22 сентября провели наш первый нестандартный митап для разработчиков высоконагруженных систем. Было очень круто, много позитивного фидбека по докладам и поэтому решил не только их выложить, но и расшифровать для Хабра. Сегодня публикуем выступление Ивана Бубнова, DevOps из компании BIT.GAMES. Он рассказал о внедрении дискавери-сервиса Consul в уже рабочий высоконагруженный проект для возможности быстрого масштабирования и failover`а stateful-сервисов. А также об организации гибкого пространства имен для бэкэнд-приложения и подводных камнях. Теперь слово Ивану.
Я администрирую продакшн-инфраструктуру в студии BIT.GAMES и расскажу историю внедрения консула от Hashicorp в наш проект «Гильдия Героев» — fantasy RPG с асинхронным pvp для мобильных устройств. Выпускаемся на Google Play, App Store, Samsung, Amazon. DAU около 100 000, online от 10 до 13 тысяч. Игру делаем на Unity, поэтому клиент пишем на С# и используем свой собственный скриптовый язык BHL для игровой логики. Серверную часть пишем на Golang (перешли на него с PHP). Дальше — схематичная архитектура нашего проекта.
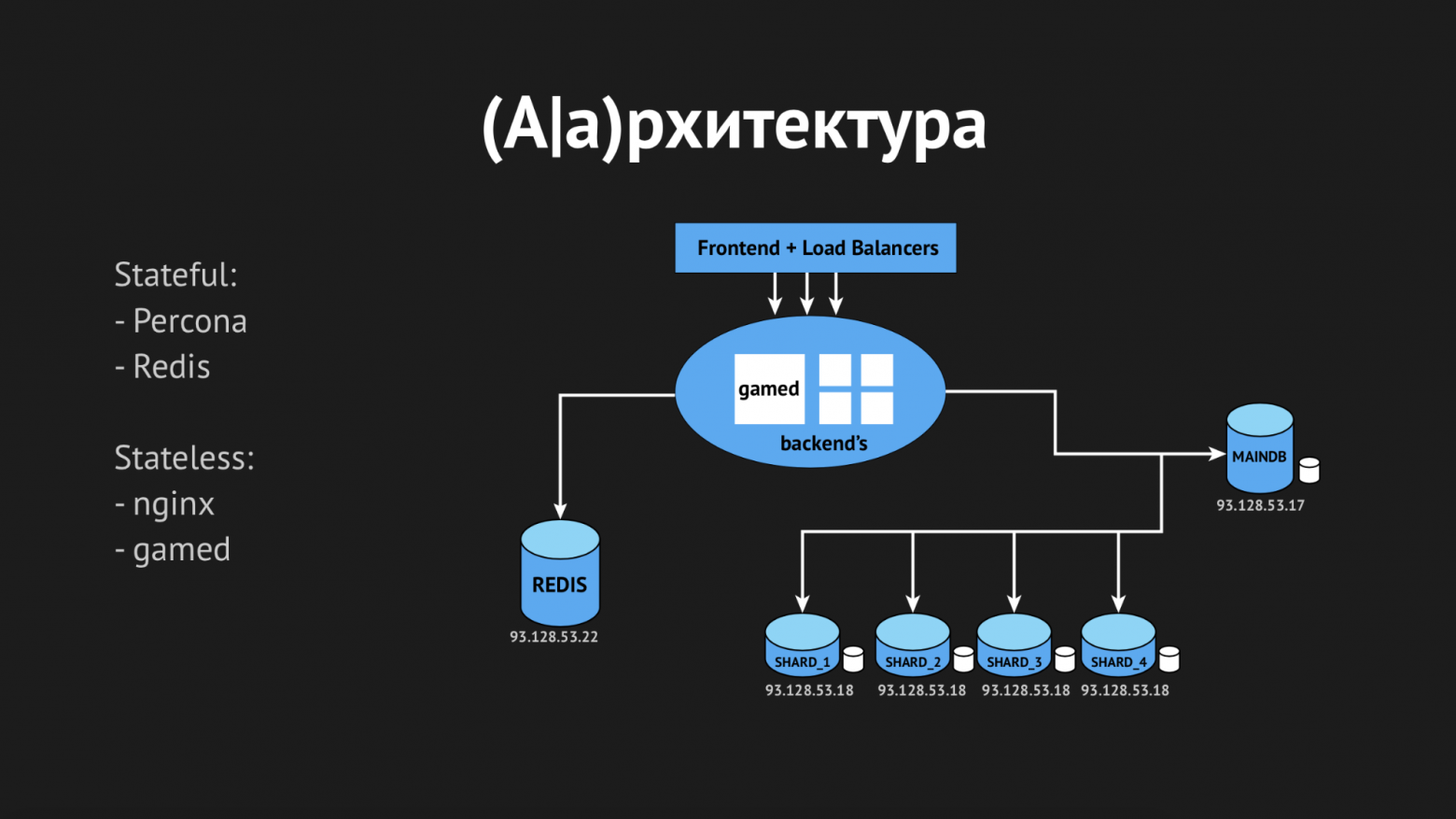
На самом деле сервисов намного больше, здесь только основы игровой логики.
Итак, что у нас есть. Из Stateless-сервисов это:
Из Stateful-сервисов основные у нас это:
В процессе проектирования мы (как и все) надеялись, что проект будет успешным и предусмотрели механизм шардирования. Он представляет из себя две сущности баз данных MAINDB и сами шарды.
MAINDB это своего рода оглавление — в нем хранится информация о том, на каком конкретно шарде хранятся данные о прогрессе игрока. Таким образом полная цепочка получения информации выглядит примерно так: клиент обращается к фронтенду, тот в свою очередь перераспределяет его по весовому коэффициенту на один из backend'ов, backend идет в MAINDB, локализует шард игрока, после чего делает выборку данных непосредственно самого шарда.
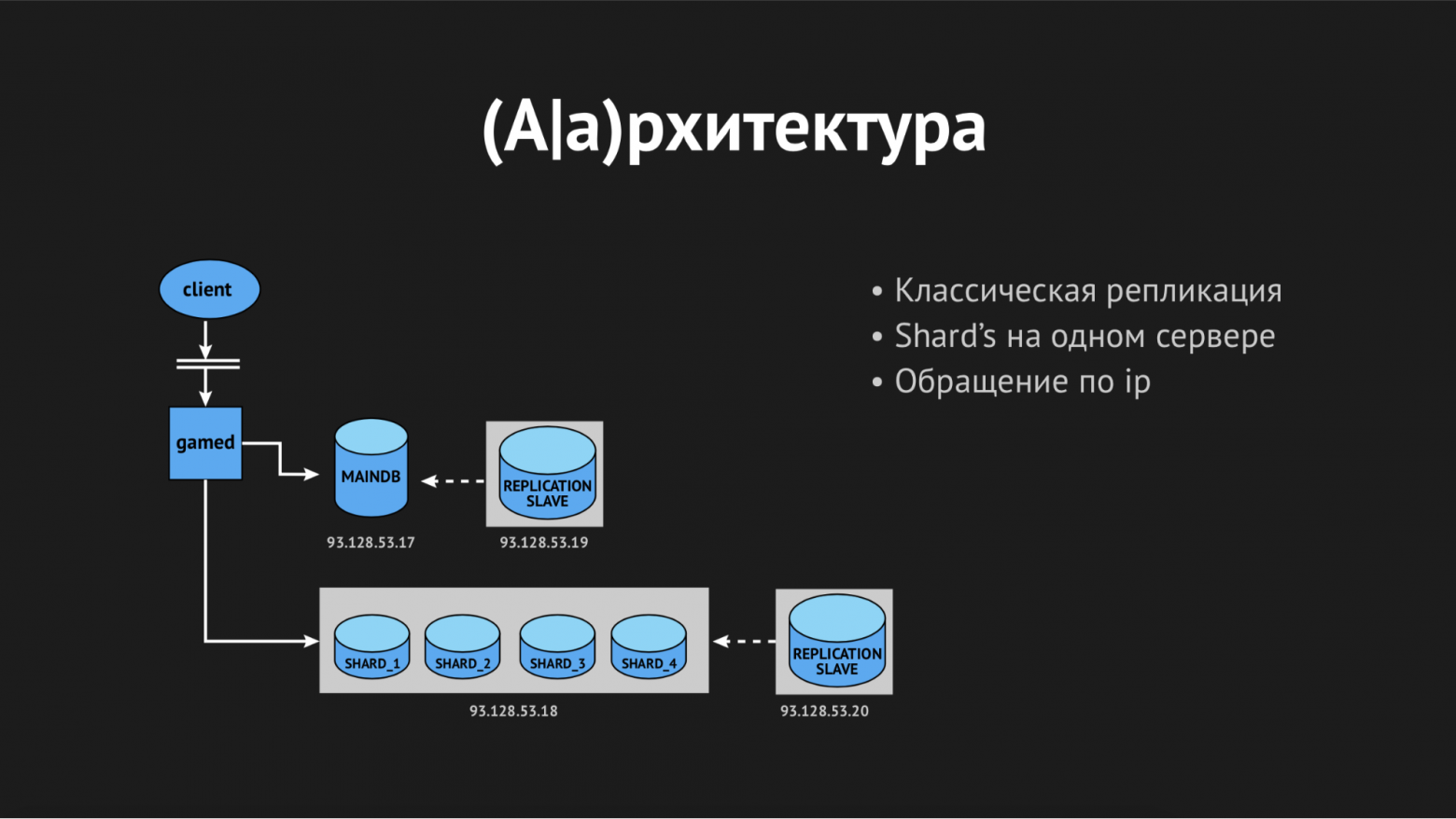
Но когда мы проектировали, то не были большим проектом, поэтому приняли решение сделать шарды шардами только номинально. Они все находились на одном физическом сервере и скорее это партицирование по базам данных в рамках одного сервера.
Для резервирования мы использовали классическую мастер-слэйв репликацию. Это было не очень удачное решение (чуть позже скажу почему), но самый главный минус той архитектуры был в том, что все наши backend'ы знали о других backend-сервисах исключительно по IP-адресам. И в случае очередной нелепой аварии в дата-центре по типу «извините, наш инженер задел кабель на вашем сервере при обслуживании другого и мы очень долго разбирались, почему же ваш сервер не выходит на связь» от нас требовались немалые телодвижения. Во-первых, это пересборка и презаливака backend'ов с IP резервного сервера за место того, который вышел из строя. Во-вторых, после инцидента необходимо восстановить из backup’a с резерва наш мастер, потому что он находился в несогласованном состоянии и привести его в согласованное состояние по средствам той же самой репликации. После чего мы снова пересобирали backend'ы и снова перезаливали. Все это, конечно, вызывало даунтайм.
Настал момент, когда наш техдиректор (за что спасибо ему огромное) сказал: «Ребят, хватит терпеть, надо что-то менять, давайте искать выходы». В первую очередь мы хотели добиться простого, понятного, а самое главное — легко управляемого процесса масштабирования и миграции с места на место наших баз данных в случае необходимости. Кроме того, мы хотели добиться высокой доступности, автоматизировав failover'ы.
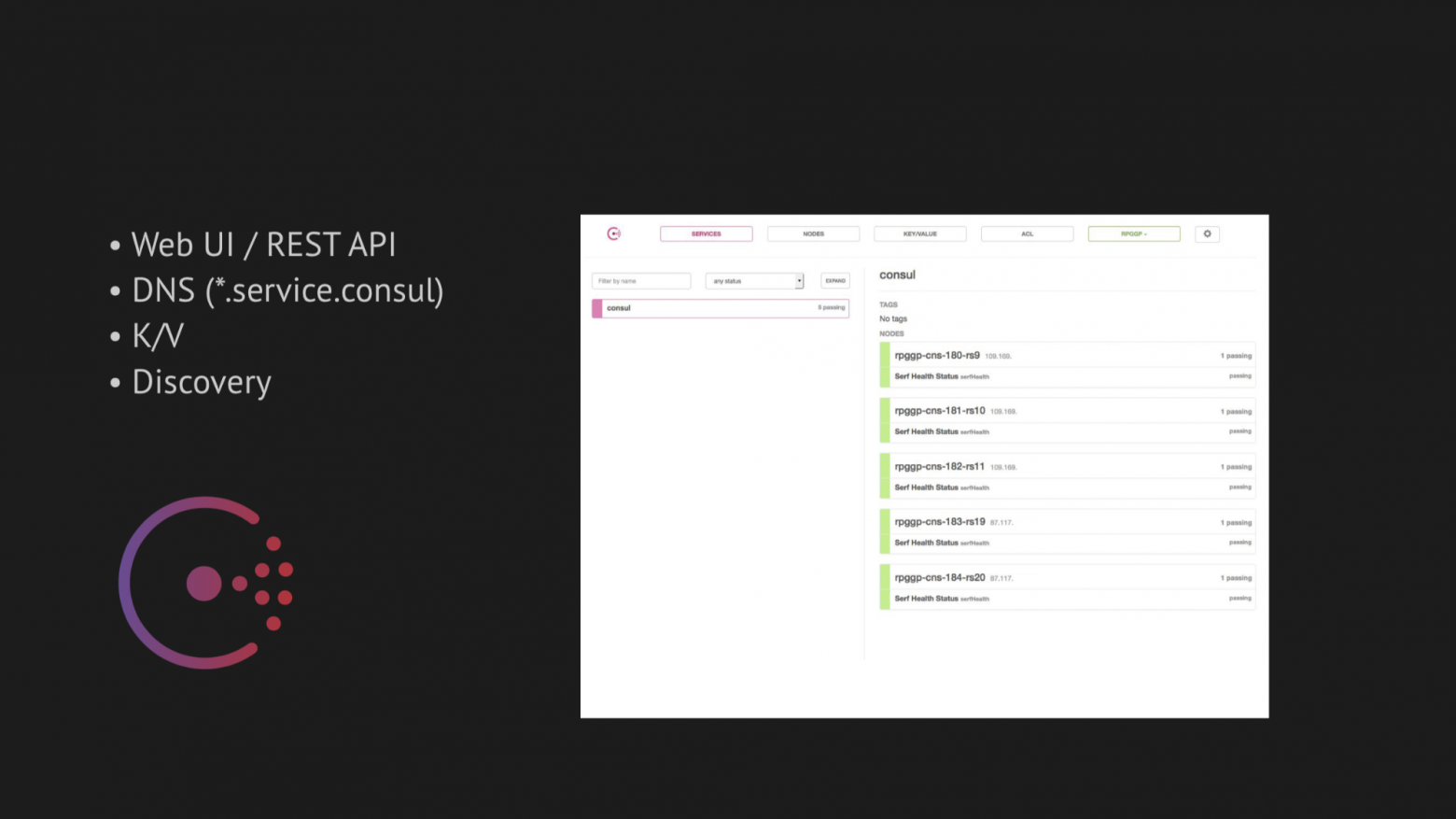
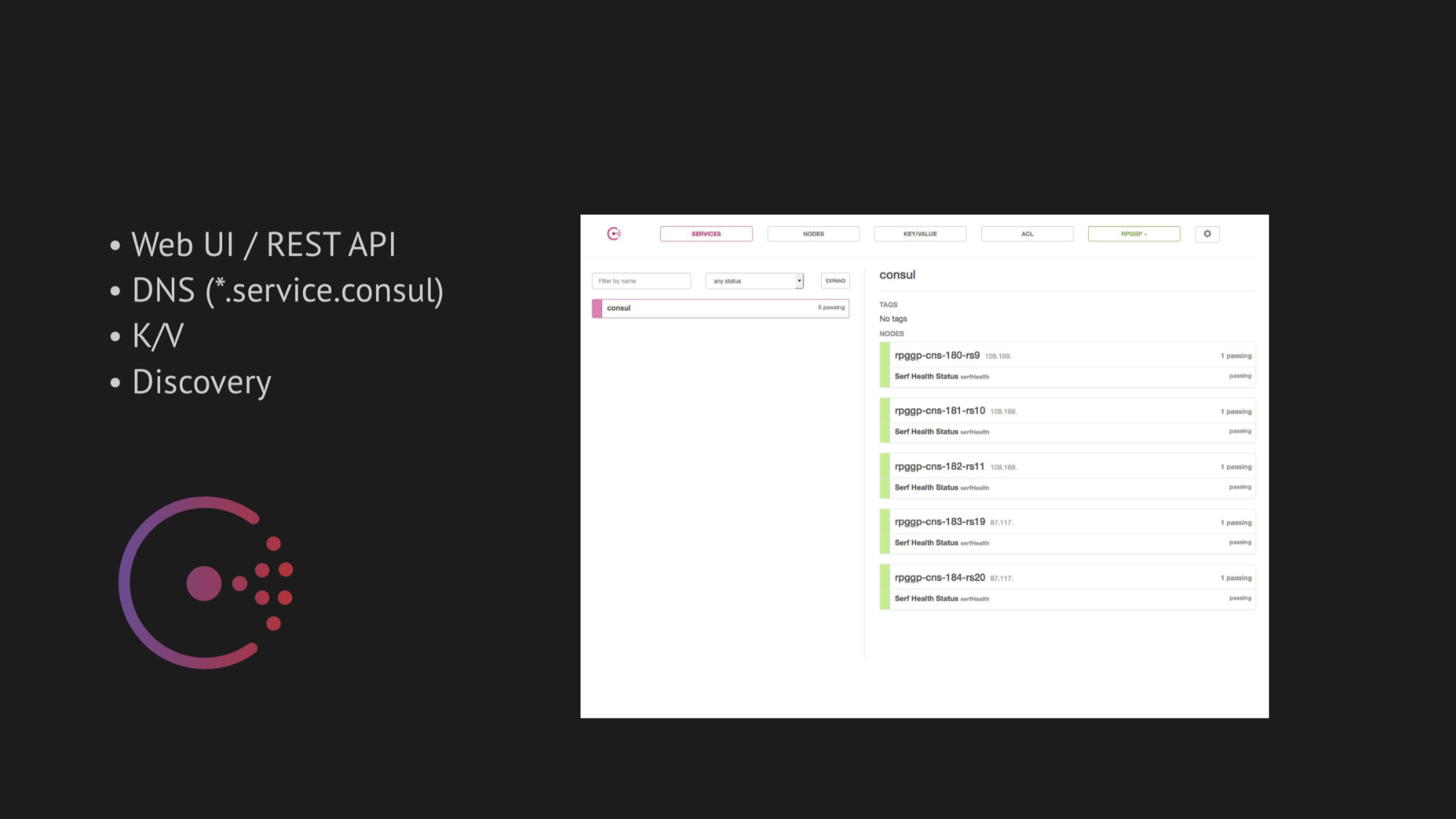
Центральной осью наших изысканий стал Consul от Hashicorp. Во-первых, нам его посоветовали, а во-вторых, нас очень привлекла его простота, приветливость и отличный стек технологии в одной коробке: discovery-сервис с healthcheck'ами, key-value хранилищем и самое важное, что мы хотели использовать — это DNS, который бы резолвил нам адреса из домена service.consul.
