 Перед вами — первая исходно русскоязычная книга, в которой на реальных примерах рассматриваются секреты обработки больших данных (Big Data) в облаках.
Перед вами — первая исходно русскоязычная книга, в которой на реальных примерах рассматриваются секреты обработки больших данных (Big Data) в облаках. Основное внимание уделено решениям Microsoft Azure и AWS. Рассматриваются все этапы работы – получение данных, подготовленных для обработки в облаке, использование облачных хранилищ, облачных инструментов анализа данных. Особое внимание уделено службам SAAS, продемонстрированы преимущества облачных технологий по сравнению с решениями, развернутыми на выделенных серверах или в виртуальных машинах.
Книга рассчитана на широкую аудиторию и послужит превосходным ресурсом для освоения Azure, Docker и других незаменимых технологий, без которых немыслим современный энтерпрайз.
Предлагаем ознакомиться с отрывком «Прямая загрузка потоковых данных»
10.1. Общая архитектура
В предыдущей главе мы рассмотрели ситуацию, когда множество клиентских приложений должны посылать большое количество сообщений, которые нужно динамически обработать, поместить в хранилище и потом снова обработать уже в нем. При этом необходимо иметь возможность менять логику потока обработки и хранения данных, не прибегая к изменению кода клиентов. И наконец, с точки зрения соображений безопасности клиенты должны иметь право делать только одно — посылать сообщения или принимать их, но никоим образом не читать данные или удалять базы, а также у них не должно быть прямых прав для записи этих данных.
Подобные задачи очень распространены в системах, работающих с подключенными через интернет-соединение IoT-устройствами, а также в системах онлайн-анализа логов. Помимо перечисленных выше требований к нашему выделенному сервису, существует еще два требования, относящиеся к специфике «Интернета вещей» и к обеспечению надежной обработки сообщений. Прежде всего, протокол взаимодействия между клиентом и сервисом-приемником должен быть очень простым, чтобы его можно было реализовать на устройстве с ограниченными вычислительными возможностями и с весьма ограниченной памятью (например, платформы Arduino, Intel Edison, STM32 Discovery и другие «недотягивающие», такие как до RaspberryPi). Следующее требование — надежная доставка сообщений вне зависимости от возможных сбоев сервисов обработки. Это более сильное требование, чем требование высокой надежности. Действительно, для обеспечения общей надежности всей системы необходимо, чтобы надежность всех ее компонентов была достаточно высока и добавление нового компонента не приводило к заметному росту количества отказов. Помимо отказа в облачной инфраструктуре, может возникнуть ошибка в сервисе, созданном пользователем. И даже тогда сообщение должно быть обработано, как только работоспособность пользовательского сервиса восстановится. Для этого сервис приема потока сообщений должен надежно хранить сообщение до тех пор, пока оно не будет обработано или пока не истечет время его жизни (это необходимо, чтобы предотвратить переполнение памяти при непрерывном потоке сообщений). Сервис, обладающий такими свойствами, называется концентратором сообщений (Event Hub). Для IoT-устройств существуют специализированные концентраторы (IoT Hub), которые обладают рядом других свойств, очень важных именно для применения совместно с устройствами «Интернета вещей» (например, двунаправленная коммуникация из одной точки, встроенная маршрутизация сообщений, «цифровые двойники» устройства и ряд других). Однако эти сервисы все-таки специализированные, и мы не будем рассматривать их подробно.
Прежде чем перейти к концепции концентрации сообщений, обратимся к идеям, лежащим в ее основе.
Предположим, у нас есть источник сообщений (например, поступающие от клиента запросы) и сервис, который должен их обрабатывать. Обработка отдельного запроса занимает время и требует затраты вычислительных ресурсов (CPU, памяти, IOPS). Причем во время обработки одного запроса не могут быть обработаны остальные запросы. Чтобы клиентские приложения не зависали в ожидании, пока освободится сервис, необходимо разделить их с помощью дополнительного сервиса, который будет ответственным за промежуточное хранение сообщений в то время, когда они ждут обработки, находясь в очереди. Такое разделение необходимо также для увеличения общей надежности системы. Действительно, клиент посылает сообщение в систему, но обрабатывающий сервис может «упасть», однако сообщение не должно быть потеряно, его нужно сохранить в сервисе, обладающем большей надежностью, чем обрабатывающий сервис. Простейший вариант такого сервиса так и называется — очередь (queue) (рис. 10.1).
