Давайте посмотрим на библиотеки не с той стороны, которая нам привычнее всего, то есть пользовательской, а с точки зрения разработчика библиотеки мобильной разработки. Поговорим, каких подходов стоит придерживаться, разрабатывая свою библиотеку. Начнем, конечно, с проектирования такого API, которым вы сами хотели бы пользоваться, который был бы удобен. Подумаем, что нужно учесть, чтобы сделать не просто работающий код, а по-настоящему хорошую библиотеку, и дойдем до того, как выпускать настоящий взрослый публичный релиз. Поможет нам в этом Ася Свириденко, которая поделится своим немалым опытом разработки мобильной библиотеки SpeechKit в Яндексе.
Материал будет полезен не только тем, кто занимается разработкой библиотеки или фреймворка, но еще и тем, кто хочет выделить часть из своего приложения в отдельный модуль, а потом его переиспользовать, или, например, поделиться своим кодом с остальным сообществом разработчиков, выложив его в публичный доступ.
Для всех остальных рассказ будет наполнен неподдельными историями из жизни команды мобильного SpeechKit, так что должно быть весело.
Содержание
Не буду спрашивать, слышали ли вы про SpeechKit, потому что даже внутри Яндекса не все знают, что это такое.
SpeechKit — это дверь во все речевые технологии Яндекса. С помощью этой библиотеки можно интегрировать в свое приложение речевые технологии: распознавание и синтез речи, голосовую активацию.
Вы наверняка слышали про голосового ассистента Алису — она как раз работает на базе SpeechKit. Сам SpeechKit не включает в себя распознавание или синтез, это происходит на сервере. Но именно через нашу библиотеку всё можно интегрировать в приложение.
Следом обычно идет вопрос — если все на сервере происходит, что делает библиотека? Зачем она нужна?
Библиотека делает очень многое:
SpeechKit используется во внутренних командах. Сейчас его интегрировали 16 команд Яндекса. И нам даже известно о нескольких внешних командах, которые тоже это сделали.
Давайте задумаемся, что мы подразумеваем под удобным приложением. Обычно, это продуманный и понятный UX, решение наших задач, стабильная работа и пр.
Когда мы говорим, что библиотека удобная, в первую очередь мы подразумеваем, что у нее такой API, которым понятно пользоваться. Как этого достичь?
Базовые принципы
Это некоторые аспекты, которые я извлекла из своего опыта работы над SpeechKit.
С одной стороны, это хорошо, потому что обычным пользователям вы не объясните: «Понимаете, у нас бэкенд лежит, и поэтому ничего не работает, а так мы в порядке!» Вы можете объяснить это разработчикам — вы многое можете объяснить разработчикам!
С другой стороны, вы получаете таких пользователей, которые обязательно воспользуются возможностью найти дыру и что-то сломать, если вы её оставите. Мы все с вами используем библиотеки и пытаемся выжать из них по максимуму. Они заявляют, что делают только это, это и это, а мы думаем: «Нет, сейчас мы тут немножко подшаманим, это передадим, и все будет, как надо».
Помимо этого, то, что пользователи — разработчики, означает, что у вас всегда будет гора советов и рекомендаций, как вам разрабатывать, и как сделать так, чтобы все было лучше.
Второй важный момент полностью соотносится с первым.
Если ваши пользователи начинают делать с библиотекой что-то, чего вы не предполагали — это прямой путь к багам, причем к тем, которые тяжело отлаживать. Постарайтесь использовать все, что дает язык и та технология, которую вы используете: public/private, final, deprecated, readonly. Уменьшайте области видимости, запрещайте наследование и использование каких-то методов, помечайте свойства, которые нельзя менять — предусмотрите все, что можно, чтобы не дать сделать то, на что ваша библиотека просто не рассчитана.
Если этот конкретный класс может быть создан единственным способом — запретите все остальные. Если это свойство не может быть null — укажите это явно. В iOS есть nullable/nonnull, designated initializer, то же самое есть в Java и Android. Используйте все это, для того чтобы пользователь открыл файл, открыл ваш класс, пробежался по нему глазами и сразу понял, что можно сделать, а что никак нельзя.
Кейс SpeechKit API
На примере SpeechKit расскажу, как мы делали рефакторинг версии 2 в версию 3. Мы сильно изменили API и постарались использовать все эти принципы.
Необходимость возникла из-за того, что API был сложный и «теоретический». В нем были глобальные компоненты, которые надо было сперва вызвать — не вызвал — все не работает. Очень странно задавались настройки. API был достаточно «теоретический», потому что SpeechKit изначально был частью Навигатора, а потом этот кусочек и вынесли в библиотеку. API по сути работал с кейсами, использующимися в Навигаторе.
Постепенно количество пользователей росло, и мы начали понимать, что им действительно нужно: какие методы, коллбэки, параметры. К нам приходили с запросами, которые API не позволял реализовать. Это повторялось раз за разом, и стало понятно, что API не выдерживает. Так мы ввязались в рефакторинг.
Процесс рефакторинга был долгий (полгода) и мучительный (все были недовольны). Основная сложность была не в том, чтобы взять гору кода и переписать. Нельзя было просто уйти на рефакторинг, а надо было поддерживать все активные версии, которые были в использовании. Мы не могли просто сказать своим пользователям: «Ребята, да, у вас не работает, да, вам нужна эта фича — мы все сделаем в версии 3, подождите, пожалуйста, полгода!»
В итоге рефакторинг занял много времени, и процесс был мучительный, причем для пользователей тоже. Потому что в итоге мы поменяли API без обратной совместимости. Пришли к ним и сказали: «Вот новый прекрасный SpeechKit, пожалуйста, возьмите его!» — в ответ услышали: «Нет, у нас не запланирован переход на вашу версию 3.0 вообще». Например, у нас была команда, которая переходила на эту версию в течение года. Поэтому целый год мы поддерживали для них предыдущую версию.
Но результат того стоил. Мы получили простую интеграцию и меньше багов. Это то, о чем я упомянула, в базовых принципах проектирования API. Если вы уверены, что ваш API используется правильно, в этой части точно нет никаких проблем: все классы вызываются правильно, все параметры правильные. Найти баги гораздо легче, меньше кейсов, где что-то может пойти не так.
Ниже пример, как выглядел основной класс, который занимается распознаванием, до рефакторинга.
Это обычный класс, который наследуется от NSObject. Рассмотрим отдельно каждую его деталь. Понятно, что мы можем от него отнаследоваться, переопределить в нем какие-то методы — все, что можно делать с NSObject.
Дальше при создании ему передаются две строки (language и model). Что это за строки? Если передать в language «Hello, world», то на выходе будет перевод, или что? Не очень понятно.
Помимо этого, так как это наследник NSObject, мы можем вызвать у него init, new и т.д. А что будет? Он заработает, или будет ждать каких-то параметров?
Конечно, я знаю ответы на эти вопросы, я знаю этот код. Но люди, которые на это смотрят впервые, совершенно не понимают, к чему это все. Даже методы с setter и getter совершенно не выглядят так, как это могло бы выглядеть в iOS. Методы start, cancel, cancelSync (а тот, который просто cancel — он aSync?) — что будет, если их вызвать вместе? Очень много вопросов к этому коду.
Дальше идет объект, про который я говорила (YSKInitializer), который обязательно надо стартовать, чтобы все заработало — это вообще какая-то магия. Видно, что этот код писали разработчики, которые не пишут под iOS, а занимаются C++.
Дальше настройки для этого рекогнайзера задавались через глобальные компоненты, которые передавались в другой глобальный объект, и по сути нельзя было создать два разных рекогнайзера с разным наборов параметров. А это был, наверное, один из самых востребованных кейсов, который не поддерживал API.
Чем v3 лучше v2
Что мы получили, когда сделали рефакторинг и перешли на версию 3?
Теперь у нас API под iOS выглядел как iOS-API, API под Android — как Android.
Например, классы под Android создаются с помощью билдеров, потому что это очень понятный для Android-разработчиков паттерн. В iOS это не так популярно, поэтому используется другой подход: создаем объекты со специальным классом настроек.
Помню, как мы долго спорили на эту тему. Нам казалось важным, чтобы разработчик взял наш код на iOS или Android, и совпадение было бы 99%. Но это не так. Пусть лучше код будет похож на ту платформу, для которой он разрабатывается.
