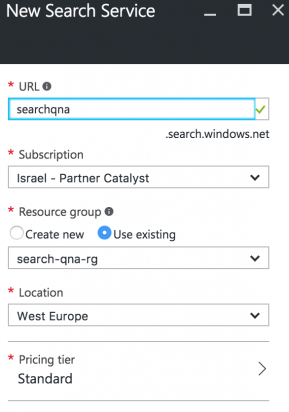
Введите имя поисковой службы, заполните остальные обязательные поля и нажмите ОК:
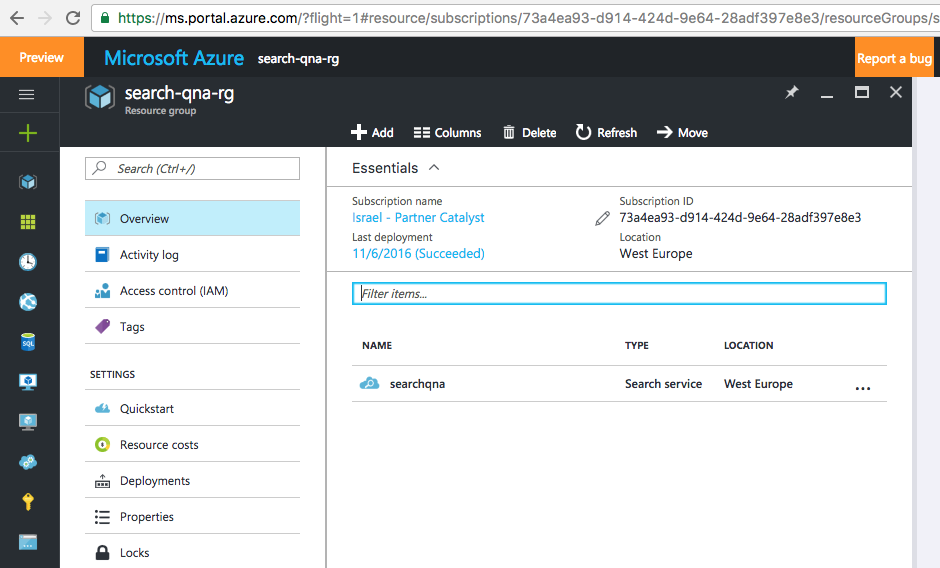
Так выглядит развернутая служба поиска Azure:
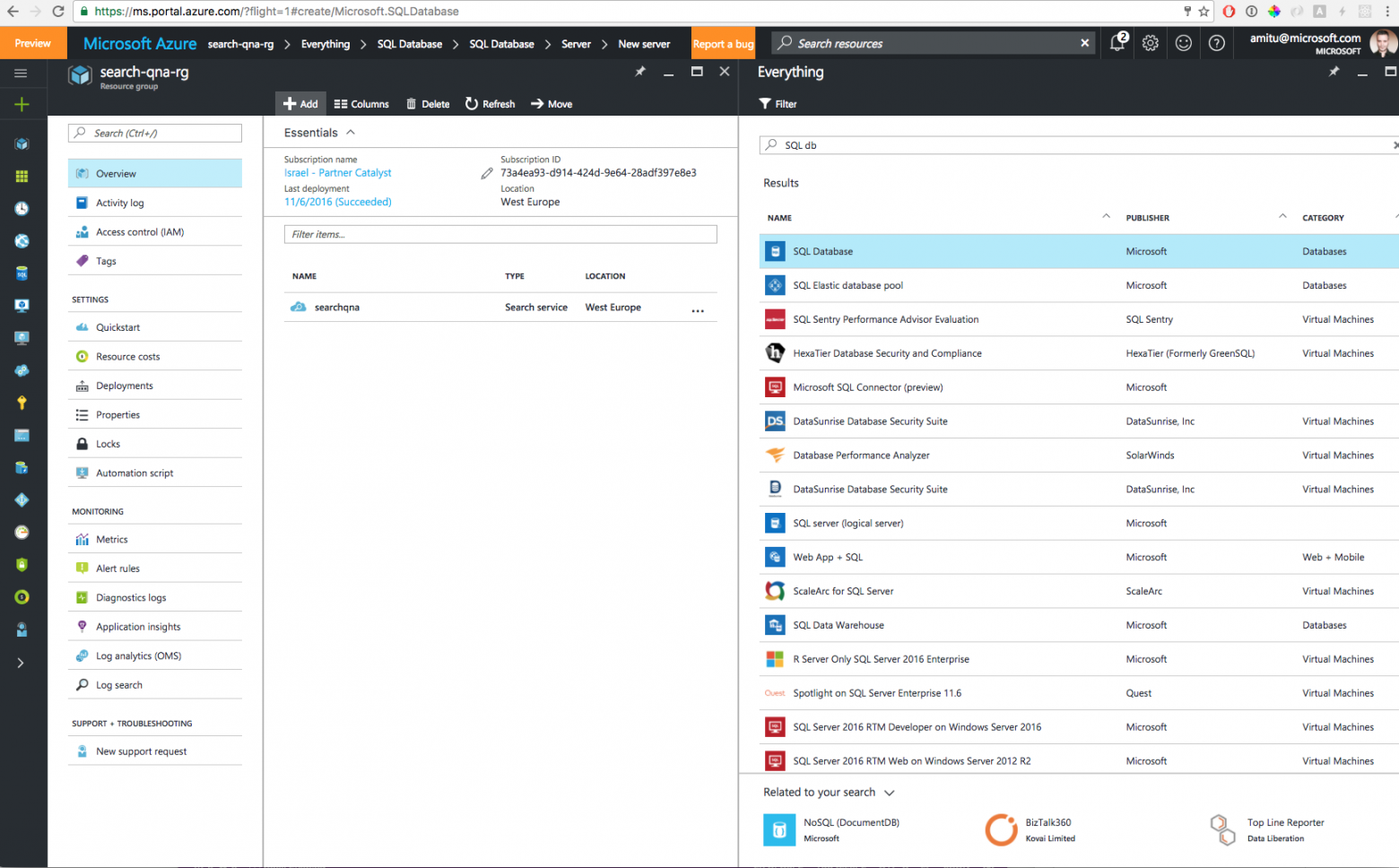
В поиск Azure можно импортировать данные из нескольких источников, например из баз данных документов, SQL или таблиц Azure. В нашем случае мы создали базу данных SQL, содержащую одну таблицу, и использовали ее в качестве источника для службы поиска:
Заполните обязательные поля:
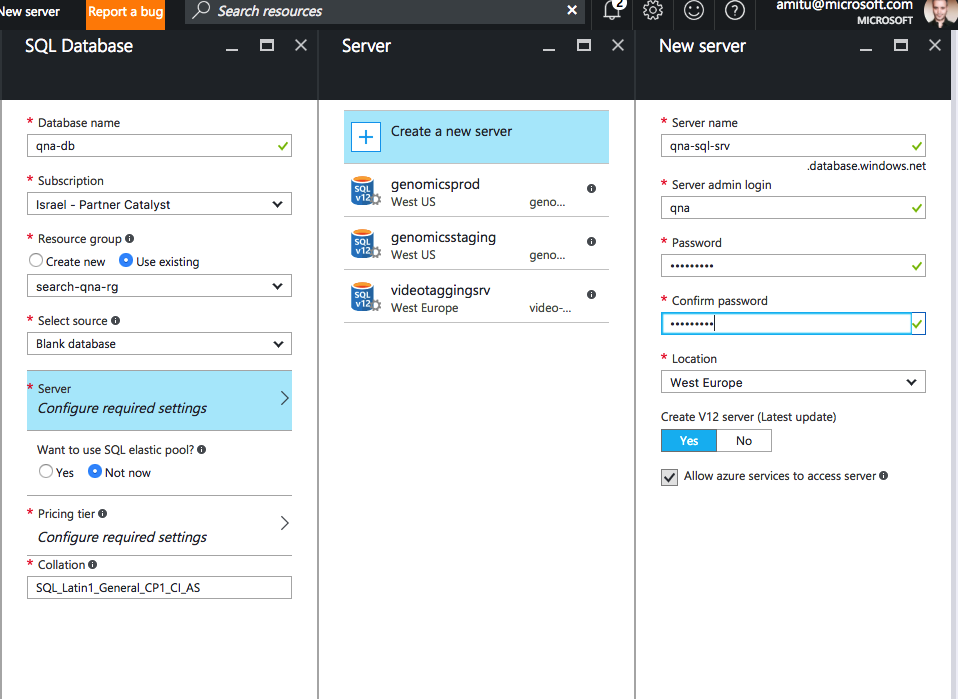
Так должна выглядеть служба после выполнения этих действий:
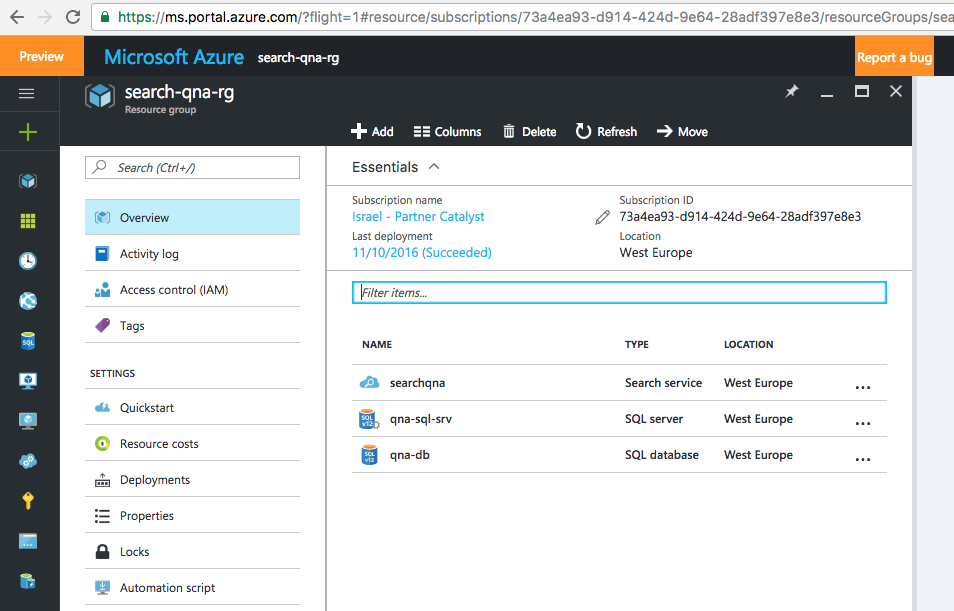
Чтобы подключиться к базе данных SQL, мы используем SQL Server Management Studio. Затем мы создаем таблицу с помощью следующего запроса:
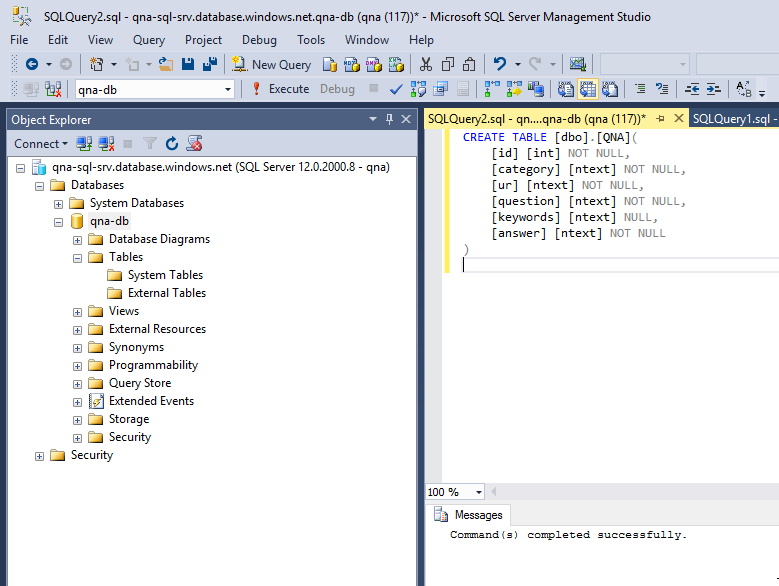
После этого мы вносим в нашу таблицу несколько вопросов и ответов:
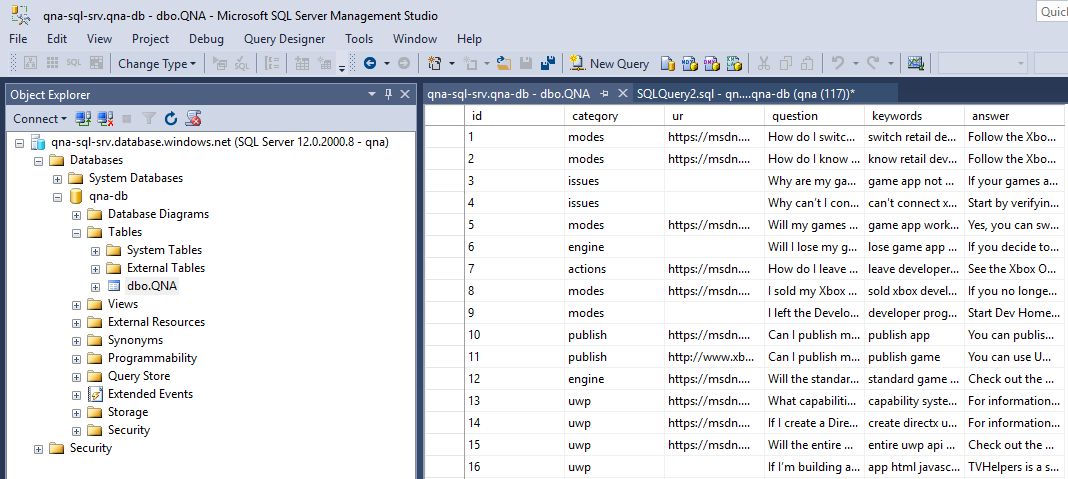
