Каким требованиям должно удовлетворять хранилище метаданных для облачного сервиса? Да не самого обычного, а для enterprise с поддержкой географически распределенных датацентров и Active-Active. Очевидно, система должна хорошо масштабироваться, быть отказоустойчивой и хотелось бы, чтобы было возможно реализовать настраиваемую консистентность операций.
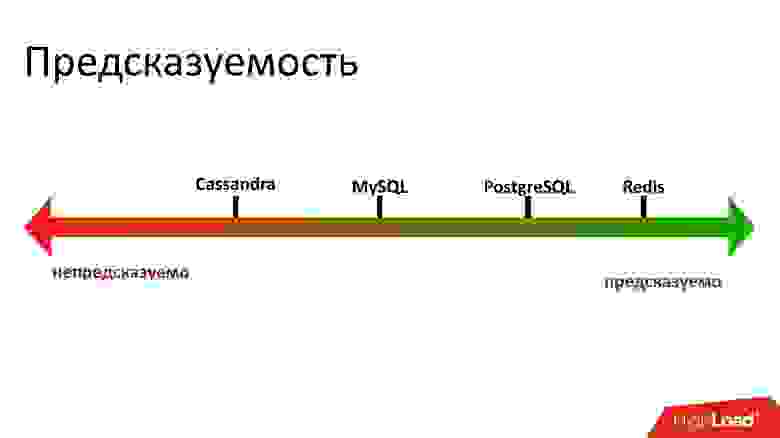
Под все эти требования подходит только Cassandra, а ничто другое не подходит. Надо заметить, Cassandra действительно классная, но работа с ней напоминает американские горки.
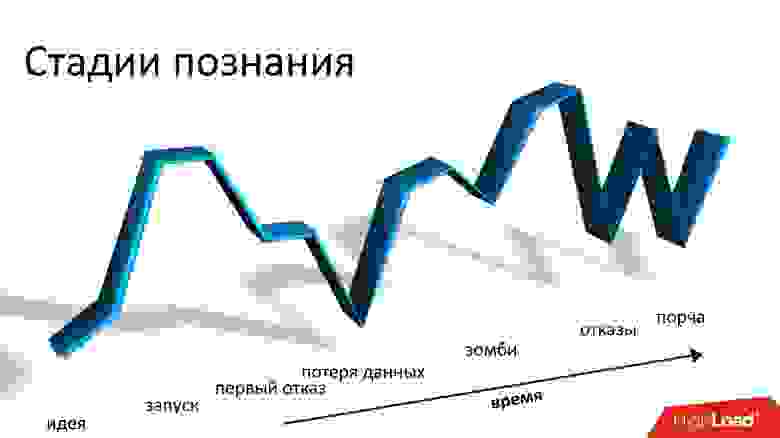
В докладе на Highload++ 2017 Андрей Смирнов (smira) решил, что о хорошем говорить неинтересно, зато подробно рассказал, про каждую проблему, с которой пришлось столкнуться: про потерю и порчу данных, про зомби и потерю производительности. Эти истории и вправду напоминают катание на горках, но на все проблемы находится решение, за которым добро пожаловать под кат.
О спикере: Андрей Смирнов работает в компании Virtustream, реализующей облачное хранилище для enterprise. Идея состоит в том, что условно Amazon делает облако для всех, а Virtustream делает специфические вещи, которые необходимы большой компании.
Мы работаем в полностью удаленной небольшой команде, и занимаемся одним из облачных решений Virtustream. Это облако хранения данных.
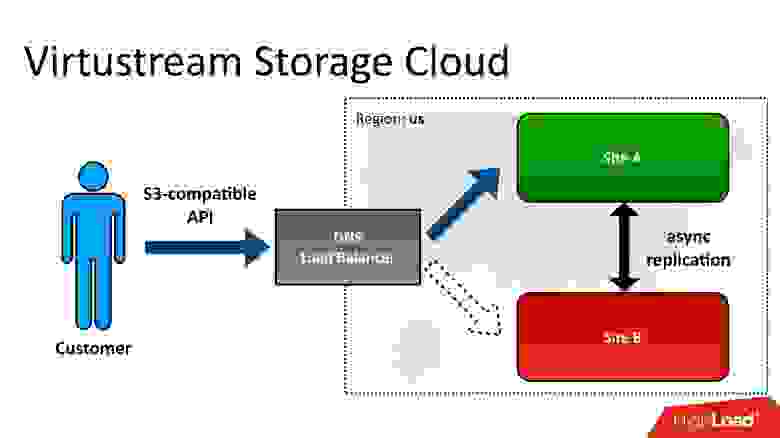
Если говорить очень просто, то это S3-совместимый API, в котором можно хранить объекты. Для тех, кто не знает, что такое S3 — это просто HTTP API, с помощью которого можно куда-то в облако загружать объекты, получать их обратно, удалять, получать список объектов и т.д. Дальше — уже более сложные фичи на основе этих простых операций.
У нас есть некоторые отличительные возможности, которых нет у Amazon. Одна из них — так называемые гео-регионы. В обычной ситуации, когда вы создаете хранилище и говорите, что будете хранить объекты в облаке, вы должны выбрать регион. Регион — это по сути дата-центр, и ваши объекты никогда не покинут этот дата-центр. Если с ним что-то случится, то ваши объекты больше не будут доступны.
Мы предлагаем гео-регионы, в которых данные находятся одновременно в нескольких дата-центрах (ДЦ), как минимум в двух, как на картинке. Клиент может обращаться к любому дата-центру, для него это прозрачно. Данные между ними реплицируются, то есть мы работаем в режиме «Active-Active», причем постоянно. Это предоставляет клиенту дополнительные возможности, в том числе:
Это интересная возможность — даже если эти ДЦ далеко друг от друга географически, то какой-то из них может быть ближе к клиенту в разные моменты времени. И обращаться к данным в ближайший ДЦ просто быстрее.
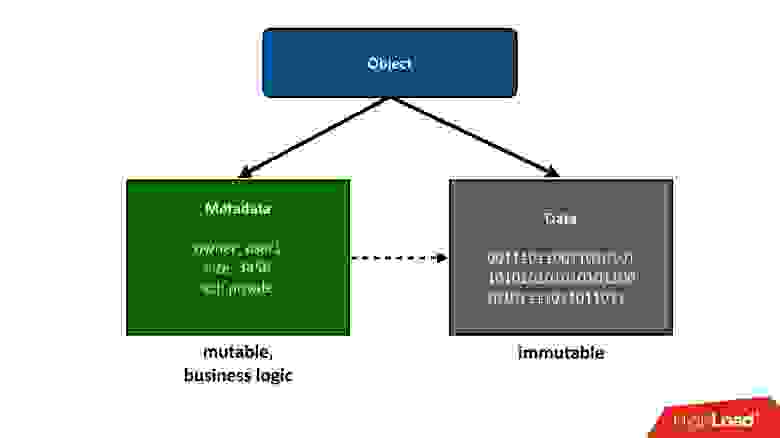
Для того, чтобы конструкцию, о которой мы будем говорить, разделить на части, я представлю те объекты, которые хранятся в облаке, как два больших куска:
1. Первый простой кусок объекта — это данные. Они неизменны, их один раз загрузили и все. Единственное, что с ними потом может случиться — мы их можем удалить, если они больше не нужны.
Предыдущий проект у нас был связан с хранением экзабайта данных, поэтому у нас проблем с хранением данных не было. Это для нас была уже решенная задача.
2. Метаданные. Вся бизнес-логика, все самое интересное, связанное с конкурентностью: обращение, записи, перезаписи — в районе метаданных.
Метаданные об объекте забирают в себя наибольшую сложность проекта, в метаданных хранится указатель на блок сохраненных данных объекта.
С точки зрения пользователя это единый объект, но мы можем разделить его на две части. Сегодня я буду говорить только о метаданных.
Цифры
Если посмотреть на эти показатели внимательно, то первое, что бросается в глаза, это очень маленький средний размер хранящегося объекта. У нас очень много метаданных на единицу объема основных данных. Для нас это было не меньшим сюрпризом, чем, возможно, для вас сейчас.
Мы планировали, что у нас данных будет, как минимум, на порядок, если не на 2, больше, чем метаданных. То есть каждый объект будет значительно больше, а объем метаданных будет меньше. Потому что данные хранить дешевле, с ними меньше операций, а метаданные гораздо дороже и в смысле железа, и в смысле обслуживания и выполнения различных операций над ними.
При этом эти данные изменяются с достаточно высокой скоростью. Я привел здесь пиковое значение, непиковое не сильно меньше, но, тем не менее, может получаться довольно большая нагрузка в конкретные моменты времени.
Данные цифры были получены уже с работающей системы, но вернемся немного назад, к моменту проектирования облачного хранилища.
Когда перед нами встала задача, что мы хотим иметь гео-регионы, Active-Active, и нам надо где-то хранить метаданные, мы думали, что это может быть?
Очевидно, что хранилище (база данных) должна иметь следующие свойства:
Мы бы очень хотели, чтобы наш продукт пользовался бешеной популярностью, и как он при этом будет расти, мы не знаем, поэтому система должна масштабироваться.
Метаданные надо хранить надежно, потому что если мы их потеряем, а в них была ссылка на данные, то мы потеряем весь объект.
В силу того, что мы работаем в нескольких ДЦ и допускаем возможность того, что ДЦ может быть недоступен, более того, ДЦ находятся далеко друг от друга, то мы не можем во время выполнения большинства операций через API требовать, чтобы эта операция выполнялась одновременно в двух ДЦ. Это будет просто слишком медленно и невозможно, если второй ДЦ недоступен. Поэтому часть операций должна работать локально в одном ДЦ.
Но, очевидно, когда-то должна происходить некая конвергенция, и после разрешения всех конфликтов данные должны быть видны в обоих дата-центрах. Поэтому консистентность операций должна настраиваться.
Под эти требования, с моей точки зрения, подходит Cassandra.
Я был бы очень рад, если бы нам не пришлось использовать Cassandra, потому что для нас это был некий новый опыт. Но ничего другого не подходит. Это, мне кажется, самая печальная ситуация на рынке подобных систем хранения — безальтернативность.
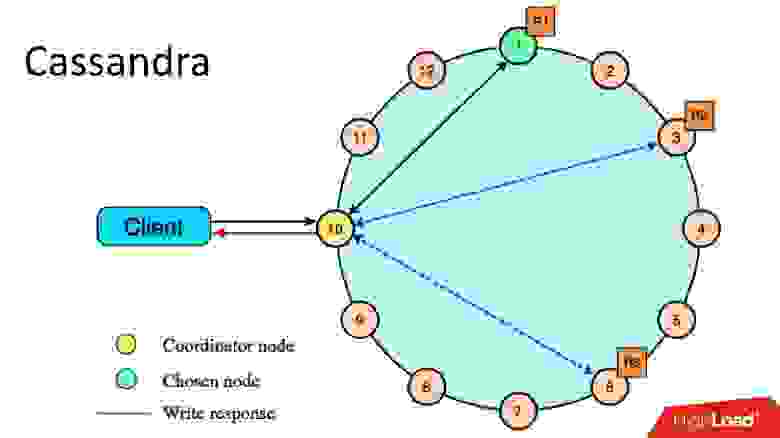
Что такое Cassandra?
Это распределенная key-value база данных. С точки зрения архитектуры и идей, которые в нее заложены, мне кажется, все классно. Если бы я делал, то делал бы то же самое. Когда мы только начинали, мы задумывались о написании своей системы хранения метаданных. Но чем дальше, тем мы больше и больше понимали, что нам придется сделать что-то очень похожее на Cassandra, и те усилия, которые мы на это потратим, того не стоят. На всю разработку у нас было всего полтора месяца. Было бы странно потратить их на написание своей базы данных.
Если Cassandra разделить по слоям, как слоеный пирог, я бы выделил 3 слоя:
1. Локальное KV-хранилище на каждом узле.
Это кластер из узлов, каждый из которых уметь хранить key-value данные локально.
2. Шардирование данных по узлам (consistent hashing).
Cassandra умеет распределять данные по узлам кластера, включая репликацию, причем делает это так, что кластер может расти или уменьшаться в размерах, и данные будут перераспределяться.
3. Координатор для перенаправления запросов к другим узлам.
Когда мы обращаемся из нашего приложения к данным по каким-то запросам, Cassandra умеет наш запрос распределить по узлам так, чтобы мы получили те данные, которые мы хотим, и с тем уровнем консистентности, который нам нужен — хотим мы их прочитать просто quorum, или хотим quorum с учетом двух ДЦ и т.д.
Для нас два года с Cassandra — это американские или русские горки — как хотите называйте. Начиналось все глубоко внизу, у нас был нулевой опыт работы с Cassandra. Нам было страшно. Мы запустились, и все было хорошо. Но дальше начинаются постоянные падения и взлеты: проблема, все плохо, мы не знаем, что делать, у нас сыпятся ошибки, потом мы проблему решаем, и т.д.
Эти американские горки, в принципе, не заканчиваются по сей день.
Первая и последняя глава, где я скажу, что Cassandra классная. Она действительно классная, отличная система, но, если я буду дальше говорить, какая она хорошая, думаю, вам не будет интересно. Поэтому плохому уделим больше внимания, но позже.
Cassandra действительно хорошая.
Повторюсь, Cassandra хорошая, у нас она работает, но расскажу пять историй о плохом. Думаю, это то, ради чего вы это читаете. Истории приведу в хронологическом порядке, хотя они не очень друг с другом связаны.