Нужен этот объект — вот его настройки, создаешь их, передаешь — профит! То есть нет каких-то скрытых глобальных настроек, которые надо куда-то передавать.
Мы выкинули глобальные компоненты, которые всех путали, пугали и вызывали много вопросов даже у самих разработчиков этой библиотеки, не только у пользователей.
Теперь тот же самый класс в новой версии выглядит так (это все еще Objective-C — на Swift нельзя тогда было перейти).
Это наследник NSObject, но теперь мы явно говорим о том, что от него нельзя наследоваться. Все методы, которые характерны для этого объекта, перенесены в специальный протокол. Он создается с помощью настроек и audioSource. Теперь все настройки инкапсулированы в один объект, который передается конкретно сюда, чтобы задать настройки для конкретного рекогнайзера.
Более того, мы вынесли отсюда работу с аудио, то есть рекогнайзер теперь — это не та компонента, которая пишет аудио. Эта компонента занимается вопросами распознавания, а передать сюда можно любой источник.
Другие методы создания через new или через init запрещены, потому что этому классу нужны настройки по умолчанию. Будьте добры, если вы хотите его использовать, создайте хотя бы какие-то настройки по умолчанию.
Главное, что те настройки, которые сюда передаются, иммутабельны, то есть вы не можете поменять их в процессе работы. Не надо пытаться, когда что-то распознается, подменить модель или язык. Соответственно, мы не даем пользователям возможность изменить объект с настройками, который уже передан.
Макросы NS_ASSUME_NONNULL_BEGIN/NS_ASSUME_NONNULL_END для того, чтобы подчеркнуть, что эти настройки не могут быть null: audioSource не может быть null — это все должно иметь какое-то определенное значение, чтобы работать.
Как я говорила, методы start и cancel (cancelSync ушел) переехали в отдельный протокол. В библиотеке есть места, в которых можно использовать не наш рекогнайзер, а любой другой. Например, мы используем нативный от Apple, который реализует этот протокол и в который может передать наши компоненты.
Настройки здесь NSCopying для того, чтобы мы могли их копировать, и их нельзя было поменять в процессе работы. В init обязательные параметры язык, модель и NS_DESIGNATED_INITIALIZER. Здесь не показана часть кода, которая идентична deprecate методов, но идея ясна. Это обязательные параметры, с которыми создаются настройки. Они должны быть, и должны быть ненулевые.
Весь остальной набор — это порядка 20 настроек рекогнайзера задаются здесь же. Даже настройки языка или модели — это тоже отдельные классы, которые не позволяют передать что-то абстрактное, с чем мы не умеем работать. То есть мы явно говорим: «Пожалуйста, не давайте нам то, с чем мы не умеем работать. Компилятор вам не даст это сделать».
Итак, мы поговорили про то, что можно сделать с API. В разработке тоже есть свои нюансы.
В первую очередь библиотека должна делать то, ради чего вы ее писали, — хорошо выполнять свою функциональность. Но вы можете сделать свой код по-настоящему хорошей библиотекой. Предлагаю несколько ремарок, которые были собраны мной в процессе разработки SpeechKit.
Код не только для себя
Собирать Debug информацию абсолютно точно нужно, потому что вы не хотите, чтобы пользователи сказали, что их сервис не работает из-за вашей библиотеки.
В iOS есть debug information level, который показывает, какую информацию надо собирать. По умолчанию он будет собирать абсолютно все, что может найти: все вызовы, все значения. Это здорово, но это очень большой объем данных. Настройка -gline-tables-only позволяет собирать информацию именно о вызовах функций. Этого более, чем достаточно, для того чтобы найти проблему и исправить ее.
Включается это в настройках Xcode (Build Settings), так и называется debug information level. К примеру, мы, включив эту настройку, уменьшили размер бинарного файла SpeechKit с 600 Мбайт до 90 Мбайт. Это не очень нужная информация и мы ее просто выкинули.
Вторая важная вещь — скрывайте приватные символы. Все вы знаете, что каждый раз, выкладывая библиотеку в iTunes, вы рискуете получить новое предупреждение, что вы что-то используете не так, что-то не добавляете. Поэтому, если вы используете библиотеки, которые Apple считает приватными, не забудьте их скрыть. Для вас это ничего не значит, вы также можете с ними работать, но как только ваши пользователи попробуют залить приложение с вашей библиотекой в iTunes, они получат ошибку. Не каждый попросит вас это исправить, большинство просто откажется от использования вашего решения.
Не допускайте конфликтов символов: добавляйте префиксы ко всему, что у вас есть, к своим классам, к категориям. Если в библиотеке есть категория UIColor+HEX, будьте уверены, что у ваших пользователей есть ровно такая же категория, и когда они интегрируют вашу библиотеку, они получат конфликты символов. И опять, не все захотят рассказать вам и сказать об этом.
Другой вопрос, когда вы сами используете сторонние библиотеки в своей библиотеке. Тут есть пара нюансов, о которых стоит помнить. Во-первых, если вы используете что-то, что появилось в версии старше, чем ваша библиотека, не забудьте использовать Weak Linking (включается Xcode -> Build Phases -> Link Binary With Libraries -> Status). Это позволяет не падать, если вдруг этой библиотеки нет.
В документации Apple подробно описано, как это работает. Но weak linking не значит, что библиотека не загрузится, если она не используется. То есть если вашим пользователям важно время старта приложения, и, возможно, не нужна та часть вашей библиотеки, которая использует стороннюю библиотеку и занимает время на старте, weak linking вам не поможет. С ним библиотека все равно загружается, используется она или нет.
Если вы хотите загружать в runtime, это поможет избавиться от проблемы линковки на старте, то надо использовать dlopen и динамическую загрузку. Это требует достаточно много возни, и нужно сначала понять, имеет ли это смысл. У Facebook выложен достаточно интересный код примера того, как они динамически линковали.
Последнее — старайтесь не использовать внутри глобальные сущности. В каждой платформе есть какие-то глобальные компоненты. Их желательно не тянуть в свою библиотеку. Это кажется очевидным, потому что это глобальный объект, и пользователи вашей библиотеки могут взять его и настроить так, как им хочется. Вы используете его у себя в библиотеке, вам надо как-то сохранить его состояние, перенастроить, потом восстановить состояние. Тут много нюансов, и есть где ошибиться. Помните об этом и старайтесь избегать.
У нас, например, в SpeechKit до третьей версии внутри библиотеки шла работа с аудио, и мы явно настраивали и активировали аудио-сессию. Аудио-сессия в iOS — это такая штука, которая есть у каждого приложения, — не говорите, что у вас его нет. Она создается на старте, отвечает за взаимодействие приложения и системного медиа-демона и говорит, что ваше приложение хочет делать с аудио. Это объект singleton в прямом смысле этого слова. Мы спокойно его брали, настраивали, как нам надо, но это приводило к тому, что у пользователей были мелкие проблемы вроде изменения громкости звука. Еще метод аудио-сессий, который отвечает за установку настроек, достаточно долгий. Он занимает порядка 200 мс, и это заметное подтормаживание на активации или деактивации.
В третьей версии я радостно вынесла аудио-сессию из библиотеки. После этого практически все пользователи всех сервисов, у которых был интегрирован SpeechKit, сказали, как они страшно недовольны. Теперь должны знать, что есть какая-то аудио-сессия, которую надо специальным образом настроить для нашего SpeechKit.
Делаем пользователям удобно
Как еще можно помочь вашим пользователям?
Самый простой способ — это подкладывание файла, на наличие которого запускается мега debug-режим. Это действительно помогает сделать отладку в ситуации, когда у ваших пользователей есть пользователи, у которых происходит ошибка, и вам надо понять, что же именно произошло.
Помните о том, что когда вы говорите о поддержке версий в библиотеке — это не то же самое, что поддержка версий в обычном приложении. В обычном приложении мы смотрим статистику, что, например, всего 2% наших пользователей используют iOS 8, и значит можно перестать поддерживать iOS 8. В библиотеке не так, здесь отказ от версии ОС означает полностью отказ от вашего пользователя и всех его пользователей. Это может быть половина ваших пользователей в принципе.
