
Материал, перевод которого мы сегодня публикуем, подготовили Матиас Байненс и Бенедикт Мейрер. Они занимаются работой над JS-движком V8 в Google. Эта статья посвящена некоторым базовым механизмам, которые характерны не только для V8, но и для других движков. Знакомство с внутренним устройством подобных механизмов позволяет тем, кто занимается JavaScript-разработкой, лучше ориентироваться в вопросах производительности кода. В частности, здесь речь пойдёт об особенностях работы конвейеров оптимизации движков, и о том, как осуществляется ускорение доступа к свойствам прототипов объектов.

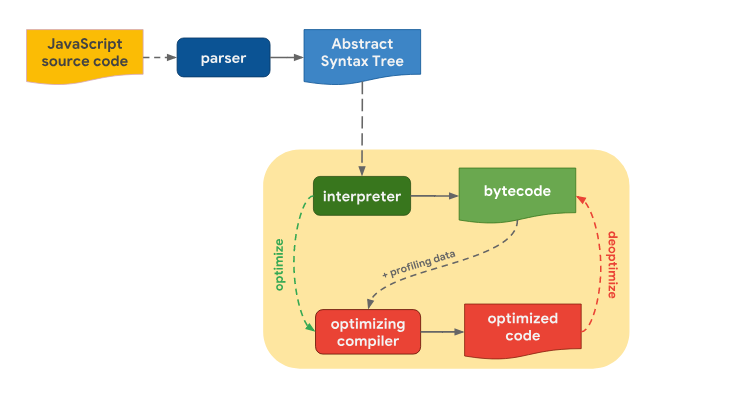
Процесс превращения текстов программ, написанных на JavaScript, в пригодный для выполнения код, в разных движках выглядит примерно одинаково. Процесс преобразования исходного JS-кода в исполняемый код
Процесс преобразования исходного JS-кода в исполняемый код
Подробности об этом можно посмотреть здесь. Кроме того, надо отметить, что хотя, на высоком уровне, конвейеры преобразования исходного кода в исполняемый у различных движков очень похожи, их системы оптимизации кода часто различаются. Почему это так? Почему у одних движков больше уровней оптимизации, чем у других? Оказывается, движкам приходится, так или иначе, идти на компромисс, который заключается в том, что они могут либо быстро сформировать код, не самый эффективный, но пригодный для выполнения, либо потратить на создание такого кода больше времени, но, за счёт этого, добиться оптимальной производительности. Быстрая подготовка кода к выполнению и оптимизированный код, который готовится дольше, но быстрее выполняется
Быстрая подготовка кода к выполнению и оптимизированный код, который готовится дольше, но быстрее выполняется
Интерпретатор способен быстро сформировать байт-код, но такой код обычно не отличается особенной эффективностью. Оптимизирующему компилятору, с другой стороны, требуется больше времени на формирование кода, но в итоге у него получается оптимизированный, более быстрый машинный код.
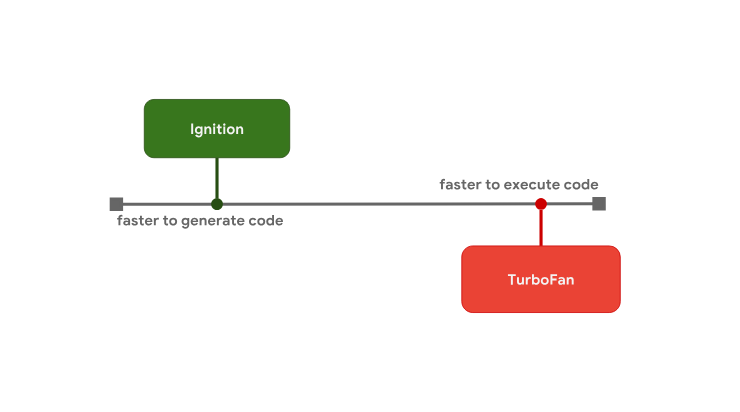
Именно такая модель подготовки кода к выполнению используется в V8. Интерпретатор V8 называется Ignition, он является самым быстрым из существующих интерпретаторов (в плане выполнения исходного байт-кода). Оптимизирующий компилятор V8 называется TurboFan, он отвечает за создание высокооптимизированного машинного кода. Интерпретатор Ignition и оптимизирующий компилятор TurboFan
Интерпретатор Ignition и оптимизирующий компилятор TurboFan
Компромисс между задержкой запуска программы и скоростью выполнения является причиной наличия у некоторых JS-движков дополнительных уровней оптимизации. Например, в SpiderMonkey, между интерпретатором и оптимизирующим компилятором IonMonkey, имеется промежуточный уровень, представленный базовым компилятором (он, в документации Mozilla, называется «The Baseline Compiler», но «baseline» — это не имя собственное). Уровни оптимизации кода в SpiderMonkey
Уровни оптимизации кода в SpiderMonkey
Интерпретатор быстро генерирует байт-код, но выполняется такой код сравнительно медленно. Базовому компилятору, для того, чтобы сгенерировать код, требуется больше времени, но этот код работает уже быстрее. И, наконец, оптимизирующему компилятору IonMonkey требуется больше всего времени на создание машинного кода, но этот код может выполняться очень эффективно.
Взглянем на конкретный пример и посмотрим на то, как обращаются с кодом конвейеры различных движков. В представленном здесь примере имеется «горячий» цикл, содержащий код, который повторяется очень много раз.
V8 начинает выполнять байт-код в интерпретаторе Ignition. В некий момент времени движок выясняет, что код это «горячий», и запускает фронтенд TurboFan, который является частью TurboFan, работающей с данными профилирования и создающей базовое машинное представление кода. Затем данные передаются оптимизатору TurboFan, работающему в отдельном потоке, для дальнейших улучшений.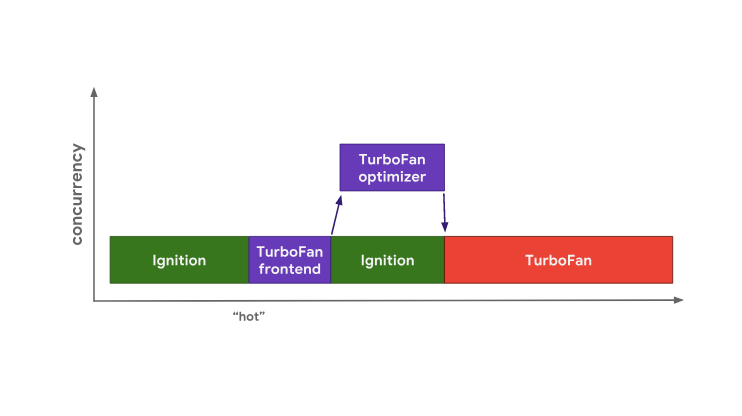 Оптимизация «горячего» кода в V8
Оптимизация «горячего» кода в V8
Во время оптимизации V8 продолжает выполнять байт-код в Ignition. Когда оптимизатор завершает работу, у нас имеется исполняемый машинный код, которым можно пользоваться в дальнейшем.
Движок SpiderMonkey тоже начинает выполнять байт-код в интерпретаторе. Но у него имеется дополнительный уровень, представленный базовым компилятором, что приводит к тому, что «горячий» код сначала попадает к этому компилятору. Он генерирует базовый код в главном потоке, переход на выполнение этого кода производится тогда, когда он будет готов. Оптимизация «горячего» кода в SpiderMonkey
Оптимизация «горячего» кода в SpiderMonkey
Если базовый код выполняется достаточно долго, SpiderMonkey, в итоге, запускает фронтенд IonMonkey и оптимизатор, что очень похоже на то, что происходит в V8. Базовый код продолжает выполняться в процессе оптимизации кода, выполняемой IonMonkey. В итоге, когда оптимизация оказывается завершённой, вместо базового кода выполняется оптимизированный код.