Также Consul предоставляет отличные Web UI и REST API для управления всем этим.
Что касается высокой доступности — для авто-failover'а мы выбрали две утилиты:

В случае с MHA for MySQL мы разливали агенты на ноды с базами данных, а те мониторили свое состояние. При фейле мастера был определенный таймаут, после чего производился стопслейв, чтобы сохранить согласованность и наш резервный мастер из появившегося мастера в неконсистентном состоянии не стал забирать данные. И мы дописали веб-хук в эти агенты, который регистрировал туда новый IP резервного мастера в самом Consul, после чего он попадал в выдачу DNS.
С Redis-sentinel все даже проще. Так как он сам выполняет львиную долю работы, все что нам оставалось сделать — это учесть в healthcheck'е то, чтобы Redis-sentinel проходил исключительно на мастер-ноде.
Сначала все работало отлично, как часы. На тестовом стенде у нас не возникло никаких проблем. Но стоило переместиться в естественную среду передачи данных нагруженного дата-центра, вспомнить о каких-нибудь OOM-kill`ах (это out of memory, при котором процесс убивается ядром системы) и восстановления сервиса или более изощренных вещах, которые влияют на доступность сервиса — как мы сразу получали серьезный риск ложных срабатываний или вообще отсутствия гарантированного срабатывания (если в попытке убежать от ложных срабатываний перекрутить какие-то проверки).

В первую очередь все упирается в сложность написания правильных healthcheck'ов. Кажется, что задача довольно тривиальная — проверь, что сервис запущен у тебя на сервере и пингани порт. Но, как показала дальнейшая практика, написание healthcheck'а при внедрении Consul — это крайне сложный и распределенный во времени процесс. Потому что очень многие факторы, которые влияют на доступность вашего сервиса в дата-центре, невозможно предусмотреть — они выявляются только по прошествии определенного времени.
Кроме того, дата-центр — это не статичная структура, в которую вы залились и он работает, как задумывалось. Но об этом мы, к сожалению (или к счастью), узнали только потом, а пока были воодушевлены и полны уверенности, что внедрим все на продакшн.

Что касается масштабирования, скажу коротко: мы пытались найти готовый велосипед, но все они рассчитаны на определенные архитектуры. И, как в случае с Jetpants, мы не могли соответствовать условиям, которые он предъявлял к архитектуре персистентного хранилища информации.
Поэтому мы подумали о собственном скриптовом обвязе и отложили этот вопрос. Решили действовать последовательно и начать с внедрения Consul.
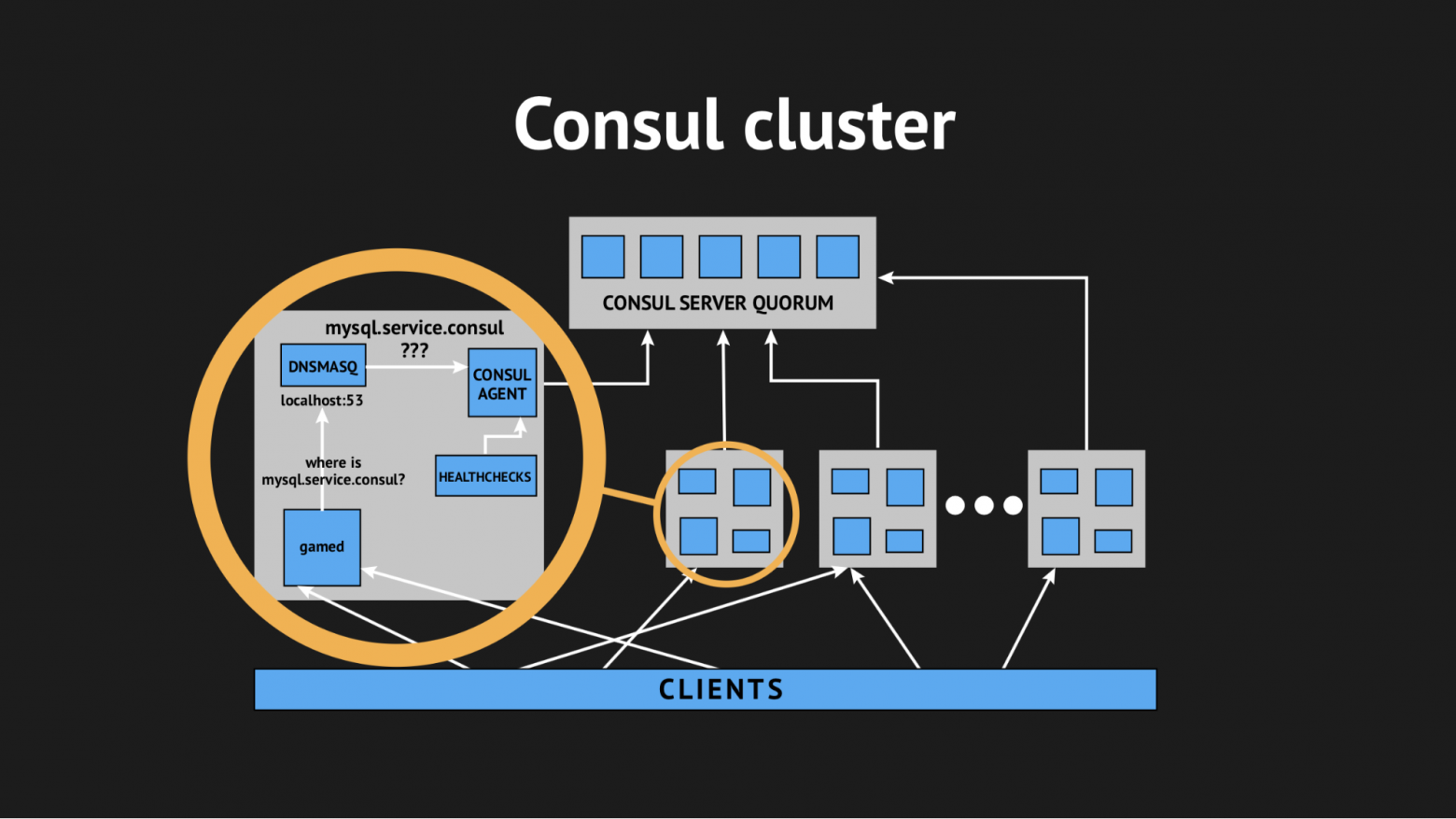
Consul — это децентрализованный, распределенный кластер, который работает на основе протокола gossip и алгоритма кoнсенсуса Raft.
У нас есть независимый экворум из пяти серверов (пять — чтобы избежать ситуации с split-brain). На каждую ноду мы разливаем Consul-агент в режиме агента и разливаем все healthcheck'и (т.е. не было такого, что на определенный сервера мы заливаем одни healthcheck'и, а на определенные сервера — другие). Healthcheck'и были написаны так, чтобы они проходил только там, где есть сервис.
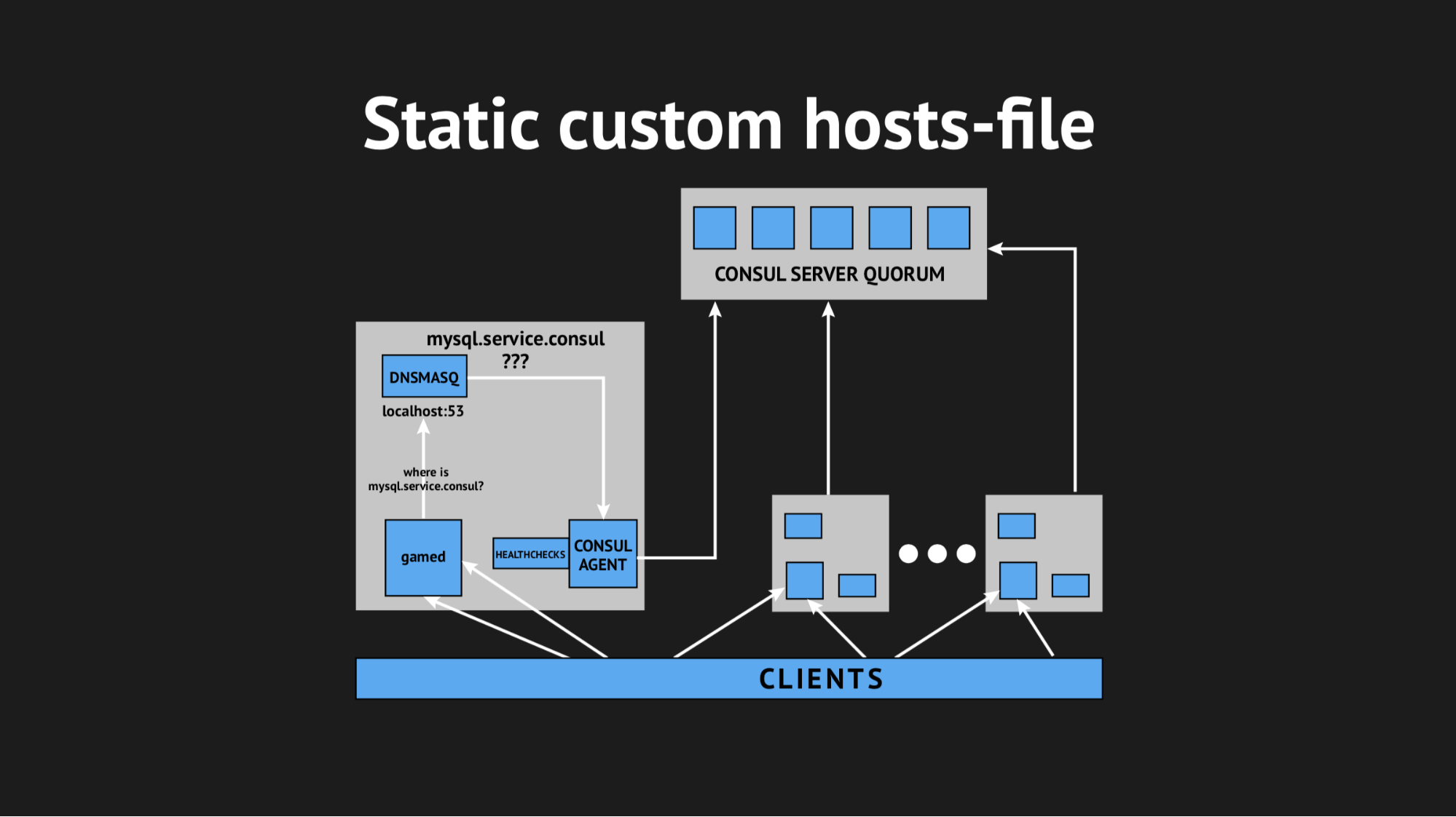
Также мы воспользовались еще одной утилитой, чтобы не пришлось учить свой backend резолвить адреса из какого-то определенного домена на нестандартном порту. Мы использовали Dnsmasq — она предоставляет возможность полностью прозрачно резолвить на нодах кластера те адреса, которые нам нужны (которые в реальном мире, так скажем, не существуют, а существуют исключительно в рамках кластера). Подготовили автоматический сценарий заливки на Ansible, залили все это в продакшн, подигали пространство имен, убедились, что все целостно. И, скрестив пальцы, перезалили наши backend'ы, которые обращались уже не по ip-адресам, а по этим именам из домена server.consul.
Все завелось с первого раза, нашей радости не было предела. Но радоваться было рано, потому что в течение часа мы подметили, что на всех нодах, где расположены наши backend'ы, показатель load average возрос от 0.7 до 1.0, что довольно жирный показатель.
