Привет, Хабр!
Мы давно и практически безуспешно ищем светлую голову, желающую потеснить на рынке господина Кента Бека — то есть, ищем того, кто готов написать для нас книгу по TDD. C реальными примерами, рассказом о собственных шишках и достижениях. Книг на эту тему совсем мало, да и не будешь ведь классику оспаривать… может быть, поэтому мы с этой головой пока не встретились.
Поэтому мы решили не только вновь напомнить, что ищем такого человека, но и предложить перевод достаточно дискуссионной статьи, автор которой, Дуг Аркури (Doug Arcuri), делится собственными соображениями о том, почему TDD так и не стала мейнстримом. Давайте обсудим, прав ли он, и если нет — почему.

Это – не вводный курс по разработке через тестирование. Здесь я изложу собственные идеи по поводу перезагрузки этой дисциплины и расскажу о практических сложностях модульного тестирования.
Легендарный программист Кент Бек – автор методологии TDD (разработка через тестирование) в ее современном понимании. Кент также вместе с Эрихом Гаммой участвовал в создании JUnit, широко используемого тестировочного фреймворка.
В своей книге XP Explained (второе издание) Кент описывает, как на стыке ценностей и практик формируются принципы. Если построить список концепций и подставить их в своеобразную формулу, то получится преобразование.
Я глубоко уважаю эту работу, которая является для Кента делом всей жизни – не только за созданные им шедевры в области программирования, но и за то, что он без устали исследует суть доверия, смелости, отдачи, простоты и уязвимости. Все эти атрибуты оказались незаменимы для изобретения Экстремального Программирования (XP).
TDD – это принцип и дисциплина, которой придерживаются в сообществе XP. Этой дисциплине уже 19 лет.
В этой статье я поделюсь моим мнением о том, насколько TDD успела усвоиться. Затем поделюсь интересными личными наблюдениями, которые появились у меня при занятии TDD. Наконец, попробую изложить, почему TDD выстрелила не так сильно, как, казалось, должна была. Поехали.
TDD, исследования и профессионализм
Вот уже 19 лет дисциплина TDD – предмет споров в программистском сообществе.
Первый вопрос, который бы вам задал профессионал-аналитик – «каков процент разработчиков, которые сегодня пользуются TDD»? Если бы вы спросили об этом какого-нибудь друга Роберта Мартина (дядюшки Боба) и друга Кента Бека, то ответ был бы «100%».
Просто дядюшка Боб уверен, что невозможно считать себя профессионалом, если не практикуешь разработку через тестирование.
Дядюшка Боб несколько лет вплотную занимался данной дисциплиной, поэтому естественно уделить ему внимание в данном обзоре. Дядюшка Боб отстаивал TDD и существенно расширил границы этой дисциплины. Можете не сомневаться, что я предельно уважаю и дядюшку Боба, и его прагматичный догматизм.
Однако, никто не задает следующего вопроса: «ведь практиковать – означает «сознательно использовать» — но ведь о процентном соотношении оно судить не позволяет, так?» На мой субъективный взгляд, большинство программистов не занимались TDD даже в течение какого-либо символического периода.
Реальность такова, что мы и в самом деле не знаем этих цифр, поскольку никто активно не исследовал этого процентного показателя. Все конкретные данные ограничиваются небольшой подборкой компаний, собранных на сайте WeDoTDD. Здесь вы найдете статистику по таким компаниям, интервью с теми, кто практикует TDD все время, но этот список невелик. Кроме того, он неполон, так как даже простой поиск показывает и другие крупные организации, занимающиеся TDD – но, пожалуй, не на полную мощность.
Если мы не знаем, сколько же компаний практикует TDD, то возникает следующий вопрос: «Насколько TDD эффективна, если судить по ее измеримым достоинствам»?
Вероятно, вас обрадует, что за эти годы был проведен ряд исследований, подтвердивших эффективность TDD. Среди них – безусловно авторитетные отчеты от Microsoft, IBM, Университета Северной Каролины и Университета Хельсинки.
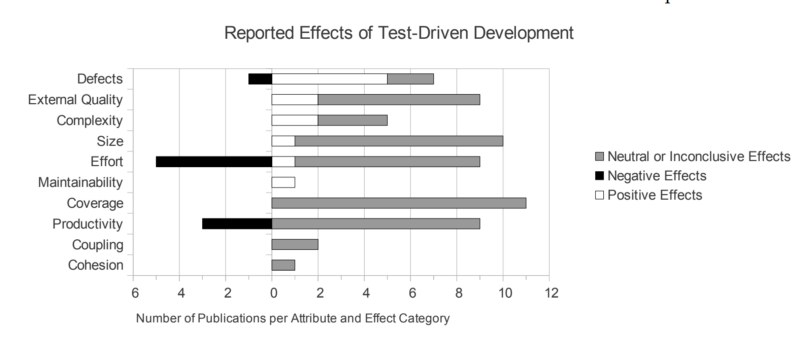
Выразительная диаграмма, взятая из отчета Хельсинского университета.
В определенной степени эти отчеты доказывают, что плотность ошибок удается снизить на 40-60%, для чего требуется работать усиленнее; время выполнения при этом возрастает на 15-35%. Эти числа уже начинают прослеживаться в книгах и новых промышленных методологиях, в частности, в сообществе DevOps.
Отчасти ответив на эти вопросы, переходим к последнему: «На что я могу рассчитывать, начиная практиковать TDD»? Именно для ответа на него я и сформулировал мои личные наблюдения TDD. Давайте к ним перейдем.
