До того, как написанный нами код будет исполнен, он проходит довольно долгий путь. Андрей Мелихов в своем докладе на РИТ++ 2018 разобрал каждый шаг на этом пути на примере движка V8. Заходите под кат, чтобы выяснить, что даёт нам глубокое понимание принципов работы компилятора и как сделать JavaScript код производительнее.

Узнаем, является ли WASM серебряной пулей для повышения производительности кода, и всегда ли оправданы оптимизации.
Спойлер: «Преждевременная оптимизация — корень всех бед», Дональд Кнут.

О спикере: Андрей Мелихов работает в компании Яндекс.Деньги, активно пишет на Node.js, а в браузере — меньше, поэтому ему ближе серверный JavaScript. Андрей поддерживает и развивает сообщество devShacht, заходите познакомиться на GitHub или Medium.
Сегодня мы будем говорить про JIT компиляцию. Думаю, вам это интересно, раз вы это читаете. Тем не менее, давайте уточним, зачем нужно знать, что такое JIT и как устроен V8, и почему недостаточно писать на React в браузере.
В Википедии написано, что JavaScript — это высокоуровневый интерпретируемый язык программирования с динамической типизацией. Разберемся с этими терминами.
Компиляция и интерпретация
Компиляция — когда программа поставляется в бинарном коде, и изначально оптимизирована под среду, в которой будет работать.
Интерпретация — когда мы поставляем код, как есть.
JavaScript поставляется, как есть — это интерпретируемый язык, как и написано в Википедии.
Динамическая и статическая типизация
Статическую и динамическую типизации часто путают со слабой и сильной типизацией. Например, С — это язык со статической слабой типизацией. У JavaScript слабая динамическая типизация.
Что из этого лучше? Если программа компилируется, она заточена на ту среду, в которой будет исполняться, а значит —будет работать лучше. Статическая типизация позволяет сделать этот код эффективнее. В JavaScript все наоборот.
Но при этом наше приложение становится все сложнее: и на клиенте, и на сервере появляются огромные кластеры на Node.js, которые прекрасно работают и приходят на замену Java-приложениям.
Но каким образом это все работает, если изначально кажется, что оно в проигрыше.
У нас есть JIT (Just In Time компиляция), которая происходит во время выполнения программы. О ней и будем говорить.
Вы можете написать свой движок, но если вы будете двигаться к эффективному исполнению, то придете примерно к одной и той же схеме, которую я дальше покажу.
Сегодня мы будем говорить о V8, и да, он назван в честь 8-цилиндрового двигателя.
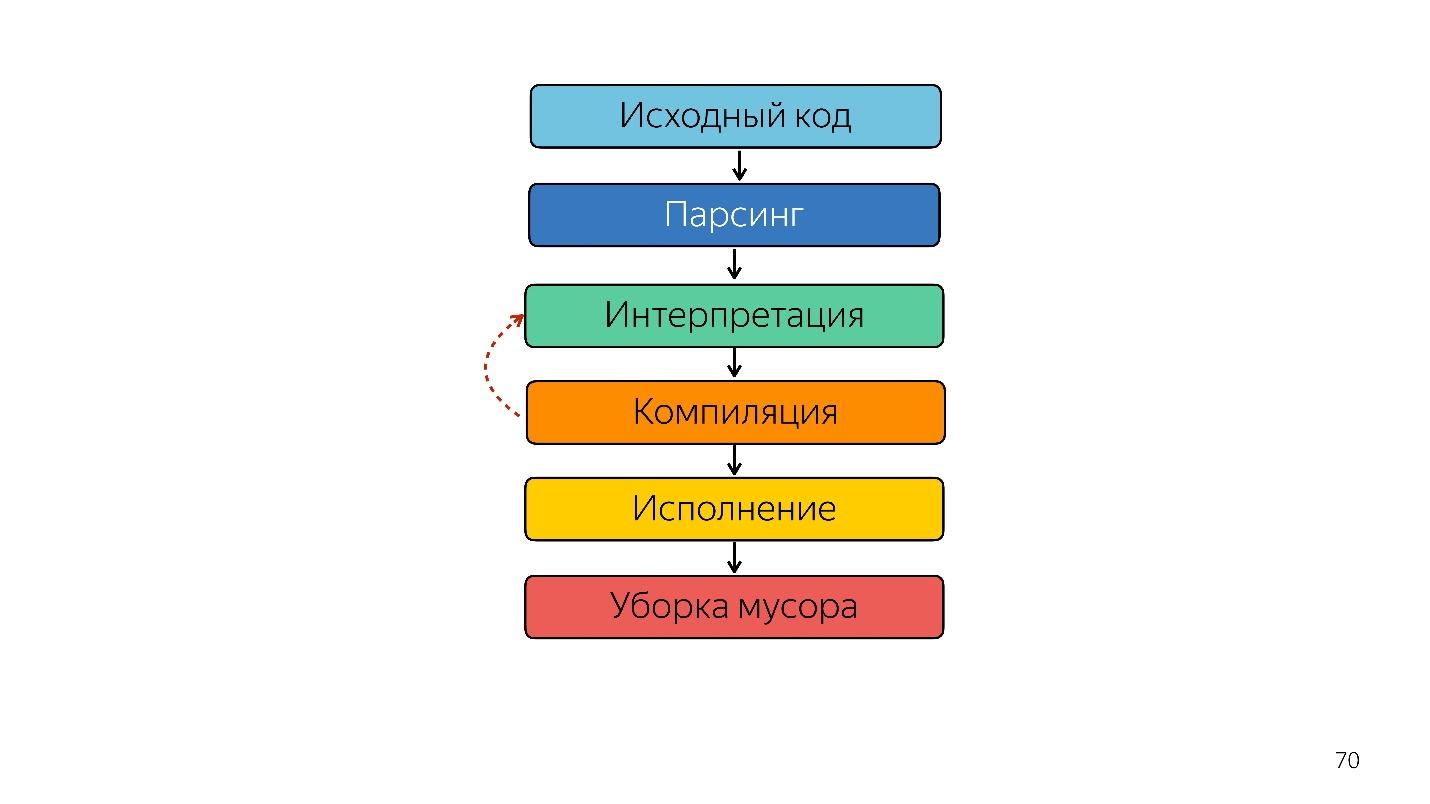
Как исполняется JavaScript?
Парсинг превращает код в абстрактное синтаксическое дерево. AST — это отображение синтаксической структуры кода в виде дерева. На самом деле это удобно для программы, хотя и тяжело читать.
Получение элемента массива с индексом 1 в виде дерева представляется в виде оператора и двух операндов: загрузить свойство по ключу и эти ключи.
AST есть не только в движках. С использованием AST во многих утилитах пишутся расширения, в том числе:
Например, крутая штука Jscodeshift, про которую пока не все знают, позволяет писать преобразования. Если вы изменили API у какой-то функции, то можете натравить на нее эти преобразования и внести изменения во всем проекте.

Двигаемся дальше. Процессор не понимает абстрактное синтаксическое дерево, ему нужен машинный код. Поэтому дальше происходит преобразование через интерпретатор, потому что язык интерпретируемый.
Так было, пока браузерах было немного JavaScript — подсветить строчку, что-то открыть, закрыть. Но сейчас у нас приложения — SPA, Node.js, и интерпретатор становится узким местом.
Вместо интерпретатора появляется оптимизирующий JIT-компилятор, то есть Just-in-time компилятор. Ahead-of-time компиляторы работают до исполнения приложения, а JIT — во время. В вопросе оптимизации JIT-компилятор пытается угадать, как код будет исполняться, какие будут использоваться типы, и оптимизировать код так, чтобы он лучше работал.
Такая оптимизация называется спекулятивной, потому что она спекулирует на знаниях о том, что происходило с кодом раньше. То есть если 10 раз было вызвано что-то с типом number, компилятор думает, что так будет все время и оптимизирует под этот тип.
Естественно, если на вход попадает Boolean, происходит деоптимизация. Рассмотрим функцию, которая складывает числа.
Сложили один раз, второй раз. Компилятор строит предсказание: «Это числа, у меня есть крутое решение для сложения чисел!» А вы пишете
В этот момент происходит деоптимизация.
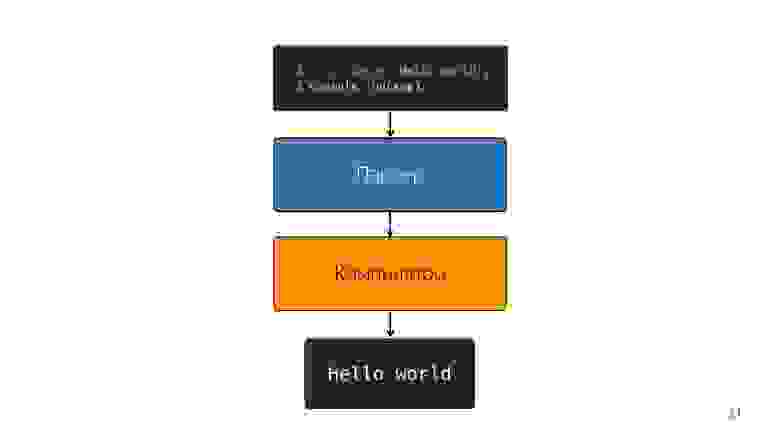
Итак, интерпретатор заменился на компилятор. Кажется, что на схема выше очень простой pipeline. В реальности все немного иначе.
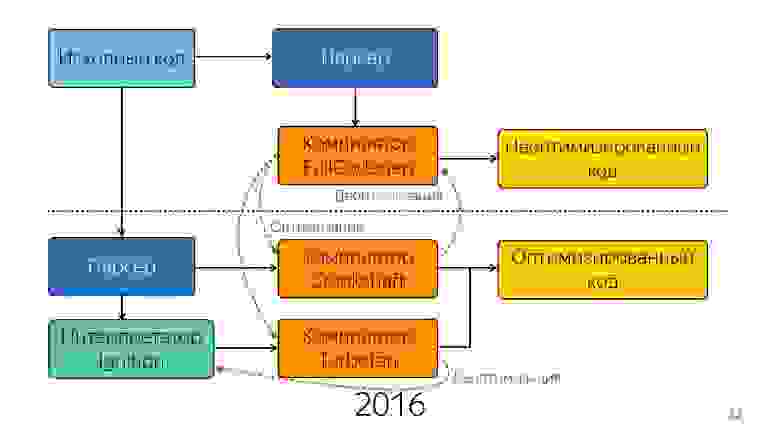
Так было до прошлого года. В прошлом году вы могли слышать много докладов от Google о том, что они запустили новый pipeline с TurboFan и теперь схема выглядит проще.
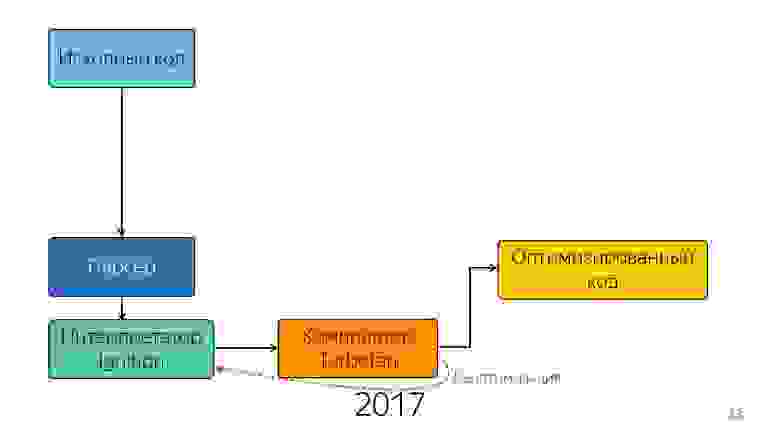
Интересно, что здесь появился интерпретатор.

Интерпретатор нужен, чтобы превратить абстрактное синтаксическое дерево в байткод, и предать байткод в компилятор. В случае деоптимизации он опять идет в интерпретатор.
Раньше в схеме интерпретатора Ignition не было. Google изначально говорили о том, что интерпретатор не нужен — JavaScript и так достаточно компактный и интерпретируемый — мы ничего не выиграем.
Но команда, которая работала с мобильными приложениями, столкнулась со следующей проблемой.
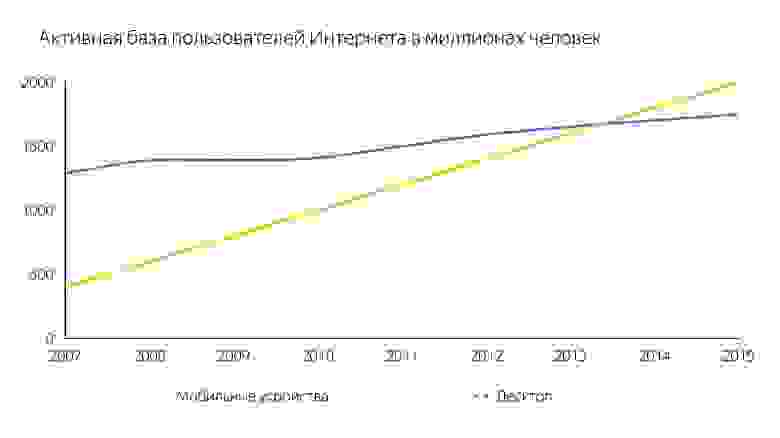
В 2013-2014 году люди стали чаще использовать для выхода в интернет мобильные устройства, чем десктоп. В основном это не iPhone, а с устройств попроще — у них мало памяти и слабый процессор.
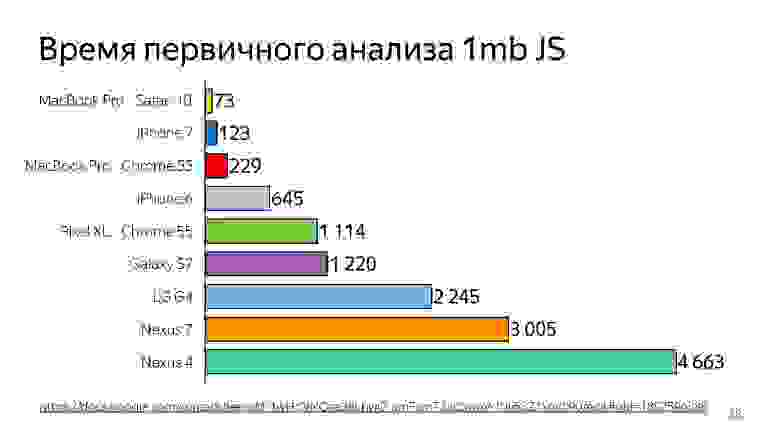
Выше график первичного анализа 1 МБ кода до запуска интерпретатора. Видно, что десктоп выигрывает очень сильно. iPhone тоже неплох, но у него другой движок, а мы говорим сейчас о V8, который работает в Chrome.
Таким образом время тратится — и это только анализ, а не исполнение — ваш файл загрузился, и он пытается понять, что в нем написано.
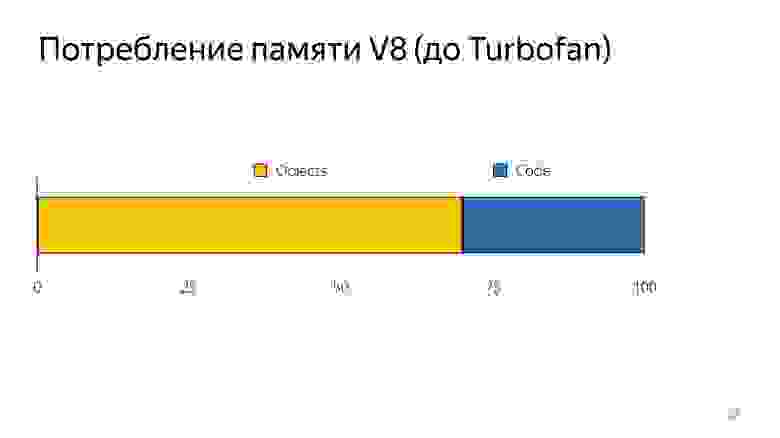
Когда происходит деоптимизация, нужно снова исходный взять код, т.е. его надо где-то хранить. На это уходило много памяти.
Таким образом у интерпретатора было две задачи:
Задачи были решены переходом на интерпретатор с байткодом.
Байткод в Chrome — это регистровая машина с аккумулятором. В SpiderMonkey стековая машина, там все данные лежат на стеке, а регистров нет. Здесь они есть.
Не будем полностью разбирать, как это работает, просто посмотрим на фрагмент кода.

