Всем привет.
Меня зовут Александр Черников, я руководитель разработки в дивизионе «Цифровой Корпоративный Банк» Сбербанка и Сбертеха.
Расскажу вам сегодня про DevOps в Сбербанк Бизнес Онлайн (СББОЛ), который мы выстроили в немаленькой команде (125 разработчиков) с большим Review (75 ПРов в день). Теперь отлаженный процесс CD(CI) на pull-requests (далее PR) — это неотъемлемая часть работы и наша гордость.

Итак, что же мы сделали:
Теперь подробнее, как всё начиналось. Рассказывать буду на примере одного репозитория UI, и если будут какие-то интересные особенности в других репозиториях, напишу отдельно.
Когда-то наш develop постоянно ломался из-за каких-то мелких ошибок, которые просмотрели на code-review. Это были ошибки JS runtime, ошибки компиляции Typescript, глобальные ошибки стилей приложения (когда вся страница «разъехалась») и пр. В чате постоянно звучали всем знакомые вопросы: «develop не сломан? Можно обновиться?», «У кого еще develop не собирается? Или у меня одного так?" и другие. Тогда команда была из 10 человек. И на горизонте начали маячить планы вырасти до 10-15 скрам-команд по 9-10 человек. Наши суперАдмины и эксперты (ревьюеры) загрустили.
Думали решить проблему стабильности через git pre-push hook, но этот подход тоже не заработал по двум причинам:
Начали думать в сторону барьера на этапе PR.
В первых реализациях запуск job делался этим плагином. Т.е. он через каждые 15 мин (cron) обходил PR с новыми комментариями test this please или новые PR, и просто запускал job. После сборки мы в shell скрипте писали коммент в PR (успех/неудача). Эксперты смотрели код, ставили свои апрувы (за англицизмы не судите строго, хорошего синонима не нашёл).
НО вливать код могли только избранные, god mode. Обычно это был один человек на репозиторий, которому нужно было убедиться в успешной сборке, найти «BUILD SUCCESS», посчитать количество апрувов и только после этого нажать кнопку Merge. И я вам скажу, по опыту, морально это очень тяжело. Вроде и апрувы есть, и «чеки» прошли, а вливаешь всё равно ты, и ответственный тоже ты. Никто из наших больше трех недель не выдерживал. Начались дежурства :) И с точки зрения процесса это все равно было узким горлышком, потому что даже после того, как все требования выполнены, команде нужно было найти того, кто нажмет кнопку. В итоге от 1 часа до целого дня, а порой и неделями команды не могли найти этого «избранного», забившегося в угол Главного Разработчика.
Стоит упомянуть, что у Bitbucket есть стандартная опция — отображать статус сборки. И ещё merge checklist: минимальное число апрувов, хотя бы одна успешная сборка, все замечания разрешены (галочки) и др. Но нам этого было мало.
Потом уже только родилась идея плагина, быстро накидали минимальные требования к нему и приступили к разработке. Всего один человек МаратСадретдинов, который ни разу не писал ничего для Bitbucket и не работал с его api, дал нам рабочий прототип уже через месяц (писал в свободное время). Самым приоритетным было требование: получить список PRов, готовых к влитию. Какие критерии мы установили:
Как это работало:
Создается PR >> Пишется комментарий test this please >> Наш плагин блокирует кнопку Merge, а github plugin мониторит комменты и запускает job на Jenkins >> Jenkins по окончании присылает успех/неуспех >> Плагин активирует кнопку Merge, если все критерии успешны >> «God mode user» вливает код, каждый раз немножечко постарев.
Всё. Одна-две недели на отладку, исправление багов, задержек между Jenkins & Bitbucket (каждую секунду опрашивать все PRы было тяжело, потому что плагин сканировал все комментарии). И ура! Вопросы про сломанный develop пропали.
Но потом всё стало еще интереснее, руководители разработки и жадные разработчики захотели «жира».
Много чего хотели, давайте я расскажу, что же у нас в итоге получилось.
Начнем с главного лейбла — expert.
