
Масштабирование СУБД – это непрерывно наступающее будущее. СУБД совершенствуются и лучше масштабируются на аппаратных платформах, а сами аппаратные платформы наращивают производительность, число ядер, памяти — Ахиллес догоняет черепаху, но все еще не догнал. Проблема масштабирования СУБД стоит во весь рост.
Компании Postgres Professional с проблемой масштабирования довелось столкнуться не только теоретически, но и практически: у своих заказчиков. И не раз. Об одном из таких случаев и пойдёт речь в этой статье.
PostgreSQL неплохо масштабируется на NUMA-системах, если это одна материнская плата с несколькими процессорами и несколькими шинами данных. О некоторых оптимизациях можно почитать здесь и здесь. Однако есть и другой класс систем, у них несколько материнских плат, обмен данными между которыми осуществляется с помощью интерконнекта, при этом на них работает один экземпляр ОС и для пользователя такая конструкция выглядит как единая машина. И хотя формально такие системы можно также отнести к NUMA, но по своей сути они ближе к суперкомпьютерам, т.к. доступ к локальной памяти узла и доступ к памяти соседнего узла отличаются радикально. В сообществе PostgreSQL считают, что единственный экземпляр Postgres, работающий на таких архитектурах, это источник проблем, и системного подхода к их решению пока нет.
Это объясняется тем, что программная архитектура, использующая разделяемую память, принципиально рассчитана на то, что время доступа разных процессов к своей и удаленной памяти более-менее сравнимо. В случае когда мы работаем с многими узлами, ставка на разделяемую память как быстрый канал коммуникации перестаёт себя оправдывать, т. к. из-за задержек (latency) намного «дешевле» отправить запрос на выполнение определённого действия на узел (ноду), где находятся интересующие данные, чем пересылать эти данные по шине. Поэтому для суперкомпьютеров и вообще систем со многими узлами актуальны кластерные решения.
Это не значит, что на комбинации многоузловых систем и типичной для Postgres архитектуры с разделяемой памятью нужно ставить крест. В конце концов, если процессы postgres будут проводить большую часть времени за выполнением сложных вычислений локально, то эта архитектура будет даже весьма эффективна. В нашей же ситуации клиентом был уже закуплен мощный многоузловый сервер, и нам предстояло решать проблемы PostgreSQL на нём.
А проблемы были серьезные: простейшие запросы на запись (изменить несколько значений полей в одной записи) исполнялись за время от нескольких минут до часа. Как потом подтвердилось, эти проблемы проявились во всей красе именно из-за большого количества ядер и, соответственно, радикального параллелизма в исполнении запросов при относительно медленном обмене между узлами.
Поэтому статья получится как бы двойного назначения:
- Поделиться опытом: что делать, если в многоузловой системе база тормозит не на шутку. С чего начинать, как диагностировать, куда двигаться.
- Рассказать, как могут решаться проблемы самой СУБД PostgreSQL, при большом уровне параллелизма. В том числе о том, как изменение алгоритма взятия блокировок сказывается на эффективности работы PostgreSQL.
Сервер и БД
Система состояла из 8 лезвий по 2 сокета в каждой. В сумме более 300 ядер (без учета гипертрединга). Быстрая шина (проприетарная технология производителя) соединяет лезвия. Не то, чтобы суперкомпьютер, но для одного экземпляра СУБД конфигурация впечатляющая.
Нагрузка тоже немаленькая. Более 1 терабайта данных. Около 3000 транзакций в секунду. Более 1000 коннектов к postgres.
Начав разбираться с часовыми ожиданиями записи, первым делом мы исключили как причину задержек запись на диск. Как только начались непонятные задержки, тесты стали делать исключительно на
tmpfs. Картина не изменилась. Диск не при чем.Начинаем добычу диагнозов: представления
Поскольку проблемы возникли, скорее всего, из-за высокой конкуренции процессов, которые «стучатся» к одним и тем же объектам, первое, что надо проверить — это блокировки. В PostgreSQL для такой проверки существует представление
pg.catalog.pg_locks и pg_stat_activity. Во второе уже в версии 9.6 добавлена информации о том, чего ждёт процесс (Амит Капила, Ильдус Курбангалиев) — wait_event_type. Возможные значения этого поля описаны здесь.Но для начала просто сосчитаем:
postgres=# SELECT COUNT(*) FROM pg_locks;
count
—---—
88453
(1 row)
postgres=# SELECT COUNT(*) FROM pg_stat_activity;
count
—---—
1826
(1 row)
postgres=# SELECT COUNT(*) FROM pg_stat_activity WHERE state ='active';
count
—---—
1005Это реальные цифры. Доходило до 200 000 блокировок.