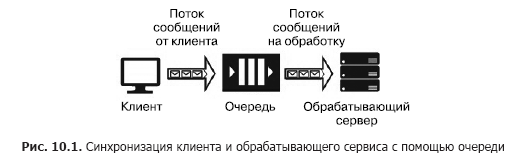
Сервис очередей работает следующим образом: клиент знает URL очереди и имеет ключи доступа к ней. Используя SDK или API очереди, клиент помещает в нее сообщение, содержащее в своем составе временну'ю метку, идентификатор и тело сообщения с полезной нагрузкой в JSON-, XML- или бинарном формате.
Программный код сервиса включает в себя цикл, который «прослушивает» очередь, извлекая очередное сообщение на каждом шаге, и если в очереди есть сообщение, то оно извлекается и обрабатывается. При успешной обработке сообщения сервисом оно удаляется из очереди. При возникновении ошибки во время обработки оно не удаляется и может быть обработано повторно, когда новая версия сервиса, с исправленным кодом, будет запущена. Очередь предназначена для синхронизации одного клиента (или группы однотипных клиентов) и ровно одного обрабатывающего сервиса (хотя последний может быть расположен на кластере серверов или на серверной ферме). К облачным сервисам очередей относятся Azure Storage Queue, Azure Service Bus Queue и AWS SQS. К сервисам, размещаемым на виртуальных машинах, можно отнести RabbitMQ, ZeroMQ, MSMQ, IBM MQ и др.
Различные сервисы очередей гарантируют различные виды доставки сообщений:
- как минимум однократную доставку сообщения;
- строго однократную доставку;
- доставку сообщений с сохранением порядка;
- доставку сообщений без сохранения порядка.
Очередь обеспечивает надежную доставку сообщений из одного источника в один обрабатывающий сервис, то есть взаимодействие «один к одному». Но как быть, если необходимо обеспечить доставку сообщений нескольким сервисам? В этом случае нужно использовать сервис под названием «топик» (topic) (рис. 10.2).
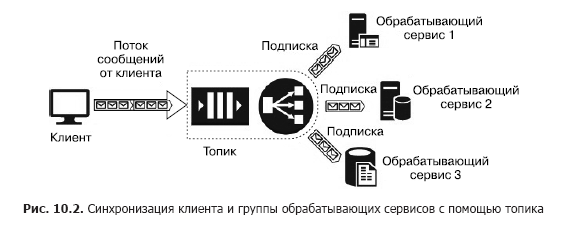
Важный элемент такой архитектуры — «подписки». Это зарегистрированный в разделе путь, по которому направляется сообщение. Сообщения публикуются в топике клиентом и передаются на одну из подписок, из которой извлекаются одним из сервисов и обрабатываются им. Топики обеспечивают архитектуру взаимодействия клиента и сервисов как «один ко многим». В качестве примеров таких сервисов можно привести Azure Service Bus Topic и AWS SNS.
А теперь предположим, что есть большое количество разнородных клиентов, которые должны посылать много сообщений различным сервисам, то есть нужно построить систему взаимодействия «многие ко многим». Конечно, подобную архитектуру можно построить с помощью нескольких разделов, но такое построение немасштабируемо и требует усилий для администрирования и мониторинга. Однако существуют отдельные сервисы — концентраторы сообщений (рис. 10.3).
