
На момент написания этой статьи большинство крупных технологических компаний (вроде IBM, Google, Microsoft и Amazon) предлагают простые в использовании API визуального распознавания. Аналогичные инструменты предлагают и более мелкие компании, например, Clarifai. Но никто из них не предлагает средств по обнаружению объектов (object detection).

На обеих картинках показаны примеры тегирования с помощью стандартного классификатора Watson Visual Recognition. Только первая картинка была сначала пропущена через модель обнаружения объектов.
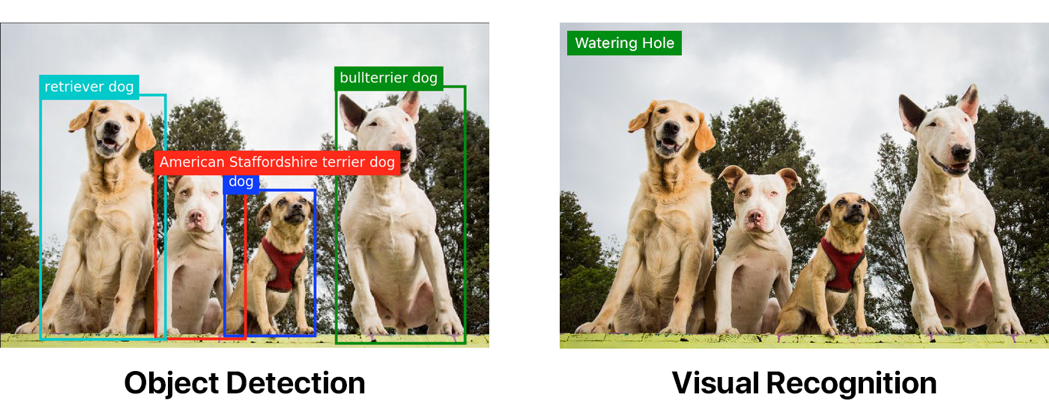
Обнаружение объектов может значительно превосходить «простое» визуальное распознавание. Но если вы хотите реализовать обнаружение объектов, придётся потрудиться.
В зависимости от ситуации, вам может и не понадобиться кастомная модель обнаружения объектов. Соответствующий API TensorFlow предоставляет несколько моделей с разной производительностью и точностью, основанных на датасете COCO.
Для вашего удобства я собрал полный список объектов, которые могут обнаруживать модели COCO:

