Начать стоит с того, что это, статья совершенно не серьёзна. Новый год, праздник, сил никаких нет заниматься чем-то серьёзным как писателям, так и читателям. Именно поэтому было принято решение о написании статьи про, внезапно, статистику.
Эта статья косвенно связана с одним из обсуждений, в котором мы приняли участие, касательно возможности наличия некоторой закономерности в проявлении ошибок в тех или иных местах при копировании кода. Мы очень часто ссылаемся на статью "Эффект последней строки" – согласно наблюдениям, в однотипных, полученных методом копирования и вставки строчках кода ошибка наиболее часто встречается в последней из них. Обсуждение касалось того, нельзя ли каким-то образом вывести некую закономерность появления ошибки в других местах однотипных блоков? К сожалению, примеры построены так, что собрать какую бы то ни было статистику касательно проявления таких ошибок достаточно сложно. Однако это подало идею провести небольшое статистическое исследование на нашей базе примеров.
Скажем сразу, что статья эта будет носить шуточный характер, так как серьёзных закономерностей мы найти не смогли. Многие помнят, что "Существуют три вида лжи: ложь, наглая ложь и статистика", поэтому зачастую с недоверием относятся к любым статистическим исследованиям. И поделом, ведь статистика, ориентированная на «толпу», зачастую используется для поиска закономерностей там, где их нет. Один из наиболее ярких примеров – "Эффект Марса". Но у нас всё не так. Мы изначально говорим, что это статистическое исследование не претендует на то, чтобы быть серьёзным. Любые статистические зависимости, которые здесь будут описаны, либо довольно очевидны сами по себе, либо имеют характер "ложной корреляции", либо не превышают статистическую погрешность из-за небольшого размера выборки.
Ну что ж, приступим? Пока что Google собирает статистики, чего не по душе людям, мы соберём статистики, чего не по душе анализатору.
Предположение 1. Некоторые слова встречаются чаще других
Да ладно? Вы, должно быть, шутите?
Любой человек, который знаком с любым языком программирования, может сказать, что некоторые слова или символы встречаются в тексте программы чаще, чем другие. Даже в программировании на языке Brainfuck символ '+' встречается чаще символа '.'. Единственный «язык программирования», на котором кто-то когда-то реально писал и где с этим фактом можно поспорить – программирование даже не в ассемблере, а напрямую в машинных кодах. Знатоки вдобавок к этому наверняка назовут контрпримеры из эзотерических языков вроде Malbolge и так далее. А что С++? И так понятно, что ключевое слово int будет встречаться в исходном коде в среднем чаще, чем float, public – чем protected и class – чем struct или тем более union. Но всё же. Какие наиболее часто встречаемые слова в участках кода на языке C++, содержащих ошибку? Подсчёт вёлся путём элементарного вычисления количества слов по всем примерам; то есть если в одном примере дважды встречалось слово if, то оно было посчитано дважды. Слова в комментариях не считались. Итак, список наиболее часто встречающихся слов (число до двоеточия обозначает количество раз, сколько слово встретилось во всех примерах):
- 1323: if
- 798: int
- 699: void
- 686: i
- 658: const
- 620: return
- 465: char
- 374: static
- 317: else
- 292: sizeof
- 258: bool
- 257: NULL
- 239: s
- 223: for
- 194: unsigned
- 187: n
- 150: struct
- 146: define
- 137: x
- 133: std
- 121: c
- 121: new
- 115: typedef
- 113: j
- 107: d
- 105: a
- 102: buf
- 102: case
«Вывод»: 'if' порождает ошибки.
Следующие слова же дают надежду; вернее, их количество по сравнению с if и даже case:
- 15: goto
- 13: static_cast
- 6: reinterpret_cast
Похоже, не всё так плохо со структурой приложений Open Source.
А вот слова auto не было замечено практически нигде (менее пяти включений), равно как и constexpr, и unique_ptr, и так далее. Это, с одной стороны, закономерно, поскольку база примеров начала набирать примеры ещё давным-давно, когда о реализации стандарта C++11 даже ещё и не думали. С другой стороны, в этом есть и другой подтекст: расширения языка вводятся в первую очередь для его упрощения и уменьшения вероятности появления новых ошибок. Напоминаем, что в нашу базу попадают лишь примеры с ошибками, найденными анализатором PVS-Studio.