Есть группа экспертов, это в первую очередь наиболее опытные на проекте разработчики, которые знают даты релизов, зависимость и влияние кода, общие подходы и практики и, конечно же, как лучше писать код.
team.
Лейбл твоей команды. Выставляется минимальное число апрувов от твоей команды. Это не обязательно должен быть разработчик, или js-ник, если PR в UI. Главная цель, чтобы команда подтвердила, что разработка движется в том направлении, которое они запланировали. Иногда это могли быть более опытные разработчики, которые до экспертов выставляли замечаниями своему коллеге.
arch
Мы себе придумали такой лейбл, когда менялись ядро, общие компоненты, утилиты. Каждый такой PR обычно затрагивал очень многие формы и страницы, и мог существенно поломать функционал. Определялся он обычной регуляркой по структуре проекта (папка src/Core, src/Common и т.п.)
prCheck
Самый главный технический лейбл. Гарант надежности. В UI репозитории это tslint, lesslint, jsonlint, typescript, webpack, одно время даже e2e тесты на groovy. На бэке — компиляция, интеграционные тесты API. Всё в докере.
oracle, security, admin, devops
Узкоспециализированные эксперты в своих областях.
sonar
Это Сонар, на бэке. Сканирует код, заводит таски на правила, которые вы приняли на проекте.
predvnedrezh
Специальный лейбл для поры «Предвнедрежа», когда внедрение на носу (одна-две недели), и вливать ничего нельзя. И мы ничего не вливаем. Почти. Ну вы поняли ;)
not_task, not_story, not_bug, not_test
Лейблы с приветом от Jira. У PRа всегда есть связи с задачами из Jira, потому что commit без указания номера задачи сделать нельзя (я думаю многие на сервере ставят себе такие git hooks). Плагин просто смотрит тип таски в Jira. Так вот этот лейбл говорит о том, что код правит что-то другое, не то, что вы ожидаете.
css
Говорит о том, что в PRе есть файлы стилей, нужен гуру по стилям, верстке и дизайну.
На этом месте мог бы быть ваш Label
Также реализовали возможность ручного добавления лейблов (если какие-то правила нельзя регламентировать), автор PR или сам эксперт мог добавить еще экспертов (еще больше экспертов!).
Еще лейблы можно делать опциональными, они не блокируют кнопку Merge.
Другое интересное умение плагина — это назначение экспертов автоматом. До плагина каждый разработчик руками выставлял экспертов, коллег по команде и других, чьи интересы задел соответствующий лейбл. Сначала это просто была русская рулетка, с небольшим счетчиком внутри. Если в вашем репозитории работает правило минимум двух апрувов эксперта, то выбирались три эксперта из всех.
Вы спросите, зачем вообще выбирать двух-трех экспертов на PR? Почему бы не назначать весь список на каждый PR? Кто сможет — тот и посмотрит. Но, как говорится, «общее — значит ничье». В битбакете есть колокольчик с уведомлениями, и если у нас в день 50 PRов, то каждому эксперту (допустим, их 10), приходилось постоянно «гнать» этот счётчик к нулю. Это было почти невозможно (учитывая, что эксперты тоже пишут код), опять встал вопрос деморализации команды. Плагин нас всех спас.
Потом мы добавили возможность отключения эксперта (отпуск, болезнь), и введения личного графика работы. Некоторые команды и эксперты сидят в других городах. Но когда плагин это не учитывал, получалось так, что разработчик в 5 утра МСК создавал PR, и ему назначались 2 москвича, которые приходили к 10 МСК. Хотя были эксперты, которые могли бы посмотреть этот PR сразу же.
В одном из репозиториев сервера захотели такую примочку, как приоритеты (или вес) апрувов. Что это такое?