Теперь данные готовы, пора импортировать их в службу поиска. Чтобы сделать это, выполните действия, указанные в красных рамках:
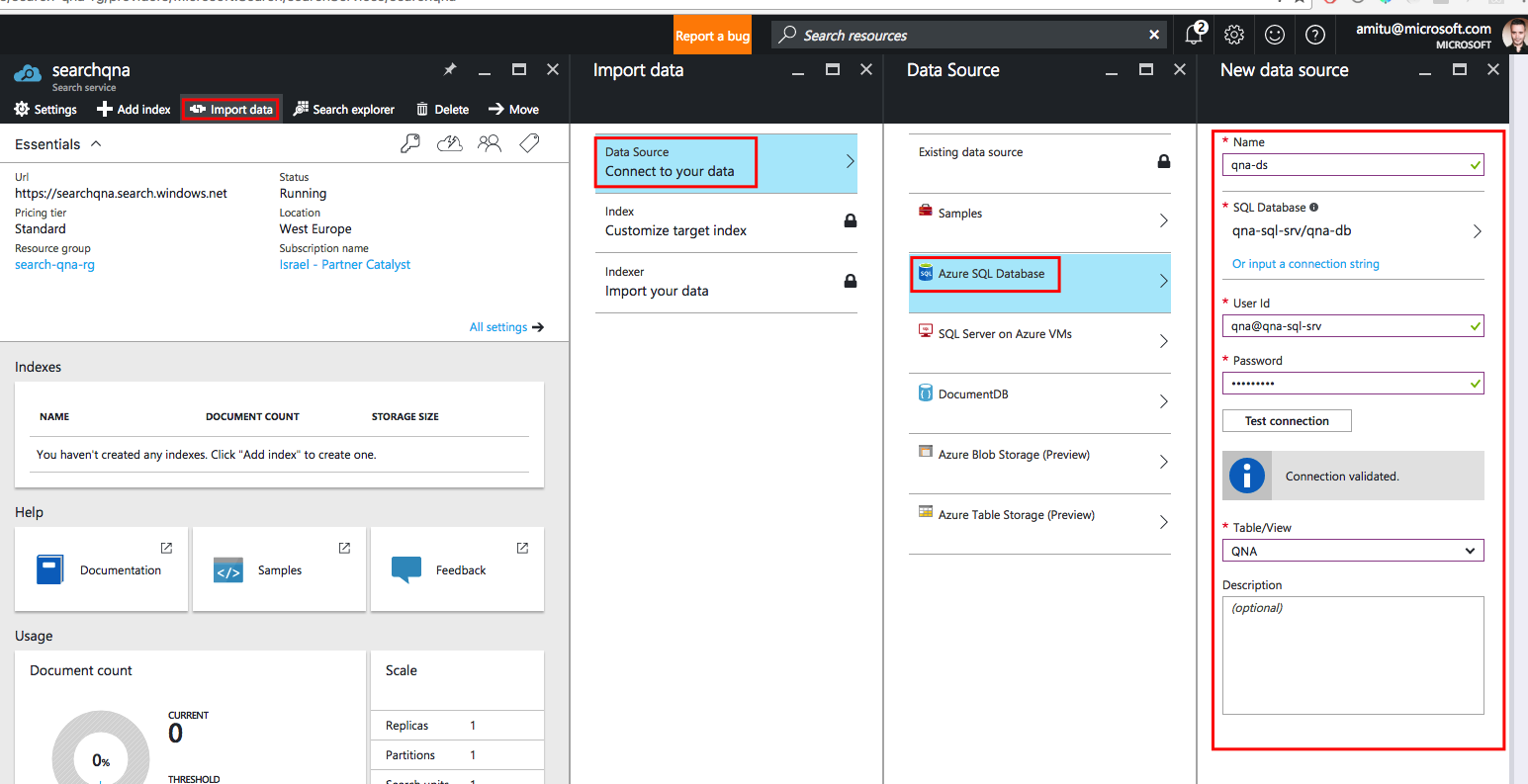
После подключения к SQL мастер импорта данных позволяет нам определить атрибуты индекса. Введите имя индекса, а затем в выпадающем списке «Ключевое поле» выберите поле Id.
Теперь для каждого из полей таблицы нам нужно выбрать несколько атрибутов:
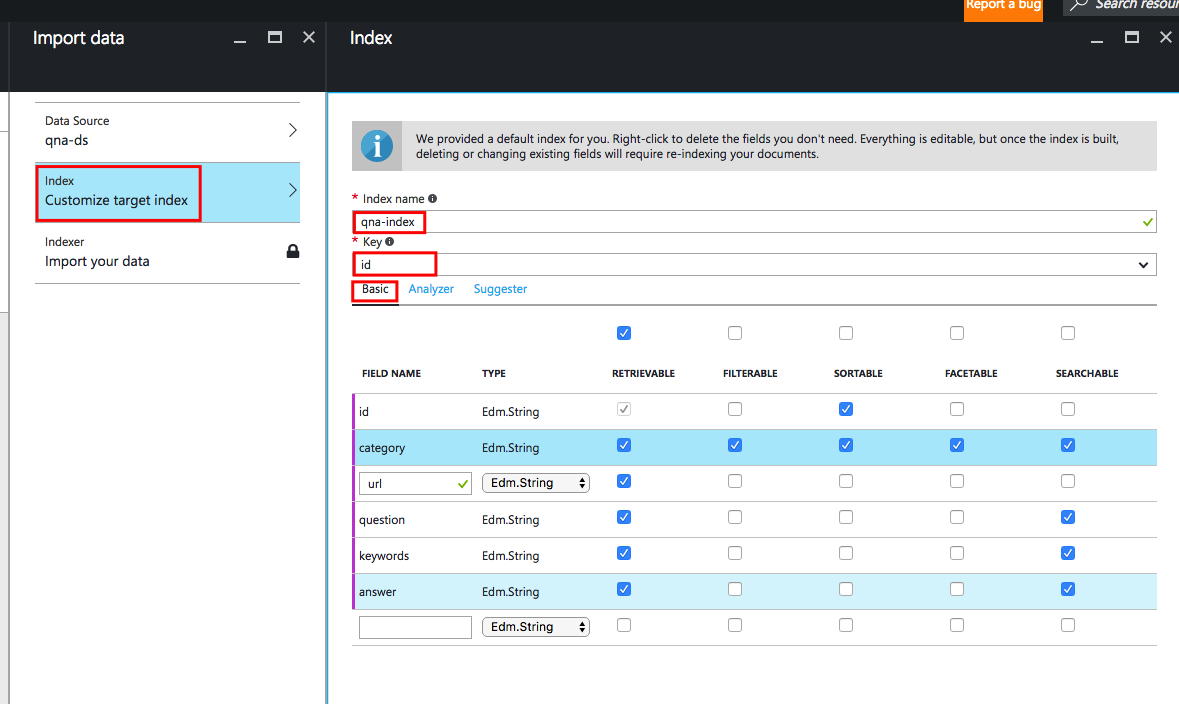
Теперь мы определим анализаторы, использующиеся для каждого поля. В данном случае мы использовали анализатор «
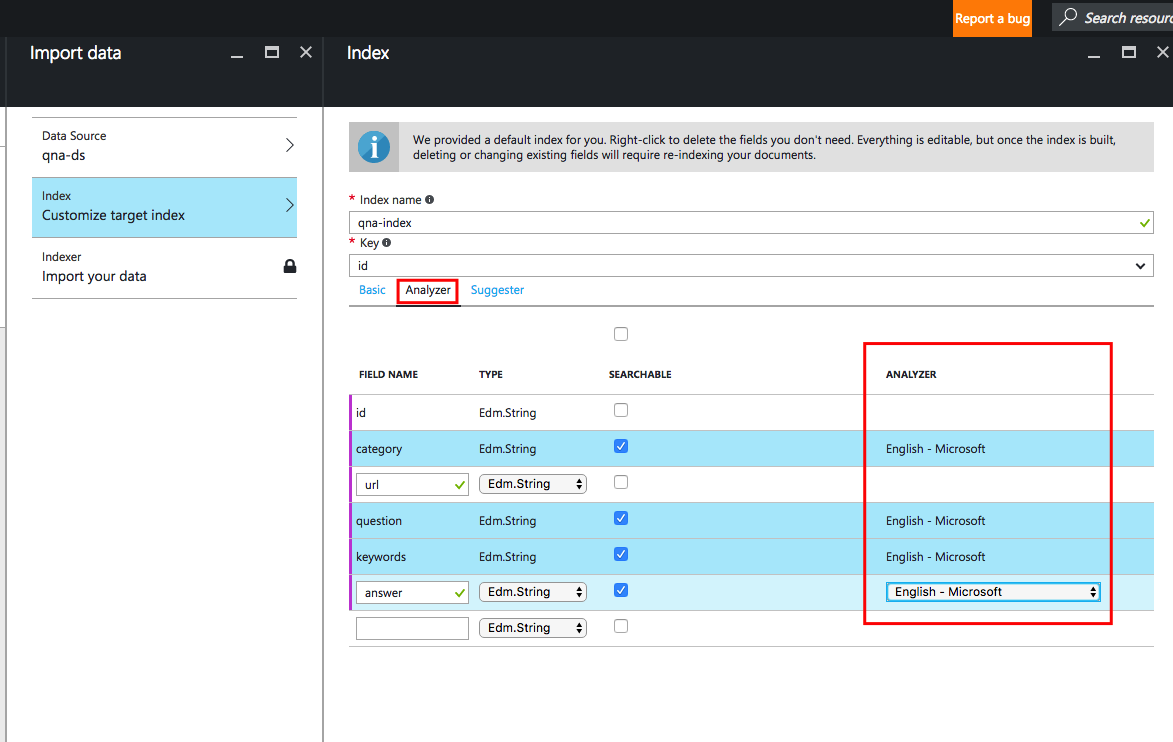
Для нашей пробной модели я поставлю значение планировщика «Однократно». Здесь вы можете выбрать, насколько часто система должна переиндексировать вашу базу данных в поисках изменений и обновлений:
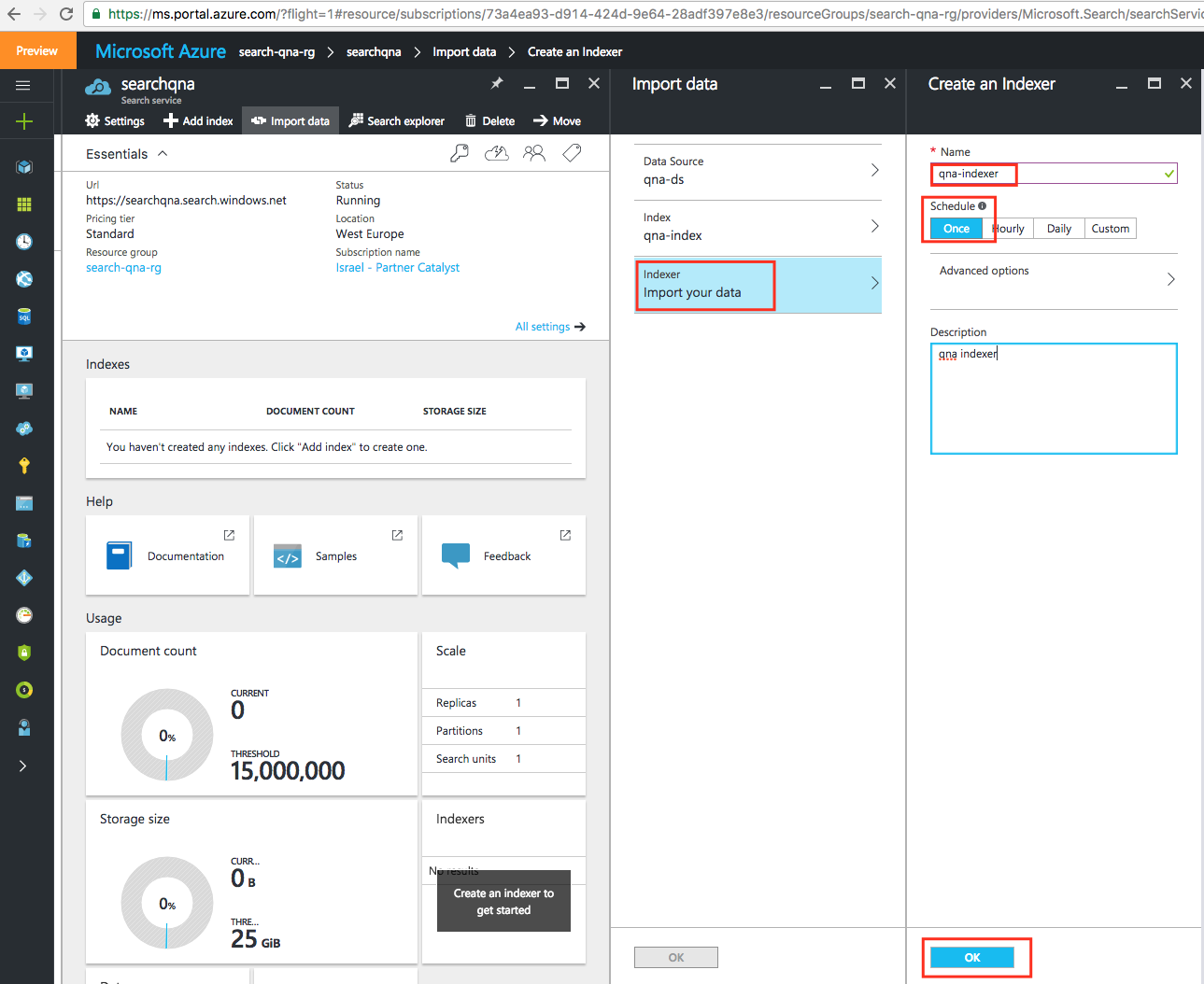
Нажмите OK. После выполнения предыдущих шагов вы получите оповещение об успешном выполнении импорта данных.