1. TDD требует вербализировать подход
Практикуя TDD, мы начинаем сталкиваться с феноменом «обозначения цели». Проще говоря, такие краткие проекты, как подготовка провальных и успешных тестов – серьезный интеллектуальный вызов для разработчика. Разработчику приходится четко артикулировать: «считаю, что этот тест пройдет успешно» и «считаю, что этот тест будет провален» или «Я не уверен, позвольте поразмыслить после того как я попробую этот подход».
IDE стала для разработчика той резиновой уточкой, которая умоляет активно с ней беседовать. Как минимум, на TDD-предприятиях разговоры такого плана должны сливаться в сплошной гул.
Сначала подумайте — а потом сделайте ваш следующий шаг (или шаги).
Подобное подкрепление играет ключевую роль при коммуникации: позволяет не только спрогнозировать ваш следующий шаг, но и простимулировать вас писать простейший код, обеспечивающий прохождение модульного теста. Разумеется, если разработчик будет отмалчиваться, то практически наверняка собьется с курса, после чего должен будет возвращаться в колею.
2. TDD прокачивает моторную память
Разработчик, пробиваясь через свои первые циклы TDD, быстро утомляется – ведь этот процесс неудобен и постоянно буксует. Это обычная ситуация с любой деятельностью, к которой человек только приступает, но еще не освоил. Разработчик будет прибегать к шорткатам, стремясь оптимизировать этот цикл, чтобы набить руку и улучшить моторную память.
Моторная память незаменима для того, чтобы работа стала приносить удовольствие и пошла как по маслу. В TDD подобное необходимо из-за повторения действий.
Выведите шпаргалку с такими шорткатами. Выучите в вашей IDE максимум горячих клавиш, чтобы циклы стали эффективными. Затем продолжайте искать.
Разработчик всего за несколько сессий в совершенстве осваивает подбор шорткатов, в частности, нескольких сессий достаточно, чтобы собирать и запускать тестовый стенд. Когда напрактикуетесь в создании новых артефактов, подсвечивании текста и навигации по IDE, все это покажется вам совершенно естественным. Наконец, вы станете настоящим профессионалом и освоите все приемы рефакторинга: в частности, извлечение, переименование, генерацию, подъем, переформатирование и спуск.
3. TDD требует хотя бы немного продумывать свои действия наперед
Всякий раз, когда разработчик подумывает приступать к TDD, ему требуется держать в уме краткую ментальную карту тех задач, которые требуется решить. При традиционном подходе к программированию такая карта есть не всегда, a сама задача может быть представлена «на макроуровне» или иметь исследовательскую природу. Может быть, разработчик и не знает, как решить задачу, а лишь примерно представляет себе цель. На пути к этой цели модульными тестами пренебрегают.
Усаживаясь за работу и заканчивая очередной «присест» — также старайтесь сделать из этого ритуал. Сначала думайте и перечисляйте. Играйте с этим. Еще перечисляйте. Затем приступайте, делайте, думайте. Отмечайте. Повторите несколько раз. После чего еще раз подумайте и остановитесь.
Будьте непреклонны в работе. Отслеживайте, что уже сделано – ставьте галочки. Никогда не сворачивайтесь, пока нет хотя бы одной. Думайте!
Возможно, на формулировку списка потребуется некоторое время, не вписывающееся в рабочий цикл. Однако, перед началом работы список у вас должен быть обязательно. Не имея его, вы не знаете, куда движетесь. Без карты – никуда.
Разработчик должен составить список тестов, как описано у Кента Бека. Тестовый список позволяет решать задачу в виде циклов, плавно переходящих друг в друга. Над списком тестов нужно постоянно обработать и обновлять, пусть даже за несколько секунд до начала тестов. Если тестовый список пройден почти полностью минус последний этап – то результат «красный», и весь тест провален.
4. TDD зависит от коммуникации с коллегами
После того, как вышеприведенный список будет заполнен, некоторые шаги могут оказаться заблокированы, поскольку на них не вполне ясно описано, что делать. Разработчик не разобрался в списке тестов. Случается и обратное – составлен слишком сырой список, в котором очень много допущений по поводу пока не сформулированных требований. Если у вас получается нечто подобное – сразу остановитесь.
Если действовать без TDD, то могут получиться избыточно сложные реализации. Работа в стиле TDD, но бездумно, без списка, не менее опасна.
Если видите, что списке тестов есть пробелы – встаньте и громко об этом скажите.
В TDD разработчик должен понимать, какой продукт делать, руководствуясь при этом представлениями о необходимых требованиях в трактовке владельца – и ничем больше. Если требование в данном контексте получилось неясным, то список тестов начинает разваливаться. Этот сбой необходимо обсудить. Спокойное обсуждение быстро помогает наладить доверие и уважение. Кроме того, так формируются циклы быстрой обратной связи.
5. TDD требует итерационную архитектуру
Еще в первом издании своей книги по XP Кент предположил, что именно тесты должны быть движущей силой в основе архитектуры. Однако, за несколько лет появились истории о том, как спринт-команды натыкаются на стену уже через считанные спринты.
Разумеется, выстраивать архитектуру на основе тестов нерационально. Сам дядюшка Боб согласился с другими экспертами в том, что это никуда не годится. Требуется более обширная карта, но не слишком далеко отстоящая от тестовых списков, которые вы разрабатывали «в полевых условиях».
Кент спустя много лет также озвучил этот тезис в своей книге TDD By Example. Конкурентность и безопасность – две основные сферы, где TDD не может быть движущей силой, и разработчик должен заниматься ими отдельно. Можно сказать, что конкурентность – это иной уровень проектирования системы, конкурентность нужно разрабатывать итерациями, согласовывая этот процесс с TDD. Сегодня это особенно верно, поскольку некоторые архитектуры развиваются в направлении реактивной парадигмы и реактивных расширений (реактивность – это конкурентность в зените).