Архитектура движка Chakra очень похожа на архитектуру SpiderMonkey, но Chakra стремится к более высокому уровню параллелизма для того, чтобы избежать блокировки главного потока. Вместо того чтобы решать какие-либо задачи компиляции в главном потоке, Chakra копирует и отправляет байт-код и данные профилирования, которые, весьма вероятно, понадобятся компилятору, в отдельный процесс компиляции.
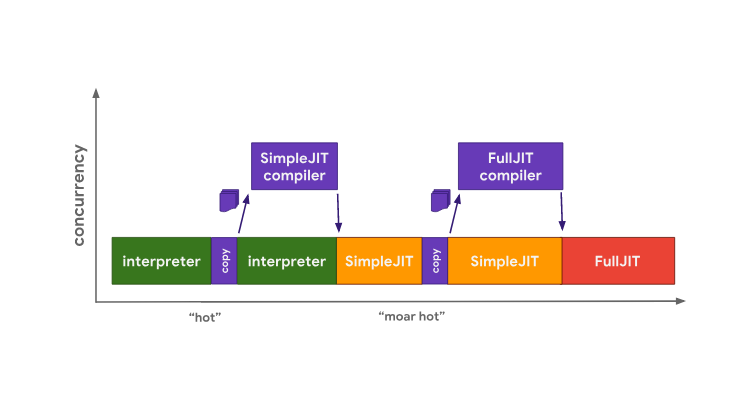 Оптимизация «горячего» кода в Chakra
Оптимизация «горячего» кода в Chakra
Когда сгенерированный код, подготовленный средствами SimpleJIT, будет готов, движок будет выполнять его вместо байт-кода. Этот процесс повторяется для перехода к выполнению кода, подготовленного средствами FullJIT. Преимущество такого подхода заключается в том, что паузы, связанные с копированием данных, обычно гораздо короче, чем те, которые вызваны работой полноценного компилятора (фронтенда). Однако минусом такого подхода является тот факт, что эвристические алгоритмы копирования могут пропустить какую-то информацию, которая может оказаться полезной для выполнения некоей оптимизации. Здесь мы видим пример компромисса между качеством получаемого кода и задержками.
В JavaScriptCore все задачи оптимизирующей компиляции выполняются параллельно с основным потоком, ответственным за выполнение JavaScript-кода. При этом тут нет стадии копирования. Вместо этого главный поток просто вызывает задачи компиляции в другом потоке. Затем компилятор использует сложную схему блокировок для доступа к данным профилирования из главного потока.
 Оптимизация «горячего» кода в JavaScriptCore
Оптимизация «горячего» кода в JavaScriptCore
Преимущество такого подхода заключается в том, что он сокращает вынужденные блокировки главного потока, вызванные тем, что в нём выполняются задачи оптимизации кода. Минусы такой архитектуры в том, что для её реализации требуется решение сложных задач многопоточной обработки данных, и в том, что в ходе работы, для выполнения различных операций, приходится прибегать к блокировкам.
Только что мы обсудили компромиссы, на которые вынуждены идти движки, выбирая между быстрым генерированием кода с помощью интерпретаторов и созданием быстрого кода с помощью оптимизирующих компиляторов. Однако, это далеко не все проблемы, которые встают перед движками. Память — это ещё один системный ресурс, при использовании которого приходится прибегать к компромиссным решениям. Для того чтобы это продемонстрировать, рассмотрим простую JS-программу, которая складывает числа.
Вот байт-код функции
В смысл этого байт-кода можно не вдаваться, на самом деле, его содержимое нас не особенно интересует. Главное здесь то, что в нём всего четыре инструкции.
Когда подобный фрагмент кода оказывается «горячим», за дело принимается TurboFan, который генерирует следующий высокооптимизированный машинный код:
Как видите, объём кода, в сравнении с вышеприведённым примером из четырёх инструкций, очень велик. Как правило, байт-код оказывается гораздо компактнее, чем машинный код, а в особенности — оптимизированный машинный код. С другой стороны, для выполнения байт-кода нужен интерпретатор, а оптимизированный код можно выполнять прямо на процессоре.
Это — одна из основных причин того, почему JavaScript-движки не занимаются оптимизацией абсолютно всего кода. Как мы видели ранее, создание оптимизированного машинного кода занимает много времени, и, более того, как мы только что выяснили, для хранения оптимизированного машинного кода требуется больше памяти.
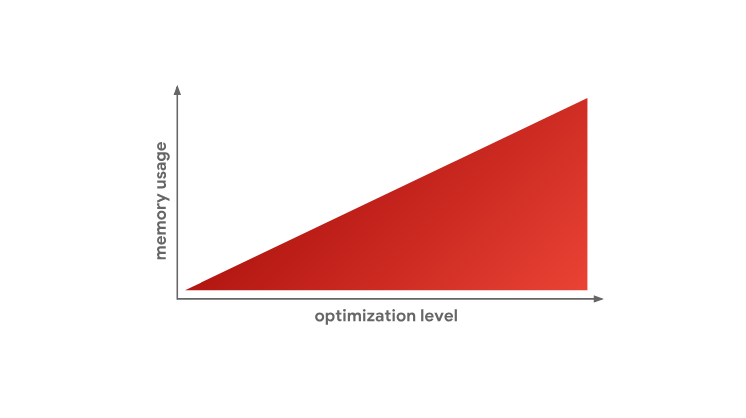 Использование памяти и уровень оптимизации
Использование памяти и уровень оптимизации
В итоге можно сказать, что причина, по которой JS-движки имеют различные уровни оптимизации, заключается в фундаментальной проблеме выбора между быстрым генерированием кода, например, с помощью интерпретатора, и генерированием быстрого кода, выполняемым средствами оптимизирующего компилятора. Если говорить об уровнях оптимизации кода, применяемых в движках, то, чем их больше, тем более тонким оптимизациям может быть подвергнут код, но достигается это за счёт усложнения движков и за счёт дополнительной нагрузки на систему. Кроме того, тут нельзя забывать и о том, что уровень оптимизации кода влияет на объём памяти, который занимает этот код. Именно поэтому JS-движки стараются оптимизировать лишь «горячие» функции.
JavaScript-движки занимаются оптимизацией доступа к свойствам объектов благодаря использованию так называемых форм объектов (Shape) и инлайн-кэшей (Inline Cache, IC). Подробности об этом можно почитать в данном материале, если же выразить это в двух словах, то можно сказать, что движок хранит форму объекта отдельно от значений объекта.
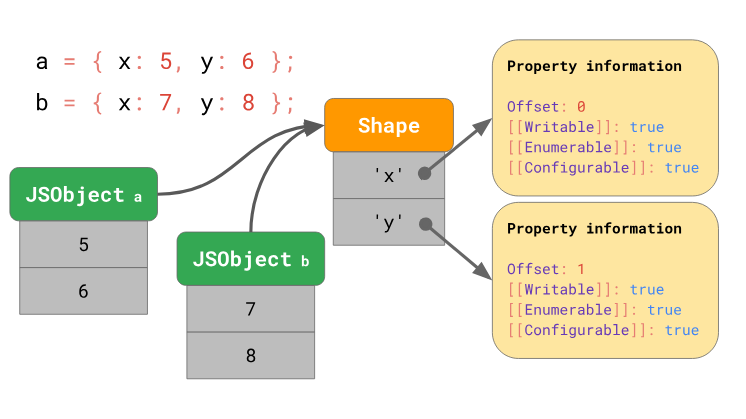 Объекты, имеющие одну и ту же форму
Объекты, имеющие одну и ту же форму
Использование форм объектов даёт возможность выполнить оптимизацию, называемую инлайн-кэшированием. Совместное использование форм объектов и инлайн-кэшей позволяет ускорить повторяющиеся операции обращения к свойствам объектов, выполняемые из одного и того же места кода.