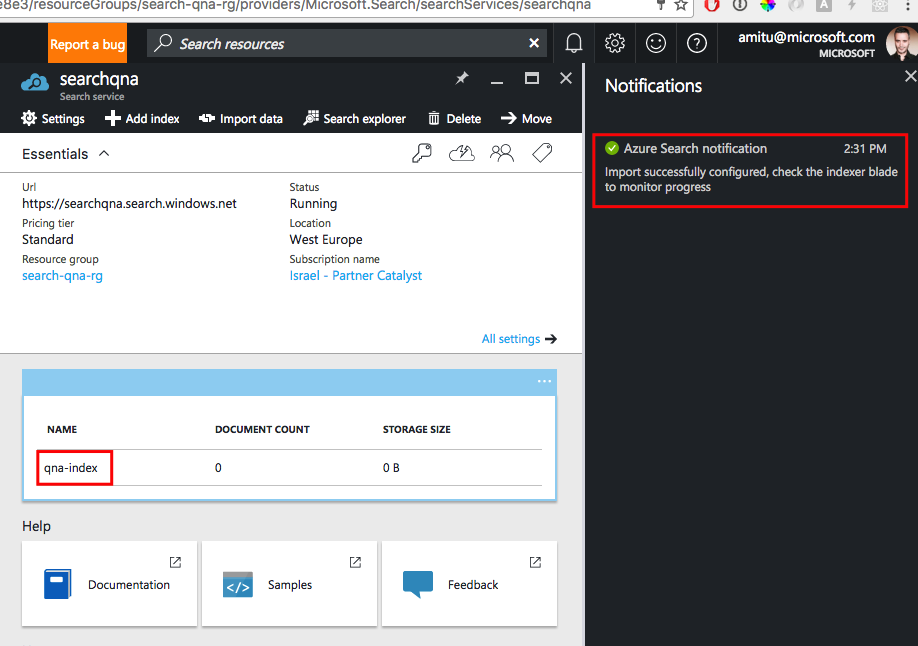
Чтобы создать свой профиль оценки, выполните действия, указанные в красных рамках на снимке экрана ниже:
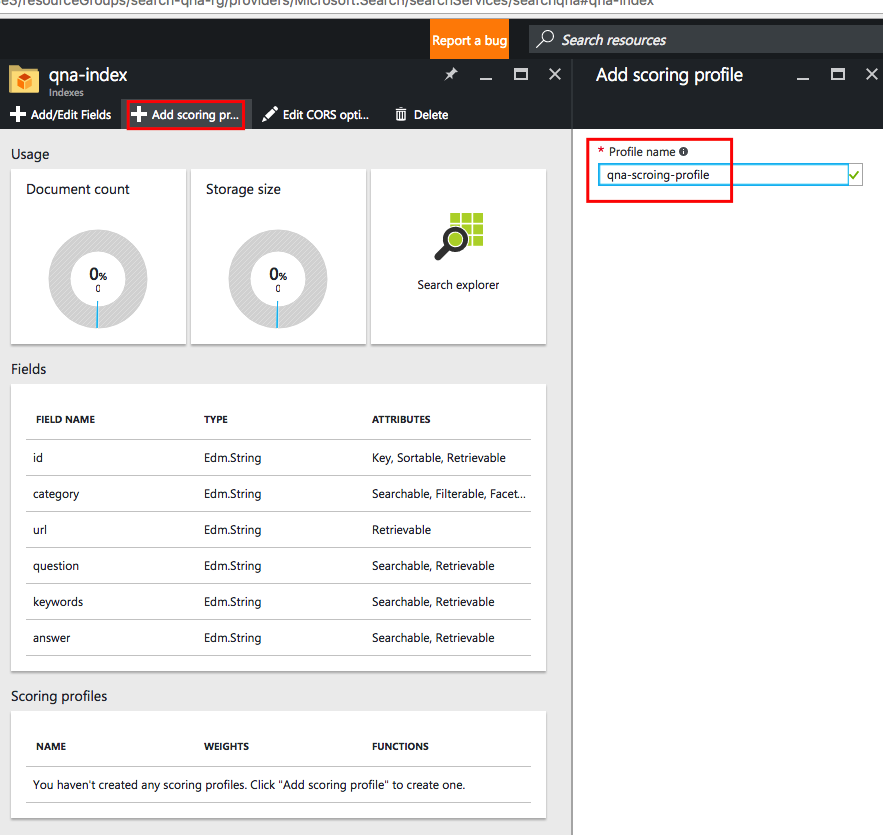
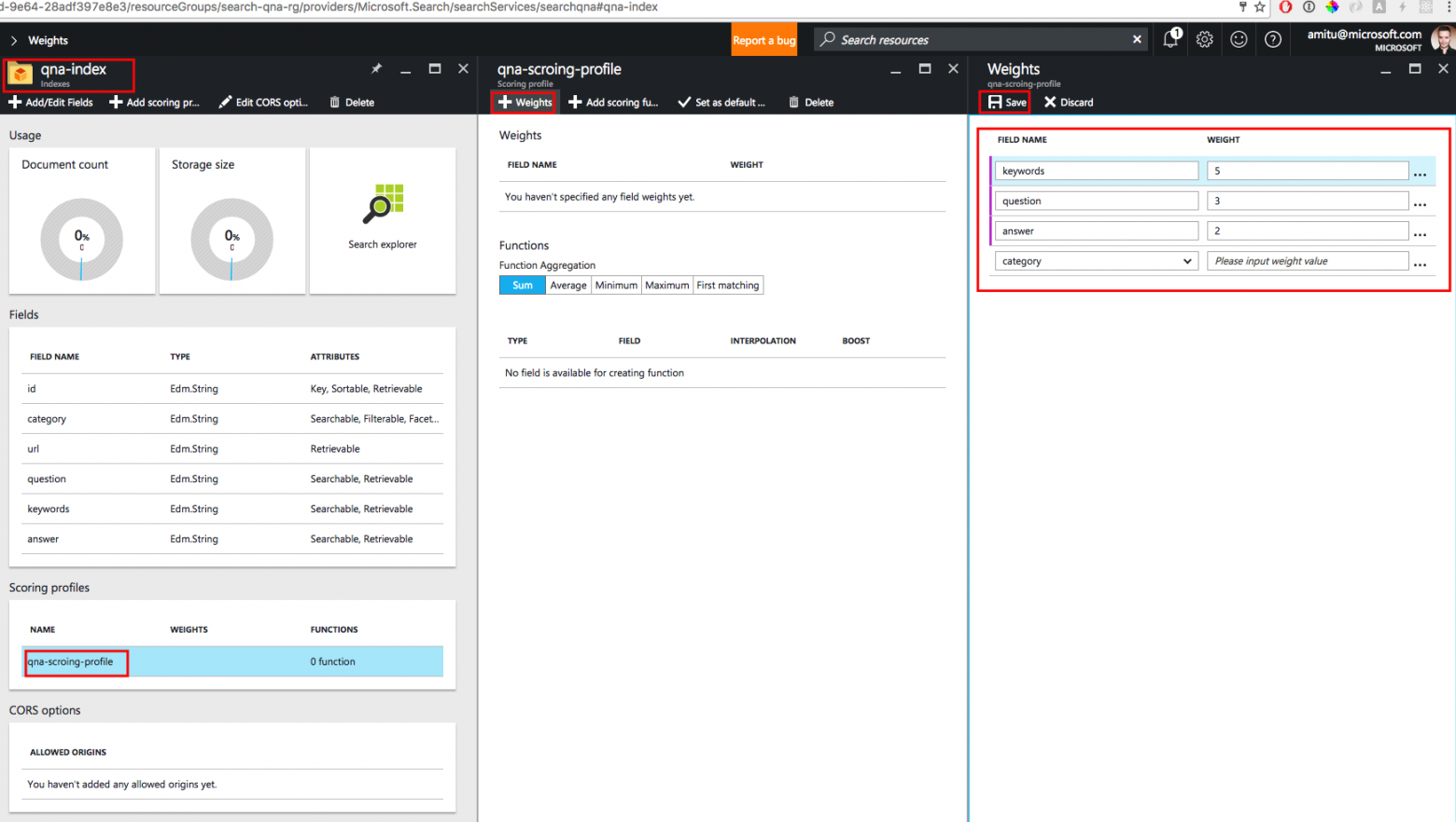
Затем нам нужно задать для полей базы данных вес, о котором мы говорили ранее:
Теперь мы готовы к поиску по нашему корпусу вопросов и ответов. Нажмите на плитку обозревателя поиска, как показано на снимке экрана ниже:
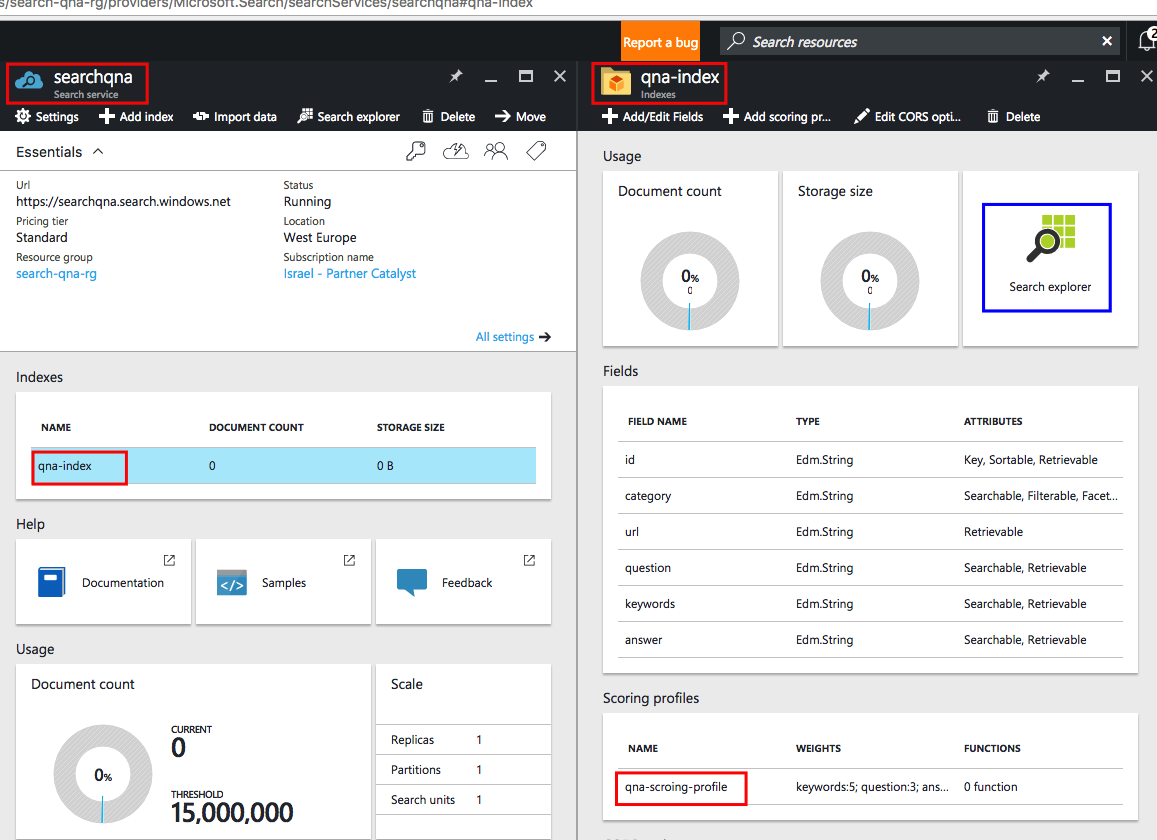
Обозреватель поиска позволяет легко вызывать REST API, не покидая портал. На этом этапе мы можем начать экспериментировать с нашей поисковой системой.
