Публикуем обзор первого дня Data Science Week 2017, в течение которого наши спикеры говорили о применении анализа данных в сфере недвижимости.

Касательно конкретных кейсов применения, освещать тему всего дня начал Павел Тарасов — руководитель отдела машинного обучения в ЦИАН — крупнейшем сервисе по аренде и продаже недвижимости, где публикуется более 65 000 новых объявлений в день, среди которых от 500 до 1000 являются мошенническими. Главная цель злоумышленников — собрать как можно больше звонков для того, чтобы заставить клиента перевести им деньги или, в случае недобросовестных риэлторов, продать какой-то другой продукт.
Для решения данной задачи компанией активно применяется машинное обучение с использованием большого количества факторов: от описания объявления и до цены, при этом наиболее важной фичей являются фотографии. Яркий пример:

Следовательно, необходимо применять алгоритмы поиска по фотографии для того, чтобы выявлять объявления с украденными фото и несуществующими квартирами. Существуют 3 основных подхода:
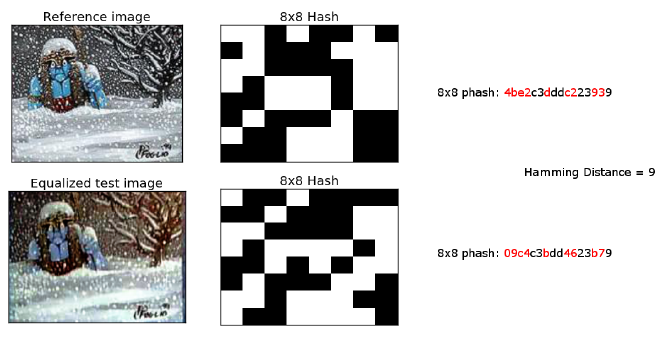
Perceptive Hash — самый распространенный алгоритм решения подобных задач, суть которого заключается в том, что мы сжимаем картинку до размера 32х32, для каждого пикселя считаем, ярче он среднего значения или нет, и затем сравниваем картинки по расстоянию Хэмминга. Стоит отметить, что помимо сжатия также необходимо убрать цвет, яркость и контраст, чтобы в случае, если, к примеру, немного изменилась яркость фотографии, пиксели не меняли своего значения относительно среднего. Алгоритм хорошо работает в случае изменения цветов и яркости, обрезанных фотографий, но хуже — с поворотами, что очевидно: ведь тогда меняется расположение пикселей.
ORB-дескрипторы — алгоритм, в основе которого лежит идея расчета дескрипторов, которые позволяют найти на картинках некоторые ключевые точки, посчитать для них хеши и таким образом по этим точкам сравнивать фотографии между собой:

Такой подход также хорошо работает с «обрезками», лучше работает с поворотами, но вычислительно более сложен. Основная проблема алгоритма заключается в том, что он очень сильно опирается на геометрию объекта: все дома для него будут одинаковыми, ведь у них треугольная крыша, несколько окон и т.д., что выливается в большое количество ложных срабатываний.
Следующий алгоритм основан на Deep Learning: нейросетевые дескрипторы — берется многослойная, обученная на размеченном датасете нейросеть и через нее «прогоняется» каждое изображение, после чего на каждом слое сети у нас получается по набору чисел для каждой картинки. Эти наборы чисел и будут являться дескрипторами (как правило в качестве дескрипторов берутся последние несколько слоев).
Проблема нейросетевых дескрипторов в том, что для обучения глубокой сети необходимо иметь сотни тысяч размеченных изображений, по несколько тысяч на каждый класс, дома должна различаться между собой и т.д., но даже выполнение этих условий не гарантирует, что нейросеть не будет классифицировать многие дома как одинаковые и на последних слоях не окажутся одинаковые числа.
Таким образом, получив новое объявление мы можем, используя один из вышеописанных подходов, выяснить, была ли опубликована эта фотография на нашем сервисе ранее, однако тут возникает следующая проблема: если объявление с этой фотографией уже имеется в нашей базе, то это не всегда значит, что оно мошенническое. Например, строители типовых новостроек по всему городу могут использовать одну фотографию для всех своих объявлений. Как тут быть?