У вас есть эксперт (допустим Mario), который в команде (допустим Nintendo). Коллега выставляет PR, а Mario апрувит и зеленит сразу два лейбла — nintendo_team & expert. Вроде нормально, он же эксперт. Отвечает за этот код, но всё же подозрения есть. Мы в своём репозитории решили не заморачиваться, а в другом — захотели. Выставили командному лейблу приоритет выше, и следовательно эксперты этой команды не могут позеленить expert. Это забавно, но проблему кумовства между командами (какие-нибудь 2 команды Nintendo & Dendy), так и не решили :) А может ее и нет…
Еще у нас есть, да и не только у нас, такая потребность — выставлять зависимые PRы на UI & Back сразу, с одновременными правками api например, и проверкой всего приложения на уже новом коде. Для этого придумали доработку плагина «Зависимые PR и их одновременное влитие». В PRе ставишь ссылку, какой PR в другом репозитории тебе нужен, и сборка будет собираться одновременно с твоей ветки и ветки зависимого PRа. Это очень выручает, когда ты меняешь модель api одновременно на клиент+сервер, допустим, был
Или если ты правишь тест в одном репозитории, где ищешь кнопку в браузере фразой
а в UI коде она по-старому:
тогда тебе надо править опять в двух репозиториях.
Есть кнопки Restart, которая перезапускает чеки, если вдруг что-то пошло не так.
Есть кнопка Recalculate, Recycle, если нужно скинуть все лейблы и просчитать заново.
Есть кнопка «Too long review» для тех, кто любит пожаловаться. Отправляется письмо «куда следует». Возможно, скоро добавим кнопочку «Поменять экспертов», «Пожертвовать 50 руб» или еще что-нибудь важное и интересное.
Пожалуй, это всё, чем я особенно хотел поделиться. А, чуть не забыл. Еще есть админка плагина.
Спасибо за внимание, пишите вопросы. Надеюсь, наш интересный опыт пригодится вам в работе.
Меня зовут Александр Черников, я руководитель разработки в дивизионе «Цифровой Корпоративный Банк» Сбербанка и Сбертеха.
Расскажу вам сегодня про DevOps в Сбербанк Бизнес Онлайн (СББОЛ), который мы выстроили в немаленькой команде (125 разработчиков) с большим Review (75 ПРов в день). Теперь отлаженный процесс CD(CI) на pull-requests (далее PR) — это неотъемлемая часть работы и наша гордость.

Итак, что же мы сделали:
- Написали специальный плагин для Bitbucket — «Мega Plugin»
- Научили его взаимодействовать с Jenkins
- Прикрутили так называемые PrCheck (сборка, тесты Selenium, линтеры)
Процесс в картинке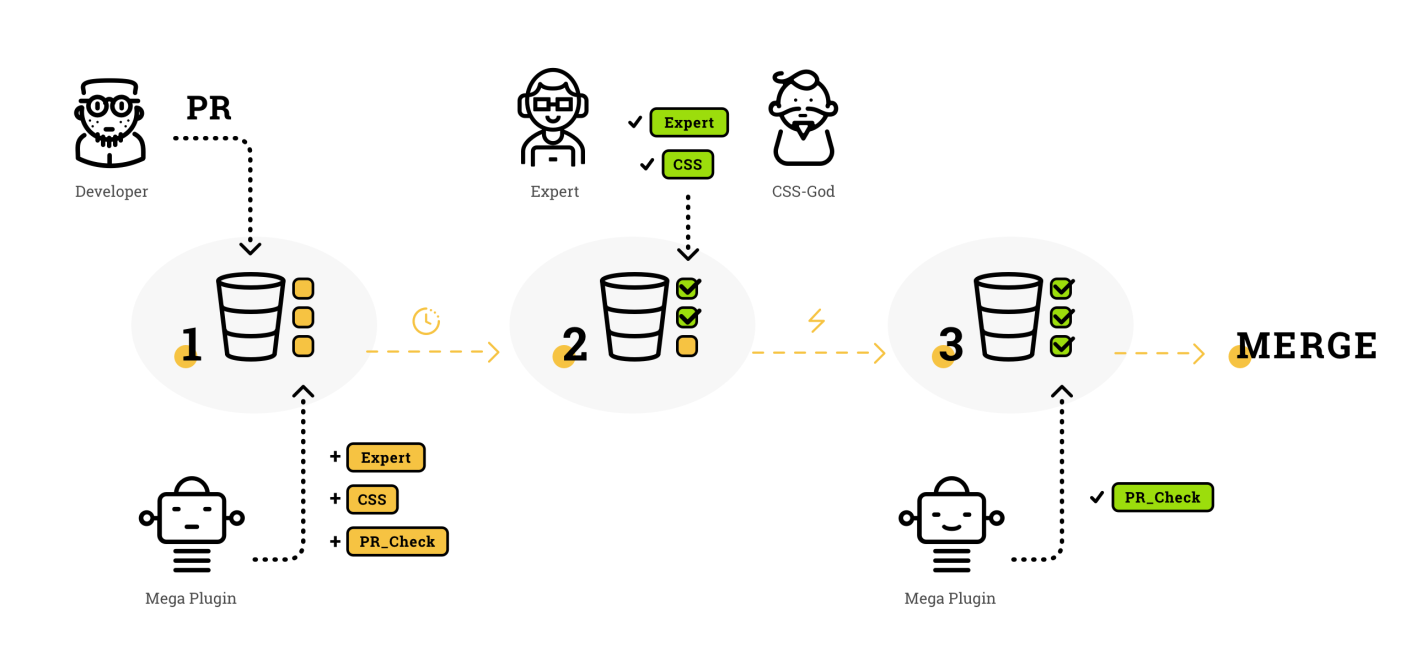