Здесь написано: взять значение, которое лежит в аккумуляторе, и сложить со значением, которое лежит в регистре a0, то есть в переменной a. Здесь еще ничего не известно о типах. Если бы это был настоящий ассемблерный код, то он бы писался с пониманием того, какие есть сдвиги в памяти, что в ней находится. Здесь же просто инструкция — возьми то, что лежит в регистре a0 и сложи со значением, лежащим в аккумуляторе.
Конечно, интерпретатор не просто берет абстрактное синтаксическое дерево и переводит его в байткод.
Здесь также происходят оптимизации, например, dead code elimination.
Если участок кода не будет вызван, он выкидывается и дальше не хранится. Если Ignition увидит сложение двух чисел, он их сложит и оставит в таком виде, чтобы не хранить лишнюю информацию. Только после этого получается байткод.
Это самая простая тема.
Холодные функции — это те, которые вызывались один раз или не вызывались совсем, горячие — это те, которые вызывались несколько раз. Сколько именно раз, сказать нельзя — в любой момент это могут переделать. Но в какой-то момент функция становятся горячей, и движок понимает, что ее надо оптимизировать.
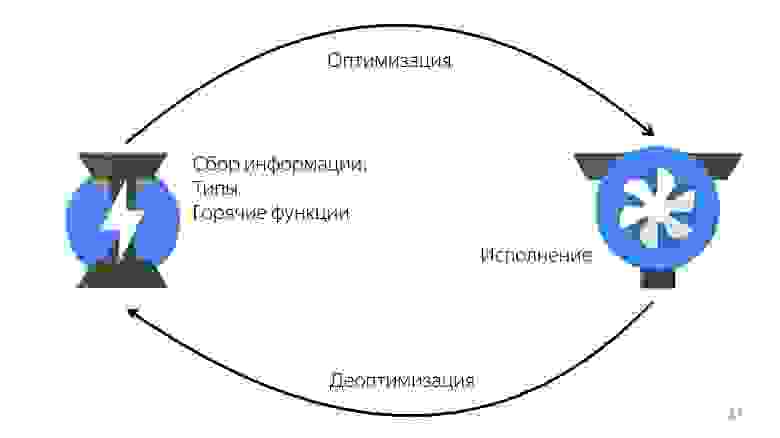
Схема работы.
Это нормальный цикл, который происходит все время, но он не бесконечный. В какой-то момент движок говорит: «Нет, это невозможно оптимизировать», и начинает выполнять без оптимизации. Важно понимать, что нужно соблюдать мономорфность.
Мономорфность — это когда на вход вашей функции всегда приходят одни и те же типы. То есть если у вас все время приходит string, то не надо передавать туда boolean.
Но что делать с объектами? Объекты все object. У нас есть классы, но ведь они не настоящие — это просто сахар над прототипной моделью. Но внутри движка есть так называемые скрытые классы.
Скрытые классы есть во всех движках, не только в V8. Везде они называются по-разному, в терминах V8 это Map.
Все объекты, которые вы создали, имеют скрытые классы. Если вы
посмотрите в профилировщик памяти, вы увидите, что там есть elements, где хранится список элементов, properties, где хранятся property, и map (обычно первым параметром), где указана ссылка на его на его скрытый класс.
Map описывает структуру объектов, потому что в принципе в JavaScript типизация возможна только структурная, не номинальная. Мы можем описать, как выглядит наш объект, что за чем в нем идет.
При удалении/добавлении свойств объектов Hidden classes у объекта меняется, присваивается новый. Посмотрим на коде.
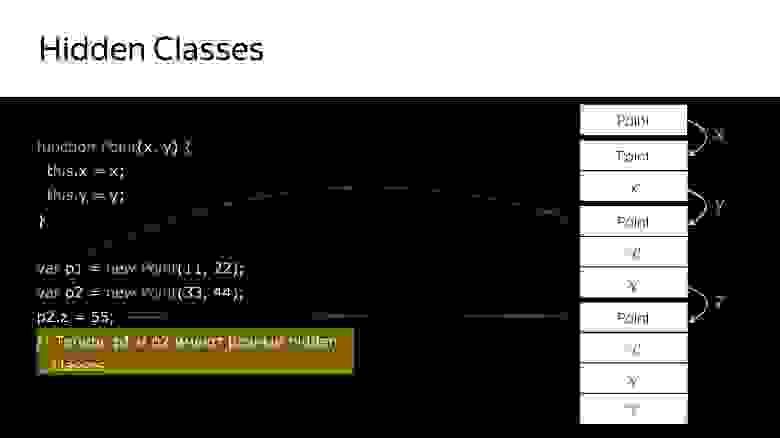
У нас есть конструктор, который создает новый объект типа Point.
Как можно проверить Hidden classes?
В Node.js можно запустить node —allow-natives-syntax. Тогда вы получите возможность писать команды в специальном синтаксисе, который, конечно, нельзя использовать в продакшене. Это выглядит так:
Никто не гарантирует, что это завтра эти команды будут работать, их нет в спецификации ECMAScript, это всё для отладки.
Как вы думаете, какой будет результат вызова функции %HaveSameMap для двух объектов. Правильный ответ — false, потому что у одного поле называется a, у второго — b. Это разные объекты. Это знание можно использовать для техники Inline Caches.
Вызовем очень простую функция, которая возвращает поле из объекта. Кажется, вернуть единицу очень просто. Но если вы посмотрите спецификацию ECMAScript, вы увидите, что там огромный список того, что нужно сделать, чтобы получить поле из объекта. Потому что, если поля нет в объекте, возможно, оно есть в его прототипе. Может быть, это setter, getter и так далее. Все это нужно проверять.
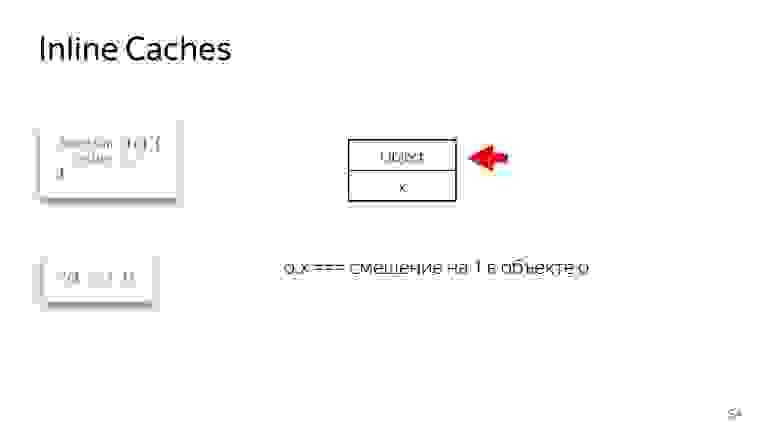
В данном случае в объекте есть ссылка на map, которая говорит: чтобы получить поле x, нужно сделать смещение на единицу, и мы получим x. Никуда не надо лазить, ни в какие прототипы, все рядом. Inline Caches использует это.
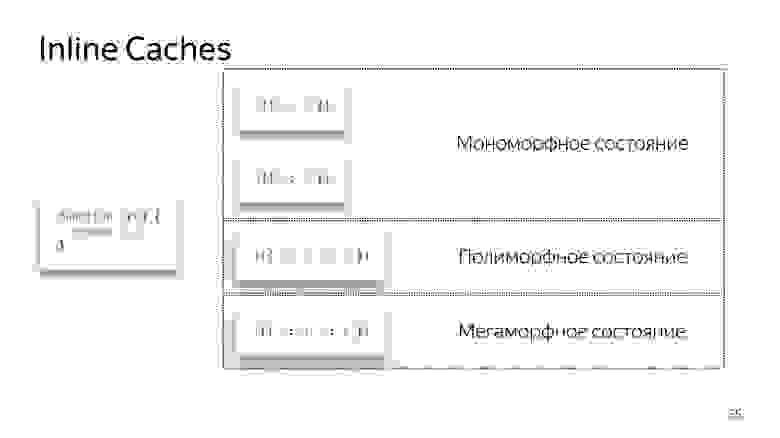
Кажется, сейчас допускается 4 полиморфных состояний, но завтра их может быть 8. Это решают разработчики движка. Нам лучше оставаться в мономорфном, в крайнем случае, в полиморфном состоянии. Переход между мономорфным и полиморфным состояниями дорогой, потому что нужно будет сходить в интерпретатор, получить код заново и заново его оптимизировать.
В JavaScript, не считая специфичных Typed Arrays, есть один тип
массива. В движке V8 их 6:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS — просто упакованный массив small integer. Для него есть оптимизации.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS — упакованный массив double элементов, для него тоже есть оптимизации, но более медленные.
3. [1, 2, 3, 4, ’X’] // PACKED_ELEMENTS — упакованный массив, в котором есть объекты, строки и все остальное. Для него тоже есть оптимизации.
Следующие три типа — это массивы того же типа, что первые три, но с дырками:
4. [1, /*hole*/, 2, /*hole*/, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, /*hole*/, 2, /*hole*/, 3, 4] // HOLEY_DOUBLE_ELEMENTS
6. [1, /*hole*/, ’X’] // HOLEY_ELEMENTS
Когда в ваших массивах появляются дырки, оптимизации становятся менее эффективными. Они начинают работать плохо, потому что невозможно подряд пройти по этому массиву, перебирая его итерациями. Каждый последующий тип хуже оптимизируется
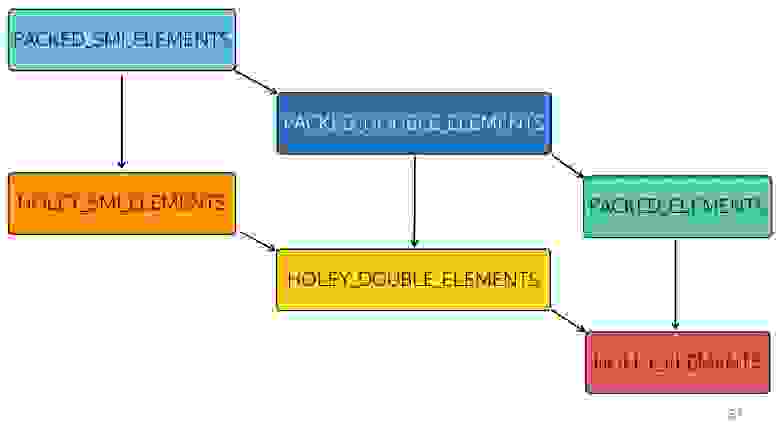
На схеме все, что выше, быстрее оптимизируется. То есть все ваши нативные методы — map, reduce, sort — внутри хорошо оптимизированы. Но с каждым типом оптимизация становится хуже.
Например, на вход пришел простой массив [1, 2,3] (тип — упакованный small integer). Чуть-чуть изменили этот массив, добавив в него double — перешли в состояние PACKED_DOUBLE_ELEMENTS. Добавляем в него объект — перешли в следующее состояние, зеленый прямоугольник PACKED_ELEMENTS. Добавляем в него дырок — переходим в состояние HOLEY_ELEMENTS. Хотим восстановить его в предыдущее состояние, чтобы он снова стал «хорошим» — удаляем все, что написали, и остаемся в том же состоянии… с дырками! То есть HOLEY_ELEMENTS справа внизу на схеме. Назад это не работает. Ваши массивы могут становиться только хуже, но не наоборот.
Мы часто сталкиваемся с Array-Like Object — это объекты, которые похожи на массивы, потому что у них есть признак длины. На самом деле они как кот-пират, то есть вроде похожи, но в эффективности потребления рома котик будет хуже, чем пират. Точно так Array-Like Object похож на массив, но не эффективен.

Два наших самых любимых Array-Like Object — это arguments и document.querySelectorAII. Есть такие красивые функциональные штуки.

У нас появился map — мы его выдрали из прототипа и вроде бы можем использовать. Но если ему на вход пришел не массив, никакой оптимизации не будет. Наш движок не умеет делать оптимизацию по объектам.
Что нужно сделать?
С querySelectorAll то же самое — за счет spread мы можем превратить его в полноценный массив и работать со всеми оптимизациями.
Правильный ответ: зависит от.
В чем отличие?
То есть в первом случае быстро пишем — медленно работаем; во втором медленно пишем — быстро работаем.
Сборщик мусора тоже немножко ест время и ресурсы. Глубоко не погружаясь, дам самую общую базу.

В нашей генеративной модели есть пространство молодых и старых объектов. Создаваемый объект попадает в пространство молодых объектов. Через какое-то время запускается очистка. Если объект невозможно достичь по ссылкам от корневого, то его можно собрать в мусор. Если объект еще используется, он перемещается в пространство старых объектов, которое чистится реже. Тем не менее в какой-то момент удаляются и старые объекты.