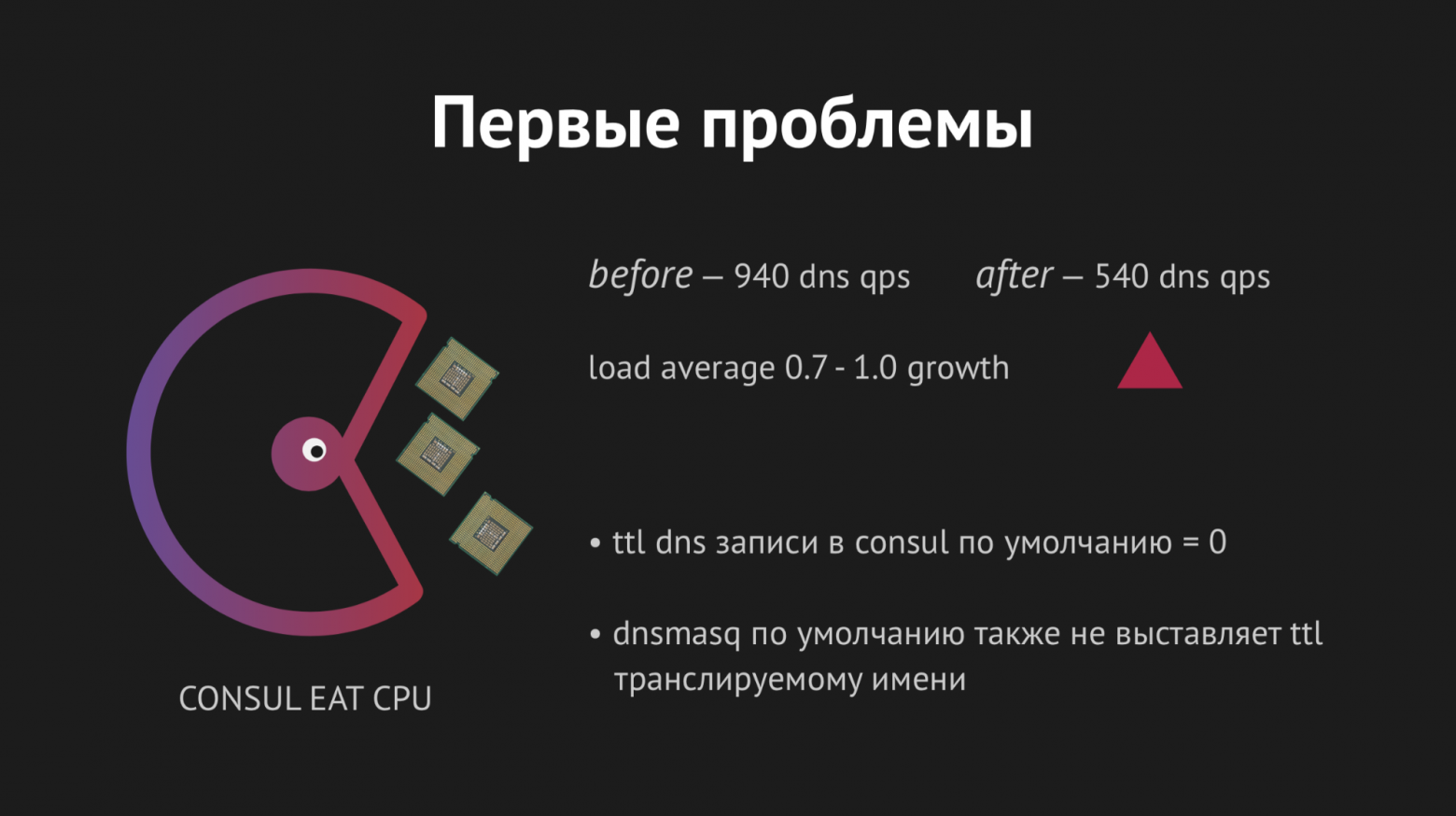
Я полез на сервера смотреть, что у нас происходит и стало очевидно, что CPU ест Consul. Тут мы начали разбираться, начали шаманить со strace (утилита для unix-систем, позволяющая отследить какие syscall выполняет процесс), сбрасывать статистику Dnsmasq, чтобы понять, что вообще происходит на этой ноде и оказалось, что мы упустили очень важный момент. Планируя интеграцию, мы упустили кэширование DNS-записей и получилось, что наш backend на каждое свое телодвижение дергал Dnsmasq, а та в свою очередь обращалась к Consul и все это выливалось в нехилые 940 DNS-запросов в секунду.
Выход казался очевидным — достаточно покрутить ttl и все поправится. Но тут нельзя было быть фанатичным, потому что мы хотели внедрить эту структуру, чтобы получить динамическое легкоуправляемое и быстроизменяемое пространство имен (поэтому поставить, например, 20 минут мы не могли). Мы выкрутили ttl до предельных для нас оптимальных величин, удалось снизить показатель запросов в секунду до 540, но это никак не отразилось на показателе потребления CPU.
Тогда мы решили выкрутиться по-хитрому, с помощью кастомного hosts-file.
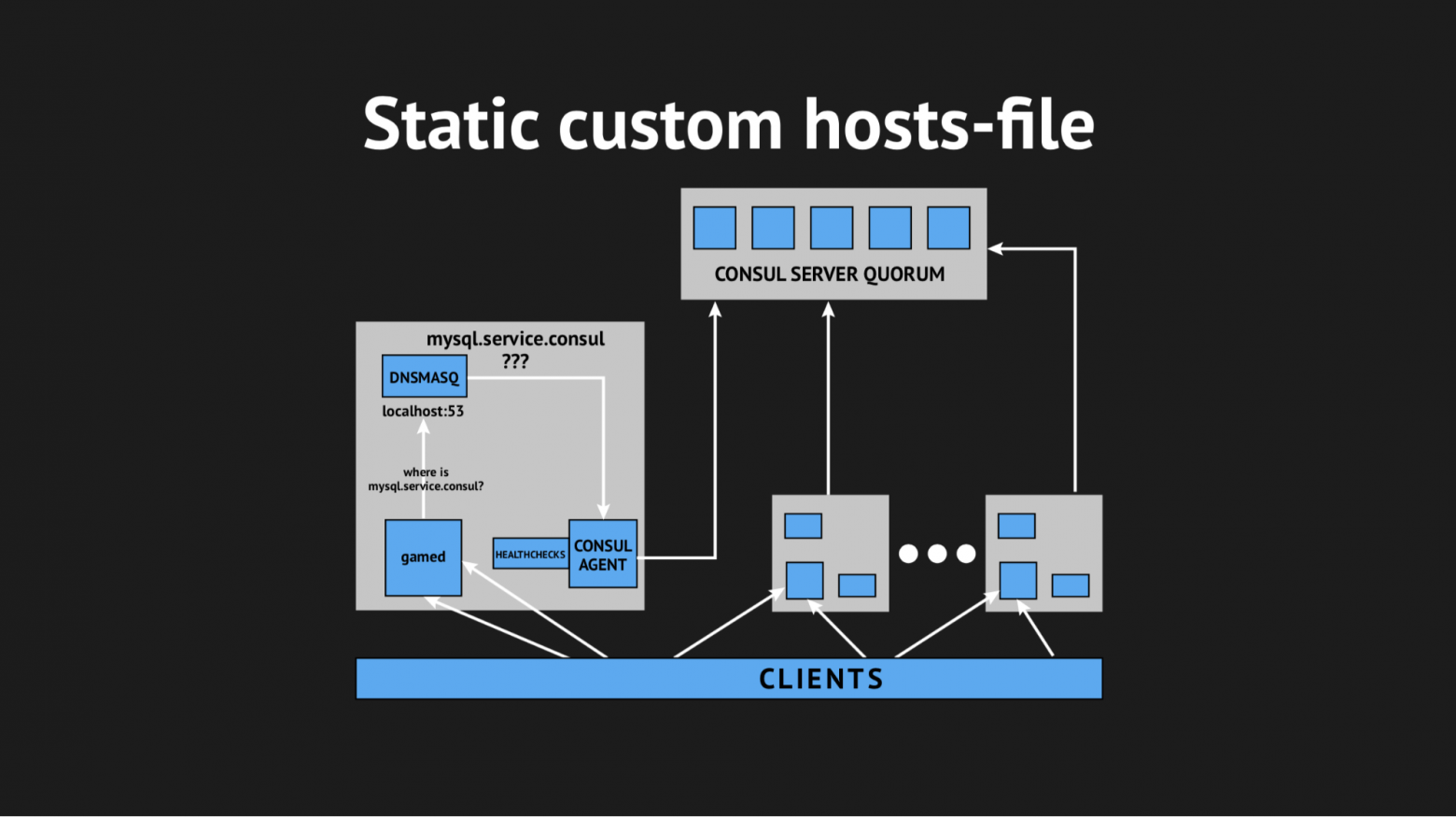
Хорошо, что у нас все для этого было: прекрасная template-система от Consul, которая на основе состояния кластера и template-сценария генерирует файл любого вида, любой конфиг — всё, что хотите. Помимо этого у Dnsmasq есть конфигурационный параметр addn-hosts, который позволяет использовать несистемный hosts-файл в качестве такого же дополнительного hosts-файла.
Что мы и сделали, опять подготовили сценарий в Ansible, залили в продакшн и это стало выглядеть примерно вот так:
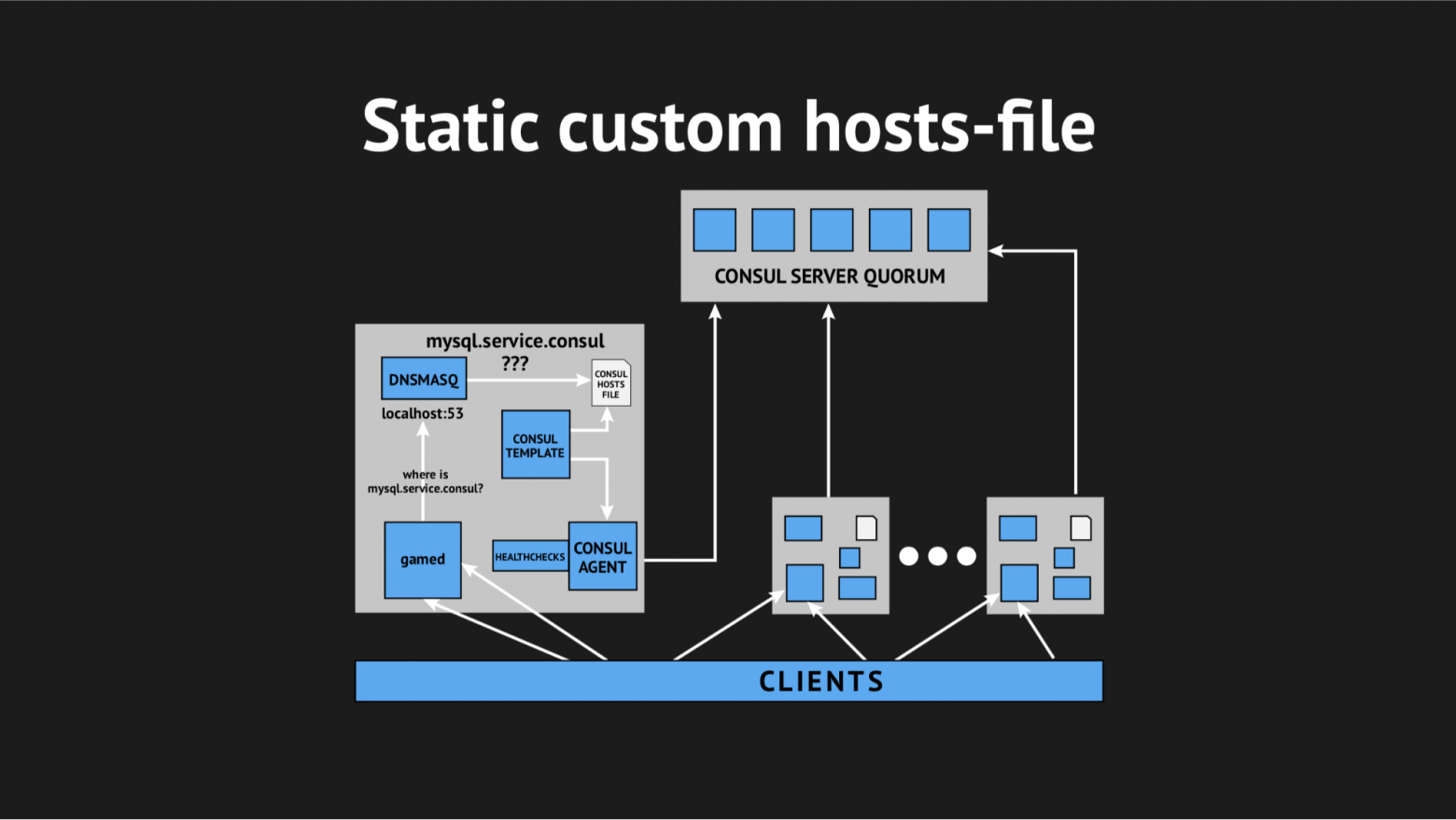
Появился дополнительный элемент и статический файл на диске, который достаточно оперативно перегенерируется. Теперь цепочка выглядела довольно просто: gamed обращается к Dnsmasq, а та в свою очередь (вместо того, чтобы дергать Consulа-агент, который будет спрашивать у серверов, где у нас находится та или иная нода) просто смотрела файл. Это и решило проблему с потреблением CPU Consul'ом.
Теперь все стало выглядеть, как мы и планировали — абсолютно прозрачно для нашего продакшена, практически не потребляя ресурсов.
Мы изрядно замучались в тот день и с большой опаской разошлись по домам. Опасались не зря, потому что ночью меня разбудил алерт от мониторинга и оповестил, что у нас произошел довольно масштабный (хоть и кратковременный) всплеск ошибок.
Разбираясь утром с логами, я увидел, что все ошибки одного и того же вида unknown host. Было непонятно, почему Dnsmasq не может из файла зарезолвить тот или иной сервис — такое ощущение, что его вообще не существует. Чтобы попробовать понять, что происходит, я добавил кастомную метрику на перегенирацию файла — теперь я точно знал время, когда он перегенерируется. Помимо этого, в самом Consul template есть прекрасный параметр бэкапирование, т.е. можно видеть предыдущее состояние перегенерированного файла.