Здесь нам на помощь снова приходят нейронные сети и Transfer Learning: берем уже обученную нейронную сеть (например, GoogleNet) и фиксируем веса слоев, кроме нескольких последних (зависит от нашей стратегии обучения). Ввиду того, что тот же GoogleNet обучен распознавать «котиков» и «собачек» и не может отличить дом от сарая, мы собираем выборку из домов и квартир, размечаем данные и прогоняем их через эту обученную нейросеть. В результате она сможет распознавать, что действительно находится на фото и отличит повторяющуюся планировку квартир от действительно украденных фотографий.
На очереди следующий вопрос: у нас есть 2 объявления, 2 одинаковых фотографии, какая из них фейковая? Самый простой вариант — правило «первой ночи»: кто первый разместил фотографию, тот и прав. Понятно, что не всегда это верно, поскольку, например, арендодатели при смене арендатора могут заново использовать те же фотографии в новом объявлении, которое может быть выложено уже после того, как мошенник украл и выложил свое. Другой подход — использовать машинное обучение, собрав выборку из пар объявлений с одинаковыми фотографиями, но отличающимися параметрами (ценой, описанием, временем размещения и т.д.) и, обучившись на этой выборке, выявлять мошенников по всем факторам сразу.
В итоге у нас получился готовый пайплайн по распознаванию мошеннических объявлений, используя фотографии.
Продолжил тему применения Data Science в недвижимости Алексей Гречишкин — директор python-разработки ДомКлик — сервиса для поиска и покупки недвижимости в ипотеку, дочерней компании Сбербанка. Алексей рассказал о 3 главных направлениях деятельности компании, где применяется машинное обучение:
Во-первых, компании необходимо ускорять время обработки заявок клиентов. Норматив — 30 минут, в то время как на деле среднее время ожидания — 4 часа. Происходит это из-за того, что поток клиентов неравномерен, поэтому на первый план выходит задача планирования расписания менеджеров, чтобы на местах их было больше в периоды пиковой нагрузки и меньше, когда клиентов почти нет. Сразу к результатам:
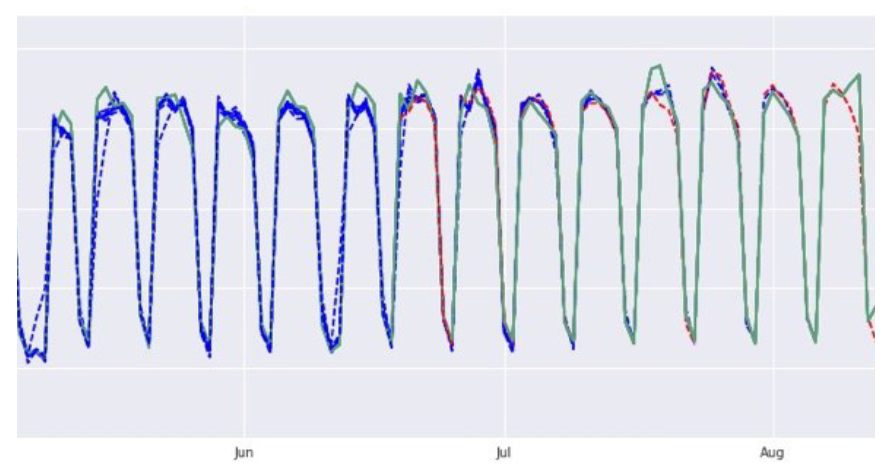
Зеленый временной ряд — действительное количество заявок на единицу времени. Синий — предсказание по обучающей выборке (использовать нельзя). Красный — предсказание по тестовой выборке.
Для того, чтобы получить такую точность были предприняты следующие шаги. Берем данные за полгода и сдвигаем их на неделю назад, чтобы текущая неделя, за которую данные у нас только что появились, оказалась тестовой, затем повторяем эту процедуру 8 раз. В результате средний коэффициент детерминации по тестовой выборке равен 98%, за исключением последней недели, где часто попадаются неполные и недообработанные данные, поэтому R-квадрат получается ниже — 92%.