Эта история была самой грустной для нас. Так как мы храним данные пользователей, самое страшное из возможного — это их потерять, причем потерять безвозвратно, как случилось в этой ситуации. У нас были предусмотрены способы, как восстановить данные, если мы их потеряем в Cassandra, но мы их потеряли так, что действительно не могли восстановить.
Для того, чтобы объяснить, как это происходит, мне немножко придется рассказать о том, как у нас все устроено внутри.
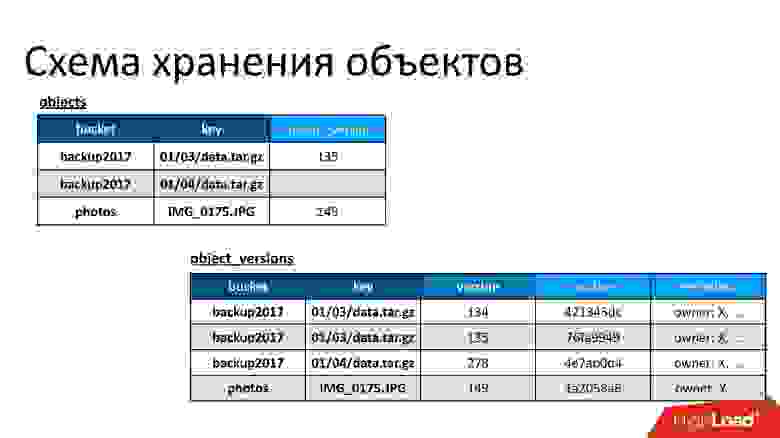
С точки зрения S3 есть несколько базовых вещей:
В нашей ситуации active-active, операции могут происходить, в том числе, конкурентно в разных ДЦ, не только в одном. Поэтому нам нужна какая-то схема сохранения, которая позволит реализовывать такую логику. В конечном итоге мы выбрали простую политику: побеждает последняя по времени записанная версия. Иногда происходит несколько конкурентных операций, но не обязательно, что наши клиенты специально это делают. Это может быть просто запрос, который начался, но клиент не дождался ответа, что-то еще произошло, попытался снова, и т.д.
Поэтому у нас есть две базовые таблицы:
На рисунке пример того, как связаны таблицы объектов и версий объектов.
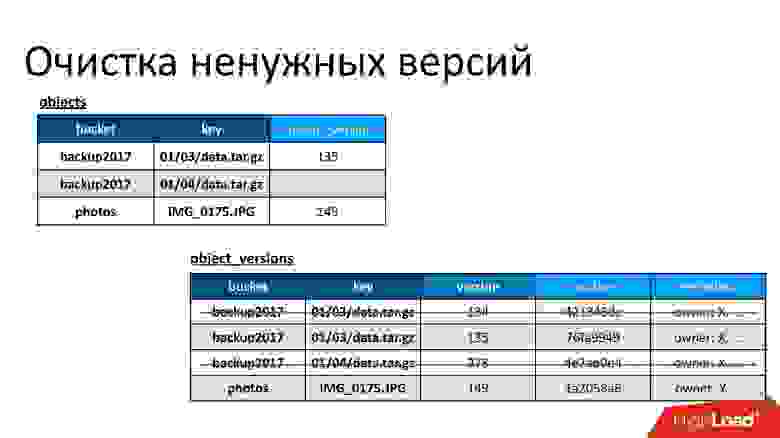
Здесь есть объект, у которого две версии — одна текущая и одна старая, есть объект, который уже удален, а его версия все еще есть. Нам надо время от времени заниматься очисткой ненужных версий, то есть удалять то, на что уже никто не ссылается. Причем удалять нам необязательно сразу же, мы можем делать это в отложенном режиме. Это наша внутренняя очистка, мы просто удаляем то, что больше не нужно.
Тут возникла проблема.
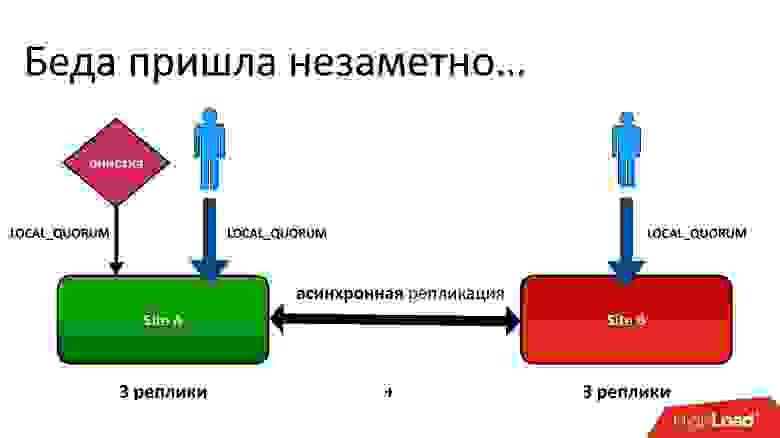
Проблема была в следующем: у нас есть active-active, два ДЦ. В каждом ДЦ метаданные хранятся в трех копиях, то есть у нас 3+3 — всего 6 реплик. Когда к нам обращаются клиенты, мы операции выполняем с консистентностью (с точки зрения Cassandra называется LOCAL_QUORUM). То есть гарантируется, что запись (или чтение) произошло в 2 реплики в локальном ДЦ. Это гарантия — иначе операция не выполнится.
Cassandra всегда будет пытаться писать во все 6 реплик — 99% времени все будет хорошо. На самом деле, все 6 реплик будут одинаковые, но гарантированы нам 2.
У нас была сложная ситуация, хотя это был даже не гео-регион. Даже для обычных регионов, которые в одном ДЦ, мы все равно хранили вторую копию метаданных в другом ДЦ. Это длинная история, я не буду все детали приводить. Но в конечном итоге у нас был процесс очистки, который удалял ненужные версии.
И тут встала та самая проблема. Процесс очистки работал тоже с консистентностью локального кворума в одном дата-центре, потому что в двух смысла запускать его нет — они будут друг с другом бороться.
Все было хорошо, пока не оказалось, что наши пользователи еще иногда пишут в другой дата-центр, о чем мы не подозревали. У нас все было настроено на всякий случай для фейловера, но оказалось, что они уже пользуются этим.
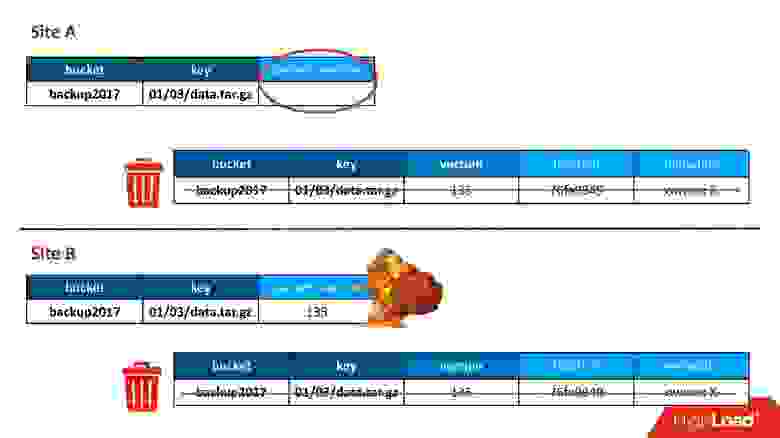
Большую часть времени все было хорошо, пока однажды не возникла ситуация, когда в оба ДЦ отреплицировалась запись в таблицу версий, но запись в таблице объектов оказалась только в одном ДЦ, а во второй не попала. Соответственно, процедура очистки, запущенная в первом (верхнем) ДЦ, увидела, что есть версия, на которую никто не ссылается, и ее удалила. Причем удалила не только версию, но и, само собой, данные — все полностью, потому что это просто ненужный объект. И это удаление безвозвратное.
Конечно, дальше происходит «бум», потому что у нас в таблице объектов осталась запись, которая ссылается на версию, которой больше нет.
Так мы первый раз потеряли данные, и потеряли их действительно безвозвратно — благо, немного.
Что делать? В нашей ситуации все просто.
Так как у нас данные хранятся в двух ДЦ, процесс очистки является процессом некоей конвергенции и синхронизации. Мы должны читать данные с обоих ДЦ. Этот процесс будет работать только тогда, когда оба ДЦ доступны. Так как я говорил, что это отложенный процесс, который не происходит в процессе обработки API, это не страшно.
Консистентность ALL — это особенность Cassandra 2. В Cassandra 3 все немножко лучше — есть уровень консистентности, который называется quorum в каждом ДЦ. Но в любом случае есть проблема того, что это медленно, потому что нам, во-первых, приходится обращаться к удаленному ДЦ. Во-вторых, в случае консистентности всех 6 узлов это означает, что он работает со скоростью худшего из этих 6 узлов.
Но одновременно происходит процесс так называемого read-repair, когда не все реплики синхронны. То есть когда где-то запись не прошла, этот процесс одновременно их чинит. Так устроена Cassandra.
Когда это случилось, нам поступила жалоба от клиента, что объект недоступен. Мы разобрались, поняли, почему, и первое, что мы захотели сделать, это узнать, сколько у нас еще таких объектов. Мы запустили скрипт, который пытался найти конструкцию, похожую на эту, когда есть запись в одной таблице, но записи в другой — нет.
Вдруг мы обнаружили, что у нас 10% таких записей. Ничего хуже, наверное, не могло бы быть, если бы мы не догадались, что дело не в этом. Проблема была в другом.

В нашу базу данных прокрались Зомби. Это полуофициальное название этой проблемы. Для того, чтобы понять, что это такое, надо поговорить о том, как работает удаление в Cassandra.
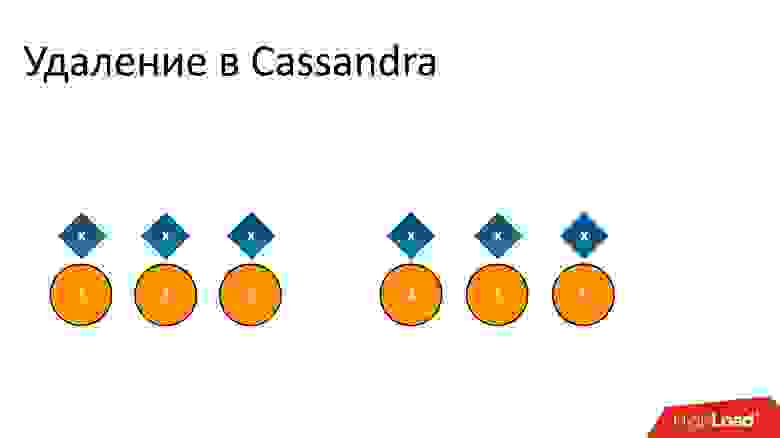
Например, у нас есть какой-то кусок данных x, который записан и идеально реплицирован на все 6 реплик. Если мы хотим его удалить, удаление, как и любая операция в Cassandra, может быть выполнено не на всех узлах.
Например, мы хотели гарантировать консистентность 2 из 3 в одном ДЦ. Пусть операция удаления выполнилась на пяти узлах, а на одном запись осталась, например, потому что узел в этот момент был недоступен.
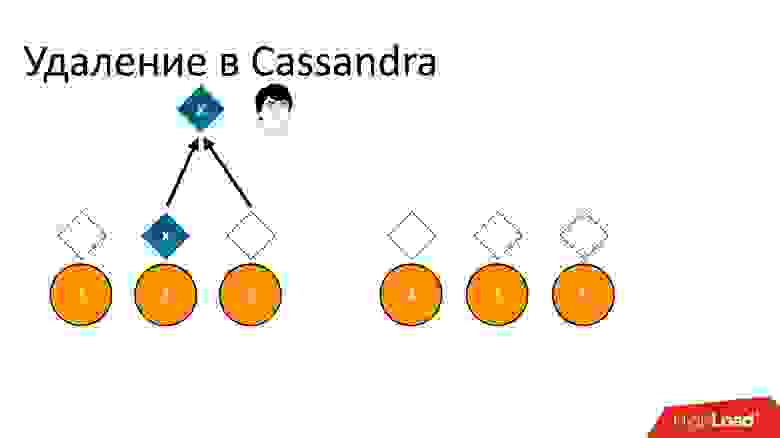
Если мы так удалим и потом попытаемся прочитать с такой же консистентностью «хочу 2 из 3», то Cassandra, увидев значение и его отсутствие, интерпретирует это как наличие данных. То есть при чтении обратно она скажет: «О, данные есть!», хотя мы их удалили. Поэтому удалять таким образом нельзя.
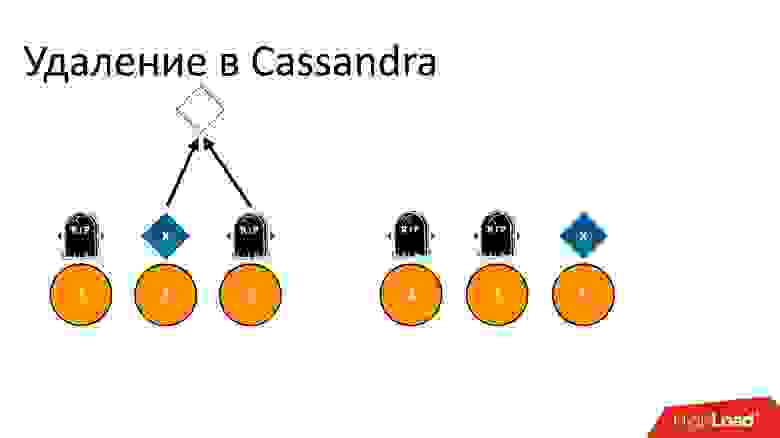
Cassandra удаляет по-другому. Удаление на самом деле является записью. Когда мы удаляем данные, Cassandra записывает некий маркер небольшого размера, который называется Tombstone (надгробная плита). Он помечает, что данные удалены. Таким образом, если мы читаем одновременно маркер удаления и данные, Cassandra всегда предпочитает маркер удаления в этой ситуации и говорит, что данных на самом деле нет. Это то, что нужно.
Хотя Tombstone — это маленький маркер, понятно, что, если мы удаляем и удаляем данные, когда-то надо и эти маркеры удалять, иначе они будут копиться бесконечно. Поэтому у Tombstone есть некоторое конфигурируемое время жизни. То есть Tombstone удаляются через gc_grace_period секунд. Когда маркера нет, ситуация эквивалентна ситуации, когда данных нет.
Что может произойти?
Repair
В Cassandra есть процесс, который называется Repair (починка). Его задача — сделать так, чтобы все реплики были синхронны. У нас возможны разные операции в кластере, может быть, не на всех узлах они выполнились, или мы меняли размер кластера, добавляли/убавляли реплики, может быть, какой-то узел когда-то упал, жесткие диски и т.д. Реплики могут быть не консистентны. Repair делает так, чтобы они стали консистентны.
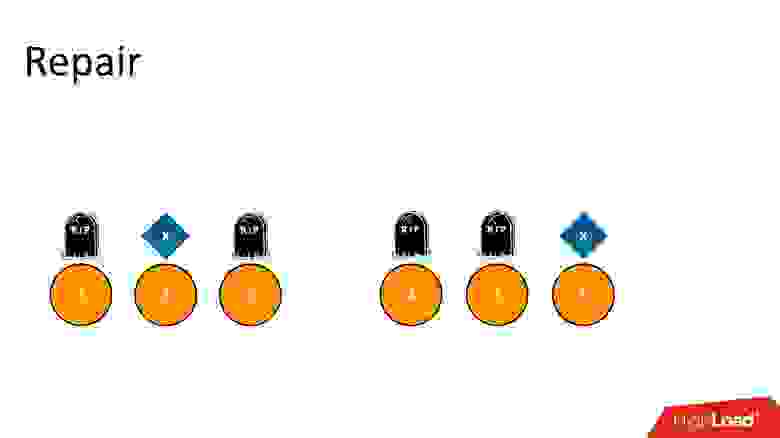
Мы удалили данные, где-то появились маркеры удаления, где-то остались сами данные. Но Repair мы пока не сделали, и оно в состоянии, как на картинке выше. Прошло какое-то время, и маркеры удаления исчезли — просто вышел их срок жизни. Вместо них осталось пустое место, как будто данных нет.
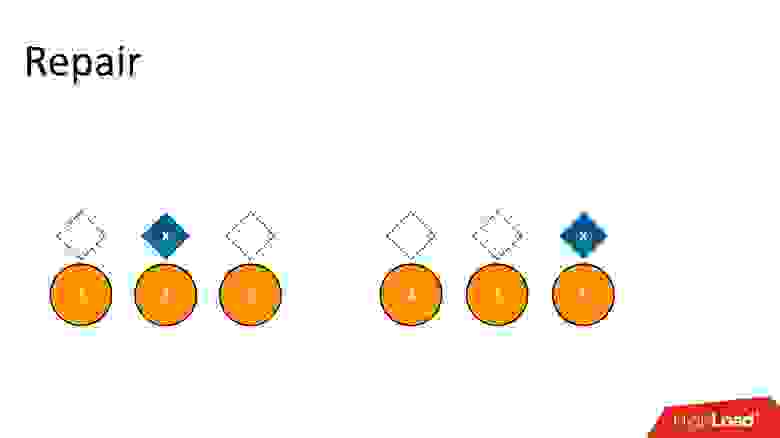
Если после этого запустить Repair, который должен привести реплики в консистентное состояние, он увидит, что на одних узлах есть данные, на других нет — значит, надо их восстановить. Соответственно все 6 узлов снова будут с данными. Это те самые Зомби — данные, которые мы удалили, но которые вернулись в кластер.
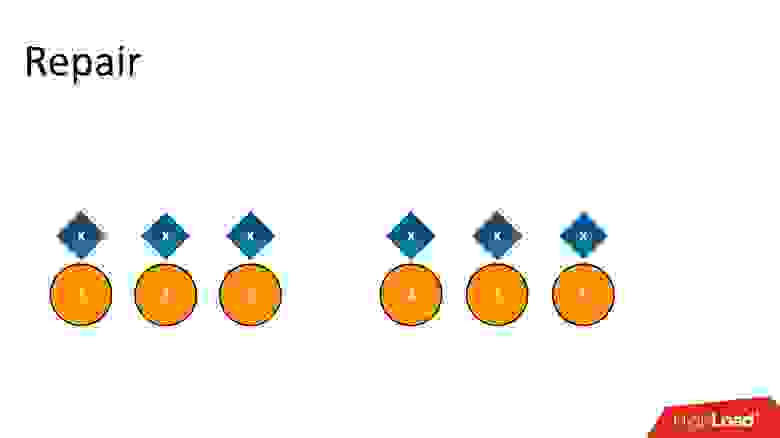
Обычно мы их не видим, если к ним не обращаемся — возможно, это какие-то случайные ключи. Если на него ничто не ссылается, мы его не увидим. Но если мы попробуем просканировать всю базу данных, пытаясь что-то найти, как мы тогда искали, сколько у нас записей с удаленными объектами, эти Зомби очень мешают.
Решение
Решение очень простое, но довольно важное:
Но бывают разные ситуации, когда мы не успеваем сделать repair. Он идет очень долго, потому что это одна из самых тяжелых операций для кластера, которая связана со сравнением данных на узлах.
Интервал repair — это то время, за которое удается сделать repair. Например, мы знаем, что мы успеваем для этого кластера провести починку за 10-20 дней, неделю, 3 дня. Но период удаления Tombstone должен быть выше этого значения, которое постигается только из практики. Если мы слишком агрессивно будем репейрить, окажется так, что кластер плохо отвечает на фронтенд-запросы.