Так работает автоматический сборщик мусора — он сам подчищает объекты, основываясь на том, что к ним нет ссылок. Это два разных алгоритма.
Если в Node.js запустить профилирование потребления памяти, то получится примерно такой график.
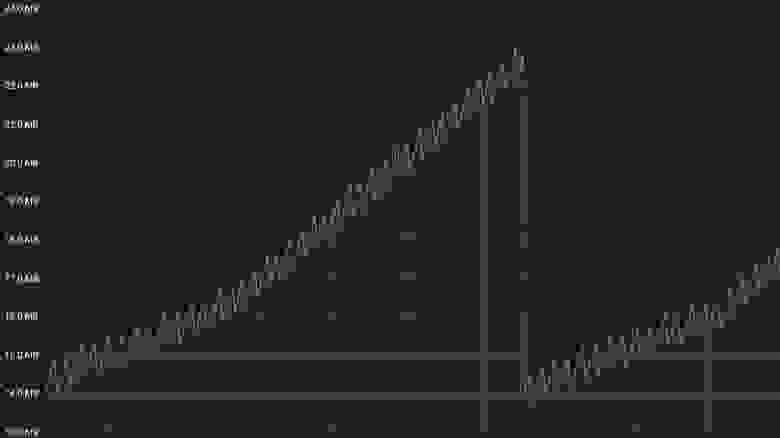
Сначала он скачкообразно растет — это работе алгоритма Scavenge. Потом происходит резкое падение — это Mark-Sweep-алгоритм собрал мусор в пространстве старых объектов. В этот момент все начинает немножко тормозить. Вы не можете этим управлять, поскольку не знаете, когда это произойдет. Вы можете только настроить размеры.
Поэтому в pipeline есть стадия сборки мусора, которая потребляет время.
Заглянем в будущее. Что делать дальше, как быть быстрее?
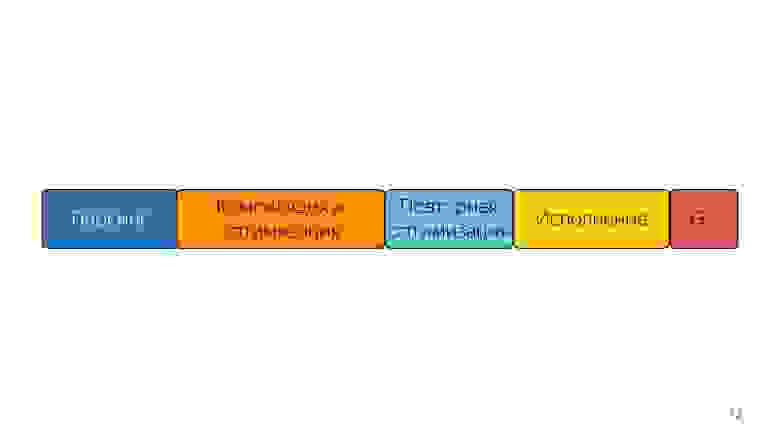
На этой линейке размеры блоков примерно соотносятся в временем, которое он занимают.
Первое, что приходит в голову людям, которые услышали про байткод — сразу подавать на вход байткод и декодировать его, а не парсить — будет быстрее!
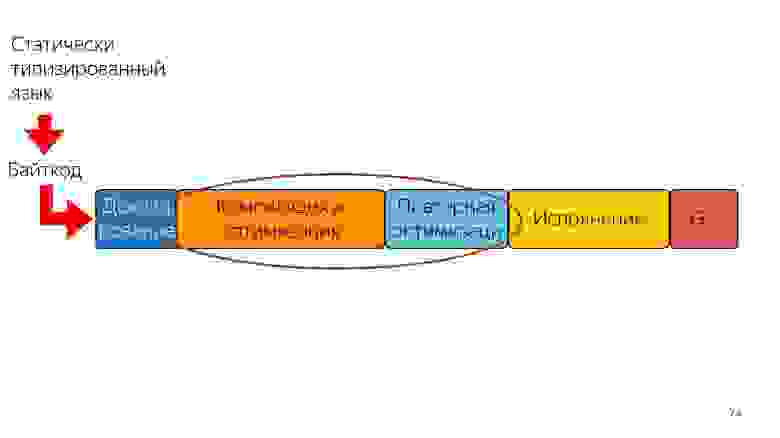
Проблема в том, что байткод сейчас разный. Как я уже сказал: в Safari один, в FireFox другой, в Chrome третий. Тем не менее разработчики из Mozilla, Bloomberg и Facebook выдвинули такой Proposal, но это будущее.
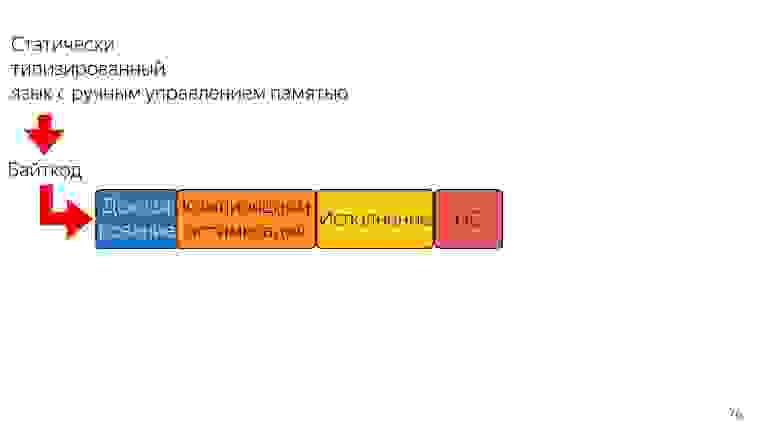
Есть другая проблема — компиляция, оптимизация, и повторная оптимизация, если компилятор не угадал. Представим, что есть статически типизированный язык на входе, который выдает эффективный код, и значит уже не нужна повторная оптимизация, потому что то, что мы получили, уже эффективно. Такой вход можно только один раз скомпилировать и оптимизировать. Полученный код будет более эффективным и исполнится быстрее.
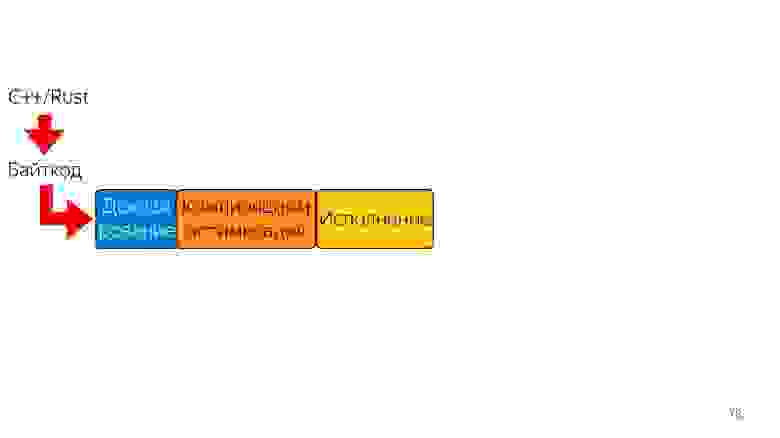
Что еще можно сделать? Представим, что в этом языке есть ручное управление памятью. Тогда не нужен сборщик мусора. Линейка стала короче и быстрее.
Догадываетесь, на что это похоже? WebAssembly примерно
так и работает: ручное управление памятью, статически типизированные
языки и быстрое выполнение.
Является ли WebAssembly серебряной пулей?
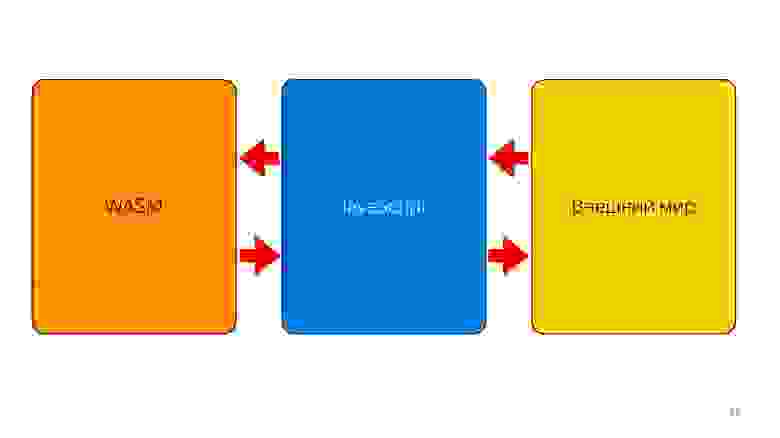
Нет, потому что он стоит за JavaScript. WASM пока сам ничего не может делать. У него нет доступа к DOM API. Он внутри движка для JavaScript — внутри того же самого движка! Он все делает через JavaScript, поэтому WASM не ускорит ваш код. Он может ускорить отдельные вычисления, но у вас обмен между JavaScript и WASM будет узким местом.
Поэтому пока наш язык — это JavaScript и только он, и какая-то помощь из черной коробки.
Можно выделить три вида оптимизации.
● Алгоритмические оптимизации
Есть статья "Возможно вам не нужен Rust, чтобы ускорить ваш JS" Вячеслава Егорова, который когда-то разрабатывал V8, а сейчас разрабатывает Dart. Кратко перескажу её историю.
Была библиотека на JavaScript, которая работала не очень быстро. Какие-то ребята переписали ее на Rust, скомпилировали и получили WebAssembly, и приложение стало работать быстрее. Вячеслав Егоров как опытный JS-разработчик решил им ответить. Он применил алгоритмические оптимизации, и решение на JavaScript стало сильно быстрее решения на Rust. В свою очередь те ребята это увидели, сделали те же самые оптимизации, и снова выиграли, но не сильно — зависит от движка: в Mozilla выиграли, в Chrome — нет.
Мы сегодня не говорили про алгоритмические оптимизации, и фронтэндеры о них обычно не говорят. Это очень плохо, потому что алгоритмы тоже позволяют коду работать быстрее. Вы просто убираете ненужные вам циклы.
● Специфичные для языка оптимизации
Это то, о чем мы сегодня говорили: наш язык интерпретируемый динамически типизированный. Понимание того, как работают массивы, объекты, мономорфность позволяет писать эффективный код. Это надо знать и писать правильно.
● Специфичные для движка оптимизации
Это самые опасные оптимизации. Если ваш очень умный, но не очень общительный, разработчик, который применил очень много таких оптимизаций, и никому о них не рассказал, не написал документацию, то, если вы откроете код, то увидите не JavaScript, а, например, Crankshaft Script. То есть JavaScript, написанный с глубоким пониманием того, как работал движок Crankshaft два года назад. Это все работает, но сейчас уже не нужно.
Поэтому такие оптимизации обязательно должны быть задокументированы, покрыты тестами, доказывающими их эффективность в данный момент. За ними надо следить. К ним нужно переходить только в тот момент, когда вы где-то реально замедлились — прямо никак не обойтись без знания таких глубинных устройств. Поэтому кажется логичной знаменитая фраза Дональда Кнута.

Не нужно пытаться внедрить какие-то жесткие оптимизации только потому, что вы про них прочитали положительные отзывы.
Таких оптимизаций надо бояться, обязательно документировать и оставлять метрики. Вообще всегда собирайте метрики. Метрики — это важно!
Полезные ссылки:

Узнаем, является ли WASM серебряной пулей для повышения производительности кода, и всегда ли оправданы оптимизации.
Спойлер: «Преждевременная оптимизация — корень всех бед», Дональд Кнут.