Если говорить о моделях, которые используются в процессе, то это в первую очередь SARIMAX, поскольку она позволяет учесть как сезонную компоненту, так и экзогенные переменные (отпуска, болезни и т.д.):
Использование двух моделей для предсказания одного временного ряда обуславливается тем, что первая работает с рядом разности («Насколько количество заявок за текущую неделю изменилось по сравнению с предыдущей?»), в то время как вторая работает непосредственно с прошлыми значениями ряда. Затем предсказания обоих моделей взвешиваются в соотношении 2:1 (подобрано вручную, как чаще всего и делают в продакшене), получаем конечный результат.
Прогнозирование конверсии сделки начинается с момента подачи заявки на ипотеку клиентом. Мы сразу же начинаем предсказывать, дойдет ли человек до непосредственно покупки или «отвалится» в середине. На первом этапе разработки моделей мы использовали лишь динамические факторы: качество работы менеджера, история его сделок, регион сделки, возраст клиента и т.д. Количество факторов было ограничено, а модели неустойчивы, поэтому было решено добавить более информативные параметры: звонки, приходил ли к нам в офис, присылал ли какие-то документы, благодаря чему удалось увеличить точность прогнозов на 30-40% и теперь мы можем с 80% вероятностью предсказать совершите ли вы покупку в первый же день подачи вашей заявки. При этом с каждым последующим днем точность растет, в частности, на последних этапах подачи документов точность уже 95-99% (отличный результат, учитывая, что и на последнем этапе нередко случаются отказы). Модель была сделана на xgboost (хотя пробовали на CatBoost — «не взлетело»).
Наконец, работа с витриной и модерация объявлений также являются приоритетными задачами компании. На сервисе ДомКлик публикуются объявления только от проверенных агентов, тем не менее и от них могут приходить дубли фотографий, нецензурная лекция в описании и т.д., поэтому важно выявлять и устранять такие явления. Также мы активно используем технологию speech-to-text, расшифровывая разговор продавца и клиента, анализируем определенные маркеры: договорились ли о встрече, не ругались ли.
Вдобавок, компания старается облегчить клиентам поиск квартиры: благодаря алгоритмам распознавания типов изображений пользователь может фильтровать объявления по фото. Например, искать квартиры только с фотографиями планировки или двора.
Завершал разговор о применении машинного обучения в области недвижимости Евгений Шапиро — специалист компании Airbnb, базирующейся в Сан-Франциско и выпускник нашей программы «Специалист по большим данным». Евгений рассказал о схеме выявления и предотвращения мошенничества на платформе.
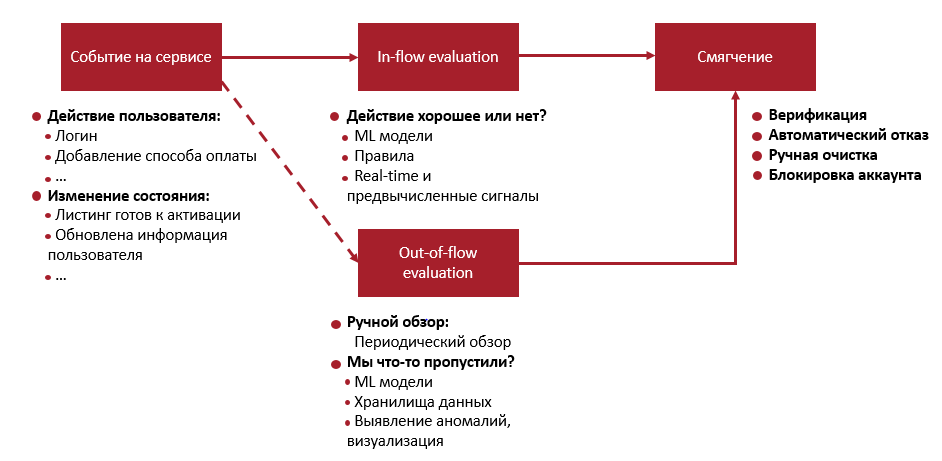
Существует множество видов мошеннических операций, совершаемых на платформе: кража аккаунтов, фишинг, фейковые страницы и листинги, оплата украденными кредитными картами самим себе, спам. Следовательно для выявления мошенников нам сначала необходимо понять, какое именно действие совершает пользователь, потому что интерфейс сервиса позволяет сделать одно и то же действие разными способами. Мы начинаем собирать различную информацию (действия клиента, «следы», которые он оставляет, разные cookies и т.д.) и, классифицировав тип выполняемого действия, подключаем модели машинного обучения, которые оценивают вероятность того, что мы можем позволить это действие (in-flow evaluation). Если эта вероятность недостаточно высока, то мы предлагаем пользователю предоставить какие-то дополнительные данные, чтобы удостовериться, что у него нет никаких плохих намерений (верификация по телефону или email). К примеру, если в Ваш аккаунт был совершен вход из Гайаны, то скорее всего, это не Вы (хотя на 100% мы не уверены, для этого и верификация).