Поэтому вам надо мониторить, какие версии используют те приложения, которые используют вашу библиотеку, и на основании этого уже делать вывод, поддерживаете вы что-то или нет. Мы очень долго не отказывались от iOS 7. Мне кажется, уже были люди, которые отказались от iOS 8 и были готовы отказаться от iOS 9. Мы все еще поддерживали iOS 7, потому что у нас был браузер, который до последнего держал всех пользователей, а мы с ним тесно работали и не могли его бросить в такой ситуации.
Опять-таки ваши пользователи не скажут: «Давайте мы выключим эту функциональность на той версии, которая её не поддерживает», — нет, они просто уберут вашу библиотеку и найдут ту, которая поддерживает весь ряд версий.
Это очень «не очень» для разработчиков библиотеки. В релиз хочется выпустить все, что готово. Ты сделал фичи, пофиксил баги — сейчас всю пачку положим и выкатим в релиз. Релиз — тоже процесс. Для ваших пользователей это не так. Когда они находятся в процессе тестирования своего продукта и готовятся его к выпуску, они не хотят получить от вас сборку с новыми фичами, которые нужно дополнительно тестировать.
У нас действительно были случаи, когда мы откатывали какие-то релизы, делили их на части и выкатывали уже кусочками. Тогда те команды, для которых мы реализовывали изменения, могли взять именно ту версию, в которой есть маленькие изменения, а не все сразу.
Тестов много не бывает
Это верно и для обычного приложения, и для библиотеки. Но в случае опять библиотеки есть особенности.

Автотесты, конечно, нужны, но помимо них здорово иметь тестовое приложение для вашей библиотеки. Оно поможет вам самостоятельно интегрировать то, что вы написали, и понять, какие проблемы или подводные камни могут возникнуть. Вы сможете ощутить на себе, каково же вашим пользователям.
Если ваша библиотека хоть как-то взаимодействует с сетью, включает шифрование, есть хоть что-то, что связано с данными и с безопасностью, отдайте ее на проверку безопасникам. Вы абсолютно точно не хотите быть той библиотекой, в которой найдут уязвимость, — это клеймо на всю жизнь. Практически во всех крупных компаниях есть целый отдел, который занимается проверкой продуктов на безопасность — отдайте им. Если у вас такого нет, есть внешний аудит. Если вы не можете себе позволить внешний найдите тесты в сети, прогоните их, убедитесь, что ваша библиотека не допускает утечек пользовательских данных.
Последнее, что очень важно в тестах — с самого начала постарайтесь добавлять замеры всего, чего только можно: времени, энергопотребления, всего, что характерно для вашей конкретной библиотеки. Вам все равно в итоге придется это сделать, так почему бы не подумать о замерах с самого начала.
Это не оградит от изменений и от необходимости ускорять библиотеку, но поможет разобраться, что же пошло не так. Если у вас есть графики, это поможет в режиме реального времени мониторить, какая же функциональность добавила задержки по времени или увеличила энергопотребление.
На это практически никогда нет времени, потому что это не функциональность библиотеки, это не то, ради чего вы ее разрабатываете. Но это то, что поможет вам поддерживать ее в надлежащем состоянии и в хорошем качестве.
Здесь можно почитать, как мы в Яндексе измеряем энергопотребление мобильных устройств. Про замеры времени была забавная история. Нам, как разработчикам библиотеки, сложно измерять поведение в конкретных кейсах, потому что не все сценарии SpeechKit используются всеми командами. Чтобы засечь время, мы использовали наше тестовое приложение. Были написаны специальные кейсы использования, например, рекогнайзера или компоненты для синтеза речи, каждый шаг записывались и сохранялись логи, а в итоге строились классные графики.
Все было бы ничего, но мы работаем с аудио, и чтобы все проверить, в определенных случаях действительно проигрывается звуковая дорожка. Причем, надо же сделать очень много замеров, поэтому тест оставили на ночь: поставили колонки, положили рядом какой-то девайс, и запустили аудиофайлы. Утром все оказалось выключено, на следующую ночь это повторилось, и потом снова. Дело было вовсе не в каких-то волшебных существах, которые ходили по офису, — просто уборщицы пугались. Там действительно был очень странный текст, который читался с интервалами.
В итоге было решено сделать локальный тестовый стенд, который мы назвали Шкафом. Это натуральный шкаф, только звукоизолированный. В нем лежит много устройств, целая ферма с устройствами, каждый из которых можно много раз запускать в течение рабочего дня, потому что это никому не помешает.
Наконец мы подошли последней важной части — это запуск. Код написан, спроектирован хороший API, чтобы пользователям было удобно. Как же теперь это все выпустить в релиз.
Начну с локальных релизов для пользователей внутри Яндекса. Схема тут такая же, как и в разработке обычного приложения: регулярные, ежемесячные или еженедельные релизы.
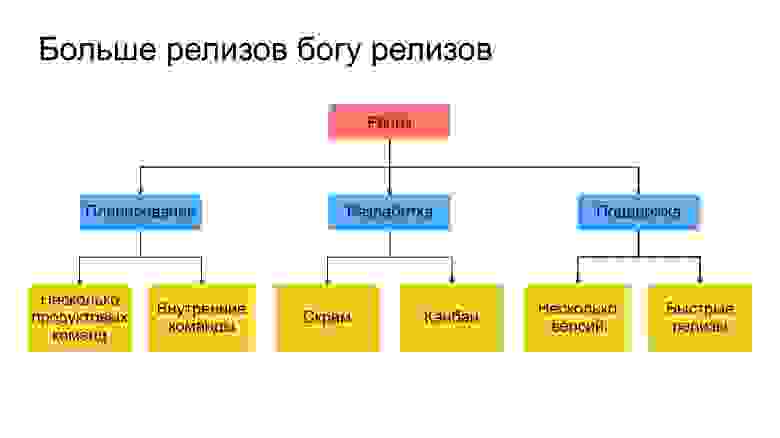
Процесс состоит из привычных стадий, но при разработке библиотеки в каждом из этих пунктов есть свои особенности.
Планирование
Для меня это самая болезненная часть, потому что у библиотеки несколько продуктовых команд. В обычном приложении один менеджер продукта, который ставит задачи, которые команда приоритезирует и по одной начинает делать.
Если продуктовых команд несколько, то от каждой из них поступают запросы, которые надо обрабатывать в режиме реального времени. Дам совет: если есть человек, который умеет разбираться с множеством, поступающих в один момент, задач, постарайтесь забрать его в свою команду. Потому что должен быть кто-то между всеми внешними менеджерами и разработкой — тот, кто возьмет на себя функциональность по приоритезации задач.
Вторая важная особенность особенно характерная для SpeechKit возникает, когда в реализации задачи задействованы другие внутренние команды, например, бэкенд. Нужно учитывать, что может возникнуть задержка, что что-то будет не готово вовремя или готово не совсем так. И именно вы должны предупредить об пользователей, потому что именно вы как библиотека — вход в технологии. Пользователям не нужно знать, что за вашей спиной еще n команд. Они не будут говорить с ними о сроках, они говорят об этом разработчикам библиотеки. Это вы знаете про сроки и про важность продуктовых фичей, это вам нужно донести внутренним командам и заказчикам функциональности, что могут возникнуть какие-то накладки по времени.
Разработка
Разработка, как в любом приложении, начинается обычно как в стартапе: просто работаем днями, ночами, нам не важны все эти процессы. Потом вспоминаются слова об Agile-методологии и начинается построение процессов работы команды.
После того, как мы поработали как стартап, мы поняли, что есть проблема — непредсказуемость. Никто не мог сказать, какие именно фичи и когда будут запущены. А это было очень важно!
Тогда мы решили попробовать Scrum. Он действительно помог, мы стали планировать некоторое множество задач, реализовывать их, выпускать в релиз. То есть мы вроде как справились с задачей сделать релизы предсказуемыми. Я говорю «вроде как», потому что не надо забывать о проблеме нескольких продуктовых команд.
Scrum продержался недолго, потому что мы планировали, развивали задачи, спринт — вы знаете все эти слова — но во время спринта прилетали продуктовые задачи, баги. Мы пытались с этим работать. У нас даже было правило — не брать в спринт никаких задач, если это не баг в продакшене у какой-то команды. Угадайте, сколько раз это правило сработало? Примерно ноль, потому что нельзя сказать другой команде: «Да, у вас регресс и вы нашли у нас баг, но мы исправим его, когда вы уже будете в паблике с этим багом». Так нельзя, и нам приходилось брать это в работу, и брать какие-то фичи, которые в этот момент были высокоприоритетные, и Scrum ломался полностью. Процесс был просто ужасающий! Бывало, что весь скоуп перекраивался к середине спринта.