Аналогичная статистика была собрана и на числах.
- 1304: 0
- 653: 1
- 211: 2
- 120: 4
- 108: 3
- 70: 8
- 43: 5
- 39: 16
- 36: 64
- 29: 6
- 28: 256
Любопытно, что число 4 в примерах ошибочного кода встречается чаще, чем число 3, причём это не связано с 64-битными диагностиками – в примерах они если и имеются, то в очень незначительном количестве (не более одного-двух экземпляров кода). Подавляющее большинство примеров (как минимум 99%) было собрано на диагностиках общего назначения.
Скорее всего, появление четвёрки выше тройки, пусть и с небольшим отрывом, связано с тем, что четыре – это «круглое» число, а три – «некруглое», если вы понимаете, о чём я. По той же причине, похоже, уходят в значительный отрыв числа 8, 16, 64 и 256. Вот такое вот странное распределение.
А далее – на смекалку и знание. Как думаете, откуда взялись вот эти числа, 4996 и 2047?
- 6: 4996
- 5: 2047
Ответ – в конце следующего раздела.
Предположение 2. Наиболее часто встречаемая в коде буква – буква 'e'
Согласно статистике, в литературном английском языке буква 'e' встречается чаще всего. Десять наиболее часто встречающихся букв в английском языке – e, t, a, o, i, n, s, h, r, d. А какова вероятность встретить тот или иной символ в текстах исходного кода на языке C++? Давайте поставим и такой эксперимент. Подход к эксперименту на этот раз даже ещё более брутальный и бессердечный, чем к предыдущему. Мы просто пройдёмся по всем-всем примерам и просто посчитаем количество всех символов. Регистр не учитывался, то есть 'K' = 'k'. Итак, результаты:
- 82100:
- 28603: e
- 24938: t
- 19256: i
- 18088: r
- 17606: s
- 16700: a
- 16466: .
- 16343: n
- 14923: o
- 12438: c
- 11527: l
Наиболее часто встречаемый символ – пробел. В литературном английском языке символ пробела немногим опережает букву e, но в нашем случае это далеко не так. Пробел очень широко используется для выравнивания кода, что обеспечивает ему лидирующую позицию с огромным отрывом по крайней мере в наших примерах, ведь для удобства форматирования мы заменяем символы табуляции пробелами. Что касается остальных символов – очень сильно вперёд вышли символы i (лидер на рынке имён для счётчиков с 19XX года), r (по нашим предположениям – есть в нескольких часто используемых именах, таких как run, rand, vector, read, write и особенно – error) и s(std::string s). Однако из-за достаточно большой статистической выборки мы можем утверждать, что буквы e и t точно так же являются наиболее частыми в исходных кодах программы, как и в текстах на английском языке.
По поводу точки. Конечно же, в реальных программах точка встречается не так часто, как можно судить по списку выше. Дело в том, что у нас в примерах четырьмя точками очень часто опускается избыточный код, не требуемый для понимания ошибки. Поэтому на самом деле точка вряд ли входит в набор наиболее частых символов языка C++.
Что кто там говорил про энтропийное кодирование?
А если посмотреть с другого угла. Какой символ встречался в примерах наиболее редко?
- 90: ?
- 70: ~
- 24: ^
- 9: @
- 1: $
Ещё один очень странный результат, что поразил нас. Посмотрите на количество этих символов. Оно практически совпадает (а кое-где даже и совпадает до последнего знака!). Мистика, да и только. Как такое могло произойти?
- 8167: (
- 8157: )
- 3064: {
- 2897: }
- 1457: [
- 1457: ]
Ах да, обещанный ответ на вопрос из предыдущего раздела. 2047 = 2048 — 1, а число 4996 набралось из-за строчек в стиле
#pragma warning (disable:4996)Предположение 3. Существует зависимость между появлениями тех или иных слов
Это чем-то напоминает корреляционный анализ. Задача ставилась примерно так: есть ли зависимость между появлением в примерах некоторых двух слов?
