В первой части мы рассмотрели, как в компании Wish была перестроена инфраструктура данных для того, чтобы увеличить их аналитические возможности. На этот раз уделим внимание человеческим ресурсам и поговорим о том, как дальше масштабировать компанию и создать идеальные команды инженеров и аналитиков. Также расскажем и о нашем подходе к найму самых талантливых кандидатов на рынке.

Data engineering в компании может развиваться по двум противоположным направлениям. Первый путь является классическим, и в этом случае инженеры данных в основном занимаются построением и поддержкой пайплайнов данных, которые затем используются аналитиками. Главный недостаток такого подхода — это рутина и монотонность, которые могут превратить любого инженера в шестеренку работающей системы, а значит труднее будет удерживать талантливых сотрудников в компании.
Второй подход отличается тем, что при нем инженеры данных занимаются построением и поддержкой не пайплайнов данных, а платформ, с помощью которых любой в компании может строить и использовать собственные пайплайны. Это позволяет аналитикам и data scientist-ам работать end-to-end и полностью контролировать свои проекты.
Если вы хотите привлекать в компанию самых талантливых — то этот путь для вас, поскольку лучшие хотят работать над масштабированием систем и платформ, решая сложные технические задачи. Также увеличивается и продуктивность аналитиков, поскольку они больше ни от кого не зависят.
Конечно, есть и пара недостатков. Во-первых, появится слишком много новых таблиц, поскольку всегда легче создать новые, чем пытаться изменить и подстроить старые. Это приведет к путанице и несопоставимости разных метрик и отчетов. Во-вторых, увеличатся затраты и загруженность инфраструктуры, так как ETL job-ы, написанные аналитиками, чаще всего неоптимальны.
В итоге, ни один из двух подходов неидален, а истина находится где-то посередине.
Масштабирование ETL и Luigi. Наш пайплайн данных на основе Luigi, описанный в первой части, работал отлично, однако, как только мы начали надстраивать дополнительные функции, стали появляться проблемы:
Нам удалось найти этим проблемам весьма простые решения:
Таким образом, простой пайплайн, с которым работают несколько человек, и тот, которым пользуется более сотни, — это совершенно разные вещи и требуют разных подходов.
Масштабирование хранилища данных. Так как у нас в компании стоят кластеры Redshift и Hive, мощности которых небесконечны, необходимо следить за запросами и таблицами, чтобы они не тормозили систему, и она могла продолжать расти. Для этого мы приняли несколько мер. Во-первых, мы анализируем логи запросов, ищем медленные и, в случае чего, денормализуем их. Во-вторых, это code review, чтобы поддерживать качество кода и обучать аналитиков. Скрипты наших пайплайнов регулярно заливаются на Git-репозиторий.

Обработка системных ошибок. Одна из ключевых обязанностей инженера данных — это обработка ошибок системы, которая генерирует немалое их количество. На данный момент у нас есть более 1000 активных ETL job-ов, написанных data engineer-ами и аналитиками, часть из которых уже ушла из компании, часть — это стажеры, которые еще недавно вышли из школы. Поэтому, даже 1% ошибок в неделю будет означать 10 сломанных пайплайнов за этот период.
Чтобы избегать негативных последствий этих ошибок, мы назначаем “дежурных”, которые ответственны за их исправление, причем каждую неделю “дежурные” меняются.
Строим команду инженеров. В нашей команде роли в data engineering-е распределены вот так:
Не важно, насколько хороша инфраструктура данных, если люди, которые ее используют, некомпетентны. Ниже мы обсудим, как создать сильную команду аналитиков.
В самом начале аналитики занимались лишь тем, что извлекали данные и строили отчеты. Это было неправильно: аналитиками становятся не ради этого. Им всегда хочется контролировать не только сам процесс построения отчета, но и конечный результат — принимаемое на его основе решение. Они хотят влиять на компанию, а не быть всего лишь API для предоставления информации.
3 ключевых навыка для аналитика. Конечно, аналитики имеют специализацию и то, что делает аналитика в сфере логистики успешным, не обязательно обеспечит ему такой же успех в маркетинге. Однако все же есть 3 навыка, которые необходимы каждой команде аналитиков, чтобы быть эффективной:

Поддержка бизнес-аналитики. Главная цель всех BI инструментов — демократизация данных, предоставление каждому возможности анализировать данные и принимать решения на их основе. Именно поэтому мы и развернули у себя Looker.
Проблема заключается в том, что не каждый обладает достаточными навыками, чтобы качественно анализировать данные. Плохие данные, нелогичные отчеты — все это заполонило компанию. Вдобавок, взлетело количество запросов, поскольку люди не могли справиться с плохими данными и вместо их обработки, требовали новые метрики.