О спикере: Андрей Мелихов работает в компании Яндекс.Деньги, активно пишет на Node.js, а в браузере — меньше, поэтому ему ближе серверный JavaScript. Андрей поддерживает и развивает сообщество devShacht, заходите познакомиться на GitHub или Medium.
Мотивация и глоссарий
Сегодня мы будем говорить про JIT компиляцию. Думаю, вам это интересно, раз вы это читаете. Тем не менее, давайте уточним, зачем нужно знать, что такое JIT и как устроен V8, и почему недостаточно писать на React в браузере.
- Позволяет писать более эффективный код, потому что язык у нас специфичный.
- Раскрывает загадки, почему в чужих библиотеках код написан именно так, а не иначе. Иногда мы сталкиваемся со старыми библиотеками и видим, что там написано как-то странно, а нужно это, не нужно — непонятно. Когда знаешь, как это работает, то понимаешь, зачем это было сделано.
- Это просто интересно. К тому же позволяет понять, о чём общаются в твиттере Аксель Раушмайер, Бенедикт Мойрер и Дэн Абрамов.
В Википедии написано, что JavaScript — это высокоуровневый интерпретируемый язык программирования с динамической типизацией. Разберемся с этими терминами.
Компиляция и интерпретация
Компиляция — когда программа поставляется в бинарном коде, и изначально оптимизирована под среду, в которой будет работать.
Интерпретация — когда мы поставляем код, как есть.
JavaScript поставляется, как есть — это интерпретируемый язык, как и написано в Википедии.
Динамическая и статическая типизация
Статическую и динамическую типизации часто путают со слабой и сильной типизацией. Например, С — это язык со статической слабой типизацией. У JavaScript слабая динамическая типизация.
Что из этого лучше? Если программа компилируется, она заточена на ту среду, в которой будет исполняться, а значит —будет работать лучше. Статическая типизация позволяет сделать этот код эффективнее. В JavaScript все наоборот.
Но при этом наше приложение становится все сложнее: и на клиенте, и на сервере появляются огромные кластеры на Node.js, которые прекрасно работают и приходят на замену Java-приложениям.
Но каким образом это все работает, если изначально кажется, что оно в проигрыше.
JIT всех примирит! Или хотя бы попытается.
У нас есть JIT (Just In Time компиляция), которая происходит во время выполнения программы. О ней и будем говорить.
JS-движки
- Всеми нелюбимая Chakra, которая находится в Internet Explorer. Она даже работает не с JavaScript, а с Jscript — есть такое подмножество.
- Современные Chakra и ChakraCore, которые работают в Edge;
- SpiderMonkey в FireFox;
- JavaScriptCore в WebKit. Также он используется в React Native. Если у вас RN-приложение под Android, то оно так же исполняется на JavaScriptCore — движок идёт в комплекте с приложением.
- V8 — мой самый любимый. Он не самый лучший, просто я работаю с Node.js, в котором это основной движок, как и во всех Chrome Based браузерах.
- Rhino и Nashorn — это движки, которые используются в Java. С их помощью там тоже можно исполнять JavaScript.
- JerryScript — для встраиваемых устройств;
- и другие...
Вы можете написать свой движок, но если вы будете двигаться к эффективному исполнению, то придете примерно к одной и той же схеме, которую я дальше покажу.
Сегодня мы будем говорить о V8, и да, он назван в честь 8-цилиндрового двигателя.
Лезем под капот
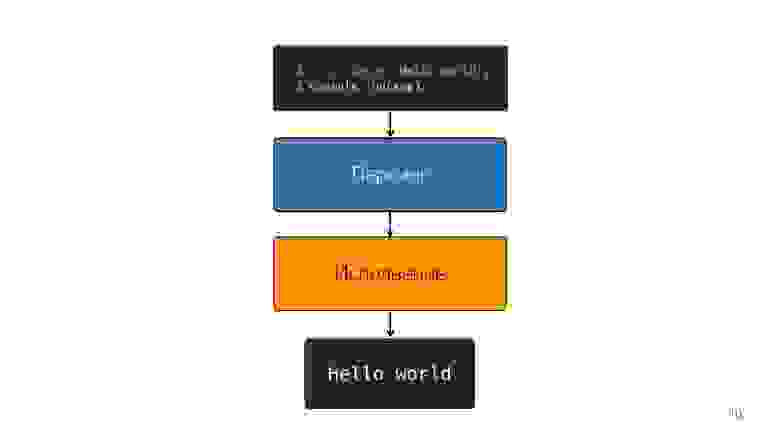
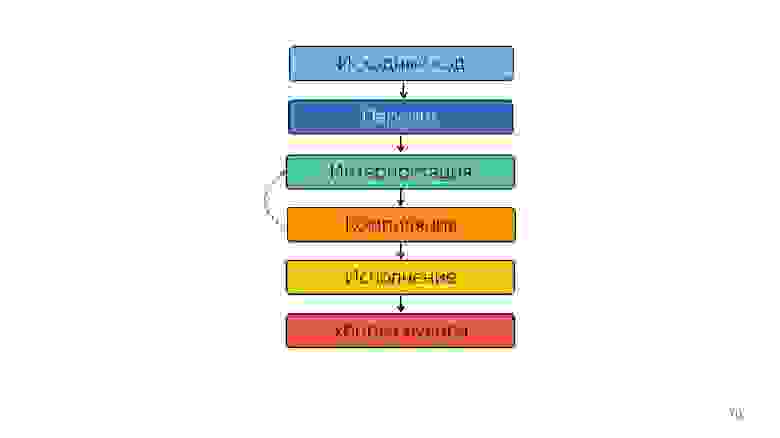
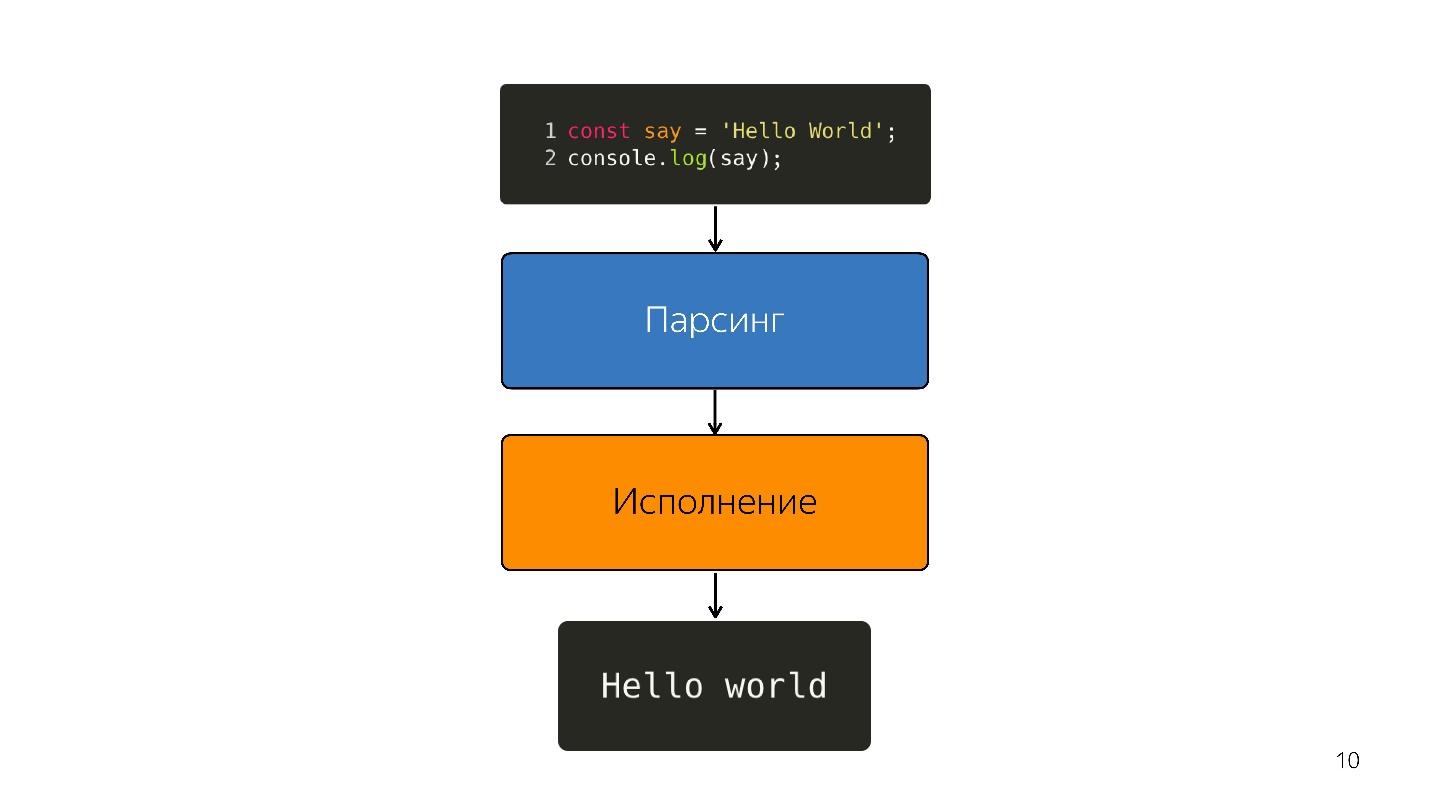
Как исполняется JavaScript?
- Есть код, написанный на JavaScript, который так и поставляется.
- он парсится;
- исполняется;
- получается результат.
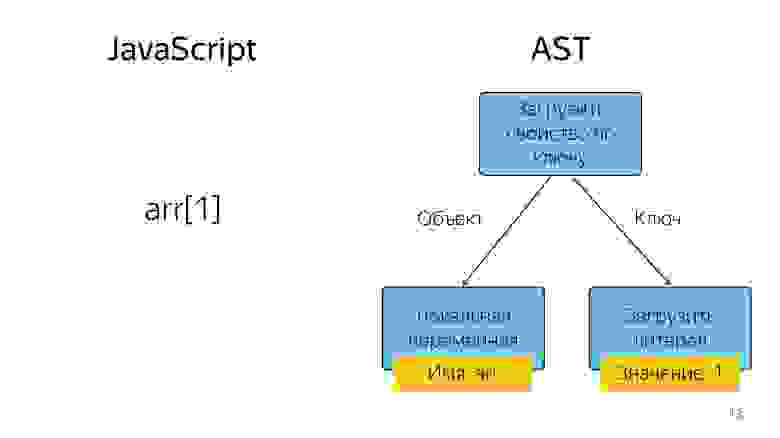
Парсинг превращает код в абстрактное синтаксическое дерево. AST — это отображение синтаксической структуры кода в виде дерева. На самом деле это удобно для программы, хотя и тяжело читать.
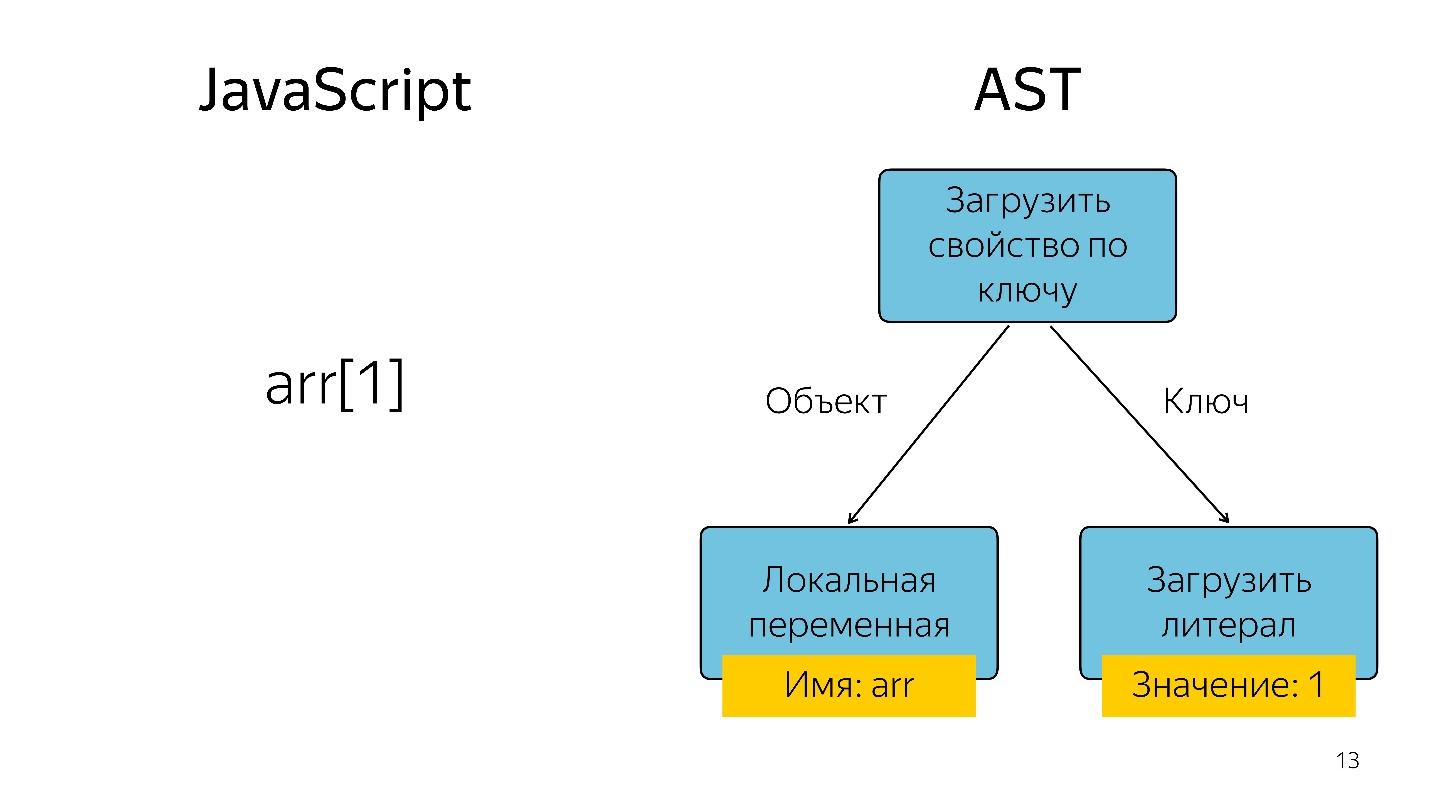
Получение элемента массива с индексом 1 в виде дерева представляется в виде оператора и двух операндов: загрузить свойство по ключу и эти ключи.
Где используется AST
AST есть не только в движках. С использованием AST во многих утилитах пишутся расширения, в том числе:
- ESLint;
- Babel;
- Prettier;
- Jscodeshift.
Например, крутая штука Jscodeshift, про которую пока не все знают, позволяет писать преобразования. Если вы изменили API у какой-то функции, то можете натравить на нее эти преобразования и внести изменения во всем проекте.