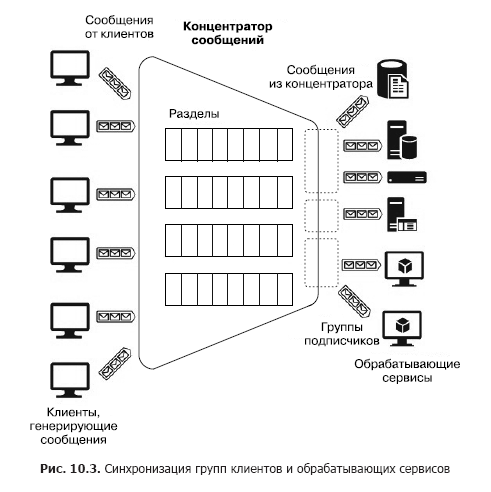
Концентратор принимает сообщения от многих клиентов. Все клиенты могут посылать сообщения в одну общую конечную точку сервиса или подключаться раздельно к различным конечным точкам через специальные ключи. Эти ключи позволяют гибко управлять клиентами: отключать некоторые, подключать новые и др. Внутри концентратора тоже есть разделы (partitions). Но в данном случае они могут быть распределены между всеми клиентами в целях повышения производительности (round robin — «с циклическим добавлением») или клиент может публиковать сообщения в один из разделов. С другой стороны, обрабатывающие сервисы объединены в группы потребителей (consumer group). К одной группе могут быть подключены один или несколько сервисов. Таким образом, концентратор сообщений — наиболее гибкий сервис, который можно сконфигурировать как очередь, раздел или группы очередей либо набор разделов. В общем виде концентратор сообщений обеспечивает схему «многие ко многим» между клиентами и сервисами. К таким концентраторам можно отнести Apache Kafka, Azure Event Hub и AWS Kinesis Stream.
Прежде чем рассмотреть облачные PaaS-сервисы, обратим внимание на очень мощный и известный сервис — Apache Kafka. В облачных средах он может быть доступен в виде дистрибутива, развернутого в кластере виртуальных машин напрямую или с помощью сервиса HDInsight. Итак, Apache Kafka представляет собой сервис, обеспечивающий следующие возможности:
- публикацию и подписку на поток сообщений;
- надежное хранение сообщений;
- применение сторонних сервисов потоковой обработки сообщений.
Физически Kafka запускается в кластере из одного или нескольких серверов. Kafka предоставляет API для взаимодействия с внешними клиентами (рис. 10.4).
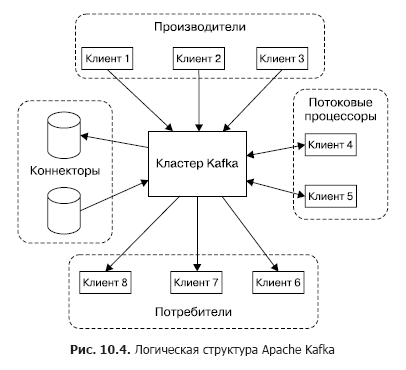
Рассмотрим эти API по порядку.
- API производителя позволяют клиентским приложениям публиковать потоки сообщений в одном или нескольких топиках Kafka.
- API потребителя дают клиентским приложениям возможность подписаться на один или несколько топиков и обработать потоки сообщений, доставленных топиками клиентам.
- API потоковых процессоров позволяют приложениям взаимодействовать с кластером Kafka в качестве процессора потоковой обработки данных. Источниками для одного процессора может быть один или несколько топиков. При этом обработанные сообщения также помещаются в один или несколько топиков.
- API коннекторов помогают подключать внешние источники данных (например, РБД) в качестве источников сообщений (так, возможен перехват событий изменения данных в базе) и в качестве приемников.
В Kafka взаимодействие между клиентами и кластером происходит по протоколу TCP, чему способствуют имеющиеся SDK для различных языков программирования, в том числе и .Net. Но базовые языки SDK — Java и Scala.
В кластере хранение потоков сообщений (в терминологии Kafka именуемых еще записями) происходит логически в объектах, называемых топиками (рис. 10.5). Каждая запись состоит из ключа, значения и временной метки. По сути, топик — это последовательность записей (сообщений), которые были опубликованы клиентами. Топики Kafka поддерживают от 0 до нескольких подписчиков. Каждый топик физически представлен в виде разделяемого журнала (partitioned log). Каждый раздел есть упорядоченная последовательность записей, к которой постоянно добавляются новые, поступающие на вход Kafka.