Введите search=вопрос_в_свободной_форме в строке запроса, как показано ниже. По этому запросу система выполнит простой поиск по полям, доступным для поиска, не используя профиль оценки.
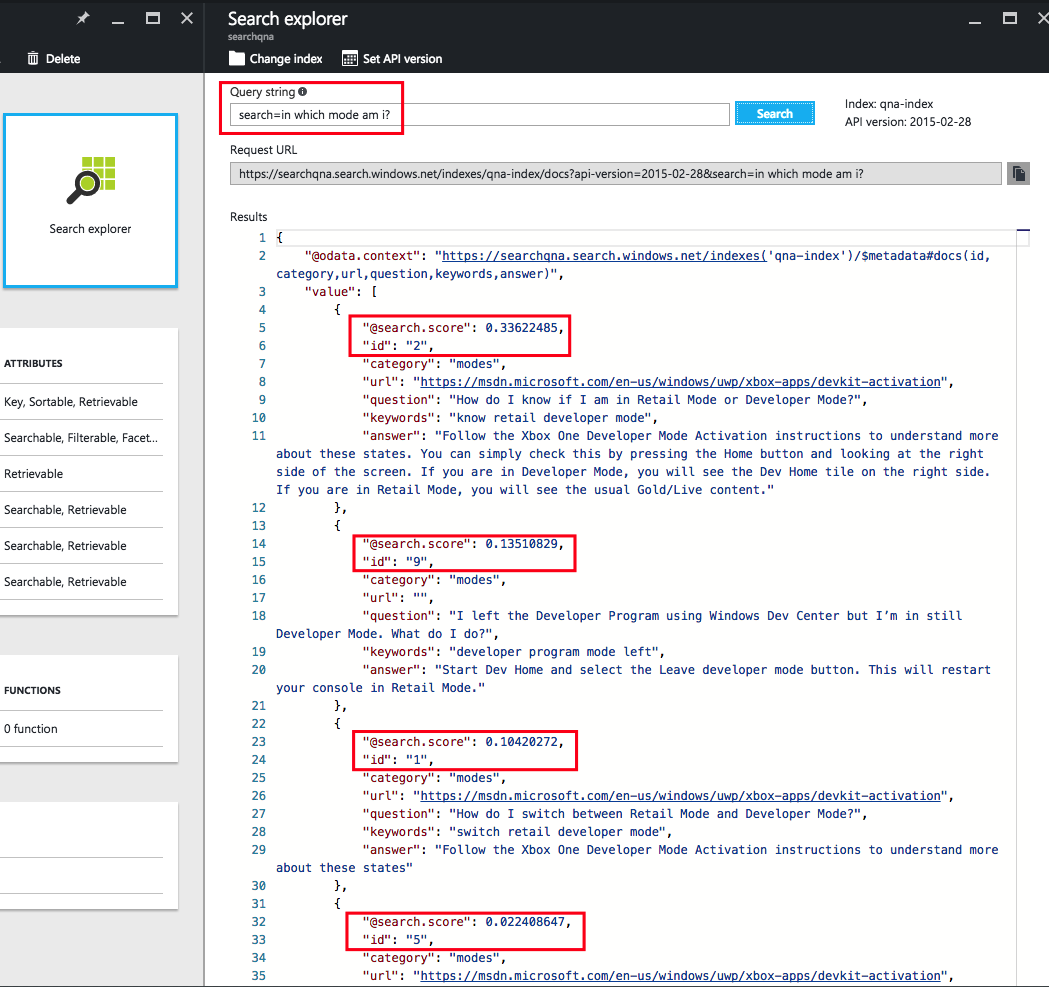
Давайте используем профиль оценки, добавив его в строку запроса:
Примечание. Можно заметить, что в выдачу результатов поиска Azure попали не те же элементы и оценки, что раньше (последним элементом будет не 5, как при поиске без профиля оценки, а 14). На маленьком корпусе сложно продемонстрировать, как сильно помогает профиль оценки. Однако при наличии большого корпуса профиль оценки имеет огромное значение.
Узнать больше о параметрах поиска и вызове API поисковой службы вы можете из этой статьи.
В данном примере мы использовали функцию аспектов, чтобы поисковая система посчитала количество элементов поисковой выдачи, входящих в каждую из категорий. Эта функция может быть полезна, если результатов в каждой категории немного. В таком случае пользователя можно спросить, результаты из какой категории он хотел бы увидеть, и показать ему количество элементов в каждой. После того как пользователь выберет категорию, мы можем детализировать запрос, отфильтровав результаты внутри категории с помощью дополнительного поиска:
В этой статье мы описали порядок действий для создания бота «вопросов/ответов». Например, с помощью данного подхода можно создать систему вопросов и ответов для норвежского языка или иврита — языков, не поддерживаемых в официальной версии QnA Maker.
Примечание. Описанным в статье путем можно создавать не только роботов. Этот подход применим и к созданию поисковой службы общего назначения, работающей в определенной тематике. Профили оценки помогут улучшить ее работу.
Кроме того, благодаря функции добавления меток к отдельно проиндексированным записям в поиске Azure алгоритм выше можно использовать для масштабируемой мультиклассовой классификации текста. Такая способность полезна для программ, которым необходимо категоризировать намерения пользователей, выражаемые ими в сообщениях. Конечно, для этих целей уже существуют отдельные продукты, например Luis или Azure ML, но при наличии более 10–15 категорий классификация может стать для них сложной задачей. Описанный подход могут использовать, к примеру, врачи для классификации протоколов лечения в системе, куда уже внесены сотни протоколов. Поиск Azure поможет классифицировать текст, сравнив его с крупным корпусом схожих материалов.
Напоминаем, что недавно мы рассказывали о том, как научить LUIS понимать другие языки.

Ситуация
Недавно наши коллеги сотрудничали с корейской компанией, которая хотела использовать на своем интернет-портале робота, способного отвечать пользователям на часто задаваемые вопросы (FAQ, QnA). Платформа Bot Framework предоставляет сервис такого типа (QnA Maker), в который для работы нужно загрузить список часто встречающихся вопросов и ответов по определенной тематике. Этот список также называют QnA-корпус. Проиндексировав такой корпус, QnA Maker предоставляет работающую через REST API службу поиска, способную находить наиболее подходящий ответ на вопрос в свободной текстовой форме.
Проблема
В настоящее время QnA Maker не поддерживает корейский язык, поэтому нам пришлось создать похожую службу для ответа на частые вопросы без использования QnA Maker.
Решение
В данной статье описан способ создания внутренней службы, которая с помощью поиска Azure обеспечивает работу программы для обработки частых вопросов на языках, в настоящее время не поддерживаемых QnA Maker. В целях ознакомления с продуктом мы создадим службу для обработки вопросов на английском языке. Однако все описанные здесь шаги применимы к любому из языков, в настоящее время поддерживаемых поиском Azure (их список можно найти здесь).
Поиск Azure — это поисковая система, предлагаемая в Azure как услуга. Поиск Azure можно использовать для индексации пользовательских данных и выполнения поисковых запросов по индексированному корпусу. Мы можем настроить поиск Azure так, чтобы он проиндексировал имеющийся список вопросов и ответов и нашел наиболее близкие к вопросу пользователя ответы и метки. Поиск Azure отлично подходит для создания собственной службы вопросов и ответов не только из-за поддержки большинства распространенных языков, но и благодаря двум функциям:
- Анализаторы расширяют поисковый запрос с помощью словаря синонимов и связанных выражений, чтобы увеличить вероятность нахождения подходящих единиц в корпусе.
- Профиль оценки позволяет придавать больший или меньший относительный вес различным полям индексированных элементов. В системе поиска Azure этот профиль используется для оценки результатов запроса и напрямую влияет на их расположение при выдаче.
В нашем решении мы обработаем в поиске Azure QnA-корпус, имеющий форму таблицы со следующими параметрами:
[
id, category, url, question, answer, keywords]- Поле id — уникальный ключ элемента.
- Поле keywords — ключевые слова, которые лучше всего описывают вопрос.
- Поле url используется в случаях, когда в рамках ответа мы хотим направить пользователя по внешней ссылке.
- Свойства и задачи поля category будут описаны позднее, когда мы перейдем к более сложному сценарию.
Здесь можно найти пример такой таблицы.
Использование функции профилей оценки позволяет нам создать несколько таких профилей и опробовать каждый из них на поисковом запросе для сравнения. В данном случае не существует магических чисел, определяющих идеальный профиль, и нам придется экспериментировать с различными весами полей, чтобы добиться наиболее точного результата.
Наше решение основано на использовании ключевых слов. Поле keywords помогает нам продвигать суть вопроса. Сообщив этому полю наибольший вес, мы «сдвигаем» результаты поиска в этом направлении: элементы, ключевые слова которых совпадают с ключевыми словами запроса, получат более высокую оценку.
В нашем примере мы создадим профиль оценки, в котором вышеописанным полям задан такой числовой вес:
keywords— 5;question— 3;answer— 2.
В данном случае подразумевается, что в поле keywords содержатся ключевые слова, которые пользователь с наибольшей вероятностью использует в своем вопросе, поэтому этому полю дан наибольший вес. Следует также использовать поле question, но с меньшим весом, чем у поля keywords. В профиль оценки также следует включить поле answer: можно предположить, что некоторые слова будут употребляться и в вопросе, и в ответе на него. Однако этому полю мы зададим наименьший вес.
Чтобы облегчить создание нашей пробной модели, мы будем использовать QnA-корпус небольшого размера. Именно из-за малого объема корпуса может показаться, что мы получаем хорошую выдачу результатов и без использования профилей оценки. Однако чем больше элементов содержит корпус, тем лучше будет проявлять себя функция профиля оценки, помогая получать более точные результаты.