Еще одна классическая проблема для Cassandra, на которую часто наталкиваются разработчики. На самом деле с этим сложно бороться.
В S3 есть бакет. Как я сказал, он может быть произвольного размера — 10 ключей, 100 млрд ключей. Один из API, который мы должны поддерживать — это отдать список ключей в бакете. Причем список должен быть отсортирован, отдаваться, само собой, постранично, его можно листать, и он должен быть всегда консистентен с текущими операциями. То есть, если я записал объект, удалил объект, беру список ключей — и он тот же самый, как после моей операции. Я не могу его отложено перестроить.
Как реализовать такой API?

Есть таблица объектов, которую я показывал ранее — бакет, ключ, текущая версия — вроде бы именно та, которая нужна для того, чтобы построить список ключей. Но есть небольшая проблема. Я совершенно правильно выбрал для этой таблицы в качестве первичного ключа пару бакет — ключ. Первичный ключ определяет, где эта строка будет находиться, на каком узле. Это то самое, почему хэшируется объект, когда он будет храниться в Cassandra. Но это одновременно означает, что ключи одного бакета хранятся на разных узлах — вообще говоря, на всех, если их достаточное количество, потому что они все равномерно размазаны.
С точки зрения хранения этой таблицы это классно, потому что у меня бакеты могут быть совершенно разного размера, и я не могу заранее угадать, какой большой, какой маленький. Если бы данные одного бакета хранились бы на одном узле, то возникла бы проблема с масштабированием. Но, с другой стороны, я не могу никаким образом построить список объектов в кластере из такой таблицы. Значит, нужен еще какой-то способ, с помощью которого можно было бы этот самый список объектов получить.
Cassandra говорит, что у нее есть более сложные конструкции. Можно завести еще одну таблицу специально для списка ключей в бакете, в которой будет храниться ровно та информацию, которая нужна, а именно бакет, ключ и минимальное количество метаданных об объекте, чтобы построить ответ на запрос.
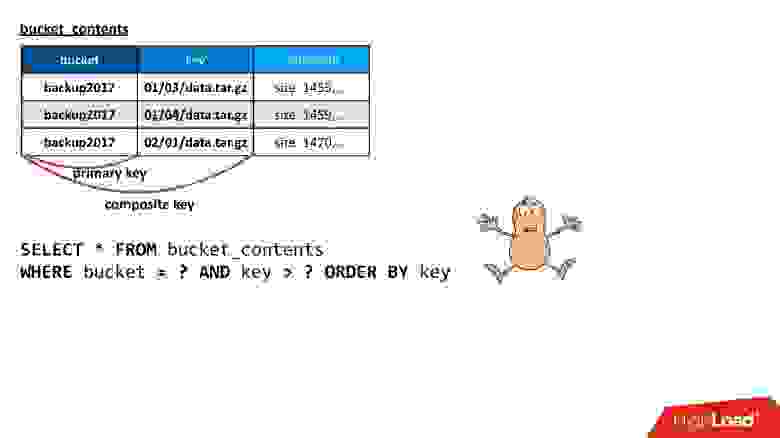
Здесь я использую то, что в Cassandra называется composite key. Если я построю к этой таблице запрос, который мне нужен — выбрать данные из бакета, начиная с какого-то ключа, и чтобы они были отсортированы — запрос работает. Он делает ровно то, что мне нужно. Рад ли я? Да, я конечно рад, у меня все получилось!
Но если вы внимательно читали то, о чем говорилось раньше, то помните, что, если первичный ключ из бакета — это означает, что все данные кладутся на один и тот же узел.
На самом деле проблема хуже. В Cassandra есть некая шизофрения, потому что разные слои Cassandra по сути разговаривают на разных языках. Тот слой, с которым мы сегодня взаимодействуем, чаще всего представляет Cassandra, как нечто отдаленно похожее на реляционную базу данных: с таблицами, с запросами, похожими на SQL и т.д. Вроде бы все хорошо!
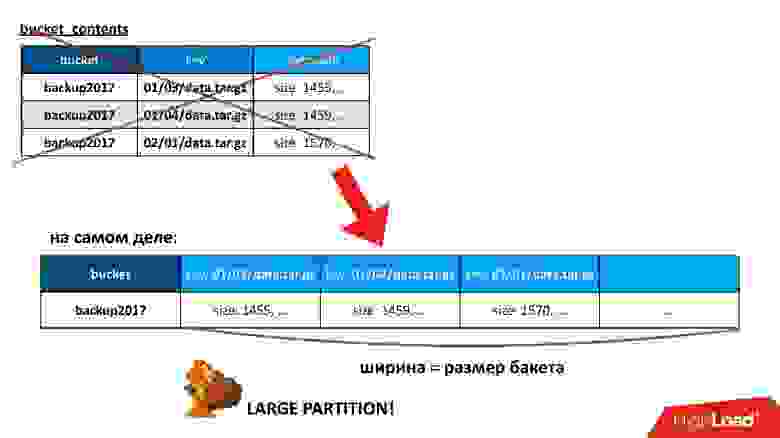
Но есть еще внутренний слой данных. Как на самом деле Cassandra его хранит? Исторически он был первичный, и к нему был свой, совершенно другой API. Такая конструкция, которую я описал, внутри на самом деле хранится, как длинная строка, в которой каждый ключ (в данной ситуации ключ в бакете) является отдельной колонкой. Чем больше размер бакета, тем больше колонок в этой таблице.
Когда я делаю запрос, я этого не вижу и никак не могу об этом узнать. Если я попытаюсь залезть на уровень или почитать, как оно устроено, да, я могу это узнать. Это и означает, что ширина такой строки — количество колонок — равно в моей ситуации размеру моего бакета. Это, кстати, хорошо работает, потому что колонки на физическом уровне хранятся отсортированными по имени.
Но в Cassandra есть куча операций, при которых она оперирует целиком значением строки. Даже если я спрашиваю: «Дай мне 100 ключей», а там хранится миллион, в зависимости от версии, для того, чтобы построить ответ на мой вопрос, ей приходится буквально прочитать всю строку в миллион, оттуда выбрать 100, а все остальное выбросить.
Представьте, что эти данные еще распределены по нескольким узлам (это же несколько реплик), и любой запрос — это же на самом деле не запрос к конкретной реплике, а по сути запрос, который пытается построить консистентное представление по нескольким узлам одновременно. Если у меня есть миллион колонок в одном узле, миллион в другом, миллион в третьем, формально для того, чтобы построить ответ на запрос, невозможно сделать что-то простое. Если я прошу дать 100 ключей, которые больше такого-то значения, и все узлы идеально совпадают, это просто. Если же узлы не совсем совпадают, то этот запрос с лимитом с точки зрения SQL становится вовсе не тривиальным.
Cassandra пытается такую широкую строчку протянуть в память, и когда она это делает, а она написана на Java, ей становится очень плохо. Эта конструкция, называемая Large Partition, возникает незаметно. Пока данных немного — десятки, сотни, тысячи, десятки тысяч, даже сотни тысяч ключей — все хорошо. Но потом начинается экспоненциальное падение с точки зрения производительности, узлы начинают падать, garbage collection не справляется и т.д. В результате получается каскадный эффект.
Плюс к тому, широкая строка реплицирована, и падает не только один узел, а сразу много, потому что у них у всех одинаковая проблема.
Конечно, мы сразу знали об этой проблеме и подумали, что надо что-то заранее сделать.

Поэтому в таблице, которая используется для листинга объектов, мы заранее предусмотрели возможность разбросать данные одного бакета по нескольким колонкам. Я их буду называть условно партициями. То есть партиционировать таблицу так, чтобы у нас не было Large Partition.
У нас есть два требования:
Когда мы запустились, мы так и не придумали, как распределять данные, и в качестве колонки key_hash всегда использовали 0. Как всегда бывает, фичи идут впереди любых улучшений, которые не приносят непосредственного профита с точки зрения продукта. Поэтому мы конечно же пропустили тот момент, когда партиции стали большими. У нас было несколько очень веселых месяцев, когда мы прикручивали решение к системе, которая находилась практически в состоянии агонии.
Давайте обсудим, как это можно было сделать.
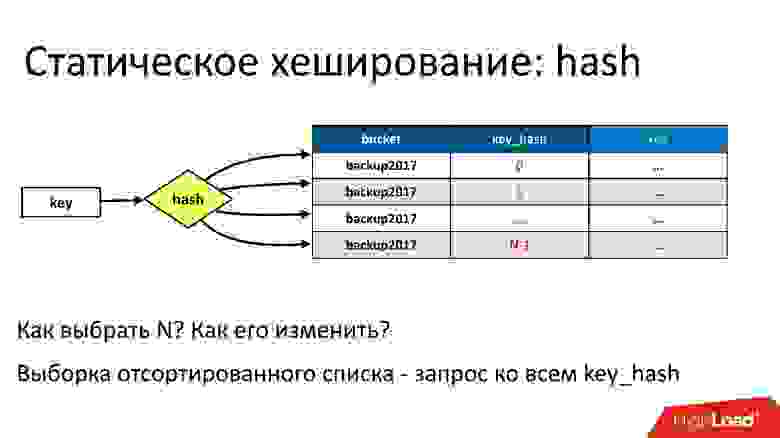
Мы сразу подумали — хорошо, у нас есть бакет, у него куча ключей, давайте все ключи прогоним через какую-нибудь хэш-функцию и таким образом распределим по партициям.
Первая проблема — какого размера должно быть это хэширование, какое нам N выбрать? Если выбрать слишком маленькое, будет Large Partition, слишком большое — слишком много партиций будет создано. При этом, мы ничего не знаем о размере бакета заранее. Он может изменяться: расти или уменьшаться. Самое главное, если это просто хэширование, то получается, что свойство отсортированности пропадет, и в каждой партиции будут лежать какие-то случайные ключи. Чтобы получить отсортированный список, надо делать запрос ко всем партициям и объединять результаты от них. Крайне неудобно и неэффективно, особенно, если этих партиций станет много.
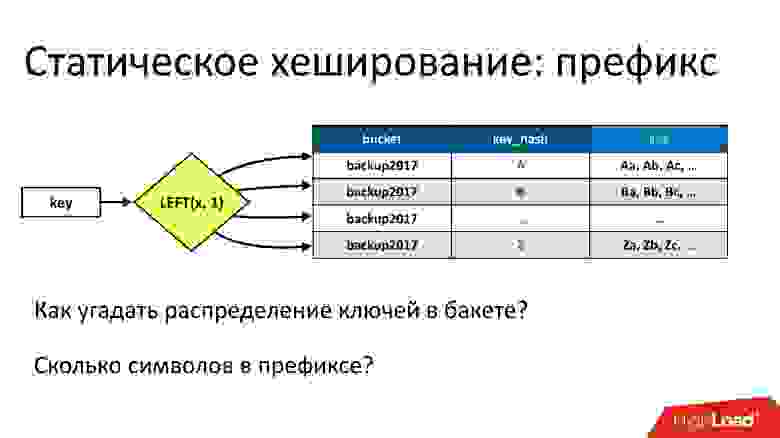
Второе достаточно очевидное решение — раз мы хотели, чтобы свойство отсортированности сохранялось, давайте использовать какой-то префикс ключа. Если мы возьмем сколько-то символов слева, и ключи будут хорошо распределены по бакетам, то мы можем распределить бакеты по партициям. Каждая партиция будет префиксом, в каждой будут ключи, причем они будут отсортированы. Если мы знаем, какие ключи нам нужны, мы знаем в какую партицию обратиться и т.д.
Но тут опять возникает та же самая проблема — как угадать, каким образом именуются ключи? Именуем ключи не мы, а наши клиенты. Как они их называют? Кто-то их называет как результат md5-хеширования — это идеально подходит под такую схему, а у кого-то первые 30 символов — это константа у всех ключей, или что-то еще. Мы не можем угадать. Эта схема работала бы хорошо, только если бы мы знали, как выглядит ключ.
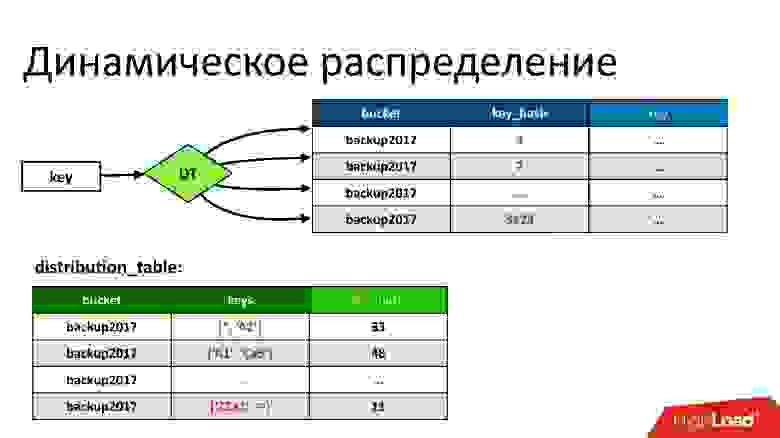
В итоге мы пришли к схеме, когда мы динамически угадываем, точнее, анализируем, как распределены ключи. Это распределение со временем может измениться — бакет может расти, может меняться структура ключей. Мы адаптируемся под это, и динамически с помощью таблицы их распределяем. В таблице указано, что ключи с такого-то по такой-то лежат в такой-то партиции, с такого-то по такой-то — в такой. Это условно решение с префиксом, только префикс сложный и динамический. Да и не совсем это префикс.
Чтобы сделать динамическое хэширование, нам пришлось много повозиться, потому что здесь много интересных, вполне себе научных задач.
Мы имеем какое-то состояние бакета сейчас, он каким-то образом разбит на партиции. Потом мы понимаем, что какие-то партиции слишком большие или слишком маленькие. Нам надо найти новое разбиение, которое, с одной стороны, будет оптимальным, то есть размер каждой партиции будет меньше какого-то нашего предела, и они будут более-менее равномерные. При этом переход от текущего состояния к новому должен требовать минимального количества действий. Понятно, что любой переход требует перемещения ключей между партициями, но чем меньше мы их перемещаем, тем лучше.
У нас это получилось. Наверное, часть, которая занимается подбором распределения, это самый сложный кусок всего сервиса, если говорить о работе с метаданными в целом. Мы его переписывали, переделывали, и делаем до сих пор, потому что всегда обнаруживаются какие-то клиенты или некие паттерны создания ключей, которые бьют в слабое место этой схемы.
Например, мы предполагали, что бакет будет расти более-менее равномерно. То есть мы подобрали какое-то распределение, и надеялись, что все партиции будут расти соответственно этому распределению. Но у нас нашелся клиент, который пишет всегда в конец, в том смысле, что у него ключи всегда в отсортированном порядке. Он все время бьет в самую последнюю партицию, которая растет с такой скоростью, что за минуту это может быть 100 тысяч ключей. А 100 тысяч — это примерно то значение, которое влезает в одну партицию.
Мы просто не успевали бы обрабатывать такой добавление ключей нашим алгоритмом, и нам пришлось для этого клиента ввести специальное предварительное распределение. Так как мы знаем, как выглядят его ключи, если мы видим, что это он, мы просто начинаем ему заранее создавать пустые партиции в конце, чтобы он мог туда спокойно писать, а мы пока немножко бы отдохнули до следующей итерации, когда нам снова придется все перераспределить.
Все это происходит в онлайн в том смысле, что мы не останавливаем операции. Могут быть операции чтения, записи, в любой момент можно запросить список ключей. Он всегда будет консистентный, даже если мы находимся в процессе переразбиения.
Это довольно интересно, и это получается с Cassandra. Здесь можно играть с трюками, связанными с тем, что Cassandra умеет разрешать конфликты. Если мы в одну и ту же строку записали два разных значения, то выигрывает то значение, у которого timestamp больше.
Обычно timestamp — это текущий timestamp, но его можно передать вручную. Например, мы хотим записать в строку значение, которое в любом случае должно быть перетерто, если клиент сам что-то запишет. То есть мы копируем какие-то данные, но хотим, чтобы клиент, если вдруг он одновременно с нами пишет, мог их перезаписать. Тогда мы можем просто копировать наши данные с timestamp‘ом чуть-чуть из прошлого. Тогда любая текущая запись заведомо будет их перетирать, вне зависимости о того, в каком порядке была произведена запись.
Такие трюки позволяют сделать это онлайн.
Если в схеме данных намечается что-то похожее на large partition, надо сразу попытаться что-то с этим сделать — придумать, как его разбить и как от него уйти. Рано или поздно это возникает, потому что любой инвертированный индекс рано или поздно возникает практически в любой задаче. Я уже рассказывал про такую историю — у нас есть бакет-ключ в объект, и нам нужно получить из бакета список ключей — по сути, это индекс.
Причем партиция может быть большой не только от данных, но еще и от Tombstones (маркеров удаления). Маркеры удаления точно также с точки зрения внутренностей Cassandra (мы их никогда не видим снаружи) являются данными, и партиция может быть большой, если в ней много чего удалено, потому что удаление является записью. Об этом тоже не стоит забывать.

