
Мы в отделе аналитики онлайн-кинотеатра Okko любим как можно сильнее автоматизировать подсчёты сборов фильмов Александра Невского, а в освободившееся время учиться новому и реализовывать классные штуки, которые почему-то обычно выливаются в ботов для Телеграма. К примеру, перед началом чемпионата мира по футболу 2018 мы выкатили в рабочий чат бота, который собирал ставки на распределение итоговых мест, а после финала подсчитал результаты по заранее придуманной метрике и определил победителей. Хорватию в четвёрку не поставил никто.
Недавнее же свободное от составления ТОП-10 российских комедий время мы посвятили созданию бота, который находит знаменитость, на которую пользователь больше всего похож лицом. В рабочем чате идею все настолько оценили, что мы решили сделать бота общедоступным. В этой статье мы кратко вспомним теорию, расскажем о создании нашего бота и о том, как сделать такого самому.
Немного теории (в основном в картинках)
Подробно о том, как устроены системы распознавания лиц я рассказывал в одной из предыдущих своих статей. Интересующийся читатель может перейти по ссылке, а я изложу ниже лишь основные моменты.
Итак, у вас есть фотография, на которой, возможно, даже изображено лицо и вы хотите понять, чьё же оно. Для этого вам необходимо выполнить 4 простых шага:
- Выделить прямоугольник, ограничивающий лицо.
- Выделить ключевые точки лица.
- Выровнять и обрезать лицо.
- Преобразовать изображение лица в некоторое машинно интерпретируемое представление.
- Сравнить это представление с другими, имеющимися у вас в наличии.
Выделение лица
И хотя свёрточные нейронные сети в последнее время уже научились находить лица на изображении не хуже классических методов, они всё-ещё уступают классическому HOG-у по скорости и удобству использования.
HOG — Histograms of Oriented Gradients. Каждому пикселю исходного изображения этот парень ставит в соответствие его градиент — вектор, в направлении которого яркость пикселей изменяется сильнее всего. Преимущество такого подхода в том, что ему не важны абсолютные значения яркости пикселей, достаточно лишь их отношения. Поэтому и нормальное, и затемнённое, и плохо освещённое, и шумное лицо отобразится в примерно одинаковую гистограмму градиентов.
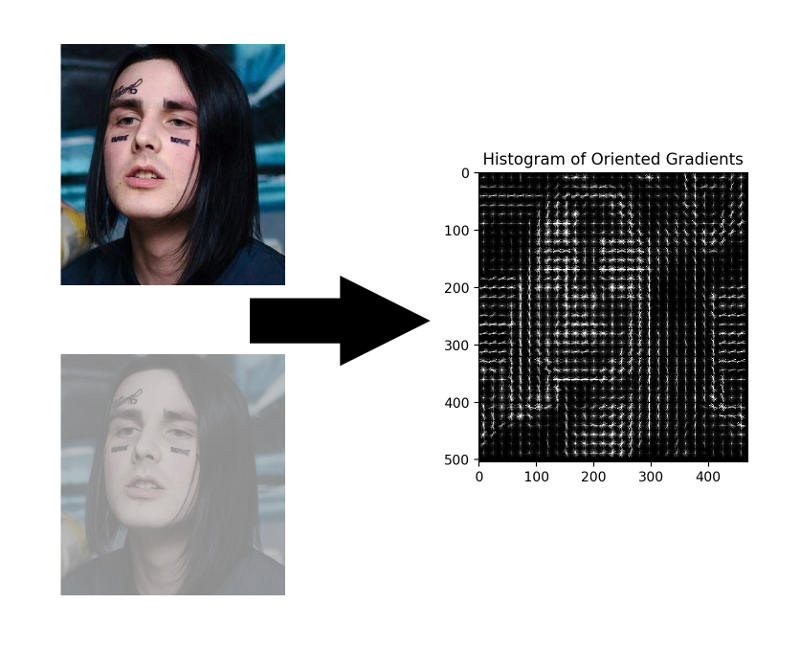
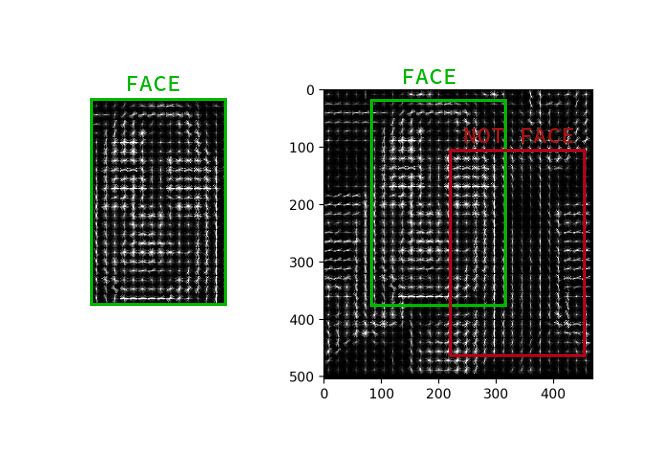
Считать градиент для каждого пикселя нет необходимости, достаточно посчитать средний градиент для каждого маленького квадратика n на n. По полученному векторному полю затем можно пройтись некоторым детектором с окном и определить для каждого окна, насколько вероятно в нём находится лицо. В качестве детектора может выступать и SVM, и случайный лес, и вообще всё что угодно.