Сейчас мы перешли на некое подобие Канбана. Есть доска с задачами, которые выставлены в порядке приоритета, и мы просто берем верхние задачи. С одной стороны, мы потеряли в предсказуемости нашего релиза. Мы теперь не можем сказать, использующим нашу библиотеку командам, что, если задача попала на доску, то она точно будет в следующем релизе. Но зато мы можем точно сказать, что в релиз попадут самые важные задачи. Сейчас это для нас приоритетнее.
Поддержка
Стоит помнить, что когда вы выпускаете релиз — это не просто одна версия, которую вы отправили и которую кто-то взял в использование. Возможно, те изменения, которые вы сделали в этом релизе, нужны еще и в других версиях, которые используются другими командами. Это то, что я говорила про минимальную инкрементацию версий. Вы не можете сказать своим пользователям: «Мы исправили ошибку в версии 4, а у вас версия 3 — просто переходите на четвертую». Можно иногда и так сделать, но лучше этим не злоупотреблять. Если в релизе какие-то баги или мелкие дополнения, посмотрите, у кого какие версии, и выпустите фиксы на все версии, которые сейчас используются.
Отсюда следует следующий пункт — все ваши релизы должны быть быстрые. Настройте Continuous Integration так, чтобы можно было действительно нажимать одну большую красную кнопку и отправлять на те версии, на которые надо, потому что релизов будет много.
Приоритезируй это
Немножко про то, как мы решали проблему с приоритезацией задач. Выделю два типа задач.
1. Продуктовые задачи.
Здесь все ясно — в первую очередь нужно смотреть на важность для компании. Если бы к нам как-то пришел Аркадий и попросил заняться киллер-фичей для Яндекса, мы бы, конечно, все оставили и делали бы её. Хотя он никогда так не делал.
Время релиза других команд важный параметр для приоритета продуктовых задач. Если одна фича понадобится через месяц, а другая — через неделю, то, кажется, очевидно, что делать. Но не забывайте предупредить команду, которая ждет первую фичу, что начали делать что-то более приоритетное.
2. Хотелки пользователей.
Немного сложнее обстоит дело с хотелками пользователей, потому что, как я говорила, ваши пользователи — разработчики, они хотят сделать вашу библиотеку лучше, они знают, как ее сделать лучше, они лучше вас знают, как сделать ее лучше!
Мы поступали следующим образом. Сначала смотрели, насколько полезно другим командам. То есть если это полезно не только тому, кто предлагает, но и еще кому-то, то мы за это беремся.
Другой очень важный и самый холиварный вопрос — сохраняется ли консистентность библиотеки. Что только не пытались втянуть в SpeechKit за это время. Мы оборонялись, как могли, потому что мы — библиотека, которая делает что-то конкретное. Не надо пытаться сделать все — помните об этом, даже если кому-то одному это сделает жизнь легче.
Дальше смотрим, насколько это упростит жизнь пользователю. Если работа приведет к тому, что пользователь вместо 4 строчек кода вызывает 2, кажется, что это не совсем правильный подход к приоритезации. Если же огромное полотно кода заменится на один вызов, или станет возможно делать что-то, что до этого было нельзя сделать, то берем это на доску.
Последнее — как долго это реализовывать. Когда фича интересная, хотелка классная, но делать ее месяц, то нужно тщательно все взвесить.
Документация. Это. Серьёзно
Особенно для библиотеки, потому что ей пользуется кто-то, кто не писал этот код. Поэтому обязательно добавляйте документацию в коде. Она должна быть написана в файлах, чтобы люди могли открыть, почитать, посмотреть help и увидеть, как это все использовать.

Добавляйте быстрый запуск. Мы все ищем библиотеки так: находим что-то, берем кусочек кода из GitHub, вставляем его к себе, запускаем. Работает — ура, не работает — ищем дальше. Наличие быстрого запуска в документации поможет быть ближе к пользователям, вашу библиотеку будет проще интегрировать и понять, что она может.
После этого приводите примеры использования, чтобы можно было понять, как сделать что-то более хитрое и сложное с вашей библиотекой, понять как настраивать параметры, вызовы и т.д.
Публичный релиз
Последнее важное, о чем не стоит забывать, когда выпускаете публичный релиз:
Итоги
Yandex.SpeachKit на GitHub под iOS, под Android, и документация Mobile SDK.
Материал будет полезен не только тем, кто занимается разработкой библиотеки или фреймворка, но еще и тем, кто хочет выделить часть из своего приложения в отдельный модуль, а потом его переиспользовать, или, например, поделиться своим кодом с остальным сообществом разработчиков, выложив его в публичный доступ.
Для всех остальных рассказ будет наполнен неподдельными историями из жизни команды мобильного SpeechKit, так что должно быть весело.
Содержание
- Минутка SpeechKit.
- Проектирование удобного, понятного API, которым хочется пользоваться.
- Разработка. Что добавить в код, чтобы он не просто работал и выполнял функциональность, но и помогал вашим пользователям.
- Запуск — о чем надо не забыть, когда катишь релиз.
Минутка SpeechKit
Не буду спрашивать, слышали ли вы про SpeechKit, потому что даже внутри Яндекса не все знают, что это такое.
SpeechKit — это дверь во все речевые технологии Яндекса. С помощью этой библиотеки можно интегрировать в свое приложение речевые технологии: распознавание и синтез речи, голосовую активацию.
Вы наверняка слышали про голосового ассистента Алису — она как раз работает на базе SpeechKit. Сам SpeechKit не включает в себя распознавание или синтез, это происходит на сервере. Но именно через нашу библиотеку всё можно интегрировать в приложение.
Следом обычно идет вопрос — если все на сервере происходит, что делает библиотека? Зачем она нужна?
Библиотека делает очень многое:
- Синхронизация всех процессов. Например, используя голосовой ассистент, пользователь нажимает на кнопку, что-то говорит, прерывает ассистента, делает запросы — это все идет через библиотеку. Для пользователя нашей библиотеки это прозрачно, они не должны обо всем этом переживать.
- Сетевое взаимодействие. Так как все происходит на сервере, то нужно получать оттуда данные, обрабатывать их, отдавать пользователю. Сейчас SpeechKit умеет в рамках одного сетевого соединения ходить в несколько разных серверов: один занимается распознаванием, другой выделением смысла, третий распознаванием музыки и т.д. Это все скрыто внутри библиотеки, пользователям не надо об этом беспокоиться.
- Работа с источниками аудио. Мы имеем дело с речью человека, и работа с аудио тоже происходит внутри SpeechKit. Причем мы можем не только писать со стандартного устройства, но и принимать данные, откуда угодно. Это может быть файл или стрим — со всем этим мы умеем работать.
SpeechKit используется во внутренних командах. Сейчас его интегрировали 16 команд Яндекса. И нам даже известно о нескольких внешних командах, которые тоже это сделали.
Проектирование
Давайте задумаемся, что мы подразумеваем под удобным приложением. Обычно, это продуманный и понятный UX, решение наших задач, стабильная работа и пр.
Когда мы говорим, что библиотека удобная, в первую очередь мы подразумеваем, что у нее такой API, которым понятно пользоваться. Как этого достичь?
Базовые принципы
Это некоторые аспекты, которые я извлекла из своего опыта работы над SpeechKit.
- Прежде всего, помните о том, что ваши пользователи — разработчики.
С одной стороны, это хорошо, потому что обычным пользователям вы не объясните: «Понимаете, у нас бэкенд лежит, и поэтому ничего не работает, а так мы в порядке!» Вы можете объяснить это разработчикам — вы многое можете объяснить разработчикам!
С другой стороны, вы получаете таких пользователей, которые обязательно воспользуются возможностью найти дыру и что-то сломать, если вы её оставите. Мы все с вами используем библиотеки и пытаемся выжать из них по максимуму. Они заявляют, что делают только это, это и это, а мы думаем: «Нет, сейчас мы тут немножко подшаманим, это передадим, и все будет, как надо».