Еще одна история, которая на самом деле постоянная — от начала до конца что-то идет не так. Например, вы видите, что время отклика от Cassandra выросло, она отвечает медленно. Как понять и разобраться, в чем проблема? Никогда не бывает внешнего сигнала, что проблема именно там-то.
Для примера приведу график — это усредненное время отклика кластера в целом. На нем видно, что у нас проблема — максимальное время отклика уперлось в 12 с — это внутренний таймаут Cassandra. Это означает, что она таймаутится сама. Если таймаут выше 12 с, это скорее всего означает, что работает garbage collector, и Cassandra не успевает даже ответить в нужное время. Она отвечает сама по таймауту, но время отклика на большинство запросов, как я говорил, должно быть в среднем в пределах 10 мс.
На графике среднее превысило уже сотни миллисекунд — что-то пошло не так. Но глядя на эту картинку, невозможно понять, в чем причина.
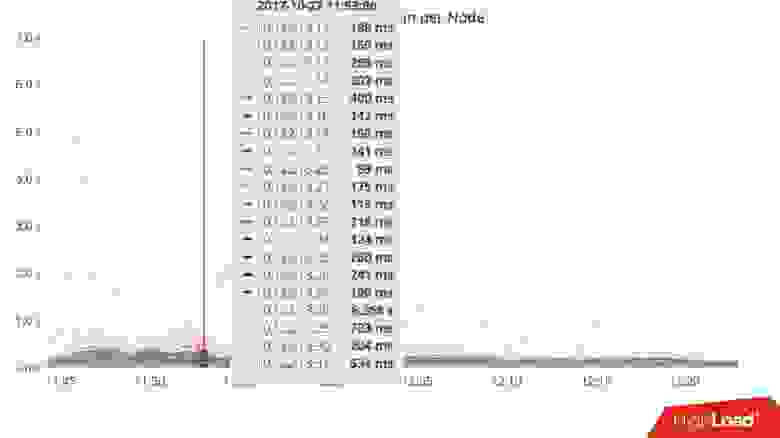
Но если ту же самую статистику развернуть по узлам Cassandra, то видно, что в принципе все узлы более-менее ничего, но у одного узла время отклика отличается на порядки. Скорее всего, с ним какая-то проблема.
Статистика по узлам изменяет картинку полностью. Эта статистика со стороны приложения. Но и здесь на самом деле очень часто сложно понять, в чем проблема. Когда приложение обращается к Cassandra, оно обращается к какому-то узлу, используя его как координатор. То есть приложение дает запрос, и координатор его перенаправляет к репликам с данными. Те уже отвечают, и координатор формирует конечный ответ обратно.
Но почему координатор отвечает медленно? Может быть, проблема с ним, как с таковым, то есть он тормозит и отвечает медленно? А может быть, он тормозит, потому что ему медленно реплики отвечают? Если реплики отвечают медленно, с точки зрения приложения это будет выглядеть как медленный ответ координатора, хотя он здесь ни при чем.
Здесь счастливая ситуация — видно, что только один узел отвечает медленно, и скорее всего, проблема именно в нем.
Всегда сложно понять, что не так. Просто нужно много статистики и мониторинга, как со стороны приложения, так и самой Cassandra, потому что, если ей совсем плохо, со стороны Cassandra ничего не видно. Можно смотреть и на уровне отдельных запросов, на уровне каждой конкретной таблицы, на каждом конкретном узле.
Может быть, например, ситуация, когда у одной таблицы того, что называется в Cassandra SSTables (отдельные файлы) слишком много. Для чтения Cassandra приходится, грубо говоря, перебирать все SSTables. Если их слишком много, то просто процесс этого перебора занимает слишком много времени, и чтение начинает проседать.
Решением является compaction, который уменьшает количество этих SSTables, но надо заметить, что это может быть всего на одном узле для одной конкретной таблицы. Так как Cassandra написана, к сожалению, на Java и работает на JVM, может быть, garbage collector ушел в такую паузу, что просто не успевает ответить. Когда garbage collector уходит в паузу, не только ваши запросы тормозят, но и взаимодействие внутри кластера Cassandra между узлами начинает тормозить. Узлы друг друга начинают считать ушедшими в down, то есть упавшими, мертвыми.
Начинается еще более веселая ситуация, потому что когда узел считает, что другой узел в down, он, во-первых, к нему запросы не направляет, во-вторых, он начинает пытаться сохранять данные, которые ему нужно было бы реплицировать на другой узел у себя локально, таким образом он и себя начинает потихоньку убивать, и т.д.
Бывают ситуации, когда эту проблему можно решить просто с помощью правильных настроек. Например, может быть достаточно ресурсов, все хорошо и замечательно, но просто Thread Pool, число которых фиксированного размера, надо увеличить.
Наконец, может быть, нам надо со стороны драйвера ограничить конкурентность. Иногда бывает, что отправлено слишком много конкурентных запросов, и как любая база данных, Cassandra не может с ними справиться и уходит в клинч, когда время отклика растет экспоненциально, а мы пытаемся еще больше и больше дать работы.
Всегда есть какой-то контекст у проблемы — что происходит в кластере, работает ли сейчас Repair, на каком узле, в каком key spaces, в какой таблице.
У нас, например, были достаточно смешные проблемы с железом. Мы видели, что часть узлов работает медленно. Позже обнаружилось, что причина была в том, что в BIOS их процессоры стояли в энергосберегающем режиме. По какой-то причине во время начальной установки железа так получилось, и использовалось примерно 50% ресурсов процессора по сравнению с другими узлами.
Разобраться в такой проблеме может быть тяжело, на самом деле. Симптом такой — вроде бы узел делает compaction, но делает его медленно. Иногда это связано с железом, иногда нет, но это просто очередной баг Cassandra.
Поэтому мониторинг обязателен и его нужно много. Чем сложнее фича в Cassandra, чем дальше она отстоит от простой записи и чтения, тем больше с ней проблем, и тем быстрее она может убить БД при достаточном количестве запросов. Поэтому, если есть возможность, не надо смотреть на какие-то «вкусные» фишки и пытаться их использовать, лучше их избегать насколько это возможно. Не всегда возможно — конечно, рано или поздно приходится.

Последняя история про то, как Cassandra испортила данные. В этой ситуации это произошло внутри Cassandra. Это было интересно.
Мы видели, что примерно раз в неделю у нас в базе данных появляется несколько десятков испорченных строк — они буквально забиты мусором. Причем Cassandra валидирует данные, которые поступают к ней на вход. Например, если это строка, то она должна быть в utf8. Но в этих строках находился мусор, не utf8, и Cassandra с ним даже ничего делать не давала. При попытке удалить (или что-то еще сделать), я не могу удалить значение, которое не является utf8, потому что, в частности, не могу никак вписать в WHERE, потому что ключ должен быть utf8.
Испорченные строки появляются, как вспышка, в какой-то момент, и дальше их нет опять в течение нескольких дней или недель.
Мы начали искать проблему. Мы думали, может быть проблема в определенном узле, с которым мы возились, делали что-то с данными, SSTables копировали. Может быть, все-таки у этих данных можно посмотреть их реплики? Может быть, у этих реплик есть общий узел, наименьший общий делитель? Может быть, какой-то узел дает сбой? Нет, ничего подобного.
Может быть, что-то с диском? На диске данные испортились? Опять нет.
Может быть, память? Нет! Разбросано по кластеру.
Может быть, это какая-то проблема репликации? Один узел все попортил и дальше реплицировал плохое значение? — Нет.
Наконец, может быть, это проблема приложения?
Причем в какой-то момент испорченные строки стали появляться в двух кластерах Cassandra. Один работал на версии 2.1, второй на третьей. Вроде и Cassandra разные, а проблема одна и та же. Может, у нас сервис отправляет плохие данные? Но верилось в это с трудом. Cassandra валидирует данные на входе, она не могла записать мусор. Но вдруг?
Ничего не подходит.
Мы бились долго и упорно, пока не обнаружили маленькую проблему: почему у нас на узлах есть какие-то crash dump от JVM, на которые мы особо внимания не обращали? И как-то подозрительно выглядит в stack trace garbage collector… И почему-то некоторые stack trace тоже мусором забиты.
В итоге мы поняли — о, мы почему-то используем JVM старой версии 2015 года. Это было единственным общим, что объединяло кластеры Cassandra на разных версиях Cassandra.
Я до сих пор не знаю, в чем была проблема, потому что в официальных релиз-ноутах JVM про это ничего не написано. Но после обновления все исчезло, проблема больше не возникала. Причем она возникала в кластере не с первого дня, а с какого-то момента, хотя он работал на том же самом JVM довольно долго.
Какой урок мы вынесли из этого:
● Backup бесполезен.
Данные, как мы выяснили, портились в ту же секунду, когда они были записаны. В момент, когда данные входили в координатор, они уже были испорчены.
● Возможно частичное восстановление неповрежденных колонок.
Какие-то колонки были не повреждены, мы могли эти данные прочитать, частично восстановить.
● В конечном итоге нам приходилось делать восстановление из разных источников.
У нас был backup метаданных в объекте, но в самих данных. Чтобы восстановить связь с объектом, мы использовали логи и т.д.
● Логи — это бесценно!
Мы смогли восстановить все данные, которые были испорчены, но в конечном итоге очень тяжело доверять базе данных, если она ваши данные теряет даже без какого-то действия с вашей стороны.
● Низкое качество тестирования релизов
Когда вы начинаете работать с Cassandra, возникает постоянное ощущение (особенно, если вы переходите, условно говоря, с «хороших» баз данных, например, с PostgreSQL), что если в релизе исправили баг предыдущего, то обязательно добавили новый. Причем баг — это не какая-нибудь ерунда, это обычно испорченные данные или другое некорректное поведение.
● Постоянные проблемы со сложными фичами
Чем сложнее фича, тем больше с ней проблем, багов и т.д.
● Не используйте инкрементальный repair в 2.1
Знаменитый repair, о котором я рассказывал, который чинит консистентность данных, в стандартном режиме, когда он опрашивает все узлы, работает хорошо. Но не в так называемом инкрементальном режиме (когда repair пропускает данные, которые не изменились со времени предыдущего repair, что вполне логично). Он был заявлен давно, формально, как фича существует, но все говорят: «Нет, в версии 2.1 не используйте его никогда! Он обязательно что-нибудь пропустит. В 3 мы исправим»
● Но не используйте инкрементальный repair и в 3.x
Когда вышла третья версия, через несколько дней они сказали: «Нет, в 3-й использовать его нельзя. Есть список из 15 багов, поэтому ни в коем случае не используйте инкрементальный repair. В 4-й мы сделаем лучше!»
Я им не верю. А это большая проблема, особенно с ростом размера кластера. Поэтому нужно следить постоянно за их bugtracker и смотреть, что происходит. Без этого с ними, к сожалению, жить невозможно.
● Надо следить за JIRA

Я вам желаю найти другие грабли и на них наступать, потому что, с моей точки зрения, несмотря ни на что, Сassandra — это хорошо и, несомненно, нескучно. Только помните о кочках на дороге!
Под все эти требования подходит только Cassandra, а ничто другое не подходит. Надо заметить, Cassandra действительно классная, но работа с ней напоминает американские горки.
В докладе на Highload++ 2017 Андрей Смирнов (smira) решил, что о хорошем говорить неинтересно, зато подробно рассказал, про каждую проблему, с которой пришлось столкнуться: про потерю и порчу данных, про зомби и потерю производительности. Эти истории и вправду напоминают катание на горках, но на все проблемы находится решение, за которым добро пожаловать под кат.
О спикере: Андрей Смирнов работает в компании Virtustream, реализующей облачное хранилище для enterprise. Идея состоит в том, что условно Amazon делает облако для всех, а Virtustream делает специфические вещи, которые необходимы большой компании.
Пару слов о Virtustream
Мы работаем в полностью удаленной небольшой команде, и занимаемся одним из облачных решений Virtustream. Это облако хранения данных.