Выделение ключевых точек

Ключевые точки — точки, которые помогают идентифицировать лицо в пространстве. Слабым и неуверенным в себе дата саентистам обычно нужно 68 ключевых точек, а в особо запущенных случаях и того больше. Нормальным же и уверенным в себе пацанам, зарабатывающим 300к в секунду, всегда было достаточно пяти: внутренние и внешние уголки глаз и нос.
Извлечь такие точки можно, например, каскадом регрессоров.
Выравнивание лица
Клеил в детстве аппликации? Тут всё точно так же: строишь аффинное преобразование, которое переводит три произвольные точки в их стандартные позиции. Нос можно оставить как есть, а для глаз посчитать их центры — вот и три точки готовы.

Преобразование изображения лица в вектор

С момента публикации статьи про FaceNet прошло уже три года, за это время появилось множество интересных схем обучения и функций потерь, но среди доступных OpenSource решений доминирует именно она. Видимо, всё дело в комбинации простоты понимания, реализации и приличных достигаемых результатах. Спасибо хоть на том, что архитектуру за эти три года таки сменили на ResNet.
FaceNet учится на тройках примеров: (anchor, positive, negative). Anchor и positive примеры принадлежат одному человеку, negative же выбирается как лицо другого человека, которое сеть почему-то располагает слишком близко к первому. Функция потерь спроектирована таким образом, чтобы исправить это недоразумение, сблизить нужные примеры и отодвинуть от них ненужный.

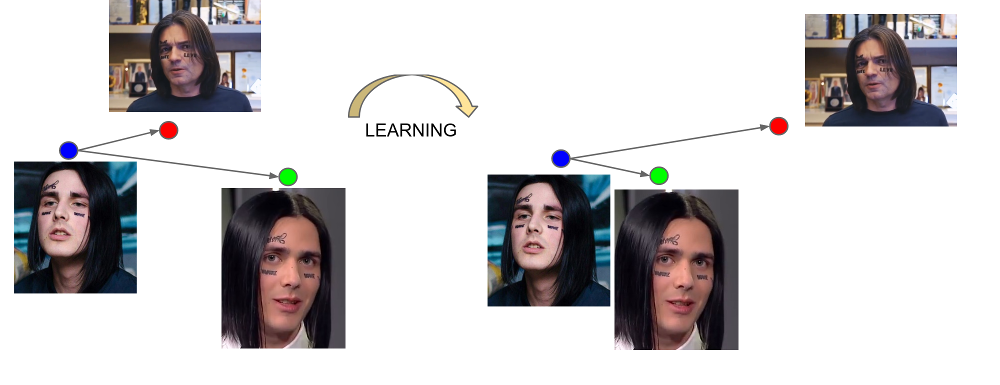
Выход последнего слоя сети называется эмбедингом — репрезентативным представлением лица в некотором пространстве малой размерности (как правило, 128-мерном).
Сравнение лиц
Прелесть хорошо обученных эмбедингов в том, что лица одного человека отображается в некоторую небольшую окрестность пространства, отдалённую от эмбедингов лиц других людей. А значит, для этого пространства можно ввести меру схожести, обратную расстоянию: евклидову или косинусному, в зависимости от того, с помощью какой дистанции сеть обучали.