Теперь подробнее, как всё начиналось. Рассказывать буду на примере одного репозитория UI, и если будут какие-то интересные особенности в других репозиториях, напишу отдельно.
Что с develop, чувак?
Когда-то наш develop постоянно ломался из-за каких-то мелких ошибок, которые просмотрели на code-review. Это были ошибки JS runtime, ошибки компиляции Typescript, глобальные ошибки стилей приложения (когда вся страница «разъехалась») и пр. В чате постоянно звучали всем знакомые вопросы: «develop не сломан? Можно обновиться?», «У кого еще develop не собирается? Или у меня одного так?" и другие. Тогда команда была из 10 человек. И на горизонте начали маячить планы вырасти до 10-15 скрам-команд по 9-10 человек. Наши суперАдмины и эксперты (ревьюеры) загрустили.
Думали решить проблему стабильности через git pre-push hook, но этот подход тоже не заработал по двум причинам:
- стабильности не может быть там, где есть человеческий фактор;
- жестоко было заставлять всех разработчиков перед push ждать полной сборки проекта, прогона линтеров и других проверок (тогда еще не было тестов Selenium). К тому же большой простой по времени.
Начали думать в сторону барьера на этапе PR.
Операция «Jenkins impossible»
В первых реализациях запуск job делался этим плагином. Т.е. он через каждые 15 мин (cron) обходил PR с новыми комментариями test this please или новые PR, и просто запускал job. После сборки мы в shell скрипте писали коммент в PR (успех/неудача). Эксперты смотрели код, ставили свои апрувы (за англицизмы не судите строго, хорошего синонима не нашёл).
НО вливать код могли только избранные, god mode. Обычно это был один человек на репозиторий, которому нужно было убедиться в успешной сборке, найти «BUILD SUCCESS», посчитать количество апрувов и только после этого нажать кнопку Merge. И я вам скажу, по опыту, морально это очень тяжело. Вроде и апрувы есть, и «чеки» прошли, а вливаешь всё равно ты, и ответственный тоже ты. Никто из наших больше трех недель не выдерживал. Начались дежурства :) И с точки зрения процесса это все равно было узким горлышком, потому что даже после того, как все требования выполнены, команде нужно было найти того, кто нажмет кнопку. В итоге от 1 часа до целого дня, а порой и неделями команды не могли найти этого «избранного», забившегося в угол Главного Разработчика.
Стоит упомянуть, что у Bitbucket есть стандартная опция — отображать статус сборки. И ещё merge checklist: минимальное число апрувов, хотя бы одна успешная сборка, все замечания разрешены (галочки) и др. Но нам этого было мало.