Если говорить очень просто, то это S3-совместимый API, в котором можно хранить объекты. Для тех, кто не знает, что такое S3 — это просто HTTP API, с помощью которого можно куда-то в облако загружать объекты, получать их обратно, удалять, получать список объектов и т.д. Дальше — уже более сложные фичи на основе этих простых операций.
У нас есть некоторые отличительные возможности, которых нет у Amazon. Одна из них — так называемые гео-регионы. В обычной ситуации, когда вы создаете хранилище и говорите, что будете хранить объекты в облаке, вы должны выбрать регион. Регион — это по сути дата-центр, и ваши объекты никогда не покинут этот дата-центр. Если с ним что-то случится, то ваши объекты больше не будут доступны.
Мы предлагаем гео-регионы, в которых данные находятся одновременно в нескольких дата-центрах (ДЦ), как минимум в двух, как на картинке. Клиент может обращаться к любому дата-центру, для него это прозрачно. Данные между ними реплицируются, то есть мы работаем в режиме «Active-Active», причем постоянно. Это предоставляет клиенту дополнительные возможности, в том числе:
- большая надежность хранения, чтение и запись при отказе ДЦ или потере связности;
- доступность данных даже при отказе одного из ДЦ;
- перенаправление операций в «ближайший» ДЦ.
Это интересная возможность — даже если эти ДЦ далеко друг от друга географически, то какой-то из них может быть ближе к клиенту в разные моменты времени. И обращаться к данным в ближайший ДЦ просто быстрее.
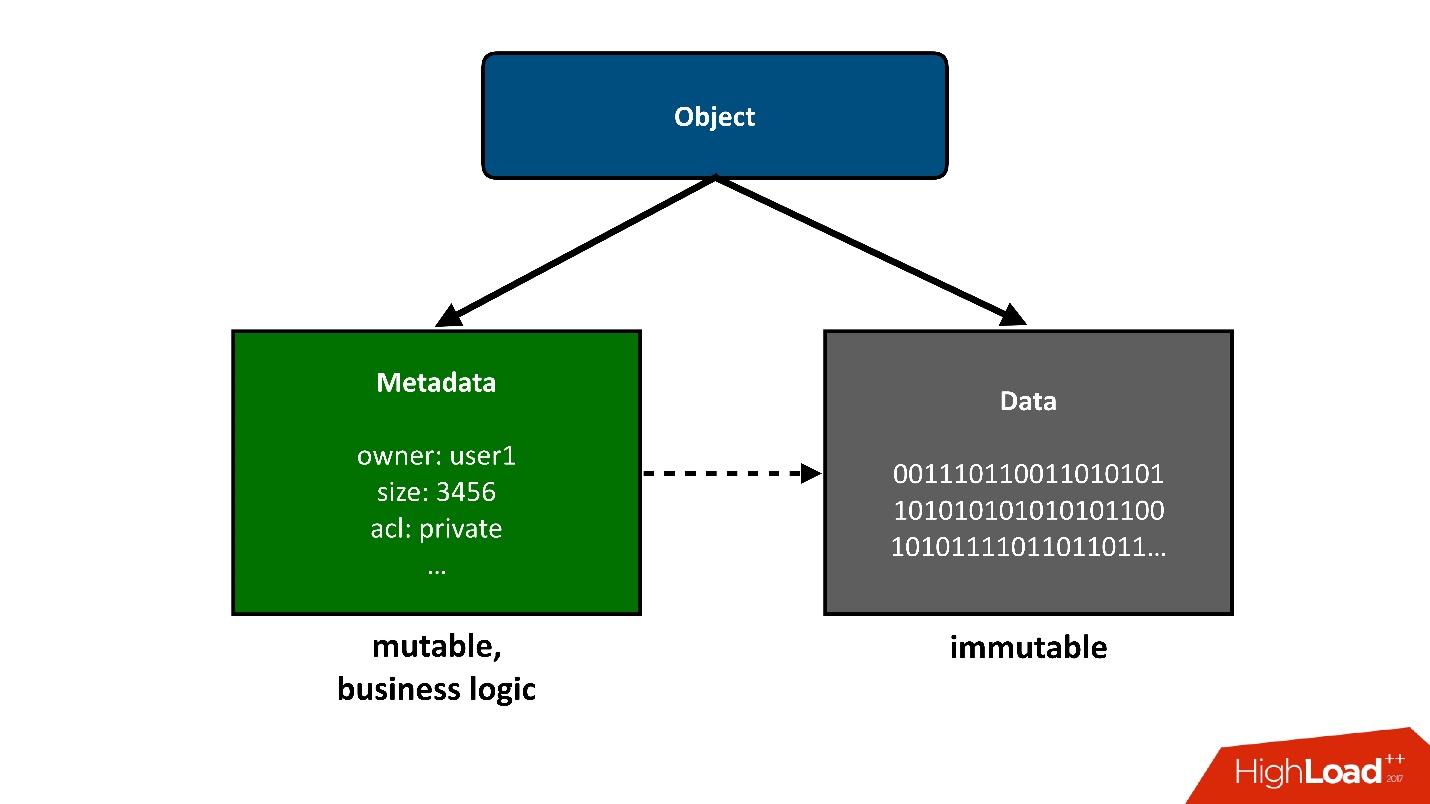
Для того, чтобы конструкцию, о которой мы будем говорить, разделить на части, я представлю те объекты, которые хранятся в облаке, как два больших куска:
1. Первый простой кусок объекта — это данные. Они неизменны, их один раз загрузили и все. Единственное, что с ними потом может случиться — мы их можем удалить, если они больше не нужны.
Предыдущий проект у нас был связан с хранением экзабайта данных, поэтому у нас проблем с хранением данных не было. Это для нас была уже решенная задача.
2. Метаданные. Вся бизнес-логика, все самое интересное, связанное с конкурентностью: обращение, записи, перезаписи — в районе метаданных.
Метаданные об объекте забирают в себя наибольшую сложность проекта, в метаданных хранится указатель на блок сохраненных данных объекта.
С точки зрения пользователя это единый объект, но мы можем разделить его на две части. Сегодня я буду говорить только о метаданных.
Цифры
- Данные: 4 Пбайта.
- Кластеры метаданных: 3.
- Объекты: 40 миллиардов.
- Объем метаданных: 160 Тбайт (с учетом репликации).
- Скорость изменений (метаданных): 3000 объектов/с.
Если посмотреть на эти показатели внимательно, то первое, что бросается в глаза, это очень маленький средний размер хранящегося объекта. У нас очень много метаданных на единицу объема основных данных. Для нас это было не меньшим сюрпризом, чем, возможно, для вас сейчас.
Мы планировали, что у нас данных будет, как минимум, на порядок, если не на 2, больше, чем метаданных. То есть каждый объект будет значительно больше, а объем метаданных будет меньше. Потому что данные хранить дешевле, с ними меньше операций, а метаданные гораздо дороже и в смысле железа, и в смысле обслуживания и выполнения различных операций над ними.
При этом эти данные изменяются с достаточно высокой скоростью. Я привел здесь пиковое значение, непиковое не сильно меньше, но, тем не менее, может получаться довольно большая нагрузка в конкретные моменты времени.
Данные цифры были получены уже с работающей системы, но вернемся немного назад, к моменту проектирования облачного хранилища.
Выбор хранилища для метаданных
Когда перед нами встала задача, что мы хотим иметь гео-регионы, Active-Active, и нам надо где-то хранить метаданные, мы думали, что это может быть?
Очевидно, что хранилище (база данных) должна иметь следующие свойства:
- Поддержка Active-Active;
- Масштабируемость.
Мы бы очень хотели, чтобы наш продукт пользовался бешеной популярностью, и как он при этом будет расти, мы не знаем, поэтому система должна масштабироваться.
- Баланс отказоустойчивости и надежности хранения.
Метаданные надо хранить надежно, потому что если мы их потеряем, а в них была ссылка на данные, то мы потеряем весь объект.
- Настраиваемая консистентность операций.
В силу того, что мы работаем в нескольких ДЦ и допускаем возможность того, что ДЦ может быть недоступен, более того, ДЦ находятся далеко друг от друга, то мы не можем во время выполнения большинства операций через API требовать, чтобы эта операция выполнялась одновременно в двух ДЦ. Это будет просто слишком медленно и невозможно, если второй ДЦ недоступен. Поэтому часть операций должна работать локально в одном ДЦ.
Но, очевидно, когда-то должна происходить некая конвергенция, и после разрешения всех конфликтов данные должны быть видны в обоих дата-центрах. Поэтому консистентность операций должна настраиваться.
Под эти требования, с моей точки зрения, подходит Cassandra.
Cassandra
Я был бы очень рад, если бы нам не пришлось использовать Cassandra, потому что для нас это был некий новый опыт. Но ничего другого не подходит. Это, мне кажется, самая печальная ситуация на рынке подобных систем хранения — безальтернативность.

Что такое Cassandra?
Это распределенная key-value база данных. С точки зрения архитектуры и идей, которые в нее заложены, мне кажется, все классно. Если бы я делал, то делал бы то же самое. Когда мы только начинали, мы задумывались о написании своей системы хранения метаданных. Но чем дальше, тем мы больше и больше понимали, что нам придется сделать что-то очень похожее на Cassandra, и те усилия, которые мы на это потратим, того не стоят. На всю разработку у нас было всего полтора месяца. Было бы странно потратить их на написание своей базы данных.
Если Cassandra разделить по слоям, как слоеный пирог, я бы выделил 3 слоя:
1. Локальное KV-хранилище на каждом узле.
Это кластер из узлов, каждый из которых уметь хранить key-value данные локально.
2. Шардирование данных по узлам (consistent hashing).
Cassandra умеет распределять данные по узлам кластера, включая репликацию, причем делает это так, что кластер может расти или уменьшаться в размерах, и данные будут перераспределяться.
3. Координатор для перенаправления запросов к другим узлам.
Когда мы обращаемся из нашего приложения к данным по каким-то запросам, Cassandra умеет наш запрос распределить по узлам так, чтобы мы получили те данные, которые мы хотим, и с тем уровнем консистентности, который нам нужен — хотим мы их прочитать просто quorum, или хотим quorum с учетом двух ДЦ и т.д.
Для нас два года с Cassandra — это американские или русские горки — как хотите называйте. Начиналось все глубоко внизу, у нас был нулевой опыт работы с Cassandra. Нам было страшно. Мы запустились, и все было хорошо. Но дальше начинаются постоянные падения и взлеты: проблема, все плохо, мы не знаем, что делать, у нас сыпятся ошибки, потом мы проблему решаем, и т.д.
Эти американские горки, в принципе, не заканчиваются по сей день.
Хорошее
Первая и последняя глава, где я скажу, что Cassandra классная. Она действительно классная, отличная система, но, если я буду дальше говорить, какая она хорошая, думаю, вам не будет интересно. Поэтому плохому уделим больше внимания, но позже.
Cassandra действительно хорошая.
- Это одна из систем, которая позволяет нам иметь время отклика в миллисекундах, то есть заведомо меньше 10 мс. Это хорошо для нас, потому что нам важно время отклика в целом. Операция с метаданными для нас является лишь частью любой операции, связанной с хранением объекта, будь то получение или запись.
- С точки зрения записи достигается высокая масштабируемость. В Cassandra можно писать с сумасшедшей скоростью, а а некоторых ситуациях это необходимо, например, когда мы перемещаем большие объемы данных между записями.
- Cassandra действительно отказоустойчива. Падение одного узла не приводит в ту же секунду к проблемам, правда рано или поздно они начнутся. Cassandra декларирует, что в ней нет единой точки отказа, но, по сути, точки отказа есть везде. На самом деле тот, кто работал с БД, знает, что даже падение узла — это не то, что обычно терпит до утра. Обычно, такую ситуацию надо починить быстрее.
- Простота. Все-таки по сравнению с другими стандартными реляционными базами данных Cassandra проще в плане понимания того, что происходит. Очень часто что-то идет не так, и нам нужно понять, что происходит. С Cassandra больше шансов разобраться, дойти до малейшего винтика, наверное, чем с другой БД.
Пять историй о плохом
Повторюсь, Cassandra хорошая, у нас она работает, но расскажу пять историй о плохом. Думаю, это то, ради чего вы это читаете. Истории приведу в хронологическом порядке, хотя они не очень друг с другом связаны.

Эта история была самой грустной для нас. Так как мы храним данные пользователей, самое страшное из возможного — это их потерять, причем потерять безвозвратно, как случилось в этой ситуации. У нас были предусмотрены способы, как восстановить данные, если мы их потеряем в Cassandra, но мы их потеряли так, что действительно не могли восстановить.
Для того, чтобы объяснить, как это происходит, мне немножко придется рассказать о том, как у нас все устроено внутри.
С точки зрения S3 есть несколько базовых вещей:
- Bucket — его можно представить, как огромный каталог, в который пользователь заливает объект (далее бакет).
- У каждого объекта есть имя (ключ) и связанные с ним метаданные: размер, content type и указатель на данные объекта. При этом размер бакета ничем не ограничен. То есть это может быть 10 ключей, может быть 100 млрд ключей — разницы никакой нет.
- Возможны любые конкурентные операции, то есть может быть несколько конкурентных заливок в один и тот же ключ, может быть конкурентное удаление и т.д.
В нашей ситуации active-active, операции могут происходить, в том числе, конкурентно в разных ДЦ, не только в одном. Поэтому нам нужна какая-то схема сохранения, которая позволит реализовывать такую логику. В конечном итоге мы выбрали простую политику: побеждает последняя по времени записанная версия. Иногда происходит несколько конкурентных операций, но не обязательно, что наши клиенты специально это делают. Это может быть просто запрос, который начался, но клиент не дождался ответа, что-то еще произошло, попытался снова, и т.д.
Поэтому у нас есть две базовые таблицы:
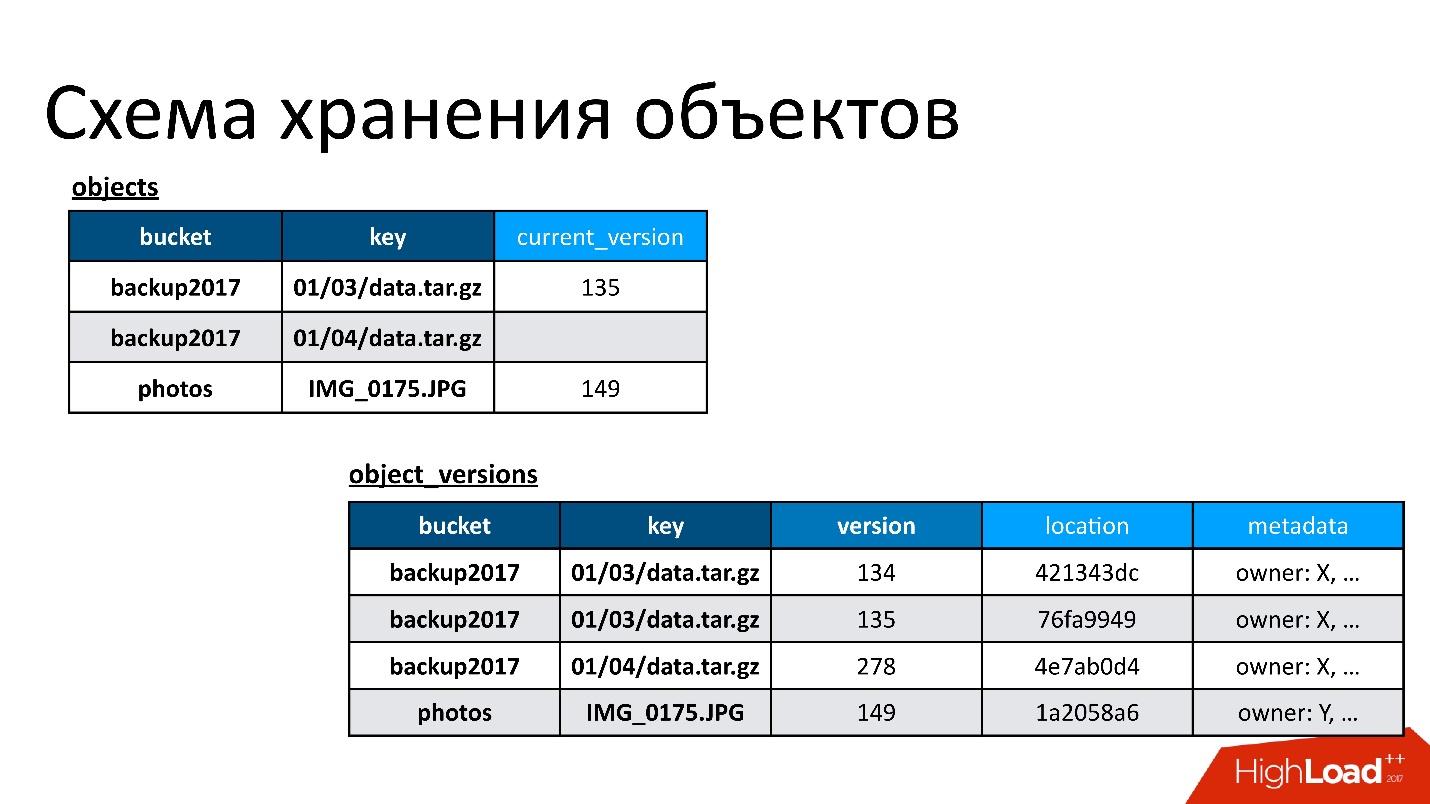
- Таблица объектов. В ней пара — имя бакета и имя ключа — связывается с его текущей версией. Если объект удален, то в этой версии ничего нет. Если объект существует, там есть его текущая версия. По сути, в этой таблице мы только изменяем поле текущей версии.
- Таблица версий объектов. В эту таблицу мы только вставляем новые версии. Каждый раз, когда происходит загрузка нового объекта, мы вставляем новую версию в таблицу версий, даем ей некий уникальный номер, сохраняем о ней всю информацию, и в конце обновляем на нее ссылку в таблице объектов.
На рисунке пример того, как связаны таблицы объектов и версий объектов.