Постройте более крупную карту всей организации. Помогающую видеть вещи немного в перспективе. Убедитесь, что и вы, и команда движетесь одним курсом.
Однако, наиболее важна идея организации всей системы, а одной TDD организация не обеспечивается. Дело в том, что модульные тесты – низкоуровневая вещь. Итерационная архитектура и оркестрация TDD сложны на практике и требуют доверия между всеми членами команды, парного программирования и солидных ревью кода. Не вполне понятно, как этого добиться, но вскоре можно убедиться, что краткие сессии проектирования должны проводиться в унисон с выполнением тестовых списков в предметной области.
6. TDD выявляет хрупкость модульных тестов и вырожденную реализацию
У модульных тестов есть одно забавное свойство, и TDD в полной мере его выдает. Они не позволяют доказать корректность. Э. В. Дейкстра работал над этой проблемой и обсуждал, насколько в нашем деле возможны математические доказательства, которые позволили бы заполнить этот пробел.
Например, в следующем примере решаются все тесты, связанные с гипотетическим несовершенным палиндромом, продиктованные бизнес-логикой. Пример разработан по методологии TDD.
Действительно, в этих тестах есть изъяны. Модульные тесты хрупки даже в самых тривиальных случаях. Доказать их корректность не удается никогда, поскольку если бы мы попытались – это потребовало бы неимоверной умственной работы, а требуемый для этого ввод было бы невозможно вообразить.
Вопрос в том – когда разработчик должен прекратить писать тесты? Ответ кажется простым: когда этого достаточно с точки зрения бизнес-логики, а не по мнению автора кода. Это может уязвить нашу конструкторскую страсть, а простота может кого-то выбешивать. Эти чувства компенсируются удовлетворением при виде собственного чистого кода и пониманием, что впоследствии код можно будет уверенно рефакторить. Весь код получится очень аккуратным.
Учтите, что при всей ненадежности модульные тесты необходимы. Понимайте их сильные и слабые стороны. Если полная картина не складывается – возможно, этот пробел поможет восполнить мутационное тестирование.
В TDD есть свои выгоды, но эта методология может отвлекать нас на строительство ненужных замков из песка. Да, это ограничение, но, благодаря нему, можно продвигаться быстрее, дальше и надежнее. Возможно, именно это и имел в виду дядюшка Боб, описывая, что с его точки зрения значит «быть профессионалом».
Но! Какими бы хрупкими ни казались нами модульные тесты, они – абсолютная необходимость. Именно они превращают страх в смелость. Тесты обеспечивают щадящий рефакторинг кода; более того, они могут послужить руководством и документацией любому новому разработчику, который сможет сразу войти в курс дела и трудиться на пользу проекта – если этот проект хорошо покрыт модульными тестами.
7. TDD демонстрирует обратный цикл выполнения тестовых утверждений
Сделаем еще шаг вперед. Чтобы разобраться в следующих двух феноменах, исследуем странные повторяющиеся события. Для начала давайте бегло рассмотрим FizzBuzz. Вот наш список тестов.
Прошли на несколько шагов вперед. Теперь наш тест проваливается.
Естественно, если продублировать ожидаемые данные утверждения в
Иногда провальные тесты выдают корректный результат, необходимый для прохождения теста. Не знаю, как назвать такие события… может быть, вуду-тестирование. Сколько раз вам доведется такое увидеть – отчасти зависит от вашей ленивости и этикета при тестировании, но я много раз замечал подобные вещи, когда человек старается получить реализацию, нормально работающую с готовыми и предсказуемыми множествами данных.
8. TDD демонстрирует условие очередности преобразований
TDD может загнать вас в ловушку. Случается, что разработчик запутывается в собственноручно сделанных преобразованиях, которые применяет для достижения нужной реализации. В какой-то момент тестовый код превращается в узкое место, в котором мы буксуем.
Образуется тупик. Разработчику приходится отступить и разоружиться, удалив часть тестов, чтобы выбраться из этой западни. Разработчик остается незащищен.
Вероятно, дядюшка Боб и сам попадал в такие тупики за годы карьеры, после чего, видимо, осознал, что, обеспечивая прохождение теста, нужно задать правильную очередность действий, чтобы минимизировать вероятность попадания в тупик. Кроме того, он должен был осознать еще одно условие. Чем специфичнее становятся тесты, тем более обобщенным получается код.

Очередность преобразований. Всегда нужно стремиться к простейшему варианту (в верхней части списка).
Это и есть Условие очередности преобразований. По-видимому, есть некий порядок риска рефакторинга, на который мы готовы выйти по прохождении теста. Обычно лучше всего выбирать вариант преобразования, показанный в самом верху списка (простейший) – в таком случае вероятность попадания в тупик остается минимальной.
TPP или, так сказать, Тестовый анализ дядюшки Боба – один из наиболее интригующих, технологичных и захватывающих феноменов, наблюдаемых в настоящее время.
Руководствуйтесь им, чтобы ваш код получался настолько простым, насколько это возможно.
Распечатайте TPP-список и положите у себя на столе. Сверяйтесь с ним, чтобы не попадать в тупики. Возьмите за правило: порядок должен быть простым.
На этом завершается рассказ о моих первичных наблюдениях. Однако, в заключительной части статьи я хотел бы вернуться к вопросу, на который мы забыли ответить в начале: «Каков процент профессиональных программистов, использующих TDD на сегодняшний день?». Я бы ответил: «Думаю, их мало». Хотелось бы исследовать этот вопрос ниже и попытаться объяснить, почему.