Потом уже только родилась идея плагина, быстро накидали минимальные требования к нему и приступили к разработке. Всего один человек МаратСадретдинов, который ни разу не писал ничего для Bitbucket и не работал с его api, дал нам рабочий прототип уже через месяц (писал в свободное время). Самым приоритетным было требование: получить список PRов, готовых к влитию. Какие критерии мы установили:
- сборка прошла успешно;
- нужные эксперты поставили апрув (в будущем объединили это в лейблы, о чем расскажу ниже).
Как это работало:
Создается PR >> Пишется комментарий test this please >> Наш плагин блокирует кнопку Merge, а github plugin мониторит комменты и запускает job на Jenkins >> Jenkins по окончании присылает успех/неуспех >> Плагин активирует кнопку Merge, если все критерии успешны >> «God mode user» вливает код, каждый раз немножечко постарев.
Всё. Одна-две недели на отладку, исправление багов, задержек между Jenkins & Bitbucket (каждую секунду опрашивать все PRы было тяжело, потому что плагин сканировал все комментарии). И ура! Вопросы про сломанный develop пропали.
Но потом всё стало еще интереснее, руководители разработки и жадные разработчики захотели «жира».
- Давайте уберем фразу test this please и будем запускать автоматом.
- А что, если человек обновил свой PR, надо предыдущую сборку грохать, запускать новую.
- А в какой последовательности ее запускать, там же уже очередь на Jenkins, значит он будет вставать в самый конец очереди?
- Давайте вливать автоматом! Не руками нажимать.
- Давайте создадим лейблы, которые по разным правилам навешиваются на PR, изначально жёлтые. Как только они все становятся зелёными — PR вливается.
- Давайте экспертам в Телеграм писать, если у них новый PR или не вливается больше двух дней и т.д.
- Не запускать сборку до тех пор, пока все апрувы не собраны
- Если сборка прошла, но очень давно (неделя или больше), т.е. «старый» PR, то нужно сбрасывать лейбл успешности.
Много чего хотели, давайте я расскажу, что же у нас в итоге получилось.
Labels
Начнем с главного лейбла — expert.
Есть группа экспертов, это в первую очередь наиболее опытные на проекте разработчики, которые знают даты релизов, зависимость и влияние кода, общие подходы и практики и, конечно же, как лучше писать код.
team.
Лейбл твоей команды. Выставляется минимальное число апрувов от твоей команды. Это не обязательно должен быть разработчик, или js-ник, если PR в UI. Главная цель, чтобы команда подтвердила, что разработка движется в том направлении, которое они запланировали. Иногда это могли быть более опытные разработчики, которые до экспертов выставляли замечаниями своему коллеге.
arch
Мы себе придумали такой лейбл, когда менялись ядро, общие компоненты, утилиты. Каждый такой PR обычно затрагивал очень многие формы и страницы, и мог существенно поломать функционал. Определялся он обычной регуляркой по структуре проекта (папка src/Core, src/Common и т.п.)
prCheck
Самый главный технический лейбл. Гарант надежности. В UI репозитории это tslint, lesslint, jsonlint, typescript, webpack, одно время даже e2e тесты на groovy. На бэке — компиляция, интеграционные тесты API. Всё в докере.
oracle, security, admin, devops
Узкоспециализированные эксперты в своих областях.
sonar
Это Сонар, на бэке. Сканирует код, заводит таски на правила, которые вы приняли на проекте.
predvnedrezh
Специальный лейбл для поры «Предвнедрежа», когда внедрение на носу (одна-две недели), и вливать ничего нельзя. И мы ничего не вливаем. Почти. Ну вы поняли ;)
not_task, not_story, not_bug, not_test
Лейблы с приветом от Jira. У PRа всегда есть связи с задачами из Jira, потому что commit без указания номера задачи сделать нельзя (я думаю многие на сервере ставят себе такие git hooks). Плагин просто смотрит тип таски в Jira. Так вот этот лейбл говорит о том, что код правит что-то другое, не то, что вы ожидаете.
css
Говорит о том, что в PRе есть файлы стилей, нужен гуру по стилям, верстке и дизайну.