Здесь есть объект, у которого две версии — одна текущая и одна старая, есть объект, который уже удален, а его версия все еще есть. Нам надо время от времени заниматься очисткой ненужных версий, то есть удалять то, на что уже никто не ссылается. Причем удалять нам необязательно сразу же, мы можем делать это в отложенном режиме. Это наша внутренняя очистка, мы просто удаляем то, что больше не нужно.
Тут возникла проблема.
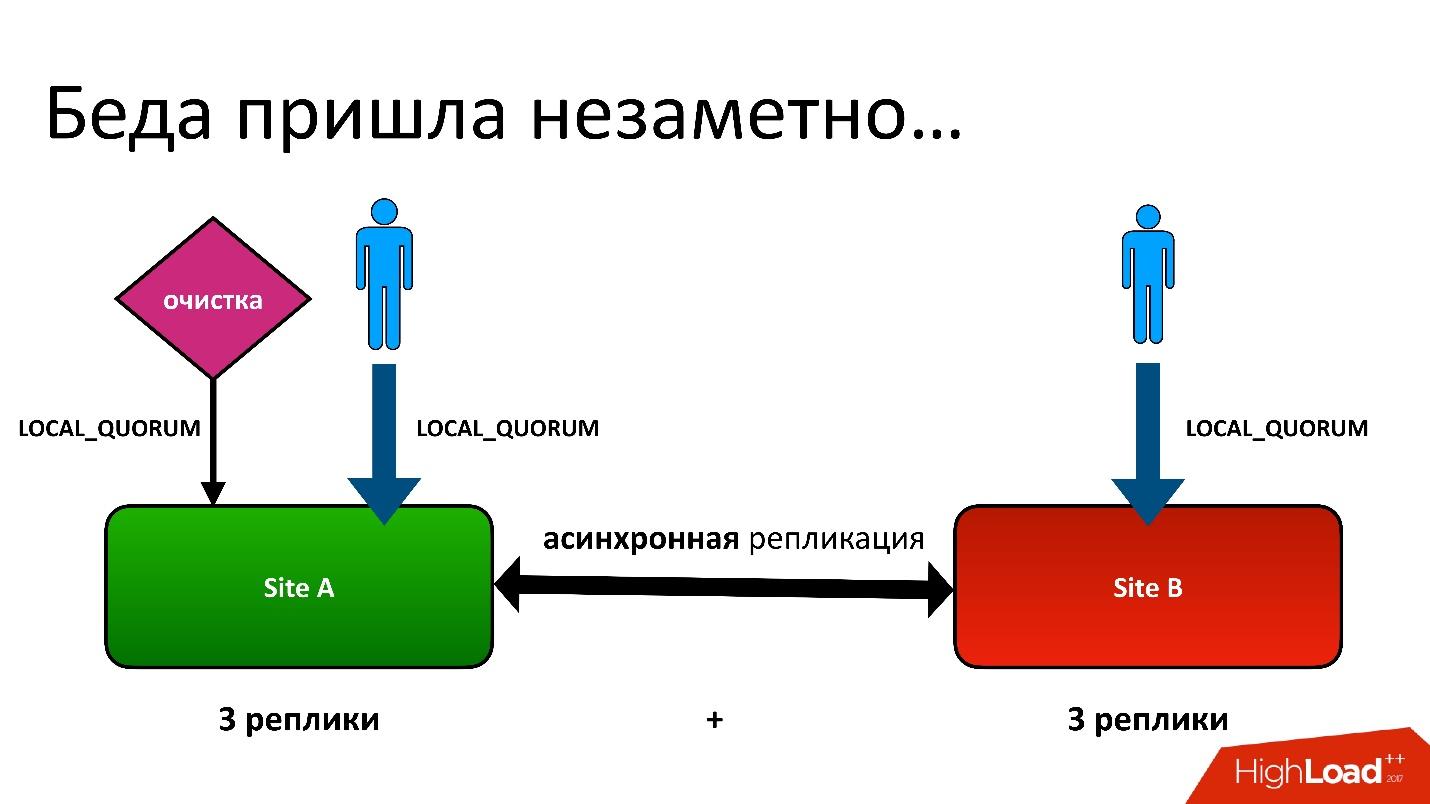
Проблема была в следующем: у нас есть active-active, два ДЦ. В каждом ДЦ метаданные хранятся в трех копиях, то есть у нас 3+3 — всего 6 реплик. Когда к нам обращаются клиенты, мы операции выполняем с консистентностью (с точки зрения Cassandra называется LOCAL_QUORUM). То есть гарантируется, что запись (или чтение) произошло в 2 реплики в локальном ДЦ. Это гарантия — иначе операция не выполнится.
Cassandra всегда будет пытаться писать во все 6 реплик — 99% времени все будет хорошо. На самом деле, все 6 реплик будут одинаковые, но гарантированы нам 2.
У нас была сложная ситуация, хотя это был даже не гео-регион. Даже для обычных регионов, которые в одном ДЦ, мы все равно хранили вторую копию метаданных в другом ДЦ. Это длинная история, я не буду все детали приводить. Но в конечном итоге у нас был процесс очистки, который удалял ненужные версии.
И тут встала та самая проблема. Процесс очистки работал тоже с консистентностью локального кворума в одном дата-центре, потому что в двух смысла запускать его нет — они будут друг с другом бороться.
Все было хорошо, пока не оказалось, что наши пользователи еще иногда пишут в другой дата-центр, о чем мы не подозревали. У нас все было настроено на всякий случай для фейловера, но оказалось, что они уже пользуются этим.
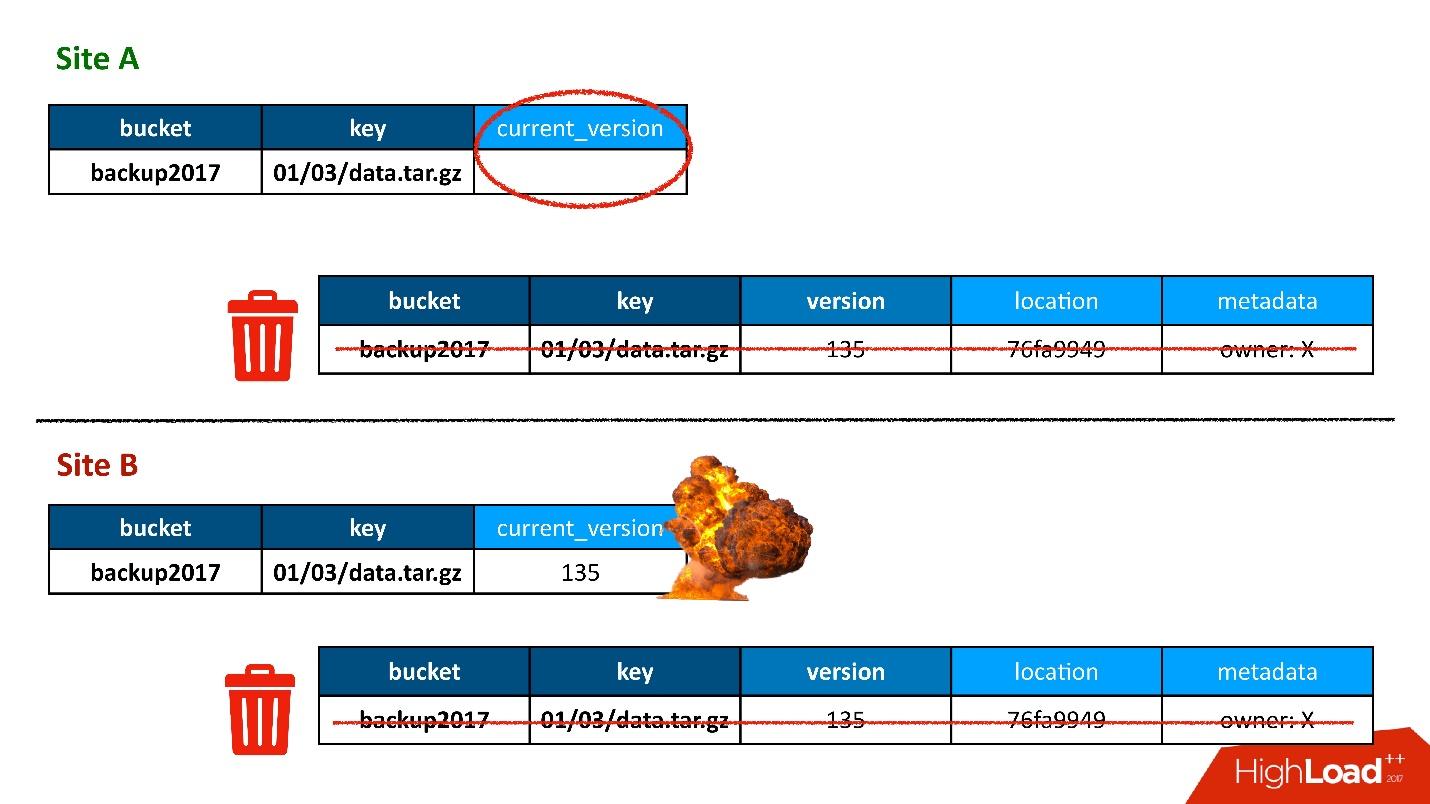
Большую часть времени все было хорошо, пока однажды не возникла ситуация, когда в оба ДЦ отреплицировалась запись в таблицу версий, но запись в таблице объектов оказалась только в одном ДЦ, а во второй не попала. Соответственно, процедура очистки, запущенная в первом (верхнем) ДЦ, увидела, что есть версия, на которую никто не ссылается, и ее удалила. Причем удалила не только версию, но и, само собой, данные — все полностью, потому что это просто ненужный объект. И это удаление безвозвратное.
Конечно, дальше происходит «бум», потому что у нас в таблице объектов осталась запись, которая ссылается на версию, которой больше нет.
Так мы первый раз потеряли данные, и потеряли их действительно безвозвратно — благо, немного.
Решение
Что делать? В нашей ситуации все просто.
Так как у нас данные хранятся в двух ДЦ, процесс очистки является процессом некоей конвергенции и синхронизации. Мы должны читать данные с обоих ДЦ. Этот процесс будет работать только тогда, когда оба ДЦ доступны. Так как я говорил, что это отложенный процесс, который не происходит в процессе обработки API, это не страшно.
Консистентность ALL — это особенность Cassandra 2. В Cassandra 3 все немножко лучше — есть уровень консистентности, который называется quorum в каждом ДЦ. Но в любом случае есть проблема того, что это медленно, потому что нам, во-первых, приходится обращаться к удаленному ДЦ. Во-вторых, в случае консистентности всех 6 узлов это означает, что он работает со скоростью худшего из этих 6 узлов.
Но одновременно происходит процесс так называемого read-repair, когда не все реплики синхронны. То есть когда где-то запись не прошла, этот процесс одновременно их чинит. Так устроена Cassandra.
Когда это случилось, нам поступила жалоба от клиента, что объект недоступен. Мы разобрались, поняли, почему, и первое, что мы захотели сделать, это узнать, сколько у нас еще таких объектов. Мы запустили скрипт, который пытался найти конструкцию, похожую на эту, когда есть запись в одной таблице, но записи в другой — нет.
Вдруг мы обнаружили, что у нас 10% таких записей. Ничего хуже, наверное, не могло бы быть, если бы мы не догадались, что дело не в этом. Проблема была в другом.

В нашу базу данных прокрались Зомби. Это полуофициальное название этой проблемы. Для того, чтобы понять, что это такое, надо поговорить о том, как работает удаление в Cassandra.
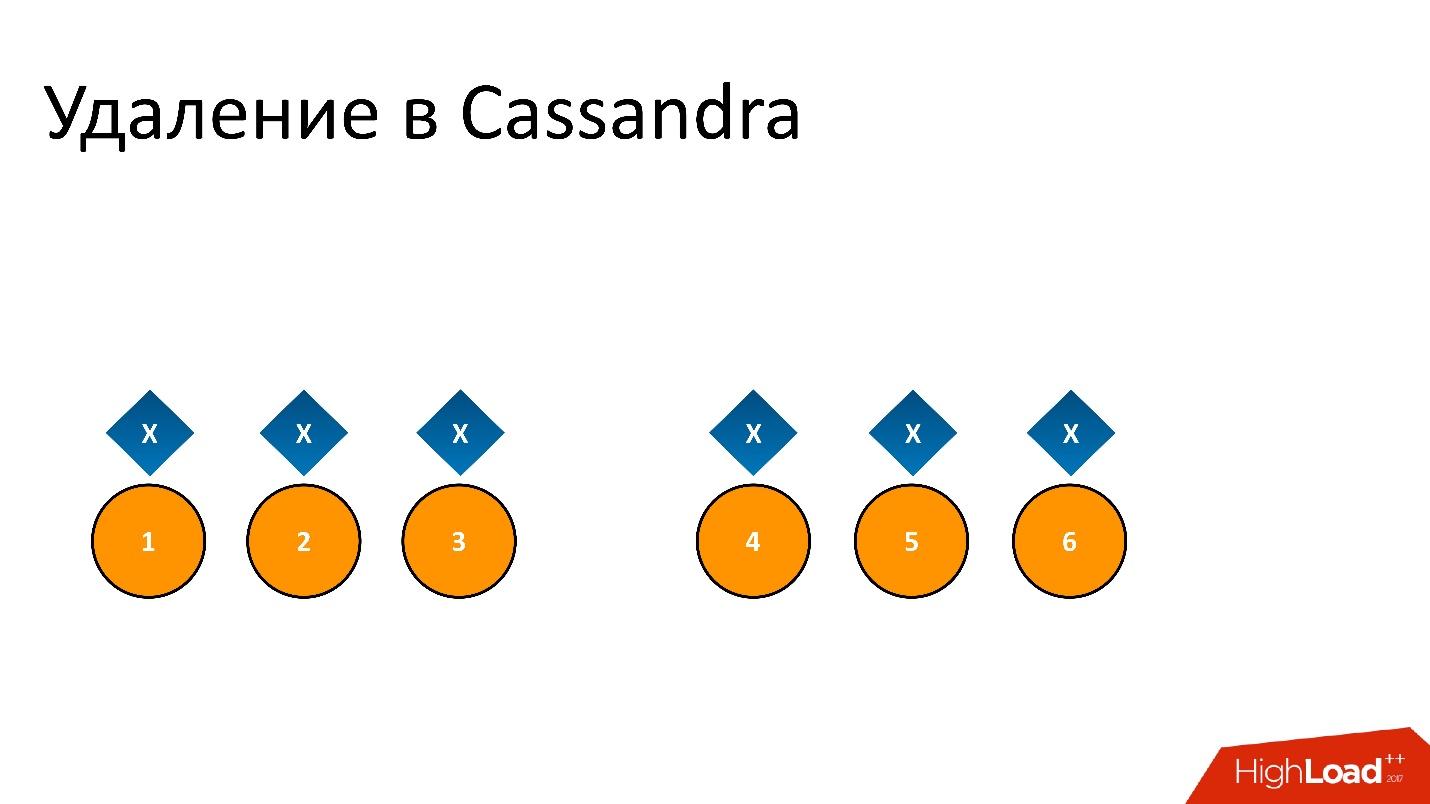
Например, у нас есть какой-то кусок данных x, который записан и идеально реплицирован на все 6 реплик. Если мы хотим его удалить, удаление, как и любая операция в Cassandra, может быть выполнено не на всех узлах.
Например, мы хотели гарантировать консистентность 2 из 3 в одном ДЦ. Пусть операция удаления выполнилась на пяти узлах, а на одном запись осталась, например, потому что узел в этот момент был недоступен.
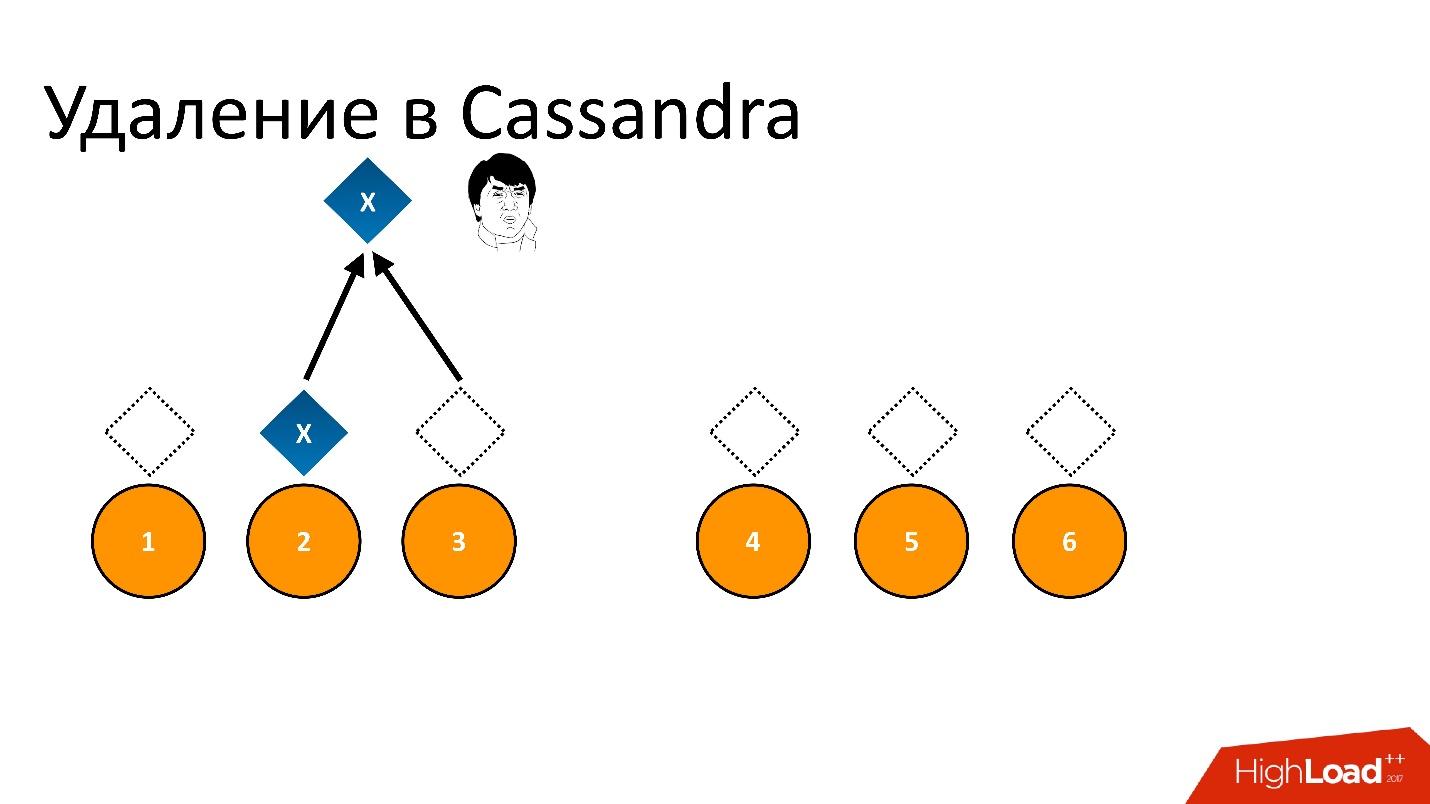
Если мы так удалим и потом попытаемся прочитать с такой же консистентностью «хочу 2 из 3», то Cassandra, увидев значение и его отсутствие, интерпретирует это как наличие данных. То есть при чтении обратно она скажет: «О, данные есть!», хотя мы их удалили. Поэтому удалять таким образом нельзя.