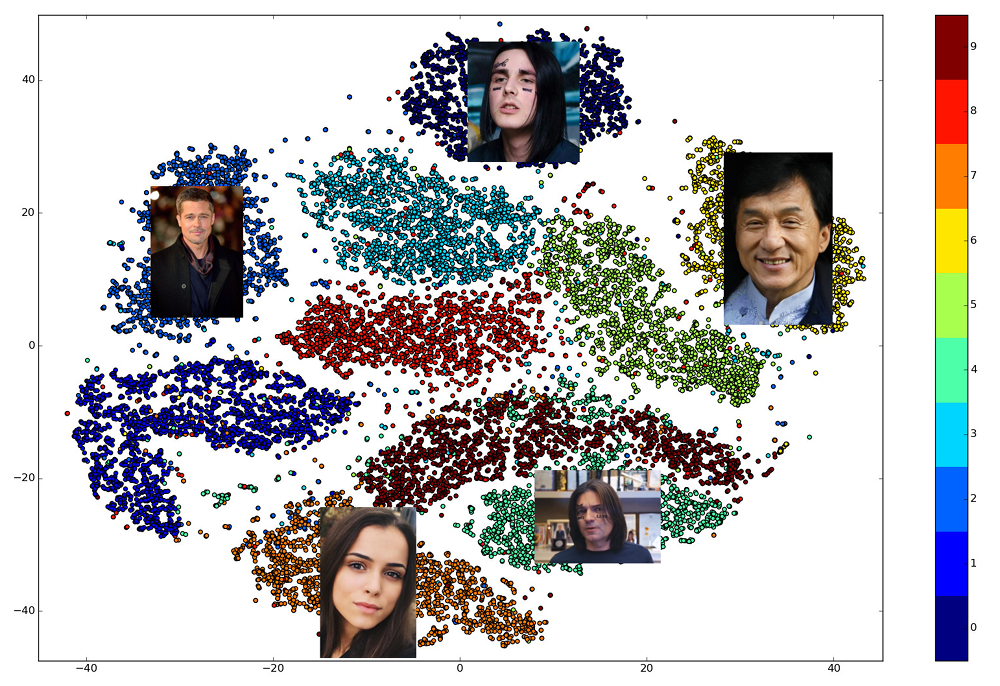
Таким образом, нам заранее нужно построить эмбединги для всех людей, среди которых будет производиться поиск, а затем, для каждого запроса, найти среди них ближайший вектор. Или, по-другому, решить задачу нахождения k ближайших соседей, где k может быть равно одному, а может и нет, если мы хотим использовать какую-нибудь более продвинутую бизнес-логику. Лицо, которому принадлежит вектор-результат, и будет самым похожим на лицо-запрос.

Какую библиотеку использовать?
Выбор открытых библиотек, которые реализуют различные части пайплайна велик. Находить лица и ключевые точки умеют dlib и OpenCV, а предобученные версии сетей можно найти для любого крупного нейросетевого фреймворка. Существует проект OpenFace, где можно подобрать архитектуру под свои требования скорости и качества. Но только одна библиотека позволяет реализовать все 5 пунктов распознавания лиц в вызовах трёх высокоуровневых функций: dlib. При этом она написана на современном C++, использует BLAS, имеет обёртку для Python, не требует GPU и достаточно быстро работает на CPU. Наш выбор пал именно на неё.
Делаем собственного бота
Данная секция уже описывалась буквально в каждом руководстве по созданию ботов, но раз и мы пишем такое же, придется повториться. Пишем @BotFather и просим у него токен для нашего нового бота.
Токен выглядит примерно так: 643075690:AAFC8ola8WRdhGbJtzjmkOhne1FGfu1BFg. Он необходим для авторизации при каждом запросе к API Телеграм ботов.
Надеюсь, ни у кого на данном этапе не возникнет раздумий при выборе языка программирования. Конечно же, писать надо на Хаскелле. Начнём с главного модуля.
import System.Process
main :: IO ()
main = do
(_, _, _, handle) <- createProcess (shell "python bot.py")
_ <- waitForProcess handle
putStrLn "Done!"Как видно из кода, в дальнейшем мы будем использовать специальный DSL для написания телеграм ботов. Код на этом DSL пишется в отдельных файлах. Установим доменный язык и всё необходимое.
python -m venv .env
source .env/bin/activate
pip install python-telegram-botpython-telegram-bot на данный момент является самым удобным фреймворком для создания ботов. Он простой в освоении, гибкий, масштабируемый, поддерживает многопоточность. К сожалению, на данный момент не существует ни одного нормального асинхронного фреймворка и вместо божественных корутин приходится использовать древние потоки.

Начать писать бота с python-telegram-bot очень просто. Добавим в bot.py следующий код.
from telegram.ext import Updater
from telegram.ext import MessageHandler, Filters
# здесь должен быть ваш токен
TOKEN = '<TOKEN>'
def echo(bot, update):
bot.send_message(chat_id=update.message.chat_id, text=update.message.text)
updater = Updater(token=TOKEN)
dispatcher = updater.dispatcher
echo_handler = MessageHandler(Filters.text, echo)
dispatcher.add_handler(echo_handler)Запустим бота. В отладочных целях это можно делать командой python bot.py, не запуская Хаскелльный код.
Такой простой бот способен поддержать минимальную беседу, а следовательно, легко может устроиться работать фронтенд разработчиком.