Таким образом, мы развернули систему самостоятельной аналитики слишком рано. Проблем оказалось так много, что нам пришлось ограничивать доступ и нанимать больше аналитиков, которые бы могли помочь другим сотрудникам обрабатывать данные.
Строим команду аналитиков. Лишь в случае, когда ваши аналитики идеальны и будто посланы свыше, вам не нужно прорабатывать стратегию развития своей команды. Я считаю, что аналитики в команде должны быть по трем основным направлениям: бизнес, техническая составляющая и статистика:
И напоследок, проведя более чем 150 собеседований с инженерами, аналитиками и менеджерами в Wish, я набрался достаточно опыта, чтобы рассказать о том, как мы подходим к найму сотрудников и как найти достойных кандидатов на должность.

Скрининг по резюме. Для недавних выпускников первое, на что мы смотрим в резюме — это оценки и учебное заведение, которое они закончили. Для более опытных кандидатов нам важно, в каких компаниях и командах они работали: в организациях с сильной инженерной составляющей или data-driven? Насколько важную роль они играли в них?
Собеседования. Сильные интервьюеры должны задавать гибкие вопросы, которые можно менять в зависимости от реакции кандидата. Если кажется, что у кандидата довольно слабые аналитические способности, то нужно надавить на более сложные вопросы, а если он выглядит некоммуникабельным, то можно задать ему неопределенный и пространный вопрос и посмотреть, как он его объяснит.
В целом, чтобы попасть в Wish, кандидаты должны пройти через 1-2 скрининга по телефону и 4 очных интервью. Собеседования проходят быстро, с написанием заметок, чтобы следующий интервьюер мог скорректировать свои вопросы.
Интервью должны заканчиваться на позитивной ноте, поскольку это очень волнительный опыт для кандидатов, они могут быть уязвимы. Нет легче способа уничтожить всю мотивацию человека, чем унизить его на собеседовании. Также, проводя интервью в негативном ключе, компания может достаточно быстро заработать плохую репутацию.
За последние пару лет нам удалось добиться невероятных вещей. Мы перестроили инфраструктуру и создали команду по работе данных для одного из крупнейших интернет-ритейлеров в мире. И все это было сделано на ходу, за этот период бизнес не остановился ни на секунду. Можно сказать, что мы поменяли шины на болиде Формулы-1 прямо во время езды. У нас это получилось, надеюсь, что благодаря этой серии статей, удастся и вам!
А если вы решили стать аналитиком больших данных или data engineer’ом, но самому разбираться во всем долго, а спросить не у кого, то приходите на программы Newprolab:

Масштабирование data engineering-а
Data engineering в компании может развиваться по двум противоположным направлениям. Первый путь является классическим, и в этом случае инженеры данных в основном занимаются построением и поддержкой пайплайнов данных, которые затем используются аналитиками. Главный недостаток такого подхода — это рутина и монотонность, которые могут превратить любого инженера в шестеренку работающей системы, а значит труднее будет удерживать талантливых сотрудников в компании.
Второй подход отличается тем, что при нем инженеры данных занимаются построением и поддержкой не пайплайнов данных, а платформ, с помощью которых любой в компании может строить и использовать собственные пайплайны. Это позволяет аналитикам и data scientist-ам работать end-to-end и полностью контролировать свои проекты.
Если вы хотите привлекать в компанию самых талантливых — то этот путь для вас, поскольку лучшие хотят работать над масштабированием систем и платформ, решая сложные технические задачи. Также увеличивается и продуктивность аналитиков, поскольку они больше ни от кого не зависят.
Конечно, есть и пара недостатков. Во-первых, появится слишком много новых таблиц, поскольку всегда легче создать новые, чем пытаться изменить и подстроить старые. Это приведет к путанице и несопоставимости разных метрик и отчетов. Во-вторых, увеличатся затраты и загруженность инфраструктуры, так как ETL job-ы, написанные аналитиками, чаще всего неоптимальны.
В итоге, ни один из двух подходов неидален, а истина находится где-то посередине.