Cassandra удаляет по-другому. Удаление на самом деле является записью. Когда мы удаляем данные, Cassandra записывает некий маркер небольшого размера, который называется Tombstone (надгробная плита). Он помечает, что данные удалены. Таким образом, если мы читаем одновременно маркер удаления и данные, Cassandra всегда предпочитает маркер удаления в этой ситуации и говорит, что данных на самом деле нет. Это то, что нужно.
Хотя Tombstone — это маленький маркер, понятно, что, если мы удаляем и удаляем данные, когда-то надо и эти маркеры удалять, иначе они будут копиться бесконечно. Поэтому у Tombstone есть некоторое конфигурируемое время жизни. То есть Tombstone удаляются через gc_grace_period секунд. Когда маркера нет, ситуация эквивалентна ситуации, когда данных нет.
Что может произойти?
Repair
В Cassandra есть процесс, который называется Repair (починка). Его задача — сделать так, чтобы все реплики были синхронны. У нас возможны разные операции в кластере, может быть, не на всех узлах они выполнились, или мы меняли размер кластера, добавляли/убавляли реплики, может быть, какой-то узел когда-то упал, жесткие диски и т.д. Реплики могут быть не консистентны. Repair делает так, чтобы они стали консистентны.

Мы удалили данные, где-то появились маркеры удаления, где-то остались сами данные. Но Repair мы пока не сделали, и оно в состоянии, как на картинке выше. Прошло какое-то время, и маркеры удаления исчезли — просто вышел их срок жизни. Вместо них осталось пустое место, как будто данных нет.

Если после этого запустить Repair, который должен привести реплики в консистентное состояние, он увидит, что на одних узлах есть данные, на других нет — значит, надо их восстановить. Соответственно все 6 узлов снова будут с данными. Это те самые Зомби — данные, которые мы удалили, но которые вернулись в кластер.

Обычно мы их не видим, если к ним не обращаемся — возможно, это какие-то случайные ключи. Если на него ничто не ссылается, мы его не увидим. Но если мы попробуем просканировать всю базу данных, пытаясь что-то найти, как мы тогда искали, сколько у нас записей с удаленными объектами, эти Зомби очень мешают.
Решение
Решение очень простое, но довольно важное:
- Repair в кластере нужно делать в любом случае.
Но бывают разные ситуации, когда мы не успеваем сделать repair. Он идет очень долго, потому что это одна из самых тяжелых операций для кластера, которая связана со сравнением данных на узлах.
- Но в любом случае период, через который удаляются Tombstones, должен быть больше, чем интервал repair.
Интервал repair — это то время, за которое удается сделать repair. Например, мы знаем, что мы успеваем для этого кластера провести починку за 10-20 дней, неделю, 3 дня. Но период удаления Tombstone должен быть выше этого значения, которое постигается только из практики. Если мы слишком агрессивно будем репейрить, окажется так, что кластер плохо отвечает на фронтенд-запросы.

Еще одна классическая проблема для Cassandra, на которую часто наталкиваются разработчики. На самом деле с этим сложно бороться.
В S3 есть бакет. Как я сказал, он может быть произвольного размера — 10 ключей, 100 млрд ключей. Один из API, который мы должны поддерживать — это отдать список ключей в бакете. Причем список должен быть отсортирован, отдаваться, само собой, постранично, его можно листать, и он должен быть всегда консистентен с текущими операциями. То есть, если я записал объект, удалил объект, беру список ключей — и он тот же самый, как после моей операции. Я не могу его отложено перестроить.
Как реализовать такой API?

Есть таблица объектов, которую я показывал ранее — бакет, ключ, текущая версия — вроде бы именно та, которая нужна для того, чтобы построить список ключей. Но есть небольшая проблема. Я совершенно правильно выбрал для этой таблицы в качестве первичного ключа пару бакет — ключ. Первичный ключ определяет, где эта строка будет находиться, на каком узле. Это то самое, почему хэшируется объект, когда он будет храниться в Cassandra. Но это одновременно означает, что ключи одного бакета хранятся на разных узлах — вообще говоря, на всех, если их достаточное количество, потому что они все равномерно размазаны.
С точки зрения хранения этой таблицы это классно, потому что у меня бакеты могут быть совершенно разного размера, и я не могу заранее угадать, какой большой, какой маленький. Если бы данные одного бакета хранились бы на одном узле, то возникла бы проблема с масштабированием. Но, с другой стороны, я не могу никаким образом построить список объектов в кластере из такой таблицы. Значит, нужен еще какой-то способ, с помощью которого можно было бы этот самый список объектов получить.
Cassandra говорит, что у нее есть более сложные конструкции. Можно завести еще одну таблицу специально для списка ключей в бакете, в которой будет храниться ровно та информацию, которая нужна, а именно бакет, ключ и минимальное количество метаданных об объекте, чтобы построить ответ на запрос.
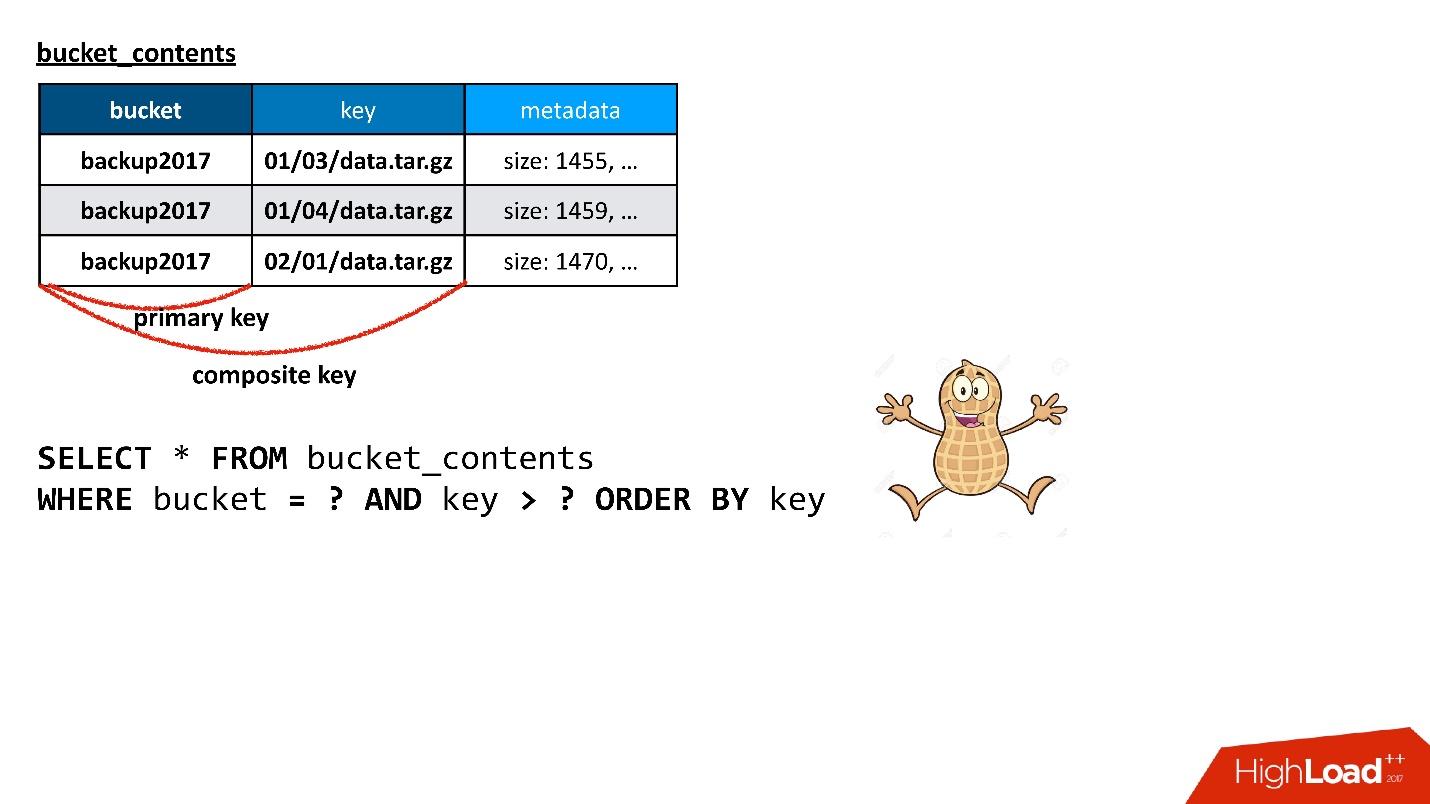
Здесь я использую то, что в Cassandra называется composite key. Если я построю к этой таблице запрос, который мне нужен — выбрать данные из бакета, начиная с какого-то ключа, и чтобы они были отсортированы — запрос работает. Он делает ровно то, что мне нужно. Рад ли я? Да, я конечно рад, у меня все получилось!
Но если вы внимательно читали то, о чем говорилось раньше, то помните, что, если первичный ключ из бакета — это означает, что все данные кладутся на один и тот же узел.
На самом деле проблема хуже. В Cassandra есть некая шизофрения, потому что разные слои Cassandra по сути разговаривают на разных языках. Тот слой, с которым мы сегодня взаимодействуем, чаще всего представляет Cassandra, как нечто отдаленно похожее на реляционную базу данных: с таблицами, с запросами, похожими на SQL и т.д. Вроде бы все хорошо!

Но есть еще внутренний слой данных. Как на самом деле Cassandra его хранит? Исторически он был первичный, и к нему был свой, совершенно другой API. Такая конструкция, которую я описал, внутри на самом деле хранится, как длинная строка, в которой каждый ключ (в данной ситуации ключ в бакете) является отдельной колонкой. Чем больше размер бакета, тем больше колонок в этой таблице.
Когда я делаю запрос, я этого не вижу и никак не могу об этом узнать. Если я попытаюсь залезть на уровень или почитать, как оно устроено, да, я могу это узнать. Это и означает, что ширина такой строки — количество колонок — равно в моей ситуации размеру моего бакета. Это, кстати, хорошо работает, потому что колонки на физическом уровне хранятся отсортированными по имени.
Но в Cassandra есть куча операций, при которых она оперирует целиком значением строки. Даже если я спрашиваю: «Дай мне 100 ключей», а там хранится миллион, в зависимости от версии, для того, чтобы построить ответ на мой вопрос, ей приходится буквально прочитать всю строку в миллион, оттуда выбрать 100, а все остальное выбросить.
Представьте, что эти данные еще распределены по нескольким узлам (это же несколько реплик), и любой запрос — это же на самом деле не запрос к конкретной реплике, а по сути запрос, который пытается построить консистентное представление по нескольким узлам одновременно. Если у меня есть миллион колонок в одном узле, миллион в другом, миллион в третьем, формально для того, чтобы построить ответ на запрос, невозможно сделать что-то простое. Если я прошу дать 100 ключей, которые больше такого-то значения, и все узлы идеально совпадают, это просто. Если же узлы не совсем совпадают, то этот запрос с лимитом с точки зрения SQL становится вовсе не тривиальным.
Cassandra пытается такую широкую строчку протянуть в память, и когда она это делает, а она написана на Java, ей становится очень плохо. Эта конструкция, называемая Large Partition, возникает незаметно. Пока данных немного — десятки, сотни, тысячи, десятки тысяч, даже сотни тысяч ключей — все хорошо. Но потом начинается экспоненциальное падение с точки зрения производительности, узлы начинают падать, garbage collection не справляется и т.д. В результате получается каскадный эффект.
Плюс к тому, широкая строка реплицирована, и падает не только один узел, а сразу много, потому что у них у всех одинаковая проблема.
Конечно, мы сразу знали об этой проблеме и подумали, что надо что-то заранее сделать.

Поэтому в таблице, которая используется для листинга объектов, мы заранее предусмотрели возможность разбросать данные одного бакета по нескольким колонкам. Я их буду называть условно партициями. То есть партиционировать таблицу так, чтобы у нас не было Large Partition.
У нас есть два требования:
- чтобы каждая партиция была ограничена в размере (не больше, чем сколько-то ключей);
- несмотря на то, что мы распределяем данные, мы хотим получить отсортированный список ключей быстро. Это было нашей изначальной задачей, ради этого все и затевалось.
Когда мы запустились, мы так и не придумали, как распределять данные, и в качестве колонки key_hash всегда использовали 0. Как всегда бывает, фичи идут впереди любых улучшений, которые не приносят непосредственного профита с точки зрения продукта. Поэтому мы конечно же пропустили тот момент, когда партиции стали большими. У нас было несколько очень веселых месяцев, когда мы прикручивали решение к системе, которая находилась практически в состоянии агонии.
Давайте обсудим, как это можно было сделать.

Мы сразу подумали — хорошо, у нас есть бакет, у него куча ключей, давайте все ключи прогоним через какую-нибудь хэш-функцию и таким образом распределим по партициям.
Первая проблема — какого размера должно быть это хэширование, какое нам N выбрать? Если выбрать слишком маленькое, будет Large Partition, слишком большое — слишком много партиций будет создано. При этом, мы ничего не знаем о размере бакета заранее. Он может изменяться: расти или уменьшаться. Самое главное, если это просто хэширование, то получается, что свойство отсортированности пропадет, и в каждой партиции будут лежать какие-то случайные ключи. Чтобы получить отсортированный список, надо делать запрос ко всем партициям и объединять результаты от них. Крайне неудобно и неэффективно, особенно, если этих партиций станет много.

Второе достаточно очевидное решение — раз мы хотели, чтобы свойство отсортированности сохранялось, давайте использовать какой-то префикс ключа. Если мы возьмем сколько-то символов слева, и ключи будут хорошо распределены по бакетам, то мы можем распределить бакеты по партициям. Каждая партиция будет префиксом, в каждой будут ключи, причем они будут отсортированы. Если мы знаем, какие ключи нам нужны, мы знаем в какую партицию обратиться и т.д.
Но тут опять возникает та же самая проблема — как угадать, каким образом именуются ключи? Именуем ключи не мы, а наши клиенты. Как они их называют? Кто-то их называет как результат md5-хеширования — это идеально подходит под такую схему, а у кого-то первые 30 символов — это константа у всех ключей, или что-то еще. Мы не можем угадать. Эта схема работала бы хорошо, только если бы мы знали, как выглядит ключ.