На случай если по какой-то причине системой было пропущено нежелательное действие, то применяется out-of-flow evaluation — ML модели проверяют хранилища данных на предмет уже совершенных мошеннических действий, которые затем необходимо как можно скорее «зачистить». Например, если кто-то создал 1000 аккаунтов с одной и той же картинкой мы можем их выявить и массово устранить. Сюда же относится и account suspension: если мы уверены, что какой-то аккаунт совершал странные действия против других пользователей, то мы его блокируем.
Если подробнее разбирать in-flow evaluation, то все действия клиентов оцениваются rules engine с именем Kyoo (так звали судью в StarTrek), который, собирая данные из различных источников, оценивает события с точки зрения набора простых правил (например, если залогинился с нескольких ID сразу, то что-то не так) и присваивает каждому один из лейблов: аккаунт украден, оплата ворованной картой и т.д. Kyoo был написан на Scala наподобие Facebook Haxl.
Говоря об источниках данных, стоит отметить, что, просто обращаясь к разным API, данные будут не очень интересными (состояние аккаунта, его листинга), хотя как правило для оценки риска важны более агрегированные метрики: с какой частотой совершаются действия на сайте, с какой скоростью загружаются страницы, сколько платежей мы видели с кредитных карт клиента. Эти параметры вычисляются постоянно, агрегировать их из баз данных невозможно, поэтому оптимальным вариантом будет предвычислить некоторое количество таких сигналов и поместить в хранилище по типу «ключ — значение», чтобы к тому времени, как осуществляется какое-то действие, у нас уже был большой объем информации о пользователе.
Однако здесь у нас возникает проблема архитектуры: часто для принятия решения нам нужен сигнал не только на исторических данных, но и на текущий момент (точнее по завершении текущего дня). Таким образом, в Airbnb следующая имплементация лямбда-архитектуры с 2 частями: первая отвечает за оффлайн-сигналы, которые можно вычислить в Hive, там можно делать сколь угодно сложные вычисления, пока они укладываются в 24 часа, а вторая — это real-time события, которые через Kafka уходят в real-time aggregation.
В результате получаем стабильный пайплайн обработки данных, максимально эффективно реагирующий на запросы. К примеру, сколько платежей за последние 7 дней по этой кредитной карте произошло? Фактически этот сигнал является комбинацией того, что мы знаем: количество платежей за последние 30 дней (из 1 части архитектуры) и за текущий день (из 2 части). Такой подход позволяет нам одновременно и тренировать модели, и скорить их на основании реальных данных.
Партнером Data Science Week 2017 выступает компания МегаФон, а инфо-партнером — компания Pressfeed.
Pressfeed — Способ бесплатно получать публикации о своей компании. Сервис подписки на запросы журналистов для представителей бизнеса и PR-специалистов. Журналист оставляет запрос, вы отвечаете. Регистрируйтесь. Удачной работы.

ЦИАН
Касательно конкретных кейсов применения, освещать тему всего дня начал Павел Тарасов — руководитель отдела машинного обучения в ЦИАН — крупнейшем сервисе по аренде и продаже недвижимости, где публикуется более 65 000 новых объявлений в день, среди которых от 500 до 1000 являются мошенническими. Главная цель злоумышленников — собрать как можно больше звонков для того, чтобы заставить клиента перевести им деньги или, в случае недобросовестных риэлторов, продать какой-то другой продукт.