Но фронтенд разработчиков и так слишком много, поэтому убьём его поскорее и приступим к реализации главной функциональности. В целях простоты наш бот будет отвечать только на сообщения, содержащие фотографии и игнорировать любые остальные. Изменим код на следующий.
from telegram.ext import Updater
from telegram.ext import MessageHandler, Filters
# здесь должен быть ваш токен
TOKEN = '<TOKEN>'
def handle_photo(bot, update):
bot.send_message(chat_id=update.message.chat_id, text='nice')
updater = Updater(token=TOKEN)
dispatcher = updater.dispatcher
photo_handler = MessageHandler(Filters.photo, handle_photo)
dispatcher.add_handler(photo_handler)
updater.start_polling()
updater.idle()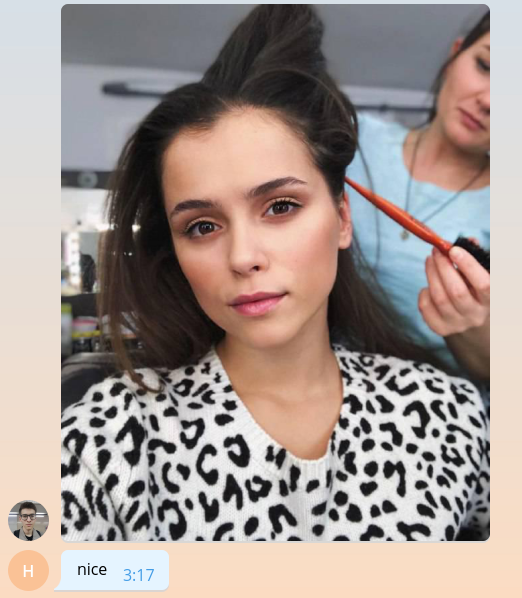
Когда картинка попадает на сервера Telegram, она автоматически подгоняется под несколько заранее заданных размеров. Бот в свою очередь может скачать изображение любого размера из тех, что содержатся в списке message.photo отсортированные по возрастанию. Самый простой вариант: взять наибольшее изображение. Конечно, в продуктовой среде нужно думать о нагрузке на сеть и времени загрузки и выбирать изображение минимально подходящего размера. Добавим код скачивания изображения в начало функции handle_photo.
import iomessage = update.message
photo = message.photo[~0]
with io.BytesIO() as fd:
file_id = bot.get_file(photo.file_id)
file_id.download(out=fd)
fd.seek(0)Изображение скачано и находится в памяти. Для его интерпретации и представления в виде матрицы интенсивности пикселей воспользуемся библиотеками Pillow и numpy.
from PIL import Image
import numpy as npСледующий код необходимо добавить в блок with.
image = Image.open(fd)
image.load()
image = np.asarray(image)Настало время dlib. За пределами функции создадим детектор лиц.
import dlibface_detector = dlib.get_frontal_face_detector()А внутри функции используем его.
face_detects = face_detector(image, 1)Второй параметр функции означает увеличение, которое необходимо применить перед попыткой обнаружения лиц. Чем он больше, тем более мелкие и сложные лица детектор сможет обнаружить, но тем дольше он будет работать. face_detects — список лиц, отсортированный в порядке убывания уверенности детектора в том, что перед ним находится лицо. В реальном приложении вам, скорее всего, захочется применить некоторую логику выбора главного лица, а в учебном примере мы ограничимся лишь выбором первого.
if not face_detects:
bot.send_message(chat_id=update.message.chat_id, text='no faces')
face = face_detects[0]Переходим к следующему этапу — поиску ключевых точек. Скачиваем обученную модель и выносим её загрузку за пределы функции.
shape_predictor = dlib.shape_predictor('path/to/shape_predictor_5_face_landmarks.dat')Находим ключевые точки.
landmarks = shape_predictor(image, face)Дело осталось за малым: выровнять лицо, прогнать его через ResNet и получить 128-мерный эмбединг. К счастью, dlib позволяет сделать всё это одним вызовом. Нужно только скачать предобученную модель.
face_recognition_model = dlib.face_recognition_model_v1('path/to/dlib_face_recognition_resnet_model_v1.dat')embedding = face_recognition_model.compute_face_descriptor(image, landmarks)
embedding = np.asarray(embedding)Только посмотрите, в какое прекрасное время мы живём. Вся сложность свёрточных нейронных сетей, метода опорных векторов и аффинных преобразований, применённых к распознаванию лиц, инкапсулирована в три библиотечных вызова.
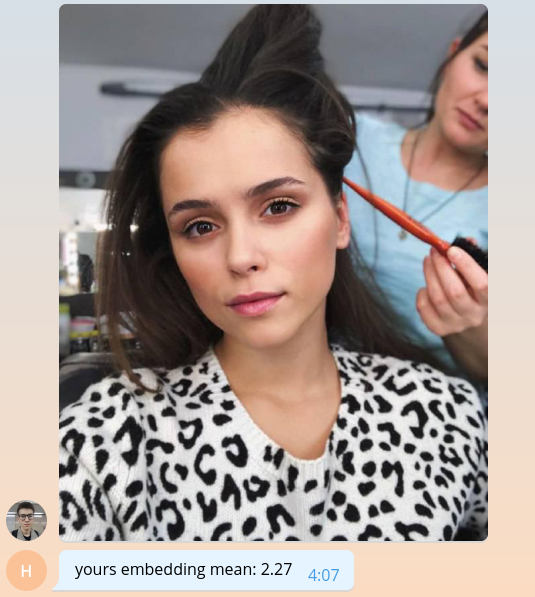
Так как мы пока не умеем делать ничего осмысленного, давайте возвращать пользователю среднее значение его эмбединга, умноженное на тысячу.