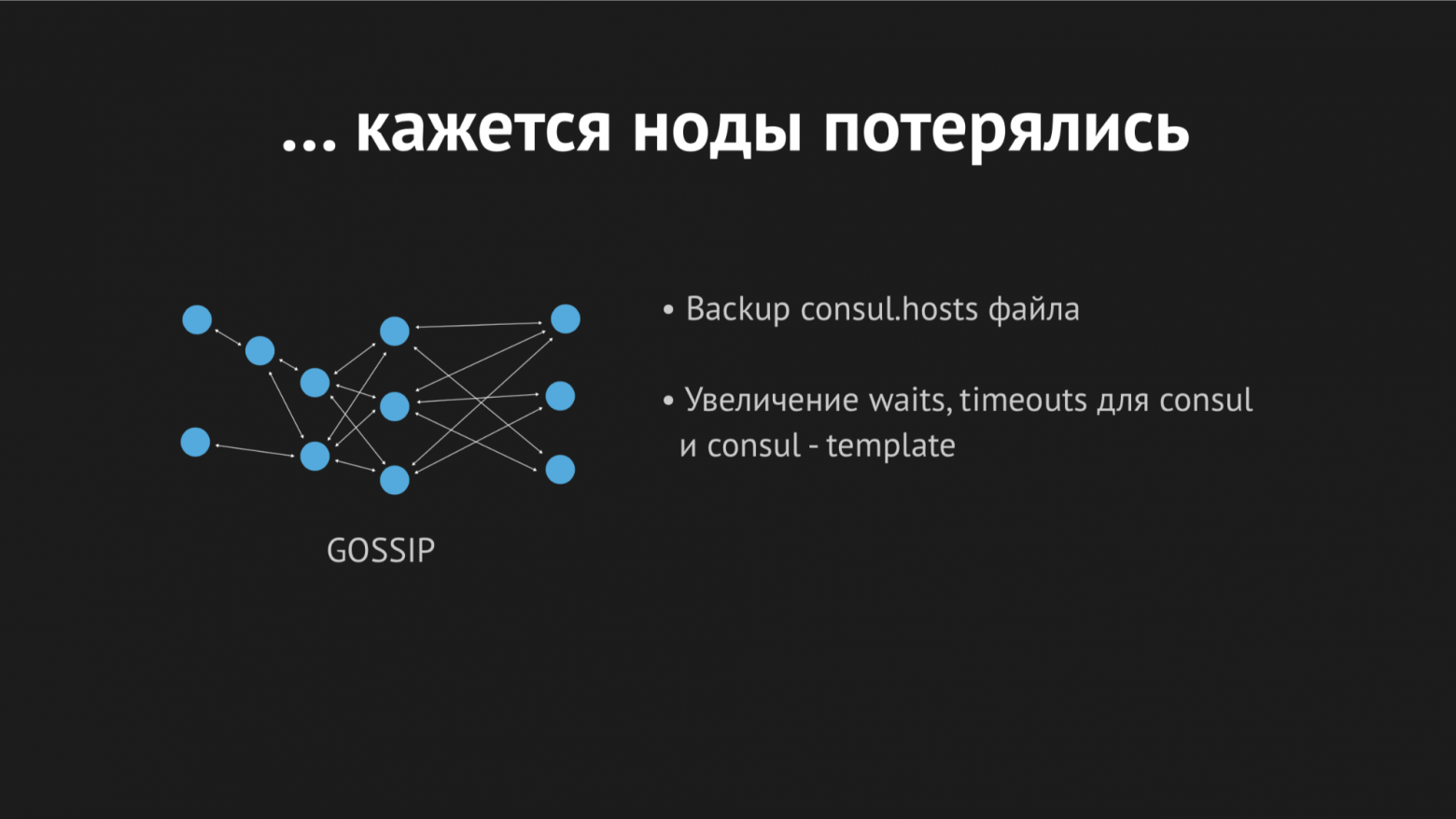
В течение дня инцидент еще несколько раз повторился и стало понятно, что в некий момент времени (хотя он носил спорадический, бессистемный характер) у нас перегенирируется hosts-файл без определенных сервисов. Оказалось, что в конкретном дата-центре (не буду делать антирекламу) довольно нестабильные сети — из-за флопинга сети у нас абсолютно непредсказуемо переставали проходить healthcheck'и, либо даже ноды вываливались из кластера. Выглядело это примерно так:
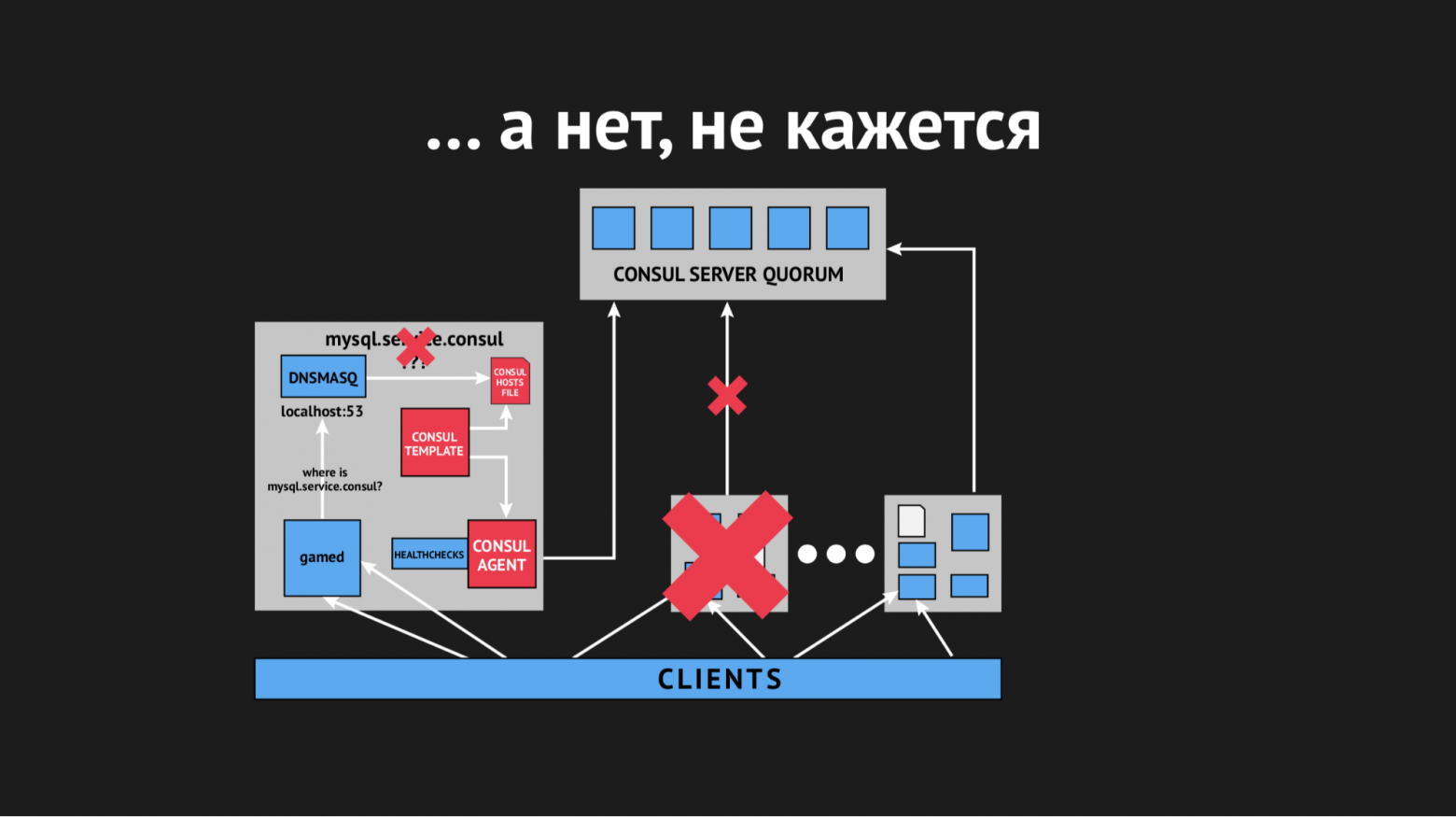
Нод вываливался из кластера, Consul-агент сразу же об этом оповещался и Consul template сразу перегенерировал hosts-файл без требуемого нам сервиса. Это было вообще неприемлемо, потому что проблема смешная: если несколько секунд сервис недоступен — настрой таймауты и ретраи (один раз не подключились, а второй раз уже получилось). Мы же новой структурой в продашкене спровоцировали ситуацию, когда сервис просто исчезает из вида и никакой возможности к нему подключиться не было.
Начали думать, что с этим делать и крутить в Consul параметр таймаутов, после которых идентифицируется, через сколько вываливается нода. Достаточно небольшим показателем нам удалось решить эту проблему, ноды перестали вываливаться, но с healthcheck'ами это не помогло.
Мы начали думать подбирать разные параметры для healthcheck'ов, пытаясь хоть как-то понять, когда и как это происходит. Но из-за того, что все происходило спорадически и непредсказуемо, нам это не удавалась это сделать.
Тогда пошли в Consul template и решили сделать для него таймаут, после которого он реагирует на изменение состояния кластера. Опять же здесь нельзя было быть фанатичным, потому что мы могли прийти к ситуации, когда результат будет не лучше, чем классический DNS, когда мы стремились к совершенно другому.
И тут на помощь в очередной раз пришел наш техдиректор и сказал: «Ребят, давайте попробуем отказаться от всей этой интерактивщины, у нас все в продакшене и нет времени на изыскания, нам нужно решать этот вопрос. Давайте воспользуемся простыми и понятными вещами». Так мы пришли к концепции использования key-value хранилища, как источника для генерации hosts-файла.
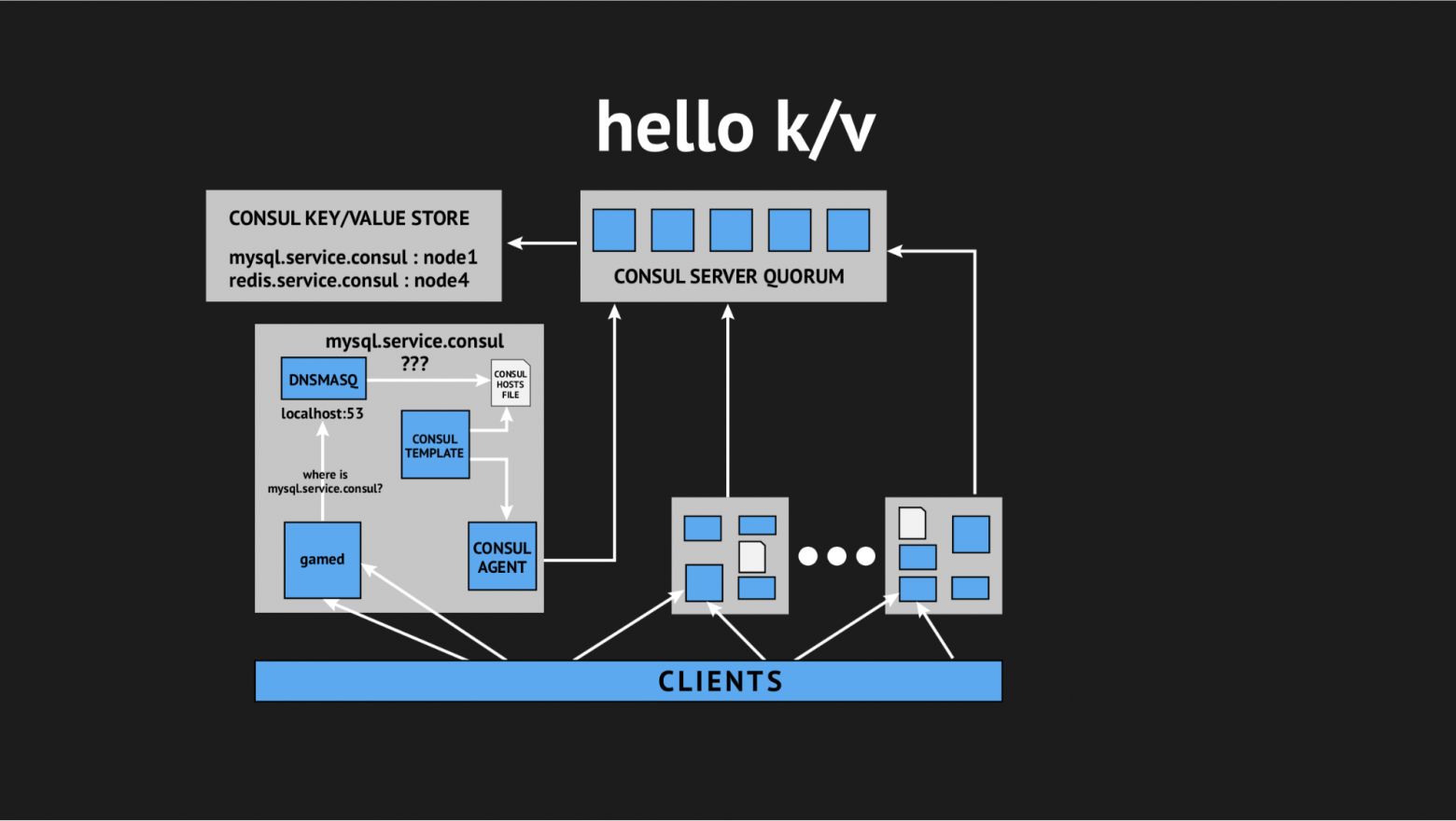
Как это выглядит: мы отказываемся от всех динамических healthcheck'ов, переписываем наш template-сценарий, чтобы он генерировал файл на основании данных, записанных в key-value хранилище. В key-value хранилище мы описываем всю нашу инфраструктуру в виде имя ключа (это имя требуемого нам сервиса) и значения ключа (это имя ноды в кластере). Т.е. если нода присутствует в кластере, то мы очень легко получаем ее IP-адрес и записываем его в hosts-файл.
Мы все оттестили, залили в продакшн и это стало серебряной пулей в конкретной ситуации. Мы изрядно опять же замучившиеся за целый день пошли по домам, но вернулись уже отдохнувшие, воодушевленные, потому что больше эти проблемы не повторялись и уже на протяжение года в подакшене не повторяются. Из чего я лично делаю вывод, что это было правильное решение (конкретно для нас).
Итак. Мы наконец-то добились чего хотели и организовали динамическое пространство имен для наших backend'ов. Дальше мы пошли в сторону обеспечения высокой доступности.
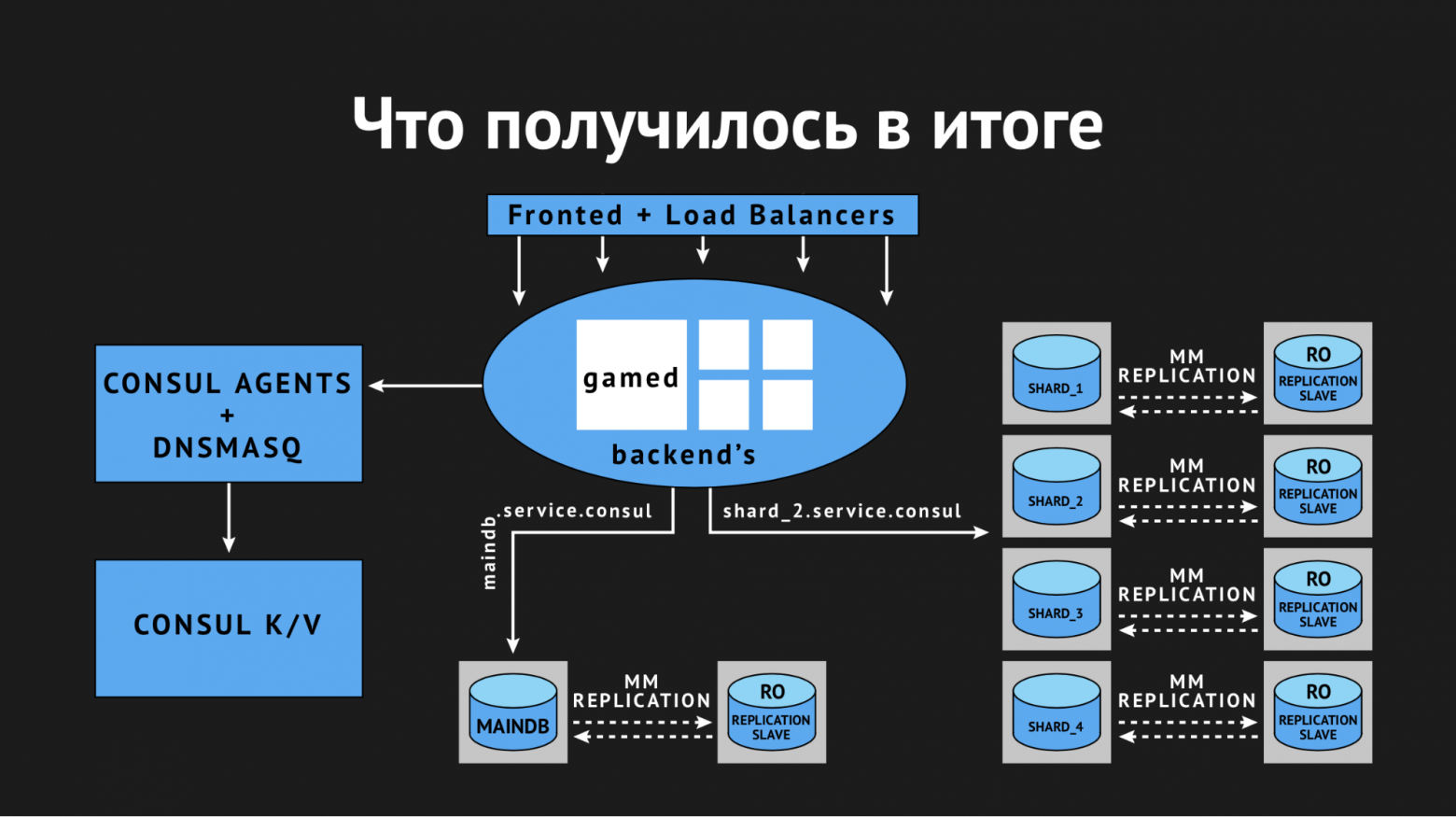
Но дело в том, что изрядно напугавшись интеграции Consul и из-за проблем, с которыми мы столкнулись, мы подумали и решили, что внедрять авто-failover'ы — это не такое уж и хорошее решение, потому что мы опять рискуем ложными срабатываниями или несрабатываниями. Этот процесс непрозрачен и неконтролируем.