Почему только «напоминает». Мы решили вычислять относительную величину, более похожую на линейный коэффициент корреляции, но таковой не являющейся, поскольку изменяется для удобства от 0 до 1 и измерена для каждой пары слов (a,b) следующим образом: если слово a встретилось в Na примерах, слово b – в Nb примерах, а одновременно они встретились в Nab примерах, то коэффициент Rab = Nab / Na, а Rba = Nab / Nb. Поскольку известно, что 0 <= Nab <= Na, Nb; Na, Nb > 0 можно очевидным образом вывести, что 0 <= Rab, Rba <= 1.
Как это работает. Предположим, что слово void встретилось в 500 примерах, слово int – в 2000, а слова void и int одновременно – в 100. Тогда коэффициент Rvoid,int = 100 / 500 = 20%, а коэффициент Rint,void = 100 / 2000 = 5%. Да, коэффициент получился несимметричный (Rab в общем случае не равно Rba), но это вряд ли можно считать помехой.
Наверное, можно говорить хоть о какой-то статистической зависимости, когда R >= 50%. Почему именно 50%? Да просто потому, что так захотелось. На самом деле пороговые значения выбираются достаточно приближённо, тут обычно нет никаких рекомендаций. Значение 95% же, по идее, должно указывать на сильную зависимость. По идее.

Итак, при помощи корреляционного анализа удалось выяснить следующие удивительные, неортодоксальные факты:
- В примерах, где употребляется ключевое слово else, в подавляющем большинстве случаев (95.00%) также употребляется ключевое слово if! (интересно, куда подевались оставшиеся 5%?)
- В примерах, где употребляется ключевое слово public, в подавляющем большинстве случаев (95.12%) также употребляется ключевое слово class!
- В примерах, где употребляется ключевое слово typename, в подавляющем большинстве случаев (90.91%) также употребляется ключевое слово template!
И так далее, и тому подобное. Приведём несколько «очевидных» блоков ниже.
- 100.00% ( 18 из 18): argc -> argv
- 100.00% ( 18 из 18): argc -> int
- 94.44% ( 17 из 18): argc -> char
- 90.00% ( 18 из 20): argv -> argc
- 90.00% ( 18 из 20): argv -> char
- 90.00% ( 18 из 20): argv -> int
- 75.00% ( 12 из 16): main -> argv
- 60.00% ( 12 из 20): argv -> main
По крайней мере, этот пример показывает, что программа хотя бы работает, пусть и производит бессмысленные операции по выявлению всех зависимостей между main, argc и argv.
- 100.00% ( 11 из 11): disable -> pragma
- 100.00% ( 11 из 11): disable -> default
- 100.00% ( 11 из 11): disable -> warning
- 91.67% ( 11 из 12): warning -> pragma
- 91.67% ( 11 из 12): warning -> default
- 91.67% ( 11 из 12): warning -> disable
- 78.57% ( 11 из 14): pragma -> warning
- 78.57% ( 11 из 14): pragma -> disable
- 78.57% ( 11 из 14): pragma -> default
- 57.89% ( 11 из 19): default -> warning
- 57.89% ( 11 из 19): default -> disable
- 57.89% ( 11 из 19): default -> pragma
Безумие директив компилятору. Анализ выявил все зависимости между словами disable, pragma, warning и default. Судя по всему, все эти примеры были подёрганы из базы данных диагностики V665 – особенно обратите внимание на то, что там всего одиннадцать примеров. Кстати, эти зависимости могут показаться абсолютно неясными для тех, кто незнаком с языком C++, но для программиста они могут показаться очевидными.
А мы продолжаем.
- 100.00% ( 24 из 24): WPARAM -> LPARAM
- 92.31% ( 24 из 26): LPARAM -> WPARAM
- 91.30% ( 21 из 23): wParam -> WPARAM
- 91.30% ( 21 из 23): lParam -> LPARAM
- 91.30% ( 21 из 23): wParam -> LPARAM
- 87.50% ( 21 из 24): WPARAM -> wParam
- 86.96% ( 20 из 23): wParam -> lParam
- 86.96% ( 20 из 23): lParam -> wParam
- 86.96% ( 20 из 23): lParam -> WPARAM
- 83.33% ( 20 из 24): WPARAM -> lParam
- 80.77% ( 21 из 26): LPARAM -> wParam
- 80.77% ( 21 из 26): LPARAM -> lParam
Вот это, я думаю, в комментариях вообще не нуждается. Достаточно стойкая взаимосвязь между типами WPARAM, LPARAM, а также стандартными их именами lParam и wParam. Эти слова, между прочим, тянутся с 16-битных версий Windows, причём, похоже, ещё аж из Windows 3.11, что наглядно показывает нам, сколько работы производит Microsoft в целях совместимости из года в год.