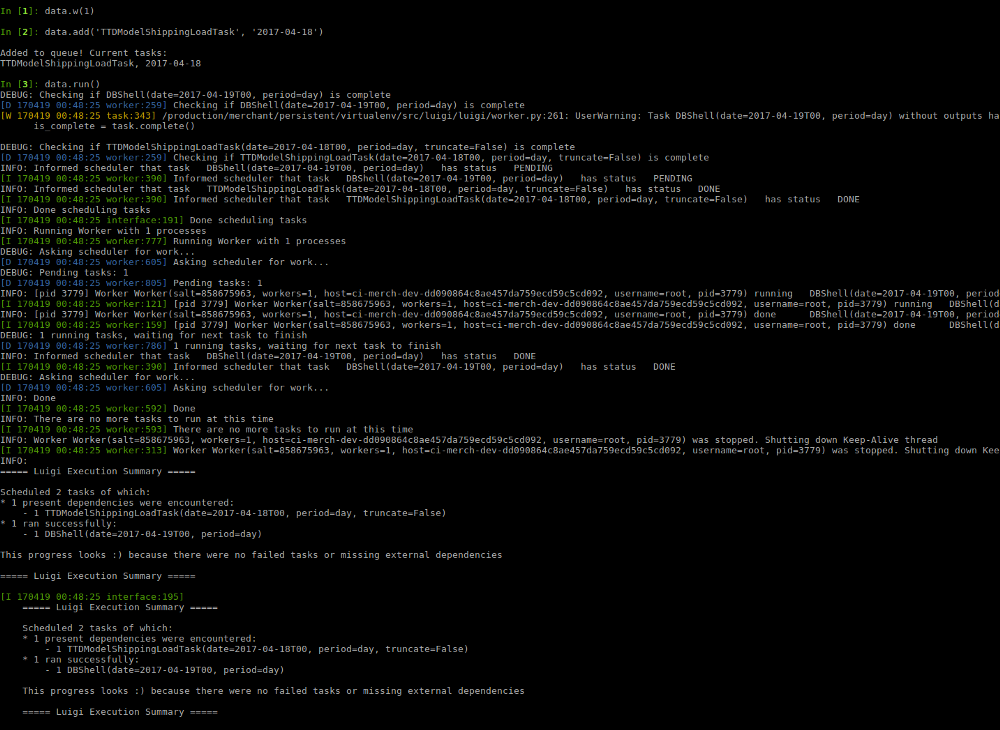
Масштабирование ETL и Luigi. Наш пайплайн данных на основе Luigi, описанный в первой части, работал отлично, однако, как только мы начали надстраивать дополнительные функции, стали появляться проблемы:
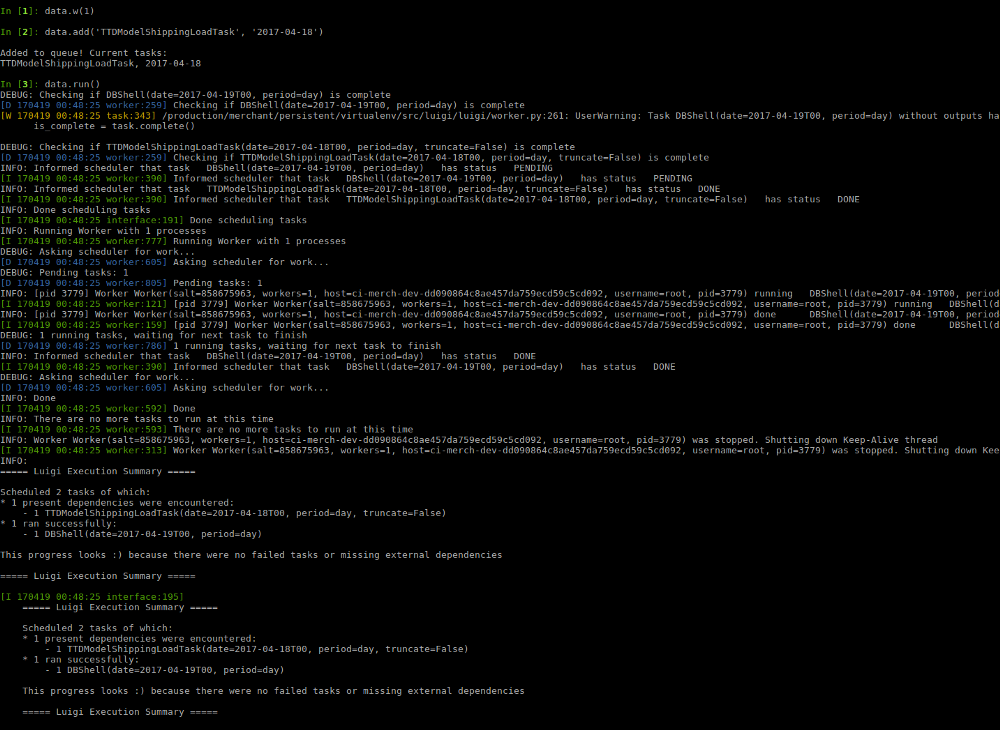
- Система была хрупкой, поскольку все задачи приходилось выполнять в рамках одной очереди. Одна ошибка или некачественный запрос могли сломать весь пайплайн.