Поэтому мы пошли по более простому (или сложному) пути: мы решили оставить failover на совести у дежурного администратора, но дали ему в руки еще один дополнительный инструмент. Мы заменили мастер-слэйв репликацию на мастер-мастер репликацию в режиме Read only. Это снимает огромное количество головной боли в процессе failover'ов — когда у вас выпадает мастер, все, что вам нужно сделать, это поменять значение в k/v-хранилище с помощью Web UI или команды в API и до этого убрать режим Read only на резервном мастере.
После того как инцидент исчерпан, мастер выходит на связь и автоматически приходит в согласованное состояние без каких-либо вообще лишних действий. На этом варианте мы остановились и используем его по-прежнему — для нас это максимально удобно, а самое главное максимально просто, понятно и контролируемо.
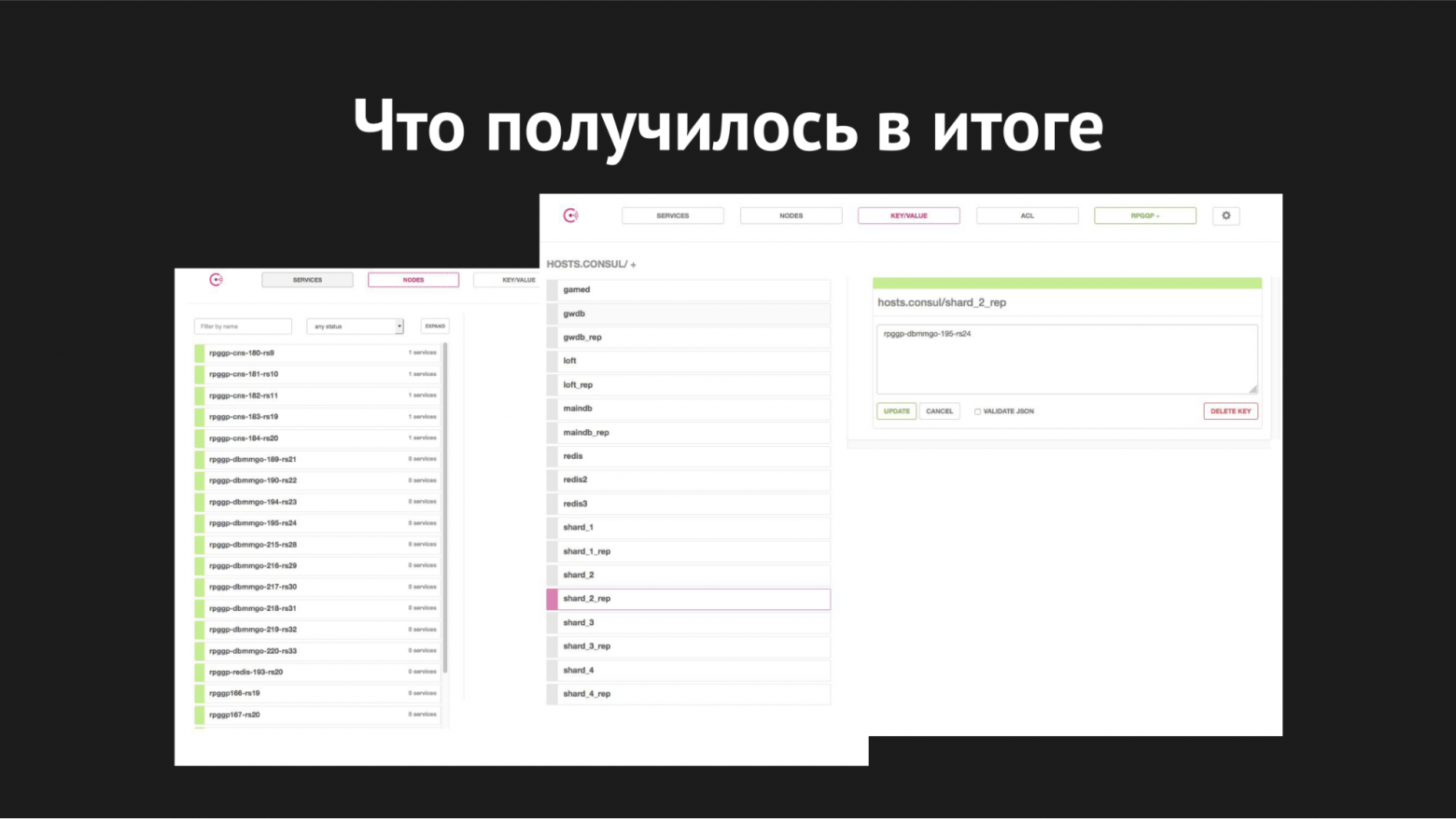
Веб-интерфейс Consul
Справа изображено k/v-хранилище и видны наши сервисы, которые используем в работе gamed; значение — это имя нода.
Что касается масштабирования — внедрять это мы начали, когда шардам становилось уже тесно на одном сервере, базы росли, становились медленными, количество игроков увеличивалось, мы свопились (swap) и перед нами стояла задача развести все шарды по своим разным отдельным серверам.
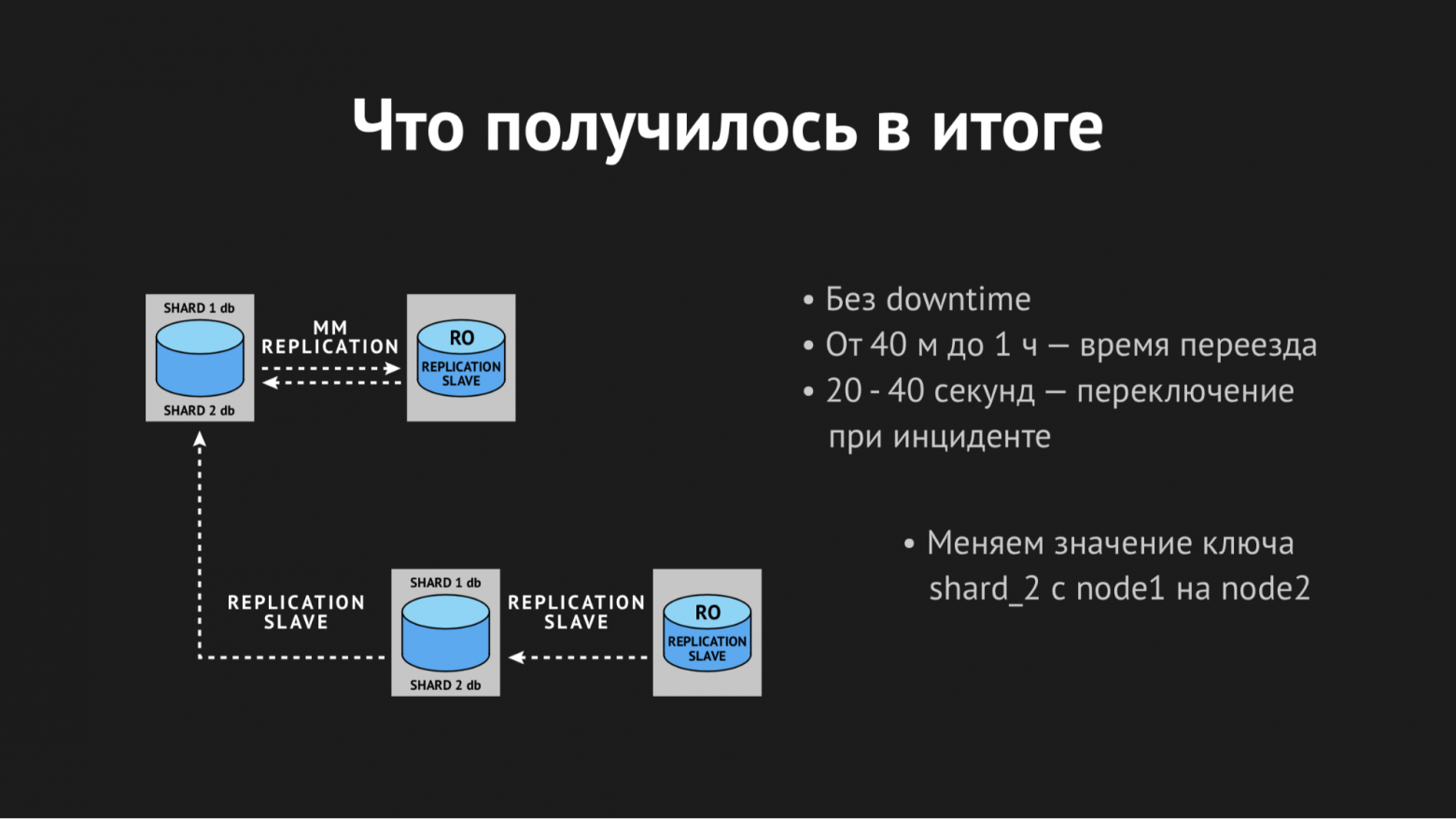
Как это выглядело: с помощью утилиты XtraBackup мы восстанавливали на новой паре серверов наш бэкап, после чего новый мастер вешали слэйвом на старый. Он приходил в согласованное состояние, мы меняли значение ключа в k/v-хранилище с имени ноды старого мастера на имя ноды нового мастера. Потом (когда мы считали, что все прошло корректно и все gamed со своими селектами, апдейтами, инсертами ушли на новый мастер) оставалось только убить репликацию и сделать заветный drop database на продакшене, как мы все любим делать с ненужными базами.
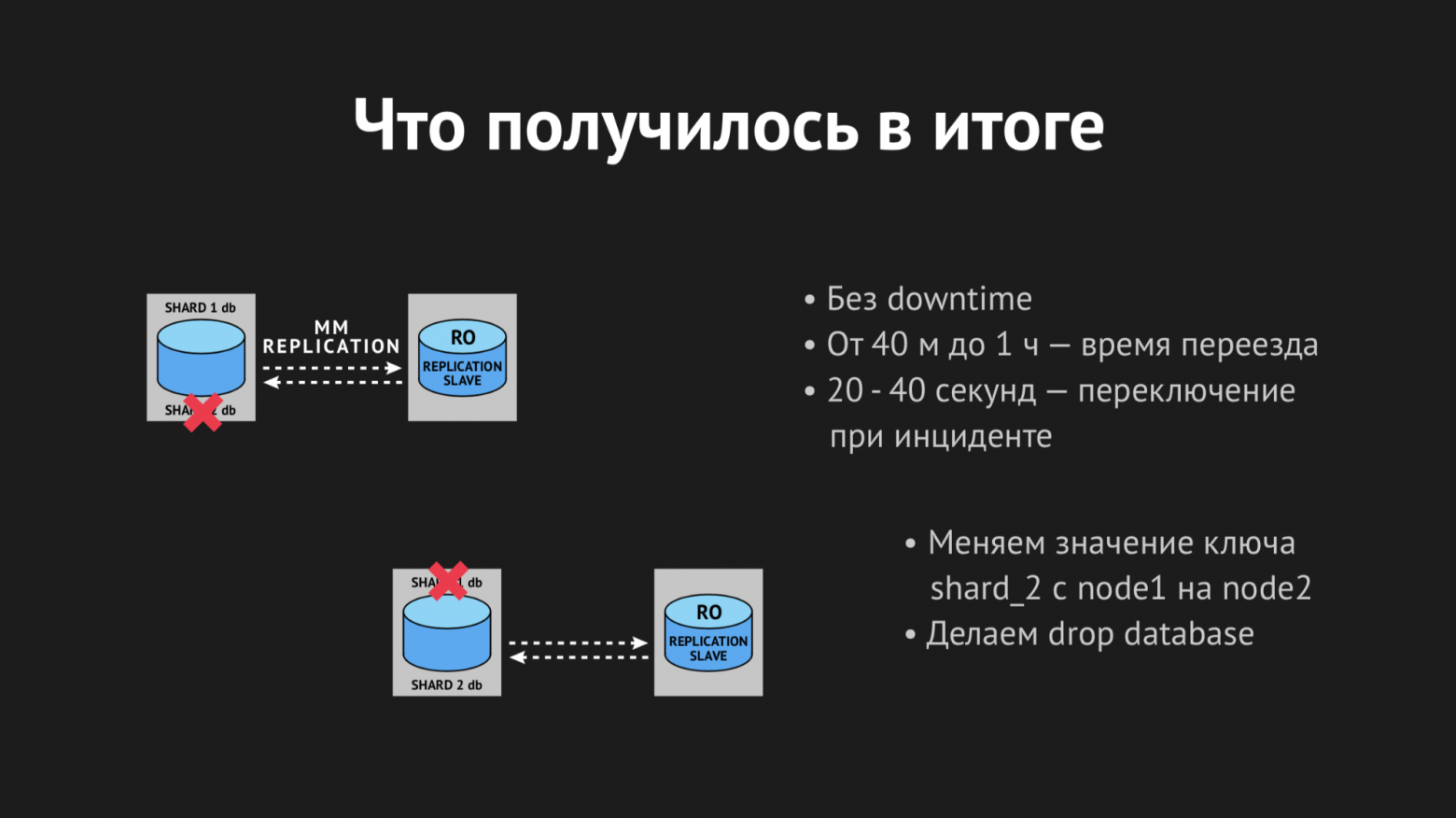
Таким образом мы получали разъехавшиеся шарды. Весь процесс переезда занимал от 40 минут до часа и не вызывал никого даунтайма, был полностью прозрачен для наших backend'ов и само собой был полностью прозрачен для игроков (за исключением того, что как только они переехали — им играть стало легче и приятнее).
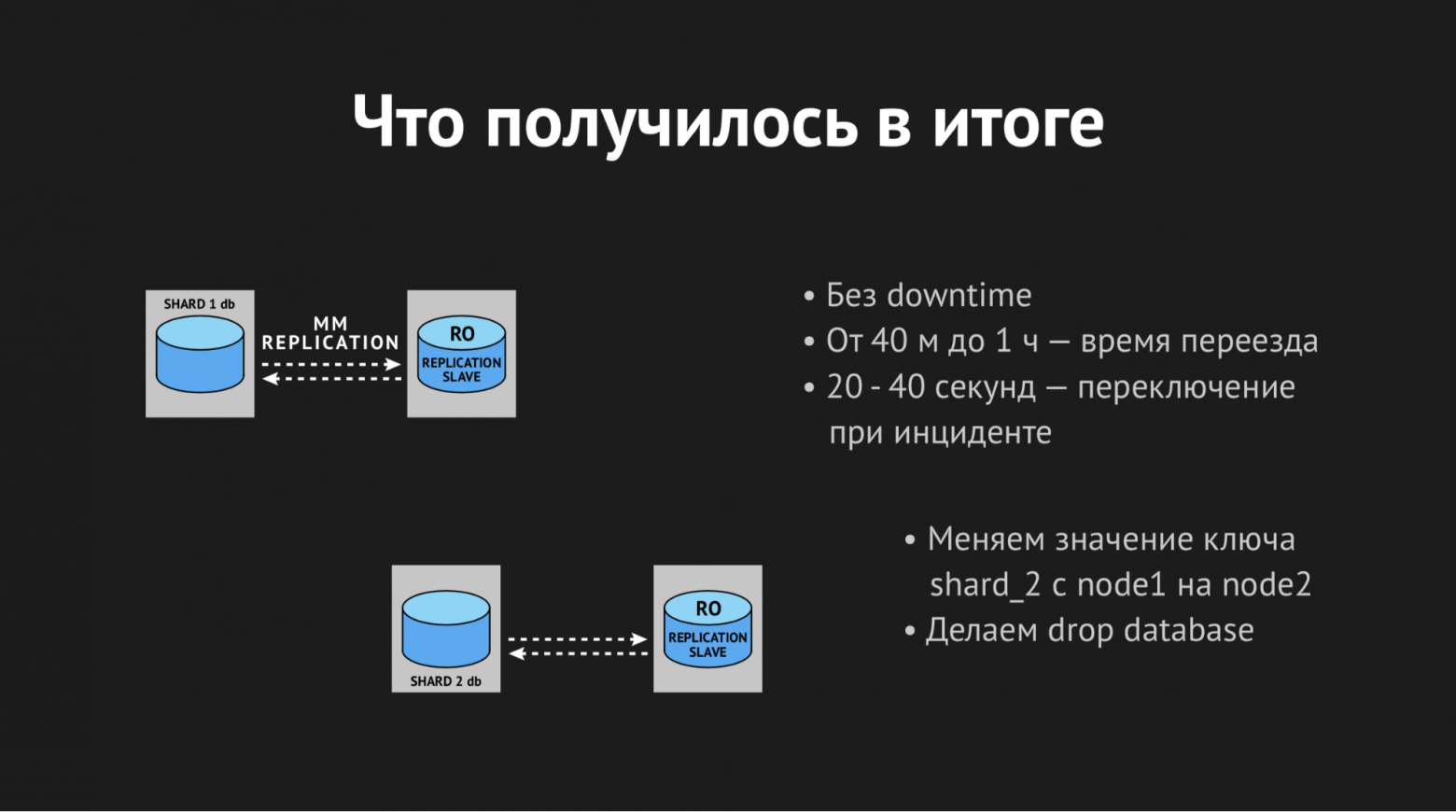
Что касается процессов failover'а, то здесь время переключения — от 20 до 40 секунд плюс время реакции дежурного сисадмина. Вот примерно так сейчас все это выглядит у нас.