Были, впрочем, и более интересные результаты.
- 100.00% ( 12 из 12): continue -> if
- 100.00% ( 13 из 13): goto -> if
- 68.25% ( 43 из 63): break -> if
Первые два примера говорят, что, скорее всего, в примерах нет ни одного безусловного continue и goto. Третий, в принципе, не показывает ничего, поскольку break может использоваться не только в цикле, но и в операторе switch, который сам по себе заменяет собой «гирлянду» из операторов if. Или нет? Говорит ли наличие оператора if в примере о том, что break/continue/goto – условные? Кто-то что-то сказал про диагностику V612? В свою защиту могу сказать, впрочем, что в примерах нет ни одного не то чтобы безусловного continue и goto, но continue и goto вообще! А вот с break ситуация намного более печальна.
- 85.00% ( 17 из 20): vector -> std
Всё-таки авторы реального кода стараются избегать конструкции «using namespace std;» в заголовочных файлах, что точно имеет благоприятные последствия для читателей, пусть иногда и не совсем удобно для программистов (как же, пять лишних символов набирать!).
- 94.87% ( 74 из 78): memset -> 0
- 82.05% ( 64 из 78): memset -> sizeof
Чаще всего заполнение памяти происходит нулями, по крайней мере в наших примерах. Да, скорее всего, на эту статистику очень повлияла диагностика V597. А также V575, V512 и так далее. Кстати, нулями память заполняется чаще, чем используется sizeof, что по крайней мере странно и оправдано только в том случае, если заполняется массив байт известного размера. Ну или в том случае, если была допущена ошибка, например, V512, когда в третьем аргументе memset попросту забыт sizeof.
- 76.80% ( 139 из 181): for -> 0
В подавляющем большинстве случаев циклы for начинаются с нуля. Нет, это не фраза в противовес языку Pascal или там, к примеру, Mathematica. Разумеется, что многие циклы ведут свой счёт с нуля. Именно из-за этого, наверное, и был в C++11 введён цикл foreach, который вполне сносно «расправляется» не только с классами с переопределёнными begin(), end() и т.п., но и с обычными массивами (но не с указателями на массивы). К тому же, в цикле foreach допустить ошибку намного сложнее, чем в цикле for.
Такие дела. Кстати, этот анализ занимал на нашей восьмиядерной машине один час и семь минут в release-сборке.
Предположение 4. Существуют опасные имена функций, в которых чаще ошибаются
Собственно, заглавие параграфа должно говорить само за себя. Возникло подозрение, что в некоторых функциях ошибаются чаще. Это подозрение было едва ли не тут же разбито о суровую реальность – функции называются ну очень по-разному, и в нескольких проектах одна и та же функция может называться ReadData(), readData(), read_data(), ReAdDaTa() и так далее. Поэтому первой идеей стало написать дополнительную подпрограмму, которая разобьёт имена функций на отдельные слова, такие как read и data в первых трёх случаях, а четвёртый попытается выжечь огнём.
После разбивки всех имён функций, в которых были обнаружены ошибки, на слова, было получено вот такое распределение.
- 159: get
- 69: set
- 46: init
- 44: create
- 44: to
- 38: on
- 37: read
- 35: file
- 34: is
- 30: string
- 29: data
- 29: operator
- 26: proc
- 25: add
- 25: parse
- 25: write
- 24: draw
- 24: from
- 23: info
- 22: process
- 22: update
- 20: find
- 20: load
Судя по всему, в функциях со словом 'get' в имени ошибки допускаются чаще, чем в функциях с 'set'. Ну или, возможно, наш анализатор находит больше ошибок в функциях get, чем в функциях set. Может, функции get программируются чаще, чем функции set.
На множестве слов в функциях был проведён анализ, аналогичный анализу в предыдущем пункте. На этот раз результаты имеют всё-таки не очень большой размер и могут быть приведены сюда полностью. В именах функций не очень-то и прослеживаются какие бы то ни было зависимости. Хотя кое-чего вычленить всё-таки удалось.