При этом на злополучном запросе висели такие блокировки:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode;
count | mode
—-----+---------------—
93 | AccessShareLock
1 | ExclusiveLockПри чтении буфера СУБД использует блокировка
share, при записи — exclusive. То есть блокировки на запись составляли менее 1% от всех запросов.В представлении
pg_locks виды блокировок не всегда выглядят так, как описано в документации для пользователя.Вот табличка соответствий:
AccessShareLock = LockTupleKeyShare
RowShareLock = LockTupleShare
ExclusiveLock = LockTupleNoKeyExclusive
AccessExclusiveLock = LockTupleExclusiveЗапрос SELECT mode FROM pg_locks показал, что исполнения команды CREATE INDEX (без CONCURRENTLY) ждут 234 INSERT-ов и 390 INSERT-ов ждут
buffer content lock. Возможное решение — «научить» INSERT-ы из разных сессий меньше пересекаться по буферам.Пора задействовать perf
Утилита
perf собирает немало диагностической информации. В режиме record … она записывает статистику событий системы в файлы (по умолчанию они в ./perf_data), а в режиме report анализирует собранные данные, можно, например, отфильтровать события, касающиеся только postgres или данного pid:$ perf record -u postgres или
$ perf record -p 76876 а затем, скажем
$ perf report > ./my_resultsВ результате увидим что-то вроде
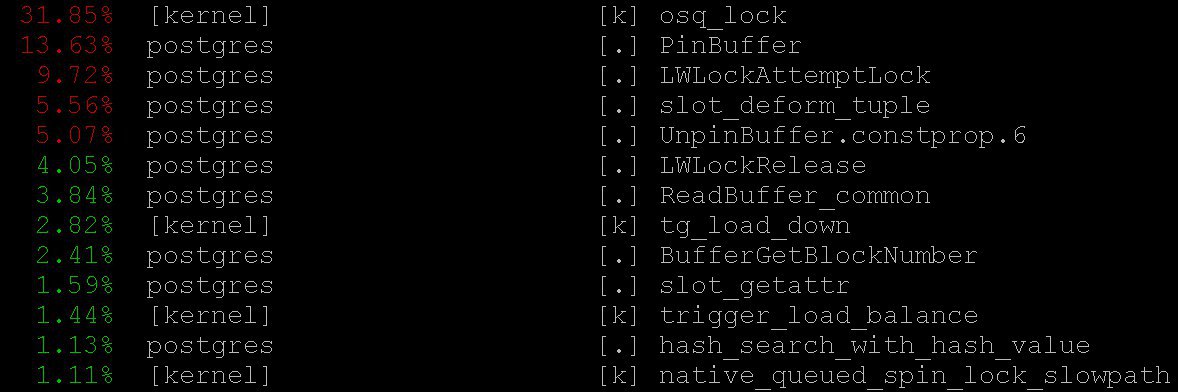
Как использовать
perf для диагностики PostgreSQL описано, например, здесь, а также в pg-вики.В нашем случае важную информацию дал даже самый простой режим —
perf top, работающий, естественно, в духе top операционной системы. С помощью perf top мы увидели, что большую часть времени процессор проводит в локах ядра, а также в функциях PinBuffer() и LWLockAttemptLock()..PinBuffer() – это функция, которая увеличивает счётчик ссылок на буфер (отображение страницы данных на оперативную память), благодаря которому процессы postgres'а знают какие буфера можно вытеснять, а какие нет.LWLockAttemptLock() – функция взятия LWLock'а. LWLock – это разновидность лока c двумя уровнями shared и exclusive, без определения deadlock'ов, локи предварительно выделяются в shared memory, ожидающие процессы ждут в очереди.Эти функции уже были достаточно серьёзно оптимизированы в PostgreSQL 9.5 и 9.6. Спинлоки внутри них были заменены на прямое использование атомарных операций.
Флейм-графы
Без них никак нельзя: даже если бы они были бесполезны, о них все равно стоило бы рассказать — они необыкновенно красивы. Но они полезны. Вот иллюстрация из
github, не из нашего кейса (ни мы, ни клиент не готовы пока к раскрытию деталей).