Для решения данной задачи компанией активно применяется машинное обучение с использованием большого количества факторов: от описания объявления и до цены, при этом наиболее важной фичей являются фотографии. Яркий пример:

Следовательно, необходимо применять алгоритмы поиска по фотографии для того, чтобы выявлять объявления с украденными фото и несуществующими квартирами. Существуют 3 основных подхода:
- Locality-sensitive hashing (aHash, pHash, dHash ...)
- Дескрипторы ORB/ SIRF/ SURF
- Нейросетевые дескрипторы
Perceptive Hash — самый распространенный алгоритм решения подобных задач, суть которого заключается в том, что мы сжимаем картинку до размера 32х32, для каждого пикселя считаем, ярче он среднего значения или нет, и затем сравниваем картинки по расстоянию Хэмминга. Стоит отметить, что помимо сжатия также необходимо убрать цвет, яркость и контраст, чтобы в случае, если, к примеру, немного изменилась яркость фотографии, пиксели не меняли своего значения относительно среднего. Алгоритм хорошо работает в случае изменения цветов и яркости, обрезанных фотографий, но хуже — с поворотами, что очевидно: ведь тогда меняется расположение пикселей.

ORB-дескрипторы — алгоритм, в основе которого лежит идея расчета дескрипторов, которые позволяют найти на картинках некоторые ключевые точки, посчитать для них хеши и таким образом по этим точкам сравнивать фотографии между собой:

Такой подход также хорошо работает с «обрезками», лучше работает с поворотами, но вычислительно более сложен. Основная проблема алгоритма заключается в том, что он очень сильно опирается на геометрию объекта: все дома для него будут одинаковыми, ведь у них треугольная крыша, несколько окон и т.д., что выливается в большое количество ложных срабатываний.
Следующий алгоритм основан на Deep Learning: нейросетевые дескрипторы — берется многослойная, обученная на размеченном датасете нейросеть и через нее «прогоняется» каждое изображение, после чего на каждом слое сети у нас получается по набору чисел для каждой картинки. Эти наборы чисел и будут являться дескрипторами (как правило в качестве дескрипторов берутся последние несколько слоев).
Проблема нейросетевых дескрипторов в том, что для обучения глубокой сети необходимо иметь сотни тысяч размеченных изображений, по несколько тысяч на каждый класс, дома должна различаться между собой и т.д., но даже выполнение этих условий не гарантирует, что нейросеть не будет классифицировать многие дома как одинаковые и на последних слоях не окажутся одинаковые числа.
Таким образом, получив новое объявление мы можем, используя один из вышеописанных подходов, выяснить, была ли опубликована эта фотография на нашем сервисе ранее, однако тут возникает следующая проблема: если объявление с этой фотографией уже имеется в нашей базе, то это не всегда значит, что оно мошенническое. Например, строители типовых новостроек по всему городу могут использовать одну фотографию для всех своих объявлений. Как тут быть?
Здесь нам на помощь снова приходят нейронные сети и Transfer Learning: берем уже обученную нейронную сеть (например, GoogleNet) и фиксируем веса слоев, кроме нескольких последних (зависит от нашей стратегии обучения). Ввиду того, что тот же GoogleNet обучен распознавать «котиков» и «собачек» и не может отличить дом от сарая, мы собираем выборку из домов и квартир, размечаем данные и прогоняем их через эту обученную нейросеть. В результате она сможет распознавать, что действительно находится на фото и отличит повторяющуюся планировку квартир от действительно украденных фотографий.
На очереди следующий вопрос: у нас есть 2 объявления, 2 одинаковых фотографии, какая из них фейковая? Самый простой вариант — правило «первой ночи»: кто первый разместил фотографию, тот и прав. Понятно, что не всегда это верно, поскольку, например, арендодатели при смене арендатора могут заново использовать те же фотографии в новом объявлении, которое может быть выложено уже после того, как мошенник украл и выложил свое. Другой подход — использовать машинное обучение, собрав выборку из пар объявлений с одинаковыми фотографиями, но отличающимися параметрами (ценой, описанием, временем размещения и т.д.) и, обучившись на этой выборке, выявлять мошенников по всем факторам сразу.
В итоге у нас получился готовый пайплайн по распознаванию мошеннических объявлений, используя фотографии.