Двигаемся дальше. Процессор не понимает абстрактное синтаксическое дерево, ему нужен машинный код. Поэтому дальше происходит преобразование через интерпретатор, потому что язык интерпретируемый.
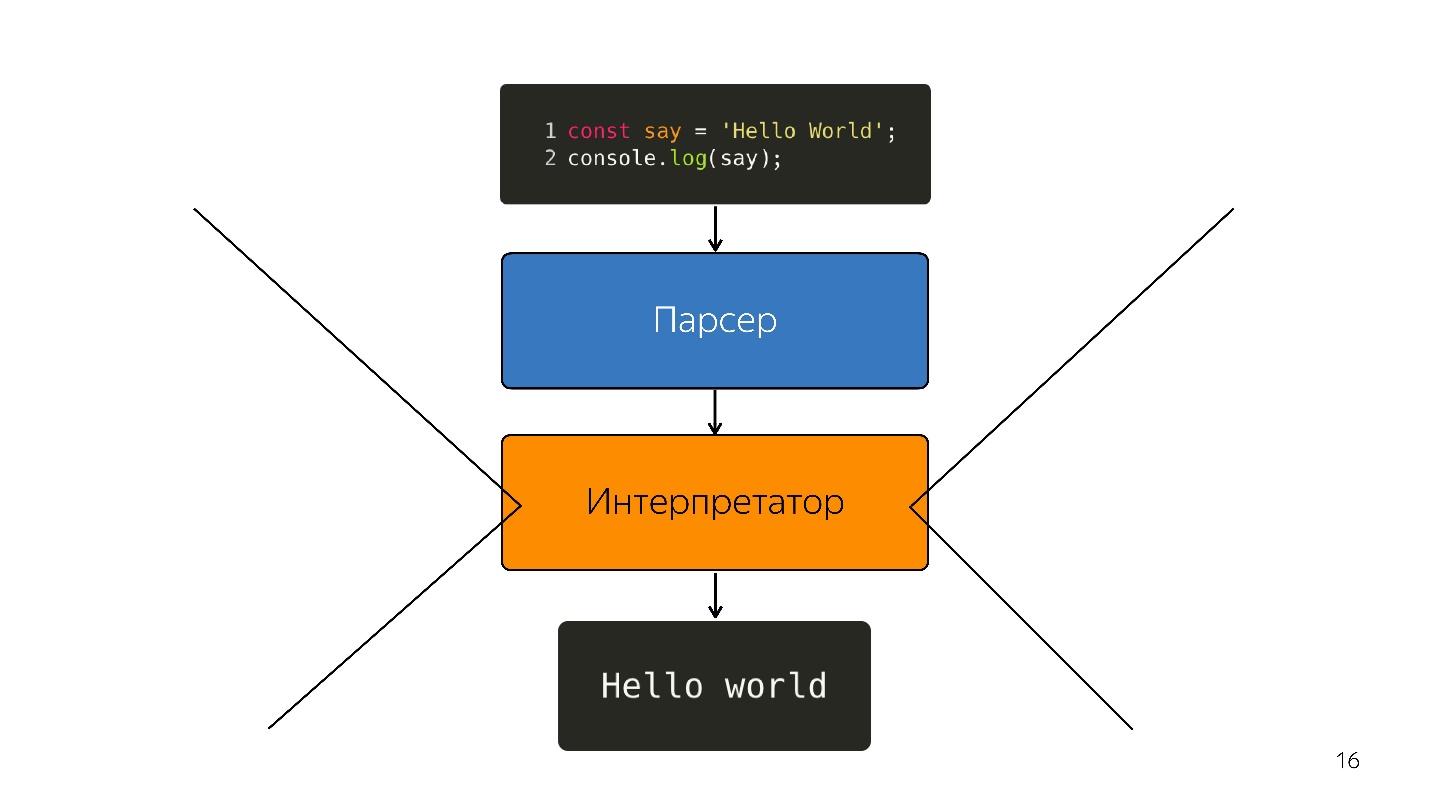
Так было, пока браузерах было немного JavaScript — подсветить строчку, что-то открыть, закрыть. Но сейчас у нас приложения — SPA, Node.js, и интерпретатор становится узким местом.
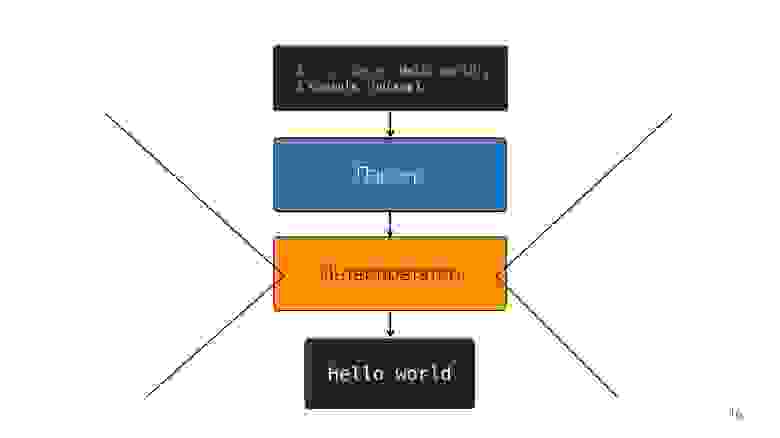
Оптимизирующий JIT-компилятор
Вместо интерпретатора появляется оптимизирующий JIT-компилятор, то есть Just-in-time компилятор. Ahead-of-time компиляторы работают до исполнения приложения, а JIT — во время. В вопросе оптимизации JIT-компилятор пытается угадать, как код будет исполняться, какие будут использоваться типы, и оптимизировать код так, чтобы он лучше работал.
Такая оптимизация называется спекулятивной, потому что она спекулирует на знаниях о том, что происходило с кодом раньше. То есть если 10 раз было вызвано что-то с типом number, компилятор думает, что так будет все время и оптимизирует под этот тип.
Естественно, если на вход попадает Boolean, происходит деоптимизация. Рассмотрим функцию, которая складывает числа.
const foo=(a, b) => a + b;
foo (1, 2);
foo (2, 3);Сложили один раз, второй раз. Компилятор строит предсказание: «Это числа, у меня есть крутое решение для сложения чисел!» А вы пишете
foo('WTF', 'JS'), и передаете в функцию строки — у нас же JavaScript, мы можем и строку с числом сложить.В этот момент происходит деоптимизация.
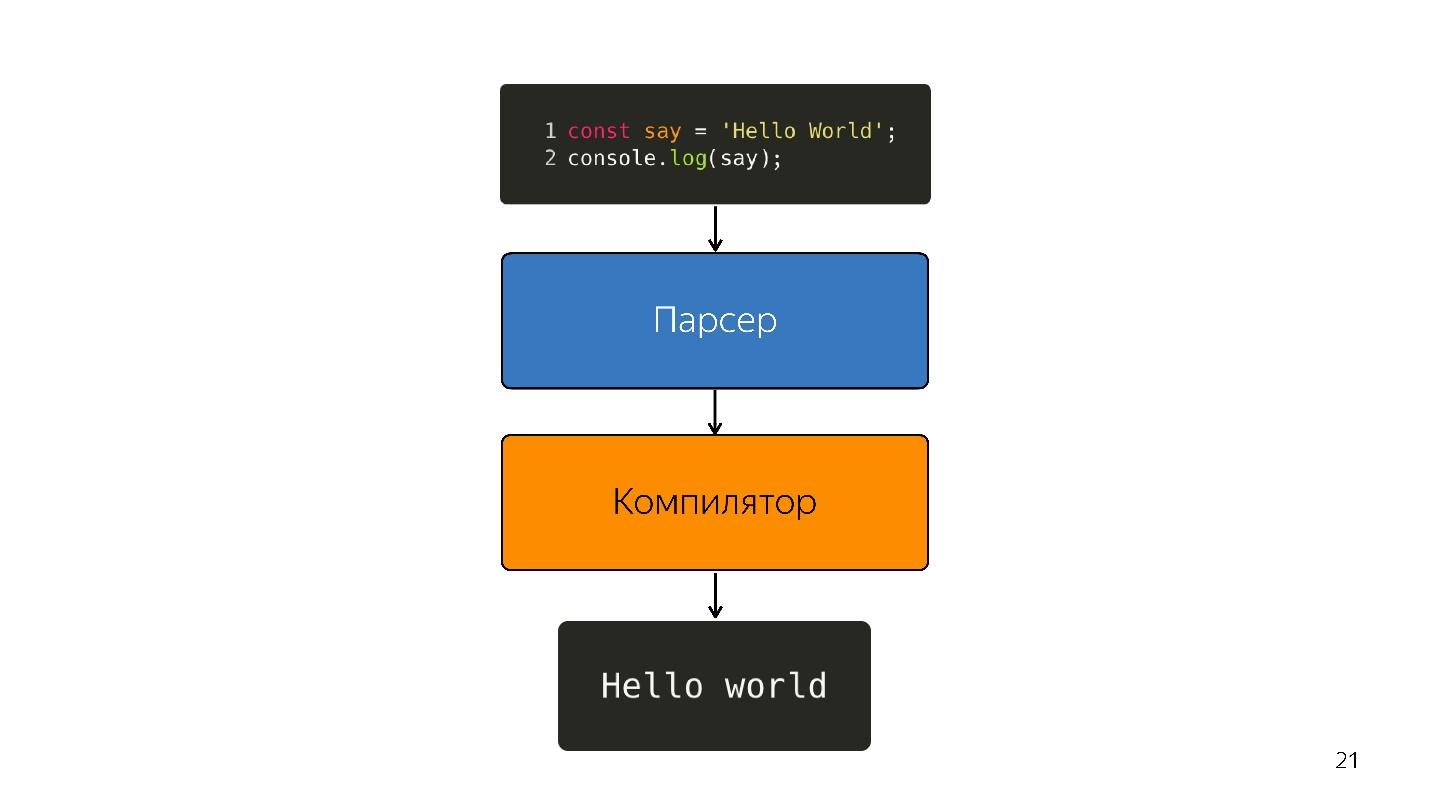
Итак, интерпретатор заменился на компилятор. Кажется, что на схема выше очень простой pipeline. В реальности все немного иначе.
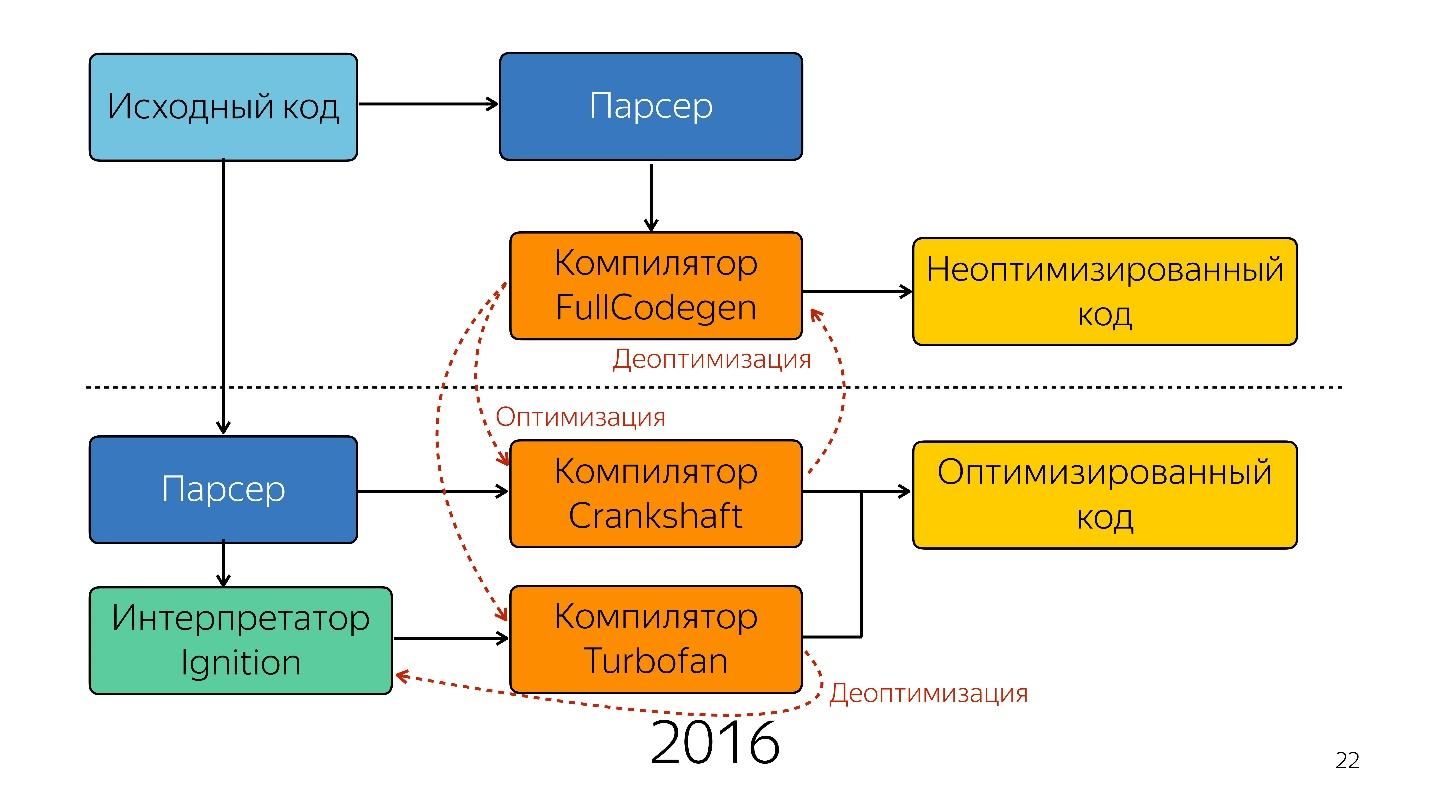
Так было до прошлого года. В прошлом году вы могли слышать много докладов от Google о том, что они запустили новый pipeline с TurboFan и теперь схема выглядит проще.
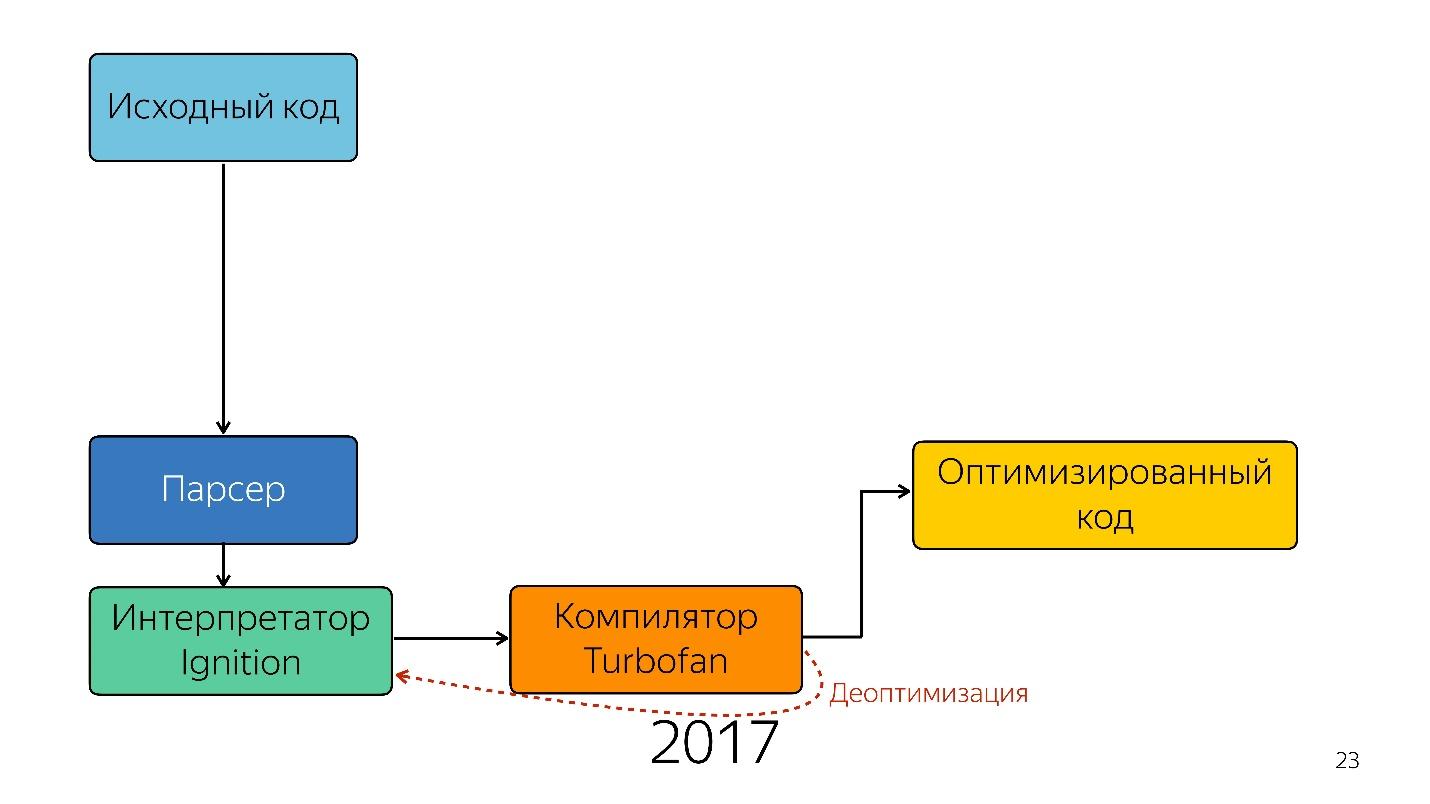
Интересно, что здесь появился интерпретатор.
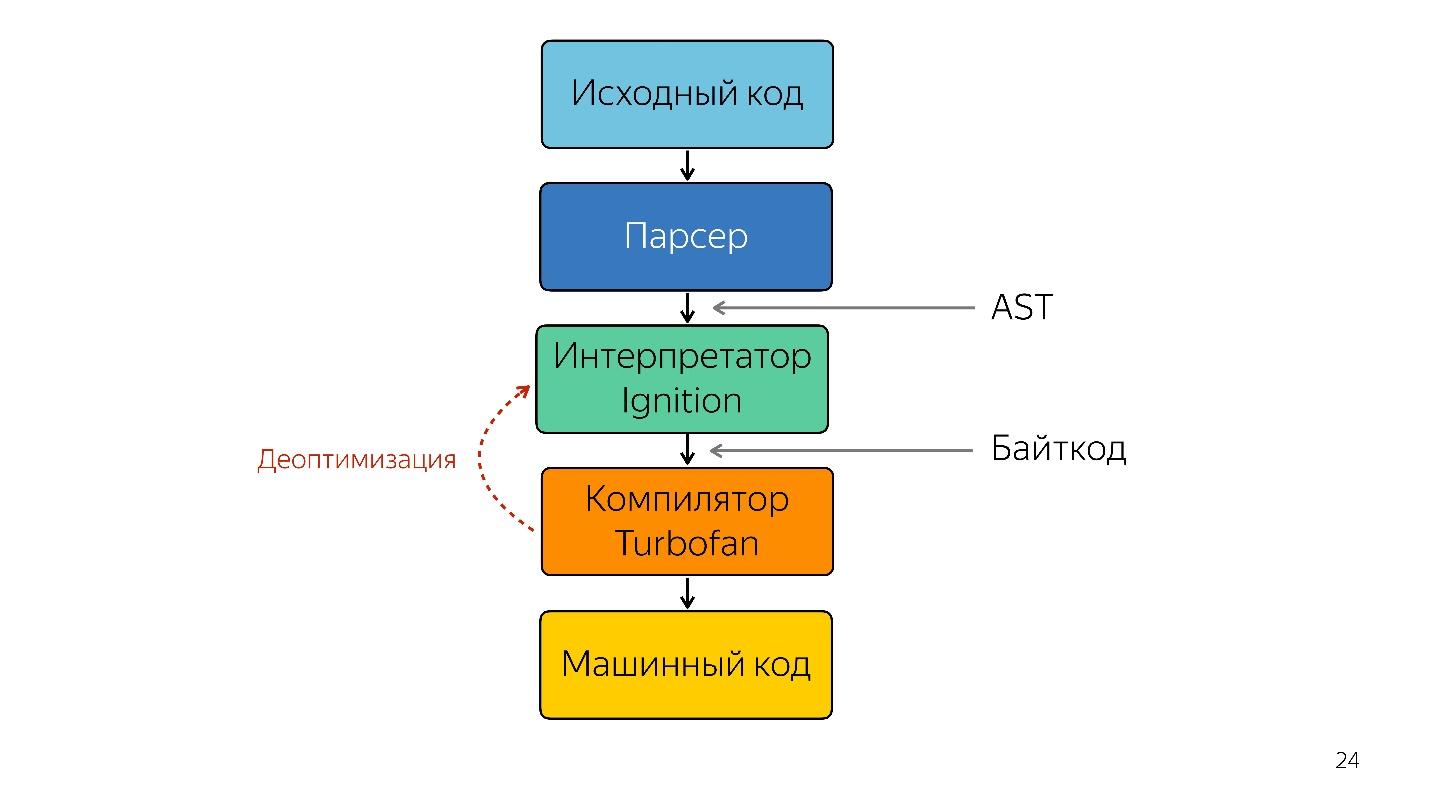
Интерпретатор нужен, чтобы превратить абстрактное синтаксическое дерево в байткод, и предать байткод в компилятор. В случае деоптимизации он опять идет в интерпретатор.
Интерпретатор Ignition
Раньше в схеме интерпретатора Ignition не было. Google изначально говорили о том, что интерпретатор не нужен — JavaScript и так достаточно компактный и интерпретируемый — мы ничего не выиграем.
Но команда, которая работала с мобильными приложениями, столкнулась со следующей проблемой.