bot.send_message(
chat_id=update.message.chat_id,
text=f'yours embedding mean: {embedding.mean() * 1e3:.2f}'
)
Чтобы наш бот умел определять на кого из знаменитостей похож пользователей, нам теперь необходимо найти хотя-бы по одной фотографии каждой знаменитости, построить по ней эмбединг и куда-нибудь его сохранить. В наш учебный бот мы добавим всего 10 знаменитостей, найдя их фотографии руками и сложив в директорию photos. Вот так примерно это должно выглядеть:
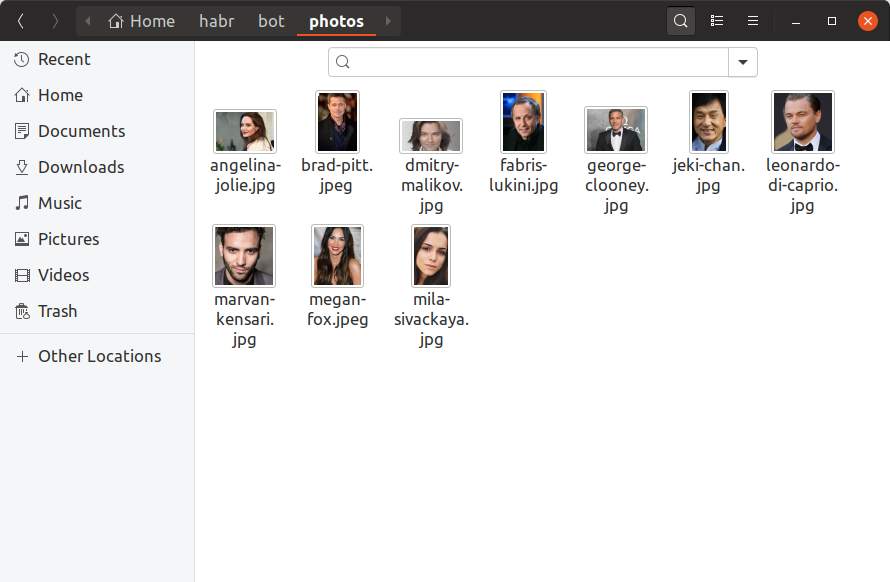
Если вы хотите иметь в базе миллион знаменитостей, всё будет выглядеть точно так же, только файлов побольше и искать их руками уже вряд ли получится. Теперь создадим утилиту build_embeddings.py, используя уже известные нам вызовы dlib и сохраним эмбединги знаменитостей вместе с их именами в бинарном формате.
import os
import dlib
import numpy as np
import pickle
from PIL import Image
face_detector = dlib.get_frontal_face_detector()
shape_predictor = dlib.shape_predictor('assets/shape_predictor_5_face_landmarks.dat')
face_recognition_model = dlib.face_recognition_model_v1('assets/dlib_face_recognition_resnet_model_v1.dat')
fs = os.listdir('photos')
es = []
for f in fs:
print(f)
image = np.asarray(Image.open(os.path.join('photos', f)))
face_detects = face_detector(image, 1)
face = face_detects[0]
landmarks = shape_predictor(image, face)
embedding = face_recognition_model.compute_face_descriptor(image, landmarks, num_jitters=10)
embedding = np.asarray(embedding)
name, _ = os.path.splitext(f)
es.append((name, embedding))
with open('assets/embeddings.pickle', 'wb') as f:
pickle.dump(es, f)Добавим загрузку эмбедингов в код нашего бота.
import picklewith open('assets/embeddings.pickle', 'rb') as f:
star_embeddings = pickle.load(f)И методом полного перебора найдём, на кого же всё-таки похож наш пользователь.
ds = []
for name, emb in star_embeddings:
distance = np.linalg.norm(embedding - emb)
ds.append((name, distance))
best_match, best_distance = min(ds, key=itemgetter(1))
bot.send_message(
chat_id=update.message.chat_id,
text=f'your look exactly like *{best_match}*',
parse_mode='Markdown'
)Обратите внимание, что в качестве расстояния мы используем евклидову дистанцию, т.к. сеть в dlib была обучена именно с помощью неё.

Вот и всё, поздравляю! Мы с вами создали простейшего бота, который умеет определять, на кого из знаменитостей похож пользователь. Осталось найти побольше фотографий, добавить брендирования, масштабируемости, щепотку логгирования и всё, можно выпускать в продакшен. Все эти темы слишком объёмные, чтобы подробно рассказывать про них с огромными листингами кода, поэтому я просто изложу основные моменты в формате вопроса-ответа в следующем разделе.