Закрепилась ли TDD на практике?
К сожалению, нет. Субъективно кажется, что процент ее сторонников низок, и я продолжаю поиск данных. Мой опыт в рекрутинге, руководстве командами и самостоятельной разработке (которая меня увлекает) позволяет мне сделать следующие наблюдения.
Причина 1: Недостаточный контакт с реальной культурой тестирования
Могу обоснованно предположить, что большинству разработчиков не довелось учиться и работать в условиях настоящей культуры тестирования.
Культура тестирования – это среда, в которой разработчики осознанно практикуются и совершенствуются в искусстве тестирования. Постоянно обучают коллег, которым еще не достает опыта в этой сфере. В каждой паре и при каждом пул-реквесте налажена обратная связь, помогающая всем участникам развивать навыки тестирования. Кроме того, существует серьезная поддержка и чувство локтя в рамках всей иерархии инженеров. Все менеджеры понимают суть тестирования и верят в него. Когда сроки начинают поджимать, дисциплина тестирования не отбрасывается, а ей продолжают следовать.
Тем, кому повезло самому испытать себя в такой культуре тестирования, как мне например – довелось и сделать подобные наблюдения. Этот опыт пригодится нам и в новых проектах.
Причина 2: Дефицит образовательных ресурсов
Уже были попытки писать книги на тему TDD, например, xUnit Patterns и Effective Unit Testing. Однако, по-видимому, пока отсутствует источник, в котором было бы описано, что и зачем тестировать. В большинстве имеющихся источников не удается четко донести всю силу тестовых утверждений и их проверки.
В опенсорных проектах тоже то густо то пусто с хорошими модульными тестами. В таких незнакомых проектах я первым делом смотрю, а как там с тестами. Почти наверняка меня ждет разочарование. Кроме того, могу припомнить считанные случаи восторга, когда тесты не только присутствуют, но и… удобочитаемы.
Причина 3: Темой пренебрегают в университетах
Подметил: среди соискателей, недавно закончивших университет, почти никто не приучен к строгому и дисциплинированному тестированию. Почти все разработчики, которых я знаю, научились тестированию уже после университета; кто-то самостоятельно, другие – освоившись в компании с развитой культурой тестирования.
Причина 4: Требуется сильная увлеченность тестами и стремление заниматься ими
Также нужен известный запал, чтобы заинтересоваться тестированием, понимать детали TDD и ее пользу в долгосрочной перспективе. Нужна ненасытность и тяга к созданию чистого кода, к совершенствованию в своем искусстве.
Большинству достаточно добиться, чтобы все работало, а это лишь полдела из тезиса Кента Бека: «Сначала сделай работу, затем сделай ее правильно». Подчеркну: добиться, «чтобы все работало» — уже означает одержать серьезную победу.
Не менее сложно научиться делать тестирование качественно – давайте эту мысль обсудим в заключении.
Заключение
Формулировка XP от Кента – это простое сочетание чутья, мышления и опыта. Три этих уровня – как ступени к достижению того уровня качества, который определяется как порог. Именно эта модель отлично объясняет проблему с TDD.
Порог для чистого выполнения теста высок, поэтому он как бы затмевает, насколько высокая планка опыта позволяет преодолеть этот порог. Большинство специалистов никогда не «вынырнет» на следующем рисунке, а те, кто смогут – сделают это благодаря редкому опыту, приобретаемому в условиях развитой культуры тестирования.

Из книги XP Explained. Изначально эта схема иллюстрировала качество проектирования, поэтому представьте, что пороговый уровень еще выше.
Создавать и организовывать компьютерные программы достаточно сложно, но тестирование по-настоящему открывает вам глаза на эту работу.
Изначально я чуял, что тестирование – важная вещь, но опыт в культуре тестирования приобрел позже. На это у меня ушли годы размышлений на протяжении всей карьеры, но, не имея опыта работы в развитой тестовой культуре, я бы не поднялся выше порогового уровня.
Считаю, что такая мысль посещала и многих других разработчиков, но они не смогли оценить истинную пользу культуры тестирования, поскольку не получили специфического опыта.
Дисциплина TDD так и «не взлетела» отчасти потому, что кривая обучения искусству тестирования очень крута. Даже при наличии многолетних знаний и опыта в тестировании TDD также требует уникального и нетривиального менталитета. Но попробовать TDD стоит.
Подчеркну. Для TDD требуются все эти размышления и опыт, и даже больше. TDD — это навык, причем, непростой. Я так считаю, поскольку TDD требует от разработчика выдавать максимальную производительность, постоянно и неуклонно. Все мы при этом уязвимы, и немногим разработчикам нравится трудиться в таких условиях.
Однако, TDD – интригующая дисциплина, а также инструмент, на который можно положиться. Ее феномены следует детально изучать. Как бы то ни было, эта дисциплина помогает разработчику совершенствоваться, а на практике усиливает не только отдельного разработчика, но и всю команду.
Мы давно и практически безуспешно ищем светлую голову, желающую потеснить на рынке господина Кента Бека — то есть, ищем того, кто готов написать для нас книгу по TDD. C реальными примерами, рассказом о собственных шишках и достижениях. Книг на эту тему совсем мало, да и не будешь ведь классику оспаривать… может быть, поэтому мы с этой головой пока не встретились.
Поэтому мы решили не только вновь напомнить, что ищем такого человека, но и предложить перевод достаточно дискуссионной статьи, автор которой, Дуг Аркури (Doug Arcuri), делится собственными соображениями о том, почему TDD так и не стала мейнстримом. Давайте обсудим, прав ли он, и если нет — почему.