Помимо этого, то, что пользователи — разработчики, означает, что у вас всегда будет гора советов и рекомендаций, как вам разрабатывать, и как сделать так, чтобы все было лучше.
Второй важный момент полностью соотносится с первым.
- Всё, что не разрешено в вашей библиотеке, должно быть запрещено,
чтобы не было нежелательных лазеек.
Если ваши пользователи начинают делать с библиотекой что-то, чего вы не предполагали — это прямой путь к багам, причем к тем, которые тяжело отлаживать. Постарайтесь использовать все, что дает язык и та технология, которую вы используете: public/private, final, deprecated, readonly. Уменьшайте области видимости, запрещайте наследование и использование каких-то методов, помечайте свойства, которые нельзя менять — предусмотрите все, что можно, чтобы не дать сделать то, на что ваша библиотека просто не рассчитана.
- Не допускайте двоякости в трактовке API вашей библиотеки.
Если этот конкретный класс может быть создан единственным способом — запретите все остальные. Если это свойство не может быть null — укажите это явно. В iOS есть nullable/nonnull, designated initializer, то же самое есть в Java и Android. Используйте все это, для того чтобы пользователь открыл файл, открыл ваш класс, пробежался по нему глазами и сразу понял, что можно сделать, а что никак нельзя.
Кейс SpeechKit API
На примере SpeechKit расскажу, как мы делали рефакторинг версии 2 в версию 3. Мы сильно изменили API и постарались использовать все эти принципы.
Необходимость возникла из-за того, что API был сложный и «теоретический». В нем были глобальные компоненты, которые надо было сперва вызвать — не вызвал — все не работает. Очень странно задавались настройки. API был достаточно «теоретический», потому что SpeechKit изначально был частью Навигатора, а потом этот кусочек и вынесли в библиотеку. API по сути работал с кейсами, использующимися в Навигаторе.
Постепенно количество пользователей росло, и мы начали понимать, что им действительно нужно: какие методы, коллбэки, параметры. К нам приходили с запросами, которые API не позволял реализовать. Это повторялось раз за разом, и стало понятно, что API не выдерживает. Так мы ввязались в рефакторинг.
Процесс рефакторинга был долгий (полгода) и мучительный (все были недовольны). Основная сложность была не в том, чтобы взять гору кода и переписать. Нельзя было просто уйти на рефакторинг, а надо было поддерживать все активные версии, которые были в использовании. Мы не могли просто сказать своим пользователям: «Ребята, да, у вас не работает, да, вам нужна эта фича — мы все сделаем в версии 3, подождите, пожалуйста, полгода!»
В итоге рефакторинг занял много времени, и процесс был мучительный, причем для пользователей тоже. Потому что в итоге мы поменяли API без обратной совместимости. Пришли к ним и сказали: «Вот новый прекрасный SpeechKit, пожалуйста, возьмите его!» — в ответ услышали: «Нет, у нас не запланирован переход на вашу версию 3.0 вообще». Например, у нас была команда, которая переходила на эту версию в течение года. Поэтому целый год мы поддерживали для них предыдущую версию.
Но результат того стоил. Мы получили простую интеграцию и меньше багов. Это то, о чем я упомянула, в базовых принципах проектирования API. Если вы уверены, что ваш API используется правильно, в этой части точно нет никаких проблем: все классы вызываются правильно, все параметры правильные. Найти баги гораздо легче, меньше кейсов, где что-то может пойти не так.
Ниже пример, как выглядел основной класс, который занимается распознаванием, до рефакторинга.
// SpeechKit v2
@interface YSKRecognizer: NSObject
@property (nonatomic, strong, readonly, getter=getModel) NSString* model;
@property (nonatomic, assign, getter=isVADEnabled) BOOL VADEnabled;
- (instancetype)initWithLanguage:(NSString *)language model:(NSString *)m;
- (void)start;
- (void)cancel;
- (void)cancelSync;
@end
@interface YSKInitializer: NSObject
- (instancetype)init;
- (void)dealloc;
- (void)start;
+ (BOOL)isInitializationCompleted;
@end
extern NSString *const YSKInactiveTimeout;
extern NSString *const YSKVADEnabled;
@interface YSKSpeechKit: NSObject
+ (instancetype)sharedInstance;
– (void)setParameter:(NSString *)name withValue:(NSString *)value;
@end
Это обычный класс, который наследуется от NSObject. Рассмотрим отдельно каждую его деталь. Понятно, что мы можем от него отнаследоваться, переопределить в нем какие-то методы — все, что можно делать с NSObject.
Дальше при создании ему передаются две строки (language и model). Что это за строки? Если передать в language «Hello, world», то на выходе будет перевод, или что? Не очень понятно.
Помимо этого, так как это наследник NSObject, мы можем вызвать у него init, new и т.д. А что будет? Он заработает, или будет ждать каких-то параметров?
Конечно, я знаю ответы на эти вопросы, я знаю этот код. Но люди, которые на это смотрят впервые, совершенно не понимают, к чему это все. Даже методы с setter и getter совершенно не выглядят так, как это могло бы выглядеть в iOS. Методы start, cancel, cancelSync (а тот, который просто cancel — он aSync?) — что будет, если их вызвать вместе? Очень много вопросов к этому коду.
Дальше идет объект, про который я говорила (YSKInitializer), который обязательно надо стартовать, чтобы все заработало — это вообще какая-то магия. Видно, что этот код писали разработчики, которые не пишут под iOS, а занимаются C++.
Дальше настройки для этого рекогнайзера задавались через глобальные компоненты, которые передавались в другой глобальный объект, и по сути нельзя было создать два разных рекогнайзера с разным наборов параметров. А это был, наверное, один из самых востребованных кейсов, который не поддерживал API.
Чем v3 лучше v2
Что мы получили, когда сделали рефакторинг и перешли на версию 3?
- Полностью нативный API.
Теперь у нас API под iOS выглядел как iOS-API, API под Android — как Android.
Важный момент, который мы не сразу осознали, — гайдлайны платформы гораздо важнее единообразия API вашей библиотеки.
Например, классы под Android создаются с помощью билдеров, потому что это очень понятный для Android-разработчиков паттерн. В iOS это не так популярно, поэтому используется другой подход: создаем объекты со специальным классом настроек.
Помню, как мы долго спорили на эту тему. Нам казалось важным, чтобы разработчик взял наш код на iOS или Android, и совпадение было бы 99%. Но это не так. Пусть лучше код будет похож на ту платформу, для которой он разрабатывается.
- Простая и понятная инициализация.
Нужен этот объект — вот его настройки, создаешь их, передаешь — профит! То есть нет каких-то скрытых глобальных настроек, которые надо куда-то передавать.
- Отсутствие глобальных компонентов.
Мы выкинули глобальные компоненты, которые всех путали, пугали и вызывали много вопросов даже у самих разработчиков этой библиотеки, не только у пользователей.
Теперь тот же самый класс в новой версии выглядит так (это все еще Objective-C — на Swift нельзя тогда было перейти).
// SpeechKit v3
NS_ASSUME_NONNULL_BEGIN
__attribute__((objc_subclassing_restricted))
@interface YSKOnlineRecognizer: NSObject<YSKRecognizing>
@property (nonatomic, copy, readonly) YSKOnlineRecognizerSettings *settings;
- (instancetype)initWithSettings:(YSKOnlineRecognizerSettings *)s audioSource:(id<YSKAudioSource>)as
NS_DESIGNATED_INITIALIZER;
+ (instancetype)new __attribute__((unavailable("Use designated initializer.")));
- (instancetype)init __attribute__((unavailable("Use designated initializer.")));
@end
NS_ASSUME_NONNULL_END
@protocol YSKRecognizing <NSObject>
- (void)prepare;
- (void)startRecording;
- (void)cancel;
@end
@interface YSKOnlineRecognizerSettings: NSObject<NSCopying>
@property (nonatomic, copy, readonly) YSKLanguage *language;
@property (nonatomic, copy, readonly) YSKOnlineModel *model;
@property (nonatomic, assign) BOOL enableVAD;
- (instancetype)initWithLanguage:(YSKLanguage *)l model:(YSKOnlineModel *)m NS_DESIGNATED_INITIALIZER;
@end
@interface YSKLanguage: YSKSetting
+ (instancetype)russian;
+ (instancetype)english;
@end
Это наследник NSObject, но теперь мы явно говорим о том, что от него нельзя наследоваться. Все методы, которые характерны для этого объекта, перенесены в специальный протокол. Он создается с помощью настроек и audioSource. Теперь все настройки инкапсулированы в один объект, который передается конкретно сюда, чтобы задать настройки для конкретного рекогнайзера.