Полный код учебного бота доступен на GitHub.
Рассказываем про нашего бота
Сколько у вас в базе знаменитостей? Где вы их нашли?
Самым логичным решением при создании бота показалось взять данные о знаменитостях из нашей внутренней контентной базы. Она в формате графа хранит фильмы и все сущности, которые с фильмами связаны, в том числе актёров и режиссёров. Для каждой персоны нам известны её имя, логин и пароль от iCloud, связанные фильмы и alias, который можно использовать для генерации ссылки на сайт. После очистки и извлечения только необходимой информации остаётся json файл следующего содержания:
[
{
"name": "Тильда Суинтон",
"alias": "tilda-swinton",
"role": "actor",
"n_movies": 14
},
{
"name": "Майкл Шеннон",
"alias": "michael-shannon",
"role": "actor",
"n_movies": 22
},
...
]Таких записей в каталоге оказалось 22000. Кстати, не каталог, а каталог.
Где найти фотографии для всех этих людей?

Ну знаете, то тут, то там. Есть, например, прекрасная библиотека, которая позволяет загружать картинки-результаты запроса из гугла. 22 тысячи человек — не так уж и много, используя 56 потоков нам удалось скачать фотографии для них меньше чем за час.
Среди скаченных фотографий нужно отбросить битые, шумные, фотографии в неправильном формате. Затем оставить только те, где есть лица и где эти лица удовлетворяют определённым условиям: минимальному расстоянию между глаз, наклоном головы. Всё это оставляет нас с 12000 фотографий.
Из 12 тысяч знаменитостей пользователи на данный момент обнаружили только 2. То есть существуют примерно 8 тысяч знаменитостей пока ещё ни на кого не похожих. Не оставляйте это просто так! Открывайте телеграм и найдите их всех.
Как определить процент схожести для евклидовой дистанции?
Отличный вопрос! Действительно, евклидово расстояние, в отличии от косинусного, не ограничено сверху. Поэтому возникает резонный вопрос, как показать пользователю нечто более осмысленное, чем "Поздравляем, расстояние между вашим эмбедингом и эмбедингом Анжелины Джоли составляет 0.27635462738"? Один из членов нашей команды предложил следующее простое и гениальное решение. Если построить распределение расстояний между эмбедингами, оно окажется нормальным. А значит, для него можно посчитать среднее и стандартное отклонение, а затем для каждого пользователя по этим параметрам считать сколько процентов людей менее похожи на своих знаменитостей, чем он. Это эквивалентно интегрированию функции плотности вероятности от d до плюс бесконечности, где d — дистанция между эмбедингами пользователя и знаменитости.
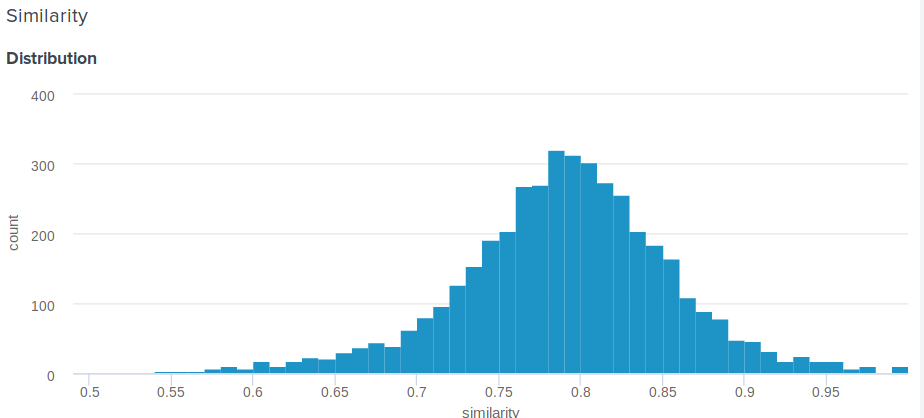
Вот точная функция, которую мы используем:
def _transform_dist_to_sim(self, dist):
p = 0.5 * (1 + erf((dist - self._dist_mean) / (self._dist_std * 1.4142135623730951)))
return max(min(1 - p, 1.0), self._min_similarity)Неужели нужно перебирать список всех эмбедингов, чтобы найти совпадение?