Чтобы создать службу обработки вопросов и ответов в поиске Azure, выполните следующие действия
Откройте портал Azure и создайте новую группу ресурсов. Создайте в этой ресурсной группе новую службу поиска Azure так, как показано ниже:
Введите имя поисковой службы, заполните остальные обязательные поля и нажмите ОК:
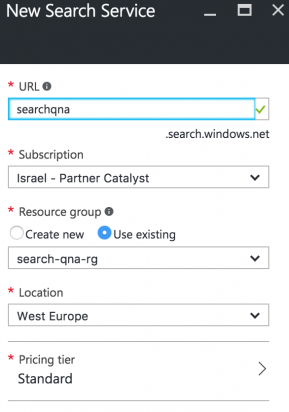
Так выглядит развернутая служба поиска Azure:
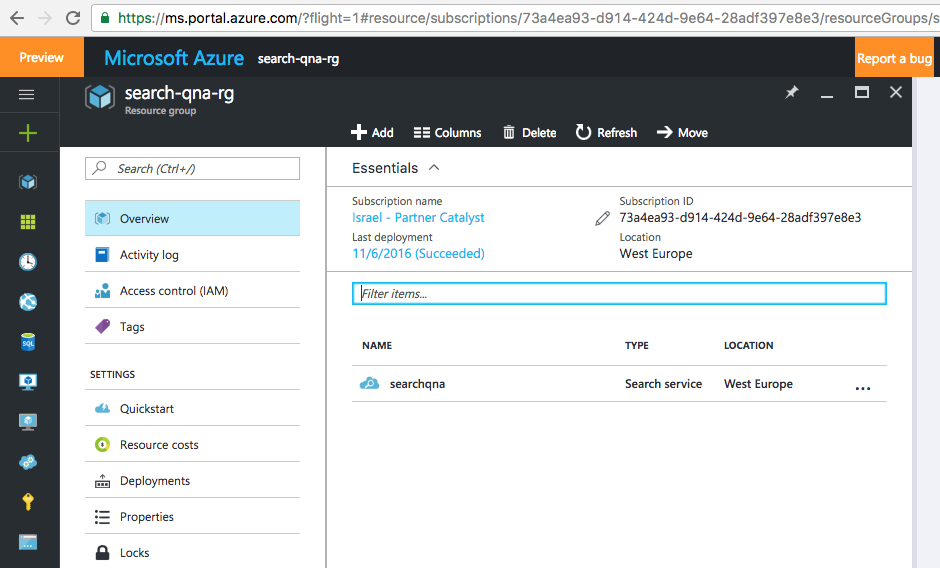
В поиск Azure можно импортировать данные из нескольких источников, например из баз данных документов, SQL или таблиц Azure. В нашем случае мы создали базу данных SQL, содержащую одну таблицу, и использовали ее в качестве источника для службы поиска:

Заполните обязательные поля:
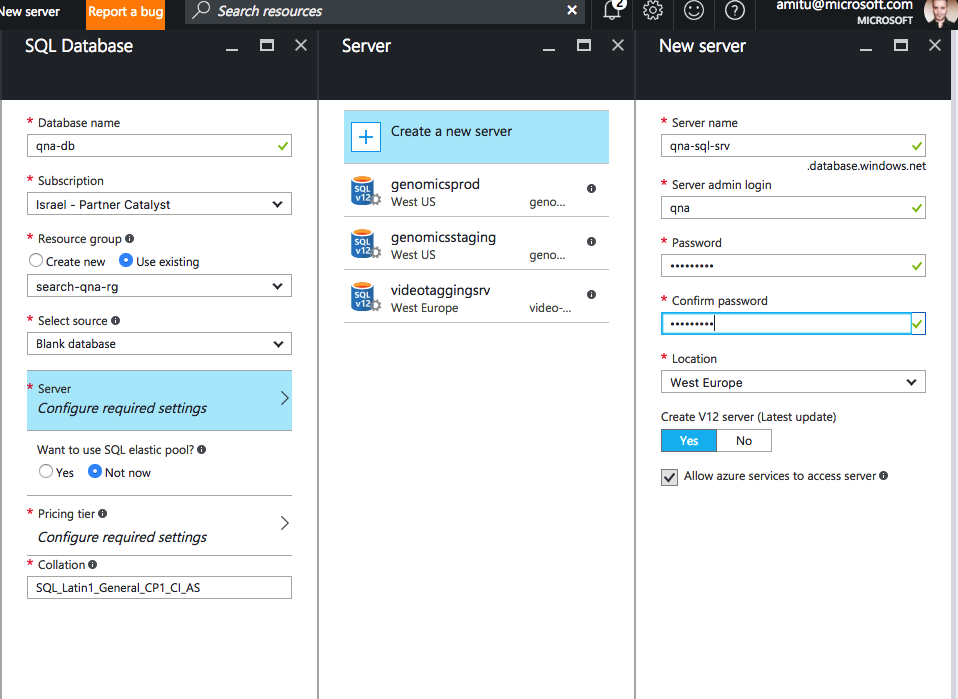
Так должна выглядеть служба после выполнения этих действий:
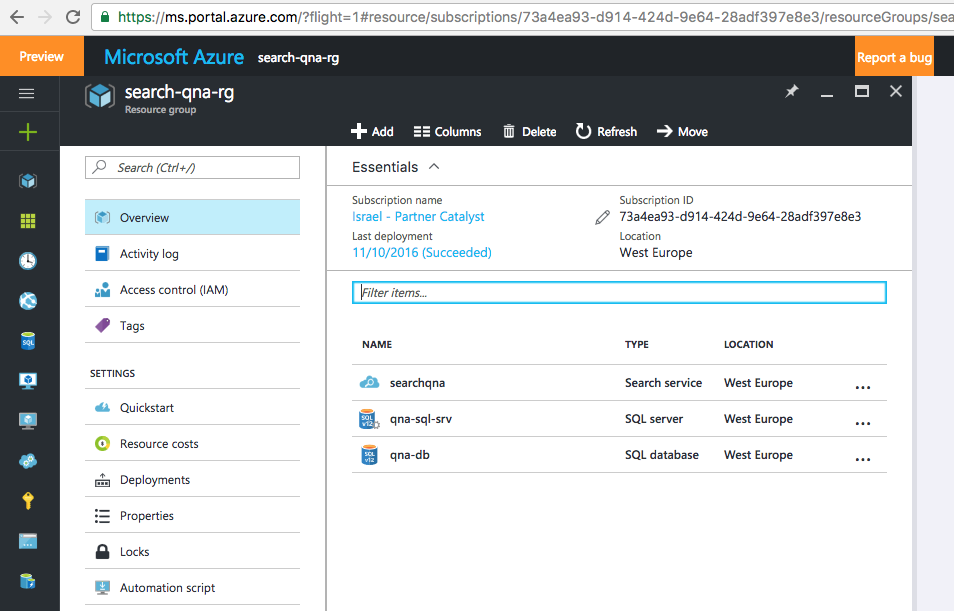
Чтобы подключиться к базе данных SQL, мы используем SQL Server Management Studio. Затем мы создаем таблицу с помощью следующего запроса:
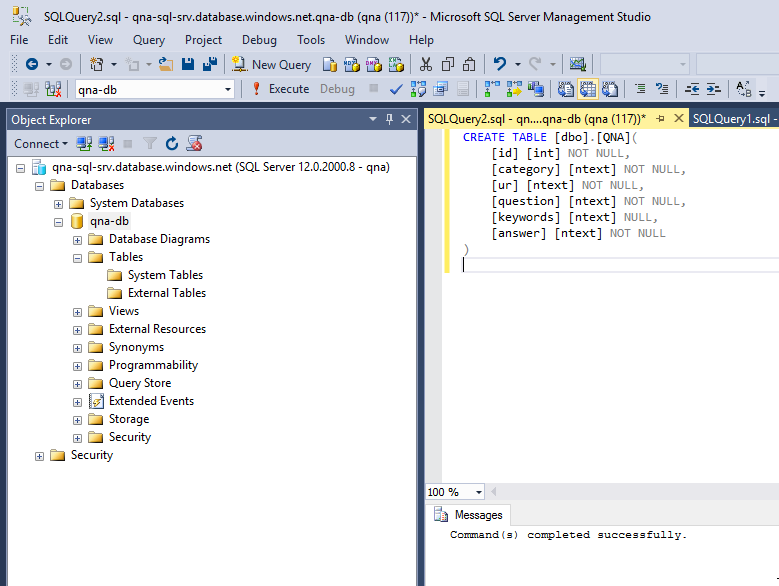
После этого мы вносим в нашу таблицу несколько вопросов и ответов:
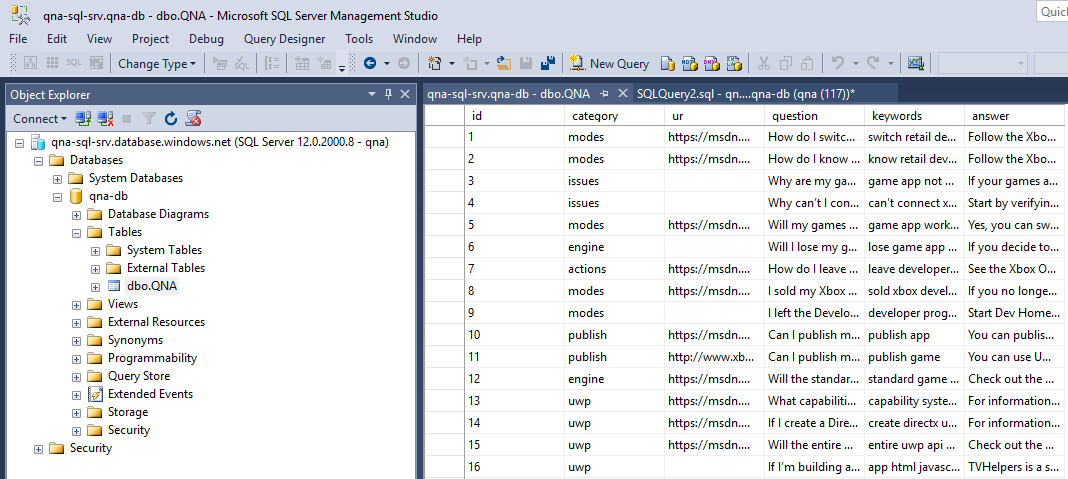
Теперь данные готовы, пора импортировать их в службу поиска. Чтобы сделать это, выполните действия, указанные в красных рамках:
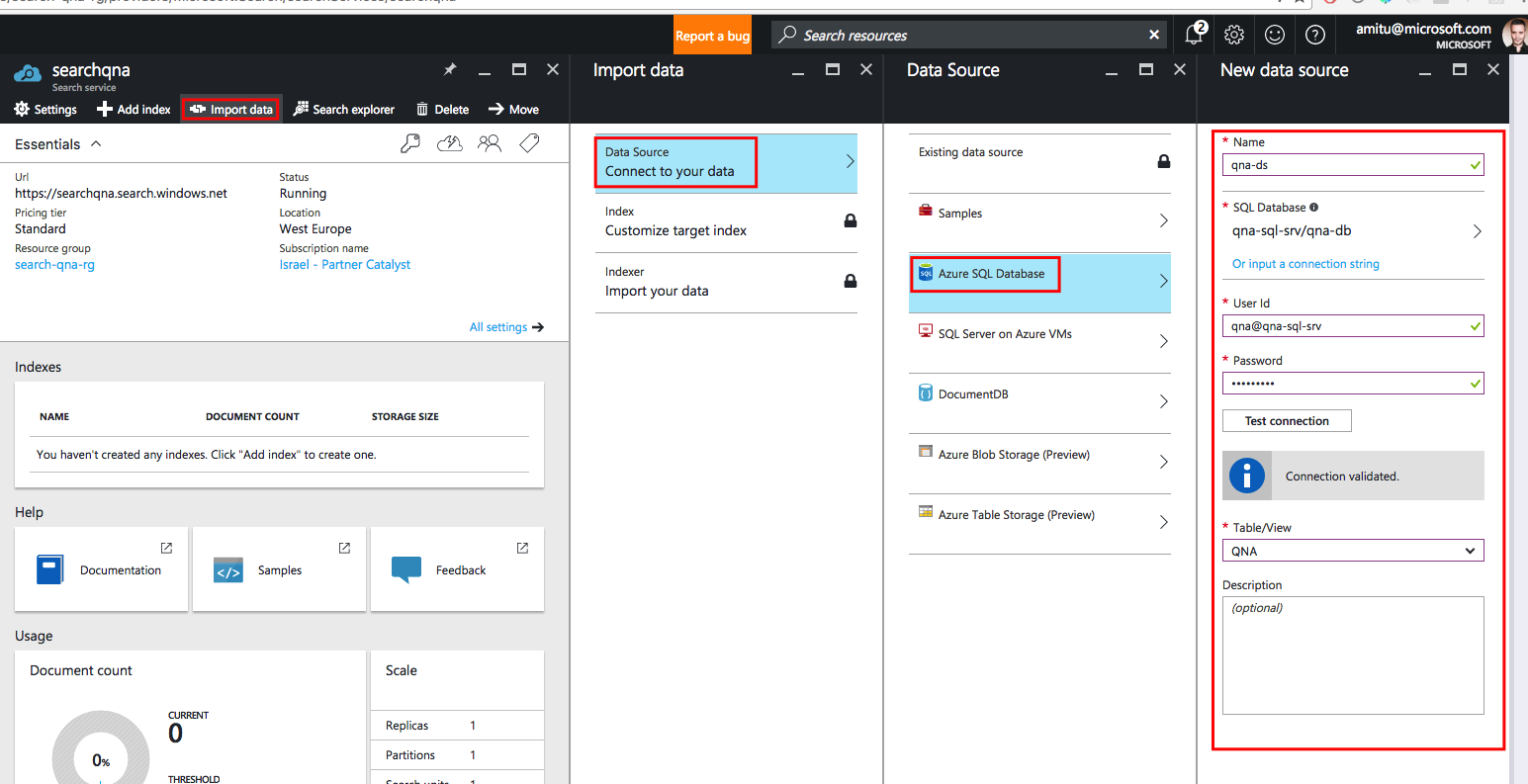
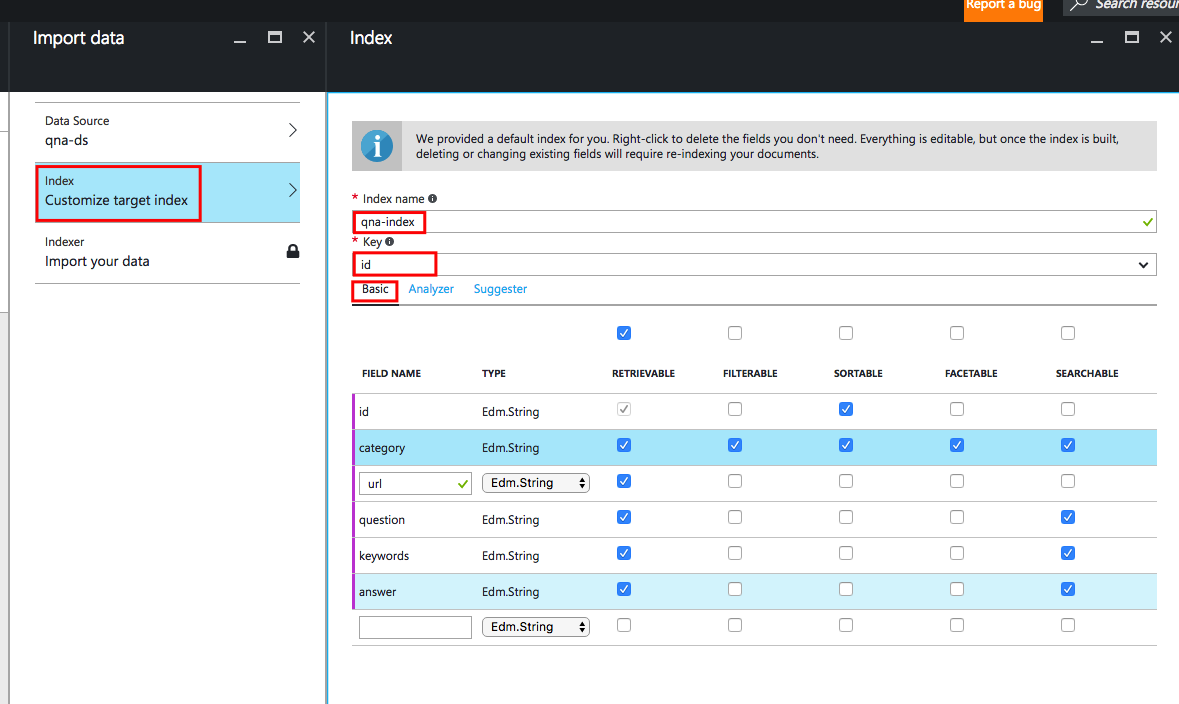
После подключения к SQL мастер импорта данных позволяет нам определить атрибуты индекса. Введите имя индекса, а затем в выпадающем списке «Ключевое поле» выберите поле Id.