 Ускорение доступа к свойству объекта
Ускорение доступа к свойству объекта
Теперь, когда мы знаем о том, как ускорить доступ к свойствам объектов в JavaScript, взглянем на одно из недавних новшеств JavaScript — на классы. Вот как выглядит объявление класса:
Хотя выглядеть это может как появление в JS совершенно новой концепции, классы, на самом деле — лишь синтаксический сахар для прототипной системы конструирования объектов, которая присутствовала в JavaScript всегда:
Здесь мы записываем функцию в свойство
Приглядимся к тому, что происходит, так сказать, за кулисами, когда мы создаём новый экземпляр объекта
После выполнения подобного кода у экземпляра созданного здесь объекта будет форма, содержащая единственное свойство
 Объект и его прототип
Объект и его прототип
У
Посмотрим теперь, что произойдёт, если создать ещё один объект типа
 Несколько объектов одного типа
Несколько объектов одного типа
Как видно, и объект
Итак, теперь мы знаем о том, что происходит, когда мы объявляем новый класс и создаём его экземпляры. А что можно сказать о вызове метода объекта? Рассмотрим следующий фрагмент кода:
Вызов метода можно воспринимать как операцию, состоящую из двух шагов:
На первом шаге осуществляется загрузка метода, который представляет собой всего лишь свойство прототипа (значением которого оказывается функция). На втором шаге производится вызов функции с установкой
 Загрузка метода getX из объекта foo
Загрузка метода getX из объекта foo
Движок анализирует объект
Гибкость JavaScript даёт возможность менять цепочки прототипов. Например, так:
В этом примере мы вызываем метод
Если рассмотреть реально существующие программы, то окажется, что загрузка свойств прототипов — это операция, которая встречается очень часто. Она выполняется каждый раз, когда производится вызов метода.
Ранее мы говорили о том, как движки оптимизируют загрузку обычных, собственных свойств объектов благодаря использованию форм объектов и инлайн-кэшей. Как оптимизировать повторяющиеся загрузки свойств прототипа для объектов с одной и той же формой? Выше мы видели как производится загрузка свойств.
 Загрузка метода getX из объекта foo
Загрузка метода getX из объекта foo
Для того чтобы ускорить доступ к методу при повторяющихся обращениях к нему, в нашем случае, нужно знать следующее:
В общем случае это означает, что нам нужно произвести 1 проверку самого объекта, и 2 проверки для каждого прототипа вплоть до прототипа, хранящего свойство, которое мы ищем. То есть, нужно провести 1+2N проверок (где N — количество проверяемых прототипов), что в данном случае выглядит не так уж и плохо, так как цепочка прототипов у нас довольно короткая. Однако движкам часто приходится работать с гораздо более длинными цепочками прототипов. Это, например, характерно для обычных DOM-элементов. Вот пример:
Тут у нас имеется
 Цепочка прототипов
Цепочка прототипов
Метод
Как видите, тут выполняется 7 проверок. Так как подобный код очень часто встречается в веб-программировании, движки применяют оптимизации для уменьшения числа проверок, необходимых для загрузки свойств прототипов.
Если вернуться к одному из предыдущих примеров, можно вспомнить, что при обращении к методу
Для каждого объекта, имеющегося в цепочке прототипов, вплоть до того из них, который содержит нужное свойство, нам нужно проверить форму объекта только для того, чтобы выяснить отсутствие там того, что мы ищем. Было бы хорошо, если бы мы могли уменьшить число проверок, сведя проверку прототипа к проверке наличия или отсутствия того, что мы ищем. Именно это и делает движок с помощью простого хода: вместо того, чтобы хранить ссылку на прототип в самом экземпляре, движок хранит её в форме объекта.
 Хранение ссылок на прототипы
Хранение ссылок на прототипы
Каждая форма имеет ссылку на прототип. Это ещё означает, что всякий раз, когда прототип
Благодаря этому подходу мы можем уменьшить число проверок с 1+2N до 1+N, что позволит ускорить доступ к свойствам прототипов. Однако такие операции всё ещё являются достаточно ресурсозатратными, так как между их количеством и длиной цепочки прототипов имеется линейная зависимость. В движках реализованы различные механизмы, направленные на то, чтобы число проверок не зависело от длины цепочки прототипов, выражаясь константой. Это особенно актуально в ситуациях, когда загрузка одного и того же свойства выполняется несколько раз.
V8 обращается к формам прототипов специально для вышеозначенной цели. Каждый прототип имеет уникальную форму, которая не используется совместно с другими объектами (в частности, с другими прототипами), и каждая из форм объектов-прототипов имеет связанное с ними свойство
 Свойство ValidityCell
Свойство ValidityCell
Это свойство объявляется недействительным при изменении прототипа, связанного с формой, или любого вышележащего прототипа. Рассмотрим этот механизм подробнее.
Для того чтобы ускорить последовательные операции загрузки свойств из прототипов, V8 использует инлайн-кэш, содержащий четыре поля:
 Поля инлайн-кэша
Поля инлайн-кэша
В ходе «разогрева» инлайн-кэша при первом запуске кода, V8 запоминает смещение, по которому свойство было найдено в прототипе, прототип, в котором было найдено свойство (в данном примере —
В следующий раз, когда произойдёт обращение к инлайн-кэшу, движку нужно будет проверить форму объекта и
Когда прототип меняется, создаётся новая форма, а предыдущее свойство
 Последствия изменения прототипа
Последствия изменения прототипа
Если вернуться к примеру с DOM-элементом, это означает, что любое изменение, например, в прототипе
 Последствия изменения Object.prototype
Последствия изменения Object.prototype
Фактически, модификация
Исследуем вышесказанное на примере. Предположим, у нас имеется класс
Инлайн-кэш в
Менять
Мы расширили
Уборка, как кажется, идея хорошая. Но в данном случае это ещё сильнее ухудшает и без того плохую ситуацию. Удаление свойства модифицирует
В результате можно сделать выводы о том, что хотя прототипы — это обычные объекты, JS-движки относятся к ним по-особому для того, чтобы оптимизировать производительность поиска в них методов. Поэтому прототипы существующих объектов лучше всего не трогать. А если вам действительно нужно их менять, то делайте это до того, как будет выполняться любой другой код. Так вы, по крайней мере, не разрушите результаты усилий по оптимизации кода, достигнутые движком во время его выполнения.
Из этого материала вы узнали о том, как JS-движки хранят объекты и классы, о том, как формы объектов, инлайн-кэши, свойства
Уважаемые читатели! Сталкивались ли вы на практике со случаями, когда низкую производительность какой-нибудь программы, написанной на JS, можно объяснить вмешательством в прототипы объектов во время выполнения кода?


Уровни оптимизации кода и компромиссные решения
Процесс превращения текстов программ, написанных на JavaScript, в пригодный для выполнения код, в разных движках выглядит примерно одинаково.
Подробности об этом можно посмотреть здесь. Кроме того, надо отметить, что хотя, на высоком уровне, конвейеры преобразования исходного кода в исполняемый у различных движков очень похожи, их системы оптимизации кода часто различаются. Почему это так? Почему у одних движков больше уровней оптимизации, чем у других? Оказывается, движкам приходится, так или иначе, идти на компромисс, который заключается в том, что они могут либо быстро сформировать код, не самый эффективный, но пригодный для выполнения, либо потратить на создание такого кода больше времени, но, за счёт этого, добиться оптимальной производительности.