В 2013-2014 году люди стали чаще использовать для выхода в интернет мобильные устройства, чем десктоп. В основном это не iPhone, а с устройств попроще — у них мало памяти и слабый процессор.
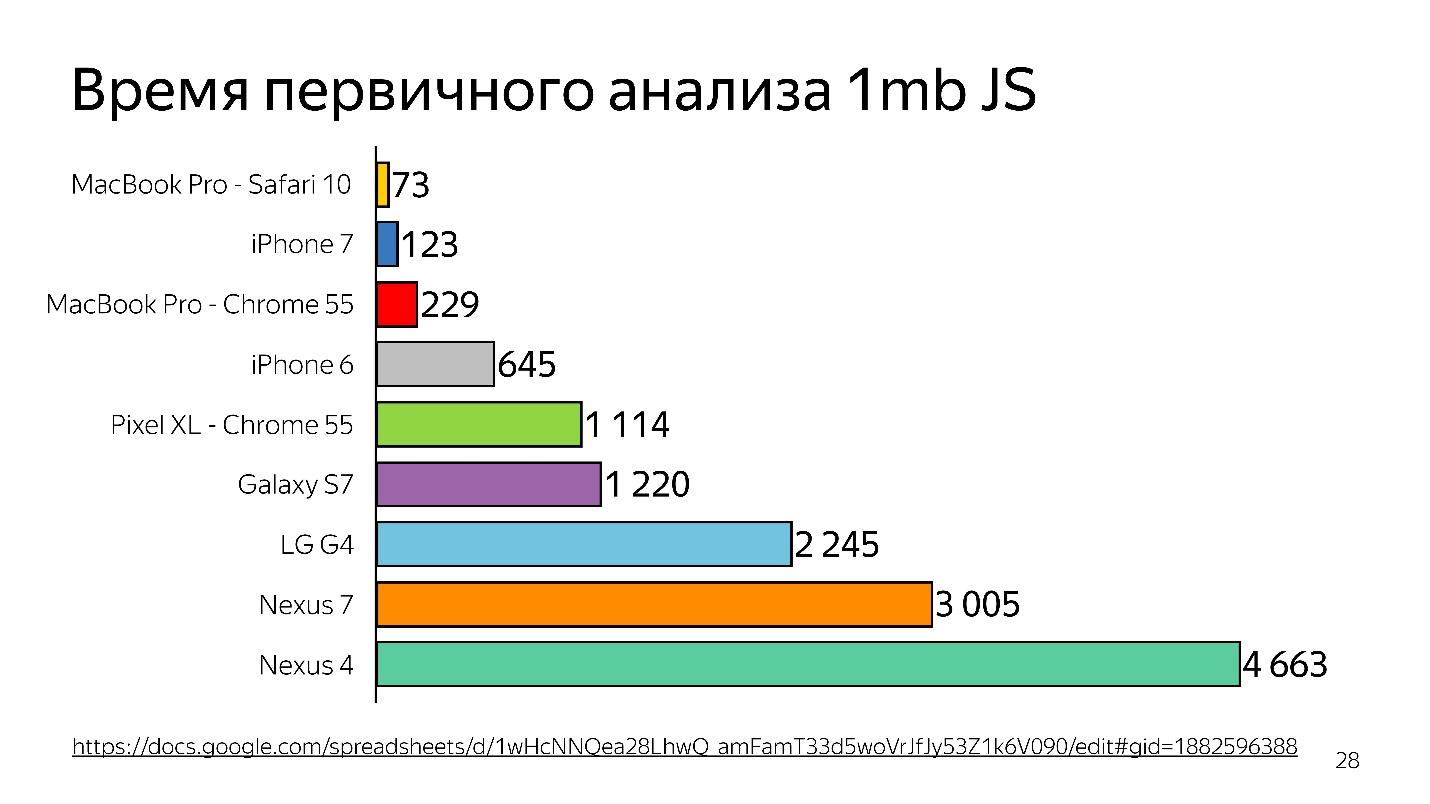
Выше график первичного анализа 1 МБ кода до запуска интерпретатора. Видно, что десктоп выигрывает очень сильно. iPhone тоже неплох, но у него другой движок, а мы говорим сейчас о V8, который работает в Chrome.
А вы знаете, что, если вы поставите Chrome на iPhone, он все равно будет работать на JavaScriptCore?
Таким образом время тратится — и это только анализ, а не исполнение — ваш файл загрузился, и он пытается понять, что в нем написано.
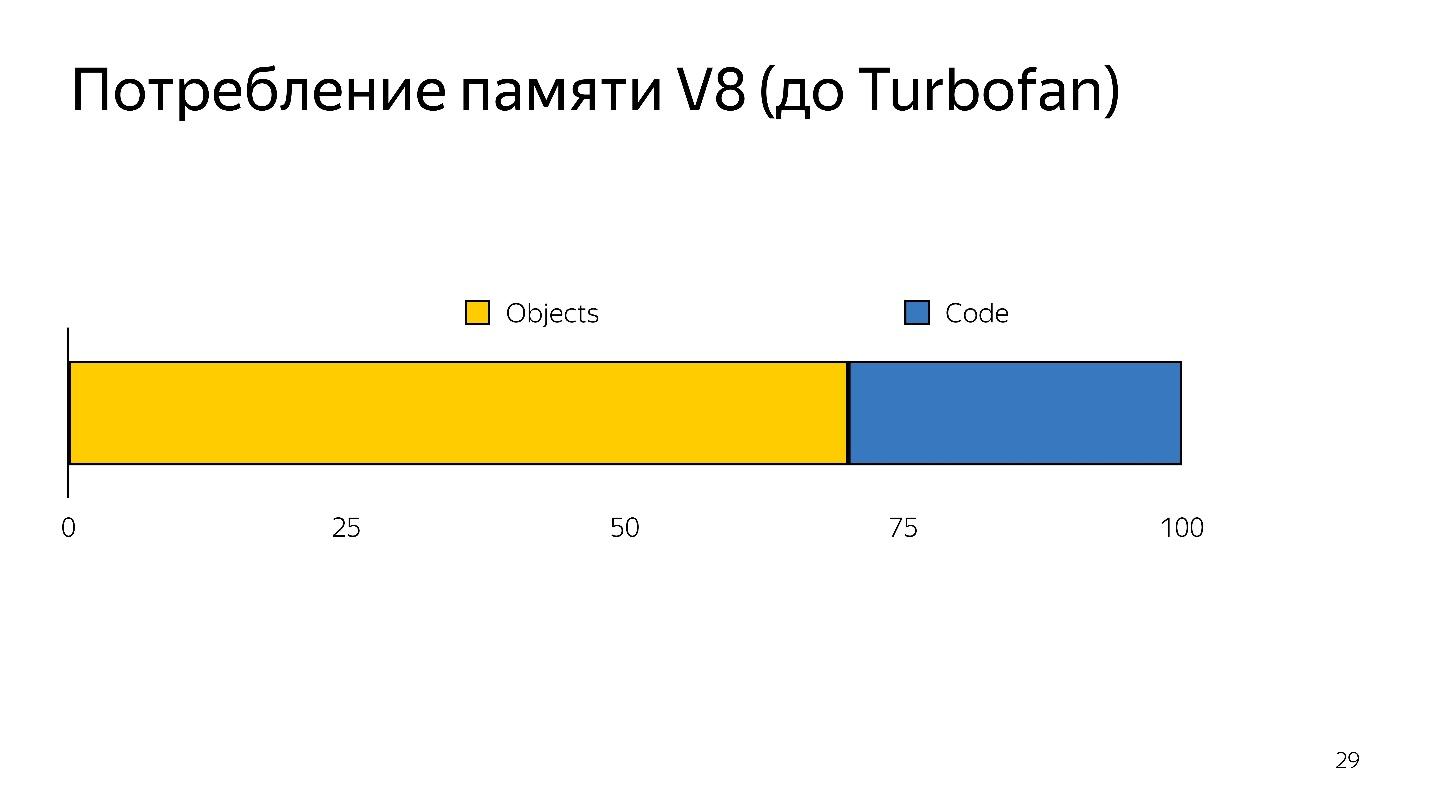
Когда происходит деоптимизация, нужно снова исходный взять код, т.е. его надо где-то хранить. На это уходило много памяти.
Таким образом у интерпретатора было две задачи:
- уменьшить накладные расходы на парсинг;
- уменьшить потребление памяти.
Задачи были решены переходом на интерпретатор с байткодом.
Байткод в Chrome — это регистровая машина с аккумулятором. В SpiderMonkey стековая машина, там все данные лежат на стеке, а регистров нет. Здесь они есть.
Не будем полностью разбирать, как это работает, просто посмотрим на фрагмент кода.

Здесь написано: взять значение, которое лежит в аккумуляторе, и сложить со значением, которое лежит в регистре a0, то есть в переменной a. Здесь еще ничего не известно о типах. Если бы это был настоящий ассемблерный код, то он бы писался с пониманием того, какие есть сдвиги в памяти, что в ней находится. Здесь же просто инструкция — возьми то, что лежит в регистре a0 и сложи со значением, лежащим в аккумуляторе.
Конечно, интерпретатор не просто берет абстрактное синтаксическое дерево и переводит его в байткод.
Здесь также происходят оптимизации, например, dead code elimination.
Если участок кода не будет вызван, он выкидывается и дальше не хранится. Если Ignition увидит сложение двух чисел, он их сложит и оставит в таком виде, чтобы не хранить лишнюю информацию. Только после этого получается байткод.
Оптимизации и деоптимизации
Холодные и горячие функции
Это самая простая тема.
Холодные функции — это те, которые вызывались один раз или не вызывались совсем, горячие — это те, которые вызывались несколько раз. Сколько именно раз, сказать нельзя — в любой момент это могут переделать. Но в какой-то момент функция становятся горячей, и движок понимает, что ее надо оптимизировать.