Теперь для каждого из полей таблицы нам нужно выбрать несколько атрибутов:
- Атрибут «Доступный для получения» означает, что поле будет отображаться в результатах поиска.
- Атрибут «Фильтруемый» означает, что результаты можно будет отфильтровать по этому полю.
- Атрибут «Сортируемый» означает, что результаты можно будет отсортировать по этому полю.
- Атрибут «Аспектируемый» означает, что результаты поиска будут разбиваться на группы согласно содержимому этого поля, и рядом с каждой из групп будет отображаться число элементов в ней. Позже мы увидим, как работает этот атрибут.
- Атрибут «Доступный для поиска», присвоенный полям, означает, что поисковая система будет анализировать содержащиеся в них данные при фактическом выполнении поиска.
Теперь мы определим анализаторы, использующиеся для каждого поля. В данном случае мы использовали анализатор «
Английский — Microsoft» для всех полей, доступных для поиска. Используйте анализатор «Язык — Microsoft», соответствующий используемому вами языку: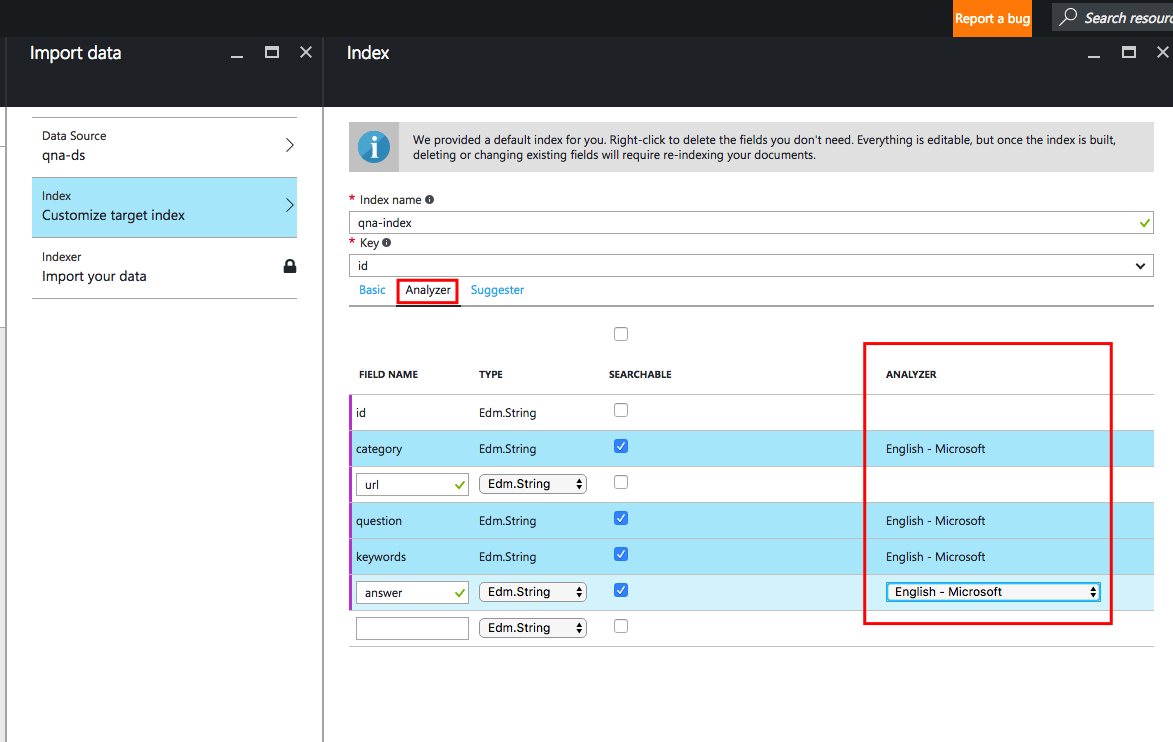
Для нашей пробной модели я поставлю значение планировщика «Однократно». Здесь вы можете выбрать, насколько часто система должна переиндексировать вашу базу данных в поисках изменений и обновлений:
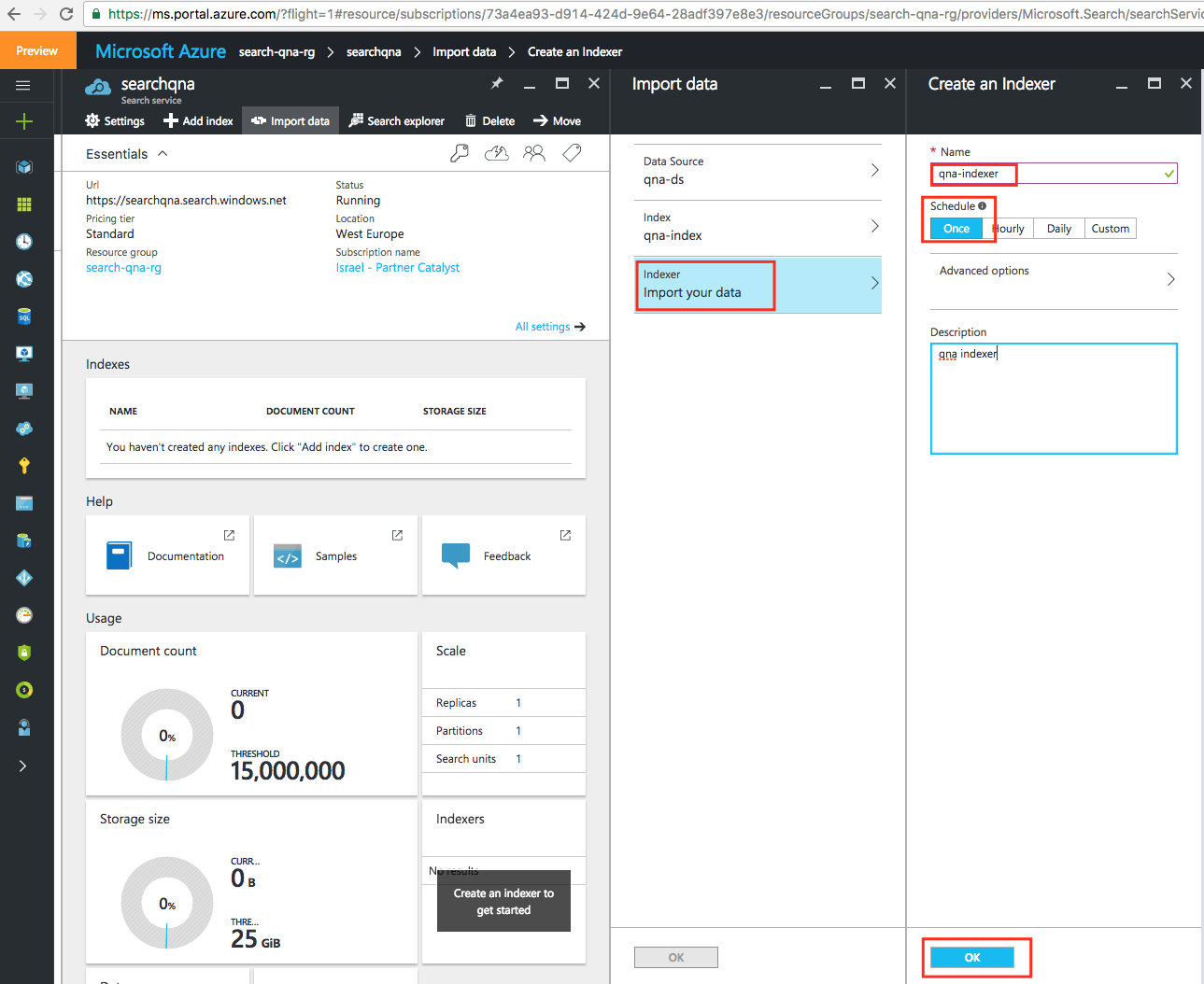
Нажмите OK. После выполнения предыдущих шагов вы получите оповещение об успешном выполнении импорта данных.