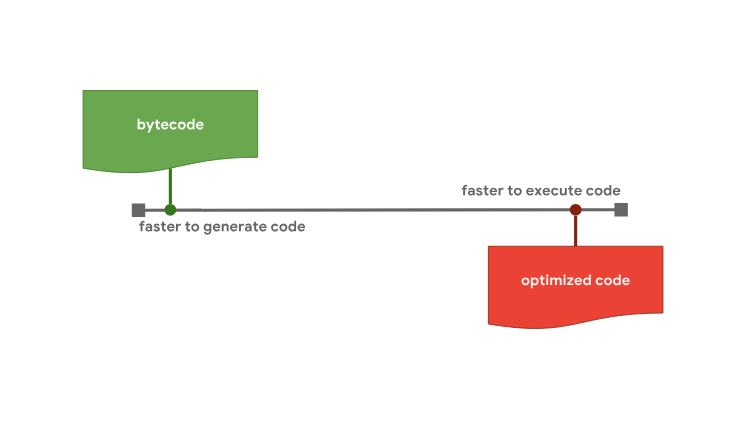
Интерпретатор способен быстро сформировать байт-код, но такой код обычно не отличается особенной эффективностью. Оптимизирующему компилятору, с другой стороны, требуется больше времени на формирование кода, но в итоге у него получается оптимизированный, более быстрый машинный код.
Именно такая модель подготовки кода к выполнению используется в V8. Интерпретатор V8 называется Ignition, он является самым быстрым из существующих интерпретаторов (в плане выполнения исходного байт-кода). Оптимизирующий компилятор V8 называется TurboFan, он отвечает за создание высокооптимизированного машинного кода.
Компромисс между задержкой запуска программы и скоростью выполнения является причиной наличия у некоторых JS-движков дополнительных уровней оптимизации. Например, в SpiderMonkey, между интерпретатором и оптимизирующим компилятором IonMonkey, имеется промежуточный уровень, представленный базовым компилятором (он, в документации Mozilla, называется «The Baseline Compiler», но «baseline» — это не имя собственное).
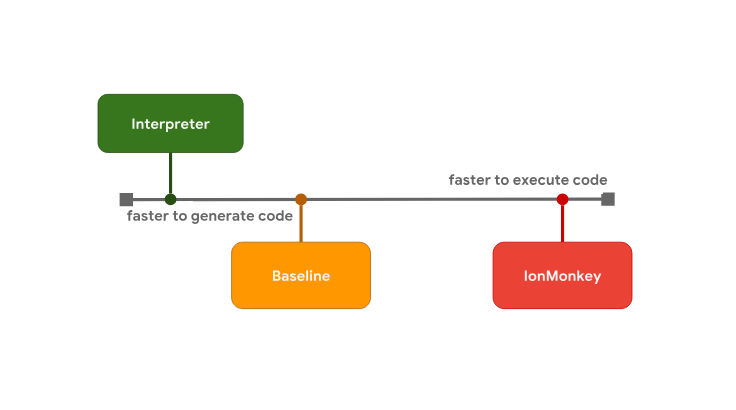
Интерпретатор быстро генерирует байт-код, но выполняется такой код сравнительно медленно. Базовому компилятору, для того, чтобы сгенерировать код, требуется больше времени, но этот код работает уже быстрее. И, наконец, оптимизирующему компилятору IonMonkey требуется больше всего времени на создание машинного кода, но этот код может выполняться очень эффективно.
Взглянем на конкретный пример и посмотрим на то, как обращаются с кодом конвейеры различных движков. В представленном здесь примере имеется «горячий» цикл, содержащий код, который повторяется очень много раз.
let result = 0;
for (let i = 0; i < 4242424242; ++i) {
result += i;
}
console.log(result);V8 начинает выполнять байт-код в интерпретаторе Ignition. В некий момент времени движок выясняет, что код это «горячий», и запускает фронтенд TurboFan, который является частью TurboFan, работающей с данными профилирования и создающей базовое машинное представление кода. Затем данные передаются оптимизатору TurboFan, работающему в отдельном потоке, для дальнейших улучшений.
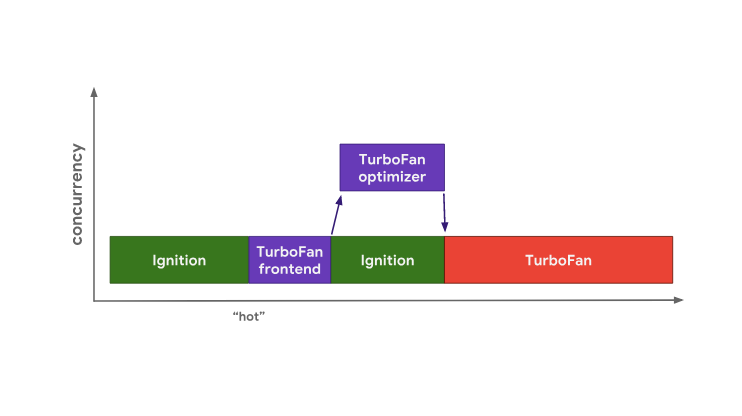
Во время оптимизации V8 продолжает выполнять байт-код в Ignition. Когда оптимизатор завершает работу, у нас имеется исполняемый машинный код, которым можно пользоваться в дальнейшем.
Движок SpiderMonkey тоже начинает выполнять байт-код в интерпретаторе. Но у него имеется дополнительный уровень, представленный базовым компилятором, что приводит к тому, что «горячий» код сначала попадает к этому компилятору. Он генерирует базовый код в главном потоке, переход на выполнение этого кода производится тогда, когда он будет готов.
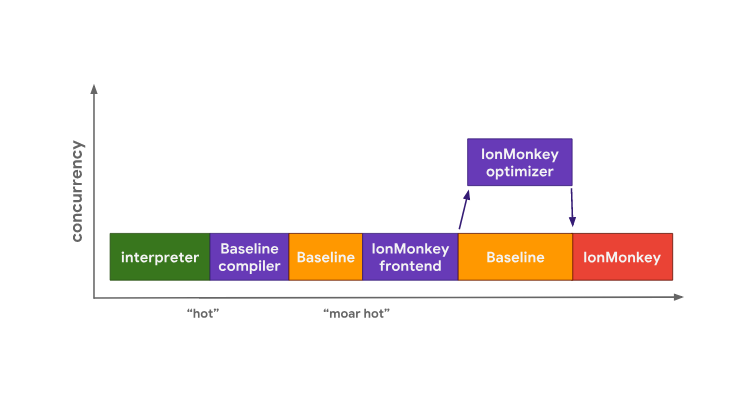
Если базовый код выполняется достаточно долго, SpiderMonkey, в итоге, запускает фронтенд IonMonkey и оптимизатор, что очень похоже на то, что происходит в V8. Базовый код продолжает выполняться в процессе оптимизации кода, выполняемой IonMonkey. В итоге, когда оптимизация оказывается завершённой, вместо базового кода выполняется оптимизированный код.
Архитектура движка Chakra очень похожа на архитектуру SpiderMonkey, но Chakra стремится к более высокому уровню параллелизма для того, чтобы избежать блокировки главного потока. Вместо того чтобы решать какие-либо задачи компиляции в главном потоке, Chakra копирует и отправляет байт-код и данные профилирования, которые, весьма вероятно, понадобятся компилятору, в отдельный процесс компиляции.
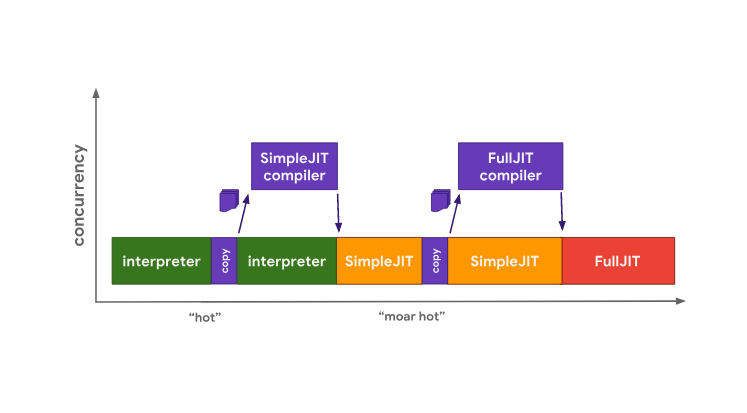
Когда сгенерированный код, подготовленный средствами SimpleJIT, будет готов, движок будет выполнять его вместо байт-кода. Этот процесс повторяется для перехода к выполнению кода, подготовленного средствами FullJIT. Преимущество такого подхода заключается в том, что паузы, связанные с копированием данных, обычно гораздо короче, чем те, которые вызваны работой полноценного компилятора (фронтенда). Однако минусом такого подхода является тот факт, что эвристические алгоритмы копирования могут пропустить какую-то информацию, которая может оказаться полезной для выполнения некоей оптимизации. Здесь мы видим пример компромисса между качеством получаемого кода и задержками.