Если хотите обнаруживать логотипы или что-то ещё, не вошедшее в список, то придётся писать собственный кастомный детектор. Я хотел, чтобы машина обнаруживала корабль Хана Соло Millennium Falcon и имперские истребители Tie Fighter. Очевидно, что это очень важная задача, ведь никогда не знаешь, когда это пригодится в жизни…
Аннотирование изображений
Обучение модели — задача трудоёмкая. Наверное, вы сейчас подумали: «Эй, я не хочу тут костьми ложиться!». Если так, то можете почитать мою статью об использовании готовой модели. Этот путь гораздо проще.
Вам нужно будет собрать много изображений и снабдить их аннотациями. Они включают в себя определение координат объекта и соответствующее обозначение. Для картинки с двумя Tie Fighter аннотации может выглядеть так:
<annotation>
<folder>images</folder>
<filename>image1.jpg</filename>
<size>
<width>1000</width>
<height>563</height>
</size>
<segmented>0</segmented>
<object>
<name>Tie Fighter</name>
<bndbox>
<xmin>112</xmin>
<ymin>281</ymin>
<xmax>122</xmax>
<ymax>291</ymax>
</bndbox>
</object>
<object>
<name>Tie Fighter</name>
<bndbox>
<xmin>87</xmin>
<ymin>260</ymin>
<xmax>95</xmax>
<ymax>268</ymax>
</bndbox>
</object>
</annotation>Для своей модели, которая будет работать со «Звёздными войнами», я собрал 308 изображений, на каждом из которых по 2-3 объекта. Рекомендую собирать не менее 200-300 примеров каждого объекта.
«Ого», подумали вы, «придётся перелопатить сотни изображений и написать кучу XML для каждого?»
Конечно нет! Существует немало инструментов для аннотирования, например, labelImg или RectLabel. Я использовал RectLabel, но он только для macOS. Хотя и с инструментом придётся попотеть, уж поверьте. У меня ушло 3-4 часа непрерывной работы на аннотирование всего моего датасета.
Если есть деньги, может нанять для этого кого-нибудь. Или воспользоваться чем-то вроде Mechanical Turk. Если вы бедный студент, как я, и/или вам нравится многочасовая монотонная работа, то можете сделать аннотации самостоятельно.
Если не хотите писать скрипт преобразования, то при написании аннотаций удостоверьтесь, что они экспортированы в формате PASCAL VOC. Его используют многие, в том числе и я, так что можете позаимствовать вышеприведённый скрипт (я его и сам позаимствовал у кого-то).
Перед запуском скрипта нужно подготовить данные для обработки TensorFlow.
Клонирование репозитория
Сначала клонируйте мой репозиторий. Структура директорий должна выглядеть так:
models
|-- annotations
| |-- label_map.pbtxt
| |-- trainval.txt
| `-- xmls
| |-- 1.xml
| |-- 2.xml
| |-- 3.xml
| `-- ...
|-- images
| |-- 1.jpg
| |-- 2.jpg
| |-- 3.jpg
| `-- ...
|-- object_detection
| `-- ...
`-- ...
Я включил туда свои обучающие данные, так что можете запускать всё из коробки. Но если хотите создать модель со своими данными, придётся добавлять обучающие изображения в images, XML-аннотации — в annotations/xmls, а также придётся обновить trainval.txt и label_map.pbtxt.
trainval.txt — это список файлов, позволяющий найти и коррелировать JPG- и XML-файлы. Ниже приведено содержимое списка trainval.txt, позволяющего найти abc.jpg, abc.xml, 123.jpg, 123.xml, xyz.jpg и xyz.xml:
abc
123
xyz
Примечание: проверьте, чтобы за исключением расширений имена JPG- и XML-файлов совпадали.
label_map.pbtxt — список объектов, которые мы хотим обнаруживать. Он должен выглядеть примерно так:
item {
id: 1
name: 'Millennium Falcon'
}
item {
id: 2
name: 'Tie Fighter'
}
Запуск скрипта
Установите Python и pip, а затем установите требования скрипта:
pip install -r requirements.txtДобавьте
models и models/slim в PYTHONPATH:export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slimВажно: эта команда должна выполняться при каждом запуске терминала. Или добавьте её в файл
~/.bashrc.Запускаем скрипт:
python object_detection/create_tf_record.pyКогда он закончит работу, у вас появятся файлы train.record и val.record. Мы будем использовать их для обучения модели.
Скачивание базовой модели
Обучение с нуля детектора объектов может занять дни, даже при использовании нескольких видеокарт. Для ускорения процесса мы возьмём уже обученный на другом датасете детектор и воспользуемся некоторыми его параметрами для инициализации нашей новой модели.
Можете скачать модель отсюда. Здесь все модели различаются точностью и скоростью работы. Я использовал
faster_rcnn_resnet101_coco.Извлеките и перенесите все файлы model.ckpt в корневую директорию вашего репозитория.
У вас должен быть файл faster_rcnn_resnet101.config. Это настройки для работы с моделью
faster_rcnn_resnet101_coco. Если вы взяли другую модель, можете найти соответствующий конфигурационный файл здесь. Можно обучать
Запускаем скрипт, после чего должно начаться обучение!
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.configПримечание: замените
pipeline_config_path на путь к своему конфигурационному файлу.global step 1:
global step 2:
global step 3:
global step 4:
...
Ура! Работает!
10 минут спустя.
global step 41:
global step 42:
global step 43:
global step 44:
...
Компьютер начинает дымиться.
global step 71:
global step 72:
global step 73:
global step 74:
...
Сколько же это будет продолжаться?
Модель, которую я использовал в заглавной гифке, прошла примерно через 22 000 циклов.
Чего?!
Я использовал MacBook Pro. Если вы запустили эту модель на подобной машине, то предполагаю, что каждый цикл занимает около 15 секунд. Такими темпами на получение приличной модели уйдёт 3-4 дня непрерывной работы.
Это глупо, у меня нет столько времени
PowerAI спешит на помощь!
PowerAI
PowerAI позволяет обучить нашу модель на IBM Power Systems с графическими процессорами P100!
У меня ушёл всего час на 10 000 циклов. И это была лишь один графический процессор. Реальная мощь PowerAI заключается в способности выполнять распределённое обучение с помощью сотен графических процессоров с 95-процентной эффективностью.
Благодаря PowerAI корпорация IBM недавно установила новый рекорд по обучению распознаванию изображений с точностью 33,8 % за 7 часов. Предыдущий рекорд принадлежал Microsoft — точность 29,9 % за 10 дней.
ОООООЧЕНЬ быстро!
Поскольку я обучаю не на миллионах изображений, мне точно не нужны такие ресурсы. Достаточно одного процессора.
Создание аккаунта в Nimbix
Nimbix предоставляет разработчикам пробные аккаунты с 10 часами бесплатной работы на платформе PowerAI. Зарегистрироваться можно здесь.
Примечание: регистрация не автоматическая, так что её одобрение может занять до 24 часов.
После одобрения регистрации вы получите письмо с инструкциями по подтверждению и созданию аккаунта. У вас попросят промокод, оставьте поле пустым.
Теперь можете залогиниться здесь.
Развёртываем приложение PowerAI Notebooks
Поищите по запросу PowerAI Notebooks.