- 77.78% ( 14 из 18): dlg -> proc
- 70.59% ( 12 из 17): name -> get
- 53.85% ( 14 из 26): proc -> dlg
- 43.48% ( 10 из 23): info -> get
Уровень обоснованности данного результата в чём-то сравним с этой корреляцией:
Предположение 5. Некоторые диагностики срабатывают чаще, чем другие
Опять же, предположение в достаточно очевидном стиле. При разработке анализатора никто себе не ставил задачу сделать так, чтобы различные диагностики выдавались примерно с одинаковой частотой. Да и даже если такая задача и ставилась, некоторые ошибки могут быть замечены едва ли не сразу (такие как V614) и предназначены, в основном, для ускорения разработки путём автоматического вывода сообщения при инкрементальном анализе. А некоторые же, наоборот, могут оставаться незамеченными до конца жизненного цикла продукта (такие как V597). В базе же находятся найденные ошибки по результатам анализа Open Source (по большей части) проектов, причём в основном это именно стабильные версии. Нужно ли говорить, что в таких случаях куда чаще находятся ошибки второго класса, нежели первого?
Методика подсчёта достаточно простая. Разберём на примере. В базе данных содержится следующая запись:
NetXMS
V668 There is no sense in .... calltip.cpp 260
PRectangle CallTip::CallTipStart(....)
{
....
val = new char[strlen(defn) + 1];
if (!val)
return PRectangle();
....
}
Identical errors can be found in some other places:
V668 There is no sense in .... cellbuffer.cpp 153
V668 There is no sense in .... document.cpp 1377
V668 There is no sense in .... document.cpp 1399
And 23 additional diagnostic messages.Первая строка – это краткое имя проекта. Оно потребуется чуть позже. Во второй записи содержится информация об ошибке – номер сработавшей диагностики, описание диагностики, имя .cpp-файла, в котором была обнаружена ошибка, и номер строки. Далее идёт код, который нам неинтересен. Далее идёт запись насчёт дополнительных мест, где была найдена диагностика, тоже с диагностическим сообщением, именем модуля и строкой, в которой была найдена ошибка. Этой информации вполне может и не быть. Последняя строка тоже необязательная и содержит только количество ошибок, опущенных для краткости. В итоге из этого примера мы получаем информацию о том, что в проекте NetXMS диагностика V668обнаружила 1 + 3 + 23 = 27 ошибок. Можно обрабатывать следующий.
Итак, номера наиболее часто встречаемых диагностик:
- 1037: 668
- 1016: 595
- 311: 610
- 249: 547
- 231: 501
- 171: 576
- 143: 519
- 141: 636
- 140: 597
- 120: 512
- 89: 645
- 83: 611
- 81: 557
- 78: 624
- 67: 523
Две диагностики, связанные с работой с памятью, явно лидируют. Оно и неудивительно, ведь в языках C/C++ как раз «опасное» управление памятью. Диагностика V595 ищет случаи, когда возможно разыменование объекта по нулевому указателю, а диагностика V668 предупреждает, что проверять выданный оператором new указатель на то, что он будет нулевым, бессмысленно, поскольку new выбрасывает исключение при невозможности выделения памяти. Да, 9X.XX% программистов ошибаются при работе с памятью в языках C/C++.

А далее возникла идея проверить, в каких проектах было найдено больше всего ошибок и даже какие они. Что ж, сказано – сделано.
- 640: Miranda NG:
- — V595: 165 (25.8%)
- — V645: 84 (13.1%)
- — V668: 83 (13%)
- 388: ReactOS:
- — V595: 213 (54.9%)
- — V547: 32 (8.25%)
- 280: V8:
- — V668: 237 (84.6%)
- 258: Geant4:
- — V624: 71 (27.5%)
- — V668: 70 (27.1%)
- — V595: 31 (12%)
- 216: icu:
- — V668: 212 (98.1%)
Предположение 6. Плотность ошибок в начале файла выше, чем в его конце
Последнее предположение тоже не отличалось особенной изящностью. Идея такая: а нет ли какой-нибудь строки или группы строк (например, с 67 по 75), где программисты допускают ошибки чаще всего? Достаточно очевидно, что программисты будут редко допускать ошибки в первых десяти строках (ну, в тех, где часто пишут #pragma once или #include «file.h»), также было достаточно очевидно, что программисты редко допускают ошибки в строках с 30000 по 30100. Хотя бы потому, что таких больших файлов в реальных проектах обычно попросту нет.