В JavaScriptCore все задачи оптимизирующей компиляции выполняются параллельно с основным потоком, ответственным за выполнение JavaScript-кода. При этом тут нет стадии копирования. Вместо этого главный поток просто вызывает задачи компиляции в другом потоке. Затем компилятор использует сложную схему блокировок для доступа к данным профилирования из главного потока.
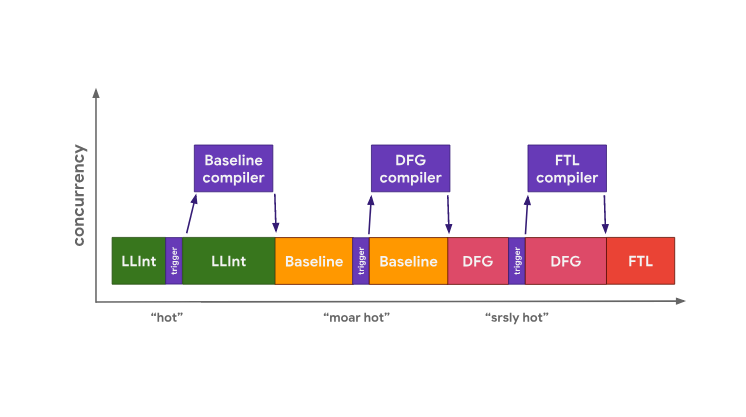
Преимущество такого подхода заключается в том, что он сокращает вынужденные блокировки главного потока, вызванные тем, что в нём выполняются задачи оптимизации кода. Минусы такой архитектуры в том, что для её реализации требуется решение сложных задач многопоточной обработки данных, и в том, что в ходе работы, для выполнения различных операций, приходится прибегать к блокировкам.
Только что мы обсудили компромиссы, на которые вынуждены идти движки, выбирая между быстрым генерированием кода с помощью интерпретаторов и созданием быстрого кода с помощью оптимизирующих компиляторов. Однако, это далеко не все проблемы, которые встают перед движками. Память — это ещё один системный ресурс, при использовании которого приходится прибегать к компромиссным решениям. Для того чтобы это продемонстрировать, рассмотрим простую JS-программу, которая складывает числа.
function add(x, y) {
return x + y;
}
add(1, 2);Вот байт-код функции
add, сгенерированный интерпретатором Ignition в V8:StackCheck
Ldar a1
Add a0, [0]
ReturnВ смысл этого байт-кода можно не вдаваться, на самом деле, его содержимое нас не особенно интересует. Главное здесь то, что в нём всего четыре инструкции.
Когда подобный фрагмент кода оказывается «горячим», за дело принимается TurboFan, который генерирует следующий высокооптимизированный машинный код:
leaq rcx,[rip+0x0]
movq rcx,[rcx-0x37]
testb [rcx+0xf],0x1
jnz CompileLazyDeoptimizedCode
push rbp
movq rbp,rsp
push rsi
push rdi
cmpq rsp,[r13+0xe88]
jna StackOverflow
movq rax,[rbp+0x18]
test al,0x1
jnz Deoptimize
movq rbx,[rbp+0x10]
testb rbx,0x1
jnz Deoptimize
movq rdx,rbx
shrq rdx, 32
movq rcx,rax
shrq rcx, 32
addl rdx,rcx
jo Deoptimize
shlq rdx, 32
movq rax,rdx
movq rsp,rbp
pop rbp
ret 0x18Как видите, объём кода, в сравнении с вышеприведённым примером из четырёх инструкций, очень велик. Как правило, байт-код оказывается гораздо компактнее, чем машинный код, а в особенности — оптимизированный машинный код. С другой стороны, для выполнения байт-кода нужен интерпретатор, а оптимизированный код можно выполнять прямо на процессоре.
Это — одна из основных причин того, почему JavaScript-движки не занимаются оптимизацией абсолютно всего кода. Как мы видели ранее, создание оптимизированного машинного кода занимает много времени, и, более того, как мы только что выяснили, для хранения оптимизированного машинного кода требуется больше памяти.
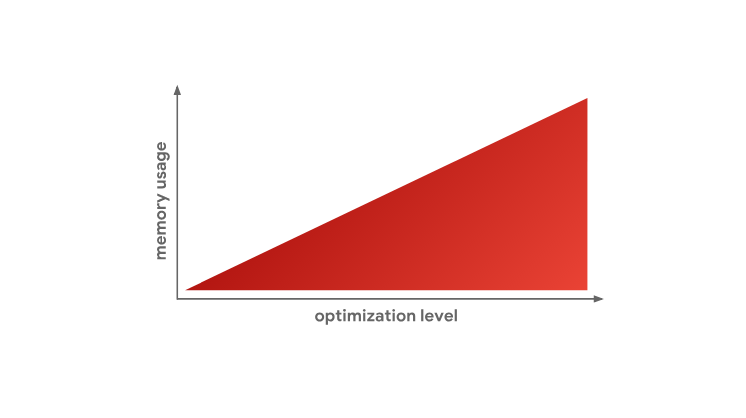
В итоге можно сказать, что причина, по которой JS-движки имеют различные уровни оптимизации, заключается в фундаментальной проблеме выбора между быстрым генерированием кода, например, с помощью интерпретатора, и генерированием быстрого кода, выполняемым средствами оптимизирующего компилятора. Если говорить об уровнях оптимизации кода, применяемых в движках, то, чем их больше, тем более тонким оптимизациям может быть подвергнут код, но достигается это за счёт усложнения движков и за счёт дополнительной нагрузки на систему. Кроме того, тут нельзя забывать и о том, что уровень оптимизации кода влияет на объём памяти, который занимает этот код. Именно поэтому JS-движки стараются оптимизировать лишь «горячие» функции.
Оптимизация доступа к свойствам прототипов объектов
JavaScript-движки занимаются оптимизацией доступа к свойствам объектов благодаря использованию так называемых форм объектов (Shape) и инлайн-кэшей (Inline Cache, IC). Подробности об этом можно почитать в данном материале, если же выразить это в двух словах, то можно сказать, что движок хранит форму объекта отдельно от значений объекта.
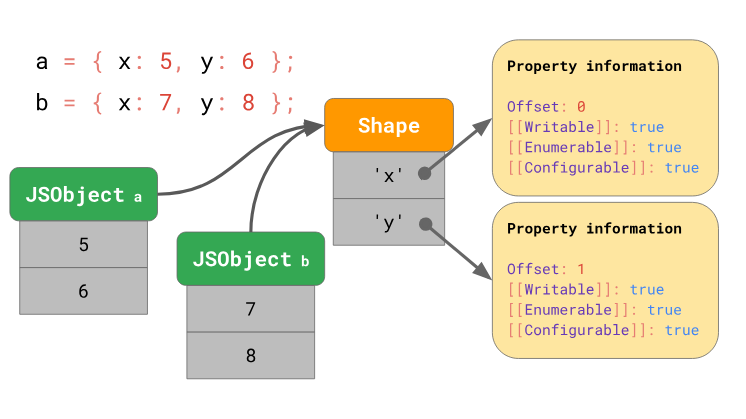
Использование форм объектов даёт возможность выполнить оптимизацию, называемую инлайн-кэшированием. Совместное использование форм объектов и инлайн-кэшей позволяет ускорить повторяющиеся операции обращения к свойствам объектов, выполняемые из одного и того же места кода.