Чтобы я хотел сказать в заключение — к сожалению, наши надежды на абсолютную, всеобъемлющую автоматизацию разбились о суровую реальность среды передачи данных в нагруженном дата-центре и рандомных факторов, которые мы не могли предусмотреть.
Во-вторых, это лишний раз нас научило, что лучше простая и проверенная синица в руках вашего сисадмина, чем новомодный самореагирующий, самомасштабирующий журавль где-то за облаками, что вы даже не понимаете, то ли он там разваливается на части, то ли действительно начал масштабироваться.
Внедрение какой-либо инфраструктуры, автоматизации в ваш продакшн не должно вызывать лишней головной боли у персонала, который его обслуживает; оно не должно значительно повышать стоимость поддержания продакшна инфраструктуры — решение должно быть простым, понятным, прозрачным для ваших клиентов, удобным и контролируемым.
Как вы пишите k/v с серверами — скрипт или вы просто патчите его?
K/v-хранилище находится у нас на Consul-серверах и либо что-то удаляем оттуда, либо пополняем с помощью http-запросов RESTful API или Web UI.
Я этим докладом хотел донести, что сейчас почему-то очень часто преследует идеология автоматизации всего на свете с лютым фанатизмом без понимания, что это иногда усложняет жизнь, а не упрощает.
Почему вы балансируете между шардами через базы данных, почему не тот же Redis?
Это исторически сложившееся решение и я забыл сказать, что сейчас концепция чуть-чуть изменилась.
Во-первых, мы вынесли конфиги и теперь нам не нужно перезаливать backend. Во-вторых, мы ввели параметр в сами backend'ы, которые и есть главное шардирующее звено — это они распределяют игроков. Т.е. если у нас появляется новая сущность игрока, он делает запись в MAINDB и потом уже сохраняет данные на тот шард, который он выбрал. А выбирает он сейчас его по весовым коэффициентам. И это очень быстро и легко управляется и на данным момент не возникает потребности взять и использовать какую-то другую технологию, потому что это все сейчас работает быстро.
Но если мы столкнемся с какой-то проблемой, то возможно будет лучше воспользоваться быстрым inmemory key-value хранилищем или еще чем-то.
Какая у вас база?
Мы используем форк MySQL — Percona server.
А вы не пробовали ее объединить в кластер и за счет этого балансировать? Если бы у вас была Maria, которая тот же самый MHA for MySQL, у него есть Galera.
У нас была на вооружении Galera. Был еще один дата-центр для проекта «Гильдии Героев» для Азии и там мы использовали Galera и она часто дает очень неприятный сбой, ее периодически нужно руками поднимать. Имея такой опыт использования конкретно этой технологии, нам пока не очень хочется ее использовать.
Опять же стоит понимать, что внедрение любой технологии — это не просто потому что вам хочется сделать лучше, а потому что у вас есть потребность в этом, вам нужно выйти из какой-то сложившейся ситуации, либо вы уже спрогнозировали, что ситуация скоро случится и вы выбираете конкретную технологию, чтобы ее внедрять.
Я администрирую продакшн-инфраструктуру в студии BIT.GAMES и расскажу историю внедрения консула от Hashicorp в наш проект «Гильдия Героев» — fantasy RPG с асинхронным pvp для мобильных устройств. Выпускаемся на Google Play, App Store, Samsung, Amazon. DAU около 100 000, online от 10 до 13 тысяч. Игру делаем на Unity, поэтому клиент пишем на С# и используем свой собственный скриптовый язык BHL для игровой логики. Серверную часть пишем на Golang (перешли на него с PHP). Дальше — схематичная архитектура нашего проекта.

На самом деле сервисов намного больше, здесь только основы игровой логики.
Итак, что у нас есть. Из Stateless-сервисов это:
- nginx, который мы используем в роли Frontend и Load Balancers и по весовым коэффициентам распределяем клиентов на наши backend'ы;
- gamed — backend'ы, скомпилированные приложения из Go. Это центральная ось нашей архитектуры, они выполняют львиную долю работы и связываются со всеми остальными backend-сервисами.
Из Stateful-сервисов основные у нас это:
- Redis, который используем для кэширования «горячей» информации (также мы используем его для организации внутриигрового чата и хранения нотификаций для наших игроков);
- Percona Server for Mysql — хранилище персистентной информации (наверное, самое большое и неповоротливое в любых архитектурах). Мы используем форк MySQL и вот о нем сегодня поговорим подробнее.
В процессе проектирования мы (как и все) надеялись, что проект будет успешным и предусмотрели механизм шардирования. Он представляет из себя две сущности баз данных MAINDB и сами шарды.

MAINDB это своего рода оглавление — в нем хранится информация о том, на каком конкретно шарде хранятся данные о прогрессе игрока. Таким образом полная цепочка получения информации выглядит примерно так: клиент обращается к фронтенду, тот в свою очередь перераспределяет его по весовому коэффициенту на один из backend'ов, backend идет в MAINDB, локализует шард игрока, после чего делает выборку данных непосредственно самого шарда.
Но когда мы проектировали, то не были большим проектом, поэтому приняли решение сделать шарды шардами только номинально. Они все находились на одном физическом сервере и скорее это партицирование по базам данных в рамках одного сервера.
Для резервирования мы использовали классическую мастер-слэйв репликацию. Это было не очень удачное решение (чуть позже скажу почему), но самый главный минус той архитектуры был в том, что все наши backend'ы знали о других backend-сервисах исключительно по IP-адресам. И в случае очередной нелепой аварии в дата-центре по типу «извините, наш инженер задел кабель на вашем сервере при обслуживании другого и мы очень долго разбирались, почему же ваш сервер не выходит на связь» от нас требовались немалые телодвижения. Во-первых, это пересборка и презаливака backend'ов с IP резервного сервера за место того, который вышел из строя. Во-вторых, после инцидента необходимо восстановить из backup’a с резерва наш мастер, потому что он находился в несогласованном состоянии и привести его в согласованное состояние по средствам той же самой репликации. После чего мы снова пересобирали backend'ы и снова перезаливали. Все это, конечно, вызывало даунтайм.
Настал момент, когда наш техдиректор (за что спасибо ему огромное) сказал: «Ребят, хватит терпеть, надо что-то менять, давайте искать выходы». В первую очередь мы хотели добиться простого, понятного, а самое главное — легко управляемого процесса масштабирования и миграции с места на место наших баз данных в случае необходимости. Кроме того, мы хотели добиться высокой доступности, автоматизировав failover'ы.
Центральной осью наших изысканий стал Consul от Hashicorp. Во-первых, нам его посоветовали, а во-вторых, нас очень привлекла его простота, приветливость и отличный стек технологии в одной коробке: discovery-сервис с healthcheck'ами, key-value хранилищем и самое важное, что мы хотели использовать — это DNS, который бы резолвил нам адреса из домена service.consul.
Также Consul предоставляет отличные Web UI и REST API для управления всем этим.
Что касается высокой доступности — для авто-failover'а мы выбрали две утилиты:
- MHA for MySQL
- Redis-sentinel

В случае с MHA for MySQL мы разливали агенты на ноды с базами данных, а те мониторили свое состояние. При фейле мастера был определенный таймаут, после чего производился стопслейв, чтобы сохранить согласованность и наш резервный мастер из появившегося мастера в неконсистентном состоянии не стал забирать данные. И мы дописали веб-хук в эти агенты, который регистрировал туда новый IP резервного мастера в самом Consul, после чего он попадал в выдачу DNS.
С Redis-sentinel все даже проще. Так как он сам выполняет львиную долю работы, все что нам оставалось сделать — это учесть в healthcheck'е то, чтобы Redis-sentinel проходил исключительно на мастер-ноде.
Сначала все работало отлично, как часы. На тестовом стенде у нас не возникло никаких проблем. Но стоило переместиться в естественную среду передачи данных нагруженного дата-центра, вспомнить о каких-нибудь OOM-kill`ах (это out of memory, при котором процесс убивается ядром системы) и восстановления сервиса или более изощренных вещах, которые влияют на доступность сервиса — как мы сразу получали серьезный риск ложных срабатываний или вообще отсутствия гарантированного срабатывания (если в попытке убежать от ложных срабатываний перекрутить какие-то проверки).

В первую очередь все упирается в сложность написания правильных healthcheck'ов. Кажется, что задача довольно тривиальная — проверь, что сервис запущен у тебя на сервере и пингани порт. Но, как показала дальнейшая практика, написание healthcheck'а при внедрении Consul — это крайне сложный и распределенный во времени процесс. Потому что очень многие факторы, которые влияют на доступность вашего сервиса в дата-центре, невозможно предусмотреть — они выявляются только по прошествии определенного времени.
Кроме того, дата-центр — это не статичная структура, в которую вы залились и он работает, как задумывалось. Но об этом мы, к сожалению (или к счастью), узнали только потом, а пока были воодушевлены и полны уверенности, что внедрим все на продакшн.

Что касается масштабирования, скажу коротко: мы пытались найти готовый велосипед, но все они рассчитаны на определенные архитектуры. И, как в случае с Jetpants, мы не могли соответствовать условиям, которые он предъявлял к архитектуре персистентного хранилища информации.
Поэтому мы подумали о собственном скриптовом обвязе и отложили этот вопрос. Решили действовать последовательно и начать с внедрения Consul.

Consul — это децентрализованный, распределенный кластер, который работает на основе протокола gossip и алгоритма кoнсенсуса Raft.
У нас есть независимый экворум из пяти серверов (пять — чтобы избежать ситуации с split-brain). На каждую ноду мы разливаем Consul-агент в режиме агента и разливаем все healthcheck'и (т.е. не было такого, что на определенный сервера мы заливаем одни healthcheck'и, а на определенные сервера — другие). Healthcheck'и были написаны так, чтобы они проходил только там, где есть сервис.
Также мы воспользовались еще одной утилитой, чтобы не пришлось учить свой backend резолвить адреса из какого-то определенного домена на нестандартном порту. Мы использовали Dnsmasq — она предоставляет возможность полностью прозрачно резолвить на нодах кластера те адреса, которые нам нужны (которые в реальном мире, так скажем, не существуют, а существуют исключительно в рамках кластера). Подготовили автоматический сценарий заливки на Ansible, залили все это в продакшн, подигали пространство имен, убедились, что все целостно. И, скрестив пальцы, перезалили наши backend'ы, которые обращались уже не по ip-адресам, а по этим именам из домена server.consul.
Все завелось с первого раза, нашей радости не было предела. Но радоваться было рано, потому что в течение часа мы подметили, что на всех нодах, где расположены наши backend'ы, показатель load average возрос от 0.7 до 1.0, что довольно жирный показатель.
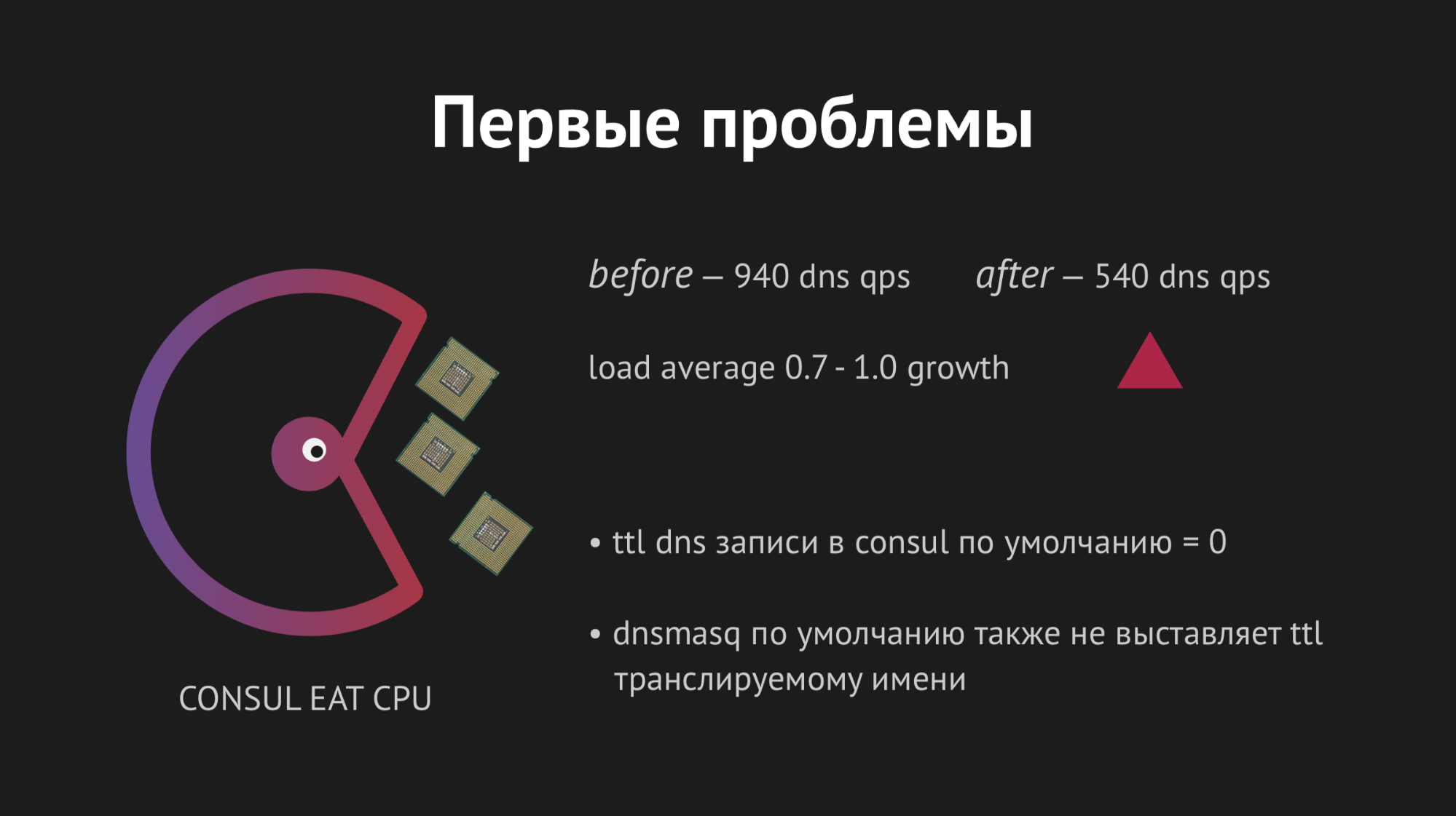
Я полез на сервера смотреть, что у нас происходит и стало очевидно, что CPU ест Consul. Тут мы начали разбираться, начали шаманить со strace (утилита для unix-систем, позволяющая отследить какие syscall выполняет процесс), сбрасывать статистику Dnsmasq, чтобы понять, что вообще происходит на этой ноде и оказалось, что мы упустили очень важный момент. Планируя интеграцию, мы упустили кэширование DNS-записей и получилось, что наш backend на каждое свое телодвижение дергал Dnsmasq, а та в свою очередь обращалась к Consul и все это выливалось в нехилые 940 DNS-запросов в секунду.