Схема работы.
- Ignition (интерпретатор) собирает информацию. Он не только преобразует JavaScript в байткод, но еще и понимает, какие на вход пришли типы, какие функции стали горячими, и обо всем этом говорит компилятору.
- Происходит оптимизация.
- Компилятор исполняет код. Все работает хорошо, но тут прилетает тип, который он не ожидал, у него нет кода для работы с этим типом.
- Происходит деоптимизация. Компилятор обращается к интерпретатору Ignition за этим кодом.
Это нормальный цикл, который происходит все время, но он не бесконечный. В какой-то момент движок говорит: «Нет, это невозможно оптимизировать», и начинает выполнять без оптимизации. Важно понимать, что нужно соблюдать мономорфность.
Мономорфность — это когда на вход вашей функции всегда приходят одни и те же типы. То есть если у вас все время приходит string, то не надо передавать туда boolean.
Но что делать с объектами? Объекты все object. У нас есть классы, но ведь они не настоящие — это просто сахар над прототипной моделью. Но внутри движка есть так называемые скрытые классы.
Hidden classes
Скрытые классы есть во всех движках, не только в V8. Везде они называются по-разному, в терминах V8 это Map.
Все объекты, которые вы создали, имеют скрытые классы. Если вы
посмотрите в профилировщик памяти, вы увидите, что там есть elements, где хранится список элементов, properties, где хранятся property, и map (обычно первым параметром), где указана ссылка на его на его скрытый класс.
Map описывает структуру объектов, потому что в принципе в JavaScript типизация возможна только структурная, не номинальная. Мы можем описать, как выглядит наш объект, что за чем в нем идет.
При удалении/добавлении свойств объектов Hidden classes у объекта меняется, присваивается новый. Посмотрим на коде.
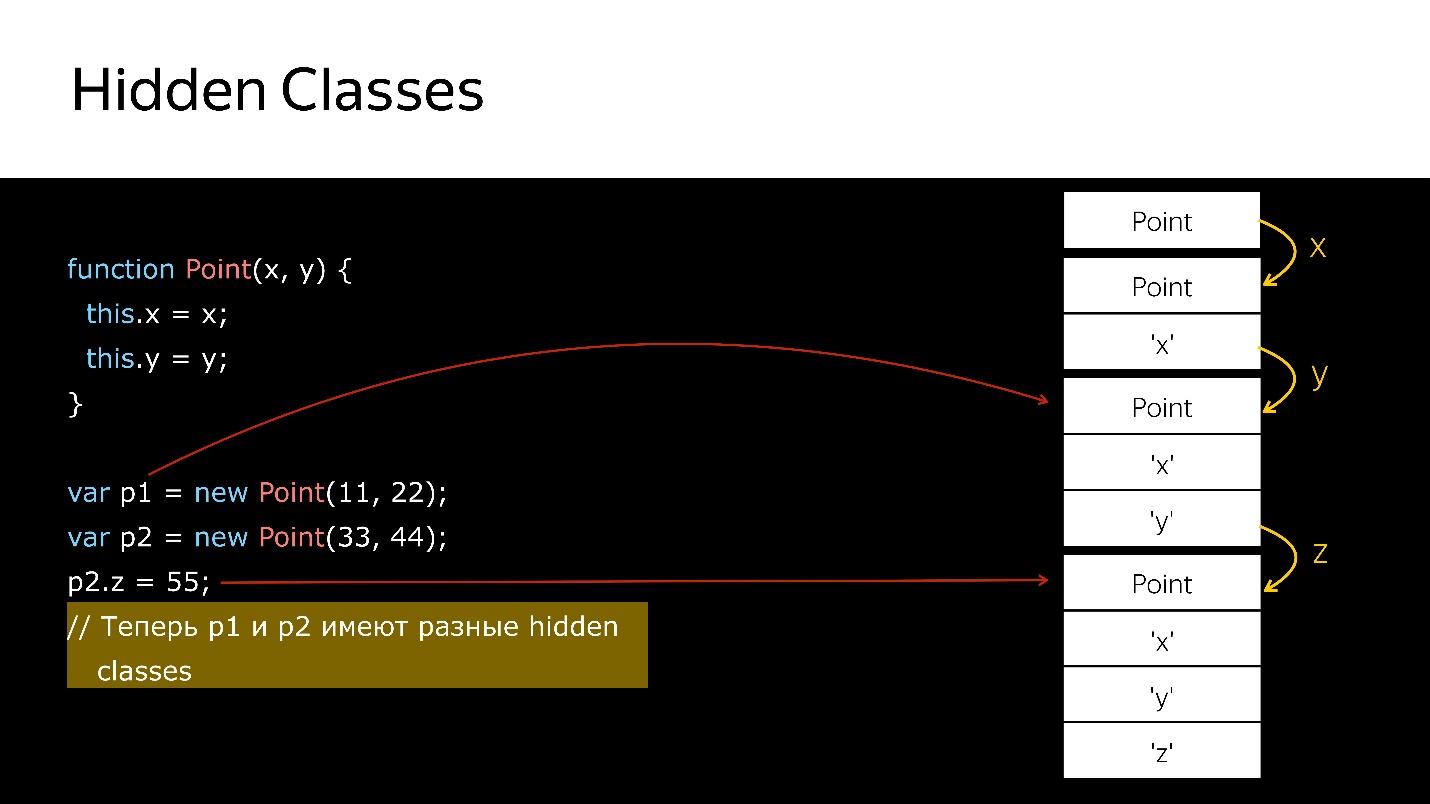
У нас есть конструктор, который создает новый объект типа Point.
- Создаем объект.
- Привязываем к нему скрытый класс, который говорит, что это объект типа Point.
- Добавили поле x — новый скрытый класс, который говорит, что это объект типа Point, в котором первым идет значение x.
- Добавили y — новый Hidden classes, в котором x, а потом y.
- Создали еще один объект — происходит то же самое. То есть он так же привязывает то, что уже создано. В этот момент эти два объекта имеют одинаковый тип (через Hidden classes).
- Когда во второй объект добавляется новое поле, у объекта появляется новый Hidden classes. Теперь для движка p1 и p2 это объекты разных классов, потому что у них разные структуры
- Если передать куда-то первый объект, то, когда вы передадите туда же второй, произойдет деоптимизация. Первый ссылается на один скрытый класс, второй — на другой.
Как можно проверить Hidden classes?
В Node.js можно запустить node —allow-natives-syntax. Тогда вы получите возможность писать команды в специальном синтаксисе, который, конечно, нельзя использовать в продакшене. Это выглядит так:
%HaveSameMap({'a':1}, {'b':1})Никто не гарантирует, что это завтра эти команды будут работать, их нет в спецификации ECMAScript, это всё для отладки.
Как вы думаете, какой будет результат вызова функции %HaveSameMap для двух объектов. Правильный ответ — false, потому что у одного поле называется a, у второго — b. Это разные объекты. Это знание можно использовать для техники Inline Caches.
Inline Caches
Вызовем очень простую функция, которая возвращает поле из объекта. Кажется, вернуть единицу очень просто. Но если вы посмотрите спецификацию ECMAScript, вы увидите, что там огромный список того, что нужно сделать, чтобы получить поле из объекта. Потому что, если поля нет в объекте, возможно, оно есть в его прототипе. Может быть, это setter, getter и так далее. Все это нужно проверять.

В данном случае в объекте есть ссылка на map, которая говорит: чтобы получить поле x, нужно сделать смещение на единицу, и мы получим x. Никуда не надо лазить, ни в какие прототипы, все рядом. Inline Caches использует это.
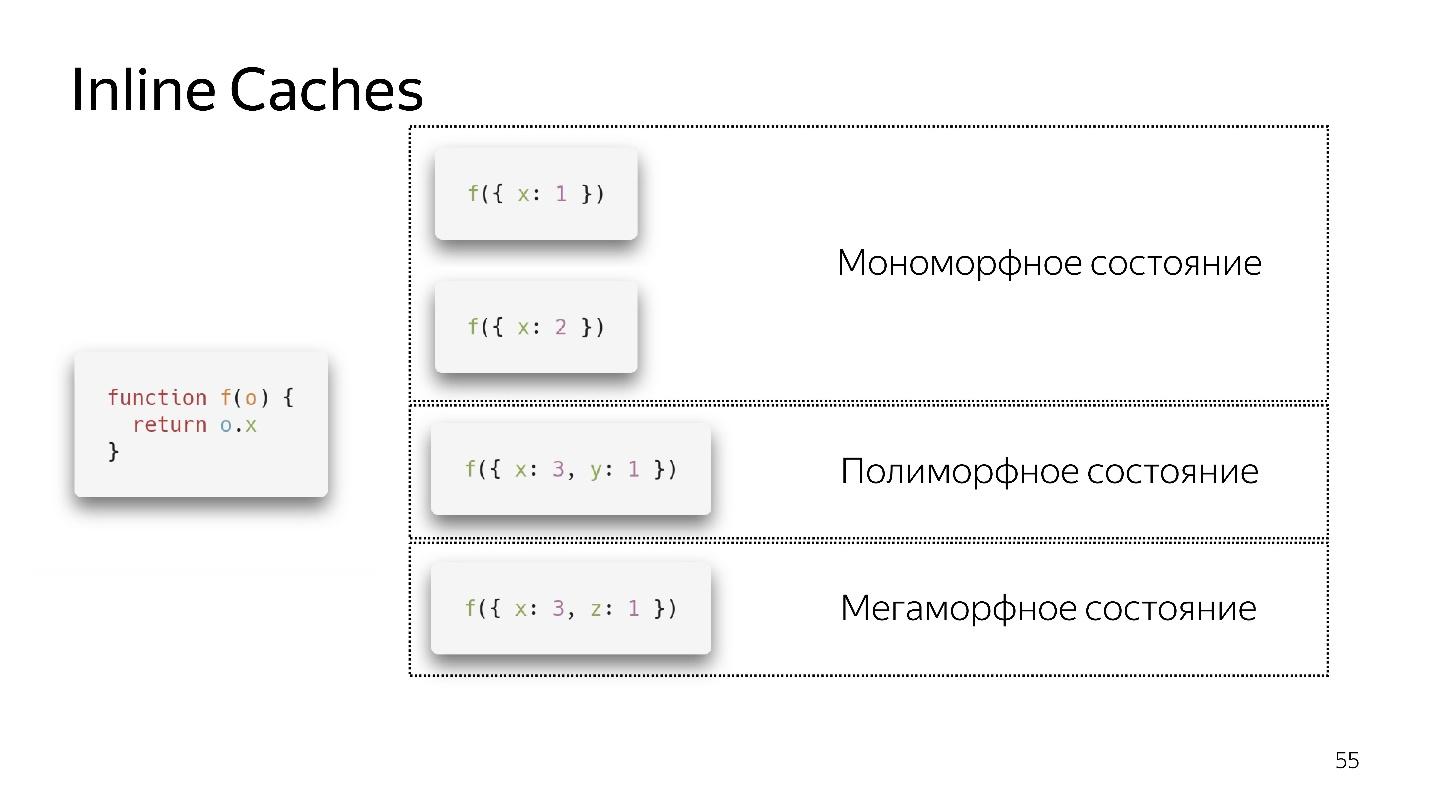
- Если мы вызываем функцию первый раз, все хорошо, интерпретатор сделал оптимизацию
- Для второго вызова сохраняется мономорфное состояние.
- Вызываю функцию третий раз, передаем чуть-чуть другой объект {x:3, y:1}. Происходит деоптимизация, появляется if, мы переходим в полиморфное состояние. Теперь код, который исполняет эту функцию, знает — ей на вход могут прилететь два разных типа объектов.
- Если мы несколько раз передаем разные объекты, он остается в полиморфном состоянии, добавляя новые if. Но в какой-то момент сдается и переходит в мегаморфное состояние, т.е. когда: «На вход прилетает слишком много разных типов — я не знаю, как это оптимизировать!»
Кажется, сейчас допускается 4 полиморфных состояний, но завтра их может быть 8. Это решают разработчики движка. Нам лучше оставаться в мономорфном, в крайнем случае, в полиморфном состоянии. Переход между мономорфным и полиморфным состояниями дорогой, потому что нужно будет сходить в интерпретатор, получить код заново и заново его оптимизировать.
Массивы
В JavaScript, не считая специфичных Typed Arrays, есть один тип
массива. В движке V8 их 6:
1. [1, 2, 3, 4] // PACKED_SMI_ELEMENTS — просто упакованный массив small integer. Для него есть оптимизации.
2. [1.2, 2.3, 3.4, 4.6] // PACKED_DOUBLE_ELEMENTS — упакованный массив double элементов, для него тоже есть оптимизации, но более медленные.
3. [1, 2, 3, 4, ’X’] // PACKED_ELEMENTS — упакованный массив, в котором есть объекты, строки и все остальное. Для него тоже есть оптимизации.
Следующие три типа — это массивы того же типа, что первые три, но с дырками:
4. [1, /*hole*/, 2, /*hole*/, 3, 4] // HOLEY_SMI_ELEMENTS
5. [1.2, /*hole*/, 2, /*hole*/, 3, 4] // HOLEY_DOUBLE_ELEMENTS
6. [1, /*hole*/, ’X’] // HOLEY_ELEMENTS
Когда в ваших массивах появляются дырки, оптимизации становятся менее эффективными. Они начинают работать плохо, потому что невозможно подряд пройти по этому массиву, перебирая его итерациями. Каждый последующий тип хуже оптимизируется
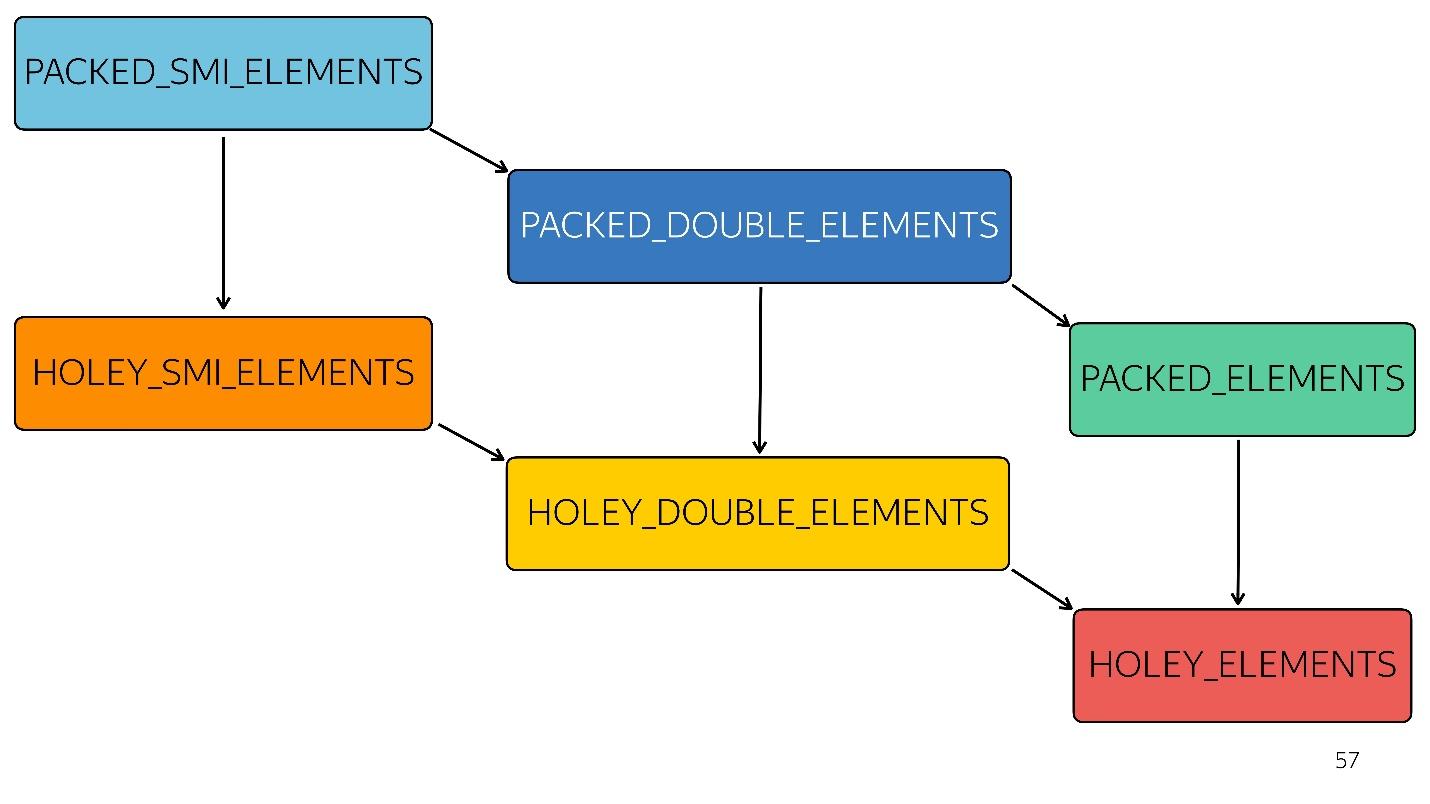
На схеме все, что выше, быстрее оптимизируется. То есть все ваши нативные методы — map, reduce, sort — внутри хорошо оптимизированы. Но с каждым типом оптимизация становится хуже.
Например, на вход пришел простой массив [1, 2,3] (тип — упакованный small integer). Чуть-чуть изменили этот массив, добавив в него double — перешли в состояние PACKED_DOUBLE_ELEMENTS. Добавляем в него объект — перешли в следующее состояние, зеленый прямоугольник PACKED_ELEMENTS. Добавляем в него дырок — переходим в состояние HOLEY_ELEMENTS. Хотим восстановить его в предыдущее состояние, чтобы он снова стал «хорошим» — удаляем все, что написали, и остаемся в том же состоянии… с дырками! То есть HOLEY_ELEMENTS справа внизу на схеме. Назад это не работает. Ваши массивы могут становиться только хуже, но не наоборот.
Array-Like Object
Мы часто сталкиваемся с Array-Like Object — это объекты, которые похожи на массивы, потому что у них есть признак длины. На самом деле они как кот-пират, то есть вроде похожи, но в эффективности потребления рома котик будет хуже, чем пират. Точно так Array-Like Object похож на массив, но не эффективен.