Классы и прототипы
Теперь, когда мы знаем о том, как ускорить доступ к свойствам объектов в JavaScript, взглянем на одно из недавних новшеств JavaScript — на классы. Вот как выглядит объявление класса:
class Bar {
constructor(x) {
this.x = x;
}
getX() {
return this.x;
}
}Хотя выглядеть это может как появление в JS совершенно новой концепции, классы, на самом деле — лишь синтаксический сахар для прототипной системы конструирования объектов, которая присутствовала в JavaScript всегда:
function Bar(x) {
this.x = x;
}
Bar.prototype.getX = function getX() {
return this.x;
};Здесь мы записываем функцию в свойство
getX объекта Bar.prototype. Работает такая операция точно так же, как при создании свойства любого другого объекта, так как прототипы в JavaScript являются объектами. В языках, основанных на использовании прототипов, таких, как JavaScript, методы, которыми могут совместно пользоваться все объекты некоего типа, хранятся в прототипах, а поля отдельных объектов хранятся в их экземплярах.Приглядимся к тому, что происходит, так сказать, за кулисами, когда мы создаём новый экземпляр объекта
Bar, назначая его константе foo.const foo = new Bar(true);После выполнения подобного кода у экземпляра созданного здесь объекта будет форма, содержащая единственное свойство
x. Прототипом объекта foo будет Bar.prototype, который принадлежит классу Bar.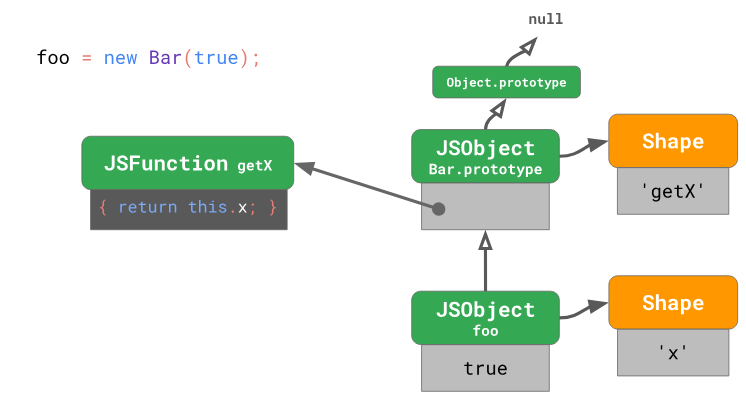
У
Bar.prototype имеется собственная форма, содержащая единственное свойство getX, значением которого является функция, которая, при её вызове, возвращает значение this.x. Прототип прототипа Bar.prototype — это Object.prototype, являющийся частью языка. Object.prototype является корневым элементом дерева прототипов, поэтому его прототип — это значение null.Посмотрим теперь, что произойдёт, если создать ещё один объект типа
Bar.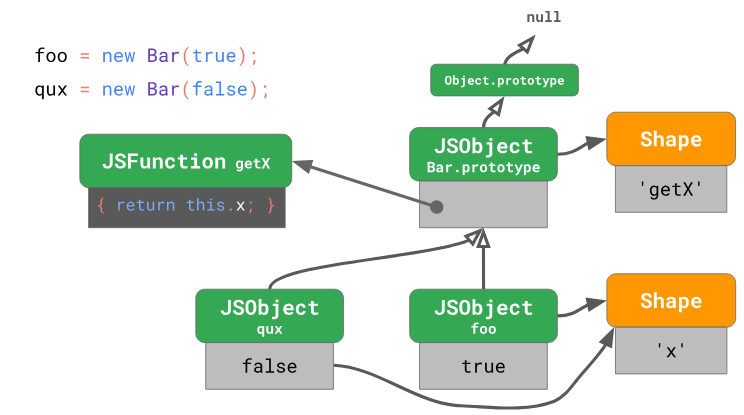
Как видно, и объект
foo, и объект qux, являющиеся экземплярами класса Bar, как мы уже говорили, используют одну и ту же форму объекта. Оба они используют и один и тот же прототип — объект Bar.prototype.Доступ к свойствам прототипа
Итак, теперь мы знаем о том, что происходит, когда мы объявляем новый класс и создаём его экземпляры. А что можно сказать о вызове метода объекта? Рассмотрим следующий фрагмент кода:
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^Вызов метода можно воспринимать как операцию, состоящую из двух шагов:
const x = foo.getX();
// на самом деле эта операция состоит из двух шагов:
const $getX = foo.getX;
const x = $getX.call(foo);На первом шаге осуществляется загрузка метода, который представляет собой всего лишь свойство прототипа (значением которого оказывается функция). На втором шаге производится вызов функции с установкой
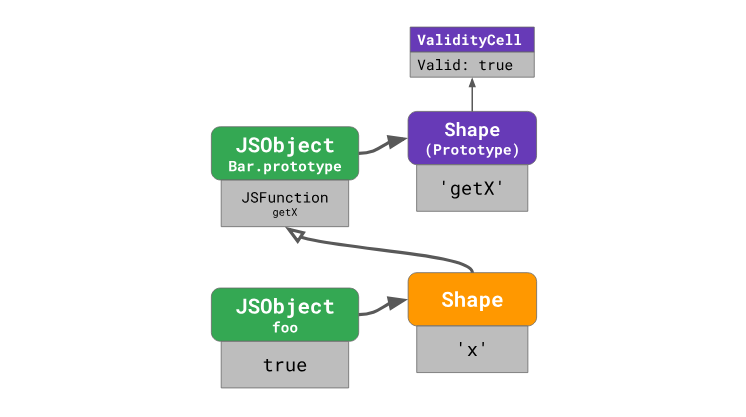
this. Рассмотрим первый шаг, на котором выполняется загрузка метода getX из объекта foo:
Движок анализирует объект
foo и выясняет, что в форме объекта foo нет свойства getX. Это значит, что движку надо просмотреть цепочку прототипов объекта для того, чтобы найти этот метод. Движок обращается к прототипу Bar.prototype и смотрит на форму объекта этого прототипа. Там он находит нужное свойство по смещению 0. Далее, осуществляется обращение к значению, хранящемуся по этому смещению в Bar.prototype, там обнаруживается JSFunction getX — а это как раз то, что мы ищем. На этом поиск метода завершается.Гибкость JavaScript даёт возможность менять цепочки прототипов. Например, так:
const foo = new Bar(true);
foo.getX();
// true
Object.setPrototypeOf(foo, null);
foo.getX();
// Uncaught TypeError: foo.getX is not a functionВ этом примере мы вызываем метод
foo.getX() дважды, но каждый из этих вызовов имеет совершенно разный смысл и результат. Именно поэтому, хотя прототипы в JavaScript — это всего лишь объекты, ускорение доступа к свойствам прототипов — это задача даже более сложная для JS-движков, чем ускорение доступа к собственным свойствам обычных объектов.Если рассмотреть реально существующие программы, то окажется, что загрузка свойств прототипов — это операция, которая встречается очень часто. Она выполняется каждый раз, когда производится вызов метода.
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const x = foo.getX();
// ^^^^^^^^^^Ранее мы говорили о том, как движки оптимизируют загрузку обычных, собственных свойств объектов благодаря использованию форм объектов и инлайн-кэшей. Как оптимизировать повторяющиеся загрузки свойств прототипа для объектов с одной и той же формой? Выше мы видели как производится загрузка свойств.