Эти красивые картинки весьма наглядно показывают, на что уходят циклы процессора. Данные может собирать тот же
perf, но flame graph доходчиво визуализирует данные, а на основании собранных стеков вызовов строит деревья. Подробно о профилировании с флейм-графами можно прочитать, например, здесь, а скачать всё необходимое здесь.В нашем случае на флейм-графах видно было огромное количество
nestloop. Видимо, JOIN-ы большого числа таблиц в многочисленных параллельных запросах на чтение стали причиной большого числа access share блокировок.Статистика, собираемая
perf, показывает то, куда уходят циклы процессора. И хотя мы видели, что большая часть процессорного времени проходит на локах, мы не увидели что именно приводит к таким длительным ожиданиям локов, поскольку мы не видим где именно происходят ожидания локов, т.к. в ожидании процессорное время не тратится.Для того, чтобы увидеть сами ожидания, можно построить запрос к системному представлению
pg_stat_activity.SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;выявил, что:
LWLockTranche | buffer_content | UPDATE *************
LWLockTranche | buffer_content | INSERT INTO ********
LWLockTranche | buffer_content | \r
| | insert into B4_MUTEX
| | values (nextval('hib
| | returning ID
Lock | relation | INSERT INTO B4_*****
LWLockTranche | buffer_content | UPDATE *************
Lock | relation | INSERT INTO ********
LWLockTranche | buffer_mapping | INSERT INTO ********
LWLockTranche | buffer_content | \r(звездочки здесь просто заменяют детали запроса, которые не обнародуем).
Видны значения
buffer_content (блокировка содержимого буферов) и buffer_mapping (блокировки на составные части хэш-таблички shared_buffers).За помощью к GDB
Но почему так много ожиданий для данных видов локов? Для более детальной информации об ожиданиях пришлось использовать отладчик
GDB. С помощью GDB мы можем получать стек вызовов конкретных процессов. Применив сэмплинг, т.е. собрав определённое число случайных стеков вызовов, можно составить представление о том, в каких стеках происходят самые долгие ожидания.Рассмотрим процесс сборки статистики. Мы будем рассматривать «ручной» сбор статистики, хотя в реальной жизни применяются специальные скрипты, которые делают это автоматически.
Сначала
gdb надо присоединить к процессу PostgreSQL. Для этого нужно найти pid серверного процесса, скажем из$ ps aux | grep postgresДопустим, мы обнаружили:
postgres 2025 0.0 0.1 172428 1240 pts/17 S июл23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/dataи теперь вставим
pid в дебагер:igor_le:~$gdb -p 2025Оказавшись внутри дебагера, пишем
bt [то есть backtrace] или where. И получаем массу информации примерно такого вида:(gdb) bt
#0 0x00007fbb65d01cd0 in __write_nocancel () from
/lib64/libc.so.6
#1 0x00000000007c92f4 in write_pipe_chunks (
data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]:
[392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163
(http://192.168.70.163) LOG: relation 23554 new block 493:
248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1]
db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at
elog.c:3123
#2 0x00000000007cc07b in send_message_to_server_log
(edata=0xc6ee60 <errordata>) at elog.c:3024
#3 EmitErrorReport () at elog.c:1479Собрав статистику, включающую в себя стеки вызовов от всех процессов постгреса, собранные многократно в разные моменты времени, мы увидели, что 3706 секунд (примерно час) длилось ожидание
buffer partition lock внутри relation extension lock, то есть блокировки на кусочка хэш-таблицы буфер-менеджера, которая была необходима для вытеснения старого буфера, чтобы в последствии заменить его на новый, соответствующий расширенной части таблицы. Также было заметно некоторое число buffer content lock, что соответствовало ожиданию блокировки страниц B-tree-индекса для осуществления вставки.
Поначалу приходило два объяснения такому чудовищному времени ожидания:
- Кто‐то другой взял этот
LWLockи залип. Но это маловероятно. Потому что ничего сложного внутри buffer partition lock не происходит. - Мы столкнулись с каким-то паталогическим поведением
LWLock'а. То есть несмотря на то, что лок слишком на долго никто не брал, его ожидание растянулось неоправданно долго.
Диагностические патчи и лечение деревьев
Уменьшив количество одновременных соединений, мы бы наверняка разрядили поток запросов на локи. Но это было бы похоже на капитуляцию. Вместо этого Александр Коротков, главный архитектор «Postgres Professional (разумеется, он помогал готовить эту статью), предложил серию патчей.
Прежде всего надо было получить более детальную картину бедствия. Как ни хороши готовые инструменты, пригодятся и диагностические патчи собственного изготовления.