ДомКлик
Продолжил тему применения Data Science в недвижимости Алексей Гречишкин — директор python-разработки ДомКлик — сервиса для поиска и покупки недвижимости в ипотеку, дочерней компании Сбербанка. Алексей рассказал о 3 главных направлениях деятельности компании, где применяется машинное обучение:
- Оптимизация расписания работы сотрудников в соответствии с потоком клиентов
- Прогнозирование конверсии сделки
- Выбор объявлений для витрины и модерация
Во-первых, компании необходимо ускорять время обработки заявок клиентов. Норматив — 30 минут, в то время как на деле среднее время ожидания — 4 часа. Происходит это из-за того, что поток клиентов неравномерен, поэтому на первый план выходит задача планирования расписания менеджеров, чтобы на местах их было больше в периоды пиковой нагрузки и меньше, когда клиентов почти нет. Сразу к результатам:

Зеленый временной ряд — действительное количество заявок на единицу времени. Синий — предсказание по обучающей выборке (использовать нельзя). Красный — предсказание по тестовой выборке.
Для того, чтобы получить такую точность были предприняты следующие шаги. Берем данные за полгода и сдвигаем их на неделю назад, чтобы текущая неделя, за которую данные у нас только что появились, оказалась тестовой, затем повторяем эту процедуру 8 раз. В результате средний коэффициент детерминации по тестовой выборке равен 98%, за исключением последней недели, где часто попадаются неполные и недообработанные данные, поэтому R-квадрат получается ниже — 92%.
Если говорить о моделях, которые используются в процессе, то это в первую очередь SARIMAX, поскольку она позволяет учесть как сезонную компоненту, так и экзогенные переменные (отпуска, болезни и т.д.):
model = sm.tsa.statespace.SARIMAX(table_name[:], exog = Cal[:],
order=(1,1,0), seasonal_order=(2,1,0,7), enforce_stationarity =
False).fit()
model2 = sm.tsa.statespace.SARIMAX(table_name[:], exog = Cal[:],
order=(1,0,0), seasonal_order=(2,0,0,7), enforce_stationarity =
False).fit()
forecast['forecast'] = model.forecast(b, exog =
Cal_Pred[:b])*2/3+model2.forecast(b, exog = Cal_Pred[:b])*1/3Использование двух моделей для предсказания одного временного ряда обуславливается тем, что первая работает с рядом разности («Насколько количество заявок за текущую неделю изменилось по сравнению с предыдущей?»), в то время как вторая работает непосредственно с прошлыми значениями ряда. Затем предсказания обоих моделей взвешиваются в соотношении 2:1 (подобрано вручную, как чаще всего и делают в продакшене), получаем конечный результат.
Прогнозирование конверсии сделки начинается с момента подачи заявки на ипотеку клиентом. Мы сразу же начинаем предсказывать, дойдет ли человек до непосредственно покупки или «отвалится» в середине. На первом этапе разработки моделей мы использовали лишь динамические факторы: качество работы менеджера, история его сделок, регион сделки, возраст клиента и т.д. Количество факторов было ограничено, а модели неустойчивы, поэтому было решено добавить более информативные параметры: звонки, приходил ли к нам в офис, присылал ли какие-то документы, благодаря чему удалось увеличить точность прогнозов на 30-40% и теперь мы можем с 80% вероятностью предсказать совершите ли вы покупку в первый же день подачи вашей заявки. При этом с каждым последующим днем точность растет, в частности, на последних этапах подачи документов точность уже 95-99% (отличный результат, учитывая, что и на последнем этапе нередко случаются отказы). Модель была сделана на xgboost (хотя пробовали на CatBoost — «не взлетело»).
Наконец, работа с витриной и модерация объявлений также являются приоритетными задачами компании. На сервисе ДомКлик публикуются объявления только от проверенных агентов, тем не менее и от них могут приходить дубли фотографий, нецензурная лекция в описании и т.д., поэтому важно выявлять и устранять такие явления. Также мы активно используем технологию speech-to-text, расшифровывая разговор продавца и клиента, анализируем определенные маркеры: договорились ли о встрече, не ругались ли.
Вдобавок, компания старается облегчить клиентам поиск квартиры: благодаря алгоритмам распознавания типов изображений пользователь может фильтровать объявления по фото. Например, искать квартиры только с фотографиями планировки или двора.