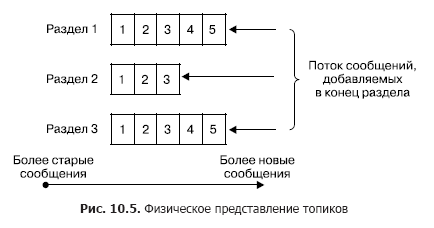
Каждой записи в разделе соответствует номер в последовательности, называемый еще смещением, которое однозначно определяет данное сообщение в последовательности. В отличие от очереди Kafka удаляет сообщение не после обработки сервиса, а по истечении времени жизни сообщений. Это очень важное свойство, обеспечивающее возможность читать из одного топика разным потребителям. Притом с каждым потребителем ассоциировано смещение (рис. 10.6). И каждый акт чтения приводит лишь к увеличению значения для каждого клиента в отдельности и определяется именно клиентом.
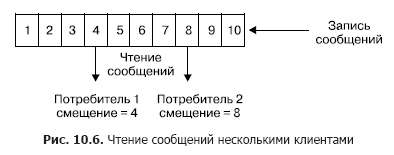
В нормальном случае это смещение увеличивается на единицу после успешного чтения одного сообщения из топика. Но при необходимости клиент может сдвинуть данное смещение и повторить операцию чтения.
Использование концепции разделов преследует следующие цели.
Во-первых, разделы обеспечивают возможность масштабировать топики в том случае, когда один топик не помещается в пределах одного узла. При этом каждый раздел имеет один ведущий (не путайте его с головным узлом всего кластера) узел и ноль или несколько узлов-последователей. За обработку операций чтения-записи отвечает головной узел, в то время как последователи являются его пассивными копиями. При отказе ведущего узла один из узлов-последователей автоматически станет головным. Каждый узел кластера — головной для некоторых разделов и последователь для других. Во-вторых, такая репликация увеличивает производительность чтения за счет возможности параллельных операций чтения.
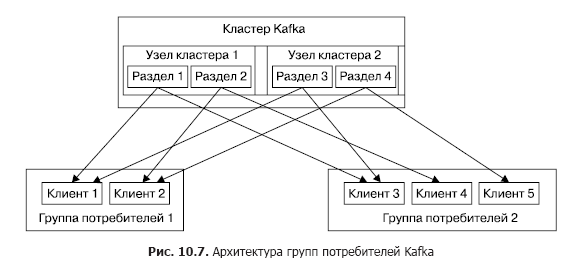
Производитель может помещать сообщение в любой топик по его выбору явно или в режиме round robin неявно (то есть с равномерным заполнением). Потребители объединены в так называемые группы потребителей, и каждое сообщение, публикуемое в топике, доставляется одному клиенту в каждой группе потребителей. Клиенты в данном случае могут физически размещаться на одном или нескольких серверах/виртуальных машинах. Более детально доставка сообщений выглядит следующим образом. Для всех клиентов, относящихся к одной группе потребителей, сообщения могут быть распределены между клиентами с целью оптимизировать нагрузку. Если клиенты относятся к разным группам потребителей, то каждое сообщение будет разослано в каждую группу. Разделение сообщений из разделов по разным группам потребителей показано на рис. 10.7.
Теперь кратко опишу основные параметры доставки и хранения сообщений, гарантированные Kafka.
- Сообщения, посылаемые производителем в конкретный топик, будут добавлены строго в том порядке, в каком они были отосланы.
- Клиент видит тот порядок сообщений в топике, который был получен при сохранении сообщений. В итоге доставка сообщений от производителя к потребителю производится строго в порядке их поступления.
- N-кратная репликация топика обеспечивает устойчивость топика к отказу N – 1 узлов без потери работоспособности.
Итак, сервис Apache Kafka может быть использован в следующих режимах.