Выход казался очевидным — достаточно покрутить ttl и все поправится. Но тут нельзя было быть фанатичным, потому что мы хотели внедрить эту структуру, чтобы получить динамическое легкоуправляемое и быстроизменяемое пространство имен (поэтому поставить, например, 20 минут мы не могли). Мы выкрутили ttl до предельных для нас оптимальных величин, удалось снизить показатель запросов в секунду до 540, но это никак не отразилось на показателе потребления CPU.
Тогда мы решили выкрутиться по-хитрому, с помощью кастомного hosts-file.
Хорошо, что у нас все для этого было: прекрасная template-система от Consul, которая на основе состояния кластера и template-сценария генерирует файл любого вида, любой конфиг — всё, что хотите. Помимо этого у Dnsmasq есть конфигурационный параметр addn-hosts, который позволяет использовать несистемный hosts-файл в качестве такого же дополнительного hosts-файла.
Что мы и сделали, опять подготовили сценарий в Ansible, залили в продакшн и это стало выглядеть примерно вот так:
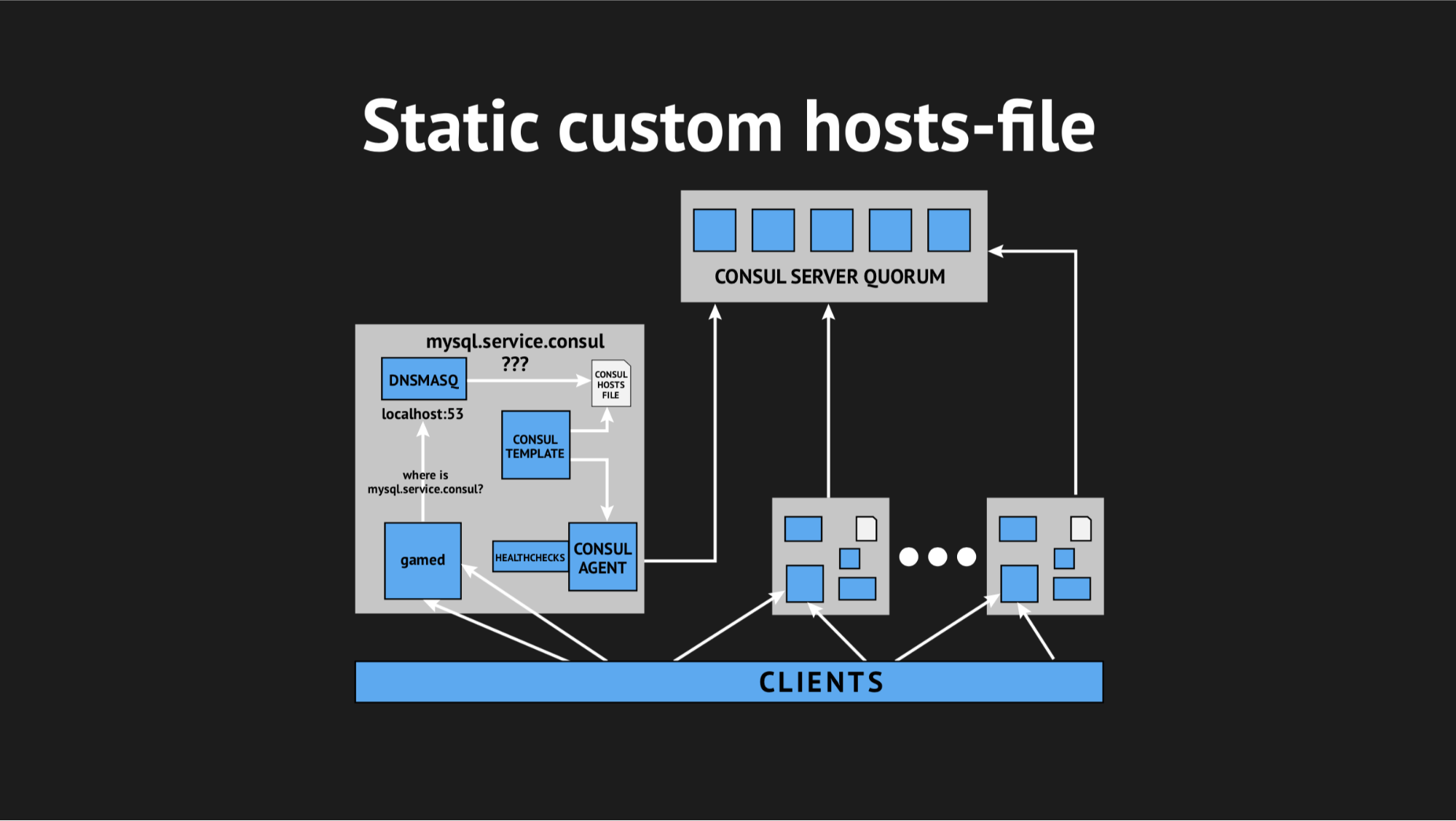
Появился дополнительный элемент и статический файл на диске, который достаточно оперативно перегенерируется. Теперь цепочка выглядела довольно просто: gamed обращается к Dnsmasq, а та в свою очередь (вместо того, чтобы дергать Consulа-агент, который будет спрашивать у серверов, где у нас находится та или иная нода) просто смотрела файл. Это и решило проблему с потреблением CPU Consul'ом.
Теперь все стало выглядеть, как мы и планировали — абсолютно прозрачно для нашего продакшена, практически не потребляя ресурсов.
Мы изрядно замучались в тот день и с большой опаской разошлись по домам. Опасались не зря, потому что ночью меня разбудил алерт от мониторинга и оповестил, что у нас произошел довольно масштабный (хоть и кратковременный) всплеск ошибок.
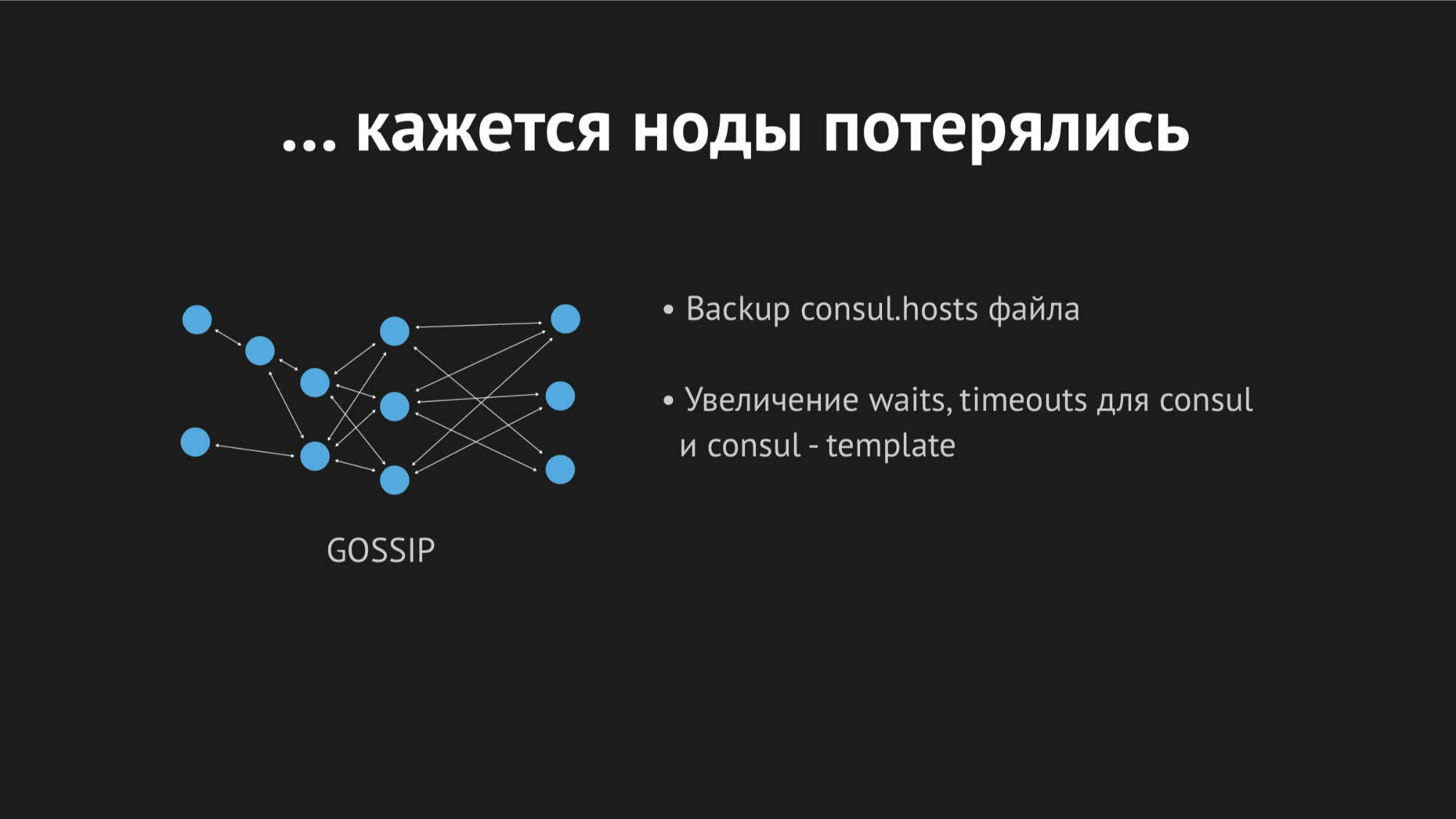
Разбираясь утром с логами, я увидел, что все ошибки одного и того же вида unknown host. Было непонятно, почему Dnsmasq не может из файла зарезолвить тот или иной сервис — такое ощущение, что его вообще не существует. Чтобы попробовать понять, что происходит, я добавил кастомную метрику на перегенирацию файла — теперь я точно знал время, когда он перегенерируется. Помимо этого, в самом Consul template есть прекрасный параметр бэкапирование, т.е. можно видеть предыдущее состояние перегенерированного файла.
В течение дня инцидент еще несколько раз повторился и стало понятно, что в некий момент времени (хотя он носил спорадический, бессистемный характер) у нас перегенирируется hosts-файл без определенных сервисов. Оказалось, что в конкретном дата-центре (не буду делать антирекламу) довольно нестабильные сети — из-за флопинга сети у нас абсолютно непредсказуемо переставали проходить healthcheck'и, либо даже ноды вываливались из кластера. Выглядело это примерно так:
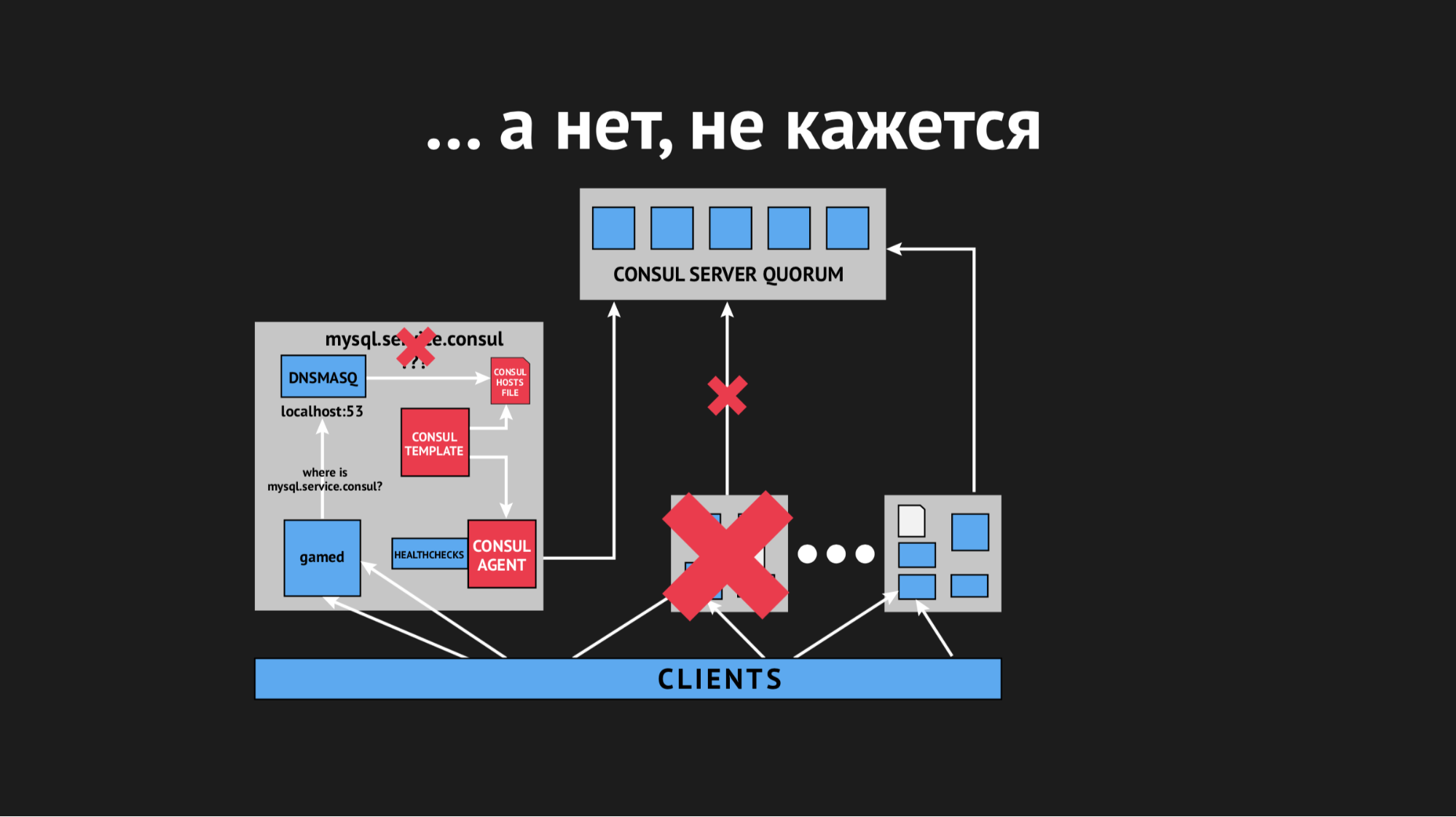
Нод вываливался из кластера, Consul-агент сразу же об этом оповещался и Consul template сразу перегенерировал hosts-файл без требуемого нам сервиса. Это было вообще неприемлемо, потому что проблема смешная: если несколько секунд сервис недоступен — настрой таймауты и ретраи (один раз не подключились, а второй раз уже получилось). Мы же новой структурой в продашкене спровоцировали ситуацию, когда сервис просто исчезает из вида и никакой возможности к нему подключиться не было.
Начали думать, что с этим делать и крутить в Consul параметр таймаутов, после которых идентифицируется, через сколько вываливается нода. Достаточно небольшим показателем нам удалось решить эту проблему, ноды перестали вываливаться, но с healthcheck'ами это не помогло.