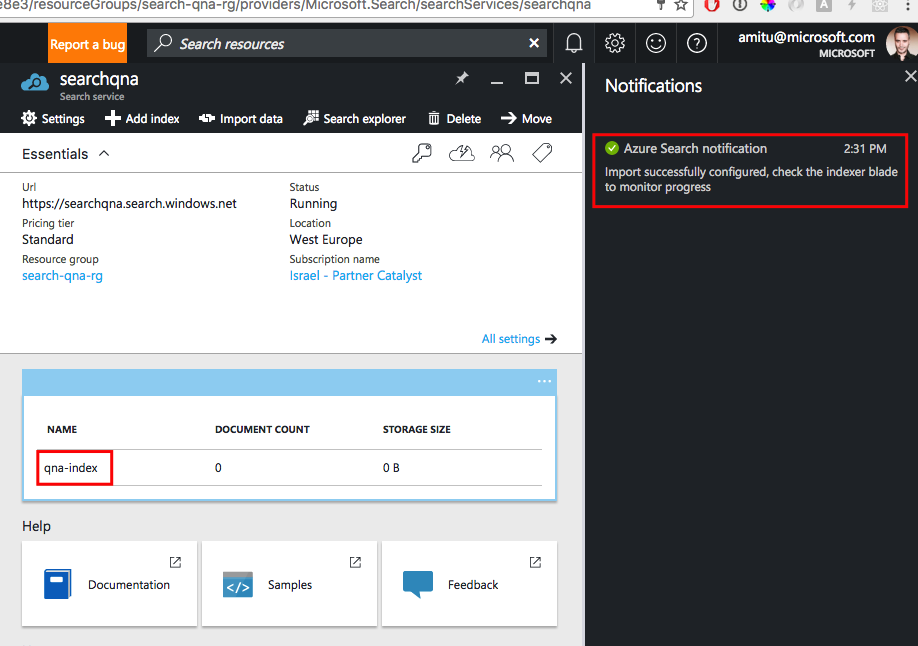
Чтобы создать свой профиль оценки, выполните действия, указанные в красных рамках на снимке экрана ниже:
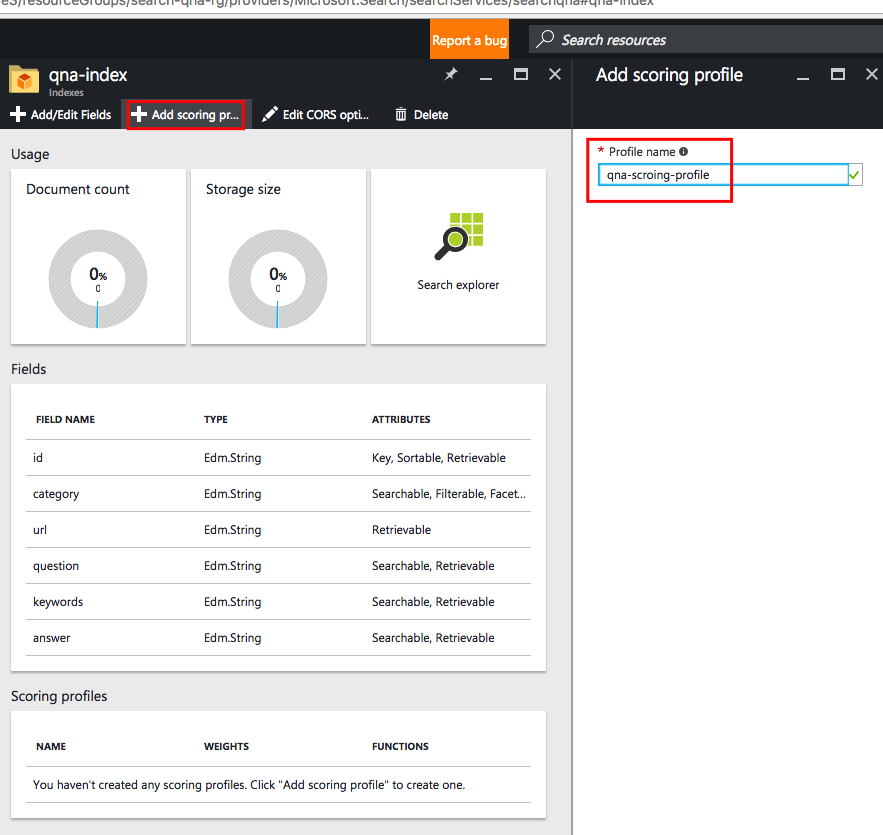
Затем нам нужно задать для полей базы данных вес, о котором мы говорили ранее:
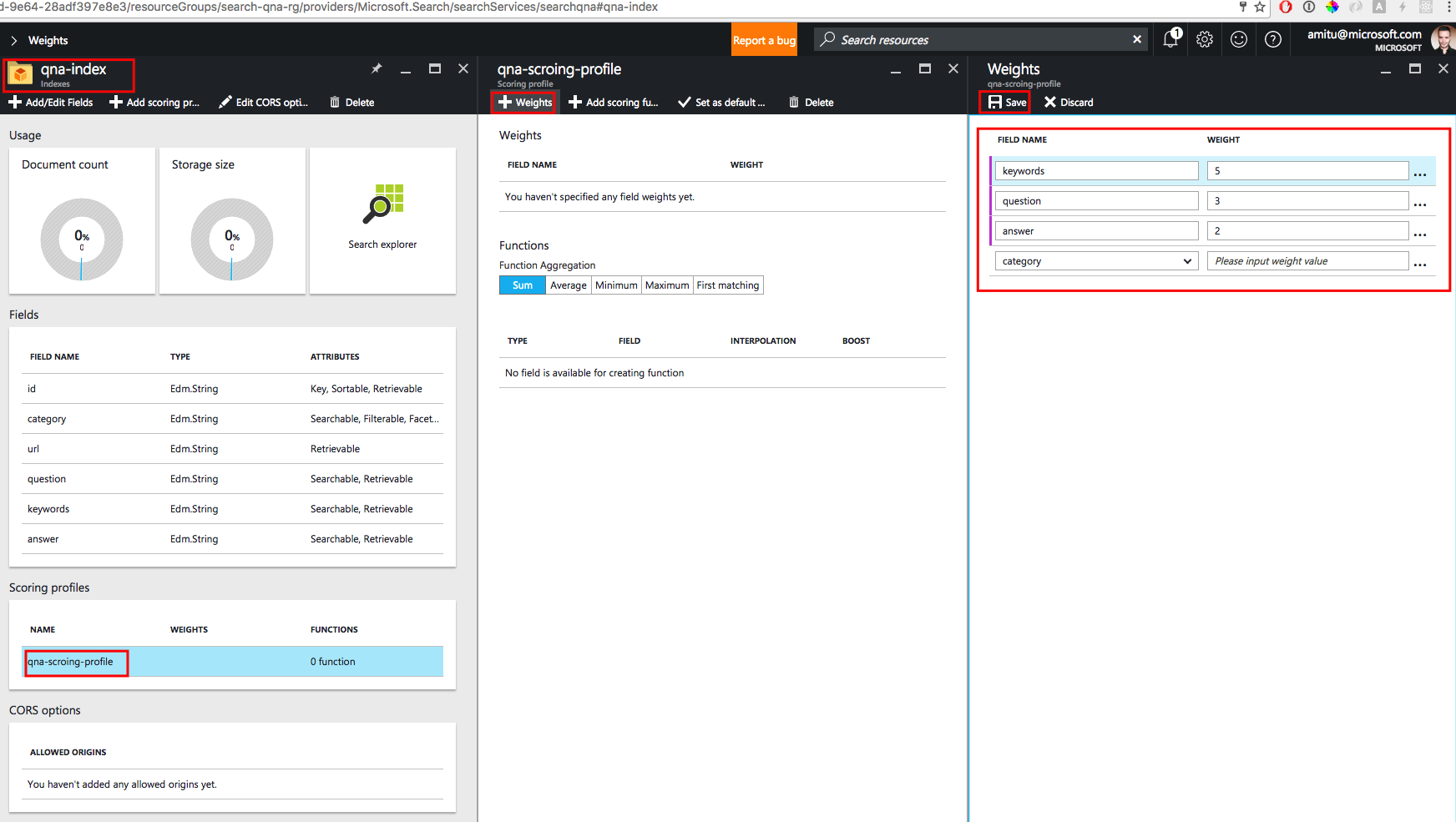
Теперь мы готовы к поиску по нашему корпусу вопросов и ответов. Нажмите на плитку обозревателя поиска, как показано на снимке экрана ниже:

Обозреватель поиска позволяет легко вызывать REST API, не покидая портал. На этом этапе мы можем начать экспериментировать с нашей поисковой системой.
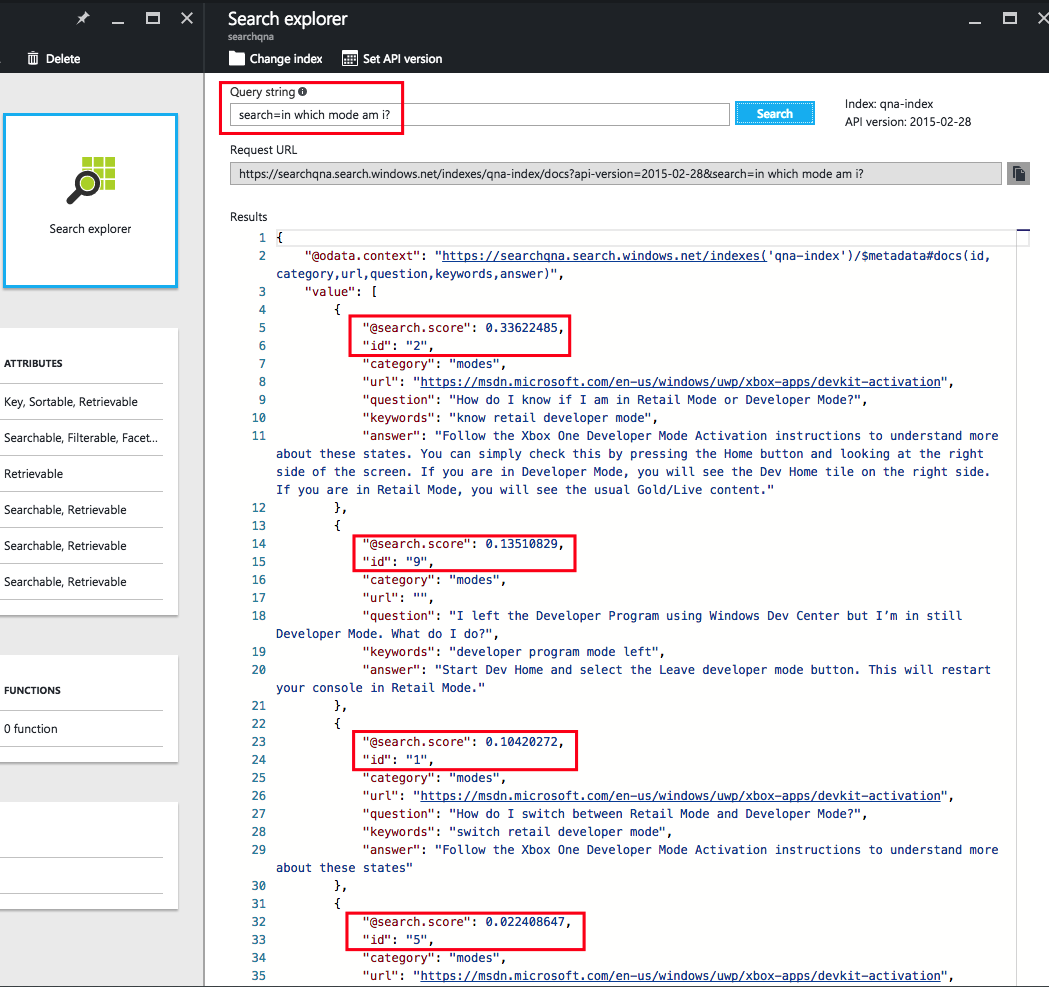
Введите search=вопрос_в_свободной_форме в строке запроса, как показано ниже. По этому запросу система выполнит простой поиск по полям, доступным для поиска, не используя профиль оценки.
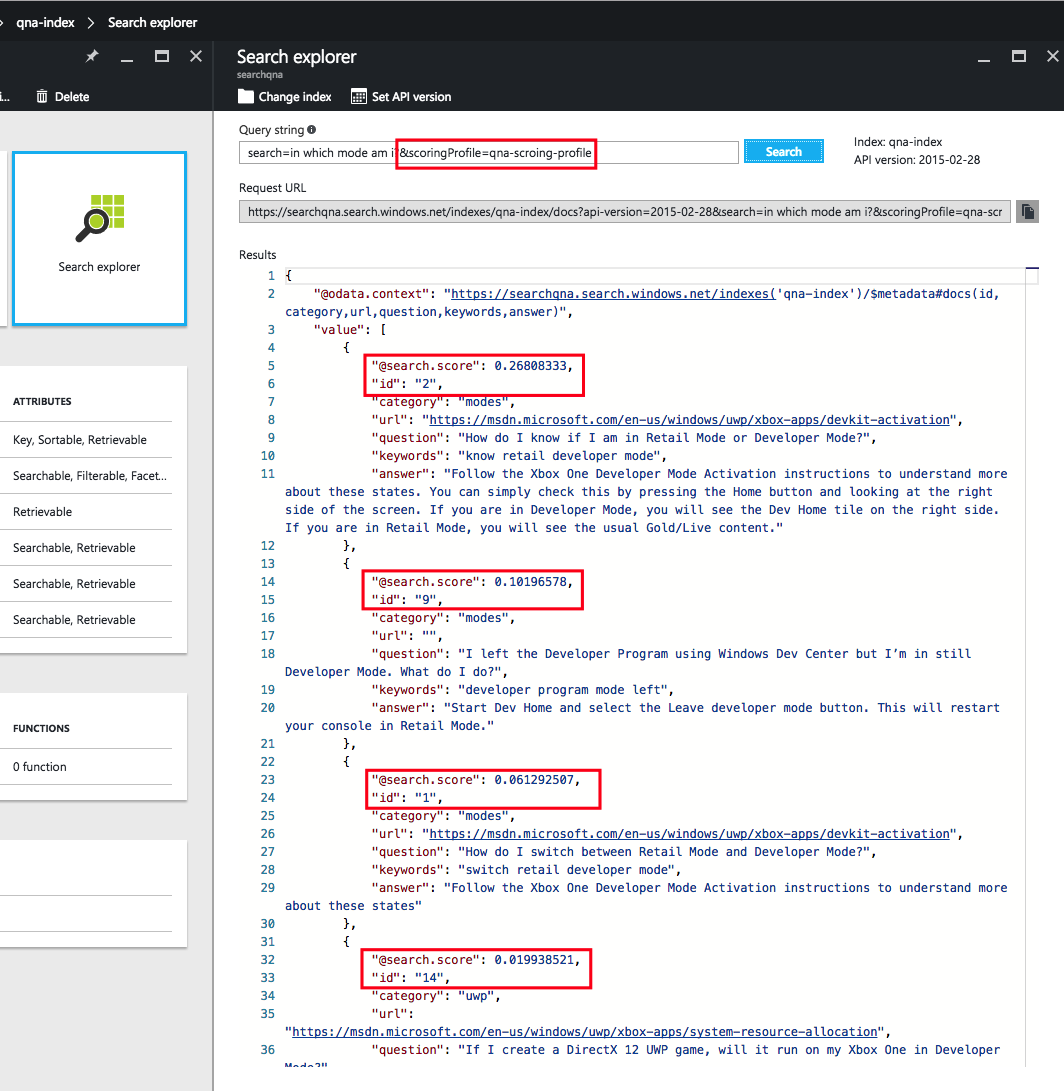
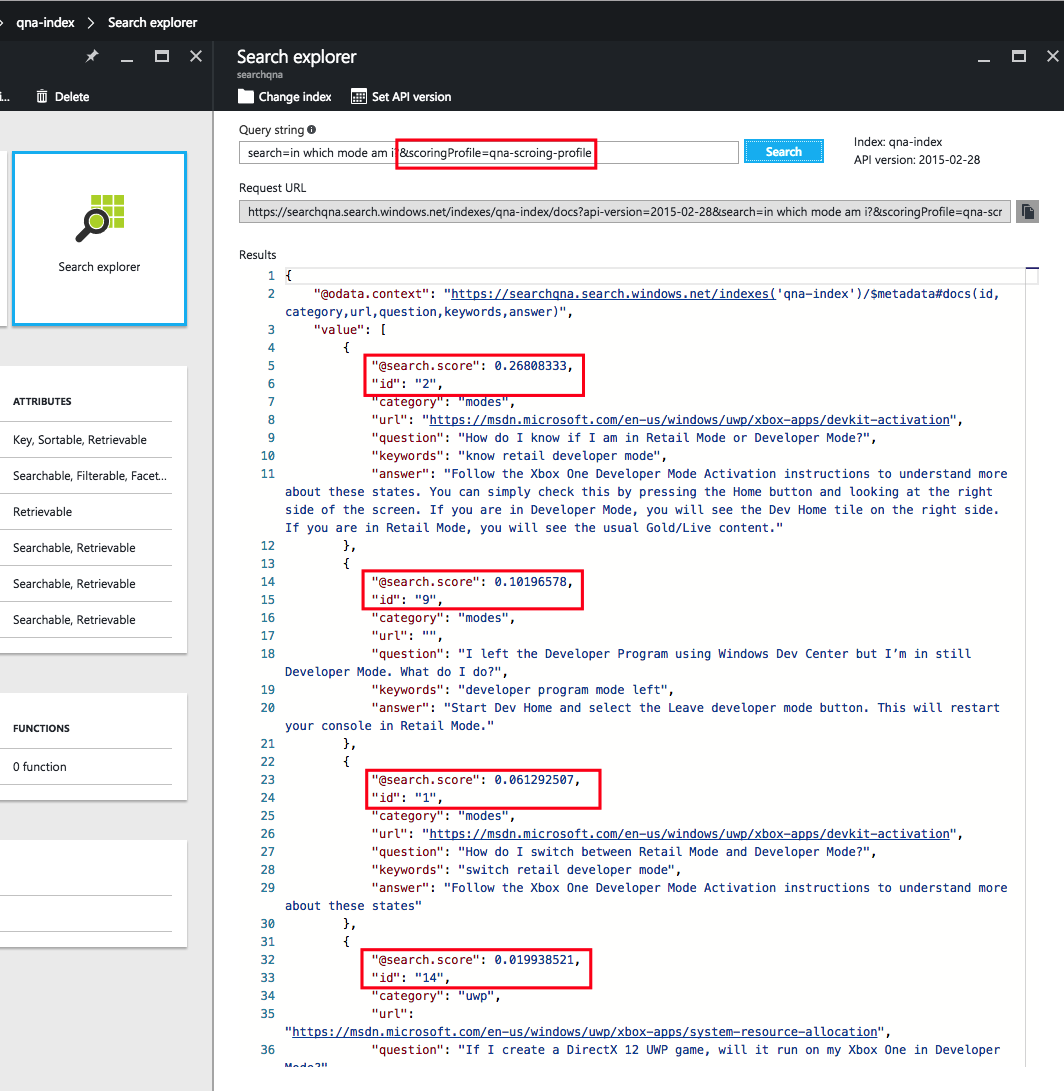
Давайте используем профиль оценки, добавив его в строку запроса:
search=in which mode am i&scoringProfile=qna-scoring-profileПримечание. Можно заметить, что в выдачу результатов поиска Azure попали не те же элементы и оценки, что раньше (последним элементом будет не 5, как при поиске без профиля оценки, а 14). На маленьком корпусе сложно продемонстрировать, как сильно помогает профиль оценки. Однако при наличии большого корпуса профиль оценки имеет огромное значение.