На этом месте мог бы быть ваш Label
Также реализовали возможность ручного добавления лейблов (если какие-то правила нельзя регламентировать), автор PR или сам эксперт мог добавить еще экспертов (еще больше экспертов!).
Еще лейблы можно делать опциональными, они не блокируют кнопку Merge.
Default Reviewers
Другое интересное умение плагина — это назначение экспертов автоматом. До плагина каждый разработчик руками выставлял экспертов, коллег по команде и других, чьи интересы задел соответствующий лейбл. Сначала это просто была русская рулетка, с небольшим счетчиком внутри. Если в вашем репозитории работает правило минимум двух апрувов эксперта, то выбирались три эксперта из всех.
Вы спросите, зачем вообще выбирать двух-трех экспертов на PR? Почему бы не назначать весь список на каждый PR? Кто сможет — тот и посмотрит. Но, как говорится, «общее — значит ничье». В битбакете есть колокольчик с уведомлениями, и если у нас в день 50 PRов, то каждому эксперту (допустим, их 10), приходилось постоянно «гнать» этот счётчик к нулю. Это было почти невозможно (учитывая, что эксперты тоже пишут код), опять встал вопрос деморализации команды. Плагин нас всех спас.
Потом мы добавили возможность отключения эксперта (отпуск, болезнь), и введения личного графика работы. Некоторые команды и эксперты сидят в других городах. Но когда плагин это не учитывал, получалось так, что разработчик в 5 утра МСК создавал PR, и ему назначались 2 москвича, которые приходили к 10 МСК. Хотя были эксперты, которые могли бы посмотреть этот PR сразу же.
Приоритеты апрувов или как бороться с кумовством
В одном из репозиториев сервера захотели такую примочку, как приоритеты (или вес) апрувов. Что это такое?
У вас есть эксперт (допустим Mario), который в команде (допустим Nintendo). Коллега выставляет PR, а Mario апрувит и зеленит сразу два лейбла — nintendo_team & expert. Вроде нормально, он же эксперт. Отвечает за этот код, но всё же подозрения есть. Мы в своём репозитории решили не заморачиваться, а в другом — захотели. Выставили командному лейблу приоритет выше, и следовательно эксперты этой команды не могут позеленить expert. Это забавно, но проблему кумовства между командами (какие-нибудь 2 команды Nintendo & Dendy), так и не решили :) А может ее и нет…
Клуб зависимых pull-requests
Еще у нас есть, да и не только у нас, такая потребность — выставлять зависимые PRы на UI & Back сразу, с одновременными правками api например, и проверкой всего приложения на уже новом коде. Для этого придумали доработку плагина «Зависимые PR и их одновременное влитие». В PRе ставишь ссылку, какой PR в другом репозитории тебе нужен, и сборка будет собираться одновременно с твоей ветки и ветки зависимого PRа. Это очень выручает, когда ты меняешь модель api одновременно на клиент+сервер, допустим, был
//до
Dog: {age: number, id: string}
//после
Dog: {age: string, guid: string}
Или если ты правишь тест в одном репозитории, где ищешь кнопку в браузере фразой
@FindBy("//button[text()="Сохранить"]")
class MyButton
а в UI коде она по-старому:
<button>Подтвердить</button>тогда тебе надо править опять в двух репозиториях.
Различные кнопки-команды
Есть кнопки Restart, которая перезапускает чеки, если вдруг что-то пошло не так.
Есть кнопка Recalculate, Recycle, если нужно скинуть все лейблы и просчитать заново.
Есть кнопка «Too long review» для тех, кто любит пожаловаться. Отправляется письмо «куда следует». Возможно, скоро добавим кнопочку «Поменять экспертов», «Пожертвовать 50 руб» или еще что-нибудь важное и интересное.
Пожалуй, это всё, чем я особенно хотел поделиться. А, чуть не забыл. Еще есть админка плагина.
Спасибо за внимание, пишите вопросы. Надеюсь, наш интересный опыт пригодится вам в работе.