- Сервис — брокер сообщений (очередь) или сервис публикации — подписки сообщений (топик). Действительно, в основе Kafka лежит группа топиков, которую можно преобразовать в очередь при наличии одного подписчика. (Следует помнить: в отличие от обычных сервисов брокеров сообщений, построенных по принципу очередей, в Kafka удаление сообщений происходит только по истечении его времени жизни, в то время как в брокерах реализован принцип Peek-Delete, то есть извлечения и удаления после успешной обработки.) Принцип групп потребителей обобщает две эти концепции, а возможность публикации сообщений во всех топиках с распределением round robin делает Kafka универсальным многорежимным брокером сообщений.
- Сервис потокового анализа сообщений. Это возможно благодаря включенным в Kafka API для потоковых процессоров, что позволяет строить сложные системы, созданные по принципу Event Driven, с сервисами, фильтрующими сообщения или реагирующими на них, а также с сервисами, агрегирующими сообщения.
Все указанные свойства позволяют использовать Kafka как ключевой компонент платформы, работающей с потоковыми данными и обладающей широкими возможностями для построения сложных систем обработки потоков сообщений. Но вместе с тем Kafka достаточно сложен в плане развертывания и настройки кластера из нескольких узлов, что требует существенных усилий административного плана. Но, с другой стороны, поскольку идеи, лежащие в основе Kafka, очень хорошо подходят для построения систем, потокового приема и обработки сообщений, то облачные провайдеры предоставляют PaaS-сервисы, реализующие эти идеи и скрывающие все сложности построения и администрирования кластера Kafka. Но так как указанные сервисы имеют ряд ограничений в плане кастомизации и расширения за пределами выделенных для сервисов лимитов, облачные провайдеры предоставляют специальные IaaS/PaaS-сервисы для физического развертывания Kafka в кластере виртуальных машин. В этом случае пользователь обладает практически полной свободой конфигурирования и расширения. К таким сервисам относится Azure HDInsight. Он уже упоминался выше. Он создан для того, чтобы, с одной стороны, предоставить пользователю сервисы из экосистемы Hadoop сами по себе, без внешних оберток, а с другой — избавить от сложностей, возникающих при прямом инсталлировании, администрировании и конфигурировании IaaS. Несколько особняком стоит Docker-хостинг. Поскольку это чрезвычайно важная тема, то мы рассмотрим ее, но сначала познакомимся с PaaS-сервисами, реализованными с помощью основных концепций Kafka.
10.2. Azure Event Hub
Рассмотрим сервис концентратора сообщений Azure Event Hub. Он представляет собой сервис, построенный по модели PaaS. В качестве источников сообщений для Azure Event Hub могут выступать различные группы клиентов (рис. 10.8). Прежде всего, это очень большая группа облачных сервисов, чьи выходы или триггеры можно сконфигурировать для посылки сообщений напрямую в Event Hub. Это могут быть Stream Analytics Job, Event Grid и значительная группа сервисов, перенаправляющих события — логи в Event Hub (прежде всего, построенные с помощью AppService: Api App, Web App, Mobile App и Function App).
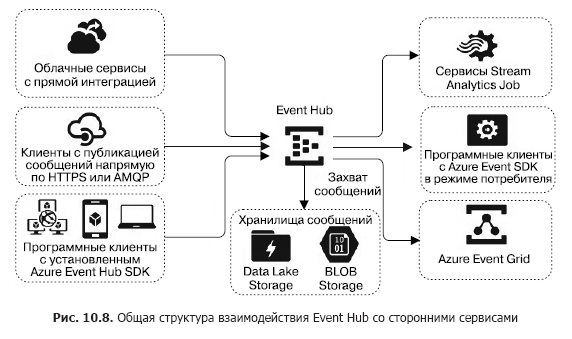
Доставленные в концентратор сообщения могут быть напрямую захвачены (capture) и помещены в хранилище Blob Storage или Data Lake Store.
Следующая группа источников — внешние программные клиенты или устройства, для которых отсутствует Azure Event Hub SDK и которые не могут быть напрямую интегрированы с сервисами Azure. К таким клиентам относятся прежде всего устройства IoT. Они могут посылать сообщения во вход Event Hub с помощью протоколов HTTPS или AMQP. Рассмотрение способов подключения данных устройств выходит за рамки нашей книги.