Это – не вводный курс по разработке через тестирование. Здесь я изложу собственные идеи по поводу перезагрузки этой дисциплины и расскажу о практических сложностях модульного тестирования.
Легендарный программист Кент Бек – автор методологии TDD (разработка через тестирование) в ее современном понимании. Кент также вместе с Эрихом Гаммой участвовал в создании JUnit, широко используемого тестировочного фреймворка.
В своей книге XP Explained (второе издание) Кент описывает, как на стыке ценностей и практик формируются принципы. Если построить список концепций и подставить их в своеобразную формулу, то получится преобразование.
[KISS, Quality, YAGNI, ...] + [Testing, Specs, ...] == [TDD, ...]Я глубоко уважаю эту работу, которая является для Кента делом всей жизни – не только за созданные им шедевры в области программирования, но и за то, что он без устали исследует суть доверия, смелости, отдачи, простоты и уязвимости. Все эти атрибуты оказались незаменимы для изобретения Экстремального Программирования (XP).
TDD – это принцип и дисциплина, которой придерживаются в сообществе XP. Этой дисциплине уже 19 лет.
В этой статье я поделюсь моим мнением о том, насколько TDD успела усвоиться. Затем поделюсь интересными личными наблюдениями, которые появились у меня при занятии TDD. Наконец, попробую изложить, почему TDD выстрелила не так сильно, как, казалось, должна была. Поехали.
TDD, исследования и профессионализм
Вот уже 19 лет дисциплина TDD – предмет споров в программистском сообществе.
Первый вопрос, который бы вам задал профессионал-аналитик – «каков процент разработчиков, которые сегодня пользуются TDD»? Если бы вы спросили об этом какого-нибудь друга Роберта Мартина (дядюшки Боба) и друга Кента Бека, то ответ был бы «100%».
Просто дядюшка Боб уверен, что невозможно считать себя профессионалом, если не практикуешь разработку через тестирование.
Дядюшка Боб несколько лет вплотную занимался данной дисциплиной, поэтому естественно уделить ему внимание в данном обзоре. Дядюшка Боб отстаивал TDD и существенно расширил границы этой дисциплины. Можете не сомневаться, что я предельно уважаю и дядюшку Боба, и его прагматичный догматизм.
Однако, никто не задает следующего вопроса: «ведь практиковать – означает «сознательно использовать» — но ведь о процентном соотношении оно судить не позволяет, так?» На мой субъективный взгляд, большинство программистов не занимались TDD даже в течение какого-либо символического периода.
Реальность такова, что мы и в самом деле не знаем этих цифр, поскольку никто активно не исследовал этого процентного показателя. Все конкретные данные ограничиваются небольшой подборкой компаний, собранных на сайте WeDoTDD. Здесь вы найдете статистику по таким компаниям, интервью с теми, кто практикует TDD все время, но этот список невелик. Кроме того, он неполон, так как даже простой поиск показывает и другие крупные организации, занимающиеся TDD – но, пожалуй, не на полную мощность.
Если мы не знаем, сколько же компаний практикует TDD, то возникает следующий вопрос: «Насколько TDD эффективна, если судить по ее измеримым достоинствам»?
Вероятно, вас обрадует, что за эти годы был проведен ряд исследований, подтвердивших эффективность TDD. Среди них – безусловно авторитетные отчеты от Microsoft, IBM, Университета Северной Каролины и Университета Хельсинки.

Выразительная диаграмма, взятая из отчета Хельсинского университета.
В определенной степени эти отчеты доказывают, что плотность ошибок удается снизить на 40-60%, для чего требуется работать усиленнее; время выполнения при этом возрастает на 15-35%. Эти числа уже начинают прослеживаться в книгах и новых промышленных методологиях, в частности, в сообществе DevOps.
Отчасти ответив на эти вопросы, переходим к последнему: «На что я могу рассчитывать, начиная практиковать TDD»? Именно для ответа на него я и сформулировал мои личные наблюдения TDD. Давайте к ним перейдем.
1. TDD требует вербализировать подход
Практикуя TDD, мы начинаем сталкиваться с феноменом «обозначения цели». Проще говоря, такие краткие проекты, как подготовка провальных и успешных тестов – серьезный интеллектуальный вызов для разработчика. Разработчику приходится четко артикулировать: «считаю, что этот тест пройдет успешно» и «считаю, что этот тест будет провален» или «Я не уверен, позвольте поразмыслить после того как я попробую этот подход».
IDE стала для разработчика той резиновой уточкой, которая умоляет активно с ней беседовать. Как минимум, на TDD-предприятиях разговоры такого плана должны сливаться в сплошной гул.
Сначала подумайте — а потом сделайте ваш следующий шаг (или шаги).
Подобное подкрепление играет ключевую роль при коммуникации: позволяет не только спрогнозировать ваш следующий шаг, но и простимулировать вас писать простейший код, обеспечивающий прохождение модульного теста. Разумеется, если разработчик будет отмалчиваться, то практически наверняка собьется с курса, после чего должен будет возвращаться в колею.
2. TDD прокачивает моторную память
Разработчик, пробиваясь через свои первые циклы TDD, быстро утомляется – ведь этот процесс неудобен и постоянно буксует. Это обычная ситуация с любой деятельностью, к которой человек только приступает, но еще не освоил. Разработчик будет прибегать к шорткатам, стремясь оптимизировать этот цикл, чтобы набить руку и улучшить моторную память.
Моторная память незаменима для того, чтобы работа стала приносить удовольствие и пошла как по маслу. В TDD подобное необходимо из-за повторения действий.