В итоге мы пришли к схеме, когда мы динамически угадываем, точнее, анализируем, как распределены ключи. Это распределение со временем может измениться — бакет может расти, может меняться структура ключей. Мы адаптируемся под это, и динамически с помощью таблицы их распределяем. В таблице указано, что ключи с такого-то по такой-то лежат в такой-то партиции, с такого-то по такой-то — в такой. Это условно решение с префиксом, только префикс сложный и динамический. Да и не совсем это префикс.
Динамическое хэшировнаие
Чтобы сделать динамическое хэширование, нам пришлось много повозиться, потому что здесь много интересных, вполне себе научных задач.
- Динамическая таблица распределения.
- Генетический алгоритм для поиска идеального распределения и идеального перераспределения.
- Подсчет размера патриции вне Cassandra.
- Online-перераспределение (без остановки операций и потери консистентности).
Мы имеем какое-то состояние бакета сейчас, он каким-то образом разбит на партиции. Потом мы понимаем, что какие-то партиции слишком большие или слишком маленькие. Нам надо найти новое разбиение, которое, с одной стороны, будет оптимальным, то есть размер каждой партиции будет меньше какого-то нашего предела, и они будут более-менее равномерные. При этом переход от текущего состояния к новому должен требовать минимального количества действий. Понятно, что любой переход требует перемещения ключей между партициями, но чем меньше мы их перемещаем, тем лучше.
У нас это получилось. Наверное, часть, которая занимается подбором распределения, это самый сложный кусок всего сервиса, если говорить о работе с метаданными в целом. Мы его переписывали, переделывали, и делаем до сих пор, потому что всегда обнаруживаются какие-то клиенты или некие паттерны создания ключей, которые бьют в слабое место этой схемы.
Например, мы предполагали, что бакет будет расти более-менее равномерно. То есть мы подобрали какое-то распределение, и надеялись, что все партиции будут расти соответственно этому распределению. Но у нас нашелся клиент, который пишет всегда в конец, в том смысле, что у него ключи всегда в отсортированном порядке. Он все время бьет в самую последнюю партицию, которая растет с такой скоростью, что за минуту это может быть 100 тысяч ключей. А 100 тысяч — это примерно то значение, которое влезает в одну партицию.
Мы просто не успевали бы обрабатывать такой добавление ключей нашим алгоритмом, и нам пришлось для этого клиента ввести специальное предварительное распределение. Так как мы знаем, как выглядят его ключи, если мы видим, что это он, мы просто начинаем ему заранее создавать пустые партиции в конце, чтобы он мог туда спокойно писать, а мы пока немножко бы отдохнули до следующей итерации, когда нам снова придется все перераспределить.
Все это происходит в онлайн в том смысле, что мы не останавливаем операции. Могут быть операции чтения, записи, в любой момент можно запросить список ключей. Он всегда будет консистентный, даже если мы находимся в процессе переразбиения.
Это довольно интересно, и это получается с Cassandra. Здесь можно играть с трюками, связанными с тем, что Cassandra умеет разрешать конфликты. Если мы в одну и ту же строку записали два разных значения, то выигрывает то значение, у которого timestamp больше.
Обычно timestamp — это текущий timestamp, но его можно передать вручную. Например, мы хотим записать в строку значение, которое в любом случае должно быть перетерто, если клиент сам что-то запишет. То есть мы копируем какие-то данные, но хотим, чтобы клиент, если вдруг он одновременно с нами пишет, мог их перезаписать. Тогда мы можем просто копировать наши данные с timestamp‘ом чуть-чуть из прошлого. Тогда любая текущая запись заведомо будет их перетирать, вне зависимости о того, в каком порядке была произведена запись.
Такие трюки позволяют сделать это онлайн.
Решение
- Никогда, никогда не допускайте появления large partition.
- Разбивайте данные по primary key в зависимости от задачи.
Если в схеме данных намечается что-то похожее на large partition, надо сразу попытаться что-то с этим сделать — придумать, как его разбить и как от него уйти. Рано или поздно это возникает, потому что любой инвертированный индекс рано или поздно возникает практически в любой задаче. Я уже рассказывал про такую историю — у нас есть бакет-ключ в объект, и нам нужно получить из бакета список ключей — по сути, это индекс.
Причем партиция может быть большой не только от данных, но еще и от Tombstones (маркеров удаления). Маркеры удаления точно также с точки зрения внутренностей Cassandra (мы их никогда не видим снаружи) являются данными, и партиция может быть большой, если в ней много чего удалено, потому что удаление является записью. Об этом тоже не стоит забывать.

Еще одна история, которая на самом деле постоянная — от начала до конца что-то идет не так. Например, вы видите, что время отклика от Cassandra выросло, она отвечает медленно. Как понять и разобраться, в чем проблема? Никогда не бывает внешнего сигнала, что проблема именно там-то.

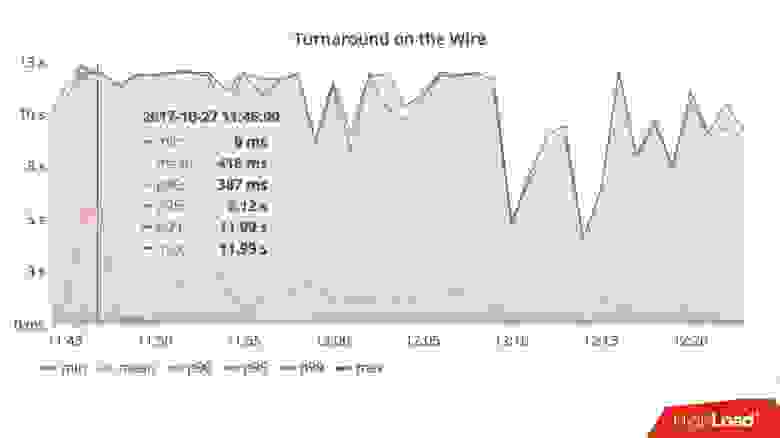
Для примера приведу график — это усредненное время отклика кластера в целом. На нем видно, что у нас проблема — максимальное время отклика уперлось в 12 с — это внутренний таймаут Cassandra. Это означает, что она таймаутится сама. Если таймаут выше 12 с, это скорее всего означает, что работает garbage collector, и Cassandra не успевает даже ответить в нужное время. Она отвечает сама по таймауту, но время отклика на большинство запросов, как я говорил, должно быть в среднем в пределах 10 мс.
На графике среднее превысило уже сотни миллисекунд — что-то пошло не так. Но глядя на эту картинку, невозможно понять, в чем причина.

Но если ту же самую статистику развернуть по узлам Cassandra, то видно, что в принципе все узлы более-менее ничего, но у одного узла время отклика отличается на порядки. Скорее всего, с ним какая-то проблема.
Статистика по узлам изменяет картинку полностью. Эта статистика со стороны приложения. Но и здесь на самом деле очень часто сложно понять, в чем проблема. Когда приложение обращается к Cassandra, оно обращается к какому-то узлу, используя его как координатор. То есть приложение дает запрос, и координатор его перенаправляет к репликам с данными. Те уже отвечают, и координатор формирует конечный ответ обратно.
Но почему координатор отвечает медленно? Может быть, проблема с ним, как с таковым, то есть он тормозит и отвечает медленно? А может быть, он тормозит, потому что ему медленно реплики отвечают? Если реплики отвечают медленно, с точки зрения приложения это будет выглядеть как медленный ответ координатора, хотя он здесь ни при чем.
Здесь счастливая ситуация — видно, что только один узел отвечает медленно, и скорее всего, проблема именно в нем.
Сложность интерпретации
- Время отклика координатора (сам узел vs. реплики).
- Конкретная таблица или весь узел?
- GC Pause? Недостаточный Thread Pool?
- Слишком много uncompacted SSTables?
Всегда сложно понять, что не так. Просто нужно много статистики и мониторинга, как со стороны приложения, так и самой Cassandra, потому что, если ей совсем плохо, со стороны Cassandra ничего не видно. Можно смотреть и на уровне отдельных запросов, на уровне каждой конкретной таблицы, на каждом конкретном узле.
Может быть, например, ситуация, когда у одной таблицы того, что называется в Cassandra SSTables (отдельные файлы) слишком много. Для чтения Cassandra приходится, грубо говоря, перебирать все SSTables. Если их слишком много, то просто процесс этого перебора занимает слишком много времени, и чтение начинает проседать.
Решением является compaction, который уменьшает количество этих SSTables, но надо заметить, что это может быть всего на одном узле для одной конкретной таблицы. Так как Cassandra написана, к сожалению, на Java и работает на JVM, может быть, garbage collector ушел в такую паузу, что просто не успевает ответить. Когда garbage collector уходит в паузу, не только ваши запросы тормозят, но и взаимодействие внутри кластера Cassandra между узлами начинает тормозить. Узлы друг друга начинают считать ушедшими в down, то есть упавшими, мертвыми.
Начинается еще более веселая ситуация, потому что когда узел считает, что другой узел в down, он, во-первых, к нему запросы не направляет, во-вторых, он начинает пытаться сохранять данные, которые ему нужно было бы реплицировать на другой узел у себя локально, таким образом он и себя начинает потихоньку убивать, и т.д.
Бывают ситуации, когда эту проблему можно решить просто с помощью правильных настроек. Например, может быть достаточно ресурсов, все хорошо и замечательно, но просто Thread Pool, число которых фиксированного размера, надо увеличить.
Наконец, может быть, нам надо со стороны драйвера ограничить конкурентность. Иногда бывает, что отправлено слишком много конкурентных запросов, и как любая база данных, Cassandra не может с ними справиться и уходит в клинч, когда время отклика растет экспоненциально, а мы пытаемся еще больше и больше дать работы.
Понимание контекста
Всегда есть какой-то контекст у проблемы — что происходит в кластере, работает ли сейчас Repair, на каком узле, в каком key spaces, в какой таблице.
У нас, например, были достаточно смешные проблемы с железом. Мы видели, что часть узлов работает медленно. Позже обнаружилось, что причина была в том, что в BIOS их процессоры стояли в энергосберегающем режиме. По какой-то причине во время начальной установки железа так получилось, и использовалось примерно 50% ресурсов процессора по сравнению с другими узлами.
Разобраться в такой проблеме может быть тяжело, на самом деле. Симптом такой — вроде бы узел делает compaction, но делает его медленно. Иногда это связано с железом, иногда нет, но это просто очередной баг Cassandra.
Поэтому мониторинг обязателен и его нужно много. Чем сложнее фича в Cassandra, чем дальше она отстоит от простой записи и чтения, тем больше с ней проблем, и тем быстрее она может убить БД при достаточном количестве запросов. Поэтому, если есть возможность, не надо смотреть на какие-то «вкусные» фишки и пытаться их использовать, лучше их избегать насколько это возможно. Не всегда возможно — конечно, рано или поздно приходится.

Последняя история про то, как Cassandra испортила данные. В этой ситуации это произошло внутри Cassandra. Это было интересно.
Мы видели, что примерно раз в неделю у нас в базе данных появляется несколько десятков испорченных строк — они буквально забиты мусором. Причем Cassandra валидирует данные, которые поступают к ней на вход. Например, если это строка, то она должна быть в utf8. Но в этих строках находился мусор, не utf8, и Cassandra с ним даже ничего делать не давала. При попытке удалить (или что-то еще сделать), я не могу удалить значение, которое не является utf8, потому что, в частности, не могу никак вписать в WHERE, потому что ключ должен быть utf8.
Испорченные строки появляются, как вспышка, в какой-то момент, и дальше их нет опять в течение нескольких дней или недель.
Мы начали искать проблему. Мы думали, может быть проблема в определенном узле, с которым мы возились, делали что-то с данными, SSTables копировали. Может быть, все-таки у этих данных можно посмотреть их реплики? Может быть, у этих реплик есть общий узел, наименьший общий делитель? Может быть, какой-то узел дает сбой? Нет, ничего подобного.
Может быть, что-то с диском? На диске данные испортились? Опять нет.
Может быть, память? Нет! Разбросано по кластеру.
Может быть, это какая-то проблема репликации? Один узел все попортил и дальше реплицировал плохое значение? — Нет.
Наконец, может быть, это проблема приложения?
Причем в какой-то момент испорченные строки стали появляться в двух кластерах Cassandra. Один работал на версии 2.1, второй на третьей. Вроде и Cassandra разные, а проблема одна и та же. Может, у нас сервис отправляет плохие данные? Но верилось в это с трудом. Cassandra валидирует данные на входе, она не могла записать мусор. Но вдруг?
Ничего не подходит.
Иголка нашлась!
Мы бились долго и упорно, пока не обнаружили маленькую проблему: почему у нас на узлах есть какие-то crash dump от JVM, на которые мы особо внимания не обращали? И как-то подозрительно выглядит в stack trace garbage collector… И почему-то некоторые stack trace тоже мусором забиты.
В итоге мы поняли — о, мы почему-то используем JVM старой версии 2015 года. Это было единственным общим, что объединяло кластеры Cassandra на разных версиях Cassandra.
Я до сих пор не знаю, в чем была проблема, потому что в официальных релиз-ноутах JVM про это ничего не написано. Но после обновления все исчезло, проблема больше не возникала. Причем она возникала в кластере не с первого дня, а с какого-то момента, хотя он работал на том же самом JVM довольно долго.
Восстановление данных
Какой урок мы вынесли из этого:
● Backup бесполезен.
Данные, как мы выяснили, портились в ту же секунду, когда они были записаны. В момент, когда данные входили в координатор, они уже были испорчены.
● Возможно частичное восстановление неповрежденных колонок.
Какие-то колонки были не повреждены, мы могли эти данные прочитать, частично восстановить.
● В конечном итоге нам приходилось делать восстановление из разных источников.
У нас был backup метаданных в объекте, но в самих данных. Чтобы восстановить связь с объектом, мы использовали логи и т.д.
● Логи — это бесценно!
Мы смогли восстановить все данные, которые были испорчены, но в конечном итоге очень тяжело доверять базе данных, если она ваши данные теряет даже без какого-то действия с вашей стороны.
Решение
- Обновляйте JVM после длительного тестирования.
- Мониторинг JVM crash.
- Имейте независимую от Cassandra копию данных.
В качестве совета: Старайтесь иметь какую-то независимую от Cassandra копию данных, из которой вы можете восстановиться, если это необходимо. Это может быть решением последнего уровня. Пусть на это потребуется куча времени, ресурсов, но чтобы был какой-то вариант, который позволит вам вернуть данные.
Баги
● Низкое качество тестирования релизов
Когда вы начинаете работать с Cassandra, возникает постоянное ощущение (особенно, если вы переходите, условно говоря, с «хороших» баз данных, например, с PostgreSQL), что если в релизе исправили баг предыдущего, то обязательно добавили новый. Причем баг — это не какая-нибудь ерунда, это обычно испорченные данные или другое некорректное поведение.
● Постоянные проблемы со сложными фичами
Чем сложнее фича, тем больше с ней проблем, багов и т.д.
● Не используйте инкрементальный repair в 2.1
Знаменитый repair, о котором я рассказывал, который чинит консистентность данных, в стандартном режиме, когда он опрашивает все узлы, работает хорошо. Но не в так называемом инкрементальном режиме (когда repair пропускает данные, которые не изменились со времени предыдущего repair, что вполне логично). Он был заявлен давно, формально, как фича существует, но все говорят: «Нет, в версии 2.1 не используйте его никогда! Он обязательно что-нибудь пропустит. В 3 мы исправим»
● Но не используйте инкрементальный repair и в 3.x
Когда вышла третья версия, через несколько дней они сказали: «Нет, в 3-й использовать его нельзя. Есть список из 15 багов, поэтому ни в коем случае не используйте инкрементальный repair. В 4-й мы сделаем лучше!»
Я им не верю. А это большая проблема, особенно с ростом размера кластера. Поэтому нужно следить постоянно за их bugtracker и смотреть, что происходит. Без этого с ними, к сожалению, жить невозможно.
● Надо следить за JIRA

Если разбросать все базы данных по спектру предсказуемости, для меня Cassandra находится слева в красной области. Это не значит, что она плохая, просто надо быть готовым к тому, что Cassandra непредсказуема в любом смысле этого слова: и в том, как она работает, и в том, что что-то может случиться.

Я вам желаю найти другие грабли и на них наступать, потому что, с моей точки зрения, несмотря ни на что, Сassandra — это хорошо и, несомненно, нескучно. Только помните о кочках на дороге!
Открытая встреча активистов HighLoad++
31 июля в Москве, в 19:00 состоится встреча докладчиков, Программного комитета и активистов конференции разработчиков высоконагруженных систем HighLoad++ 2018. Организуем небольшой мозговой штурм по поводу программы этого года, чтобы не упустить ничего нового и важного. Встреча открытая, но нужно зарегистрироваться.
Call for Papers
Активно идет прием заявок на доклады на Highload++ 2018. Программный комитет ждет ваши тезисы до конца лета.