Кликните на результате и выберите TensorFlow.

Выберите тип машины 32 thread POWER8, 128GB RAM, 1x P100 GPU w/NVLink (np8g1).

Появится панель, как на картинке ниже. Когда статус сервера станет Processing, можно к нему обращаться.
Получите пароль, кликнув на (click to show).
Потом для запуска Notebooks кликните Click here to connect.
Залогиньтесь с именем nimbix и полученным паролем.

Начинаем обучение
Кликните на выпадающее меню New и выберите Terminal, чтобы открыть новое окно терминала.

Вас встретит знакомый интерфейс:

Примечание: терминал может не работать в Safari.
Процесс обучения запускается так же, как и на локальном компьютере. Если используете мои обучающие данные, то просто клонируйте мой репозиторий с помощью команды:
git clone github.com/bourdakos1/Custom-Object-Detection.git
Или же клонируйте свой репозиторий. Затем внутри корневой директории выполните cd:
cd Custom-Object-DetectionВыполните нижеприведённый код, скачивающий заранее обученную модель faster_rcnn_resnet101_coco, которую мы уже скачивали ранее.
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
mv faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.* Затем снова обновите PYTHONPATH, поскольку у вас новый терминал:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slimТеперь можно выполнять команду запуска обучения:
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.config
Скачивание своей модели
Когда модель будет готова? Зависит от ваших обучающих данных. Чем их больше, тем больше циклов нужно прогнать. У меня получилась довольно толковая модель после примерно 4500 циклов. А своего пика она достигла примерно за 20 000 циклов. Вообще я прогнал 200 000 циклов, но лучше модель не стала.
Рекомендую скачивать вашу модель каждые 5000 циклов или около того, и оценивать её работу, чтобы понимать, двигаетесь ли вы в нужном направлении. Кликните на логотип Jupyter в левом верхнем углу, затем идите по дереву файлов до Custom-Object-Detection/train.
Скачайте все файлы model.ckpt с самым большим числом в названии.
•model.ckpt-STEP_NUMBER.data-00000-of-00001
•model.ckpt-STEP_NUMBER.index
•model.ckpt-STEP_NUMBER.meta
Примечание: скачивать можно только по одному файлу за раз.

Примечание: после завершения обучения кликните на красную кнопку, иначе часы будут идти бесконечно.
Экспорт результирующего графа
Чтобы использовать в коде вашу модель, нужно конвертировать файлы контрольных точек (checkpoint files) (model.ckpt-STEP_NUMBER.*) в фиксированный результирующий граф (inference graph).
Перенесите скачанные файлы контрольных точек в корневую папку вашего репозитория.
Затем выполните эту команду:
python object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path faster_rcnn_resnet101.config \
--trained_checkpoint_prefix model.ckpt-STEP_NUMBER \
--output_directory output_inference_graph
Не забудьте export
PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim.Должна появиться новая директория
output_inference_graph с файлом frozen_inference_graph.pb. Он-то нам и нужен.Тестирование модели
Теперь выполните команду:
python object_detection/object_detection_runner.pyОна применит вашу модель обнаружения объектов, расположенную в output_inference_graph/frozen_inference_graph.pb, ко всем изображениям в директории test_images и запишет результаты в директорию output/test_images.
Результаты
Вот что мы получим, когда прогоним модель по всем кадрам отрывка из «Звёздные войны: Пробуждение силы».