Более того, мы вынесли отсюда работу с аудио, то есть рекогнайзер теперь — это не та компонента, которая пишет аудио. Эта компонента занимается вопросами распознавания, а передать сюда можно любой источник.
Другие методы создания через new или через init запрещены, потому что этому классу нужны настройки по умолчанию. Будьте добры, если вы хотите его использовать, создайте хотя бы какие-то настройки по умолчанию.
Главное, что те настройки, которые сюда передаются, иммутабельны, то есть вы не можете поменять их в процессе работы. Не надо пытаться, когда что-то распознается, подменить модель или язык. Соответственно, мы не даем пользователям возможность изменить объект с настройками, который уже передан.
Макросы NS_ASSUME_NONNULL_BEGIN/NS_ASSUME_NONNULL_END для того, чтобы подчеркнуть, что эти настройки не могут быть null: audioSource не может быть null — это все должно иметь какое-то определенное значение, чтобы работать.
Как я говорила, методы start и cancel (cancelSync ушел) переехали в отдельный протокол. В библиотеке есть места, в которых можно использовать не наш рекогнайзер, а любой другой. Например, мы используем нативный от Apple, который реализует этот протокол и в который может передать наши компоненты.
Настройки здесь NSCopying для того, чтобы мы могли их копировать, и их нельзя было поменять в процессе работы. В init обязательные параметры язык, модель и NS_DESIGNATED_INITIALIZER. Здесь не показана часть кода, которая идентична deprecate методов, но идея ясна. Это обязательные параметры, с которыми создаются настройки. Они должны быть, и должны быть ненулевые.
Весь остальной набор — это порядка 20 настроек рекогнайзера задаются здесь же. Даже настройки языка или модели — это тоже отдельные классы, которые не позволяют передать что-то абстрактное, с чем мы не умеем работать. То есть мы явно говорим: «Пожалуйста, не давайте нам то, с чем мы не умеем работать. Компилятор вам не даст это сделать».
Итак, мы поговорили про то, что можно сделать с API. В разработке тоже есть свои нюансы.
Разработка
В первую очередь библиотека должна делать то, ради чего вы ее писали, — хорошо выполнять свою функциональность. Но вы можете сделать свой код по-настоящему хорошей библиотекой. Предлагаю несколько ремарок, которые были собраны мной в процессе разработки SpeechKit.
Код не только для себя
Собирать Debug информацию абсолютно точно нужно, потому что вы не хотите, чтобы пользователи сказали, что их сервис не работает из-за вашей библиотеки.
В iOS есть debug information level, который показывает, какую информацию надо собирать. По умолчанию он будет собирать абсолютно все, что может найти: все вызовы, все значения. Это здорово, но это очень большой объем данных. Настройка -gline-tables-only позволяет собирать информацию именно о вызовах функций. Этого более, чем достаточно, для того чтобы найти проблему и исправить ее.
Включается это в настройках Xcode (Build Settings), так и называется debug information level. К примеру, мы, включив эту настройку, уменьшили размер бинарного файла SpeechKit с 600 Мбайт до 90 Мбайт. Это не очень нужная информация и мы ее просто выкинули.
Вторая важная вещь — скрывайте приватные символы. Все вы знаете, что каждый раз, выкладывая библиотеку в iTunes, вы рискуете получить новое предупреждение, что вы что-то используете не так, что-то не добавляете. Поэтому, если вы используете библиотеки, которые Apple считает приватными, не забудьте их скрыть. Для вас это ничего не значит, вы также можете с ними работать, но как только ваши пользователи попробуют залить приложение с вашей библиотекой в iTunes, они получат ошибку. Не каждый попросит вас это исправить, большинство просто откажется от использования вашего решения.
Не допускайте конфликтов символов: добавляйте префиксы ко всему, что у вас есть, к своим классам, к категориям. Если в библиотеке есть категория UIColor+HEX, будьте уверены, что у ваших пользователей есть ровно такая же категория, и когда они интегрируют вашу библиотеку, они получат конфликты символов. И опять, не все захотят рассказать вам и сказать об этом.
Другой вопрос, когда вы сами используете сторонние библиотеки в своей библиотеке. Тут есть пара нюансов, о которых стоит помнить. Во-первых, если вы используете что-то, что появилось в версии старше, чем ваша библиотека, не забудьте использовать Weak Linking (включается Xcode -> Build Phases -> Link Binary With Libraries -> Status). Это позволяет не падать, если вдруг этой библиотеки нет.
В документации Apple подробно описано, как это работает. Но weak linking не значит, что библиотека не загрузится, если она не используется. То есть если вашим пользователям важно время старта приложения, и, возможно, не нужна та часть вашей библиотеки, которая использует стороннюю библиотеку и занимает время на старте, weak linking вам не поможет. С ним библиотека все равно загружается, используется она или нет.
Если вы хотите загружать в runtime, это поможет избавиться от проблемы линковки на старте, то надо использовать dlopen и динамическую загрузку. Это требует достаточно много возни, и нужно сначала понять, имеет ли это смысл. У Facebook выложен достаточно интересный код примера того, как они динамически линковали.
Последнее — старайтесь не использовать внутри глобальные сущности. В каждой платформе есть какие-то глобальные компоненты. Их желательно не тянуть в свою библиотеку. Это кажется очевидным, потому что это глобальный объект, и пользователи вашей библиотеки могут взять его и настроить так, как им хочется. Вы используете его у себя в библиотеке, вам надо как-то сохранить его состояние, перенастроить, потом восстановить состояние. Тут много нюансов, и есть где ошибиться. Помните об этом и старайтесь избегать.
У нас, например, в SpeechKit до третьей версии внутри библиотеки шла работа с аудио, и мы явно настраивали и активировали аудио-сессию. Аудио-сессия в iOS — это такая штука, которая есть у каждого приложения, — не говорите, что у вас его нет. Она создается на старте, отвечает за взаимодействие приложения и системного медиа-демона и говорит, что ваше приложение хочет делать с аудио. Это объект singleton в прямом смысле этого слова. Мы спокойно его брали, настраивали, как нам надо, но это приводило к тому, что у пользователей были мелкие проблемы вроде изменения громкости звука. Еще метод аудио-сессий, который отвечает за установку настроек, достаточно долгий. Он занимает порядка 200 мс, и это заметное подтормаживание на активации или деактивации.
В третьей версии я радостно вынесла аудио-сессию из библиотеки. После этого практически все пользователи всех сервисов, у которых был интегрирован SpeechKit, сказали, как они страшно недовольны. Теперь должны знать, что есть какая-то аудио-сессия, которую надо специальным образом настроить для нашего SpeechKit.
Вывод отсюда такой: все равно старайтесь не использовать глобальные сущности, но будьте готовы к тому, что ваши пользователи не всегда будут рады вашим решениям.
Делаем пользователям удобно
Как еще можно помочь вашим пользователям?
- Добавляйте логи: разные уровни, динамическое включение.
Самый простой способ — это подкладывание файла, на наличие которого запускается мега debug-режим. Это действительно помогает сделать отладку в ситуации, когда у ваших пользователей есть пользователи, у которых происходит ошибка, и вам надо понять, что же именно произошло.
- Поддерживайте все версии ОС пользователей.
Помните о том, что когда вы говорите о поддержке версий в библиотеке — это не то же самое, что поддержка версий в обычном приложении. В обычном приложении мы смотрим статистику, что, например, всего 2% наших пользователей используют iOS 8, и значит можно перестать поддерживать iOS 8. В библиотеке не так, здесь отказ от версии ОС означает полностью отказ от вашего пользователя и всех его пользователей. Это может быть половина ваших пользователей в принципе.