- Было трудно выполнять техническое обслуживание задач, алгоритм обратного заполнения (backfill) также не справлялся, нужно было вручную обновлять/удалять задачи в MongoDB.
- Ошибки, генерируемые запросами в Hive могли легко перегрузить кластер, особенно когда их сотни из-за обратного заполнения, вызванного задачей с багом внутри.
- Система мониторинга на основе email-ов перестала справляться, поскольку с ростом количества людей, использующих пайплайн, росло и количество email-ов в день. Их стало очень тяжело сортировать и отслеживать, чтобы вовремя реагировать на ошибки.
Нам удалось найти этим проблемам весьма простые решения:
- Мы распределили все задачи на 4 основных потока: ключевые для всей компании, для команды по работе с данными, команды управления инфраструктурой и аналитиков, работающих над отдельными проектами.
- Написали собственную оболочку для технического обслуживания задач, например, для backfill-ов.
- Добавили автоматические выключатели, которые запускаются в случае ошибок, чтобы системные ресурсы не тратились на плохой код снова и снова.
- Построили свою систему предупреждения и мониторинга в Prometheus + Pagerduty, которая позволяет реагировать на ошибки и проблемы на сервере.
Таким образом, простой пайплайн, с которым работают несколько человек, и тот, которым пользуется более сотни, — это совершенно разные вещи и требуют разных подходов.
Масштабирование хранилища данных. Так как у нас в компании стоят кластеры Redshift и Hive, мощности которых небесконечны, необходимо следить за запросами и таблицами, чтобы они не тормозили систему, и она могла продолжать расти. Для этого мы приняли несколько мер. Во-первых, мы анализируем логи запросов, ищем медленные и, в случае чего, денормализуем их. Во-вторых, это code review, чтобы поддерживать качество кода и обучать аналитиков. Скрипты наших пайплайнов регулярно заливаются на Git-репозиторий.

Обработка системных ошибок. Одна из ключевых обязанностей инженера данных — это обработка ошибок системы, которая генерирует немалое их количество. На данный момент у нас есть более 1000 активных ETL job-ов, написанных data engineer-ами и аналитиками, часть из которых уже ушла из компании, часть — это стажеры, которые еще недавно вышли из школы. Поэтому, даже 1% ошибок в неделю будет означать 10 сломанных пайплайнов за этот период.
Чтобы избегать негативных последствий этих ошибок, мы назначаем “дежурных”, которые ответственны за их исправление, причем каждую неделю “дежурные” меняются.
Строим команду инженеров. В нашей команде роли в data engineering-е распределены вот так:
- Инженер инфраструктуры данных. Сосредоточен на масштабировании и надежности распределенных систем. Должен обладать опытом построения подобных систем, уметь объяснить выбор тех или иных инструментов.
- Инженер платформы данных. Занимается построением пайплайнов данных. Идеальный кандидат — человек с классическим бэкграундом в программировании и желанием строить эффективные системы.
- Инженер аналитики. Фокусируется на построении главных ETL job-ов и рефакторинге плохих запросов и моделей данных. Достаточно владеть Python+SQL и иметь развитые аналитические способности.
Масштабирование аналитики
Не важно, насколько хороша инфраструктура данных, если люди, которые ее используют, некомпетентны. Ниже мы обсудим, как создать сильную команду аналитиков.
В самом начале аналитики занимались лишь тем, что извлекали данные и строили отчеты. Это было неправильно: аналитиками становятся не ради этого. Им всегда хочется контролировать не только сам процесс построения отчета, но и конечный результат — принимаемое на его основе решение. Они хотят влиять на компанию, а не быть всего лишь API для предоставления информации.
3 ключевых навыка для аналитика. Конечно, аналитики имеют специализацию и то, что делает аналитика в сфере логистики успешным, не обязательно обеспечит ему такой же успех в маркетинге. Однако все же есть 3 навыка, которые необходимы каждой команде аналитиков, чтобы быть эффективной:

- Понимание цели. Во-первых, аналитики должны понимать, зачем они выполняют ту или иную задачу. Нужно уметь критически и с разных углов посмотреть на исходный вопрос, который поступил от менеджмента, чтобы уловить его истинную ценность и контекст.