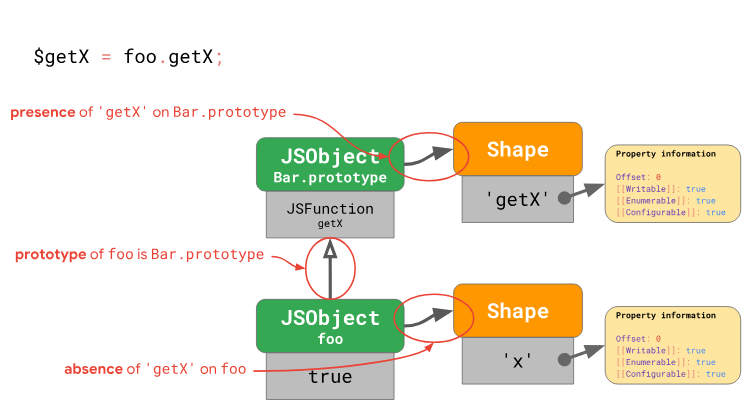
Для того чтобы ускорить доступ к методу при повторяющихся обращениях к нему, в нашем случае, нужно знать следующее:
- Форма объекта
fooне содержит методаgetXи не меняется. Это означает, что объектfooне модифицируют, добавляя в него свойства или удаляя их, или меняя атрибуты свойств. - Прототипом
fooвсё ещё является исходныйBar.prototype. Это означает, что прототипfooне меняется с использованием методаObject.setPrototypeOf()или путём назначения нового прототипа специальному свойству_proto_. - Форма
Bar.prototypeсодержитgetXи не меняется. То есть,Bar.prototypeне изменяют, удаляя свойства, добавляя их, или меняя их атрибуты.
В общем случае это означает, что нам нужно произвести 1 проверку самого объекта, и 2 проверки для каждого прототипа вплоть до прототипа, хранящего свойство, которое мы ищем. То есть, нужно провести 1+2N проверок (где N — количество проверяемых прототипов), что в данном случае выглядит не так уж и плохо, так как цепочка прототипов у нас довольно короткая. Однако движкам часто приходится работать с гораздо более длинными цепочками прототипов. Это, например, характерно для обычных DOM-элементов. Вот пример:
const anchor = document.createElement('a');
// HTMLAnchorElement
const title = anchor.getAttribute('title');Тут у нас имеется
HTMLAnchorElement и мы вызываем его метод getAttribute(). В цепочку прототипов этого простого элемента, представляющего HTML-ссылку, входит 6 прототипов! Большинство же интересных DOM-методов не находятся в собственном прототипе HTMLAnchorElement. Они находятся в прототипах, расположенных дальше в цепочке.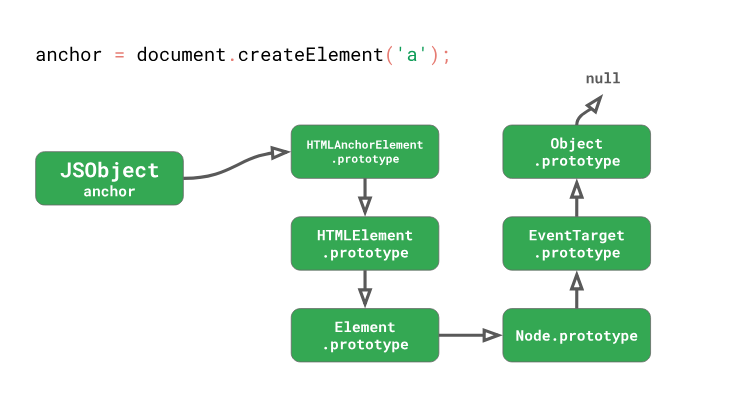
Метод
getAttribute() удаётся обнаружить в Element.prototype. Это означает, что каждый раз, при вызове метода anchor.getAttribute(), движок вынужден выполнять следующие действия:- Проверка самого объекта
anchorна наличиеgetAttribute. - Проверка того, что прямым прототипом объекта является
HTMLAnchorElement.prototype. - Выяснение, что в
HTMLAnchorElement.prototypeнет методаgetAttribute. - Проверка того, что следующим прототипом является
HTMLElement.prototype. - Выяснение того, что и здесь нет нужного метода.
- Наконец, выяснение того, что следующим прототипом является
Element.prototype. - Выяснение того, что тут имеется метод
getAttribute.
Как видите, тут выполняется 7 проверок. Так как подобный код очень часто встречается в веб-программировании, движки применяют оптимизации для уменьшения числа проверок, необходимых для загрузки свойств прототипов.
Если вернуться к одному из предыдущих примеров, можно вспомнить, что при обращении к методу
getX объекта foo, мы выполняем 3 проверки:class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const $getX = foo.getX;Для каждого объекта, имеющегося в цепочке прототипов, вплоть до того из них, который содержит нужное свойство, нам нужно проверить форму объекта только для того, чтобы выяснить отсутствие там того, что мы ищем. Было бы хорошо, если бы мы могли уменьшить число проверок, сведя проверку прототипа к проверке наличия или отсутствия того, что мы ищем. Именно это и делает движок с помощью простого хода: вместо того, чтобы хранить ссылку на прототип в самом экземпляре, движок хранит её в форме объекта.
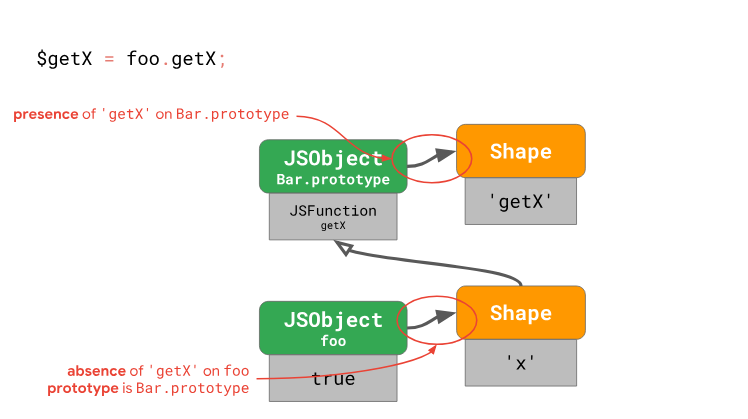
Каждая форма имеет ссылку на прототип. Это ещё означает, что всякий раз, когда прототип
foo меняется, движок переходит и к новой форме объекта. Теперь нам лишь надо проверить форму объекта на наличие в ней свойства и позаботиться о защите ссылки на прототип.Благодаря этому подходу мы можем уменьшить число проверок с 1+2N до 1+N, что позволит ускорить доступ к свойствам прототипов. Однако такие операции всё ещё являются достаточно ресурсозатратными, так как между их количеством и длиной цепочки прототипов имеется линейная зависимость. В движках реализованы различные механизмы, направленные на то, чтобы число проверок не зависело от длины цепочки прототипов, выражаясь константой. Это особенно актуально в ситуациях, когда загрузка одного и того же свойства выполняется несколько раз.
Свойство ValidityCell
V8 обращается к формам прототипов специально для вышеозначенной цели. Каждый прототип имеет уникальную форму, которая не используется совместно с другими объектами (в частности, с другими прототипами), и каждая из форм объектов-прототипов имеет связанное с ними свойство
ValidityCell.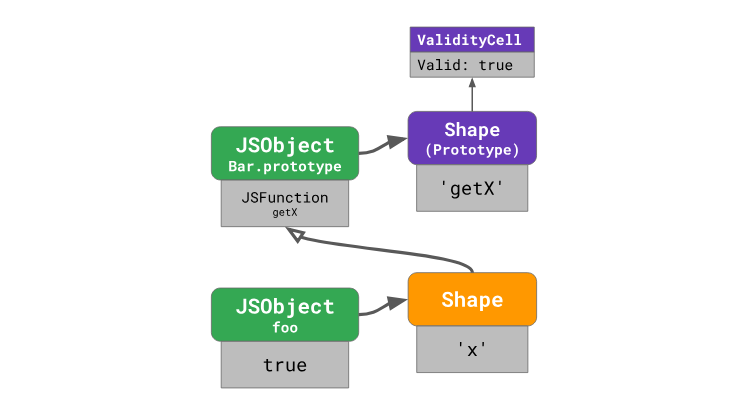
Это свойство объявляется недействительным при изменении прототипа, связанного с формой, или любого вышележащего прототипа. Рассмотрим этот механизм подробнее.