Поэтому вам надо мониторить, какие версии используют те приложения, которые используют вашу библиотеку, и на основании этого уже делать вывод, поддерживаете вы что-то или нет. Мы очень долго не отказывались от iOS 7. Мне кажется, уже были люди, которые отказались от iOS 8 и были готовы отказаться от iOS 9. Мы все еще поддерживали iOS 7, потому что у нас был браузер, который до последнего держал всех пользователей, а мы с ним тесно работали и не могли его бросить в такой ситуации.
Опять-таки ваши пользователи не скажут: «Давайте мы выключим эту функциональность на той версии, которая её не поддерживает», — нет, они просто уберут вашу библиотеку и найдут ту, которая поддерживает весь ряд версий.
- Добавляйте минимальную инкрементацию в новых версиях.
Это очень «не очень» для разработчиков библиотеки. В релиз хочется выпустить все, что готово. Ты сделал фичи, пофиксил баги — сейчас всю пачку положим и выкатим в релиз. Релиз — тоже процесс. Для ваших пользователей это не так. Когда они находятся в процессе тестирования своего продукта и готовятся его к выпуску, они не хотят получить от вас сборку с новыми фичами, которые нужно дополнительно тестировать.
У нас действительно были случаи, когда мы откатывали какие-то релизы, делили их на части и выкатывали уже кусочками. Тогда те команды, для которых мы реализовывали изменения, могли взять именно ту версию, в которой есть маленькие изменения, а не все сразу.
Это действительно не очень удобно для разработки, но минимальная инкрементация в версиях сделает ваших пользователей немножко, но счастливее.
Тестов много не бывает
Это верно и для обычного приложения, и для библиотеки. Но в случае опять библиотеки есть особенности.

Автотесты, конечно, нужны, но помимо них здорово иметь тестовое приложение для вашей библиотеки. Оно поможет вам самостоятельно интегрировать то, что вы написали, и понять, какие проблемы или подводные камни могут возникнуть. Вы сможете ощутить на себе, каково же вашим пользователям.
Если ваша библиотека хоть как-то взаимодействует с сетью, включает шифрование, есть хоть что-то, что связано с данными и с безопасностью, отдайте ее на проверку безопасникам. Вы абсолютно точно не хотите быть той библиотекой, в которой найдут уязвимость, — это клеймо на всю жизнь. Практически во всех крупных компаниях есть целый отдел, который занимается проверкой продуктов на безопасность — отдайте им. Если у вас такого нет, есть внешний аудит. Если вы не можете себе позволить внешний найдите тесты в сети, прогоните их, убедитесь, что ваша библиотека не допускает утечек пользовательских данных.
Последнее, что очень важно в тестах — с самого начала постарайтесь добавлять замеры всего, чего только можно: времени, энергопотребления, всего, что характерно для вашей конкретной библиотеки. Вам все равно в итоге придется это сделать, так почему бы не подумать о замерах с самого начала.
Это не оградит от изменений и от необходимости ускорять библиотеку, но поможет разобраться, что же пошло не так. Если у вас есть графики, это поможет в режиме реального времени мониторить, какая же функциональность добавила задержки по времени или увеличила энергопотребление.
На это практически никогда нет времени, потому что это не функциональность библиотеки, это не то, ради чего вы ее разрабатываете. Но это то, что поможет вам поддерживать ее в надлежащем состоянии и в хорошем качестве.
Здесь можно почитать, как мы в Яндексе измеряем энергопотребление мобильных устройств. Про замеры времени была забавная история. Нам, как разработчикам библиотеки, сложно измерять поведение в конкретных кейсах, потому что не все сценарии SpeechKit используются всеми командами. Чтобы засечь время, мы использовали наше тестовое приложение. Были написаны специальные кейсы использования, например, рекогнайзера или компоненты для синтеза речи, каждый шаг записывались и сохранялись логи, а в итоге строились классные графики.
Все было бы ничего, но мы работаем с аудио, и чтобы все проверить, в определенных случаях действительно проигрывается звуковая дорожка. Причем, надо же сделать очень много замеров, поэтому тест оставили на ночь: поставили колонки, положили рядом какой-то девайс, и запустили аудиофайлы. Утром все оказалось выключено, на следующую ночь это повторилось, и потом снова. Дело было вовсе не в каких-то волшебных существах, которые ходили по офису, — просто уборщицы пугались. Там действительно был очень странный текст, который читался с интервалами.
В итоге было решено сделать локальный тестовый стенд, который мы назвали Шкафом. Это натуральный шкаф, только звукоизолированный. В нем лежит много устройств, целая ферма с устройствами, каждый из которых можно много раз запускать в течение рабочего дня, потому что это никому не помешает.
Запуск
Наконец мы подошли последней важной части — это запуск. Код написан, спроектирован хороший API, чтобы пользователям было удобно. Как же теперь это все выпустить в релиз.
Начну с локальных релизов для пользователей внутри Яндекса. Схема тут такая же, как и в разработке обычного приложения: регулярные, ежемесячные или еженедельные релизы.

Процесс состоит из привычных стадий, но при разработке библиотеки в каждом из этих пунктов есть свои особенности.
Планирование
Для меня это самая болезненная часть, потому что у библиотеки несколько продуктовых команд. В обычном приложении один менеджер продукта, который ставит задачи, которые команда приоритезирует и по одной начинает делать.
Если продуктовых команд несколько, то от каждой из них поступают запросы, которые надо обрабатывать в режиме реального времени. Дам совет: если есть человек, который умеет разбираться с множеством, поступающих в один момент, задач, постарайтесь забрать его в свою команду. Потому что должен быть кто-то между всеми внешними менеджерами и разработкой — тот, кто возьмет на себя функциональность по приоритезации задач.
Вторая важная особенность особенно характерная для SpeechKit возникает, когда в реализации задачи задействованы другие внутренние команды, например, бэкенд. Нужно учитывать, что может возникнуть задержка, что что-то будет не готово вовремя или готово не совсем так. И именно вы должны предупредить об пользователей, потому что именно вы как библиотека — вход в технологии. Пользователям не нужно знать, что за вашей спиной еще n команд. Они не будут говорить с ними о сроках, они говорят об этом разработчикам библиотеки. Это вы знаете про сроки и про важность продуктовых фичей, это вам нужно донести внутренним командам и заказчикам функциональности, что могут возникнуть какие-то накладки по времени.
Разработка
Разработка, как в любом приложении, начинается обычно как в стартапе: просто работаем днями, ночами, нам не важны все эти процессы. Потом вспоминаются слова об Agile-методологии и начинается построение процессов работы команды.
После того, как мы поработали как стартап, мы поняли, что есть проблема — непредсказуемость. Никто не мог сказать, какие именно фичи и когда будут запущены. А это было очень важно!
Тогда мы решили попробовать Scrum. Он действительно помог, мы стали планировать некоторое множество задач, реализовывать их, выпускать в релиз. То есть мы вроде как справились с задачей сделать релизы предсказуемыми. Я говорю «вроде как», потому что не надо забывать о проблеме нескольких продуктовых команд.
Scrum продержался недолго, потому что мы планировали, развивали задачи, спринт — вы знаете все эти слова — но во время спринта прилетали продуктовые задачи, баги. Мы пытались с этим работать. У нас даже было правило — не брать в спринт никаких задач, если это не баг в продакшене у какой-то команды. Угадайте, сколько раз это правило сработало? Примерно ноль, потому что нельзя сказать другой команде: «Да, у вас регресс и вы нашли у нас баг, но мы исправим его, когда вы уже будете в паблике с этим багом». Так нельзя, и нам приходилось брать это в работу, и брать какие-то фичи, которые в этот момент были высокоприоритетные, и Scrum ломался полностью. Процесс был просто ужасающий! Бывало, что весь скоуп перекраивался к середине спринта.
Сейчас мы перешли на некое подобие Канбана. Есть доска с задачами, которые выставлены в порядке приоритета, и мы просто берем верхние задачи. С одной стороны, мы потеряли в предсказуемости нашего релиза. Мы теперь не можем сказать, использующим нашу библиотеку командам, что, если задача попала на доску, то она точно будет в следующем релизе. Но зато мы можем точно сказать, что в релиз попадут самые важные задачи. Сейчас это для нас приоритетнее.