- Понимание инфраструктуры и данных. Во-вторых, аналитики должны отлично понимать, как работает их система, и как это отражается на данных. Использовать данные такими, какие они есть — это отвратительная привычка, которая приводит к искажению ситуации и некачественному анализу.
- Доводить все до конца. В процессе работы очень легко забыть, о конечной цели, поэтому аналитики должны всегда доводить свои проекты до логичного завершения. Конечным результатом работы аналитика является не дашборд, в котором агрегирована вся имеющаяся информация, а рекомендации или действия, которые могут оказать позитивное влияние на бизнес.
Поддержка бизнес-аналитики. Главная цель всех BI инструментов — демократизация данных, предоставление каждому возможности анализировать данные и принимать решения на их основе. Именно поэтому мы и развернули у себя Looker.
Проблема заключается в том, что не каждый обладает достаточными навыками, чтобы качественно анализировать данные. Плохие данные, нелогичные отчеты — все это заполонило компанию. Вдобавок, взлетело количество запросов, поскольку люди не могли справиться с плохими данными и вместо их обработки, требовали новые метрики.
Таким образом, мы развернули систему самостоятельной аналитики слишком рано. Проблем оказалось так много, что нам пришлось ограничивать доступ и нанимать больше аналитиков, которые бы могли помочь другим сотрудникам обрабатывать данные.
Строим команду аналитиков. Лишь в случае, когда ваши аналитики идеальны и будто посланы свыше, вам не нужно прорабатывать стратегию развития своей команды. Я считаю, что аналитики в команде должны быть по трем основным направлениям: бизнес, техническая составляющая и статистика:
- Конструктор отчетов. Чаще всего они приходят из консалтинга, финансов или операционной деятельности. Они умеют принимать выгодные с точки зрения бизнеса решения на основе количественной информации и наиболее полезны, когда являются ключевыми драйверами изменений. Им нужно владеть SQL, но Python необязателен (хотя будет плюсом).
- Аналитики данных. Отлично владеют Python и SQL, эффективно извлекают данные и, если требуются новые таблицы, могут построить собственные ETL пайплайны. Наконец, умеют автоматизировать аналитику и писать неодноразовые скрипты, чтобы ускорить работу.
- Статистики. Аналитики данных не должны отлично владеть статистикой, однако глупо не иметь в команде человека, который с ней «на ты». Использовать агрегированные метрики, проводить A/B тестирование по ограниченным данным, строить прогностические модели — все это несомненно приносит огромную пользу бизнесу.
Рекрутинг
И напоследок, проведя более чем 150 собеседований с инженерами, аналитиками и менеджерами в Wish, я набрался достаточно опыта, чтобы рассказать о том, как мы подходим к найму сотрудников и как найти достойных кандидатов на должность.
Скрининг по резюме. Для недавних выпускников первое, на что мы смотрим в резюме — это оценки и учебное заведение, которое они закончили. Для более опытных кандидатов нам важно, в каких компаниях и командах они работали: в организациях с сильной инженерной составляющей или data-driven? Насколько важную роль они играли в них?
Собеседования. Сильные интервьюеры должны задавать гибкие вопросы, которые можно менять в зависимости от реакции кандидата. Если кажется, что у кандидата довольно слабые аналитические способности, то нужно надавить на более сложные вопросы, а если он выглядит некоммуникабельным, то можно задать ему неопределенный и пространный вопрос и посмотреть, как он его объяснит.
В целом, чтобы попасть в Wish, кандидаты должны пройти через 1-2 скрининга по телефону и 4 очных интервью. Собеседования проходят быстро, с написанием заметок, чтобы следующий интервьюер мог скорректировать свои вопросы.
Интервью должны заканчиваться на позитивной ноте, поскольку это очень волнительный опыт для кандидатов, они могут быть уязвимы. Нет легче способа уничтожить всю мотивацию человека, чем унизить его на собеседовании. Также, проводя интервью в негативном ключе, компания может достаточно быстро заработать плохую репутацию.
Итоги
За последние пару лет нам удалось добиться невероятных вещей. Мы перестроили инфраструктуру и создали команду по работе данных для одного из крупнейших интернет-ритейлеров в мире. И все это было сделано на ходу, за этот период бизнес не остановился ни на секунду. Можно сказать, что мы поменяли шины на болиде Формулы-1 прямо во время езды. У нас это получилось, надеюсь, что благодаря этой серии статей, удастся и вам!
А если вы решили стать аналитиком больших данных или data engineer’ом, но самому разбираться во всем долго, а спросить не у кого, то приходите на программы Newprolab:
- 22 марта стартует программа “Специалист по большим данным 8.0”
- 2 апреля запускаем “Data Engineer 2.0”