Выведите шпаргалку с такими шорткатами. Выучите в вашей IDE максимум горячих клавиш, чтобы циклы стали эффективными. Затем продолжайте искать.
Разработчик всего за несколько сессий в совершенстве осваивает подбор шорткатов, в частности, нескольких сессий достаточно, чтобы собирать и запускать тестовый стенд. Когда напрактикуетесь в создании новых артефактов, подсвечивании текста и навигации по IDE, все это покажется вам совершенно естественным. Наконец, вы станете настоящим профессионалом и освоите все приемы рефакторинга: в частности, извлечение, переименование, генерацию, подъем, переформатирование и спуск.
3. TDD требует хотя бы немного продумывать свои действия наперед
Всякий раз, когда разработчик подумывает приступать к TDD, ему требуется держать в уме краткую ментальную карту тех задач, которые требуется решить. При традиционном подходе к программированию такая карта есть не всегда, a сама задача может быть представлена «на макроуровне» или иметь исследовательскую природу. Может быть, разработчик и не знает, как решить задачу, а лишь примерно представляет себе цель. На пути к этой цели модульными тестами пренебрегают.
Усаживаясь за работу и заканчивая очередной «присест» — также старайтесь сделать из этого ритуал. Сначала думайте и перечисляйте. Играйте с этим. Еще перечисляйте. Затем приступайте, делайте, думайте. Отмечайте. Повторите несколько раз. После чего еще раз подумайте и остановитесь.
Будьте непреклонны в работе. Отслеживайте, что уже сделано – ставьте галочки. Никогда не сворачивайтесь, пока нет хотя бы одной. Думайте!
Возможно, на формулировку списка потребуется некоторое время, не вписывающееся в рабочий цикл. Однако, перед началом работы список у вас должен быть обязательно. Не имея его, вы не знаете, куда движетесь. Без карты – никуда.
// Список тестов
// "" -> не проходит
// "a" -> не проходит
// "aa" -> проходит
// "racecar" -> проходит
// "Racecar" -> проходит
// вывести валидацию
// отведать черничного эляРазработчик должен составить список тестов, как описано у Кента Бека. Тестовый список позволяет решать задачу в виде циклов, плавно переходящих друг в друга. Над списком тестов нужно постоянно обработать и обновлять, пусть даже за несколько секунд до начала тестов. Если тестовый список пройден почти полностью минус последний этап – то результат «красный», и весь тест провален.
4. TDD зависит от коммуникации с коллегами
После того, как вышеприведенный список будет заполнен, некоторые шаги могут оказаться заблокированы, поскольку на них не вполне ясно описано, что делать. Разработчик не разобрался в списке тестов. Случается и обратное – составлен слишком сырой список, в котором очень много допущений по поводу пока не сформулированных требований. Если у вас получается нечто подобное – сразу остановитесь.
Если действовать без TDD, то могут получиться избыточно сложные реализации. Работа в стиле TDD, но бездумно, без списка, не менее опасна.
Если видите, что списке тестов есть пробелы – встаньте и громко об этом скажите.
В TDD разработчик должен понимать, какой продукт делать, руководствуясь при этом представлениями о необходимых требованиях в трактовке владельца – и ничем больше. Если требование в данном контексте получилось неясным, то список тестов начинает разваливаться. Этот сбой необходимо обсудить. Спокойное обсуждение быстро помогает наладить доверие и уважение. Кроме того, так формируются циклы быстрой обратной связи.
5. TDD требует итерационную архитектуру
Еще в первом издании своей книги по XP Кент предположил, что именно тесты должны быть движущей силой в основе архитектуры. Однако, за несколько лет появились истории о том, как спринт-команды натыкаются на стену уже через считанные спринты.
Разумеется, выстраивать архитектуру на основе тестов нерационально. Сам дядюшка Боб согласился с другими экспертами в том, что это никуда не годится. Требуется более обширная карта, но не слишком далеко отстоящая от тестовых списков, которые вы разрабатывали «в полевых условиях».
Кент спустя много лет также озвучил этот тезис в своей книге TDD By Example. Конкурентность и безопасность – две основные сферы, где TDD не может быть движущей силой, и разработчик должен заниматься ими отдельно. Можно сказать, что конкурентность – это иной уровень проектирования системы, конкурентность нужно разрабатывать итерациями, согласовывая этот процесс с TDD. Сегодня это особенно верно, поскольку некоторые архитектуры развиваются в направлении реактивной парадигмы и реактивных расширений (реактивность – это конкурентность в зените).
Постройте более крупную карту всей организации. Помогающую видеть вещи немного в перспективе. Убедитесь, что и вы, и команда движетесь одним курсом.
Однако, наиболее важна идея организации всей системы, а одной TDD организация не обеспечивается. Дело в том, что модульные тесты – низкоуровневая вещь. Итерационная архитектура и оркестрация TDD сложны на практике и требуют доверия между всеми членами команды, парного программирования и солидных ревью кода. Не вполне понятно, как этого добиться, но вскоре можно убедиться, что краткие сессии проектирования должны проводиться в унисон с выполнением тестовых списков в предметной области.
6. TDD выявляет хрупкость модульных тестов и вырожденную реализацию
У модульных тестов есть одно забавное свойство, и TDD в полной мере его выдает. Они не позволяют доказать корректность. Э. В. Дейкстра работал над этой проблемой и обсуждал, насколько в нашем деле возможны математические доказательства, которые позволили бы заполнить этот пробел.
Например, в следующем примере решаются все тесты, связанные с гипотетическим несовершенным палиндромом, продиктованные бизнес-логикой. Пример разработан по методологии TDD.