И наконец, программные клиенты, которые генерируют сообщения и посылают их в Event Hub, задействуя Azure Event Hub SDK. Эта группа включает в себя Azure PowerShell и Azure CLI.
В качестве приемников сообщений (consumers — «потребители») из Event Hub могут выступать сервисы потоковой аналитики Stream Analytics Job или сервис интеграции Event Grid. Кроме того, возможен прием сообщений программными клиентами с помощью Azure Event Hub SDK. Потребители подключаются к Event Hub, используя протокол AMQP 1.0.
Рассмотрим основные концепции Azure Event Hub, необходимые для понимания путей его использования и конфигурирования. Любой источник (в документации называется еще издателем — publisher), который посылает сообщение в концентратор, должен применить протокол HTTPS или AMQP 1.0. Выбор того или иного протокола определяется типом клиента, сети коммуникации и требованиями к скорости передачи сообщений. Протоколу AMQP необходимо создание постоянного соединения между двумя двунаправленными TCP-сокетами. Оно защищается путем использования протокола шифрования транспортного уровня TLS или SSL/TLS. Все это означает, в частности, что для первоначального установления соединения протокол AMQP требует большего времени, чем HTTPS, но при постоянном потоке сообщений у первого производительность гораздо выше. При редких сообщениях более предпочтителен HTTPS.
Для того чтобы идентифицировать себя, источники могут использовать механизмы идентификации на основе механизма SAS (Shared Access Signature) tokens. В простейшем случае все издатели могут применить один общий SAS-токен на всех или задействовать гибкую политику распределения различных токенов SAS для разных издателей. Кроме разделения источников по различным SAS-токенам, используется разделение по ключу раздела (об этом ниже).
Каждый источник может отправлять сообщение размером не более 256 Кбайт. Это значит, что нужно разбивать длинное сообщение на несколько посылаемых последовательно или переходить к бинарному формату и использовать сжатие данных.
Теперь рассмотрим, как сообщение обрабатывается непосредственно в Event Hub. Как уже указывалось в предыдущей главе, в основе концепции концентраторов сообщений лежит группа топиков, имеющих точки входа и множественные выходы, к которым могут подключаться подписчики-потребители. В случае EventHub подобные топики именуются разделами (partitions). Концептуально разделы EventHub — это упорядоченная последовательность сообщений, организованная по принципу очереди «первым вошел — первым вышел» (FIFO) (рис. 10.9).
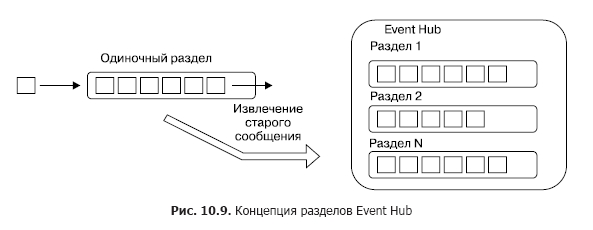
Каждый раздел — независимая последовательность сообщений в пределах всего Event Hub. Один Event Hub может включать от 2 до 32 разделов, и эта величина не может быть изменена после создания Event Hub. Очень важно понимать, что количество ОДНОВРЕМЕННО извлекаемых сообщений из концентратора равно количеству разделов.
Сообщения в разделе (а по сути в очереди) хранится до тех пор, пока его не извлечет потребитель (оно при этом не удаляется, а перестает быть доступным — см. ниже), или до истечения определенного времени хранения (retention period), которое может настраиваться. Здесь следует уточнить. В любом случае сообщение физически удаляется только по истечении времени хранения. Чтобы обеспечить возможность читать сообщения из раздела, в Azure Event Hub реализована концепция смещения (offset). Смещение в данном случае — это позиция в разделе, которая показывает текущую позицию для чтения, то есть, по сути, курсор с номером текущей читаемой позиции. После успешного извлечения сообщения потребитель сдвигает курсор на одну позицию. Azure Event Hub SDK позволяет установить произвольную позицию, с которой можно читать сообщения, но так поступать не рекомендуется. При этом за хранение смещения ответственен клиент-потребитель, и он сам должен хранить и обновлять данную величину.