Был написан патч, добавляющий детальное логирование времени проведённого в
relation extension, того, что происходит внутри функции RelationAddExtraBlocks().Так мы узнаем, на что тратится время внутри RelationAddExtraBlocks().А ему в поддержку был написан еще один патч, репортующий в
pg_stat_activity о том, что мы сейчас делаем в relation extension. Сделано было так: когда расширяется relation, application_name становится RelationAddExtraBlocks. Этот процесс теперь удобно с максимумом деталей анализировать с помощью gdb bt и perf.Собственно лечебных (а не диагностических) патчей было написано два. Первый патч изменял поведение блокировок листьев
B‐tree: раньше при запросе на вставку лист блокировался как share, а уже после этого получал exclusive. Теперь он сразу получает exclusive. Сейчас этот патч уже закоммичен для PostgreSQL 12. Благо в этом году Александр Коротков получил статус коммитера — второй коммитер PostgreSQL в России и второй в компании.Также было увеличено с 128 до 512 значение
NUM_BUFFER_PARTITIONS для уменьшения нагрузки на mapping locks: хэш-таблица менеджера буферов была поделена на более мелкие куски, в надежде что нагрузка на каждый конкретный кусок при этом уменьшится.После приложения этого патча блокировки на содержание буферов ушли, однако не смотря на увеличение
NUM_BUFFER_PARTITIONS, остались buffer_mapping, то есть, напоминаем, блокировки кусочков хэш-таблицы буфер-менеджера:locks_count | active_session | buffer_content | buffer_mapping
----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐
12549 | 1218 | 0 | 15Да и то не много. B‐tree перестало быть узким местом. На первый план вышло расширение
heap-а.Лечение совести
Далее Александр выдвинул следующую гипотезу и путь решения:
Мы очень много времени ждём на
buffer parittion lock'е при вытеснении буфера. Возможно, на этом же buffer parittion lock'е лежит какая‐нибудь очень востребованная страница, например, корень какого‐нибудь B‐tree. В этом месте есть не прекращающийся поток запросов на shared lock от читающих запросов.Очередь ожидания в
LWLock'е «не честная». Так как shared lock'ов может быть взято сколько угодно одновременно, то если shared lock уже взят, то последующие shared lock'и проходят без очереди. Таким образом если поток shared lock'ов имеет достаточную интенсивность, чтобы между ними не оставалось «окон», то ожидание exclusive lock уходит практически в бесконечность.Чтобы это починить, можно попробовать предложить — патч «джентльменского» поведения блокировок. Он пробуждает у
shared locker-ов совесть и они честно становятся в очередь, когда там уже стоит exclusive lock (интересно, что у тяжелых блокировок — hwlock — нет проблем с совестью: они всегда честно становятся в очередь)locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec
‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------
173985 | 1802 | 0 | 569 | 0 | 0Всё хорошо! Долгих
insert-ов нет. Хотя локи на кусках хэш-табличек остались. Но что поделать, таковы свойства шины нашего маленького суперкомпьютера.Этот патч тоже был предложен сообществу. Но как бы ни сложилась судьба этих патчей в сообществе, ничто не мешает им попасть в ближайшие версии Postgres Pro Enterprise, которые рассчитаны как раз на клиентов с сильно нагруженными системами.
Мораль
Высокоморальные легковесные
share-локи — пропускающие в очередь exclusive-локи — решили проблему часовых задержек в многоузловой системе. Хэш‐табличка buffer manager-а не работала из‐за слишком большого потока share lock-ов, которые не оставляли шанса блокировкам, необходимым для вытеснения старых буферов и загрузки новых. Проблемы с расширением буфера для таблиц базы была лишь следствием этого. До этого удалось расшить узкое место с доступом к корню B-tree.PostgreSQL не создавали в расчете на NUMA-архитектуры и суперкомпьютеры. Приспособить к таким архитектурам Postgres это огромная работа, которая потребовала бы (и, возможно, потребует) скоординированных усилий многих людей и даже компаний. Но неприятные следствия этих архитектурных проблем смягчить можно. И приходится: типы нагрузки, которые привели к задержкам, подобным описанным, вполне типичны, к нам продолжают поступать похожие сигналы бедствия из других мест. Схожие неприятности проявлялись и раньше — на системах с меньшим количеством ядер, просто последствия были не столь чудовищны, и симптомы лечили другими способами и другими патчами. Теперь появилось еще одно лекарство — не универсальное, но явно полезное.
Итак, когда PostgreSQL работает с памятью всей системы как с локальной, никакая скоростная шина между узлами не сравнится с временем доступа к локальной памяти. Задачи возникают из-за этого непростые, часто срочные, но интересные. И опыт их решения полезен не только решающим, но и всему сообществу.