// Не несовершенный палиндром
@Test
fun `Given "", then it does not validate`() {
"".validate().shouldBeFalse()
}
@Test
fun `Given "a", then it does not validate`() {
"a".validate().shouldBeFalse()
}
@Test
fun `Given "aa", then it validates`() {
"aa".validate().shouldBeTrue()
}
@Test
fun `Given "abba", then it validates`() {
"abba".validate().shouldBeTrue()
}
@Test
fun `Given "racecar", then it validates`() {
"racecar".validate().shouldBeTrue()
}
@Test
fun `Given "Racecar", then it validates`() {
"Racecar".validate().shouldBeTrue()
}Действительно, в этих тестах есть изъяны. Модульные тесты хрупки даже в самых тривиальных случаях. Доказать их корректность не удается никогда, поскольку если бы мы попытались – это потребовало бы неимоверной умственной работы, а требуемый для этого ввод было бы невозможно вообразить.
// Слишком обобщенная реализация, сделанная на основе предоставленных тестов
fun String.validate() = if (isEmpty() || length == 1) false else toLowerCase() == toLowerCase().reversed()
// Это наилучшая реализация, решающая все тесты
fun String.validate() = length > 1
length > 1 length > 1 можно назвать вырожденной реализацией. Она вполне достаточна для решения поставленной задачи, но сама как таковая ничего не сообщает о проблеме, которую мы пытаемся разрешить. Вопрос в том – когда разработчик должен прекратить писать тесты? Ответ кажется простым: когда этого достаточно с точки зрения бизнес-логики, а не по мнению автора кода. Это может уязвить нашу конструкторскую страсть, а простота может кого-то выбешивать. Эти чувства компенсируются удовлетворением при виде собственного чистого кода и пониманием, что впоследствии код можно будет уверенно рефакторить. Весь код получится очень аккуратным.
Учтите, что при всей ненадежности модульные тесты необходимы. Понимайте их сильные и слабые стороны. Если полная картина не складывается – возможно, этот пробел поможет восполнить мутационное тестирование.
В TDD есть свои выгоды, но эта методология может отвлекать нас на строительство ненужных замков из песка. Да, это ограничение, но, благодаря нему, можно продвигаться быстрее, дальше и надежнее. Возможно, именно это и имел в виду дядюшка Боб, описывая, что с его точки зрения значит «быть профессионалом».
Но! Какими бы хрупкими ни казались нами модульные тесты, они – абсолютная необходимость. Именно они превращают страх в смелость. Тесты обеспечивают щадящий рефакторинг кода; более того, они могут послужить руководством и документацией любому новому разработчику, который сможет сразу войти в курс дела и трудиться на пользу проекта – если этот проект хорошо покрыт модульными тестами.
7. TDD демонстрирует обратный цикл выполнения тестовых утверждений
Сделаем еще шаг вперед. Чтобы разобраться в следующих двух феноменах, исследуем странные повторяющиеся события. Для начала давайте бегло рассмотрим FizzBuzz. Вот наш список тестов.
// Вывести числа от 9 до 15. [OK]
// Для чисел, кратных 3, вывести Fizz вместо числа.
// ...
Прошли на несколько шагов вперед. Теперь наш тест проваливается.
@Test
fun `Given numbers, replace those divisible by 3 with "Fizz"`() {
val machine = FizzBuzz()
assertEquals(machine.print(), "?")
}
class FizzBuzz {
fun print(): String {
var output = ""
for (i in 9..15) {
output += if (i % 3 == 0) {
"Fizz "
} else "${i} "
}
return output.trim()
}
}
Expected <Fizz 10 11 Fizz 13 14 Fizz>, actual <?>.Естественно, если продублировать ожидаемые данные утверждения в
assertEquals, то нужный результат достигается, и тест выполняется. Иногда провальные тесты выдают корректный результат, необходимый для прохождения теста. Не знаю, как назвать такие события… может быть, вуду-тестирование. Сколько раз вам доведется такое увидеть – отчасти зависит от вашей ленивости и этикета при тестировании, но я много раз замечал подобные вещи, когда человек старается получить реализацию, нормально работающую с готовыми и предсказуемыми множествами данных.
8. TDD демонстрирует условие очередности преобразований
TDD может загнать вас в ловушку. Случается, что разработчик запутывается в собственноручно сделанных преобразованиях, которые применяет для достижения нужной реализации. В какой-то момент тестовый код превращается в узкое место, в котором мы буксуем.
Образуется тупик. Разработчику приходится отступить и разоружиться, удалив часть тестов, чтобы выбраться из этой западни. Разработчик остается незащищен.
Вероятно, дядюшка Боб и сам попадал в такие тупики за годы карьеры, после чего, видимо, осознал, что, обеспечивая прохождение теста, нужно задать правильную очередность действий, чтобы минимизировать вероятность попадания в тупик. Кроме того, он должен был осознать еще одно условие. Чем специфичнее становятся тесты, тем более обобщенным получается код.

Очередность преобразований. Всегда нужно стремиться к простейшему варианту (в верхней части списка).
Это и есть Условие очередности преобразований. По-видимому, есть некий порядок риска рефакторинга, на который мы готовы выйти по прохождении теста. Обычно лучше всего выбирать вариант преобразования, показанный в самом верху списка (простейший) – в таком случае вероятность попадания в тупик остается минимальной.
TPP или, так сказать, Тестовый анализ дядюшки Боба – один из наиболее интригующих, технологичных и захватывающих феноменов, наблюдаемых в настоящее время.