Для того чтобы ускорить последовательные операции загрузки свойств из прототипов, V8 использует инлайн-кэш, содержащий четыре поля:
ValidityCell, Prototype, Shape, Offset. 
В ходе «разогрева» инлайн-кэша при первом запуске кода, V8 запоминает смещение, по которому свойство было найдено в прототипе, прототип, в котором было найдено свойство (в данном примере —
Bar.prototype), форму объекта (foo в данном случае), и, кроме того, ссылку на текущий параметр ValidityCell непосредственного прототипа, ссылка на который имеется в форме объекта (в данном случае это тоже Bar.prototype).В следующий раз, когда произойдёт обращение к инлайн-кэшу, движку нужно будет проверить форму объекта и
ValidityCell. Если показатель ValidityCell всё ещё является действительным, движок может напрямую воспользоваться сохранённым ранее смещением в прототипе, не выполняя дополнительные операции поиска.Когда прототип меняется, создаётся новая форма, а предыдущее свойство
ValidityCell объявляется недействительным. Как результат, при следующей попытке обращения к инлайн-кэшу пользы это не приносит, что приводит к ухудшению производительности.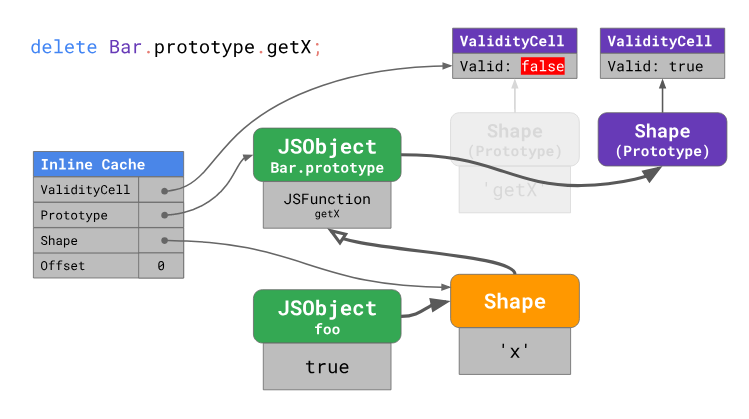
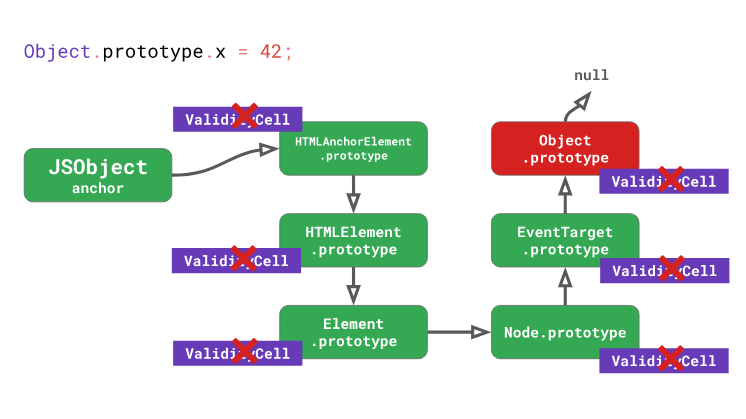
Если вернуться к примеру с DOM-элементом, это означает, что любое изменение, например, в прототипе
Object.prototype, приведёт не только к инвалидации инлайн-кэша для самого Object.prototype, но и для любых прототипов, расположенных ниже его в цепочке прототипов, включая EventTarget.prototype, Node.prototype, Element.prototype, и так далее, вплоть до HTMLAnchorElement.prototype.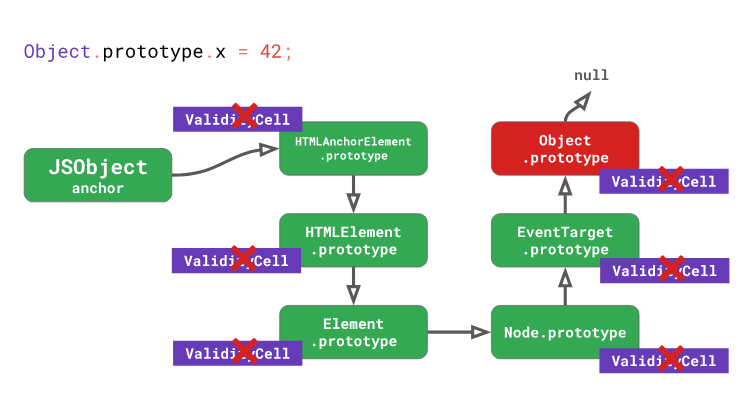
Фактически, модификация
Object.prototype в процессе выполнения кода означает нанесение серьёзного вреда производительности. Не делайте этого.Исследуем вышесказанное на примере. Предположим, у нас имеется класс
Bar, и функция loadX, которая вызывает метод объектов, созданных на основе класса Bar. Мы вызываем функцию loadX несколько раз, передавая ей экземпляры одного и того же класса.function loadX(bar) {
return bar.getX(); // IC для 'getX' в экземплярах `Bar`.
}
loadX(new Bar(true));
loadX(new Bar(false));
// IC в `loadX` теперь указывает на `ValidityCell` для
// `Bar.prototype`.
Object.prototype.newMethod = y => y;
// `ValidityCell` в IC `loadX` объявлено недействительным
// так как в `Object.prototype` внесены изменения.Инлайн-кэш в
loadX теперь указывает на ValidityCell для Bar.prototype. Если затем, скажем, изменить Object.prototype — корневой прототип в JavaScript, тогда значение ValidityCell окажется недействительным, и существующий инлайн-кэш не поможет ускорить работу при следующей попытке обращения к нему, что приведёт к ухудшению производительности.Менять
Object.prototype — это всегда плохо, так как это приводит к инвалидации всех инлайн-кэшей для операций загрузки свойств из прототипов, созданных движком до момента изменения корневого прототипа. Вот ещё один пример того, как поступать не следует:Object.prototype.foo = function() { /* … */ };
// Особо важный фрагмент кода:
someObject.foo();
// Конец особо важного фрагмента кода.
delete Object.prototype.foo;Мы расширили
Object.prototype, что привело к инвалидации инлайн-кэшей прототипов, ранее созданных движком. Затем мы запускаем некий код, использующий новый метод прототипа. Движку приходится начинать работу с инлайн-кэшами с чистого листа, создавать новые кэши для выполнения операций доступа к свойствам прототипов. Затем мы возвращаем всё к прежнему виду, «убираем за собой», удаляя метод прототипа, добавленный ранее.Уборка, как кажется, идея хорошая. Но в данном случае это ещё сильнее ухудшает и без того плохую ситуацию. Удаление свойства модифицирует
Object.prototype, а это значит, что все инлайн-кэши опять оказываются недействительными и движку снова приходится начинать их создание с нуля.В результате можно сделать выводы о том, что хотя прототипы — это обычные объекты, JS-движки относятся к ним по-особому для того, чтобы оптимизировать производительность поиска в них методов. Поэтому прототипы существующих объектов лучше всего не трогать. А если вам действительно нужно их менять, то делайте это до того, как будет выполняться любой другой код. Так вы, по крайней мере, не разрушите результаты усилий по оптимизации кода, достигнутые движком во время его выполнения.
Итоги
Из этого материала вы узнали о том, как JS-движки хранят объекты и классы, о том, как формы объектов, инлайн-кэши, свойства
ValidityCell помогают оптимизировать операции, в которых участвуют прототипы объектов. На основе этих знаний мы вывели практическую рекомендацию по программированию на JavaScript, которая заключается в том, что прототипы лучше всего не менять (а если вам без этого совершенно невозможно обойтись, то, как минимум, делать это надо до выполнения остального кода программ).Уважаемые читатели! Сталкивались ли вы на практике со случаями, когда низкую производительность какой-нибудь программы, написанной на JS, можно объяснить вмешательством в прототипы объектов во время выполнения кода?