Мы начали думать подбирать разные параметры для healthcheck'ов, пытаясь хоть как-то понять, когда и как это происходит. Но из-за того, что все происходило спорадически и непредсказуемо, нам это не удавалась это сделать.
Тогда пошли в Consul template и решили сделать для него таймаут, после которого он реагирует на изменение состояния кластера. Опять же здесь нельзя было быть фанатичным, потому что мы могли прийти к ситуации, когда результат будет не лучше, чем классический DNS, когда мы стремились к совершенно другому.
И тут на помощь в очередной раз пришел наш техдиректор и сказал: «Ребят, давайте попробуем отказаться от всей этой интерактивщины, у нас все в продакшене и нет времени на изыскания, нам нужно решать этот вопрос. Давайте воспользуемся простыми и понятными вещами». Так мы пришли к концепции использования key-value хранилища, как источника для генерации hosts-файла.
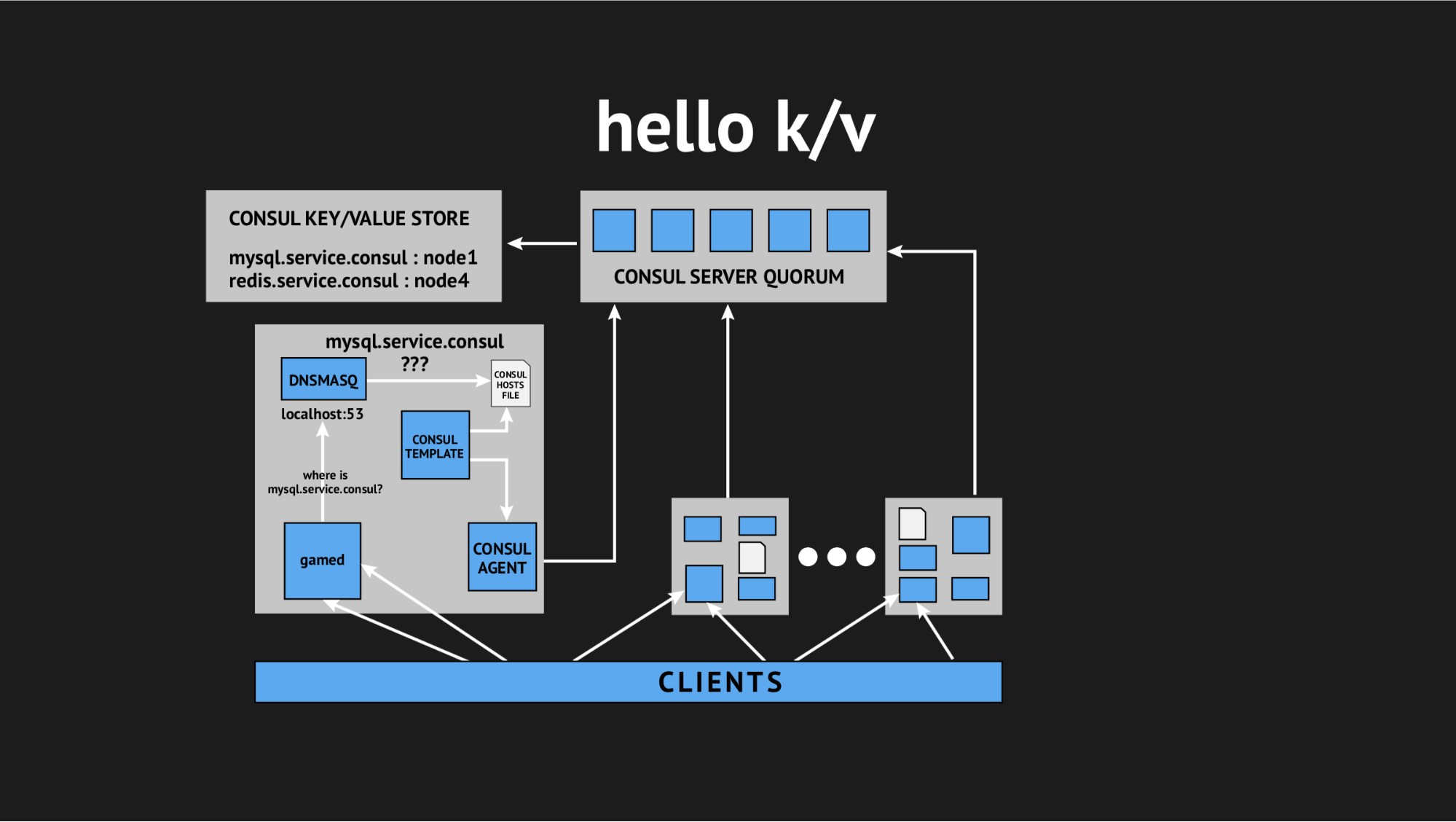
Как это выглядит: мы отказываемся от всех динамических healthcheck'ов, переписываем наш template-сценарий, чтобы он генерировал файл на основании данных, записанных в key-value хранилище. В key-value хранилище мы описываем всю нашу инфраструктуру в виде имя ключа (это имя требуемого нам сервиса) и значения ключа (это имя ноды в кластере). Т.е. если нода присутствует в кластере, то мы очень легко получаем ее IP-адрес и записываем его в hosts-файл.
Мы все оттестили, залили в продакшн и это стало серебряной пулей в конкретной ситуации. Мы изрядно опять же замучившиеся за целый день пошли по домам, но вернулись уже отдохнувшие, воодушевленные, потому что больше эти проблемы не повторялись и уже на протяжение года в подакшене не повторяются. Из чего я лично делаю вывод, что это было правильное решение (конкретно для нас).
Итак. Мы наконец-то добились чего хотели и организовали динамическое пространство имен для наших backend'ов. Дальше мы пошли в сторону обеспечения высокой доступности.

Но дело в том, что изрядно напугавшись интеграции Consul и из-за проблем, с которыми мы столкнулись, мы подумали и решили, что внедрять авто-failover'ы — это не такое уж и хорошее решение, потому что мы опять рискуем ложными срабатываниями или несрабатываниями. Этот процесс непрозрачен и неконтролируем.
Поэтому мы пошли по более простому (или сложному) пути: мы решили оставить failover на совести у дежурного администратора, но дали ему в руки еще один дополнительный инструмент. Мы заменили мастер-слэйв репликацию на мастер-мастер репликацию в режиме Read only. Это снимает огромное количество головной боли в процессе failover'ов — когда у вас выпадает мастер, все, что вам нужно сделать, это поменять значение в k/v-хранилище с помощью Web UI или команды в API и до этого убрать режим Read only на резервном мастере.
После того как инцидент исчерпан, мастер выходит на связь и автоматически приходит в согласованное состояние без каких-либо вообще лишних действий. На этом варианте мы остановились и используем его по-прежнему — для нас это максимально удобно, а самое главное максимально просто, понятно и контролируемо.
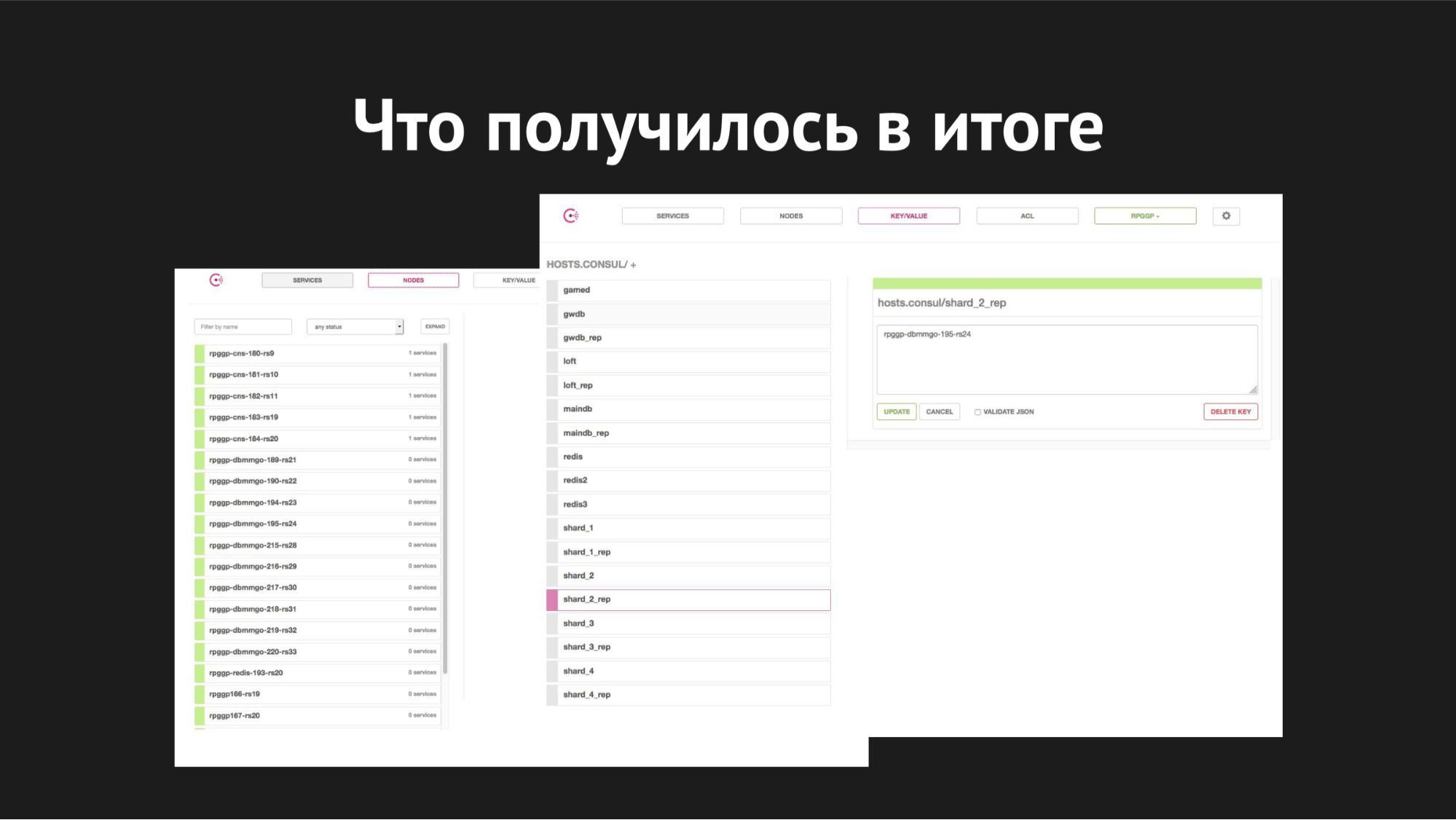
Веб-интерфейс Consul
Справа изображено k/v-хранилище и видны наши сервисы, которые используем в работе gamed; значение — это имя нода.
Что касается масштабирования — внедрять это мы начали, когда шардам становилось уже тесно на одном сервере, базы росли, становились медленными, количество игроков увеличивалось, мы свопились (swap) и перед нами стояла задача развести все шарды по своим разным отдельным серверам.

Как это выглядело: с помощью утилиты XtraBackup мы восстанавливали на новой паре серверов наш бэкап, после чего новый мастер вешали слэйвом на старый. Он приходил в согласованное состояние, мы меняли значение ключа в k/v-хранилище с имени ноды старого мастера на имя ноды нового мастера. Потом (когда мы считали, что все прошло корректно и все gamed со своими селектами, апдейтами, инсертами ушли на новый мастер) оставалось только убить репликацию и сделать заветный drop database на продакшене, как мы все любим делать с ненужными базами.

Таким образом мы получали разъехавшиеся шарды. Весь процесс переезда занимал от 40 минут до часа и не вызывал никого даунтайма, был полностью прозрачен для наших backend'ов и само собой был полностью прозрачен для игроков (за исключением того, что как только они переехали — им играть стало легче и приятнее).

Что касается процессов failover'а, то здесь время переключения — от 20 до 40 секунд плюс время реакции дежурного сисадмина. Вот примерно так сейчас все это выглядит у нас.
Чтобы я хотел сказать в заключение — к сожалению, наши надежды на абсолютную, всеобъемлющую автоматизацию разбились о суровую реальность среды передачи данных в нагруженном дата-центре и рандомных факторов, которые мы не могли предусмотреть.
Во-вторых, это лишний раз нас научило, что лучше простая и проверенная синица в руках вашего сисадмина, чем новомодный самореагирующий, самомасштабирующий журавль где-то за облаками, что вы даже не понимаете, то ли он там разваливается на части, то ли действительно начал масштабироваться.
Внедрение какой-либо инфраструктуры, автоматизации в ваш продакшн не должно вызывать лишней головной боли у персонала, который его обслуживает; оно не должно значительно повышать стоимость поддержания продакшна инфраструктуры — решение должно быть простым, понятным, прозрачным для ваших клиентов, удобным и контролируемым.
Вопросы из зала
Как вы пишите k/v с серверами — скрипт или вы просто патчите его?
K/v-хранилище находится у нас на Consul-серверах и либо что-то удаляем оттуда, либо пополняем с помощью http-запросов RESTful API или Web UI.
Я этим докладом хотел донести, что сейчас почему-то очень часто преследует идеология автоматизации всего на свете с лютым фанатизмом без понимания, что это иногда усложняет жизнь, а не упрощает.
Почему вы балансируете между шардами через базы данных, почему не тот же Redis?
Это исторически сложившееся решение и я забыл сказать, что сейчас концепция чуть-чуть изменилась.
Во-первых, мы вынесли конфиги и теперь нам не нужно перезаливать backend. Во-вторых, мы ввели параметр в сами backend'ы, которые и есть главное шардирующее звено — это они распределяют игроков. Т.е. если у нас появляется новая сущность игрока, он делает запись в MAINDB и потом уже сохраняет данные на тот шард, который он выбрал. А выбирает он сейчас его по весовым коэффициентам. И это очень быстро и легко управляется и на данным момент не возникает потребности взять и использовать какую-то другую технологию, потому что это все сейчас работает быстро.
Но если мы столкнемся с какой-то проблемой, то возможно будет лучше воспользоваться быстрым inmemory key-value хранилищем или еще чем-то.
Какая у вас база?
Мы используем форк MySQL — Percona server.
А вы не пробовали ее объединить в кластер и за счет этого балансировать? Если бы у вас была Maria, которая тот же самый MHA for MySQL, у него есть Galera.
У нас была на вооружении Galera. Был еще один дата-центр для проекта «Гильдии Героев» для Азии и там мы использовали Galera и она часто дает очень неприятный сбой, ее периодически нужно руками поднимать. Имея такой опыт использования конкретно этой технологии, нам пока не очень хочется ее использовать.
Опять же стоит понимать, что внедрение любой технологии — это не просто потому что вам хочется сделать лучше, а потому что у вас есть потребность в этом, вам нужно выйти из какой-то сложившейся ситуации, либо вы уже спрогнозировали, что ситуация скоро случится и вы выбираете конкретную технологию, чтобы ее внедрять.
Еще доклады с Pixonic DevGAMM Talks
- CICD: бесшовный деплой на распределенные кластерные системы без даунтаймов (Егор Панов, системный администратор Pixonic);
- Практика использования модели акторов в бэкэнд-платформе игры Quake Champions (Роман Рогозин, backend-разработчик Saber Interactive);
- Архитектура мета-сервера мобильного онлайн-шутера Tacticool (Павел Платто, Lead Software Engineer в PanzerDog);
- Как ECS, C# Job System и SRP меняют подход к архитектуре (Валентин Симонов, Field Engineer в Unity);
- Принцип KISS в разработке (Константин Гладышев, Lead Game Programmer в 1C Game Studios);
- Общая игровая логика на клиенте и сервере (Антон Григорьев, Deputy Technical Officer в Pixonic).
- Cucumber в облаке: использование BDD-сценариев для нагрузочного тестирования продукта (Антон Косякин, Technical Product Manager в ALICE Platform).