Руководствуйтесь им, чтобы ваш код получался настолько простым, насколько это возможно.
Распечатайте TPP-список и положите у себя на столе. Сверяйтесь с ним, чтобы не попадать в тупики. Возьмите за правило: порядок должен быть простым.
На этом завершается рассказ о моих первичных наблюдениях. Однако, в заключительной части статьи я хотел бы вернуться к вопросу, на который мы забыли ответить в начале: «Каков процент профессиональных программистов, использующих TDD на сегодняшний день?». Я бы ответил: «Думаю, их мало». Хотелось бы исследовать этот вопрос ниже и попытаться объяснить, почему.
Закрепилась ли TDD на практике?
К сожалению, нет. Субъективно кажется, что процент ее сторонников низок, и я продолжаю поиск данных. Мой опыт в рекрутинге, руководстве командами и самостоятельной разработке (которая меня увлекает) позволяет мне сделать следующие наблюдения.
Причина 1: Недостаточный контакт с реальной культурой тестирования
Могу обоснованно предположить, что большинству разработчиков не довелось учиться и работать в условиях настоящей культуры тестирования.
Культура тестирования – это среда, в которой разработчики осознанно практикуются и совершенствуются в искусстве тестирования. Постоянно обучают коллег, которым еще не достает опыта в этой сфере. В каждой паре и при каждом пул-реквесте налажена обратная связь, помогающая всем участникам развивать навыки тестирования. Кроме того, существует серьезная поддержка и чувство локтя в рамках всей иерархии инженеров. Все менеджеры понимают суть тестирования и верят в него. Когда сроки начинают поджимать, дисциплина тестирования не отбрасывается, а ей продолжают следовать.
Тем, кому повезло самому испытать себя в такой культуре тестирования, как мне например – довелось и сделать подобные наблюдения. Этот опыт пригодится нам и в новых проектах.
Причина 2: Дефицит образовательных ресурсов
Уже были попытки писать книги на тему TDD, например, xUnit Patterns и Effective Unit Testing. Однако, по-видимому, пока отсутствует источник, в котором было бы описано, что и зачем тестировать. В большинстве имеющихся источников не удается четко донести всю силу тестовых утверждений и их проверки.
В опенсорных проектах тоже то густо то пусто с хорошими модульными тестами. В таких незнакомых проектах я первым делом смотрю, а как там с тестами. Почти наверняка меня ждет разочарование. Кроме того, могу припомнить считанные случаи восторга, когда тесты не только присутствуют, но и… удобочитаемы.
Причина 3: Темой пренебрегают в университетах
Подметил: среди соискателей, недавно закончивших университет, почти никто не приучен к строгому и дисциплинированному тестированию. Почти все разработчики, которых я знаю, научились тестированию уже после университета; кто-то самостоятельно, другие – освоившись в компании с развитой культурой тестирования.
Причина 4: Требуется сильная увлеченность тестами и стремление заниматься ими
Также нужен известный запал, чтобы заинтересоваться тестированием, понимать детали TDD и ее пользу в долгосрочной перспективе. Нужна ненасытность и тяга к созданию чистого кода, к совершенствованию в своем искусстве.
Большинству достаточно добиться, чтобы все работало, а это лишь полдела из тезиса Кента Бека: «Сначала сделай работу, затем сделай ее правильно». Подчеркну: добиться, «чтобы все работало» — уже означает одержать серьезную победу.
Не менее сложно научиться делать тестирование качественно – давайте эту мысль обсудим в заключении.
Заключение
Формулировка XP от Кента – это простое сочетание чутья, мышления и опыта. Три этих уровня – как ступени к достижению того уровня качества, который определяется как порог. Именно эта модель отлично объясняет проблему с TDD.
Порог для чистого выполнения теста высок, поэтому он как бы затмевает, насколько высокая планка опыта позволяет преодолеть этот порог. Большинство специалистов никогда не «вынырнет» на следующем рисунке, а те, кто смогут – сделают это благодаря редкому опыту, приобретаемому в условиях развитой культуры тестирования.

Из книги XP Explained. Изначально эта схема иллюстрировала качество проектирования, поэтому представьте, что пороговый уровень еще выше.
Создавать и организовывать компьютерные программы достаточно сложно, но тестирование по-настоящему открывает вам глаза на эту работу.
Изначально я чуял, что тестирование – важная вещь, но опыт в культуре тестирования приобрел позже. На это у меня ушли годы размышлений на протяжении всей карьеры, но, не имея опыта работы в развитой тестовой культуре, я бы не поднялся выше порогового уровня.
Считаю, что такая мысль посещала и многих других разработчиков, но они не смогли оценить истинную пользу культуры тестирования, поскольку не получили специфического опыта.
Дисциплина TDD так и «не взлетела» отчасти потому, что кривая обучения искусству тестирования очень крута. Даже при наличии многолетних знаний и опыта в тестировании TDD также требует уникального и нетривиального менталитета. Но попробовать TDD стоит.
Подчеркну. Для TDD требуются все эти размышления и опыт, и даже больше. TDD — это навык, причем, непростой. Я так считаю, поскольку TDD требует от разработчика выдавать максимальную производительность, постоянно и неуклонно. Все мы при этом уязвимы, и немногим разработчикам нравится трудиться в таких условиях.
@Test
fun `Given software, when we build, then we expect tests`() {
build(software) shoudHave tests
}Однако, TDD – интригующая дисциплина, а также инструмент, на который можно положиться. Ее феномены следует детально изучать. Как бы то ни было, эта дисциплина помогает разработчику совершенствоваться, а на практике усиливает не только отдельного разработчика, но и всю команду.