Поддержка
Стоит помнить, что когда вы выпускаете релиз — это не просто одна версия, которую вы отправили и которую кто-то взял в использование. Возможно, те изменения, которые вы сделали в этом релизе, нужны еще и в других версиях, которые используются другими командами. Это то, что я говорила про минимальную инкрементацию версий. Вы не можете сказать своим пользователям: «Мы исправили ошибку в версии 4, а у вас версия 3 — просто переходите на четвертую». Можно иногда и так сделать, но лучше этим не злоупотреблять. Если в релизе какие-то баги или мелкие дополнения, посмотрите, у кого какие версии, и выпустите фиксы на все версии, которые сейчас используются.
Отсюда следует следующий пункт — все ваши релизы должны быть быстрые. Настройте Continuous Integration так, чтобы можно было действительно нажимать одну большую красную кнопку и отправлять на те версии, на которые надо, потому что релизов будет много.
Приоритезируй это
Немножко про то, как мы решали проблему с приоритезацией задач. Выделю два типа задач.
1. Продуктовые задачи.
Здесь все ясно — в первую очередь нужно смотреть на важность для компании. Если бы к нам как-то пришел Аркадий и попросил заняться киллер-фичей для Яндекса, мы бы, конечно, все оставили и делали бы её. Хотя он никогда так не делал.
Время релиза других команд важный параметр для приоритета продуктовых задач. Если одна фича понадобится через месяц, а другая — через неделю, то, кажется, очевидно, что делать. Но не забывайте предупредить команду, которая ждет первую фичу, что начали делать что-то более приоритетное.
2. Хотелки пользователей.
Немного сложнее обстоит дело с хотелками пользователей, потому что, как я говорила, ваши пользователи — разработчики, они хотят сделать вашу библиотеку лучше, они знают, как ее сделать лучше, они лучше вас знают, как сделать ее лучше!
Мы поступали следующим образом. Сначала смотрели, насколько полезно другим командам. То есть если это полезно не только тому, кто предлагает, но и еще кому-то, то мы за это беремся.
Другой очень важный и самый холиварный вопрос — сохраняется ли консистентность библиотеки. Что только не пытались втянуть в SpeechKit за это время. Мы оборонялись, как могли, потому что мы — библиотека, которая делает что-то конкретное. Не надо пытаться сделать все — помните об этом, даже если кому-то одному это сделает жизнь легче.
Дальше смотрим, насколько это упростит жизнь пользователю. Если работа приведет к тому, что пользователь вместо 4 строчек кода вызывает 2, кажется, что это не совсем правильный подход к приоритезации. Если же огромное полотно кода заменится на один вызов, или станет возможно делать что-то, что до этого было нельзя сделать, то берем это на доску.
Последнее — как долго это реализовывать. Когда фича интересная, хотелка классная, но делать ее месяц, то нужно тщательно все взвесить.
Документация. Это. Серьёзно
Особенно для библиотеки, потому что ей пользуется кто-то, кто не писал этот код. Поэтому обязательно добавляйте документацию в коде. Она должна быть написана в файлах, чтобы люди могли открыть, почитать, посмотреть help и увидеть, как это все использовать.
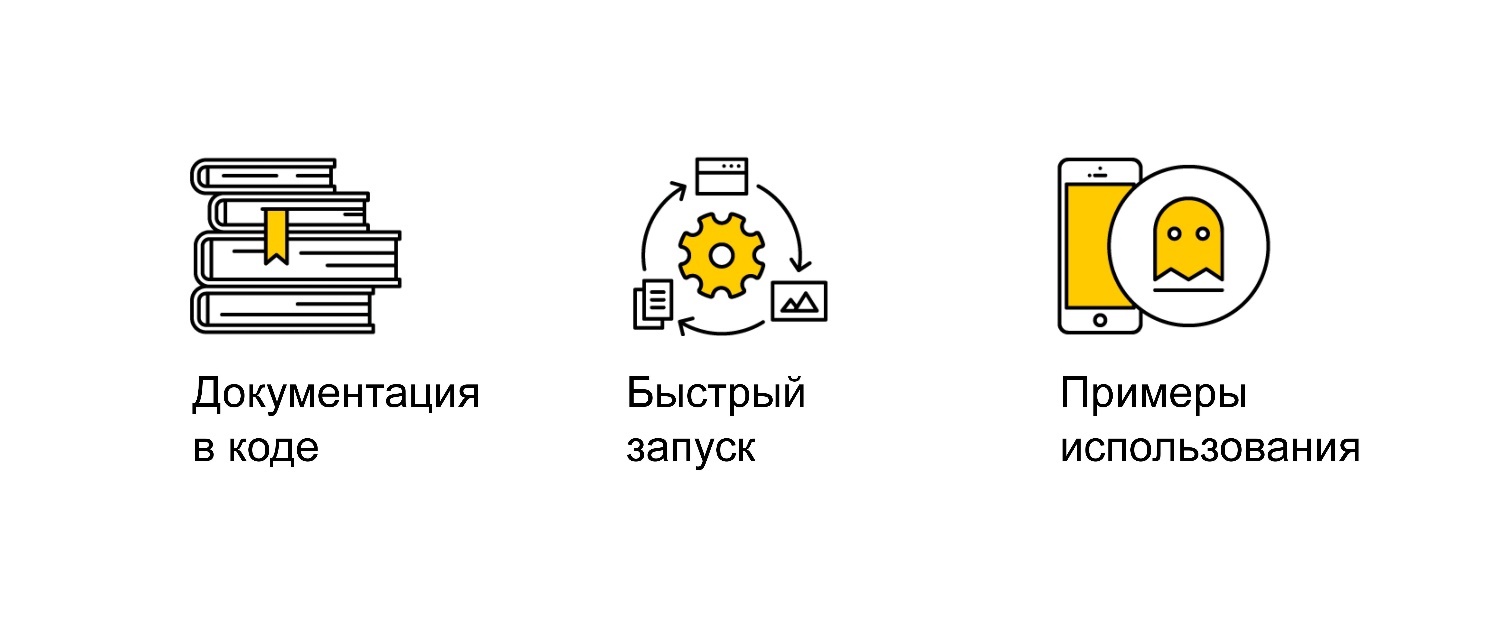
Добавляйте быстрый запуск. Мы все ищем библиотеки так: находим что-то, берем кусочек кода из GitHub, вставляем его к себе, запускаем. Работает — ура, не работает — ищем дальше. Наличие быстрого запуска в документации поможет быть ближе к пользователям, вашу библиотеку будет проще интегрировать и понять, что она может.
После этого приводите примеры использования, чтобы можно было понять, как сделать что-то более хитрое и сложное с вашей библиотекой, понять как настраивать параметры, вызовы и т.д.
Публичный релиз
Последнее важное, о чем не стоит забывать, когда выпускаете публичный релиз:
- Сервер. Обязательно предупредите команду бэкенда, чтобы сервер выдержал нагрузку и рост числа пользователей. Если есть какая-то специфичная внутренняя информация, не отдавайте трафик наружу, скажите это вашему бэкенду.
- Лицензия. Когда мы выпускаем наружу наш код, его могут использовать не совсем корректно. Если у вас открытый исходный код, добавляйте OpenSource лицензию, если нет, то обратитесь к юристам, которые напишут хорошую лицензию, чтобы оградить вас от возможных претензий.
- Поддержка. Помните, что поддержка полностью ляжет на ваши плечи. У вас не будет первой или второй линии, которая объяснит пользователям, что надо передать в функцию. Это все делаете вы. У меня поддержка пользователей SpeechKit иногда занимает больше половины рабочего времени.
Итоги
- Не давайте пользователям возможность вас сломать, учитывайте это в своем API.
- Пишите код, который облегчит жизнь вашим пользователям, а не только будет выполнять необходимую функциональность.
- Релизный цикл должен быть подстроен под несколько команд.
- Помните о том, что ваша библиотека обязательно изменит чью-то жизнь к лучшему :) Вы делаете за кого-то работу, ваш код можно будет переиспользовать.
Yandex.SpeachKit на GitHub под iOS, под Android, и документация Mobile SDK.
AppsConf — самая полезная конференция по мобильной разработке — станет еще полезнее 22 и 23 апреля 2019 года, а сейчас самое время забронировать билет, или собраться и подать заявку на доклад.
Какие у Программного комитета планы на апрельскую конференцию я рассказывал совсем недавно. Ася, например, обещает подготовить новый увлекательный доклад.