Конечно нет, это не оптимально и занимает кучу времени. Простейший способ оптимизировать вычисления — использовать матричные операции. Вместо того, чтобы вычитать вектора один из другого, можно составить из них матрицу и вычитать из матрицы вектор, а затем посчитать L2 норму по строкам.
scores = np.linalg.norm(emb - embeddings, axis=1)
best_idx = scores.argmax()Это уже даёт гигантский прирост производительности, но, оказывается, можно ещё быстрее. Поиск можно значительно ускорить, немного проиграв в его точности, используя библиотеку nmslib. Она использует метод HNSW для приближенного поиска k ближайших соседей. По всем имеющимся векторам должен быть построен так называемый индекс, в котором затем и будет производиться поиск. Создать и сохранить на диск индекс для евклидовой дистанции можно следующим образом:
import nmslib
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR)
for idx, emb in enumerate(embeddings):
index.addDataPoint(idx, emb)
index_time_params = {
'indexThreadQty': 4,
'skip_optimized_index': 0,
'post': 2,
'delaunay_type': 1,
'M': 100,
'efConstruction': 2000
}
index.createIndex(index_time_params, print_progress=True)
index.saveIndex('./assets/embeddings.bin')Параметры M и efConstruction подробно описаны в документации и подбираются экспериментально исходя из требуемой точности, времени построения индекса и скорости поиска. Перед использованием индекс необходимо загрузить:
index = nmslib.init(method='hnsw', space='l2', data_type=nmslib.DataType.DENSE_VECTOR)
index.loadIndex('./assets/embeddings.bin')
query_time_params = {'efSearch': 400}
index.setQueryTimeParams(query_time_params)Параметр efSearch влияет на точность и скорость запросов и может не совпадать с efConstruction. Теперь можно делать запросы.
ids, dists = index.knnQuery(embedding, k=1)
best_dx = ids[0]
best_dist = dists[0]В нашем случае nmslib работает в 20 раз быстрее, чем векторизованная линейная версия, а один запрос выполняется в среднем 0.005 секунды.
Как сделать моего бота готовым к продакшену?
1. Асинхронность
Для начала, необходимо сделать функцию handle_photo асинхронной. Как я уже говорил, python-telegram-bot предлагает для этого воспользоваться многопоточностью и реализует удобный декоратор.
from telegram.ext.dispatcher import run_async
@run_async
def handle_photo(bot, update):
...Теперь фреймворк сам запустит ваш обработчик в отдельном потоке в своём пуле. Размер пула задаётся при создании Updater-а. "Но в питоне же нет многопоточности!" уже воскликнули самые нетерпеливые из вас. И это не совсем правда. Из-за GIL обычный Python-код действительно не может исполнятся параллельно, но GIL отпускается для ожидания всех IO-операций, а так же может отпускаться библиотеками, которые используют расширения на C.
А теперь проанализируйте нашу функцию handle_photo: она только и состоит что из ожидания IO-операций (загрузка фотографии, отправка ответа, чтение фотографии с диска и т.п.) и вызовов функций из библиотек numpy, nmslib и Pillow.
Я не упомянул dlib неспроста. Библиотека, вызывающая нативный код, не обязана отпускать GIL и dlib этим правом пользуется. Ей не нужна эта блокировка, она просто её не отпускает. Автор говорит, что с радостью примет соответствующий Pull Request, но мне лень.
2. Многопроцессность
Простейший способ разобраться с dlib — инкапсулировать модель в отдельную сущность и запускать её в отдельном процессе. А лучше в пуле процессов.
def _worker_initialize(config):
global model
model = Model(config)
model.load_state()
def _worker_do(image):
return model.process_image(image)
pool = multiprocessing.Pool(8, initializer=_worker_initialize, initargs=(config,))result = pool.apply(_worker_do, (image,))3. Железо
Если ваш бот должен постоянно читать фотографии с диска, позаботьтесь о том, чтобы этим диском был SSD. Или вообще смонтируйте их в оперативную память. Так же важен пинг до серверов телеграма и качество канала.
4. Flood control
Телеграм не позволяет ботам отправлять больше 30 сообщений в секунду. Если ваш бот популярен и им одновременно пользуется куча народу, то очень легко поймать бан на несколько секунд, который обернётся разочаровнием от ожидания для множества пользователей. Для решения этой проблемы python-telegram-bot предлагает нам очередь, которая способна не отправлять больше заданного лимита сообщений в секунду, выдерживая равные интервалы между отправкой.
from telegram.ext.messagequeue import MessageQueueДля её использования нужно определить собственного бота и подменить его при создании Updater-а.
from telegram.utils.promise import Promise
class MQBot(Bot):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._message_queue = MessageQueue(
all_burst_limit=30,
all_time_limit_ms=1000
)
def __del__(self):
try:
self._message_queue.stop()
finally:
super().__del__()
def send_message(self, *args, **kwargs):
is_group = kwargs.get('chat_id', 0) >= 0
return self._message_queue(Promise(super().send_message, args, kwargs), is_group)bot = MQBot(token=TOKEN)
updater = Updater(bot=bot)5. Web hooks
В продуктовом окружении в качестве способа получения обновлений от серверов Телеграма вместо Long Polling всегода стоит использовать Web Hooks. Что это вообще такое и как это использовать можно почитать здесь.