Собственно, методика подсчёта была достаточно простой. Каждое диагностическое сообщение об ошибке содержит номер строки ошибочного файла. Да вот только не все ошибки показывают номер строки: из примера выше удастся получить только четыре номера строк из возможных двадцати семи, поскольку оставшиеся двадцать три не описаны. Но и при помощи такого инструмента можно получить из базы достаточно много ошибок. Вот только общий размер .cpp-файла для последующей нормировки нигде не сохраняется, поэтому приведения к относительным процентам не будет. Иными словами, по базе примеров нельзя просто так взять и проверить гипотезу о том, что 80% ошибок встречается в последних 20% файла.
На этот раз вместо текстовой информации предоставим полноценную гистограмму.
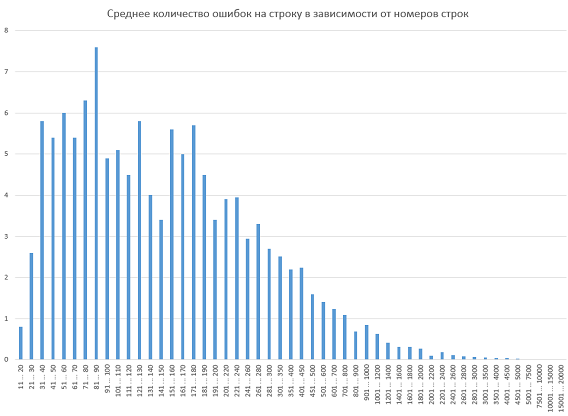
Рисунок 1 – Гистограмма распределения плотности ошибок в зависимости от номера строки кода
Подсчёт вёлся следующим образом (на примере первого столбца): мы посчитали, сколько ошибок приходится на строки с 11 по 20 и поделили это число на количество строк между двадцатой и одиннадцатой включительно (то есть на 10). В итоге по всем проектам было допущено чуть меньше одной ошибки на строках с 11 по 20. Этот показатель и отображён в гистограмме. Напоминаю, что нормировку мы не производили – важнее были не точные значения, которые всё равно вряд ли отразят динамику из-за малого размера выборки, а хотя бы вид графика.
Несмотря на то, что в гистограмме заметны резкие отклонения от нормы (и норма эта несколько напоминает логнормальное распределение), мы решили не углубляться в доказательство того, что с 81 по 90 строку кода ошибки совершаются наиболее часто. Всё-таки нарисовать график – это одна задача, а математически строго доказать на его основе что-то – другая, причём намного более сложная. Насчёт этого же графика решено ограничиться туманной фразой. «К сожалению, все отклонения, похоже, по своей величине не превосходят статистическую погрешность». Вот и всё.
Заключение
В данной статье было наглядно показано, как можно, занимаясь абсолютной ерундой, писать наукообразные тексты и получать за это зарплату.
А если серьёзно – выуживание статистической информации на базе данных ошибок имеет две серьёзные проблемы. Первая проблема – что мы будем искать? Подтвердить «эффект последней строки» вполне можно и вручную (и даже нужно, поскольку автоматизация поиска похожих блоков – дело неблагодарное), а всё остальное попросту натыкается на недостаток идей. Вторая проблема – а достаточен ли размер выборки? Возможно, для частотного анализа символов выборка вполне достаточна, однако для остальных статистик подобного сказать уже нельзя. То же можно сказать и про статистическую значимость. Более того, после сбора базы данных с большим количеством экспериментов недостаточно просто повторить то же самое. Для строгого подтверждения некоей статистической гипотезы требуется провести множество непростых математических расчётов, связанных, к примеру, с подбором функции распределения и вычисления критерия согласия Пирсона. Разумеется, в случае, если зависимость предполагается где-то на уровне предсказаний астролога, подобные тесты бессмысленны принципиально.
Эта статья была изначально предназначена для поиска направления, куда же конкретно копать в статистике на базе данных ошибок. Если бы где-нибудь произошло резкое отклонение от нормы, можно было бы задуматься об этом и провести более детальные эксперименты. Однако подобного нигде замечено, увы, не было.