Узнать больше о параметрах поиска и вызове API поисковой службы вы можете из этой статьи.
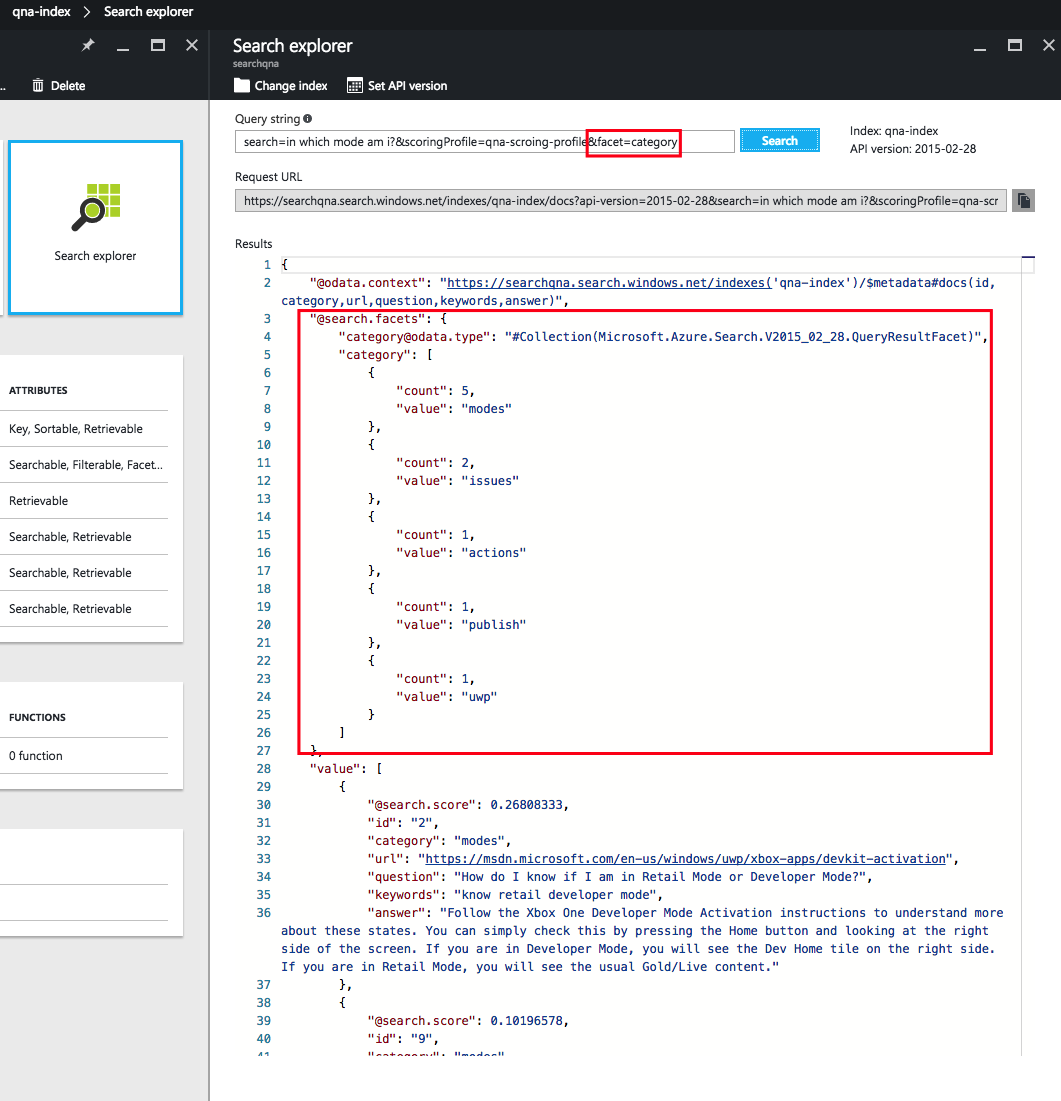
В данном примере мы использовали функцию аспектов, чтобы поисковая система посчитала количество элементов поисковой выдачи, входящих в каждую из категорий. Эта функция может быть полезна, если результатов в каждой категории немного. В таком случае пользователя можно спросить, результаты из какой категории он хотел бы увидеть, и показать ему количество элементов в каждой. После того как пользователь выберет категорию, мы можем детализировать запрос, отфильтровав результаты внутри категории с помощью дополнительного поиска:
search=in which mode am i?&scoringProfile=qna-scoring-profile&facet=category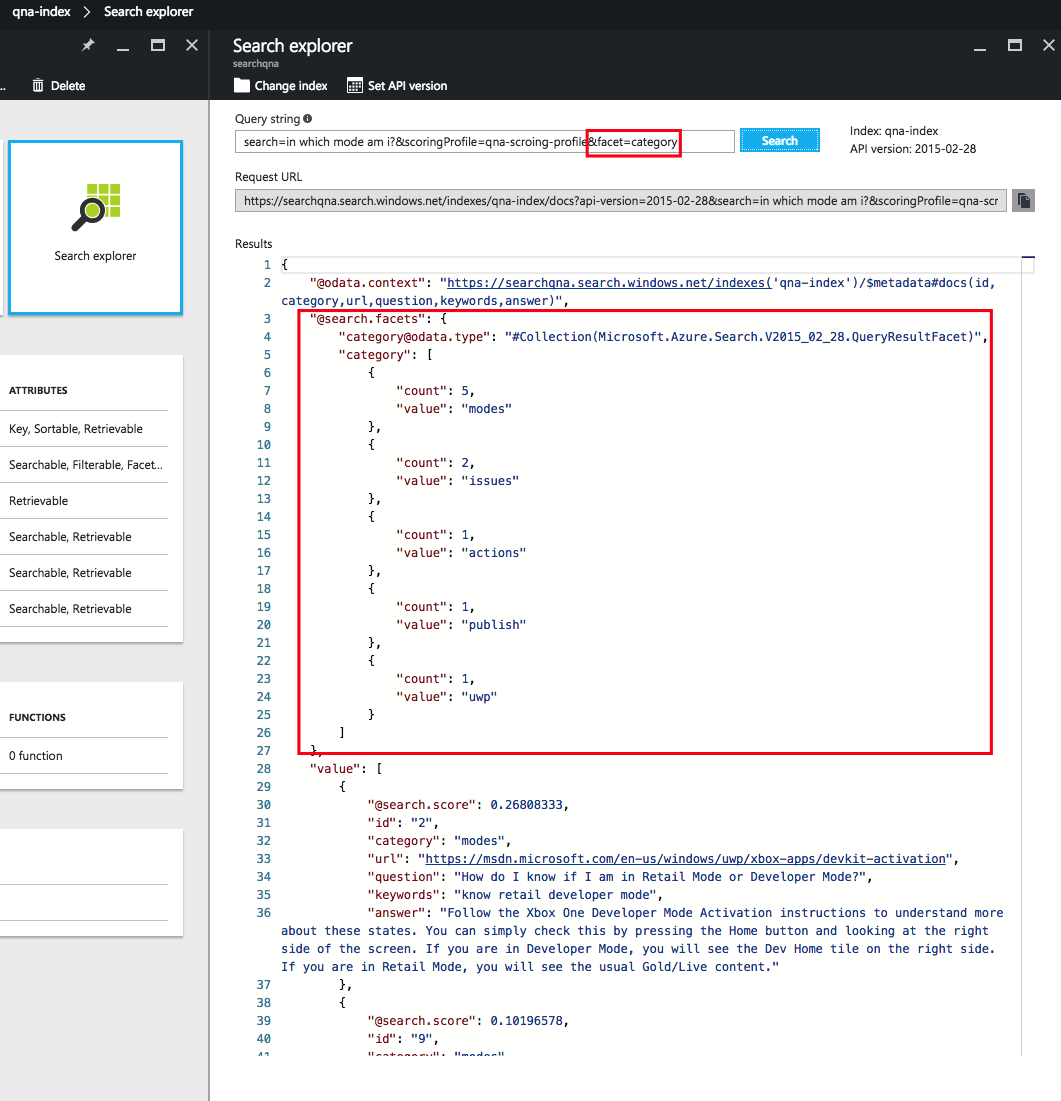
Возможности для использования
В этой статье мы описали порядок действий для создания бота «вопросов/ответов». Например, с помощью данного подхода можно создать систему вопросов и ответов для норвежского языка или иврита — языков, не поддерживаемых в официальной версии QnA Maker.
Примечание. Описанным в статье путем можно создавать не только роботов. Этот подход применим и к созданию поисковой службы общего назначения, работающей в определенной тематике. Профили оценки помогут улучшить ее работу.
Кроме того, благодаря функции добавления меток к отдельно проиндексированным записям в поиске Azure алгоритм выше можно использовать для масштабируемой мультиклассовой классификации текста. Такая способность полезна для программ, которым необходимо категоризировать намерения пользователей, выражаемые ими в сообщениях. Конечно, для этих целей уже существуют отдельные продукты, например Luis или Azure ML, но при наличии более 10–15 категорий классификация может стать для них сложной задачей. Описанный подход могут использовать, к примеру, врачи для классификации протоколов лечения в системе, куда уже внесены сотни протоколов. Поиск Azure поможет классифицировать текст, сравнив его с крупным корпусом схожих материалов.
Напоминаем, что недавно мы рассказывали о том, как научить LUIS понимать другие языки.