6. Мелочи
Во время общения с сервером телеграма ежесекундно разбираются тонны тонны сообщений в формате json. Чтобы ускорить этот процесс, можно вместо стандартной библиотеки использовать ultrajson.
Полезной мелочью стала настройка времени ожидания для всех блокирующих IO-операций: загрузки и отправки фотографий, отправки сообщений, получения обновлений. Его увеличение не сказалось на производительности, но сильно повысило стабильность бота и уменьшило число ошибок.
6. Аналитика
Нельзя улучшить то, что нельзя измерить. Собирайте статистику по действиям пользователя при использовании бота, замеряйте время ответа, время ожидания, собирайте подробную информацию по каждой произошедшей ошибке. Так вы всегда сможете корректно оценивать пользовательский опыт, заранее замечать аварийные ситуации и быстро их исправлять.
Мы, например, настроили импорт логов в наш BI-tool Splunk и постоянно следим за ситуацией.
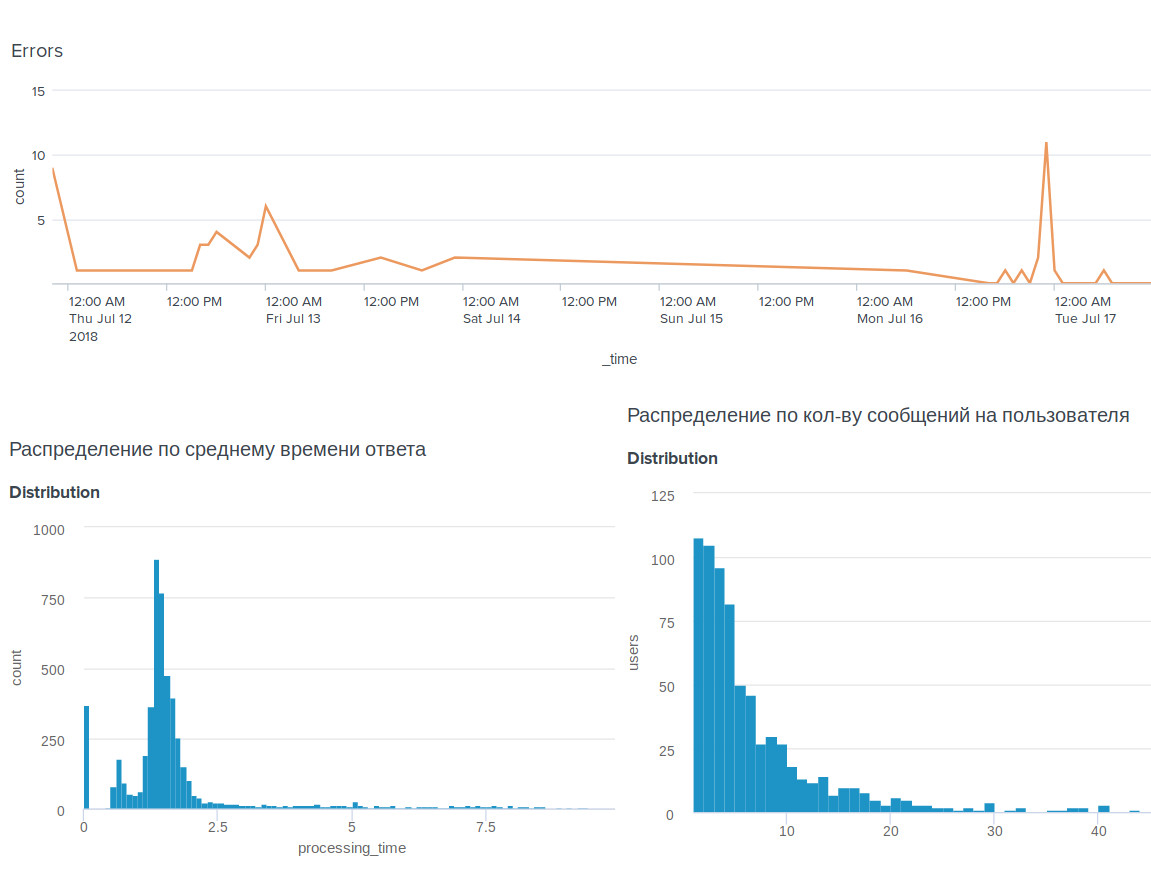
Вот и всё, о чём бы нам хотелось рассказать в этой статье. Мы вспомнили основы распознавания лиц, показали вам как создать собственного простого бота для распознавания лиц на основе открытых технологий и постарались кратко рассказать про создание нашего собственного бота.
Автоматизируйте всё что автоматизируется, уделяйте время проектам для саморазвития и приходите домой пораньше. Ну и конечно же заходите посмотреть, что у нас получилось: @OkkoFaceBot.
Можете ещё фильмы в отличном качестве посмотреть нет, это уже слишком много рекламы. Кстати, у нас в сервисе нет рекламы.