Airbnb
Завершал разговор о применении машинного обучения в области недвижимости Евгений Шапиро — специалист компании Airbnb, базирующейся в Сан-Франциско и выпускник нашей программы «Специалист по большим данным». Евгений рассказал о схеме выявления и предотвращения мошенничества на платформе.

Существует множество видов мошеннических операций, совершаемых на платформе: кража аккаунтов, фишинг, фейковые страницы и листинги, оплата украденными кредитными картами самим себе, спам. Следовательно для выявления мошенников нам сначала необходимо понять, какое именно действие совершает пользователь, потому что интерфейс сервиса позволяет сделать одно и то же действие разными способами. Мы начинаем собирать различную информацию (действия клиента, «следы», которые он оставляет, разные cookies и т.д.) и, классифицировав тип выполняемого действия, подключаем модели машинного обучения, которые оценивают вероятность того, что мы можем позволить это действие (in-flow evaluation). Если эта вероятность недостаточно высока, то мы предлагаем пользователю предоставить какие-то дополнительные данные, чтобы удостовериться, что у него нет никаких плохих намерений (верификация по телефону или email). К примеру, если в Ваш аккаунт был совершен вход из Гайаны, то скорее всего, это не Вы (хотя на 100% мы не уверены, для этого и верификация).
На случай если по какой-то причине системой было пропущено нежелательное действие, то применяется out-of-flow evaluation — ML модели проверяют хранилища данных на предмет уже совершенных мошеннических действий, которые затем необходимо как можно скорее «зачистить». Например, если кто-то создал 1000 аккаунтов с одной и той же картинкой мы можем их выявить и массово устранить. Сюда же относится и account suspension: если мы уверены, что какой-то аккаунт совершал странные действия против других пользователей, то мы его блокируем.
Если подробнее разбирать in-flow evaluation, то все действия клиентов оцениваются rules engine с именем Kyoo (так звали судью в StarTrek), который, собирая данные из различных источников, оценивает события с точки зрения набора простых правил (например, если залогинился с нескольких ID сразу, то что-то не так) и присваивает каждому один из лейблов: аккаунт украден, оплата ворованной картой и т.д. Kyoo был написан на Scala наподобие Facebook Haxl.
Говоря об источниках данных, стоит отметить, что, просто обращаясь к разным API, данные будут не очень интересными (состояние аккаунта, его листинга), хотя как правило для оценки риска важны более агрегированные метрики: с какой частотой совершаются действия на сайте, с какой скоростью загружаются страницы, сколько платежей мы видели с кредитных карт клиента. Эти параметры вычисляются постоянно, агрегировать их из баз данных невозможно, поэтому оптимальным вариантом будет предвычислить некоторое количество таких сигналов и поместить в хранилище по типу «ключ — значение», чтобы к тому времени, как осуществляется какое-то действие, у нас уже был большой объем информации о пользователе.
Однако здесь у нас возникает проблема архитектуры: часто для принятия решения нам нужен сигнал не только на исторических данных, но и на текущий момент (точнее по завершении текущего дня). Таким образом, в Airbnb следующая имплементация лямбда-архитектуры с 2 частями: первая отвечает за оффлайн-сигналы, которые можно вычислить в Hive, там можно делать сколь угодно сложные вычисления, пока они укладываются в 24 часа, а вторая — это real-time события, которые через Kafka уходят в real-time aggregation.
В результате получаем стабильный пайплайн обработки данных, максимально эффективно реагирующий на запросы. К примеру, сколько платежей за последние 7 дней по этой кредитной карте произошло? Фактически этот сигнал является комбинацией того, что мы знаем: количество платежей за последние 30 дней (из 1 части архитектуры) и за текущий день (из 2 части). Такой подход позволяет нам одновременно и тренировать модели, и скорить их на основании реальных данных.
Партнером Data Science Week 2017 выступает компания МегаФон, а инфо-партнером — компания Pressfeed.
Pressfeed — Способ бесплатно получать публикации о своей компании. Сервис подписки на запросы журналистов для представителей бизнеса и PR-специалистов. Журналист оставляет запрос, вы отвечаете. Регистрируйтесь. Удачной работы.