Таким образом, потребитель может прочитать одно и то же сообщение несколько раз, но только в том случае, если он каждый раз будет указывать смещение, соответствующее позиции этого сообщения. Однако стандартные Azure Event Hub SDK по умолчанию исключают такую возможность, поскольку обеспечивают механизм надежного хранения и обновления смещения. Как правило, для хранения смещения используется Storage Account. Сервисы Azure, являющиеся приемниками сообщений из Event Hub, берут на себя ответственность за хранение сообщений.
Каждый раздел в рамках Event Hub имеет собственный ключ раздела (partition key), который позволяет направить сообщения из конкретных источников в конкретный раздел. Цель такого действия — организация потоков сообщений. Например, концентратор содержит много разделов и источников разной производительности (количества сообщений в единицу времени) и требуется создать выделенный канал с публикацией и чтением сообщений. Если у источника явно не указан ключ раздела, то они распределяются между разделами равномерно (round robin).
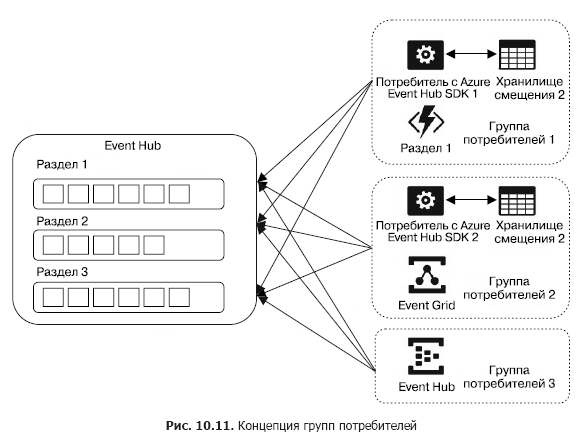
Теперь рассмотрим вопрос извлечения сообщений из концентратора. Все потребители логически объединяются в группы, управляемые совместно и называемые группами потребителей (consumer group) (рис. 10.11). Группы позволяют организовать независимое чтение из одних и тех же разделов разными потребителями. При этом каждая группа дает каждому клиентскому приложению возможность иметь свое представление (view) (величины текущих смещений для каждого раздела) и, таким образом, независимо читать данные из разделов. Для каждой группы потребителей подобные представления полностью различны, что позволяет реализовать сложные сценарии обработки данных. Максимальное количество групп потребителей — 20, при этом в каждой группе может быть не более пяти собственно потребителей, а одновременно считывать сообщение из раздела может только один потребитель из группы.
Разделение концентратора на разделы обеспечивает параллельное чтение сообщений множеством потребителей. Кроме того, производительность концентратора с точки зрения приема заданного количества в единицу времени может быть настраиваемой. Для этого существует параметр, называемый единицей пропускной способности (throughput unit). Каждая единица пропускной способности включает в себя следующие величины:
- для входного потока — 1 Mбайт в секунду или 1000 сообщений в секунду (в зависимости от того, какой из этих лимитов будет достигнут первым);
- для выходного потока — 2 Mбайт в секунду.
Конкретная величина пропускной способности настраивается для каждого концентратора отдельно. Если источники превышают допустимую пропускную способность, то у них генерируется исключение. При этом приемник просто не может принимать сообщения быстрее заданной величины. Единицы пропускной способности также влияют на стоимость использования сервиса. Будьте внимательны! Следует знать, что существуют лимиты пропускной способности, выделяемые на пространство имен, а не на отдельные экземпляры сервиса Event Hub.
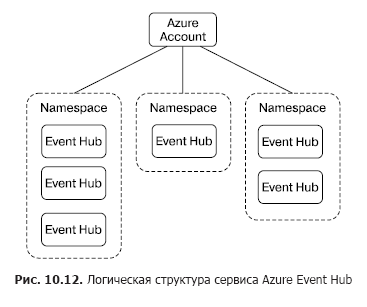
Концентраторы сообщений логически группируются в пространства имен (namespace) (рис. 10.12).
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — BigData