Два наших самых любимых Array-Like Object — это arguments и document.querySelectorAII. Есть такие красивые функциональные штуки.
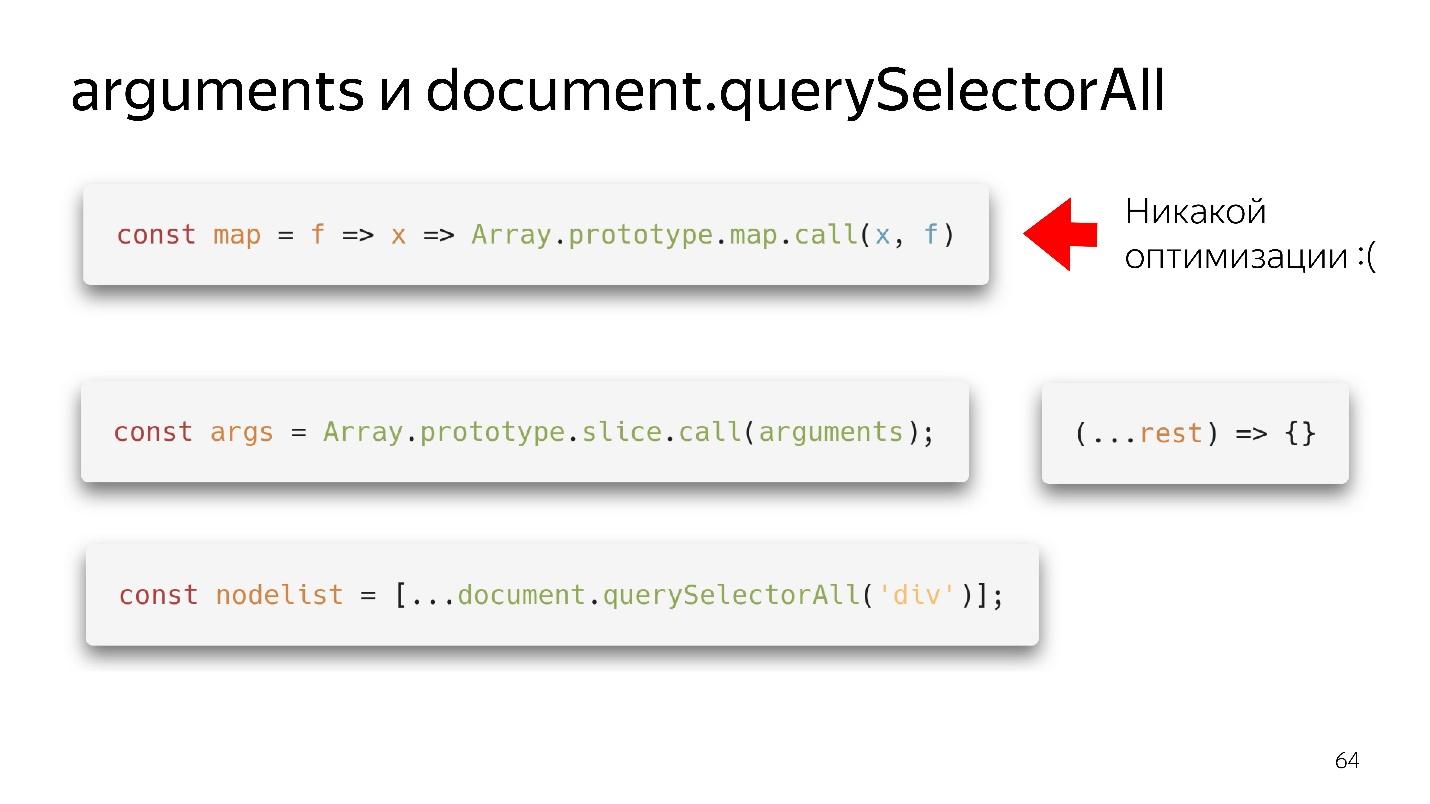
У нас появился map — мы его выдрали из прототипа и вроде бы можем использовать. Но если ему на вход пришел не массив, никакой оптимизации не будет. Наш движок не умеет делать оптимизацию по объектам.
Что нужно сделать?
- Олдскульный вариант — через slice.call() превратить в настоящий массив.
- Современный вариант еще лучше: написать (...rest), получить чистый массив — не arguments — все прекрасно!
С querySelectorAll то же самое — за счет spread мы можем превратить его в полноценный массив и работать со всеми оптимизациями.
Большие массивы
Загадка: new Array(1000) vs array = []
Какой вариант лучше: создать сразу большой массив и в цикле заполнять его 1000 объектами, или создать пустой и заполнять постепенно?
Правильный ответ: зависит от.
В чем отличие?
- Когда мы создаем массив первым способом и заполняем 1000 элементов, мы создаем 1000 дырок. Этот массив не будет оптимизирован. Но в него будет быстро писать.
- Создавая массив по второму варианту, выделяется немного памяти, мы записываем, например, 60 элементов, выделяется еще немного памяти, и т.д.
То есть в первом случае быстро пишем — медленно работаем; во втором медленно пишем — быстро работаем.
Сборщик мусора
Сборщик мусора тоже немножко ест время и ресурсы. Глубоко не погружаясь, дам самую общую базу.

В нашей генеративной модели есть пространство молодых и старых объектов. Создаваемый объект попадает в пространство молодых объектов. Через какое-то время запускается очистка. Если объект невозможно достичь по ссылкам от корневого, то его можно собрать в мусор. Если объект еще используется, он перемещается в пространство старых объектов, которое чистится реже. Тем не менее в какой-то момент удаляются и старые объекты.

Так работает автоматический сборщик мусора — он сам подчищает объекты, основываясь на том, что к ним нет ссылок. Это два разных алгоритма.
- Scavenge — быстрый, но не эффективный.
- Mark-Sweep — медленный, но эффективный.
Если в Node.js запустить профилирование потребления памяти, то получится примерно такой график.

Сначала он скачкообразно растет — это работе алгоритма Scavenge. Потом происходит резкое падение — это Mark-Sweep-алгоритм собрал мусор в пространстве старых объектов. В этот момент все начинает немножко тормозить. Вы не можете этим управлять, поскольку не знаете, когда это произойдет. Вы можете только настроить размеры.
Поэтому в pipeline есть стадия сборки мусора, которая потребляет время.
Еще быстрее?
Заглянем в будущее. Что делать дальше, как быть быстрее?
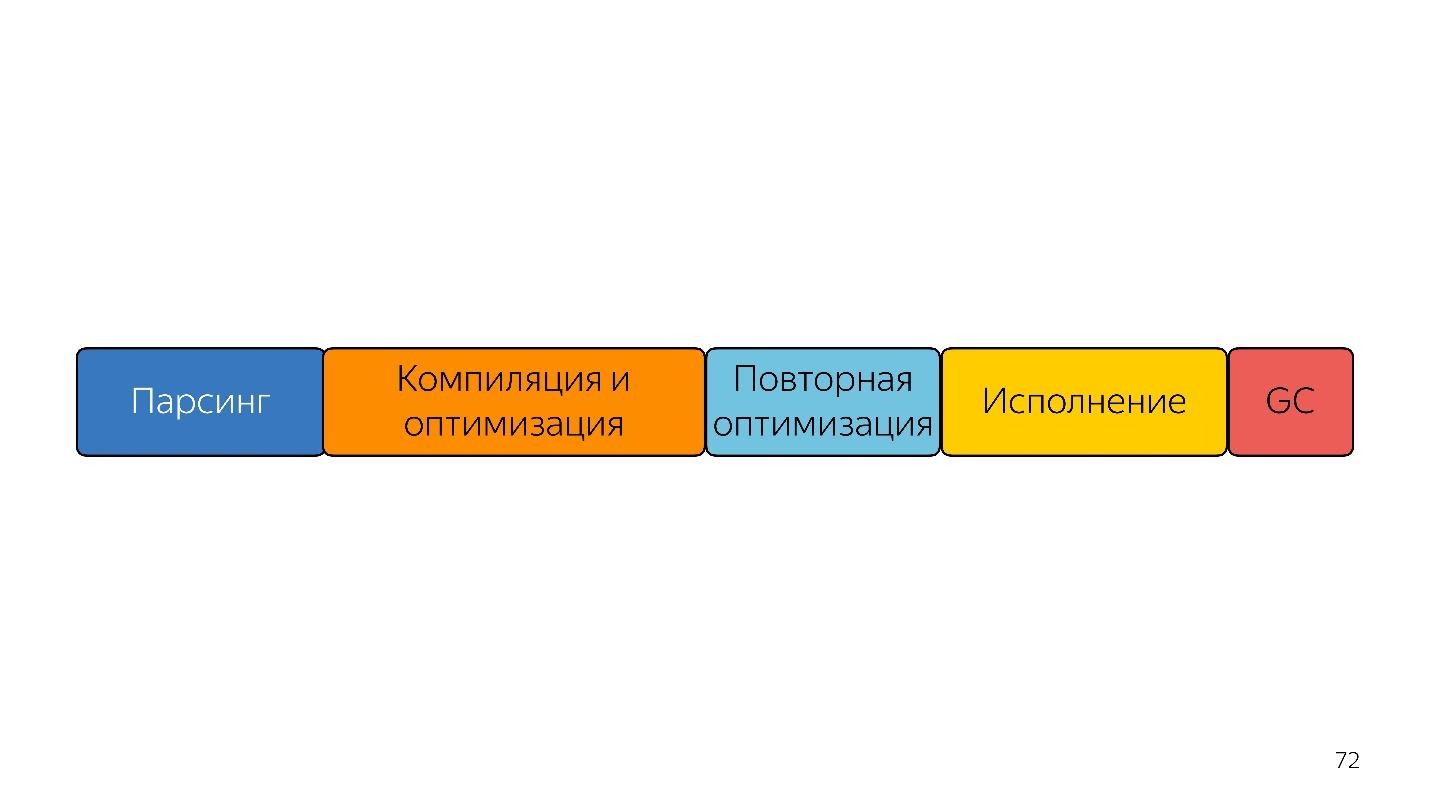
На этой линейке размеры блоков примерно соотносятся в временем, которое он занимают.
Первое, что приходит в голову людям, которые услышали про байткод — сразу подавать на вход байткод и декодировать его, а не парсить — будет быстрее!

Проблема в том, что байткод сейчас разный. Как я уже сказал: в Safari один, в FireFox другой, в Chrome третий. Тем не менее разработчики из Mozilla, Bloomberg и Facebook выдвинули такой Proposal, но это будущее.
Есть другая проблема — компиляция, оптимизация, и повторная оптимизация, если компилятор не угадал. Представим, что есть статически типизированный язык на входе, который выдает эффективный код, и значит уже не нужна повторная оптимизация, потому что то, что мы получили, уже эффективно. Такой вход можно только один раз скомпилировать и оптимизировать. Полученный код будет более эффективным и исполнится быстрее.
Что еще можно сделать? Представим, что в этом языке есть ручное управление памятью. Тогда не нужен сборщик мусора. Линейка стала короче и быстрее.

Догадываетесь, на что это похоже? WebAssembly примерно
так и работает: ручное управление памятью, статически типизированные
языки и быстрое выполнение.

Является ли WebAssembly серебряной пулей?

Нет, потому что он стоит за JavaScript. WASM пока сам ничего не может делать. У него нет доступа к DOM API. Он внутри движка для JavaScript — внутри того же самого движка! Он все делает через JavaScript, поэтому WASM не ускорит ваш код. Он может ускорить отдельные вычисления, но у вас обмен между JavaScript и WASM будет узким местом.
Поэтому пока наш язык — это JavaScript и только он, и какая-то помощь из черной коробки.
Итого
Можно выделить три вида оптимизации.
● Алгоритмические оптимизации
Есть статья "Возможно вам не нужен Rust, чтобы ускорить ваш JS" Вячеслава Егорова, который когда-то разрабатывал V8, а сейчас разрабатывает Dart. Кратко перескажу её историю.
Была библиотека на JavaScript, которая работала не очень быстро. Какие-то ребята переписали ее на Rust, скомпилировали и получили WebAssembly, и приложение стало работать быстрее. Вячеслав Егоров как опытный JS-разработчик решил им ответить. Он применил алгоритмические оптимизации, и решение на JavaScript стало сильно быстрее решения на Rust. В свою очередь те ребята это увидели, сделали те же самые оптимизации, и снова выиграли, но не сильно — зависит от движка: в Mozilla выиграли, в Chrome — нет.
Мы сегодня не говорили про алгоритмические оптимизации, и фронтэндеры о них обычно не говорят. Это очень плохо, потому что алгоритмы тоже позволяют коду работать быстрее. Вы просто убираете ненужные вам циклы.
● Специфичные для языка оптимизации
Это то, о чем мы сегодня говорили: наш язык интерпретируемый динамически типизированный. Понимание того, как работают массивы, объекты, мономорфность позволяет писать эффективный код. Это надо знать и писать правильно.
● Специфичные для движка оптимизации
Это самые опасные оптимизации. Если ваш очень умный, но не очень общительный, разработчик, который применил очень много таких оптимизаций, и никому о них не рассказал, не написал документацию, то, если вы откроете код, то увидите не JavaScript, а, например, Crankshaft Script. То есть JavaScript, написанный с глубоким пониманием того, как работал движок Crankshaft два года назад. Это все работает, но сейчас уже не нужно.
Поэтому такие оптимизации обязательно должны быть задокументированы, покрыты тестами, доказывающими их эффективность в данный момент. За ними надо следить. К ним нужно переходить только в тот момент, когда вы где-то реально замедлились — прямо никак не обойтись без знания таких глубинных устройств. Поэтому кажется логичной знаменитая фраза Дональда Кнута.

Не нужно пытаться внедрить какие-то жесткие оптимизации только потому, что вы про них прочитали положительные отзывы.
Таких оптимизаций надо бояться, обязательно документировать и оставлять метрики. Вообще всегда собирайте метрики. Метрики — это важно!
Полезные ссылки:
- Тезисы и презентация доклада
- What’s up with monomorphism?
- What makes WebAssembly fast?
- Путь к пониманию байт-кода V8
- Девшахта: Хардкор
На Frontend Conf Moscow 4 и 5 октября будем разбирать еще больше сложных случаев и залезем во внутренности еще большего числа популярных инструментов. Подавайте заявки до 15 августа, и смотрите, что интересное уже в списке:
- Тимофей Лавренюк (KeepSolid) планирует рассказать, как разработать полностью Offline First приложение с использованием Persistent Storage
- Антон Хлыновский (TradingView) обещает познакомить слушателей с основами WebGL и WebAssembly и показать, как написать на их основе несложное визуальное приложение, используя только базовый API.
- Из доклада Алексей Чернышев Алексея узнаем, как реализовать многопользовательское редактирование текста в реальном времени наподобие Google Docs.
